Part I
BIT33 (1993), 354~371.
M O D E L I N G O F S U P E R S C A L A R I N S T R U C T I O N S C H E D U L I N G A N D A N A L Y S I S O F A H E U R I S T I C
S C H E D U L I N G A L G O R I T H M
H O N G CHICH CHOU and C H U N G PING CI-IUNG Institute of Computer Science and Information Engineering
National Chiao-Tung University Hsinchu 30050, Taiwan, R.O.C.
Abstract.
The problem of superscalar instruction scheduling is studied and an analysis of a heuristic scheduling algorithm is presented. First, a superscalar architecture is characterized by k, the number of types of functional units employed, m~, the number of type i functional units, P~j, the jth functional unit of type i, and z, the maximal number of delay cycles incurred by the execution of instructions. A program trace to be scheduled is modeled by a directed acyclic graph with delay on precedence relations. These two models reflect most of the flavor of the superscalar instruction scheduling problem. A heuristic scheduling algorithm called the ECG-algorithm is designed by compiling two scheduling guidelines. The perform- ance of the ECG-algorithm is evaluated through worst-case analysis. Letting WECG denote the length of an ECG-schedule and Wopt the length of an optimal schedule, we established the bound W~cG/Wopt
< k + 1 - 2/[max {ml}(z + 1)], which is smaller than other known bounds. Classification CR: D.4.1, 1.3.1, 1.2.8, B.2.2
Keywords: Scheduling, Parallel processing, Heuristic methods, Worst-case analysis.
1. Introduction.
In contrast to vector processors, which are used to execute scientific programs,
superscalar processors are microprocessors which attempt to improve the execution rate of non-scientific programs by executing, on average, more than one instruction per clock cycle. Examples of superscalar architectures include the IBM RS/6000, Intel i860, [1, 3], and DEC Alpha. The success of superscalar machines depends not only on the vast hardware resources they provide, but even more importantly, on how efficiently these resources can be used. Efficient use of resources and reduced program execution time may be achieved through instruction scheduling. The
M O D E L I N G O F S U P E R S C A L A R I N S T R U C T I O N S C H E D U L I N G A N D . . . 3 5 5
objective of superscalar instruction scheduling is to rearrange instructions in such a way that they are executed by hardware in an optimal (or near optimal) order (that is, so that execution time is minimized). The problem of finding an optimal order is intractable, however [10].
Superscalar instructions are characterized by their types and delay cycles. The instructions may be classified into several types, such as fixed-point instructions and floating-point instructions. Each type can only be executed on corresponding type of functional unit. Though functional units are pipelined, not all instructions can produce results in one cycle. For example, a load instruction needs an additional cycle to deliver the fetched data to the waiting instructions. In this case, the load instruction is said to have one delay cycle.
Instruction scheduling can be done by hardware or by software. The scheduling of instructions by hardware was pioneered by Tomasulo [5], who designed a hardware instruction issuing mechanism called reservation stations for the IBM 360 model 91. Recent research can be found in [4]. To be fully functional, however, hardware scheduling must solve several problems, including artificial dependencies caused by register-file limitations, conditional branches, and imprecise interrupts. Solving all these problems requires hardware that is complex, costly, and, more seriously, slow. Because of the drawbacks of hardware scheduling, instruction scheduling is mostly done by software, as in the case of the VLIW, IBM RS/6000, and Intel i860. The VLIW machine [7] is an extreme case which relies in a complex way on software instruction scheduling to keep functional units busy while avoiding any data hazards [2]. In addition to identifying instructions that can be executed concurrent- ly, the scheduling software also tries to optimize delay slots. Since software exposes program parallelism to processors, the architecture can be greatly simplified by assuming that the incoming instructions in each cycle can be executed simultaneous- ly, as in the approach of the IBM RS/6000, or by setting one bit in the instructions to notify the processor to execute the next instructions in parallel, as in the approach of the Intel i860. A simple hardware design often implies a fast clock rate.
Scheduling algorithms are generally evaluated through benchmaking [8, 9]. The execution times of the unscheduled and scheduled codes are compared as a perform- ance criterion for the scheduling algorithms. However, benchmarking suffers from a number of drawbacks: (1) it is costly, since it requires a simulator and a compiler to generate code; (2) it is time-consuming; (3) it gives only statistical results and it fails to analyze the nature of an algorithm; and (4) it is a form of post-analysis, which can be done only after a processor has already been designed. Thus in this paper, instead of using benchmarking, we evaluate a scheduling algorithm (the algorithm is given below) from a mathematical point of view, using worst-case performance analysis to reveal the performance limit of the algorithm.
356 HONG CHICH CHOU AND CHUNG PING CHUNG 2. Formal specifications.
2.1. Abstract models.
Since different superscalar machines have diverse types of organizations, to keep our study universal and independent of particular machines, we define an abstract machine model and a model for a trace of code to be scheduled. As can be seen from currently available superscalar architectures and the demands of instruction sched- uling, a superscalar architecture can be denoted by a 4-tuple (k, M, ~ , z), where: • k _> 1 denotes the number of different types of processors employed in the
superscalar architecture.
• M = (ml, m 2 , . . . ,ink), where m, denotes the number of type i processors, for 1 < i < k. The instruction set is also categorized into k types. Type i instructions can only be executed on any of the m, type i processors.
• ~ ={Pii[ 1 < i < k, 1 < j <_ mi} denotes the set of processors. Pii denotes t h e j t h processor of type i.
• z > 0 denotes the maximum number of pipeline delay cycles required to execute any instruction.
The above machine model is generalized enough to encompass a wide range of superscalar architectures. For example, for the IBM RS/6000, k = 4, ml = m2 = m3 = m4 = 1, and z = 6 (floating-point compare instruction delay).
By convention, an instruction is said to have no delay if its execution is completed within one cycle and to have x cycles of delay if it needs x additional cycles to be completed.
We formally denote a program trace to be scheduled by a 4-tuple (U, < , P f, D),
where:
• U = {11,12,...,
li),
is the aggregation of the instructions to be scheduled • ~( is a transitive binary relation defined on U that specifies the precedencerelationships between instructions.
• P f i s a function, P f : U ~ {1, 2 . . . . , k}, specifying the type of processor on which an instruction can be executed.
• D is a function, D : U ~ {0, 1 .. . . . z}, specifying the number of delay cycles of each instruction.
Precedence relations originate from true data dependencies, procedural depend- encies, antidependencies, and output dependencies. If li -~ 1 i, this means that Ii must be executed before Ij. It is unnecessary to distinguish among these dependencies here, since they impose the same effect on instruction execution. Dependence and precedence are used interchangeably in the following context.
It would be convenient to represent each (U, -<, P f, D) instance by a directed acyclic graph (DAG). Figure 1 shows an instructions D A G with three types and a maximum delay of two cycles. Nodes (Circles) in Figure 1 denote instructions. If
M O D E L I N G OF S U P E R S C A L A R I N S T R U C T I O N S C H E D U L I N G A N D . . . 357
F i g u r e 1. A s a m p l e i n s t r u c t i o n D A G .
transitive edges are not shown in the figure). The number behind the slash in each node indicates the type of that instruction, and the number besides each edge denotes the number of delay cycles required by the predecessor. If//~( Ij, then
Ij(I~)
is a successor (predecessor) of Ii(Ij). If there is no 1' such that Ii ~ 1' ~( 1i, thenIj(Ii)
is said to be an immediate successor (predecessor) ofI~(Ij).P(IO
is used to denote the set of predecessors of It, andS(I~)
the set of successors of I~ (not necessarily immediate in both sets).A function 2: U--} {1,2 . . . . } is
a feasible schedule
for a given(U, ~ , P f , D)
on a given (k, M, ~ , z), if 20 meets the following conditions:1. VI~, 1 i ~ U, if I~ ~( Ij, then 2(Ig) +
D(Ii)
< 2(/j).2. Vt > 1 /x i _< k, I {I e U r 2(1) = t and
Pf(I) = i} [ < m,.
Condition 1 requires that a schedule should observe the precedence relationships; condition 2 requires that a schedule should not use more processors than available. When an instruction Ii is said to be scheduled in time slot tl, this means that 2(10 = ti. None of the successors of
Ii
can be issued until 2(//) +D(Ii)
+ 1. We define 2(//) +D(I~)
to be thecompletion time
of I~ and use the functionLen (I~) = D(I~)
+ i to denote thelength
of an instruction. The time slots (2(Ii), 2(I~) +D(I~))
are said to be theseope
o f I i. The length of a scope is also the length of that instruction.LenO
is also used to denote the length of a chain. A chain h = (11., I2., . . . . Ix, ) is a sequence of dependent358 HONG CHICH CHOU AND CHUNG PING CHUNG
instructions, such that Iv is an immediate predecessor of I(i+ 1)'- The length of a chain is the sum of the lengths of all instructions in the chain. The length of a feasible schedule is defined to be max {2(1) + O(l)}, ¥1 e U.
3. Heuristic algorithm.
Since it is not likely that an essential fast algorithm could be found for an NP- complete problem, we propose a heuristic scheduling algorithm called the ECG- algorithm. The algorithm is a List-scheduling-like algorithm. Each instruction is given a label to reflect the scheduling priority of that instruction. The scheduling discipline is as follows: Whenever a processor becomes idle, the instruction with the largest label among the instructions ready to be issued is selected to be executed on the idle processor.
Let e(I~) denote the label of I~. The ECG-algorithm is designed by the following two scheduling guidelines. For a given (U, -<, Pf, D), we define two relations among
instructions, as follows:
DEFINITION t. Dominance relation on instructions. For li, Ij~ U and P f ( I i ) = Pf(It), Ii is said to dominate I i, denoted as I~ D l~, if S(Ii) ~ S(Ij) and P(Ii) c P(Ij) and
o(i,) >_ O(I;).
DEFINITION 2. Semi-dominance relation on instructions. For Ii, 1 t ~ U and P f (li) = P f (Ig), and not li E Ij nor Ii S E I j nor IiD I g, li is said to semi-dominate I ;, denoted by Ii S D Ij, if li, I t satisfy one of the following conditions:
1. S(I~) ~_ S(I;) and D(Ii) >_ D(I~). 2. S(It) = 0 and L(Ii) >>_ D(Ij) + 1.
It can be proved that if Is D I t, It is scheduled no later than Ij is in an optimal
schedule [17]. However, no analogous property can be proven for the semi-domi- nance relation. Nevertheless, if I~ S D I t, Ii is likely to be scheduled no later than Ij.
Thus in designing the ECG-algorithm, we adopt the following guidelines: GI: If I~ DIj, then ~(Ii) > a(Ij).
G2: IfI~SDlj, then a(I,) > a(Ij).
The ECG-algorithm involves two major procedures: leveling and labelin(4. Let L(I*) denote the level of 1", and N(I*) denote the decreasing sequence of integers
formed by ordering the set {7(I')1I' e S(I*)}. The leveling procedure is then as follows:
ECG-algorithm-leveling procedure /* input: instruction D A G */
MODELING OF SUPERSCALAR INSTRUCTION SCHEDULING AND . . . 1. IfI~ has no successors, then L(Ii) = D(Ii) + 1;
2. Else L(I~) = max {L(I*)} + D(I~) + 1, VI* ~ S(Ii).
359
ECG-algorithm-labeling procedure /* input: leveled instruction D A G */ /* output: labeled instructions D A G */
1. lv = 1 ; i = 1;
2. for lv = 1 to max-Level
3. Let R be the set of instructions of level lv;
4. while R ~ 0
5. Let I* be the instruction in R such that
N ( I * ) = min {N(I)}, VI ~ R (break tie at will); 6. ~(I*) = i;
7. R = R - {I*};
8. i = i + 1 ; 9. endwhile; 10. endfor;
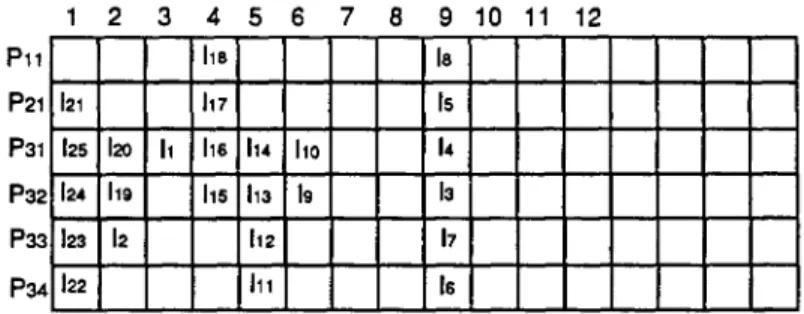
The labels of the instruction in Figure 1 are denoted by the subscripts. Figure 2 shows an ECG-schedule of the D A G in Figure 1.
1 2 3 4 5 6 7 8 9
P l l h8 18
P21 121 h7 Is
P31 12s 12o I1 lie 114 Ilo h
P32 124 119 Ils h~ le 13
P ~ 123 12 112 17
P34 122 Ill 16
10 11 12
Figure 2. An ECG-schedule of the sample DAG.
It can be proved that instructions labeled by the ECG-algorithm satisfy guidelines G1 and G2. Since the proof is not difficult, it is omitted here. Interested readers may refer to 1-17]. Let Wec~ denote the length of an ECG-schedule and Wop~ the length of an optimal schedule. For a given (k, M, ~ , z), the worst-case performance of the ECG-algorithm is to find the value
max (WecG/Wop,). 'q'( U, . ~ , P f , D)
The significance of the heuristic algorithm is that its worst case bound is smaller than the worst-case bound of other known scheduling algorithms.
360 HONG CHICH CHOU AND CHUNG PING CHUNG 4. Previous work.
In this section, we briefly review relevant known results concerning the above problem. Some of these results concern U E T task scheduling problems. We include them because the task scheduling problem and the instruction scheduling problem have some similarities. For scheduling UET tasks on m processors, the worst case of an arbitrary greedy algorithm is bound by
Wgreedy/Wop t ~ 2 - 1/m.
If the tasks are typed, there is a best possible bound, established by Jaffe [11]:
wg,eeay/Wo e, _< k + 1 - 1/max (m~} when k is the number of typed processors.
Hu [ 12] proved that executing the tasks in a highest-level-first order results in an optimal schedule when precedence relations define an in-forest or out-forest. For an arbitrary DAG, H u showed that the bound is
wnu ( 4 / 3 if m = 2 . - - <
Wopt 1 / m - - 1 if m > 2 .
Coffman and G r a h a m [13] proposed an algorithm (the CG-algorithm) which is optimal when m = 2. Lam and Sethi [14] explored the upper bound of the CG- algorithm. They established a tight worst-case bound:
W c ~ / W o m < - 2 - 2 / m for m_>2.
Bernstein and Gertner [ 15] showed that optimal scheduling of expressions on the machine (1, M = (ml),~, z = 1) can be carried out by a slightly modified CG- algorithm. E. Lawler et al. [16] showed that the completion time of a schedule constructed using a highest-level-first greedy heuristic is arbitrarily close to
2 - 2/(m(z + 1) + 1) times optimal. However, their assumption of equal delay cycles is too restrictive for superscalar instructions. In this paper, we establish that the bound value for the ECG-algorithm is
W~cG/Wop~ < k + 1 - 2 / [ m a x { m i } ( z + 1)].
Moreover, our model is very close to the actual superscalar instruction scheduling problem.
5. Upper bound analysis.
The general steps for finding the upper bound are the following:
1. Given a D A G and its ECG-schedule with length W~c~, find the minimal length
MODELING OF SUPERSCALAR INSTRUCTION SCHEDULING AND . . . 3 6 1
2. find the number of instructions and the number of idlc cycles in the ECG- schedule;
3. Then WEc~/Wopt < (no. of ins. + no. of idle cycles)/(no, of ins.).
The key point usually lies in finding Wop t.
To find wopt, we divided an ECG-schedule into segments, such that all the instructions in one segment must be completed before any instruction in the next segment can begin. Hence an optimal schedule corresponding to an ECG-schedule will be no shorter than one that arranges the instructions in each segment optimally. To identify segments, it would be easier first to identify the blocks which constitute segments. The concepts of a segment and block are borrowed from [14].
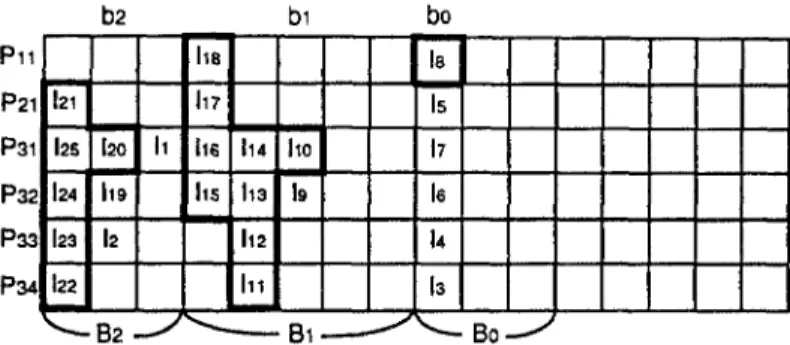
5.1. Block and segment partitioning.
Assume that if a processor does not issue a new instruction in time slot t~, then it issues a d u m m y instruction with label 0 in t~. Blocks Bi .... , Bo, for some i > 0, are defined as follows:
Block partitioning procedure.
1. Let bo be the last finished instruction.
2. For i > 1, b~ is defined to be the most recent instruction issued by P , , such that 2(bi) + D(bi) = t~, ct(bi) > ~(bi-1) and there is no other instruction whose label is greater than b~_ 1 and whose scope contains t~.
3. Repeat step 2 until no more bi can be found.
4. Block Bi-1 is the set of all instructions I* satisfying 2(bi) + D(b~) < 2(1") <
2(bi_ 1) + D(bi_ 1) and ~(I*) > c~(bi_ 1).
Suppose the above steps define bi for 0 < i < q and bq + 1 does not exist. Then
Bq
is the set of instructions I* such that 2(1") < 2(bq) + D(bq) and ~(I*) __ ~(bq).The block boundaries and block instructions of the sample ECG-schedule are surrounded by bold lines in Figure 3. Instructions belonging to a block are called
block instructions. Unless otherwise specified, instructions mentioned in the rest of this paper refer to block instructions.
After block partitioning, we may observe the following features:
1. There may be some instructions that fail to belong to any block. Such instruc- tions are called extra instructions. For example, instruction 19 in Figure 3 is an extra instruction.
2. The last time slot of Bi is in the scope ofbi only, the other slots are contained by at least two instructions in B~.
3. All the instructions in B~ depend on b~+ 1. For example,/20 and Ilo precede all the instructions scheduled behind them.
362 HONG CHICH CHOU AND CHUNG PING CHUNG P l l P21 P32 P33 P34 b2 121 12S 120 I1 124 h9 12a 12 122 ~ ' - B 2 J bl ha h7 hs 114 11o 115 h a 19 112 Ill ~ - B 1 J b0 la Is 17 le 14 13 Bo_.~
Figure 3. An ECG-schedule and its blocks of the sample DAG.
It is not always true that all instructions in one block precede all instructions in the next block. For example, instruction 111 in B 1 does not precede every instruction in Bo.
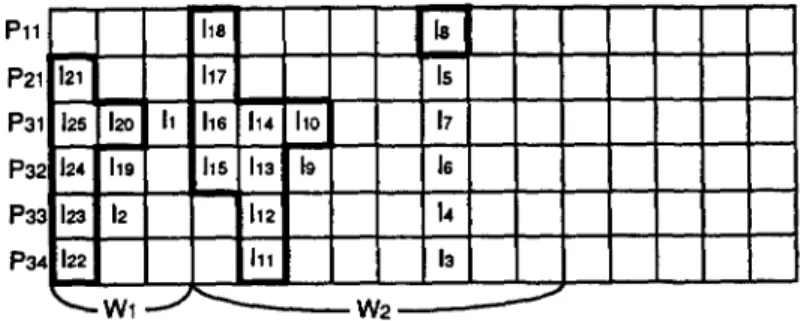
Next, blocks are used to form segments. Segments are formed by scanning blocks from left to right. If any instruction in a block on the left does not precede all the instructions in the next block on the right, then the two blocks are merged into one segment, or else a segment is terminated and a new segment begun. The important feature in forming segments is that when two blocks are to be merged, an extra instruction can always be found. The extra instruction has to be counted into the total number of instructions. For example, Figure 4 indicates the segments of the sample ECG-schedule. There are two segments in the figure. Segment 1 consists of block 2, since all the following instructions depend on every instruction in block 2. Segment 2 consists of block 1 and block 0, since I~ ~ does not precede each instruction in block 0. Since it is tedious to describe the procedure for forming segments and the proof that extra instructions can always be found, we shall not do so here. Interested readers may refer to [17].
5.2. Minimal length of segments.
After finding segments, we can obtain an optimal schedule of a set of instructions by scheduling each segment optimally. So instead of calculating the worst-case ratio of an entire schedule, we calculate the worst-case ratio of an optimal segment to an ECG-segment.
For block instructions, an ECG-schedule includes three kinds of time slots: full slots, partial slots, and delay slots.
• A full slot ty is a time slot in which all the processors of a certain type are issuing new instructions. Time slots (1, 4, 5, 9) are such slots.
• A delay slot ta is a time slot in which all processors are idle. Time slots (3, 7, 8, 10, 11) are delay slots.
• A partial slot tp is a time slot in which at least one instruction is issued and at least one processor of each type is idle. Time slots (2, 6) are partial slots.
MODELING OF SUPERSCALAR INSTRUCTION SCEIEDULING AND . . . 363 Plll P21 P31 P3~" P3~ P3~ 1211 117 12s 12o I1 hs i114 110 124 ho hs ha 19 123 12 112 122 Ill 18 Is 17 la 14 la W2
Figure 4. Segments of the sample ECG-schedule.
This classification of time slots is intended to reveal dependencies between instructions. Since the maximal delay cycle is z and the scheduling discipline is greedy, we have the following dependencies associated with partial and delay slots.
PROPERTY 1. In an ECG-schedule, all instructions scheduled after a delay slot ta depend on at least one instruction scheduled in (ta - z, td -- 1).
PROPERTY 2. In an ECG-schedule, all instructions scheduled after a partial slot tp depend on at least one instruction scheduled in (tp - z, tp).
LEMMA 1. Let W be a segment of an ECG-schedule. I f W contains d delay slots and
p partial slots, then Wovt >_ p + d + f ' , where f ' >_ 0 and p + f ' >_ d/z.
PROOF. This lemma can be proved by finding a chain h in W and showing that
Len(h) >_ p + d + f'. Consequently, wovt >_ Len(h) >_ p + d + f ' .
Suppose h = ( I r , lz,,...,Ix,), then h can be constructed from the end of W by chaining instructions to h one at a time until no more instructions can be chained. The chain construction steps are as follows:
1. Let I~, be the last completed instructions in W..
2. Suppose i instructions have been chained for i >_ 1. I~_ ~), is selected in such a way that I~x-~), is the rightmost (in terms of completion time) immediate predecessor of I(~_ i + 1)' (break tie at will).
3. Repeat step 2 until no more instructions can be chained.
If we take W2 in Figure 4 as an example, the chain constructed by the steps above is h = (I18,114, I1 o, I s ) (notice that h is not unique in this case), which has a length of 8 cycles.
It can be proved that the scopes of the instructions in h cover all p partial and d delay slots as well as any full slots. Thus Len(h) > p + d + f ' , where f ' > 0 denotes the number of full slots covered by the scopes of h.
364 HONG CHICH CHOU AND CHUNG PING CHUNG
Next, we consider the minimal number of instructions in the chain. Since the maximal delay cycle is z, there are no consecutive delay slots greater than z in W. Thus for d delay slots, there must be at least Fd/z-]instructions in the chain and these instructions reside in partial or full slots, so p + f ' >_ d/z (since p + f ' is integer, the ceiling operation can be canceled). •
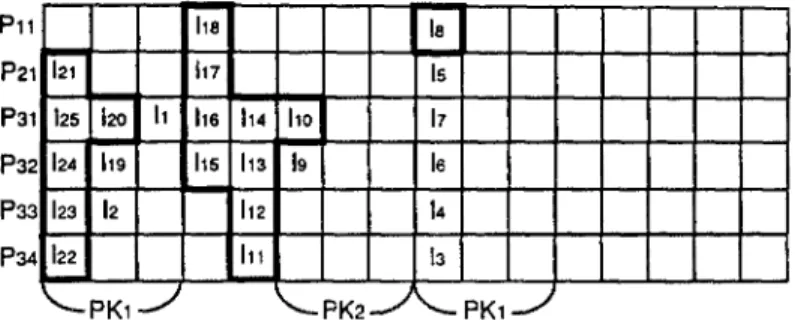
Pll P21 P31 P32 P33 P34 121 125 120 1 11 124 119 123 12 122 ~ P K I 'ha 117 ,h6 1'~5 114 11o I1z 19 112 Ill 18 17 18 14 13 ~ - - PK2 - J ~ PK1 --"
Figure 5. Packages of the ECG-schedule.
However, this minimum length may be underestimated. To explore a greater minimum length of HI, we shall introduce the concept of packages. Packages are used to expose the detailed dependence relationships inside a segment. Packages are constructed by searching from right to left of W for partial or delay slots. Each time a partial or a delay slot is found, that slot and the next z slots to its left form a package. Let P K i be used to denote the ith package. Figure 5 indicates the packages of the schedule in Figure 3. Since we start each package by finding a partial or delay slot, all p partial and d delay slots are covered by packages. From Property 1 and Property 2, each instruction scheduled after a package must depend on at least one instruction in that package. This fact encourages us to reexamine the minimal length of W.. We categorize packages into three types:
• Al-type packages are packages containing only full and delay slots.
• A2-type packages are packages containing one full slot, one partial slot with only one instruction scheduled in it, and any other full or delay slots.
• A3-type packages are the remaining cases, which include the following possibili- ties:
1. one partial slot with one instruction and delay slots, or 2. one partial slot with two instructions and any other slots, or 3. two partial slots, each with one instruction, and any other slots.
For example, the types of the three packages in Figure 5 are as follows: P K 1 of W 1 is Al-type, since time slot 1 is a full slot, while P K I and P K 2 of W2 are A3-type.
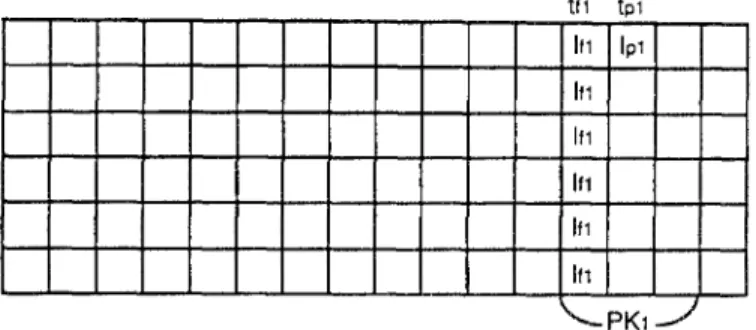
M O D E L I N G OF S U P E R S C A L A R I N S T R U C T I O N S C H E D U L I N G A N D . . . 365 tpl tfl Ipl If1 If1 If1 If1 If1 PK1
Figure 6. An A2-type p a c k a g e c o n t a i n i n g a full slot b e h i n d a p a r t i a l slot.
I f there are at A l-type packages and a 2 A 2-type packages in W, then wopt >- (P + d + al + Va2/2q).
PROOF. From the proof of Lemma 1, we can find a chain h whose scopes cover all p partial and d delay slots in W. But the length ofh equals p + d only when its scopes cover just the p partial and the d delay slots. If the scopes of h cover any full slots, these full slots have to be taken into account as contributing to the length of h.
First, we prove that A ~ type packages contribute to the minimal completion time of W. Suppose P K i is an A1 type package containing only full and delay slots (by definition). F r o m the dependency properties, every instruction scheduled after P K i
must depend on at least one instruction in PKi, hence it must depend on an instruction scheduled in a full slot. So if there are a l A 1-type packages, the scopes of h cover al full slots. The minimal completion time of W is thus p + d + al cycles.
Next, we show that A2-type packages also contribute to the minimal completion time of W, but the minimal contribution is Va2/27. Suppose without loss of generality that there are only one full slot and one one-instruction partial slot in each A2-type package. As indicated in Figure 6, let t:x denote the full slot, tpl the partial slot, 1:1
the set of the instructions scheduled in t:a, and Ip~ the only instruction scheduled in tpl.
C A S E 1. t f l > tpl.
Figure 6 shows such a case. Suppose
tfl
is not in the scopes ofh but tpl is. Since we start each package by finding a partial or a delay slot, there must be a delay slot aftert:l. If the scopes of h terminated before t:t, the successors of Ipl could be scheduled in the delay slot - a contradiction. If Ipl is the last instruction on h, its completion time should cover t:l, otherwise Ipl could not be chosen when constructing h. So the scopes of h must contain t:l.
366 HONG CHICH CHOU AND CHUNG PING CHUNG tfl tpl If1 Ipl Ill If1 If1 If1 If1 "--- PK1 ~ " Figure 7. An Az-type package with a partial slot behind a full slot.
Figure 7 indicates this situation. We prove by induction that if there are a2 packages of this kind, they contribute
Va2/2~
to the minimal length of W. Let m denote any mi for 1 < i <_ k. We claim that when a2 is odd, there are (m + 1) x [p + d + (a2 - 1)/2J-cycle chains or a [ p + d + (a 2 + 1)/2J-cycle chain in W. In both situations, W needs at least p + d + (a2 + 1)/2 cycles to be completed. When a 2 is even, there must be a [ p + d + a2/2]-cycle chain in W.First, let a2 -- 1. Taking Figure 7 as an example, we prove that there are (m + 1 ) (p + d)-cycle chains or a (p + d + 1)-cycle chain in W. If
t:l
is in the scope of h, the scope of h contain a full slot and a (p + d + 1)-cycle chain is found, so the proof is completed. Supposet:l
is not in the scope of h. Since the scope of h terminates beforet:a,
the only reason that prevents Ip from being scheduled int:~
must be e(I:l) > e(Ip), VI:i.
F r o m the scheduling discipline,L(l:l) > L(Ip)
must hold. N o w consider the length of the chains going through1:1.
The chains cover all the partial and delay slots beforet:l.
The levelof I:l
is not less than Iv, so in turn, it is not less than the summation of the numbers of partial and delay slots aftert:l.
Therefore, the lengths of the chains going throughI:~
are at least (p + d)-cycles long. So there are m + 1 (p + d)-cycle chains in W. W needs at least p + d + 1 cycles to be com- pleted.Second, let a2 = 2. We prove that there is a (p + d + 1)-cycle chain in W. Figure 8 illustrates this situation.
PK1
andPK2
in Figure 8 are two A2-type packages. We must supposet:l
andt:2
are not within the scope of h, otherwise the proof is completed.S i n c e P K 2 does not cause a block split, not all instructions after tp2 depend on
Ipz
only. In other words,
1:2 ~ Ipl
orI:z -< 1:1
must hold. IfI:2 <(Ipl,
then the length of the chain containing1:2
andlp~
is p + d + 1, because its scope contains all the p partial and d delay slots and the one full slot (tf2). If1:2 "< 1:1,
the scope of the chain containing1:1
and1:2
cover all the partial and delay slots before1:1
and the one full slot (t:2). So the length of the chain is also p + d + 1.F o r
az
> 2, similar arguments can be applied, so this part of the proof is omitted. A complete p r o o f can be found in [17].MODELING OF SUPERSCALAR INSTRUCTION SCHEDULING AND . . . 367
tf2 tp2 tfl tp~
If2 Ip2 If1 Ipl
If2 In If2 If1 If2 If1 If2 If1 If2 Ill ~ P K 2 ~ , / ~ - - PK1 ~,"
Figure 8. Two A2-type packages with partial slots behind full slots.
Finally, we compare the contribution of the A2-type packages in Case 1 and Case 2. We see that the contribution is Faz/27 in Case 2 versus a2 in Case 1. So we conclude that when there are a2 A2-type packages, the minimal length of W is
p + d + Fa2/2-]. The contributions of Al-type and A2-type packages to the minimal
length of W are independent. Thus their contributions can be added. •
LEMMA 3. Given segment W of an ECG-schedule, if there are az Az-type and
a3 A 3-type packages in W, the number of extra instructions plus instructions in partial slots is not less than a2 + 2aa - 1.
PROOF. We first prove this lemma when W contains only one block. Then we show that it is also true when W contains more than one block.
Assume that W contains only one block, and consider the number of instructions in A3-type packages. Since W has only one block, there can be only one A3-type package (P K1) that contains only one instruction. The other Aa-type packages must contain at least two instructions in partial slots. For A2-type packages, by definition, each A2-type package contains one instruction in a partial slot. Therefore the total number of instructions scheduled in partial slots of W is at least a2 + 2a3 - 1 (Al-type packages have no partial slots).
If W contains B > 1 blocks, then there could be B A3-type packages which contain one instruction only (the rightmost package of each block). But there are B - 1 extra instructions to complement these one-instruction packages. So the number of extra instructions plus the instructions in partial slots is still a2 + 2a3 - 1. •
THEOREM 1. Given W, a segment of an EC G-schedule G on a (k, M, ~', z), let Weca be
the length of W and Wopt the length of an optimal schedule of W. Then weca/wopt <_ k + 1 - 2/(max{mi}(z + 1)).
368 HONG CHICH CHOU AND CHUNG PING CHUNG
PROOF. We see that the worst-case ration of WEc~/Wopt exists in optimal schedules that contain no idle cycles. If an optimal schedule contains idle cycles, then these can be eliminated by inserting some independent instructions into the original D A G to fill up the idle cycles without affecting the length. This does not mean that the worst-case ratio always exists in an optimal schedule without idle cycles. It means that the search for the worst-case ratio can be narrowed down to those optimal schedules which have no idle cycle. By the above argument, we conclude that the first time slot of W must be a full slot; otherwise the optimal schedule will contain idle cycles.
Let the number of partial slots in W be p, the number of delay slots be d and ~ / = ~ = 1 mi. Let there be al A 1-type, a2 A2-type and a3 A3-type packages in W and let q = al + a2 + a3. Let Ui denote the set of type/instructions and Vii the set of type i instructions scheduled in partial slots.
CASE 1. P K q (the leflmost package) contains the first time slot.
SUBCASE 1. P K q is a n A 1- or A2-type package.
In this subcase, the number of partial and delay slots in P K q must be no greater than (z + 1)/2, since otherwise the optimal schedule of W will contain idle cycles. Assume P K q have d' delay and p' = 1 partial slots i f P K q is A2-type, or p' = 0 i f P K q is A3-type. All instructions scheduled after P K q are preceded by a chain at least d' + p' long. Thus only the instructions in P K q can be scheduled in the first d' + p' slots in the optimal schedule. Notice that P K q has at most one instruction in a partial slot. If d' + p' > (z + 1)/2, the number of instructions in P K q is no more than J#(z - 1)/2 + 1, which is obviously not enough to fill the first d' + p' > (z + 1)/2 slots when J¢ > 1.
According to Lemma 2, the minimal length of Wis p + d + al + Fa:/27. Consider the time-space product
k
< Jg(k - 1)Wop t - ,//g~ Vffmx + ~ V~
+ d//(p + d + al + [az/2] - al - Va2/2-] - ~] v~ + J/lWop,
WEca/Wop, <_ k + (p + d + al + [a2/27 -- al -
Fa2/27 - ~
Vffmx)/WowSince p > ~ V~/m~,, the numerator of the rightmost term on the right-hand side of the last equation is greater than zero, and Wop, > (p + d + al + ~az/2-]). Thus we have
WEc~/Wop~ <_ (k + 1) - (al + Va2/2~ + ~ Vi/m~)/(p + d + al + [a2/2~) since (p + d + al + [az/2]) < (z(al + a2 - 1) + (z + l)/2 + (z + 1)a3 + a~ + ~a2/2]).
(al + ~az/2~ + (az + 2aa -- 1)/rex) (1) WEc~/Wop~ < (k + 1)
M O D E L I N G OF S U P E R S C A L A R I N S T R U C T I O N S C H E D U L I N G A N D . . . 369
0 ~ •
Q
F i g u r e 9. A w o r s t - c a s e D A G .
SUBCASE 2. P K ~ is a n A3 type package. Using similar techniques we find
(2) Wec~/Wo., < (k + 1) - (al + [a2/2-] + 1 + (a2 + 2a3 -- 1)/m~) z(al + az) + (z + 1)a3 + a l -k
~az/2q -k
1"CASE 2.
Pgq
does n o t c o n t a i n the first slot. Again we use a c o r r e s p o n d i n g procedure; the result turns out to be the s a m e as in (2).T o find the u p p e r b o u n d of WEcG/Wop~, we m u s t m a x i m i z e the expressions 1 a n d 2, t h a t is, m i n i m i z e the m i n u s t e r m s in them. Since the variables in these terms are all integers we h a v e to use slightly u n o r t h o d o x methods. I n this w a y we find t h a t these two m i n u s t e r m s c a n n o t be smaller t h a n 2/(z + 1)rnx. H e r e al, a2 a n d a3 are variables while z a n d rn~ are r e g a r d e d as constants.
F o r expression 1:
(al + ~a2/2] + (a2 + 2a3 - 1)/mx)/(z(al + a2 - 1) + (z + 1)/2 + (z + 1)a 3 + ax + ~a2/2]) - 2/(z + 1)rex
= (al + [a22~ + (a2 + 2a3 - 1)/mx)(z + 1)m~ -
2(z(al + a2 - 1) + (z + 1)/2 + (z + l)a3 + al + [-az/2-])
= a l ( z + 1)(m~ - 2) + ~az/2](mx - 2) + Zmx~a2/2] - zaz + az - 2
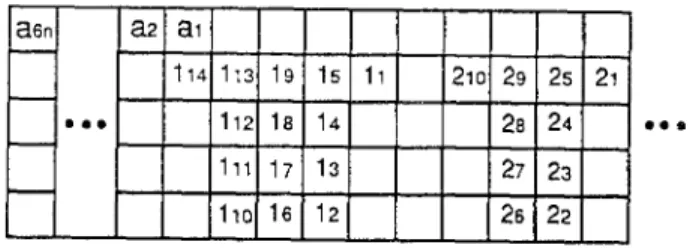
370 HONG CHICH CHOU AND CHUNG PING CHUNG a6n
I...
a2 a~ [ 114 113 112 111 1~o 19 l s l 1~ 18 14 17 13 16 12 21o 29 2S 2i 28 24 27! 23261221
Figure 10. An ECG-schedule of the worst-case DAG.
a l az a3 14 11 i s 12 16 13 17 a4 a~ 8 9 112 11¢ 113 111 21 a6 a7 ae 23 27 31 24 28 32 25 29 33 8.6f 132 136 /33 f37 n4 r18 I"15 139 114 21o
Figure 11. An optimal schedule of the worst-case DAG.
A similar approach can be applied to expression 2 to obtain the same result. So we conclude that W~c~/Wop~ > k + 1 - 2/mx(z + 1). []
From the nature of segments, an optimal schedule can be found by scheduling each segment optimally. So the result of Theorem 1 can be applied to a whole schedule.
THEOREM 2. Let G be an ECG-schedule of a given (U, -<, P f D) on a given (k, M, ~ , z). Let WECG be the length of G and wop, be the length of an optimal schedule of the same (U, -<, P f D). Then WEcG/Wop~ --< k + 1 -- 2/max {mi}(z + 1).
To show that the bound is the best possible, we give an example for k = 2, z = 2, and (ml = 1, m2 = 4). Consider the D A G in Figure 9. The D A G pattern contains 6n type 1 instructions (denoted by ai) and 6n type 2 instructions (denoted by J~). The type 1 instructions have no delay cycle but all type 2 instructions have two delay cycles. The index of each instruction is a valid ECG-algorithm label. The ECG- schedule of the D A G is shown in Figure 10, and an optimal schedule is shown in Figure 11, in which the tail of the first pattern is overlapped with the next pattern. If the D A G pattern is duplicated x times, the length of the ECG-schedule is
x(6n + 1 In), and the length of the optimal schedule is x(6n + 1) + 6n. The ratio is thus
Wv~c~ x(17n) 17
Wopt x(6n + 1) + 6n 6
MODELING OF SUPERSCALAR INSTRUCTION SCHEDULING AND . . . 371 6. Conclusion.
A heuristic instruction scheduling algorithm called the ECG-algorithm is pres- ented, and its worst-case performance is explored. A new technique called package partitioning is developed to expose the detailed dependence relationships between instructions. A bound of at most (k + 1 - 2/max {mi} (z + 1)) times the length of an optimal schedule is obtained. The bound is smaller than that of the highest-level first algorithm.
REFERENCES
1. R. R. •eh•er and R. D. Gr•ves••BM R•SC System/6••• pr••ess•r architecture. •BM J• Research and
Development. 34 (1990), 23-36.
2. J. R. Ellis, Bulldog: A Compiler for VLIW Architecture, The MIT Press, 1986.
3. N. Margulis, 1860 Microprocessor Architecture. Mcgraw-Hill Press, New York, 1990.
4. V. Propescu, M. Schultz, J. Spracklen, G. Gibson, B. Lightner and D. Isaman, The megaflow architecture. IEEE Micro. June (1991).
5. R. M. Tomasulo, An efficient algorithm for exploiting multiple arithmetic units, IBM Journal of
Research and Development 11 (1967) 25-33.
6. J. A. Fisher, Trace scheduling: A technique for global microcode compaction. IEEE Transaction on
Computers 30 (1981) 478-490.
7. J.A. Fisher, The VLIW Maehine: A multiprocessor for compiling scientific code. IEEE Computer 17,
July (1984) 45-53.
8. M. Johnson, Supersealar Microprocessor Design, Prentice Hall, London, 1990.
9. H.S. Warren, Jr., Instruction scheduling for the IBM RISC System/6000 processor. IBM J. Research
and Development 34 (1990) 85-92.
10. J. • Hennessy and T. R. Gr•ss• P•stpass ••de •ptimizati•n •f pipeline ••nstraints. ACM Transacti•n
on Programming Language and System 5 (1983) 442-448.
11. J. M. Jaffe, Bounds on the scheduling types task system. SIAM J. Computer 9 (1980) 541-551.
12. T. C. Hu, Parallel sequencing and assembly line problems. Operations Research 9 (1961) 841-884.
13. E. G. Coffman and R. L. Graham, Optimal scheduling for two-processor system. Acta Informatica
1 (1972) 200-213.
14. S. Lain and R. Sethi, Worst case analysis of two scheduling algorithm. SIAM J. Computer 6 (1977)
518-536.
15. D. Bernstein and Gertner• S•heduling expressi•ns •n a pipelined pr•cess•r with a maximal delay •f •ne cycle. J. ACM Transactions on Programming Language and System 11 (1989) 57-66.
16. E. Law•er• J. K. Lenstra• C. Marte•• B. Sim•ns and L St•ckmeyer•Pipeline schedulin•: a survey. IBM
Research Report RJ 5738, 1987, San Jose, CA.
17. H. C. Chou and C. P. Chung, A Study of Supersealar Instruction Scheduling Problem, Ph.D.
dissertation, Institute of Computer Science and Information Engineering, National Chiao-Tung University, Taiwan, 1992.