對使用者評論之情感分析研究-以Google Play市集為例 - 政大學術集成
116
0
0
全文
(2) 誌謝. 本論文能夠順利完成,首先非常感謝恩師 姜國輝 老師這兩年來教導我許多 的專業知識,在研究和學習上都得到許多的幫助,並且在課業或是學習方面都非 常關心我們,並適時給予提醒與經驗分享。在研究期間,老師不斷的激勵我們, 並給予我們方向,也鼓勵我們在解決問題中,試著採用不同的創新思維與方法來 解決問題,因此使我們碩士期間可以不斷的持續學習、成長與充實自己。在此致 上我最誠摰的謝意。. 政 治 大. 在此要感謝口試委員 林豪鏘 老師及季延平 老師在論文口試期間,對本論. 立. 文提出許多寶貴的建議,使本論文能夠更加的完整充實,謹此萬分謝意。. ‧ 國. 學. 另外,在實驗室夥伴 詩貽、佩珊的扶持下,使我於研究生涯更加的順利與 愉快,更感謝楊瑞函學長、黃聖尹學長、戴瑞辰學長和何善豪學長,在我剛進研. ‧. 究所時,給予許多協助,除了教導我許多知識外,亦幫我解決許多難題,使我能. y. Nat. sit. 夠更快速的適應研究所生活。在準備專案時,一起克服許多難關的學弟妹韋仁、. n. al. er. io. 昭元、子建、家偉和淳茜,還有後來加入的羿廷和家棋,謝謝您們的幫助,在專. Ch. i Un. v. 案期間使我受惠良多,也在這段煎熬的日子增添不少歡熱氣氛。另外不吝嗇幫助. engchi. 我解決許多問題的學弟家哲、承霖和柏元,因為有你們才能使我更順利的完成研 究。還有一直在背後支持著我的朋友們,因為有你們讓我的研究生活更加精采。 最後,我要感謝我的家人在我求學過程中,不斷地給予我鼓勵,讓我在遇到 挫折時可以給予我持續向上的力量,你們是我最重要也是最強而有力的後盾,使 我能持續的專注於課業與研究,非常感謝。. 林育龍 謹致 中華民國一○三年七. i.
(3) 摘要. 全球智慧型手機的出貨量持續提升,且熱門市集的 App 下載次數紛紛突破 500 億次。而在 iOS 和 Android 手機 App 市集中,App 的評價和評論對 App 在市 集的排序有很大的影響;對於 App 開發者而言,透過評論確實可掌握使用者的 需求,並在產生抱怨前能快速反應避免危機。然而,每日多達上百篇的評論,透 過人力逐篇查看,不止耗費時間,更無法整合性的瞭解使用者的需求與問題。 文字情感分析通常會使用監督式或非監督式的方法分析文字評論,其中監督. 政 治 大 無法預期未知趨勢的限制,且需要進行耗費人力的文章類別標注工作。 立. 式方法被證實透過簡單的文件量化方法就可達到很高的正確率。但監督式方法有. ‧ 國. 學. 本研究透過情感傾向和熱門關注議題兩個面向來分析 App 評論,提出一個混 合非監督式與監督式的中文情感分析方法。我們先透過非監督式方法標注評論類. ‧. 別,並作視覺化整理呈現,最後再用監督式方法建立分類模型,並驗證其效果。. sit. y. Nat. 在實驗結果中,利用中文詞彙網路所建立的情感詞集,確實可用來判斷評論. n. al. er. io. 的正反情緒,唯判斷負面評論效果不佳需作改善。在議題擷取方面,嘗試使用兩. i Un. v. 種不同分群方法,其中使用 NPMI 衡量字詞間關係強度,再配合社群網路分析的. Ch. engchi. Concor 方法結果有不錯的成效。最後在使用監督式學習的分類結果中,情感傾 向的分類正確率達到 87%,關注議題的分類正確率達到 96%,皆有不錯表現。 本研究利用中文詞彙網路與社會網路分析,來發展一個非監督式的中文類別 判斷方法,並建立一個中文情感分析的範例。另外透過建立全面性的視覺化報告 來瞭解使用者的正反回饋意見,並可透過分類模型來掌握新評論的內容,以提供 App 開發者在市場上之競爭智慧。. 關鍵詞:情感分析、文字分類、支援向量機、社會網路分析、對應分析 ii.
(4) Abstract While the number of smartphone shipment is continuesly growing, the number of App downloads from the popular app markets has been already over 50 billion. By Apple App Store and Google Play, ratings and reviews play a more important role in influencing app difusion. While app developers can realize users’ needs by app reviews, more than thousands of reviews produced by user everday become difficult to be read and collated. Sentiment Analysis researchs encompass supervised and unsupervised methods for analyzing review text. The supervised learning is proven as a useful method and. 治 政 大 and the labels of individual classes must be made manually. We concentrate on two立 issues, viz Sentiment Orientation and Popular Topic, to can reach high accuracy, but there are limits where future trend can not be recognized. ‧ 國. 學. propose a Chinese Sentiment Analysis method which combines supervised and unsupervised learning. At First, we use unsupervised learning to label every review. ‧. articles and produce visualized reports. Secondly, we employee supervised learning to build classification model and verify the result.. y. Nat. sit. In the experiment, the Chinese WordNet is used to build sentiment lexicon to. al. er. io. determin review’s sentiment orientation, but the result shows it is weak to find out. v. n. negative review opinions. In the Topic Extraction phase, we apply two clustering. Ch. i Un. methods to extract Popular Topic classes and its result is excellent by using of NPMI. engchi. Model with Social Network Analysis Method i.e. Concor. In the supervised learning phase, the accuracy of Sentiment Orientation class is 87% and the accuracy of Popular Topic class is 96%. In this research, we conduct an exemplification of the unsupervised method by means of Chinese WorkNet and Social Network Analysis to determin the review classes. Also, we build a comprehensive visualized report to realize users’ feedbacks and utilize classification to explore new comments. Last but not least, with Chinese Sentiment Analysis of this research, and the competitive intelligence in App market can be provided to the App develops. Keyword: Sentiment Analysis, Text Classification, Support Vector Machine, Social Network Analysis, Correspondence Analysis iii.
(5) 目錄 摘要 ........................................................................................................................................... ii Abstract .................................................................................................................................... iii 圖目錄 ...................................................................................................................................... vi 表目錄 .................................................................................................................................... viii 第一章、. 概論 ................................................................................................................. 1. 1、. 研究背景 ......................................................................................................... 1. 2、. 研究動機 ......................................................................................................... 3. 3、. 研究目的 ......................................................................................................... 4. 4、. 研究方法 ......................................................................................................... 6. 第二章、. 文獻探討 ......................................................................................................... 8. 政 治 大. 行動裝置與手機市集的發展 ......................................................................... 8. 1、 1.1. 行動裝置的發展 ........................................................................................ 8. 1.2. 手機作業系統與 App 市集的發展 ........................................................... 9. 立. 2.3. 情感分析的分類 ...................................................................................... 11 情感分析的方法 ...................................................................................... 13. ‧. 2.2. ‧ 國. 2.1. 學. 情感分析(Sentiment Analysis) ..................................................................... 11. 2、. 情感分析的應用 ...................................................................................... 19. Nat. sit. y. 特徵詞選取(Feature Selection) .................................................................... 21. 3、. 3.2. 訊息增益(Information Gain) .................................................................... 22. 3.3. 交互資訊量(Mutual Information) ............................................................ 23. 3.4. 卡方統計量(Chi-Square Statistic) ........................................................... 24. 3.5. 不同特徵詞選取方法的比較 .................................................................. 25. n. al. er. 文件頻率(Document Frequency Threshold) ............................................ 21. io. 3.1. Ch. engchi. i Un. v. 文字分類(Text Classification) ...................................................................... 27. 4、 4.1. 簡單貝氏分類器(Naïve Bayes Classifier) ............................................... 27. 4.2. kNN(k- Nearest Neighbor) ....................................................................... 29. 4.3. 支援向量機(Support Vector Machine, SVM) ......................................... 30. 4.4. 不同分類方法的比較 .............................................................................. 32. 5、 第三章、. 對應分析(Correspondence Analysis) ........................................................... 34 研究方法 ....................................................................................................... 35. 1、. 資料蒐集(Data Collection) ........................................................................... 36. 2、. 評論文章前處理(Document Preprocessing) ................................................ 37. 3、. 評論情感傾向計算(Sentiment Orientation) ................................................. 41 iv.
(6) 3.1. 建立情感詞集(Building Sentiment Term Set) ......................................... 41. 3.2. 計算評論的情感傾向 .............................................................................. 43. 4、. 評論議題擷取(Topic Extraction) ................................................................. 44. 5、. 視覺化分析(Visualization) ........................................................................... 48. 6、. 建立向量空間模型(Vector Space Model).................................................... 49. 7、. 特徵詞萃取(Feature Selection) .................................................................... 51. 8、. 分類模型建立與分類成效衡量(Classification) .......................................... 52 8.1. 監督式學習的分類演算法 ...................................................................... 52. 8.2. 分類的效果衡量 ...................................................................................... 52. 第四章、. 實驗結果與討論 ........................................................................................... 54. 1、. 實驗資料擷取結果 ....................................................................................... 54. 2、. 類別標記實驗結果 ....................................................................................... 55. 政 治 大. 2.1. 情感傾向類別標記結果 .......................................................................... 55. 2.2. 情感傾向標記實驗結果討論 .................................................................. 58. 2.3. 關注議題類別標記結果 .......................................................................... 60. ‧ 國. 學. 2.4. 立. 關注議題標記實驗結果討論 .................................................................. 67. 3.1. ‧. 視覺化分析結果 ........................................................................................... 69. 3、. 對應分析結果 .......................................................................................... 69. Nat. 情感趨勢走向分析結果 .......................................................................... 71. 3.3. 視覺化分析實驗結果討論 ...................................................................... 86. er. io. sit. y. 3.2. 監督式學習實驗結果 ................................................................................... 88. al. n. 4、. Ch. i Un. v. 4.1. 情感傾向分類結果 .................................................................................. 88. 4.2. 關注議題分類結果 .................................................................................. 89. 4.3. 監督式學習實驗結果討論 ...................................................................... 91. 第五章、. engchi. 研究結論與建議 ........................................................................................... 92. 1、. 結論與貢獻 ................................................................................................... 92. 2、. 未來研究建議 ............................................................................................... 95. 參考文獻 ................................................................................................................................. 96. v.
(7) 圖目錄 圖 一: 台灣智慧型手機普及率(Ipsos MediaCT, 2013) ............................................ 1 圖 二: 2014 百大風雲 App 調查(資策會 FIND,2014)................................................ 2 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 三:研究方法流程(本研究整理)............................................................................ 6 四: 2013 年 Google Play 前十大免費軟體(Distimo, 2013) ................................. 10 五:支援向量機示意圖 .......................................................................................... 30 六: 研究流程圖 .................................................................................................... 35 七: Google Play 的線上評價與評論..................................................................... 36 八: 區間為 4 的搜尋否定詞示意圖 .................................................................... 38 九:中文詞彙網路說明 .......................................................................................... 41 十: 利用種子詞擴充詞集範例 ............................................................................ 42 十一: 利用述詞擴充詞集範例 ............................................................................ 42 十二:候選議題詞擷取範例 .................................................................................. 44 十三: 議題詞資料對文件特徵的 TF-IDF 模型 .................................................. 45 十四: 利用 NPMI 值將議題詞建立為社會矩陣................................................ 46 十五: 議題類別判斷範例 .................................................................................... 47 十六:對應分析圖範例說明 .................................................................................. 48 十七: 應用於監督式學習分類任務之向量空間模型 ........................................ 49. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 十八: 情感詞擴增數量曲線 ................................................................................ 56 十九: 成功判別情感傾向百分比 ........................................................................ 57 二十: 候選議題詞 DF 值分布 ............................................................................. 60 二十一: 對應分析圖 ............................................................................................ 70 二十二: LINE 整體情感趨勢圖 ........................................................................... 71 二十三: LINE 介面風格與設計情感趨勢圖 ....................................................... 71 二十四: LINE 訊息傳送與社群情感趨勢圖 ....................................................... 72 二十五: LINE 帳戶與安全性類別情感趨勢圖 ................................................... 72 二十六: LINE 軟體表現與品質情感趨勢圖 ....................................................... 72 二十七: LINE 應用加值服務類別情感趨勢圖 ................................................... 72 二十八: 2/5~2/15LINE 應用加值類議題詞負面評論百分比 ............................. 73 二十九: 2/5~2/15LINE 訊息社群類議題詞負面評論百分比 ............................. 74 三十: WeChat 整體情感趨勢圖 ............................................................................ 75 三十一: WeChat 介面風格與設計類別情感趨勢圖 ............................................ 75 三十二: WeChat 訊息傳送與社群類別情感趨勢圖 ............................................ 76 三十三: WeChat 帳戶與安全性類別情感趨勢圖 ................................................ 76. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i Un. v. 圖 三十四: WeChat 軟體表現與品質類別情感趨勢圖 ............................................ 76 圖 三十五: WeChat 應用加值服務類別情感趨勢圖 ................................................ 76 圖 三十六: 2/20~3/5 WeChat 軟體品質類議題詞正面評論百分比 ........................ 77 vi.
(8) 圖 圖 圖 圖. 三十七: 2/20~3/5 WeChat 軟體品質類議題詞負面評論百分比 ........................ 78 三十八: Facebook Messenger 整體情感趨勢圖................................................... 79 三十九: Facebook Messenger 介面風格與設計類別情感趨勢圖....................... 79 四十: Facebook Messenger 訊息傳送與社群類別情感趨勢圖........................... 80. 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 四十一: Facebook Messenger 帳戶與安全性類別情感趨勢圖........................... 80 四十二: Facebook Messenger 軟體表現與品質類別情感趨勢圖....................... 80 四十三: Facebook Messenger 應用加值服務類別情感趨勢圖........................... 80 四十四: 3/10~3/31 Facebook 軟體品質議題詞負面評論百分比 ....................... 81 四十五: WhatsApp 整體情感趨勢圖 ................................................................... 82 四十六: WhatsApp 介面風格與設計類別情感趨勢圖 ....................................... 82 四十七: WhatsApp 訊息傳送與社群類別情感趨勢圖 ....................................... 83 四十八:WhatsApp 帳戶與安全性類別情感趨勢圖 ............................................ 83 四十九:WhatsApp 軟體表現與品質類別情感趨勢圖 ........................................ 83 五十: WhatsApp 應用加值服務類別情感趨勢圖 ............................................... 83 五十一: 2/19~2/26WhatsApp 訊息社群類議題詞負面評論百分比 ................... 84 五十二: 2/19~2/26WhatsApp 軟體品質類議題詞負面評論百分比 ................... 84 五十三: 3/5~3/14WhatsApp 軟體品質類議題詞負面百分比 ............................. 85 五十四: 3/19~3/26WhatsApp 軟體品質類議題詞負面百分比 ........................... 85. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vii. i Un. v.
(9) 表目錄 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表 表. 一: 中研院體詞詳細詞性表 ................................................................................ 39 二: 中研究述詞詳細詞性表 ................................................................................. 40 三:對應分析列聯表範例 ....................................................................................... 48 四:分類效果衡量 .................................................................................................. 53 五: 實驗資料統計表 ............................................................................................. 54 六: 情感傾向判斷實驗種子詞集數量表 ............................................................. 55 七: 不同實驗組別的情感詞集擴增數量表 ......................................................... 55 八: 不同實驗組別的評論情感判斷結果 ............................................................. 56 九: 人工標記情感類別情感傾向前後百分比 ..................................................... 57 十: 透過 DF 篩選議題詞前後詞數量對照.......................................................... 61 十一: Kmeans 分群結果........................................................................................ 62 十二: SOM 分群結果表 ........................................................................................ 62 十三: Concor 分群結果 ......................................................................................... 63 十四: 關注議題類別人工調整結果 ..................................................................... 64 十五: 各議題類別的評論筆數 ............................................................................. 66 十六: 對應分析列聯表 ......................................................................................... 69. 表 表 表 表. 十七: 十八: 十九: 二十:. 立. 政 治 大. ‧. ‧ 國. 學. n. al. er. io. sit. y. Nat. 特徵詞包含體詞、述詞的情感傾向分類結果 ......................................... 88 特徵詞僅包含述詞的情感傾向分類結果 ................................................. 88 特徵詞包含體詞、述詞的關注議題分類結果 ......................................... 89 特徵詞僅包含體詞的關注議題分類結果 ................................................. 90. Ch. engchi. viii. i Un. v.
(10) 第一章、. 概論. 1、 研究背景 自從蘋果的 iPhone 手機打開智慧型手機的市場,並隨著 Google 發展 Android 與手機廠商合作大舉發展行動裝置後,智慧型手機的市場便日漸蓬勃。全球有越 來越多的手機使用者拋棄傳統的功能性手機,轉而使用具有上網、定位、應用程 式等功能的智慧型手機,連台灣也不例外。 從 Google 與公證第三方民調組織 Ipsos,針對多國行動設備使用者的使用行. 政 治 大 台灣、新加坡、日本、泰國、菲律賓、 越南、韓國、香港、馬來西亞),台灣國 立. 為調查「Our Mobile Planet」的數據中,可以看到於針對亞洲十個國家中(中國、. ‧ 國. 學. 人的「智慧型手機普及率」已達 51%(圖一),在十個國家中排名第三。有 69%的 人表示最近 7 天內每天都會使用智慧型手機」 ,而「在出門必須帶著智慧型手機」. ‧. 的比率台灣為十個國家中排名第二。其中智慧型手機使用者有 81%的人在出門時. sit. y. Nat. 必須帶著智慧型手機,永不關機、如影隨行,可看出國人對於智慧型手機的依賴. n. al. er. io. 程度很高。在使用手機的行為方面,有 93%表示曾使用智慧型手機連上社群網站,. i Un. v. 並有 86%的使用者會用於和他人溝通。(Ipsos MediaCT, 2013). Ch. engchi. 智慧型手機普及率 100. %. 75. 50.8%. 50. 26%. 32.3%. 台灣|普及率. 25. 0 2011. 2012. 2013. 年份. 取樣基礎 總人口. 圖 一: 台灣智慧型手機普及率(Ipsos MediaCT, 2013) 1.
(11) 國內的資策會 FIND 亦曾針對台灣國人做智慧型手機與平板電腦的使用調查, 智慧型手機的使用者有 76%曾在一個月內到應用軟體市集下載手機 App,其中 Google Play 以 47.3%的比例高於 App Store 的 34.1%。而國人使用應用程式的類 型與國外的調查相近,大部份智慧型手機使用者所使用的手機 App 為遊戲、即 時通訊/傳訊息服務與社交互動類別(資策會,2012)。 另一份由專注行動裝置的行動廣告公司 Vpon 針對台灣國人最常使用的 Android 和 iOS 平台所作的調查報告顯示,由於行動市場發展快速,裝置普及化 提升的原因,2013 年的行動流量不斷持續的成長,從第一季到第四季達到 267% 的成長率(Vpon, 2013)。2012 年和 2013 年國人所使用的智慧型手機作業系統. 治 政 Android 都以約 60%的比率領先 iOS,最常使用的 大 App 類別流量來源皆為娛樂、 立 影音和社群,佔了所有 App 類別比重超過 60%。特別是社交類別於 2013 年的統 ‧ 國. 學. 計超過娛樂類別,佔了 26%的比重(Vpon, 2012;Vpon, 2013)。. ‧. 為瞭解消費者使用智慧型手機的狀況,創市際 ARO 與美國行動流量監控先. sit. y. Nat. 驅 Arbitiron 合作進行一項調查來偵測使用者的行為,其中到達率最高的手機應. io. er. 用程式 App 為 LINE 和 Facebook。在月到達率前十名之 App 中,包含了四項屬 於訊息傳遞類別的 App,包含 LINE、WhatsApp、Facebook 即時通和 WeChat,. al. n. iv n C 顯示使用者對於訊息傳遞功能的重視。資策會 h e n g c h FIND i U 於 2014 年首度進行大規模 跨通路的行動 APP 使用者行為調查,在 17 類 APP 中由社交聊天類拔得頭籌, 在前十名中亦包含了 LINE、Facebook 即時通、WhatsApp 和 WeChat(圖二)。 排序. App名稱. 使用率%. IOS%. Android%. 1. LINE. 66.6. 64.1. 77.0. 2. Facebook. 48.5. 47.5. 58.7. 3. 台灣蘋果日報. 35.6. 45.1. 58.5. 4. Facebook手機即時通. 35.3. 36.2. 41.5. 5. Youtube. 32.1. 32.1. 36.2. 6. WhatsApp. 27.6. 24.3. 41.6. 7. Candy Crush Saga. 26.9. 23.2. 27.8. 8. Line camera. 25.5. 25.4. 35.1. 9. 手電筒. 23.4. 26.9. 29.2. 10. WeChat. 23.3. 21.1. 33.7. 圖 二: 2014 百大風雲 App 調查(資策會 FIND,2014) 2.
(12) 2、 研究動機 從不同的研究報告中可以看到,台灣國人使用智慧型手機的普及率逐漸提高, 其中通訊與社群類別是智慧型手機使用者最常使用的手機應用程式類型。 針對 App 的下載量的研究顯示,線上手機應用程式市集內的 App 價格與下 載量兩者之不具有相關性,但是 App 的下載量卻和使用者的評價(Rating)有相關 (Harman, et al., 2012)。在針對 App 於 iOS 和 Android 兩大智慧型手機 App 市集 的排序中,下載量和手機的評價(Rating)與評論(Review)對 App 在市集裡面的排 序有大很的影響(Liu and Sun, 2013)。從這裡可以發現手機的評價會影響到手機應. 政 治 大 透過即時的情感分析與議題偵測型等工具和技術,可以提供企業進一步的瞭 立. 用程式的下載量,更會直接影響 App 在市集吸引到的眼球數與使用量。. ‧ 國. 學. 解顧向對於其產生或是服務的需求,並在顧客抱怨形成危機前作即時反應(Fan and Gordon, 2014)。從手機 App 的線上評論中,可看到不同使用者的反應與想. ‧. 法,從使用者滿意與不滿意的評論,開發者即可瞭解使用者給予的建議,並將. sit. y. Nat. App 所不足或是瑕疵作補足與修正。因此,瞭解線上評論對於 App 開發者來說,. n. al. er. io. 不止可以掌握使用者的反饋,更能透過評論找到未來改善 App 的方向。. i Un. v. 本研究希冀能透過分析 Google Play 中的 App 評論,讓開發者能掌握目前使. Ch. engchi. 用者所發表的評論內容。為此,本研究提出一套可以分析 App 線上評論之情感 分析方法,並利用 Google Play 內通訊類別中,四款國人最常使用的手機 App(LINE、Facebook Messenger、WeChat、WhatsApp)之線上評論為分析資料。 透過線上評論資料,並針對評論中所提及的正反面觀點,建立一個整合性的 分析方法。再經實證其效果後,進一步擴展到不同類型的 App,提供手機開發 者一個有效的線上評論之偵測與分析方法。. 3.
(13) 3、 研究目的 情感分析(Sentiment Analysis)又稱為意見探勘(Opinion Mining),主要在研究 人對於商品、服務或是事件等對象,所發表的評論、意見、情感或是態度。在情 感分析領域中,最初被用於預測使用者評論的正面與負面之情感傾向(Sentiment Orientation),目前也被廣泛應用在不同的資料來源,例如網站的線上評論,並用 來幫助企業找到產品的優缺點,進一步產生商業智慧(Zhang et al., 2012)。 有些研究則會針對使用者評論中,對於商品(相機)中不同特性或是議題(畫素) 的好或不好來進行整合性分析(Liu, 2012; Pang and Lee, 2008)。在 Web 2.0 和線上. 政 治 大 究,例如:電影(IMDB)(Pang, etal., 2002)、商品(Yin and Peng, 2009)和旅館或是 立. 社群服務的蓬勃發展下,已有許多針對不同的線上評論類型的網站作情感分析研. ‧ 國. 學. 社群網站(Zhou, et al., 2013)等。本研究則針對具有商品評論性質的 Android 線上 App 市集 Google Play 為研究對象。. ‧. 情感分析研究中,常會使用分類(Classification)的技術來將文章或是評論分. sit. y. Nat. 成不同的類別,將類別設定為正面與負面可用來判斷文章的正反情緒傾向,而將. n. al. er. io. 類別設定為不同的主題或是議題類別,可用來判斷文章的主題或主旨。. i Un. v. 分類的技術主要可分為監督式學習(Supervised Learning)和非監督式學習. Ch. engchi. (Unsupervised Learning)。其中監督式的學習方法是將現有的評論標上有限的類別, 透過監督式的機器學習演算法(Machine Learning Algorithm),並使用訓練資料集 (Training Data)來建立分類模型(Classification Model),再透過測試資料集(Testing Data)驗證其分類效果。其中監督式學習的機器學習演算法有支援向量機(Support Vector Machine, SVM)、第 k 個最近的鄰居(k-Nearest Neighbors, kNN)、簡單貝氏 分類器(Naïve Bayes Classifier)、決策樹(Decision Tree)等方法。 在使用監督式學習方法中,需透過不同的量化方式來完成文件量化,其中將 存在文章的詞給予權重值 1,不存在於文章的詞給予權重值 0 的簡單詞袋模型 (Bag-Of-Words Model)文件表達方法,即可達到很高的正確率(Pang, et al., 2002)。 4.
(14) 但是使用監督式學習方法仍有其限制,其中監督式學習方法所使用的訓練資 料集必須要有事前定義好的已知類別,因此使用監督式方法時,無法預期可能存 在的未知類別。因而在情感分析中,當要瞭解現今使用者對於產品大多討論的主 題內容時,若透過主觀的方式來設定所需要的議題或主題類別,將無法站在使用 者的觀點來瞭解到使用者最新的熱門討論趨勢。另外,監督式學習因為需要事前 定義好的已知類別,因此需進行耗費人力對文章進行實際類別標注的的人工類別 標注(Labelling)工作。 若先透過非督式學習的方法將文章資料標記其該所屬的類別,再使用監督式 學習的方法建立分類模型來分類文章資料,將可整合非監督式學習識別未知類別,. 治 政 與偵測新的線上評論的熱門討論趨勢的優點。故本研究將針對以下三個主題進行 大 立 詳細的分析與探討: ‧ 國. 學. ( 1 ). 使用不同非監督式的方法,將 App 評論作兩種類別的標注,一個為標注其. ‧. 所屬的正面或負面情感傾向,另一個為針對使用者所熱門討論的內容,將. sit. y. Nat. 評論標注其不同的關注議題。. io. er. ( 2 ). 對現有已標記情感傾向和關注議題類別的 App 評論,使用不同的視覺化方 法,將評論作進一步的整理呈現,來觀察不同 App 在各個關注議題的正反. n. al. C h的競爭狀況。 U n i 情感反應,並看到不同 App engchi. v. ( 3 ). 使用已標記好類別的 App 評論來建立訓練資料集,再使用監督式學習演算 法建立分類模型,最後驗證分類成效。其中會針對情感傾向和關注議題兩 種類別來將 App 評論分類。. 5.
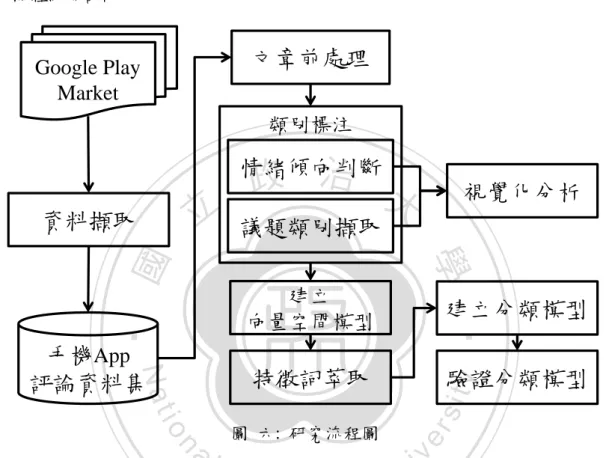
(15) 4、 研究方法 針對本研究所提出的 App 線上評論分析方法,主要分成以下階段. 資料擷取與文章前處理. 評論類別標注 以中文詞彙網路為基礎的 情感傾向判斷方法 以詞句關係並結合分群方法的 關注議題擷取方法. 立. 政 治 大. ‧. ‧ 國. 學. 使用對應分析與趨勢分析圖呈現使 用者對於App之優缺點分析. 使用監督式方法建立情感分析模型. iv n C hengchi U 三:研究方法流程(本研究整理). n 圖. 實驗結果探討. er. io. sit. y. Nat. al. 本研究由資料擷取(Data Extraction)開始,第一階段使用網路爬蟲程式(Web Crawler)於 Google Play 市集擷取所需分析之 App 線上評論(Online Review)。 在擷取實驗資料後經由評論文章前處理(Document Preprocessing)步驟例如: 文字斷詞(Segmentation/Tokenization)、詞性標注(Part-of-Speech Tagging)、負向詞 處理(Negation Process)、詞性過濾(POS Filtering)和停用詞過濾(Stop Word Filtering)等處理程序來將評論作初步的結構化整理,並計算每個字詞的字詞頻率 來完成文件量化。. 6.
(16) 第二階段於評論類別標注中可分成兩個部份,第一個部份使用中文詞彙網路 (Chinese WordNet)建立包含正負面情感詞之情感詞集(Sentiment Lexicon),並用來 計算每篇評論的情感分數以判斷評論的情感傾向。第二個部份則使用議題詞 (Topic Term)會靠近情感詞的語句特性,透過擷取最靠近情感詞的名詞建立候選 議題詞(Candidate Topic Term)找出所有可能的熱門關注議題詞。再經由過濾低文 件頻率(Document Frequency, DF)的議題詞找出所有的熱門關注議題詞後,最後使 用分群方法來對議題詞分群並彙總成多個關注議題類別(Popular Topic Class)。 第三階段使用已標注情感傾向和關注議題之評論,使用對應分析 (Correspondence Analysis, CA)與不同的視覺化圖形來展現使用者評論對於 App. 治 政 之優缺點分析,以呈現不同 App 的市場定位與討探各個 大 App 負面評論的原因。 立 第四階段先使用字詞頻率-逆向文件頻率(Term Frequency-inverse Document ‧ 國. 學. Frequency, TF-IDF)來表達每篇評論中不同字詞的特徵權重(Feature Weight),並建. ‧. 立監督式學習所需要的向量空間模型(Vector Space Model)。再經由特徵詞選取. sit. y. Nat. (Feature Selection)步驟來達成空間維度縮減(Dimension Reduction)與保留重要特. io. er. 徵詞,以提供分類演算法最佳的向量特徵。最後使用監督式的機器學習演算法 SVM 來建立情感分類模型,並使用 10 折交叉驗證(10-Fold Cross Validation)與分. al. n. iv n C 類驗證指標 Accuracy、Precision、Recall h e n g和cFhmeasure i U 來測試分類實驗的成效。. 7.
(17) 第二章、. 文獻探討. 1、 行動裝置與手機市集的發展 1.1. 行動裝置的發展. 近年來,隨著行動裝置的發展,除了三星、hTC、Apple 等先進入這塊市場 的廠商外,也有越來越多的企業(如:華為、中興)也跟隨腳步投入智慧型手機的 開發,帶動了行動裝置的熱潮。目前在世界上平均每五個人就有一支智慧型手機, 每十七個人就有一台平板電腦(BI Intelligence Estimates, 2013)。. 政 治 大. 智慧型手機的快速發展原因在於價格逐漸降低,且越來越多的行動商務服務. 立. 出現,加上智慧型手機的領導廠場結合新科技投入手機的設計與製造(ATKearney,. ‧ 國. 學. 2013),使智慧型手機逐漸普及並取代傳統功能性手機。從未來的智慧型手機成 長量來看,2014 年的智慧型手機全球出貨量將會成長 35%,且將首度超過十億. ‧. 支,預計到 2018 年將會超過二十五億支。比起傳統的功能性手機,智慧型手機. y. Nat. io. sit. 在 2014 年將會佔所有行動裝置銷售的 70%,更在 2018 年會達到 90%(BI. n. al. er. Intelligence Estimates, 2014)。而手機的出貨量增加使全球的智慧型手機使用者也. Ch. i Un. v. 逐年增加,直到 2018 年,全球智慧型手機的使用者將會超過 40 億人次(ATKearney, 2013; Ericsson, 2013)。. engchi. 8.
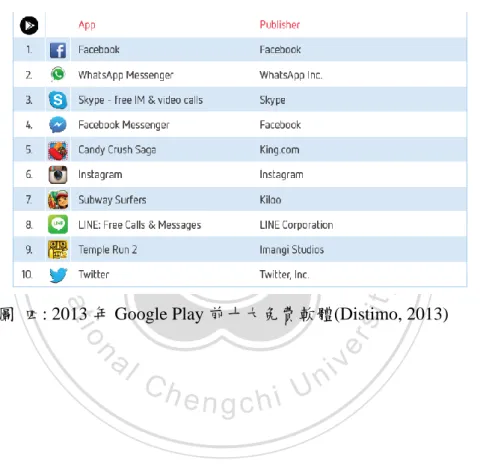
(18) 1.2. 手機作業系統與 App 市集的發展 在智慧型手機的作業系統中,前四大手機作業系統分別為 Android、iOS、. Windows 和 BlackBerry,其中發展最為快速的為 Google 於 2005 年併購並改良的 Android 系統。Android 有別於 iOS,其採取開放原始碼的策略,迅速吸引多數硬 體製造商投入結盟與發展 Android 系統的智慧型手機,使 Android 系統智慧型手 機快速發展,其市佔率並於 2010 年第二季超越 iOS 手機,且於 2011 到 2012 一 年的時間由 58%提升到 75%(Statista, 2013)。 在 2013 年第三季的全球智慧型手機的出貨先計量中,Android 作業系統更. 政 治 大 2013)。在手機 App 方面,因為 Apple 的線上應用程式商店 App Store 最先開始 立 首度達到 80%以上的市佔率,反而 iOS 市佔率下降為 12% (IDC, 2013;Garner,. ‧ 國. 學. 發展,因此一開始 App 的開發者與 App 的數量都領先其他的作業系統。Android 則在 2008 年上架第一款手機 App 後迅速增加使用者,在 2012 年改名為 Google. ‧. Play 市集後,並在 2013 年 1 月總計共有 80 萬個 App,超越蘋果 App Store 的. sit. y. Nat. App 數量,且遙遙領先 Windows Phone Store 與 Blackberry。在 2013 年 7 月 Google. n. al. er. io. Play 正式突破 100 萬個 App 數量(Statista, 2013),蘋果則晚三個月,並正式於 12. i Un. v. 月宣布 App Store 突破 100 萬個 App。從作業系統的手機出貨量和線上應用程式. Ch. engchi. 商店的 App 數量的發展中,可看到雖然蘋果一開始搶佔領智慧型手機與 App 市 集的先機,但是 Android 作業系統快速的追上蘋果,現今 Android 已經是全球智 慧型手機使用者中,市佔最高的手機作業系統。 在手機應用程式市集方面,Google 的 Google Play Store 和 Apple 的 App Store 現在已成為智慧型手機使用者最常使用的兩大 App 市集,至今兩大 App 市集的 App 下載次數也已經超過 500 億次 (Statista, 2013)。而根據 app 分析平台 Distimo 所發表的「2013 Year in Review」報告內容指出,免費的 App 所佔的比例逐漸增 加。其中針對使用者最多的 Android 系統的 App 市集,前十大免費 App 有一半 以上是屬於社群(Social Network))類別,而即時通訊(Communication)類別(分別為 9.
(19) WhatsApp Messenger、Skype、Facebook Messenger、LINE)的 App 更佔了其中四 個(Distimo, 2013)。 對於社群與即時通訊類別的手機 App 的使用者使用時間上,每個智慧型手 機的使用者平均每人每日會使用 17 分鐘(ATKearney, 2013),而且在 2013 年即時 通訊類別的手機 App 更成長了三倍之多,比去 2012 年成長了 203%(Statista, 2013)。 由此可以發現,越來越多人利用智慧型手機與他人進行社群聯繫,甚至使用即時 通訊的 App 作為聯絡方式,也越來越普遍存在於智慧型手機的使用者之間。. 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. io. n. al. er. 圖 四: 2013 年 Google Play 前十大免費軟體(Distimo, 2013). Ch. engchi. 10. i Un. v.
(20) 2、 情感分析(Sentiment Analysis) 情感分析又稱為意見探勘,其被定義為在文字上找到作者對於特定對象或主 題所發表的情感、意見與態度,以下針對情感分析作不同層面的文獻探討 (Pang and Lee, 2008; Liu, 2012; Feldman, 2013)。. 2.1. 情感分析的分類. 情感分析一直是一個熱門的研究議題,有超過七千篇的文章曾經探討這個議 題,而針對情感分析的分類,主要可以從情感分析的目的和文件的特徵來分類。. ( 1 ). 針對情感分析的層級分類. 治 政 (Liu, 2012)將情感分析的研究大致分成三個層級,分別是文件層級 大 立 (Document-Level)、語句層級(Sentence-Level)和概念層級(Aspect-Level)。文件層 ‧ 國. 學. 級的任務是對整個文件進行情感表現的分類,此層級的分析是假定每一篇文章只. ‧. 對一個對象發表意見(例如特定某一樣產品),並將一篇文章分類成正向情感或是. sit. y. Nat. 負向情感(Turney, 2002; Pang et al., 2002; Kim and Hovy, 2007)。語句層級的任務是. io. 中立的分類。. er. 對文件中不同段落的句子,分別針對句子所表達的情感傾向作正向、負向,或是. al. n. iv n C 概念層級則不同於文件層級和語句層級,專注在判斷喜歡或是不喜歡的情感 hengchi U. 傾向。概念層級又可以被稱為特微層級(Feature-Level),其目的是要找出文件中 對應情感詞或是意見詞的述敘目標(Target)。例如:這支手機的銀幕很漂亮,情 感詞「漂亮」對應到述敘目標「銀幕」,銀幕則是手機這個對象(Entity)的概念 (Aspect),另外亦稱為目標(Target)、特徵(Feature)或是議題(Topic)。. 亦有將不同層級分析結果作整合性呈現,通常為針對一個對象(如產品),並 分析對象的概念或是議題(產品特性)之情感傾向(正面或是負面),最後使用文字 性的整合報告 (Hu and Liu, 2004)或是使用視覺化(Visualization)的方式展現情感 分析結果(Oelke et al., 2009)。. 11.
(21) ( 2 ). 針對特徵的顯性和隱性分類 在情感分析中,可針對語句的特徵分成顯性(Explicit)和隱性(Implicit),具有 顯性特徵的語句通常有明確的情感詞或是目標特徵。例如:這支手機顏色很漂亮, 其中情感詞「漂亮」明確的對應到「顏色」。隱性特徵的語句中,語句背後雖然 有要表達的涵意,但卻無法直接從字句直接看出來。例如:這台相機很適合放在 口袋裡,這句話的意函在表達相機的「大小」,但是字句中卻沒有和「大小」有 相關的詞出現。這類具有隱性特徵的語句在分析上的難度,比起顯示特徵的語句 來的高(Hu and Liu, 2004; Liu 2012)。而大部份的情感分析研究都是針對顯性特徵. 政 治 大. 的語句作分析,但也有專門針對隱性特徵語句作處理的研究(Hai et al.,2011)。. 立. ( 3 ). 文章內容的主觀與客觀分類. ‧ 國. 學. 情感分析中,根據內容可分成主觀性(Subjective)和客觀性(Objective)兩種文 章內容,客觀的內容用來表達現實中實際的資訊,而主觀的內容則用來表達個人. ‧. 的看法或是個人的情緒表達(Liu, 2012; Feldman, 2013)。例如:這支手機很漂亮,. y. Nat. n. al. Ch. er. io. 機摔壞了則是表達一個實際的狀況或是實際的資訊。. sit. 但是前幾天摔壞了。其中前半段稱讚手機很漂亮為主觀的情感表達,而後半段手. i Un. v. 雖然文章內容可能為主觀或是客觀的內容,但是無論主觀客觀皆可能會有正. engchi. 面或是負面的情感表達。在許多針對線上使用者評論分析的研究中,會專注於主 觀性的文字內容來分析(Feldman, 2013)。. 12.
(22) 2.2. 情感分析的方法. 在文件層級和語句層級的感情分析研究中,主要專注於將文件或是語句根據 其情感傾向分類為正面、負面或是中立。針對情感傾向的分類上,有兩種主要的 方法,分別是監督式學習與非監督式學習(Fldman, 2013)。. ( 1 ). 應用非監督式學習的情感分析 非監督式學習方法基礎上是建立在計算情感傾向(Sentiment Orientation),因 此又被稱為情感傾向方法(SO Approach)( Pang and Lee, 2008)。非監督式學習通常 會通過計算情感分數的方式,設定一個事先定義的臨界值(Threshold),當計算的. 政 治 大. 情感分數超過臨界值時會判為正面亦或是負面。. 立. 應用非監督式情感分數計算的方法主要的方法可以分成兩個方向,一個是使. ‧ 國. 學. 用事先定義的 POS(Part of Speech)組合並結合相關性的計算。另一個是使用詞庫 來計算文章分數,再根據事先定義好的臨界值,決定文章為正面或是負面(Pang. io. er. SO-PMI 與 POS 組合的計算方法. sit. y. Nat. . ‧. and Lee, 2008; Liu, 2013; Feldman, 2013)。. 在應用 POS 組合的研究,(Turney, 2002)提出的語意導向 PMI(Pointwise. al. n. iv n C Mutual Information)演算法(Semantic SO-PMI)方法,首先找出語 h eOrientation-PMI, ngchi U 句中適當的 POS 組合,並於段落中擷取重要的情感詞。例如當副詞和形容詞兩. 詞相接,則取出副詞加形容詞的組合,或是當形容詞與名詞相連接時,則取出形 容詞作計算。 接著透過資訊檢索(Information Retrieval)的 hit 數量來計算文字間的 PMI 值, 其中將計算每個詞與正面詞「Excellent」和負面詞「Poor」之間共同發生的機率 來衡量每個段落接近正面或是負面。 SO − PMI(𝑤𝑜𝑟𝑑) = 𝑃𝑀𝐼(𝑤𝑜𝑟𝑑, "𝑒𝑥𝑐𝑒𝑙𝑙𝑒𝑛𝑡") − 𝑃𝑀𝐼(𝑤𝑜𝑟𝑑, "𝑝𝑜𝑜𝑟"). 13.
(23) 而 PMI 使用統計上的相互交互訊息(Mutual Information),進一步計算兩個事 件共同發生的機率。若兩個詞的共同發生機率愈高,則兩個詞愈相近,反之當兩 個詞為相互獨立,則 PMI 值為 0。 PMI(𝑤𝑜𝑟𝑑1 , 𝑤𝑜𝑟𝑑2 ) = log 2 (. 𝑃(𝑤𝑜𝑟𝑑1 , 𝑤𝑜𝑟𝑑2 ) ) 𝑃(𝑤𝑜𝑟𝑑1 )𝑃(𝑤𝑜𝑟𝑑2 ). 將詞透過檢索結果的 hit 數量來計算 PMI,改為以下式子表示: 1. PMI(𝑤𝑜𝑟𝑑1 , 𝑤𝑜𝑟𝑑2 ) =. log 2 (𝑁1 𝑁. . 使用外部詞庫的計算方法. ℎ𝑖𝑡𝑠(𝑤𝑜𝑟𝑑1 , 𝑁𝐸𝐴𝑅 𝑤𝑜𝑟𝑑2 ) ) 1 ℎ𝑖𝑡𝑠(𝑤𝑜𝑟𝑑1 ) ℎ𝑖𝑡𝑠(𝑤𝑜𝑟𝑑2 ) 𝑁. 政 治 大. 情感分析研究常需要使用外部語言資料,如:詞集、詞庫或是不同的語言資. 立. 料原協助完成,如使用事先定義的正負面詞庫或詞集來完成情感分數的計算. ‧ 國. 學. (Taboada et al., 2011)。在中文的情感分析研究中,因為中文的詞庫相關資源較少, 大部份的研究通常會使用 HowNet(知網)或是 NTUSD(National Taiwan University. ‧. Sentiment Dictionary)來完成情感分數計算(Wang and Lee, 2011; Sui et al., 2012 )。. y. Nat. sit. 除了使用已經事先定義好的詞庫之外,亦可透過自行建置的方式完成。其中. n. al. er. io. 會先建立一個已知情感傾向的種子詞集(Seed Words),再透過外部的語彙資料找. Ch. i Un. v. 出與種子詞所相關的詞彙,並加入種子詞集作擴充以完成自行建置的詞庫。. engchi. 詞彙網路(WordNet)是一個提供完整語義區分與詞彙關係的知識庫,WordNet 會將語彙分成兩個極性(同義與反義),透過 WordNet 即可找出與種子詞集內已知 情感傾向的關係詞。例如:事先定義「好」這個字為正面,並將「好」這個字查 詢 WordNet,再將查詢到的同義詞加入正面,反義詞加入負面,透過這個方法即 可有效的擴增種子詞集,並建立未來計算文章情感分數所需的情感詞集(Hu and Liu, 2004; Ding et al., 2008)。. 14.
(24) ( 2 ). 應用監督式學習的情感分類方法 監督式學習的情感分類方法通常為兩種類別的分類方法(正面和負面),其可 以視為文字分類(Text Classification)的問題。傳統的文字分類是將文本根據不同 議題類別作分類,如將新聞資料分成政治、科學和運動等等類別(Liu, 2012)。而 將傳統文字分類應用在情感分析上,最早(Pang et al., 2002)即使用監督式學習應 用在情感分析中,將電影的線上評論分成正面與負面兩種情感類別。 對於監督式的情感分類方法而言,最重要的關鍵是找出可以達到最佳分類效 果的資料特徵(Feature)(Liu, 2012)。如何找到適當能表達字詞對於文章的權重,. 政 治 大 類問題流程作了完整性的整理。在處理文字分類問題,將文章經過斷詞後,透過 立 與保留重要的特徵詞皆會對分類的正確率造成影響。(Hotho et al., 2005)對文字分. ‧ 國. 學. 進一步的文字前處理(Linguistic Preprocessing)可以加強分類效果。例如:移除停 用字(Stop Word)、詞性標記(POS)、文字串接(Text Chunking)等步驟。. ‧. 在移除停用字的作法,除了人工判斷停用字的方法外,(Hao and Hao, 2008). sit. y. Nat. 透過卡方統計量來衡量字詞有高詞頻,但是字詞和類別有低統計相關性的特性,. n. al. er. io. 來自動化的判斷是否為停用字。而在詞性標記(Part-of-Speeh Tagging)方面,是將. i Un. v. 各個詞標記上所屬的詞性,如:名詞、動詞、形容詞等。透過 POS 擷取重要詞. Ch. engchi. 性的字詞,在情感分析研究中可以幫助找到較重要的情感詞或是議題詞,並作進 一步的分析(Hu and Liu, 2004; Soliman et al., 2013; Wang and Lee, 2011)。 除了使用 POS 之外,亦常使用字詞的頻率來找到重要的特徵,其中在情感 分析研究中,使用 TF-IDF 權重來計算每個特徵詞的重要性已經被證明有高度的 成效(Liu, 2012),亦常於監督式學習的情感分類上被應用(Mouthami et al., 2013)。 TF-IDF 目的在表達字詞在特定文章的重要程度,如果字詞於文章內的出現頻率 高,但在其他所有文章的出現頻率低則會生高權重的 TF-IDF 值。 監督式學習會使用向量空間模型(Vector Space Model)來對大量文件作有效率 的分析。向量空間模型是由 N 個特徵維度所構成,一筆真實文章會使用一個向 15.
(25) 量來對應文章的多個特徵(Hotho et al., 2005; Manning et al, 2008),並將文章表現 成多維空間中的一點,以此來完成文章的向量化。其中可利用向量空間中特徵出 現的頻率來計算文件與文件間的相似度,以下為其中一種相似度計算方式,餘弦 ⃑⃑的相似度,當兩向量越接近代表兩 相似度(Cosine Similarity)會衡量兩個向量𝑋⃑和𝑌 向量越相似(Tata and Patel, 2007)。. Cosine Similarity (. ⃑⃑ 𝑋⃑.𝑌 ) ‖𝑋‖‖𝑌‖. 在進行監督式學習並建立訓練資料前,會透過特徵詞選取步驟來選取較佳的. 政 治 大 響分類結果品質的同時,降低向量空間的維度,並達到更快的計算速度與更佳的 立. 特徵。特徵詞選取會使用不同的演算法來計算並留下重要的特徵,其目的在不影. ‧ 國. 學. 分類正確率(Basu and Murthy, 2012; Stefano Baccianella, 2011)。最後使用監督式學 習演算法如 Naïve Bayes、Support Vector Machine、Decision Trees 等,透過訓練. ‧. 資料集作資料訓練,再由測試資料集作驗證。在監督式學習的演算法中,SVM. sit. y. Nat. 被證實比起傳統文字分類方法 Naïve Bayes 的分類效果還更好(Joachims, 1998)。. n. al. er. io. (Neethu and Rajasree, 2013)使用不同的機器學習方法來分析 Twitter 上有關於. i Un. v. 電子產品的使用者評論。其透過擷取 Twitter 上的文字資料,在經由人工標注類. Ch. engchi. 別後,建立一個能代表文章的特徵向量,其中包含了正面關鍵字的數量、負面 關鍵字的數量等等共八個特徵,並使用監督式方法且比較了 Naïve Bayes、SVM 等四種分類方法的分類效果。. 16.
(26) ( 3 ). 針對概念層級的情感分析方法 概念層級的情感分析可以視為資訊擷取(Information Extraction)的問題。在情 感分析中,每個情感或是意見詞往往都會有一個述敘的目標,而這個目標即是要 被擷取的概念詞或是議題詞。在進行概念層級的情分析進行擷取議題詞時,大至 有以下幾個簡易的方法(Liu, 2012): . 找尋高頻率的名詞(Nouns)與名詞字句(Nouns Phrases) 在中文裡議題詞往往會以名詞(體詞)的形態出現,而使用高頻率出現的字詞. 來判斷是否為議題詞之關鍵在於,當特定字詞出現的次數越多(即頻率越高),則. 政 治 大 (Ku et al., 2006)使用 TF-IDF 衡量不同的字詞在文件層級和語句層級的重要 立. 這個字詞即可能是熱門的關鍵議題詞。. ‧ 國. 學. 性,並找出重要的字詞。(Hu and Liu, 2004)使用關聯規則(Association Rule)演算 法 Apriori Algorithm 在具有顯性特徵的文章中,透過 Apriori 演算法的第一個階. ‧. 段找出高頻組合(Frequent Itemset)出現的字詞來擷取候選議題詞。例如:當在對. sit. y. Nat. 相機產品有關的文章使用 Apriori 演算法來擷取議題詞時,找出和「相機」這個. n. al. er. io. 字高頻率共同出現的詞,例如:「畫質」和「相機」出現在高頻組合內,即可判. i Un. v. 斷「畫質」這個詞可能對於相機產品的文章是熱門的關注議題。 . Ch. engchi. 使用情感詞與其述敘目標的相關性. 在情感分析中,詞句或文章內的情感詞皆有一個描述的對象,因此情感詞往 往和所述敘的議題詞會很接近。 (Hu and Liu, 2004)使用了距離最相近的方法來判斷情感詞與名詞或是名詞子 句之間的相依關係。例如:這台相機的造型好漂亮,其中「漂亮」是情感詞,而 最靠近「漂亮」的是「造型」這個名詞,「造型」即可以判斷為一個情感詞所形 容的目標詞或議題詞,故擷取出造型這個議題詞。(Lek and Poo, 2013)則針對情 感詞左和右邊找出所有候選的文章概念。亦有同時擷取情感詞與議題詞的相關研 究,(Zhuang et al., 2006)使用相依的語法圖(Dependency Grammar Graph)來剖析顯 17.
(27) 性特徵的詞句,用此方法找到共同出現的特徵與意見詞組(Feature-Opinion Pairs), 並同時擷取情感詞與議題詞。 . 使用監督式學習方法 使用監督式學習的方法來解決概念擷取或是情感目標詞擷取的問題中,最具. 優勢的方法是基於 Sequential Learning 的方式(Liu, 2012)。即透過人工方式標注 資料集的類別,再使用不同的 Sequential Learning 演算法如:Conditional Random Fields(CRF)或是 Hidden Markov Models(HMM)等方法來進行議題分類。(Jakob and Gurevych, 2010)針對語句層級來找到情感目標詞的問題中,使用 CRF 來訓練. 政 治 大 (Kovlamudi et al., 2011) 則提出一個應用在 Wikipedia 且不相依於單一領域的線 立. 相同領域或是跨領域的文章,並使用不同的特徵組合來找出最佳的分類效果。. ‧ 國. 學. 上使用者評論的屬性 (Attribute) 擷取方法。其中使用字詞頻率與文章相關性, 並使用 SVM 方法來分類資料。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 18. i Un. v.
(28) 2.3. 情感分析的應用. 在許多混合多種情感方法的情感分析應用方面,(Valakunde and Patwardhan, 2013)使用教育資料,建立一個以計算情感分數的非監督式方法,並混合監督式 方法的多概念(Multi-Aspect)與多類別(Multi-Class)的情感分析研究。其中在概念 擷取部份,其參考了印度專門評估和認證高等教育機構的 National Assessment and Accreditation Council (NAAC)所提出的關鍵準則,並採用四個概念分別為 Knowledge、Presentation、Communication 和 Regularity。透過人工標記的方式, 將包含對教師評論的實驗資料,針對四個概念分別標注其概念分數(+2 到-2 五個. 政 治 大 界值將資料劃分為+2 到-2 五個類別。其亦針對每篇資料中,正面詞和詞面負出 立 分數類別),並透過權重算出以概念為基礎的概念極性(Polarity)分數,再設定臨. ‧ 國. 學. 現的多寡給予一個直接文章極性分數。最後透過監督式演算法 Naïve Bayes 和 SVM 分別針對概念分數和直接文章分數,將文章分成五個類別。. ‧. (Farhadloo and E. Rolland, 2013)將 TripAdvisor.comd 的旅遊文章分成不同的. sit. y. Nat. 段落,並經由人工標注其情感類別。在概念擷取方面,首先使用只考量名詞的. n. al. er. io. Bag-of-Nouns 來取代傳統的文件表示模型 Bag-of-Wortds 改善概念辨識(Aspect. i Un. v. Identification)的分群成效,並以一個修改後的 Recall 作效果衡量。另外在情感傾. Ch. engchi. 向的分類方法,其提出一個分數表示(Score Representation)模型,其中透過正、 負、中立三個維度分數來代表一筆文章段落資料,並改善了三個類別(正面、中 立、負面)在 SVM 的分類效果。 (Zhang et al., 2011)針對概念擷取建立一個特徵階層(Feature-Level)的情感分 析方法來分析不同的電子產品。首先採用 Apriori 演算法來擷取文章中常共同出 現的名詞或名詞子句,來建立一個候選的特徵詞(Feature Words),接著再透過計 算產品和各個候選特徵詞的 PMI 值來過濾低 PMI 值的特徵詞,以選出對不同產 品最重要的特徵詞。在判斷文章情感傾向方面,其使用 HowNet 作為其情緒辭典, 並透過判斷每篇有出現特徵詞的文章,偵測文章中特徵詞前或後位置是否有任 19.
(29) 何出現在 HowNet 的情緒詞,來判斷每篇文章的情感傾向。 (Sui et al., 2012)提出一個針對中文微網誌(Micro Blog)的情感分析方法。在區 分文章不同議題部份,其採用了修改後的 PMI 值來衡量文章中的議題,並把不 同的文章依議題作分群。在判斷文章情感傾向方面,其合併使用了 HowNet 和 NTUSD 兩套中文情緒辭典,並透過以三個字詞為單位的掃描方法來找出一篇文 章中,所有的情感詞與否定詞,最後透過 SVM 和 kNN(k=7)來分類文章。 (Hu and Liu, 2004)在完成重要議題詞擷取的方法中,透過 Apriori 來找出高頻 率共同出現的名詞或名詞子句。在判斷文章情感傾向方面,先自定義包含各種 正反面情緒傾向形容詞的種子詞集,再透過 WordNet 來作擴充種子詞集,最後. 治 政 將擴增完的詞集應用在計算文章的情感分析上,並判斷每篇文章的情感傾向。 大 立 在將文章作議題類別和情感傾向標記後,其使用文字方式將文章作彙總呈現情 ‧. ‧ 國. 學. io. sit. y. Nat. n. al. er. 感分析結果。. Ch. engchi. 20. i Un. v.
(30) 3、 特徵詞選取(Feature Selection) 在文字分類的問題中,為降低與內容無關的特徵詞對文本分類的影響,並同 時降低向量空間的維度,會使用數學方法進行特徵詞的選取,來找出最具分類訊 息的特徵。特徵詞選取為一種較精確且人爲因素的干擾較少的方法。 特徵選取主要用來辨認文件中有意義且具代表性的片語或詞彙,而每筆資料 當中均可能含有多餘的特徵維度,因此必須予以刪除。在不影響辨識力的前提下 挑選出最佳的部分特徵,如此不僅能有效降低往後資料辨識所需花費的運算量及 時間,甚至也可提升文件識別的辨識度(Changqiu et al., 2009)。. 政 治 大 益(Information Gain)、交互資訊量(Mutual Information)及卡方統計(Chi-Square 立. 特徵詞選的方法中,常見的方法如:文件頻率(Document Frequency)、訊息增. 與其他特徵語選取方法的分類成效。. 3.1. 文件頻率(Document Frequency Threshold). Nat. y. ‧. ‧ 國. 學. Statistic)等特徵選取技術。以下分別介紹四種最常用的特徵詞選取方法,並探討. sit. 文件頻率是計算每個特徵詞在總文件中的出現次數。使用文件頻率來選擇特. n. al. er. io. 徵詞會使用一個事先定義好的臨界值(Predetermined Threshold),並將 DF 值低於. Ch. i Un. v. 此臨界值的特徵詞從向量空間中移除。使用文件頻率來對特徵詞作篩選是一個最. engchi. 簡單的降低維度方法,且可以輕易的應用在大型的資料集中。 文件頻率的假設重點在於,通常越重要的字詞會出現在越多的文件中(Yang and Pedersen, 1997)。但使用文件頻率的假設可能反而會造成分類正確率的降低, 因為在許多文件頻率很高的特徵詞,常為停用字或是普通不重要的雜訊(Yang and Pedersen, 1997;Basu and Murthy, 2012)。因此往往使用文件頻率來選擇特徵詞時, 會混合其他不同的方法進行選取特徵詞方法。. 21.
(31) 3.2. 訊息增益(Information Gain). 訊息增益由 Quinlan 於 1979 年所提出,且已被成功的用在許多關於文字學習 的研究中,並且在機器學習中成為一個衡量特徵好壞的準則(Sun et al, 2009)。訊 息增益是以資訊理論(Information Theorem)中的熵(Entropy)概念為基礎,熵在資 訊理論中是用來衡量隨機度數的期望值或是不確定性。因此使用訊息增益來作為 特徵詞選取的方法時,其定義為分類前資料的資訊量,減去依照某個屬性分類後 的子集合資訊量總合即代表資訊的獲利量。 訊息增益會透過瞭解特定詞在文件出現或是不出現,來衡量預測分類類別時. 政 治 大 個分類系統的 IG 值表示此特徵詞在整個分類系統中所能提供的資訊量,當所得 立. 所獲得的資訊量(Yang and Pedersen, 1997)。利用訊息增益法來計算特徵詞 A 於整. ‧ 國. 學. 到的 IG 值越大,表示該特徵詞 A 能為整個分類系統提供愈多的資訊量,因此該 特徵詞 A 對分類的鑑別度也愈高。以下列公式計算一特徵詞 A 於類別集合 C 的. ‧. IG 值 IG(C,A):. y. sit. io. 其中H(C) = − ∑n𝑖=1 𝑝(𝑐𝑖 ) log 𝑝(𝑐𝑖 ). n. al. er. Nat. IG(C, A) = H(𝐶) − 𝐻(𝐶|𝐴). i Un. v. 代表每個類別𝐶𝑖 的熵加總,即表示未分類前的資訊量,若是各個類別分配越. Ch. engchi. 平均則資訊量越大,若是各個類別分配越一致則資訊量(亂度)就越小。 其中𝐻(𝐶|𝐴) = 𝑃(𝐴)(− ∑𝑛𝑖=1 𝑃(𝐶𝑖 |𝐴) log 𝑃(𝐶𝑖 |𝐴)) 𝑛. +𝑃(𝐴̅)(− ∑ 𝑃(𝐶𝑖 |𝐴̅) log 𝑃(𝐶𝑖 |𝐴̅)) 𝑖=1. 代表特徵 A 在文件中,出現𝐴或是沒有出現𝐴̅的條件熵,代表加入特徵 A 後, 分類子集合之資訊量總合。(Cover and Thomas, 1991)認為,信息增益方法在分類 研究領域中,為一種穩定的特徵詞選取方法。. 22.
(32) 3.3. 交互資訊量(Mutual Information). 交互資訊量在統計上常用來衡量變數與變數之間的相互依賴程度,且常被使 用在語言統計模型中,計算字詞的關聯程度與這方面的應用(Yang and Pedersen, 1997)。交互資訊量在特徵詞選取中,假設要計算一個類別 c 和一個特徵詞 t 之間 的交互資訊量 MI(t, c)如下表示: 𝑀𝐼(𝑡, 𝑐) = 𝑙𝑜𝑔2. 𝑝(𝑡|𝑐) 𝑝(𝑡, 𝑐) = 𝑙𝑜𝑔2 𝑝(𝑡) 𝑝(𝑡) × 𝑝(𝑐). MI 值是比較並觀察字詞 t 和類別 c 的聯合機率,當 MI 值為 0 時,代表類別 c 和特徵詞 t 之間是獨立的,反之當字詞 t 和類別 c 具有高度的相似性,則會產. 政 治 大. 生高的 MI 值,表示則該字詞越重要。. 立. 因為交互資訊量是透過衡量特徵詞 t 和類別 c 之間的相依性來判斷該特徵詞 t. ‧ 國. 學. 的重要程度,因此使用交互資訊量會先定義一個選擇特徵的臨界值,並將低於臨 界值 PMI 分數的特徵從向量空間移除。在計算 MI 值在所有的類別中主要有兩個. ‧. Nat. y. 以下兩個方法(Yang and Pedersen, 1997):. 𝑀𝐼𝑎𝑣𝑔 (𝑡) = ∑ 𝑃(𝑐𝑖 )𝑀𝐼(𝑡, 𝑐𝑖 ). n. al. 𝑖=1. er. io. sit. 𝑛. Ch. i Un. v. 第一個方法為計算字詞 t 與所有類別的平均 MI 值,其中透過計算字詞 t 與每. engchi. 個類別的 MI 值,再分別乘上每個類別所佔的百分比。 𝑀𝐼max (𝑡) = max{𝑡, 𝑐𝑖 } 𝑖=1. 第二個方法是計算字詞 t 與所有類別的 MI 值後,選取出最大值來代表該字詞 的 MI 值。 MI 值的缺點在於很容易受到字詞的邊際機率影響,當有相同的𝑝(𝑡|𝑐)時,會 造成越稀少出的字詞反而 MI 值會比熱門出現的 MI 值還高,並造成誤差(Yang and Pedersen, 1997;Basu and Murthy, 2012)。. 23.
(33) 3.4. 卡方統計量(Chi-Square Statistic). 使用方卡統計量可以衡量字詞 t 與類別 c 之間的獨立性。將字詞 t 與類別 c 使用雙向列聯表(Two-Way Contingency Table)來表示 t 與 c 之間的關係,即可利用 方卡檢定來計算雙向列聯表中,行和列的關聯性,透過卡方統計量計算字詞 t 與 類別 c 的關聯性可以簡化為以下公式計算: 𝑁 × (𝐴𝐷 − 𝐶𝐵)2 (𝐴 + 𝐶) × (𝐵 + 𝐷) × (𝐴 + 𝐵) × (𝐶 + 𝐷). 𝜒 2 (𝑡, 𝑐) =. 其中 A 為字詞 t 與類別 c 共同出現的次數 B 為出現字詞 t 但不出現類別 c 的次數. 政 治 大. C 為不出現字詞 t 但出現類別 c 的次數. 立. N 為總文章數. 學. ‧ 國. D 為字詞 t 和類別 c 皆共同不出現的次數. 若是卡方值為 0,則代表字詞 t 與類別 c 為相互獨立。透過計算每個特徵詞. ‧. 與類別的卡方值可以得到一個卡方分數,並將過這個卡方分數來將低卡方值的特. y. Nat. er. io. 兩種不同的計算方法:. sit. 徵從向量空間移除(Yang and Pedersen, 1997),在計算特徵詞的卡方值可分以下成. al. n. 𝑛 iv n C U𝑐𝑖 ) h e= n ) 𝜒i2 (𝑡, 𝜒 2 𝑎𝑣𝑏 (𝑡) ∑ 𝑃(𝑐𝑖h c g 𝑖=1. 第一個方法為計算字詞 t 與所有類別的平均𝜒 2 值,其中透過計算字詞 t 與每 個類別的𝜒 2 值,再分別乘上每個類別所佔的百分比。 𝜒 2 𝑚𝑎𝑥 (𝑡) = max{𝜒 2 (𝑡, 𝑐𝑖 )} 𝑖=1. 第二個方法是計算字詞 t 與所有類別的𝜒 2 值後,選取出最大值來代表該字詞 的𝜒 2 值。. 24.
(34) 3.5. 不同特徵詞選取方法的比較. 在各種特徵詞選取的方法中,IG 和卡方兩種方法所得到的分類結果平均表現 優於 DF 和 MI (Yang and Pedersen, 1997; Sun et al., 2009; Xu et al., 2007; Uchyigit, 2012) ,且可在不降低分類的正確率下,篩選掉 90% 以上的特徵詞 (Yang and Pedersen, 1997; Sun et al., 2009) 。除了 IG 和卡方外,DF 方法甚至可以達到不錯 的成效,因此如果在有限的計算成本下,可以使用 DF 方法來取代 IG 和卡方, 其為簡單但是又有成效的特徵篩選(Yang and Pedersen, 1997)。 除了 DF、IG、卡方和 MI 四種特徵詞選取方法,(Basu and Murthy, 2012)提. 政 治 大 徵詞選取方法比較,其效果略優於卡方與 IG。(Sun et al., 2009) 比較了許多不同 立 出了字詞顯著性(Term Significance, TS)來改善特徵詞選取的效果,並與其他的特. ‧ 國. 學. 的特徵詞選取方法,其中除了 DF、IG、卡方和 MI 外,加入期望交叉熵 (Expected Cross Entropy, ECE) 、字詞強度 (Term Strength) 、針對文字的證據權重法. ‧. (Weight of Evidence for Text, WET) 與勝算比 (Odds Ratio, OR) 。結果發現卡方. sit. y. Nat. 與 IG 分類效果佳,而 OR 方法可達到與卡方和 IG 相似的分類效果,其中卡方略. n. al. er. io. 優於其他方法。(Xu, 2012)比較了卡方、IG、DF、ECE、OR 和 WET 使用在中文. i Un. v. 垃圾郵件的過濾問題的分類效果。其中結果指出雖指卡方和 IG 的結果不錯,但. Ch. engchi. 是 OR 和 WET 可得到更優秀的分類正確率,不過這兩種方法較適合用在二元的 分類(Binary Classification)問題,因此針對多類別的分類,效果還是低於卡方與 IG。(Uchyigit, 2012)加入了不同的方法並進行比較,在使用 Naïve Bayes 分類方 法下,除了 MI 之外,大多方法都可以達到不錯的結果。其中該篇報告所提出的 新方法 GU Metric 甚至可以和普遍常用的方法如卡方、GI 和 OR 達到相同的分類 結果甚至有時效果更好。(Yang and Liu, 2011)利用特徵幾何中心的變動程度提出 新的特徵詞選取方法 FCFS(Feature Centroid Feature Selection),並使用三個不同 的資料集與二種不同的分類方法,來和其他的特徵詞選取方法作比較。其中 FCFS 的成效和 GI 相差不多,但是在其中一組的資料集得到較佳的結果。 25.
(35) 根據(Yan, 2010)的分析發現,好的特徵詞選取方法總會滿足一些特定準則,如: 有利於一般化的詞、使用類別的資訊和使用字詞的頻率資訊。在該研究結果發現 IG 有滿足相關的準則且達到較高的分類正確率,而 MI 則沒有達到任何準則,且 得到較低的分類正確率。(Zhang et al., 2012)提出了新的特徵詞選取方法,將向量 空間模型轉成三維表示,有別與傳統的向量空間模型,可有效提升分類效果。 在特徵詞選取方法中,大部份的方法都專注於全域的特徵選擇(Global Selection),即判斷一個特徵對於整個系統的所有類別的重要性。然而(Qiu et al., 2008)則採用區域特徵選擇(Local Selection)加上計算平均卡方值(Chi AVG)的全域 特徵選擇兩個階段的混合法。其分成四個對照組,前三組分別先使用 DF、TF 和. 治 政 TFIDF, 針對各個類別挑選前 50%的詞,之後再利用平均卡方值選詞,而第四 大 立 個只使用平均卡方值。四個對照組的分類結果發現使用 DF 加上卡方可以達到提 ‧ 國. 學. 升整體分類正確率的效果。(Zhang et al., 2009) 結合正規化的相互訊息. ‧. (Regularized Mutual Information, RMI) 和資訊分散 (Distribute Information, DI). sit. y. Nat. 得到比較原本較佳的分類正確率。. io. er. 許多的實驗結果都指出,當特徵詞選取結果後,特徵維度愈高,對於不同的 選詞方法所得到的分類正確率結果皆會收斂,因此當分類的維度愈高,特徵詞方. al. n. iv n C 法的效果就愈不明確(Sun et al., 2009; Uchyigit, 2012; Yan, 2010)。 hen gchi U. 26.
(36) 4、 文字分類(Text Classification) 文字分類的目的在於將事先定義好的類別指派給文件或是檔案,最簡單的例 子就是將新進的新聞自動的根據新聞內容議題,將新聞分成不同的類別(如政治、 運動、科技等類別)(Hotho et al., 2005)。 為了完成分類任務,會使用訓練資料集並利用機器學習演算法建立分類模型, 最後再透過測試資料實證結果,並使用不同的指標來衡量分類的成效。在機器學 習演算法中,常見的有 Naïve Bayes、kNN、SVM、決策樹(Decision Tree)等訓練 資料的分類演算法,以下分別介紹常見的分類演算法:. 4.1. 政 治 大. 簡單貝氏分類器(Naïve Bayes Classifier). 立. 貝式分類法是以統計學機率為基礎的分類方法,主要根據貝式定理(Bayes’. ‧ 國. 學. Theorem)中透過事前機率(Prior Probability)及取得實際資訊推得的事後機率 (Posterior Probability),來實現將未知的資料分類給最大機率的類別。假設要計算. ‧. er. io. sit. Nat. 𝑃(𝐶𝑖 )𝑃(𝑋|𝐶𝑖 ) 𝑃(𝑋). P(𝐶𝑖 |𝑋) =. y. 某一筆未知類別的資料𝑋是屬於某類別𝐶𝑖 的機會可表示成下列式子:. 其中𝑃(𝐶𝑖 )為事前機率,即類別𝐶𝑖 發生的機率,而P(𝐶𝑖 |𝑋)為事後機率,表示. al. n. iv n C 未知類別的資料𝑋屬於類別𝐶𝑖 的機率 X 包含𝑎 , 𝑎 , … , 𝑎 個變數(特徵), h e,假設資料 ngchi U 1 2 𝑛 應用貝氏分類表示成下列式子:. P(𝐶𝑗 |𝑎1 , 𝑎2 , … , 𝑎𝑛 ) =. 𝑃(𝐶𝑗 )𝑃(𝑎1 , 𝑎2 , … , 𝑎𝑛 |𝐶𝑗 ) 𝑃(𝑎1 , 𝑎2 , … , 𝑎𝑛 ). 而簡單貝氏分類方法假設所有屬性對其類別具有條件獨立(Conditional Independence)的特性,因此𝑃(𝑎1 , 𝑎2 , … , 𝑎𝑛 |𝐶𝑗 ) = ∏𝑛𝑖=1 𝑃(𝑎𝑖 |𝑐𝑗 ),改寫為以下式子: P(𝐶𝑖 |𝑎1 , 𝑎2 , … , 𝑎𝑛 ) =. 27. 𝑃(𝐶𝑗 ) ∏𝑛𝑖=1 𝑃(𝑎𝑖 |𝑐𝑗 ) 𝑃(𝑎1 , 𝑎2 , … , 𝑎𝑛 ).
(37) 使用簡單貝氏分類器分類資料時,會根據資料屬性值,計算資料被指派到不 同類別的機率。並將資料分給機率最大的類別,以達到分類的效果,如下式子: 𝑛. 𝐶𝑙𝑎𝑠𝑠𝑁𝐵 = max P(𝐶𝑗 |𝑎1 , 𝑎2 , … , 𝑎𝑛 ) = max 𝑃(𝐶𝑗 ) ∏ 𝑃(𝑎𝑖 |𝑐𝑗 ) 𝐶𝑗 ∈𝐶. 𝐶𝑗 ∈𝐶. 𝑖=1. 其中𝑃(𝑎1 , 𝑎2 , … , 𝑎𝑛 )為常數略忽 (Srisukha et al., 2008) 將貝式分類運用在泰文網頁的網路爬蟲,除此之外, Naïve Bayes 被廣泛應用在傳統文字分類的問題中。 (Pang et al., 2002) 使用 Naïve Bayes 將線上電子的評論根據其情感分成正負兩個類別。(Eyheramendy et al.,. 政 治 大 Classifier。(Zheng and Tian, 2010) 使用 Naïve Bayes 來對搜狗新聞網進行中文的 立 2003) 使用四種不同的機率分配來完成文字的分類,其中包含了 Naïve Bayes. ‧ 國. 學. 文字分類,並將新聞分類成文化、運動、健康、科技等新聞類別。(Hao and Hao, 2008)結合卡方統計量衡量特徵相關性的特性,提出一個自動化的中文停用字偵. ‧. 測方法,其中即使用 Naïve Bayes 器來判定是否為停用字,分類的正確率接近 90%。. sit. y. Nat. 雖然 Naïve Bayes 被廣泛應用在不同的文字分類問題上,但是其分類效果卻不如. n. al. er. io. 其他的分類方法突出,故有研究針對 Naïve Bayes 方法來改進(Kim et al., 2006)。. Ch. engchi. 28. i Un. v.
(38) 4.2. kNN(k- Nearest Neighbor). kNN 演算法是透過計算相似度(Similarity)與距離(Distance)的方法來將資料 分類。其中 k 是指第 k 筆最相近的資料,因此當 k=1 時,會挑出 1 個最相近的資 料,並將新資料與最相近的資料分到同個類別。 在給定一個包含資料𝑥𝑖 與類別𝑦𝑖 的訓練資料集{(𝑥𝑖 , 𝑦𝑖 ), (𝑥𝑖 , 𝑦𝑖 ), … , (𝑥𝑖 , 𝑦𝑖 )},其 中𝑥𝑖 包含𝑎1 , 𝑎2 , … , 𝑎𝑛 個變數(特徵),亦可表達成 {(𝑎1 , 𝑎2 , … , 𝑎𝑛 , 𝑦𝑖 ), (𝑎1 , 𝑎2 , … , 𝑎𝑛 , 𝑦𝑖 ), … , (𝑎1 , 𝑎2 , … , 𝑎𝑛 , 𝑦𝑖 )}。當一筆新資料d𝑖 根據 kNN 分類法,如下列式子表示: y(d𝑖 ) = max y(𝑥𝑖 , 𝑐𝑘 ). 政 治 大 其中d 為一筆未分類的新資料,𝑥 是在訓練資料集中一個鄰近資料,kNN 會 立 𝑥𝑖 ∈𝑘𝑁𝑁. 𝑖. 𝑖. ‧ 國. 學. 從挑出來的 k 個鄰近資料中,將新資料給予出現最多次的資料類別。 在 kNN 常使用的距離計算方法為歐幾里得距離(Euclidean Distance),另外也. ‧. 會使用餘弦相似度(Cosine Similarity)等相似度計算方法來取代簡單的距離計算,. sit. y. Nat. 以提高 kNN 的分類效果(Han et al., 2001;Qamar et al., 2008; Erkan et al., 2011;. al. er. io. Farhoodi and Yari, 2010)。在使用相似度計算的 kNN 如下列式子表示:. n. iv n C h𝑥 ∈𝑘𝑁𝑁 i U e h n c g 其中𝑆𝑖𝑚(𝑑𝑖 , 𝑥𝑖 )為未分類資料d𝑖 和訓練資料集內的資料𝑥𝑖 的相似度,而 𝑦(d𝑖 ) = ∑ 𝑆𝑖𝑚(𝑑𝑖 , 𝑥𝑖 ) 𝑦(𝑥𝑖 , 𝑐𝑘 ) 𝑖. 𝑦(𝑥𝑖 , 𝑐𝑘 ) ∈ {0,1}指當資料𝑥𝑖 屬於類別𝑐𝑘 時為 1,不是為 0。透過計算與各個類別的 最近相似度來判斷新資料的類別。. 29.
數據

相關文件
(1999), "Mining Association Rules with Multiple Minimum Supports," Proceedings of ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,
The International Conference on Innovation and Management 2012 (IAM 2012) is an annual conference on Innovation and management since 1999, organized and sponsored by the
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
C., “Robust and Efficient Algorithm for Optical Flow Computation,” Proceeding of IEEE International Conference on Computer Vision, pp. “Determining Optical Flow.” Artificial
Selcuk Candan, ”GMP: Distributed Geographic Multicast Routing in Wireless Sensor Networks,” IEEE International Conference on Distributed Computing Systems,
Ko, “Fast Intra Prediction Mode Selection Scheme Using Temporal Correlation in H.264,” IEEE International Region 10 Conference, pp. Yu, “A Fast Mode Decision Method for
Leung, Shuk-Kwan S.; Chou, Hui-Chi(2012).A Survey Study on Parental Involvement in Mathematics Learning for Elementary School Children. Proceedings of the 36th Conference of
Leung, Shuk-Kwan S.; Chou, Hui-Chi(2012).A Survey Study on Parental Involvement in Mathematics Learning for Elementary School Children.. Proceedings of the 36th Conference of
