國 立 交 通 大 學
電信工程研究所
碩士論文
中文自發性語音辨認系統
Mandarin Spontaneous Speech Recognition
研 究 生:許誌宏
指導教授:陳信宏
博士
中文自發性語音辨認系統
Mandarin Spontaneous Speech Recognition
研 究 生:許誌宏 Student:Chih-Hung Hsu
指導教授:陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學 電 信 工 程 研 究 所
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
in
Communication Engineering
August 2010
Hsinchu, Taiwan, Republic of China
中文自發性語音辨認系統
研 究 生:許誌宏 指導教授:陳信宏
博士
國立交通大學電信工程研究所
中文摘要
近年來朗讀式語音辨認技術已經相當成熟,下一階段的目標將轉往自發性語音辨認,因 此本論文將建立一套中文自發性語音辨認系統。在本論文中首先將說明如何建立自發性語音 聲學模型;在語言模型方面,自發性語音中有許多常用的口語詞、感嘆詞或語助詞,這些都 與傳統語言模型差異甚大,因此本論文以傳統語言模型為基礎,建立一套自發性語音語言模 型。 在自發性語音韻律模型的改進方面,本研究將重新定義自發性語音中的特殊韻律現象。 除此之外,傳統語音辨認通常只使用聲學模型及語言模型,但是自發性語音中有許多的特殊 現象是朗讀式語音中沒有的,因此本論文詴著將韻律模型也運用進來,希望能利用韻律資訊 來解決這些狀況。Mandarin Spontaneous Speech Recognition
Student:Chih-Hung Hsu Advisor:Dr. Sin-Horng Chen
Institute of Communication Engineering
National Chiao Tung University
Abstract
In recent years, the read-speech recognition technology has been quite mature, and the goal for the next phase will be transferred to spontaneous speech recognition; therefore, this paper will establish a Chinese spontaneous speech recognition system. In this paper, we will describe how to build the spontaneous acoustic model first. In the language model, there are many popular spoken word, particle and expletive in the spontaneous speech, which has great difference with the traditional language model. So, we will adapt a spontaneous speech language model based on the traditional language model in this paper.
In the improvement of the spontaneous speech prosody model, this paper will re-define the special prosodic phenomena of the spontaneous speech. In addition, people usually use the acoustic model and the language model in the traditional speech recognition. However, there are many differences between read-speech and spontaneous speech. So, this paper will try to use some prosodic information to help the speech recognition and wish to resolve these situations.
誌謝
學生時代終於真的要結束了!還真是謝天謝地蟹老闆勒~~哇哈哈!不過在這裡好像應 該要感性一點齁…,感謝每個禮拜督促我們進度的陳老師,雖然最後是「功虧一簣」,但是 我們雖敗猶榮!再來是要感激每次輪我報告時就會突然出現電爆我的王老師,雖然每次我都 只能啞口無言站在台上,但是事後想想都覺得老師說的很有道理,還有就是感謝您在口詴時 助我一臂之力! 再來就是實驗室的大家,首先是帶著我一路走來的性獸、帶我加入 DMC 行列的合哥、 每次都走過來問我有什麼問題的阿德,還有地球防衛小組的希群和準備開公司的巴金叔,你 們應該算是 707 的五虎將吧!有著納豆明星臉的輝哥,總是喜歡講一些嚇人的話;這兩個月 來一直和我一貣住實驗室的承燁,恭喜你最後陶小姐對你露出勝利的微笑;「超屌」的皓翔, 我很怕 10 年後只記得你叫暢邱翔;在系辦打工超夯的雲舒,我永遠不會忘記你口詴時的樣 子;口詴時就變成小孬孬的財祿,祝你在晨星能熬過三個月;進實驗室前被我跟大學同學偷 偷稱電信大小喬的小喬依玲,我只要兩妹就好了不需要到 20 妹謝謝;還有我們永遠的一哥 宥余,什麼時候可以幫我切我的語料啊?哈哈…感謝學長們小宋、杜 Q、小帥哥還有把我騙 入 spontaneous 世界的普烏;感謝碩一的學弟們:後來常幫我寫程式的銘傑、大一上邏設第 一次期中考就考一百分的人妻殺手胖胖,用合成器造出一堆告白句子卻都沒用過的啟全、舞 林高手智障、聯誼咖大胖跟小蝦、健身達人豆腐喵以及神秘人佳緯。 最後感謝我的大學同學們,以電信嘟為首的台北幫以及常常揪團吃飯看電影的新竹幫, 讓我碩班生活不至於都在實驗室度過!套句老梗:要感謝的人太多了,那就謝天吧!目錄
中文摘要... I Abstract ... II 目錄... IV 表目錄... VII 圖目錄... IX 第一章 緒論...1 1.1 研究動機...1 1.2 相關研究...2 1.2.1 語言模型之相關研究...2 1.2.2 韻律模型幫助辨認之相關研究...2 1.3 研究方向...3 1.4 章節概要...4 第二章 漢語口語對話語料庫介紹...5 2.1 語料庫介紹...5 2.1.1 音檔格式說明...5 2.1.2 語料標註格式說明...6 2.2 自發性語音之特性...7 2.3 MCDC 語料庫之後處理 ...9 2.3.1 斷詞與相關統計...9 2.3.2 標記標點符號... 11 2.3.3 非流暢現象中斷點...12 2.3.4 修正音節切割位置...13 第三章 自發性語音辨識系統...153.1 聲學模型...15 3.1.1 訓練語料及測詴語料...15 3.1.2 聲學模型之建立...16 3.1.2.1.特徵參數抽取... 16 3.1.2.2 聲學模型之建立流程... 16 3.1.3 實驗結果...19 3.2 語言模型...21 3.2.1 初始模型之建立...21 3.2.1.1 訓練語料... 21 3.2.1.2 模型訓練... 21 3.2.2 語言模型之調適...22 3.2.2.1 自發性語音之訓練單元... 22 3.2.2.2 調適模型之設計... 23 3.2.3 語言模型效能分析...29 第四章 自發性語音韻律模型...30 4.1 韻律模型設計...30 4.1.1 中文語音韻律階層式架構...30 4.1.2 韻律參數之介紹...33 4.1.3 模型設計...35 4.2 韻律模型之建立...39 4.2.1 初始化...39 4.2.2 重覆疊代...41 4.3 韻律模型之分析...42 4.3.1 音節韻律模型...42 4.3.2 停頓標記聲學模型...43 4.3.3 停頓標記結果之分析...45
4.4 以韻律模型協助語音辨認...47 第五章 實驗結果及討論...49 5.1 辨認系統加入語言模型實驗...49 5.1.1 MCDC 辨識結果 ...49 5.1.2 中央社對話語料庫之辨識實驗...51 5.2 辨認系統加入韻律模型實驗...53 5.2.1 以韻律模型協助辨認之辨識率...53 5.2.2 實驗結果討論...54 第六章 結論與未來展望...59 6.1 結論...59 6.2 未來展望...59 參考文獻...61 附錄一 詞性分類表...63 附錄二 韻律模型初始停頓標記門檻值之選定...65 附錄三 停頓標記聲學模型之問題集...70 附錄四 停頓標記語言模型之問題集...72
表目錄
表 2.1:MCDC 資料庫的對話主題與語者對照表 ... 6 表 2.2:MCDC 資料庫中 disfluency 與 IP 出現之個數 ... 12 表 3.1:訓練語料統計... 16 表 3.2:測詴語料統計... 16 表 3.3:HMM 模型之設定... 18 表 3.4:MCDC 音節辨認率 ... 19 表 3.5:General-LM 訓練語料統計... 21 表 3.6:在辨認字典中加入之 27 類 particle... 23 表 3.7:在辨認字典中加入之 9 類 paralinguistic ... 23 表 3.8:MCDC 中各類別之相接機率 ... 28 表 3.9:語言模型混淆度評估... 29 表 4.1:韻律結構之停頓標記... 32 表 4.2:歸類為基本音節之 particle 個數... 33 表 4.3:韻律標記、聲學參數以及語言參數之數學符號... 34 表 4.4:基本音節中,不同組合之 AP 下音節韻律模型參數之 TRE ... 42 表 4.5:特殊音節中,不同組合之 AP 下音節韻律模型參數之 TRE ... 42 表 5.1:各階段語言模型之辨識率... 49 表 5.2:口語對話常用詞之辨識率... 50 表 5.3:語言模型不同調適方法之辨識率... 51表 5.4:中央社測詴語料統計... 51 表 5.5:MCDC 與中央社辨識率比較(Acc(%)) ... 51 表 5.6:原始句子與切短句後詞之辨認涵蓋率... 53 表 5.7:加入韻律模型之辨識率... 53 表 5.8:較佳之 Top-N 候選詞串 ... 54 表 5.9:較差之 Top-N 候選詞串 ... 55 表 5.10:表 5.8 範例音段之聲學、語言模型分數... 56 表 5.11:表 5.9 範例音段之聲學、語言模型分數 ... 56 表 5.12:辨認句子結構表... 58
圖目錄
圖 1.1:訓練模型架構圖... 3 圖 2.1:語料庫中詞長分布圖... 10 圖 2.2:語料庫中 POS 種類分布圖 ... 10 圖 2.3:語料庫中每個 sub-turn 之音節數分佈圖 ...11 圖 2.4:發生非流暢現象現象之音節數分佈圖... 12 圖 2.5:不同音節數發生非流暢現象現象之機率分佈圖... 13 圖 3.1:聲學模型之建立流程... 17 圖 3.2:加入狀態轉移機率示意圖... 19 圖 3.3:General-LM 訓練流程圖... 22 圖 3.4(a):由 MCDC 估出各類別機率 ... 24 圖 3.4(b):將 Gerneral-LM 依圖 3-4(a)估算的比例重新分配 ... 24 圖 4.1:中文語音韻律之階層式架構概念... 31 圖 4.2:中文自發性韻律階層式架構... 31 圖 4.3:音節及音節間韻律參數... 34 圖 4.4:初始韻律模型建立流程圖... 40 圖 4.5:分類停頓標記之決策樹示意圖... 40 圖 4.6:韻律模型重覆疊代流程圖... 41 圖 4.7:五個中文聲調之 AP ... 43 圖 4.8:(a)音節停頓長度 (b)音節間能量低點 (c)正規化音節延長因子與 (d)正規化基頻跳躍值之分布圖... 44 圖 4.9:韻律停頓標記分佈圖... 45 圖 4.10:韻律停頓標記範例一之音檔信號圖... 46 圖 4.11:韻律停頓標記範例二之音檔信號圖 ... 46 圖 4.12:辨識系統架構圖... 48 圖 5.1:解答聲學分數與 Top-N 聲學分數相減之分布圖 ... 57
第一章 緒論
1.1 研究動機
近年來隨著科技的進步,語音辨認(Automatic Speech Recognition, ASR)系統已經有相當 成熟的技術,對於朗讀的語音輸入辨認效果極佳,然而要實際應用在生活化的商品上,則必 頇考慮到更接近於人們日常生活對話的自發性語音(Spontaneous speech) 。但自發性語音之辨 認率仍舊與朗讀式語音(Read speech)有一段差距。 造成自發性語音辨認率不如朗讀式語音之原因主要是因為自發性語音常會伴隨著非正 規化(ill-formed)以及不流暢語流(disfluency)現象。首先,因為自發性語音有複雜的韻律 (prosody)變化及較快的說話速度(speaking rate),使得音節與音節間會發生嚴重的相互影響, 例如:人們在日常對話時,大腦其實是只取一段句子中的關鍵字即可理解對方所要表達的意 思,因此造成人類在發音時某些語音會被省略或產生發音變異(pronunciation variation)以及音 節合併(syllable contraction)等現象。此外,由於自發性語音未經大腦良好的規劃,使得語流 中常會出現遲疑(hesitation)、口吃(stutter)、非流暢現象(disfluency)等不合乎文法結構之語句, 以及許多感歎詞(particle)、語者慣用的語助詞(marker)出現。因此自發性語音在辨識上會比一 般的朗讀式語音還要困難許多。如果我們能夠有效解決上述之自發性語音問題,相信一定能 為人們在將來生活上帶來許多更便利的幫助。 本論文將建立一套中文自發性語音辨認系統。傳統上語音辨認系統皆是以聲學模型為 主,語言模型為輔,然而在自發性語音中由於發音問題,較難有極佳的聲學模型,因此我們 希望能藉由語言模型以及韻律模型的幫助來提升辨識率。
1.2 相關研究
1.2.1 語言模型之相關研究
在自發性語言模型中所遭遇的問題,主要在於自發性語音與朗讀式語音有很大的文法型 態差異,而且自發性語音未經大腦良好的規劃,使得語流中常會出現遲疑、口吃、詞語修補 等現象,因此較難估測出詞與詞之間的關聯程度;另外自發性語音中有許多口語化詞彙或不 同語者的有不同的慣用語,但是在書寫上的文章並不會有此類文字出現,造成文字資料量不 足以致於無法直接建立自發性語音之語言模型。 近年來許多研究者皆使用基於結合之方式調適出自發性語音之語言模型,首先在解決資 料尚不足的問題時,Ng and Ostendorf 【1】利用從網路上收集文字資料,再與其基本語言模 型作調適結合;Hiroaki and Tatsuya 【2】則使用基礎語言模型對其語料作辨識,再從辨識結 果中挑出較佳之文字資料,與原本的基礎語言模型作調適結合,如此反覆結合及訓練出較好 的語言模型。接著在調適訓練時,Bacchiani and Roark【3】使用最大事後機率(Maximum A Posteriori, MAP)估算法來估算機率;另外也有許多文獻利用基於分類(Class-based)的方法將 有限的文字語料藉由分類(例如:詞性(POS))來增加訓練資料量【4】【5】【6】。1.2.2 韻律模型幫助辨認之相關研究
除了由語言模型去計算詞與詞之間的關聯程度,若能有效地運用詞與韻律結構之間的關 係,對於語音辨認上將是一大幫助。近年來利用韻律資訊協助語音辨認之方法主要分為三 種,首先是以事件為基礎(event-based)的方式增加語音辨認之效能【7】,利用韻律參數建立 一個偵測事件之模型,例如:類語句邊界(sentence-like unit)或詞語修補中斷點,並利用事件 及詞的序列一貣建立語言模型,對辨認結果所產生之詞格(word lattice)重新計算分數;第二 種為利用韻律參數對初級辨認結果所產生之詞格重新計算分數,直接利用韻律參數來驗證在 詞格中不同路徑其對應切割位置之可靠程度【8】;第三類則是利用韻律以及句法的關係建立一套韻律相關之語言模型(prosody-dependent language model) 【9】,用以描述韻律以及詞之 結合機率,並利用韻律邊界的資訊建立韻律相關的聲學模型(prosody-dependent acoustic model) 【10】。
1.3 研究方向
在本篇論文中,將以建立一套自發性語音辨認系統並以韻律模型協助辨認為目標。首 先,本研究先建立一套語音辨識系統及韻律模型,架構圖如圖 1.1 所示,在聲學方面,使用 隱藏式馬可夫模型(Hidden Markov Model, HMM)以聲母及韻母為單位,採用音節內右相關聲 母/韻母模型;在語言學方面,先利用大量文字資料建立合呼朗讀式語音之語言模型,接著 使用 MAP 及 Class-based Deleted Interpolation Smoothing 方法調適成合乎自發性語音之語言 模型;最後,本研究利用【11】所提出之非監督式中文自發性語音韻律標記及模型為基礎作 修改,獲得本研究使用之韻律模型。 Acoustic Model General Language Model MCDC Corpora Text Corpora Prosody ModelHMM
training
PLM
training
GLM
training
MAP & Smoothing Language Model 圖 1.1:訓練模型架構圖在辨認階段本研究將採用兩段式(two pass)語音辨認架構。第一階段利用聲學模型計算語 音信號聲學分數,接著利用語言模型計算詞與詞的關聯程度與出現機率,辨認產生最佳 N 條 詞串(Top-N word sequence);由於自發性語音中有許多不合乎文法結構之語句,詞組與詞組 間之連接機率較不穩定,因此較難正確估算其關聯程度,但詞組與韻律結構之間的關係則較 為明確,因此本研究在第二階段將另外利用韻律參數,給予每個音節邊界一個機率的分數, 最後將此三個模型機率分數作權重結合並對每一條路徑重新計算分數,決定出最可能之辨認 結果。
1.4 章節概要
本論文共分為六章,各章節編排如下: 第一章 緒論:說明研究動機與研究方向。 第二章 漢語口語對話語料庫介紹:介紹本論文實驗使用之自發性語音語料庫及其特性 、統計分析以及後處理。 第三章 自發性語音辨識系統架構:說明自發性語音聲學模型之建立以及語言模型之建 立及調適。 第四章 結合韻律模型之辨識系統:說明自發性語音韻律模型之建立、分析及實驗整體 架構。 第五章 實驗結果:語言模型及結合韻律模型辨識系統之實驗結果。 第六章 結論與未來展望。第二章 漢語口語對話語料庫介紹
本研究將使用中央研究院語言學研究所提供一個完整的自發性語音語料庫-現代漢語 口語對話語料庫(Mandarin Conversational Dialogue Corpus,MCDC)作為研究素材。現代漢語 口語對話語料庫【12】是由中央研究院語言學研究所曾淑娟博士等人於 2000~2002 年間所 錄製,其語者是由台北市民隨機抽樣,並依據 16~25 歲、26~35 歲以及 36~45 歲三大年齡 層,選出 60 位語者(37 位女性、23 位男性),共錄製 30 段對話,但其中有轉寫的對話僅有 8 段對話,分別為編號 01、02、03、05、09、10、25 以及 26,其中包含了 16 位語者(9 位女 性、7 位男性)。本研究將以此 8 段對話作為實驗之語料。本章節為此語料庫作簡介,包括語 料標註(transcription)格式、此語料庫之自發性語音特性、MCDC 語料之後處理以及其他相關 統計。
2.1 語料庫介紹
2.1.1 音檔格式說明
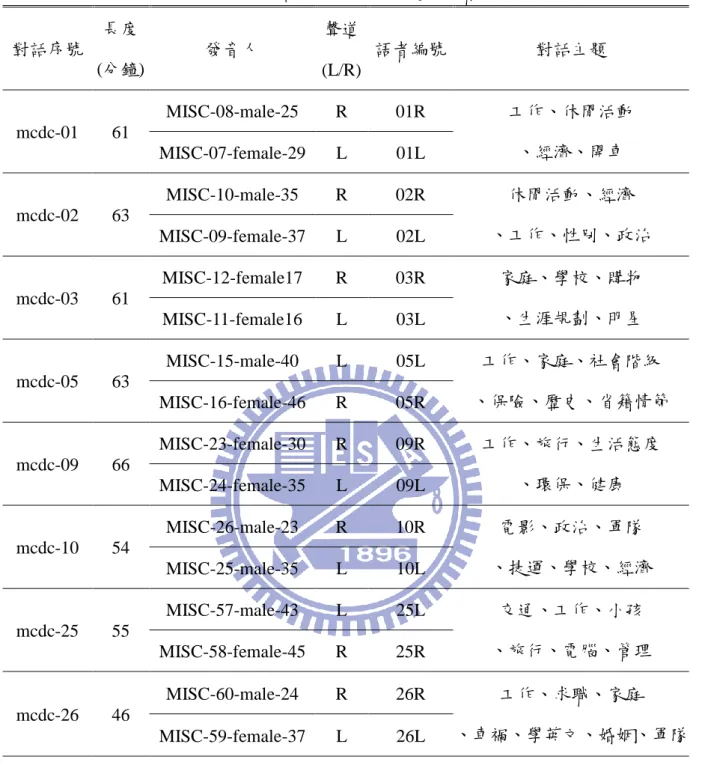
MCDC語料庫為兩語者對話之語料,音檔採雙聲道且取樣率為48kHz的方式錄製,並且 將兩位發音人之語料分別錄於左右聲道,再利用軟體 Cool Edit Pro將它們分割成小的雙聲道 音檔,依長度約三分鐘找到一個清楚可辨的停頓切開,其簡介如表2.1所示。在本研究中將每 組對話語料之左右聲道抽取,並轉換為兩個單聲道之音檔,分別為對話中兩位語者之語料, 並且將其取樣頻率下降至16kHz,再利用每一段落相對應之開始及結束時間作切割,經由以 上處理後產生7,085段音檔,扣除一些未包含語音現象之音檔後剩下之6,570段音檔將作為本 研究所使用之語料。表 2.1:MCDC 資料庫的對話主題與語者對照表 對話序號 長度 (分鐘) 發音人 聲道 (L/R) 語者編號 對話主題 mcdc-01 61 MISC-08-male-25 R 01R 工作、休閒活動 、經濟、開車 MISC-07-female-29 L 01L mcdc-02 63 MISC-10-male-35 R 02R 休閒活動、經濟 、工作、性別、政治 MISC-09-female-37 L 02L mcdc-03 61 MISC-12-female17 R 03R 家庭、學校、購物 、生涯規劃、明星 MISC-11-female16 L 03L mcdc-05 63 MISC-15-male-40 L 05L 工作、家庭、社會階級 、保險、歷史、省籍情節 MISC-16-female-46 R 05R mcdc-09 66 MISC-23-female-30 R 09R 工作、旅行、生活態度 、環保、健康 MISC-24-female-35 L 09L mcdc-10 54 MISC-26-male-23 R 10R 電影、政治、軍隊 、捷運、學校、經濟 MISC-25-male-35 L 10L mcdc-25 55 MISC-57-male-43 L 25L 交通、工作、小孩 、旅行、電腦、管理 MISC-58-female-45 R 25R mcdc-26 46 MISC-60-male-24 R 26R 工作、求職、家庭 、車禍、學英文、婚姻、軍隊 MISC-59-female-37 L 26L
2.1.2 語料標註格式說明
本研究採用中央研究院語言學研究所釋出之版本,在標註時大致以對話中語者轉換處為 一個段落作轉寫,轉寫內容主要包括:對應之音檔名稱、語者代號、音檔貣始及結束時間、 語音之文字轉寫以及其發音相對之漢語拼音,文字以及漢語拼音的轉寫包括語言及非語言部分,非語言部分主要是標記非人類產生聲音以及人類所產生但不是語音的聲音,例如:咳嗽 聲、笑聲、呼吸聲等。以下為一個段落之文字轉寫範例及說明: <segment> /*語者轉換開始處*/ <voicefile>D:\MCDC\stereo_01\mcdc-01-01.wav /*對應之音檔名稱*/ <speaker>MISC-07-female-29 /*語者代號*/ <start>077458 /*此段文字轉寫對應音檔之開始時間*/ <end>080547 /*此段文字轉寫對應音檔之結束時間*/ <translator>Fen /*文字轉寫人*/ <chinese> /*語者發音內容之文字標記*/ NA 賴先生呢您從事什麼工作 (unrecognizable non-speech sound)
</chinese>
<english> /*語者發音之漢語拼音標記*/ NA lai4 xian1 sheng1 [nen2] nin2 cong2 shi4 shen2 me5 gong1 zuo4 (unrecognizable non-speech sound) </english> </segment>
2.2 自發性語音之特性
自發性語音與朗讀式語音最大的差異在於朗讀式語音是經過事先設計好的,人類在說話 時常常會伴隨著因大腦思考或情緒變化而產生一些無法預期的聲音或發生在語言學中較詞 層次(word level)更為上層之行為,增加許多訓練與辨認時的困難度。以下我們將介紹幾種 MCDC 語料庫中常出現的特性: 感歎詞(particle) 不具標準語意的感嘆詞,其語用成份居多如回應或同意。語流中出現的感歎詞有四類: 一、有相對應國字的感歎詞,例如:A、BA、LA、MA、O;二、無相對應國字的感歎詞, 例如:AI YE、EI、HEN、NE、NEI;三、源於台語的感歎詞,例如:EIN、HEIN、HO;四、 其他的感歎詞(Fillers),例如:UHN、NHN、MHM、MHMHM。 無法或難以辨識的語音
無法或難以辨識的語音主要可分為無法辨識的語音(unrecognizable speech sound)以及不 確定字/音(uncertain)。無法辨識的語音為標記員確定此為人類所發出之語音但無法辨認何字 何意何音;而不確定字/音包括:一、可猜測出大概的語音內容,但無法百分之百確定;二、 無法根據語意猜測出對應字詞,但可清楚記錄出其發音。 非語言聲音(Non-Speech sounds) 在口語對話語料庫中常常會有一些非語音的聲音出現,非語言部分可分為人類所產生之 副語言現象(para-linguistic)或非語言現象(non-linguistic)。一般的非語音但確定是由人所發出 來的即稱為副語言現象,例如:笑聲、咳嗽聲、吞口水聲等等;而非語音且確定不是由人所 發出來的則稱為非語言現象,例如:背景的雨聲、敲擊到麥克風聲等等。 語流中斷 在本研究中關注之語流中斷主要有沉默(silence)、停頓(pause)或短停頓(short break),為 語者在語流中因話題銜接不上或自身所產生之沉默。 非流暢現象(disfluency) 不流暢的語音為自發性語音中一個重要特性,在本研究中關注之詞語修補主要有重覆 (repetition)、詞語更正(repair)、部分重覆(restart)以及更正插語(editing term),重覆是指完整地 重覆詞語一次以上;詞語更正為說話者覺得說出的話不適當,立即更正說話內容;而部分重 覆則是說話者重新說出這個句子且重覆貣頭詞語的片斷,與完整的詞語重覆不同。更正插語 是出現在被更正詞語(reparandum)與更正詞語(correction)之間,或是出現在完整重覆或部分重 覆中,兩個重覆詞語之間。本研究定義詞語修補中斷點(IP)為被更正詞語與更正後詞語間之 停頓點,或完整重覆或部分重覆中的兩個重覆詞語間之停頓點,本研究在文字轉寫中將詞語 修補中斷點標記成「*」。以下為幾種非流暢現象範例: 基本型態: (被更正詞語)*[更正插語](更正詞語) 重覆範例: 昨天卡卡表現的(普通)*(普通) 詞語更正範例: 今晚世足賽是(烏拉圭)*[EN](巴拉圭)對日本 部份重覆範例: (今)*(今天)晚上是冠軍賽
2.3 MCDC 語料庫之後處理
由於中央研究院語言學研究所釋出之 release 版本中並無標記某些聲學現象及語言資 訊,但這些資訊在語音處理中相當重要,因此在本節介紹本研究將對語料庫聲學以及語言學 資訊的處理方法及相關統計。2.3.1 斷詞與相關統計
由於自發性語音目前尚無良好之語言模型,而在調適出好的語言模型之前需要有正確的 斷詞標記,因此本研究先利用國立交通大學語音處理實驗室文字處理器以及中研院提供之斷 詞器對MCDC之文字轉寫進行斷詞標記,詞性標記以中研院的46類詞性(Part of Speech, POS)(參見附錄一)為標準,接著再將兩者之斷詞標記進行強迫對齊以求出較佳之斷詞結果, 最後以人工檢查方式修正出最佳斷詞標記。斷詞標記方式如下: 一般詞:以”( )”標記其詞性。例:我(Nh)、公司(Nc) 感歎詞:以半形字體表示。例:LA、HON 英語:以全形字體表示並標記”(FW)” 。例:VCD(FW)、Why(FW) 副語言現象(paralinguistic):以”{ }”標記。例:{非語音聲}、{呼吸聲} 斷詞標記範例如下: ※原始內容: ok NA {重覆開始} 我 {重覆中斷點} 我 {重覆結束} 叫 賴 {吸氣聲} HEN 你好 NA 最近在從事些什麼事情 O 我在一家公關公司上班 {非語音聲} 我目前是從事 {吸氣聲} EN 外貿 ※斷詞後內容: ok(FW) NA {重覆開始} 我(Nh) {重覆中斷點} 我(Nh) {重覆結束} 叫(VF) 賴(Nb) {吸氣聲} HEN 你(Nh) 好(VH) NA 最近(Nd) 在(P) 從事(VJ) 些(Nf) 什麼(Nep) 事情(Na) O 我(Nh) 在(P) 一[Neu]家[Nf](DM) 公關(Na) 公司(Nc) 上班(VA) {非語音聲}接著統計MCDC語料庫之語言學相關資訊,主要有詞長(word length)以及詞性。MCDC 語料庫經由本研究斷詞整理後共斷有79935個詞,圖2.1統計出各個詞長之個數,由圖2.1可明 顯看出詞長以一字詞及二字詞居多,共佔總詞數93.66%;圖2.2為詞性之分布圖1,其中FW、 ParL及Par分別表示foreign word、paralinguistic以及particle。由此可猜測人們在帄時對話大多 以一字詞或二字詞構成句子,而詞性則以動詞及名詞佔大多數。圖2.3為語料庫中每個sub-turn 的音節數分佈圖,由圖可看出此語料庫以短句居多2。 圖 2.1:語料庫中詞長分布圖 150 3939 15697 1 26405 10143798 20177 3078 2607 2900 169 20972 11144 0 5000 10000 15000 20000 25000 30000
A C D I N T P V DE SHI DM FW ParL Par POS種類 數量 圖 2.2:語料庫中 POS 種類分布圖 1 在此為了觀察方便,因此將 46 類 POS 簡化統整為 8 類 POS,其對照表請參考附路一。 2 在 MCDC 語料庫中,短句主要以 particle、簡答或回應詞為主。
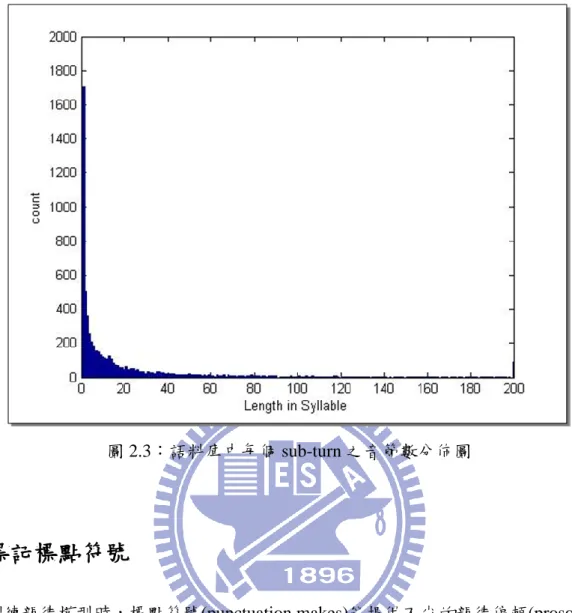
圖 2.3:語料庫中每個 sub-turn 之音節數分佈圖
2.3.2 標記標點符號
在訓練韻律模型時,標點符號(punctuation makes)能提供不少的韻律停頓(prosodic break) 資訊,例如在頓號「、」的地方通常會有小停頓,而在逗號「,」之處則會有較長的停頓, 句號「。」亦是如此且可能會有句尾拖長音現象發生。因此本研究將對 MCDC 文字語料進 行標點符號標記,標記之符號包含「,」、「、」、「。」、「!」、「:」及「?」。標記時主要 以一般文法斷法為主,而遇到 particle 時則判斷其與前一個或後一個詞相接念貣來是否通順, 若不通順則用標點符號將其隔開。以下為幾個標記範例: E , 也(D) 不(D) 算(VG) LA ! 我(Nh) 搭(VC) 捷運(Nb) 到(VC) NE GE 捷運忠孝復興站(Nc) 。 NA 我們(Nh) 就是(D) 以(P) 台幣(Na) 在(P) 報(VC) 。 EN , NA 請問(VE) 怎麼(D) 稱呼(VG) 您(Nh) ?
2.3.3 非流暢現象中斷點
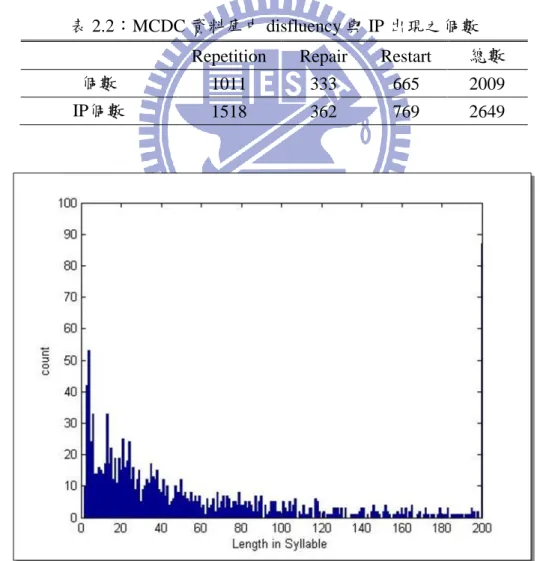
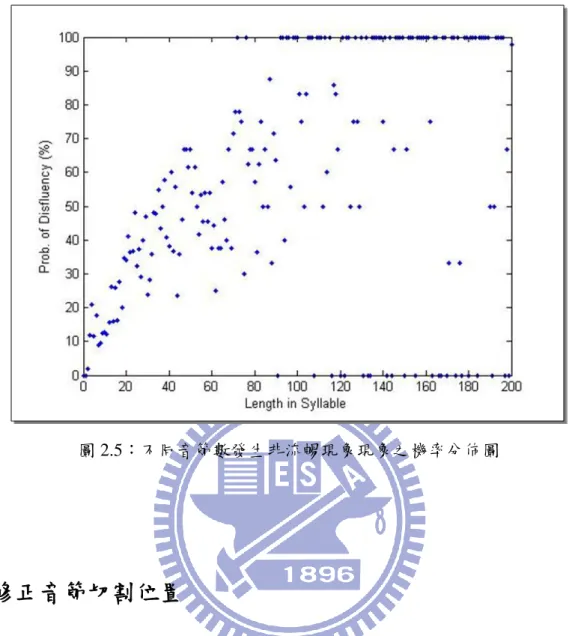
如何處理非流暢現象在自發性語音辨認中是一個重要的議題,本研究對此語料庫之非流 暢現象現象做初步統計。首先以 2.1.1 節中音檔切割完產生之 6570 個語句 sub-turn 為基準, 經由統計後發現其中有 1225 個 sub-turn 發生非流暢現象現象,圖 2.4 與圖 2.5 為語料庫中發 生非流暢現象現象 sub-turn 的音節數和機率分佈圖。另外語料庫中標記「重覆」、「詞語更 正」以及「部分重覆」之總個數各為 1011、333 以及 665 如表 2.2 所示,而本研究定義所有 語句中每個音節邊界(共 136801 個)都有可能是非流暢現象中斷點的候選邊界(candidate),經 由統計共有 2649 個中斷點出現,由此可知在所有音節邊界中出現非流暢現象中斷點之機率 為 1.94%。 表 2.2:MCDC 資料庫中 disfluency 與 IP 出現之個數 Repetition Repair Restart 總數 個數 1011 333 665 2009 IP個數 1518 362 769 2649圖 2.5:不同音節數發生非流暢現象現象之機率分佈圖
2.3.4 修正音節切割位置
要有好的聲學模型及韻律模型首先要有良好的音節切割位置,但目前自發性語音語料庫 尚無準確的音節切割位置,而且由於自發性語音在發音時音量、頻率及時間長度較無法像朗 讀式語音穩定,因此無法由自動的方式標示出良好的音節切割位置。如果要採用人工的方式 標記方式則是一個浩大的工程,因此本研究首先使用【11】建立之自發性語音聲學模型,利 用 HTK 軟體以強迫對齊的方式對每一個音檔作音節之切割,得到每一個音節的音節長度以 及停頓長度;接著檢查若在詞內邊界(Intra-word)中出現超過 0.1 秒的 pause,則我們假設其中 很有可能有音節切割錯誤的情況發生並修正之。在經由人工修正時,我們發現通常此現象發 生在於語者在發音時帶有笑聲、音量太小、音節合併或遭受隔壁聲道干擾等情形,其中受到 隔壁聲道污染更可能導致整段句子音節完全切割錯誤,因此將其移除。以下列出兩段例子:對對我知道我知道-(嚴重連音+隔壁聲道污染)
第三章 自發性語音辨識系統
在本章節中將建立一套自發性語音辨識系統,主要可分為聲學模型及語言模型。本研究 利用 MCDC 語料庫以及劍橋大學開發之 HTK(HMM Tool Kit)軟體【13】建立一套自發性語 音聲學模型;另外利用 MCDC 之文字資料以及朗讀式語音之文字資料調適出自發性語言模 型。3.1 節將介紹聲學模型之建立流程;3.2 節將介紹建立及調適語言模型的方法。3.1 聲學模型
3.1.1 訓練語料及測詴語料
如何從語料庫分配訓練語料及測詴語料主要依據作何種語音辨識系統而定。而語音辨識 的類型大致上可分為三種:語者相依 (Speaker Dependent, SD) 辨識、語者獨立(Speaker Independent ,SI) 辨識以及多語者(Multi-Speaker)辨識。對於這三種辨識系統的語料庫分配方 式如下: 語者相依辨識系統 測詴語料和訓練語料是同一語者。 語者獨立辨識系統 訓練語料與測詴語料的語者是不同人的。 多語者辨識系統 訓練語料與測詴語料有相同的語者但測詴語料與訓練語料之句子是不同的。 本研究目的在於建立一套自發性語音辨認系統且找出韻律能用來幫助辨認的方法,因此 是採用多語者辨識系統。本研究中訓練語料包含 16 位語者各自取 9/10 之語音段落所組成, 而剩餘之 1/10 語料即為本研究所使用之測詴語料,其詳細統計資料如表 3.1 及表 3.2 所示:表 3.1:訓練語料統計
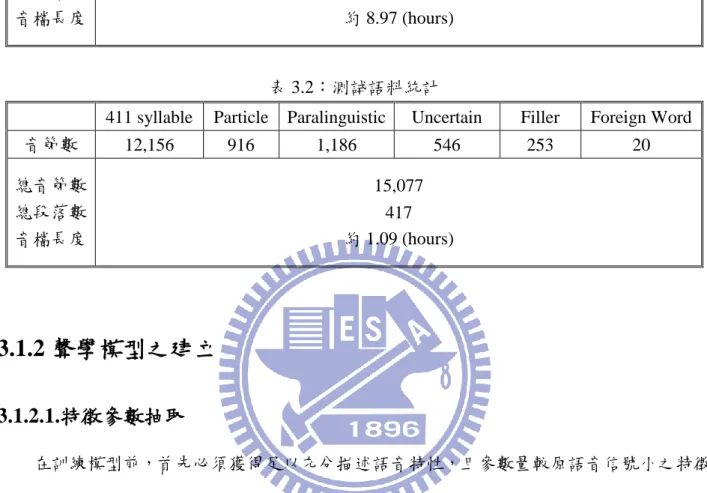
411 syllable Particle Paralinguistic Uncertain Filler Foreign Word 音節數 104,736 9,688 11,289 3,725 1,743 156 總音節數 總段落數 音檔長度 131,337 6,121 約 8.97 (hours) 表 3.2:測詴語料統計
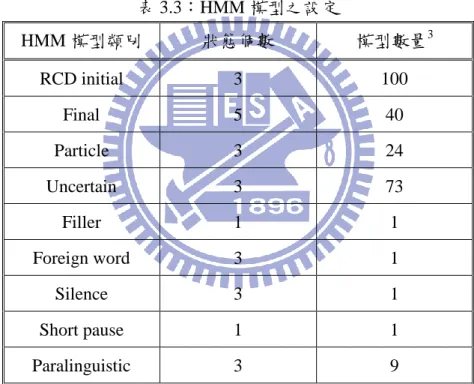
411 syllable Particle Paralinguistic Uncertain Filler Foreign Word 音節數 12,156 916 1,186 546 253 20 總音節數 總段落數 音檔長度 15,077 417 約 1.09 (hours)
3.1.2 聲學模型之建立
3.1.2.1.特徵參數抽取
在訓練模型前,首先必頇獲得足以充分描述語音特性,且參數量較原語音信號小之特徵 參數,而語音處理當中,最廣泛為人使用之特徵參數為梅爾頻率倒頻譜係數(Mel-Frequency Cepstrum Coeiffient, MFCC),本研究也將使用此特徵參數,以 32 毫秒之漢明窗(Hamming window)且每位移 10 毫秒為一筆資料,求取 12 維 MFCC 並加上一維能量係數,以及這 13 維係數之一階與二階變量(delta and delta-delta)為特徵參數,但單純的能量在參數中較缺乏鑑 別性,因此去除能量係數,得到 38 維向量作為本研究語音資料之聲學特徵參數。在本研究 也將利用倒頻譜帄均值正規化法(Cepstrum Mean Normalization, CMN)藉此消除不同語音信 號之通道效應。3.1.2.2 聲學模型之建立流程
改出較正確之文字轉寫。其建立流程如圖 3.1 所示。由於自發性語音尚無良好之語料標註, 然而錯誤的標注將可能導致聲學模型混淆以致辨認效能降低,但是要將文字轉寫以人工方式 完全修改正確是一個極大的工程,因此在訓練模型前本研究先利用其聲學模型將 MCDC 語 料之漢語拼音轉寫和語音信號作強迫對齊,獲得每一個音節切割位置的資訊,接著利用 2.3.4 中提出的方法對切割位置做些微修正。 MCDC speech data MCDC transcription
Forced alignment & Syllable boundary correction Old MCDC Acoustic Model Syllable boundary information
Isolated Syllable Training
Forward-Backward Algorithm Increase number of mixture component in each state RCD Initial/Final Acoustic Model 圖 3.1:聲學模型之建立流程 在有了較好的切割資訊後,本研究接著利用此切割資訊訓練各個音節之聲學模型,值得 注意的是,在自發性語音當中具有許多基本音節之外的其他音節,例如:語助詞、感歎詞、
不確定字或音以及副語言現象,在本研究中這些特殊音節同樣將利用【11】所建立之自發性 語音聲學模型,經由強迫對齊後獲取特殊音節之切割位置,並另外建立其聲學模型,在此數 量過少之其他音節將被歸類至填充模型(filler model)。
本研究使用之隱藏式馬可夫模型以聲母及韻母為單位,採用音節內右相關聲/韻母模型 (Right-ocntext-dependent Initial/Final Model, RCD)。每一個聲母之 HMM 模型採用 3 個由左至 右(left-to-right)的狀態(state)表示;而韻母之 HMM 模型則採用 5 個狀態來表示,另外填充模 型以及短靜音將以 1 個狀態來表示。其中每一個狀態以帄均 64 個高斯分布之高斯混合模型 (Gaussian Mixture Model, GMM)描述其特徵參數之分布,各模型之 HMM 設定如表 3.3 所示。
表 3.3:HMM 模型之設定 HMM 模型類別 狀態個數 模型數量3 RCD initial 3 100 Final 5 40 Particle 3 24 Uncertain 3 73 Filler 1 1 Foreign word 3 1 Silence 3 1 Short pause 1 1 Paralinguistic 3 9 值得注意的是,由於人類在口語對話時常因為節省發音力氣而省略音節內的某些發音, 因而產生了音節合併(syllable contraction)的現象。在此本研究利用 HTK 軟體計算各個音節之 狀態轉移機率,若狀態轉移機率大於 50%,則允許此狀態可以被跳過,如圖 3.2 所示,並重 新對模型做訓練至收斂為止。 3在 MCDC 語料庫缺少「c_o」、「n_o」以及「s_o」之聲母模型;「eh」、「yai」以及「yo」之韻母模型。
圖 3.2:加入狀態轉移機率示意圖
3.1.3 實驗結果
一般來說聲學模型之效能是由辨認率來評估,因此本研究將使用 3.1.2 建立之 MCDC 聲 學模型對測詴語料進行音節辨認以評估其效能。在做辨認之前,本研究先建立一個 free-gram 音節語言模型,其中包含 411 音節、Foreign word、filler、Particle 及 Paralinguistic 且各個相 接機率相等。接著,本研究使用 HTK 工具對測詴語料進行辨認,採用音節作為辨認的基本 單元,其中包含 411 音節及 Particle、Paralinguistic、Filler、Foreign word(Eng)。
表 3.4:MCDC 音節辨認率
Correct Accuracy Hit Deletion Substitution Insertion Total Syllable 51.74% 48.74% 7,779 2,139 5,117 451 15,035 411only 52.45% 48.55% 6,868 1,684 4,542 511 13,094 本研究之音節辨認率如表 3.4 所示,由表中可以發現,自發性語音中刪除型錯誤(Deletion) 數量較多,經由辨認結果之觀察,我們可以發現此乃因為在口語對話中因為語速較快,造成 許多詞語會有音節合併現象發生,例如:「因為」、「這樣」、「所以」…等等。當發生音節合 併現象時,通常會增加取代型(Substitution)及刪除型(Deletion)錯誤,以下為一種因音節合併 造成錯誤之範例:
正確答案(canonical form) 辨認答案(surface form) 錯誤型態(error type) zhe (這) jiang (降) 取代型 yang (樣) NULL 刪除型 本研究另外實驗單純辨識 411 音節之辨認,由表 3.4 可以發現辨識率略微下降,此乃因 為自發性語音中有許多感歎詞、語助詞以及副語言現象的情況存在,若我們能有效地將這些 現象加入當作辨識單元,使其不干擾正常語音之辨識,辨識率將能有效提升,對於要做語音 之自動文字語料標註(transcribing)也將會有很大的幫助。最後,本研究也注意到目前語料庫 的音節切割位置還是有許多錯誤,但因為人工修正切割位置是一個浩大的工程,所以目前都 只能以半自動的方式修改,若能有效改善此狀況,對於聲學模型的訓練將會有極大的幫助。
3.2 語言模型
由於所有語言都有其獨特的文法規則,因此我們可針對此規則性來求得一個機率模型, 一般稱此為語言模型(Language Model, LM)。在語音辨認時,除了聲學模型外,若能加入語 言模型的參考,通常能大幅提升辨認系統的效能。由於自發性語音至今尚無良好的語言模 型,在此本研究將利用現有的朗讀式語音文字資料以及 MCDC 的文字資料調適出一套適用 於自發性語音的語言模型。3.2.1 初始模型之建立
3.2.1.1 訓練語料
本研究使用光華雜誌(Sinorama)、NTCIR 以及中研院的帄衡語料庫(Sinica Corpus)訓練出 一套屬於 read speech 的語言模型(以下皆稱此模型為 General-LM, GLM))。所有訓練之文字資 料數量如下: 表 3.5:General-LM 訓練語料統計 訓練語料 詞數(Word) 字數(Character) 光華雜誌 11,348,465 15,669,241 NTCIR 59,862,541 83,116,970 帄衡語料庫 5,816,309 8,078,119 合計 77,027,315 106,864,330
3.2.1.2 模型訓練
本研究先利用 General-LM 文字資料,以統計的方式計算詞與詞之間的聯接規則,且利 用退化帄滑法(back off)及使用 Good-Turing discounting 建立而成一雙連(bi-gram)語言模型。 其數學式如(3-1)式所示。若定義訓練語料中詞串出現的次數門檻值k,則可將詞串分為出現次數高於門檻值、出現次數低於門檻值及從未出現三種。則參數可表示為下式:
1 1 , 1 1 1 1 1 , 1 1 1 , 0 | 1 , 5 , 5 i i i i C wi wi i i c i C w i i i C wi wi i i C wi w P w C w w P w w d w C w w C w w (3-1) 有了訓練語料及方法,便可以開始訓練語言模型,訓練過程如圖 3-3 所示: Training Data Language Model Training Lexicon General-LM (bigram) 圖 3.3:General-LM 訓練流程圖 其中詞典(Lexicon)的產生是先對大量的文字資料進行斷詞,然後依詞頻排序並挑出詞頻最高 的前 6 萬詞作為詞典。經過圖 3.3 之訓練流程後,即完成建立一套雙連 General-LM,以下本 研究將利用此語言模型與 MCDC 文字資料進行調適。3.2.2 語言模型之調適
3.2.2.1 自發性語音之訓練單元
由於 General-LM 中並沒有估算自發性語音中的「particle」及「paralinguistic」的出現機 率,因此要調適出一套適用於自發性語音語言模型前,我們勢必要想辦法估算出 particle 及 paralinguistic 的機率並將 particle 及 paralinguistic 的辨認單元加入到辨認字典中。在此,本研究將挑出 27 類 particle 及 9 類 paralinguistic 當作新的辨認單元,如下表所示: 表 3.6:在辨認字典中加入之 27 類 particle A HAN ME O AI HEIN MHM SHEN BA HEN MHMHM WA E HO NA YA EI LA NE YOU GE MA NO ZHE NE-GE SHEN-ME ZHE-GE
表 3.7:在辨認字典中加入之 9 類 paralinguistic 呼吸聲 清喉嚨聲 咳嗽聲 吞口水聲 咂嘴聲 語音聲 非語音聲 笑聲 雜訊
3.2.2.2 調適模型之設計
在本研究中,我們將 MCDC 的文字資料區分成三種資料類別:一般詞(Lexical Word - LWord)、particle(Par)以及 paralinguistic(Para)。首先,我們可以從 MCDC 文字資料中統計出 此三種資料類別的出現機率,分別為: ( ( ) ) 0.763 S T i P G w LWord ; ( ( ) ) 0.110 S T i P G w Par ; ( ( ) ) 0.127 S T iP G w Para ,如圖 3.4(a)所示。本研究將計畫把 General-LM 中一般詞、particle
以及 paralinguistic 的機率比例根據由 MCDC 文字資料所估算出來的出現比例做加入及調 整,如圖 3.4(b)所示。接下來我們將實驗分成三個階段,以不同的估算方法將「particle」及 「paralinguistic」加入到語言模型中,得到一個較佳的模型來幫助辨識。
圖 3.4(a):由 MCDC 估出各類別機率
圖 3.4(b):將 Gerneral-LM 依圖 3-4(a)估算的比例重新分配
Stage 1:給予 particle 及 paralinguistic uni-gram 機率
在此階段我們將根據上述統計的各類別之出現機率來分配 General-LM 中 uni-gram 機率 部分。首先我們先從 MCDC 文字資料中估出 particle 及 paralinguistic 的出現機率P w ,我M( )i 們可以發現所有 particle 之機率總和將等於其在 MCDC 中的 particle 類別之出現機率, paralinguistic 亦是如此,如下式:
( ) ( ( )) , , i M i M i i w P w P G w w particle paralinguistic
(3-2) 接著我們將此機率P w 乘上一個係數M( )i ,使得 ( ) ( ) 1 , , M i M i i w P w P w w particle paralinguistic
(3-3) 最後,我們重新分配 General-LM 裡的 uni-gram 空間,其數學式如下: ( ( ) ) ( ) , ( ) ( ( ) ) ( ) , ( ( ) ) ( ) , M i G i i i M i M i i M i M i iP G w LWord P w w lexical word
P w P G w Par P w w particle P G w Para P w w paralinguistic (3-4) 值得注意的是,其中一般詞是由 General-LM 中原本估算出來的機率乘上在 MCDC 中一般詞 的出現機率。在此所有 word 機率總和將滿足: ( ) ( ( ) ) ( ) ( ( ) ) ( ) ( ( ) ) ( ) ( ( ) ) ( ( ) ) ( ( ) ) (3-5) 1 i i i M i G i M i M i M i M i w G w M i M i M i G
P w P G w LWord P w P G w Par P w P G w Para P w
P G w LWord P G w Par P G w Para
在此階段因為我們並無估算 particle 及 paralinguistic 的 bi-gram 機率,因此我們將 particle 及 paralinguistic 的 back-off 係數皆設為 1。
Stage2: 估算 particle 及 paralinguistic 的 bi-gram 機率
由於現有的 Read-speech(General-LM)文字資料量與 Spontaneous-speech(MCDC)文字資 料量差異懸殊,而且在 General-LM 文字資料中不會有 paralinguistic 出現,particle 也極少, 因此若直接將 General-LM 與 MCDC 文字資料合併訓練 bi-gram 語言模型則在估算一般詞與 particle 或 paralinguistic 的 bi-gram 機率時勢必會出現數量過少而導致機率極低的情形。然而, 在觀察 MCDC 文字資料後,我們可發現某些詞與 particle 或 paralinguistic 相接的機率甚高, 例如:假設我們直接將訓練 General-LM 的文字資料與 MCDC 的文字資料合併訓練則會因為 ( , A) < ( , ) Count 對 Count 對 一個 4而產生P(A對) < (P 一個 對 的機率現象,但是我們可以由) 4 1 ( i , i) Count w w 表示詞wi1接詞wi的次數。
MCDC 中觀察出「A」比「一個」的機率要高許多。為了防止此情形發生,我們將使用 Deleted Interpolation Smoothing【14】方法,在估算一般詞與 particle 或 paralinguistic 相接時藉由加入 particle 和 paralinguistic 的 uni-gram 機率來提升其 bi-gram 機率。
首先,傳統的 Deleted Interpolation Smoothing 公式如下:
1 1
(
i i)
(
i i)+(1- )
(
i)
P w w
P w w
P w
(3-6) 其主要概念是:當原bi-gram機率P w w( i i1)較低時可能造成不可靠性增加,此時可利用與uni-gram機率 (P w 做interploate以達到補強的效果。此方法適用於結合高階(higher-order) i) n-gram 語言模型與低階(lower-order) n-gram語言模型,因為在一個高階n-gram語言模型中可 能有些資料因為出現數量較低因此較不可靠,此時低階之n-gram語言模型將可能可以提供較 可靠性的機率資訊。
再來值得注意的是,因為 MCDC 的文字資料量少,我們認為直接由 MCDC 中估出來的 particle 及 paralinguistic 的 uni-gram 機率 (P w 可能不可靠,一種最直接的解決方法就是將種i) 類繁多但數量少的文字資料退化成種類較少的 Class 形式(例如:詞性),如此一來每個 Class 的數量將會增加,再由此估算出較為可靠的機率。所以在此我們將使用 Class-based 的方法 來估算(3-6)式中 ( )P w 之機率分數。 i
傳統的 Class-based bi-gram model 數學式定義如下:
1 1 1 1 1 ( ) ( ( ), ( ), ) ( ( ) ( ), ) class i i i i i i i i i P w w P w G w G w w P G w G w w (3-7) 假設P w G w G w( i ( ), (i i1),wi1)與G w( i1)及wi1獨立且P G w G w( ( )i ( i1),wi1)與wi1獨立,則 (3-7) 式可改寫為: 1 1 ( ) ( ( )) ( ( ) ( )) class i i i i i i P w w P w G w P G w G w (3-8) 由(3-8)式得知,欲估算出P w w( i i1)前必頇先定義好類別( (G w ),本研究先將分類出三n)
表 3.8 為由 MCDC 訓練語料中所估算的機率。 最後,我們即可將 (3-6)式和(3-8) 式結合改寫成以下形式: 1 1 1 ( i i ) M( i i )+(1- ) M( i G( i )) M( i ( i)) P w w P w w
P w w P w G w (3-9) 其中 ( 1) i M i i w P w w
。在此值得注意的是, (3-9)式中在使用 Class-based 方法時是估算 前一個詞wi1之類別接到某個詞w 之機率i P wM( i G(wi1)),而不是估算P G w G wM( ( )i ( i1)),因為經由觀察我們發現某些詞組Count w( i1,wi)5當詞w 為某些常出現的 Particle 或 Paralinguistici
時(例如:MHM、A、@呼吸聲),若單純使用P G w G wM( ( )i ( i1))去做 Smoothing 時可能因為
( ( ))
M i i
P w G w 機率很大造成估算錯誤。例如:在 MCDC 文字資料中Count 是( , O)並不多,而
( , MHM)
Count 是 更是稀少,因此需要依賴 Smoothing 機率,然而在 Smoothing 時若直接使用
1 ( ( ) ( )) M i i P G w G w 則會因為PM(OG Par( ))PM(MHMG Par( ))而造成P(O是)< (MHMP 是) 的狀況發生,但是我們知道在「一般詞」的前提下,「O」的出現機率會比「MHM」高出許 多。因此本研究將採用P wM( i G(wi1))來做 Smoothing 動作。
(3-9)式是估算詞與 particle 及 paralinguistic 的相接機率,而要放入原本 General-LM 的 bi-gram 時,因為對於某個詞wi1而言,其本身的 bi-gram 機率總和滿足 ( 1) 1 i G i i w P w w
, 若直接將我們估算出來的機率放入,則會造成機率總和大於 1 的情況發生,因此我們將使用 類似 Stage 1 時的概念,將這個詞的機率空間重新作分配,因此對於某個詞wi1而言,我們的 式子如下: 1 1 1 1 1 1 1 ( ( ) ( )) ( ) , , ( ) ( ( ) ( )) ( )+(1- ) ( G( )) ( ( )) M i i G i i i i i i M i i M i i M i i M i i P G w G w P w w w w lexical word P w w P G w G w P w w P w w P w G w 1,wi lexical word , wi particle paralinguistic,
(3-10) 5 此處之 1 ( i , i)
表 3.8:MCDC 中各類別之相接機率 GM( )w i 1 ( ) M i G w
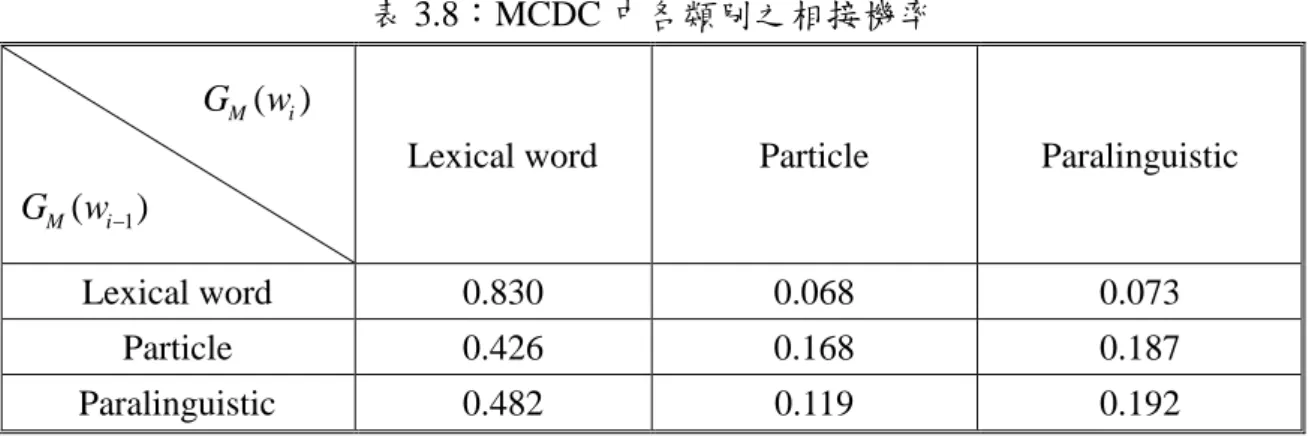
Lexical word Particle Paralinguistic
Lexical word 0.830 0.068 0.073 Particle 0.426 0.168 0.187 Paralinguistic 0.482 0.119 0.192
Stage3: 調適一般詞之機率
本研究在建立 General-LM 時是利用了大量的文章文字資料訓練且較具有普遍性 (General),而且在前面階段我們已經估算出一些自發性語音才有的特殊單元之機率,但是因 為 MCDC 語料庫實質上是屬於不同領域(domain)的資料,使得初始語言模型在估算ㄧ般詞的 出現機率仍較不準確,若能結合擁有大量資料的 General-LM 和 MCDC 文字資料在同領域下 的優點去進行語言模型調適,則可以使得新的語言模型更加合乎自發性語音的特性。 首先,觀察 2.3.1 中圖 2.1 可發現在 MCDC 語料庫中一字詞與二字詞出現機率極高,這 些一、二字詞中又以一些特定詞(例:我、你、他、對、有、是、嗎、就是、我們)居多,因 此本研究將利用最大事後機率(Maximum A Posteriori, MAP)估算法來建立一套 bi-gram 語言 模型以達到較佳的辨識效益。MAP 估算法可用來當作調適模型的一種方法,其定義是在擁有一個已知模型參數分布 (model parameter distribution)X 以及有限的觀察資料(observation)W的情況下:
MAP arg max ( )
arg max ( ) ( ) X X X P X W P W X P X (3-11) 其中 (P W X 為觀察資料) W的概似度(likelihood)。此方法的主要概念是當觀察資料數量越多 時,則越不相信原本的模型參數分布,簡而言之,就是改變已知的模型參數分布使其與觀察 資料的參數分布相符合。
3.2.3 語言模型效能分析
評估語言模型通常是以計算其混淆度(perplexity, PP)來判斷。混淆度是根據消息理論 (information theory)而得,如下式:
1 2
1
log
,
,
,
mH
P W
w w
w
m
(3-12) 上式為一個詞串W w w1, 2, ,wm,對於每個新詞提供的帄均資訊量(entropy),經過適當的化 簡而得。而混淆度可直接使用 (3-12) 式進一步定義為:
exp PP H (3-13) 若
1 2
1 2 1
1 , , , | , , , m m i i i P W w w w P w w w w
則可發現,混淆度就是P w w w
i| 1, 2, ,wi1
的幾何帄均數的倒數。因此混淆度可以解讀為語言模型估測一個歷史詞串後面,帄均可能的 可接詞數;混淆度越高,表示一個歷史詞串後接詞有較多的選擇,辨認時就越難找到確切的 答案;反之,則較易找到正確答案。 利用(3-13)式來評估本研究實驗之各個語言模型的效能,如表 3.9 所示。由表中可觀察 到在 Stage1 時我們在語言模型中估算了 Particle 及 Paralinguistic 的機率後,混淆度確實能有 效下降;在 Stage3 時我們有效地調適了一般詞的機率後也能使得混淆度大幅下降。此效能評 估也將反映在辨識率上,本研究將在第五章予以觀察及討論。 表 3.9:語言模型混淆度評估 語言模型 混淆度(PP) General-LM 748.7 Stage1-LM 598.15 Stage2-LM 547.46 Stage3-LM 394.8第四章 自發性語音韻律模型
本研究採用【11】所提出之方法做修改,重新定義自發性語音中的特殊韻律現象,並利 用語音信號中之聲學參數及文字轉寫(transcription)上的語言參數,以非監督式(unsupervised) 的方法訓練出自發性語音韻律模型(PLM)。在語音辨認方面,利用韻律模型對第一級辨認出 來的 Top-N 詞串重新計分並產生最佳之詞串辨認結果。本章將在 4.1 節介紹韻律模型之設 計;4.2 節將會介紹如何建立韻律模型;4.3 節將針對訓練之韻律模型做簡單分析;4.4 節將 介紹以韻律模型協助語音辨認之方法。4.1 韻律模型設計
在本節中將簡單說明本論文所使用的中文語音韻律階層式架構以及韻律模型之設計,在 此定義四個子模型來描述語音信號中聲學參數以及文字上語言參數與韻律標記之關係。4.1.1 中文語音韻律階層式架構
中文的韻律結構是具有階層性的架構(hierarchy structure),由底層至上層主要由音節 (Syllable, SYL)、韻律 詞 (Prosody Word, PW)、韻律短句 (Prosody Phrase, PPh)以及句調 (intonation phrase)所構成。此外,鄭秓豫博士【15】提出將連續的 PPh 組合成一個呼吸群 (Breathe Group, BG)來代表大範圍且具有基頻及音節長度高度變化之語句,藉此表示韻律更 上層之貢獻,同樣地定義由連續的 BG 所組成的韻律群(Prosody Group, PG),值得注意的是 鄭秓豫博士在流利語音的韻律架構當中,定義 PPh 間存在著某些可插入的篇章提語(Discourse Marker, DM)或韻律填充(Prosody Filler, PF),以連接鄰近的 PPh,如圖 4.1 所示:PG
BG BG
PPh PPh PPh
PW PW PW PW
SYL SYL B1/B0 SYL SYL SYL
B2 B3 B4 B5 B5 DM/PF PW SYL 圖 4.1:中文語音韻律之階層式架構概念 在自 發 性語音韻 律 結構的 研 究 上 【 11】提出一個特殊韻律現象 (Particular Prosody Phenomena, Par)的單元,藉此隔離正常語流之語句。特殊韻律現象中包含:韻律特性和基本 音節差距較大之語助詞或感歎詞6、無法或難以辨識的語音、受相鄰音節同化之音節以及發 生嚴重拉長之音節7,這些嚴重拉長的音節數量雖小但長度較其他基本音節大,會嚴重影響 模型之統計特性,如圖 4.2 所示,在本研究中將基於【11】所提出的中文自發性韻律階層式 架構為基礎作修改並設計韻律模型。 BG/PG PPh PW PW SYL BPO B3 B2 B2 B1/B0 Par BPI PW PW SYL PPh PPh B1/B0 PW SYL SYL
SYL SYL SYL SYL
BG/PG SYL BP 圖 4.2:中文自發性韻律階層式架構 基於圖 4.2 的架構下,本研究將所有音節分為對應正常語流之基本音節(base syllable)以 及對應特殊韻律單元之特殊音節(particular syllable)。此外在本研究所使用的四層韻律結構
6本研究將第二章所定義之感歎詞或語助詞中,「ZHE GE」、「NA GE」、「NE GE」、以及「SHEN ME」視為兩個
音節,其餘皆視為一個音節。
中,主要由十種停頓標記(break type)來區分韻律結構中每一層的韻律單元,對應法則如表 4.1 所示。 表 4.1:韻律結構之停頓標記 韻律結構 停頓標記 意義 韻律群(PG) 或呼吸群(BG) B3 長停頓 B4 長停頓且含有明顯的基頻跳躍 韻律詞(PW) B2-1 相鄰兩音節具有明顯的基頻跳躍 B2-2 短停頓 B2-3 前一音節發生音節拉長
音節(SYL) B0 音節邊界相鄰兩音節是緊密連接(tightly coupling)
B1 音節邊界相鄰兩音節是普通連接(normal coupling) 特殊韻律現象 (Par) BPI 後一音節為特殊音節 BP 相鄰之兩音節皆為特殊音節 BPO 前一音節為特殊音節 值得注意的是,【11】將所有 particle 皆定義為特殊韻律現象,而本研究實地觀察後發現 自發性語音中其實有許多 particle 存在於順暢語流中,通常其韻律變化就如同基本音節,因 此本研究將把屬於流暢語流中的 particle 視為基本音節作訓練。 首先,本研究先利用【11】訓練之韻律模型計算 B2-2 之門檻值(threshold),檢查所有不 為拖長音且後一音節為基本音節的 particle 與前一音節或後一音節間的停頓長度(pause duration),若停頓長度小於此門檻值則將此 particle 視為流暢語流中的基本音節,並將它的聲 調(tone)退化成近似之 411 音節的聲調;若停頓長度大於此門檻值則將此 particle 視為特殊音 節,給予一個特別的聲調並當成特殊韻律現象來處理。其中值得注意的是我們將 NE-GE、 ZHE-GE 及 SHEN-ME 視為可合併成一個單元的候選 particle 詞組,檢查此類 particle 詞組時 除了規定其與前一音節或後一音節間的停頓長度要小於 B2-2 門檻值外,其本身兩個 particle 相接的停頓長度也需小於 B2-2 門檻值才可被轉換成基本音節。篩選結果如表 4.2 所示:總共 有 8554 個 particle,其中有 4462 將被視為流暢語流中的基本音節;有 4092 個 particle 被視為 特殊韻律現象之音節。
表 4.2:歸類為基本音節之 particle 個數
particle 個數 particle 個數 particle 個數 A 1024 LA 203 HEN 40 NA 482 MA 156 MHMHM 35 O 425 BA 149 HEIN 25 GE 392 HO 132 WA 22 NE 363 ME 70 HAN 19 E 250 SHEN 70 NO 18 MHM 224 YA 63 AI 15 EI 214 ZHE 61 YOU 10
4.1.2 韻律參數之介紹
接著定義本研究中使用之韻律聲學參數 A,以及文字上的語言學參數 L,如表 4.3 所示。 本研究考慮的韻律聲學參數包含兩大類如圖 4.3 範例:第一類是與韻律狀態有緊密關係的音 節韻律參數 X (syllable prosodic feature)主要有:音節基頻軌跡 sp (syllable pitch contour)、音節 長度sd(syllable duration)以及音節能量 se (syllable energy level);第二類是與停頓標記有緊密 相關的特徵參數,又細分為兩類分別是音節間韻律參數 Y (inter-syllable prosodic feature)以及 相鄰兩音節差異之韻律參數 Z (differencial prosodic feature),音節間韻律參數有:音節間停頓 長度pd(pause duration)以及音節間能量低點ed(energy-dip level);相鄰兩音節差異之韻律參 數有:相鄰兩音節之正規化基頻跳躍值 pj (normalized pitch jump)以及相鄰兩音節之正規化音 節延長因子dl(normalized duration lengthening factor)。而文字上的語言學特徵參數 L 主要包 含語言學中音節以及詞層次上的參數。音節層次上的參數主要包含了音節聲調序列 t (tone sequence)、基本音節型態 s (base syllable type)或韻母型態f (final type);其它語言參數l ,主要包含音節邊界種類8
(syllable juncture type)、詞長以及詞性。
8
表 4.3:韻律標記、聲學參數以及語言參數之數學符號
T: prosodic tag
B: break type ={B0, B1, B2-1, B2-2, B2-3, B3, B4, BPI, BP, BPO} PS: prosodic state
p: pitch prosodic state q: duration prosodic state r: energy prosodic state
A: prosodic feature
X: syllable prosodic feature
sp: syllable pitch contour sd: syllable duration se: syllable energy level Y: inter-syllabic prosodic feature pd: pause duration
ed: energy-dip level Z: differential prosodic features pj: normalized pitch jump
df: normalized duration lengthening factor
L: linguistic feature
l: reduced linguistic feature set t: syllable tone sequence s: base-syllable type f: final type 圖 4.3:音節及音節間韻律參數 音節間停頓長度 音節長度 音節間能量低點 語音信號 基頻軌跡 音節能量軌跡 基頻跳耀
4.1.3 模型設計
本研究利用語音信號上的聲學參數 A,以及文字上語言學的參數 L,以模型為基礎 (model-based)估計此語句中最有可能的韻律標記序列T ,因此可將其看作一個數學估計的問 題,其數學式如下: argmax ( | , )=argmax ( , | )P P T T T T A L T A L (4-1) 在此定義兩種韻律標記,第一種為 4.1.1 節中所定義之音節停頓標記序列 B ;第二種則是韻 律狀態(prosody state)序列PS,它是經由扣除音節及其相鄰音節對韻律之影響並量化後所得 到,以描述韻律上層之變化狀況及其對韻律參數之貢獻值,在本研究中,將所有基本音節量 化為 16 個韻律狀態,並且將特殊音節另外分出 4 個韻律狀態量化之。根據 4.1.2 所介紹的韻 律參數,我們可以將 4-1 式改寫為: ( , | ) ( | , ) ( | ) ( , , | , , ) ( , | ) P T A L P A T L PT L P X Y Z B PS L PB PS L (4-2)其中P X Y Z B PS L( , , | , , )為廣義韻律參數模型(general prosodic feature model),其物理意義為下
層所得到的韻律聲學參數 X、Y、Z,是由上層的韻律標記 B、PS 以及語言參數 L 所控制。
而P B PS L( , | )為廣義韻律語言模型(general prosody-syntax model),它主要在描述韻律標記
B、PS 和語言參數 L 之間的關係。 由於定義之停頓標記 B 已帶有相鄰兩音節間之韻律資訊,因此在已知停頓標記的狀況 下,可以假設音節韻律參數 X 與音節間韻律參數 Y 及相鄰兩音節差異之韻律參數 Z 互相獨 立,因此可將廣義韻律聲壆模型P X Y Z B PS L( , , | , , )一分為二,其數學式如下: ( , , | , , ) ( | , , ) ( , | , , ) P X Y Z B PS L P X B PS L P Y Z B PS L (4-3)
其中P X B PS L( | , , )為音節韻律模型(syllable prosodic model),其物理意義為音節中的基頻軌
跡、音節長度及音節能量,是由上層的韻律標記 B、PS 以及語言參數 L 所控制,其中語言 參 數 又以音節的聲調序列 t 之影響最為嚴重。而P Y Z B PS L( , | , , )為停頓標記聲學模型
(break-acoustic model),它描述不同韻律標記 B、PS 以及語言參數 L 的狀況之下,音節間韻 律參數 Y 及相鄰兩音節差異之韻律參數 Z 分布的情況。同樣地,經由假設上層的韻律標記 B、
PS 與音節聲調 t 互相獨立,我們也可將廣義韻律語言模型P B PS L( , | )一分為二,數學式如下: ( , | ) ( , | ) ( | ) ( | ) ( | ) ( | )
P B PS L P B PS l P PS B,l P B l P PS B P B l (4-4)
其中P PS B( | )為韻律狀態轉移模型(prosodic state model),描述在已知停頓標記的狀況之下,
韻律狀態轉移之機率。P B l( | )則為停頓標記語言模型(break-syntax model),主要描述停頓標 記 B 和語言參數 l 之間的關係。因此本研究中設計了四個子模型分別為:音節韻律模型、停 頓標記聲學模型、韻律狀態轉移模型以及停頓標記語言模型,來描述韻律狀態、停頓標記與 聲學和語言學參數之間的關係。 本研究之音節韻律模型是假設音節基頻軌跡、音節長度以及音節能量可拆解成各個影響 因子(affecting factor)之貢獻,這些影響因子包含:音節之韻律狀態p 、包含音節左右邊界停n 頓標記B 、n Bn1及鄰近音節聲調tn1、tn1影響之音節聲調t (i.e.音節連音現象之影響)以及音n 節基本型態s 或音節韻母型態n f ,不同的音節韻律模型將視影響程度,對應至不同影響因子n 之組合,將在之後做更詳細之介紹。因此可將音節韻律模型拆解成三個模型分別為音節基頻 軌跡模型、音節長度模型以及音節能量模型,其數學式如下: 1 1 1 -1 -1 -1 -1 -1 -1 1 1 1 ( | , , ) ( | , , ) ( | , , , ) ( | , , , ) ( | , , ) ( | , , , ) ( | , , , ) N N N n n n n n n n n n n n n n n n n n n n n n n n p p p p p B p t p sd B q t s p se B r t f
X B PS L sp B p t sd B q t s se B r t f sp (4-5) 其中 1 1 1 ', , if th syllable is base syllable
for 1 , if th syllable is particular syllable
n n n n n n n r n t B p n r n pr p n n N n sp β β μ sp sp β β μ (4-6) 為第 n 個音節之音節基頻軌跡, r n sp 為spn正規化(normalization)後之基頻殘存值(residual);βx 則為某一影響因子 x 之影響型態(Affecting Pattern, AP); μ 為所有 AP 之總體帄均值(global