國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
藉由暫存器配置與指派演算法減少程式碼大小於
混合寬度指令集架構處理器
Reducing Code Size by Graph Coloring Register Allocation and
Assignment Algorithm for Mixed-Width ISA Processors
研 究 生:王志先
指導教授:單智君 博士
藉由暫存器配置與指派演算法減少程式碼大小於
混合寬度指令集架構處理器
Reducing Code Size by Graph Coloring Register Allocation and
Assignment Algorithm for Mixed-Width ISA Processors
研 究 生:王志先 Student:Jyh-Shian Wang
指導教授:單智君 Advisor:Dr. Jyh-Jiun Shann
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A Thesis
Submitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science and Engineering July 2009
Hsinchu, Taiwan, Republic of China
i
藉由暫存器配置與指派演算法減少程式碼大小
於混合寬度指令集架構處理器
學生:王志先 指導教授:單智君 博士 國立交通大學資訊科學與工程研究所碩士班摘要
由於現今的嵌入式系統需要越來越多的程式功能,但又不希望增加記憶體大小,因 此減少程式碼大小即成為一個關鍵性的問題。其中一種解決辦法是使用"混合寬度指令 集架構",這類架構通常包含一個正常寬度指令集(通常是 32 位元)以及一個短指令集(通 常是 16 位元),且短指令集僅有部分 Opcodes 以及僅能存取部分的暫存器。在以往傳統 的混合指令集架構中,一段連續程式碼僅能被編碼在相同的格式(寬度),無法使用多種 格式穿插其中,但越來越多的混合指令集架構使用了指令編碼來告知處理器該指令的寬 度,如此便可在程式之中任意穿插長短指令,不再是一個一個分開的區塊。對於這樣的 架構,有多少指令能夠被編碼成較短的格式高度依賴於如何配置這些短指令格式能存取 到有限的暫存器。在這篇論文中,我們提出了兩個基於著色演算法的暫存器配置與分派 演算法,它們使用一個估計的方法去找出適合被指派到短指令格式能存取到之暫存器的 程式變數,而適合的變數意味著如果指派它們到這些暫存器可以有效增加可以被編碼成 短指令的指令數量。透過模擬結果顯示,使用此論文所提出的演算法可以減少大約 31.90%的程式碼大小。ii
Reducing Code Size by Graph Coloring Register
Allocation and Assignment Algorithm
for Mixed-Width ISA Processors
Student: Jyh-Shian Wang Advisor:Dr. Jyh-Jiun Shann
Institute of Computer Science and Engineering National Chiao Tung University
Abstract
Reducing program size is a critical issue in many embedded systems which require more program functionalities without increasing the memory size. One of the approaches is the “mixed-width instruction set architecture (ISA)” which usually has an instruction set in general formats (usually 32-bit long) as normal instruction set, and an instruction set in shorter format (usually 16-bit long) with limited opcodes and set of registers. Traditionally, a code segment can be encoded in only one format, no multiple formats interleaved. However, more and more processors use instruction encoding to indicate the length of each individual instruction, and take mixed-width ISA into instruction-level granularity. For this kind of ISAs, the number of instructions can be encoded in shorter format is highly dependent on the limited set of registers that can be accessed by shorter format instructions. In this paper, we present a register allocation and assignment algorithm based on graph coloring, which uses a heuristic model to find out which virtual variables in program should be assigned into the set of registers accessible by shorter instructions. The simulation results show that the code size reduction is achieved 31.90% by the proposed algorithm.
iii
致謝或序言
首先感謝我的指導老師 單智君教授,在這兩年當中不論是正式報告,亦或是平日 小組討論,老師對於學生的諄諄教誨,細心指導與勉勵,使我學習到如何面對問題,以 及如何克服問題,並培養獨立研究的能力。有幸跟著老師做研究,觀察老師對於一件事 情的執著與細膩,耳濡目染,並從中學習,最後完成了研究與碩士學位。同時,也感謝 口試委員,楊武教授與雍忠教授,由於教授們的指導與建議,才使得此篇論文更加完整 與充實。另外,也謝謝實驗室的另一位老師,鍾崇斌教授,在一次次的報告之中給予學 生指導與建議。 裕生學長、奕緯學長,感謝兩位學長帶領我進入 JVM 與 Compiler 領域,不僅僅只 是給予我研究上的建議與討論,同時也常是鼓勵我前進的動力,才使得我學習到相關知 識並完成此研究。同時,實驗室的學長姐、同儕以及學弟妹,在這一起渡過的時光中, 你們不僅僅是我記憶中的好夥伴,更是人生道路上的貴人們,謝謝。 最後,對於我的家人以及總是在我低潮時給予鼓勵並且陪伴著我的親友們,志先也 在此獻上最誠摯的謝意。 王志先 2009.7.26iv
Table of Contents
摘要 ... i Abstract ... ii 致謝或序言 ... iii Table of Contents ... iv List of Figures ... viList of Tables ... viii
Chapter 1 Introduction ... 1
1.1 Research Motivation ... 4
1.2 Research Objective ... 4
1.3 Organization of this Thesis ... 6
Chapter 2 Background ... 7
2.1 Mixed-width ISA with Mode-switch by Instruction Encoding ... 7
2.1.1 S-Format Limitations ... 7
2.1.2 Encoding Formats of S-Format Instruction ... 9
2.2 Graph Coloring Register Allocation...10
2.2.1 Interference Graph ...11
2.2.2 Bottom-up Graph Coloring ...11
2.2.3 Priority-based Graph Coloring ...12
2.3 Summary of Backgrounds ...14
Chapter 3 Design of The Register Allocation and Assignment Algorithms ... 15
3.1 Compiler Back-end and Definitions for Mixed-width ISA ...16
3.1.1 Instruction Types ...18
3.1.2 Register Classes ...19
3.2 Design I : Based on Bottom-up Graph Coloring ...20
3.2.1 Allocation Pass...21
A.RegS-Simplify and RegL-Simplify Stages ...21
B. Spill Stage ...24
v
3.2.3 Discussion ...28
A.Different Assignment Orders in Assignment ...28
B. Assignment without RegS-Simplify ...31
C. Extension of the Algorithm to More Hierarchy Register Sets for Different S-Formats ...32
3.3 Design II : Based on Priority-based Graph Coloring ...34
3.3.1 Separate Stage ...37
3.3.2 LRU Allocation and Assignment ...37
3.3.3 LRL Allocation and Assignment ...38
3.3.4 LRS Allocation and Assignment ...39
3.3.5 Discussion ...39
A.Alternative Design ...40
B. Extension of the Algorithm to More Hierarchy Register Sets for Different S-Formats ...41
Chapter 4 Experiment ... 43
4.1 Environment ...43
4.2 Benchmark Evaluation Results ...44
4.2.1 Parameter Determination ...44
4.2.2 Comparisons of Design Alternatives ...46
4.2.3 Code Size Reduction ...47
4.2.4 Spill Codes ...50
4.2.5 S-Format Limitations Analysis ...51
4.3 Summary for Simulation Results ...53
Chapter 5 Conclusions and Future Works ... 54
5.1 Conclusions ...54
5.2 Future Works ...55
vi
List of Figures
Figure 1-1 – L/S-Format instructions in program code. (a) Mode-switch by mode-switch
instruction. (b) Mode-switch by instruction encoding. ... 3
Figure 1-2 – Mode-switch by instruction encoding. ... 3
Figure 2-1 - S-Format limitation distributions. ... 8
Figure 2-2 - Different encoding formats of S-Format instructions. (Rd: destination register. Rs, Rt: source destination. Imm: immediate value) ... 9
Figure 2-3 - Interference graph. ... 11
Figure 2-4 - Bottom-up graph coloring. ... 12
Figure 2-5 - Priority-based graph coloring. ... 13
Figure 3-1 - Compiler back-end for mixed-width ISA. ... 17
Figure 3-2 - Different S-Format instructions equivalent to lw. ... 17
Figure 3-3 – Register classes ... 19
Figure 3-4 - Flowchart of the proposed algorithm based on Bottom-up graph coloring for mixed-width ISA with mode-switch by instruction encoding. ... 20
Figure 3-5 – Diamond graph. ... 22
Figure 3-6 - The process sketch map of our proposed algorithm based on Bottom-up graph coloring. ... 22
Figure 3-7 - Pseudo code of allocation pass. ... 24
Figure 3-8 - Pseudo code of assignment pass. ... 28
Figure 3-9 - Different Assignment Order in Bottom-up Graph Coloring for Mixed-width ISA with mode switch by instruction encoding : (a) RegS-Assignment → RegL-Assignment (b) RegL-Assignment → RegS-Assignment. ... 30
Figure 3-10 - Assignment result without RegS-Simplify. ... 31
Figure 3-11 - Extension of Design I for different S-Formats. ... 33
Figure 3-12 - Flowchart of the register allocation and assignment algorithm based on Priority-based graph coloring for mixed-width ISA with mode-switch by instruction encoding... 35
Figure 3-13 - Pseudo code of Priority-based graph coloring for mixed-width ISA with mode-switch by instruction encoding ... 36
Figure 3-14 - Flowchart of the proposed algorithm without LRL allocation and assignment pass of Design II. ... 40
Figure 3-15 - Extension of Design II for different S-Formats. ... 42
Figure 4-1 - The evaluation of differentαvalues. ... 45
Figure 4-2 - Benchmark evaluation results of the different assignment order in MxBuGCRA. ... 46
vii
Figure 4-4 - Benchmark evaluation results of the proposed algorithms... 49
Figure 4-5 - Spill codes of the proposed and traditional algorithms. ... 50
Figure 4-6 - S-Format limitation distributions - BuGCRA v.s. MxBuGCRA. ... 52
viii
List of Tables
1
Chapter 1 Introduction
In the increasing market of embedded systems, RISC processors have been used widely. A RISC processor usually offers higher computation power and lower hardware cost and, meanwhile, suffers from the less code density than a CISC processor because of its fixed-width instruction set. However, code size is one of the major issues in embedded systems, since the larger code size may increase the memory requirement. As a result, mixed-width RISC instruction set architectures (ISAs) have been proposed to make a good tradeoff between performance and code density (i.e. low code size) [1]. Moreover, the traffic of the memory data bus for fetching instructions and the I-Cache miss rate may also be reduced.
There are several mixed-width ISAs provided commercially, for examples, ARM’s ARM/Thumb ISA, MIPS’ MIPS/MIPS16 ISA, Andes’ AndeStar ISA, etc [2-4]. They typically have one short width instruction format (S-Format) as a frequently used subset of the longer width instruction format (L-Format). For example, MIPS is a 32-bit width instruction set, and its 16-bit width subset is called MIPS16. Mixing the short width instructions into the original program which is composed with 32-bit instructions may improve the code density. However there are two main limitations exists due to the S-Format instructions have fewer bits for register indexing and immediate value storing in mixed-width ISAs.
1. Fewer bits to index registers:
One of the limitations is that the short width instructions have fewer bits to index registers. For example, 3-bit register field in S-Format can access eight physical registers only. If all of the operands of an instruction are assigned to the registers that can be accessed by S-Format instructions, then this instruction is able
2
to be encoded as an S-Format instruction to reduce code size. Otherwise, if one of its operands is out of the register indexing range of S-Format instructions, then this instruction must be encoded as an L-Format instruction definitely. Accordingly, if the compiler does not take into account these restrictions while assigning registers, the translation rate of S-Format instructions may be quite low. Therefore, the assignment of registers becomes very important for mixed-width ISAs.
2. Fewer bits to hold immediate values:
The other limitation is the short width instructions have fewer bits to store immediate values. If the immediate value is oversized for an instruction’s S-Format then the instruction can only be encoded as L-Format instruction. Although large immediate values may impact the translation rate of S-Format instructions, it varies on how complier manages constants. If a compiler uses a constant pool to hold these large immediate values, the impact of immediate values can nearly be neglected.
In addition, the different mechanisms of mode switching between L-Format and S-Format instructions make problems distinct in mixed-width ISAs. There are two types of mechanisms for switching between L-Format and S-Format instructions [5]. Some architectures use a mode switching instruction to change modes between code segments with different encoding formats, for example, ARM/Thumb. It means that all instructions in the same code segment must be encoded in the same format as shown in Figure 1-1 (a). On the other hand, there are some architectures change modes by instruction encoding so that L-Format and S-Format instructions may be interleaved freely in routines as shown in Figure 1-1 (b), i.e., L-Format and S-Format instructions may be mixed up at the instruction level granularity. For example, AndeStar ISA uses a bit (usually the MSB) in instruction field to
3
indicate whether the instruction is L-Format or S-Format as shown in Figure 1-2. For the former, existing compilers either rely on user guidance or perform an analysis to determine which code segments should use S-Format [6], then a mode switch instruction will be inserted between the code segments, and finally the compiler compiles code segments with different instruction width by different policies. For the latter, because no mode-switch instruction is needed, the compiler should eliminate the limitations of each individual instruction of its S-Format as far as possible to increase the number of instructions encoded in S-Format. However, the existing techniques for this kind of ISAs are still rudimentary.
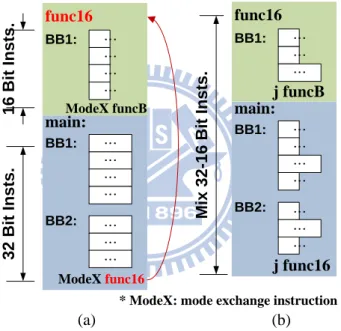
Figure 1-1 – L/S-Format instructions in program code. (a) Mode-switch by mode-switch instruction. (b) Mode-switch by instruction encoding.
Figure 1-2 – Mode-switch by instruction encoding. BB1: BB2: ModeX func16 BB1: ModeX funcB main: func16 1 6 B it I n s ts . 3 2 B it I n s ts . BB1: BB2: j func16 BB1: j funcB main: func16 M ix 3 2 -1 6 B it I n s ts . … … … … … … … … … … … … … … … … … … … … …
* ModeX: mode exchange instruction
4
1.1 Research Motivation
So far we have introduced the mixed-width ISAs, which can increase code density if the registers are used carefully especially for those with mode-switch by instruction encoding. Also, we know that the code size problem is one of the major issues in embedded systems. The larger code size needs the larger memory, and thus may consume more power. Unfortunately, the enlarging program size due to the requirement of more program functionalities in modern embedded applications is happening. For these reasons, using mixed-width ISAs is a feasible approach for code size reduction.
In order to reduce program code size for a mixed-width ISA with mode-switch by instruction encoding, registers should be allocated and assigned properly to eliminate each instruction’s limitation of translation to S-Format instructions, and, as in results, the number of instructions that can be encoded as S-Format may be increased. However, the existing techniques of compilers for mixed-width ISA with mode-switch by instruction encoding are rudimentary. Therefore, a proper register allocation and assignment algorithms should be designed for this kind of ISAs.
1.2 Research Objective
In this thesis, we proposed an algorithm for mixed-width ISA with mode-switch by instruction encoding to increase the number of instructions encoded as S-Format by allocating and assigning registers properly. The original goal of register allocator is to allocate virtual variables to registers or memory locations and optimize for generating fewest memory referenced instructions (spill codes). However, for the mixed-width ISAs, it should consider
5
the mapping of physical registers and virtual variables, and, meanwhile, the number of spill codes should be minimized due to the performance issue. To achieve the features mentioned, there are two main goals to accomplish:
1. Reducing code size:
To reduce code size by mixed-width ISA with mode-switch by instruction encoding, the usage of S-Format instructions is the key point. In other words, if we can encode more instructions as S-Format instructions, the code size will be reduced more. To achieve that, we propose a heuristic model in register assignment procedure. The proposed algorithm not only allocates virtual variables to registers or memory locations but also assigns registers by choosing virtual registers with the highest code size benefit to assign physical registers which are accessible by S-Format instructions.
2. Minimizing performance degradation:
Although our primary objective is to reduce code size, the number of spill codes generated by register allocator is critical, too. More spill codes lead to more performance degradation, and it also increases code size. To minimizing the number of spill codes, the proposed algorithm chooses variables with the lowest memory reference cost to spill while the required registers are more than the physical registers available.
6
1.3 Organization of this Thesis
The rest of this paper is organized as follows: Section 2 discusses more details of a typical mixed-width ISA and other related researches and algorithms; Section 3 gives the instruction formats and register classes defined in our algorithm and the detailed description of the proposed algorithm; Section 4 presents the experimental results and discussion follows. Finally, Section 5 dedicates to the conclusions we draw and the future work planed.
7
Chapter 2 Background
In the first part of this chapter, we will analyze the distribution of S-Format limitations in programs generated by a traditional register allocation algorithm to observe the opportunities for research and explain more details about mixed-width ISA with mode-switch by instruction encoding. In the second part, two traditional register allocation algorithms will be introduced. In the last part, a brief summary about the problems that the existing algorithms suffer from in mixed-width ISA with mode-switch by instruction encoding and the solutions we proposed for it will be described.
2.1 Mixed-width
ISA
with
Mode-switch
by
Instruction Encoding
In this section, the S-Format limitations will be introduced and analyzed. Then, the different encoding format of S-Format instructions will be explained in details.
2.1.1 S-Format Limitations
Using mixed-width ISA can reduce code size significantly in intuition: if all instructions have operational equivalent S-Format instructions and all of them can be encoded in S-Format, then the code size may be reduced by 50%. However, as mentioned above, there are many restrictions including register index, immediate values, and, even that not all the instructions have corresponding S-Format instructions.
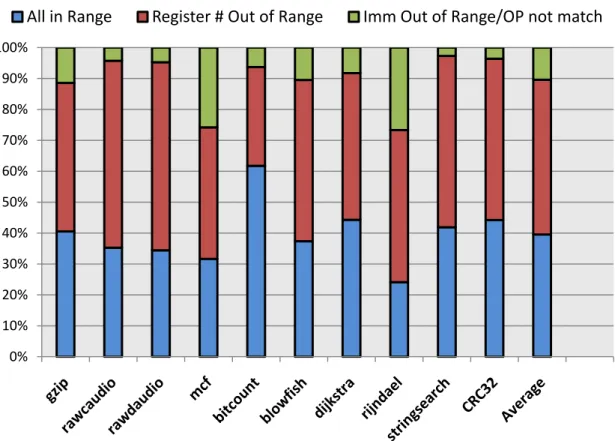
Figure 2-1 is the analysis result about the distribution of the limitations of S-Format translation in benchmark programs compiled by using traditional graph coloring register allocation. The top blocks, green colored, are the percentage of instructions which have
8
no operation equivalent S-Format instructions or the immediate value is oversized. The middle blocks, red colored, are the percentage of instructions each of which has one or more operation equivalent S-Format instructions but at least one of its operand registers is out of range to index of S-Format instruction. And the bottom blocks, blue colored, are those instructions whose register number and immediate value are in the range of S-Format instructions.
From the distribution, we found that there are only about 11% instructions which have no operation equivalent S-Format instructions or the immediate value is oversized for its S-Format. However, over 50% of the left 89% instructions are restricted by their register number for translating to S-Format instructions. If the register allocation uses registers that can be accessed by S-Format instructions carefully in a heuristic way, it is possible to make more instructions be encoded into S-Format.
Figure 2-1 - S-Format limitation distributions. 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
9
2.1.2 Encoding Formats of S-Format Instruction
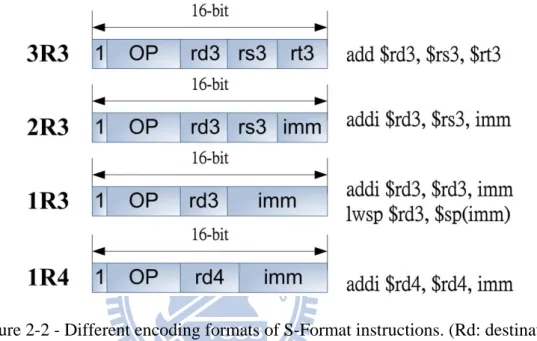
Comparing with L-Format instructions, S-Format instructions have fewer bits to index registers, and thus, the encoding formats of S-Format instructions have to be designed carefully in mixed-width ISAs. Typically, there are four S-Format encoding forms in mixed-width ISAs in present as in Figure 2-2:Figure 2-2 - Different encoding formats of S-Format instructions. (Rd: destination register. Rs, Rt: source destination. Imm: immediate value)
1. 3R3 Form
There are three registers as its operands, and three bits for each register indexing in 3R3 form.
2. 2R3 Form
There are two registers and one immediate value as its operands, and three bits for each register indexing in 2R3 form.
3. 1R3 Form
There are one register and one immediate value as its operands, and three bits for register indexing in 1R3 form. The register, rd3, in this form is used as the
10
source register and the destination register (eg. addi in Figure 2-2) or destination register when there is an implied register (eg. lwsp in Figure 2-2).
4. 1R4 Form
In a few mixed-width ISAs, some S-Format instructions may use four bits for register indexing. And the register, rd4, in this form is used as the source register and the destination register (eg. addi in Figure 2-2).
So far we have introduced four forms of instruction formats for S-Format instructions in mixed-width ISA with mode-switch by instruction encoding. From the analysis result shown above, the effect of reducing code size by using mixed-width ISAs is highly depend on the number of bits used to index registers. And thus, we concentrate on the number of bits used to index registers, meanwhile, the accessible registers of 3R3, 2R3, and 1R3 forms are limited in the same region. We have surveyed most of the mixed-width ISAs in present, and almost all of them consist of the 3R3, 2R3 and 1R3 forms only. Therefore, in this thesis, our target is the mixed-width ISAs with mode-switch by instruction encoding which comprise 3R3, 2R3, and 1R3 forms. Moreover, we will bring a briefly discussion about how to extend our algorithm to meet the requirement of 1R4 form.
2.2 Graph Coloring Register Allocation
The graph coloring algorithm is the most popular Register Allocator (RA) in general compiler for generating fewest load/store instructions, usually called “spill code”. Graph coloring for register allocation has many different versions [7]. The most well-know one is the
11
Bottom-up Graph Coloring proposed by Gregory J. Chaitin [8][9]. In addition, another frequently used version is the Priority-based Graph Coloring proposed by Fred C. Chow [10]. We will introduce these two algorithms in the following sections.
2.2.1 Interference Graph
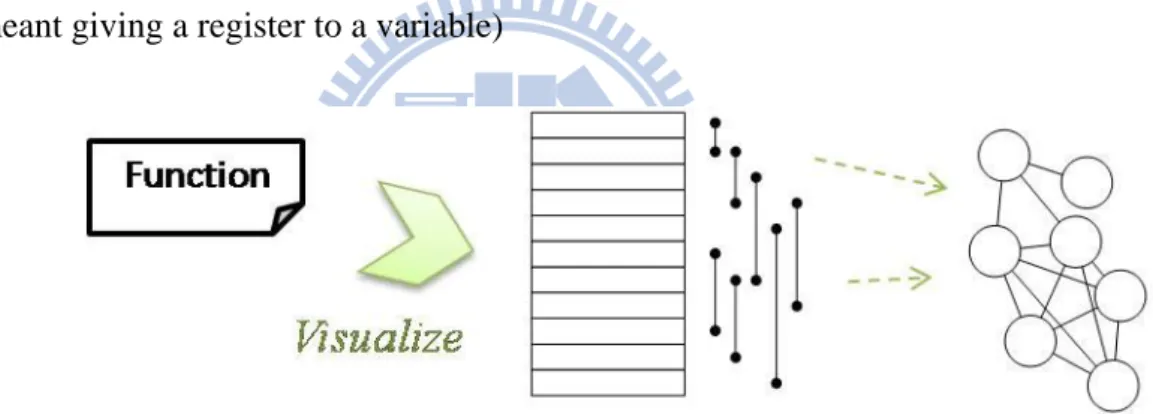
Both of these two graph coloring algorithms have to construct the same interference graph for coloring. The interference graph is constructed from a program function as in Figure 2-3. Nodes in an interference graph represent virtual variables (called variables for short) in program function, and the edges connected between nodes is the overlaps between their live ranges, i.e. they are alive in the same time. (Coloring a node in graph is meant giving a register to a variable)
Figure 2-3 - Interference graph.
2.2.2 Bottom-up Graph Coloring
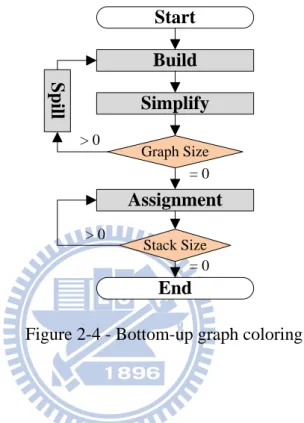
The flowchart of the bottom-up graph coloring algorithm is shown in Figure 2-4. First, it constructs an interference graph in the Build stage. If the graph can be colored with R colors then the variables can be stored in R registers [11]. This algorithm removes a node i with degree (the number of connected edges of a node) less than R, and put i into a stack, iteratively. This stage is called Simplify. Once all nodes are removed from the graph, i.e., the graph is an R-colorable graph, then pops all nodes from the stack and
12
assigns a color to each of them. Otherwise, the graph is not R-colorable, and thus, chooses one from the remaining nodes and split it into several nodes with shorter live time. This stage is called Spill. Notice that once a variable is spilled, new variables will be produced, and the algorithm must be rewound back to rebuild the interference graph.
Figure 2-4 - Bottom-up graph coloring.
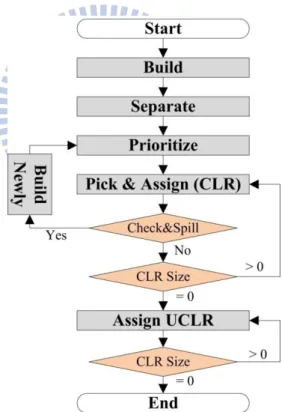
2.2.3 Priority-based Graph Coloring
The flowchart of priority-based graph coloring algorithm is shown in Figure 2-5, it also constructs an interference graph in the Build stage firstly. Then the algorithm separates nodes into two categories: UCLR (Unconstrained Live Range) and CLR (Constrained Live Range). The UCLR contains the nodes with degree less than the available number of physical registers R, and the CLR contains the others. Because the variables in UCLR have degrees (simultaneously living variables) less than the number of available physical registers, all of these variables are guaranteed to have registers. Therefore, the priority-based graph coloring makes effort on the variables in CLR only.
Build Simplify Graph Size Assignment S p ill Start End = 0 > 0 Stack Size = 0 > 0
13
It assumes that all variables in CLR are initially stored in memory, and it uses a priority function to give each variable in CLR a priority. Then pick the highest priority one to assign physical register. The priority function is composed of the cost of memory load and memory store saved if the variable was assigned to a register. In other words, the priority of a variable is similar to the access counts for the variable. After assigning one variable, the algorithm will check each neighbor of the variable to see whether it needs to be spilled. If yes, then spill it. Until all variables in CLR have been assigned registers, priority-based graph coloring then handles the UCLR. As mentioned above all variables in UCLR can be easily assigned registers.
14
2.3 Summary of Backgrounds
For mixed-width ISA with mode-switch by instruction encoding, we have indicated that the most limitation of translation to S-Format instructions is the using of the accessible registers in the register file in Section 2.1. Therefore, it is critical that which virtual registers should be assigned to which physical register in such architectures. However, both of the two traditional graph coloring register allocation algorithms consider the number of spill code only, and they do not take the mapping of virtual variables and physical registers into account. Therefore, they may result in less translation rate of S-Format instructions in generated code.
Obviously the traditional graph coloring register allocations do not suit for reducing code size in mixed-width ISA with mode-switch by instruction encoding. In this thesis, our goal is to design a register allocation and assignment algorithm to reduce code-size for mixed-width ISA with mode-switch by instruction encoding while minimizing performance degradation.
15
Chapter 3 Design of The Register
Allocation and Assignment Algorithms
In this thesis, we propose a register allocation and assignment algorithm to determine which of the virtual registers (variables) should be in which physical register or memory at each execution point. Here, register allocation decides which variables should be kept in the physical registers, and register assignment chooses physical registers for those variables which are not spilled into memory. In order to minimize the code size, the goal of the proposed algorithms is to assign as many variables which have more benefit to reduce code size (called $VarCS for short) as possible into the S-Format accessible registers. Therefore,
more instructions can be translated to S-Format instructions. Since it is difficult to assign all
$VarCSs within an application to the S-Format accessible registers, the way to determine
which $VarCS should be assigned to these registers is crucial. The basic idea of the proposed
algorithms is to let the frequently accessed and lower degree $VarCSs have higher opportunity
to be assigned to the S-Format accessible registers. In other words, the assignment order of
$VarCS is arranged from the most to the least frequently accessed and from lower to higher
degree.
The graph coloring algorithm is the most commonly used register allocation algorithm in compilers so that we use graph coloring algorithm as the base for our algorithms. In the following sections, the compiler backend and definitions used in this thesis are presented first, and then two algorithms which are modified from bottom-up and priority-based graph coloring algorithms for mixed-width ISA with mode-switch by instruction encoding will be explained in detail.
16
3.1 Compiler
Back-end
and
Definitions
for
Mixed-width ISA
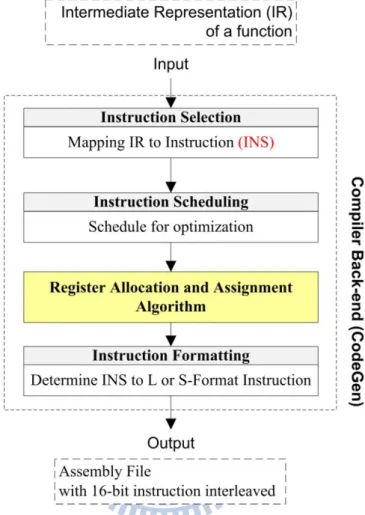
Typical compiler back-ends consist of instruction selection, instruction scheduling, and register allocation. First, instruction selection maps low-level intermediate representation (IR) to actual machine instructions (called instruction for short). This is usually done by pattern matching. And then, instruction scheduling schedules instruction for hiding some pipeline stall and/or increasing instruction-level parallelism. Finally, the register allocator will allocate virtual registers to physical registers.
However, in a mixed-width ISA, an instruction may be represented in multiple formats (e.g., L-Format and S-Format in this thesis) that are mainly different in their encoding length and the access range of register file. Therefore, instruction selection in a mixed-width ISA not only maps an operation of low-level IR (called operation for short) to instruction(s) but also chooses a proper format for each instruction. To achieve this, instruction selection is separated into two passes in this thesis as shown in Figure 3-1.
In instruction selection pass, an operation is mapped to temporary instruction(s), called as INS. Note that each INS may have multiple instruction formats which are only different in their encoding length rather than functionality. The instruction formatting pass is performed after register allocation and assignment pass. In this pass, each INS is translated to a proper instruction format according to the result of register allocation and assignment. For example, if a memory load INS lw has two equivalent S-Format instructions as shown in Figure 3-2. The instruction formatting pass will check whether its base register is $sp. If yes, and the offset is not oversize for S-Format to encode, and, thus, instruction formatting translates lw into lwsp; if not, the operation will be leaved unchanged. Because the assembly name of
17
S-Format instruction lw is the same as that of the L-Format one, the assembler will check the operands of the instruction to encode it in a proper format.
Figure 3-1 - Compiler back-end for mixed-width ISA.
18
3.1.1 Instruction Types
In mixed-width ISA, most INSs have multiple formats that are mainly different in their encoding length. In order to indicate whether an INS has multiple encoding formats or not, in this paper, INSs are classified into three categories as follows:
(1) L-INS (L-Format INS): L-INS is an INS which has no equivalent S-Format
instruction or has larger (oversized) immediate value such that it cannot be encoded in S-Format.
(2) S-INS (S-Format INS): S-INS is an INS which can be encoded in S-Format
definitely. For examples, JR and NOP. JR has only one operand and can access anyone of the physical registers. NOP does not index any registers and, thus, can be encoded in S-Format obviously.
(3) U-INS (Uncertain-Format INS): U-INS is an INS which has one or more
equivalent S-Format instructions, and can be encoded as an S-Format instruction if its physical registers may be limited in a small range. For specification, the virtual variables defined and/or used by a U-INS are marked as $VarU. And the $VarU is
exactly that variable with benefit to reduce code size as we mentioned $VarCS. Note
that U-INS is exactly what we can make efforts to increase the translation rate of S-Format instructions.
19
3.1.2 Register Classes
In this thesis, the physical registers of a mixed-width ISA are divided into two classes. Registers that can be accessed by S-Format instructions of U-INSs are denoted as RegisterSetS, and another case is RegisterSetA, which represents all accessible physical
registers for L-Format instructions, except some special register such as stack pointer (SP), global pointer (GP), etc. The number of registers of RegisterSetS and RegisterSetA
are denoted as RSNS and RSNA, respectively. Noticeably, RegisterSetS is a subset of
RegisterSetA rather than independent of each other. Now we take MIPS/MIP16
mixed-width architecture as an example. The register r0 is reserved for zero in MIPS, and MIPS16 uses three bits to index registers. Therefore, RegisterSetS contains r1~r7,
and another class, RegisterSetA, contains r1~r27 as shown in Figure 3-3.
Figure 3-3 – Register classes
Note that we do not handle the special registers, because special registers are usually used in a specific way, e.g., stack pointer ($sp) in add or lw for stack operation. Moreover, special registers usually have corresponding special S-Format instructions for them as implied operands. For example, add (SP-relative) and lw (SP-relative) instructions imply SP register as their operand as shown in Figure 3-2.
20
3.2 Design I : Based on Bottom-up Graph Coloring
In this section, the first design, register allocation and assignment algorithm based on Bottom-up graph coloring for mixed-width ISA with mode-switch by instruction encoding, will be described in detail.
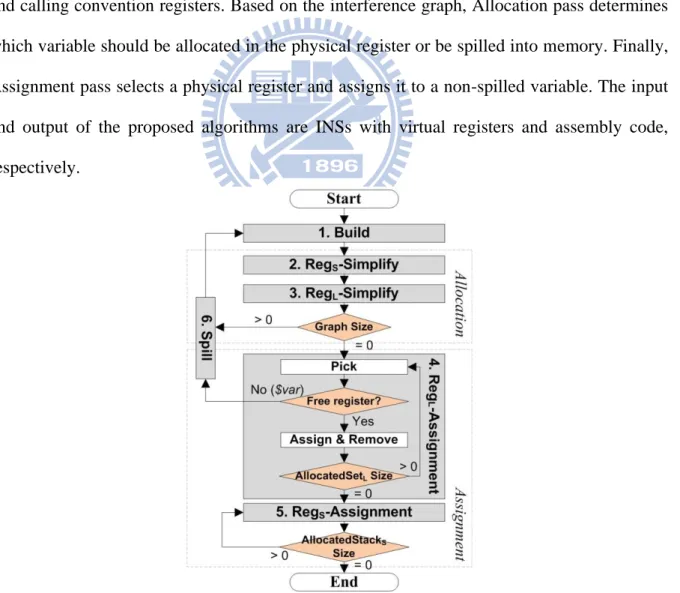
As depicted in Figure 3-4, the proposed algorithm consists of two main passes, namely Allocation, and Assignment. Firstly, the Build stage parses all necessary information, such as live rages, instruction types, etc., and constructs the interference graph, called graph for short. Note that the graph does not contain the variables which must be allocated in special registers and calling convention registers. Based on the interference graph, Allocation pass determines which variable should be allocated in the physical register or be spilled into memory. Finally, Assignment pass selects a physical register and assigns it to a non-spilled variable. The input and output of the proposed algorithms are INSs with virtual registers and assembly code, respectively.
Figure 3-4 - Flowchart of the proposed algorithm based on Bottom-up graph coloring for mixed-width ISA with mode-switch by instruction encoding.
21
3.2.1 Allocation Pass
The main purpose of Allocation pass is to determine which of the variables should be in register or in memory at each execution point. As shown in Figure 3-4, allocation pass consists of three main stages, namely RegS-Simplify, RegL-Simplify, and Spill. Firstly, RegS-Simplify and RegL-Simplify stages remove some variables from the graph and place them into the corresponding stacks. If there are any remaining variables after these two stages, then the degrees of these variables will be all larger than RSNA, and the
algorithm will enter spill stage. Spill stage shrinks the degrees of variables by removing some variables with less effect on the execution performance from the graph. In this stage, a variable removed from the graph is the one that must be spilled into memory. Since spilling a variable will generate several new variables, the algorithm must return to the Build stage and rebuild the graph, and then the allocation pass will be repeated again. When all variables are removed from the graph, it will enter the assignment pass to assign physical registers to variables.
A. Reg
S-Simplify and Reg
L-Simplify Stages
RegS-Simplify and RegL-Simplify stages are designed to remove variables from the graph. The RegS-Simplify stage is performed before the RegL-Simplify stage to find out variables which can guaranteed be assigned in RegisterSetS. It will remove
$VarUs with degree less than RSNS, i.e., these variables can be assigned in RegisterSetS
definitely. However, in RegL-Simplify stage, the removed target becomes the variables with degree less than or equal to RSNA. This is because of the special case called
“diamond” graph as shown in Figure 3-5. For example, if the target processor has two physical registers, r0 and r1, and the simplify stage removes only variables with degree less than two. Then the simplify stage removes no variables, and one of the
22
four variables, A, B, C, and D, will be chosen to spill. However, it is obvious that this diamond graph can be colored by two colors as shown in Figure 3-5. To tackle this problem, the proposed algorithm removes variables with degree less than or equal to
RSNA to make sure the remaining variables are those “must” be spilled.
Figure 3-5 – Diamond graph.
For both RegS-Simplify and RegL-Simplify stages, the removing order is arranged from lower to higher degree; and after removing a variable from the graph, the degree of all remaining variables will be updated. The variables removed from RegS-Simplify are pushed into AllocatedStackS, and from RegL-Simplify stages are stored into AllocatedSetL. Since the degrees of the variables removed in RegS-Simplify
stage are smaller than RSNS, all variables in AllocatedStackS are able to be assigned in
RegisterSetS. As for variables in AllocatedSetL, they may be assigned either in
RegisterSetS or RegisterSetA. Therefore, the way to assign proper variables to
RegisterSetS is the key issue in our design as the red arrow as shown in Figure 3-6.
Figure 3-6 - The process sketch map of our proposed algorithm based on Bottom-up graph coloring. C D B A r0 r0 r1 r1
23
RegS-Simplify and RegL-Simplify stages are performed until (1) none of the remaining variables in the graph can be removed; or (2) only variables with degrees equal to or larger than RSNS in RegS-Simplify stage or larger than RSNA in
RegL-Simplify stage are left.
Note that all variables removed in RegL-Simplify stage are stored into
AllocatedSetL, even if their degrees are smaller than RSNS. Since the degrees of
variables may decrease over time, the variables removed later will have smaller degrees. After removing a certain number of variables, the degrees of some remaining variables in the graph will be less than RSNS. Now these are two alternatives for
choice: (1) let the algorithm go back to RegS-Simplify stage to remove these variables and put them into AllocatedStackS; or (2) stay in RegL-Simplify. If the algorithm can return to RegS-Simplify stage while in RegL-Simplify when there are variables with degrees less than RSNS, then all of these variables will be pushed into AllocatedStackS
(i.e., be assigned in RegisterSetS). However, these $VarUs may be not the proper
variables to be assigned to RegisterSetS to increase the number of S-Format
instructions than the other variables in AllocatedSetL, and they may occupy registers
from their neighbors which are more proper than these variables. Therefore, in order to avoid assigning improper variables in RegisterSetS, all variables removed in
RegL-Simplify stage are only stored into AllocatedSetL and let the assignment pass to
discover which variables in AllocatedSetL should be assigned to RegisterSetS. The
24
Procedure Allocation
// Graph = {Variablei} is the set of nodes
// Degreei is the Interference_Number of variablei
While Graph ≠ 𝜙 do
RegS-Simplify:
forall variablei Graph do
if Degreei < RSNS then
Remove variablei from Graph;
Put variablei into AllocatedStackS;
endif endfor
if Graph = 𝜙 then break;
RegL-Simplify:
forall variablei Graph do
if Degreei <= RSNA then
Remove variablei from Graph;
Put variablei into AllocatedSetL;
endif endfor if Graph ≠ 𝜙 then goto Spill; endwhile endprocedure
Figure 3-7 - Pseudo code of allocation pass.
B. Spill Stage
In RegS-Simplify and RegL-Simplify stages, we remove variables from the graph. If there are remaining variables in the graph and cannot be removed anymore, the algorithm will enter the spill stage. Then spill stage must choose one of the remaining variables to spill, i.e. insert spill codes for this variable. An ideal variable for spilling is the one that requires less number of dynamic loads and stores (less number of
25
accesses) and can reduce the number of future potential spill variables (higher degree). Accordingly, the spill cost of variablei, SpillCosti, is defined as follows:
i i i Degree Access SpillCost ,
where Accessi is the number of defines and uses of variablei, and Degreei is the
number of edges in the interference graph connected to variablei. After choosing
variablei, spill stage will insert corresponding load/store instructions for it, and then
return to the Build stage. Since inserting a spill code will result in new temporary variables, it is necessary to rebuild the interference graph. In other words, the entire algorithm will be repeated again if a new actual spill is generated.
3.2.2 Assignment Pass
Assignment pass assigns a physical register to each variable in AllocatedStackS and
AllocatedSetL. This pass is divided into two stages, namely RegL-Assignment and
RegS-Assignment. The RegL-Assignment stage is performed before the RegS-Assignment stage because that variables in AllocatedStackS can be guaranteed they have registers in
RegisterSetS to use. As for more details, we will discuss in Section 3.2.3.
For the variables in AllocatedSetL, they may be assigned in RegisterSetA or in
RegisterSetS. That is, RegL-Assignment stage must determine the assignment target,
RegisterSetS or RegisterSetA, for the variables rather than just assigns all of them into
RegisterSetA. The assignment target determination can be viewed as the problem of
deciding which variables in AllocatedSetL should be assigned in RegisterSetS. The code
size reduction is proportional to the number of U-INSs being translated to S-Format instructions, and the translation ratio is dominated by the number of $VarUs being
26
assigned in RegisterSetS. Due to the size limitation of RegisterSetS, not all $VarUs can be
assigned into RegisterSetS. To determine which $VarU should be assigned into
RegisterSetS, we define a profit function in this paper. The profit function considers two
features of $VarU, namely utilization and degree.
The utilization of $VarU is the number of times that $VarU is being accessed by
S-Format instructions in a whole function. Obviously, a frequently accessed $VarU
should have higher priority to be assigned to RegisterSetS. However, it is impossible to
calculate the actual number of accesses by S-Format instructions of a $VarU before the
instruction formatting pass in which the final instruction format has been decided for INSs, and, as mentioned above, the instruction formatting pass can only be performed after register allocation and assignment. To overcome this problem, we propose an approach to evaluate the approximate number of accesses of a $VarU. The approach
consists of two parts, namely static and adaptive estimations. The static estimation calculates the initial number of times that a $VarU is being accessed by U-INSs. Note
that this value is a constant for each $VarU. As for the adaptive estimation, it computes
the current number of times that a $VarU is being accessed by U-INSs which have at
least one operand being assigned into RegisterSetS. The adaptive estimation of all $VarUs
must be updated whenever a $VarU is assigned to RegisterSetS.
The degree of $VarU represents the number of neighboring variables of $VarU in the
graph. In order to make more $VarU be assigned in RegisterSetS, a $VarU with less
degree should have higher opportunity to be assigned into RegisterSetS. Note that less
degree also implies shorter live range. Based on these two features, the profit value for
$VarUi, denoted as Sel_profiti, is defined as follows:
Degree est Adp est Init profit Sel i i i i 1 _ ) 1 ( _ _ ,
27
where Init_esti and Adp_esti represent the initial and adaptive estimation results for
$VarUi, respectively; Degreei is the degree of $VarUi. Because of the continuous
changing of Adp_esti, Sel_profiti also has to be updated after a $VarU is assigned to
RegisterSetS. Note that alpha value, α , in Sel_profiti is the weight parameter between
Init_esti and Adp_esti, and we will experiment this algorithm with different alpha values
in Chapter 4.
Moreover, during RegL-Assignment stage it is possible to encounter a variable which cannot be assigned into any physical registers, i.e., all available physical registers are occupied by its neighbors. Then the algorithm will enter the spill stage and insert spill codes for this variable directly, and the entire algorithm will be repeated again. Remind that, in this algorithm, variables which definitely cannot be assigned to any register have been discovered at allocation pass. For those variables which may not possibly be assigned to registers, they will be discovered in RegL-Assignment stage.
As mentioned above, the variables allocated into AllocatedStackS are guaranteed to
be assigned in RegisterSetS, since their degrees are smaller than RSNS. Accordingly,
RegS-Assignment stage may adopt the traditional assignment approach by following the stack pop order to choose the physical registers for the variables in AllocatedStackS.
28
Procedure Assignment
While AllocatedSetL ≠ 𝜙 do
Forall variablei AllocatedSetL do
Calculate Sel_Profiti;
endfor
pick one variablei with highest Sel_Profiti as variable*;
if variable* can be assigned into RegisterSetS then
Assign a register different from its neighbors to variable* in RegisterSetS;
Remove variable* from AllocatedSetL;
else if variable* can be assigned into RegisterSetA then
Assign a register different from its neighbors to variable* in RegisterSetA;
Remove variable*from AllocatedSetL;
else
/* it has no register to assign, pass it to spill */
goto Spill(variable*); endif
endwhile
Forall variablei AllocatedStackS do
Assign a register different from its neighbors to variablei by stack pop order;
endfor endprocedure
Figure 3-8 - Pseudo code of assignment pass.
3.2.3 Discussion
In this subsection, three issues will be discussed: (1) the effect of different assignment orders, (2) assignment without RegS-Simplify, and (3) extension of the algorithm to more hierarchy register sets for different S-Formats.
A. Different Assignment Orders in Assignment
In the proposed algorithm based on bottom-up graph coloring, the RegL-Assignment stage is processed before the RegS-Assignment stage. The main reason is that variables in AllocatedStackS are guaranteed that they have registers in
29
RegisterSetS to use. In other words, no matter how the RegL-Assignment assigns the variables in AllocatedSetL, the RegS-Assignment can assign registers in RegisterSetS to
variables in AllocatedStackS. Since only variables with degree less than RSNS are
pushed into AllocatedStackS during RegS-Simplify. For example, there is an
interference graph as shown in Figure 3-9. Assume that the architecture has three registers, $r0, $r1, and $r2. RegisterSetS contains $r0 and $r1 (RSNS = 2), and
RegisterSetA contains all of the three registers (RSNA = 3). Variables D and E in Figure
3-9 are simplified by RegS-Simplify and moved to AllocatedStackS since their degrees
are less than two. The others variables A, B, and C are simplified by RegL-Simplify and moved to AllocatedSetL. The sel_profiti for variable A, B, and C in
RegL-Assignment is A > B > C. As the result is in Figure 3-9 (a), if we assign
AllocatedSetL first, variable A can be assigned to $r0 because that there are no
registers have been occupied, then variable B is assigned in $r1, and the last register $r2 is assigned to variable C. After performing RegL-Assignment, RegS-Assignment is invoked to handle AllocatedStackS. Since variables in AllocatedStackS are guaranteed
to have registers in RegisterSetS to use, we just assign registers which are not occupied
by their neighbors in RegisterSetS. For the result shown in Figure 3-9 (a), all variables
in AllocatedStackS are assigned to RegisterSetS, and it is what we expect that variable
A and B should have higher opportunity to be assigned to RegisterSetS than variable C
does.
However, if we change the assignment order and let RegS-Assignment be performed before the RegL-Assignment, it may result in that some of the variables in
AllocatedSetL with higher priority which may be assigned to RegisterSetS in the
previous order cannot be assigned to RegisterSetS now. For example, if the assignment
30
D and E in AllocatedStackS will be assigned to $r0 directly first. Then, variables A, B,
and C in AllocatedSetL will be picked up by the sel_profiti value in descendant. First,
variable A is picked up and assigned to $r1 ($r0 is occupied by its neighbor), then variable B is assigned to $r2, and the last variable C is assigned to $r0. Because the
sel_profitB > sel_profitC, we desire that chance of variable B in RegisterSetS is higher
than variable C. However, variable B is not assigned to RegisterSetS, but the variable
C does.
Figure 3-9 - Different Assignment Order in Bottom-up Graph Coloring for Mixed-width ISA with mode switch by instruction encoding : (a) RegL-Assignment → RegS-Assignment
31
B. Assignment without Reg
S-Simplify
The second discussion issue is how about if we do not isolate variables with degree less than RSNS in RegS-Simplify of allocation pass, i.e., let all variables be simplified to AllocatedSetL in Allocation pass, and then assign those variables in
descending order of sel_profit values in Assignment pass. This method seems instinctive. However, if we do not isolate variables in RegS-Simplify, the sel_profit of some variables which are simplified to AllocatedStackS originally may be higher than
those which are simplified to AllocatedSetL originally. Therefore, it will cause the
problem similar to that of the assignment order “RegS-Assignment → RegL-Assignment” mentioned above.
For the same example given above, Figure 3-10 is the result of register assignment if RegS-Simplify stage is canceled in the allocation pass. Because all non-spilled variables are in AllocatedSetL and all of them are given a sel_profit as their
priority, in this example, the priority is D > A > E > B > C. According to this assignment order, the results in that variable B cannot be assigned in RegisterSetS
since variable E have higher priority than variable B.
32
C. Extension of the Algorithm to More
Hierarchy Register Sets for Different
S-Formats
For extending algorithm to handle the 1R4 form, we can modify the algorithm as shown in Figure 3-11. Here we have a new register class named RegisterSetM, and it
contains registers (eg. $r1 ~ $r15) can be accessed by those instructions in 1R4 form, i.e. the RSNM is 15. Moreover, the RegM-Simplify and RegM-Assignment stages are added in the extended algorithm, and the U-INS may contain 1R4, 3R3, 2R3, and 1R3 forms. For $VarUs in U-INS, a $VarU which is defined or used only by 1R4 form instructions is denoted as $VarU4, and the others are denoted as $VarU3.
At the RegM-Simplify, the algorithm removes $VarU4s which are with degree less than RSNM to AllocatedStackM. In other words, if a variable is defined/used only by
1R4 instructions and the variable can be assigned to RegisterSetM definitely, and we
directly push it into AllocatedStackM and assign it to RegisterSetM at RegM-Assignment
stage. As for those $VarU4s with the degrees are larger than or equal to RSNM, they
may be removed at the RegL-Simplify stage and stored into AllocatedSetL. Therefore,
the modification of the sel_profit function is needed. The modified sel_profit function should take those $VarU4s into account. For each $VarU4, it increases the Init_est and
Adp_est in sel_profit, but the weight should be lower than $VarU3. Since $VarU3s have higher register pressure than $VarU4s, they are intended to be assigned to RegisterSetS.
By adopting these modifications, the $VarU3s will still have the highest priority to use
RegisterSetS, then the second priority is the RegisterSetM for $VarU4s, and the last is
33
34
3.3 Design II : Based on Priority-based Graph Coloring
The second design in this thesis is based on priority-based graph coloring. The mainly difference from the previous design is that this algorithm makes efforts on selecting variables to increase the number of S-Format instructions first, and then considers the number of spill codes. In opposite, the previous design discussed in Section 3.2 makes efforts on minimizing spill codes in allocation pass first, and then considers to increase the number of S-Format instructions in assignment pass.
For the proposed algorithm based on Priority-based graph coloring for mixed-width ISA with mode-switch by instruction encoding, its flowchart is shown in Figure 3-12. There are three sets of live range (live range is the same with variable) need to be allocated and assigned are defined as follows:
1. LRS: LRS (Live Ranges in RegisterSetS) contains variables with interference number
less than RSNS. For those variables in LRS, they are guaranteed to be allocated and
assigned to RegisterSetS.
2. LRU: LRU (Live Ranges in Uncertain RegisterSet) contains variables with interference number larger than or equal to RSNS. For those variables in LRU, they may be allocated and assigned to RegisterSetS, RegisterSetA, or Memory (Spilled).
The way to determine which variables in LRU should be assigned to RegisterSetS is
critical to this algorithm.
3. LRL: LRL (Live Ranges in RegisterSetA) contains variables which cannot be assigned
a register in RegisterSetS during the LRU Allocation and Assignment pass. They will
be allocated and assigned to RegisterSetA or Memory (Spilled) during the LRL
35
First, Build stage parses all necessary information (such as live rages, instruction types) and constructs the interference graph the same way as that described in the previous design. Then the Separate pass separates variables in the graph into LRU and LRS. After Separate stage, the algorithm uses a priority function which is designed to make more instructions to be encoded as S-Format instructions to choose variables from LRU to allocate and assign registers in the Prioritize stage. During this pass, some variables in LRU may be transferred to LRL. For minimizing the generated spill codes, the algorithm uses the other priority function which is designed for minimizing the spill codes to allocate and assign registers for variables in LRL. And finally, the variables in LRS are handled. The input and output of the proposed algorithm are INSs with virtual registers and assembly code, respectively.
Figure 3-12 - Flowchart of the register allocation and assignment algorithm based on Priority-based graph coloring for mixed-width ISA with
36
The pseudo code of Priority-based graph coloring for mixed-width ISA with mode-switch by instruction encoding is shown in Figure 3-13.
Procedure MxPrGCRA
Build interference graph ifGraph; Separate LRU and LRS;
While LRU ≠ 𝜙 do
Forall variablei LRU do
Calculate Sel_Profiti;
endfor
pick one variablei with highest Sel_Profiti;
if variablei can be assigned into RegisterSetS then
Assign a register different from its neighbors to variablei in RegisterSetS;
Remove variablei from LRU;
else
Move variablei to LRL;
endif endwhile
While LRL ≠ 𝜙 do
pick one variablei with highest SpillCosti;
Assign a register different from its neighbors to variablei in RegisterSetA;
Remove variablei from LRL;
Forall variablei* neighbors of variablei do
if variablei* has to be spilled then
goto Spill(variable*);
update ifGraph with new variables produced by spilling;
endif endfor endwhile
While LRS ≠ 𝜙 do
Forall variablei LRS do
Assign a register in RegisterSetS different from its neighbors to variablei
endfor endwhile
Figure 3-13 - Pseudo code of Priority-based graph coloring for mixed-width ISA with mode-switch by instruction encoding
37
3.3.1 Separate Stage
After the interference graph has been built by Build stage, Separate stage separates variables in the graph into LRU and LRS by their interference number. Note that the variables in LRL are not discovered in Separate stage because that variables in LRU may be allocated into RegisterSetS, RegisterSetA, or Memory (Spilled), and thus, variables in
LRL are included in LRU currently.
3.3.2 LR
UAllocation and Assignment
During the LRU Allocation and Assignment pass, the algorithm needs to find out which variables in LRU should be allocated and assigned to RegsiterSetS. Because that
the variables in LRU are those variables with interference number larger than or equal to
RSNS, it means that only a part of them can be assigned to RegsiterSetS and the others
will be assigned to either RegisterSetA or Memory. Therefore, the way to determine
which variables in LRU should be assigned to RegisterSetS is critical as mentioned above.
To achieve this, a priority function for prioritize stage is used. The Prioritize stage calculates priority for each variable in LRU to make a proper order to assign registers, and the higher priority (profit) variable has higher chance to get a register in RegisterSetS.
The priority (profit) value for $VarUi (denoted as Sel_profiti) is the same as that defined
in the previous design and listed as follows:
1 _ ) 1 ( _ _ n n n n Degree est Adp est Init profit Sel
When all variables in LRU have been given a priority, Pick&Assign(S) stage picks the highest priority variable variablei, and try to assign a register in RegisterSetS to it. If
38
then variablei will be assigned this register and removed from LRU. Otherwise, variablei
will be moved to LRL.
After assigning a variable into RegisterSetS, this pass will check the LRU. If it is empty, then the algorithm will go to the next pass - "LRL Allocation and Assignment". Otherwise, it will repeat the Prioritize stage to update the Adp_est for the remaining variables in LRU and the Pick&Assign(S) stage to tackle the remaining variables in LRU until LRU is empty.
3.3.3 LR
LAllocation and Assignment
In the previous pass, variables in LRU those cannot be directly assigned to
RegisterSetS have been found and moved to LRL. The goal of this pass is to determine which variables in LRL should be assigned to RegisterSetA and the others should be
spilled to memory. Apparently, the allocation and assignment for LRL is critical to reduce the number of generated spill codes.
To minimizing the generated spill codes, a priority function for evaluating the spill cost of a variable is evolved. First, the algorithm assumes that all variables in LRL are initially stored in memory, and uses the priority function to estimate how many processor cycles can be saved if variablei in LRL is assigned a physical register. For those variables
which can save more cycles, they should have higher priority to get registers than others. This priority function is similar to the traditional priority-based graph coloring for register allocation and listed as follows:
n n n Degree SaveCycle SpillCost ,
where SaveCyclei represents the number of processor cycles saved if variablei is
39
proportional to the access counts of variablei; and Degreei is the number of edges
connected to variablei in the interference graph. This priority function makes the variable
with higher SaveCyclei and lower Degreei have higher priority to get a physical register
in RegisterSetA. Pick&Assign(L) stage picks the highest priority (SpillCost) variablei and
assigns a register in RegisterSetA to it. Then the algorithm goes through each neighbor of
variablei to check whether it needs to be spilled or not. If there is a variable spilled, the
corresponding load/store instructions for spilled variable will be inserted. Then Build Newly stage will build new variables and move them into LRL for the new temporary variables produced during spilling. Otherwise, the algorithm will go back to Pick&Assign(L) stage when LRL is not empty or go to the next pass – “LRS Allocation and Assignment” when LRL is empty.
3.3.4 LR
SAllocation and Assignment
Since all variables in LRS have degree less than RSNS, i.e., the simultaneously alive
variables with each variable in LRS of a function are no more than RSNS, all of them can
be assigned to RegisterSetS without any constrains. Therefore, the LRS Allocation and Assignment pass just picks up a variable in LRS and assigns a register in RegisterSetS to
it until LRS is empty.
3.3.5 Discussion
In this subsection, an alternative design without the "LRU allocation and assignment pass" and the extension of the algorithm to more hierarchy register sets for different S-Formats will be discussed.
40
A. Alternative Design
The traditional priority-based graph coloring uses only one priority function to pick up variables to assign. In order to increase the number of instructions encoded as S-Format instruction, we can directly use Sel_profit function to instead the traditional priority function as shown in Figure 3-14. Consequently, the Pick&Assign stage will pick the variable with highest Sel_profit up and assign a register to the variable, and thus, increasing the number of S-Format instructions. However, the algorithm is not good enough because the influence of spill codes is not taken into account. Therefore, we should allocate and assign registers hierarchically while using two priority functions to increase the S-Format translation rate and decrease the number of spill codes, respectively.
Figure 3-14 - Flowchart of the proposed algorithm without LRL allocation and assignment pass of Design II.
This is why we move a variable which cannot be assigned in RegisterSetS to LRL