國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
CAKE – 合作式演化性知識擷取方法
CAKE - Collaborative Acquisition for Knowledge Evolution
研 究 生:鄧嘉文
指導教授:曾憲雄 教授
合作式演化性知識擷取方法
Collaborative Acquisition for Knowledge Evolution
研 究 生:鄧嘉文 Student:Chia-Wen Teng
指導教授:曾憲雄博士 Advisor:Dr. Shian-Shyong Tseng
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A Thesis
Submitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science June 2006
Hsinchu, Taiwan, Republic of China
CAKE – 合作式演化性知識擷取方法
研究生:鄧嘉文 指導教授:曾憲雄 博士 國立交通大學資訊科學與工程研究所摘要
由於知識爆炸,知識可以分類為靜態知識和動態知識。儘管已有很多的知識 擷取方法可以系統化的從領域專家那取得靜態知識的規則,卻沒有任何一種方法 去 深 入 討 論 發 掘 動 態 知 識 , 其 原 因 在 於 欠 缺 足 夠 的 情 境 資 訊 (context information)。在本篇論文裡,我們提出一個方法命名為合作式演化性知識擷取 (CAKE)的新知識擷取方法,其透過收集足夠的情境資訊來幫助專家發現動態物 件的產生進而發掘動態知識。我們首先定義靜態個性化配置檔案(Profile)和動態 行為來做為情境資訊並以服務敏感性和症狀相似性等事件來做為合作啟發 (heuristic)以輔助專家意識到動態知識的發生。CAKE 中我們用變異物件知識擷取 (VODKA)和趨勢事件擷取(TEA)來建立動態擷取表格以增進發現變異物件的效率 並自動的調整屬性順序表格(AOT)內物件與屬性之間的重要程度來更進一步發 現演化性知識。這對協助專家了解屬性對物件之間的改變有很大的幫助。再來, 我們設計 CAKE 讓動態 EMCUD 增加新的物件或新的物件屬性來更新已存在的 知識表格並進而透過動態 AOT 將其原來的隱含規則具有適應的能力。除此之 外,我們開發了一個電腦蠕蟲偵測雛型系統來驗證 CAKE 的效能。 關鍵字:靜態知識,動態知識,知識擷取,VODKA,動態 EMCUD,TEA,CAKECAKE – Collaborative Acquisition for
Knowledge Evolution
Student: Chia-Wen Teng Advisor: Dr. Shian-Shyong Tseng
Department of Computer Science National Chiao Tung University
Abstract
Due to the knowledge explosion, the knowledge can be classified into static knowledge and dynamic knowledge. Although many knowledge acquisition methodologies have been proposed to systematically elicit rules of static knowledge from domain experts, none of these methods discusses the issue of discovering dynamic knowledge due to the lack of sufficient context information. In this thesis, we will propose a new collaborative knowledge acquisition methodology, Collaborative Acquisition for Knowledge Evolution (CAKE), to solve the issue of discovering dynamic knowledge by collecting sufficient relevant context information to help experts notice the occurrence of dynamic object. First, we define static profiles and dynamic behaviors as the context information to assist experts to be aware of the occurrence of dynamic knowledge based on several collaborative heuristics for service-sensitive and symptom-similar events. Variant Objects Discovering
Knowledge Acquisition (VODKA) and Trend Event Acquisition (TEA) are used to
construct a new dynamic acquisition table to facilitate the acquisition of variant knowledge and to automatically adjust the relative importance of each attribute to each object in the attribute ordering table (AOT) to discover the evolutional knowledge in CAKE. This is useful to help experts understand the changing behaviors
of attributes to each object. Furthermore, CAKE is designed to use Dynamic EMCUD, a new version of an existing knowledge acquisition system called EMCUD which relies on the repertory grids knowledge acquisition technique to manage object/ attribute-values tables and to produce inferences rules from these tables, to update existing tables by adding new objects or new object attributes in new acquisition for adapting the original embedded rules with the dynamic AOT. Besides, a Worm
detection prototype system is implemented to evaluate the effectiveness of CAKE.
Keywords: static knowledge, dynamic knowledge, knowledge acquisition,
致謝
能順利完成本篇論文,最重要的必須感謝我的指導教授,曾憲雄博士。曾教 授在我碩士班兩年期間相當耐心的對我指導、與我討論;從他身上能學習到許多 不只論文研究上甚至領導處事中的技巧,所有這些寶貴的經驗讓我獲益匪淺,感 激不盡。同時也感謝我的口試委員,黃國禎教授、陳年興教授和胡毓志教授,他 們給予了我相當多的寶貴意見,讓本篇論文更有價值。 第二位要感謝的人是林順傑學長,碩士期間讓我學會許多理論知識及研究方 法,也盡心盡力與我一起討論並分享想法,兩年先後完成的會議論文、期刊論文、 直到碩士論文,中間接受我的詢問和討論,並協助我論文修改工作,深表感激。 此外我必須感謝實驗室學長平日的諸多幫助,同時也感謝實驗室同窗夥伴, 蔡昇翰、葉展彰、張晉璿、林永彧、林喚宇、任珍妮、施南極、羅仁杰等人在生 活上和課業上互相幫忙的情誼;以及學妹陳曉涵、王芙民等人在論文實驗上的支 援,深表感激。 最後我要感謝我的家人對於我的支持與鼓勵,讓我在面對挫折的時候能夠繼 續向前,也讓我能夠有相當的自信完整本篇論文,深表感激。Table of Contents
摘要...i Abstract...ii 致謝...iv Table of Contents ...v List of Figures...viList of Algorithms ...vii
List of Tables... viii
Chapter 1 Introduction...1
Chapter 2 Related Work...6
2.1 Knowledge Acquisition Review ...6
2.2 EMCUD ...9
2.3 Variant Object Discovering Knowledge Acquisition ... 11
Chapter 3 Context Representations ...15
3.1 Behavior Description Markup Language...15
3.2 Ontology Support...19
Chapter 4 The Framework of CAKE...24
4.1 The Collaborative Architecture...24
4.2 Trend Capturing and Analysis...29
4.2.1 Constructing Attribute Signal Table...31
4.2.2 Constructing Attribute Ordering Table ...32
4.3 Collaborative Heuristics...36
Chapter 5 Case Study and Experiment...39
5.1 Brief of Worms...39
5.2 Example of Computer Worms Detection ...41
5.3 Worm Immune Service Expert System ...46
5.4 Experimental Results ...49
Chapter 6 Concluding Remarks ...52
List of Figures
Figure 2.1: The Variant Object Discovering Knowledge Acquisition Flow ...12
Figure 3.1: The Structure of BDML ...16
Figure 3.2: The Historical Context analysis ...17
Figure 3.3: Ontology Construction Flow ...20
Figure 3.4: Example of CodeRed Concept Tree ...21
Figure 3.5: Example of Nimda Concept Tree ...22
Figure 3.6: Example of Blaster Concept Tree...22
Figure 4.1: The Architecture of CAKE...24
Figure 4.2: The Learning Module ...26
Figure 4.3: The Example of Collaborative Environment...28
Figure 4.4: The Flow of TEA ...29
Figure 4.5: Unfolding...30
Figure 4.6: Reconstructing...31
Figure 5.1: Worm Life Cycle ...39
Figure 5.2: Example of Nimda Concept Tree ...42
Figure 5.3: Example of Nimda Ontology ...45
Figure 5.4: Example of Nimda ontology ...46
Figure 5.5: Worm Immune Service Expert System ...47
List of Algorithms
Algorithm 2.1: EMCUD algorithm... 11 Algorithm 2.2: VODKA algorithm ...13
List of Tables
Table 3.1: Static Profile DTD ...18
Table 3.2: Dynamic Behavior DTD ...19
Table 4.1: An example of AST table ...32
Table 4.2: A simple acquisition table for Blaster and Sasser ...38
Table 4.3: A simple AOT for Blaster and Sasser...38
Table 4.4: Part of inference logs record ...38
Table 5.1: An Example of Nimda acquisition table ...42
Table 5.2: An Example of Nimda AST ...43
Table 5.3: An Example of Nimda AOT ...43
Table 5.4: An Example of Nimda AST ...44
Table 5.5: An Example of Nimda acquisition table ...44
Table 5.6: An Example of Nimda acquisition table ...44
Table 5.7: An Example of Nimda AOT ...44
Table 5.8: An example of Nimda acquisition table...45
Table 5.9: An example of Nimda AOT ...46
Table 5.10: Knowledge base construction efficiency ...49
Table 5.11: Inference efficiency...50
Chapter 1 Introduction
Knowledge acquisition (KA) is a methodology of obtaining the knowledge of special domain from the domain expert, and knowledge based system (KBS) is an intelligent computer program that uses knowledge and inference procedures to solve problems that are difficult enough to require significant human expertise for their solutions, such as disease diagnosis, investment prediction, or computer science. Meanwhile, KA is one of the critical bottlenecks in developing a KBS for obtaining the knowledge. Traditionally, knowledge engineers retrieve knowledge from human experts by interviewing, and then a computer can be applied to perform the similar problem as human experts do in the real world. In order to facilitate the efficiency, knowledge engineers draw support from technical documents to interact with human experts; therefore, the idea of ontology helps knowledge base system overcome several bottlenecks such as knowledge representation, sharing and reusing. However, in the real world environment, there is not only static knowledge but also dynamic knowledge which is intensely fickle. With the changing environment as time goes on, new objects in many domains are incrementally evolved or developed due to the explosion of knowledge. It results in the creation of new knowledge due to the new evolved objects. Avoiding a downward efficiency spiral involves constantly hatching latest information while trying to defend an existing knowledge line. Hence, knowledge can be classified as static knowledge and dynamic knowledge according to the stability of knowledge in dynamic environment over time. The static knowledge remains the same in the changing environment as time goes on. Since the different environment can change over time, the original knowledge constructed at a time may
the knowledge will be updated or evolved over time due to the adaptation of the changing environment. The knowledge evolution we proposed in this thesis is the iterative process to acquire evolutional knowledge in the changing environment.
Traditional KA methodologies, which are capable of acquiring static knowledge, can be classified into interviewing, machine learning and knowledge acquisition systems; however, the dynamic knowledge acquisition has hardly been discussed. Knowledge engineers directly retrieve domain knowledge by interviewing with human experts, and transform the knowledge into the computerized format to help experts solve difficult problems in the real world. In general, to acquire dynamic knowledge, the experts are required to be aware of the occurrence of new objects in the interviewing approach and knowledge acquisition systems. However, it is still difficult for experts to be aware of the new object without any additional related information. The machine learning approaches, which can learn the useful knowledge of static objects according to the selected training cases, are usually lack of the ability of discovering new objects without new cases of dynamic objects in the training process. As we know, many KA systems and tools such as NeoETS [5], ACQUINS [6],
KITTEN [24], EMCUD [17], KSSO [14], have been proposed to rapidly build
prototypes and improve the quality of the elicited static knowledge of well-known objects by domain experts with/without knowledge engineers in the past twenty years. However, most of them lack the ability of incrementally acquiring dynamic knowledge since the experts may not be aware of the occurrence of new objects without sufficient information.
EMCUD (Embedded Meaning Capturing and Uncertainty Deciding) [Hwang,
1991] was proposed to elicit the embedded meanings of knowledge (embedded rules bearing on m objects (O1, O2, …, Om) and k object attributes) following repertory
grids principles, which represents the information that domain experts take for granted but are implicit to the people who are not familiar with the application domain, and guide experts to decide the certainty degree of each embedded rule for extending the coverage of the original rules generated by acquisition table. Since the relative importance of each attribute to each object could be represented as attribute ordering table (AOT) in EMCUD, some minor attributes can be relaxed or ignored to capture the embedded meanings with acceptable CF. Assume some objects in O1 class, which
are classified by original rules of O1, belong to the original object class (OO1) of O1;
the other objects in O1 class, which are classified by embedded rules of O1, belong to
the extended object class (EO1) of O1. However, some embedded rules may be with
marginally acceptable certainty factor (CF) values due to the weak suggestions of domain experts. In the age of the knowledge explosion, some objects might be evolved with the times and could be classified by the embedded rules of O1 with weak
CF values since some related ambiguous attributes (minor attributes) are ignored to classify these new evolved objects into O1 class. Although EMCUD extends the
ability of KA system to classify a new object into an original object class with the weak embedded rules with lower CF values, it still lacks the ability to incrementally discover the new objects and integrate the corresponding dynamic knowledge of new objects into original knowledge base without rerunning the whole KA procedure to generate the knowledge. Moreover, the human experts are unlikely to be aware of the occurrence of the new evolved objects due to the lack of sufficient relevant information about the new objects.
In this thesis, we will propose a new collaborative knowledge acquisition method (CAKE – Collaborative Acquisition for Knowledge Evolution) to collect useful evidence through monitoring the frequent inference behaviors of weak embedded
rules and tracing trend events of objects with time in order to assist experts to efficiently adapt the certainty factor of dynamic knowledge of new objects according to the sufficient context information. In order to discover the new object, the VODKA (Variant Object Discovering Knowledge Acquisition) is proposed to facilitate the acquisition of new knowledge of variant objects by monitoring the frequently fired weak embedded rules. Since the evidence of object evolution may appear diversely in unpredictable time, a time interval tracing oriented mechanism, Trend Event Acquisition (TEA) [22], for constructing dynamic knowledge of new objects is proposed to adapt knowledge to current time by recording each interested attribute’s information in each time interval and update evolutional knowledge base. The
VODKA generates a new acquisition table of new object, and the TEA generates a
dynamic AOT table for capturing the evolutional embedded meaning of these objects. However, some dynamic knowledge might be invisible in each KBS with VODKA and TEA. Several heuristics are proposed to assist experts in discovering the new evolved objects, including service-sensitive and symptom-similar heuristics. The context information, including static profile and dynamic behaviors, is designed to assist experts to be aware of the occurrence of dynamic objects according to service-sensitive heuristic and symptom-similar heuristic by collecting sufficient information of multiple sensors. The service-sensitive heuristic can help experts to discover similar behaviors result in different symptoms due to different individual or environment configurations. The symptom-similar heuristic can assist experts to recognize different behaviors result in similar symptoms between multiple sensors due to the polymorphic configurations. We think the legacy knowledge acquisition methods are inefficient to acquire the evolutional knowledge because it is unable to learn the evidences of variation and development. Finally, we will propose the
Dynamic EMCUD (D-EMCUD) to integrate new dynamic knowledge into original
knowledge base.
Based upon the CAKE framework, a worm detection prototype system with the CAKE module is implemented to evaluate the effectiveness of integrating the new evolved knowledge into original knowledge base. Based upon the collaborative framework, the dynamic knowledge of new evolved objects could be elicited to discover the new variant worms generated by the attacking traffic generator in the experimental environment.
Chapter 2 Related Work
Several knowledge acquisition methodologies and related systems are introduced in this chapter. Here we also introduce repertory grid, one of the popular indirect knowledge acquisition techniques. Finally, the elicitation of embedded meaning and some problems of traditional knowledge acquisition methodologies are discussed.
2.1 Knowledge Acquisition Review
In general, there are three approaches for knowledge acquisition (Mcgraw et al., 1989; Hwang and Tseng, 1990; Crowther and Hartnett, 1996):
(1) Interviewing experts by experienced knowledge engineers: interviewing experts is usually time-consuming if the communication between domain experts and knowledge engineers is insufficient.
(2) Machine learning: learning the knowledge by collecting many useful cases and instances with/without the involvement of domain experts. However, the quality of the results usually relies on the selected training cases.
(3) Knowledge acquisition systems: assisting domain experts in generating useful rules using knowledge acquisition systems with/without the help of knowledge engineers. These tools could reduce the effort of communication between knowledge engineers and domain experts and could reduce the risk and difficulty of selecting the suitable training cases.
Many researches like ETS [4], AQUINAS [6], RuleCons [23], MOLE [12] and
KSSO [14] were developed to build rapid prototypes (knowledge acquisition systems)
and to improve the quality of the elicited static knowledge. Most of them employed the repertory grid test originally developed by George Kelly [19], and had discovered
unexpected interesting results. The repertory grid could be used as efficient knowledge acquisition technique in identifying different objects and distinguishing these objects in a domain. A single repertory grid represented as a matrix whose columns have element objects (labels) and whose rows have construct attributes (labels) can classify a class of objects, or individuals. The value assigned to an element-construct pair need not be Boolean. Grid values have numeric ratings, probabilities, and other characteristics, where each value reflects the degree. Then, the expert is asked to fill the grid with 5-scale ratings, where “1” represents the most relevant attribute to the object; “2” represents that the attribute may relevant to the object; “3” represents “unknown” or “no relevance”; “4” represents that the object may have the opposite characteristic; “5” represents the most relevant opposite characteristic to the object. Also, several researches focused on building an intelligent expert system like MYCIN project [1], a well-known medical expert system for diagnosing infectious diseases, encouraged the advent of expert system studies. Moreover, ontologies and information sharing have a major role to play in the development of knowledge-based agents and the overcome of the knowledge acquisition bottleneck. Then, in 2003, an intelligent DNS management system [9], a web-based DNS expert system, was proposed to assist DNS administrators in managing their DNS by efficiently eliciting rules from experts or cases based on an efficient DNS ontology construction algorithm.
In summary, the knowledge acquisition bottleneck can be described as follows [26].
(1) Narrow bandwidth:
The existing channels converting organizational knowledge from its source (either experts or documents, or transactions) are relatively narrow. Knowledge engineers can
only focus on a few key applications, but not the bulk of all organizational knowledge. The uses of data and text mining are limited by cost and mining effort. End user experts are slow in capturing their own knowledge.
(2) Acquisition latency:
The slow speed of acquisition is frequently accompanied by a delay between the time when knowledge (or the underlying data) is created and when the acquired knowledge becomes available to be shared. This is especially a concern in dynamic environments where knowledge changes quickly and therefore the knowledge repositories always appear outdated. This challenge is related to the method of knowledge acquisition as well as the incentive systems, which often do not encourage experts to freely share their newest, most innovative, and most personal or tacit knowledge.
(3) Knowledge inaccuracy:
Experts make mistakes and so do data mining technologies. Furthermore, maintenance can introduce inaccuracies or inconsistencies into previously correct knowledge bases. With little available bandwidth to create new knowledge, even fewer resources are likely available to check the accuracy of knowledge already in the system. Furthermore, correction procedures can be difficult and cumbersome (Who is permitted to correct errors? What is the procedure? What incentives are there to report errors?).
(4) Maintenance Trap:
As the knowledge in the knowledge base grows, so does the requirement for maintenance. Furthermore, previous updates that were made with sufficient care and foresight (“hacks”) will accumulate and render future maintenance.
It appears there are few opportunities for breaking the knowledge acquisition bottleneck. Several possible remedies have been discussed, for example, the work of Boicu [7] described a practical approach, methodology and tool, for the development of static knowledge bases and agents by subject matter experts, with limited assistance from knowledge engineers. And the work of Wagner [26] described the use of collaborative, conversational knowledge management to demonstrate the opportunity for more effective knowledge acquisition. Obviously, the idea of collaboratively and systematically constructing the dynamic knowledge bases is launched. However, the dynamic environment limits all their efficiencies for the knowledge acquisition methodologies. The real world knowledge in a dynamic environment is often considered evolutional, because the knowledge can change or evolve over time due to the advent of information century. The speed changing in knowledge is too fast to manually accumulate the information by experts, and it usually results in the ritualistic batch process analysis which is always tough and time consuming.
Although many methodologies are proposed to extend the ability of uncertain reasoning to classify the objects, none of them discusses the issue of discovering dynamic knowledge of the new objects. It is also difficult for experts to notice the occurrence of new object, which is evolved with dynamic environment as time goes on.
2.2 EMCUD
The “embedded meanings” referred in this thesis represent the information that domain experts take for granted but are implicit to people who may not feel familiar with the application domain. The lack of embedded meaning will probably make an
expert system fail to infer some cases being trivial to experts. SEEK (Politakis and Weiss, 1987) and SEEK2 (Ginsberg et al., 1988) have been proposed to obtain embedded meanings by some efficient refinement processes. EMCUD is proposed to elicit the embedded meanings of knowledge from the existing hierarchical repertory grids given by experts (Hwang and Tseng, 1990). EMCUD, a table-based knowledge acquisition method, is proposed to be able to elicit the embedded meanings of rules and guide experts to decide certainty factors from the existing hierarchical repertory grids. Additionally, it interacts with experts and guides them to decide the certainty degree with the embedded meaning. To capture the embedded meanings of the resulting grids, the Attribute-Ordering Table (AOT), recording the relative importance of each attribute to each object, is employed. There are three kinds of values in each AOT attribute/object entry: “X”, “D” or an integer. “X” represents “don’t care” which means that the attribute does not relate to the object, “D” represents “Dominate” which means that the object cannot be supported without the attribute, and an integer represents the relative degree of importance for the attributes to the object.
It is noticed that the integer ranges from 0 to 5, and 0 is treated as “X” while 5 is treated as “D”. Besides the original rules, embedded rules can be generated by negating the minor (non-dominate) attributes recorded in AOT. Each embedded rule is assigned a certainty sequence (CS) by formula (1) and the certainty factor (CF) calculated by formula (2) which is between 0 and 1 can represent the degree of certainty for each embedded rule. Each of them is assigned a certainty factor (CF) between 0 and 1 while the value approaches to 1 means more important; otherwise, the value approaches to 0 means less important,
i k i
CS( R ) = SUM( AOT[Att , Obj ] ) (1) where Attk belongs to the attribute set of Ri, and Obji is the object of Ri.
(
)
i i a a a i CS(R ) CF(R ) = UB(R ) - UB( R ) - LB( R ) MAX(CS ) ⎛ ⎞ × ⎜ ⎟ ⎝ ⎠ (2)MAX(CSi) is the maximum CS value in all embedded rules generated from the original Ra with the same object. The EMCUD algorithm is listed in Algorithm 2.1:
EMCUD algorithm.
Algorithm 2.1: EMCUD algorithm
Input: The hierarchical grids.
Output: The guiding rules with embedded meaning.
Step1: Build the corresponding AOT with each grid of the hierarchical
multiple grids.
Step2: Generate the possible rules with embedded meaning.
Step3: Select the accepted rules with embedded meaning through the
interaction with experts.
Step4: Generate automatically the CF of each rule with embedded meaning.
To decide the CF of each embedded rule, the upper and the lower bounds values are defined for accepted embedded rules. Then CF values of each rule can be automatically determined by mapping function, formula (2). Thus, the useful embedded rules with corresponding CF values could be used to cover more uncertainty cases.
All rules generated by EMCUD can be categorized into two classes: original and embedded rules with acceptable CF value, and discarded rules with unacceptable CF value, according to the confidence degree of domain experts.
2.3 Variant Object Discovering Knowledge Acquisition
repertory grids, including knowledge representation and embedded meaning, it might still exist several problems such as hard to explain the rules with lower CF value, difficulty in deciding attribute ordering, and infeasible to elicit the knowledge of a new variant object due to the knowledge explosion of the changing environment over time. Hence, VODKA [25] is proposed to help experts be aware of the occurrence the occurrence of the new objects by monitoring the inference behaviors of the weak embedded rules with the lower CF values and incrementally extract the knowledge of the new discovered objects to enhance the explanation power of the original embedded knowledge base.
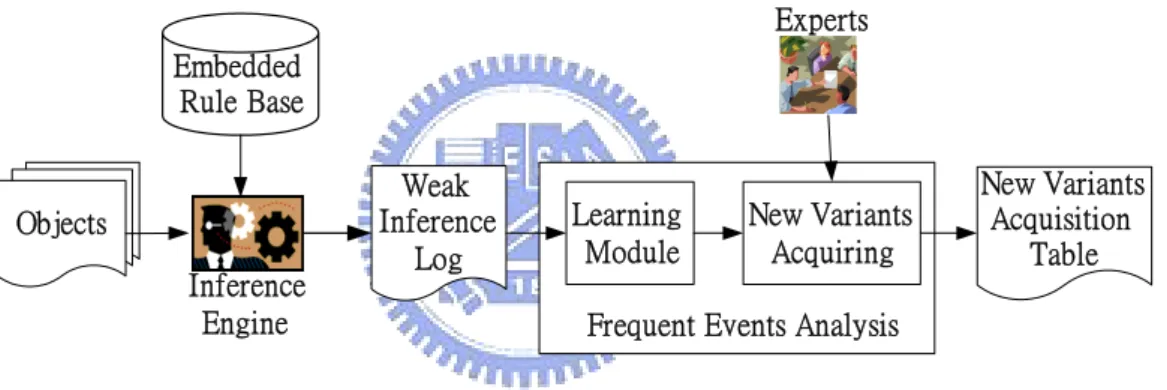
Embedded Rule Base Objects Inference Engine Weak Inference Log Experts New Variants Acquiring Learning Module New Variants Acquisition Table Frequent Events Analysis
Figure 2.1: The Variant Object Discovering Knowledge Acquisition Flow
The novelty of VODKA approach, shown in Figure 2.1, collects the inference logs of weak embedded rules from KBS to learn the candidates of new evolved objects. Since the new evolved objects may derive from well-known objects, some of them can be classified into well-known object class with lower certainty factor according to the nature of embedded rules in EMCUD. The learning module can be customized according to the different applications. In this thesis, we use the frequent based heuristic in learning module to discover the frequent attribute-value pairs between collected inference logs since the new object could be fired frequently when it is evolved. Hence, the discovered frequent attribute-value pairs could be used to help
experts find out the new objects using the new variant acquiring module includes three recommendations. Furthermore, the input facts which are different from original acquisition table may be considered as the possible new attributes or attribute values of a variant object. Therefore, if the variants could be detected and recommended as the new objects by experts, the related ambiguous attributes (minor attributes) which might result in the marginally acceptable CF values of original rules suggested by experts could be refined or new attributes could be added to improve the classification ability. According to the complexity of relations between objects and attributes or even each relation between different tables, it is hard for experts to cooperate with each other in building every column and every row for each table. The acquired new objects can be used to construct the new variant acquisition table. The algorithm of
VODKA [25] is shown as follows.
Algorithm 2.2: VODKA algorithm
Input: The original main acquisition table T and embedded rule base RB. Output: The rules with embedded meaning about variants.
Stage I: Collect all facts of the weak embedded rules as real inference log of the RB. Stage II: Generate the new variants acquisition table T’.
Step1: Discover large itemsets L using the inference log.
Step2: Generate T’ using L and additional attributes provided by experts. Stage III: Use E-EMCUD to generate rules of new variants.
Step1: Generate rules according to T’.
Step2: Merge T’ into original main acquisition table T.
VODKA has been implemented based upon DRAMA [21], an object-oriented
inference engine with NORM (New Oriented-original Rule-based Model) knowledge representation providing high maintainability, reusability, sharability, and abstraction
implemented to refine the embedded rule base.
However, it is still hard to have a certain command of the evolutional knowledge, so we proposed CAKE to efficiently discover the evolutional knowledge by context information analysis and collaborative heuristics. On the other hand, the repertory grid-oriented method to construct acquisition table is somehow strenuous for an expert and even more strenuous to solve the adaptive problem in a dynamic environment; therefore, we proposed TEA to cope with the problems above by further enhancing the original EMCUD method to become D-EMCUD (Dynamic EMCUD) method [22].
Chapter 3 Context Representations
We use XML, a simplified dialect of SGML (Standard Generalized Markup Language), to model the behavior as a kind of context information for several reasons. First, XML-based applications and tools are widely used and developed, and it has been standard in World Wide Web Consortium (W3C) already. Seconds, software tools for processing XML documents are easily obtained since file of XML is also machine-readable. It provides a common descriptive specification framework that can be used to enhance the reusability of the software documents. The heart of an XML application is a file called the DTD (Document Type Definition), which describes the hierarchical structure of a class of documents. Note that DTD is an XML document on which we can reuse the content of the document.
3.1 Behavior Description Markup Language
In this thesis, a Behavior Description Markup Language (BDML) based upon XML protocol is proposed to provide a general model for expressing computer’s network behavior. But, there are two categories of context information should be considered. First, static profile including environment configuration and individual configuration represents the location information and the basic information of the object. Second, dynamic behavior including individual trend and environment trend records the historical behaviors of the objects and objects’ environment to further help experts analyze the variant trend information and evolutional behaviors.
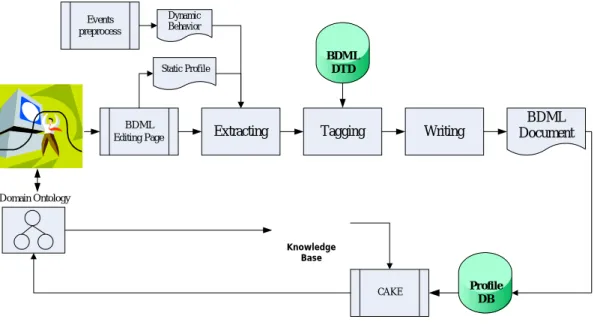
BDML
Editing Page Extracting Tagging Writing
BDML Document BDML DTD Domain Ontology Static Profile Dynamic Behavior Events preprocess CAKE Knowledge Base Profile DB
Figure 3.1: The Structure of BDML
It is noticed that the dynamic context information includes static profile, dynamic behaviors, the frequency, time based trend, and the correlations information between individual and environmental behaviors to assist experts to be aware of the occurrence of dynamic knowledge according to several collaborative heuristics for service-sensitive and symptom-similar events. The structure of BDML is shown in Figure 3.1. Since knowledge can be evolved with the dynamic environment as time goes on, how to acquire and represent the dynamic context information becomes an important issue. The context information can be classified into two categories: static profiles and dynamic behaviors information.
(1) Static Profile:
In the real world, the environment includes individuals, the relationships between individuals, and the related configurations. The environment could be considered as a collection of network properties and each individual has its own properties in the environment. Therefore, the static profile can be considered as environment configuration and individual configuration. The environment configurations describe the description of the environment, members in the environment, the status of the
environment, and other relative properties rely on domain. The individual configurations describe the individual ID, Location, Role of individual, and other relative properties depending on the domain. Through the static profile, we could classify the knowledge occurred in similar configuration.
(2) Dynamic Behaviors:
Some knowledge will be evolved to adapt the dynamic environment due to the natural of knowledge evolution. Owing to clear representing the behaviors of individual and environment, the trend of individual and environment can be easily acquired. The individual trend consists of the sequence of status of time and the occurrence of events pair. Also, the other relative properties should be also considered in each domain. Like the individual trend, the evolutional trend also combines the sequence of environment status and other properties to analyze the trend of environment for capturing evolutional knowledge.
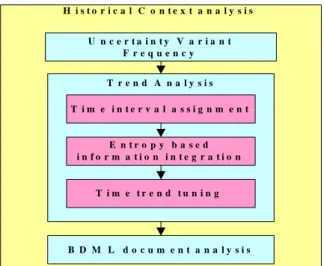
Figure 3.2 shows the analysis of historical context information which is considered as dynamic. First it receives the information of uncertain variant frequency from VODKA, and then processes the trend analysis by TEA. Finally, the BDML can be constructed by combining all the static and dynamic components.
U n c e r t a i n t y V a r i a n t F r e q u e n c y T i m e i n t e r v a l a s s i g n m e n t E n t r o p y b a s e d i n f o r m a t i o n i n t e g r a t i o n T i m e t r e n d t u n i n g T r e n d A n a l y s i s B D M L d o c u m e n t a n a l y s i s H i s t o r i c a l C o n t e x t a n a l y s i s
We design an XML based language that facilitates the machine readability for the KA framework to model the context information. In this model, not only the static profile but also the dynamic behaviors can be modeled using XML based description because the structure of XML is regular expression. Furthermore, the stored context can be easily reused, and the representation can be extended to describe new added properties of individual or environmental profile and behaviors due to the standardized property of XML.
Modeling the internet behavior by BDML, static profile DTD and dynamic behavior DTD can be shown in Table 3.1 and Table 3.2. The corresponding DTD of static profile in BDML includes environment configuration (network configuration) and individual configuration (host configuration). The environment configuration consists of description, members, status, and set of other properties, and the individual configuration consists of ID (IP address), location (LAN address), Roles (Server or Client), status, and a set of other properties.
Table 3.1: Static Profile DTD
<? Xml version=“1.0” encoding=“Big5”> <!DOCTYPE Static Profile [
<!ELEMENT Static Profile (Environment configuration, Individual configuration)> <!ELEMENT Environment configuration (Description, Members, Status, Properties)> <!ELEMENT Description (#PCDATA)>
<!ELEMENT Members (#PCDATA)> <!ELEMENT Status (#PCDATA)>
<!ELEMENT Properties (#PCDATA)>
<!ELEMENT Individual configuration (ID, Location, Roles, Status, Properties)> <!ELEMENT ID(#PCDATA)> <!ELEMENT Location(#PCDATA)> <!ELEMENT Roles(#PCDATA)> <!ELEMENT Status(#PCDATA)> <!ELEMENT Properties(#PCDATA)> ]>
Table 3.2: Dynamic Behavior DTD
<? Xml version=“1.0” encoding=“Big5”> <!DOCTYPE Dynamic Behavior [
<!ELEMENT Dynamic Behavior (Individual trend, Environment trend)> <!ELEMENT Individual trend (#PCDATA)>
<!ELEMENT Environment trend (#PCDATA)> ]>
The corresponding DTD of dynamic behavior in BDML includes individual trend and environment trend, including information of time, environment status, individual events and some set of properties. Taking computer worms as an example, the properties mentioned above consist of the basic information of the worms, the service what the worms aim at, the exploitation what the worms use, the carrier what the worms provide, the symptoms what the worms bring and the defense instructions to the worms.
3.2 Ontology Support
According to the complexity of relations between objects and attributes, it is hard for experts to cooperate with each other in building every column and every row for each table. Therefore, an ontology strategy is firstly designed in this thesis to help experts construct the knowledge in ontology and then the ontology will be transformed into the acquisition table. Therefore, we can easily define every relation between objects and attributes, and can easily assign a new attribute ordering value.
One of the purposes of applying ontology is to provide domain of discourse that is understandable by human and computers, so ontology can be represented by machine readable markup languages such as RDF. Moreover, the reusability of ontology has become increasingly important for developing intelligent systems. In
this thesis, we proposed an ontology based knowledge acquisition method that makes the ontology not only reusable but also adaptive to the current environment. The method of constructing the ontology is based upon a concept tree consisting of several prior knowledge including BDML model and real cases provided by knowledge engineers and domain experts to further help experts to construct the original EMCUD method as an initial prototype of knowledge.
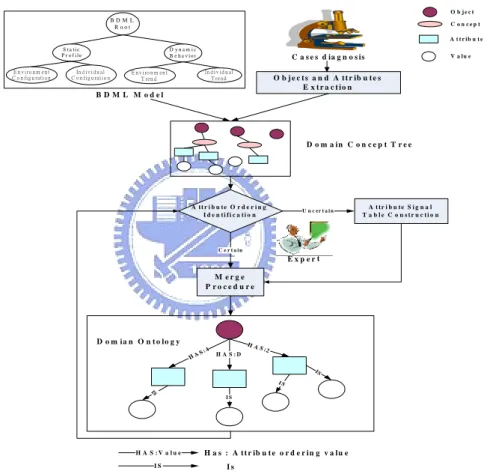
B D M L M o d e l C a s e s d ia g n o s is D o m a i n C o n c e p t T r e e M e r g e P r o c e d u r e H AS : 4 H A S : D H A S:2 IS I S IS I S D o m ia n O n t o lo g y E x p e r t A t t r i b u t e O r d e r i n g I d e n t i f i c a t i o n A t t r i b u t e S i g n a l T a b l e C o n s t r u c t i o n U n c er t a i n C e r t a i n O b j e c t s a n d A t t r ib u t e s E x t r a c t i o n O b j e c t A t t r i b u t e V a l u e H A S : V a l u e H a s : A t t r ib u t e o r d e r i n g v a l u e I S I s C o n c e p t B D M L R o o t S t a t i c P r o f i l e D y n a m i c B e h a v i o r E n v i ro n m e n t C o n fi g u ra t i o n In d i v i d u a l C o n fi g u ra t i o n E n v i ro n m e n t T ren d In d i v i d u a l T re n d
Figure 3.3: Ontology Construction Flow
Figure 3.3 illustrates the flow of constructing the domain ontology. To construct the ontology more easily, the following four steps are proposed:
Step 1, BDML model construction:
dynamic behavior. For example, we can model a worm BDML by identifying each worm with six general attributes, including the basic information and the service for static profile, then the exploitation, the carrier, the symptoms and the defense instruction for dynamic behavior.
Step 2, Concept tree construction:
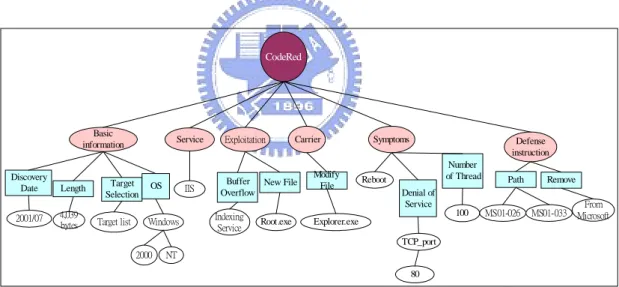
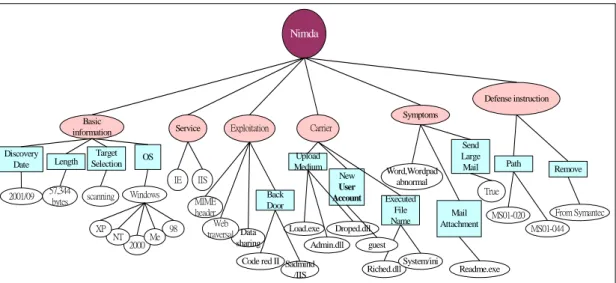
Since it is often easier and more accurate for experts to provide critical cases rather than domain ontology, the power of critical cases described in terms of relevant objects and attributes to build domain ontology is remarkable. Therefore, after case diagnosing a concept tree is created based upon the skeletal model in Step 1. The example of CodeRed worm, Nimda worm and Blaster worm concept trees are shown in Figure 3.4, Figure 3.5 and Figure 3.6, respectively.
CodeRed Basic information 2000 NT Service Defense instruction 2001/07 4,039
bytes Target list Indexing Service
100 Reboot Windows Exploitation IIS Symptoms Carrier TCP_port 80 Root.exe Explorer.exe MS01-026 MS01-033 From Microsoft Discovery
Date Length Target Selection OS
New File Modify File
Denial of Service Buffer Overflow Path Remove Number of Thread
Nimda Basic information 98 2000 NT Exploitation Symptoms Defense instruction Word,Wordpad abnormal Me 2001/09 57,344 bytes scanning XP Readme.exe Data sharing Web traversal MIME header
Code red II Sadmind /IIS Load.exe Admin.dll Riched.dllSystem/ini Droped.dll MS01-020 MS01-044 From Symantec Windows Service Carrier IE IIS guest Discovery Date Length Target Selection OS Back Door Upload Medium New User Account Executed File
Name Attachment Mail Path Remove Send Large Mail True
Figure 3.5: Example of Nimda Concept Tree
Blaster Basic information 2000 XP Symptoms Defense instruction New file TCP_port 2003/08 6,176 bytes scannning DCOM RPC msblast .exe MS03-026 From Symantec Send large RPC packet and HTTP packet Reboot 2003 NT 135 4444 UDP_port 69 System Crash Internet Explorer Microsoft Outlook Outlook Express Microsoft Office From Trend Windows Carrier Application program Abnormal Denial of Service Remove Patch Discovery date Length Target selection O.S Service Exploitation
Figure 3.6: Example of Blaster Concept Tree
Step 3, Concept tree transformation:
The concept tree is transformed into acquisition table, and attribute ordering will be next acquired from experts. Then the original EMCUD method can be processed to generate the initial rules. However, because it is not easy to identify some attribute ordering values precisely, the attribute which is uncertain to identify the ordering
value should be traced and analyzed with time by constructing an AST. Each attribute signal is recorded in each time interval, when the attribute appears important the signal equals one and when it appears unimportant the signal equals zero. Then the attribute ordering table will be reconstructed according to the attribute signals collected with time.
Step 4, Merge procedure:
There are only two relations for constructing worm ontology during the merge procedure, including “has” relation and “is” relation. The “has” relation embeds attribute ordering value, for example, when the attribute ordering value equals 3 then the relation should be “HAS:3”. Therefore, from Step 3, the ordering value would be retrieved from the reconstructed AOT by AST method. Hence, the ontology can be easily transformed into D-EMCUD method, and be updated whenever the AOT is reconstructed or the variants are discovered.
Chapter 4 The Framework of CAKE
4.1 The Collaborative Architecture
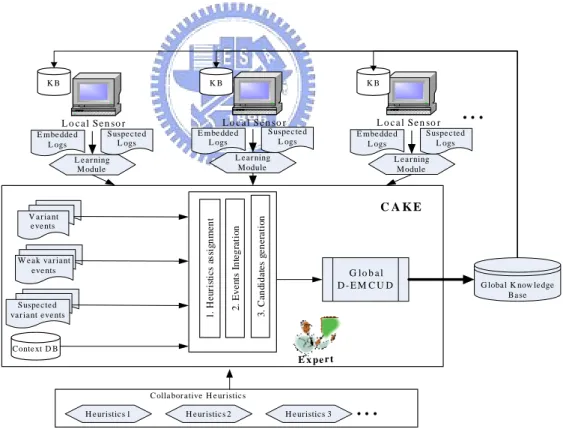
For the evolving environment, the important evidences could occur in every location and in every minute; therefore, deploying several kinds of specific inference engines to the significant environment is designed to cope with the problem. The collaborative architecture is shown in Figure 4.1. By collecting inference results from each inference engine, some results in the same period or in the sequential periods can further approve or disprove the evidence.
L o c a l Se n so r L o c a l Se n so r L o c a l Se n so r L e a r ning M odule K B K B K B V a r ia nt e ve nts
H e ur istic s 1 H e ur istic s 2 H e ur istics 3 C olla bor a tive H e ur istic s
G l o b a l D - E M C U D W e a k va r ia nt e ve nts 1. H e ur is ti c s as si gn m e n t 2 . E v en ts I n te g ra tio n
…
G loba l K now le dge B a se E mbe dde d L ogs
…
S uspe c te d L ogs S uspe c ted va r ia nt e ve nts 3. Ca n d id a te s g e n e ra tio n L e a r ning Module E m be dde d L ogs S uspe c te d L ogs L e a r ning M odule E mbe dde d L ogs S uspe c ted L ogs E x pe r t Conte xt D B C A K EFigure 4.1: The Architecture of CAKE
For example, suppose there are smoke detectors and temperature detectors in a hotel. A simple meta rule can show that if there is a result of smoke form smoke
engine and the other result of sparkle form temperature engine then it then triggers the fire alarm service; however, if temperature engine sends back the result which is around the temperature of a human body then it disproves the evidence of fire and further approves that someone is smoking under the detectors. Obviously, the scenario described above can not be handled by single sensor environment. Hence, we use sensors with different configurations to represent such kind of expert systems or KBS with embedded rule bases. When the system is operating, some inference logs of cases, including old and new, will be recorded. By collecting and analyzing the relationships between these inference logs using the collaborative heuristics with sufficient context information, the occurrence of candidates of dynamic knowledge could be discovered. The CAKE consists of log collector, frequency analysis, trend analysis, collaborative analysis, dynamic EMCUD, and context DB to learn the dynamic behaviors and to record the configurations of different environment. The frequency-based analysis is proposed to discover significant variant knowledge by monitoring the inference behaviors of weak embedded rules. Moreover, the sequence of inference log will be considered to discover the relations between them to monitor the occurrence of evolutional knowledge as time goes on. All discovered information will be collected and further be analyzed by using collaborative analysis with consideration of the static configurations and dynamic behaviors, since some insignificant variant or evolutional knowledge might evade the frequency-based and time-based analysis. Finally, the dynamic EMCUD will incrementally integrate the discovered evolutional knowledge confirmed by experts, and then update the evolutional knowledge base.
In Figure 4.1, every local sensor collects logs from the inference engine based on the knowledge base (KB). Through the learning module, including components of
VODKA and TEA, can provide information of embedded logs and suspected logs.
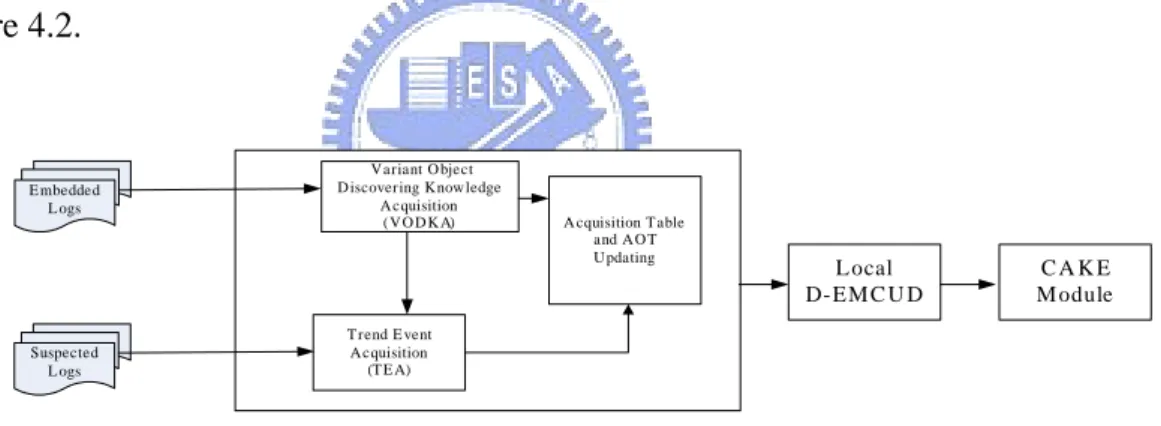
Embedded logs can be learned by VODKA to discover variants, and some of them which are weak to be identified by VODKA can be traced by TEA methodology to adjust the importance and further discover the variants. However, the logs considered suspected are logs without fired rules but are suspected of evolutional knowledge. When there is no matching rule after inferring through the inference engine, the log then contains no information of fired rule. The unexpected patterns were too uncertain to be accepted by experts at the beginning; however, they may evolve and become new knowledge as time goes on. Therefore, those suspected logs can be retrieved by context analysis based upon several collaborative heuristics and further the events of suspected variant can be identified via experts. The learning module is shown in Figure 4.2. E mbedded L ogs Suspected L ogs T rend E vent A cquisition (T E A) A cquisition T able and A O T U pdating L ocal D- EM C U D Variant O bject D iscovering Know ledge
A cquisition (V O D K A)
C A K E M odule
Figure 4.2: The Learning Module
We consider that the knowledge can be classified into static one and dynamic one. The static knowledge can be designed and built by following the static knowledge acquisition methodology such as EMCUD. But the dynamic knowledge could be variant or evolutional. For variant knowledge, it can be discovered by VODKA strategy when human experts themselves have enough abilities to decide the variant configuration; however, human experts have no abilities to discover the evolutional knowledge if without sufficient information, so in many situations, the evolutional
knowledge is negated easily when experts select the acceptable embedded rules. Hence, BDML based behavior context analysis is proposed to model ones’ behavior according to their own environments. By BDML, the profile database can be constructed to support the collaborative analysis, and finally the experts can use
D-EMCUD to construct or adjust the knowledge bases.
Taking Internet security as an example, there are many researches work on collaborative intrusion detection system (CIDS), many of them use lots of techniques such as the data mining technique to discover the intrusion; however they still have several limitations like false alarm reduction and inability to discover the variants. False alarms are too many to be handled due to lacking of environment context analysis. Different host computers may have different symptoms but suffered with the same attack. By the way, several attacks like computer worms may mutate in order to evade the detection mechanism of CIDS. Therefore, Figure 4.3 shows the example of collaborative architecture for CIDS, each of them has their own sensors and knowledge bases according to their profile configurations. The monitoring report from each one of sensors will be collected by the collaborative analysis center to further manage the security tasks in their network environment.
LA N LAN
Internet
C o lla b o ra tiv e A n a lys is C e n te r
R o u te r L A N P C P C P C S e rve r S e rv e r N etw o rk Se nso r Syste m Sen sor L o c a l K B L o c a l K B L o c a l K B L o c a l K B L o c a l K B G lo ba l K B Profile Profile P ro file P rofile Pro file N e tw o rk Sen sor System Se nso r System Se nso r
Figure 4.3: The Example of Collaborative Environment
In Internet, the environment configuration can be considered as network configuration while the individual configuration can be considered as host configuration. Hence, the network configuration can involve information like the network description, the number of members, the status information and other properties. Also, the host configuration can then involve the unique ID such as IP address, network location, the role it plays as server or client, the status information and also the other properties. For the dynamic behavior, the individual trend is retrieved from the TEA analysis drawn support from VODKA, and for the environment trend, the context information modeled by BDML is additionally retrieved to support the collaborative analysis.
4.2 Trend Capturing and Analysis
Embedded Rule Base Objects Inference Engine Weak Inference Log Experts Attribute Significance Sequencing Objects SelectingTrend Events Analysis New Variants Acquisition Table Dynamic AOT Constructing Dynamic AOT Table
Figure 4.4: The Flow of TEA
The flow of Trend Event Acquisition (TEA) is shown in Figure 4.4. As mentioned before, VODKA [25] has been proposed to help experts to discover the knowledge of variant object by monitoring the inference behaviors but it lacks the ability of discovering evolutional knowledge over time. Although the original idea of constructing AOT table makes it more adaptive to elicit embedded meanings, it may not be so sure to exactly define each relative importance of each attribute to each object since the dynamic knowledge may change or evolve over time. It means that some rules, which are recommended by experts now, may become uncertain in the near future. Moreover, VODKA learns the behaviors of weak embedded rules with low CF values, and if the CF value is not adaptive in the past few days then it may encounter the problem of inefficiency in learning the variant object. In this thesis, decomposing each object in the AOT to record the relative importance of each attribute to the object into several time intervals is proposed. Each time interval represents in a short period according to the viewpoints of experts or the learning results of VODKA. It can simply assign “0” or “1” for each attribute to each object in each time interval, where “0” represents the attribute is considered as the unimportant attribute to the object and “1” represents the attribute is important to the object in this
time interval.
The signals of “0” and “1” are called the attribute signals in each time interval, and a table recording the information is called the attribute signal table (AST). There are two steps, including unfolding and reconstructing to help experts trace the evolutional behaviors. In order to capture the evolutional information of each object, the original AOT table will be decomposed into several AST tables to record the specific information in each interval with time in the first step shown in Figure 4.5. Then, we will reconstruct the AOT table by renewing the relative importance of each attribute to each object (ordering values) according to the sequence of “0” and “1” signal recording with time in the second step shown in Figure 4.6. Since the ordering values are recalculated at the present time according to all the evidences collected with time, the AOT table becomes more flexible and robust to adapt the changing environment.
Figure 4.6: Reconstructing
4.2.1 Constructing Attribute Signal Table
In the changing environment, the knowledge will evolve over time. The relative importance of each attribute to each object may need to be adjusted. Since not all the attributes are working well after a period of time because of some characteristics of the attribute. The domain expert can decide which attributes are required to be traced with time if ordering values of the ambiguous attributes are hard to be decided immediately. There are two ways of constructing AST:
(1) Interacted with human experts:
It is designed to acquire the attribute signals from domain experts in every time interval for deciding whether the attribute is important or not. It is simpler to decide whether it is “1” or “0” rather than to decide a relative importance of each attribute to each object, the ordering value ranged from 0 to 5.
(2) Interacted with VODKA:
As mentioned above, VODKA can be used to learn and level up the CF of each weak embedded rule by monitoring their inference behaviors. It can be helpful to decide the attribute signal of importance or unimportance by directly mapping each embedded rule to the AST.
For example, assume VODKA generated after learning the candidates of variant and then confirmed by experts, is shown as follows:
R1: IF A and B and not C Then Goal *2 R2: IF A and not B and C Then Goal *3
where *2 represents that the rule R1 has been fired two times, and R2 is inferred after R1. The AST can be constructed as Table 4.1 according to the inference logs collected in the five time intervals.
Table 4.1: An example of AST table
Attribute/ Object Goal.1 Goal.2 Goal.3 Goal.4 Goal.5
A 1 1 1 1 1
B 1 1 0 0 0
C 0 0 1 1 1
Since the attribute B is not negated in R1 according to the first two inference results, but it is negated three times after in R2, the signal would be collected as “11000” shown in the second row of Table 4.1. Finally the scoring method is presented in the following subsection to help experts automatically renew the ordering value in the AOT table to enhance the dynamic ability of AOT table.
4.2.2 Constructing Attribute Ordering Table
To capture the adaptively relative importance of each attribute to each object from the AST table after a time period, the dynamic value adjusting method based upon entropy formula (3) [16] is applied to transform AST to AOT instead of simple leveling up the attribute’s ordering value when the attribute’s signal is “1” or leveling down when the attribute’s signal is “0” ,
2 2
log log
pos pos neg neg
Entropy
pos neg pos neg pos neg pos neg
⎛ ⎞ ⎛ ⎞
= − ⎜ ⎟− ⎜ ⎟
+ ⎝ + ⎠ + ⎝ + ⎠ (3)
where “pos” represents positive case and “neg” represents negative case. In this case, the positive case means that the attribute is decided as an important attribute to this object such as signal “1” in AST table, and the negative value occurred in AST table can not be an important attribute in this time interval such as signal “0”.
As you move from perfect balance or perfect homogeneity, entropy function could be smoother between zero and one. The entropy is zero when the set of collecting instances is perfectly homogeneous like all positive or negative instances, and the entropy is one when the set is perfectly heterogeneous like half positive and half negative instances. Hence, it is obvious to decide the new adjusting value of the attribute in dynamic AOT table which should be set into a dominated attribute (D in AOT) or irrelevant attribute (X in AOT) to the object depending on number of positive and negative instances in this set when the entropy value approximates to zero. In other words, if an attribute is continuous important (unimportant) to an object in the collecting time period, then it could be a dominated (irrelevant) attribute to the object in this time moment. The strategy of dynamic EMCUD is shown as follows:
Step 1, Summing:
Add up each number of positives and negatives, and then apply entropy formula (3) to calculate the entropy weight of each attribute to each object.
Step 2, Mapping:
Transform the obtained entropy weight into relative importance of each attribute to each object according to the following three cases:
Case 1:
If the entropy weight approximates to zero and the number of positive instances is larger than that of negative instances, the ordering value of the
attribute to the object could be assigned into “D” or “4” in the dynamic AOT table.
Case 2:
In case 1, if the number of negative instances is larger than that of positive instances, the ordering value of the attribute to the object could be assigned into “X” or “1” in the dynamic AOT table.
Case 3:
If the entropy weight approximates to one, the ordering value of the attribute to the object could be set into “2” or “3” in the dynamic AOT table.
Step 3, Tuning:
If the attribute is time relevant, the trend of the attribute should be applied to adapt the obtained entropy weight according to the following three cases.
Case 1: Increasing trend.
The ordering value of this kind of attribute should be increased since the attribute seems to become more and more important in the collected period such as the sequence “001111”.
Case 2: Decreasing trend.
The ordering value of this kind of attribute should be degraded since the attribute seems to become less and less important in the collected period such as the sequence of “110000”.
Case 3: Uncertain trend.
The ordering values of this kind of attribute would not be tuned since this kind of attribute has no significant trend in the collected period such as the sequence of “010101” or “101010”.
table for comparing the numbers of positive and negative instances. The entropy weight will be calculated to represent the distribution of “1” and “0” in each set in Step 2. When the number of positives surpasses the number of negatives, the entropy weight approximates zero and vice versa. It is obvious to assign a higher ordering value (D or 4) when most of information represent important; otherwise, a lower ordering value (X or 1) would be assigned due to the observation of unimportant attribute. However, other relative importance of each attribute to each object would be assigned when the entropy weight approximates one, which would be considered uncertain degree. That is, it is usually uncertain to decide a decision when getting half positive advices and half negative advices at a time; moreover, in Step 3, when the set is heterogeneous, but the characteristic of attribute is time relevant then it can be considered homogenous in some ways.
For example, suppose there are two sets in AST recorded as “000111” and “111000”. After Step 1, both of “000111” and “111000” in entropy method are considered uncertain because of perfectly heterogeneous. Since these two sets can be considered time relevant, it is very certain that attribute with signals “000111” should be assigned a higher ordering since it is important in the present time intervals. Therefore, after calculating with entropy method in Step 2, there is still a time bonus weighting in Step 3 to adjust each ordering value at final. Accordingly, the AOT is considered dynamic by following the time interval tracing oriented mechanism, and each CF value of a rule can now be leveled up or down automatically.
The mechanism not only applies VODKA to construct AST but also offers more robust information for VODKA to learn the variant objects since each CF value is also updated by the dynamic AOT.
4.3 Collaborative Heuristics
Furthermore, according to the specific environment for a particular domain, heuristic approach makes the collaborative analysis workable. Since some invisible or unrecognizable behaviors might be ignored without sufficient information, collaborative multiple sensors to collect more evidence of evolutional knowledge becomes more important. The static profile and dynamic behaviors of individual and environment could be used to help discover evolutional knowledge since they could assist experts to trace the changing behaviors. The static profile can be used to analyze the co-occurrence behaviors between different profiles since some behaviors might exist in similar environment. The dynamic behavior can be used to analyze the similar behaviors in different environment as time goes on. Based upon the collection of the sufficient context information including the unrecognizable or invisible behaviors in single sensor to discover the evolutional knowledge, the static profile and dynamic behaviors of individual and environment could be used to help discover evolutional knowledge. We propose two simple heuristics as followings based upon three distributed inference engines, including Service-Exploitation Engine, Carrier Engine, and Symptoms Engine.
(1) Service-sensitive event:
Different configuration may encounter with different symptoms or different degree of damage in each progress. When several Service-Exploitation Engines responds higher frequency of similar intrusion behaviors but with different behavior presentations from the corresponding Symptoms Engines, CAKE then triggers the trend analysis mechanism on the Symptom Knowledge Class by the aid of BDML. Consequently, by the trend from BDML we may learn that it is because the firewall
setting of some computer hosts are different from others. The central administrator can thus forward the better firewall settings to those who do not have the proper settings; furthermore, we may stumble upon a solution that the intrusion may be limited to some special configuration setting. For example, some intrusion behavior such as SQL Slammer which uses UDP port 1434 to exploit a buffer overflow in MS SQL server, then it can simply switch off this port since CAKE learns that others SQL servers which are unavailable to the Internet are immune.
(2) Symptom-similar event:
However, some computers come up with similar symptoms but with sort of different behavior from the Carrier sensor or even the Service-Exploitation sensor. We consider it is kind of polymorphic process for the intrusion like polymorphic worm which is considered as the variant knowledge or the evolutional knowledge in this thesis.
For heuristics above, the knowledge which is variant or evolutional, CAKE triggers the specific trend analysis process on special knowledge class like Carrier Knowledge Class or Service-Exploitation Class for symptom-similar events and Symptom Knowledge Class for the those events which are service-sensitive respectively. For example, D-EMCUD generates rules for Blaster and Sasser from acquisition table and AOT shown in Table 4.2 and Table 4.3. VODKA discovers variants from Log1 and Log2 in Table 4.4 since we suppose expert define CS value as 4 to be a threshold. According to the embedded rule represented as “IF A1 and A2 and
NotA3”, VODKA confirms the variants named as Blaster.B and Sasser.D. However,
Log3, a suspected log in Table 4.4, is negated since both of attribute A2 and A3 are
negative; therefore, the CS value is 7 (3+4) which is higher then the defined threshold. Unfortunately, it is the variant information of Sasser.E; hence, to enhance the
weakness, CAKE is applied and discovers the variant by Service-sensitive heuristic to find out the evolutional information such as 1022 for port number and ftplog.txt for carrier. By applying the heuristic, all information of suspected logs will be integrated by intersection. Then those suspected logs with most frequency (suspected events) will be further compared by BDML documents. Subsequently, the candidates of evolutional knowledge will be generated and further confirmed by experts.
Table 4.2: A simple acquisition table for Blaster and Sasser
Object
Attribute Blaster Sasser
Symptom (A1)
System Reboot; System Crash; Word, Excel, Power
point abnormal
System Reboot; System Crash; 128-threads Service & Exploitation (A2)
RPC Buffer Overflow (135;4444)
RPC Buffer Overflow (445;5554;9996)
Carrier (A3) Msblast.exe avserve.exe; win2.log
Table 4.3: A simple AOT for Blaster and Sasser Blaster Sasser
A1 4 4
A2 4 4
A3 4 3
Table 4.4: Part of inference logs record
IF Part Then
Part Logs #
A1 A2 A3 Rule
CF Log1 System Reboot Port:4444 penis32.exe RBlaster 0.6 Log2 System Crash Port:445 skynetave.exe RSasser 0.74 Log3 System Crash Port:1022 ftplog.txt - -
Chapter 5 Case Study and Experiment
5.1 Brief of Worms
In order to understand the threat posed by computer worms, Figure 5.1 shows the life cycle of worms [13] consists of five phases. In Initial Phase, each worm agent begins with installing software, determining the configuration of the local machine, instantiating global variables and beginning the main worm process. To find vulnerable candidates in Target Selection Phase, a worm usually first discovers that the other potential victim exists. Then in Network Reconnaissance Phase, a worm can actively spread itself among machines or can be carried along as part of normal communication traffic through the network. Next in Infect Phase, system which is attacked may result in many abnormal behaviors in Attack Phase and may further infect other victims.
Initial Target Selection Network Reconnaissance Attack Infect
Target Scanning
N etw ork Propagation
Phase 1 Phase 2 Phase 3 Phase 4 Phase 5
Figure 5.1: Worm Life Cycle
Since most of the worms follow the life cycle, we can construct the semi-structured document represented as a worm concept tree by interaction between domain experts and knowledge engineers with support of BDML model, then the