國立臺中教育大學資訊科學學系碩士論文
無線感測網路之語音傳輸與流量控制
系統設計與實作
Design and Implementation of Voice
Transmission and Flow Control
over WSN
指導教授:張林煌 教授
研究生:陳朝傑 撰
中華民國 101 年 7 月
i
摘要
由於無線感測網路技術的進步與快速發展,近年來利用無線感測網路技術於 各種災難與搜救之應用的議題備受關注,其中利用無線感測網路傳送語音已成為 重要之研究領域。本篇論文中我們設計與實作一套具有藍芽與 ZigBee 語音閘道 器(Bluetooth and ZigBee Voice Gateway, BZVG),藉由無線感測網路與資料傳輸技 術進行語音訊息交換,利用 Speex 壓縮技術以降低語音的編碼率,以利於傳輸於 ZigBee 網路。當語音訊息能有效的傳達時,將有助於提供一套可用於偏遠地區之 通訊平台。例如,當遊客攀爬高山發生意外時,可提供緊急語音通話服務。
由於藍芽與 ZigBee 具有不對稱的頻寬差異,而無線感測網路亦可能發生連 線不穩定之現象,當 BZVG 藍芽端接收大量封包並轉傳至 ZigBee 端時,將導致 語音閘道器 ZigBee 端發生壅塞的現象。本論文提出利用 Traffic Shaping Buffer 暫 存語音資料,並且 Leaky Bucket 維持穩定的輸出頻寬,以降低封包遺失。本論文 在實驗架構中以四種不同距離進行實測,藉以觀察無線感測網路傳輸語音封包的 情形,並採用 PESQ 與 E-model 兩種語音評估模型,分析封包遺失率與語音品質 之對應關係。
本研究設計與實作一個使用 ZigBee 來傳送語音封包的閘道器(Bluetooth and ZigBee Voice Gateway),並運作於嵌入式系統,於嵌入式系統內建置流量控制機 制,有效的降低語音封包的遺失率,並維持良好的語音通話品質。因此,本論文 主要研究工作著重於流量控制機制,讓 ZigBee 更加適合用來進行語音封包的傳 輸。
ii
Abstract
Audio over ZigBee network has become emerged research filed currently. On the other hand, there are many hazard scenarios such as emergency response, rescue, and disaster during mountain climbing. Our goal is to develop an end-to-end rescue communication voice gateway which provides voice communications via ZigBee networks. In this paper, we design and implement Bluetooth and ZigBee Voice Gateway (BZVG), using a combination of Arduino and Xbee module.
Due to the different bandwidth of Bluetooth and ZigBee network, the wireless sensor network transmission may be unstable. When Bluetooth receiver on BZVG receives a large number of packets and transfer to ZigBee transceiver on BZVG, it will lead to congestion. Result in packet loss and the packet cannot successfully sent to WSN. Therefore, how to manage an asymmetric bandwidth for data transmission will be inevitable challenge. We will focus on the transmission reliability as well as the latency and voice quality in WSN.
We design and implement a gateway for voice transmission over WSN and operation in embedded system. We design a flow control mechanism for embedded systems. Our goal is to reduce the packet loss rate effectively and maintain a good voice quality. Therefore, this research will focus on traffic control to allow the ZigBee to be more suitable for the transmission of voice packets.
iii
誌謝
感謝指導教授張林煌教授,感謝您不論在研究上的訓練,以及待人處事上, 皆細心給予學生很多指導,引導正確的研究方向。感謝老師在學習上所給予的支 持與鼓勵,並適時的提點學生與提供完善的資源,讓學生能從困難中學會堅持與 解決問題之能力,在老師辛勤的指導下,讓我得以順利的完成這份碩士論文。同 時,也要感謝李宗翰博士在這兩年以來對學生的指導與協助。感謝論文口試委員 竇其仁博士、賴坤助博士,在口試時提出精闢的見解與建議,使得本論文的內容 能夠更加完善。 研究所生涯中,無論在課程的修習上或是研究層面的發展,對自己都是十分 的紮實與堅苦。感謝實驗室學習夥伴,鈺軒學姐、冠宇、智鈞學長,在研究上的 建議與鼓勵;碩瑤同學這兩年的互相扶持與協助;宸勳、政彥學弟,給予我許多 幫助;謝謝你們對我的支持與協助。 最後,感謝我的父母與家人,由於父母對我的栽培與肯定,不僅是我在求學 的過程中向前邁進的力量,更讓我在求學過程中能無後顧之憂。每每遇到挫折時, 家庭的支持與關心都能夠讓自己克服心理的困頓,使得自我有所成長並且重新出 發。在此,謹將此篇論文獻最感謝的你們。 陳朝傑 謹誌 中華民國 101 年 7 月iv
目錄
摘要 ... I ABSTRACT ... II 誌謝 ... III 目錄 ... IV 表目錄 ... VI 圖目錄 ... VII 第一章、緒論 ... 1 1.1 研究背景 ... 1 1.2 研究動機與目的 ... 3 1.3 論文架構 ... 4 第二章、文獻探討 ... 5 2.1 藍芽無線傳輸技術 ... 7 2.2IEEE802.15.4 與 ZIGBEE簡介 ... 9 2.3 語音壓縮原理 ... 12 2.3.1 Speex 語音壓縮技術簡介... 13 2.3.2 語音壓縮技術比較 ... 14 2.4 語音品質的衡量指標與量測方法... 152.4.1 平均意見分數(Mean Opinion Score, MOS) ... 17
2.4.2 Perceptual Evaluation of Speech Quality, PESQ ... 18
2.4.3 E-Model ... 20 2.4.4 Reduced E-Model ... 22 2.4.5 結合 PESQ 與 E-Model 之對話式語音品質量測 ... 24 2.5 語音傳輸於無線感測網路相關文獻探討 ... 28 第三章、於無線感測網路中傳送語音封包之機制 ... 33 3.1 語音閘道器系統 ... 34
3.2TRAFFIC SHAPING BUFFER 語音資料暫存與 拋棄機制 ... 37
3.3LEAKY BUCKET動態輸出配置與 XBEE DIBUFFER狀態整合 ... 43
第四章、系統測試與效能分析 ... 47
4.1 系統測試平台架構 ... 47
v
第五章、結論與未來研究方向 ... 65
5.1 結論 ... 65
5.2 未來研究方向 ... 66
vi
表目錄
表 1 2.4GHZ 頻帶的無線通訊技術比較 ... 6 表 2 不同語音壓縮比較 ... 14 表 3 平均意見分數級別判斷標準 ... 17 表 4 PESQ 適用環境 ... 19表 5 R-FACTOR, QUALITY RATINGS AND THE ASSOCIATED MOS ... 22
表 6 原始 SPEEX 封包表頭內容 ... 41 表 7 加入拋棄標籤之 SPEEX 封包表頭內容 ... 41 表 8 OGG/SPEEX HEADER ... 41 表 9 環境參數設定 ... 47 表 10 100 公尺之傳輸表現 ... 54 表 11 200 公尺之傳輸表現 ... 57 表 12 250 公尺之傳輸表現 ... 59 表 13 300 公尺之傳輸表現 ... 61
vii
圖目錄
圖 1 藍芽與 ZIGBEE 語音閘道器傳輸示意圖 ... 2 圖 2 無線通訊網路傳輸距離與傳輸速率分佈 ... 5 圖 3 藍芽微網路拓樸 ... 8 圖 4 IEEE 802.15.4/ZIGBEE 堆疊架構圖 ... 10 圖 5 ZIGBEE 應用領域 ... 11 圖 6 PESQ 概觀流程圖 ... 19 圖 7 E-MODEL 架構 ... 21 圖 8 結合 PESQ 與 E-MODEL 之對話式語音品質量測架構[32] ... 25 圖 9 點對點傳輸延遲因素 ... 26 圖 10 系統架構圖 ... 34 圖 11 單向語音傳輸流程 ... 35 圖 12 閘道器流量控制架構圖 ... 37圖 13 TRAFFIC SHAPING BUFFER 架構圖 ... 38
圖 14 E-MODEL 與絕對延遲(ABSOLUTE DELAY)影響對照圖[36] ... 40
圖 15 TSB 流量控制機制流程圖 ... 42
圖 16 LEAKY BUCKET 與 XBEE 架構整合 ... 44
圖 17 XBEE FLOW CONTROL 示意圖 ... 44
圖 18 無線感測網路測試環境架構圖 ... 47 圖 19 實地量測架構 ... 48 圖 20 SPEEX 編碼延遲時間 ... 49 圖 21 SPEEX 解碼延遲時間 ... 49 圖 22 TSB 在低輸出速率與高輸出速率時的使用率 ... 51 圖 23 TSB 在相等輸入與輸出速率時之使用率 ... 52 圖 24 BZVG 在 100 公尺傳輸距離之 MOS(PESQ)與 MOSC 的語音評估分數 ... 53 圖 25 BZVG 在 100 公尺傳輸距離之封包遺失率 ... 53 圖 26 BZVG 在 200 公尺傳輸距離之 MOS(PESQ)與 MOSC 的語音評估分數 ... 56
viii 圖 27 BZVG 在 200 公尺傳輸距離之封包遺失率 ... 56 圖 28 BZVG 在 250 公尺傳輸距離之 MOS(PESQ)與 MOSC 的語音評估分數 ... 58 圖 29 BZVG 在 250 公尺傳輸距離之封包遺失率 ... 58 圖 30 BZVG 在 300 公尺傳輸距離之 MOS(PESQ)與 MOSC 的語音評估分數 ... 60 圖 31 BZVG 在 300 公尺傳輸距離之封包遺失率 ... 60 圖 32 各距離之 MOS(PESQ)的最大值、最小值與平均值 ... 62 圖 33 各距離之 MOSC 的最大值、最小值與平均值 ... 62 圖 34 各距離之封包遺失率的最大值、最小值與平均值 ... 63
1
第一章、緒論
本章節主要說明無線感測網路傳輸的研究背景,以及解決語音封包傳輸於無 線感測網路所延伸的研究動機及目的,最後為本論文架構。1.1 研究背景
隨著電腦硬體製造技術的進步,各種嵌入式系統產品日益普及,再加上短 距離通訊無線網路技術的快速成長,使得目前小型嵌入式系統結合無線網路的 應用越來越廣泛與多元;其中無線感測網路(Wireless Sensor Network, WSN)就是 一個很好的例子。過去幾年來無線感測網路成為熱門的研究議題,人們想要利 用無線感測網路來監控各種環境,並於無線感測節點之間進行資料的傳送。其 中全球電子電機工程協會(Institute of Electrical and Electronics Engineers, IEEE) 提出的 IEEE 802.15.4 標準之低頻寬無線個人網路(Low-Rate Wireless Personal Area Network, LR-WPAN)與 ZigBee 為主要標準。IEEE 802.15.4 與 ZigBee 的應 用在過去幾年大部份的研究偏向於環境感測與監控,主要是以單向式回傳所偵 測取得的資料至骨幹節點,而利用無線感測網路於特殊應用如支援多媒體或語 音正逐漸被重視。使用無線感測網路傳輸語音的優點在於利用小型無線感測節 點傳輸語音封包,不需要透過架設大型基地台,對於偏遠地區等如高山環境, 無疑是最不影響環境,且無需花費高成本的好方法。 在 IEEE 802.15.4 標準所制定傳輸頻寬最高為 250 kbps,而語音數位壓縮編2 碼技術,可將聲音進行編碼,以減少語音的網路傳輸資料量。因此,以目前無 線感測網路所能提供的最大傳輸頻寬,理當有足夠的能力負荷語音通訊時所需 的傳輸頻寬。而無線感測節點也具有可攜式的優點,由此可見,將語音傳輸技 術建置於無線感測網路,勢必成為應用趨勢。 圖 1 為語音封包經由藍芽與 ZigBee 語音閘道器進行點對點方式傳輸,在有效 的傳輸範圍內,登山客可於緊急狀況時,與登山道上其他人員進行通訊。在無線 感測網路環境提供語音封包傳輸,並維持理想的語音服務品質,並不容易,主要 難度在於無線感測網路運算能力較小,而且記憶體有限,小型嵌入式系統內部需 要一套有效的流量控制機制。除此之外,封包遺失與延遲抖動(Jitter)的處理要控 制得當,因為這些將大幅地影響在無線感測網路中,進行語音通話的效能與品 質。 圖 1 藍芽與 ZigBee 語音閘道器傳輸示意圖
3
1.2 研究動機與目的
在無基礎建設且偏遠地區提供語音傳輸服務,如果能夠支援長距離的語音封 包傳輸,將有助於緊急訊息的傳遞與交換,提供緊急求救等相關訊息給救難人員。 例如,當登山客受傷、迷路或求救而需要幫助時,因此提供一套可靠且穩定的語 音傳輸系統給登山客是必要的。 本論文目的為針對於高山登山步道之情境,在緊急狀況發生時,登山客可透 過無線感測網路對外進行通話。為克服傳統長距離無線通訊系統可能無法佈建於 自然環境之瓶頸,本論文提出設計與實作藍芽與 ZigBee 之語音閘道器,此閘道 器以點對點(Peer-to-Peer)無線傳輸方式傳送語音資料於無線感測網路。此架構可 讓使用者透過藍芽裝置傳輸語音至語音閘道器,再經由語音閘道器轉換語音資料, 以傳送於無線感測網路。 為了克服藍芽與 ZigBee 因頻寬差異所造成的壅塞問題,本論文將在語音閘道 器內設計一套流量控制機制。我們以達到高傳輸速率、有效內部流量控制與降低 封包遺失率,作為語音閘道器的主要設計考量,維持較佳且穩定的無線感測網路 傳輸效能,以期獲得更好的通話服務品質。4
1.3 論文架構
本論文的架構區分為五章,分別敘述如下,第一章即為緒論予說明本論文之 動機與目的;第二章為無線感測網路的簡介,以及相關的語音傳輸與流量控制等 研究之介紹與討論;第三章將介紹本論文所提出運用 ZigBee 的機制與架構,並 設計與實作流量控制於非對等頻寬之語音閘道器;第四章針對我們所提出的架構 進行實測與效能分析;最後,第五章是本篇論文的結論與未來之研究。5
第二章、文獻探討
由於本論文將設計具藍芽與 ZigBee 語音傳輸閘道器,因此本章節將分別針對 無線感測網路(Wireless Sensor Network,WSN)與 ZigBee 進行簡介,接著探討語音 封包傳輸於無線感測網路為導向之相關研究。無線通訊網路領域傳輸距離與速率 分佈[1]如圖 2 所示,由於無線發射功率會隨著距離成對數比例增加,在目前廣泛 被使用的無線通訊網路中包括:
無線個人網路(Wireless Personal Area Network, WPAN) 無線區域網路(Wireless Local Area Network, WLAN) 無線廣域網路(Wireless Wide Area Network, WWAN)
無線都會網路(Wireless Metropolitan Area Network, WMAN)
6 其中,在 IEEE 802 無線通訊標準系列,採用 2.4GHz 頻帶的無線通訊技術有 三種,分別為 802.15.4 的 ZigBee、802.15.1 的藍芽與 802.11b 的 Wifi。表 1 為以 上三種 2.4GHz 頻帶的無線通訊技術大略比較表。 由表 1 可看出這三種技術雖然皆採用相同的頻帶,但因為應用環境的不同, 傳輸速度也有很大的差別。可看出 ZigBee 與其他通訊技術的優缺點,ZigBee 最 明顯的缺點在於傳輸速率較其他通訊技術慢,如何提高傳輸效能,亦是近年來相 當重要的議題。以下章節將針對藍芽與 802.15.4 逐一介紹。 表 1 2.4GHz 頻帶的無線通訊技術比較 IEEE Standard 802.15.4 802.15.1 802.11b
Standard ZigBee Bluetooth Wifi
Frequency Band 2.4GHz 2.4GHz 2.4GHz
Modulation Type O-QPSK GFSK CCK, PBCC
Spreading DSSS FHSS DSSS
Max Signal Rate 250 Kbps 1 Mbps 11 Mbps
Nominal Range 70m~300m 10m 100m
Max cell nodes 65,536 7 32
Encryption 128 bit AES and
7
2.1 藍芽無線傳輸技術
藍芽為短距離無線傳輸技術,其有效傳輸範圍為 10 公尺(0 dBm),所採用之 頻率範圍介於 2400 MHz 到 2483.5 MHz,藍芽應用頻帶有 79 個無線電頻率通道, 每個頻寬為 1MHz。藍芽利用 Gaussian Frequency Shift Keying(GFSK)進行調變, 最高傳輸速率為每秒 1 MB,同時可設定加密保護。藍芽使用了跳頻(Frequency Hopping)與展頻(Spread Spectrum)等技術,為了避免同一頻段之電子裝置相互 干擾,藍芽具備每秒 1600 Hop 的跳頻率,在兼顧品質與速度的前提下進行資料 的傳輸。
藍芽藉由 Receive Signal Strength Incident(RSSI)偵測通道之訊號強度與藍芽 裝置是否有重複,若藍芽裝置偵測到已受干擾的通道時,將避免選擇這些通道作 為跳頻的通道,選擇良好的通道以達到最佳傳輸狀態。 藍芽標準中制定主動要求連線之裝置,需為藍芽的主裝置(Master),而被要求 連線的裝置為從屬裝置(Slave) 當搜尋到其他的藍芽裝置後,就可以依據其屬性 進行點對點(Peer-to-Peer)或是點對多點(Peer-to-Many)的傳輸。在藍芽網路 或微網路(Piconet)中,每個藍芽連接裝置都具有根據 IEEE 802 標準所制定的 48-bit 地址,一個主裝置最多可以和 7 個從屬裝置進行連線,而主裝置負責管理 媒介存取與頻道分配,也因此可以藉由這樣的網路連接方式將藍芽裝置串在一起 達到分散式網路(Scatternet)的拓樸。其網路架構如圖 3 所示。
8
圖 3 藍芽微網路拓樸
原則上任何藍芽裝置皆可為 Master 或 Slave,但首次提出連線請求的設備將 成為 Master,被請求連結的設備為 Slave,角色分配在 Piconet 形成時就需確定。
藍芽技術具備同時傳送語音(Voice)與數據(Data)兩種資料形態,最主要的原因 在於藍芽支援電路交換與封包交換兩種資料傳輸方式,在藍芽標準中電路交換的 傳輸 稱 為 Synchronous Connection-Oriented(SCO) 連線,封包交換的傳輸稱為 Asynchronous Connectionless Link (ACL)連線。ACL 為傳送數據才運用之時槽, 最高下載速度為 723.2 kbps 與最高上傳速度 57.6 kbps 的非對稱性傳輸速率,以及 433.9 kbps 的對稱式傳輸速率。SCO 連線屬於電路交換的同步傳輸型態,當 Master 與 Slave 一旦建立連線之後,不論是否有資料傳送,系統皆預留固定間隔的時槽 予 Master 與 Slave。SCO 適合語音傳輸,每一個 SCO 支援 64 kbps 的語音通話。
9
2.2 IEEE 802.15.4 與 ZigBee 簡介
ZigBee 通訊協定是由 HONEYWELL 公司於 1998 年發展,組成 ZigBee Alliance 制定的無線網路協定。個人區域無線感測網路以電子電機工程師學會(Institute of Electrical and Electronics Engineers, IEEE)所制定的 IEEE 802.15.4[2],低速率無線 個人區域網路(Low-Rate Wireless Personal Area Network, LR-WPAN)結合 ZigBee[3] 為主流的通訊協定,主要以低傳輸速率與短距離傳輸範圍為主。ZigBee 通訊協定 主要分為三個頻段,分別為全世界通用的 2.4GHz、歐洲地區使用的 868MHz 及 美國使用的 915MHz,其傳輸速率介於 20 kbps 至 250 kbps 之間。本論文主要著 重 於 ZigBee , 亦 是 LR-WPAN 中 廣 泛 被 採 用 的 標 準 。 ZigBee 與 Wireless Fidelity(Wi-Fi)等網路協定不同的地方,在於 ZigBee 具有以下特點: (1)WSN 節點的運算能力和記憶體較小 (2)短距離通訊能力,最遠為 300 公尺。 (3)具有低傳輸速率,最大通訊速率為 250Kbps。 (4)低消耗功率,適用於無電源供應之偏遠地帶。 (5)具有適用於全球的 2.4GHz 工作頻率。 802.15.4/ZigBee 的堆疊架構,參考了國際標準組織的開放系統基本參考模型 (Open Systems Interconnection, OSI),如下圖 4 所示:
10 圖 4 IEEE 802.15.4/ZigBee 堆疊架構圖 第一層:實體層定義無線電波發射的頻率、頻道、調變方式、發射功率與通信 Frame 等電子物理特性的載體。 第二層:媒體存取控制層(MAC)傳送封包資訊的正確性,其中包括檢測錯誤、修 正錯誤、再次發送請求和 ACK 回應。 第三層:網路層(NEK)負責路由及網路管理,透過網路啟動、連接、位址的分配 與轉送,還包括傳輸路徑選擇,以及資料加密功能。 第四層:應用支援子層(APS)負責做為邏輯子通道的終端,確認被構建訊況的送 達資訊,以及再次發送的功能。 第五層:應用層(APL)負責構建用程式,ZigBee 提供應用框架(AF),配置管理 ZigBee 網路裝置物件(ZDO)。 在 點 對 點 拓 樸 架 構 中 , 可 建 立 包 括 個 人 區 域 網 路 協 調 者 (Personal Area Network Coordinator, PAN Coordinator)與終端裝置(End Device)所組成之無線感測
11 網路。只要裝置皆於彼此的通訊範圍內,任何裝置皆可與其他裝置互相通訊,因 此點對點拓樸可允許較複雜的網路形式,並實現大傳輸範圍應用。ZigBee 點對點 拓樸之相關應用在[4][5][6]皆有詳細探討。 ZigBee 應用如圖 5 所示,ZigBee 的發展目標,主要是設計出可長時間使用於 偵測與監控的通訊技術,一開始是應用於軍事安全方面,而後 IEEE 協會與產業 界大力推廣無線感測網路應用於更廣泛的領域。例如消費性電子、電腦及週邊、 住宅燈光通訊控制、建築自動化、個人健康管理與工業控制等等無線感測網路的 應用層面。ZigBee 無線感測技術具有低傳輸速率與低耗電量等特點,可進行點對 點(Peer-to-Peer Topology)節點間互相通訊的對等網路。 圖 5 ZigBee 應用領域 由圖 5 可知,ZigBee 的應用範圍相當廣大,本論文中主要將 ZigBee 無線傳 輸應用在語音傳輸系統,透過 ZigBee 傳輸我們所需要的語音或資訊,以達成系 統所需要的功能。
12
2.3 語音壓縮原理
由於語音資料是透過封包傳送於網路,其傳送的資料皆為數位訊號,但礙於 網路頻寬有限,須對語音進行壓縮,因此各種壓縮技術便因應而生。語音壓縮編 碼技術最廣泛被採用為波形編碼(Waveform Coding),直接對語音取樣並加以處理, 使 解 碼 後 的 語 音 波 形 能 保 持 原 始 信 號 的 波 形 。 例 如 , 差 值 脈 衝 編 碼 調 變 (Differential Pulse-Code Modulation, DPCM)利用過去已編碼過的語音訊號進行線 性預估,再將原訊號與預估值之誤差量化,因為誤差值遠比語音取樣值還小,因 此傳送誤差值即可降低量化位元數目,以實現語音壓縮的目的。當前語音壓縮規 格與標準種類繁多,傳統 Voice over IP(VoIP)語音壓縮皆選用 G.723.1、G.729、iLBC 與 Speex[7]等幾種語音壓縮方法,藉由這些壓縮方法才可實現於網路間傳送較小 的網路封包,減少封包受到網路延遲的影響。13
2.3.1 Speex 語音壓縮技術簡介
Speex 語音壓縮不同於其他壓縮技術,是基於網路應用而開發的,為開放源 碼軟體(Open-Source)壓縮軟體,Speex 主要使用的壓縮技術是基於以碼簿激發線 性預測編碼(Code Excited Linear Prediction, CELP)[8],由於 CELP 存在已久且已被 驗證,適用於高位元率及低位元率。其設計非常具有彈性,能調整壓縮品質及位 元率範圍相當廣,可對 2 kbps 至 44kbps 之間的 Bit-Rate 進行壓縮。Speex 可支援 取樣頻率 8 kHz 窄頻(Narrowband)、取樣頻率 16 kHz 寬頻(Wideband)和取樣頻率 32 kHz 超寬頻(Ultra-wideband)壓縮模式。另外,Speex 是設計用於多種不同設備, 因此具有可調整的複雜度,以及較小的記憶體使用量。
Speex 被設計用於 Voice over IP(VoIP),對於封包遺失所造成的影響能夠妥善 處理,並將語音品質損失降低。Speex 為了能有廣泛的相容性,因此可調整編解 碼運算複雜度(Complexity),並且僅占用少量記憶體。Speex 可對壓縮複雜度進行 調整,其參數控從 1 至 10。複雜度 1 之雜訊準位(Noise Level)比複雜度 10 的雜訊 準位高出 1dB 至 2dB,但複雜度 10 的 CPU 運算需求遠比複雜度 1 多五倍。在延 遲(Latency)部分,在 Speex 中延遲時間等於 frame size 加上查詢時間,窄頻延遲 時間為 30 毫秒,寬頻延遲時間為 34 毫秒。
14
2.3.2 語音壓縮技術比較
在表 2 中,分別為 Speex、iLBC、G.729 與 G.723.1 的語音壓縮方式,其中列 出各語音編解碼的編碼率(Rate)、Bitrate、延遲和 License 等。目前語音壓縮技術 發展成熟,語音在經過編解碼器壓縮與解壓縮之後,皆還可保持良好的語音品質。 但考量到無線感測網路頻寬為 250 kbps,而且無線感測網路節點採用嵌入式設備, 其 CPU 與記憶體容量較小,能源消耗也有限制。因此在 E. Touloupis 等學者[9] 利用建置 Speex 於嵌入式設備的研究結果中,量測 Speex 的編解碼複雜度、編解 碼延遲時間、Data rate 與 PESQ MOS 值量測的結果,結果顯示 Speex 在以上四項 皆符合本論文建置系統的需求。 表 2 不同語音壓縮比較 Codec Rate (kHz) bitrate (kbps) delay frame+ lookahead (ms) VBR PLC license Speex 8, 16, 32 2.15-24.6 (NB) 4-44.2 (WB) 20+10 (NB) 20+14 (WB) yes yes open-source free softwareiLBC 8 15.2 or 13.3 20+5 or 30+10 none yes
no charge, but not
open-source
G.729 8 8 10+5 none yes proprietary
G.723.1 8 5.3 6.3 37.5 none yes proprietary
VBR:Variable Bit Rate PLC:Packet Loss Concealment
綜合以上分析結果,我們考慮到無線感測網路頻寬較小,而且在需具有良好 的語音品質要求下,本系統架構選用 Speex 作為語音編解碼器。
15
2.4 語音品質的衡量指標與量測方法
人類說話的類比聲音,必須先轉換成數位化之後,才可經由無線感測網路傳 送,脈波編碼調變(Pulse Code Modulation, PCM)數位化技術,可將語音編碼成數 位訊號後,傳送於無線感測網路上,然後接收端轉換成類比訊號,使其語音可於 接收端播放。因此語音編解碼技術是經過多年的研究成果,目的是在傳輸成本與 聲音品質上取得平衡,而無線感測網路傳輸語音其最基本的主要要求是能夠提供 一個連續且穩定的語音資料傳輸,以達到使用者的語音服務品質。而語音服務品 質是由使用者的角度來定義,除了對無線感測網路的品質表現進行評價,亦包括 對語音品質的呈現,因此無線感測網路的穩定性將直接反映在語音服務品質的表 現上。 對於網路語音的服務品質評估,是以點對點延遲(Delay)、延遲抖動(Jitter)與 封包遺失率(Packet Loss Rate)參數來判定。點對點延遲是指資料從來源端發送到 目的端所需時間,延遲時間長短將影響資料在無線感測網路上的傳輸效能,對於 時間較為敏感的語音傳輸服務,其影響甚大,最終可能造成語音通話品質不佳的 現象,因此延遲被視為重要的服務品質衡量指標。 延遲抖動代表的是當封包送達目的端時,封包的時間延遲變化,此變化必須 以固定的時間間隔(ΔT),如果封包之間的ΔT 不固定,即被視為延遲抖動,可能 造成封包不依照順序送達之問題。當延遲抖動之變化超過一定標準值之後,將對
16 語音通話品質造成影響,因此,延遲抖動亦被視為重要的服務品質衡量指標。 封包遺失率所指的是來源端所送出之封包,未能送達目的端時,所發生的封 包遺失狀況。由於本系統之無線感測網路在傳輸過程中,假如發生封包遺失,並 不會將遺失的封包重送,否則將會干擾目前正在進行的通話。假如傳輸過程發生 嚴重的封包遺失,將導致通話的不連續,嚴重影響通話品質,因此封包遺失率也 視為服務品質衡量指標之一。 以下將針對目前主要之語音服務品質衡量 方法如:平均意見分數(Mean Opinion Score, MOS)、Perceptual Evaluation of Speech Quality (PESQ)和 E-Model 進行介紹,以及本論文所採用結合 PESQ 和 E-Model 之 MOS Conversational(MOSc) 評分模型進行說明。
17
2.4.1 平均意見分數(Mean Opinion Score, MOS)
語音品質量測可採用主觀和客觀的測試方法取得,在主觀的服務品質衡量標 準中 Mean Opinion Score (MOS)最被廣泛採納,MOS 是由 ITU-T P.800[10]標準所 制定的「平均意見分數」,其量測方法是透過受話端測試者在聆聽聲音片段後給 予主觀的評分,再取平均值。評分分數總共五分,分數由低至高依序為 Excellent、 Good、Fair、Poor 和 Bad,如表 3 所示。由於此一方法需藉由受過訓練的專業人 士,用人耳來對語音品質進行評分,需耗費較多時間、人力與昂貴的成本,而且 也無法確實反應網路傳輸所造成的損害,以及評估通話延遲所帶來的影響。除此 之外,容易受到測試環境的潛在干擾影響,準確性容易遭受質疑。 表 3 平均意見分數級別判斷標準
MOS Voice Quality User Satisfaction
5 Excellent Imperceptible
4 Good Perceptible but not annoying
3 Fair Slightly annoying
2 Poor Annoying
1 Bad Very annoying
由於 MOS 的方法完全依據人的感覺來判斷語音品質的好壞,其測試結果很 難對語音傳輸系統的改進與設備之間性能的比較做出實際意義的判別。因此近來 的趨勢逐漸採用客觀性量測為主,客觀性量測可分為侵入式(Intrusive)和非侵入式 (Non-intrusive)。
18
2.4.2 Perceptual Evaluation of Speech Quality, PESQ
侵入式方法較為精準,其中廣泛被採用的方法為 ITU-T P.862 Perceptual Evaluation of Speech Quality (PESQ)[11][12][13]。PESQ 為 2001 年國際電信聯盟標 準化部門所提出之語音品質測量方法,可稱為「侵入式客觀語音品質量測」 (Intrusive-Objective Speech Quality Measurement),量測適用於窄頻通訊。由於其 評分結果與實際的平均意見分數(MOS)有高達百分之九十以上的相關性,因此在 侵入式語音品質量測中仍常被採用。
PESQ 參考了 PSQM(Perceptual Speech Quality Measure)的聽覺模型,運用了 梅爾倒頻譜係數(Mel-scale Frequency Cepstral Coefficients, MFCC),並且參照 PAMS(Perceptual Analysis Measurement System) 的 時 間 對 位 法 (Time-Alignment Algorithm)。由於 PESQ 主要用於語音編碼的評測,並注重於單向傳輸失真 (One-way Speech Distortion),以及外部噪音(Noise on Speech Quality)的影響,因 此有需多因素仍無法有效測量,例如回音(Echo)、響度失真(Loudness Loss)等等。 但是由於時間對位法的不準確性,使得語音訊號稍有時間上的位移(Shift),有可 能無法準確評分。PESQ 之基本流程如圖 6 所示。
19
圖 6 PESQ 概觀流程圖
圖 6 中,PESQ 是比對原始輸入之語音訊號(Reference Speech)與通過網路傳 輸後的失真輸出之解碼訊號(Degraded Speech)之間的差異,再將結果以 MOS 的評 分法來量化。首先將失真訊號與原始訊號做時間軸上的對準,再以感知模型做轉 換,接著利用兩個訊號之時間,以頻域的相異程度作為差距,最後則以此差距給 予評分,運用更複雜但所採用的演算法,更貼近人類聽覺感受。表 4 為 PESQ 語 音品質適用的測試情況及適用的語音標準,其中 Speex 在適用語音標準中屬於 CELP 類型編碼器。 表 4 PESQ 適用環境
Test Factors Coding/network technologies
Coding distortions Transmission/packet loss errors Multiple transcodings Environmental noise * Time warping (variable delay) Waveform codecs (e.g. G.711, G.726, G.727)
CELP/hybrid codecs at 4kbit/s and above (e.g. G.728, G.729, G.723.1)
Mobile codecs and systems
(e.g. GSM FR, EFR, HR, AMR; CDMA EVRC, TDMA ACELP, VSELP; TETRA)
20
2.4.3 E-Model
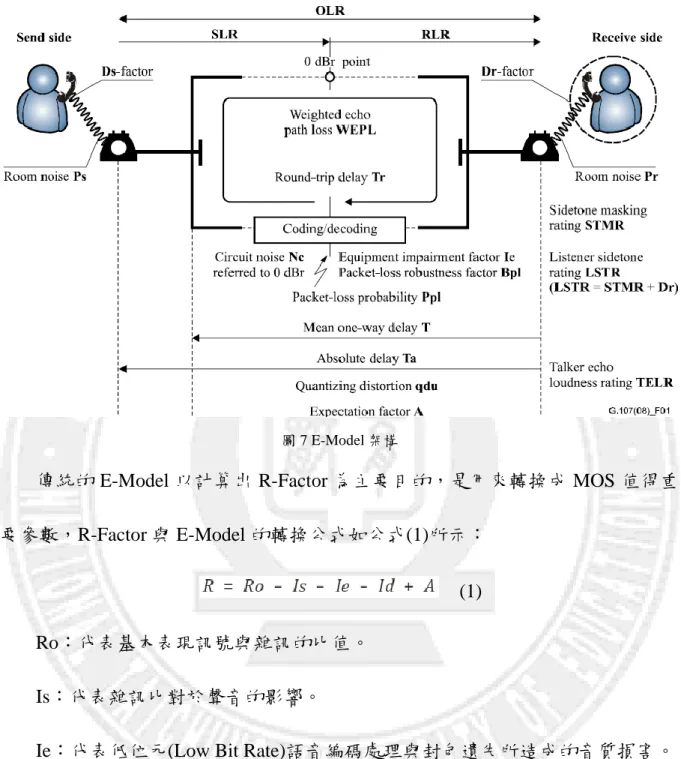
非侵入式方法中,以 ITU-T G.107[14]制定的 E-Model 評估標準最廣泛採用, 最早 是 由歐 洲 電 信 標準 協 會 (European Telecommunications Standards Institute, ETSI)所提出,後來經由 ITU-T 進行標準化後,形成 G.107 標準評估模型。E-Model 假設語音品質的損失因素是由網路實體層於傳遞過程中所附加的,若可加入雜訊 比、回音、延遲、編解碼器效能、抖動率等網路損失因素的估算值,使用者主觀 性的體驗因素將可由完全客觀性的服務品質等級所估計。傳統 E-Model 中制定了 量化 R-Factor,是用來轉換成 MOS 值的主要目標,評估分數介於 0 到 100,其 中數值越大表示語音品質越好。
圖 7 為 E-Model 架構,E-Model 的評量是透過 R-Factor 來表示,R-Factor 代 表傳輸品質的計量分數,用於預期在聲音經過網路傳輸後,由人耳聽到最後聲音 的品質度量。透過 E-Model 中所提出的方法,計算雜訊、延遲、設備所造成對聲 音的損害與其他無形的人為觀感等可能對聲音的影響量。
21
圖 7 E-Model 架構
傳統的 E-Model 以計算出 R-Factor 為主要目的,是用來轉換成 MOS 值得重 要參數,R-Factor 與 E-Model 的轉換公式如公式(1)所示:
(1) Ro:代表基本表現訊號與雜訊的比值。
Is:代表雜訊比對於聲音的影響。
Ie:代表低位元(Low Bit Rate)語音編碼處理與封包遺失所造成的音質損害。 Id:代表語音延遲造成的音質損害因子。
A:為補償損害因子,用以補償因採用某些帶來便捷接入的設備而導致語音 品質的影響,通常設定為零。
22 成平均意見分數 (MOS) ,其相對應的表格如表 5,而兩者之間數值轉換如公式 (2)所示: (2) 在公式(2)中,其中由於考量到實際類比語音資料與網路傳輸的數位語音資料 之間,存在著必然的轉換損失,這使得 R 值最大僅能達 93.2 分,對應到平均主 觀的 MOS 值則為 4.4 分。MOS 值達 4 分以上時,一般被認定為較佳的語音品質, 若低於 3.6 分則表示大部分使用者不滿意該語音品質。
表 5 R-factor, Quality Ratings and the Associated MOS
R-factor Quality MOS
90 < R <100 Best 4.34~4.50 80 < R < 90 High 4.03~4.34 70 < R < 80 Medium 3.60~4.03 60 < R < 70 Low 3.10~3.60 50 < R < 60 Poor 2.58~3.10
2.4.4 Reduced E-Model
由於傳統 E-Model 是使用於電路交換網路的語音品質評估模型,不適用於封 包交換網路上的語音品質評估,因此必須對 E-Model 中的 R-Factor 量測進行調整。 AT&T 兩位成員 R. G. Cole 和 J. Rosenbluth 在 2001 年提出用於封包交換網路的 語音量測解決辦法[15]。主要是修改原使用於電路交換網路上的 E-Model,加入 量測在網際網路中對通訊品質會有影響的各種因素,將 E-Model 中對 R-Factor 的 計算方法修改如以下公式(3)所示。23 (3) 在公式(1)中的參數 A 並不適用在封包交換網路的語音品質,故不納入計算。 Is 為雜訊比對於聲音的影響,但我們假設通話是沒有回音的情況下進行,因此將 不做深入討論並以預設值代入,於是,經過修改後得到下列公式(4)所示。 (4) 其中 93.2 為依據 ITU-T G.701 之預設值,由公式(4)可看出簡化後之 R-Factor 計算公式,已經將會影響語音通訊品質的因素減少至兩個,其詳細描述如下: Id:封包延遲對於語音品質的影響。在 Id 中與傳輸延遲有關的參數有三個, 分別為: Ta單向傳輸絕對延遲 T 平均單音回音路徑延遲 Tr 線路來回傳輸延遲 由於無線感測網路並非採線路交換技術,所以三種延遲可簡化為一種,如公 式(5)所示。 (5) Ie:語音編碼處理與封包遺失所造成的音質損害因子。 將傳統 E-Model 經過簡化後,便符合封包交換網路的特性,以更精準的方式 量測語音品質。
24
2.4.5 結合 PESQ 與 E-Model 之對話式語音品質量測
主觀的語音品質評估方式可以直接統計使用者對於系統語音品質的滿意程度, 但是此評估方式需要符合 ITU-T P.800 標準所規範之測試環境,而且測試過程不 但耗時,也需要昂貴的成本。客觀的語音品質評估則可以快速的評估系統的語音 品質,在 E-Model 的評估方法中,雖然有將網路延遲納入計算,但是 E-Model 還 有很多影響語音品質的參數,例如空氣中的雜訊、硬體所產生的雜訊等,通常會 將這些參數設定為預設值,但會因此造成誤差。除此之外,E-Model 並不支援本 系統架構所使用之 Speex 編解碼器,因此無法直接使用 E-Model 評估本系統之語 音品質。而 PESQ 有將語音編解碼器與封包遺失程度納入考量,以量測語音品質 的受損程度,但是 PESQ 並不將封包延遲的因素納入考量,這將造成時間語音品 質與經由 PESQ 所計算的結果有落差。 基於以上原因,因此本論文之語音品質量測方法,採用結合 PESQ 與 E-Model 之對話式語音品質量測,其架構如圖 8 所示。PESQ 之 MOS 值可直接透過 PESQ 演算法,比較將原始檔(Reference Speech)與經傳輸後語音品質變為劣質的接收檔 (Degraded Speech)進行比對,計算出 PESQ MOS 值,之後將 PESQ MOS 值轉換 成 R-Factor,並再依據編解碼的類型,轉換成具 Ie 值。最後,將 Ie 值與點對點 (End-to-end)延遲輸入至 E-Model 中,計算封包延遲所帶來的影響,最終可準確地 計算出經過語音閘道器傳輸的語音品質 MOSc。25
圖 8 結合 PESQ 與 E-Model 之對話式語音品質量測架構[32]
PESQ 與 E-Model 之對話式語音品質詳細計算步驟如下:
(1) 將語音品質之 MOS(PESQ)值轉換成 Ie值:
ITU-T G.107 定義了 R-Factor 與 MOS 之間的關聯,通用之 R-Factor 與 MOS 值轉換公式如(6)所示:
(6)
公式(6)中的 MOS 值依據是否考慮延遲,分別視為 Listening-only 語 音品質(MOS),以及 Conversational 語音品質(MOSc)。而要將 MOS(PESQ) 值轉換為 R-Factor 則將參考 L.Sun 在[16]中所提出之 3rd-order polynomial fitting,其計算方式如公式(7)所示。 (7) 由於 MOS(PESQ)為接聽端的語音品質結果,轉換為 R-Factor 時並不 考慮延遲因素 Id 值。如果僅只考量到封包遺失與編碼器所造成的失真, R-Factor 將可以轉換成 Ie值,根據公式(8)進行換算: (8) 其中 R0預設值為 93.2[15]。
26 (2) 從 One-way delay(d)中取得 Id: 延遲失真 Id 包括所有因語音訊號延遲所造成失真的因素,包括聽話 端回音、說話端回音和絕對延遲。在本論文將根據[15]所提出之計算方 式: (9) 在上述公式(9)中, 根據本論文的系統架構,d 的計算方式將參照 Cisco 訂定的語音延遲計算之技術規範文件[17]。圖 9 表示點對點傳輸延 遲因素包括編碼延遲、封包封裝化延遲、佇列延遲、串列延遲與網路傳 輸延遲。 圖 9 點對點傳輸延遲因素
27 (3) 利用 Id和 Ie計算 MOSc 在取得 Id和 Ie之後,MOSc 的 R-Factor 將以預設值 93.2 相繼減去 Id 與 Ie 取得,如下列公式(10)所示。在取得 MOSc 的 R-Factor 之後,必須 將 R-Factor 轉換為 MOSc 值,轉換方式為前述中的公式(2)之計算方式。 (10) R-Factor 已將封包遺失與延遲所造成的失真納入考量,最後利用公式(2) 將 R 值轉換成 MOS 值,其所取得的 MOS 為對話式(Conversational)語音品質, 以 MOSc 表示之。總言而論,依據圖 8 架構所量測之 MOSc,將是結合由 PESQ 與 E-Model 之計算取得,為語音品質評估方式做了全面性的考量。
28
2.5 語音傳輸於無線感測網路相關文獻探討
關於語音封包傳輸於 ZigBee 的研究,目前有眾多的論文提出一些解決方法, 以下本論文將會針對不同類型的設計方式進行一些介紹。首先介紹的是由學者 R. Mangharam 等人在[18]的研究中,提出一個運用在緊急需求及佈建不易的礦坑 環境下開發 ZigBee 語音通訊技術,使用 ADPCM 編碼器做語音編解碼,並且可 支援多種編碼率(Multi-rate)。其硬體使用 Atmel ATmega32[19]微處理器,除了利 用 IEEE 802.15.4 傳送語音封包之外,還利用 AM 頻帶做時間同步。但由於語音 通訊是頻繁且隨機的,大量的語音資料可能造成微處理器無法負荷,並同時進行 編解碼與封包傳送,此方法未對流量控制機制加以考量,如此可能導致封包錯誤 率(Error Rate)提高。H. Y. Song 等人在[20][21]提出修改 IEEE 802.15.4 PHY/MAC 標準所使用的參 數 , 簡 化 MAC Header 並 將 MAC Payload 調 整 為 102 Bytes , 並 採 用 Non-Acknowledgement 模式,藉此提高頻寬使用率已達到多方同時通話的功能。 除此之外,使用 G.729.A 編碼器將語音壓縮成 8kbps,並以每 20 毫秒傳送 20 Bytes 速率進行傳送。實驗以點對點全雙工(Peer to peer full-duplex)方式進行,分別量測 室內短距離傳輸與室外長距離傳輸之封包遺失率,以及多方同時傳輸之封包遺失 率,由其量測結果中,點對點全雙工之封包在 22 公尺的距離時,遺失率維持在 2%內,不過在 27 公尺的距離時,封包遺失率大幅提高至 20.13%。
29
L. Li 等人在[22]中提出一個以語音品質為導向之語音傳輸系統,其運作的方 式主要是每個節點隨時監控其封包遺失率與延遲,根據連線狀態而動態調整語音 壓縮比,以維持語音傳輸品質。並提出一個分散式權限控制演算法(Distributed Admission Control Algorithm),計算各區域中每個節點可提供的傳輸量,以分配資 料傳輸頻寬,當有更多節點加入語音傳輸時,可以動態調整整體網路效能。
T. Facchinetti 等學者在[23]中提出一個針對即時語音串流(Real-time Voice Streaming)特性,利用 Moving Picture Experts Group(MPEG-Model I) 與快速傅立 葉轉換(Fast Fouier Transform)將聲音壓縮,並實作於嵌入式系統。除此之外,作 者也提出固定優先權(Fixed Priority)演算法,給予每個封包送達 的時間限制 (Deadline),以維持即時語音串流品質。在實驗結果方面其取樣、壓縮、封裝和傳 送之延遲時間確實可維持在即時傳輸的時間限制內,並提供尚可語音品質。
D. Brunelli 等學者在[24]提出 ZigBee-like 協定堆疊,其主要的網路層(Network Layer, NWK) 、 應 用 支 援 子 層 (Application Support Sub-layer, APS) 和 應 用 Frame(Application Framework, AF)之欄位格式依然延續 ZigBee 標準,但在 MAC 層和 PHY 層則採用自訂欄位。除此之外作者也提出空間再利用(Spatial Reuse)演 算法,其主要目的是將感測節點之傳輸範圍盡量縮小,以避免和其他節點競爭通 道。在其系統架構中將 Tx 與 Rx 各建置兩組緩衝存儲器(Buffer),以確保訊號處 理與串流傳送皆可獨立運作,以降低延遲時間。
30 M. Petracca 等人在[25]中提出將傳送端和接收端波形進行比對以計算其頻譜 失真的程度,採用非線性傅立葉轉換進行運算。根據每個封包所含的資料量與資 料保護之百分比門檻值進行計算,而當失真的情況越嚴重時,含有較多資料量與 權重較高之封包,才會進行優先傳送。此研究採用 ITU-T G.711 作為語音的編解 碼器,在多點跳躍的傳輸架構中,由於所有節點皆透過廣播(Broadcast)進行傳輸 並共享相同頻道與傳輸媒介,因此中繼節點皆可獲得傳送端所發送的資料,在封 包遺失率提高的情況發生時,中繼節點將會把權重較高之封包優先進行傳送或重 傳,以維持語音品質。 在[26]研究中,Kyriakos K.等作者提出流量管理機制以支援即時傳輸於高度 難以預測的無線感測網路。該論文設計一套名為 SUPORTS 的方法,藉由持續監 控流量負載狀況來計算封包的延遲,使得輸入端流量趨於穩定狀態,以達到可接 受的點對點延遲。透過此一佇列管理與封包排程機制,實現保證語音即時性傳 送。 在[27][28][29][30][31][32]提出了許多種語音傳輸於網路的系統架構與機制, 雖然不一定是在無線感測網路,但也是值得參考的語音封包傳輸機制。尤其是在 [32]中,提到如何做語音品質評量的方法。該作者提出利用結合 PESQ 與 E-Model 語音品質量測方法,除了具有 PESQ 客觀且準確的評分外,並考量點對點延遲, 再套用 E-Model 計算以獲得更精準的語音品質量測。在介紹了眾多的論文及其方
31
法之後,將在第四章中說明關於流量控制於非對等頻寬之語音傳輸於無線感測網 路,其中包括系統架構與運作機制,以達到提升整體傳輸量與降低延遲時間之目 標,最終以獲得良好的語音品質。
32
33
第三章、於無線感測網路中傳送語音封包之機制
如同在 2.1 節至 2.3 節所提到基於藍芽與 ZigBee 語音閘道器所需要的技術, 如要將這些技術實作在嵌入式系統中,並且滿足語音服務品質的要求,那麼一定 會遇到一個問題,如何達到延遲、傳輸量、抖動等各方面的要求。在第三章討論 的相關參考文獻當中,雖然有針對語音傳輸於無線感測網路之研究有提出可行的 設計,但相對的則會增加或犧牲其延遲或是語音品質,除此之外,並沒有利用語 音評估系統如 MOS 等,評估語音品質的好壞。為了改善這個現象,因此本論文 將要設計一個可傳輸於藍芽與 ZigBee 之間的語音閘道器,並結合流量控制機制 以有效降低封包遺失率、延遲與抖動率。在進入各項機制的說明之前,將先介紹 關於語音閘道器的運作模式,最後說明各機制在系統中的位置與功能。34
3.1 語音閘道器系統
本研究提出的 BZVG 系統架構,如圖 10 所示,其中包括藍芽模組、Speex 編解碼器、流量控制機制與 Xbee[33]模組。BZVG 中的藍芽模組將與使用者的藍 芽耳機進行連線與傳輸,Speex 編解碼器將對語音進行低碼率的編解碼,而流量 控制機制包括三個部分,分別為 Traffic Shaping Buffer(TSB)、Leaky Bucket 與 Xbee 硬體流量控制架構,Xbee 模組負責傳送與接收語音資料於無線感測網路,章節 3.2 與 3.3 有更詳細的說明。 圖 10 系統架構圖 圖 11 為本論文單向語音傳輸流程,將依序說明每個步驟流程。首先一開始藍 芽耳機的麥克風將收錄人的聲音,經由 PCM 將類比訊號(1)轉換成數位訊號(2), 而數位訊號將送至藍芽內建的 Subband 編碼器進行編碼(3),經過編碼之後的語音 資料將透過無線藍芽傳送至 BZVG 的藍芽接收器(4),以上步驟將於藍芽耳機內 進行。當 BZVG 的藍芽接收器接收到語音資料後,須先由藍芽 Subband 解碼器進 行解碼(5),才可將語音資料解讀出來,由於藍芽的 Data Rate 為 64 kbps,必須壓 縮成較小的 Data Rate 才可於無線感測網路傳輸,因此本研究採用 Speex 窄頻模
35
式(Narrow Mode),編碼率為 11 kbps,於(6)進行 Speex 的編碼,每個音 Frame 為 20 毫秒的 160 個取樣。
由於藍芽端具有較高頻寬,將產生大量的資料,因此當 Speex 編碼後的語音 封包將暫存於 TSB 中,做為緩衝區塊(7)。接著由(8)Leaky Bucket 依據 Xbee 內部 Buffer 的狀態(9),進行輸出頻寬的調整,(10)(11)Xbee 微處理器為執行將 Buffer 的資料送至 Xbee 收發器,傳輸於無線感測網路中(12)。 當接收端之 BZVG 的 Xbee 收發器接收到資料之後(13),微處理器資料先暫存 於 Buffer(14),BZVG 會將資料送至 Speex 解碼器進行解碼(15),並傳送至藍芽模 組(16)。藍芽將對語音資料進行解碼(17),並傳輸至接收端藍芽耳機(18),,最終 由接收端之藍芽耳機進行解碼與播放(19)(20),而聲音將經由內建耳機播出(21)。 (Human Voice) Mic Analogue To Digital (PCM) Bluetooth Subband Encoder Speex Encoder Bluetooth Transceiver Bluetooth Subband Decoder Sender Bluetooth Headset Traffic Shaping Buffer Sender
Bluetooth and ZigbeeVoice Gateway
Xbee Buffer Xbee Micro-Controller Xbee Transceiver Leaky Bucket Flow Control Receiver
Bluetooth and ZigbeeVoice Gateway
Xbee Buffer Xbee Micro-Controller Xbee Transceiver Speex Decoder Bluetooth Transceiver Bluetooth Transceiver (Human Voice) Speaker Analogue To Digital (PCM) Bluetooth Subband Decoder Bluetooth Transceiver Receiver Bluetooth Headset Bluetooth Subband Encoder 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 圖 11 單向語音傳輸流程 本研究利用 ZigBee 協定來設計一個新的語音系統架構,接著針對點對點語音 通話的情境做一分析,並利用結合 PESQ 與 E-Model 量測語音服務品質,將可獲
36 得精準的語音評量分數。下列將針對本論文所提出的結合藍芽與 ZigBee 於語音 閘道器的系統架構與運作方式,做詳細的介紹與說明。 在本論文中,我們提出一個利用 ZigBee 傳輸協定來進行語音傳輸於無線感測 網路的架構,建構可應用於非對等頻寬之語音傳輸系統。在系統傳輸架構方面, 提出以點對點(Peer to Peer)傳輸的方式,當作語音傳輸的骨幹,因此在本論文並 不討論多點跳耀(Multi-hop)的傳輸架構。
37
3.2 Traffic Shaping Buffer 語音資料暫存與拋棄機制
本論文在語音閘道器內部之語音資料暫存機制的設計上,主要是為了解決藍 芽與 ZigBee 因為傳輸速率差異過大,造成語音資料遺失的問題。在傳輸速率差 異的改進上,除了維持 Xbee 的高吞吐量之外,更進一步的方法為結合語音資料 暫存的方式,語音資料暫存架構如圖 12 所示。將經由 Speex 所編碼完成的資料, 暫存於快閃記憶體(Flash Memory),透過暫存語音資料以避免因為 ZigBee 網路頻 寬較小無法順利傳送,而造成資料損壞。
圖 12 閘道器流量控制架構圖
本研究提出 Traffic Shaping Buffer(TSB)的功能為儲存語音資料,如圖 13 所 示。由於 XBee 模組傳送資料至無線感測網路之頻寬並非為固定速率(Constant Bit Rate, CBR),而閘道器的藍芽接收端則是以較高且固定速率傳送資料製 TSB, 因此 TSB 的作用為盡可能地暫存編碼後的語音資料,提供 Leaky Bucket 以穩定 的速率送至 XBee 模組,以確保語音資料的完整性,並且避免語音資料於閘道 器內發生壅塞。
38 由於當無線感測網路傳輸狀況不佳,造成語音資料持續累積於 TSB,使得 TSB 儲存量已達最大容量門檻值(Upper Bound)時,將會造成 TSB 無法再儲存新進的 資料。為了改善此問題,必須將已儲存在記憶體內部的語音資料先進行拋棄,以 容納後續新進語音資料。在拋棄機制的設計方面,本論文參考 Random Early Detection(RED)[34]中的封包拋棄機制,但由於 RED 選擇拋棄封包的方式為隨機, 考量到隨機方式可能發生拋棄之封包過於集中於某一語音片段,可能造成重要通 話內容無法被傳達,甚至造成語音品質低落。因此本研究採用週期性(Periodic)拋 棄機制,達到拋棄之語音片段缺口可以平均的分散,以確保所有重要通話內容皆 可被辨別。
圖 13 Traffic Shaping Buffer 架構圖
本 系 統 在 TSB 中 設 立 兩 個 門 檻 值 分 別 為 Upper Bound(UB) 和 Lower Bound(LB),而門檻值之設定,則是依據 M. Kwon 等學者於[35]的研究中,說明
39 了佇列延遲和輸出頻寬是各自獨立並且成反比,當需要處理的資料增加,且輸出 頻寬不足或越來越小時,佇列延遲將會越長。因此,可以表示佇立大小可由延遲 與輸出頻寬相乘取得,如公式(11)所示: (11) 預期佇列大小 預期延遲 為輸出頻寬 本論文根據此一公式,結合 ITU-T G.114[36]標準規定中所分析之延遲與 E-Model R-Factor 對應圖,如圖 14 所示。在 150 毫秒時,語音品質為最佳(Users very satisfied),在 400 毫秒時,語音品質為勉強可接受(Some users dissatisfied)的最低 範圍。而 Xbee 輸出頻寬為 108kbps,導入公式(11),如公式(12)所得到的 LB 門檻 值為:
(12) UB 門檻值,如公式(13)所示:
40
圖 14 E-model 與絕對延遲(Absolute delay)影響對照圖[36]
TSB 所儲存的資料為 Speex 編碼後的資料格式,因此必須先識別出 Speex 的 表頭,才可正確地判斷出每一個封包,而拋棄之標籤則置於 Frame 表頭之前。在 Speex 的標準規格[7]當中,制訂出 Speex Frame 表頭中的種類、變數型態與大小, 如表 8 所示。其中 Speex 表頭為 8 個 Bytes,根據 Speex 所制定的表頭,系統找 出每個 Speex Frame 的起始數據,如表 6 所示,每一個經過 Speex 編碼後的 Frame 表頭皆由.F 為起始值。因此,根據判斷 Frame 表頭的起始值,TSB 即可識別出是 否為 Frame 表頭的起始數據,並加入拋棄標籤。
具有拋棄標籤之 Frame 其起始字元為*,如表 7 ,由於拋棄標籤僅作用於 TSB 之內,因此當具有拋棄標籤之 Frame 在送至 Leaky Bucket 之前並沒有執行拋棄程 序的話,系統將自動移除拋棄標籤,而不將拋棄標籤一併送至 Leaky Bucket 傳送。
41
表 6 原始 Speex 封包表頭內容
Header .F.fh...9.sGl...+...F...9vsGl6..6...6..
表 7 加入拋棄標籤之 Speex 封包表頭內容 Header *.F.fh...9.sGl...+...F...9vsGl6..6...6..
表 8 為 Speex Frame 表頭所包含的資訊,其中包括 speex_string 和 speex_version 各占 8 和 20 個位元,其他欄位如 speex_version_id、header_size 等共 9 個欄位皆 為 4 個位元。因此整個 Speex 封包表頭總共為 64 個位元,亦為 8 個位元組。
表 8 Ogg/Speex Header
Field Type Size
speex_string char[] 8 speex_version char[] 20 speex_version_id int 4 header_size int 4 rate int 4 mode int 4 mode_bitstream_version int 4 nb_channels int 4 bitrate int 4 frame_size int 4 frames_per_packet int 4 圖 15 為完整 TSB 流量控制機制流程圖,Speex 編碼完成之後的資料將會儲存 於快閃記憶體,系統將判斷當下記憶體使用容量是否超過最低門檻值 Lower Bound。如果超過最低門檻值,將會進行週期性加入拋棄標籤於 Frame,每讀取 4 個 Frame 加入一個拋棄標籤,具有標籤之 Frame 將視為可能被拋棄。接著將再判 斷 TSB 使用容量是否超過最高門檻值 Upper Bound,如果資料儲存量達到 Upper
42
Bound 門檻值時,則將重新檢查儲存空間,將含有拋棄標籤之 Frame 進行拋棄。 如果沒有超過最高門檻值或最低門檻值,Leaky Bucket 將根據 Xbee CTS 高低電 位狀態,執行輸出的程序。Leaky Bucket 動態輸出配置與 Xbee 模組之緩衝記憶 體狀態整合於章節 3.3 將有更詳細的說明。
圖 15 TSB 流量控制機制流程圖
總言而論,為了達到語音封包可以傳輸於藍芽與 ZigBee 網路間,以避免壅塞情況,
本論文所提出之 TSB 語音資料暫存機制,將可保留完整語音片段,避免因為無線感測
43
3.3 Leaky Bucket 動態輸出配置與 Xbee DI Buffer 狀態整合
Leaky Bucket 主要為控制資料流傳速度率的快慢,當無線感測網路越順暢且 穩定時,輸出頻寬將會提高。本論文選擇結合 Leaky Bucket 於語音閘道器,主要 是因為該機制易於實作,而且能有效根據無線感測網路的狀態動態調整輸出頻寬。 Leaky Bucket 將決定網路上資料傳輸速率的快慢,有效地控制 Leaky Bucket,便 能避免整體系統的不穩定,讓系統的輸出效能更加地平滑順暢。
Xbee 模組內部有一暫存器稱為 Data-In(DI) Buffer,圖 16 為 Xbee 模組架構, 當資料經由 DIN 腳位輸入 Xbee 模組之後,資料將暫存於 DI Buffer,最大暫存容 量為 202 Bytes。當前一個 RF TX Buffer 內的資料經由發送器(Transmitter)傳送完 成之後,DI Buffer 才會將下一筆資料送至 RF TX Buffer,並再次由發送器送出。 發送器每次讀取 RF TX Buffer 之大小可經由 Xbee 韌體進行設定,其參數名稱為 RO(Packetization Timeout),參數設定範圍由 0-0xFF,代表每次可讀取之範圍介於 0 至 255 Bytes。由於 Speex Frame 為 28 Bytes,而 Xbee Payload 為 100 Bytes,每 個 Xbee Payload 最大僅能容納三個 Xbee Frame,因此 RO 參數將設定為 0x54, 代表當 RF TX Buffer 每讀取 84 Bytes 即經由發送器送出。
44
圖 16 Leaky Bucket 與 Xbee 架構整合
Xbee DI Buffer 有一硬體流量控制機制,如圖 17 所示,DI Buffer 有一CTS狀態,
當 DI Buffer 空間剩下 17 Bytes 時,模組會透過CTS顯示高電位訊號,通知前端裝
置(Host Device)停止傳送資料,直到 DI Buffer 閒置容量超過 34 Bytes 時,CTS才會
恢復為低電位。
圖 17 Xbee Flow Control 示意圖
由於當CTS連續出現高電位時,由於 DI Buffer 剩餘 17 Bytes 空間即將耗盡,
Leaky Bucket 將無法正常傳送資料至 DI Buffer,造成語音資料遺失與延遲時間的 增加。Xbee 內部流量控制區塊之機制適用於一般低傳輸量的無線感測傳輸環境,
45
然而當用於傳輸語音資料時,將具有短時間內需連續傳送之需求,如果按照原始
硬體內部流量控制區塊,將會發生CTS頻繁處於高電位狀態,造成語音資料無法順
利傳送,而封包遺失率(Packet Loss Rate)亦隨之提高,導致語音品質下降。 由於高低電位門檻值之間僅相差 17 Bytes,小於 Speex Frame 28 Bytes,為了
避免下個 Frame 暫存於 Buffer 時再次產生高電位,本系統設計當CTS為高電位狀態
時,Leaky Bucket 將暫時停止傳送 Speex Frame,直到CTS恢復為低電位狀態,Leaky
47
第四章、系統測試與效能分析
4.1 系統測試平台架構
表 9 環境參數設定
Xbee Frequency Band 2.4GHz
Topology Peer-to-peer
XBee Antenna 2.1dBi Omni Antenna
XBee Transmission Power 0 dBm(1mW)
XBee Retransmission 0
Data communication
modes Direct transfer, Unicast
Network modes Beaconless
Interface Data Rate 115,200
為獲取合理且正確的系統測試與效能分析數據,本研究的系統測試平台設定 如表 9 所示。本論文採用之硬體方面以 Arduino Mega Board[37]嵌入式系統開發 板作為主要的系統開發平台,而無線感測節點則為使用 Xbee 模組[33],軟體方面 主要以 Arduino 1.0[38]作為系統軟體開發平台。無線感測網路環境架構方面,如 圖 18 所示,兩組 BZVG 端點以無線方式進行點對點傳輸,本實驗於上述情境之 接收端(Receiver),使用 Sniffer 觀察與分析封包的動態。
48 圖 19 為量測地點空照圖,傳輸距離分別為 100、200、250 與 300 公尺,量測 地點並無其他 Wifi 等訊號干擾,以避免實驗受到衰減(Fading)影響。 圖 19 實地量測架構
4.2 系統實測與分析
本實驗主要目的是驗證本研究提出的語音封包傳輸於無線感測網路確實可以 有效的進行傳輸,並且維持可接受之語音品質。因此,本研究於傳送端以 Speex 編 碼,採用 8,000 取樣頻率來取樣,原始檔語音採用ITU-T P.50[39]所提供之語音檔,British English - B_eng_m1.wav,為男子以英式英文說話之聲音,語音總長度為 7 分 30 秒,經由 Speex 編碼後的語音資料,總計 410 kB ,共計 5,000 個封包傳送 至接收端。 在點對點延遲因素當中,本研究量測 Speex 分別於編碼與解碼時所產生的延 遲時間,以獲得更準確的 Speex 編解碼延遲計算數據。本實驗量測方式為在每個 Frame 編碼前後分別加入時戳,透過計算兩者時間差,取得編碼延遲時間,總共 量測 1,000 Frame 數量,解碼延遲亦以相同方式取得。
49
圖 20 Speex 編碼延遲時間
50
圖 20 為 Speex Frame 編碼延遲量測結果,平均編碼延遲時間為 28.561 毫秒。 圖 21 為 Speex Frame 解碼延遲量測結果,平均解碼延遲時間為 2.87 毫秒。MOSc 語音品質評分之編解碼延遲將以 28.561 毫秒和 2.87 毫秒之總和,作為編解碼器 延遲時間。編解碼延遲時間量測結果,符合 Cisco 語音封包網路[17]中,解碼延 遲時間為編碼延遲時間的十分之一之比例原則。
為了瞭解 TSB 運作狀態,我們設計一實驗情境,模擬 Speex 以 11kbps 輸入 頻寬至 TSB,而輸出頻寬分別設定為 2.464kbps 與 7.329kbps,這兩個頻寬分別代 表 Leaky Bucket 每次讀取一個 Frame 與三個 Frames 之對應頻寬,從中觀察 Speex Frames 在 TSB 時的累積程度。當 Speex 持續輸入至第 1, 000 個 Frames 時,TSB 輸出速率將調高至 11kbps,使得輸入頻寬與輸出頻寬一致,藉此觀察 TSB 空間 使用率狀態。圖 22 與圖 23 為 TSB 在低輸出速率與高輸出速率時的使用率圖,橫 軸為 Frame 編號,縱軸為 TSB 使用率。 由圖 22 所量測之結果可看出,當 TSB 輸出頻寬為 2.464kbps 時,由於輸入與 輸出頻寬不對稱且差異較大,大量 Speex Frames 將被儲存於 TSB 之中,並在第 269 個 Frames 時,超過 UB 門檻值,使得 TSB 使用率達百分之百,並將含有拋 棄標籤之 Frame 進行拋棄,以維持新進之 Frame 能夠儲存於 TSB。當 TSB 輸出 頻寬為 7.329kbps 時,由於輸出頻寬較大,因此 TSB Frames 累積程度相對較慢, 於第 912 個 Frames 時,超過 UB 門檻值,TSB 使用率達百分之百,並開始進行
51 Frame 拋棄程序。 圖 22 TSB 在低輸出速率與高輸出速率時的使用率 當 Speex 持續輸入至第 1, 000 個 Frames 時,由於輸出頻寬提升至 11kbps,維 持輸入與輸出頻寬為相等,因此 TSB 使用率將略為下降,並且停止進行 Frames 拋棄動作,如圖 23 所示。由於先前所累績 Frames 仍需要暫存於 TSB 一段時間, 才會被 TSB 輸出,因此 TSB 使用率維持在穩定的狀態,唯有 TSB 輸入頻寬小於 TSB 輸出頻寬時,TSB 使用率才會降低。
52
圖 23 TSB 在相等輸入與輸出速率時之使用率
本研究將量測語音封包在長距離傳輸下,其語音品質表現,實驗將以四種不 同的傳輸距離進行量測,分別為 100 公尺、200 公尺、250 與 300 公尺,觀察封 包遺失率、One-way Delay、MOS(PESQ)與 MOS Conversational(MOSc)的語音品 質表現。 首先,圖 24、圖 26、圖 28、圖 30 為分別在 100 公尺、200 公尺、250 公尺、 300 公尺的 4 種不同距離量測所得到的 MOS(PESQ)與 MOS 值,橫軸為量測次數, 縱軸為 MOS 值。而圖 25、圖 27、圖 29、圖 31 為分別在 100 公尺、200 公尺、 250 公尺、300 公尺的四種不同距離量測所得到的封包遺失率,橫軸為量測次數, 縱軸為封包遺失率。
53 圖 24 BZVG 在 100 公尺傳輸距離之 MOS(PESQ)與 MOSc 的語音評估分數 圖 25 BZVG 在 100 公尺傳輸距離之封包遺失率 在 100 公尺之傳輸距離共進行五次量測,由圖 24 與圖 25 可以看出在 100 公 尺的傳輸距離下,第一、二、三與五次的 MOS(PESQ)皆可維持 3.7 以上,主要是 由於封包遺失率皆在 2.5%以下,第四次語音品質相對低落,除了因為封包遺失率
54
高於 2.5%之外,語音資料遺失集中於同一區塊,使得 PESQ 在進行訊號波形比對 時,語音評估分數會有明顯的降低。
表 10 100 公尺之傳輸表現
Number of Measurement 1 2 3 4 5
Amount of Packet Loss 96 87 123 137 124
Packet Loss Rate(%) 1.92 1.74 2.46 2.74 2.48
Network Delay(ms) 31.2 29.5 29.3 32.3 30.3
End-to-end Delay(ms) 195.6 193.9 193.7 196.7 194.7
Mean Jitter(ms) 8.79 5.22 8.97 10.2 12.6
LQI 156 144 140 136 140
RSSI(dBm) -51 -54 -55 -56 -55
Diff. between MOS(PESQ) and MOSc 0.14 0.09 0.1 0.15 0.15
表 10 為在 100 公尺傳輸距離下,所測得之各項數據。其中單向延遲(One-way Delay)為無線感測節點之間的 Network Delay, 而 End-to-end Delay 則是包括了兩 端的 Coder Delay、Packetization Delay、Queuing/Buffer Delay、Serialization Delay 與 Network Delay。Coder Delay 為本研究針對 Speex 之編解碼延遲進行量測所取 得 知 之 數 據 ; 兩 端 XBee 節 點 之 Packetization Delay , 則 是 經 由 韌 體 參 數 Packetization Timeout 所設定,為總共為 40 毫秒;Queuing/Buffer Delay 為語音資 料在 TSB 與 Leaky Bucket 中之暫存時間,為 87 毫秒。本實驗在 Data Rate 為 115,200 bps,依照 XBee Specification 所列出之 Data Rate 與延遲之計算,兩端之 Serialization Delay 總共為 6 毫秒。
圖 23 中 MOSc 為結合 PESQ 與 E-model 語音評估模型,並且將延遲納入計算, 此一延遲即為 End-to-end Delay。由於 MOSc 有計算延遲因素,因此 MOS 值將會
55 比 MOS(PESQ)低,延遲時間越長,MOSc 分數相對越低。而 100 公尺語音品質 量測結果在 G.711 所評估的層級中,仍在一般語音品質服務可接受(acceptable) 的範圍之中。在五次量測中,MOS(PESQ)與 MOSc 語音評量分數差距以第四次 和第五次量測為最大,皆為 0.15,主要原因是由於兩次的封包遺失率較高,同時 點對點延遲時間也較長所致,整體 MOSc 下降幅度維持在 0.2 以內。
56 圖 26 BZVG 在 200 公尺傳輸距離之 MOS(PESQ)與 MOSc 的語音評估分數 圖 27 BZVG 在 200 公尺傳輸距離之封包遺失率 在 200 公尺之傳輸距離共進行五次量測,由圖 26 與圖 27 可以看出在 200 公 尺的傳輸距離下,由於隨著距離增加,訊號也會衰減,導致封包遺失率上升至 4% 以上。以第一、三、五次的量測結果來看,如果封包遺失率維持在 5%以內,
57 MOS(PESQ)值仍可維持在 3.6 以上。在圖 25 中第二次與第四次的量測中,封包 遺失率增加至 5%以上,對應於圖 24 第二次與第四次之量測中,可看出封包遺失 率上升至 5%以上造成 MOS(PESQ)皆低於 3.5。 表 11 200 公尺之傳輸表現 Number of Measurement 1 2 3 4 5
Amount of Packet Loss 216 285 237 328 241
Packet Loss Rate(%) 4.32 5.7 4.74 6.56 4.82
Network Delay(ms) 70.5 73.1 69.1 72.5 75.1
End-to-end Delay(ms) 234.9 237.5 233.5 236.9 239.5
Mean Jitter(ms) 6.59 6.92 12.1 7.8 4.2
LQI 92 87 87 78 87
RSSI(dBm) -66 -68 -68 -71 -68
Diff. between MOS(PESQ) and MOSc 0.2 0.23 0.21 0.22 0.21
表 11 為在 200 公尺傳輸距離下,所測得之各項數據,其中單向延遲(One-way Delay)至少為 100 公尺之單向延遲的兩倍。由表 10 與表 11 的訊號強度之差異中, 可看出 200 公尺訊號強度 RSSI 比 100 公尺訊號強度 RSSI 還小,是因為傳輸距離 延長而降低,相對地連線品質 LQI 變差,也成為封包遺失率提高的主因。
圖 24 之 MOSc 語音評估分數中,由於每次量測點對點之延遲)皆為 230 毫秒 以上,相較於 100 公尺之 End-to-end Delay 還長,因此 MOS(PESQ)與 MOSc 語音 評量分數之差距會比 100 公尺的差距大,200 公尺之 MOS(PESQ)與 MOSc 之差 距介於 0.2 至 0.23 之間。
58
圖 28 BZVG 在 250 公尺傳輸距離之 MOS(PESQ)與 MOSc 的語音評估分數
圖 29 BZVG 在 250 公尺傳輸距離之封包遺失率
由於 300 公尺量測結果不如預期,造成語音品質變差,因此特別針對 250 公 尺之距離進行量測,觀察其傳輸效能與語音品質結果。在 250 公尺之傳輸距離總
59
共進行三次量測,由圖 28 與圖 29 可以看出在 250 公尺的傳輸距離下,封包遺失 率介於 6.18%到 7.08%之間。根據本論文在 2.4.3 節所提到關於 E-Model 於評估語 音品質時,最顯著的兩個影響因素為網路中的封包延遲與封包遺失率。其中封包 遺失將對於 E-Model 中的 R-Value 有直接的影響。E-Model 中明確指出封包遺失 的類型,對於聲音品質有著不一樣的影響。主要是因為突然且密集的封包遺失 (Burst Loss)與平均且分散的封包遺失(Random Loss),對於聲音品質的影響有明顯 的差異。因此,在第一次量測時,由於突然且密集的封包遺失在一個區段,導致 語音品質有明顯的低落,語音品質分數僅至 2.63。 在第二、第三次的量測結果中,當封包遺失率維持在 6.68%之內,語音品質 仍可維持在 3.3 以上。 表 12 250 公尺之傳輸表現 Number of Measurement 1 2 3
Amount of Packet Loss 354 309 334
Packet Loss Rate(%) 7.08 6.18 6.68
Network Delay(ms) 80.8 86.3 80.3
End-to-end Delay(ms) 245.2 250.7 244.7
Mean Jitter(ms) 9 6.4 3.4
LQI 67 72 72
RSSI(dBm) -75 -73 -73
Diff. between MOS(PESQ) and MOSc 0.17 0.24 0.24
表 12 為在 250 公尺傳輸距離下,所測得之各項數據,其中第二次與第三次的 量測之單向傳輸延遲分別為 80.3 毫秒與 86.3 毫秒,而 MOS(PESQ)與 MOSc 語音 評量分數差距皆為 0.24。




![圖 8 結合 PESQ 與 E-Model 之對話式語音品質量測架構[32]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7453143.110752/34.892.162.771.148.250/圖8結合PESQ與EModel之對話式語音品質量測架構32.webp)


![圖 14 E-model 與絕對延遲(Absolute delay)影響對照圖[36]](https://thumb-ap.123doks.com/thumbv2/9libinfo/7453143.110752/49.892.111.786.135.973/圖14Emodel與絕對延遲Absolutedelay影響對照圖36.webp)
