Mining generalized fuzzy association rules from web taxonomic Mining generalized fuzzy association rules from web taxonomic
6
0
0
全文
(2) association rules within large databases, but a large number of the candidate itemsets are generated from single itemsets. This method also needs to perform contrasts against all of the transactions, level by level, in the process of creating association rules. The database is repeatedly scanned to contrast each candidate itemset, that performance is dramatically affected.. stored in the browse information database (BIDB).This method not only needs only one database scans, but also requires less contrast.. 2. CBFAR Mining Framework The hierarchical relationships and cluster-based concepts are used to discover generalized fuzzy association rules from browse information database (BIDB). We propose a CBFAR mining framework for discovering generalized fuzzy association rules. The proposed framework is shown in. After Agrawal et al. proposed the Apriori association rule, Tsay et al. have used cluster-based association rule (CBAR) approach.[8] This method used cluster-based table to reduce the number of database scans and requiring less contrast. Recently, the fuzzy set theory[3] has been used more and more frequently in intelligent systems. It’ s simplicity and similarity to human reasoning.[1] Hong et al. also proposed a fuzzy mining algorithm.[7] The items considered in their approach had hierarchical relationships. However, items in real-world applications are usually organized in some hierarchies. Mining multiple-concept-level fuzzy rules may lead to discovery of more general and important knowledge from data.. Fig. 1. Fuzzy membership functions and taxonomy relationships. Browse Information Database. Fuzzy Cluster_Table(1). Fuzzy Mining. Fuzzy Cluster_Table(2). …. Fuzzy Cluster_Table(M). Fuzzy association rules. Figure1: CBFAR Mining Framework. We proposed mining framework maintains fuzzy association rules, and uses the hierarchical relationships and cluster-based fuzzy table to derive the fuzzy association rules. Previous studies on data mining focused on finding association rules on the single-concept level. However, relevant web page taxonomies are usually predefined in the web site service and can be represented using hierarchical trees.[6] Terminal nodes on the trees represent actual web pages appearing in networks structure; internal nodes represent classes or concepts of web pages formed by lower-level nodes.. In this paper, we present a new method called cluster-based fuzzy association rule (CBFAR), for efficient fuzzy association rules mining. We considered the hierarchical relationships to discover the generalized fuzzy association rules from the browse information database (BIDB) and used the cluster-based concept to reduce the number of database scans. When the customer clicking the web pages, then the click times 2.
(3) [6]A simple example is given in Fig. 2.. T2 T1. A. In the third phase, creates M cluster tables. Scan the browse information database once and cluster the browsed data. If the length of browsed data is k, the browsed record and the fuzzy region value of items in this browsed record will be stored in the table, named Fuzzy_Cluster Table (k), 1 k M, where M is the length of the longest browsed record in database.. T3 C. D. E. B. Figure2: An example of taxonomic structures. In this example, the T2 web class falls into one class and one web page: T1 and web page C. T1 can be further classified into page. In the fourth phase, the set of candidate itemsets Cn is generated. When the length of. A and page B. Similarly, assume T3 are divided into page D and page E. Only the terminal web pages (A, B, C, D and E) can appear in browse information records. The CBFAR mining method is divided into four phases.. calculated with reference to the Fuzzy_Cluster Table(k). If the fuzzy region value of Cn is greater than or equal to the. candidate itemset is k, the support is. predefined minimum support value , the candidate itemsets becomes the large itemsets, put Cn in the large itemsets Ln . Otherwise, it Fuzzy_Cluster. In the first phase, ancestors of web pages in each given browsed record are added according to the predefined taxonomy.. is contrasted with the Table(k+1). The large. itemsets is Ln maxRj | maxcount j ,1 j m. Until the large itemsets Ln is null, this process terminates when the calculated support is greater than or equal to the predefined minimum support or the the end of the Fuzzy_Cluster Table(M) has been reached. Finally, use the predefined minimum confidence value to discover fuzzy association rules. If the candidate fuzzy association rule is larger than or equal to the predefined confidence value, put it in the rule base.. In the second phase, transform the quantitative value vij of each browsed data Di (i=1 to n), for each expanded item name I j appearing into a fuzzy set fij .The f ij are represented as ( fij1 / R j1 + fij 2 / R j 2 + + fij1 / R j1 ) using the given membership functions, where h is the number of fuzzy regions for I j . R jl is the lth fuzzy region of I j , 1 l h, and fijl is vij ’ s fuzzy membership value in region R jl . Calculate the value of each fuzzy region R jl. 3. An Example. n. in the browsed data. ( count jl fijl ). In this section, an example is given to. i 1. 3.
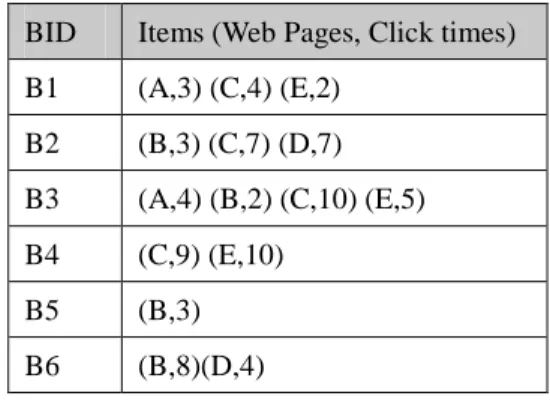
(4) illustrate the proposed mining method. This is a simple example to show how the proposed method can be used to discover fuzzy association rules from browsed data. There are six browsed records and five items (web pages) in a browse information database: A, B, C, D and E. An example browse information database is shown in Table 1. The taxonomy tree is shown in Fig. 3. The ancestors of appearing web pages are added to browsed records according to the predefined taxonomy tree. The expanded browsed record is shown in Table 2.. values are produced for each item according. T2 T1. A. T3 C. D. E. B. Figure3: Taxonomy tree in this example. values are produced for each item according to the predefined membership function.. Table 1. Six browsed records in this example BID. Items (Web Pages, Click times). B1. (A,3) (C,4) (E,2). B2. (B,3) (C,7) (D,7). B3. (A,4) (B,2) (C,10) (E,5). B4. (C,9) (E,10). B5. (B,3). B6. (B,8)(D,4). The length of the longest browsed record in this database is six, and creates six fuzzy_cluster tables as shown in Table 3. The fuzzy region value of items in this browsed record will be stored in the Fuzzy_Cluster Tables.. 1. Table 2: The expanded browsed records BID. Items (Web Pages, Click times). B1. (A,3) (C,4) (E,2) ( T1 ,3) ( T2 ,4) ( T3 ,2). B2. (B,3) (C,7) (D,7) ( T1 ,3) ( T2 ,7) ( T3 ,7). B3. (A,4) (B,2) (E,5) ( T1 ,6) ( T3 ,5). B4. (C,9) (E,10) ( T2 ,9) ( T3 ,10). B5. (B,3) ( T1 ,3). B6. (B,8)(D,4) ( T1 ,8) ( T3 ,4). Low. Middle. 1. 6. High. 0 0. 11. Figure4: The membership function. Assume the minimum support value is 2.0. We can discover the Large-1 itemsets ( L1 ) which is large than or equal to the. In this example, assume that the fuzzy membership functions are the same for all the items and are as shown in Fig. 4. The fuzzy membership function is represented by three fuzzy regions: Low(L), Middle(M) and High(H), and three fuzzy membership. predefined minimum support value according to the Fuzzy_Cluster Tables. The itemsets of L1 are {B.Low = 2.0}, { T1 .Middle = 2.8}, { T3 .Middle = 2.6}.. 4.
(5) we can transform each large itemsets into a fuzzy association rule.. Table 3: Fuzzy_Cluster Tables BID. A. B. C. D. E. T1. T2. T3. Fuzzy_Cluster Table(1). 4. Conclusions. NULL. Fuzzy_Cluster Table(2) B5. 0. L,0.6 M,0.4. 0. 0. 0. L,0.6 M,0.4. 0. 0. M,0.2 H,0.8 L,0.4 M,0.6. In this paper, we have proposed a generalized fuzzy association rules mining framework for extracting fuzzy association rules from browse information database. The cluster-based fuzzy association rule (CBFAR) method creates Fuzzy_Cluster Tables to discover the large itemsets. Contrasts are performed only against the partial Fuzzy_Cluster Tables that were. Fuzzy_Cluster Table(3) NULL. Fuzzy_Cluster Table(4) B4. 0. 0. M,0.4 H,0.6. 0. M,0.2 H,0.8. 0. M,0.4 H,0.6. B6. 0. M,0.6 H,0.4. 0. L,0.4 M,0.6. 0. M,0.6 H,0.4. 0. 0. L,0.2 M,0.8. M,1. 0. L,0.2 M,0.8. 0. L,0.8 M,0.2. M,0.8 H,0.2. 0. L,0.6 M,0.4 L,0.6 M,0.4. L,0.4 M,0.6 M,0.8 H,0.2. L,0.8 M,0.2 M,0.8 H,0.2. Fuzzy_Cluster Table(5) B3. L,0.4 M,0.6. L,0.8 M,0.2. 0. Fuzzy_Cluster Table(6) B1. L,0.6 M,0.4. 0. B2. 0. L,0.6 M,0.4. L,0.4 M,0.6 M,0.8 H,0.2. created in advance. It only requires a single scan of the browse information database, and contrasts with the partial Fuzzy_Cluster Tables. This method not only needs only one database scans, but also requires less contrast. In the future, we will continuously for the huge database, and discussing with the performance of CBFAR method.. Generate the large 2-itemsets L2 . Combining the items of L1 in order to generate candidate 2-itemsets C2 . The procedure is similar to the candidate generation of Apriori algorithm[5]. The itemsets of C2 are {B.Low, T1 .Middle}, {B.Low, T3 .Middle}, { T1 .Middle, T3 .Middle}. In order to generate L2 , it is necessary to compute the fuzzy region values of each candidate itemset in the Fuzzy_Cluster Table(2). If the value is larger than or equal to the predefined minimum support value, put C2 in the L2 . Otherwise, compute the. 5. References [1] A. Kandel, Fuzzy Expert Systems, CRC Press, Boca Raton, FL, 1992, pp. 8-19. [2] J. Han, Y. Fu, Discovery of multiple-level association rules from large database, The Internet. Conf. on Very Large Databases, 1995. [3] L.A. Zadeh, Fuzzy sets, Inform. and Control 8(3), 1965 pp. 338-353. [4] R.Agrawal, T. Imielinksi, A. Swami, Mining association rules between sets of items in large database, the 1993 ACM SIGMOD Conf., Washington, DC, USA, 1993.. fuzzy region values in the next cluster table (Fuzzy_Cluster Table(3)). Until the calculated support is greater than or equal to the predefined minimum support or the end of the Fuzzy_Cluster Table(M). The other large itemsets Ln are in the similar way. Therefore, the large itemsets in this example are {B.Low}, { T1 .Middle}, { T3 .Middle},{ T1 .Middle, T3 .Middle}. Then, 5.
(6) [5] R. Agrawal, R. Srikant, Fast algorithm for mining association rules in large databasaes, Proceedings of 1994 International Conference on VLDB, 1994 pp. 487-499. [6] R. Srikant, R. Agrawal, Mining generalized association rules, The Internat. Conf. on Very Large Databases, 1995.. [7]. Tzung-Pei Hong, Kuei-Ying Lin, Shyue-Liang Wang, Fuzzy data mining for interesting generalized association rules, Fuzzy Sets and Systems, 2003 pp. 255-269. [8] Yuh-Jiuan Tsay, Jiunn-Yann Chiang, CBAR: an efficient method for mining association rules, Knowledge-Based Systems, 2005 pp. 99-105.. 6.
(7)
數據

相關文件
From the existence theorems of solution for variational relation prob- lems, we study equivalent forms of generalized Fan-Browder fixed point theorem, exis- tence theorems of
- - A module (about 20 lessons) co- designed by English and Science teachers with EDB support.. - a water project (published
The presented methods for mining semantically related terms are based on either internal lexical similarities or external aspects of term occurrences in documents
• Information retrieval : Implementing and Evaluating Search Engines, by Stefan Büttcher, Charles L.A.
Since the FP-tree reduces the number of database scans and uses less memory to represent the necessary information, many frequent pattern mining algorithms are based on its
We try to explore category and association rules of customer questions by applying customer analysis and the combination of data mining and rough set theory.. We use customer
Step 5: Receive the mining item list from control processor, then according to the mining item list and PFP-Tree’s method to exchange data to each CPs. Step 6: According the
According to the related researches the methods to mine association rules, they need too much time to implement their algorithms; therefore, this thesis proposes an efficient
