.
國 立 交 通 大 學
電信工程學系
博 士 論 文
中文聽障語者的強健性辨認研究
Robust Distributed Recognition of
Hearing-impaired Mandarin Speech over Wireless
Networks
研 究 生:李承龍
指導教授:張文輝 博士
.
中文聽障語者的強健性辨認研究
研究生:李承龍
指導教授:張文輝 博士
摘 要
本篇論文旨在分散式語音辨認架構下,針對語者變異與傳輸錯誤的影響分別提供其強健 性處理。語者變異所造成的效能失真,其影響源自於語音辨認器在模型訓練與實際測試 兩個階段的語者不匹配。針對聽障中文語者的發聲,我們提出語音轉換機制使其能匹配 辨認模型所蘊含的語音特性。此轉換系統的設計乃是基於中文語音的特性,考慮聲母-韻 母組合的音節結構及聲調變化,分別針對頻譜與韻律兩層次的特徵參數進行轉換,而特 徵參數的擷取則是依據正弦語音模型。頻譜轉換需考慮不同音類在聲學特性的明顯差 異,並據以針對聲母及韻母所屬的次音節參數分別設計其最佳化轉換函數。此外,構音 速度的調變亦針對不同類型的次音節,設計其線性或非線性的轉換機制。至於聲調的調 變,則考慮中文四聲變化的結構,先藉由正交轉換分析基頻變化曲線的特徵參數,再利 用向量對應機制估算最佳的基頻轉換曲線。系統模擬證實,語音轉換機制可有效改善聽 障者語音的清晰度,進而有效提升其語音辨認的正確率。分散式辨認系統的另一研究重 點是語音特徵參數於無線傳輸過程中,將遭遇叢發性通道錯誤而導致其辨認效能衰減。 有鑑於此,我們設計一錯誤隱匿解碼機制,其關鍵在於有效整合訊源編碼輸出的殘餘冗 息以及通道錯誤的相關特性。在辨認特徵參數的冗息分析中,編碼輸出的量化索引序列 仍存在大量的相關特性,而行動通訊的叢發性錯誤則適於以馬可夫模型來模擬。我們結 合這兩種訊息,再依據最大後驗機率準則設計一合併訊源通道解碼演算法。實驗結果證 實訊源通道解碼器在無線傳輸環境能有效提升其錯誤隱匿效能。Robust Distributed Recognition of
Hearing-impaired Mandarin Speech over Wireless
Networks
Student: Cheng-Lung Lee Advisor: Dr. Wen-Whei Chang
Department of Communication Engineering, National Chiao Tung University Hsinchu, Taiwan, Republic of China
ABSTRACT
This study focuses on the robustness of distributed speech recognition (DSR) sys-tems against the inter-speaker and channel variabilities. In the first part, we develop joint source-channel decoding algorithms with increased robustness against channel er-rors in mobile DSR applications. An MAP symbol decoding algorithm which exploits the combined a priori information of source and channel is proposed. This is used in conjunction with a modified BCJR algorithm for decoding convolutional channel codes based on sectionalized code trellises. Performance is further enhanced by the use of the Gilbert channel model that more closely characterizes the statistical depen-dencies between channel bit errors. In the second part, we develop voice conversion approaches based on the feature transformation to perform speaker adaptation for hearing-impaired Mandarin speech. The basic strategy is the combined use of spec-tral and prosodic conversions to modify the hearing-impaired Mandarin speech. The analysis-synthesis system is based on a sinusoidal representation of the speech produc-tion mechanism. By taking advantage of the tone structure in Mandarin speech, pitch contours are orthogonally transformed and applied within the sinusoidal framework to perform pitch modification. Also proposed is a time-scale modification algorithm that finds accurate alignment between hearing-impaired and normal utterances. Using
the alignments, spectral conversion is performed on subsyllabic acoustic units by a continuous probabilistic transform based on a Gaussian mixture model.
.
Acknowledgements
這博士班研讀的過程中,首先要感謝我的指導老師張文輝教授悉
心的引導,更感染自老師對於教學及研究的熱誠與認真,故期許自己
對於電信相關領域能有多一分的貢獻。此外,個人非常感謝交通大學
所提供優良的學術環境,讓學生在科技與人文的素養均能有所成長。
再者,特別感謝新竹教育大學江源泉教授對於研究所提供的協助與指
導。在語音通訊實驗室裡的研究生活中,有學長蔡偉和、許亨仰與同
學何宗仁、吳政麟、蔡若望、楊雅茹、李世耀、李維晟、葉志杰、蔡
淑羚、吳俊鋒、傅泰魁、曹正宏、林宜德、許忠安、蔡知鑑、何依信
等相互提攜與砥礪,由於大家的相伴,即使在最苦悶的日子裡依然能
開心的向目標邁進,研究也方能如此順利。最後,感謝父母親以及家
人在這段時間裡的支持跟鼓勵,若個人能對研究與社會能有絲毫的貢
獻,願將一切的成就與榮耀與你們一同分享。
Contents
Abstract i
Acknowledges iv
Contents v
List of Tables vii
List of Figures viii
1 Introduction 1
2 Distributed Recognition of Mandarin Speech 8
2.1 Distributed Speech Recognition System . . . 8
2.2 The ETSI-DSR Framework . . . 13
2.3 Chinese Language Characteristics . . . 15
3 Channel-Robust DSR over Wireless Networks 18 3.1 Joint Source-Channel Coding . . . 19
3.2 Modified BCJR Algorithm . . . 21
3.3 Probability Recursions for Gilbert channel . . . 24
3.4 Experimental Results . . . 27
4 Speaker-Adaptive DSR for Hearing-Impaired Mandarin Speech 32
4.1 Characteristics of Hearing-Impaired Mandarin Speech . . . 33
4.2 Sinusoidal Framework for Voice Conversion . . . 35
4.3 Spectral Conversion . . . 38
4.4 Prosodic transformation . . . 41
4.5 Experimental Results . . . 44
4.6 Summary . . . 51
5 Conclusions and Future Work 56 5.1 Summary . . . 56
5.2 Future Work . . . 57
List of Tables
3.1 Entropies for DSR feature pairs. . . 21 3.2 SNR(dB) performance for various decoders on a Gilbert channel. . . 28 3.3 Estimated Gilbert model parameters for GSM TCH/F4.8 data channels. 29 3.4 SNR performance of the SMAP2 over the GSM data channel under
channel mismatch conditions. . . 29 4.1 Incremental distortions and slope weights for local paths. . . 45 4.2 Confusion matrix showing tone recognition results for source syllables. . 47 4.3 Confusion matrix showing tone recognition results for converted syllables. 47 4.4 Raw data and tone recognition rates derived from Tables 2 and 3. . . . 48
List of Figures
1.1 Structure of a speech recognition system based on HMM models. . . 2
1.2 The principle framework of DSR. . . 3
1.3 Speaker adaptation approach using voice conversion for HMM-based ASR. 6 2.1 Block diagram of a DSR system. . . 9
2.2 Block diagram of the different approaches for DSR. . . 12
2.3 Block diagram of the ETSI-DSR system. . . 14
3.1 Transmission scheme for each DSR feature pair. . . 20
3.2 Trellis diagrams used for (a) the encoder and (b) the MAP decoder. . . 22
3.3 Gilbert channel model. . . 25
3.4 Recognition performances for DSR transmission over a Gilbert channel. 30 4.1 Phoneme duration statistics for (a) vowels and fricative consonants and (b) affricate consonants. . . 35
4.2 Block diagram of the voice conversion system. . . 37
4.3 F0 contours for syllable /ti/ spoken with four different tones: (a) source speech, (b) converted speech, and (c) target speech. . . 46
4.4 F0 contours for a four-syllable utterance /ying-4 yong-4 ruan-3 ti-3/(Application software): (a) source speech, (b) converted speech, and (c) target speech. . . 49
4.5 Spectrograms for syllable /shu/: (a) source speech, (b) converted speech, and (c) target speech. . . 53
4.6 Spectrograms for syllable /chii/: (a) source speech, (b) converted speech, and (c) target speech. . . 54 4.7 Percent correct phoneme recognition scores for source and converted
Chapter 1
Introduction
Recent progress in automatic speech recognition (ASR) technology has enabled the development of more sophisticated spoken language interface applications. These ap-plications make use of speech to replace or complete an interface for communicating with a machine, e.g. for accessing a service or controlling a functionality of an equip-ment. Moreover, combined with use of distributed client-server operation mode, ASR has become a common service for mobile communications and computing devices. The fantastic growth of the Internet has also created a demand for easy ways of accessing and retrieving all the available information and services. Through the use of distributed ASR capability, people can access information anytime and anywhere [1].
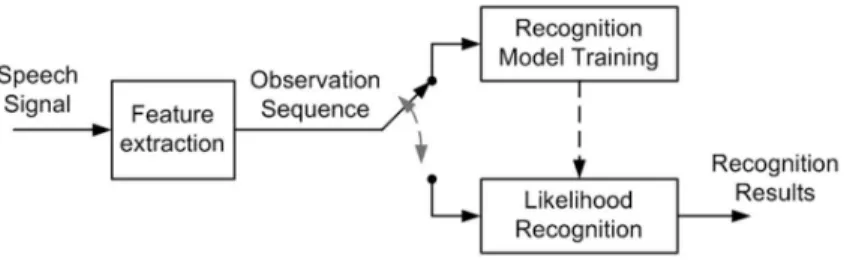
The block diagram of the speech recognition system is shown in Figure 1.1. The basic strategy begins with an extraction of parameter set from the speech signal. These parameters describe the speech by their variation over time and hence can be used to build up a pattern that characterizes the speech. In the training phase statistic models are estimated for every phoneme used in the target application, which are then concatenated to form the word-based models. In the recognition phase testing speech signals are analyzed to compute the acoustic parameters and the acoustical decoding block is used to search for the closest speech templates whose corresponding models are
Figure 1.1: Structure of a speech recognition system based on HMM models.
the closest to the observed sequence of acoustic parameters. The most common way to characterize acoustic modelling is based on the Hidden Markov Models(HMMs).
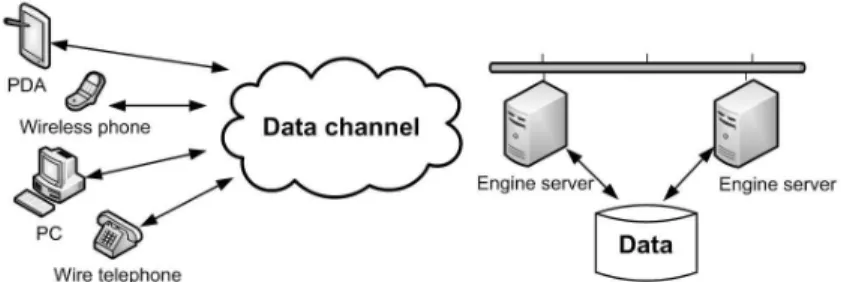
Due to the diversity of the capabilities and characteristics of terminal devices and networks, it is expected that various client-server modalities of speech recognition exist in the mobile environment. The client-server framework of distributed speech recogni-tion (DSR) is shown in Figure 1.2. Various kinds of devices such as personal computers, smart devices, wire and wireless telephones can act as speech-enabled client devices. Through the data channel, the characteristic features of speech are transmitted to the engine server for back-end recognition. Finally, the server recognizes the speech ac-cording to an application-specific servers and sends the result string or action back to the client.
In a DSR system, centralized servers can share the computational burden between users and enable the easy upgrade of new services without any additional cost for the user. However, transmitting acoustic data over communication networks changes the encoded information and consequently leads to severe degradation in the recognizer performance. In the case of packet-erasure channels, several packet loss compensation techniques such as interpolation [13] and error control coding [14] have been intro-duced for DSR. For wireless channels, joint source-channel decoding (JSCD) techniques
Figure 1.2: The principle framework of DSR.
[15,16,17] have been shown effective for error mitigation using the source residual re-dundancy and assisted with the bit reliability information provided by the soft-output channel decoder. However, the usefulness of these techniques may be restricted be-cause they only exploited the bit-level source correlation on the basis of a memoryless AWGN channel assumption. In the thesis, we attempt to capitalize more fully on the a priori knowledge of source and channel and then develop a DSR system with increased robustness against channel errors. The first step toward realization is to use quantizer indexes rather than single index-bits as the bases for the JSCD, since the dependencies of quantizer indexes are much stronger than the correlations of the index-bits. The next knowledge source to be exploited is the channel error characteristics on which the decoder design is based [18]. For this investigation, we focused on the Markov chain model proposed by Gilbert [19]. This model can characterize a wide range of digital channels and has a recursive formula for computing the channel transition probabilities. Speech is a dynamic acoustic signal with many sources of variation. As the produc-tion of phonemes involves different movements of the speech articulators in different en-vironments, there is much freedom in the timing and degree of vocal tract movements. A more difficult challenge is that the speech recognition system is very sensitive to variations and mismatches between training and testing environments. Several speech variabilities can be due to the following [2].
• Inter-speaker variability: Physiological differences, articulatory habits and speak-ing styles are important sources of variation between speakers. For example, male-female differences account for some basic differences between speakers, since a shorter vocal tract length generally yields higher formant values.
• Intra-speaker variability: A speaker can change his/her voice quality, speaking rate, fundamental frequency or articulation patterns. Small changes in articula-tion patterns can result in big changes at the acoustic level. The environment changes also induce intra-speaker variability. Background noise or stress condi-tions yield an increase in the speakers’ vocal effort and a modification of speech production.
• Environment variability: The environment in which speech is produced plays an important role and affects its production, perception, and acoustic repre-sentation. The elements of this variability include: room acoustics and rever-beration, recording equipment, microphone placement, background noise, and transmission channel. Often environmental changes are difficult to simulate in the laboratory because of their large variation. This explains why there is a big difference between laboratory and filed performance. To combat the environment variability, researchers have developed algorithms for environment normalization, microphone independence, and noise robustness.
• Linguistic variability: Linguistic variations are generally associated with audible variations in terms of accents and dialects. Often the major differences which occur between dialects are apparent in their phonological, phonetic, and lexical composition. It is still not clear where the boundary is between speaker charac-teristics and the linguistic variations.
• Contextual variation: There exists different kinds of contextual relevant sources, such as coarticulation, local phonetic environment, and linguistic context includ-ing syntax, semantics, and pragmatics. Coarticulation is a language-dependent
phenomenon, which involves changes in the articulation and acoustics of a phoneme due to its phonetic context. Recent research has shown that it is able to provide important cues and should be exploited in ASR.
The aim of this thesis is to enhance the robustness of DSR systems against the inter-speaker and channel variabilities. First, it is well known that the performance of ASR systems is sensitive to mismatches between training and testing conditions. Especially, when the acoustic characteristics of a new speaker are very different from those of the speakers in the training data, the recognition accuracy for the new speaker might be far below the average accuracy. Several different approaches to solve this problem have been proposed. They are roughly grouped into two categories, namely feature transfor-mation methods [3,4] and model adaptation methods [5,6,7]. Feature transfortransfor-mation approaches attempt to transform the speaker’s feature space to match the space of the training population. These approaches have the advantage of simplicity. In addition, if the number of free parameters is small, then transformation techniques adapt to the new user with only a small number of adaptation data. Among model-adaptation approaches, the maximum a posteriori (MAP) technique [5] and maximum likelihood linear regression (MLLR) technique [6] have been widely used. The MAP adaptation process is referred to as Bayesian adaptation, which involves the use of priori knowl-edge about the model parameter distribution. With a large amount of adaptation data, the MAP method can adapt model parameters to be converged to the corresponding speaker-dependent model parameters. On the other hand, the MLLR methods are popular due to their effectiveness and computational advantages. MLLR adaptation formulae take only a limited amount of adaptation data from a new speaker and update the HMM model parameters to maximize the likelihood of the adaptation data.
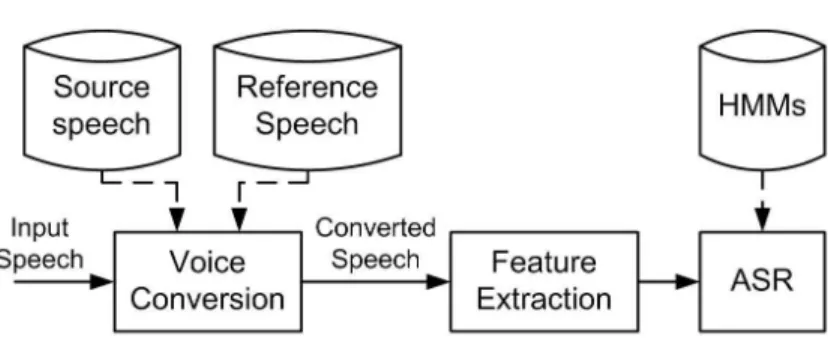
Unlike previous work, we investigate the use of voice conversion based on feature transformation to perform speaker adaptation for hearing-impaired Mandarin speaker. In Figure 1.3, this approach behaves as a preprocessing step at the speech recognizer in order to reduce the speaker variability. The goal of voice conversion is to improve the
Figure 1.3: Speaker adaptation approach using voice conversion for HMM-based ASR.
intelligibility and the naturalness of hearing-impaired speech. By controlling speech individuality or adding individual cues to converted speech, it can be used to con-vert voice quality from one speaker to another. The technique of voice conversion has many applications, such as text-to-speech synthesis [8] and improving the qual-ity of alaryngeal speech [9]. Most current systems [10,11] concentrate on the spectral envelope transformation, while the conversion of prosodic features is essentially ob-tained through a simple normalization of the average pitch. Such systems may lead to an unsatisfactory conversion quality for tonal languages, such as Chinese, which uses lexical tones to distinguish meanings of syllables that have the same phonetic com-positions. In view of the important roles of prosody in Mandarin speech perception, further enhancement is expected by better modelling of pitch contour dynamics and by additionally incorporating prosodic transformation into the voice conversion system. The key to solving the problem of voice conversion lies in the detection and exploitation of characteristic features that distinguish the source speech from the reference speech [12]. To proceed with this, we found the phonological structure of Chinese language could be used to advantage in the search for the basic speech units. Also proposed is a subsyllable-based approach to voice conversion that takes into consideration both the prosodic and the spectral characteristics.
speech recognition system and examine alternative architectures for the implementation of client-server system. Chapter 3 investigates the error mitigation algorithms for DSR systems to increase the robustness against wireless channels. In Chapter 4, we present the combined use of spectral and prosodic conversion to enhance the quality of hearing-impaired Mandarin speech and therefore reduce inter-speaker variability for their use of commercial speech recognition systems. Finally, chapter 5 concludes this thesis and outlines some directions for future research.
Chapter 2
Distributed Recognition of
Mandarin Speech
The primary objective of using speech recognition technique is to enable an easy access of the information. For multimedia communication over wireless network, the concept of distributed client-server system is considered by the mobile devices in lack of com-putational power. In this chapter we briefly examine alternative architectures for the design of distributed recognition systems and discuss their core techniques.
2.1
Distributed Speech Recognition System
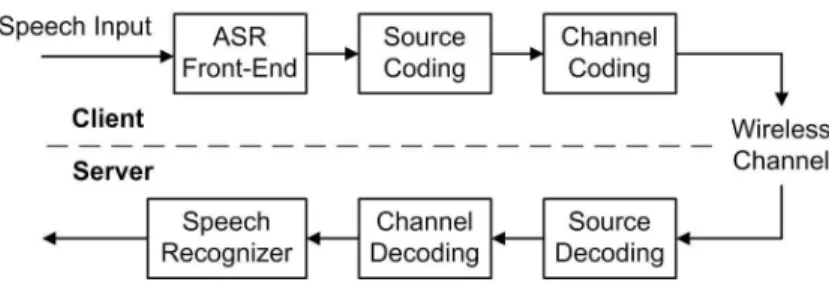
Figure 2.1 illustrates the functional blocks for a distributed speech recognition system. Typically, the front-end processing performs a short-time Fourier analysis and extracts a sequence of feature vectors used for speech recognition. The source encoder removes the redundancy from the speech features to achieve lower data rate. In addition, the channel encoder adds controlled redundancy to overcome the adverse effects of noise and interference. At the receiver the channel decoder and source decoder are used to reconstruct the desired speech parameters. After that the speech recognizer
Figure 2.1: Block diagram of a DSR system.
based on the acoustic and language models is used to perform the features recognition and language understanding. The final goal of our system design is to provide high recognition accuracy over wireless channel, which keeping low bit rate and complexity for the client device. A detailed description of each functional block is given as follows.
• Front-end signal processing The way how to extract speech feature is an important task in the speech signal processing. Depending on the problem to be solved, the extracted features can be very simple such as zero-crossing rate, energy and pitch period, or more complex. For speech recognition applications, the power spectrum representing information about the source signal energy and vocal tract is generally used. The human ear resolves nonlinear frequency re-sponse across the audio spectrum. Empirical evidence suggests that designing a front-end to operate in a nonlinear manner improves recognition performance. The front-end processing performs a short-time Fourier analysis and extracts a sequence of acoustic vectors. Mel Frequency Cepstral Coefficients (MFCC) are typical feature vectors for ASR. The nonlinear Mel frequency scale, which is used by the MFCC representation, approximates the behavior of the human auditory response. The MFCC ci is defined as the discrete cosine transform of the M filter
outputs as follows ci = s 2 N M X j=1 mjcos( πi N(j − 0.5)), 1 ≤ i ≤ N (2.1)
where mj is the jth log filterbank amplitude, M is the number of filterbank
channels and N is the number of cepstral coefficients. Davis and Mermelstein [20] showed MFCC parameters are beneficial for speech recognition with increased robustness to noise and spectral estimate error.
• Source coding The task of the source coder is to compress the source signal so that the signal can be reconstructed with as little distortion as possible, under the constraint that the source coding rate cannot exceed the channel capacity. Vari-ous data compression techniques can be applied to remove redundancy from the original signal to achieve low bit rate for transmission and storage. Among them, vector quantization (VQ) has been widely used in many applications and allows optimum mapping a large set of input vectors into finite set of representative codevectors.
• Channel coding The function of the channel encoder is to introduce some artificial redundancy, which can be used at the receiver to combat the noise encountered in the data transmission. The encoding process generally involves taking k information bits and mapping each k-bit sequence into a unique n-bit sequence. The amount of redundancy introduced is measured by the ratio k/n, also called the code rate. The added redundancy serves to increase the reliability of the received data and aids the receiver in decoding the desired information sequence.
• Communication Channel The channel is a transmission medium which pro-vides the connection between the transmitter and the receiver, and introduces distortion and noise to the transmitted signals. Transmission errors encountered in most real communication channels exhibit various degrees of statistical depen-dencies that are contingent on the transmission medium and on the particular
modulation technique used. A typical example occurs in digital mobile radio channels, where speech parameters suffer severe degradation from error bursts due to the combined effects of fading and multipath propagation. In this the-sis we focused on the Markov channel model. This model has several practical advantages over the Gaussian channel [4]-[6] and binary symmetric channels [9]. • HMM-Based Speech Recognition Hidden Markov models are often used to characterize the non-stationary stochastic process represented by the sequence of observation vectors. In HMM-based speech recognition, it is assumed that the sequence of observed vectors O corresponding to each word is generated by a Markov model. In the recognition phase, the acoustical decoding searches the state sequence for each vocabulary word and finds the most likely sequence of words W with the highest accumulated probability. This can be done by using Bayes’ rule
c
W = arg max
W P (W |O) = arg maxW
P (W )P (O|W )
P (O) . (2.2)
The probability P (W ) of the word sequence W is obtained from the language model, whereas the acoustic model determines the probability P (O|W ). A Markov model is a finite state machine which changes state once every time unit and the state sequence S is not observed. The probability of O is obtained by summing the joint probability over all possible state sequences S, giving P (O|W ) = PSP (O|S, W )P (S|W ), where the probability P (S|W ) is governed
by the state transition probability and the probability P (O|S, W ) is based on the observation distribution.
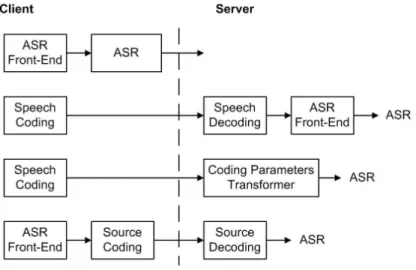
A client-server speech recognition system is implemented to provide speech-enabled applications over the Internet network. This system uses two major signal processing technologies, source coding and speech recognition, to provide efficient transmission and recognition performance. There are several alternative architectures for the client-server applications [21] over wireless communication, as shown in Figure 2.2.
Figure 2.2: Block diagram of the different approaches for DSR.
• The first strategy(client-only processing) is to perform most of the speech recog-nition processing at the client side and then transmit results to the remote server. The recognition can obtain high quality speech parameters with less transmis-sion channel error and more reliability. However, these client systems must be powerful enough to perform the recognition decoding with the heavy computa-tion and memory resources. In addicomputa-tion, the recognicomputa-tion processing may not be inconvenient for upgrading applications.
• The second alternative(server-only processing) is to perform speech compression and coding at the client side, and transmit the user’s voice parameters to the server for recognition processing. Alternatively, the recognition engine may uti-lize the synthesized speech as an input to ASR feature extraction or directly bitstream-based feature extraction without the synthesis process. This approach has the smallest computational and memory requirements on the client and allows a wide range of mobile communication systems to access the speech-enable appli-cations. The disadvantage of this approach is that the recognition performance is degraded in low bit-rate connections.
the client and transmit characteristic features for speech recognition to the server. This approach only has a small part of computation for the front-end processing at the client, allows a wide range of mobile systems to operate various applications, and also enables the easy upgrade of technologies and services provided. To make speech recognition servers available from variety systems, front-end processing and compression need to be standardized and ensure compatibility between the client machines and the remote recognizer.
2.2
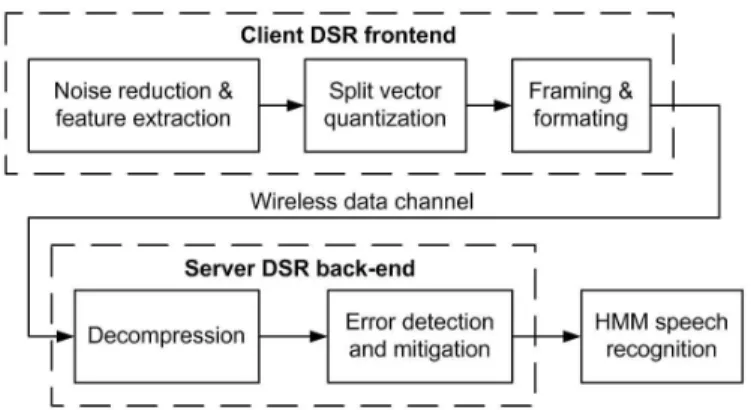
The ETSI-DSR Framework
The standard ETSI ES 202 212 [22] describes the speech processing, transmission, and quality aspects of a DSR system. The block diagram is shown in Figure 2.3. In the client side, the specification defines three major parts: the algorithm for front-end feature extraction, the processing to compress these features, and the formatting of these features. In the feature extraction part, noise reduction is performed on a frame-by-frame basis, and then mel-cepstral features are extracted. Noise reduction is performed based on Wiener filter theory in the frequency domain. After subdividing the input signal, the linear spectrum of each speech frame and the frequency-domain Wiener filter coefficients are calculated by using the estimates of speech spectrum and noise spectrum. The noise spectrum is estimated only within the silence frames, which are located by a voice activity detector. An adaptive noise reduction filter is used to subtract an additive noise from the input signal so as to improve the signal-to-noise ratio. For the cepstral analysis, noise-reduced speech signals are analyzed using a 25 ms Hamming window with 10 ms frame shift. The ceptsral coefficients are calculated from the mel-frequency warped Fourier transform representation of the log-magnitude spectrum. Mel-cepstral coefficients contain important cues in characterizing the speech sounds and are widely used in speech recognition applications.
Figure 2.3: Block diagram of the ETSI-DSR system.
scheme for speech input to be transmitted to a remote recognizer. Each speech frame is represented by a 14-dimension feature vector containing log-energy logE and 13 Mel-frequency cepstral coefficients (MFCCs) ranging from C0 to C12. These features
are further compressed based on a split vector codebook where the set of 14 features is split into 7 subsets with two features in each. Each feature pair is quantized using its own codebook to obtain a lower transmission data rate. MFCCs C1 to C10 are
quantized with 6 bits each pair, (C11, C12) is quantized with 5 bits, and (C0, logE) is
quantized with 8 bits. Experiments on small and large vocabularies indicated that the compression of mel-cepstrum parameters does not produce a significant degradation in recognition performance. After the split vector quantization, two quantized frames are grouped together and protected by a 4-bit cyclic redundancy check creating a 92-bit frame-pair packet. Twelve of these frame-pairs are combined and appended with overhead bits resulting in an 1152-bit multiframe packet representing 240 ms of speech. Multiframe packets are concatenated into a bit-stream for transmission via a data channel with an overall data rate of 4800 bits/s.
The remote back-end server performs three procedures step-by-step, including the error mitigation, decompression and recognition decoding. The error mitigation al-gorithm consists of two stages: detection of speech frames received with error and substitution of parameters when error are detected. The error detection includes a
CRC checking and a data consistency test. When an incorrect CRC is detected, the corresponding frame pair is classified as received with error. Besides, the consistency test is used to determine whether adjacent frames in a frame pair have a minimal conti-nuity. When a frame is labelled as having errors, then the whole frame is replaced with the copy of the parameters from the nearest correct frame received. The front-end parameter are decompressed to reconstitute the DSR mel-cepstrum features. These are passed to the recognition decoder residing on the server. The reference recognizer is based on the HTK software package from Entropic. HTK is primarily designed for building HMM-based speech processing tools, in particular recognizers. HMM ap-proach to speech recognition is a well-known statistical method used for characterizing the spectral properties of the speech.
In our work, the recognition of Mandarin digit strings is considered as the task without restricting the string length. A mandarin digit string database recorded by 50 male and 50 female speakers was used in our experiments. Each speaker pronounced 10 utterances and 1-9 digits in each utterance. The speech of 90 speakers (45 male and 45 female) was used as the training data, and the speech of other 10 as test data. The number of digits included in the training and test data were 6796 and 642, respectively. The digits were modelled as whole word Hidden Markov Models (HMMs) with 8 states per word and 64 mixtures for each state. In addition, a 3-state HMM was used to model pauses before and after the utterance and a one-state HMM was used to model pauses between digits. For recognition the 12 Mel-cepstrum coefficients and log-energy plus the corresponding delta and acceleration coefficients are considered.
2.3
Chinese Language Characteristics
Mandarin Chinese is a tonal language in which each syllable, with few exceptions, rep-resents a morpheme [23]. A distinctive feature of the language is that all the characters are monosyllabic. Traditional descriptions of the Chinese syllable structure divide
syl-lables into combinations of initials and finals rather than into individual phonemes. An initial is the consonant onset of a syllable, while a final comprises a vowel or diph-thong but includes a possible medial or nasal ending. There are 22 initials and 38 finals in Mandarin and all the syllables with the initial-final combinations have 408 possible candidates. To convey different lexical meanings, each syllable can be pro-nounced with four basic tones; namely, the high-level tone (tone 1), the rising tone (tone 2), the falling-rising tone (tone 3), and the falling tone (tone 4). The tones are acoustically correlated with different fundamental frequency (F0) contours, and they use duration and intensity of the vowel nucleus to provide secondary information. It has been found that for Mandarin speech the vocal tract shape or parameters are es-sentially independent of the tones, and the tones can be separately recognized using the pitch contour information. Therefore, the tone-syllable structure is able to provide a concise and practical recognition unit and is helpful to design the Mandarin speech recognition system.
Vowels and consonants are different in the manner of their production. Most vowels are pronounced with the vocal folds vibrating, with each vowel being modified by the particular shape of the vocal tract. Depending on the manner of articulation, initial consonants can be further categorized into five phonetic classes including fricatives, affricates, stops, nasals, and glides. The major distinction in consonant type is between resonant and occlusive. Occlusive consonants depend on the obstruction degree of the airstream. Stops are produced with the mouth completely closed, and the airstream is completely stopped. In fricative consonants the mouth is not shut and the airstream is only directed through a narrow space. Affricates can be considered a combination of a stop and a fricative. In general, they start out with complete closure of the vocal tract, but then they are released in a fricative. Moreover, resonant consonants, like nasals and glides, are closer to vowels, and the vocal tract is not obstructed. Furthermore, vowels can be considered as more steady-state in nature with several hundred milliseconds in duration. By contrast, consonants are characterized by a more rapid changing
Chapter 3
Channel-Robust DSR over Wireless
Networks
The increasing use of mobile communications has lead to DSR systems being devel-oped. Transmitting DSR data over wireless environments can suffer from channel errors and consequently leads to degraded recognition performance. The ETSI Aurora DSR standard includes a basic error mitigation algorithm that has been shown effective for medium and good quality channels. In the case of packet-erasure channels, several packet loss compensation techniques such as interpolation and error control coding have been introduced for DSR. However, better mitigation algorithms have been de-rived from the joint source-channel decoding. In this chapter we attempt to capitalize more fully on the a priori knowledge of source and channel, and investigate the er-ror mitigation algorithms for DSR systems with increased robustness against channel errors.
3.1
Joint Source-Channel Coding
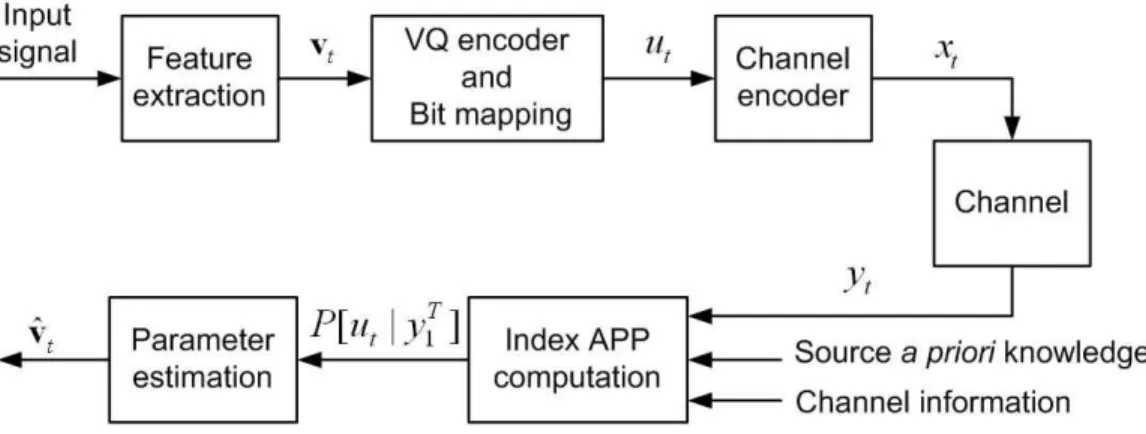
This work is devoted to channel error mitigation for DSR over burst error channels. Figure 3.1 gives the block diagram of the transmission scheme for each DSR feature pair. Suppose at time t, the input vector vt is quantized to obtain a codevector
ct ∈ {c(i), i = 0, 1, . . . , 2k − 1} that, after bit mapping, is represented by a k-bit
combination ut = (ut(1), ut(2), . . . , ut(k)). Each bit combination ut is assigned to a
quantizer index i ∈ {0, 1, . . . , 2k− 1} and we write for simplicity u
t= uitto denote that
ut represents the i-th quantizer index. Unlike source coding, the goal of DSR front-end
for speech recognition is not to obtain a very low bit rate by removing the redundancy in the speech signal. Therefore, the VQ encoder exhibits considerable redundancy within the encoded index sequence, either in terms of a non-uniform distribution or in terms of correlation. If only the non-uniform distribution is considered and the indexes are assumed to be independent of each other, the redundancy is defined as the difference of between the index length k and the entropy given by
H(ut) = −
X
ut
P (ut) · log2P (ut). (3.1)
If inter-frame correlation of indexes is considered by using a first-order Markov model with transition probabilities P (ut, ut−1), the redundancy is then defined as the index
length k and the conditional entropy given by
H(ut|ut−1) = − X ut X ut−1 P (ut, ut−1) · log2P (ut|ut−1). (3.2)
Table 3.1 shows the index lengths and entropies for the seven feature pairs of the ETSI DSR frond-end. For each column in Table 3.1, the probabilities P (ut) and
P (ut, ut−1) have to be estimated in advance from a training speech database. There is
considerable residual redundancy left in the encoded index. From it we see that the DSR index sequence is better characterized by a first-order Markov process. For error protection individual index-bits are fed into a binary convolutional encoder consisting
Figure 3.1: Transmission scheme for each DSR feature pair.
of M shift registers. The register shifts one bit at a time and its state is determined by the M most recent inputs. After channel encoding, the code-bit combination cor-responding to the quantizer index ut is denoted by xt = (xt(1), xt(2), . . . , xt(n)) with
the code rate R = k/n. One of the principal concerns in transmitting VQ data over noisy channels is that channel errors corrupt the bits that convey information about quantizer indexes. Assume that a channel’s input xt and output yt differ by an error
pattern et, so that the received bit combination is yt= (yt(1), yt(2), . . . , yt(n)) in which
yt(l) = xt(l) ⊕ et(l), l = 1, 2, . . . , n, and ⊕ denotes the bitwise modulo-2 addition. At
the receiver side, instead of using a conventional codebook-lookup decoder, the JSCD decoder will find the most probable transmitted quantizer index given the received sequence. The decoding process starts with the formation of a posteriori probability (APP) for each of possibly transmitted indices ut = i, which is followed by choosing
the index value ˆi that corresponds to the maximum a posteriori (MAP) probability for that quantizer index. Once the MAP estimate of the quantizer index is determined, its corresponding codevector becomes the decoded output ˆvt = c(ˆi). The APP that a
decoded index ut = i can be derived from the joint probability P (uit, st, yT1), where st
is the channel encoder state at time t and yT
Table 3.1: Entropies for DSR feature pairs.
from time t = 1 through some time T . We have chosen the length T = 24 in compliance with the ETSI bit-streaming format, where each multiframe message packages speech features from 24 frames. Proceeding in this way, the symbol APP can be obtained by summing the joint probability over all encoder states, as follows:
P (ut= i|y1T) = X st P (ui t, st, y1T) P (yT 1) , i = 0, 1, . . . , 2k− 1. (3.3)
As measure of quality the parameter signal-to-noise ratio can be formulated as
SN R = 10 log10 E{v 2 t} E{(ˆvt− vt)2} . (3.4)
3.2
Modified BCJR Algorithm
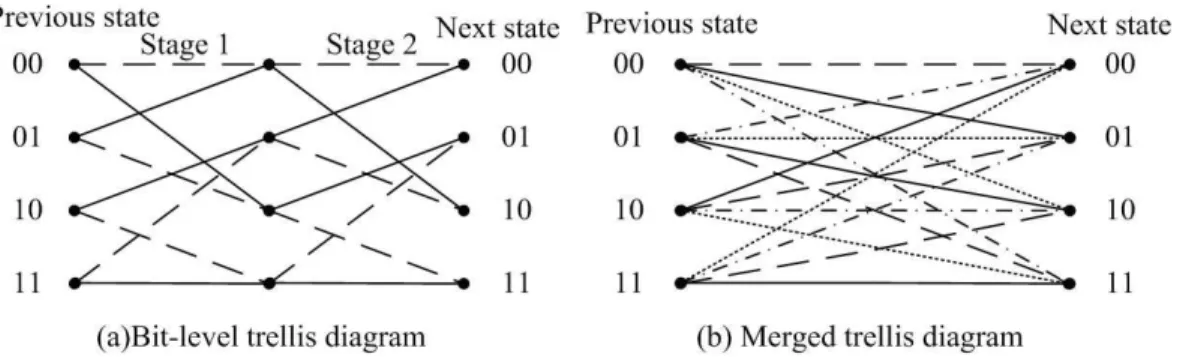
Depending upon the choice of the symbol APP calculator, a number of different MAP decoder implementations can be realized. For decoding convolutional codes, conven-tional BCJR algorithm [24] has been devised based on a bit-level code trellis. In a bit-level trellis diagram, there are two branches leaving each state and every branch represents a single index-bit. Proper sectionalization of a bit-level trellis may result in useful trellis structural properties [25] and allow us to devise MAP decoding algo-rithms which exploits bit-level as well as symbol-level source correlations. To advance with this, we propose a modified BCJR algorithm which parses the received code-bit
Figure 3.2: Trellis diagrams used for (a) the encoder and (b) the MAP decoder.
sequence into blocks of length n and computes the APP for each quantizer index on a symbol-by-symbol basis. Unlike conventional BCJR algorithm that decodes one bit at a time, our scheme proceeds with decoding the quantizer indexes in a frame as nonbi-nary symbols according to their index length k. By parsing the code-bit sequence into n-bit blocks, we are in essence merging k stages of the original bit-level code trellis into one. As an example, we illustrate in Figure 3.2 two stages of the bit-level trellis diagram of a rate 1/2 convolutional encoder with generator polynomial (5, 7)8. The
solid lines and dashed lines correspond to the input bits of 0 and 1, respectively. Figure 3.2 also shows the decoding trellis diagram when two stages of the original bit-level trellis are merged together. In general, there are 2k branches leaving and entering each
state in a k-stage merged trellis diagram. Having defined the decoding trellis diagram as such, there will be one symbol APP corresponding to each branch which represents a particular quantizer index ut= i. For convenience, we say that the sectionalized trellis
diagram forms a finite-state machine defined by its state transition function S(ui t, st)
and output function X(ui
t, st). Viewing from this perspective, the code-bit combination
xt = X(uit, st) is associated with the branch from state st to state st+1 = S(uit, st) if
We next modified the BCJR algorithm based on sectionalized trellis to exploit the combined a priori information of source and channel. We begin our development of the modified BCJR algorithm by rewriting the joint probability in (3.3) as follows:
P (uit, st, yT1) = αti(st)βti(st), (3.5)
where αi
t(st) = P (uit, st, y1t) and βti(st) = P (yTt+1|uit, st, yt1). For the MAP symbol
de-coding algorithm, the forward and backward recursions are to compute the following metrics: αit(st) = X st−1 X j P (uit, st, ujt−1, st−1, yt, yt−11 ) = X st−1 X j αjt−1(st−1)γi,j(yt, st, st−1) (3.6) βti(st) = X st+1 X j P (ujt+1, st+1, yt+1, yt+2T |u i t, st, y1t) = X st+1 X j βt+1j (st+1)γj,i(yt+1, st+1, st) (3.7) in which γi,j(yt, st, st−1) = P (uit, st, yt|u j t−1, st−1, yt−11 ) = P (st|u j t−1, st−1, yt−11 )P (u i t|st, u j t−1, st−1, yt−11 ) · P (yt|uit, st, u j t−1, st−1, yt−11 ). (3.8)
Having a proper representation of the branch metric γi,j(yt, st, st−1) is the critical
step in applying MAP symbol decoding to error mitigation and one that conditions all subsequent steps of the implementation. As a practical manner, several additional factors must be considered to take advantage of source correlation and channel memory. First, making use of the sectionalized structure of a decoding trellis, we write the first
term in (3.8) as P (st|ujt−1, st−1, y1t−1) = P (st|ujt−1, st−1) = 1 , st = S(ujt−1, st−1) 0, otherwise. (3.9)
The next knowledge source to be exploited is the residual redundancy remaining in the DSR features. Assuming that the quantizer index is modelled as a first-order Markov process with transition probabilities P (ut|ut−1), the second term in (3.8) is reduced to
P (ui
t|st, ujt−1, st−1, y1t−1) = P (ut = i|ut−1 = j). (3.10)
In addition to source a priori knowledge, specific knowledge about the channel memory must be taken into consideration. There are many models describing the correlation of bit error sequences. If no channel memory information is considered, which means that the channel bit errors are assumed to be random, the third term in (3.8) is reduced to
P (yt|uit, st, u j
t−1, st−1, yt−11 ) = P (yt|xt= X(uit, st)) = P (et) = ǫl(1 − ǫ)n−l (3.11)
where ǫ is the channel bit error rate (BER) and l is the number of ones occurring in the error pattern et. When intraframe and interframe memory of the channel are
considered, the third term in (3.8) becomes
P (yt|uit, st, ujt−1, st−1, yt−11 ) = P (yt|xt= X(uit, st), xt−1 = X(ujt−1, st−1), yt−1)
= P (et|et−1). (3.12)
3.3
Probability Recursions for Gilbert channel
Designing a robust DSR system requires that parameterized probabilistic models be used to summarize some of the most relevant aspects of error statistics. It is apparent from previous work on channel modelling [26] that we are confronted with contrasting
Figure 3.3: Gilbert channel model.
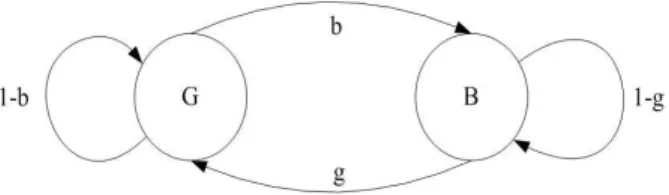
requirements in selecting a good model. A model should be representative enough to describe real channel behavior and yet it should not be analytically complicated. To permit theoretical analysis, we assumed that the encoded bits of DSR features were subjected to the sample error sequences typical of the Gilbert channel [27]. The Gilbert channel model consists of a Markov chain having an error-free state G and a bad state B, in which errors occur with the probability (1 − h). The state transition probabilities are b and g for the G to B and B to G transitions, respectively. The model state-transition diagram is shown in Figure 3.3. The effective BER produced by the Gilbert channel is ǫ = (1 − h)b/(g + b). Notice that in the particular case of a Gilbert model with parameter values b = 1, g = 0, h = 1 − ǫ, the channel model reduces to a memoryless binary symmetric channel with the BER ǫ.
The effectiveness of the MAP symbol decoding depends crucially on how well the error characteristics are incorporated into the calculation of channel transition probabil-ities P (et|et−1). Although using channel memory information was previously proposed
for MAP symbol decoding [28], their emphasis were placed upon channels with no inter-frame memory. When only access to the intrainter-frame memory is available, it was shown [27] that the channel transition probabilities of the Gilbert channel have closed-form expressions that can be represented in terms of model parameters {h, b, g}. Under such conditions, we can proceed the MAP symbol decoding in a manner similar to the work of [28]. Extensions of these results to channels with both intraframe and interframe memory has been found difficult. Recognizing this, we next develop a general
treat-ment of probability recursions for the Gilbert channel. The main result is a recursive implementation of MAP symbol decoder being closer to the optimal for channels with memory. For notational convenience, channel bit error et(l) will be denoted as rm, in
which the bit time m is related to the frame time t as m = n(t − 1) + l, l = 1, 2, . . . , n. Let qm ∈ {G, B} denote the Gilbert channel state at bit time m. The memory of the
Gilbert channel is due to the Markov structure of the state transitions, which lead to a dependence of the current channel state qm on previous state qm−1.
To develop a recursive algorithm, it is more convenient to rewrite the channel transition probabilities as P (et|et−1) = nt Y m=n(t−1)+1 P (rm = 1|rm−1m0 ) rmP (r m = 0|rmm−10 ) 1−rm (3.13) where rm−1
m0 = (rm0, rm0+1, . . . , rm−1) represents the bit error sequence starting from
bit m0 = n(t − 2) + 1. The following is devoted to a way of recursively computing
of P (rm = 1|rmm−10 ) from P (rm−1 = 1|r
m−2
m0 ). The Gilbert channel has two properties,
P (qm|qm−1, rmm−10 ) = P (qm|qm−1) and P (rm|qm, r
m−1
m0 ) = P (rm|qm), which facilitate the
probability recursions. By successively applying Bayes rule and the Markovian property of the channel, we have
P (rm= 1|rm−1m0 ) = P (rm = 1|qm = B, r m−1 m0 )P (qm = B|r m−1 m0 ) = (1 − h)P (qm = B|rmm−10 ) (3.14) in which P (qm = B|rmm−10 ) = P (qm = B|qm−1 = G, r m−1 m0 )P (qm−1 = G|r m−1 m0 ) +P (qm = B|qm−1 = B, rm−1m0 )P (qm−1 = B|r m−1 m0 ) = b + (1 − g − b)P (rm−1|qm−1 = B) P (rm−1|rmm−20 ) P (rm−1 = 1|rm−2 m0 ) 1 − h .(3.15)
3.4
Experimental Results
Computer simulations were conducted to evaluate three MAP-based error mitigation schemes for DSR over burst error channels. First a bit-level trellis MAP decoding scheme BMAP is considered that uses the standard BCJR algorithm to decode the index-bits. The decoders SMAP1 and SMPA2 exploit the symbol-level source redun-dancy by using a modified BCJR algorithm based on a sectionalized trellis structure. The SMAP1 is designed for a memoryless binary symmetric channel, whereas the SMAP2 exploits the channel memory though the Gilbert channel characterization. The channel transition probabilities to be used for the SMAP1 is p(et) in (3.11), and
p(et|et−1) in (3.12) for the SMAP2. For purpose of comparison, we also investigated
an error mitigation scheme [15] which applied the concept of softbit speech decoding (SBSD) and achieved good recognition performance for AWGN and burst channels. A preliminary experiment was first performed to evaluate various decoders for reconstruc-tion of the feature pair (C0, logE) encoded with the DSR front-end. A rate R = 1/2
convolutional code with memory order M = 6 and the octal generator (46, 72)8 is
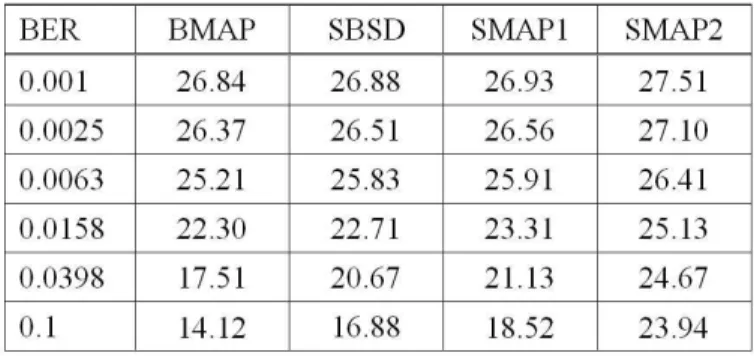
cho-sen as the channel code. Table 3.2 precho-sents the signal-to-noise ratio (SNR) obtained from transmission of the index-bits over Gilbert channel with BER ranging from 10−3
to 10−1. The results of these experiments clearly demonstrate the improved
perfor-mance achievable using the SMAP1 and SMAP2 in comparison to those of BMAP and SBSD. Furthermore, the improvement has a tendency to increase for noisy channels with higher BER. This indicates that the residual redundancy of quantizer indexes is better to be exploited at the symbol level to achieve more performance improvement. A comparison of the SMAP1 and SMAP2 also revealed the importance of matching the real error characteristics to the channel model on which the MAP symbol decoder design is based. The better performance of SMAP2 can be attributed to its ability to compute the symbol APP taking interframe and intraframe memory of the channel into consideration, as opposed to the memoryless channel assumption made in the SMAP1. We further validate the proposed decoding algorithms for the case where error
se-Table 3.2: SNR(dB) performance for various decoders on a Gilbert channel.
quences were generated using a complete GSM simulation. The simulator is based on the CoCentric GSM library [29] with TCH/F4.8 data and channel coding, interleaving, modulation, a channel model, and equalization. The channel model represents a typical case of a rural area with 6 propagation paths and a user speed of 50 km/h. Further, cochannel interference was simulated at various carrier-to-interference ratios (CIR). In using the SMAP1 and SMAP2 schemes, the channel transition probabilities have to be combined with a priori knowledge of Gilbert model parameters which can be estimated once in advance using the gradient iterative method [30]. For each of simulated error sequences, we first measured the error-gap distribution by computing the probability that at least l successive error-free bits will be encountered next on the condition that an error bit has just occurred. The optimal identification of Gilbert model parame-ters was then formulated as the least square approximation of the measured error-gap distribution by exponential curve fitting. Table 3.3 gives estimated Gilbert model pa-rameters for the GSM TCH/F4.8 data channels operating at CIR = 1, 4, 7, 10 dB. The next step in the present investigation concerned the performance degradation that may result from using the SMAP2 scheme under channel mismatch conditions. In Table 3.4, CIRd refers to the CIR value assumed in the design process, and CIRa refers to
the true CIR used for the evaluation. The best results are in the main diagonal of the table, where channel-matched Gilbert model parameters are used for the channel
tran-Table 3.3: Estimated Gilbert model parameters for GSM TCH/F4.8 data channels.
Table 3.4: SNR performance of the SMAP2 over the GSM data channel under channel mismatch conditions.
sition probability computation of (3.13). The performance decreases in each column below the main diagonal when the CIRdis increased. The investigation further showed
that the SMAP2 is not very sensitive to a channel mismatch between the design and evaluation assumptions.
We next considered the speaker-independent recognition of Mandarin digit strings as the task without restricting the string length. A Mandarin digit string database recorded by 50 male and 50 female speakers was used in our experiments. Each speaker pronounced 10 utterances and 1-9 digits in each utterance. The speech of 90 speakers (45 male and 45 female) was used as the training data, and the other 10 as test data. The total numbers of digits included in the training and test data were 6796 and 642, respectively. The DSR results obtained by various error mitigation algorithms for the
Figure 3.4: Recognition performances for DSR transmission over a Gilbert channel.
Gilbert channel are shown in Figure 3.4. It can be seen that employing the source a priori information, sectionalized trellis MAP decoding, and channel memory constantly improves the recognition accuracy. The SMAP2 scheme performs the best in all cases, showing the importance of combining the a priori knowledge of source and channel by means of a sectionalized code trellis and Gilbert channel characterization.
3.5
Summary
A JSCD scheme which exploits the combined source and channel statistics as an a priori information is proposed and applied to the channel error mitigation in DSR applica-tions. We first investigate the residual redundancies existing in the DSR features and find ways to exploit these redundancies in the MAP symbol decoding process. Also proposed is a modified BCJR algorithm based on sectionalized code trellises which
uses Gilbert channel characterization for better decoding in addition to source a priori knowledge. Experiments on Mandarin digit string recognition indicate that the pro-posed decoder achieved significant improvements in recognition accuracy for DSR over burst error channels.
Chapter 4
Speaker-Adaptive DSR for
Hearing-Impaired Mandarin Speech
In this chapter we investigate the use of voice conversion based on feature transforma-tion to perform speaker adaptatransforma-tion and to reduce the speaker variability for hearing-impaired speaker. Due to the lack of adequate auditory feedback, the hearing-hearing-impaired speakers produce speech with segmental and suprasegmental errors. This motivates our research into trying to devise a voice conversion system that modifies the speech of a hearing-impaired (source) speaker to be perceived as if it was uttered by a normal (tar-get) speaker. The key to our proposed conversion lies in the detection and exploitation of characteristic features that distinguish the impaired speech from the normal speech at segmental and prosodic levels. Segmental features that contribute to speech individ-uality are encoded in the spectral envelop, whereas prosodic information can be found in pitch, energy, and duration variations that span across segments. Thus, we present that speech waveforms are modelled by the sinusoidal framework which decomposes speech signals into the product of excitation and system spectra and makes the recon-struction a best fit to the original speech [31]. Next, the conversion techniques were applied on the framework to enhance the hearing-impaired Mandarin speech.
4.1
Characteristics of Hearing-Impaired Mandarin
Speech
Speech communication by profoundly hearing-impaired individuals suffers not only from the fact that they cannot hear other people’s utterances, but also from the poor quality of their own productions. Due to the lack of adequate auditory feedback, the hearing-impaired speakers produce speech with segmental and suprasegmental errors [32]. It is common to hear their speech flawed by misarticulated phonemes, with vary-ing degrees of severity associated with their hearvary-ing thresholds [33,34]. Their speech intelligibility is further affected by abnormal control over phoneme duration and pitch variations. Specifically, the duration of vowels, glides, and nasals were longer while the duration of fricatives, affricates, and plosives were shorter than in normal speech, and the pitch contour over individual syllables is either too varied or too monotonous. Their intonation also shows limited pitch variation, erratic pitch fluctuations, and in-appropriate average F0 [35].
Recent perceptual work on Chinese deaf speech [36,37] has shown that speakers with greater than moderate degrees of losses (≥ 50 dB HL bilaterally) were perceived with an average accuracy of 31% in phoneme production, and further, that the most errors in the consonants were affricates and fricatives. This finding may have more serious implications for Mandarin than for other languages as these two phonetic classes make up more than half of the consonants in Mandarin Chinese. Moreover, since most of them are palatal or produced without apparent visual cues, they are difficult to correct through speech training. In tone production, their accuracy only reached an average of 54%, with most errors involving confusions between tones 1 and 4, tones 1 and 2, and tones 2 and 3. The results also showed that tones produced by speakers with profound losses were only half as likely to be judged correct as those produced by speakers with less loss. Again, as tones are produced by phonatory, rather than articulatory control, they are almost impossible to correct through non-instrumental-based speech therapy.
The four basic Mandarin tones mentioned earlier have distinctive shapes of F0 contours, whose perception is correlated with the starting frequency, the initial fall and the timing when the turning point appears, as involved in tones 2 and 3 [38]. Our teenage data supported the general conclusion with a different measure. Specifically, instead of focusing on the interactions between the frequency and temporal aspects, we recorded the frequency differences between the highest and the lowest point found on the contours. The results showed a clear trend for the normal speakers with the difference increased when going from tone 1 to tone 4 (e.g., 19.6, 24.8, 53, 113.1 Hz), which was less orderly (e.g., 9.3, 16, 28, 66.4 Hz) for the impaired speakers. The most frequent perceptual mistakes made by our impaired speakers were substitutions of tone 3 with tone 2, which left only three perceptual categories 1, 2, and 4 in their tonal repertoire. Unstable tonal productions across recorded tokens were also common. As stated earlier [35], the speech of the hearing-impaired speakers contains numer-ous timing errors, including a lower speaking rate, insertion of long pauses, and failure to modify segment duration as a function of phonetic environment. In Figure 4.1 the mean phoneme durations produced by the hearing impaired were plotted against those produced by the normal speakers. Data were collected from two normal speakers (one male and one female) and three hearing-impaired speakers (one male and two females), all aged 15. The phonemes tested were five fricatives, six affricates, and three vowels. It can be seen that the mean duration ratios of impaired-to-normal utterances were quite different for different phonemes and that vowels, as a group, stayed much in line with the normal production than the two consonant groups, with the mean ratios for vowels, fricatives, and affricates being 1.12, 0.4, and 0.34, respectively. All consonants, with the exception of /h/, of the hearing impaired were shorter, as indicated by their uniform appearances on the lower half of the graph. Our perceptual judgment showed that this shortening that could measure 10 to 1 (as seen in /sh/ and /shi/) was the result of substituting the two consonant classes with stops.
Figure 4.1: Phoneme duration statistics for (a) vowels and fricative consonants and (b) affricate consonants.
4.2
Sinusoidal Framework for Voice Conversion
The general approach to voice conversion consists of first analyzing the input speech to obtain characteristic features, then applying the desired transformations to these fea-tures, and synthesizing the corresponding signal. Essentially, the production of sound can be described as the output of passing a glottal excitation signal through a linear system representing the characteristics of the vocal tract. To track the nonstationary evolution of characteristic features, both the spectral and prosodic manipulations will be performed on a frame-by-frame basis. In this work, speech signals were sampled at 11 kHz and analyzed using a 46.4 ms Hamming windows with a 13.6 ms frame shift. Therefore, the analysis frame interval Q was fixed at 13.6 ms. For the speech on the mth frame, the vocal tract system function can be described in terms of its amplitude function M (w; m) and phase function Φ(w; m). Usually the excitation signal is repre-sented as a periodic train during voiced speech, and is reprerepre-sented as a noise-like signal during unvoiced speech. An alternative approach [39] is to represent the excitation signal by a sum of K(m) sine waves, each of which is associated with the frequency
wk(m) and the phase Ωk(m). Passing this excitation signal through the vocal tract
system results in a sinusoidal representation of speech production. As noted elsewhere [40], this sinusoidal framework allows flexible manipulation of speech parameters such as pitch and speaking rate while maintaining high speech quality.
A block diagram of the proposed voice conversion system is shown in Figure 4.2. The system has five major components: speech analysis, spectral conversion, pitch modification, time-scale modification, and speech synthesis. The analysis begins by es-timating from the Fourier transform of input speech the pitch period P0(m), the voicing
probability Pv(m), and the system amplitude function M (w; m). The voicing
probabil-ity will be used to control the harmonic spectrum cutoff frequency, wc(m) = πPv(m),
below which voiced speech was synthesized and above which unvoiced speech was syn-thesized. The second step in the analysis is to represent the system amplitude function M (w; m) in terms of a set of cepstral coefficients {cl(m)}24l=0. The main attraction of
cepstral representation is that it exploits the minimum-phase model, where the log-magnitude and phase of the vocal tract system function can be uniquely related in terms of the Hilbert transform [41]. A more comprehensive discussion of the sine-wave speech model and the corresponding analysis-synthesis system can be found in [39].
The main part of the modification procedure involves the manipulation of functions which describe the amplitude and phase of the excitation and vocal tract system con-tributions to each sine-wave component. The effectiveness of voice conversion depends on a successful modification of prosodic features, especially of the time-scale and the pitch-scale. With reference to the sinusoidal framework, speech parameters included in the prosodic conversion are P0(m), Pv(m), and the synthesis frame interval. The
time-scale modification involves scaling the synthesis frame of original duration Q by a factor of ρ(m), i.e., Q′(m) = ρ(m)Q. The pitch modification can be viewed as a
transformation which, when applied to the pitch period P0(m), yields the new pitch
period P′
0(m), with an associated change in the F0 as w0′(m) = 2π/P0′(m). It is worth
Figure 4.2: Block diagram of the voice conversion system.
sine-wave frequencies w′
k(m) and the excitation phases Ω′k(m) used in the
reconstruc-tion. Below the cutoff frequency the sine-wave frequencies are harmonically related as w′
k(m) = kw′0(m), whereas above the cutoff frequency wk′(m) = k∗w0′(m) + wu, where
k∗ is the largest value of k for which k∗w′
0 ≤ wc(m), and where wu is the unvoiced F0
corresponding to 100 Hz. A two-step procedure is used in estimating the excitation phase Ω′
k(m) of the kth sine wave. The first step is to obtain the onset time n′0(m)
relative to both the new pitch period P′
0(m) and the new frame interval Q′(m). This
is done by accumulating a succession of pitch periods until a pitch pulse crosses the center of the mth frame. The location of this pulse is the onset time n′
0(m) at which
sine waves are in phase. The second step is to compute the excitation phase as follows: Ω′
k(m) = −n′0(m)wk′(m) + ǫ′k(m), (4.1)
where the unvoiced phase component ǫ′
k(m) is zero for the case of wk′(m) ≤ wc(m) and
is made random on [−π, π] for the case of w′
k(m) > wc(m).
In addition to prosodic conversion, the technique of spectral conversion is also needed to modify the articulation-related parameters of speech. The problem with the
spectral conversion lies with the corresponding modification of the vocal tract system function. Thus there is a need to estimate the amplitude function M′(w; m) and the
phase function Φ′(w; m) of the vocal tract system. If it is assumed that the vocal tract
system function is minimum phase [41], the log-magnitude and phase functions form a Hilbert transform pair and hence can be estimated from a set of new cepstral coefficients {c′
l(m)}24l=0. The system amplitudes Mk′(m) and phases Φ′k(m) are then given by samples
of their respective functions at the new frequencies w′
k(m), i.e., Mk′(m) = M′(wk′; m)
and Φ′
k(m) = Φ′(wk′; m). Finally, in the synthesizer the system amplitudes are linearly
interpolated over two consecutive frames. Also, the excitation and system phases are summed and the resulting sine-wave phases, θ′
k(m) = Ω′k(m) + Φ′k(m), are interpolated
using the cubic polynomial interpolator. The final synthetic speech waveform on the mth frame is given by s(n) = K(m)X k=1 M′ k(m)cos[nw′k(m) + θk′(m)], tm ≤ n ≤ tm+1− 1 (4.2)
where tm =Pm−1i=1 Q′(i) denotes the starting time of the current synthesis frame.
4.3
Spectral Conversion
Mandarin is a syllable-timed language in which each syllable consists of an initial part and a final part. The primary difficulties in the recognition of Mandarin syllables are tied to the durational differences between the syllable-initial and syllable-final part. Specifically, the initial part of a syllable is short when compared with the final part, which usually causes distinctions among the initial consonants in different syllables to be swamped by the following irrelevant differences among the finals. This may help explain why early approaches that used whole-syllable models as the conversion units did not produce satisfactory results for Mandarin speech conversion. To circumvent this pitfall, we perform spectral conversion only after decomposing the Mandarin syllables into smaller sound units as in phonetic classes. The acoustic features included in
the conversion are cepstral coefficients derived from the smoothed spectrum. The conversion system design involves two essential problems: 1) developing a parametric model representative of the distribution of cepstral coefficients, and 2) mapping the spectral envelopes of the source speaker onto those of the target. In the context of spectral transformation, Gaussian mixture models (GMMs) have been shown to provide superior performance to other approaches based on VQ or neural networks [42]. Our approach began with a training phase in which all cepstral vectors of the same phonetic class were collected and used to train the corresponding GMM associated with the phonetic class by a supervised learning procedure. We consider that the available data consists of two sets of time-aligned cepstral vectors xt and yt, corresponding,
respectively, to the spectral envelopes of the source and the target speakers. The GMM assumes that the probability distribution of the cepstral vectors x takes the following parametric form
p(x) = I X i=1 αiN (x; µxi, Σ xx i ) (4.3)
where αi denotes a weight of class i, I = 24 denotes the total number of Gaussian
mixtures, and N (x; µx
i, Σxxi ) denotes the normal distribution with mean vector µxi and
covariance matrix Σxx
i . It therefore follows the Bayes theorem that a given vector x is
generated from the ith class of the GMM with the probability:
hi(x) =
αiN (x, µxi, Σxxi )
PI
j=1αjN (x, µxj, Σxxj )
. (4.4)
With this, cepstral vectors are converted from the source speaker to the target speaker by the conversion function that utilizes feature parameter correlation between the two speakers. The conversion function that minimizes the mean squared error between converted and target cepstral vectors was given by [42],
F(xt) = I X i=1 hi(xt)[µ y i + Σ yx i (Σxxi )−1(xt− µxi)], (4.5)
where for class i, µyi denotes the mean vector for the target cepstra, Σxxi denotes
covariance matrix for the source cepstra, and Σyxi denotes the cross-covariance matrix.
Within the GMM framework, training the conversion function can be formulated as one of the optimal estimation of model parameters λ = {αi, µxi, µ
y
i, Σxxi , Σ yx
i }. Our
approach to parameter estimation is based on fitting a GMM to the probability distri-bution of the joint vector zt = [xt, yt]T for the source and target cepstra. Covariance
matrix Σz
i and mean vector µzi of class i for joint vectors can be written as
Σzi = Σxx i Σ xy i Σyxi Σyyi , µzi = µ x i µyi . (4.6)
The expectation-maximization (EM) algorithm [43] is applied here to estimate the model parameters which guarantees a monotonic increase in the likelihood. Starting with an initial model λ, the new model ¯λ is estimated by maximizing the auxiliary function Q(λ, ¯λ) = T X t=1 I X i=1
p(i|zt, λ) · log p(i, zt|¯λ), (4.7)
where p(i, zt|¯λ) = ¯αiN (zt, ¯µzi, ¯Σ z i), (4.8) and p(i|zt, λ) = αiN (zt, µzi, Σzi) PI j=1αjN (zt, µzj, Σzj) . (4.9)
On each EM iteration, the reestimation formulas derived for individual parameters of class i are of the form
¯ αi = 1 T T X t=1 p(i|zt, λ), (4.10)