亞東技術學院
資訊與通訊工程研究所
碩士論文
通道迴旋碼於 SDR 系統上之實現及驗證
Implementation and Verification of
Convolutional Code on SDR System
研 究 生 : 倪
逸
凡
誌謝
研究所三年學習的時間終於結束了,首先最感謝的當然是我的指導教 授陳益華老師,謝謝老師在專業知識的教導上總是不厭其煩的詳細說明, 並安排我在資策會與遠傳電信的實習以及參與 SDR 系統的團隊開發,讓 我了解當下業界的環境,使我可以將在課堂上的知識學以致用,並清楚 自己研究的方向與目標;也謝謝老師安排我在學校課堂上當助教,讓我 可以仔細複習無線通訊相關的專業知識,透過輔導大學部的學弟妹來加 強自己的專業能力,也讓我的敘述能力與台風都更為穩健,並培養出我 獨立思考及解決問題的能力,藉此讓本論文可以順利完成。 感謝我的爸爸媽媽,雖然當初在選擇念研究所的決定上有點衝突,但 在完成學業的這一刻還是非常謝謝爸媽,特別謝謝媽媽這段時間的鼓勵, 讓我心無旁騖的繼續研究所的學業;也謝謝兩位姐姐與哥哥在這段時間 的幫助,減輕我在念書這段時間的經濟壓力,特別謝謝二姐夫和二姐的 照顧,讓我減少往返家裡的時間,還有生活上的幫助,謝謝。 謝謝遠傳電信 Darrow 經理,讓我有機會可以參與相關的量測。謝謝 遠傳電信的宗仁學長,讓我的量測成果與報告可以順利完成,並教導我 很多電信的相關知識與簡報技巧。謝謝邦復、正璿、純君學長姐在課業 上的指導與照顧,謝謝曜駿、柏煒、維哲等同學及宗毅、長青、凱鴻等 學弟妹,每天一起吃飯、閒聊、一起熬夜作報告、寫程式,有妳們的參 與使我的研究更加順利,研究室也熱鬧不少,謝謝你們。 謝謝佳敏、維寧、盈娟、依婷、元鈞、孙恩、嘉鴻這群學生們,在我 研究空閒之餘陪我吃飯、看電影、聊近況,有你們的陪伴讓我的研究生 生活增添不少樂趣,也祝福你們大學畢業後的一切都順利,未來大家一 起加油。最後將本論文的貢獻與成果獻給這三年來所有一起共同努力的家人、 老師、朋友與學生們,謝謝。
摘要
以軟體定義無線電系統(Soft Defined Radio, SDR)硬體架構和 Lab VIEW 軟體設計平台,便可以透過前端的軟體控制,設計不同的通道編碼 (Channel Coding)及調變(Modulation)來快速驗證不同規範底下的通道編 碼及調變的效益;有別以往通訊系統的設計,模組電路經過編譯後即被 定型,若要改變通道編碼及調變方式必頇重新設計電路。本文利用 SDR 硬體架構和 LabVIEW 軟體設計平台,只需更新軟體編譯即可重新定義系 統架構,可以加速產品驗證的測詴過程和開發的效率,更可以減少電路 的廢棄物及降低成本的開銷,藉此來提高更彈性的系統測詴。
本論文對迴旋碼(Convolutional code),編碼率(Code Rate) = 1/2 中不同 的限制長度(Constraint length, K)架構,設計迴旋解碼器來分析及探討其解 碼 效 能 , 對 於 解 碼 前 端 解 調 變 (Demodulation) 使 用 星 座 圖 映 射 (Constellation Mapping) 的 方 式 , 搭 配 硬 式 解 碼 決 策 (Hard-Decision Decoding)和三位元軟式解碼決策(3 bits Soft-Decision Decoding)來比較碼 符號(Codeword)決策的信心測度(Measure of Confidence)做其說明;根據 迴旋碼解碼演算法–斐特比解碼演算法(Viterbi Decode Algorithm)中的回 朔追蹤(Trace Back)和暫存器交換(Register Exchange)之計算方式的設計 作說明,並描述詳細的圖解、分析與討論;也對斐特比解碼演算法中解 碼路徑深度(Decode path depth)的差異,探討其不同限制長度倍率的深度 路徑之效益比較。
本論文以 LabVIEW 設計迴旋編碼器(Convolutional Encoder)和斐特比 解碼器(Viterbi Decoder)之程式,在 AWGN 通道下進行模擬分析,並與 QPSK 錯誤機率曲線理論值對照,分析於 QPSK 調變下,發現(2,1,3)迴旋 碼在斐特比解碼演算法(硬式解碼決策, 解碼路徑深度 h=5)中,當錯誤機 率 Pb = 1E-3 時,相對於 QPSK Eb/N0編碼增益為 3.5dB;相對於(2,1,3)旋
碼在斐特比解碼演算法(軟式解碼決策, 解碼路徑深度 h=5)中相對於 QPSK Eb/N0編碼增益為 5dB。其模擬結果可以發現硬式解碼決策在斐特 比解碼演算法中解碼路徑深度倍率為限制長度的 5 倍收斂,而軟式解碼 決策在斐特比解碼演算法中解碼路徑深度倍率可以增加至限制長度的 7~8 倍,比解碼路徑深度 5 倍時而多增加 0.4 dB 的編碼增益。
關鍵字 : 迴旋碼,軟式解碼決策,斐特比解碼,軟體定義無線
電,Lab VIEW
Abstract
The hardware architechture of software-defined radio (SDR) and the design platform of the LabVIEW software can be implemented using front-end software control for designing various types of channel coding and modulation. This implementation can be used to rapidly verify the performance of channel coding and modulation under differing standards. In contrast with the design of previous communication systems, module circuits are fixed following compilation. Therefore, circuit redesign is required when adjusting channel coding and modulation. The hardware architecture of SDR and the software design platform of the LabVIEW software were employed in the present study so that the system architecture could be defined by simply updating the software compilation, thus accelerating product testing procedures and enhancing development efficiency, as well as further reducing circuit wastage and cost and promoting high-flexibility system testing.
A convolutional decoder was designed based on a structure of various constraint lengths (K) for a convolutional code with a code rate of 1/2. The proposed decoder was used to analyze and examine decoding performance. Constellation mapping was used for demodulation in front-end decoding, and hard-decision decoding and 3-bit soft-decision decoding were combined to compare and explain the measures of confidence for codeword decisions. The design of the track-back and register-exchange calculations of the Viterbi algorithm, a decoding algorithm for convolutional codes, was explained. Detailed figures, analyses, and discussions were presented. Differences in the decoding path depth of the Viterbi algorithm were explored to determine the performance at various constraint length ratios.
LabVIEW was employed to design a convolutional encoder and Viterbi decoder program. Simulation analysis was conducted using an additive white Gaussian noise channel. The results were then compared to the theoretical value of the error probability curve for quadrature phase shift keying (QPSK). In QPSK modulation, the code gain of Eb/N0 compared to QPSK was 3.5 dB
when the error probability of convolutional code (2, 1, 3) in the Viterbi algorithm (hard-decision decoding; decoding path depth h = 5) Pb = 1E-3. The code gain of Eb/N0 compared to QPSK was 5 dB when the error probability of
convolutional code (2, 1, 3) in the Viterbi algorithm (soft-decision decoding; decoding path depth h = 5) = 1E-3. The simulation results indicated that the depth ratio of the decoding path for hard-decision decoding in the Viterbi algorithm is five times that of the constraint length, whereas that for soft-decision decoding can be increased to seven to eight times the constraint length, consequently increasing code gain by 0.4 dB.
Index Terms: convolutional code, LabVIEW, soft-decision
decoding, software-defined radio (SDR), Viterbi algorithm.
目錄
第一章 緒論………...1 1.1 研究背景………2 1.2 研究動機………3 1.3 通道編碼………4 1.3.1 結構序列………..5 1.3.2 通道模型………..5 1.3.3 編碼率與冗餘………..5 1.3.4 錯誤校正編碼………...6 1.4 驗證平台………8 1.4.1 Lab VIEW 軟體……….9 1.4.2 NI SDR 系統平台………10 第二章 迴旋編碼………...14 2.1 編碼架構………..14 2.2 迴旋碼………..15 2.2.1 迴旋編碼器表示法………..16 2.2.2 狀態圖, 樹狀圖, 籬柵圖………21 第三章 迴旋解碼-斐特比解碼演算法………..26 3.1 解碼架構………..263.2 硬式解碼決策與軟式解碼決策………..27 3.3 婓特比解碼演算法………..29 3.3.1 回朔追蹤………34 3.3.2 暫存器交換………35 3.4 迴旋碼的性質………..41 3.4.1 距離性質與錯誤校正能力………41 3.4.2 對稱與非對稱(系統性與非系統性)………..42 3.4.3 災難性錯誤傳播………..43 3.4.4 編碼器限制長度與解碼路徑深度………..44 3.4.5 路徑距離的轉換函數………..45 3.5 迴旋碼的性能界限………..49 3.6 硬式解碼決策的編碼增益上限………51 第四章 迴旋編碼器與迴旋解碼器設計與實作………...53 4.1 迴旋編碼器程式設計與實作………..53 4.2 硬式解碼決策與軟式解碼決策設計與實作………54 4.3 迴旋解碼器-斐特比解碼演算法程式設計與實作……….56 4.4 迴旋編碼與斐特比解碼驗證………..57 第五章 NI SDR 系統上實現-模擬驗證與效能分析………..59 5.1 系統驗證架構程式設計與實作………59
5.2 效能分析-硬式解碼決策、限制長度 K=3~7、解碼路徑深度 h=2~8………62 5.3 效能分析-三位元軟式解碼決策、限制長度 K=3~7、解碼路徑深 度 h=2~8………...73 第六章 結論與未來展望………...84 參考文獻……….87 附錄……….90
表目錄
表 3.4.2-1 系統性與非系統性迴旋碼的自由距離比較,碼率為 1/2………44 表 3.4.5-1 本論文所使用的迴旋碼轉換函數………...50 表 3.5-1 硬式解碼決策的編碼增益上限………..53 表 3.5-2 硬式解碼決策的編碼增益上限………..53 表 3.5-3 本論文所使用的硬式解碼決策迴旋碼的編碼增益上限………..54圖目錄
圖 1.1-1 通道編碼架構………....2
圖 1.3-1 波形編碼與結構序列………....4
圖 1.3.3-1 原始資料與冗餘位元架構……….…6
圖 1.3.4-1 編碼與未編碼錯誤性能的比較……….7
圖 1.4.1-1 Front Panel Window and Block Diagram Window………..9
圖 1.4.2-1 SDR 系統………10 圖 1.4.2-2 控制器(NI PXIE-8106)...11 圖 1.4.2-3 收發器(NI PXIE-5641R)………..………12 圖 1.4.2-4 降頻轉換器(NI PXI-5610)………...….12 圖 1.4.2-5 升頻轉換器(NI PXI-5600)………....13 圖 2.1-1 通訊系統架構………..14 圖 2.2.1-1 (2, 1, 3)迴旋編碼器………16 圖 2.2.1-2 (2,1,3)迴旋編碼器編碼過程,t1………...………..17 圖 2.2.1-3 (2,1,3)迴旋編碼器編碼過程,t2………...……..17 圖 2.2.1-4 (2,1,3)迴旋編碼器編碼過程,t3………...…..18 圖 2.2.1-5 (2,1,3)迴旋編碼器編碼過程,t4………...18 圖 2.2.1-6 (2,1,3)迴旋編碼器編碼過程,t5……….19 圖 2.2.2-1 (2,1,3)迴旋編碼器狀態圖表示法………..22
圖 2.2.2-2 (2,1,3)迴旋編碼器樹狀圖表示法………..23 圖 2.2.2-3 (2,1,3)迴旋編碼器籬柵圖表示法………..25 圖 3.1-1 解碼架構………..27 圖 3.2-1 硬式解碼決策與軟式解碼決策………..28 圖 3.2-2 兩位準硬式決策星座圖………..………..…..29 圖 3.2-3 八位準軟式決策星座圖………..………..…..29 圖 3.2-4 軟式解碼決策碼字距離例子………..30 圖 3.2-5 硬式解碼決策與軟式解碼決策的差異………..30 圖 3.3-1 (2,1,3)解碼器的籬柵圖……….31 圖 3.3-2 合併路徑的路徑度量………..32 圖 3.3-3 K=3 的解碼器細胞例子………32 圖 3.3-4 比較時間點 t5的路徑累積度量………...33 圖 3.3-5 時間點 t5的倖存路徑………...34 圖 3.3-6 (2,1,3)軟式解碼決策解碼器的籬柵圖……….35 圖 3.3-7 比較時間點 t5的軟式解碼決策路徑累積度量………...35 圖 3.3-8 時間點 t5軟式解碼決策的倖存路徑………...36 圖 3.3-9 斐特比解碼流程………..37 圖 3.3.1-1 回朔追蹤路徑………...38 圖 3.3.2-1 籬柵圖路徑性質………...39
圖 3.3.2-2 時間 t0的暫存器交換狀態………40 圖 3.3.2-3 時間 t1的暫存器交換狀態………41 圖 3.3.2-4 時間 t2的暫存器交換狀態………41 圖 3.3.2-5 時間 t3的暫存器交換狀態………42 圖 3.3.2-6 時間 t4的暫存器交換狀態………...….42 圖 3.3.2-7 時間 t5的暫存器交換狀態………43 圖 3.4.1-1 籬柵圖上(2,1,3)迴旋碼的自由距離路徑……….45 圖 3.4.2-1 (2,1,3)系統迴旋編碼器………..46 圖 3.4.3-1 災難性錯誤傳播的迴旋編碼器範例………...47 圖 3.4.5-1 標示與全為零路徑距離的狀態圖………...49 圖 3.4.5-2 引進因子 L 與 N 的全為零路徑距離的狀態圖………51 圖 3.5-1 自由距離=5 的性能界線與最佳化解碼器性能比較……….54 圖 4.1-1 迴旋編碼器程式設計與實作………..57 圖 4.2-1 決策解碼器程式設計與實作………..59 圖 4.3-1 迴旋解碼器-斐特比解碼演算法程式設計與實作……….60 圖 4.4-1 迴旋編碼與斐特比解碼驗證程式設計與實作……… ……61 圖 4.4-2 迴旋編碼與婓特比解碼驗證程式-人機介面……….62 圖 5.1-1 迴旋碼於 AWGN 環境下之模擬程式架構……….64 圖 5.1-2 迴旋碼於 AWGN 環境下之模擬程式人機介面……….66
圖 5.2-1 (2,1,3)迴旋碼於硬式解碼決策在不同解碼路徑深度的比較…….67 圖 5.2-2 (2,1,4)迴旋碼於硬式解碼決策在不同解碼路徑深度的比較…….67 圖 5.2-3 (2,1,5)迴旋碼於硬式解碼決策在不同解碼路徑深度的比較…….69 圖 5.2-4 (2,1,6)迴旋碼於硬式解碼決策在不同解碼路徑深度的比較…….70 圖 5.2-5 (2,1,7)迴旋碼於硬式解碼決策在不同解碼路徑深度的比較…….71 圖 5.2-6 硬式解碼決策在解碼路徑深度(h=2)與不同限制長度的比較….72 圖 5.2-7 硬式解碼決策在解碼路徑深度(h=3)與不同限制長度的比較….73 圖 5.2-8 硬式解碼決策在解碼路徑深度(h=4)與不同限制長度的比較….73 圖 5.2-9 硬式解碼決策在解碼路徑深度(h=5)與不同限制長度的比較….74 圖 5.2-10 硬式解碼決策在解碼路徑深度(h=6)與不同限制長度的比較...75 圖 5.2-11 硬式解碼決策在解碼路徑深度(h=7)與不同限制長度的比較...75 圖 5.2-12 硬式解碼決策在解碼路徑深度(h=8)與不同限制長度的比較...76 圖 5.3-1 (2,1,3)迴旋碼於軟式解碼決策在不同解碼路徑深度的比較…….77 圖 5.3-2 (2,1,4)迴旋碼於軟式解碼決策在不同解碼路徑深度的比較…….78 圖 5.3-3 (2,1,5)迴旋碼於軟式解碼決策在不同解碼路徑深度的比較…….79 圖 5.3-4 (2,1,6)迴旋碼於軟式解碼決策在不同解碼路徑深度的比較…….80 圖 5.3-5 (2,1,7)迴旋碼於軟式解碼決策在不同解碼路徑深度的比較…….81 圖 5.3-6 軟式解碼決策在解碼路徑深度(h=2)與不同限制長度的比較….82 圖 5.3-7 軟式解碼決策在解碼路徑深度(h=3)與不同限制長度的比較….83
圖 5.3-8 軟式解碼決策在解碼路徑深度(h=4)與不同限制長度的比較….84
圖 5.3-9 軟式解碼決策在解碼路徑深度(h=5)與不同限制長度的比較….84
圖 5.3-10 軟式解碼決策在解碼路徑深度(h=6)與不同限制長度的比較...85
圖 5.3-11 軟式解碼決策在解碼路徑深度(h=7)與不同限制長度的比較...86
第一章緒論
無 線 行 動 通 訊 演 進 於 1990 年 由 歐 洲 電 信 標 準 協 會 (European Telecommunications Standards Institute, ETSI)完成第二代行動通訊標準
(2rd-Generation, 2G) 全 球 通 訊 系 統 (Global System for Mobile communication, GSM) 的制訂,平均速率 9600 bps~64k bps;1999 年由國 際 電 信 聯 盟 (International Telecommunication Union, ITU) 所 制 訂 的 IMT-2000 (International Mobile Telecommunications-2000) 規格發展第三 代 行 動 通 訊 標 準 (3rd-Generation, 3G) 全 球 行 動 通 訊 系 統 (Universal Mobile Telecommunications System, UMTS) 平均速率 300k bps~2M bps, 部分系統服務業者更新更高速的系統如:3.5G 高速下行分封存取技術 (High Speed Downlink Packet Access, HSDPA) 下傳速率 14M bps;2007 年 3.75G 高速上行封包接入 (High Speed Uplink Packet Access, HSUPA) 下傳速率 10~15M bps、上傳速率 5.76M bps (搭配 MIMO 技術下傳速率 28M bps、上傳速率 11.5M bps) ;2008 年 3.9G 演進式高速分封存取技術 (HSPA Evolution, HSPA+) 搭配 MIMO 技術與更高速的調變技術,下傳速 率 42M bps、上傳速率 23M bps,到第四代行動通訊技術標準 (the fourth generation of mobile phone mobile communication technology standards, 4G) 從技術標準的角度看 ITU 的定義,靜態傳輸速率達 1G bps 動態傳輸速率 達 100M bps 就可以做為 4G 的技術之一.目前長期演進技術(Long Term Evolution, LTE)是 ITU 第一批承認的 4G 標準,也是目前 4G 的主流,全 球大部份的營運商也是以 LTE 為主,台灣亦是如此。
在這資訊與通訊技術快速發展的時代,無線通訊系統的技術不斷演進, 資料傳輸速率的品質要求更快,無線行動通訊涵蓋要求更廣,在有限頻 寬條件下需要更有效率的使用頻寬,藉此達到更快的傳輸率與更大的涵
技術的搭配與基地台發射接受功率的控制就是一個很重要的課題。
1.1 研究背景
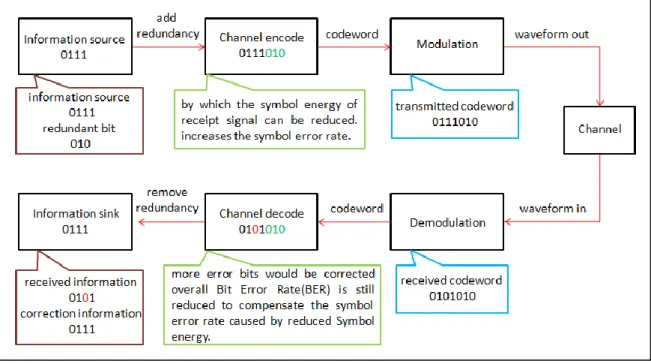
通道編碼技術是 1948 年一位數學家 Richard Hamming 提出的漢明碼 (Hamming code) ,使用同位檢驗的方式在原始資料加上同位位元 (parity bit) 來偵測錯誤並且更正錯誤。如圖 1.1-1,通道編碼技術需要在原始資 料加上多餘的位元,加入多餘的位元會降低接受訊號符元(symbol)的能量, 使符元錯誤率提高,但若可以更正更多的錯誤位元,便可以補償因加入 多餘位元減少的符元能量所提高的符元錯誤率 (Symbol Error Rate) ,降 低整體接收訊號的位元錯誤率 (Bit Error Rate, BER)。
圖 1.1-1 通道編碼架構
由圖 1.1-1 可以知道原始資料為 0111,經過通道編碼後加入冗元 010, 而原始資料加上冗元稱作碼字 (codeword) 為 0111010,而碼字也就是經 過編碼的序列,在傳送過程經過無線通道雜訊的影響使接收的碼字 0101010 在第三個位元發生錯誤,這時候就可以透過通道編碼加入的冗元
來更正發生的錯誤,並且在移除冗元時還原原始資料 0111。 當然這樣的通道編碼技術並不是完全沒有缺點,簡單的通道編碼雖然 降低了位元錯誤率,但是卻因為要加入額外的冗元而犧牲了部分的頻寬 來更正錯誤,因此再使用通道編碼時相對的要考慮系統的需求來做取捨, 在 1.3.4 章節會將通道編碼技術所影響的系統權衡取捨來說明。
1.2 研究動機
隨著資訊與通訊科技的進步,人們在彈指之間便可以分享全球的人事 時地物,不管是文字、照片、影片或是即時的視訊都可以經由智慧型手 機隨時隨地的分享給親朋好友。這樣便利的科技就是無線行動通訊技術 進步快速最好的證明,從 1990 年 2G 的速率 64k bps、1999 年 3G 的速率 2M bps、3.5G 的速率 14M bps、2007 年 3.75G 的 28M bps、2008 年 3.9G 的速率 42M bps 到現在 4G 的速率 100M bps,從行動通訊標準的制定可 以看出近年來無線通訊迫切的發展,智慧型手機的開發也跟著加快腳步, 更多的社群網站、網路遊戲、層出不窮且多樣化的 App,讓每個人對行 動通訊更加依賴,速率的需求也更大。 要讓這些需求一一達成,通道編碼與調變的技術是不可或缺的。人在 面對面溝通時都有可能傳遞錯誤的消息,現代的通訊也存在著相同的問 題,由於訊號在傳遞的過程中會受到環境因素的干擾 (折射、繞射、反射、 多重路徑(Multipath)、訊號衰降(Fading)等) 導致收到的訊息產生錯誤, 一旦通訊失去了正確性便失去了溝通的意義,因此如何降低數位訊號在 接收時的錯誤機率是非常重要的,而通道編碼技術就是一種可以抵抗各 種通道的損傷,以改善通訊的性能。簡單且容易實現,3GPP-LTE 的渦輪編碼器中也使用了兩組迴旋碼;在衛 星通訊通道中,針對特定的錯誤性能所需的 SNR,編碼增益可以直接轉 化為衛星有效輻射功率所需要的等效縮減,並針對硬式解碼決策與軟式 解碼決策的解碼路徑深度作效能分析與比較。
1.3 通道編碼
通道編碼 (Channel coding) 是一種訊號傳輸的類別,它的設計使得所 傳輸的訊號更能夠抵抗各種通道的干擾,這種訊號處理技術可以改善通 訊性能,來達到我們所需求的系統取捨的工具。 如圖 1.3-1 通道編碼主要可以分為兩個領域,分別是波形編碼與結構 化序列。波形編碼 (Waveform coding) 將發射波形轉換為較佳波形,使偵 測過程比較不受錯誤的影響;結構序列 (Structured sequences) 將資料序 列轉換為較佳序列,使其具有結構化的冗餘用來偵測與改正錯誤,本文 所使用的迴旋碼便是結構序列的一種。 圖 1.3-1 波形編碼與結構序列1.3.1 結構序列
結構化序列這種通道編碼的程序是將結構化的冗餘插入來源資料中, 以便於偵測出錯誤或校正錯誤,雖然波形編碼也可以降低 BER,但是卻 無法有效的利用頻寬。在前面章節提到,在這頻寬資源有限的狀況下, 如何有效的利用頻寬是必然的,因此在通道編碼上都是使用結構化序列 這種技術。結構化序列可以分為三個類別:區塊碼 (block code) 、迴旋 碼 (convolutional code) 、渦輪碼 (turbo code) ,本文主要針對迴旋碼討 論其編碼性質與解碼的效能做分析。1.3.2 通道模型
可加性高斯白雜訊 (Additive White Gaussian Noise, AWGN) 在通訊 領域中指的是一種通道模型,頻譜分量均勻分布(即白雜訊)且振幅是 高斯分布的雜訊訊號,因其可加性振幅由高斯分布且為白雜訊的一種而 得名。該雜訊訊號為一種便於分析的理想雜訊訊號,實際的雜訊訊號只 在某一頻段內可以用高斯白雜訊的特性來進行近似處理。由於 AWGN 訊 號易於分析、近似,因此在訊號處理領域,對訊號處理系統的雜訊性能 的簡單分析中,可假設系統所產生的雜訊或受到的雜訊訊號干擾在頻段 或限制條件之下是高斯白雜訊。
1.3.3 編碼率與冗餘
編碼器將每一個輸入的原始資料 k 位元資料區塊轉換輸出為較大的 n 位 元 區 塊 , 在 加 入 的 每 個 資 料 區 塊 的 (n-k) 個 位 元 稱 為 冗 餘 位 元 (redundancy bit) 、同位位元 (parity bit) 或檢查位元 (check bit)。在區塊之 中 的 冗 餘 位 元 對 資 料 位 元 的 比 值 (n-k) / k , 稱 為 編 碼 的 冗 餘 度 (redundancy),而資料位元對全部位元的比值則稱為編碼率 (code rate), 編碼率可視為組成資訊編碼位元的部分。如圖 1.3.3-1 所示,編碼率為 1/2 時,每一個碼字位元傳送了 1/2 位元的資訊。 圖 1.3.3-1 原始資料與冗餘位元架構
1.3.4 錯誤校正編碼
傳輸數位訊號時會以 BER 來評估系統性能,但是我們知道不管系統 如何設計,無法避免傳輸位元資料時發生錯誤,導致在傳送得資料中有 一個或多個位元發生錯誤。常用來處理資料傳輸錯誤的方法有兩種:自 動重送請求 (automatic repeat request, ARQ) 、直接錯誤更正 (forward error correction, FEC) 。ARQ 是當接收端偵測接收資料有錯誤後,接收端送回一個回覆訊號 要求發射端將有錯誤的資料重新傳送一次,這是一種反向錯誤更正的方 法,這種重送技術在其接收端必頇擁有錯誤偵測能力,並且通訊系統需
要具備雙向通訊之連結,因此重送技術無法用於單向通訊系統,而且重 送技術在許多無線通訊的應用上很不實際,如衛星通訊若使用 ARQ 會因 延遲造成傳輸時間過久而不切實際,另外在無線行動通訊中因為傳輸時 資料的錯誤率太高,且重送的資料也可能再次發生錯誤,使得接收端可 能一直停留在重送的狀態中,因此在無線行動通訊中不採用這種處理資 料傳輸錯誤的方法。 FEC 是指接收端對輸入的數位資料進行偵測或更正資料中有錯誤的 位元,並不會請求發射端重新傳送資料,利用編碼技術在原有的資料加 上冗元,將訊息資料與冗元的組合成的碼字一起傳送,接收端用相對應 的解碼技術可以偵測錯誤並且更正錯誤。 圖 1.3.4-1 編碼與未編碼錯誤性能的比較 錯誤校正編碼可當作影響系統權衡取捨的一種工具,圖 1.3.4-1 是
紅色曲線則是透過通道編碼且採用相同的 BPSK 調變,由圖中可以看出 系統性能的取捨。 錯誤性能對頻寬:當使用者要求降低 BER,但是系統只能提供的 Eb/N0 最多只有 5dB 時,我們只能從系統操作點 A 點移到 C 點就能降低 BER, 但是這樣做需要使用通道編碼,而通道編碼需要額外的冗元,所以便需 要額外的頻寬來負荷。 功率對頻寬:當資料的 BER 達到要求時,但是又想要降低 Eb/N0來確 保設備的可靠度時,我們可以從系統的 D 點移到 E 點,使用通道編碼後 得到相同的資料品質,並且降低使用的功率,所需要犧牲的依然是需要 額外的頻寬來負荷。 編碼增益:從功率對頻寬的例子可以知道,當需要保持相同的錯誤性 能時,透過通道編碼所縮減的 Eb/N0,我們定義為編碼增益 (coding gain), 編碼增益 G 一般以 dB 為單位: G(dB) = (Eb/N0)u(dB)– (Eb/N0)c(dB) (1-1) 其中(Eb/N0)u 與 (Eb/N0)c 代表未編碼和已編碼的 Eb/N0。
1.4 驗證平台
本論文利用 LabVIEW 軟體與 NI SDR 系統[1]來撰寫通道編碼之迴旋 碼與解碼演算法,透過 LabVIEW 內建的 AWGN 通道模型環境下進行模 擬與分析,並於 NI SDR 系統上實現與驗證。1.4.1 LabVIEW 軟體
圖 1.4.1-1 顯示人機界面 (Front Panel Window) 和 程式撰寫界面 (Block Diagram Window)。
人機界面:這是使用者和程式設計人員接觸的地方,所以你會在人機 界面上放置不同的元件,一方面可以讓使用者輸入資料,一方面也可以 將資料顯示給使用者看。 程式撰寫界面:人機界面規畫完成後,切換到程式撰寫界面去撰寫你 的程式,而 LabVIEW 最大的特色就是 G 語言(圖形化語言),也就是圖 形化的程式開發,所有的函式都是以圖示的方式呈現,所以寫程式的方 式就是使用接線的方法來做。
1.4.2 NI SDR 系統平台
美商國家儀器軟體定義無線電系統 (National Instruments Soft Defined Radio, NI SDR) ,屬於無線電通訊系統,其中包含以軟體所架構的特定 硬體元件。這些硬體元件可為濾波器、放大器、調變器,與解調器等。 這些元件可透過 SDR 系統於軟體之下進行定義,且往後不需大幅變更硬 體,亦可依需要重新定義。這幾年無線通訊功能不斷大幅成長,且無線 標準也不斷在更新,因此系統大部分用於測詴與原型製作。SDR 已經普 及於軍事上和行動電話領域。 圖 1.4.2-1,首先 SDR 系統硬體的部份,在發射端的訊號會從控制器 (NI PXIE-8106)產生,經由背板送入收發器(NI PXIE-5641R),透過收發器 裡的數位轉類比 DAC 傳送到升頻轉換器(NI PXI-5600)之後由 RF output 發射出去,這邊的輸出可用實體纜線也可以用天線來做界接;接收端訊 號由實體纜線或是天線接入降頻轉換器(NI PXI-5610),接收後傳送到收 發器(NI PXIE-5641R),透過收發器裡的類比轉數位 ADC 做接收,而在軟 體部分,訊號單純在控制器(NI PXIE-8106)做模擬。
圖 1.4.2-2,控制器(NI PXIE-8106) ,NI PXIE-8106 Core 2 Duo 2.16 GHz Controller, Win XP FES,高效能的 PXI Express 控制器,可透過高速 雙核心 CPU 提供浮點處理功能,以於 FPGA 上進行定點訊號處理作業。
圖 1.4.2-2 控制器(NI PXIE-8106)
圖 1.4.2-3 收發器(NI PXIE-5641R),20 MHz 頻寬 IF 收發器-搭載 DSP-optimized Xilinx Virtex-5 SX95T FPGA (NI PXIe-5641R)具備中頻(IF) 輸入與輸出,可介接類比升頻/降頻轉換器,以擷取並產生 RF 訊號。此 介面卡的 FPGA 亦可透過 LabVIEW 進行程式設計,於硬體中執行複雜的 調變與訊號處理作業;而其高傳輸率與低延遲,皆是軟體定義的無線電 系統所必備。
圖 1.4.2-3 收發器(NI PXIE-5641R)
圖 1.4.2-4 降頻轉換器(NI PXI-5610),2.7 GHz RF 降頻轉換器 (NI PXI-5610) ,以最高 20 MHz 頻寬,接收 9 kHz ~2.7 GHz 的 RF 訊號,並 接著降轉換為 15 MHz 的 IF 訊號,適於介接 PXIe-5641R。
圖 1.4.2-4 降頻轉換器(NI PXI-5610)
圖 1.4.2-5 升頻轉換器(NI PXI-5600),2.7 GHz RF 升頻轉換器 (NI PXI-5600),可透過最高 20 MHz 頻寬,接收 NI PXIe-5641R 所輸出 25MHz
的 IF 訊號,並接著升轉換為 250 kHz ~ 2.7 GHz 的 RF 訊號。
第二章 迴旋編碼
前面的章節提到,(n , k) 區塊碼一次處理 k 位元的原始資料,經過編 碼後產生 n 位元的區塊碼,如果在傳送或是接收連續資料流時,大的區 塊碼不適合連續的偵測與更正錯誤,這時需要一種可以連續產生冗元(檢 查位元),並且可以更正錯誤的編碼技術:迴旋碼。迴旋碼[2]在高位元錯 誤率的雜訊通道有較好的性能,許多無線通訊應用皆採用此通道編碼技 術,迴旋碼是除了區塊碼另一種被廣泛用於無線通訊的錯誤更正碼。2.1 編碼架構
一般通訊系統架構的訊號流程如圖 2.1-1,發射端的原始資料在經過 通道編碼後加上冗元形成碼字,將碼字經過調變形成類比訊號,再經由 升頻轉換成高頻訊號(RF signal),透過天線輻射到無線通道,接收端相對 由天線接收到高頻訊號,由降頻轉換成類比訊號經由解調變形成碼字, 再透過通道解碼進行偵測錯誤改正錯誤,並且移除冗元還原原始資料。 圖 2.1-1 一般通訊系統架構由圖 2.1-1 可以看出一般通訊系統架構,通道編碼和調變是分別獨立的區 域,相對的通道解碼與解調變亦同。 為了提高編碼增益,在通道解碼前端可以選擇使用硬式解碼決策或是 軟式解碼決策。如果是使用硬式解碼決策,可以依照圖 2.1-1 通訊系統架 構,將解調變後的 Channel bit(雙位準)直接送入通道解碼,使用漢明距離 (Hamming Distance)演算法做運算;若是使用軟式解碼決策,就將解調變 後量化過的 Channel bit(八位準)送入通道解碼,並使用歐式距離(Squared Euclidian Distance, SED)演算法做運算(在 3.2 章節會針對硬式解碼決策與 軟式解碼決策做詳細說明)。
2.2 迴旋碼
迴旋碼是由三個整數 n、k 與 K (n, k, K)來定義描述的,k 是資料位元 的個數;n 是在編碼器輸出端碼字所含位元的總數;K 是所謂的限制長度 (constraint length)代表編碼移位暫存器中 k 值組階段的個數;比率 k/n 稱 為編碼的比率,用於測量附加冗餘的總量,與章節 1.3.3 提到的編碼率相 同。迴旋碼有一個重要的特徵,就是編碼器具有記憶性,迴旋編碼程序 所產生的 n 值組不只是輸入的 k 值組的函數,同時也是 K-1 個輸入 k 值 組的函數;實務上,n 與 k 是小的整數,利用限制長度 K 的變化,可以 控制編碼的能力與複雜度。 描述迴旋碼必頇說明編碼函數的特徵,使得提供輸入序列 m(X)便可 以快速的計算出輸出的序列 U(x)。常用的表示法與圖解說明[4]會於下列 章節來說明範例(2, 1, 3)迴旋碼的描述。2.2.1 迴旋編碼器表示法
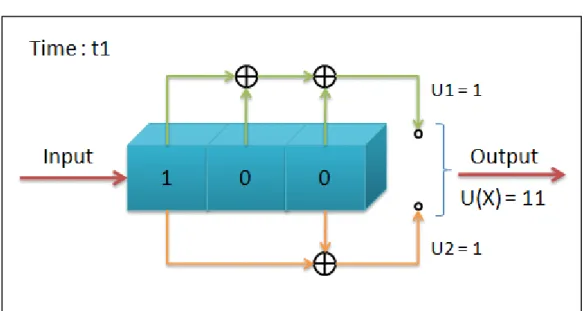
連接表示法:如圖 2.2.1-1 描述(2, 1, 3) 的迴旋編碼器。 圖 2.2.1-1 (2, 1, 3)迴旋編碼器 在限制長度 K=3 的迴旋編碼器中,會有ν= K-1 個暫存器,稱為編碼 器記憶量(encoder memory),碼率 k/n = 1/2,n = 2 因此會有兩個模餘 2 的 加法器;在每個輸入位元的時間都從最左邊開始輸入,暫存器裡面的位 元則往右位移一個位置,每個模餘 2 的加法器再對所連結暫存器裡的資 料取樣然後輸出,輸出的 u1、u2則交錯輸出合併形成碼字 U(X)。由於加 法器與暫存器之間的連接方式是整個編碼器的特徵,所以任何連接選項 的變動都會造成不同的編碼,因此不能隨意選擇或是變動連接方式,在 下個章節 2.3 迴旋碼的性質會詳細說明原因。 用圖 2.2.1-2 ~ 圖 2.2.1-6 來說明(2, 1, 3) 迴旋編碼器的編碼過程,輸 入訊息序列 m = 101 經過編碼器後所輸出碼字序列 U = 11 10 00 10 11 的 圖解步驟。 t0 時間:暫存器初始值皆為 0,u1、u2沒有輸出11。
圖 2.2.1-2 (2,1,3)迴旋編碼器編碼過程,t1
t2 時間:訊息序列 m 第二個位元 0 輸入,u1輸出 1、u2輸出 0,U 輸出
10。
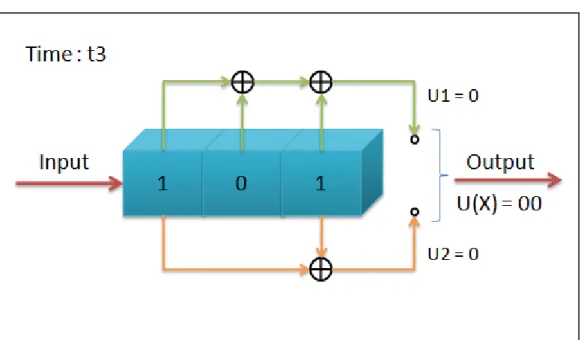
00。
圖 2.2.1-4 (2,1,3)迴旋編碼器編碼過程,t3
接著在 t4 與 t5 輸入(K-1) = 2 個 0 來清除暫存器,確保所輸入的 m 序列完 全進入暫存器,而清除暫存器所產生的碼字也是解碼時所需要的訊息。
t4 時間:清除位元 0 輸入,u1輸出 1、u2輸出 0,U 輸出 10。
t5 時間:清除位元 0 輸入,u1輸出 1、u2輸出 0,U 輸出 10。 圖 2.2.1-6 (2,1,3)迴旋編碼器編碼過程,t5 (本論文所使用的其他限制長度(K=4~7)之編碼器連接架構於附錄說明) 多項式表示法:根據圖 2.2.1-1 的(2, 1, 3)迴旋編碼器,可以將 u1的上 部連接方式表示為生成多項式 g1(X)與 u2的下部連接方式表示為生成多項 式 g2(X),多項式中的最低次項對應於暫存器的輸入級: g1(X) = 1 + X + X2 g2(X) = 1 + X2 (2-1) 輸出序列為:
假設訊息位元之後的輸出是以 0 將暫存器加以清除所得到的碼字。 將訊息序列 m = 101 改寫多項式表示法 m(X) = 1+X2,根據上列公式我們 可以針對輸入訊息 m 解出編碼器裡的輸出多項式 U(X),步驟如下: Step 1: 將訊息序列多項式 m(X)分別乘上生成多項式 g1(X)、g2(X)。 m(X)g1(X) = (1+X2)(1+X+X2) m(X)g2(X) = (1+X 2 )(1+ X2) Step 2: m(X)g1(X)、m(X)g2(X)的乘積依照升冪式排列。 m(X)g1(X) = 1+X+X 3 +X4 m(X)g2(X) = 1+X4 Step 3: 將乘積沒有的次方項補上係數 0。 m(X)g1(X) = 1+X+0X2+X3+X4 m(X)g2(X) = 1+0X+0X 2 +0X3+X4
Step 4: 次方向係數交錯取出。 U(X) = (1,1)+(1,0)X+(0,0)X2+(1,0)X3+(1,1)X4 Step 5: 移除次方項,得到輸出碼字序列。 U = 11、10、00、10、11 以生成多項式表示的編碼步驟其輸出與上一個例子連接表示法的輸 出序列一樣,所以兩種表示法皆可以呈現迴旋編碼器的連接狀況與運算 過程[3]。
2.2.2 狀態圖, 樹狀圖, 籬柵圖
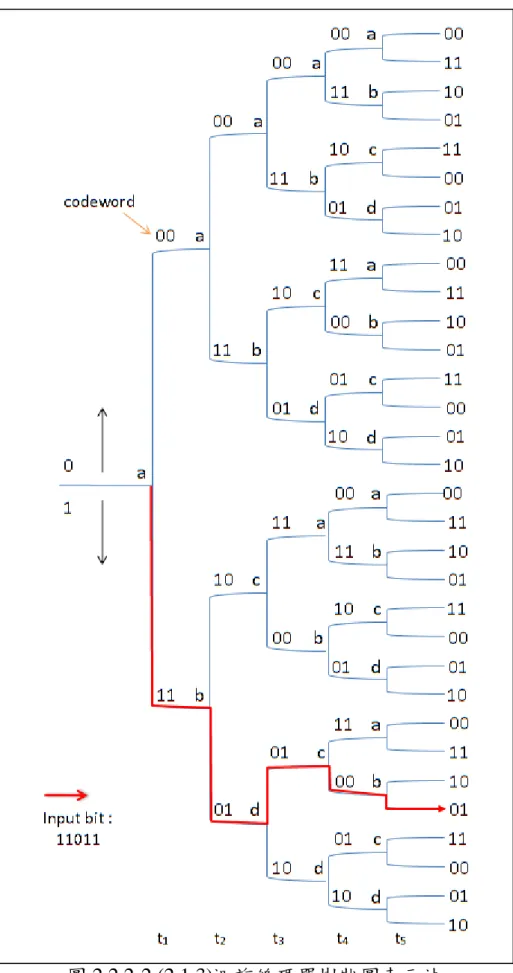
狀態圖(state diagram):簡單的編碼器可以用狀態圖來呈現,以圖 2.2.2-1 來說明(2,1,3)迴旋編碼器的狀態表示,由於 K=3 所以ν=2,因此 有兩個暫存器,圖中方塊顯示的狀態就是表示暫存器裡最右邊 K-1 級的 內容,而狀態之間的路徑代表不同的輸入(0 或 1)而轉變為另一個狀態, 也附帶著說明不同的輸入產生不同的碼字。由於ν=2 因此有 22 = 4 個狀 態變化,如圖將編碼器的狀態標示為 a = 00、b = 10、c = 01、d = 11,每 個狀態因為不同的輸入只有兩個轉變,對應於兩個可能的輸入位元,在 狀態轉換的路徑間記錄與狀態轉變有關的輸出碼字。圖 2.2.2-1 (2,1,3)迴旋編碼器狀態圖表示法 樹狀圖(tree diagram):狀態圖雖然可以完全呈現編碼器的特徵,但 是卻無法紀錄每一個輸入序列的時間狀態,因此在追蹤資料的路徑時並 不易達成。樹狀圖是將狀態圖加入時間的維度來呈現,如圖 2.2.2-2 是針 對(2,1,3)迴旋編碼器來表示,每個連續的輸入位元時間裡,從左到右穿越 圖形來描述編碼過程,而且每個分支都描述著不同的輸入位元所對應的 輸出碼字。
描述訊息序列所產生碼字的分支規則:當輸入位元為 0 時,路徑則往上 移動到下一個右邊的分支得到相關的輸出碼字,當輸入位元為 1 時,路 徑則往下移動到下一個右邊的分支得到相關的輸出碼字。 如圖 2.2.2-2 紅線所示,當輸入的訊息序列為 11011 時,編碼的順序如下: t1時間: 輸入的位元為 1,則路徑往下走,由狀態 a 到狀態 b,得到輸出碼字 11。 t2時間: 輸入的位元為 1,則路徑往下走,由狀態 b 到狀態 d,得到輸出碼字 01。 t3時間: 輸入的位元為 0,則路徑往上走,由狀態 d 到狀態 c,得到輸出碼字 01。 t4時間: 輸入的位元為 1,則路徑往下走,由狀態 c 到狀態 b,得到輸出碼字 00。 t5時間: 輸入的位元為 1,則路徑往下走,得到輸出碼字 01。 所以得到的輸出碼字序列為 11、01、01、00、01。 雖然樹狀圖可以附加狀態圖所沒有的時間維度,由於分支的個數是由輸 出碼字的長度來決定,因此圖 2.2.2-2 也不適合用來表示龐大的樹狀分布, 畢竟太多使用不到的路徑會占用到表示空間,也增加了整個表示法的複 雜度。
籬柵圖(trellis diagram):藉由圖 2.2.2-2 我們可以發現在 t4時間點上, 在第三個分支的路徑會重複,也就表示樹狀結構會在 K 個分支後重複。 若將樹狀圖的每個節點都加以標示,對應到暫存器的四種狀態,在每個 後續的分支上,從相同狀態的兩個節點所發出的所有分支都會產生相同 的分支碼字序列,如圖 2.2.2-3 使用這種方法重新整理出來的樹狀圖稱做 籬柵圖,利用重複結構的籬柵圖比樹狀圖更容易清楚暫存器內的狀態與 編碼路徑的過程。 圖 2.2.2-3 (2,1,3)迴旋編碼器籬柵圖表示法 在 K 個解碼深度後會完成固定結構,從樹狀圖和籬柵圖中一樣可以看出 在 t3 時間點後,每個路徑與狀態皆重複,利用此重複結構可以更清楚整 個時間歷史的路徑。從籬柵圖可以知道每個狀態可能來自於兩個狀態中 的其中一個,每一個狀態也可能轉變成其他兩個狀態之一。
第三章 迴旋解碼-斐特比解碼演算法
斐特比解碼演算法(Viterbi Decode Algorithm)由 Viterbi 於 1967 年所發 現並分析,演算法的本質為最大概似解碼,以這種方法利用籬柵圖中特 殊結構的優點,可以縮減解碼運算上的負擔;演算法與時間 ti的接收訊號 以及在時間 ti進入的每個狀態的所有路徑,兩者之間的相似度(measure of similarity)或距離的計算有關,演算法將不可能具有最大概似的路徑刪除; 若有兩個路徑進入同一個狀態,選取具有最佳度量的路徑,稱為倖存路 徑(surviving path);然而所有的狀態都要選取倖存路徑,解碼器持續以這 種方式運算,將最不可能的路徑刪除,所以刪除的路徑便可以將解碼的 複雜度縮減,減輕了運算上的負擔就可以更加的深入籬柵路徑中。 1969 年,Omura 證明了 Viterbi 解碼演算法則就是最大概似度,最佳 路徑的選擇可以等效視之,所以利用最大概似度量(maximum likelihood metric)或稱最小距離度量(minimum distance metric)來選取碼字。
3.1 解碼架構
區塊解碼演算法則與迴旋碼的斐特比解碼演算法則都會有硬式解碼 決策與軟式解碼決策兩種不同的方式,而區塊碼很少使用軟式解碼決策, 是因為與硬式解碼決策相比在實作上困難很多,而且在傳送或是接收連 續資料流時,大的區塊碼不適合連續的偵測與更正錯誤。 迴旋碼是一種可以連續產生冗元(檢查位元)的通道編碼技術,利用迴 旋碼所產生的連續冗元與其特殊性質 (3.4 章節說明),在斐特比解碼演算 法中可以即時修正解碼訊息,於籬柵圖的表示方式中顯示其優勢的解碼 方式。 圖 3.1-1 說明本文所使用的解碼架構:圖 3.1-1 解碼架構 於解調變出來的 Channel bit,在進入斐特比解碼演算法之前必頇先選擇 解碼決策的方式再送入通道解碼器做運算。與區塊碼相比,斐特比解碼 演算法最適合使用軟式解碼決策,是因為軟式解碼決策在斐特比解碼演 算法中只增加了普通計算,卻大大增加了編碼增益。
3.2 硬式解碼決策與軟式解碼決策
說明斐特比解碼演算法則前,先描述通道的性質。碼字序列是由分支 碼字組成,每個分支碼字是由 n 個位元組成,所以我們可以將碼字序列 當作無止盡的串流,由於碼字序列是從迴旋編碼器出來進入調變器,位 元在調變器裡轉換為訊號波形,假設 AWGN 通道造成在其中傳輸的波形 有誤,當接收到有誤的訊號時,先以解調器處理才進行解碼。 如圖 3.2-1,傳輸的二元訊號是由 s1(t)代表 1 和 s2(t)代表 2 來描述,接 收到的訊號為 r(t) = si(t)+n(t),n(t)是零均值的高斯隨機變數,取決所傳送量、n0為雜訊分量,n0是零均值的高斯隨機變數,z(T)是均值的 a1或 a2 的高斯隨機變數,取決於所傳送的 1 或 0。z(T)的條件機率 P(z∣s1)與 P(z ∣s2)分別代表 s1與 s2的概似度。 圖 3.2-1 硬式解碼決策與軟式解碼決策 當 z(T)的量化值大於兩個位準時,稱為軟式解碼決策[5]。當解碼器將 單一軟式二元決策傳送到八個位準,則是沿著 z(T)描述一個區間的三位 元文字,傳送三位元的文字非單一二元位元相當於將碼字決策的信心測 度(measure of confidence)傳送到解碼器。 針對碼率=1/2 的迴旋碼系統,一個時間點內傳送兩個位元到解碼器中, 硬式解碼決策可以將每一組碼字的兩個位元描述於一個平面上,如圖 3.2-2 的四個角以(0,0)、(0,1)、(1,0)、(1,1)標示,描述兩個位元可能具有 的四個硬式決策值。若是八位準的軟式決策,如圖 3.2-3 將每一組碼字以 八位準在平面上等距分佈,形成六十四組軟式決策值,此時解調器所傳 送的直接是經過量化的雜訊訊號。
圖 3.2-2 兩位準硬式決策星座圖 圖 3.2-3 八位準軟式決策星座圖 硬式解碼決策與軟式解碼決策在斐特比解碼演算法中的差異,受其解析 度的影響,軟式解碼決策不能使用漢明距離度量只能使用歐式距離度量, 為了使運算方便將二元數字 1 和 0 轉換成 7 和 0(避免有負數),如上圖 3.2-3。 圖 3.2-4 說明軟式解碼決策使用歐式距離度量計算的例子,當訊號被 雜 訊 干 擾 的 點 (2,3) 與 未 被 雜 訊 干 擾 的 點 (0,0) 的 歐 式 距 離 為 0,0 1,0 1,1 0,1 0,0 1,0 1,1 0,1 0,0 7,0 7,7 0,7 0,0 7,0 7,7 0,7
的點(7,7)的歐式距離為 2 − 7 2 + 3 − 7 2 = 41。 圖 3.2-4 軟式解碼決策碼字距離例子 圖 3.2-5,說明硬式解碼決策與軟式解碼決策路徑間碼字距離的差異,軟 式解碼決策使用歐式距離來記錄路徑間的分支度量,而硬式解碼決策使 用漢明距離來記錄路徑間的分支度量。 圖 3.2-5 硬式解碼決策與軟式解碼決策的差異
3.3 斐特比解碼演算法
針對斐特比解碼演算法[6],我們在解碼器籬柵圖上表示輸入資料序列、 傳送碼字序列、接收碼字序列,各時間點與每個狀態路徑距離的對應關 係描述在圖 3.3-1。 圖 3.3-1 (2,1,3)解碼器的籬柵圖 圖 3.3-1 以硬式解碼決策為例,圖中時間點上接收的碼字與路徑上的狀態 做漢明距離計算,將所有計算的路徑度量紀錄在籬柵圖上。 斐特比解碼演算法的基礎就是任何兩個籬柵中的路徑合併為單一狀 態,則在計算最佳路徑時可以永遠將兩者其一個刪除。如圖 3.3-2,在時 間點 t5時,兩條路徑合併至狀態 a,將時間 ti的已知路徑的累積漢明路徑度量(cumulative Hamming path metric)定義成沿著路徑直到時間 ti的分支
漢明距離度量的和。因此圖中上面的路徑度量是 4、下面的路徑度量是 1, 進入相同狀態的下面路徑具有較低的度量,所以為最佳路徑的一部分。
圖 3.3-2 合併路徑的路徑度量 以 K = 3 為例,在籬柵圖裡,任何一個時間點的轉變可以組成 2ν-1個 不相交的 cells,每一個 cell 描述四種狀態的轉變,其中ν= K-1 稱為編碼 器記憶量(encoder memory),ν= 2,所以 2ν-1 = 2 有兩個 cell,狀態更新 如下圖 3.3-3 所示: 圖 3.3-3 K=3 的解碼器細胞例子
其中 a、b、c、d 指時間 ti的狀態,a’、b’、c’、d’指時間 ti+1的狀態,而 δxy是每個路徑狀態轉變的分支度量。 以斐特比解碼演算法的基礎,任何兩個籬柵中的路徑合併為單一狀態, 則在計算最佳路徑時可以永遠將兩者其一個刪除,邏輯執行上稱為相加-比較-選擇(add-compare-select, ACS)的計算。相加就是把過去的累積度量 加上當下時間點δxy的分支度量,再將進入相同狀態的兩個路徑比較,選 擇較低的路徑累積度量,繼續送到下一個時間點繼續做相加-比較-選擇運 算。 然而在每個時間 ti,籬柵中都有 2 K-1個狀態,每個狀態都來自於兩個 路徑,斐特比解碼就是計算度量後將其中一個路徑刪除,留下最佳路徑, 而這個計算是針對時間 ti的 2 K-1個狀態來執行,然後移動到時間 t i+1再重 複過程。圖 3.3-4 描述在籬柵圖中刪除其一路徑,並保留最佳路徑。 圖 3.3-4 比較時間點 t5的路徑累積度量 在 t5時間
進入狀態 b 的上面路徑累積度量為 4,下面路徑累積度量為 1。 進入狀態 c 的上面路徑累積度量為 3,下面路徑累積度量為 4。 進入狀態 d 的上面路徑累積度量為 5,下面路徑累積度量為 2。 (如果兩個進入的路徑累積度量相同,則可以任意刪除其中一個。) 如圖 3.3-5,經過累積度量比較之後,狀態 a 選擇保留下面路徑、狀態 b 選擇保留下面路徑、狀態 c 選擇保留上面路徑、狀態 d 選擇保留下面路 徑。 圖 3.3-5 時間點 t5的倖存路徑 圖 3.3-6 以軟式解碼決策為例,假設圖中時間點上所接收的訊號(碼字) 受到雜訊的干擾,將受到雜訊干擾的碼字與路徑上的狀態做歐式距離計 算,將所有計算的路徑度量紀錄在籬柵圖上。
圖 3.3-6 (2,1,3)軟式解碼決策解碼器的籬柵圖
圖 3.3-7 描述軟式解碼決策在籬柵圖中刪除其一路徑,並保留最佳路徑。
在 t5時間 進入狀態 a 的上面路徑累積度量為 22.1,下面路徑累積度量為 10.6。 進入狀態 b 的上面路徑累積度量為 19.5,下面路徑累積度量為 13.2。 進入狀態 c 的上面路徑累積度量為 18.6,下面路徑累積度量為 20.4。 進入狀態 d 的上面路徑累積度量為 22.6,下面路徑累積度量為 16.4。 圖 3.3-8 時間點 t5軟式解碼決策的倖存路徑 如圖 3.3-8,經過累積度量比較之後,狀態 a 選擇保留下面路徑、狀態 b 選擇保留下面路徑、狀態 c 選擇保留上面路徑、狀態 d 選擇保留下面路 徑,雖然保留的倖存路徑與硬式決碼決策相同,但是卻大大的提升了訊 息的可靠度,讓解碼器有更準確的運算。 利用迴旋碼的重複結構來修剪籬柵,確保路徑個數不會超過狀態個數。 在每個時間點上都有八條路徑分別進入四個狀態,每個狀態透過相加-比 較-選擇,刪除其一保留一條倖存路徑,藉此來降低解碼的複雜度。
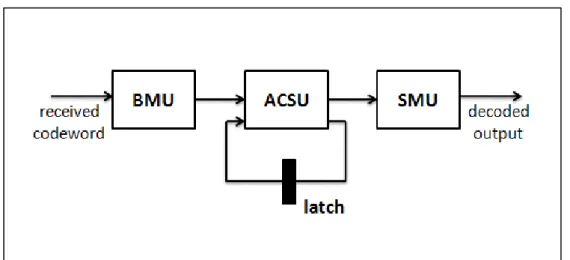
在解碼器實作上,斐特比解碼流程可以分成三個部分,如圖 3.3-9。
圖 3.3-9 斐特比解碼流程
由左到右依序是分支路徑產生單元(Branch Metric generation Unit, BMU)、相加比較選擇單元(Add-Compare-Select Unit, ACSU)、存活記憶 單元(Survivor Memory management Unit, SMU)。
分支路徑產生單元,它的功用就是產生每一段分支接收訊號與籬柵圖 上訊號的距離,在硬式決策上即是計算漢明距離,而軟式決策必頇計算 歐式距離。 相加比較選擇單元,此部分的功能是將分支路徑產生單元出來每一段 分支距離相加,並比較進入相同狀態的兩個分支路徑哪一個較佳,進而 累積到下一個狀態上,所以相加比較選擇單元紀錄的是累積路徑。 存活記憶單元,此部分的功能是透過相加比較選擇單元所計算出來的 最佳累積路徑也就是相似度最大的倖存路徑,透過其回朔找出原始的編 碼路徑,進而解出原始訊號,而一般斐特比解碼特別著重於存活記憶單 元的設計,其中主要分為回朔追蹤(trace back, TB)以及暫存器交換 (register exchange, RE)兩種方式。
3.3.1 回朔追蹤
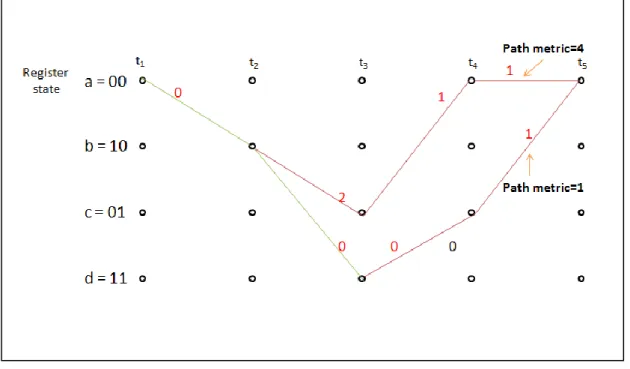
回朔追蹤的概念很簡單,就是當解碼路徑到一定的深度時,以當下最 佳路徑(累積度量最低的路徑)往回尋找前面走過的路徑,由於斐特比解碼 演算法在籬柵圖會利用重複結構來修剪籬柵,因此會保留下路徑合併之 後的狀態,在判斷過去的輸出。 圖 3.3.1-1 回朔追蹤路徑 如圖 3.3.1-1 在時間 t5,各狀態路徑的累積度量為 a = 1、b = 1、c = 3、 d = 2,依最佳路徑的判斷選擇狀態 a 路徑開始回朔追蹤(由於解碼深度不 足,所以狀態 b 路徑回朔追蹤也可以,解碼深度的說明會在後面章節提 到),如圖以藍色路徑表示回朔追蹤路徑,回到時間 t0時判斷當下的輸出 為 1(當下走的是綠色路徑) ,再將此結果輸出。這種程序的方法即是回 朔追蹤。3.3.2 暫存器交換
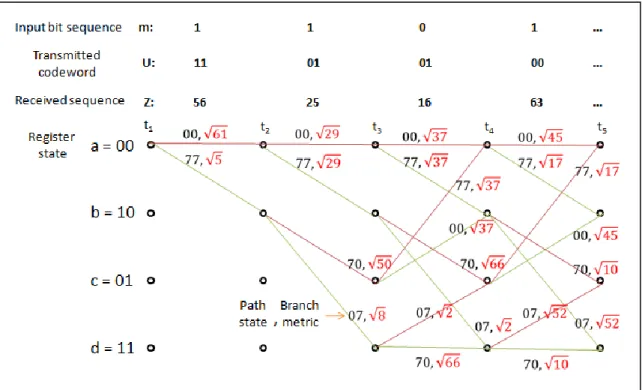
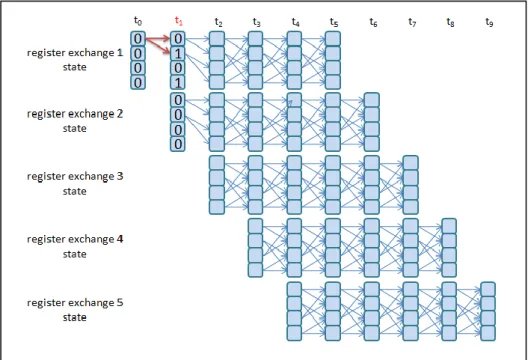
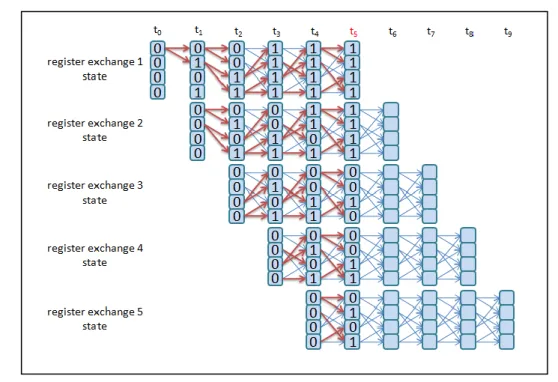
描述暫存器交換設計之前先說明籬柵圖的路徑產生與輸入資料位元 的對應關係。 圖 3.3.2-1 籬柵圖路徑性質 圖中在時間 ti的每個狀態到時間 ti+1會轉換成兩種狀態,而轉換的兩個狀 態都是上下兩條路徑的關係(輸入位元 0 和 1 分別依序對應紅色路徑與綠 色路徑),可以看出輸入位元為 0(紅色路徑)的皆在上面路徑,而輸入位元 為 1(綠色路徑)皆在下面路徑,這種性質我們可以將暫存器的起始狀態設 定為 0 和 1 的交錯。利用籬柵圖對應的路徑性質關係與在每個時間 ti籬柵 中都有 2K-1個狀態的關係,可以描述出暫存器交換的設計概念。 利用圖 3.3.2-2~圖 3.3.2-6 來圖解說明暫存器交換的設計,並對照圖 3.3.2-1 的籬柵圖來描述暫存器裡值的交換路徑,並描述各個時間點暫存 器裡值的交換方式。首先我們先了解 K=3 的解碼器會有 23-1 = 4 個狀態的 轉換,因此每個交換的暫存器裡必需儲存四位元的資料,並且設定暫存 器初始狀態為 0000,起始狀態為 0101。假設輸入位元序列 m = 11011, 編碼完之後接收端收到的碼字序列 z = 11、01、01、10、01,解碼的路徑深度為 5 個時間點,因此設定有五個編號 1~5 的交換暫存器。 圖 3.3.2-2 時間 t0,編號 1 暫存器裡的初始值為 0000,編號 2~5 的暫存器 不動作。(初始值為 0000,起始值為 0101) 圖 3.3.2-2 時間 t0的暫存器交換狀態 圖 3.3.2-3 依時間 t1的倖存路徑,各暫存器裡的值:編號 1 為起始值,編 號 2 為初始值,編號 3~5 不動作。
圖 3.3.2-3 時間 t1的暫存器交換狀態
圖 3.3.2-4 依時間 t2的倖存路徑,各暫存器裡的值:編號 1 的值位移為 0011,
編號 2 為起始值,編號 3 為初始值,編號 4~5 不動作。
圖 3.3.2-4 時間 t2的暫存器交換狀態
動作。 圖 3.3.2-5 時間 t3的暫存器交換狀態 圖 3.3.2-6 依時間 t4的倖存路徑,各暫存器裡的值:編號 1 的值位移為 1111, 編號 2 的值位移為 1101,編號 3 的值位移為 0011,編號 4 為起始值,編 號 5 為初始值。 圖 3.3.2-6 時間 t4的暫存器交換狀態
圖 3.3.2-7 依時間 t5的倖存路徑,各暫存器裡的值:編號 1 和 2 的值皆位 移為 1111,編號 3 的值位移為 0010,編號 4 的值位移為 0011,編號 5 為 起始值。 圖 3.3.2-7 時間 t5的暫存器交換狀態 從暫存器交換的圖解可以看到在時間 t3時,編號 1 暫存器內的值已收斂 為 1,並且不會再變換。而在時間 t5時,編號 1 暫存器已達設定的解碼深 度,故將編碼器裡收斂的值(1)輸出;而編號 2 暫存器內的值也收斂為 1, 但是未達設定的解碼深度,因此需等待至時間 t6才能將收斂的值輸出。 由於上述說明的例子為 K=3,所以暫存器裡的值只有四個,比較容易 達到收斂的狀況。在限制長度增加時,相對暫存器裡的狀態也會隨之增 加(解碼器會有 2K-1個狀態的轉換),如果在解碼深度不足時暫存器裡的值 將有可能無法收斂為單一的值,此時便需要比較暫存器裡值的比例來做 為輸出的判斷。 說明完回朔追蹤和暫存器交換的設計之後,如果用簡單的方式來描述
每次輸出必輸回朔追蹤到既定的解碼深度,因此解碼的效率會降低,而 在回朔追蹤浪費大量的時間;而暫存器交換是直接將原始訊號在經過相 加比較選擇單元之後就隨著倖存路徑到下一個狀態,因此不需要回朔, 解碼上也會比回朔追蹤有效率,但相對的限制長度增加時,需要使用到 大量的暫存器,因此在空間上的使用相對於回朔追蹤的方式就會佔用較 多的記憶體。換個方式比較,回朔追蹤是利用時間來換取空間,而暫存 器交換是利用空間來換取時間。 本論文主要探討迴旋碼在不同的限制長度、不同的解碼決策、不同的 解碼路徑深度,模擬於 AWGN 通道下解碼效率的影響,並與未編碼的 QPSK 調變作編碼增益的數據比較,由於實現於 SDR 系統上大量的暫存 器不是限制條件,因此選擇較不浪費時間的暫存器交換方式。
3.4 迴旋碼的性質
在這個章節會詳細說明迴旋碼的特殊性質,對於碼字序列間的距離與 錯誤校正能力的關係、系統迴旋碼與非系統迴旋碼的差異、災難性錯誤 的影響條件、解碼路徑深度的解碼效率、距離轉換函數的描述與限制長 度與距離性質的關係,透過這些迴旋碼的相關性質來說明所互相對應的 關係。3.4.1 距離性質與錯誤校正能力
在編碼中,碼字序列之間的最小距離與編碼的錯誤校正能力有關。一 般線性碼計算編碼的錯誤校正能力會找出每個碼字與所有元素為零的序 列,這兩者之間的最小距離,再依公式(3-1)計算錯誤更正能力(t)。t = dmin−1
2 (3-1)
在計算迴旋碼錯誤更正能力時,一樣傳送所有為零的序列,觀察籬柵 圖上重新合併到零序列路徑,計算其路徑的漢明距離,就是迴旋碼的最 小距離。在所有發散後合併的任意長度的路徑距離中,其中最小的路徑 稱做最小自由距離(minimum free distance),又簡稱自由距離(free distance, df)。圖 3.4.1-1 說明 K=3 迴旋碼的自由距離,依圖所示,藍色路徑為自由 距離。 路徑從 t1到 t2之間的漢明距離為 2,從 t2到 t3之間的漢明距離為 1,從 t3到 t4之間的漢明距離為 2,路徑在 t4重新合併回到零序列路徑, 而這段累積路徑 2+1+2=5,即為這個(2,1,3)迴旋編碼器的最小自由距離。 而計算錯誤更正能力(t)的公式(3-1)只要將原本的 dmin改成 df即可。 圖 3.4.1-1 籬柵圖上(2,1,3)迴旋碼的自由距離路徑
3.4.2 對稱與非對稱(系統性與非系統性)
所謂的對稱迴旋碼又稱系統性迴旋碼(systematic convolutional code), 意指輸入的 k 值組成為輸出碼字 n 值組的一部分[7]。如圖 3.4.2 便是(2,1,3) 系統迴旋編碼器的例子。
圖 3.4.2-1 (2,1,3)系統迴旋編碼器
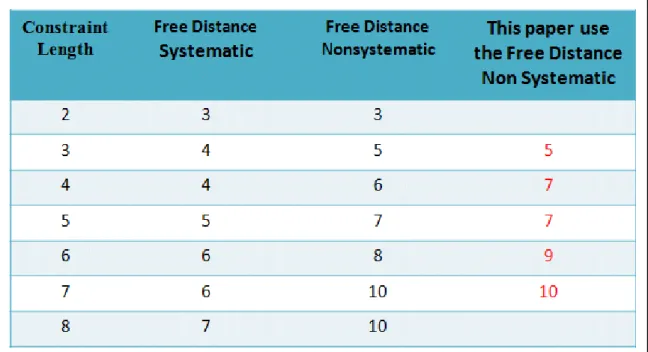
由上一個章節提到,迴旋碼的自由距離會影響錯誤校正的能力,從表 3.4.2-1 可以看到一般系統性迴旋碼會將既定的限制長度與碼率的自由距 離加以縮減,因此系統性迴旋碼在錯誤校正能力方面也會比非系統性迴 旋碼來的差,但是系統性迴旋碼的唯一好處為每個封閉迴路必頇包含一 個以上由非零輸入位元所產生的分支,因此在每個封閉迴路都具有非零 的碼子,因此系統性迴旋碼永遠不會形成災難性錯誤[8](下一個章節會描 述災難性錯誤的影響條件與例子)。
3.4.3 災難性錯誤傳播
災難性錯誤(catastrophic error)指在有限個碼字錯誤卻造成無限多個 解碼資料位元的錯誤。[9]推導出呈現災難性錯誤的迴旋碼的必要條件。 以圖 3.4.3-1 (2,1,3)迴旋編碼器架構來當災難性錯誤的例子。 圖 3.4.3-1 災難性錯誤傳播的迴旋編碼器範例圖 3.4.3-1 迴旋編碼器的連結方式,用多項式表示法來描述: g1(X) = 1 + X g2(X) = 1 + X2 (3-2) 災難性錯誤傳播的條件就是生成多項式有次數最少一次的公因式。由於 g2(X) = 1 + X2 = (1 + X)(1 + X) (3-3) 生成多項式 g1(X)與 g2(X)具有共同的多項式因式 1+X,因此圖中迴旋編 碼器的連結方式有可能呈現災難性錯誤傳播。
3.4.4 編碼器限制長度與解碼路徑深度
由於斐特比解碼器所需的解碼資料儲存容量是以限制長度 K 的指數 函數增加的,在每個解碼步驟之後,解碼器就必頇記錄 2K-1 個路徑,而 保留下來的所有路徑皆傾向相同的起源,所以解碼器只要能夠儲存足夠 的 2K-1個路徑,那所有路徑上最老的位元(解碼的位元)將會是相同的。包 含固定總量的路徑歷史,每此往籬柵更深入一層時,任意的路徑都將會 以最老的位元輸出,而所需的路徑暫存器總數是: u = h2K−1 (3-4) 其中公式(3-4),h 為狀態的資訊位元路徑歷史的長度,[5]經過證實,當 h 等於 4 或 5 時,h 乘以限制長度便足以提供近乎最佳化解碼器的性能所需。 本論文的存活記憶單元使用暫存器交換的設計,其中一個暫存器就表示 儲存 2K-1個狀態結果,依 h 乘以限制長度即為整個解碼器的暫存器數量, 因此 h 解碼深度為描述限制長度的倍率表示。商業用途的解碼器限制長 度大約 K=10,靠增加限制長度來增加編碼增益。本論文研究以軟式解碼決策時,收斂的解碼深度 h 不再是硬式解碼決 策裡的 h=5,h 的增加是可以再提高編碼增益的,雖然提高的幅度不大, 但是對於錯誤率與功率要求甚高的系統依然有幫助。
3.4.5 路徑距離的轉換函數
在 3.4.4 章節,我們直接利用籬柵圖計算(2,1,3)迴旋碼的自由距離,若 由狀態圖觀察可以導出封閉形式(class-form)表示法。將原本的狀態圖修 改成如圖 3.4.5-1 所示,D 的指數表示該分支的碼字到全為零的分支,這 兩者之間的漢明距離[5]。刪除圖中節點 a 的自迴路(self-loop),對於碼字 序列與全為零的序列的距離性質而言,此迴路沒有作用;將節點 a 分為 兩個節點(a 與 e),分別代表狀態圖的輸入與輸出,讓源自節點狀態 a(00) 終止於節點狀態 e(00)的路徑方便追蹤與計算其自由距離。由上圖可以清楚知道路徑 a b c e 即為與全為零的路徑的漢明距離,也就 是 D2 +D+D2=D5藉此來計算路徑的轉換函數,因此自由距離為 5。 狀態公式(3-5)表示: Xb = D2X a + Xc Xc = DXb + DXd Xd = DXb + DXd Xe = D2X c (3-5) 轉換函數 T(D)也稱為編碼的生成函數,可以為 T(D) = X e / X a。套入狀態 公式,可以導出以下公式(3-6)[10, 11]: T D = 1−2DD5 (3-6) 與不同路徑的距離相比,可以將轉換函數引進一個因子 L,使 L 的指 數成為每一個狀態的任何既定路徑,使其成為分支個數的計數器;再將 轉換函數引進一個因子 N,使 N 的指數成為所有由輸入位元 1 所造成的 分支,使其成為輸入位元 1 個數的計數器。附加因子 L 與 N 後,公式() 可以改為以下公式(3-7): Xb = D2LNX a + LNXc Xc = DLXb + DLXd Xd = DLNXb + DLNXd Xe = D2LX c (3-7)
而附加因子 L 與 N 後的轉換函數公式(3-8)為: T D, L, N = 1−DL 1+L ND5L3N (3-8) 圖 3.4.5-2 中可以看到原本的路徑 a b c e 的轉換函數計算變成 D2LN+DL+D2L=D5L3N,即這個路徑距離 D 為 5,路徑長度 L 為 3,輸入 位元 1 的 N 為 1。 附加因子 L 與 N 的函數轉換狀態圖,如下圖所示: 3.4.5-2 引進因子 L 與 N 的全為零路徑距離的狀態圖
上圖描述,如果全為零的路徑為正確的路徑,即表示雜訊使選擇 a b c e 這個路徑距離 D=5,路徑長度 L 為 3,將會造成一個位元的錯誤(N=1); 若選擇路徑 a b d c e 這個路徑,D2 LN+DLN+DL+D2L=D6L4N2,路徑距離 D=6 , 路 徑 長 度 L 為 4 , 若 選 擇 路 徑 a b c b c e 這 個 路 徑 , D2LN+DL+LN+DL +D2L=D6L5N2,路徑距離 D=6,路徑長度 L 為 5,這 兩個路徑則都會造成二個位元的錯誤(N=2)。 從轉換函數可以知道路徑長度對於造成位元的錯誤並沒有直接的影 響,即說明限制長度亦是如此(最短的自由距離路徑長度即為限制長度), 只有路徑距離 Df會影響位元的錯誤。 本論文所使用的迴旋碼相關轉換函數如表 3.4.5-1: 表 3.4.5-1 本論文所使用的迴旋碼轉換函數
3.5 迴旋碼的性能界限
本論文的迴旋碼於 AWGN 通道下進行模擬,使用同調 QPSK 調變(位 元錯誤率同 BPSK 調變),可以藉由上述的轉換函數證明迴旋碼的位元錯 誤機率上限,來描述迴旋碼的性能界限。 於 AWGN 通道下,迴旋碼的位元錯誤機率上限公式(3-9)為: PB ≤ Q 2df Ec N0 exp df Es N0 dT D,N dN N=1,D = exp (−Ec/N0) (3-9) 其中 Es/N0 = r Eb/N0 r = k/n = 編碼率 Eb/N0 = 資訊位元能量對雜訊功率頻譜密度的比率 Es/N0 = 通道符號能量對雜訊功率頻譜密度的比率 以上述(2,1,3)迴旋碼為例,碼率為 1/2,自由距離 df=5,使用同調 QPSK 與硬式解碼決策,便可以導出以下公式(3-9, 3-10): PB ≤ Q 5Eb N0 exp 5Eb 2N0 exp −5Eb 2N0 1−2exp −Eb 2N0 2 (3-9) PB < Q 5Eb N0 2 (3-10)圖 3.5-1 自由距離=5 的性能界線與最佳化解碼器性能比較 從上圖可以看出,由公式(3-10)帶出的迴旋碼性能界限錯誤機率曲線(Free distance = 5)與本論文模擬的限制長度 K=3 解碼路徑深度 h=5 的最佳化性 能表現的錯誤機率曲線比較,路徑解碼深度最佳化的性能表現會比迴旋 碼性能界限帶來多 1(dB)的編碼增益。
3.6 硬式解碼決策的編碼增益上限
編碼增益定義為,比較相同調變與通道特性的編碼系統與未經編碼系 統,達成特定錯誤機率所需的 Eb/N0的縮減量,以分貝為單位。然而編碼 增益不可能無限制的增加[12],以分貝為單位來表示: 編碼增益 ≦ 10 log10(rdf) (3-11) 其中 r 為碼率 k/n,df為自由距離。 1.E-08 1.E-07 1.E-06 1.E-05 1.E-04 1.E-03 1.E-02 1.E-01 1.E+00 0 1 2 3 4 5 6 7 8 9 10 B it Er ro r R ate Eb/ N0(dB)BER V.S E
b/N
0,Performance Bounds for
K=3, h=5
uncoded Free distance= 5 K=3, h=5
表 3.5-1 硬式解碼決策的編碼增益上限
(資料來源:[13])
表 3.5-2 硬式解碼決策的編碼增益上限
表 3.5-3 本論文所使用的硬式解碼決策迴旋碼的編碼增益上限
表 3.5-1 和表 3.5-2 為部分硬式解碼決策迴旋碼的編碼增益上限[13];表
第四章迴旋編碼器與迴旋解碼器設計與實作
本章節迴旋編碼器與迴旋解碼器的設計與實作[14,15]以碼率為 1/2 的 迴旋碼為主,設計說明與實作描述以前面章節的(2,1,3)迴旋碼為例,其他 不同限制長度的迴旋編碼器(K=3~7),不同解碼深度的迴旋解碼器(h=2~8) 將會於附錄呈現。4.1 迴旋編碼器程式設計與實作
迴旋編碼器程式設計與實作,如圖 4.1-1: 圖 4.1-1 迴旋編碼器程式設計與實作 如圖 4.1-1 編號所示說明:1. information bits 以 stream array 的方式送入 convolutional encoder。(針 對 K=3 編碼器於資料最後多送入 K-1=2 個 0 資料,以清除暫存器裡的 值)
2. 以迴圈隔離暫存器來達到暫存器位移的效果。(針對 K=3 編碼器會有 K-1 個暫存器,稱為編碼器記憶量)
3. 依照上部與下部的連接方式分別連結於不同的模餘 2 加法器,再對所 連結暫存器裡的資料取樣然後輸出。(上部加法器產生 u1 - first bit,下
部加法器產生 u2 - second bit)
4. 將 u1 - first bit 與 u2 - second bit 交錯輸出,儲存成 encode bits stream
array(也就是 Channel bits stream)。
4.2 硬式解碼決策與軟式解碼決策設計與實作
解碼決策程式設計與實作如圖 4.2-1,針對碼率=1/2 的迴旋碼系統, 硬式決策可以將每一組碼字的兩個位元描述於一個平面上,描述兩個位 元可能具有的四個硬式決策值。若是八位準的軟式決策,將每一組碼字 以八位準在平面上等距分佈,形成六十四組軟式決策值,此時解調器所 傳送的直接是經過量化的雜訊訊號。 將經過量化的雜訊訊號送入決策解碼器,當解碼器選擇硬式決策解碼 (雙位準)時,直接與具有四個硬式決策值作距離比較,取最短距離的值直 接將量化後的訊號映射到所對應的硬式決策值(漢明距離),輸出至斐特比 解碼演算法計算;若解碼器選擇軟式決策解碼(八位準)時,直接與具有六 十四個軟式決策值作距離比較,取最短距離的值直接將量化後的訊號映 射到所對應的軟式決策值(歐式距離),輸出至斐特比解碼演算法計算。4.3 迴旋解碼器-斐特比解碼演算法程式設計與實作
迴旋解碼器-斐特比解碼演算法程式設計與實作,如圖 4.3-1:
圖 4.3-1 迴旋解碼器-斐特比解碼演算法程式設計與實作
如圖 4.3-1 編號所示說明:
1. information bits 以 stream array 的 方 式 送 入 viterbi convolutional decoder。
2. 分支路徑產生單元(Branch Metric generation Unit, BMU),產生每一段 分支接收訊號與籬柵圖上訊號的距離,在硬式決策上即是計算漢明距 離,而軟式決策必頇計算歐式距離。
3. 相加比較選擇單元(Add-Compare-Select Unit, ACSU),將分支路徑產生 單元出來每一段分支距離相加,並比較進入相同狀態的兩個分支路徑 哪一個較佳,進而累積到下一個狀態上。
4. 存活記憶單元(Survivor Memory management Unit, SMU),透過相加比 較選擇單元所計算出來的最佳累積路徑也就是相似度最大的倖存路徑, 本論文存活記憶單元所使用的設計為暫存器交換,因此會根據路徑解 碼深度而有相對應的暫存器數量。 5. 將暫存器交換最後輸出的值取樣,輸出並儲存。