Eye detection based on head contour geometry
and wavelet subband projection
Jing-Wein Wang
National Kaohsiung University of Applied Sciences
Institute of Photonics and Communications 415 Chien Kung Road
Kaohsiung, Taiwan 807
E-mail: jwwang@cc.kuas.edu.tw
Wen-Yuan Chen
National Chin-Yi Institute of Technology 35 Lane 215, Section 1, Chung-Shan Road Taiping City, Taichung County, Taiwan 411
Abstract. We propose a novel two-step approach for eyes detection in complex scenes including both indoor and outdoor environments. This approach adopts face localization to eye extraction strategy. First, we use energy analysis to remove most noise-like regions to enhance face localization performance, and then use the head contour detection 共HCD兲 approach to search for the best combinations of facial sides and head contours with an anthropometric measure, and thereafter the face-of-interest 共FOI兲 region is located. In the meantime, via the deedging preprocessing for facial sides, a wavelet subband interorientation projec-tion method is adopted to select eye-like candidates. Along with the geo-metric discrimination among the facial components, such as the eyes, nose, and mouth, this eye verification rule verifies the selected eyes candidates. The eye positions are then marked and refined by the bounding box of FOI region as the ellipse being the best fit of the facial oval shape. The experimental results demonstrate that the performance of our proposed method has significant improvement compared to others on three head-and-shoulder databases. © 2006 Society of Photo-Optical Instru-mentation Engineers.关DOI: 10.1117/1.2205225兴
Subject terms: eye detection; head contour detection; anthropometric measure; eye verification rule.
Paper 050200R received Mar. 14, 2005; revised manuscript received Aug. 6, 2005; accepted for publication Oct. 2, 2005; published online May 25, 2006.
1 Introduction
Biometric technology uses distinctive physiological or be-havioral characteristics of individuals for verification and identification. It ensures greater reliability and security than password- and number-based systems. However, biometrics such as eye detection in an image is a challenging problem because it must locate eyes with no prior knowledge about their scales, locations, pose, and image content. Back-ground and illumination are also problems not yet fully solved. Many other factors can also contribute to the exter-nal variability of the eyes-like makeups, facial expressions, and occlusions. Past research focused on two major catego-ries facial feature extraction: direct-eye-detection ap-proaches and face-detection-based apap-proaches.
Direct eye detection is a “bottom-up” process consisting of two steps: using eye pair detectors to explore facial land-marks and to determine the saliency map location; and then using a classifier to cross-validate each salient location. Ex-isting eye pair detectors are mostly based on template matching schemes. Fixed templates1 and deformable templates2,3 are used for the detection of eyes that have approximately fixed appearance. A simple template-matching method is not robust since it cannot deal with faces in different poses, scales, expressions, and illumina-tion condiillumina-tions. A more common method is the deformable template, which is specified by a set of parameters and a
priori knowledge of the expected shape of the eyes; it is
used to locate the eyes in human face images. However, the deformable template scheme always accompanies problems
such as slow convergence, lengthy processing time, and parameters of energy terms determined manually. In Ref. 4, to decrease the sensitivity of the matching process to initial parameters, Feng and Yuen employed a variance projection function for locating the landmarks of eyes. However, this method is feasible only if the eye image contrast is rela-tively high. To overcome the shortcomings of the deform-able template methods, Li et al.5 developed a fuzzy tem-plate matching based on the piecewise boundary and feature-parameter-based judgment approach for eye detec-tion. This method was developed for a frontal upright face with open eyes, so it has difficulty when the appearance of the feature changes significantly, e.g., closed eyes or eyes with glasses. While cross-validation is an elegant way to estimate true classifier error rates, artificial neural network approaches are generally good, as reported by previous re-search. In these approaches, detection is based on learned models from both positive and negative examples of eye patterns to train the eye detection system. Negative ex-amples are usually obtained from some false detection re-sults produced by the system at the initial stages of training, but it requires too many training images before it works well.6,7An eye detection technique that requires just a few training images is desirable in practice. A wavelet trans-form with fast implementations due to their hierarchical spatial structure is another strategy for eye detection ap-proaches. Huang and Wechsler8used wavelet functions as activation functions in eye detection, and their experimental results were good. The detected algorithm takes the wavelet packet representation for eyes, and takes the radial basis functions共RBFs兲 to classify facial areas into eye and
eye regions. The performance of the eye detection algo-rithm may degrade when the geometrical features of an eye do not express clearly; this causes the feature subspaces of eyes and noneyes to overlap and the subsequent neural net-work classifier cannot classify them easily. Wavelet decom-positions can map the useful information content into a lower dimensional feature space; nevertheless, what feature is an efficient representation and how to develop a compu-tationally efficient eye detection algorithm still deserve fur-ther study. Ofur-ther impressive methods including visual learning,9 genetic evolving algorithms,10 and the general-ized projection function11 can reach better accuracy; the underlying assumption is to find invariant features in dif-ferent poses and lighting conditions for efficiency detec-tion.
The second category is a top-down process of a face-based-matching approach; it provides robustness and auto-mation in terms of holistic descriptions and serves as a front end for a finer eye extraction scheme in a complex background. To detect a face from an image, the whole image is scanned at different scales to find the likely area of the face pattern, and then to create a location and boundary description of that area. The initial screening scheme is indeed important and can greatly reduce the time-consuming nature of later processing. On the other hand, a bad segmentation may miss the face. Since the detector may take the most execution time, it is common to structure a face detector as a cascade of weak classifiers to identify potential regions. Such case is the Viola and Jones12 boost-ing cascade, which was built on an overcomplete set of Haar-like features; it has been proved to be a powerful learning algorithm for face detection. While the AdaBoost-ing methods13,14 have advantages and disadvantages, they mostly rely on the quality and quantity of the training data. Even if the viewing geometry is fairly good in the presence of hairstyle, beards, occlusion, glasses, illumination, etc., they will obscure or alter the appearance of facial land-marks, which makes the task of face detection harder. A support vector machine15 共SVM兲 training is computation-ally quite expensive, but it is a two-class classifier for find-ing the optimum boundary between classes, and has been applied to object detection such as face detection. Osuna et al.,16 used face detections to preprocess image intensity, such as those used in Rowley et al.,17to learn the face and nonface patterns from face and nonface examples. In Ref. 18, classification of the wavelet-transformed features19 is performed by an SVM. Sahbi et al.20 described a method for finding the face in an image. Their work used the coarse-to-fine SVM classifiers to locate the face. In Ref. 21, the genetic algorithm 共GA兲 was used as an optimizer for principal component analysis共PCA兲 feature selection, and the SVM was constructed for classification. Segmentation is the process of clumping individual pixels together to form regions, where the location and actual shape of the complete face in an image might be found. Color is a good feature for classifying the image into skin-like and non-skin-like regions. Skin-like regions are analyzed by facial features or elliptical shapes to confirm whether or not the image really is a face, and eye extraction methods usually can extract landmark features with the expected geometry of a face. Preliminary results exploit skin tone segmenta-tion to locate face region and eyes.22–25Although skin
col-ors differ among races, they are distributed in a very narrow range in the chrominance plane. The variability as the illu-mination condition changes between the skin tones is inten-sity. The color-based method often encounters problems in robustly detecting skin colors in complex background. The other possible strategy is to start with low-level cues corre-sponding to the so-called early attentive visual features in the biological vision, such as head corner and facial side, and to combine them by means of anthropometry, to locate potential face targets in eye detection. The head contour is composed of the head corner and the facial side; it is a discriminative characteristic of a face object in a cluttered background. A novel aspect of the proposed method can exploit the possible combinations of right and left head contours that are caused by the difference of depth of focus between the foreground face object and the background.
For gray-level still image with cluttered backgrounds, illumination changes, pose and expression changes, head rotation, and scale variation, an accurate and efficient method for human eye detection is still deficient since the facial features may not easily be detected independently. Experimental research through years proved that each cat-egory covers techniques that perform better on the localiza-tion of certain features only. This implies that for every selected feature, a fusion of methods of both categories should provide more stable results than the corresponding method alone. Following this reasoning and motivated by the observation of the oval shape of human face, in this current paper, we propose complementary techniques based on head contour geometry characteristics and wavelet sub-band interorientation projection. The technique aims at pro-viding an efficient system to operate on complex back-grounds and must tolerate illumination changes, scale variations, and moderate head rotations of, say, 45 deg.
The paper is organized as follows. In the next section, we set up the eye detection problem in a face localization to eye extraction framework. Section 3 presents the head con-tour detection共HCD兲 approach used as a justified way of locating a face-of-interest 共FOI兲 region. The approximate size of the face from the FOI region is thus obtained. Using this size estimate, we define a wavelet subband interorien-tation projection method for generating and selecting the eye-like candidates. Eye extraction is achieved by examin-ing the correlation between eyes and detectexamin-ing geometrical relationships among the facial components such as the eyes, nose, and mouth. In Sec. 4, experimental results on three head-and-shoulder image databases indicate the novel approach’s significant improvement in eye detection. Fi-nally, Sec. 5 concludes the paper.
2 Eye Detection Framework
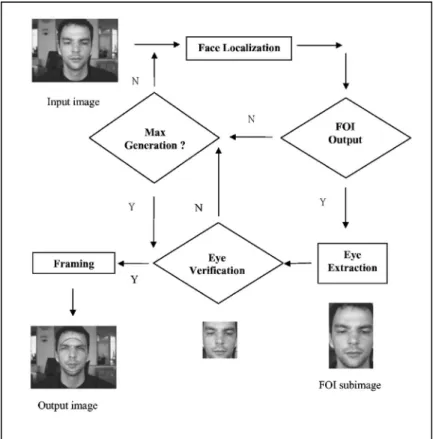
A good eye detector must be robust in the sense that the detector does not vary widely with changing illumination or when eyes vary in scale and orientation. The detector must provide enough detail for successful detection, while not being too sensitive to changes in eyes orientation, illumina-tion, and so on. A useful detector also must be computa-tionally tractable and flexible to enable scalability in appli-cations. Figure 1 is a flow chart of our novel eye-detection system, which contains the following two major modules.
2.1 Face Localization
We use face localization to determine the location and size of a face in an image, which is crucial to the eye extraction. Preceded by a local energy processing, we use a global threshold to extract dominant objects from the input image, and then we use the proposed HCD approach to exclude the nonfacial area from the background to locate the desired facial region. The approximate size of the face from the FOI region is then obtained—where we take an overlaid bounding box to frame the FOI region. Finally, we feed the facial size and the location of the FOI into the eyes extrac-tion process to detect the eye pair.
2.2 Eye Extraction
In the eye extraction process, a wavelet-based interorienta-tion projecinterorienta-tion method for generating and selecting the eye-like candidates is proposed. The FOI subimage is decom-posed into subbands by the multiresolution wavelet. We conduct the thresholing and binarization along with facial side deedging to process the horizontal subband; then it is more suitable for finding the most probable location of eyes. Next, we use an interorientation projection to gener-ate and select eye-like candidgener-ate regions according to the similarity between projective relieves. Of course, this pro-cess may extract one or more eye candidate that are true eyes or false ones. We use eye verification to identify eyes and their locations. We also take the geometric discrimi-nated information among the facial components, such as the eyes, nose, mouth, and cheeks to examine the matching accuracy. Then, we take a correlation function to calculate
the matching score between the left eye and right eye pro-jection relieves for each filtering eye-pair candidate. In gen-eral, the true eyes have the strongest resemblance. A suc-cessful eyes extraction also serves to refine the bounding box of the FOI region, as the ellipse is the best fit of the facial oval shape. If it fails to detect, our system just out-puts the earlier result of face localization. Our system is performed on three head-and-shoulder face databases con-sisting of oriental, occidental, and hand-drawn cartoon faces for a total over 2000 gray-level images with different sizes.
In the eye detection framework, as shown in Fig. 1, the face localization and eye extraction steps can repeat until we find the eyes, or until the number of generations reach the threshold value. We use the head-and-shoulder input image and the output image as an example to illustrate each process at each stage.
3 Face Localization and Eye Extraction
To detect eyes more reliably and efficiently, this paper pro-poses a robust eye detector composed of the geometry mea-sure of the head contour, the wavelet projection method, and geometrical constraints on the facial components. Here, the detector is intended for view-independent applications corresponding to moderate perspective variations in both indoor and outdoor environments with fair lighting varia-tions; it is expected to handle head orientations up to ±45 deg with respect to frontal view and size variations of up to 3 times in complex background. The goal of eye detection is to determine the human face’s size and position
in image, and to specify eye location while the face is lo-cated. The proposed scale- and pose-tolerance eye detector consists of two modules, namely face localization and eye extraction. The detailed procedure for locating the FOI re-gion and the eyes is described in the following.
3.1 Face Localization
Face localization involves locating and extracting human faces from an image. By analyzing the energy distribution in the spatial domain from the public face images taken in unconstrained environments with uncontrolled illumina-tion, occlusion of facial structure, and cluttered back-ground, we observed a prominent distinction between the face object and the complex background due to the differ-ence of depth of focus. The proposed head and face land-marks extraction approach is based on the energy differ-ence between the head contour and background scene. The motivation of our scheme is its inherent efficiency com-pared with the related works12,13owing to the fact that it does not use any detailed biometric knowledge of the hu-man face. In this section, we describe the novel HCD algo-rithm that combines the head corner and facial edge infor-mation to locate the FOI region in the image. The processes are described as follows.
3.1.1 Energy analysis
One obvious feature of human face is texture.26In the head-shoulder image, the head contour and the facial landmarks, such as eyebrows, eyes, nose, and mouth, exhibit various energy roughnesses in FOI region. Roughness corresponds to the perception that our sense of touch will feel with an object and it can be characterized in two-dimensional scans by depth共energy strength兲 and width 共separation between edges兲. It is proper in reality to distinguish head-face tex-ture from background by a suitable binary threshold ob-tained from the energy analysis, being very useful as a dis-tinctive preprocessing of face localization. Prior to face object extraction, a smoothing filter is used to smooth the image and to enhance the desired local edge. The local standard averageand energy E of the 3⫻3 pixels defined by the mask are given in following expressions:
共x,y兲 = 1 Ni=−1
兺
1兺
j=−1 1 I共x + i, y + j兲, 共1兲 E共x,y兲 = 1 Ni=−1兺
1兺
j=−1 1 关I共x + i, y + j兲 −共x,y兲兴2, 共2兲 where N = 9 is a normalizing constant, I共x,y兲 is the input image of size W⫻H, and E共x,y兲 is the local energy image. The global mean depends on E共x,y兲 is then defined asMOE = 1 W⫻ H
兺
x=0 W−1兺
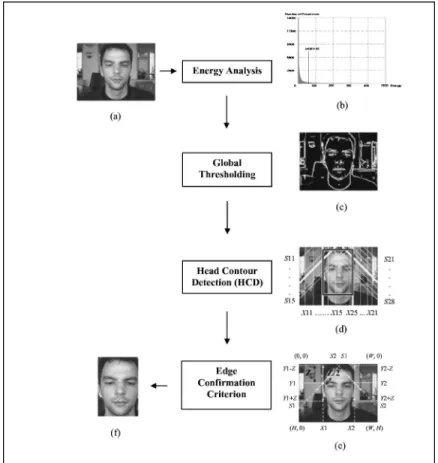
y=0 H−1 E共x,y兲. 共3兲Figure 2共a兲 shows the example image I共x,y兲 of size 384 ⫻286 pixels whose gray levels are represented with 8 bits, and Fig. 2共b兲 shows its energy histogram.
3.1.2 Binary thresholding
To extract the interested object from the background, a thresholded image is selected as the following:
B共x,y兲 = thresholding of 关I共x,y兲兴
=
再
255 if E共x,y兲 ⱖ T0 otherwise
冎
. 共4兲Pixel values labeled 255 are objects of interest, whereas pixel values labeled 0 are undesired ones. Initial threshold
T is set as MOE in this work, then the thresholded value is
gradually changed until the observed pixel-of-threshold 共point兲 density of the whole image is around 10 to 20%, which is considerably good representation for objects to be detected. Comparing Fig. 2共c兲 with the original image 关Fig. 2共a兲兴, we find that it is a reasonable representation of what we could consider to the brightest objects in that image.
3.1.3 HCD approach
The human head contour, which contains relatively concen-trated information of the face, is more reliable than the feature of eyes or other face organs, especially in unclear images or small face images. If the feature of head contour is stable, then all of the differences from person to person or from bright to dark or different backgrounds can be eliminated. Using the head contour signature to detect hu-man objects in images is possible. Locating eyes with fea-ture of head contour has the advantage of scale invariance and simplification. Human head contours have different ap-pearances with different hairstyles, different persons, even the same person under different lighting source or wearing different hats. However, they are in a relatively narrow en-ergy space. In the previous subsections, we investigated the distribution of face images in complex backgrounds, and found that the human head contour is clustered in the larger energy space. Because most human head contours are el-lipses, especially in an image that is passing through the binarization processing. Thus, our algorithm uses edge de-tection to extract the unique arc profile of the head corner from the interested objects27 and then selects the desired FOI area that is primarily used to differentiate an area from the rest of the image for further processing. To this end, the left and right diagonal projections for the elliptical face are devised to handle both in-depth rotation and on-the-plane rotation under about ±45 deg. Therefore, the proposed method is insensitive to face orientation. In the following, we show the details of the proposed HCD algorithm, and how it effectively locates the head-face profile. The algo-rithm consists of the following details, as shown in Fig. 3. Beginning, if
Nr关B共x,y兲兴 =
再
1 if B共x,y兲 = 2550 if B共x,y兲 = 0
冎
, 共5兲and 0ⱕkⱕH, for each left diagonal projection 关Fig. 3共a兲兴,
Dlkis computed by
Dlk=
兺
共x,y兲=共0,k兲共k,0兲
Nr关B共x,y兲兴, 共6兲
and for each left vertical projection关Fig. 3共b兲兴, Vlkis com-puted by
Vlk=
兺
共x,y兲=共0,0兲共k,H兲
Nr关B共x,y兲兴. 共7兲
Next, for each right diagonal projection关Fig. 3共c兲兴, Drk is computed by
Drk=
兺
共x,y兲=共W,k兲共W−k,0兲
Nr关B共x,y兲兴, 共8兲
and for each right vertical projection 关Fig. 3共d兲兴, Vrk is computed by
Vrk=
兺
共x,y兲=共W,0兲共W−k,H兲
Nr关B共x,y兲兴. 共9兲
According to the point projection waveforms, as shown in Fig. 3, the diagonal head boundary candidates and horizon-tal facial side candidates are displayed as black solid lines and determined from the peak responses with wide enough spreading, which are defined as projection relief slope greater than 1.0, respectively. The pseudoline drawn from
the valley to the peak of response measures the slope. Af-terward, the lines marked by white solid lines denote all candidate locations of head-face, as presented in Fig. 2共d兲, i.e.,
S1苸 兵S11,S12,S13,S14,S15其, 共10兲
S2苸 兵S21,S22,S23, ... ,S28其, 共11兲
X1苸 兵X11,X12,X13,X14,X15其, 共12兲
X2苸 兵X21,X22,X23,X24,X25其. 共13兲
For each pair of head candidates S1⫻ and S2⫻, the algo-rithm gives the cost for each pair of facial side candidates
X1⫻ and X2⫻, where ⫻ stands for a digit 1,2,3,.... Next,
the proposed edge confirmation criterion measures the fit of line candidates to the original image I共x,y兲 by using the Eqs. 共14兲 and 共18兲. We cite one illustrated example for localization as displayed in lines S1 , S2 , X1, and X2 of Fig. 2共e兲. The cost of the possible head-face boundary, lines S1 and X1, on the left side of the image is given by
#LV1 =
兺
i=Y1−ZY1−1
Nr关B共x,i兲兴, 共14兲
Fig. 2 Block diagram of face localization steps:共a兲 input image, 共b兲 histogram and MOE value of the
smoothing input image,共c兲 result of global thresholding, 共d兲 head contour detection, 共e兲 edge confir-mation criterion, and共f兲 located FOI region.
Acknowledgments
This work has been partly supported by the National Sci-ence Council under Grant No. NSC 94-2213-E-151-012. In addition, we would like to thank Mr. Bak-Teik Lim for his programming help in the experiments.
References
1. P. W. Hallinan, “Recognizing human eyes,” Proc. SPIE 1570, 214– 226共1991兲.
2. K. M. Lam and H. Yan, “Locating and extracting the eye in human face images,” Pattern Recogn. 29共5兲, 771–779 共1996兲.
3. W. Huang, Q. Sun, C.-P. Lam, and J.-K. Wu, “A robust approach to face and eyes detection from images with cluttered background,” in
Proc. Int. Conf. Pattern Recognition, pp. 110–114共1998兲.
4. G. C. Feng and P. C. Yuen, “Variance projection function and its application to eye detection for human face recognition,” Pattern
Recogn. Lett. 19, 899–906共1998兲.
5. Y. Li, X.-L. Qi, and Y.-J. Wang, “Eye detection by using fuzzy tem-plate matching and feature-parameter-based judgment,” Pattern
Rec-ogn. Lett. 22, 1111–1124共2001兲.
6. Y.-S. Ryu and S.-Y. Oh, “Automatic extraction of eye and mouth fields from a face image using eigenfeatures and multilayer percep-trons,” Pattern Recogn. 34, 2459–2466共2001兲.
7. X. Li and C. Yuan, “A learned saliency map for eye detection,” in
Proc. 8th Int. Conf. on Neural Information Processing (ICONIP 2001), Shanghai, China共2001兲.
8. J. Huang and H. Wechsler, “Eye detection using optimal wavelet packets and radial basis functions共RBFs兲,” Int. J. Pattern Recognit.
Artif. Intell. 13共7兲, 1009–1026 共1999兲.
9. B. Moghaddam and A. Pentland, “Probabilistic visual learning for object recognition,” IEEE Trans. Pattern Anal. Mach. Intell. 19共7兲, 696–710共1997兲.
10. J. Huang and H. Wechsler, “Visual routines for eye location using learning and evolution,” IEEE Trans. Evol. Comput. 4, 73–82共2000兲. 11. Z.-H. Zhou and X. Geng, “Projection functions for eye detection,”
Pattern Recogn. 37, 1049–1056共2004兲.
12. P. Viola and M. Jones, “Rapid object detection using a boosted cas-cade of simple features,” in Proc. 2001 IEEE Computer Soc.
Com-puter Vision and Pattern Recognition, pp. 511–518共2001兲.
13. R. Lienhart, A. Kuranov, and V. Pisarevsky, “Empirical analysis of detection cascades of boosted classifiers for rapid object detection,” in Proc. DAGM’03 25th Pattern Recognition Symp., pp. 297–304, Magdeburg, Germany共2003兲.
14. B. Froba, A. Ernst, and C. Kublbeck, “Real-time face detection,” in
Proc. 4th IASTED Int. Conf. on Signal and Image Processing, pp.
479–502, Kauai共2002兲.
15. C. Burges, “Tutorial on support vector machine for pattern recogni-tion,” Data Min. Knowl. Discov. 2共2兲, 955–974 共1998兲.
16. E. Osuna, R. Freund, and F. Girosi, “Training support vector ma-chines: an application to face detection,” in Proc. IEEE Conf. on
Computer Vision and Pattern Recognition, pp. 130–136共1997兲.
17. H. A. Rowley, S. Baluja, and T. Kanade, “Neural network-based face detection,” IEEE Trans. Pattern Anal. Mach. Intell. 20, 23–38共1998兲. 18. C. Papageorgiou and T. Poggio, “A trainable system for object
detec-tion,” Int. J. Comput. Vis. 38共1兲, 15–33 共2000兲.
19. S. Mallat, “Multifrequency channel decomposition of images and wavelet models,” IEEE Trans. Acoust., Speech, Signal Process.
37共12兲, 2091–2110 共1989兲.
20. H. Sahbi, D. Geman, and N. Boujemaa, “Face detection using coarse-to-fine support vector classifiers,” in Proc. IEEE Int. Conf. Image
Processing (ICIP2002), Rochester, NY共2002兲.
21. Z. Sun, G. Bebis, and R. Miller, “Object detection using feature sub-set selection,” Pattern Recogn. 37, 2165–2176共2004兲.
22. Y. Wang and B. Yuan, “A novel approach for human face detection from color images under complex background,” Pattern Recogn. 34, 1983–1992共2001兲.
23. C. Garcia and G. Tziritas, “Face detection using quantized skin color regions merging and wavelet packet analysis,” IEEE Trans.
Multime-dia 1共3兲, 264–277 共1999兲.
24. S. A. Sirohey and A. Rosenfeld, “Eye detection in a face image using linear and nonlinear filters,” Pattern Recogn. 34, 1367–1391共2001兲. 25. G. C. Feng and P. C. Yuen, “Multi-cues eye detection on gray
inten-sity image,” Pattern Recogn. 34, 1033–1046共2001兲.
26. I. Craw, N. Costen, T. Kato, and S. Akamatsu, “How should we represent faces for automatic recognition,” IEEE Trans. Pattern Anal.
Mach. Intell. 21, 725–736共1999兲.
27. R. C. Gonzalez and R. E. Woods, Digital Image Processing, Prentice-Hall, Upper Saddle River, NJ共2002兲.
28. I. Daubechies, “Orthonormal bases of compactly supported wave-lets,” Commun. Pure Appl. Math. 91, 909–996共1998兲.
29. http://www.humanscan.de/.
30. http://www.mis.atr.co.jp/~mlyons/jaffe.html. 31. http://www.vision.caltech.edu/html-files/archive.html.
32. K. J. Kirchberg, O. Jesorsky, and R. W. Frischholz, “Genetic model optimization for Hausdorff distance-based face localization,” in Proc.
Int. ECCV 2002 Workshop on Biometric Authentication, LNCS-2359,
pp. 103–111, Copenhagen, Denmark共2002兲.
33. J. Wu and Z.-H. Zhou, “Efficient face candidates selector for face detection,” Pattern Recogn. 36, 1175–1186共2003兲.
Jing-Wein Wang received his BS and MS
degrees in electronic engineering from Na-tional Taiwan University of Science and Technology, in 1986 and 1988, respectively, and his PhD degree in electrical engineer-ing from National Cheng Kung University, Taiwan, in 1998. From 1992 to 2000, he was a principal project leader with Equip-ment Design Center of Philips, Taiwan. In 2000, he joined the faculty of National Kaohsiung University of Applied Sciences, where he is currently an associate professor with the Institute of Photonics and Communications. His current research interests are combinatorial optimization, pattern recognition, and wavelets and their applications.
Wen-Yuan Chen received his BS, and MS
degrees in electronic engineering from Na-tional Taiwan University of Science and Technology in 1982 and 1984, respectively, and his PhD degree in electrical engineer-ing from National Cheng Kung University, Tainan, Taiwan, in 2003. Since 2003 he has been an associate professor with the De-partment of Electronic Engineering, Na-tional Chin-Yi Institute of Technology. His re-search interests include digital signal processing, image compression, pattern recognition, and water-marking.