Research Article
Self-Organized Cognitive Sensor Networks: Distributed Channel
Assignment for Pervasive Sensing
Li-Chuan Tseng,
1Feng-Tsun Chien,
1Abdelwaheb Marzouki,
2Ronald Y. Chang,
3Wei-Ho Chung,
3and ChingYao Huang
11Department of Electronics Engineering, National Chiao Tung University, Hsinchu 30010, Taiwan
2Institut Mines-T´el´ecom, T´el´ecom SudParis, 91011 ´Evry, France
3Research Center for Information Technology Innovation, Academia Sinica, Taipei 11529, Taiwan
Correspondence should be addressed to Feng-Tsun Chien; [email protected] Received 21 October 2013; Accepted 9 February 2014; Published 17 March 2014 Academic Editor: Luis Javier Garcia Villalba
Copyright © 2014 Li-Chuan Tseng et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. We study the channel assignment strategy in multichannel wireless sensor networks (WSNs) where macrocells and sensor nodes are overlaid. The WSNs dynamically access the licensed spectrum owned by the macrocells to provide pervasive sensing services. We formulate the channel assignment problem as a potential game which has at least one pure strategy Nash equilibrium (NE). To achieve the NE, we propose a stochastic learning-based algorithm which does not require the information of other players’ actions and the time-varying channel. Cluster heads as players in the game act as self-organized learning automata and adjust assignment strategies based on their own action-reward history. The convergence property of the proposed algorithm toward pure strategy NE points is shown theoretically and verified numerically. Simulation results demonstrate that the learning algorithm yields a 26% sensor node capacity improvement as compared to the random selection, and incurs less than 10% capacity loss compared to the exhaustive search.
1. Introduction
In wireless sensor networks [1], spatially distributed, low-power, and low-cost sensor nodes are deployed in a geo-graphical area to monitor the environment. The sensor nodes usually form clusters, and in each cluster there is an energy-rich sensor node acting as the cluster head, while other sensor nodes are referred to as cluster members. A cluster head is a special sensor node with better cognitive radio (CR) [2,3] functionality and is responsible for the spectrum sensing and the channel assignment among its cluster members.
To enable the various kinds of services [4–6] provided by a pervasive sensing system, proper radio resource man-agement [7] is important. Due to the spectrum scarcity and the ad hoc nature of sensor network deployment, it could be hard to assign licensed bands to sensor networks. Therefore, the CR technology has been considered as a
promising solution to the channel assignment problem of sensor networks. CR technology enables dynamic spectrum access (DSA) of unlicensed users in distributed networks. The key idea for CR operation is to allow the active sensing of the dynamic radio environment so as to improve the spectrum utilization. Akan et al. [8] provided a survey on cognitive radio sensor networks. By utilizing the CR technology, the sensor networks are able to attain high data rate due to available spectrum holes. In addition, dynamic spectrum access helps mitigate the interference incurred by dense deployment of sensor nodes.
Despite the promising features of cognitive sensor net-works, the deployment of such heterogeneous networks with sensor clusters underlying the same spectrum as macrocells and in the same geographical area brings new technical chal-lenges. In particular, we are interested in the case of densely populated sensor networks where, due to extensive frequency
Volume 2014, Article ID 183090, 10 pages http://dx.doi.org/10.1155/2014/183090
reuse, the cochannel interference (CCI) among sensor nodes and the cross-tier interference (between the macrocell and sensor networks) affect the system performance.
In the absence of a central controller, channel assignment in cognitive sensor networks is implemented in a distributed manner. In this paper, we consider the distributed channel assignment for self-organized cognitive sensor networks from a game-theoretic perspective. The main contributions of this paper are summarized as follows.
(i) We model the femtocell channel assignment problem as an ordinal potential game (OPG). The game con-siders time-varying channel availability as its external state.
(ii) We propose a fully decentralized channel assign-ment algorithm in which the channel is selected by each cluster head independently based on its action-reward history. The convergence property of the algorithm to a pure strategy NE point is verified theoretically as well as numerically.
This paper is organized as follows. We review the related work and compare it with our study inSection 2. InSection 3, the system model for a cognitive sensor network is pre-sented.Section 4describes the game-theoretic model of the distributed channel assignment problem.Section 5presents the stochastic learning procedure carried out by the cluster heads. Finally, numerical results are given inSection 6, with the conclusion drawn inSection 7.
Notations. Normal letters represent scalar quantities;
upper-case and lowerupper-case boldface letters denote matrices and vectors, respectively. Given a finite set A, Δ(A) represents the set of all probability distributions over the elements of
A. 1{cond} is the indicator function which equals one if the
condition cond is satisfied and zero otherwise.
2. Related Works
Distributed channel assignment has been extensively investi-gated for different networking applications where concurrent transmissions among neighboring wireless links exist.
In an interference avoidance scenario, different channels must be assigned to neighboring links. In femtocell net-works [9], different methods have been proposed to assign different spectrum to adjacent femtocells. Examples include distributed random access [9], dynamic frequency planning [10], and clustering [11]. For sensor networks with multiple channels, graph theory-based methods have also been con-sidered [12]. These methods can be viewed as variations of frequency planning and usually rely on negotiations among neighboring links. Graph theory is also a popular approach as the interference condition can be represented as nodes and edges in a graph. In sensor networks, Chowdhury et al. [13] proposed the dynamic channel allocation (DCA) and studied the related protocol design. Yu et al. [14] considered a game theory-based approach which takes into account both the network topology and transmission routing information.
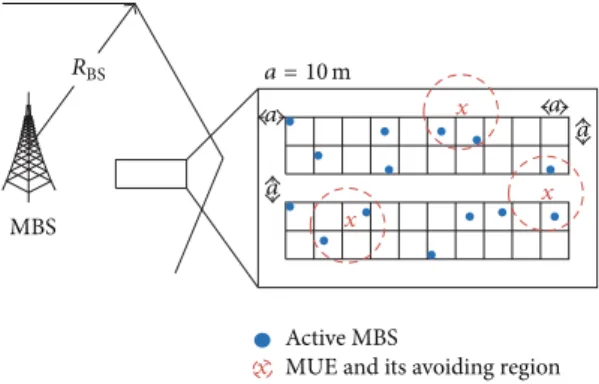
a = 10 m x a a a a x x
x Active MBSMUE and its avoiding region
MBS
RBS
Figure 1: Dual-stripe deployment of sensor clusters.
Channel selection for multicell orthogonal frequency divi-sion multiple access- (OFDMA-) based networks using graph framework was considered in [15].
On the other hand, in an interference mitigation sce-nario, mutual interference is tolerated. Channel assignment for cognitive sensor networks has been studied in [16]. Recently, self-organization of distributed agents based upon reinforcement learning (RL) mechanisms [17,18] has been shown to be effective in the literature. Multiagent Q-learning (MAQL) was applied to femtocell networks in [19,20]. MAQL involves the actions of other agents as the external state and thus requires the sharing of the knowledge of all agents’ actions. The stochastic learning (SL), in contrast, updates the actions of users based on their individual action-reward history. Nie and Comaniciu [21] considered the channel selection in cognitive radio using interference mitigation game formulation. SL was also applied to the opportunis-tic spectrum access in cognitive radio networks [22] to achieve the Nash equilibrium (NE) strategy. However, fully distributed resource allocation in cognitive sensor networks has not been extensively investigated.
3. System Model
We consider a cognitive radio sensor network consisting of one MBS and𝑁 sensor clusters under the coverage of the MBS. The method of sensor node clustering and cluster head selection [23] are also interesting topics but are out of the scope of this paper. Also we consider only the single-hop transmission and omit the multihop routing issue for ad hoc networks [24]. The sensors are deployed in an apartment block with a dual-stripe room layout, as shown inFigure 1.
In our considered system, the medium access control (MAC) function in a cluster resembles that of cellular systems. The time domain is divided into frames, and a frame is further divided into time slots. In each frame, a cluster head allocates its cluster members (i.e., sensor nodes) in different time slots following a time division multiple access (TDMA) rule. For simplicity, we assume that in each slot each cluster head allocates one sensor node over one of the available channels. We emphasize that the proposed method can be easily generalized to the cases with multiple sensor nodes per slot. A sensor node is in idle mode unless the current time
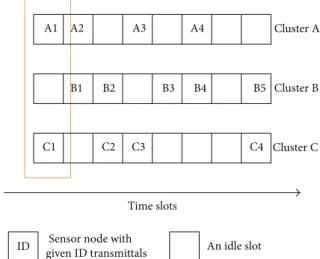
A1 A2 A3 A4 Cluster A
Cluster B
Cluster C
B1 B2 B3 B4 B5
C1 C2 C3 C4
Sensor node with given ID transmittals
Time slots
An idle slot ID
Figure 2: Exemplary time slot allocation in a frame. In the first slot, cluster heads A and C assign channels for sensor nodes A1 and C1, respectively.
slot is allocated for it. A cluster head is idle if none of its sensor nodes is transmitting data and active otherwise. We therefore introduce an active ratio, which is defined as the percentage of active clusters in a time slot. An exemplary time slot allocation is depicted inFigure 2.
The spectrum is divided into𝐶 channels, and the channels may be licensed to different macrocells (a.k.a spectrum owners). By utilizing CR, the sensor nodes access the same frequency band as the macrocell does. Since the sensor nodes are in an energy-tight situation and operate with ultralow power, we assume that the transmission power of a macrocell user equipment (MUE) is much higher than that of the sensors. Thus, the uplink transmission of an MUE will block the nearby sensor nodes using the same spectrum. For cross-tier interference mitigation, we define an avoiding region for each MUE. A channel is available to a cluster only if the channel is not assigned to an MUE whose avoiding region covers the cluster head. The channel availability for sensor clusters is expressed as a binary matrixX ∈ {0, 1}𝑁×𝐶, in which the element 𝑥𝑖,𝑐 equals one if channel 𝑐 is available to link𝑖 and zero otherwise. The elements of X follow the Bernoulli distribution and can be described by a probability matrixΘ ∈ [0, 1]𝑁×𝐶, where the element𝜃𝑖,𝑐is the probability that𝑥𝑖,𝑐= 1.
Assuming perfect synchronization in time and frequency, let𝑃𝑖denote the power of sensor node𝑖, and let |ℎ𝑖,𝑗|2indicate the link gain between cluster head𝑖 and sensor node 𝑗. The interference received by cluster head𝑖 from sensor node 𝑗 is given by
𝐼𝑗 → 𝑖 = 1{𝑎𝑖(𝑛)=𝑎𝑗(𝑛)}𝑃𝑗ℎ𝑖,𝑗2, ∀𝑖, 𝑗 ∈ N, (1)
where𝑎𝑖(𝑛) is the action (channel selection) of cluster head 𝑖 in frame𝑛. For notational brevity, we will hereafter discard the timing dependence of the action 𝑎𝑖(𝑛) in occasions
without ambiguity. Then, the signal-to-interference-and-noise ratio (SINR) at cluster head𝑖 can be expressed as
𝛾𝑖= 𝑃𝑖ℎ𝑖,𝑖
2
∑𝑁𝑗=1,𝑗 ̸= 𝑖𝐼𝑗 → 𝑖+ 𝜎2. (2)
Consequently, the expected capacity for link𝑖 in bits/s/Hz is given by
𝑅𝑖= 𝜃𝑖,𝑎𝑖log2(1 + 𝛾𝑖) . (3)
Leta = (𝑎1, . . . , 𝑎𝑁) be the channel assignment profile of all
active clusters. The global objective of the system is to find the optimal channel selection profileaoptthat maximizes the sum
capacity. Formally, consider
aopt= argmax a 𝑁 ∑ 𝑖=1 𝜃𝑖,𝑎𝑖log2(1 + 𝛾𝑖) . (4) To reflect a practical cognitive sensor network, our system model incorporates the following considerations.
(1) The uplink resource allocation for MUE is time-varying during the learning period, and the channel availability statistics (i.e.,Θ) are fixed but unknown to any sensor nodes.
(2) There is no centralized controller and the channel selection is performed independently by each cluster head.
(3) The number of sensor clusters in the system,𝑁, is unknown.
With these considerations, solving (4) is a challenging task, since the only available information for decision making at each individual player is its own action-reward history. Thus, a fully distributed channel selection scheme is pro-posed.
4. Game-Theoretic Model and
Channel Selection
In this section, we present the game-theoretic formulation of the self-organized cognitive sensor network channel selection problem. Our objective is to devise for each cluster head a distributed channel assignment strategy that takes into account the effect of both the sensor-tier and cross-tier interference. We summarize our notations related to the game formulation inTable 1.
4.1. Problem Formulation and Game Model. The channel
selection problem described in the previous section can be modeled by a normal-form game with external state, expressed as a 4-tuple:
G = (X, N, {A𝑖}𝑖∈N, {𝑢𝑖}𝑖∈N) , (5) whereX is the external state (channel availability) space, N is the set of players (cluster heads),A𝑖is the set of actions
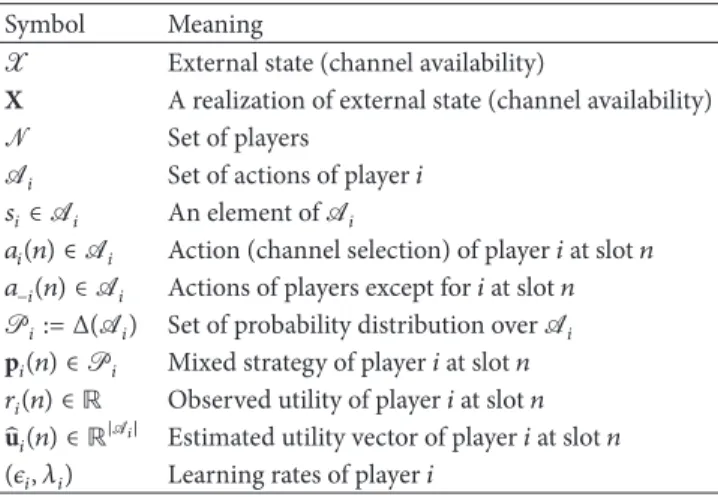
Table 1: Summary of notations in game-theoretic formulation. Symbol Meaning
X External state (channel availability)
X A realization of external state (channel availability) N Set of players
A𝑖 Set of actions of player𝑖
𝑠𝑖∈ A𝑖 An element ofA𝑖
𝑎𝑖(𝑛) ∈ A𝑖 Action (channel selection) of player𝑖 at slot 𝑛
𝑎−𝑖(𝑛) ∈ A𝑖 Actions of players except for𝑖 at slot 𝑛
P𝑖:= Δ(A𝑖) Set of probability distribution over A𝑖
p𝑖(𝑛) ∈ P𝑖 Mixed strategy of player𝑖 at slot 𝑛
𝑟𝑖(𝑛) ∈ R Observed utility of player𝑖 at slot 𝑛
̂u𝑖(𝑛) ∈ R|A𝑖| Estimated utility vector of player𝑖 at slot 𝑛
(𝜖𝑖, 𝜆𝑖) Learning rates of player𝑖
(selections of channels) that player𝑖 can take, and {𝑢𝑖}𝑖∈Nis the utility function of player𝑖 that depends on his own action as well as on the actions of other players.
Inspired by [21], the reward function is designed to consider the interference received (inward) and generated (outward) by each link. In this way, the cluster heads implic-itly cooperate to reduce the interference generated toward other sensor nodes. We define the generalized SINR (gSINR) for player𝑖 as
̃𝛾𝑖= 𝑃𝑖ℎ𝑖,𝑖 2
∑𝑁𝑗=1,𝑗 ̸= 𝑖(𝐼𝑗 → 𝑖+ 𝐼𝑖 → 𝑗) + 𝜎2. (6)
Then the instantaneous reward function of cluster head𝑖 is designed as
𝑟𝑖= {log2(1 + ̃𝛾𝑖) , if 𝑥𝑖,𝑎𝑖= 1;
0, otherwise. (7)
By the definition in (7), when the channel is available, the reward is given by Shannon’s capacity formula where both inward and outward interference are accounted for. When the channel is not available, the reward is zero. Notice that the calculation of the reward function in (7) relies on the knowledge of other players’ action. This leads to overhead due to the required information. The implementation is possible, and discussion on such protocol design can be found in [21]. The self-organization claimed in this paper is based on the fact that the action in each time instant is selected by each player independently and simultaneously.
For systems with the channel availability as the external state, the utility function is defined as the expected reward of player𝑖 over the external state (i.e., channel availability X); that is,
𝑢𝑖(𝑎𝑖, 𝑎−𝑖) = 𝜃𝑖,𝑎𝑖log2(1 + ̃𝛾𝑖) . (8)
Furthermore, if the cluster heads are assumed to be selfish and rational players, they will compete to maximize their own individual utility. In fact, a selfish cluster head will not only
maximize the capacity of its own user but also reduce the interference. Formally, the gameG is expressed as
(G) : max
𝑎𝑖∈A𝑖𝑢𝑖(𝑎𝑖, 𝑎−𝑖) , ∀𝑖 ∈ N. (9)
4.2. Analysis of Nash Equilibrium. With the utility function
defined in (8), we show the existence of an NE point for the proposed game in the following proposition.
Proposition 1. The game G is an ordinal potential game
(OPG) which possesses at least one pure strategy NE.
Proof. Consider the functionΦ : ×𝑖∈NA𝑖 → R+: Φ (a) = log2(1 +
∑𝑁𝑘=1𝑃𝑘ℎ𝑘,𝑘2
∑𝑁𝑘=1∑𝑁𝑗=1,𝑗 ̸= 𝑘𝐼𝑘 → 𝑗) . (10)
Now consider an improvement step made by cluster head 𝑖 that changes its action unilaterally from 𝑎𝑖 to 𝑖̆𝑎, so that 𝑢𝑖( ̆𝑎𝑖, 𝑎−𝑖) > 𝑢𝑖(𝑎𝑖, 𝑎−𝑖). Defining 𝐼̆𝑖→ 𝑗 ≜ 1{ ̆𝑎𝑖=𝑎𝑗}𝑃𝑖|ℎ𝑗,𝑖|2 and 𝐼𝑗 → ̆𝑖≜ 1{ ̆𝑎𝑖=𝑎𝑗}𝑃𝑗|ℎ𝑖,𝑗| 2, we have 𝑢𝑖( ̆𝑎𝑖, 𝑎−𝑖) > 𝑢𝑖(𝑎𝑖, 𝑎−𝑖) ⇐⇒ ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 [𝐼̆𝑖→ 𝑗+ 𝐼𝑗 → ̆𝑖] < ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 [𝐼𝑖 → 𝑗+ 𝐼𝑗 → 𝑖] ⇐⇒ ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 [𝐼̆𝑖→ 𝑗+ 𝐼𝑗 → ̆𝑖] + ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 𝑁 ∑ 𝑘=1,𝑘 ̸= 𝑖,𝑗 𝐼𝑗 → 𝑘 < ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 [𝐼𝑖 → 𝑗+ 𝐼𝑗 → 𝑖] + ∑𝑁 𝑗=1,𝑗 ̸= 𝑖 𝑁 ∑ 𝑘=1,𝑘 ̸= 𝑖,𝑗 𝐼𝑗 → 𝑘. (11) Here we have used the fact that when cluster head𝑖 changes its action, the effects are only on the interference that it receives
(𝐼𝑗 → 𝑖) and generates (𝐼𝑖 → 𝑗). From (10) and (11), we obtain
𝑢𝑖( ̆𝑎𝑖, 𝑎−𝑖) − 𝑢𝑖(𝑎𝑖, 𝑎−𝑖) > 0 ⇐⇒ Φ ( ̆𝑎𝑖, 𝑎−𝑖) − Φ (𝑎𝑖, 𝑎−𝑖) > 0. (12) Therefore,G is an OPG with potential function Φ, and the existence of a pure strategy NE is always guaranteed [26] since it coincides with the local maxima of the potential function. This completes the proof.
Notice that the term∑𝑁𝑘=1∑𝑁𝑗=1,𝑗 ̸= 𝑘𝐼𝑘 → 𝑗in the potential functionΦ denotes the summation of all mutual interference in the sensor network. Therefore, every NE point is the strategy profile, that is, a local maximum of the summed interference.
5. Stochastic Learning Procedure
Here, we discuss obtaining the NE via stochastic learning. As the channel state is time-varying and the action is selected
(1) Initially, set𝑛 = 0. Set the channel assignment probability vector and utility estimation as 𝑝𝑖,𝑠𝑖(0) = 1/ A𝑖, ̂𝑢𝑖,𝑠𝑖(−1) = 0, ∀𝑖 ∈ N, 𝑠𝑖∈ A𝑖.
(2) At the beginning of the𝑛th slot, each player selects an action 𝑎𝑖(𝑛) according to the current channel assignment probability
p𝑖(𝑛).
(3) In each slot, each BS transmits data. At the end of each slot, each BS receives the instantaneous reward𝑟𝑖(𝑛) specified by (15) depending on the precoding scheme.
(4) All players update their channel assignment probability vector and utility estimation according to the rules: ̂𝑢𝑖,𝑠𝑖(𝑛) − ̂𝑢𝑖,𝑠𝑖(𝑛 − 1) = 𝜂𝑖1{𝑎𝑖(𝑛)=𝑠𝑖}(𝑟𝑖(𝑛) − ̂𝑢𝑖,𝑠𝑖(𝑛 − 1)) , 𝑝𝑖,𝑠𝑖(𝑛 + 1) = 𝑝𝑖,𝑠𝑖(𝑛)(1 + 𝜖𝑖) ̂𝑢𝑖,𝑠𝑖(𝑛) ∑𝑠 𝑖∈A𝑖𝑝𝑖,𝑠𝑖(𝑛)(1 + 𝜖𝑖) ̂𝑢𝑖,𝑠𝑖(𝑛), (∗)
where𝜖𝑖and𝜂𝑖are the learning rates for action probability and utility estimation, respectively. Algorithm 1: Distributed channel assignment (DCA).
by each player simultaneously and independently in each play, previous algorithms that require complete information (e.g., better response dynamics [26]) may not be applicable here. Thus, we propose a decentralized stochastic learning-(SL-) based algorithm by which the BSs learn toward the equilibrium strategy profile from their individual action-reward history.
To facilitate the development of the SL-based channel selection algorithm, we extend the channel selection game into a mixed strategy form. Letp𝑖(𝑛) = [𝑝𝑖,1(𝑛), . . . , 𝑝𝑖,𝐶(𝑛)]𝑇, for all 𝑖 ∈ N, be the channel selection probability vector for player 𝑖, where 𝑝𝑖,𝑠𝑖(𝑛) is the probability that player 𝑖 selects strategy𝑠𝑖∈ A𝑖at slot𝑛. More precisely, using mixed strategies means that the channel assignment of cluster head 𝑖 is the outcome of a probabilistic experiment based on the probability vectorp𝑖(imagine that each SU rolls a biased dice in each strategy update). The mixed-strategy extension of the utility function is defined upon×𝑖∈NP𝑖, whereP𝑖is the set of probability distributions over the action space of player𝑖.
LetP(𝑛) = [p1(𝑛), . . . , p𝑁(𝑛)] be the mixed strategy profile of
G, and let 𝜓𝑖(𝑠𝑖, P) be the expected reward function of player 𝑖 if he employs pure strategy 𝑠𝑖while other players𝑗, for all 𝑗 ∈ N, 𝑗 ̸= 𝑖, employ a mixed strategy p𝑗; that is,
𝜓𝑖(𝑠𝑖, P) = ∑
𝑎𝑙,𝑙 ̸= 𝑖
𝑢𝑖(𝑎1, . . . , 𝑠𝑖, . . . , 𝑎𝑁) ∏ 𝑗 ̸= 𝑖
𝑝𝑗,𝑎𝑗. (13)
The proposed distributed channel assignment (DCA) algorithm for cognitive sensor networks is described in
Algorithm 1.
In each play, the channel selection is based on a proba-bility distribution over the set of channels. After each play, cluster head𝑖 obtains the instantaneous reward and updates the mixed strategy (i.e., channel selection vector)p𝑖(𝑛) and utility estimation̂u𝑖(𝑛). Notably, the utility estimation serves as a reinforcement signal so that higher utility induces higher probability in the next play. Furthermore, the proposed learn-ing algorithm is fully distributed, and the channel selection is solely based on individual action-reward experience without a centralized controller. In fact, the proposed algorithm belongs to the combined fully distributed payoff strategy
reinforcement learning (CODIPAS-RL) [27]. The evolution of the mixed strategies is described as follows.
Proposition 2. If the learning rates are sufficiently small, the
sequence{P(𝑛)} converges to P∗, which is the solution for the following ordinary differential equation (ODE):
𝑑𝑝𝑖,𝑠𝑖(𝑡) 𝑑𝑡 = 𝑝𝑖,𝑠𝑖(𝑡) [ [ 𝜓𝑖(𝑠𝑖, P) − ∑ 𝑠 𝑖∈A𝑖 𝜓𝑖(𝑠𝑖, P) 𝑝𝑖,𝑠 𝑖(𝑡)] ] . (14)
Proof. Please refer to [28, Section 4].
The ODE in (14) is actually the ODE of the replicator
dynamics [29]. An intuitive interpretation is that the prob-ability of taking an action increases if the utility is higher than the average utility over all possible actions and decreases otherwise.
The convergence property of the proposed algorithm is discussed in the following proposition.
Proposition 3. The SOCA algorithm converges to a pure
strategy NE for OPGs if the learning rates are sufficiently small.
Proof. First, we rewrite the ODE in (14) as follows: 𝑑𝑝𝑖,𝑠𝑖(𝑡) 𝑑𝑡 = 𝑝𝑖,𝑠𝑖(𝑡) ∑ 𝑠 𝑖∈A𝑖 𝑝𝑖,𝑠 𝑖(𝑡) [𝜓𝑖(e𝑠𝑖, P−𝑖) − 𝜓𝑖(e𝑠𝑖, P−𝑖)] . (15)
LetΨ(P) be the expected potential function; that is, Ψ (P) = ∑
𝑎𝑖∈A𝑖
Φ (𝑎1, . . . , 𝑎𝑁)∏𝑁
𝑖=1
𝑝𝑖,𝑎𝑖. (16) For OPGs, Ψ(e𝑠𝑖, P−𝑖) = 𝜕Ψ(P)/𝜕𝑝𝑖,𝑠𝑖 is an increasing function of𝜓𝑖(e𝑠𝑖, P−𝑖). Let
𝐷𝑖,𝑠𝑖,𝑠
𝑖 = 𝜓𝑖(e𝑠𝑖, P−𝑖) − 𝜓𝑖(e𝑠𝑖, P−𝑖) ,
𝐸𝑖,𝑠𝑖,𝑠𝑖 = Ψ (e𝑠𝑖, P−𝑖) − Ψ (e𝑠𝑖, P−𝑖) ,
0 0.5 1 Prob abi lit y 0 20 40 60 80 100 Iteration (n) 𝜀 = 0.5 0 0.5 1 0 20 40 60 80 100 Prob abi lit y Iteration (n) 𝜀 = 0.1 pi,1(t) pi,2(t) pi,1(t) pi,2(t)
Figure 3: Evolution of the mixed strategies (probability of taking different actions) of all players. Each pair of𝑝𝑖,1(𝑡) and 𝑝𝑖,2(𝑡) shows the behavior of player𝑖.
and we may write 𝐷𝑖,𝑠𝑖,𝑠
𝑖 > 0 ⇐⇒ 𝐸𝑖,𝑠𝑖,𝑠𝑖 > 0. (18)
By applying (15) and (18), the derivation ofΨ(P) with respect to𝑡 is given by 𝑑Ψ (P) 𝑑𝑡 = ∑𝑖∈N𝑠∑ 𝑖∈A𝑖 𝜕Ψ (P) 𝜕𝑝𝑖,𝑠𝑖 𝑑𝑝𝑖,𝑠𝑖 𝑑𝑡 = ∑ 𝑖∈N ∑ 𝑠𝑖,𝑠𝑖∈A𝑖 𝑝𝑖,𝑠𝑖𝑝𝑖,𝑠 𝑖Ψ (e𝑠𝑖, P−𝑖) ⋅ 𝐷𝑖,𝑠𝑖,𝑠𝑖 = 1 2𝑖∈N∑𝑠 ∑ 𝑖,𝑠𝑖∈A𝑖 𝑠𝑖<𝑠𝑖 𝑝𝑖,𝑠𝑖𝑝𝑖,𝑠 𝑖𝐸𝑖,𝑠𝑖,𝑠𝑖 ⋅ 𝐷𝑖,𝑠𝑖,𝑠𝑖 ≥ 0, (19)
where the last inequality holds since, given the condition in (18),𝐷𝑖,𝑠𝑖,𝑠
𝑖 and𝐸𝑖,𝑠𝑖,𝑠𝑖always have the same sign.
Thus, Ψ is nondecreasing along the trajectories of the ODE, and asymptotically all the trajectories will be in the set {P ∈ P : 𝑑Ψ(P)/𝑑𝑡 = 0}. From (15) and (19), the following is known: 𝑑Ψ (P) 𝑑𝑡 = 0 ⇒ 𝑝𝑖,𝑠𝑖𝑝𝑖,𝑠 𝑖[𝜓𝑖(e𝑠𝑖, P−𝑖) − 𝜓𝑖(e𝑠𝑖, P−𝑖)] 2 = 0 ⇒ 𝑑𝑝𝑖,𝑠𝑖 𝑑𝑡 = 0, ∀𝑖, 𝑠𝑖, 𝑠𝑖
⇒ P is a stationary point of the ODE (14) . (20)
In other words, when starting from an interior point of the simplex of the mixed strategy space P, the sequence
P(𝑛) converges to a stationary point of the ODE in (15). By
Proposition 3, we complete the proof.
While the SL-based learning algorithm converges to an NE point when the learning rates approach zero, smaller learning rates lead to a slower convergence. Therefore, the
Table 2: Simulation parameters.
Parameter Value
Minimum distance between nodes 3 m
Carrier frequency 2 GHz
Number of channels 2
Transmission bandwidth of each channel 180 kHz Path loss and shadowing Table A.2.1.1.2-8 [25] Penetration loss Table A.2.1.1.2-8 [25]
Sensor transmission power 1 mW
Thermal noise −174 dBm/Hz
Learning rates (default) (𝜆𝑖, 𝜖𝑖) = (0.1, 0.1)
choice of the learning rates strikes a trade-off between accuracy and speed and may be determined by training in practice.
6. Numerical Results
For system-level simulations, we consider a cognitive sensor network deployed within the coverage of a cellular network. As in Figure 1, the simulation environment includes one macrocell covering one dual-stripe apartment block. The apartment block contains 40 single-floor apartments. There is one sensor cluster in each apartment. When a sensor cluster is active, its cluster head assigns one channel to cluster members randomly located in the same apartment. Without loss of generality, we consider the channel assignment in the first slot of each frame, in which for each active cluster there is one cluster member. The simulation parameters are listed in
Table 2.
6.1. Convergence of the Proposed SL-Based Learning Algo-rithm. We first study the time-evolving behaviors of the
proposed stochastic learning method.
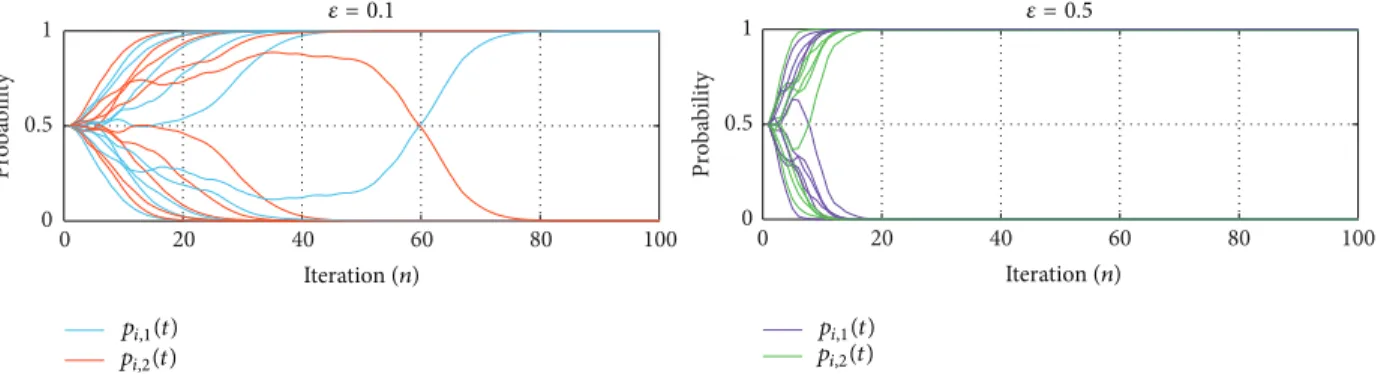
6.1.1. Evolution of Mixed Strategies. Figure 3shows the evo-lutions of the channel assignment probabilities (i.e., mixed strategy) using the proposed SL-based algorithm. We con-sider different learning rates and study the convergence behaviors. It is observed that, with equal initial probability,
1 2 3 4 5 6 7 8 9 10 0 2 4 6 8 Link ID U tili ty NE Deviation (a)𝜀 = 0.1 NE Deviation 1 2 3 4 5 6 7 8 9 10 0 5 10 Link ID Ut il it y (b)𝜀 = 0.5
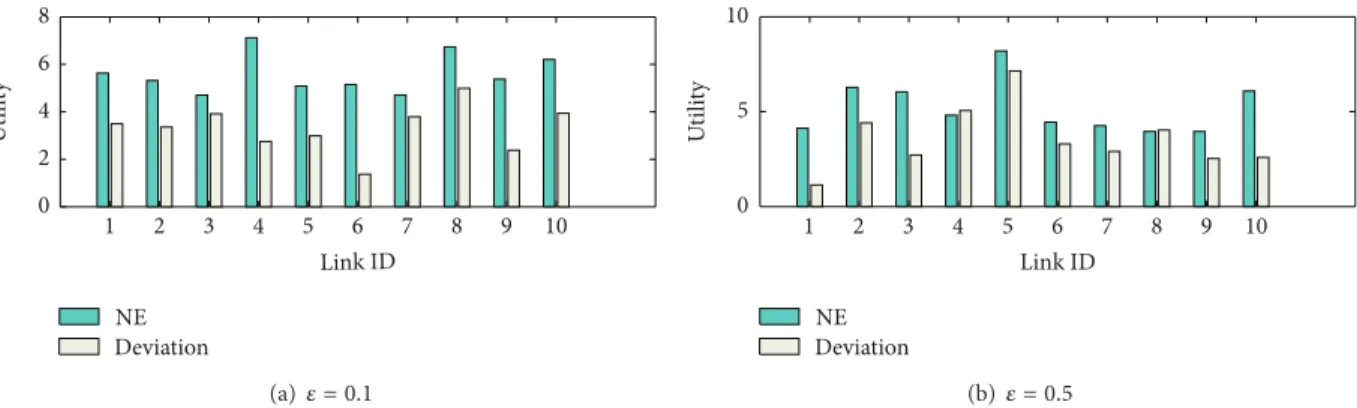
Figure 4: Test of unilateral deviation from the resulting strategy profile of each of the 10 players.
1 1.5 2 0 20 40 60 80 100 Ac ti o n Iteration (n) a3(j) 1 1.5 2 0 20 40 60 80 100 Ac ti o n Iteration (n) a5(j) 1 1.5 2 0 20 40 60 80 100 Ac ti o n Iteration (n) a6(j) 1 1.5 2 0 20 40 60 80 100 Ac ti o n Iteration (n) a10(j)
Figure 5: Evolution of the actions𝑎𝑖(𝑗) for some players.
the channel assignment probability converges to a pure strat-egy (i.e., the probability of choosing one stratstrat-egy approaches one) in around 80 and 20 iterations for𝜖 = 0.1 and 𝜖 = 0.5, respectively. As expected, larger learning rate results in faster convergence.
6.1.2. Verification of NE. As shown inFigure 3, the conver-gence toward pure strategy is observed for both𝜖 = 0.1 and 𝜖 = 0.5. An intuitive question to ask is as follows: does the resulting strategy profile achieve the Nash equilibrium? In
Figure 4, we verify the NE property by testing the unilateral deviation with a 25% active ratio and different learning rates. As can be seen fromFigure 4(a), when𝜖 = 0.1, a unilateral deviation results in lower utility for all players. In other words, the outcome of the learning algorithm is an NE point. On the other hand, when𝜖 = 0.5, as shown inFigure 4(b), links number 4 and number 8 both achieve higher throughput by unilateral deviation, and thus the resulting strategy is no longer an NE point. These results reflect the trade-off between accuracy and convergence speed which we mentioned before.
6.1.3. Evolution of Actions. During the learning procedure,
the channel assignment is based on probabilistic experiments. When the channel assignment changes in the next frame, the switching between different channels brings overhead since the sensor node needs to be reconfigured. The evolution of actions for selected players is shown inFigure 5. As can be seen, while Figure 3 (Left) reveals that it takes around 80 iterations for all players to converge to pure strategies, the actions seldom change after about 60 iterations in the learning procedure. This suggests that channel switching, if at all happens, usually happens only in the beginning of the entire learning procedure. Actually, our proposed learning algorithm aims at learning the equilibrium strategy in the long run. The channel switching and the incurred sensor node reconfiguration are manageable overheads compared to the long operation time.
6.1.4. Different Active Ratios. We further consider different
active ratios and investigate the convergence behaviors under different levels of mutual interference. The results for active ratio of 50% and 75% are shown inFigure 6. We observe that the convergence toward pure strategy takes around 100 and 150 iterations for active ratio of 50% and 75%, respectively. Comparing the case of 25% active ratio inFigure 3(Left), we see that it takes fewer iterations for densely active networks to converge than for sparsely active sensor networks.
6.2. Capacity Performance
6.2.1. Capacity under Unilateral Deviation. In Figure 4 we have shown that unilateral deviation leads to decreased utility.
Prob abi lit y 0 50 100 150 200 0 0.2 0.4 0.6 0.8 1 Active ratio = 50% Iteration (n) Active ratio = 75% Prob abi lit y 0 50 100 150 200 0 0.2 0.4 0.6 0.8 1 Iteration (n) pi,1(t) pi,2(t) pi,1(t) pi,2(t)
Figure 6: Evolution of the mixed strategies (probability of taking different actions) of all players with active ratios of 50% and 75%. Each pair of𝑝𝑖,1(𝑡) and 𝑝𝑖,2(𝑡) shows the behavior of player 𝑖.
1 2 3 4 5 6 7 8 9 10 0 2 4 6 8 Link ID C apaci ty NE Deviation
(a) Link capacity
1 2 3 4 5 6 7 8 9 10 0 2 4 6 8 Link ID Ca pa ci ty NE Deviation (b) Average capacity Figure 7: Test of unilateral deviation from the resulting strategy profile of each of the 10 players.
While the altruistic utility function design reduces the mutual interference, we are also interested in the performance of Nash equilibrium strategy in terms of the throughput of each cluster as well as the whole system. Therefore, inFigure 7, we test the change in capacity under unilateral deviation from the NE strategy for all players. As depicted in Figure 7(a), there is no significant change in the average capacity per sensor link when only one player unilaterally deviates from its NE strategy. FromFigure 7(b)we observe that, for all players, deviation from NE strategy decreases their own capacity.
6.2.2. Comparison with Other Methods. We further compare
the performance of the proposed channel selection scheme with two other approaches, namely, random allocation and exhaustive search, described as follows.
(i) In the random allocation scheme, each cluster head randomly selects a channel for its sensor node in each frame. Neither learning algorithm nor centralized controller is implemented.
(ii) In the exhaustive search scheme, it is assumed that there exists a centralized controller which knows all system information including the channel gains, the channel availability statistics, and the number of clus-ters. The channel assignment profile is determined by maximizing the expected sum capacity (i.e., solving (4)).
Table 3: Comparison of the capacity and fairness for different channel assignment schemes.
Number of SUs Proposed Exhaustive Random Active ratio = 25%,𝑅avg 6.0426 6.2433 4.7912 Active ratio = 25%,𝐽 0.9370 0.8512 0.9516 Active ratio = 50%,𝑅avg 4.8375 4.9454 4.0955
Active ratio = 50%,𝐽 0.8855 0.8235 0.9056
The performance of different channel selection schemes is evaluated by the average capacity per sensor node,𝑅avg =
(1/𝑁) ∑𝑁𝑖=1𝑅𝑖, and the fairness among sensor nodes. In the literature, fairness of resource allocation is usually quantified by Jain’s fairness index (JFI) [30], which is defined as
𝐽 = (∑ 𝑁 𝑖=1𝑅𝑖)2 𝑁 ∑𝑁𝑖=1𝑅2 𝑖 . (21)
The value of JFI falls in the interval of[1/𝑁, 1], and a higher JFI value indicates better fairness.
The simulation results of average capacity and JFI for different active ratios are summarized inTable 3. We observe that the exhaustive search method results in the best aver-age capacity with the worst fairness. The random selection scheme, in contrast, has the lowest average capacity but good fairness due to its randomness nature. The proposed
method shows well-balanced performance in terms of both average capacity and fairness. The results show the advantages of the proposed method; through the learning procedure toward equilibrium, the capacity of each player is considered and fewer players are sacrificed. If we examine the final channel selection profile, it is observed that, in the progress of convergence toward the NE point, the proposed learning algorithm allocates the mutually interfered users on different channels.
7. Conclusion
In this paper, we have studied the problem of distributed channel assignment in self-organized cognitive sensor net-works with unknown channel and unknown number of clusters. We have presented a game-theoretic approach to distributively manage interference and enable the coexistence of sensor and macrocell operations in a scenario where sensor nodes operate in the same spectrum as a cellular system. We modeled channel assignment problem by means of an ordinal potential game. A decentralized stochastic learning algorithm has been proposed. Simulation results have demonstrated the convergence of the algorithm toward a pure strategy Nash equilibrium with sufficiently small learning rates. The proposed method outperforms the random selection scheme in terms of average capacity, while the performance loss compared to the exhaustive search is limited. In addition, its fairness level is comparable to that of the random selection and surpasses the exhaustive search scheme.
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Acknowledgment
This work was supported in part by the National Science Council, Taiwan, under Grant NSC 102-2218-E-001-001.
References
[1] I. F. Akyildiz, W. Su, Y. Sankarasubramaniam, and E. Cayirci, “A survey on sensor networks,” IEEE Communications Magazine, vol. 40, no. 8, pp. 102–105, 2002.
[2] B. Wang, Y. Wu, and K. J. R. Liu, “Game theory for cognitive radio networks: an overview,” Computer Networks, vol. 54, no. 14, pp. 2537–2561, 2010.
[3] C. Liu, O. Granados, R. Duarte, J. Andrian, and C. Author, “Energy efficient architecture using hardware acceleration for software defined radio components,” Journal of Information
Processing Systems, vol. 8, no. 1, pp. 133–144, 2012.
[4] J. Ng, “Ubiquitous healthcare: healthcare systems and applica-tion enabled by mobile and wireless technologies,” Journal of
Convergence, vol. 3, no. 2, pp. 31–36, 2012.
[5] Y. Zhu and Q. Jin, “An adaptively emerging mechanism for context-aware service selections regulated by feedback distri-butions,” Human-Centric Computing and Information Sciences, vol. 2, no. 1, pp. 1–15, 2012.
[6] S. Silas, K. Ezra, and E. Blessing Rajsingh, “A novel fault tolerant service selection framework for pervasive computing,”
Human-Centric Computing and Information Sciences, vol. 2, no. 1, pp.
1–14, 2012.
[7] G. H. Carvalho, A. Anpalagan, I. Woungang, and S. K. Dhu-randher, “Energy-efficient radio resource management scheme for heterogeneous wireless networks: a queueing theory per-spective,” Energy, vol. 3, no. 4, 2012.
[8] O. B. Akan, O. B. Karli, and O. Ergul, “Cognitive radio sensor networks,” IEEE Network, vol. 23, no. 4, pp. 34–40, 2009. [9] K. Sundaresan and S. Rangarajan, “Efficient resource
manage-ment in OFDMA femto cells,” in Proceedings of the 10th ACM
International Symposium on Mobile Ad Hoc Networking and Computing (MobiHoc ’09), pp. 33–42, New York, NY, USA, May
2009.
[10] D. L´opez-P´erez, A. Valcarce, G. de la Roche, and J. Zhang, “OFDMA femtocells: a roadmap on interference avoidance,”
IEEE Communications Magazine, vol. 47, no. 9, pp. 41–48, 2009.
[11] A. Hatoum, N. Aitsaadi, R. Langar, R. Boutaba, and G. Pujolle, “FCRA: femtocell cluster-based resource allocation scheme for OFDMA networks,” in Proceedings of the IEEE International
Conference on Communications (ICC ’11), pp. 1–6, Kyoto, Japan,
June 2011.
[12] C. Seneviratne and H. Leung, “A game theoretic approach for resource allocation in cognitive wireless sensor networks,” in
Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC ’11), pp. 1992–1997, Anchorage,
Alaska, USA, October 2011.
[13] K. R. Chowdhury, N. Nandiraju, P. Chanda, D. P. Agrawal, and Q.-A. Zeng, “Channel allocation and medium access control for wireless sensor networks,” Ad Hoc Networks, vol. 7, no. 2, pp. 307–321, 2009.
[14] Q. Yu, J. Chen, Y. Fan, X. Shen, and Y. Sun, “Multi-channel assignment in wireless sensor networks: a game theoretic approach,” in Proceedings of the IEEE INFOCOM, pp. 1–9, San Diego, Calif, USA, March 2010.
[15] R. Y. Chang, Z. Tao, J. Zhang, and C.-C. J. Kuo, “Multicell OFDMA downlink resource allocation using a graphic frame-work,” IEEE Transactions on Vehicular Technology, vol. 58, no. 7, pp. 3494–3507, 2009.
[16] J. Ansari and P. M¨ah¨onen, “Channel selection in spectrum agile and cognitive MAC protocols for wireless sensor networks,” in
Proceedings of the 8th ACM International Workshop on Mobility Management and Wireless Access (MobiWac ’10), pp. 83–90,
Bodrum, Turkey, October 2010.
[17] Y. Sung and K. Cho, “A method for learning macro-actions for virtual characters using programming by demonstration and reinforcement learning,” Journal of Information Processing
Systems, vol. 8, no. 3, pp. 409–420, 2012.
[18] B. J. Oommen, A. Yazidi, and O.-C. Granmo, “An adaptive approach to learning the preferences of users in a social net-workusing weak estimators,” Journal of Information Processing
Systems, vol. 8, no. 2, pp. 191–212, 2012.
[19] M. Bennis and D. Niyato, “A Q-learning based approach to interference avoidance in self-organized femtocell networks,” in
Proceedings of the IEEE GLOBECOM Workshops, pp. 706–710,
Miami, Fla, USA, December 2010.
[20] A. Galindo-Serrano and L. Giupponi, “Femtocell systems with self organization capabilities,” in Proceedings of the 5th
Interna-tional Conference on Network Games, Control and Optimization (NetGCooP ’11), pp. 1–7, Paris, France, October 2011.
[21] N. Nie and C. Comaniciu, “Adaptive channel allocation spec-trum etiquette for cognitive radio networks,” in Proceedings
of the 1st IEEE International Symposium on New Frontiers in Dynamic Spectrum Access Networks (DySPAN ’05), pp. 269–278,
Baltimore, Md, USA, November 2005.
[22] Y. Xu, J. Wang, Q. Wu, A. Anpalagan, and Y.-D. Yao, “Oppor-tunistic spectrum access in unknown dynamic environment: a game-theoretic stochastic learning solution,” IEEE Transactions
on Wireless Communications, vol. 11, no. 4, pp. 1380–1391, 2012.
[23] B. Singh and D. Lobiyal, “A novel energy-aware cluster head selection based on particle swarm optimization for wireless sensor networks,” Human-Centric Computing and Information
Sciences, vol. 2, no. 1, pp. 1–18, 2012.
[24] X. Li, N. Mitton, A. Nayak, and I. Stojmenovic, “Achieving load awareness in position-based wireless ad hoc routing,” Journal of
Convergence, vol. 3, no. 3, 2012.
[25] 3GPP, “E-UTRA: further advancements for E-UTRA physical layer aspects,” Tech. Rep. TR 36.814, v 9.0.0, 3GPP, Sophia Antipolis, France, 2010.
[26] D. Monderer and L. S. Shapley, “Potential games,” Games and
Economic Behavior, vol. 14, no. 1, pp. 124–143, 1996.
[27] M. A. Khan, H. Tembine, and A. V. Vasilakos, “Game dynamics and cost of learning in heterogeneous 4G networks,” IEEE
Journal on Selected Areas in Communications, vol. 30, no. 1, pp.
198–213, 2012.
[28] H. Tembine, Distributed Strategic Learning for Wireless
Engi-neers, CRC Press, New York, NY, USA, 2012.
[29] D. Fudenberg and D. Levine, The Theory of Learning in Games, vol. 2, The MIT press, Cambridge, Mass, USA, 1998.
[30] R. Jain, D. Chiu, and W. Hawe, “A quantitative measure of fairness and discrimination for resource allocation in shared computer systems,” Tech. Rep. TR-301, DEC, Maynard, Mass, USA, 1984.
Submit your manuscripts at
http://www.hindawi.com
VLSI Design
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Machinery
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Hindawi Publishing Corporation http://www.hindawi.com
Journal of
Engineering
Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Shock and Vibration
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Mechanical Engineering
Advances in
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Civil Engineering
Advances inAcoustics and VibrationAdvances in
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Electrical and Computer Engineering
Journal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Distributed Sensor Networks International Journal of
The Scientific
World Journal
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Sensors
Journal ofHindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Modelling & Simulation in Engineering
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Active and Passive Electronic Components
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Chemical Engineering International Journal of Control Science and Engineering Journal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Antennas and
Propagation International Journal of
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014 Navigation and Observation International Journal of Advances in OptoElectronics
Hindawi Publishing Corporation
http://www.hindawi.com Volume 2014