英文詞叢中 Verb-Particle 結構於學術論文語料庫之分析
研究:探討 On 與 In 在此結構中之意涵
研究成果報告(精簡版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 99-2410-H-004-206- 執 行 期 間 : 99 年 08 月 01 日至 100 年 07 月 31 日 執 行 單 位 : 國立政治大學英國語文學系 計 畫 主 持 人 : 鍾曉芳 共 同 主 持 人 : 賴惠玲 計畫參與人員: 碩士班研究生-兼任助理人員:李旻倩 碩士班研究生-兼任助理人員:謝怡箴 碩士班研究生-兼任助理人員:陳俊宏 碩士班研究生-兼任助理人員:曾郁雯 博士班研究生-兼任助理人員:趙逢毅 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 100 年 10 月 24 日
前言
Recent corpus-based studies have shifted from lexical to pattern analysis (Hunston & Francis, 1999). Corpus examination based on a single word has been undertaken for years and this project intended to inspect patterns of language using lexical bundles and longer sequence of words. Adopting Biber et al.’s (2004) lexical bundle framework, the project further presented refinements of methodologies. Lexical bundles or idiomatic expressions found within these corpora were presented utilizing both general corpus and a self-compiled dissertation corpus. Measurement of probability and semantic relatedness were also performed to reflect upon the fixedness of a string of expression.
研究目的
Based on the approved project, the following research questions were addressed. (These research questions were the results of modification based on the proposal reviews and the PI’s own consideration of possible execution of the project within one year. The first question below shows an adjustment of corpora used for this project – though still keeping a general versus a specific one. The second and third research questions are modification and expansion of the original second research question.)1
1. What might be the distributions of preposition-containing lexical bundles in a general corpus versus an academic corpus of specific genre (dissertation abstracts)?
2. How will a preposition behave (similarly or differently) with and without the presence of a verb preceding a lexical string? [Thus, this research question explores the verb+particle strings versus strings that contain particles only]
3. How can the strength of connection between a verb and particle be measured? What could be the possible patterns for idiomatic versus free combinations of verb-particle constructions?
1
These were the original two research questions intended for two years respectively:
(a) What are the distributions of the different types of verb-particle constructions found in academic dissertation abstracts in local versus overseas universities (particularly in the U.S. and in Canada)? How do the results provide implications toward expanding the framework of lexical bundles and toward teaching and learning of verb-particle constructions?
(b) By focusing on the particles on and in, what types of literal and figurative meanings can one discover based on the different uses of on-ness (put on, take on, carry on, etc.) and in-ness (put in,
take in, hand in, etc.)? What could be the possible patterns for idiomatic versus free combinations
of verb-particle constructions and what could be the reasons for some less possible combinations?
文獻探討
Multi-word units may appear in various forms (light verb constructions, idioms, phrasal verbs, etc.). Verb-particle constructions refer to phrases which “consist of a head verb and one or more obligatory particles, in the form of intransitive prepositions (e.g., hand in), adjectives (e.g., cut short) or verbs (e.g., let go)” (Baldwin, 2005: 399). Many previous studies (e.g., Fraser (1976), Dikken (1995), and Bannard (2005)) have investigated verb-particle constructions from both theoretical and computational perspectives.
On the other hand, in a study by Biber et al. (2004), they suggested that a frequency-driven approach can be utilized to extract fixed sequences of words from specific register. These fixed sequences of words are called ‘lexical bundles,’ referring to ‘multi-word sequences’ in specific registers such that in university teaching (spoken) and textbook (written). Biber (2009) further examined several fillers in lexical bundles such as [the * of the] in academic prose. He compared the words in the of the asterisk slots which might be filled by similar or different nouns when different prepositions were concerned (e.g., at the *of, on the * of, it the * of, and to the * of).
研究方法
The methodology employed was mainly data-driven, utilizing corpora data for exploration of patterns of lexical bundles. Furthermore, computation of probability and semantic relatedness was undertaken in the investigation of the patterns of lexical bundles or strings of words in corpora. More specific elaboration of methodology will be given below.
結果與討論(含結論與建議)
Lexical Bundles
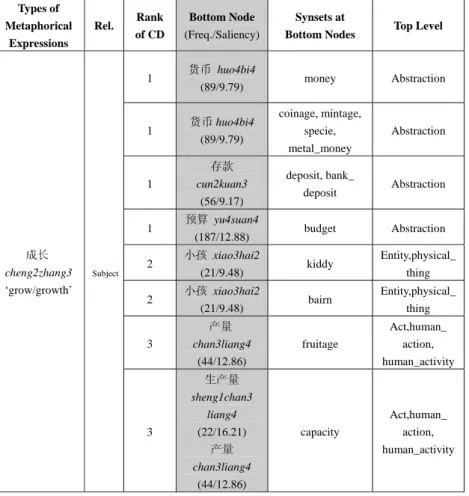
In order to test the patterns of lexical bundles in a general corpus, Chung, Chao, Lan, and Lin (2011) examined twenty-two prepositions (about, above, across, after, against, among, around, as, at, beside, by, down, for, from, in, into, like, of, off, on, onto, and with) in the written portion of the British National Corpus. Through the BNCWeb (Hoffmann et al., 2008), all occurrences of these twenty-two prepositions in both patterns of [PREPOSITION the NOUN of] (373,258 instances) and [VERB PREPOSITION the NOUN of] (86,877 instances) were extracted. The purpose of designing these two patterns was to observe whether a lexical bundle will behave similarly or differently (research question 2) when a verb is present (as in submitted by the time of) or absent (only by the time of). Chung et al. postulated a testable hypothesis that “the groups of words that appear with a similar preposition would share some similarities in semantic features” (pg. 6). In order to verify this hypothesis,
they (a) searched for distribution patterns of both constructions; (b) conducted an experiment in which human subjects were asked to tag the semantic categories of the nouns (and verbs); and (c) designed a computer program in which the semantic similarities of the words in the similar positions could be computed through finding possible shared hypernyms of any two words. These steps allowed them to arrive at the following conclusions: First, a four-word-lexical bundle is less constrained than a five-word lexical bundle. This is commonsensical because with the presence of a verb (submitted in the earlier example), the noun that follows (time) is often constrained when the verb is present (thus, by the sight of, by the look of, etc. were found with the four-word bundles but are not possible combinations with the additional verb submitted). Second, some prepositions (against, around) were found less constrained by the verbs – similar nouns were found for cases when the verb is present and absent. For example, in against the background of and around the time of, the nouns (background and time) remain prominent regardless whether or not a verb is present before the preposition. These cases were predicted to possess weaker connection with the verbs than with the nouns that follow (thus, answering the research question 4). Third, the semantic-coding experiment showed that the list of nouns (coding of verbs was not completed at the stage of writing this report) do show similarities of meanings as their most frequent category of meaning reflects an average of 23.97% from the total number of nouns. Fourth, when a computational program was written, the results of the following table were found. Some prepositions (as, with, from, and of) showed to display a higher z-score (a measurement of similarity) for the list of nouns that fall into the [PREPOSITION the NOUN of] construction (indicated by the column named ‘Nouns’); some others (off and by) show to display comparatively higher scores for the verbs in the pattern [VERB PREPOSITION the NOUN of] (shown in the column named ‘Verbs’).
Total Z-scores of Different Types of Nouns and Verbs (Chung, Chao, Lan, and Lin, 2011: 15)
Prep Total Z-score Prep Total Z-score
Nouns Verbs Nouns Verbs
as 12.01 -1.5 off -0.17 1.22 with 11.72 -1.25 onto -0.42 -0.51 from 11.65 -2.41 above -0.73 0.14 of 10.25 -0.08 in -1.19 0.83 across 1.94 -0.7 down -1.8 -1.09 like 1.73 0.03 on -3.25 -1.66 around 1.49 1.60 about -4.36 -0.35 against 1.21 0.07 into -4.86 -2.21 among 0.97 0.31 for -5.35 -2.19
at -0.01 0.87 after -6.14 -0.51
beside -0.13 0.04 by -7.82 4.90
The ones with higher z-scores with the nouns (as, with, from, and of) yet display low scores (all in negative z-scores) with the verbs. By, on the contrary, displays extremely low z-score for nouns than for verbs. These above showed that as, with, from, and of are often collocated with nouns that are high in similarity but when a verb is present, the similarity of the verbs is negative. This shows that these four prepositions are possibly free combinations and their strength with the verbs is less strong than those which possess higher value for verbs. Off and by are the two prepositions that show higher values for verbs, indicating their stronger semantic meaning with the verbs than with the nouns. These results will help answer the third research questions earlier about the degree of fixedness or free combination.
In a different study, Chung and Chao (2011) examined specific lexical bundles that were found in the economic dissertation abstracts produced by Taiwanese learners. Using a part-of-speech tagger called CLAWS (Garside, 1987), Chung and Chao extracted all multi-word sequences containing prepositions from the corpus. An example of these ditto tags is by_II31 means_II32 of_II33, in which these three words are tagged as a multi-word sequence. The patterns extracted are twelve preposition-containing lexical bundles such as according to, away from, in accordance with, etc. which are tagged as idiomatic expressions in CLAWS.
Using a similar methodology, Chung and Chao derived 26 patterns from these twelve lexical bundles. A possible slot was defined as any word that may appear in any position of the multi-word sequence. Thus, by means of will enable slot-filling in three different positions, namely * means of, by * of, and by means *, a similar logic following Biber et al. Chung and Chao then computed the probability of the above lexical bundles to appear as fixed expressions in the corpus. This was carried out through computing the probability of according to in * to, and according * respectively. Several findings were observed: First, it was found that certain strings (* means of, in accordance *, or even due *) are highly predictive. This is not the case when only a preposition is left (e.g., * to from due to). It is, thus, the presence of certain words (usually not a single preposition) in a lexical string that might determine whether a string will become fixed or not (thus, answering the issue of fixedness of a lexical bundle). Second, lexical bundles with higher predictability generally return higher z-scores in terms of the semantic similarities of any missing slots. In contrast, lexical bundles with lower predictability (below 50%) return lower z-scores because of the vast many types of possible words that can fill in a missing slot. This thus explains the relationship between fixedness of constructions and the semantic relatedness of words with similar or almost similar constructions.
In Chen et al. (Forthcoming), they examined [V NP1 into NP2] constructions and proposed that this construction enables a third PP-attachment structure which is different from the two (VP-attachment and NP-attachment) that have been established in previous literature. They found that a third type exist (spending themselves into poverty; vote an individual into the presidency) which can only be explained using construction grammar or caused-motion construction.
The above three papers contain important research finding regarding fixedness of lexical bundles. Furthermore, an important hypothesis was attested using both psycholinguistic and computational methodologies.
Prepositions-related
In addition to the above-mentioned papers, Chung and Tseng’s (2011) study of to in a learner corpus was seen. The results showed that learners’ errors occur in combination which are larger than two words (e.g., according to, intend to, etc.) when to is concerned. Any combinations under two words are possibly conventionalized and learners hardly committed errors in producing them. If error analysis was intended for to, longer string of words is thus necessary. In Chung’s (2011c) invited conference speaker’s talk, the preposition after was inspected. Chung pointed out that this preposition was seldom studied (unlike on, in, at) because it was said to contain less complex meaning (only ‘behind’ and ‘order’). Chung thus searched in the corpus and found that the distinguishing features of after lie not in its meanings but its collocated patterns. After was found to strongly collocate with adverbs of swiftness (shortly after, immediately after) and preciseness (particularly after, especially after). More importantly, the nouns that follow after are either indicating bounded events (war, election, period) or inchoative changes (birth, arrival, death). The results again suggest that an inspection into lexical bundles or strings of words is necessary. Chung also found that the phrasal-verb status of VERB-after combination is not strong – only look after and name after were found among the top collocates of the preposition (some even criticized that these two are not phrasal verbs, though listed in dictionary of phrasal verbs). In a different study, Chen and Chung (2010) investigated the possible uses of online resources and corpora to teach polysemous phrasal verbs related to pull in/off/up. Chung (2010b), on the other hand, examined the use of verb-particle constructions with engine, information, and data produced by learners in Taiwan. (Details of this paper will be presented in the travel grant section.)
In two other talks by the PI, preposition patterns in corpora were presented.
Metaphor-related
metaphor-related papers published after the execution of the last NSC projects. These papers are such as Chung and Huang’s (2010) study on source domains of metaphors; Lin and Chung’s (2010) study on the semantic relatedness of CHALLENGE; Hsu and Chung’s (2011) of Mandarin soaking verbs; Wang and Chung’s (2010) study on HAPPEN, Wang and Chung’s (2011) study on teaching vocabulary through using corpora; as well as Chen and Chung’s (2011) study on the writing of a computer science scholar. Another paper related to studies of vocabulary lists are such as Skoufaki, Chung and Chao (2011).
In addition to the above, Chung (2011a) and Chung (2010a) are two SSCI-indexed papers on the topic of Malay ter- and Malay classifier buah. Both papers used corpus linguistics methodology and presented connection among seemingly unrelated meanings. In October 2011, Chung (2011b) will feature an examination of the Malay preposition di and dalam, a topic of the current NSC project, which reflects the PI’s interest in prepositions in cross-linguistic comparisons.
The PI’s research team has published one book chapter on the preposition to, four journal papers (including three SSCI-indexed), seven papers in conference proceedings (with full papers), and five conference papers. The PI has given four talks (including one conference invited speaker’s talk), two dissertation-directing, one NSC College Student Project directing, and multiple reviews of papers submitted to Taiwan Journal of TESOL, English Teaching and Learning, Journal of Pragmatics, Language and Linguistics, etc.
References
Baldwin, Timothy. 2005. “The Deep Lexical Acquisition of English Verb-particle Constructions.” Computer Speech and Language. Special Issue on Multiword Expressions. 19(4). pp. 398-414.
Bannard, Colin. 2005. “Learning about the Meaning of Verb-particle Constructions from Corpora.” Computer Speech and Language. Special Issue on Multiword Expressions. 19(4). pp. 467-478.
Biber, Douglas, Susan Conrad and Viviana Cortes. 2004 “If you look at…: Lexical Bundles in University Teaching and Textbooks.” Applied Linguistics. 25(3). pp. 371-405.
Biber, Douglas. 2009. “A corpus-driven approach to formulaic language in English: Multi-word patterns in speech and writing”. International Journal of Corpus Linguistics, 14 (3), 275-311.
Dikken, Marcel den. 1995. Particles: On the Syntax of Verb-particle, Triadic, and Causative Constructions. New York : Oxford University Press.
Fraser, Bruse. 1976. The verb-Particle Combinations in English. New York and London: Academic Press.
Garside, R. 1987. The CLAWS Word-tagging System. In: R. Garside, G. Leech and G. Sampson (eds), The Computational Analysis of English: A Corpus-based Approach. London: Longman.
Hoffmann, Sebastian, Stefan Evert, Nicholas Smith, David Lee and Ylva Berglund Prytz. 2008. Corpus Linguistics with BNCweb - a Practical Guide. Frankfurt am Main: Peter Lang.
Hunston, Susan and Gill Francis. 1999. Pattern Grammar: A Corpus-drivenApproach to the Lexical Grammar of English. Amsterdam and Philadelphia: John Benjamins.
Research Outcomes
Chen, Li-Yin, Siaw-Fong Chung, and Chao-Lin Liu. Forthcoming. “A Construction Grammar Approach to Prepositional Phrase Attachment: Semantic Feature Analysis of V NP1 into NP2 Construction.” Poster to be presented at the 25th Pacific Asia Conference on Language Information and Computing (PACLIC 25). Also appearing in the conference proceedings. Nanyang Technology University, Singapore. December 16-18.
Chen, Li-Yin and Siaw-Fong Chung. 2010. “Enhancing the Learning of Polysemous Phrasal Verbs through Online Resources and Corpora.” In the Proceedings of the Fourteenth International Conference on Multimedia Language Education (ROCMELIA). National Kaohsiung Normal University, Taiwan. December 17-19.
pp. 155-166.
Chen, Li-Yin and Siaw-Fong Chung. 2011. “Writing for English Publishing on the Periphery of the Periphery: A Case Study of a Taiwanese Computer Science Scholar.” Presented at the 2011 Symposium on Second Language Writing. National Taiwan Normal University, Taipei. June 9-11.
Chung, Siaw-Fong and Chu-Ren Huang. 2010. “Using Collocations to Establish the Source Domains of Conceptual Metaphors.” Journal of Chinese Linguistics. 38(2). pp. 183-223. (SSCI, AHCI)
Chung, Siaw-Fong and F. Y August Chao. 2011. “Preposition-Containing Lexical Bundles and Idiomatic Expressions in Economics Dissertations.” Presented at the 10th Conference for the American Association for Corpus Linguistics (AACL), Georgia State University in Atlanta, GA, USA, October 7-9.
Chung, Siaw-Fong and Yu-Wen Tseng. 2011. “Learning Prepositions: A Corpus-based Study in Taiwan EFL Contexts.” In Marek Konopka, Jacqueline Kubczak, Christian Mair, František Štícha, and Ulrich H.Waßner (Hgg.). (Eds.). Grammar & Corpora 2009: Third International Conference. Corpus Linguistics and Interdisciplinary Perspectives on Language Series. Volume 1. Tübingen, Germany: Narr Francke Attempto Verlag GmbH + Co. KG. pp. 575-583. Also presented as a poster at the Third International Conference Grammar and Corpora. Mannheim, Germany. September 22-24, 2009.
Chung, Siaw-Fong, F. Y. August Chao, Tien-Yu Lan, and Yen-Yu Lin. Forthcoming. “Analyses of the Semantic Features of the Lexical Bundle [(VERB) PREPOSITION the NOUN of]” To appear in the Proceedings of the Third International Seminar on Metaphor and Discourse: Verb-particle Constructions and their Underlying Semantic Systems. Universitat Jaume I, Castelló de la Plana, Spain. October 19-20.
Chung, Siaw-Fong, Shu-Yi Wang, and Yu-Wen Tseng. 2010. “The Construction of the NCCU Foreign Language Learner Corpus.” Foreign Language Studies. 12. pp. 71-98. (THCI)
Chung, Siaw-Fong. 2010. “Concordancing in Corpus Linguistics.” Research in Applied Linguistics (Course Title). Department of Foreign Languages and Applied Linguistics, Yuanze University, Taiwan. November 30. (Invited lecture) Chung, Siaw-Fong. 2010a. “Numeral Classifier Buah in Malay: A Corpus-based
Chung, Siaw-Fong. 2010b. “The Use of Verb-Particle Constructions with Engine, Information and Data by EFL Students in Taiwan: A Corpus-based Study.” In the Proceedings of the 2nd International Conference on the Role of Social Sciences and Humanities in Engineering (ICoHSE). Universiti Malaysia Perlis, Penang. November 12-14. [CD-Rom]
Chung, Siaw-Fong. 2011. “From Lexical to Pattern Analysis: A Corpus-Driven Analysis of Prepositions.” Department of Foreign Languages, National Chia-Yi University. June 3. (Talk)
Chung, Siaw-Fong. 2010. “Use of ‘In’ and ‘On’: An Investigation in a Corpus of Dissertation Writing by Medical Students.” (以語料庫角度探索英語醫學論文 中的介系詞使用).「語言學與語言學習工作坊」 . Center for General Education, Taipei Medical University, Taiwan. November 24. (Talk)
Chung, Siaw-Fong. 2011a. “Uses of Ter- in Malay: A Corpus-based Study.” Journal of Pragmatics.43(3). pp. 799-813. (SSCI, AHCI)
Chung, Siaw-Fong. 2011b. “Investigating Di and Dalam in Standard Malaysian Malay through Corpus Data.” To appear in the Proceedings of the Workshop on the Representation of Time in Asian Languages. Academia Sinica, Taiwan. October 26-28.
Chung, Siaw-Fong. 2011c. “Observing After and its Collocations through Corpora Data.” In the Proceedings of the 2011 年東吳大學外國語文學院 語言、文學與 文化學術研討會.「資料庫與人文研究」. March 26. pp. 22-33. (Invited Speaker)
[Hsu and Chung]許尤芬、鍾曉芳. 2011.《中文「泡」、「浸」之辨析—以語料庫為
本》. In the Proceedings of the Twelfth Chinese Lexical Semantics Workshop 2011. Taipei, Taiwan. May 3-5. pp. 301-308.
Lin, Yen-Yu and Siaw-Fong Chung. 2011. “A Study on the Semantic Preference and Semantic Prosody of “CHALLENGE”.” Presented at the 2011 Corpus Linguistics Conference (Discourse and Corpus Linguistics). Birmingham, England. July 20-22.
Skoufaki, Sophia
,
Siaw-Fong Chung,and
AugustF. Y.
Chao. 2011. “Low-intermediate EFL Writing Assessment: Does a Varied Vocabulary Lead to Higher Scores?” Presented at the Learners and Networks Conference. Swansea University, Wales, United Kingdom. March 16-18.Wang, Liang-Chun and Siaw-Fong Chung. 2010. “A Comparison of HAPPEN and its Synonyms based on Native Speaker and Learner Corpora.” Presented at the Sixteenth Conference of the International Association for World Englishes. Vancouver, BC, Canada. July 25-27.
Wang, Liang-Chun and Siaw-Fong Chung. 2011. “Using Corpora to Motivate Vocabulary Learning and Acquisition.” In the Proceeding of the Korea Association of Teachers of English (KATE) 2011 International Conference: Empowering English Teachers in the Globalization Era. Yonsei University, Seoul. July 1-2. pp. 32-37.
Liyin Chen & Siaw-Fong Chung
Department of English, National Chengchi University [email protected]; [email protected] Abstract
Technology provides language teachers with tools that diversify classroom instruction. While much research has explored the teaching of vocabulary words with the help of computer tools such as cloze-builder, hypertext, dictionary use and concordance (Horst, Cobb & Nicolae, 2005; Peters, 2007), little attention has been paid to phrasal verbs as the teaching target. Phrasal verbs are complex in both form and meaning. The particles of phrasal verbs sometimes need to be distinguished from prepositions for parsing (e.g., pull in thousands of new investors and pull
in opposite direction). In addition, some phrasal verbs are polysemous which require contextual
clues for pinning down the precise meaning. Previous studies in second language research have demonstrated that learners have difficulties with phrasal verbs especially whose first language lacks phrasal verbs (Liao & Fukuya, 2004; Yasuda, 2010). In this paper, we design tasks that involve the use of online tools, namely, concordance, dictionary and a quiz generator to enhance learners learning three polysemous phrasal verbs, pull in, pull off and pull up. Pedagogical implications are discussed.
1. Introduction
Computers, according to Kern (2006), have three roles in CALL, namely, tutor, tool and medium. Much effort has been made to demonstrate the importance of technology in fostering vocabulary retention by providing in-depth processing with online activities such as cloze-builder, hypertext, dictionary use and concordance (Horst, Cobb & Nicolae, 2005; Peters, 2007). However, to our best knowledge, few of the studies included phrasal verbs as their target teaching materials although phrasal verbs have been recognized as challenging for ESL learners (Dagut & Laufer, 1985; Larsen-Freeman, 1991; Liao & Fukuya, 2004; Liu, 2008; Side, 1990). These studies found that ESL/EFL learners sometimes have problems with phrasal verbs (e.g.,
come across, look up, and hang up), particularly in their figurative meanings and semantic
opaqueness (e.g., come across does not mean ‘come and cross the road,’ etc.). Side (1990), for example, points out that both size and seemingly random combination of phrasal verbs puzzle learners (e.g., make and go can both be combined with up/away/off, etc.). In addition, in another study examining EFL learners’ use of avoidance strategy, Liao and Fukuya (2004) found that figurative phrasal verbs are more likely to be avoided by Chinese learners of English, particularly at lower proficiency level. Therefore, how EFL/ESL instructors can facilitate
learners in identifying contextual meanings. This study adopts three online activities, namely, dictionary use, concordance and quiz-generator, to enhance learners’ awareness of the polysemous nature of phrasal verbs associated with the verb pull, a frequently used English word which can be found in the 500-1000 word range in the General Service List (West, 1953), but it is rich in phrasal verb forms with a fair number of particles including away, back, down, in, into,
off, out, over, through, together and up. While the majority of the phrasal forms are semantically
transparent (e.g., pull back, pull together, and pull through), pull in, pull up and pull off are more polysemous in nature. The classroom activity involves the following steps. First, Cambridge International Dictionary of Phrasal Verbs is used to identify the meanings of the targets. Then, the concordance and sort functions of BNCWeb are used to obtain query results. Next, the query results are examined to match with the dictionary entries. Finally, a quiz-creating program, Wondershare QuizCreator 3.0 Beta, is used to allow learners to generate a quiz of five questions based on the corpus data and their understanding of the phrasal verbs.
This study attempts to provide an instruction on how phrasal verbs can be taught with the aid of online tools. These tools are particularly useful and needed for learning words or phrasal verbs with multiple and/or figurative meanings. By critically examining the data, in-depth processing would be involved to facilitate memory retention through learning.
2. Literature Review
A brief overview of research in cognitive linguistics on phrasal verbs and their applications to second language research will be discussed in the following subsections.
2.1 A Cognitive Perspective to Phrasal Verbs
Research in cognitive linguistics has changed our interpretation of idiomatic expressions such as phrasal verbs. Empirical evidence has been amounted in the last two decades to refute the traditional view on idiomatic expressions as arbitrary and non-compositional. In other words, cognitive linguists posit that idiomatic expressions are systematically organized in our mental lexicon based on metaphorical extensions such as conceptual metaphor or orientational metaphor (Lakoff & Johnson, 1980). Orientational metaphors are realized by particles that concern with spatial orientations based on our bodily experience. Particles have been analyzed and served as good illustrations of image schema (e.g., Lakoff, 1987). Tyler and Evans (2003) provide a framework of analysis that explains how spatio-physical conception of in and on can give rise to non-spatial or non-physical concepts of the particles. They state that “the spatial scene relating to
disconnection and separation. Up has a core meaning that denotes going an upward direction and extended meanings of action completion and for a purpose. However, some studies have demonstrated that a particle may exhibit more than one meaning at a time. For example, Machonis (2009) examines over 300 transitive and neutral compositional phrasal verbs containing the particle up listed in several publications of phrasal verbs. The results show that the meanings associated with the compositional phrasal verbs under analysis tend to cluster. The most frequent combination was completed action and high intensity (25%), whereas other combinations such as direction and completed action (4.6%), direction and high intensity (0.3%), and the combination of all three (0.7%) are much less frequent. In sum, this review illustrates the complex nature of particles which is strikingly difficult for second language learners (e.g., Side, 1990). Previous research suggests that particles of phrasal verbs also play an important role in contributing the meaning of phrasal verbs, and learners are likely to benefit from learning of the particles for meaningful interpretation of phrasal verbs. The next section will discuss some applications of the cognitive perspective to phrasal verbs in second language learning
2.2 Phrasal verbs in Second Language (L2)
A number of L2 researchers/instructors have acknowledged that learners have problems for learning phrasal verbs (e.g, Liu, 2008; Liao & Fukuya, 2004; Side, 1990; Yasuda, 2010). Liu (2008) lists the following three reasons to account for the challenge encountered by L2 learners. First, some phrasal verbs have figurative meanings in addition to literal (e.g., fall apart means
break down or unable to work effectively). Second, some phrasal verbs are opaque without
having compositionality and figurative sense (e.g., turn up means appear). Third, phrasal verbs often have more than one meaning (e.g., turn on means both switch on and excite).
Liao & Fukuya (2004) investigated the strategy adopted by Chinese learners of English at both intermediate and advanced levels when confronted with questions contain both literal and figurative phrasal verbs. They found that Chinese learners of English resort to an avoidance strategy depending on their proficiency level and the presence of figurative phrasal verbs. The researchers conclude that learners’ avoidance behavior with figurative phrasal verbs is part of the interlanguage development. A more recent study conducted by Yasuda (2010) provides empirical evidence that supports for learning phrasal verbs through conceptual metaphors. A group of Japanese EFL undergraduate students undertaking a lesson in orientational metaphors were found to perform better than the control group who learned phrasal verbs through translation. In brief, these studies suggest that phrasal verbs require explicit instruction to help learners cope with the seemingly random verb-particle combinations. The meanings of each particle appear to
these online tools, learners would have deeper understanding with phrasal verbs.
3. Methodology
3.1 Target Phrasal Verbs: Pull in/off/up
The verb pull is a frequently used English word which can be found in the 500-1000 word range in the General Service List (West, 1953). It is productive in phrasal verb forms which associate with particles such as away, back, down, in, into, off, out, over, through, together and
up. While the majority of the phrasal forms are semantically transparent (e.g., pull back, pull together, and pull through), pull in, pull up and pull off are more polysemous in nature. For
example, all three have figurative meanings in addition to literal (e.g., pull in a big crowd means
attract the crowd) and some are semantically opaque (e.g., pull off the deal means successfully complete an agreement). Moreover, these phrasal verbs have more than one meaning as shown in
Table 1. Due to such complexity, learners tend to have problems learning the multiple meanings of these phrasal units.
Table 1 Senses of pull in/off/up Phrasal
verbs
Particle interpretatio ns
Senses Examples from BNCWeb
pull in sb / pull sb in
containment S1: (Informal) if the police pull someone in, they take that person to a police station because they think they have done something wrong.
…to keep your arrest rate up than to go out and pull in some black kids off the street.
containment S2: If an event, especially a show, pulls people in, a lot of people go to see it.
…the one hundred and first Crufts Show, which is expected to pull in a hundred thousand visitors by the time it closes on Sunday.
pull in sth / pull sth in
containment S3: To earn a large amount of money.
If it is a runaway success the draw could pull in more than £3 billion, creating at least two new millionaires each…
into a place, it moves to the side of the road or to another place where it can stop.
and had to pull in to the side of the road.
pull off (sth)
departure S1: If a car pulls off or it pulls off a main road, it leaves that main road, often in order to turn into a smaller road
After another mile or so, Ellwood saw them pull off into the gated driveway of a hotel.
pull off sth / pull sth off
separation S2: To succeed in doing or achieving something difficult
…backing Billy Bingham to pull off another World Cup miracle.
pull up action completion
S1: If a car pulls up, it stops, often for a short time.
Evelyn heard a car pull up and poked her head through the heavy curtains of the front room
pull up sth / pull sth up direction/for a purpose S2: To move a piece of furniture [esp. chair] near to something or someone.
…because she told him to pull up a chair and warm himself by the fire.
Pull sb up
for a purpose
S3: To tell someone that they have done something wrong.
…but you sound angry when you say that you expect me to pull you up or not describing her as a lover, too.
Pull sb up
for a purpose
S4: If someone pulls you up or if you pull yourself up, you improve your situation or your skill at something.
The only solution to the ‘opponent block’ is to pull yourself up by your bootstraps so that you come to believe that you can…
3.2 Online Tasks
To illustrate the polysemous nature of pull phrasal verbs to learners, online Cambridge International Dictionary of Phrasal Verbs is used for students to identify various senses for each phrasal unit, followed by a match to the core meaning(s) of each particle. Students then use the concordance function of BNCweb to obtain authentic data. The search procedure involves a general query of each phrasal unit (e.g., pull * in), followed by the use of Sort function to roughly cluster similar objects from the queried sentences. After data collection, students are advised to find and fill in at least one example for each of the senses as demonstrated in Table 1.
sentence. QuizCreator allows the creation of questions in several test types including true or false, multiple choice, multiple response, fill in the blanks, matching, sequencing and short essay questions. Figure 1 is an illustration of creating a multiple choice question with QuizCreator.
Figure 1: A demonstration of a multiple choice question in QuizCreator.
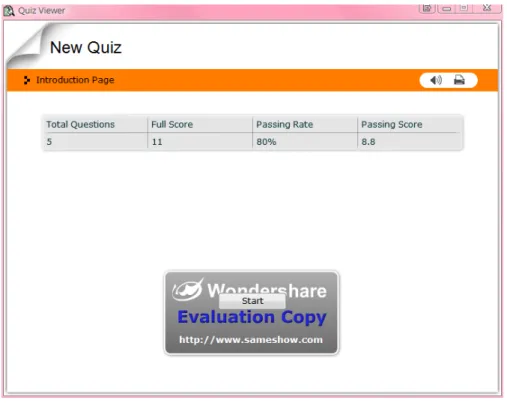
The software allows feedback of the answers to the questions and provides a scoring system to be specified with a passing rate as shown in Figure 2. After constructing all five questions, the quiz can be previewed and then published onto a webpage. Figure 3 and 4 demonstrate the appearance of a question on a computer screen and immediate feedback after answer submission, respectively.
After completion of the quiz, an overall evaluation will be provided (see Figure 5). Finally, each question in the quiz can be reviewed to identify the errors (see Figure 6).
4. Pedagogical Implications
The use of online tools has several implications for lexical pedagogy particularly in L2 context. First, the use of online dictionary alongside with queried corpus results not only provides authentic materials but also raises learners’ awareness that each dictionary entry is not equal in distribution. Second, the incorporation of authentic materials gathered from the corpus serves as good input for tasks organized by computer application programs such as QuizCreator. Simple and user-friendly software would be feasible for in-class activity. In the main, research-based learning involving online activities as described in this article diversifies classroom activities and provides learners with opportunity for in-depth processing. This method can be particularly useful for tackling linguistic expressions such as idioms or phrasal verbs that have been found to be challenging for L2 learners.
References
Dagut, M., & Laufer, B. (1985). Avoidance of phrasal verbs: A case for contrastive analysis. Studies in Second Language Acquisition, 7, 73-79.
Horst, M., Cobb, T., & Nicolae, I. (2005). Expanding academic vocabulary with an interactive on-line database. Language Learning & Technology, 9, 90-110. Retrieved October 8, 2010, from http://llt.msu.edu/vol9num2/horst/default.html
Quarterly, 40, 183-210.
Lakoff, G. (1987). Women, fire, and dangerous things: What categories reveal about the mind. Chicago: University of Chicago.
Lakoff, G., & Johnson, M. (1980). Metaphors we live by. Chicago: University of Chicago.
Larsen-Freeman, D. (1991). Teaching grammar. In Celce-Murcia, M. (Ed.), Teaching English as
a Second or Foreign Language, Boston: Heinle & Heinle.
Liu, D. (2008). Idiom definition and classification. In D. Liu. Idioms: Description, comprehension, acquisition, and pedagogy (pp. 3-24). New York/London: Routledge.
Machonis, P. (2009). Compositional phrasal verbs with up: Direction, aspect, intensity.
Lingvisticae Investigationes, 32, 253-264.
Peters, E. (2007). Manipulating L2 learners’ online dictionary use and its effect on L2 word retention. Language Learning & Technology, 11, 36-58. Retrieved October 8, 2010, from http://llt.msu.edu/vol9num2/horst/default.html
Side, R. (1990). Phrasal verbs: Sorting them out. ELT Journal, 44, 2, 144-152.
Tyler, A., & Evans, V. (2003). The Semantics of English Prepositions: Spatial
Scenes, Embodied Meaning and Cognition. Cambridge: Cambridge University Press. West, M. (1953). A General Service List of English Words. London: Longman.
Yasuda, Y. (2010). Learning phrasal verbs through conceptual metaphors: A case of Japanese EFL learners. TESOL Quarterly, 44, 250-273.
Resources:
Taiwanese Scholar in Computer Science Liyin Chen & Siaw-Fong Chung 300 words abstract including references
Second language scholars on the Periphery encounter a lot of difficulties in publication in mainstream journals (Swales, 1990; Belcher, 2007). However, the homogeneity of either the Center or Periphery has rarely been questioned. In this study, we explore the English publishing experience of a Taiwanese scholar who had obtained his degrees at a local university. In contrast to those second language scholars who had obtained their higher degrees from mainstream English-speaking countries, locally educated scholars are disadvantageous at two levels. The first is their limited strings attached to the Center. The second concerns their limited exposure to English (Flowerdew, 2000). With a growing number of doctoral graduates from non-English-speaking educational institutions such as those in Taiwan, how writing instructors can help these researchers in their English publications therefore becomes crucial. This study investigates the writing problems encountered by our informant and his emerging writing strategies at different stages of the past ten-year research career. We analyze various reviewers’ comments on the informant’s writing in 24 manuscripts as the basis. Further data collection through interviews and anecdotal notes based on informal discussions are also added. The preliminary results show that reviewers’ comments on writing, such as “The whole paper requires a major English revision” or “This letter…is well written and appropriate for this venue”, can serve as an important venue for building our informant’s confidence in English academic writing. We will conclude our study with some suggestions for EAP curriculum design in Taiwan for technical writing based on an insider’s perspective.
Belcher, D. (2007). Seeking acceptance in an English-only research world. Journal of Second Language Writing, 16, 1-22.
Flowerdew, J. (2000). Discourse community, legitimate peripheral participation, and the nonnative-English-speaking scholar. TESOL Quarterly, 34, 127-150.
Swales, J. (1990). Genre analysis: English in academic and research settings. Cambridge: Cambridge University Press.
50 words summary
This study explores the English publishing experience of a Taiwanese scholar who had obtained his degrees at a local university. Through an analysis of reviewers’ comments on 24 manuscripts and interviews with the informant, preliminarily we
USING COLLOCATIONS TO ESTABLISH THE SOURCE DOMAINS OF CONCEPTUAL METAPHORS
Siaw-Fong Chung
National Chengchi University, Taiwan Chu-Ren Huang
The Hong Kong Polytechnic University, Hong Kong Academia Sinica, Taiwan
ABSTRACT
The Conceptual Metaphor Theory (Lakoff and Johnson, 1980; Lakoff, 1993) proposes a scenario-approach to conceptual metaphors, whereby prior knowledge of the mapped domains (target domains and source domains) is assumed to already exist before conceptual metaphors are created. However, this prior knowledge is not constrained. In this work, we instead propose that collocations can be integrated into lexical and computational methods to determine and constrain source domains. Our study uses a large sampling of corpora data and four computational steps to determine source domains. The results show that source domains can be identified through computational and criteria-based methodologies. This study will provide evidence to integrate linguistic collocations in order to test the Conceptual Metaphor Theory. Our results support the use of data-driven principles to predict the cognitively motivated conceptual relation between source and target domains.
SUBJECT KEYWORDS
Conceptual metaphors Source domain Collocations Bottom-up approach Corpus
1. INTRODUCTION
Bottom-up approaches to linguistic research usually ‘begin with an extensive (not selective) set of data, make minimal generalizations about the data, and are much less in the business of suggesting global cognitive structures that account for the data’ (Kövecses,
2006: 191). For example, Conceptual Metaphor Theory does not specify what concepts can be considered a coherent source domain. Studies that work within this theory also have different ways of determining the scope of source domains (Charteris-Black and Ennis, 2001; Charteris-Black and Musolf, 2003; White, 2003; Chung et al., 2003; etc.). The variety of methods employed in the determination of source domains is also due to the limitations of the model regarding the provision of quantitative data to build a logical statistical analysis. In addition, no specific principles can be said to exist between the source-target domain mappings. Instead, the Conceptual Metaphor Theory operates through Idealized Cognitive Models (ICMs) (Lakoff, 1993) that assumes the existence of a cluster of concepts, from which a conceptual category can be derived. These ‘cognitive models structure thought and are used in forming categories’ (Lakoff, 1993: 13). Lakoff emphasizes the variation in ‘classical’ categories using ICMs. He claims that ‘classical’ categories are based on ‘folk theory’ (Lakoff, 1993: 5). He goes on to state that how laymen categorize things in their daily lives may not be true scientifically. For example, a person will naturally categorize colors according to the visual experiences encountered in his or her daily life but the person has no way of knowing whether or not these categories are the same as those of any other community (Lakoff, 1993: 24-6). Because Lakoff suggests that ICMs are based on subconscious conceptual knowledge, he does not attempt to differentiate between various communities.
This paper approaches the issues of source domain determination from a data-driven and bottom-up approach. We suggest that the criteria used in determining source domains can be stated clearly using frequency patterns found in collocations. In view of the problems in identifying source domains, two research questions are postulated in this paper:
(1) (a) Can source domains be empirically determined in a principled way?
(b) Can a bottom-up approach to source domain determination solve source domain indeterminacy in the Conceptual Metaphor Theory?
The hypotheses for these two research questions are:
(2) (a) Lexical and computational methods are able to reduce human subjectivity in determining source domains.
(b) A bottom-up approach can help solve source domain indeterminacy in Conceptual Metaphor Theory.
These two hypotheses will be examined based on the Taiwan data in the Chinese Gigaword Corpus version 1.0 (Graff and Chen, 2003). (This corpus contains data from Taiwan and China, but this paper will discuss the Taiwan data only.)1 Taiwan data are taken from the Central News Agency of Taiwan (CNA).
2. A BOTTOM-UP APPROACH TO SOURCE DOMAIN DETERMINATION A bottom-up approach to determining source domains has been looked at in studies such as Charteris-Black and Ennis (2001) and Chung et al. (2003). These studies do not try to claim universal regularities but, rather, draw conclusions from the results of the (sampled) data analyzed. Nevertheless, the source domains identified by these studies are based on different levels of abstraction.
One example of studies is found in Charteris-Black and Ennis’ (2001) examination of metaphor in Spanish and English financial reports. In this study, the authors collected financial reports from newspapers published during the October 1997 stock market crash. In terms of similarities, both Spanish and English are shown to have used the conceptual metaphors ECONOMY IS AN ORGANISM and MARKET MOVEMENTS ARE PHYSICAL MOVEMENTS. Both languages also describe the downward spiral of the market as NATURAL DISASTERS. The authors also find that more psychological metaphors are found in the Spanish data (pánico ‘panic,’ tranquilizador ‘calming,’ desconfianza ‘distrust,’ etc.), while more metaphors related to nautical movement are found in the English data (‘plunge,’ ‘weather the storm,’ ‘haven,’ etc.). In a separate study, Charteris-Black and Musolff (2003) compare metaphors for euro trading in British and German reports and find that both languages have metaphors that describe euro trading as an up/down movement and as being healthy. They note that the British use more combat metaphors in their reports compared to those of the Germans, owing to the fact that the German reports perceive the trading of the euro as beneficial action. Another study of interest is that of O’Connor (1998), which examines FINANCE metaphors in Spanish and suggests that MONEY and FINANCE metaphors can be categorized into three different types, i.e., SOLID, LIQUID and GAS. It is seldom questioned, however, whether or not SOLID, LIQUID and GAS are suitable source domains. In the examination of euro metaphors in British and Italian newspapers, Semino (2002) also suggests the use of the source domain of BIRTH; we can see that the levels of abstraction differ amongst the source domains determined by these different studies. Although these studies provide a comparative examination of conceptual
metaphors in different languages, these papers do not clearly define the scope of a source domain. For instance, the source domain can be as general as ‘PHYSICAL MOVEMENTS’ in MARKET MOVEMENTS ARE PHYSICAL MOVEMENTS (Charteris-Black and Ennis, 2001) or as specific as ‘COMBAT’ in EURO TRADING IS COMBAT (Charteris-Black and Musolff, 2003), in which COMBAT is also a type of PHYSICAL MOVEMENT.
The problems associated with identifying source domains are acknowledged by Chung et al. (2003, 2004ab, 2005). In particular, Chung et al. (2003) re-analyze the metaphor MARKET MOVEMENTS ARE NAUTICAL OR ARE WAYS OF MOVING IN THE WATER in Charteris-Black and Ennis (2001).2 They proceed to re-categorize the items into two source domains, i.e., BOAT (with the linguistic items of ‘plunge,’ ‘ripples,’ ‘floating,’ ‘bale out,’ ‘dive,’ ‘anchor’ and ‘flagship’) and OCEAN WATER (‘haven,’ ‘turn tide’ and ‘calm’). Their re-analysis also illustrates that a general source domain can be divided into more specific domains, such as BOAT and OCEAN WATER, which allows for different linguistic interpretations to take place.
In terms of computational works that make use of a bottom-up approach, Mason (2004) stands out as one example that also works within the paradigm of collocation. Mason was the first dissertation that used large corpora (i.e., the Web) and domain-specific documents to determine the selectional preferences of verbs that are used metaphorically.3 For instance, when Mason examines words, such as ‘pour,’ ‘flow’ and ‘freeze,’ he finds a selectional preference for ‘liquid’ and ‘assets.’ He then, accordingly, decides that the conceptual metaphor is FINANCE IS LAB based on a polarity measure. However, the way Mason defines source domains raises a labeling issue: Specifically, the final labeling for the conceptual metaphor FINANCE IS LAB (FINANCE for ‘assets’ and LAB for ‘liquid’) is subjectively determined. Mason (2004) does not explain why ‘assets’ cannot be a source domain by itself but, instead, must be assigned to another source domain of FINANCE. Likewise, he also does not explain why he has grouped ‘liquid’ as a part of LAB.
Another computational work that also makes use of the selectional restriction paradigm is that of Wilks (1975). A newer version of this work can be seen in Fass and Wilks (1983: 179). Fass and Wilks implement a system called ‘Preference Semantics,’ a model that suggests a ‘semantic formula’ to be the representation of each word-sense. For instance, the word ‘drink’ shows the sense-frame for the word ‘drink.’
(3) ((*ANI SUBJ) (((FLOW STUFF) OBJE) (MOVE CAUSE)))
This formula suggests that ‘drink’ ‘is an action, preferably done by animate things (*ANI SUBJ) to liquids ((FLOW STUFF) OBJE). The SUBJ (subject) displays the preferred agents of actions, while the OBJE (object) displays the preferred objects or patients’ (Fass and Wilks, 1983: 179).4 Sense-frames such as (3) serve as templates to decide whether a query sentence violates the template. If the literal templates are violated, a metaphorical interpretation will then be derived. This system, which was built in the late 1970s, also operates under the traditional pragmatic interpretation of Searle (1979), where a falsehood decision has to be made before a metaphorical interpretation is employed.
The bottom-up approach to metaphor identification has the advantage of having empirical evidence, but it also has a large disadvantage: the problem of how to label source domains. When lexical items have been collected under different groups using a bottom-up approach, a final category name must be assigned manually to the source domains in the end. This is a weakness in all studies previously mentioned, where the automatic naming of a source domain is an issue that is not easily resolved. If we look at the sense-frame of Fass and Wilks (1983), there is no indication of what the source domain is. In fact, most metaphor identification like this downplays the roles of source domains because the aim is always to identify metaphors, not the source domains. This problem, however, will be limited in this paper, because the source domains will be determined at the outset of the study. For example, when Mason (2004) found the use of ‘pour’ with ‘money’ as well as ‘pour’ with ‘liquid,’ he could have searched for all other collocates of ‘pour’ in a general corpus so that clusters of words relating to ‘liquid’ could have been found in order to identify what the source domain for ‘pour’ is. For example, if ‘pour’ takes an argument that belongs to the source domain of LIQUID, automatic extraction of metaphors can be easily accomplished by ruling out collocates of ‘pour’ that are not LIQUID. However, this step is not carried out in Mason (2004). Instead, he assigns ‘liquid’ to LAB by intuition without first ascertaining the existence of the domain of ‘liquid.’
The observations made from the previous studies show that the definitions for source domain vary. As all of these variations rely on the individual author’s judgment to make a final decision, all of the aforementioned studies have notably
different criteria for source domain determination. The main factor at the root of this inconsistency is the fact that what constitutes a source domain has always been based on intuition. In the next section, we will outline our data-driven and bottom-up approach to source domain determination.
3. A DATA-DRIVEN BOTTOM-UP APPROACH TO SOURCE DOMAIN DETERMINATION
In terms of taking a bottom-up approach, this paper emphasizes the importance of collocation in metaphor analysis. Previous studies that have examined this aspect of metaphor analysis include Deignan (1999, 2005) and Stefanowitsch (2005, 2006). In particular, Stefanowitsch (2006) argues that the literal meanings of the metaphors can be identified when a metaphor’s target domain terms are replaced by its source domain terms. For example, in the sentence ‘He shot down all of my arguments,’ ‘arguments’ can be replaced by words such as ‘planes’ and ‘missiles’ to form the literal meaning of the sentence.5
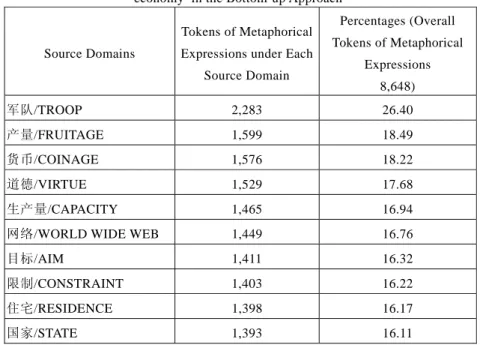
A similar method also proves workable with Chinese metaphors, as illustrated in (4), where examples of the metaphorical uses of 经济 jing1ji4 ‘economy’ with 起飞 qi3fei1 ‘take off’ and 瘫痪 tan1huan4 ‘paralytic’ can be seen. In these examples, all lexical items carrying the target domain information are in boxes; those carrying the source domain information are underlined. These two types of information are mapped in the formation of conceptual metaphors.
(4) (a) 以免 苏联 经济 瘫痪 yi3mian3 su1lian2 jing1ji4 tan1huan4 to.avoid Soviet.Union economy paralytic
‘In order to avoid the economy of the Soviet Union becoming paralytic…’
(b) 但 在 台湾 经济 起飞 后 dan4 zai4 tai2wan1 jing1ji4 qi3fei1 hou4 but at Taiwan economy take.off after
In order to ascertain whether the replacement of the target domain can indeed yield the literal meanings of these sentences, the following tests are carried out to see which terms can successfully replace the target domain of 经济 jing1ji4 ‘economy’ in each sentence. For example, in (4a), 经济 瘫痪 jing1ji4 tan1huan4 ‘the economy is paralytic’ can be replaced by 老人 瘫痪 lao3ren2 tan1huan4 ‘the old man is paralytic’ as well as 病人 瘫痪 bing4ren2 tan1huan4 ‘the patient is paralytic’ based on intuition. As for (4b), 经济 jing1ji4 ‘economy’ can be substituted by 飞机 fei1ji1 ‘airplane’ as well as 蝴蝶 hu2die2 ‘butterfly.’ These replaced terms are possible collocates that provide clues as to what the source domains could be for these metaphors.
In order to test a group of Chinese metaphorical expressions in terms of their source domains, 651 types of metaphorical expressions (such as 成长 cheng2zhang3 ‘grow/growth,’ 瘫 痪 tan1huan4 ‘paralytic’ and 起 飞 qi3fei1 ‘take off,’ without considering their tokens of occurrences) were collected from the first 4 per cent of the instances for 经济 jing1ji4 ‘economy’ in the Taiwan data of the Chinese Gigaword corpus.6 These types of metaphorical expressions were extracted based on manual analysis of the corpora instances, employing the criterion of deciding whether the target domains are used with expressions that are potentially from a different knowledge domain (or are used literally). For example, the use of 策略 ce4lue4 ‘tactics’ in (5a) is identified as a type of metaphorical expression because, intuitively, 策略 ce4lue4 ‘tactics’ does not belong to the literal uses of 经济 jing1ji4 ‘economy.’ This means that 策略 ce4lue4 ‘tactics’ possibly comes from a different domain that may not be part of the literal meanings of 经济 jing1ji4 ‘economy.’
(5) (a) 使 双方 经济 策略 采取 同一 步调 shi3 shuang1fang1 jing1ji4 ce4lue4 cai3qu3 tong2 yi1 bu4diao4
cause both.sides economy tactic adopt same one step
‘To cause the economic tactics of both sides to adopt the same step…’
(b) 但是 困扰 经济 正常 运行 的 深 dan4shi4 kun4rao3 jing1ji4 zheng4chang2 yun4xing2 de shen1 but disturb economy normal operate DE deep 层次 问题 , 尚未 解决
ceng2ci4 wen4ti2 shang4wei4 jie3jue2 level question not.yet solve
‘...but the seriousness of the problem that is disturbing the normal functioning of the economy has not yet been solved.’
At the same time, an additional criterion may be employed in the identification of metaphorical expressions: that is, by observing whether or not a target domain can be put in the place of the source domain. This follows the criteria of Stefanowitsch’s Metaphorical Pattern Analysis (2006). For example, 经济 策略 jing1ji4 ce4lue4 ‘economic tactics’ (5a) and 经济 运行 jing1ji4 yun4xing2 ‘the functioning of the economy’ (5b) are metaphors, because 经 济 jing1ji4 ‘economy’ as the target domains can be replaced by words such as 战争 zhan4zheng1 ‘war’ or 机器 ji1qi4 ‘machine,’ respectively, when used literally.7 The examples in (5) may thus be identified as metaphorical expressions. An example of a non-metaphorical expression is the use of 学者 xue2zhe3 ‘scholar’ in (6), in which the first 经济 jing1ji4 ‘economy’ is used literally.
(6) 经济 学者 专家 多 不 敢 看好 jing1ji4 xue2zhe3 zhuan1jia1 duo1 bu4 gan3 kan4hao3 economy scholar expert many Neg. dare look.good
今年 的 经济 前景 jin1nian2 de jing1ji4 qian2jing3
this.year DE economy prospect
‘A majority of the expert scholars in economy do not hope much for this year’s economic prospect.’
In this example, the use of 学者 xue2zhe3 ‘scholar’ does not need to be replaced by another literal collocate because it itself contains a literal meaning.
From the examples in (4) and (5), we know that it is necessary that the metaphorical expressions are, in particular, grammatical relations to the target domains—for instance, examples in (4a and 4b) and (5b) have 经 济 jing1ji4 ‘economy’ as the subject of their metaphorical expression, while the example in (5a)
has 经济 jing1ji4 ‘economy’ as a modifier term. A further example can be found in 伤 害 经 济 shang1hai4 jing1ji4 ‘to hurt the economy’ where 经 济 jing1ji4 ‘economy’ is the object of 伤害 shang1hai4 ‘hurt.’ Therefore, it is important that the replaced terms are in particular grammatical relations in addition to being literal collocates, as the grammatical positions of target domains appear to play a crucial role when this approach is employed.
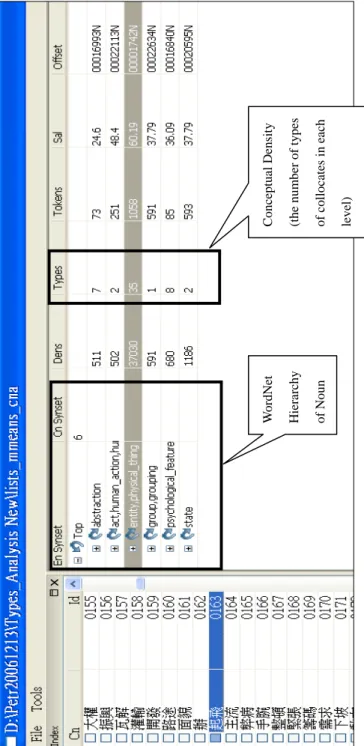
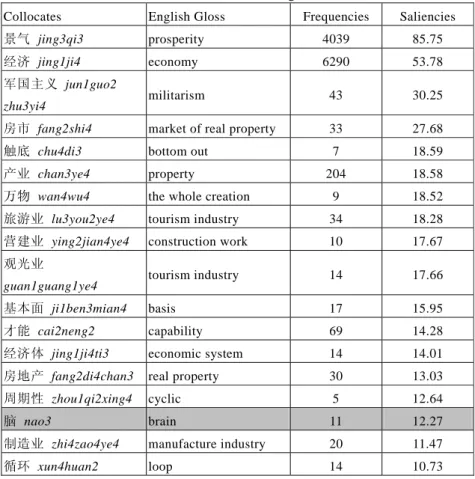
In order to determine the patterns of collocates that are arranged in different grammatical relations with 经济 jing1ji4 ‘economy,’ we use the saliency lists from the Chinese Sketch Engine. Sketch Engine (Kilgarriff and Tugwell, 2001) is a system that provides the collocations of words according to grammatical relations. The Chinese Sketch Engine was created by Kilgarriff et al. (2005), and it has the same functions as the English Sketch Engine, i.e., it also arranges collocates for query words in grammatical relations. Each grammatical relation has a saliency value listed in descending order, from the most salient to the least salient. Figure 1 shows a snapshot of the search results for 成长 cheng2zhang3 ‘grow/growth’ in the Chinese Sketch Engine.
Figure 1: Collocates of 成长 cheng2zhang3 ‘grow/growth’ in the Chinese Sketch Engine8
In the Chinese Sketch Engine, all collocates are arranged according to grammatical relation, as shown in Figure 1. Therefore, in order to find literal terms that can replace 经 济 jing1ji4 ‘economy’ in a metaphorical phrase, such as 经济 成 长 jing1ji4 cheng2zhang3 ‘the economy grows’ in the SUBJECT column in Figure 1, literal collocates that appear in the same grammatical relation as 经济 jing1ji4 ‘economy’ can be sought out in the Chinese Sketch Engine. If a metaphorical
expression can also be used in different relations such as SUBJECT in 经济 瘫痪 jing1ji4 tan1huan4 ‘the economy is paralytic’ as well as MODIFIERin the example 瘫痪的 经济 tan1huan4 de jing1ji4 ‘the economy that is paralytic,’ then more than one grammatical relation will be collected for each type of metaphorical expression (all grammatical relations are in small capitals.).9
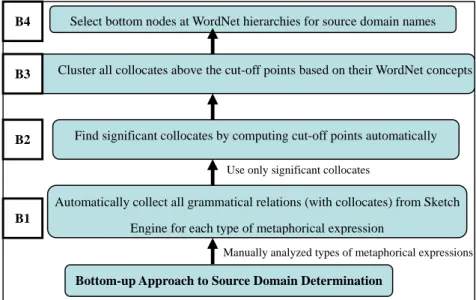
In our approach, four main steps are taken to determine source domains. These steps are given in Figure 2. The first step, shown in (B1) of Figure 2, is to extract different grammatical relations in the Chinese Sketch Engine that contain the target domain terms ( 经 济 jing1ji4 ‘economy’).10 These grammatical relations are collected automatically. After this has been completed, step two (B2) will then divide the collocate lists into significant and non-significant lists, in order to reduce the number of collocates that are of no significance and that will only create noise in the analysis. Step three (B3) involves the clustering of the selected collocates according to their WordNet synsets. After the selected collocates are clustered, their source domain names will be determined by searching for their shared WordNet hypernyms within the clusters (B4).
Figure 2: Steps Involved in the Bottom-up Approach to Source Domain Determination
Each step is elaborated and exemplified below.
Select bottom nodes at WordNet hierarchies for source domain names
Bottom-up Approach to Source Domain Determination
Automatically collect all grammatical relations (with collocates) from Sketch Engine for each type of metaphorical expression
Find significant collocates by computing cut-off points automatically Cluster all collocates above the cut-off points based on their WordNet concepts
Manually analyzed types of metaphorical expressions Use only significant collocates
B1 B2 B3 B4
3.1 Extraction of Collocates from the Chinese Sketch Engine (Step One)
Based on the 651 types of metaphorical expressions from CNA, each type of metaphorical expression will be searched in the Chinese Sketch Engine so as to retrieve all uses of these expressions in the corpus. Only the grammatical relations where these types of metaphorical expressions co-occur with 经 济 jing1ji4 ‘economy’ will be selected. For example, Figure 1 previously shows the various grammatical relations of collocates for 成长 cheng2zhang3 ‘grow/growth.’ If only the relation of SUBJECT is required (as the target domain of 经 济 jing1ji4 ‘economy’ forms constructions with only 成长 cheng2zhang3 ‘grow/growth’ in this relation), the other relations will not be extracted. If 经济 jing1ji4 ‘economy’ and 成长 cheng2zhang3 ‘grow/growth’ appear in several grammatical relations, all of these grammatical relations will be extracted.
One way to filter out the unwanted relations is to search for whether 经济 jing1ji4 ‘economy’ appears in any of the collocates of any of the relations. Once 经 济 jing1ji4 ‘economy’ is spotted, the relations containing 经济 jing1ji4 ‘economy’ will be extracted, and the relations that do not contain 经济 jing1ji4 ‘economy’ will be filtered out.11 Some types of the metaphorical expressions will have more grammatical relations than others if their target domains are found in several relations (such as SUBJECT, OBJECT, MODIFIER, etc.).
3.2 Computing Cut-off Points (Step Two)
In the Chinese Sketch Engine, each grammatical relation has a saliency value listed in descending order, from the most salient to the least salient. The lists are long, with many collocates, including significant ones and non-significant ones. In this second step, all saliency lists are programmed and their cut-off points are computed automatically. In order to include only significant collocates in each list, the saliency lists will be cut into significant and non-significant lists using one of the methods (mean of means) proposed in Chung et al. (2007). The purpose of computing cut-off points for the saliency lists is to find significant collocates for each grammatical relation to determine the source domain. In calculating ‘mean of means,’ a threshold value is computed based on the mean of a group of means (cf. Chung et al., 2007; Chung, 2007). This threshold value is calculated based on each grammatical relation, and a mean is computed from a group of means of saliency values. The final mean is the cut-off point of each grammatical list. Our results produce cut-off points, on average, after 30 per cent of each grammatical relation (i.e., after one-third of the
significant collocates are found, the remaining ones are considered non-significant). We use only the significant collocates for determining source domains. The non-significant collocates will be dropped after this second step.
3.3 Clustering (Step Three)
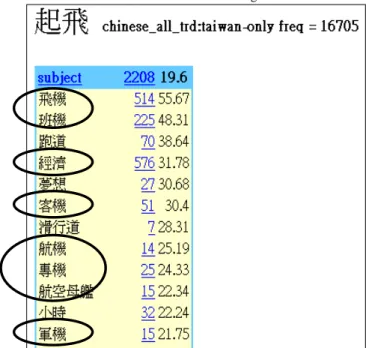
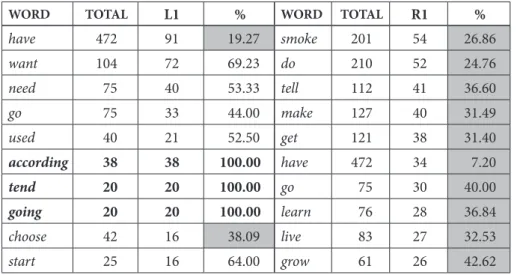
Earlier in this section, we have discussed that in examples such as 经济起飞 jing1ji4 qi3fei1 ‘economy takes off,’ the target domain of 经济 jing1ji4 ‘economy’ can possibly be replaced by stating 飞机 起飞 fei1ji1 qi3fei1 ‘airplane takes off’ as well as 蝴蝶 起飞 hu2die2 qi3fei1 ‘butterfly takes off’ (by intuition). The terms replacing 经济 jing1ji4 ‘economy’ will appear in the same collocation list as 经济 jing1ji4 ‘economy’ in the Chinese Sketch Engine. In Figure 3, the occurrences of 经 济 jing1ji4 ‘economy,’ as well as other possible replacement terms such as 飞机 fei1ji1 ‘airplane’ and 班机 ban1ji1 ‘airliner,’ are found in the same collocation list of 起飞 qi3fei1 ‘take off’ when searched for in CNA.
Figure 3: Collocates of SUBJECT of 起飞 qi3fei1 ‘take off’ in the CNA in the Chinese Sketch Engine
By utilizing the results of computed cut-off points, we are better equipped to select collocates that are significant (above the cut-off points), which, in turn, can
then be used to carry out the analyses of source domains.
Step three will take collocates above the cut-off points and group them into different clusters of concepts. Therefore, we need a resource that provides all of the concept information for collocates, such as 飞机 fei1ji1 ‘airplane,’ 班机 ban1ji1 ‘airliner’ and other collocates in Figure 3. The purpose for doing so, it must be stressed, is to figure out which possible concepts are involved within all the surrounding words of a metaphorical expression, such as 起飞 qi3fei1 ‘take off.’ The resource that we use is called WordNet (http://wordnet.princeton.edu/). WordNet provides all the senses of a particular word and its semantic relations (hypernyms, hyponyms, synonyms, etc.) to other words. In a way, WordNet provides the conceptual information we need for this step. However, since the original WordNet allows searches only in English, we use an additional two resources that provide a bilingual interface for WordNet. These two resources are (a) SinicaBow, or the Academia Sinica Bilingual Ontological WordNet (Huang et al., 2004) (http://bow.sinica.edu.tw/); and (b) Academia Sinica in-house database of the Chinese-English Merged Word List (hereafter ‘the Merged Word List’), which contains translated Chinese-English words collected from several bilingual dictionaries.12 These two resources allow both Chinese and English searches of WordNet senses and their upper ontological concepts. In order to ensure uniformity of conceptual representation, only Wordnet senses are used in this study, in contrast to our previous study (Huang et al. 2006) where ontological concepts play a central role. These resources are needed because only through the mappings can the WordNet concepts of each collocate be found. For example, 飞机 fei1ji1 ‘airplane’ has two senses in WordNet, shown in (7). The synsets (or synonym sets) for each sense are given in brackets.
(7) WordNet 1.7.1 senses for 飞机 fei1ji1 ‘airplane’
(a) A vehicle that can fly (synset: aircraft)
(b) An aircraft that has a fixed wing and is powered by propellers or jets (synsets: airplane, aeroplane, plane)
The synsets provide information regarding the conceptual hierarchy of each sense. For example, in (8), we can see that both ‘aircraft’ and ‘airplane, aeroplane, plane’