依據空間特徵點特性以階層遞迴方式三角形結構化雷射掃
描點雲資料
計畫類別: 個別型計畫 計畫編號: NSC93-2211-E-004-003- 執行期間: 93 年 08 月 01 日至 94 年 07 月 31 日 執行單位: 國立政治大學地政學系 計畫主持人: 邱式鴻 計畫參與人員: 李宏君 邱煥智 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國 94 年 10 月 28 日
行政院國家科學委員會補助專題研究計畫
J 成 果 報 告
□期中進度報告
(計畫名稱)
依據空間特徵點特性以階層遞迴方式三角形結構化
雷射掃描點雲資料
計畫類別:J 個別型計畫 □ 整合型計畫
計畫編號:NSC 93-2211-E-004-003-
執行期間: 93 年 8 月 1 日至 94 年 7 月 31 日
計畫主持人:邱式鴻助理教授
共同主持人:
計畫參與人員:李宏君、邱煥智
成果報告類型(依經費核定清單規定繳交):J精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、列
管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
執行單位:國立政治大學地政學系
中 華 民 國 93 年 8 月 31 日
中文摘要
將空載雷射掃描技術(Airborne Laser Scanning 或稱光達 ALS or LIght Detection And Ranging,簡稱 LIDAR)所獲取的高精度高解析度的地表數值覆面資料結構化,然後供後續應 用是非常重要的一項工作。在此結構化的意義乃將點雲資料依據物空間上幾何特性,如共 線、或共面特徵加以組織分類,並減少其資料量。最後建構點雲資料的不規則三角網結構供 後續研究之用。由試驗分析中,發現以共面特徵的資料最能大量減少點雲資料量並達到較佳 的結構化成果,文中也提出以共面特徵為主的另一種結構化的演算法,以發展便於後續處理 的點雲結構化方法。
英文摘要
It is an essential task to organize the dense point cloud data with high accuracy from the Airborne Laser Scanning (ALS) or LIght Detection And Ranging (LIDAR) for the successive application. The so-called structurization process is to organize LiDAR data into the same groups according to the similar spatial characteristics, e.g. collinear or coplanar features in object space to reduce the data amount. Finally, the non-coplanar LiDAR points are used to establish Triangulated Irregular Network (TIN) structure to represent the terrain for subsequent process. From the experiments, the coplanar feature is best spatial characteristics used to organize and structure the LiDAR data for optimal structurized results.
一、 前言、研究目的、與文獻探討
所謂雷射掃描點雲資料的結構化就是將雷射掃描技術(Airborne Laser Scanning, ALS)或 稱光達(LIght Detection And Ranging, LIDAR)測量技術獲取的高密度、高精度、且高解析度不 規則分佈的大量光達點雲資料,經過有系統的解析、組織並減少其資料量之後,供後續的應 用 [賴志恆, 2003][Lin and Jaw, 2004]。這樣的好處在於可以有效率協助後續資料的處理。而 目前點雲結構化可以是用規則網格的方式將資料結構化[Hu and Tao, 1999; Maas 1999; Priestnall et al., 2000; Tao and Yasuoka, 2002]、或是以不規則三角網的方式將資料結構化 [Axelsson, 1999; Mass and Vosselman, 1999; Woo et al., 2002]、也可以是用物空間物體某一特 性[賴志恆, 2003] [Lin and Jaw, 2004],如平面特性、將資料予以結構化。規則網格結構化的 方式會利用到內插演算法而降低點位精度,不規則三角網的結構化方式則可以保有原資料的 精度。若僅利用原始掃描點的點雲資料,而未加入任何空間物點的特性進行不規則三角網結 構化,則無法達到減少資料量讓後續資料處理更加有效與便利的目標。因此,本研究在維持 原掃瞄點精度和減少資料量讓後續資料處理更加有效與便利的目標之下,先分析並探討可以 用來將掃描點雲資料結構化的空間特徵,然後以此特徵進行資料的組織與簡化並進行後續的 不規則三角網結構化的處理。雷射掃描點雲分地面和空載雷射掃描,本文以空載雷射掃描點 為討論對象。最後並提出結論與建議。
二、 研究方法
由前言中可知本研究在維持原掃瞄點精度和減少資料量的目標之下,先分析掃描點雲資 料中可以用來進行結構化的空間特徵,然後以此空間特徵進行資料的組織與簡化並進行後續 的不規則三角網結構化的建構工作。並由空載雷射掃描點雲資料,加以測試和分析,進而提 出結論與建議。因此,整個試驗大致分成兩部分一是點雲資料的特性分析與分類、二是點雲 資料不規則三角網之建立。最後提出一個適合進行結構化的演算法。 要由龐大點雲資料中,分析每個點的特性,進而將代表相同意義的冗餘點資料去除,並 以明確的特性取代原本個別點雲資料,加以結構化進而供後續快速的處理和運用是一項重要 的工作。因為點雲資料僅僅包含空間坐標和反射強度值,因此如何由這僅有的座標和反射強 度資料中,探討究竟有何空間物點特徵可以加以運用並進一步用於點雲結構化的處理中,將 是本研究的首要目標。在本研究中所使用的點雲資料是假定先經過過濾處理的地表數值表面 資料,所以若以純幾何的方式描述空間中的地物,地物不外乎是由點、線、面等三種幾何特 徵所組成,因此若能從點雲資料中得知每個點的幾何特性,相信對後續進行資料簡化會有所 助益。本研究將採用 Förstner[1994]所提出對影像進行「多型態特徵萃取法」(Polymorphic Feature Extraction) 的概念,將密集的光達點雲資料的高程值視為影像中的灰階值,以此為基 礎進行點位幾何特徵的分析。因此,本試驗第一步先探討 Förstner 提出對影像中的點、線、 面特徵同時萃取的概念是否也可以利用來萃取光達點雲資料中點、線、面特徵。之後參考 Förstner 所提的概念進行特徵點雲資料的分類,研究將點雲資料進行「共面特徵」與「非共 面特徵」的點雲資料分類,再從分類出的非共面點雲特徵中判別屬於線和點的點雲特徵。由 這些分類出的結果中除了說明利用何種特徵點雲將適合用於點雲資料之結構化之外並利用 結構化之點雲資料進行不規則三角網資料的建立。而所謂不規則的三角網(Triangulated Irregular Network,TIN)是一個常用來呈現地形的方 法,TIN 紀錄模式是以不規則連結的三角形平面來表示數值資料的特徵,以三角形節點的紀 錄結構為基礎,首先將所有節點的名稱及 3D 坐標紀錄成一表格(或一檔案),依各三角形分
別紀錄其節點名稱再結合所有連續的不規則三角形,形成三角網來代表連續的三度空間資 料。此種方式由紀錄三角形的屬性及相鄰關係進行地形資料分析及表現,解析度隨地形資料 複雜程度而不同,較能掌握地形資料的變化,有效的紀錄地形資料的起伏並且節省紀錄空 間。本試驗中將由結構化之後的特徵點雲資料利用 Delanuay 三角網組成方式建立不規則之 三 角 網 , 此 步 驟 稱 二 維 Delaunay 三 角 網 化 , 而 由 Midtbø[1993] 文 章 中 所 列 之 定 義 [Delaunay,1934],Delaunay 三角網指的是一群點集合中,由不重疊的三角形所構成的二維三 角網中,則此不重疊的任一三角形的三個點所形成外接圓中,都不會有任何一點位於此外接 圓的内部。而本研究的成果即以 Delanuay 三角網組成方式建立不規則之三角網,最後再以 每點的原始高程資料附加在每個不規則三角網的點資料上並展示最後建置的成果。
三、 結果與討論
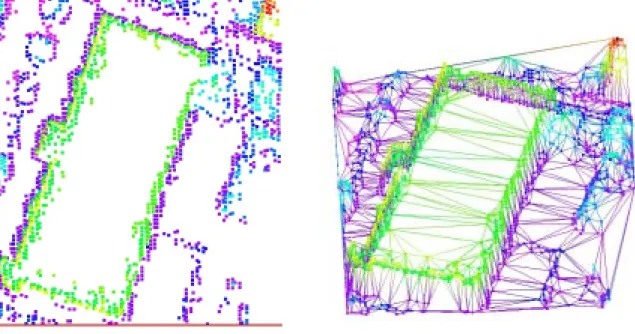
本研究之測試例擷取自行政院農委會於 2002 年 4 月 14 日對新竹地區進行掃描的空載光 達資料,使用的光達掃描儀器為 LHALS40,掃描時航高約 800 公尺、視角 35 度,經過濾除 多重反射(multiple echoes)訊號之前處理,只取地表之點雲資料,其點密度約為 1.7p/m2。涵 蓋區域約 11.7km * 5km 的面積範圍,由上述資料選取四組區域範圍內含建物屋頂面資訊的 光達資料進行測試。 第一組光達資料含一近似水平面的屋頂面資訊,第二以及第三組資料內含兩斜面所構成 的山形屋頂資訊,第四組資料內則含兩棟山形屋頂資訊。圖 1 至圖 4 的左圖就是原始光達資 料的俯視圖,而右圖則為利用原始資料和 Surefer8.0 軟體所建構的二維 Delaunay 三角網,然 後加入其點位對應的高程資訊之後所顯示之 3D 不規則三角網形狀。在圖中,不同顏色表示 不同的高程資訊。而為了顯示資料,圖中原始點位的顯示大小均誇大表示。 圖 1 第一組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右)圖 2 第二組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右) 圖 3 第三組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右) 圖 4 第四組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右)
3-1、光達點雲資料中點、線、面特徵的分類與萃取
由李宏君和邱式鴻[2005]的分析過程中得知多形態特徵萃取法應用於光達資料特徵萃 取時,首先罩窗(filter)的選擇便是一個問題。由於影像是規則的網格資料,罩窗的選擇較為單純且固定,如 3*3、5*5、7*7…等,但光達點雲資料是不規則的資料,雖然可以嘗試用內 插的方式將之規則網格化,但為了不失去點雲資料原有的精度,在此並不採行這樣的方法, 而是直接用原始資料處理。至於罩窗大小的選擇方法是以一點為中心,慢慢地擴大正方形罩 窗範圍,直到罩窗範圍內所能容納的點數符合給定的點數為止,如圖 5 所示。 其次 Förstner 多型態特徵萃取是利用影像在均調區時,其 灰階梯度平方的平均值之期望值是零的情況下,進行統計假說 測試來萃取影像中的面與非面資訊,但是若用相同的概念來分 類光達點雲資料的共面與非共面資訊時可能會發生問題,因為 共面的點雲中,其高程變化率平方的平均值之期望值並不會是 零,這在理論假設上已不相符。舉具有屋脊線的雙屋頂的例子 來說,如圖 6(a)的影像資料,利用 Förstner 的多型態特徵萃取 法在分類均調區 (1 區、3 區)與非均調區 (2 區)時,是根據在 均調區中灰階的梯度是趨近於零,而非均調區中灰階的梯度並 不趨近於零的特性來分類的,所以採用梯度平方的平均值來進 行分類是可行的;但應用在光達資料中,參考圖 6(b)之對照組 中的 1 區及 3 區,其高程變化率並非趨近零,而 2 區所計算的 高程變化率卻趨近於零,所以以高程變化率平方的平均值來進 行分類會有問題。由上述可知兩種資料在性質上有很大的不同,並不能完全套用同一個法則 來進行點雲資料中共面點與非共面點的分類。 圖 6 圖 5
有鑒於此,光達點雲資料進行完第一次的高程平均變化率的計算後,必須再依(1)式進 行高差平均變化率的計算,如圖 6(b)之右圖所示,這才會符合數學統計上的基本假設,亦即 高差平均變化率平方之平均值的期望值也是零。
∑
∑
∑
∑
−− ⋅ = ′ ⋅ − − = ′ i i i i i i i i W W Y Y hy hy hy W W X X hx hx hx ) ( ) ( 0 0 0 0(1) 在求得高差變化率∇zz=(hx′ hy′)T後,利用(2)式計算出Γzz與均勻度指標 = Γ = ′2+ ′2 hy hx zz tr h 。 2 2 2 2 × ′ ′ ′ ′ ′ ′ = ∇ ⋅ ∇ = Γ hy hy hx hy hx hx zz zz zz T
(2) 此外,Förstner 在分類均調區域與非均調區域時,是利用均勻度指標 h 與門檻值Th的關 係來判斷的,計算門檻值時所用到的雜訊變方σn2(x,y)與訊號(灰階值)是成正比的關係,因為 在影像處理中有考慮到攝影時光通量的問題,光通量愈多,訊號愈大,亮度(灰階值)愈高, 當然雜訊也就可能愈大。但是點雲資料並沒有光通量的問題,高程愈高,點位誤差愈大的概 念顯然也不合理,故對於雜訊變方的估計必須做適度修改。在此則引用訊號與雜訊比 (signal-to-noise ratio,S/N)的概念來處理,即利用均勻度指標 h 除以高程差變化率之中誤差, 然後進行 F 分佈的單尾統計測試來分類屬於共面與非共面的點,如(3)式所示,若訊雜比值大 於 F 值(F2,2, α)則訊號(高程差變化率)遠大於點位高程差變化率的中誤差,即將此點視為非共 面點;若訊雜比值小於 F 值則訊號是不明顯的,即將此點視為共面點。此處顯著水準 α 預 設為 0.01,可視情況調整,經查表得知 F2,2, α=99。 2 2 / ′ ′ + = hy hx h N S σ σ (3) 如上段所述,在計算訊雜比時要先求得每個點位高程差變化率的中誤差,即 2 ′ hx σ 與 2 ′ hy σ 。在此利用誤差傳播的概念求得。如以下之計算步驟所示,在這裡假設光達點的平面坐 標並無誤差而只考慮高程存在誤差,推導如下所示。
) , , , , ( ) ( 3 2 1 0 1 1 0 0 n n i i n i i i i Z Z Z Z Z f W W X X Z Z hx = L ⋅ − − = ∑ ∑ = =
n n i dZ Z f dZ Z f dZ Z f dZ Z f Z Z Z Z Z df hx d = L = ∂∂ +∂∂ +∂∂ 2+L+∂∂ 2 1 1 0 0 3 2 1 0, , , , ) (
2 2 2 2 2 2 2 1 2 1 2 0 2 0 2 Zn n Z Z Z hx Z f Z f Z f Z f σ σ σ σ σ ∂ ∂ + + ∂ ∂ + ∂ ∂ + ∂ ∂ = L 假設上式每個點的高程中誤差皆相同,即 2 0 2 2 1 2 0 σ σ σ σZ = Z =L= Zn = 。 可計算得 ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =
∑
∑
= = 2 1 1 2 2 2 0 2 1 ( 1 ) n 1 ( 1 ) i i i n i i i hx σ P X W P X W σ (4) 其中∑
= = n i Wi P 1 ,同理可得 ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =∑
∑
= = 2 1 1 2 2 2 0 2 ) 1 ( 1 ) 1 ( 1 n i i i n i i i hy σ P Y W P Y W σ (5)再利用(4)式及(5)式之計算結果及(1)式之函式,同理依據誤差傳播定律即可求得 2 ′ hx σ 與 2 ′ hy σ 。 ⋅ ⋅ ∆ ⋅ + ⋅ ∆ ⋅ = ⋅ ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =
∑
∑
∑
∑
= = ′ = = ′ 2 0 2 1 1 2 2 2 2 0 2 1 1 2 2 2 ) 1 ( 1 ) ( 1 ) 1 ( 1 ) ( 1 hy n i i i n i i i i hy hy hx n i i i n i i i i hx hx W Y P W Y P W X P W X P σ σ σ σ σ σ (6) 分類出屬於共面與非共面點之後,緊接著就是從非共面點雲資料中分類出屬於點和線 的光達點。這裡的分類概念便與 Förstner 分類點區域和線區域的概念相同。由計算出的平均 高程變化率∇z=(hx hy)T ,可進一步計算平均平方梯度矩陣Γz,再利用形狀指標 v 分類屬於 點和線的光達點,vmin約取 0.4~0.8 之間。(
)
T T hy hx z where hy hy hx hy hx hx G z z G z ) ( * * 2 2 2 2 = ∇ = ∇ ⋅ ∇ = Γ × σ σ(7) Förstner 多型態特徵萃取法在經過部分修正之後應用於光達資料的點線面萃取,由李宏 君和邱式鴻[2005]的試驗分析可得知,想要直接將光達點雲資料進行點線面等特徵的分類, 並不容易得到理想的效果,尤其是分類「點」的部份更是不理想,認為原因如下: 1. 用光達點雲資料計算高程變化率時只能以大概的點數去估算罩窗的大小,無法 確定所納入罩窗內計算平均高程變化率的點是否都能確切地表示該地表點的 真實高程變化率。這點是用此法分類光達點雲資料之特徵時影響最大的因子。 2. 光達點雲資料並無法真正地表示特徵所在的位置。舉例來說:光達點位幾乎不 可能會完整地分布在屋簷、屋角點或屋脊線上,故想運用以數學上解析交會概 念所計算的形狀指標 v 判斷點特徵時,就顯得效果並不是很好。此外,對分類 出來的點或線特徵,在此並不進行後續點約化、線細化和擬合的動作,因為這 樣處理所得出來點不會是屋角或線交會的位置上,且擬合的線並不一定位於真 正的斷線上,在精度上並不精確,所以類似的處理並沒有太大的意義。 3. 本實驗方法亦有一個無法克服的問題:由夾很大角度的兩屋頂面所組成的屋脊 線很難將它萃取出來,原因是因為此處的高差變化率並不明顯(訊號弱),故在 用訊雜比值不容易超過門檻值。此問題的解決可以透過先尋找面特徵資訊(邱 煥智、邱式鴻,2005),然後利用面交會的方法找出屋脊線。
3-2、以空間非共面的點雲資料進行不規則三角網結構化
由李宏君和邱式鴻[2005]的試驗分析亦可得知,透過點位分析過程中雖然不易得到理想 的結果,但共面點雲資料的特性卻適合用來將光達點雲資料進行結構化進一步簡化點雲資料 達到結構化的目標。以下即利用圖 7 至圖 10 四組資料利用分類得到的非共面點雲資料進行 不規則三角網結構化之後的成果。其進行點線面特徵分類所採用點在 4 到 8 點間,分類時的 顯著水平為 5%,分類時的點位高程中誤差為 0.07m。圖 7 左圖:第一組資料分類後之非共面的點雲資料;右圖:不規則三角網建置成果
圖 9 左圖:第三組資料分類後之非共面的點雲資料;右圖:不規則三角網建置成果 圖 10 左圖:第四組資料分類後之非共面的點雲資料;右圖:不規則三角網建置成果
3-3、以空間共面特徵進一步發展結構化的演算法
由上述圖 7 至圖 10 中雖然仍有分類時所分析的缺點,然而亦發現共面資料較適合用來 進行點雲資料的結構化,因此在本研究中亦嘗試以四分樹及類似區域成長概念[邱煥智和邱 式鴻, 2005]來進行光達點雲資料中共面點結構化的工作,達到結構化的目標,以下試驗中就 共面特徵提出結構化的方法但不再對結構化後的點資料進行不規則三角網的建置。 以四分樹及類似區域成長概念將光達點雲資料中面資訊進行結構化的過程是重複的分 割與合併。以四分樹進行資料分割結構化時,每次分割均對分割出的點雲區塊進行平面擬合 計算,並以擬合中誤差進行判斷,若中誤差小於臨界值即停止分割,並定義此結構化區塊的 點雲為一平面,若大於臨界值則繼續進行結構化分割,直到產生平面或小於 3 個點為止。四 分樹分割結構化完後以平面相交角度合併同性質平面的結構化工作,然後再以平面的相鄰性由合併的平面群中再將空間中不相鄰的相異平面分離成不同的平面。接下來再利用得到的平 面,與其鄰近獨立點做比對,並以高程判斷是否合併獨立點。到此完成所有平面結構化的工 作,供後續研究。 本測試例仍是以前述進行光達點雲點線面特徵分類時所用的四組資料為例,並根據空載 雷射掃瞄數具精度評估程序之研究[史天元,彭淼祥,2003],本試驗將平面擬合中誤差的臨 界值(σ0)設定為 0.15m。 首先以第四組資料加以說明,圖11為第四組點雲進行四分樹分割結構化的結果,圖11和 之後所有的圖例中,紫紅色的點都代表獨立點。 圖12為平面角度判斷合併結果,在研究方法中探討的兩個問題可以在圖12中觀察到,以 紅色點雲為例,原本兩大平面的編碼假定皆設定為3,但經過相鄰性判斷後,就可以分出3和 4兩組編碼,代表他們是不同平面。分離和排除小區塊的結果從圖13可以明顯的看出。 圖13的結果,主要的面資訊已初步成形,但絕不是完整的平面,在紫紅色的單獨點群中, 仍有很多是屬於平面,因此必須對這些單獨點群和平面進行擬合的動作。圖14為擬合後的結 果,可明顯看出比圖13的平面完整。到此算是完成所有面的結構化。 圖11 第四組資料以四分樹分割結構化的結果 圖12第四組資料以平面角度判斷合併結果 圖13 第四組資料相鄰性判斷分離結果 圖14 第四組資料以平面特徵進行結構化成果 A B
由邱煥智和邱式鴻[2005]分析中得知在圖14中部份在白色圓圈內的部分點雲被結構化到 A平面中,此外黑色圓圈內的部分點雲被結構化到B平面中。這些散點很明顯不屬於相同平 面,結構化過程中應該被排除。解決的辦法可針對每一塊平面,去判斷每一塊平面中點群的 相鄰性,並配合航空影像等資料輔助判斷,如此應可將不同的平面加以分離。 此外在圖14中的屋脊線有鋸齒狀現象,可能原因是屋頂面相交的角度過小,導致在一開 始的四分樹分割時,某些區塊容易越界,使得屋頂面交接處不完整。對於這個問題的初步解 決想法為,先利用兩屋頂面交會出屋脊線,再利用此交會出的線段,將其左右兩旁的點重新 編碼,也就是說,假設某點應該屬於線段右方的面,但卻出現在線段左方,就可將其編碼定 義為與右方點群相同,當判斷完所有的點,就不會有鋸齒狀的現象。但是這條屋脊線是否達 到可接受的精度範圍,應在後續的研究中加以探討。 除了對第四組點雲資料作測試外,另外對第一組和第三組的結構化成果如圖15和圖16。 圖15 第一組資料以平面特徵進行結構化成果 圖16 第三組資料以平面特徵進行結構化成果
四、 結論與建議
本研究在維持原掃瞄點精度和減少資料量讓後續資料處理更加有效與便利的目標之 下,先分析掃描點雲資料可以顯示的空間特徵,然後以此特徵進行資料的簡化並進行後續的 不規則三角網結構化的處理。雷射掃描點雲分地面和空載雷射掃描,本文以空載雷射掃描點 雲資料為主,先探討 Förstner 多型態特徵萃取法應用在光達資料點線面特徵分類的適用性, 然後將 Förstner 多型態特徵萃取法經過部分修正之後應用於光達資料的點線面萃取,發現想 單純以點位的高差以及高差變化得到理想的點線分類結果仍有困難,而在平面和平面相交的 夾角若近似水平利用修正的 Förstner 多型態特徵萃取法想得到交線處理想的共線點分類亦有 困難,但若先以共面特性先去除共面的點雲資料而且不細分點線的非共面光達點雲資料仍是 可以得到不錯的成果來進行不規則三角網結構化,且此結果亦有利後續處理之用。此外,由 於共面特徵較適合用於光達點雲結構化的工作,本研究中亦嘗試以四分樹及類似區域成長概 念[邱煥智和邱式鴻, 2005]來進行光達點雲資料中共面點結構化的工作,達到結構化的目標, 其初步成果亦令人滿意。而本試驗中,由於程式設計上的因素,應用於大量點雲資料的結構 化仍有問題,仍有待改進之處。此外本試驗僅針對包含建物區的光達資料進行測試,未來也 應該對非都市區的光達資料加以測試。五、 參考文獻
史天元,彭淼祥, 2003,”空載雷射掃描數據精度評估程序之研究”,第二十一屆測量學術 及應用研討會論文集,第 247-256 頁。 李宏君、邱式鴻,2005,”由光達點雲資料進行點、線、面特徵分類之研究”,第二十四屆 測量學術及應用研討會論文集,國立政治大學,第 389-396 頁,中華民國九十四年九月。 邱煥智、邱式鴻,2005,”由光達點雲資料萃取建物屋頂面資訊”,第二十四屆測量學術及 應用研討會論文集,國立政治大學,第 331-338 頁,中華民國九十四年九月。 賴志恆,2003,”雷射點雲資料八分樹結構之研究”,國立成功大學測量工程學系碩士論文。 Axelsson, P., 1999,“Processing of laser scanner data-algorithms and applications”, ISPRSJournal of Photogrammetry & Remote Sensing, vol.54, pp.138-147.
Delaunay,B., 1934, Sur la sphere vide. Bulletin of Academy of Sciences of the USSR, pages 793-800.
Förstner, 1994. A Framework for Low Level Feature Extraction, Institute of Photogrammetry, Universität Bonn.
Hu, Y. and Tao, V., 2002, “Bald DEM Generation and Building Extraction Using Range and Reflectance Lidar Data”, Procesdings of ASPRS 2002 Conference (CD-ROM).
Lin, Shing-Hung and Jen-Jer Jaw, 2004,”STRUCTURALIZATION OF LIDAR POINT CLOUD”, pp.102-107, 25th ACRS 2004, Chiang Mai, Thailand.
Mass, H. G. and Vosselman, G., 1999, “ Two Algorithms for Extracting Building Models from Raw Laser Altimetry Data ”, ISPRS Journal of Photogrammetry & Remote Sensing, vol.54,
pp.153-163.
Priestnall, G., J. Jaafar and A. Duncan, 2000. Extracting Urban Feature from LiDAR Digital Surface Models, Computers, Environment and Urban Systems, Vol. 24, pp. 65-78.
Tao, G. and Yasuoka, Y., 2002, “Combing High Resolution Satellite Imagery and Airborne Laser Scanning Data for Generation Bareland DEM in Urban Areas”, International Archives of Photogrammetry and Remote Sensing, vol.34, Part 5, Kuming.
Woo, H., Kang, E., Wang, S. and Lee, K.H., 2002, “A New Segmentation Method For Point Cloud Data”, International Journal of Machine Tools & Manufacture, vol.42, pp.167-178.
Midtbø, T., 1993, “Spatial Modelling by Delaunay Networks of Two and Three Dimensions”, Dr.Ing. thesis, Faculty of Electrical Engineering and Computing. University of Zagreb. URL:http://helga.zesoi.fer.hr/triangulation/iko_no/tmp/term/term.html
六、 計畫成果自評部份,請就研究內容與原計畫相符程度、達成預期目標情
況、研究成果之學術或應用價值、是否適合在學術期刊發表或申請專利、
主要發現或其他有關價值等,作一綜合評估。
本計劃對於參與之工作人員,獲得原先預期之(1).了解目前最新之測量技術;(2).訓練撰 寫程式之能力;(3).了解數值覆面資料結構化的理論和方法;(4).培養資料分析和處理之能 力等訓練之外,亦訓練參與人員李宏君、邱煥智於第二十四屆測量學術及應用研討會發表 口頭報告的能力。其中邱煥智並獲得第二十四屆測量學術及應用研討會的年輕學子論文獎。 而就研究內容與原計畫相符程度約為百分之七十。而以達成預期目標情況而言,本研究對 於學術而言的確發展出雷射掃描的地面數值覆面點雲資料另外一種結構化的演算法,但對 於精進建構不規則三角網以期更有效反應真實的地表數值覆面模型(DSM)方面卻尚未達 成,而由結構化建構的 DSM 中,經過[邱煥智、邱式鴻,2005]的初步試驗的確可以供後續 萃取都市區建物幾何模型(DBM)或數值地形模型(DTM)。而都市區建物模型和數值覆面模 型對構建三維城市模型是相當基礎的資訊,就研究成果之學術或應用價值而言將來可以改 善[邱煥智、邱式鴻,2005]的演算法將其應用於三維城市模型的建立並作為景觀規劃設計、 環境評估、防災甚至是通訊電訊等等的熱門應用。因此,本研究部分試驗成果可以作為建 構三維城市模型之基本資料。而[邱煥智、邱式鴻,2005]的演算法進一步改善將適合在學術 期刊發表或申請專利。 此外,在本試驗中發現以往宣稱可以將 Förstner 多型態特徵萃取法直接應用在光達資料 上進行萃取,在學理上有些理論需進行部份修正才能應用於原始光達點雲資料之點線面特 徵的萃取。 雖然研究內容與原計畫相符程度僅約為百分之七十。但是就整體而言本研究所導致的兩 項研究成果發表,卻是豐碩的。此兩篇論文已經發表於中華民國九十四年九月於國立政治大 學舉行的第二十四屆測量學術及應用研討會。 李宏君、邱式鴻,2005,”由光達點雲資料進行點、線、面特徵分類之研究”,第二十四屆 測量學術及應用研討會論文集,國立政治大學,第 389-396 頁,中華民國九十四年九月。 邱煥智、邱式鴻,2005,”由光達點雲資料萃取建物屋頂面資訊”,第二十四屆測量學術及 應用研討會論文集,國立政治大學,第 331-338 頁,中華民國九十四年九月。由光達點雲資料進行點、線、面特徵分類之研究
The Study of Feature Classification from LIDAR Point Cloud Data
李宏君
1邱式鴻
2Hung-Chun,Li Shih-Hong,Chio
摘要
Förstner 於 1994 年提出對影像中的點、線、面特徵同時萃取的方法。使得在分析光達 點雲資料時,引導出是否也可以利用相同的概念來萃取光達點雲資料中點、線、面特徵。因 此本實驗的構想是將光達點雲資料中的高程視為影像中的灰階值,並參考 Förstner 所提的概 念進行特徵點雲資料的分類,研究主要是先對點雲資料進行「共面特徵」與「非共面特徵」 的點雲資料分類,再從分類出的非共面點雲特徵中判別屬於線和點的點雲特徵。文中將會說 明採行 Förstner 所提概念進行點雲特徵分類時該如何進行,而分類過程中對結果產生的影響 有哪些參數,以及分析分類的成果。 關鍵字:光達、點雲資料、分類ABSTRACT
In 1994, Förstner had devised a polymorphic feature classification method that simultaneously extracts points, lines, and segments features from image. Could the concept of this classification method be used to analyze the point, line and area features implied in the point cloud data? Therefore, in thisstudy, the height of Lidar point cloud data is regarded as the gray level of an image and firstly the point cloud data is classified into homogeneous and non-homogeneous LIDAR point data. After that, the non-homogeneous point cloud data is further classified into line and point LIDAR point data. Finally, the result of classification will be evaluated and the essential parameters and their effect in the classification process will be discussed.
Keyword: LIDAR, point cloud data, classification
一、 前言
光達(Light Detection And Ranging, LIDAR)測量是一種新興的測量技術,其利用雷射 掃瞄的方式,精確且快速地獲取大量的物表點位座標,改進了過去利用傳統測量儀器進行測 量時耗費過多時間和人力的缺點。光達大致上可分為地面光達和空載光達兩大類:空載光達 是由航空載具搭載雷射掃描儀器,配合 GPS 和 INS 來定位定向求得外方位參數,在高空飛 1國立政治大學地政學系 學士班學生,email: [email protected] 2國立政治大學地政學系 助理教授,email: [email protected]
行途中對地面進行雷射掃瞄測量;地面光達是在地面上架設掃描儀器,設定好其外方位參數 後,直接對地物進行雷射掃瞄。 光達測量所獲取的點資料非常地龐大,雖然其觀測量多到幾乎能表達整個掃描覆面的 外形,但是明確的空間資訊卻無法直接表達,而是隱藏在龐雜的點雲分布中(劉嘉銘,2005)。 對於部分的應用而言,例如:特徵物的辨識、建物模型的重建等,往往需要重要特徵點位的 資訊,例如:斷線、屋角點、屋頂面等。故最好能設法分類出這些特徵點位的資料,再進行 資料的後處理。目前已有利用航空影像作出類似的萃取技術,航空影像雖有精確的平面精 度,但高程精度還是比不上光達資料來的精確,故往後若能將光達點雲資料分類出來的結 果,搭配航空影像的處理技術,或許會使萃取的效果更為理想,而本研究便是期望先將光達 點雲資料進行分類並將分類結果提供後續研究的一個參考。 目前已有不少針對光達點雲資料進行分類的研究,其中常採用的方法就是先萃取出空 間中的面特徵,例如:八分樹結構化的平面特徵萃取(賴志恆,2003),再利用面特徵交會出 線特徵與點特徵(劉嘉銘,2005)。本實驗所採取的方法是參考 Förstner 於 1994 年所提出對影 像進行特徵萃取的影像處理技術「多型態特徵萃取法」(Polymorphic Feature Extraction) (Förstner, 1994),雖然此法是針對影像來進行處理的,但在此可以將密集的光達點雲資料看 成是由許多像素點的集合所構成的影像,其高程值即視為影像中的灰階值,以此為基礎進行 特徵萃取的工作。在這裡考慮為了不失去光達點雲資料原有的精度,並不把點雲資料以規則 網格的方式結構化,而是直接地採用原始的點雲資料進行處理。
二、
多型態特徵萃取(Polymorphic Feature Extraction)之分類概念
多型態特徵萃取是 Förstner 所提 出的影像處理方法,主要目的是以數 理解析和統計假說測試為基礎,分析 並萃取數值影像中的簡單幾何特徵: 點、線、面,以作為影像解析或影像 辨 識 的 基 礎 。 此 法 並 非 只 個 別 考 慮 點、線、面等單一類型特徵的萃取, 而是同時萃取此三類型的特徵。如圖 1 所示,分類步驟是先將影像全部內容分類成「面」與「非面」兩大類,再由非面區中分類「線」 與「點」特徵區域。另外,線特徵區又可分成獨立直線(“bar edges” or “lines”)特徵和邊緣線 (“step edges” or “edges”)特徵;點特徵區中又可分成交叉點(junction regions)、角點(corner regions)和圓形對稱點(circular symmetric point regions)特徵,在本文中僅列出 Förstner 對點、 線、面的初步分類法的觀念簡介,暫不討論上述細分類型的分類,詳細的分類萃取說明可參 考(Förstner,1994)。
2.1 「均調區」與「非均調區」的特徵像元分類
位於同一均調區域內影像的灰階值相近,而非均調區域則出現在灰階值劇烈變化的地 方,由此概念作為分類面區域與非面區域的基礎。此分類的方法是利用灰階值變化率的大小
來 分 類 , 藉 由 (1) 式 平 均 平 方 梯 度 (average squared gradient , Γg ) 矩 陣 的 均 勻 度 指 標 (homogeneity criterion) h=trΓg 來 判 斷 。 假 如 均 勻 度 指 標 小 於 門 檻 值 2 1 , 2 2 ) , ( . ) , (x y =const⋅σ x y ⋅χ −α Th n ,則將像元判斷為「面」特徵區域;若h大於Th,則將其判斷為 「非面」特徵區域。
(
)
T y x s y y x y x x T s s g g g where g g g g g g G g g G g ) ( * * 2 2 2 2 = ∇ = ∇ ⋅ ∇ = Γ × σ σ(1) 門檻值Th(x)中的 ( , ) 2 y x n σ 為局部雜訊變方(noise variance),其與訊號(灰階值) f(x,y)成線 性關係,如(2)式所示。 σn2(x,y)=a+bf(x,y) b>0 (2) 2.2 從「非面」區域中分類「線」與「點」特徵像元 如(3)式所示,藉由形狀指標(shape criterion)v判別影像中非均調區域內的點特徵和線特 徵像元。若形狀指標
v
>
v
min,則將像元分類成點特徵像元;否則即屬於線特徵像元。其中ν
min 約為 0.1 到 0.5 之間。 g tr g q q q v Γ Γ = + + − − = 2 det 4 1 1 1 1(3) 形狀指標的意義如同誤差橢圓中的長短軸上最小定位中誤差和最大定位中誤差之比。 比值愈大則該像元愈可能為角點或單獨點,比值愈小則越可能為線特徵。
三、 多形態特徵萃取法應用於光達資料特徵萃取之探討
在考慮運用 Förstner 影像處理方法處理光達點雲資料資料時,首先罩窗(filter)的選擇便 是一個問題。由於影像是規則的網格資料,罩窗的選擇較為單純且固定,如 3×3、5×5、7×7… 等,但光達點雲資料是不規則的資料,雖然可以嘗試用內插的方式將之規則網格化,但為了 不失去點雲資料原有的精度,在此並不採行這樣的方法,而是直接用原始資料處理。至於罩 窗大小的選擇方法是以一點為中心,慢慢地擴大正方形罩窗範圍,直到罩窗範圍內所能容納 的點數符合給定的點數為止,如圖 3 所示。 由於光達點雲資料是不規則的點位資料,故每點的罩窗大小不一定相同,且不一定會 符合所給定的點數。罩窗內的點數以盡量不超過某 一數量為原則,如圖 2 罩窗內所包含的綠色區域, 因為罩窗太大(選擇容納的點數太多)而涵蓋到週遭 不相干的地物點,使高程變化的計算可能失去參考價值,不能確切表示實地真實的高程變化。選擇一適當罩窗後,再依(4)式計算出每點
x方向的平均高程變化量
hx、y方向的平均 高程變化量hy,其中 A0 (X0,Y0,Z0)為中心點、Ai (Xi,Yi,Zi) (i:1~n)為納入計算的 n 個點、 Wi是權,為距離A0Ai 的倒數,求得∇z=(hx hy)T。∑ ∑ ∑ ∑ −− ⋅ = ⋅ − − = i i i i i i i i W W Y Y Z Z hy W W X X Z Z hx ) ( ) ( 0 0 0 0
(4)
由 2-1 節中的描述清楚了解 Förstner 多型態特徵萃取是利用影像在均調區時,其灰階梯 度平方的平均值 之期望值是零的 情況下,進行統 計假說測試來萃 取影像中的面與 非面資訊,但是 若用相同的概念 來分類光達點雲 資料的共面與非 共面資訊時可能 會發生問題,因 為 共 面 的 點 雲 中,其高程變化 率平方的平均值 之期望值並不會是零,這在理論假設上已不相符。舉具有屋脊線的雙屋頂的例子來說,如圖 4(a)的影像資料,利用 Förstner 的多型態特徵萃取法在分類均調區 (1 區、3 區)與非均調區 (2 區)時,是根據在均調區中灰階的梯度是趨近於零,而非均調區中灰階的梯度並不趨近於零 的特性來分類的,所以採用梯度平方的平均值來進行分類是可行的;但應用在光達資料中, 參考圖 4(b)之對照組中的 1 區及 3 區,其高程變化率並非趨近零,而 2 區用(4)式計算的高 程變化率卻趨近於零,所以以高程變化率平方的平均值來進行分類會有問題。由上述可知兩 種資料在性質上有很大的不同,並不能完全套用同一個法則來進行點雲資料中共面點與非共 面點的分類。 有鑒於此,光達點雲資料進行完第一次的高程平均變化率的計算後,必須再依(5)式進 行高差平均變化率的計算,如圖 4(b)之右圖所示,這才會符合數學統計上的基本假設,亦即 高差平均變化率平方之平均值的期望值也是零。
∑
∑
∑
∑
−− ⋅ = ′ ⋅ − − = ′ i i i i i i i i W W Y Y hy hy hy W W X X hx hx hx ) ( ) ( 0 0 0 0(5) 在求得高差變化率∇zz=(hx′ hy′)T後,利用(6)式計算出Γzz與均勻度指標 = Γ = ′2+ ′2 hy hx zz tr h 。 2 2 2 2 × ′ ′ ′ ′ ′ ′ = ∇ ⋅ ∇ = Γ hy hy hx hy hx hx zz zz zz T
(6) 參考 2.1 小節,Förstner 在分類均調區域與非均調區域時,是利用均勻度指標 h 與門檻
值Th 的關係來判斷的,計算門檻值時所用到的雜訊變方 ( , ) 2 y x n σ 與訊號(灰階值)是成正比的關 係,因為在影像處理中有考慮到攝影時光通量的問題,光通量愈多,訊號愈大,亮度(灰階 值)愈高,當然雜訊也就可能愈大。但是點雲資料並沒有光通量的問題,高程愈高,點位誤 差愈大的概念顯然也不合理,故對於雜訊變方的估計必須做適度修改。在此則引用訊號與雜 訊比(signal-to-noise ratio,S/N)的概念來處理,即利用均勻度指標 h 除以高程差變化率之中誤 差,然後進行 F 分佈的單尾統計測試來分類屬於共面與非共面的點,如(7)式所示,若訊雜比 值大於 F 值(F2,2, α)則訊號(高程差變化率)遠大於點位高程差變化率的中誤差,即將此點視為 非共面點;若訊雜比值小於 F 值則訊號是不明顯的,即將此點視為共面點。此處顯著水準 α 預設為 0.01,可視情況調整,經查表得知 F2,2, α=99。 2 2 / ′ ′ + = hy hx h N S σ σ (7) 如上段所述,在計算訊雜比時要先求得每個點位高程差變化率的中誤差,即 2 ′ hx σ 與 2 ′ hy σ 。在此利用誤差傳播的概念求得。如以下之計算步驟所示,在這裡假設光達點的平面坐 標並無誤差而只考慮高程存在誤差,推導如下所示。
) , , , , ( ) ( 3 2 1 0 1 1 0 0 n n i i n i i i i Z Z Z Z Z f W W X X Z Z hx = L ⋅ − − = ∑ ∑ = =
n n i dZ Z f dZ Z f dZ Z f dZ Z f Z Z Z Z Z df hx d = L = ∂∂ +∂∂ +∂∂ 2+L+∂∂ 2 1 1 0 0 3 2 1 0, , , , ) (
2 2 2 2 2 2 2 1 2 1 2 0 2 0 2 Zn n Z Z Z hx Z f Z f Z f Z f σ σ σ σ σ ∂ ∂ + + ∂ ∂ + ∂ ∂ + ∂ ∂ = L 假設上式每個點的高程中誤差皆相同,即 2 0 2 2 1 2 0 σ σ σ σZ = Z =L= Zn = 。 可計算得 ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =
∑
∑
= = 2 1 1 2 2 2 0 2 1 ( 1 ) n 1 ( 1 ) i i i n i i i hx σ P X W P X W σ (8) 其中∑
= = n i Wi P 1 ,同理可得 ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =∑
∑
= = 2 1 1 2 2 2 0 2 ) 1 ( 1 ) 1 ( 1 n i i i n i i i hy σ P Y W P Y W σ (9) 再利用(8)式及(9)式之計算結果及(5)式之函式,同理依據誤差傳播定律即可求得 2 ′ hx σ 與 2 ′ hy σ 。 ⋅ ⋅ ∆ ⋅ + ⋅ ∆ ⋅ = ⋅ ⋅ ∆ ⋅ + ⋅ ∆ ⋅ =∑
∑
∑
∑
= = ′ = = ′ 2 0 2 1 1 2 2 2 2 0 2 1 1 2 2 2 ) 1 ( 1 ) ( 1 ) 1 ( 1 ) ( 1 hy n i i i n i i i i hy hy hx n i i i n i i i i hx hx W Y P W Y P W X P W X P σ σ σ σ σ σ (10) 分類出屬於共面與非共面點之後,緊接著就是從非共面點雲資料中分類出屬於點和線 的光達點。這裡的分類概念便與 Förstner 分類點區域和線區域的概念相同。由(4)式計算出的平均高程變化率∇z=(hx hy)T,可進一步計算平均平方梯度矩陣Γz,如(11)式。再如 2.2 節所 述,利用形狀指標 v 分類屬於點和線的光達點,vmin約取 0.4~0.8 之間。
(
)
T T hy hx z where hy hy hx hy hx hx G z z G z ) ( * * 2 2 2 2 = ∇ = ∇ ⋅ ∇ = Γ × σ σ(11)
四、 實作成果與分析
本節對於應用本文所述之方法進行分類的結果加以分析說明。測試過程中不僅使用空 載亦使用地面光達點雲資料,但因篇幅有限,以下僅列出一空載光達點雲資料測試例(如圖 5 所示)的分類成果加以分析說明。 本測試例擷取自行政院農委會於 2002 年 4 月 14 日對新竹地區進行掃描的空載光達資料, 使用的光達掃描儀器為 LHALS40,掃描時航高約 800 公尺、視角 35 度,經過濾除多重反射 (multiple echoes)訊號之前處理,只取地表之點 雲資料,其點密度約為 0.5p/m2。 以本文所提方法進行共面與非共面點雲資 料分類時,須以誤差傳播計算每個點位高程差 變化率的中誤差,此時必須先知道點位量測的 高程中誤差。本實驗中是以擷取點雲資料中近 似平面之數個區塊,將高程值視為等權以平面 擬合之後所求得之後驗中誤差(σ0)視為點位量 測的高程中誤差,經計算之後約為±0.07m。 在分類的過 程中會對結果產 生影響的參數大 致 有 : 點 密 度 (p/m2)、罩窗內之 點數(p)、光達點 雲之後驗高程中 誤差(±σ0)、顯著 水準(α)、形狀指 標(v)等。原始資 料之「點密度」愈 大者,對地物細節 的描述愈詳盡,利 用罩窗進行平均 高程變化率運算 時,較不容易將不 相干之地物點納入計算,而造成分類的效果變差,但這條件視原始點雲資料之品質而定,並無法於實驗中隨 意改變。此外,在試驗過程中也發現距罩窗中心過近的點會嚴重影響高程和高差變化率,因 此在本試驗中嘗試濾除 x 方向和 y 方向相距 10cm 以內的點以獲得較佳的結果。選擇納入之 「罩窗內之點數」愈多則相對的罩窗範圍愈大,納入不相干地物點的機會也變多,也會造成 分類的效果較差,如圖(6c)所示。原始資料之「後驗高程中誤差」愈大者,會導致訊雜比值 變小(分母變大),而容易將高程差變化率不明顯之非共面點誤判成共面點,此參數視資料品 質而定。「顯著水準」愈小者,即訊雜比之門檻值愈高,易將矮小之地形特徵物略去,如圖 (6d)右上區之矮小建物與左上區之矮樹叢並不明顯;但若「顯著水準」愈大者,所判斷出的 非共面點就愈多,愈難區分實際共面點與非共面點的位置,如圖(6f)右上區之矮小建物之間 的區隔。「形狀指標」的區間範圍為 0<v<=1,若 v 值愈大,表示此點可分類為明顯之角點( corner) 或獨立點,相對地 vmin門檻值取的愈大,濾除愈多的點位,所以判斷出的「點」愈少。但是 由圖 6 中發現點的萃取並非十分理想。綜合上述分類結果和多組資料測試可得知,想要直接 將光達點雲資料進行點線面等特徵的分類,並不容易得到理想的效果,尤其是分類「點」的 部份更是不理想,認為原因如下: 4. 用光達點雲資料計算高程變化率時只能以大概的點數去估算罩窗的大小(如第 三節一開始決定罩窗大小時所述),無法確定所納入罩窗內計算平均高程變化 率的點是否都能確切地表示該地表點的真實高程變化率。這點是用此法分類光 達點雲資料之特徵時影響最大的因子。 5. 光達點雲資料並無法真正地表示特徵所在的位置。舉例來說:光達點位幾乎不 可能會完整地分布在屋簷、屋角點或屋脊線上,故想運用以數學上解析交會概 念所計算的形狀指標 v 判斷點特徵時,就顯得效果並不是很好。此外,對分類 出來的點或線特徵,在此並不進行後續點約化、線細化和擬合的動作,因為這 樣處理所得出來點不會是屋角或線交會的位置上,且擬合的線並不一定位於真 正的斷線上,在精度上並不精確,所以類似的處理並沒有太大的意義。 6. 本實驗方法亦有一個無法克服的問題:由夾很大角度的兩屋頂面所組成的屋脊 線很難將它萃取出來(如上節之測試例中之屋脊線),原因是因為此處的高差變 化率並不明顯(訊號弱),故在用訊雜比值不容易超過門檻值。此問題的解決可 以透過先尋找面特徵資訊(邱煥智,2005),然後利用面交會的方法找出屋脊線。
五、 結論與建議
由實驗分析可得知,想要直接將光達點雲資料運用本文所提的方法進行點線面等特徵 的分類,並不容易得到理想的效果,雖然此法所分類出之效果不佳且存在著些不可避免的缺 點,但仍存在了它的利用價值。例如利用較高的顯著水準門檻值,先篩選出非共面的點群, 此時並不進一步去分類點和線點雲特徵,接著利用非共面的點雲資料,融合航空影像資料, 利用影像處理的技術和航空影像擁有精確平面資訊的性質,應該可以相互結合進而精確決定 線和點特徵的資訊。而至於共面的點群則可以運用尋找面特徵資訊(邱煥智,2005)的方法進 一步處理得到面資訊,甚至可以利用面交會的方法找出隱含的線特徵。致謝
本研究是國科會專題研究計畫之部分成果,承蒙國科會提供研究經費,計畫編號 NSC-93-2211-E-004-003。亦承蒙行政院農業委員會提供新竹地區空載光達資料供本研究實驗 之用,特此致謝。參考文獻
邱煥智、邱式鴻,2005。由光達點雲資料萃取建物平面資訊,第二十四屆測量學術及應用研 討會論文。 賴志恆,2003。雷射掃描點雲資料八分樹結構化之研究,國立成功大學測量及空間資訊研究 所碩士論文。 劉嘉銘,2005。光達點雲資料特徵萃取之研究,國立成功大學測量及空間資訊研究所碩士論 文。Förstner, 1994. A Framework for Low Level Feature Extraction, Institute of Photogrammetry, Universität Bonn.
由光達點雲資料萃取建物屋頂面資訊
Extracting Rooftops From LIDAR Point Cloud Data
邱煥智
3邱式鴻
4Huan-Chih,Chiu Shih-Hong,Chio
摘要
本文提出的以四分樹及類似區域成長概念來萃取光達點雲資料中建物屋頂面的資訊,其 過程是重複的分割與合併。以四分樹進行資料分割時,每次分割均對分割出的點雲區塊進行 平面擬合計算,並以擬合中誤差進行判斷,若中誤差小於臨界值即停止分割,並定義此區塊 的點雲為一平面,若大於臨界值則繼續分割,直到產生平面或小於 3 個點為止。四分樹分割 完後以平面相交角度合併同性質平面,然後再以平面的相鄰性由合併的平面群中再將空間中 不相鄰的相異平面分離成不同的平面。接下來再利用萃取得到的平面,與其鄰近獨立點做比 對,並以高程判斷是否合併獨立點。到此完成所有平面的萃取,最後再以萃取出的平面高程 進行屋頂面的萃取。實驗結果顯示本文所提方法的可行性,且深具自動化的潛力。 關鍵字:光達資料、四分樹、區域成長Abstract
The concepts of quadtree and region growing is used in this study to extract rooftops from LIDAR point cloud. The process is continuous segmentation and merging. Firstly, quadtree segmentation is used to plane-fitting computation. The plane-fitting standard deviation will be examined to decide whether the quadtree segmentation will proceed or not. Next step is to merge segmented planes by the similarity of normal vector among planes. In the third step, the adjacent relation among planes is used to extract the different planes in space. Then, the individual LIDAR points will be merged into the planes by comparison of the elevation between the point and the extracted plane. Finally, the rooftops can be extracted by comparison the rooftop elevation and the ground elevation. The results prove the feasibility and the potential of automation of the proposed approach.
Keywords:LIDAR、quadtree、region growing
一.前言
光達(Light Detection And Ranging, Lidar)利用雷射回波對實體物進行掃描,進而獲取該物
3國立政治大學地政學系 學士班學生,email:
4國立政治大學地政學系 助理教授,email:
體在三度空間中的相關位置,而在測量相關領域中,最常見的運用為對地面進行大面積的掃 描,來獲取地表物的空間資訊,由於 LIDAR 具有高精度極高解析度的優勢,較以往以傳統 測量的方式,所獲取的地表物空間資訊來的快速有效率,且能得到較正確的地表資訊,唯一 缺點為點資料量過大,即使現階段電腦在速度處理上已有不錯的能力,遇到龐大的點雲資料 仍顯的有些吃力,這也是其中一個原因,讓許多針對 LIDAR 的相關研究,著重在特徵物的 萃取上,只要能在如此龐大的點雲資料中,找出幾個代表性的點,就能大量減少不必要的點 雲資料,來提高後續應用的效率,而 LIDAR 在後續應用上非常廣泛,舉凡工程建設、都市 計劃管理、山坡地監測、土地利用等,因此有絕對的研究價值。 由於地表物包羅萬象,想辨識完所有的物體存在許多困難,因此在本研究中,選擇地表 物較具應用價值的建物屋頂面為萃取對象。而在屋頂面萃取的相關研究中,如以八分樹法將 雷射點雲階層式三維網格結構化之後,進行最小二乘平面擬合和平面特徵萃取[賴志恆, 2002]。或以切割技術(segmentation)之方法,以網格化灰階不連續之特性,進行不同屋頂面 偵測[Rottensteiner, 2003]。亦有研究將每個網格像元中之面方程式之三個係數,轉換至參數 空間,在參數空間中進行群聚分析,將不同屋頂面偵測出來[Elaksher &Bethel, 2002]等。而 在研究中的萃取方式,最終的目標都是希望在不需人工介入情況下,以自動化的方式獲得建 物的屋頂面。 因此在本文中提出一個由光達點雲資料中自動萃取建物屋頂面的演算法,在本文整個自 動化萃取過程中,主要分為四個步驟: (一)採用四分樹分割法,分割出許多具有相同平面特性 的點雲平面區塊。(二)合併相同特性的區塊成為一平面。(三)對於步驟(一)(二)分割合併完後, 屬於非平面區塊的獨立點,以相鄰且是否屬於此平面的判斷方式,擬合到各個平面。(四)對 於所有擬合過的平面,以高度判斷來分離出屬於屋頂面的平面。至於採四分樹法的原因,一 來是因為本研究只針對建物屋頂面的萃取,而不考慮建物牆面,因此,只需用到以二維分割 為基礎的四分樹法,二來四分樹的結構較八分樹簡單,不論在資料的儲存及分析上都較簡便。
二.研究方法
2.1 四分樹法分割共面的點雲區塊 對於本研究中採用的四分樹法,並不著重在對點雲資料的結構化,只是利用四分樹的特 性,將不規則分佈的資料集,以特定的條件,分割出相同特性的資料集,然後給予每個資料 集不同的編碼。首先,對原始點資料進行四分樹分割,然後對分出的區塊中所有的點,以最 小自乘法進行平差,此法必須針對大於三個點的區塊。若小於或等於三個點時,剛好可構成 一平面或無法構成平面,而無法平差,因此將這些點暫定為獨立點(編碼為0),並中止四分樹 分割。至於可進行平差的區塊,其平差方法如下: 假設三維空間中的平面方程式: z = Ax + By + C (1) 其中x、y、z三個變數代表點在空間中的座標,A、B、C為平面參數。 任一點(Xi,Yi,Zi)和對應平面位置的高(zi = AXi + BYi + C)之差: i i i i Z z v H = − = ∆ (2) 利用間接觀測平差法,n個點(Xi,Yi,Zi)可產生n組觀測方程式,根據最小二乘法,假設觀測量等權,在 i n 1 i iv v
∑
= 為最小時,可解的未知參數A、B、C。觀測方程式的係數矩陣、未知 數矩陣、觀測值矩陣和殘差矩陣分別為A、X、L、V。 則 = = = = n n n n v v v v V z z z z L C B A X y y x x y x y x A M M M M M 3 2 1 3 2 1 3 3 2 2 1 1 , , , 1 1 1 1 (3) 利用最小自乘法原理:QVTV →min∴X =(ATA)−1(ATL) (4) 如此解算得到擬合平面的三個平面方程式參數,代回(1)式並計算此平面的參考標準偏差 (也可以說是單位權的中誤差): u n WV V S T − = 0 (5) 在此得到的參考標準差,即為區塊是否繼續分割下去的依據,根據空載LIDAR的地面掃描平 均高程精度,大約是0.15公尺,因此,當擬合平面的參考標準差小於0.15公尺時,即可中止 此區塊的分割,其他的區塊也依照此方式分到上述的兩個條件為止,分別是: (1) 區塊內的點個數小於等於3個。 (2) 平面擬合後的參考標準差(中誤差)小於0.15公尺。 2.2 合併同性質平面 四分樹分割完成後,每一個判斷為平面的區塊都會有一組獨立的編碼,但在這群區塊 中,在空間上可能分別屬於不同平面,例如某一群區塊是屬於屋頂面,而某一群區塊屬於地 表面,此時,可用平面之間的夾角及相鄰性來判斷,區分出屬於同一平面的區塊,並重新編 碼,實作方法如下: (一) 以平面夾角判斷合併區塊: 首先,搜尋最大區塊作為後續判斷的種子,所謂最大區塊為內含最多的點個數,以表一 說明,如以區塊B為起始種子,接著以A、C、D、E分別和B計算兩兩平面之間的夾角,以A、 B為例: A的平面方程式為:A1x+B1y+C1 =z (6) B的平面方程式為:A2x+B2y+C2 =z (7) 則夾角 ) 1 1 1 ( cos 2 2 2 2 2 1 2 1 2 1 2 1 1 + + ⋅ + + + + = − B A B A B B A A θ ,(0o ≤θ ≤90o) (8) 若夾角小於一設定的臨界值( o 3 ),則將A初步判為和B是同一平面,並且將A、B重新編 碼為1,以B為種子和所有平面比對完畢後,根據表(二)的假設,可得A、E兩區塊符合角度條 件,則A、B、E的編碼重新定義為1,表示說A、B、E三區塊為同一平面,而剩下的區塊C、 D則繼續以上述方式合併同性質區塊,直到所有區合併完畢才中止判斷。表(一)中的新編碼欄位為夾角判斷後的結果。 表(一)以交角合併說明例表 表(二)與區塊B的夾角 區塊名稱 點個數 四分樹編碼 新編碼 區塊名稱 夾角(度) A 40 1 1 A 2.5 B 50 2 1 B 0 C 45 3 2 C 35.3 D 30 4 2 D 37.9 E 25 5 1 E 1.3 (二) 分離不相鄰區塊: 執行角度判斷後,會產生兩個問題: (1) 在空間中兩個明顯分離的平面,卻被判斷為相同平面,這是因為這兩平面在空間中 的法向量非常相近。 (2) 四分樹分割之後由於許多區塊過小,區塊小代表內部的點較少,因此在擬合平面後, 得到的法向量也會有較大的偏差,導致角度的判斷易大於臨界值,而產生許多零散 的平面。根據多組資料實驗的結果,這些零散平面的點個數介於3~100之間,而在 屋頂面萃取完成後,會繼續存在,使得平面誤判。 針對第二個問題,因為在後續動作,只需取一些代表性的大區塊來判斷即可,因此必須 排除點數少於100的區塊,並把這些區塊內的點群編碼為0,即視為獨立點。至於第一個問題, 也是這部份要討論的重點,解決的辦法如副標題,為分離不相鄰區塊,可再度採用區域成長 法的概念,所謂區域成長法為在相同編碼的區塊群中,搜尋一個最大的區塊(內包點數最多) 作為區域成長的種子,以此區塊往外擴展一公尺來判斷相同編碼的區塊,其四個角點是否在 此範圍內,若是則代表相鄰並合併之,第一次合併完後會得到一個較大的區塊,再以此區塊 繼續合併剩餘的區塊(相同編碼),直到無區塊相鄰為止,即可停止合併。此時,若還有剩餘 的區塊,即將其視為另一個區塊群,再從這群區塊中搜尋最大的區塊作為區域成長的種子, 並重複上述步驟,直到成長完所有平面為止。 對於重新編碼後的所有平面,必須再進行一次平面擬合的動作,即依據式(1)~式(5),計 算每個新平面的平面參數和擬合的中誤差,作為後續獨立點(編碼0)合併之用。 2.3 擬合獨立點到平面 合併相同性質的平面後,主要的屋頂面和地表面已初步成形,但絕不是完整的平面,因 為在目前定義為非平面的點(獨立點)中,仍有很多是屬於平面的點,因此,接下來的步驟就 是將這些屬於平面的獨立點擬合到平面,而判斷的條件分別為相鄰性和高度,這兩個條件必 須同時符合才進行合併的動作,實作步驟如下,並參照圖(一)的圖示說明: (1) 先選編碼最小的平面開始,如2.1節所述,對所有點進行擬合的動作,以計算平面參 數並確立平面範圍。 (2) 如圖(一),紫色的點代表此平面的點群,粉紅色的點則為獨立點,以此平面的範圍往 外擴展一公尺,搜尋拓展範圍內的點。 (3) 對於在拓展範圍內的點群做高度的比對,比對的方式如下:
將點的二維座標(Xi,Yi)代入此平面方程式,可得一高程值zi,將此高程值zi 與原本 點的高程值Z 相減,可得平面和點之間的高程差,再以此高程差與平面擬合的中誤i 差做比對,若高程差小於三倍中誤差,此點即可納入與之比對的平面,所謂的納入, 就是將點的編碼重新定義為與平面的編碼相同,並重新確立平面範圍。 (4) 由重新確立的平面範圍,往外持續拓展1公尺(如圖(一)所示),搜尋可能屬於平面的 點,若擴張到某一範圍時,已無任何點可納入平面時,則停止擴張。到此,平面的 樣貌可算是完整的呈現。 (5) 繼續對其他平面(另一組編碼)重複上述步驟(1)~(4),直到擬合完所有平面。 圖(一)擬合獨立點到平面圖示說明 - 2.4 依高度判斷屋頂面 雖然在2.3節的結果中,已找到LIDAR點雲的平面資訊,但本研究的目的為萃取屋頂面, 因此,還必須對此結果做最後的高度判斷,判斷的步驟如下: (1) 先計算每一平面的平均高程。 (2) 找出高程平均值最小的平面,將其視為地面高程。 (3) 將其他平面和地面高程比較,若相減大於三公尺,則將其歸為屋頂面。
三.實作成果與分析
本測試例擷取自行政院農委會於 2002 年 4 月 14 日對新竹地區進行掃描的空載光達資料, 使用的光達掃描儀器為 LHALS40,掃描時航高約 800 公尺、視角 35 度,經過濾除多重反射 (multiple echoes)訊號之前處理,只取最表面之點雲資料,其點密度約為 0.5p/m2,並根據空 載雷射掃瞄數具精度評估程序之研究[史天元,彭淼祥,2003],本試驗將平面擬合中誤差的 臨界值(σ0)設定為 0.15m。 圖(二)為double_roof範例點雲的高程資料,圖(三)為double_roof範例點雲進行四分樹分割 的結果,圖(三)和之後所有的圖例中,紫紅色的點都代表獨立點。 圖(三)為平面角度判斷合併結果,在研究方法中探討的兩個問題可以在圖(三)中觀察 到,以紅色點雲為例,原本兩大平面的編碼假定皆設定為3,但經過相鄰性判斷後,就可以 分出3和4兩組編碼,代表他們是不同平面。分離和排除小區塊的結果從圖(四)可以明顯的看 出。圖(四)的結果,主要的屋頂面和地表面已初步成形,但絕不是完整的平面,在紫紅色的 單獨點群中,仍有很多是屬於平面,因此必須對這些單獨點群和平面進行擬合的動作。圖(五) 為擬合後的結果,可明顯看出比圖(四)的平面完整。 圖(六)為從圖(五)中,根據高度判斷取出的平面,到此算是完成所有屋頂面的萃取。除 了對double_roof點雲資料作測試外,在此試驗了另一組點雲資料,名為single_roof,圖(七) 為其俯視圖,圖(八)為萃取出的屋頂面的萃取成果。 圖(二) double_roof俯視圖(不同顏色代 表不同高度) 圖(三) double_roof四分樹分割的結果圖 示 圖(三) double_roof平面角度判斷合併 結果 圖(四) double_roof相鄰性判斷分離結果
圖(五) double_roof所有平面萃取的成果 圖(六) double_roof屋頂面萃取的成果 圖(七)single_roof俯視圖 圖(八) single_roof屋頂面的萃取成果
四.問題探討
(1) 以double_roof的結果來分析,圖(六)中的屋脊線有鋸齒狀現象,可能原因是屋頂面相交 的角度過小,導致在一開始的四分樹分割時,某些區塊容易越界,使得屋頂面交接處不 完整。圖(九)和圖(十)是另一組點雲資料的測試例,為這類問題的明顯例子。從這組點 雲資料可看出,圖(十)中屋頂面交接處的鋸齒狀十分明顯,而從圖(九)的剖面圖可看出 原因所在,就是屋脊線過於平坦。對於這個問題的初步解決想法為,先利用兩屋頂面交 會出屋脊線,再利用此交會出的線段,將其左右兩旁的點重新編碼,也就是說,假設某 點應該屬於線段右方的面,但卻出現在線段左方,就可將其編碼定義為與右方點群相 同,當判斷完所有的點,就不會有鋸齒狀的現象。但是這條屋脊線是否達到可接受的精 度範圍,會在後續的研究中加以探討。圖(九)剖面圖 圖(十)萃取結果 (2) 同樣是以double_roof的結果來分析,圖(六)中,呈現青綠色的點,除了包含正確的屋頂 面外(如圖六(A)所示),在黃色點群附近也有少數散點存在(如圖六(B)所示),這些散點 很明顯不屬於屋頂面,應該被排除。解決的辦法可針對每一塊平面,去判斷每一塊平面 中點群的相鄰性,並配合航空影像等資料輔助判斷,如此應可區分出正確及不正確的平 面,通常點數包含最多的面為正確的平面,因此,只要把點數較少的平面排除即可。
![圖 2 第二組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右) 圖 3 第三組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右) 圖 4 第四組原始光達資料俯視圖(左)和原始資料建構的 2D Delaunay TIN 三角網(右) 3-1、光達點雲資料中點、線、面特徵的分類與萃取 由李宏君和邱式鴻[2005]的分析過程中得知多形態特徵萃取法應用於光達資料特徵萃 取時,首先罩窗(filter)的選擇便是一個問題。由於影像是](https://thumb-ap.123doks.com/thumbv2/9libinfo/7281100.70963/6.892.133.675.112.377/料建構料建構俯視圖左和原始資料建構三角面特徵式鴻萃取法應用於.webp)
![圖 9 左圖:第三組資料分類後之非共面的點雲資料;右圖:不規則三角網建置成果 圖 10 左圖:第四組資料分類後之非共面的點雲資料;右圖:不規則三角網建置成果 3-3、以空間共面特徵進一步發展結構化的演算法 由上述圖 7 至圖 10 中雖然仍有分類時所分析的缺點,然而亦發現共面資料較適合用來 進行點雲資料的結構化,因此在本研究中亦嘗試以四分樹及類似區域成長概念[邱煥智和邱 式鴻, 2005]來進行光達點雲資料中共面點結構化的工作,達到結構化的目標,以下試驗中就 共面特徵提出結構化的方法但不再對結構化後](https://thumb-ap.123doks.com/thumbv2/9libinfo/7281100.70963/11.892.131.764.134.428/非共面非共面進一步發展此在亦嘗試以四分樹及類似區域成長概念.webp)
