動漫魔鏡:運用圖文關聯探勘的動漫網站搜索引擎 - 政大學術集成
58
0
0
全文
(2) 動漫魔鏡:運用圖文關聯探勘的 動漫網站搜索引擎 Comirror: A Search Engine for Comic Web Based on Textual and Visual Correlation Mining 研 究 生:孫世通. Student:Shi-Tong Sun. 指導教授:沈錳坤. Advisor:Man-Kwan Shan. 資訊科學系. 學. ‧ 國. 立. 政 治 大 國立政治大學 碩士論文. ‧ er. io. sit. y. Nat. A Thesis. n. a lDepartment of Computer Submitted to i v Science n U i National Chengchi e n g c hUniversity. Ch. in Partial Fulfillment of the Requirements for the Degree of Master in Computer Science. 中華民國一零二年十月 October 2013.
(3) 摘要. 近年來,動漫(動畫、漫畫與線上遊戲)越來越受歡迎。全球資訊網也陸續出現 收集大量包括故事情節、動漫角色、作者等動漫相關資訊的動漫網站。多數動 漫網站都提供使用者文字檢索的功能,以搜尋動漫網站文字內容。但是動站網 站若能提供根據文字與圖形風格來搜尋圖文內容,對於動漫使用者而言,將更. 政 治 大. 為方便。圖文風格可能是漫畫人物的繪畫風格、動畫故事的敘事風格等等。. 立. 為了方便使用者以圖文風格進行搜尋相關資訊,本論文根據動漫關連探勘. ‧ 國. 學. 技術,研究並開發一個動漫網站的搜尋引擎:動漫魔鏡,以提供使用者根據圖 文關連來搜尋動漫網站中風格相似的動漫資訊。本論文的搜索方法關聯了圖像. ‧. 特徵和文字特徵。首先,針對圖像特徵,由於動漫角色是動漫的靈魂,因此經. y. Nat. al. er. io. sit. 過動漫臉部偵測後,我們以電腦視覺中的局部二值樣式(Local Binary Pattern,. n. LBP)與灰階值分佈來抽取並表示動漫角色的臉部特徵。針對文字特徵,我們利. Ch. engchi. i n U. v. 用一般全文檢索技術來擷取文字特徵。接著,運用階層式分群技術將文字特徵 與圖像特徵值轉換為文字與圖像關鍵詞。最後,以語意主題模型中的隱含狄利 克雷分布(Latent Dirichlet Allocation, LDA)分析圖文關鍵詞的潛在語意,並據此 計算動漫網頁之間的相似性。實驗結果顯示本論文所研發的風格搜尋,其效果 優於其他三種基本作法。. 關鍵字:. 動漫網站,搜尋引擎,圖文關連,動漫風格. i.
(4) Abstract. Animations, comics, and games (ACG) have become more and more popular in recent years. There exist many ACG web sites which contain lots of textual and visual information on stories, characters and authors of animations, comics and games. Most ACG web sites provide users text retrieval capability to search for textual contents. However, there is a need for users to search for textual and visual contents by styles. Examples of styles are drawing styles of comic characters, narrative styles of animation stories and so on.. 立. 政 治 大. In order to help users to search for textual and visual contents by similar styles,. ‧ 國. 學. this thesis investigates and develops a search engine, Comirror, for ACG web sites based on latent correlation between textual and visual contents. First, while facial. ‧. styles of characters play important roles in ACG, after comic face detection, Local. y. Nat. Binary Pattern (LBP) along with gray-value histogram is utilized to extract and. sit. represent the visual features. For the textual contents, traditional full-text indexing. n. al. er. io. technique is employed to extract textual features. Then, hierarchical clustering is. i n U. v. performed to quantize and transform the textual and visual features into textual and. Ch. engchi. visual words. Finally, Latent Dirichlet Allocation (LDA) is utilized to discover the latent semantic correlation between visual and textual words. Experiments show that the developed approach performs better than the other baseline approaches.. Keywords: ACG Websites, Search Engines, Correlation Mining, Comic Styles. ii.
(5) 誌謝. 從踏足台灣,步入政大 DMLAB 至今,不知不覺已度過近兩年半的研究生生 活。在即將完成碩士論文之際,特此感謝幫助過我以及默默支持我的師友、親 人們。 在我印象中,沈錳坤教授一直是一位盡職盡力的老師,依照嚴謹求學,多. 政 治 大. 看多想的標準要求著 DMLAB 的每一位學生。是老師引領我們進入研究的大門. 立. ,敦促我們用嚴謹的思維方式對待研究,在不斷學習和實驗的過程中言傳身教. ‧ 國. 學. 不取巧、不懼困難、實事求是的研究態度。在整個碩士論文的撰寫過程中,老 師幫助我把關研究方向,與我探討研究方法,提示我修改並完善實驗設計的思. ‧. 路,是我由衷感謝的一位長者。. y. Nat. al. er. io. sit. 與此同時,我也要感謝 LAB 中的師兄弟們,有幫助我認識台灣風土人情,. n. 幫助我從通訊背景順利轉入資科領域研究的范斯越、林志傑、黃柏堯、賴建成. Ch. engchi. i n U. v. 和戴張戎學長;有陪伴我走過整個研究生涯,探討 paper、研究方法、演算法和 coding 等問題,共進退的好兄弟陳柏聿;再有新進入 DMLAB,卻很快與我們 打成一片,互相學習幫助的蘇翰學長,邱楚翔、徐嘉泰、楊元翰學弟。是你們 讓我感受到台灣友善與積極上進的一面,我發自內心的感激大家。 碩士論文中實驗資訊的收集部份,感謝給我幫助,花費個人時間幫我做測 詴的朋友們:有就讀政大勞工所的陸生朋友潘發鑾,中文所的馬來西亞朋友林 如隆,宗教所的台灣朋友李明傑,東亞所的台灣朋友黃亦鳴,元智大學艺术与 设计學系的徐羽飛,銘傳大學財金學系的李亦晗以及上文提及的我們 DMLAB iii.
(6) 的學長學弟們,正是有了你們的付出,我才得以完成實驗評估的部份。 最後,我無法忘記給與我的最無私、最真摯支持的父母與親友們。不論是 金錢還是精神方面,你們使我更有動力、有勇氣面對每一個困難與挫折。在完 善學業與研究的路途上,我銘記我的每一步都含有你們每一個人的助力。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. iv. i n U. v.
(7) 目錄 中文摘要......................................................................................................................... i 英文摘要........................................................................................................................ii 致謝.............................................................................................................................. iii 目錄................................................................................................................................ v 圖目錄..........................................................................................................................vii. 政 治 大. 表目錄........................................................................................................................... ix. 立. 前言 ............................................................................................................. 1. 第2章. 相關研究 ..................................................................................................... 3. ‧ 國. 學. 第1章. 2.1. 動漫圖像的獨有特性及其特徵區域選取...................................................... 3. ‧. 2.2. 動漫圖像的特徵描述...................................................................................... 5. y. Nat. sit. n. al. er. io. 2.2.1. LBP Descriptor ...................................................................................... 5 2.2.2. SIFT Descriptor ..................................................................................... 6 2.2.3. HOG Descriptor ..................................................................................... 7 2.3. Web Image Retrieval ........................................................................................ 8 第3章. Ch. engchi. i n U. v. 研究方法 ..................................................................................................... 9. 3.1. 動漫圖像特徵................................................................................................ 10 3.1.1. Detection of Comic Face ..................................................................... 10 3.1.2. Representation of Comic Face ............................................................. 14 3.1.3. Facial Word Transformation ................................................................ 17 3.2. 動漫文字特徵................................................................................................ 18 3.2.1. 中文環境下的 Text Segmentation 及 Bag-of-Words .......................... 18 3.3. 圖文整合分析................................................................................................ 20 3.3.1. Feature Combination ............................................................................ 20 3.3.2. Feature Correlation between Image and Text ...................................... 21 第4章. 系統實作 ................................................................................................... 25 v.
(8) 4.1. 資料來源........................................................................................................ 25 4.2. 線下部份實作流程........................................................................................ 26 4.2.1. Comic Face 的訓練與測詴 ................................................................. 26 4.2.2. Facial Word Matrix 的產生 ................................................................. 29 4.2.3. 網頁文字處理...................................................................................... 31 4.2.4. 圖文矩陣 & 網頁相似度 .................................................................... 31 4.3. 網站應用工具及介面.................................................................................... 33. 政 治 大 5.1. 實驗資料來源................................................................................................ 36 立. 第5章. 實驗評估 ................................................................................................... 36. ‧ 國. 學. 5.2. 實驗目的........................................................................................................ 37 5.3. 實驗設計........................................................................................................ 37. ‧. 5.4. 實驗結果........................................................................................................ 38. y. Nat. io. sit. 結論與未來工作 ....................................................................................... 43. er. 第6章. 參考文獻...................................................................................................................... 45. n. al. Ch. engchi. vi. i n U. v.
(9) 圖目錄 圖 2-1 Viola 等人提出的 Haar-like features ......................................................... 5 圖 2-2 LBP 特徵值的提取 .................................................................................... 6 圖 2-3 HOG 流程 ................................................................................................... 8 圖 3-1 基於圖文關聯語義的動漫搜索研究架構 ................................................ 9 圖 3-2 Lienhart 等人提出的 Haar-like features 擴展 ......................................... 11. 政 治 大. 圖 3-3 Viola-Jones Detection Framework 中的 Integral Image 原理 ................. 11. 立. 圖 3-4 Face detection 中的 Cascade AdaBoost 訓練流程 .................................. 12. ‧ 國. 學. 圖 3-5 Facial ROIs Detection .............................................................................. 13 圖 3-6 Facial ROIs 的截取 .................................................................................. 15. ‧. 圖 3-7 Facial ROIs 的分割與 Sub-window 的 LBP 特徵描述 ........................... 15. y. Nat. al. er. io. sit. 圖 3-8 LBP 旋轉不變式的參考點選取 .............................................................. 16. n. 圖 3-9 LBP 旋轉不變式 ...................................................................................... 16. Ch. engchi. i n U. v. 圖 3-10 Agglomerative Hierarchical Clustering .................................................. 18 圖 3-11 中文斷詞前後效果對比......................................................................... 19 圖 3-12 David M. Blei 等人對 PLSA 模型的圖形描述 ..................................... 22 圖 3-13 David M. Blei 等人對 LDA 模型的圖形描述 ...................................... 22 圖 3-14 某一動漫 Topic 的構成模式.................................................................. 24 圖 4-1 基於圖文關聯語義的動漫搜索系統架構 .............................................. 25 圖 4-2 網絡爬蟲抓取邏輯 .................................................................................. 26 圖 4-3 用 multi-model 過濾 Face ROIs ............................................................... 28 vii.
(10) 圖 4-4 Comic Face 的取捨與權重規則 .............................................................. 29 圖 4-5 Face ROIs Clusters 到 Facial Word 的映射 ............................................. 31 圖 4-6 Web Topic Possibility Feature 的顯示效果(局部) ............................. 32 圖 4-7 系統的動漫搜索介面 .............................................................................. 34 圖 4-8 系統的搜索結果返回介面 ...................................................................... 34 圖 4-9 依據圖、文特徵給出推薦 ...................................................................... 35 圖 5-1 排在第 n 名的網頁的評分均值............................................................... 39. 政 治 大 圖 5-3 前 n 個網頁的評分均值對比(動漫本體類別) ................................... 40 立 圖 5-2 前 n 個網頁的評分均值對比................................................................... 39. ‧ 國. 學. 圖 5-4 前 n 個網頁的評分均值對比(動漫元素類別)................................... 40 圖 5-5 前 n 個網頁的評分均值對比(聲優/漫畫家類別) ............................. 41. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. viii. i n U. v.
(11) 表目錄 表 2-1 SIFT、PCA-SIFT、SURF 優劣比較 ........................................................ 7 表 3-1 TP, TN, FP, FN 在 Face Detection 的意涵 ............................................... 12 表 4-1 Face ROIs detection model 的評估 .......................................................... 28 表 5-1 網頁、圖像的數量統計 .......................................................................... 36 表 5-2 實驗中 17 個動漫種子網頁種子類別的劃分......................................... 38. 政 治 大. 表 5-3 四種評估方法在不同類別的種子網頁前提下的 DCG 表現 ................ 41. 立. 表 5-4 四種評估方法在不同類別的種子網頁前提下的 NDCG 表現 ............. 41. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. ix. i n U. v.
(12) 第1章. 前言. 動漫產業鏈,包含有動畫(anime)、漫畫(comic)、遊戲(game)及其相關產 業,在近年來有著難以估量的活力與影響力。以日本動漫[30]為例,日本動漫 的觀眾(讀者)包含了所有的年齡層,題材非常廣泛,正因如此,數十年來一 直保持了很高的動漫品質和產量;而中國大陸也在近些年開始大力發展動漫產. 政 治 大. 業,其全國動畫作品時長也以每年 20%的奇跡般的速度增長;此外全世界遊戲. 立. 的產量也一直都是居高不下,隨著製作數位化、視覺 3D 化、網路遊戲的發展. ‧ 國. 學. 將成為趨勢,遊戲業的火熱程度或許還將一直延續下去。在此大前提下,給人. ‧. 們搜索並瞭解動漫、遊戲帶來了三點新的挑戰。. Nat. sit. y. 首先,全世界動畫、漫畫、遊戲的年產量將非常巨大,這將使得當使用者. n. al. er. io. 想在動漫網站依據動漫風格尋找一部相似的動漫時,要花費大量時間。因為風. i n U. v. 格很難用文字確切描述,檢索時需要使用者自己逐一去評估。. Ch. engchi. 其次,華語區現有的動漫檢索方式通常可分爲三類,其一為各大搜尋引 擎,其二爲各類中英文百科,其三爲形形色色的動漫觀看網站;然而以上三者 在動漫搜索用戶體驗方面,都有著各自的不足之處:1)搜尋引擎的資源包羅萬 象,使得搜索的結果會夾雜不少無關動漫的內容 ,不可能全與動漫主題相關。 2)Wikipedia 爲代表的百科類搜索網站,根據檢索關鍵字(query)直接返回系 統認為最正確的結果,只有在系統無法判斷時才會將可能的結果羅列出來,請 使用者自行選擇。但當使用者無法用關鍵字來確切描述自己想要的動漫時,搜. 1.
(13) 索過程或許就並不十分高效了。3)動漫觀看網站,或許是明確知曉想要觀看哪 一部作品的動漫愛好者們的最愛;但當使用者陷入漫畫荒,想要找一部新的但 又無從找起時,只能從候選作品中逐一篩選,直到找到喜歡的作品爲止;這是 最花費時間的一種做法。 最後,人物是動漫的靈魂,談及某部動漫的畫風,首先映入腦海的是動漫 角色肖像;而文字賦予靈魂骨肉,將故事、細節講述清楚。因此有必要結合動 漫人臉和文字介紹的特徵來表述動漫元素(動漫角色、動漫情節等),並分析兩. 政 治 大 本研究的目的在於設計一個動漫主題的、基於網頁圖文相似性推薦的、向 立. 種特徵之間的關聯性,以期對動漫整體作出更適合的詮釋與描述。. ‧ 國. 學. 使用者展示動漫簡介的搜索引擎,而該搜索引擎的主要特色在於同時考慮了圖 文特徵之間關聯性以及動漫百科網頁之間的圖文潛在語義。當使用者想要檢索. ‧. 動漫時;此時可通過該搜索引擎進行 Two-Stage Search。User 下文字方面的. y. Nat. er. io. sit. query,系統返回檢索的結果作為候選動漫種子網頁。此時 User 確定心目中的 動漫種子網頁,系統依據動漫風格相似性給出最終的搜索結果。. n. al. Ch. engchi. 2. i n U. v.
(14) 第2章. 相關研究. 目前有關動漫的研究大多是基於動漫內容的,譬如手繪漫畫中 copy 現象的偵 測,相似漫畫作品的查詢等。這些研究大多包含兩個基本步驟,1)從動漫相關 的圖像中找出含有動漫圖像特性的區域,2)將動漫圖像的特性區域用特徵表. 政 治 大 站檢索的研究。目前有關動漫的研究中,Weihan Sun 等人提出的相似手繪漫畫 立 示。但現有的有關動漫的研究中,卻並沒有特別針對動漫的風格來進行動漫網. ‧ 國. 學. 的查詢[24],與本研究有著較強的相關性。. 而在網路圖像檢索(Web Image Retrieval, WIR)的領域,較經典的有 1998. ‧. 年 M. La Cascia 等人[11]以及 2007 年 S. Tollari 等人[25]的研究。他們考慮了結. y. Nat. 著不同的特質,其方法卻不一定適用於動漫領域。. n. al. Ch. engchi. er. io. sit. 合圖像與文字的一般特徵進行分析,但鑒於動漫網站的圖像相較于一般圖像有. i n U. v. 2.1. 動漫圖像的獨有特性及其特徵區域選取 動漫圖像不同於一般圖像,它有著自己的特性,往往並不非常嚴謹地根據透視 原理等物理規則來實際描繪景物。再說動漫人物,不同動漫的創作者通常有著 迥然不同的繪畫風格,而且他們筆下的動漫人物有的甚至與現實中的人物,照 片中的人物,素描、速寫等通常意義下的繪畫方法中的人物的有着全然不同的 表現手法。因此,為了進行動漫圖片之間的對比,我們需要根據動漫圖片的特 殊性來考慮分析、處理的方法。 3.
(15) 現有的分析處理圖像的方法中,通常以從圖像中的重點區域抽取特徵向量 的方式為主。Weihan Sun 等人也在關於線條為主的手繪動漫圖像相似度比對的 論文中印證了該觀點同樣適用與動漫圖像分析的領域,理由是鑒於動漫的數量 非常之巨大,無論是資料庫存儲的空間複雜度、亦或是特徵運算的時間見複雜 度都使得全圖分析成為不易實現的分析方法[23]。因此,在動漫圖像分析的過 程中,第一步要做的就是偵測出動漫圖像中的重點區域 ,這涉及到物件偵測 (Object Detection)方面相關的研究,常見的有關物件偵測的研究有人臉偵. 政 治 大 Detection Framework[26]把人的臉部當作 Regions of Interest(ROIs)來偵測也被 立. 測,行人偵測,機動車輛偵測[5, 27, 21]等;此外,Viola 等人提出的 Viola-Jones. ‧ 國. 學. 證明有著不俗的表現。. 在最近的研究中[23],Weihan Sun 等人認為在手繪的線條為主的動漫圖像. ‧. 中,較重要的物件包括動漫人臉和整幅圖像中一些邊界較明顯的部份。其中關. y. Nat. er. io. sit. 於動漫人臉部份的偵測,他們通過實踐檢驗了 Viola-Jones Detection Framework 應用在漫畫領域的可行性,該 Framework 應用了 Haar-like Features。如圖 2-1 所. al. n. v i n Ch 示,Haar-like features 通過檢測視窗在待測圖片上滑動並計算出各區域的特徵 engchi U. 值,然後用訓練好的級聯分類器進行篩選,一旦該特徵通過了所有弱分類器的 篩選,則判定該區域為人臉。在關於動漫圖像的研究中,則可以通過使用 Viola-Jones Detection Framework,從整張動漫圖像中確定較為重要的人臉區 域,在 Weihan Sun 等人的研究中,他們稱這些被偵測出來的人臉區域為 face ROIs。由此得以進一步從 Facial ROIs 中提取出描述這些人臉區域的特徵向量。. 4.
(16) 圖 2-1 Viola 等人提出的 Haar-like features. 2.2. 動漫圖像的特徵描述. 政 治 大. 在確定了分析的主體區域後,需要對目標區域提取特徵值或者特徵向量。目前. 立. 有關圖像特徵向量提取的較主流、成熟的研究有 T. Ojala 等人在 1994 年提出的. ‧ 國. 學. LBP(Local Binary Pattern)[16, 17]及之後被陸續提出的一系列 LBP 變形等,. ‧. David Lowe 在 1999 年提出並於 2004 年進行了改良和完善的 SIFT (Scale-. sit. y. Nat. invariant feature transform)[13, 14] 以及 N. Dalal 等人在 2005 年提出的 HOG. io. n. al. er. (Histograms of Oriented Gradients)[5]。. 2.2.1. LBP Descriptor. Ch. engchi. i n U. v. LBP 是一種描述圖像局部紋理特徵的 descriptor,它具有局部光照不變性的優 勢。LBP 應用廣泛,在指紋識別、人臉識別、脣語識別、表情檢測、車牌識別 等領域有着不錯的表現。其基本原理則如圖 2-2 所示,是通過待測像素點與周 圍 8 個像素的值比較大小,從而確定周圍像素點的二進制數值(0 或 1),並以 統一的順序排列成串,最後轉換成十進制數得到。在圖 2-2 中,3*3 的圖像區域 中,灰度值爲 136 的點最後計算得到的 LBP 值爲 199,我們可以觀察到該方法 只關心被檢測像素與周圍像素的值的強弱,而不關心其強弱的差值,這樣的紋 5.
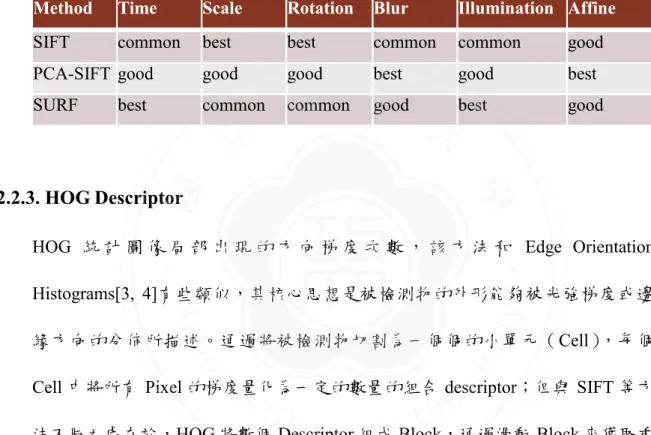
(17) 理表示法對於光線變化較不敏感,但是對於雜訊卻會比較敏感。推及動漫網頁 中的圖像,這些圖像在網路上流傳,往往會被不同的使用者保存為不同的顏色 格式(RGB,CYMK 等),容易出現一定程度的顏色微弱變化(相當於明暗的 變化),此時 LBP 對光線變化較不敏感的特性就能夠確保將這類動漫圖像重新 識別爲同一張。. 立. 政 治 大. ‧. ‧ 國. 學. 圖 2-2 LBP 特徵值的提取. 2.2.2. SIFT Descriptor. sit. y. Nat. io. al. er. SIFT 可以處理兩幅圖像之間發生平移、旋轉、仿射變換情況下的匹配問題,具. v. n. 有很強的圖形匹配能力。在 Mikolajczyk[15]對包括 SIFT 在內的十種 local. Ch. engchi. i n U. descriptors 所做的不變性對比實驗中,SIFT 及其擴展演算法已被證實在同類描 述子中具有最強的健壯性。由此可見 SIFT 適用性非常廣泛。總體而言,SIFT 同時具備以下優點:1)穩定性好;2)多量性(幾個 object 即可產生大量 SIFT 特徵向量),3)可擴展性強(方便與其他形式的特徵向量結合)等。. 相較於 SIFT 因其龐大計算量不用與行人檢測而言,Yan Ke 等人在 2004 年 提出的 PCA-SIFT[10]過濾了較多維資訊而只保留了 20 個主分量, 因此 PCASIFT 較適用于行為變化不大的物體檢測。而另一種方法,H. Bay 等人於 2006. 6.
(18) 年提出的 SURF[1],基於 integral image,利用 determination of Hessian matrix 來 描述極值點(可能的特徵點)來表述被檢測物。Luo Juan 等人對這三種演算法 (SIFT,PCA-SIFT,SURF)進行了實驗比較[9],闡述了各自的優劣如表 2-1 所示。 表 2-1 SIFT、PCA-SIFT、SURF 優劣比較 Method. Time. Scale. Rotation. Blur. Illumination Affine. SIFT. common. best. best. common. common. good. PCA-SIFT good. good. good. best. good. best. SURF. common. best. 立. common 治 good best 政 大. good. ‧ 國. 學. 2.2.3. HOG Descriptor. ‧. HOG 統 計 圖 像 局 部 出 現 的 方 向 梯 度 次 數 , 該 方 法 和 Edge Orientation. sit. y. Nat. Histograms[3, 4]有些類似,其核心思想是被檢測物的外形能夠被光強梯度或邊. io. al. er. 緣方向的分佈所描述。通過將被檢測物切割為一個個的小單元(Cell),每個. v. n. Cell 中將所有 Pixel 的梯度量化為一定的數量的組合 descriptor;但與 SIFT 等方. Ch. engchi. i n U. 法不同之處在於,HOG 將數個 Descriptor 組成 Block,通過滑動 Block 來獲取重 疊的區域特徵向量;最後把區域特徵向量組合為全域特徵向量用以表示被檢測 物的整體特徵。圖 2-3 中的流程通過 HOG 的組合 descriptor 得以保持了被檢測 物的幾何和光學轉化不變性(除非物體方向改變)。因此 HOG 描述子尤其適合 人的檢測,而在 Weihan Sun 等人關於線條為主的手繪動漫圖像相似度比對的研 究中,也正是使用了 HOG 特徵來對 face ROIs 進行描述的。. 7.
(19) 圖 2-3 HOG 流程. 2.3. Web Image Retrieval. 立. 政 治 大. Web Image Retrieval 是一個專門針對網路圖像檢索的研究領域。在該領域中,. 學. ‧ 國. M. La Cascia 等人[11]於 1998 年曾提出一種結合將網路上的圖像資訊和文字資 訊的分析方式。在 M. La Cascia 等人的研究中,文字資訊以 textual statistics 的. ‧. 形式表述,而圖像資訊則使用顏色和方向直方圖(orientation histograms)來表. y. Nat. al. er. io. sit. 述。他們通過潛在語義分析(Latent Semantic Indexing, LSI)[6]的方式,計算得. n. 到圖像與圖像之間的相似度,最終實現網路圖像檢索的目的。. Ch. engchi. i n U. v. 類似的研究還有 S. Tollari 等人在 2007 年發表的的研究[25]。該研究同樣是 通過結合文字與圖像特徵,以實現檢索網路圖像的目的。但相比 M. La Cascia 等人的研究,S. Tollari 等人的不同之處在於圖像特徵的部份。他們提出了一種 Subband Entropy Profile Visual Feature,並通過引入權重的方式,來調節融合 (fusion)之後的特徵中文字部份與圖像部份的重要性。 但在有關 Web Image Retrieval 的研究中,並無特別針對動漫網站來進行分 析的先例,因此這類研究的研究方法並無特別針對動漫的特性去設計。. 8.
(20) 第3章. 研究方法. 有別於主流的動漫研究的客體,本研將究著眼于“介紹動漫的網頁”之搜索與推 薦。我們考慮將介紹動漫的網頁中,動漫人物的影像特徵,結合動漫文章的文 字特徵,做關連分析;進而提供基於動漫風格(畫風+文風)的檢索功能。如圖 3-1 所示,我們的研究方法(Off-Line)將基於動漫圖像特徵與動漫文字特徵兩. 政 治 大 條主線分別進行,並在最後將兩類特徵統和分析。 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-1 基於圖文關聯語義的動漫搜索研究架構. 在圖像特徵部份主要包含:1)Comic Face Detection 模組,該模組主要從 動漫圖像中偵測出動漫人臉的區域,2)Comic Face Feature Extraction 模組,該 模組將人臉區域用合適的特徵向量表示, 3)形成 Facial Word Feature 的模組, 該模組將形成能夠描述網頁整體文字特徵的特徵向量;在文字特徵部份則主要 包括:1)文字的斷詞模組,2)利用 Bag-of-Words 模型形成 Textual Word 9.
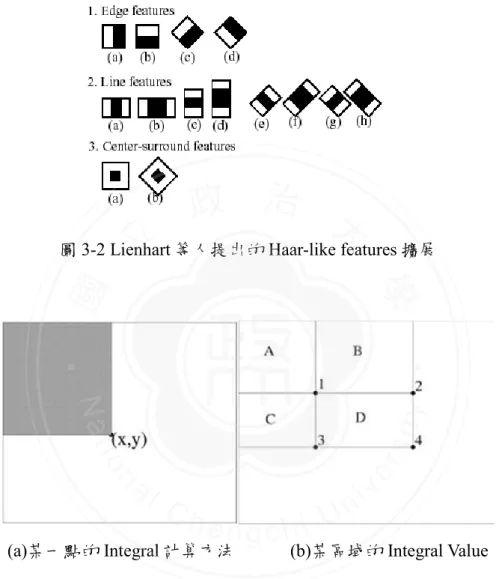
(21) Feature 的模組;最後,在統合分析的部份則還有潛在語義分析模組(LDA),該 模組考慮如何將文字與圖像特徵進行合併,並且對合併後的新的圖文特徵向量 進行分析,找出動漫介紹網頁中圖和文字所隱含的潛在關聯特性。. 3.1. 動漫圖像特徵 由於是研究網頁的檢索,考慮到網頁的呈現方式是以文字居多,所以我們首先 需要探討,關於動漫主題的網頁中,圖像所具備的特殊性,以及動漫圖像中人. 政 治 大. 物所不可替代的重要性。動漫主題的網頁有別與其他網頁的一個顯著的特質就. 立. 是包含有大量與動漫主題相關的圖片,可以說對動漫的分析往往和對圖像的分. ‧ 國. 學. 析是不可分割的。而動漫人物又在大多數動漫圖像中佔據了絕對主體的地位。. ‧. 爲此我們設計了簡單的統計分析的實驗,從 269671 張圖像庫(包含少量動漫無. sit. y. Nat. 關的雜質)中隨機抽取 2000 張圖像,發現其中無角色存在的圖像(動漫環境,. n. al. er. io. 雜質圖等)有 97 張,佔總數的 4.85%;其中含有非人形角色(擬人形的動物,. i n U. v. 機器人,怪物類等)有 134 張,佔總數的 6.7%;即使把這兩部分合併,網路上. Ch. engchi. 收集的動漫圖像中含有人形角色的比例依然高達 88.45%,由此印證了分析動漫 圖像中的人臉特徵,並獲取這些特徵向量的重要性。. 3.1.1. Detection of Comic Face 由於把動漫人臉特徵作爲重要的描述特徵之一,因此需要對圖像進行 Comic Face Detection 並提取特徵,我們把被提取的動漫人臉區域稱爲 Comic Face。 Haar-like features 是 在 物 件 偵 測 中 應 用 廣 泛 , 效 果 優 秀 的 一 種 特 徵 , Face Detection 就是其效果優良的領域之一。而爲了使該特徵更有效,Lienhart 等人 10.
(22) 又 提 出 了 Haar-like Features 的 一 系 列 擴 展 [12] 。 由 圖 3-2 可 知 , Haar-like Features 由按比例縮放尺寸的黑白矩形框組成,而某類 Feature 的值則是該 Feature 中白色區域值的和減去黑色區域的和。. 立. 政 治 大. 圖 3-2 Lienhart 等人提出的 Haar-like features 擴展. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. (b)某區域的 Integral Value. (a)某一點的 Integral 計算方法. 圖 3-3 Viola-Jones Detection Framework 中的 Integral Image 原理. 然而這樣的計算方式將使得得計算量非常巨大。以一個 20*20 像素的待測 圖像爲例,僅圖 3-2 的類別 1 的(a)特徵,其特徵向量的維度將高達 21000 維, 若合併所有類別的特徵向量後,其維度更是可怕。Viola 等人在 Viola-Jones detection Framework[26]中提出 Integral Image 的概念,使得計算量得以減少。假 11.
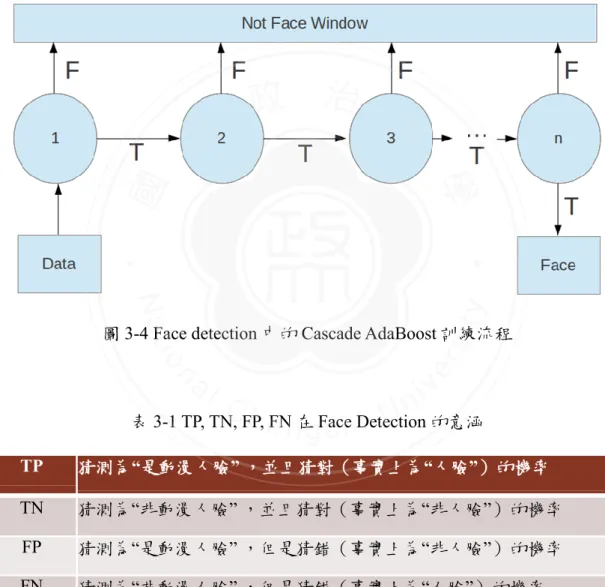
(23) 設我們有一點 P 座標爲(x,y),現在用 S(P)表示圖像中該點左上方像素值之和, 如圖 3-3(a)中灰色區域,則一張圖中任意矩形區域的 Haar-like Feature 值都可以 被近似積分的形式表示出來。以圖 3-3 (b)中的區域 D 爲例,則該區域的面積 Area(D)可以表示為: Area(D) = S(4) – S(3) – S(2) + S(1). 立. 政 治 大. ‧. ‧ 國. 學 sit. y. Nat. io. n. al. er. 圖 3-4 Face detection 中的 Cascade AdaBoost 訓練流程. Ch. engchi. i n U. v. 表 3-1 TP, TN, FP, FN 在 Face Detection 的意涵 TP. 猜測為“是動漫人臉” ,並且猜對(事實上為“人臉”)的機率. TN. 猜測為“非動漫人臉” ,並且猜對(事實上為“非人臉”)的機率. FP. 猜測為“是動漫人臉” ,但是猜錯(事實上為“非人臉”)的機率. FN. 猜測為“非動漫人臉” ,但是猜錯(事實上為“人臉”)的機率. 這種利用先前計算過的值來獲取之後需要計算的值的方式,使得許多重複計算 的部分得以省略,極大提高了 Haar-like Features 的實用性。然而加快的計算速 度並沒有減少特徵的數量,爲了選取合適的特徵來描述,Viola 等人引入了 12.
(24) Cascade AdaBoost Learning Procedure,這是一種用弱分類器組合成強分類器, 並將強分類器級聯起來進行訓練的過程,我們把該訓練過程描述在圖 3-4 中。. 爲了方便說明,我們定義 TP(True Positive)、TN(True Negative)、FP(False Positive)、FN(False Negative)的含義如. 表 3-1 所示。則對於圖 3-4 中的每個 Stage 而言,分類器將從正負樣本總集合中 抽出部分來進行訓練,且儘可能使得該分類器能獲得較低的 FN,但在多個. 政 治 大. Stage 級聯後,最終形成的強分類器仍然能有不錯的表現。舉例而言,假設每個. 立. stage 中,FN = 0.001,FP = 0.6,則在 20 個 stage 後,仍然有 TN = 1 - 0.620 ≈. ‧ 國. 學. 0.99,而 TP = (1-0.001)20 ≈ 0.98。最後把所有的圖像用訓練得到的 Model 來進行. ‧. 測詴,從而完成 Comic Face Detection,其結果如圖 3-5 所示。. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. 圖 3-5 Facial ROIs Detection. 13. v.
(25) 3.1.2. Representation of Comic Face 在 Weihan Sun 等人的研究中,驗證了對手繪動漫人臉進行特徵提取時,HOG 特徵相較與 SIFT 特徵具有較優的表現[22],然而本研究所獲取的 data 多數來源 於動漫海報、漫畫封面、動畫截圖,這些圖像的特質與一般手繪(Line Drawings) 漫畫有以下顯著區別,1)相較與一般手繪的黑白線條的表現手法,這些圖像用 色豐富,輪廓處用顏色的過渡來代替線條的勾勒;2)部分遊戲截圖、3D 動畫 更是立體感強烈,在某種程度上更接近現實中人物的比例與特質,與手繪的平. 政 治 大 時,沒有參考文獻論證是否適用於這類動漫圖像。而 T. Gritti 等人的研究中[7] 立. 面質感截然不同。這使得用 HOG 特徵來描述這類圖像中截取的 Comic Face. ‧ 國. 學. 比較了多種特徵描述方法在人臉識別領域的測詴結果,並驗證了在該領域下, 通常 LBP 特徵相較與 HOG 具有更優的表現。此外,考慮到 LBP 表現了圖像的. ‧. 紋理特徵,即圖像中變化強烈的部份;但動漫的風格在某種程度上也受到明暗. y. Nat. er. io. sit. 分佈的影響,因此我們考慮引入 Gray 特徵來描述明暗分佈的特徵,用以彌補 LBP 特徵的局限性,實現兩種特徵的優勢互補。最後,我們以 LBP 統計直方圖. al. n. v i n Ch Gray 統計直方圖特徵來描述從圖像中偵測到的 engchi U. 特徵爲主,並輔以. Comic. Faces。 爲了對 Comic Face 提取圖像特徵,方便的方法是先將它們從偵測結果中截 取出來(如圖 3-6)。我們將每一個 Comic Face 轉化到相同尺寸,並切分成 10*10 pixel 組成的 Blocks,之後對每個 Block 分別求取 LBP 特徵與圖像 Gray 特 徵(如圖 3-7 所示),並分別以 LBP Histogram 與 Gray Histogram 的方式來描 述。. 14.
(26) 圖 3-6 Facial ROIs 的截取. 立. 政 治 大. ‧. ‧ 國. 學 er. io. sit. y. Nat. al. n. v i n 圖 3-7 Facial ROIs C 的分割與 Sub-window h e n g c h i U的 LBP 特徵描述 此處我們應用了 LBP 特徵的一種變形,LBP 旋轉不變式;該方法由 T. Ojala 等 人提出[18],如圖 3-8 所示,該變形將 LBP 特徵的參考點選取方式由相鄰 8 點 轉換爲以 R 爲半徑的圓周上取任意數量的點,這使得 LBP 能夠更好地應對各類 尺寸的圖像。 LBP 旋轉不變式使得按序排列的比特環不論在哪一種狀態,都能夠映射到 同樣一種結果,這使得 LBP 得以較好地處理旋轉後的圖像;且在此基礎上同時 15.
(27) 也降低了 LBP 特徵的維度,以取 8 點爲參考系的 LBP 爲例,將原本的 256 種狀 態成功映射到了 36 種,縮減了 Facial ROIs 的特徵表示的空間複雜度及特徵相 似度運算的時長(如圖 3-9 所示)。由此 Comic Face Feature 被描述爲: Feature = [[LBP11, LBP12, …,LBPij, …,LBPnn],[Gray11,Gray12,…,Grayij,…,Graynn]]. 其中 LBPij 表示 row 為 i,column 為 j 的 block 的 LBP Histogram 向量,Grayij 表 示 row 為 i,column 為 j 的 Block 的 Gray Histogram 向量,而 n 表示 Comic Face 切割成 Blocks 後的行(列)數。. 學 圖 3-8 LBP 旋轉不變式的參考點選取. Nat. n. al. er. io. sit. y. ‧. ‧ 國. 立. 政 治 大. Ch. engchi. i n U. 圖 3-9 LBP 旋轉不變式. 16. v.
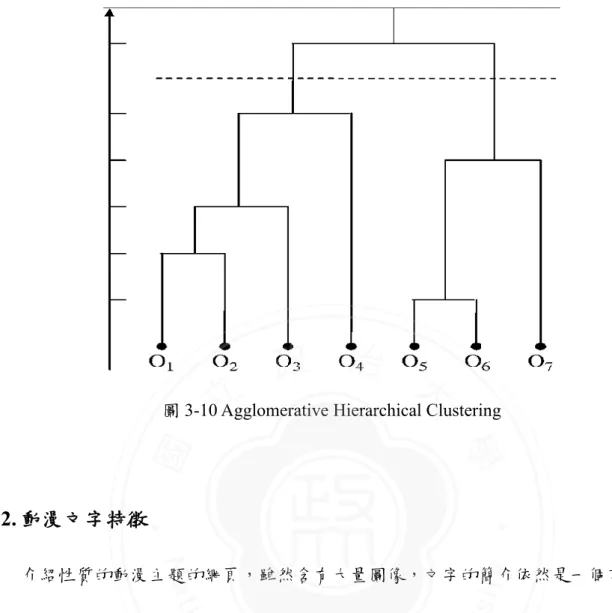
(28) 3.1.3. Facial Word Transformation 現在我們已經獲得了所有 Comic Face 的特徵向量,而我們的目標是用這些特徵 向量構建出 Facial Word Dictionary,從而與文字特徵結合,並實現圖文的潛在 語義分析。 考慮到網頁中也許會出現重複的圖像,也有可能不同的圖像中卻有着相似 的人物,這使得該網頁中所有的 Comic Face 的特徵向量很有可能出現近似甚至 相同的部分。我們把這些 Comic Face 分為一群,並用一個符號代表它們,視作. 政 治 大 重複出現的次數。這就是構建 Bag-of-Facial ROIs 的過程,並且網頁中的 Comic 立 一個 Facial Word,而這群“相同的”Comic Face 的數量則表示該群在當前網頁中. ‧ 國. 學. Face 是獨立而無序的,而每一群 Comic Face 在网页中出现的次数也已知。我們 採用分群效率較高的 Hierarchical Clustering 算法,在本研究中,我們選了用. ‧. agglomerative 中的 Single Link Clustering Algorithm 來做分群。Agglomerative 分. y. Nat. er. io. sit. 群模式的 Hierarchical Clustering 算法流程如圖 3-10 所示,1)從底層起兩兩計算 各個 Comic Face 之間的相似度;2)將最相似的合併爲一群,並把合併後的這. al. n. v i n Ch Comic Face;3)重複以上過程,直到任兩群 Comic Face engchi U. 一群看作是一個新的. 之間的距離大於 Threshold 所設定的臨界直,從而獲得被 Threshold 切割後下方 的各個 Clusters。 最後我們將每一個 Cluster 中的 Comic Face 都用一個獨立的符號表示。所有 的符號構建成最終的 Facial Word Dictionary,並依據 Dictionary 中每個 Cluster 及其權重,生成每個網頁的動漫人臉特徵向量: Facial Word Feature = [(C1, W1), (C2, W2), … , (CN, WN)]. 其中 Ci 代表網頁中的 Facial Word i,Wi 代表其權重。 17.
(29) 立. 政 治 大. 圖 3-10 Agglomerative Hierarchical Clustering. ‧ 國. 學 ‧. 3.2. 動漫文字特徵. y. Nat. io. sit. 介紹性質的動漫主題的網頁,雖然含有大量圖像,文字的簡介依然是一個不可. n. al. er. 或缺、甚至可以稱為主體的部分。我們同樣需要對文字內容進行整理與分析,. Ch. i n U. 並將其轉化爲描述這些動漫網頁特質的文字特徵向量。. engchi. v. 3.2.1. 中文環境下的 Text Segmentation 及 Bag-of-Words 目前從網上抓取下來的文字檔案,普遍具有格式紊亂,無關雜訊較多等特質。 由於本研究的主題與動漫及中文相關,因此我們特意在廣度優先搜索的機器人 爬蟲程式中添加了針對動漫的一系列過濾程序,並對已經下載下來的網頁文檔 進行半人工模式的二次過濾,以期望檔案的內容緊扣動漫主題。一些主要的過 濾參考條件以及前處理的注意事項將在實作部分提及。經過文本過濾以及前處 18.
(30) 理後,我們留下了僅保留中文段落的網頁文本,如圖 3-11(a)所示。然而不同與 英文檔案,中文檔案中詞與詞緊密連接,並無空格的存在。爲了以經典的 Bagof-Words 的方式重構文本中的文字進行分析,常規的英文斷詞方法並不適用於 中文的情況。中文斷詞需要詞庫的支持,同時需要考慮大量中文語法、文法的 慣用特性,在此我們引用了第三方中文斷詞系統 JIEBA,斷詞後的結果如圖 3-11 (b)所示。 文本分類、分群的應用中常涉及 Bag-of-Words,指將文字分別打包成詞. 政 治 大 構建成 Word Dictionary。最後利用統計特性來作爲包的重要性的評判依據。 立. 袋,且遵循詞袋與詞袋之間並無先後順序關係的假設條件,然後將所有的詞袋. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. (a)前處理之後的文本. engchi. i n U. v. (b)斷詞之後的文本. 圖 3-11 中文斷詞前後效果對比. 值得注意的是,有時候並不一定是出現次數越多的文字越重要,例如中文 中 的 助 詞 。 爲 此 大 多 數 文 字 分 析 都 引 入 了 TF-IDF ( Term Frequency–Inverse Document Frequency)來平衡這些高頻但低“內涵”的詞彙。TFij = nij / Ni,其中 nij. 表示單詞 j 出現在文檔 i 中的次數,Ni 表示文檔 i 中單詞總數;IDFj = log( D / dj ),其中 D 表示文檔總數,dj 表出現單詞單詞 j 的文檔數目;最後,TFIDFij = 19.
(31) TFij * IDFj,該值在某些程度上表示了一個單詞在整個詞庫中的重要程度。其基 本思想在於,出現次數越多的詞越重要,但是在很多文檔中都出現的詞卻顯得 很大衆,無法凸顯出它的特性(重要性)。至此,我們將每個網頁中出現的詞 袋,依據 Word Dictionary 及其重要程度,構建出文字特徵向量: Textual Word Feature = [(Ti1, Wi1), (Ti2, Wi2), … , (TiM, WiM)]. 其中 Tij 代表第 i 個網頁中的第 j 個單詞,Wij 代表第 i 個網頁中的第 j 個單詞的 權重。. 立. ‧ 國. 學. 3.3. 圖文整合分析. 政 治 大. 在前面兩小節,我們從網頁中分別抽取了圖像特徵向量和文字特徵向量,為了. ‧. 更好地描述這些網頁,我們還需要融合圖像特徵向量與文字特徵向量,並形成. y. Nat. n. al. er. io. sit. 新的網頁特徵向量,從而實現動漫網頁之間關聯性的查詢。. 3.3.1. Feature Combination. Ch. engchi. i n U. v. 我們需要將 Textual Word Dictionary 與 Facial Word Dictionary 進行合併,形成 Word-Image Dictionary;然後把動漫人臉特徵向量與動漫文字特徵向量按以下方 式拼接結合,構建出能夠描述整個動漫網頁的特徵向量,其中第 i 個動漫網頁的 Word-Image Feature 表示為:. Word-Image Feature = [(Ti1, Wi1), (Ti2, Wi2), … , (TiM, WiM), (Ci1, Wi1), (Ci2, Wi2), … , (CiN, WiN)]. 20.
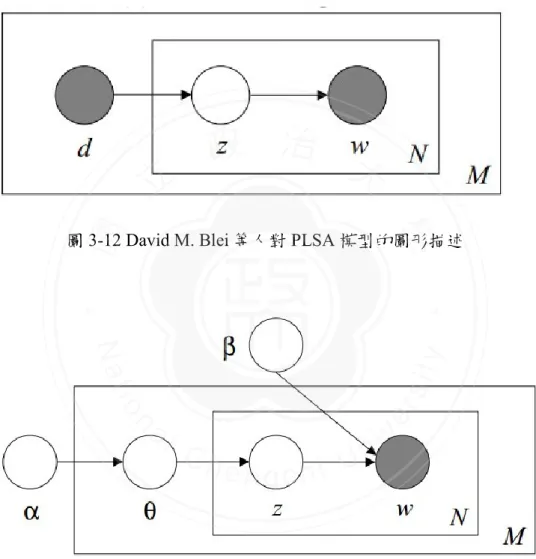
(32) 3.3.2. Feature Correlation between Image and Text 在我們的研究中,爲了獲得動漫網頁中的圖文關聯潛在語義,我們需要從 Word-Image Feature 中萃取出一些語義 Topic,每個 Topic 中包含一些相似動漫 風格的 word(包含 Textual Word 和 Facial Word),此時我們就可以根據不同的動 漫網頁與不同 Topic 的關聯緊密程度,來判斷動漫網頁之間的風格相似性。舉 例而言,若某 Topic S 同時包含了描述動漫人物 A 的 Textual word“Text_A”和該 人物的 Facial Word“Photo_A”;而此外,該語義還包含了與 A 出現在同一部動. 政 治 大 同一部動漫)的 Facial Word;那麼我們就認為動漫人物 B 和動漫人物 C 是存在 立. 漫中的人物 B 的 Textual Word,以及與 A 形象非常相似的人物 C(與 A 不屬於. ‧ 國. 學. 著某種關聯性的,我們希望找到這些相關的動漫網頁。. 潛在語義分析(Latent Semantic Analysis) [6]是由 S.T. Dumais 等人在 1988 年. ‧. 提出並於 1990 年發表的一種資訊檢索代數模型,被廣泛應用於資訊濾波、文檔. y. Nat. er. io. sit. 索引、視頻檢索、文本分類與分群、圖像檢索、資訊抽取等領域。此後,又有 Thomas Hofmann 等人於 1999 年提出的 Probabilistic Latent Semantic Analysis. al. n. v i n C h等人在 2003 年提出的 (PLSA)[8]以及 David M. Blei e n g c h i U Latent Dirichlet Allocation (LDA)[2]等潛在語義的分析、改進方案。潛在語義分析應用于文本分類與分 群這一議題時,對於檔案 A“Steve Jobs 過世了”與檔案 B“蘋果明天的股價會下 跌嗎”,兩者看似並無逐字對應的文字相似性,但在語義上卻存在著一定的關 聯,這種關聯的緊密程度就可以通過潛在語義分析的方式來獲取。 在我們的研究中,將對合併後的網頁圖、文特徵向量進行 LDA(Latent Dirichlet Allocation ) [2] 的 模 型 訓 練 , 該 方 法 是 繼 承 於 PLSA ( Probabilistic Latent Semantic Analysis)的基礎上演化而來的潛在語義分析方法,爲了方便理 21.
(33) 解,我們先簡單介紹一下 PLSA。PLSA 是一個 Generative Probabilistic Model, 如圖 3-12 所示,可以理解為一個文檔 d 中出現文字 w 的機率可以表示為,該文 檔 d 中出現 Topic z 的機率與該 Topic z 中出現文字 w 的機率的乘積,即: P(w|d) = P(z|d) ×P(w|z). 立. 政 治 大. ‧ 國. 學. 圖 3-12 David M. Blei 等人對 PLSA 模型的圖形描述. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 3-13 David M. Blei 等人對 LDA 模型的圖形描述. 而 LDA 則是對 PLSA 的改進,它同樣也是一個 Generative Probabilistic Model(如圖 3-13 所示)。需要注意的是,LDA 需要預先設定 Topic 的數量 k, 這一點與 PLSA 一致。α 作為調節 Topic 生成機率的 parameter,是一個 k 維的向 22.
(34) 量,θi 表示所有 Topic 在 doci 中的機率分佈,θi ~ Dir(α);β 作為調節 word 生成 的 parameter,是一個 k × V 的參數矩陣,且 βij 表示 Topic zi 中出現文字 wj 的機 率。. LDA training 的過程如下: 1) 把每個 doc 中的每個 word 隨機分配給 k 個 Topics(則初始 Topic 的機率分佈 P(z|d)與 word 的機率分佈 P(w|z)已知) 2) 對每個 doc 中的每個 word,計算 P(w|d) = P(z|d) × P(w|z),然後根據 P(w|d) 生成所有的 documents。. 立. 政 治 大. ‧ 國. 學. 3) 根據之前所有的 generated document 中的 P(z|d) 與 P(w|z)調整 α 和 β,重複 步驟 2)。由概率,當 generate 的次數越多,P(z|d) 與 P(w|z)越接近真實。. ‧. 我們對合併後的網頁圖文特徵向量進行 LDA 的模型訓練,希望根據現有的. y. Nat. io. sit. data 產生出 k 個關於動漫的 Topics,通過每個動漫網頁屬於各個 Topic 的機率. n. al. er. 值,我們可以判斷出這些動漫網頁之間的“距離”。我們用以下向量表示:. Ch. i n U. v. Web Topic Possibility Feature = [PT1, PT2, … , PTk]. engchi. 其中 PTk 指網頁包含第 k 個 Topic 的機率值(即距離有多近似)。同理,LDA 在 也可以讓我們觀察到每個 Topic 中包含的每個單詞的機率,圖 3-14 例舉了某個 Topic 中一些較高機率出現的單詞,我們可以借此瞭解每個 Topic 主要在描述哪 些事物,並由此推斷該 Topic 的含義。若該 Topic 有較高機率同時含有一些文字 特徵以及動漫人臉圖像特徵,那我們可以認爲這些文字,和動漫人臉圖像(圖 3-14 中以編號 c8_127_ed 表示),在當前 Topic 下有着較緊密的關聯性。. 23.
(35) 圖 3-14 某一動漫 Topic 的構成模式. 最後,爲了實現依據動漫網頁圖文特性檢索到其他不同動漫網頁,我們需. 治 政 要選擇距離公式比較不同 Web Topic Possibility Feature 大 之間的距離,或者選取相 立. 似性公式比較它們之間的相似程度。然後依據以上結果找出每個動漫網頁最爲. ‧ 國. 學. 相似的一系列動漫網頁作爲被推薦的對象,在我們的研究中,我們選取的 Web. ‧. Topic Possibility Feature 相似度算法爲 cosine similarity。. n. er. io. sit. y. Nat. al. Ch. engchi. 24. i n U. v.
(36) 第4章. 系統實作. 本章節主要介紹本研究的具體實作包括系統架構與使用的工具程式。我們對系 統的流程歸納在圖 4-1 中,整個系統實作流程同樣劃分爲兩個部分,離線的部 分主要關注系統後端的圖文特徵及關連分析的實作;而線上的部分則主要涵蓋. 政 治 大. 了網站前端以及界面的設計所應用到的技術及工具。. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4-1 基於圖文關聯語義的動漫搜索系統架構. 4.1. 資料來源 本研究的資料來源與百度百科[29],它是一個互動百科性質的中文搜索網站, 在中文資料方面相較與其他網站比較豐富。 爲了儘量收集只與動漫主題相關的網頁,我們設計廣度優先搜索的爬蟲程 25.
(37) 式,並在抓取的過程中對每個節點進行關鍵詞過濾,若該節點被判定與動漫主 題不再相關,那麼它的子網頁也將不再繼續抓取。其設計思路如圖 4-2 所示。 此外,爲了保證抓取的 data 相較與動漫主題的純度,我們通過重複的“觀察 – 過 濾”流程,對抓取下來的網頁進行進一步的過濾。該過程主要包含了對網頁文字 進行動漫關鍵詞的共存、異或組合關係的篩選,利用與動漫無關的關鍵詞進行 篩選等。. 政 治 大. 立. ‧. ‧ 國. 學 圖 4-2 網絡爬蟲抓取邏輯. n. al. er. io. sit. y. Nat 4.2. 線下部份實作流程. Ch. engchi. i n U. v. 該部份作為整個實作中的主體部份,將會詳細介紹我們在 Comic Face 的模型訓 練中所遇到的、受設備限制而產生的問題及解決方法;對動漫圖像中 Comic Face 的篩選與權重定義,Facial Word 的產生及網頁文檔處理過程中的一些參數 設定及細節問題。. 4.2.1. Comic Face 的訓練與測詴 在 Comic Face Detection 的 部 分 , 我 們 使 用 了 Viola-Jones Detection. 26.
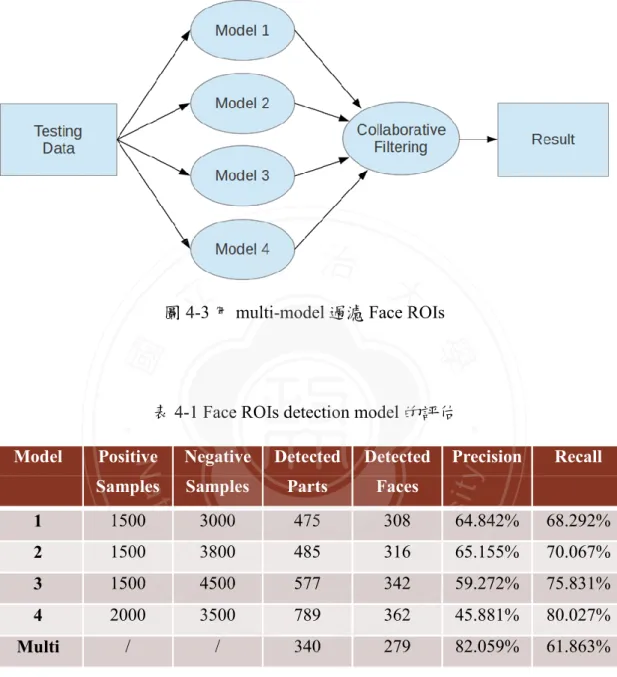
(38) Framework[26],該 Framework 需要預先收集正負樣本進行訓練。我們把所有的 圖片劃分爲兩部分,第一部分用以訓練,第二部分用以測詴評估。從第一部分 中,我們以人工標定及 opencv 偵測的方式截取了正樣本(動漫人物正臉)總共 共 6541 張,組成正樣本集。而負樣本總共 4877 張,由一些不含動漫人臉的圖 像組成;其中人工標定的動漫背景 1858 張, Naotoshi Seo[28]的 note site 中提供 的 Negative Set 共 3019 張。需要說明的是,Naotoshi Seo 的 note site 中提供的 3019 張負樣本為現實生活中的照片,而並非來自動漫。選取這部份非動漫背景. 政 治 大 等真人的照片;同時也會有一些在爬蟲抓取動漫百科網頁的過程中因超鏈接的 立. 的圖像作為負樣本,是因為考慮到在我們收集的 data set 中包含了聲優、漫畫家. ‧ 國. 學. 不准確而引入的雜訊(與動漫無關的、現實生活中的圖像),而我們的訓練過程 需要過濾掉這一類的圖像。. ‧. 由於 Viola-Jones Detection framework 訓練時,隨着樣本數量的增加,其花. y. Nat. er. io. sit. 費的時間則成幾何倍數增長;且該 Framework 對正負樣本的選取也有“少重複, 多類別,具有代表性”等要求,若樣本不合適會造成 Haar training 的過程進入運. n. al. 算死循環,從而卡在某個. v i n Ch U stage;受限於 Core™ i7e n g cPC h i的運算能力(Intel®. 3630QM CPU @ 2.40GHz × 8),無法一次性全取正負樣本進行訓練,在我們的 多次測詴過程中從未成功過,且會花費極大量的時間。 我們採取的應對措施是類似 Ensemble 的方式,將數個相對較弱的模型(由 正負樣本數量各不相同的 Training data 訓練得到)組合成一個相對較強的模 型,並評估了每個 Comic Face 的權重。如圖 4-3 所示,Testing Data 經過每個 model 後,都會獲得各自對應的 Facial ROIs,我們對每個 Comic Face 取 LBP 特 徵,並通用第三章中對網頁 comic face 分群的方式進行簡單的分群。我們將被 27.
(39) 劃分在一群的 Comic Face 看作一個 Facial Word,該群的權重被設定爲群中 Comic Face 的數量。通過若干實驗測詴,相似度計算的 Threshold 設定爲 0.9。. 政 治 大. 立. 圖 4-3 用 multi-model 過濾 Face ROIs. ‧ 國. 學. Negative. Detected. Detected. Samples. Samples. Parts. Faces. 1. 1500. 3000. 308. 2. 1500. 485. 3. 1500. a3800 l C 4500 h. 475. i n U 342. 4. 2000. 3500. Multi. /. /. Recall. n. sit. 64.842%. 68.292%. 65.155%. 70.067%. 59.272%. 75.831%. er. io. e n577 gchi. 316. Precision. y. Positive. Nat. Model. ‧. 表 4-1 Face ROIs detection model 的評估. v. 789. 362. 45.881%. 80.027%. 340. 279. 82.059%. 61.863%. 對於訓練時正負樣本選取的比例問題,一方面考慮到 Universal Negative 現 象的影響,另一方面我們也希望能以降低部分 Recall 爲代價提升 Precision 的值 (即 FN 值越低越好),因此我們傾向於負樣本的數量要多於正樣本。在此前提 下,我們從先前預留的用以測詴評估的 Data 中以隨機選取的方式收集了 300 張 圖像,以專家標定的方式對這些圖像中的人臉進行了統計,標定了 451 張動漫 28.
(40) 人物正臉(臉部偏轉角小於 45 度及臉部傾斜角小於 30 度動漫人臉)作爲 ground truth。然後我們對 300 張測詴圖像分別用四個 model 以及他們的 multimodel 共五種方式進行了 comic face detection,並把結果總結在了表 4-1 中。 在實驗觀察的過程中,我們發現,對於被偵測出來的 comic face 爲 False Negative 的情況,較多集中在像素尺寸較小的背景圖案中。雖然無法證明,但 依據經驗法則,我們仍將該現象考慮進過濾的過程中去,則過濾規則如圖 4-4 所示。. 政 治 大. _____________________________________________________________________ •. if weight < 3 → delete. •. elseif weight = 3 → new_weight = 1. •. elseif weight mod 4 = 0. 學. – if size > 60 pixel – else. → new_weight = weight/4+1. n. al. → new_weight = weight/5+2. → new_weight = weight/6+1. er. io. – else. sit. – if size > 60 pixel. y. elseif weight mod 4 != 0. Nat. •. → new_weight = weight/4+2. ‧. ‧ 國. 立. Ch. i n U. v. _____________________________________________________________________. engchi. 圖 4-4 Comic Face 的取捨與權重規則. 4.2.2. Facial Word Matrix 的產生 Facial Word Matrix 的產生主要分爲三個部分。1)對 Comic Faces 進行 clustering 的工作。但由於資料量較大,實作時爲了防止 Clustering 過程中記憶體不足的 問題,我們把每個網頁內相似的 Comic Face 優先合併為一個 Facial Word。這樣 可以減少之後對所有網頁進行 Hierarchical Clustering 時的空間複雜度和時間複 29.
(41) 雜度。我們採用的方法是: Step 1: 將一個網頁中所有的 Comic Face 及其 Euclidean Distance 建立成一個 Graph。每個 Comic Face 是 Graph 中的 Vertex, 兩個 Comic Face 之間 的 Distance 以 Edge 表示。 Step 2: 設定 Threshold,將距離大於 threshold 的 Edge 去除; Step 3: 最後將 Graph 中每個 Connected Component 中的 Comic Faces 視為一個 Facial Word。. 政 治 大 行全局的 Hierarchical Clustering。實作中我們使用了 Python2.7 的 SciPy Lib 中自 立. 完成每個網頁相似 Comic Faces 的合併後,再對所有網頁中的所有的 clusters 進. ‧ 國. 學. 帶的 Hierarchical Clustering 模組來運算後一步驟中的全局分群。在該 Lib 中, Hierarchical Clustering 的 threshold 有 3 種,分別是 inconsistent,distance 與. ‧. max_clusters。我們選用了 inconsistent 作為 Hierarchical Clustering 的分群標準,. y. Nat. er. io. sit. inconsistent 指某個 cluster 中父元素與他的子元素們的不一致性,而參照的子元 素的數量則由變數 depth 控制。在我們的實作中, inconsistent threshold 設定爲. al. n. v i n Ch 0.95,depth 設定為 20,距離計算的方式爲 e n g cEuclidean h i U Distance。在實際計算的過 程中,該部份由於需要較大的 RAM,我們將資料上傳至 AWS 進行分群的計 算,並在完成後將結果下載回本機端。2)將每一個分好群的 Clusters 映射爲一 個 Facial Word(如圖 4-5 所示),從而構建成 Facial Word Dictionary。3)針對每 個網頁,統計出該網頁中所有 Facial Word 出現的次數作爲權重,並使用 Vector Space Model [20]的形式表現。最後將所有網頁的 Facial Word Vector 整合,形成 Facial Word Matrix,這將使用在最後的圖文特徵整合部分。. 30.
(42) 圖 4-5 Face ROIs Clusters 到 Facial Word 的映射. 4.2.3. 網頁文字處理. 立. 政 治 大. 由於網頁文檔(HTML 檔案)的結構和語法規則相對鬆散,這使得在進行文字. ‧ 國. 學. 分析前,對於網頁文檔的內容提純成爲必頇。實作中我們使用了“Beautiful Soup 4” 對 網 頁 文 本 進 行 內 容 提 取 的 工 作 , 實 際 結 果 表 明 Beautiful Soup 對. ‧. HTML/XML 解析有不錯的效果。. y. Nat. er. io. sit. 在提取了 HTML 中的中文文字後,我們使用中國大陸研發的 jieba 斷詞工 具進行了中文斷詞的工作,其效果可見第 3 章圖 3-11。最後我們根据經典的. al. n. v i n Ch Bag-of-Words 文檔分析方法,將斷詞後的每一個文檔都表示成 engchi U. Vector Space. Model 的形式,最後將這些向量拼合成 Textual Word Matrix。. 4.2.4. 圖文矩陣 & 網頁相似度 在進行圖文特徵矩陣的語義分析時,我們使用 Gensim Library 進行 LDA Model 的訓練,實現了對圖文特徵矩陣從高維到低維的映射。但由於資料量較大,這 一過程我們運用 AWS 將 Large Scale Matrix 的降維計算放到雲端進行,但是計 算後的 LDA model 同樣是個很大的檔案,無法從 AWS 上整個下載到本機端, 31.
(43) 也就無法進行高精度的 Web Topic Possibility Feature 之間的相似度計算。因此我 們退而求其次,我們在實作中使用 Gensim 計算得到的 LDA model 所自帶的 show 函數,將每個網頁的 Web Topic Possibility Feature 中較重要得維度顯示 (如圖 4-6 所示)並保存到本機端,之後自行運算網頁間的相似度。由於只保 留了向量中部分權重較高的維度,因此這使得實作中網頁之間通過 Web Topic Possibility Feature 進行相似度計算存在誤差。這種情況的優勢在於,它忽略了 權重較低的特徵維度,使得明顯不相關的網頁之間的相互干擾降到了最低;但. 政 治 大. 這同樣也是缺點,它使得不同網頁之間的關聯不再那麼頻繁,缺失了不少資. 立. 訊。. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4-6 Web Topic Possibility Feature 的顯示效果(局部). 此外還有一個較明顯的問題,因爲 Web Topic Possibility Feature 中的低權重 分量被刪除,導致原本經過 Normalization 的向量之間變得權重不再等同,這等 價於網頁之間的重要性失去平衡;對於網頁而言,被刪除的 Topic 分量的模越 大,將會使得該網頁的重要性越低。爲此我們針對這一情況,重新對每個網頁 32.
(44) 的 Web Topic Possibility Feature 進行了 Normalization 的工作,此後才重新計算 相互之間的網頁相似度。. 4.3. 網站應用工具及介面 在完成了網頁之間的相似度計算並取得結果後,則是最後的網頁呈現的部份。 我 們 選 擇 使 用 了 Python/Django/MySQL 的 組 合 進 行 搭 建 網 站 , 這 類 MVC (Model-View-Controller)[19]的架構能夠以較簡潔的代碼實現完整的系統架. 政 治 大. 構,同時一定程度上保證了系統的健壯性,對於系統將來功能的擴展也能夠較. 立. 好地支持。. ‧ 國. 學. 我們將系統命名為 Comirror,取義為 Comic 與 Mirror 的結合,象徵著其功. ‧. 能是能夠像鏡子一般映射出原動漫介紹網頁風格相似的其他網頁;這種相似可. sit. y. Nat. 以是基於動漫人物的故事情節,也可是是依據動漫人物的本身形象。網站的介. n. al. er. io. 面則如圖 4-7~圖 4-9 所示,我們通過一個具體的例子來說明系統所實現的功. i n U. v. 能。當我們鍵入 query 為“佐助”(動漫《火影忍者》的主要角色之一)時,系. Ch. engchi. 統將會檢索出一系列與佐助相關 Topic 的頁面;此時我們對返回的第一個網 頁,“孙智波佐助”感到有興趣,於是點擊了網頁鏈接旁邊的“Mirror”按鈕(圖 4-8 所示);則系統將會根據該網頁的圖文特徵,給出綜合風格較為相似的頁 面,我們可以看到在圖 4-9 中,系統推薦出的第一項為“孙智波佐助”本身,而 第二項“孙智波鼬”在動漫中是佐助的哥哥,而且他的形象比之佐助也非常的接 近。. 33.
(45) 圖 4-7 系統的動漫搜索介面. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 4-8 系統的搜索結果返回介面. 34.
(46) 治 政 大 圖 4-9 依據圖、文特徵給出推薦 立 ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 35. i n U. v.
(47) 第5章. 實驗評估. 5.1. 實驗資料來源 我們的詴驗資料來源自百度百科網頁及其相關的相冊中。資料細節如表 5-1 所 示。. 政 治 大. 表 5-1 網頁、圖像的數量統計. 立. 28,898. 學. ‧ 國. Number of Web Pages. Number of Web Pages with Images. 17,655. Number of Images. 269,671 9.33. Average Number of Images per Web Pages with Images. 15.27. ‧. Average Number of Images per Web Page. y. Nat. 767,220. sit. Number of Textual Words. 155,606. n. al. er. io. Number of Facial Words. Ch. engchi. i n U. v. 我們不僅希望由種子網頁所推薦出來的動漫網頁都與種子網頁同屬於一部 動漫。事實上我們的初衷就是將所屬不同卻風格相似動漫元素推薦出來。具體 而言,所謂的風格,在我們的測詴中將會被明確地告知受詴者:即包含動漫所 屬、作者、文章語義上的風格(熱血/勵志/黑暗/戀愛/…)、動漫人物人臉形 象、髮型、以及畫面用色的深淺和習慣。這些都是我們希望受測者考慮的範 疇。. 36.
(48) 5.2. 實驗目的 驗證四種特徵(評估方法)依據圖文風格檢索動漫網站的準確率。 1) 文字特徵:LDA 從動漫網頁的文字特徵中萃取了 k 個 Topics。 2) 圖像特徵:LDA 從動漫網頁的圖像特徵中萃取了 k 個 Topics。 3) 圖 文 組 合 特 徵 , 文 字 特 徵 k1 個 Topics , 圖 像 特 徵 k2 個 Topics 。 k1+k2=k,並且,k1:k2=|Dict(文字特徵)|:|Dict(圖像特徵)|。. 政 治 大. 4) 圖文關聯特徵:從動漫網頁的圖文特徵中萃取了 k 個 Topics。. 立. ‧ 國. 學. 5.3. 實驗設計. ‧. 我們將每個種子網頁所推薦的前 10 個結果抽取出來,並以亂序的形式展示在受. sit. y. Nat. 詴者面前,請他們按照推薦結果與種子網頁動漫風格的相似程度進行打分,並. n. al. er. io. 記錄在案。需要重點說明的是,動漫網頁“風格”的相似度的含義,將會在測詴. i n U. v. 前告知受詴者。動漫網頁的風格包含網頁中文字內容(劇情、文風等)、圖像內. Ch. engchi. 容(人臉、色調、畫風等)兩大綜合因素,同時我們期望受詴者在確定了 3 點 基本知識之後才開始打分: 1)動漫元素的所屬、作者 2)文章語義上的風格(熱血/勵志/黑暗/戀愛/…) 3)動漫人物人臉形象、髮型、以及畫面用色的深淺和筆觸習慣等。 受詴者將依據自身的評判標準給分,我們採取 11 分制度,滿分為 11 分,最不 像為 1 分。基準分(並未相似,也不衝突)被建議為 5 分,如果推薦結果為種子網. 37.
(49) 頁自身,則建議評分為 11 分。 我們共邀請了 14 位受詴者進行實驗,將 30 個隨機產生的動漫 Topic 種子 網頁作爲候選項,實驗者從中挑選 3~10 個自己熟悉的動漫的種子網頁,分別使 用 5.2 節提及的 4 種特徵進行動漫網頁的推薦,我們統計得到的有效種子共 17 個,每個種子網頁有 2~5 個人評分。此外我們還對種子的類別做了初步的劃 分,其結果如表 5-2 所示。其中動漫本體類的網頁是指以某部動漫的整體來作 為主題的動漫網頁,例如介紹“海賊王”、“火影忍者”的動漫網頁;動漫元素類. 政 治 大. 的網頁特指介紹角色、事件、專有名詞的動漫網頁,例如介紹“魯夫” 、“王下七. 立. 武海”的動漫網頁;聲優/漫畫家類的網頁則是介紹給動漫角色配音的人、介紹. ‧ 國. 學. 動漫作者的網頁。. 動漫元素. 聲優/漫畫家. 4. 11. 2. n. 5.4. 實驗結果. sit. 總共 17. er. io. al. y. 動漫本體. Nat. 種子數量. ‧. 表 5-2 實驗中 17 個動漫種子網頁種子類別的劃分. Ch. engchi. i n U. v. 受詴者在測詴時,網頁呈現亂序排列狀態,本小節所實驗排序結果已做過還原 處理。在圖 5.1 中,我們展示了圖文關聯特徵被推薦的前 10 個動漫網頁中,排 列在第 n 項的網頁評分的均值。從本次測詴的結果來看,受詴者給予的評分基 本滿足分數遞減的期望,但由於評分的主觀性較強,每種方法都不可避免的, 在局部區域出現了系統排名較後的網頁卻在人為評分時獲得較高分數的現象。 在圖 5-2 中,我們給出了所有種子所推薦的前 10 個網頁中,前 n 項的網頁. 38.
(50) 評分的均值。從該圖上可以比較直觀的看到圖文關聯特徵擁有較優秀的表現, 然後則依次是純文字特徵,圖、文比例特徵,最後則是純圖像特徵。對於不同 類別的種子在四種特徵(評估方法)下的表現,我們依據所有種子所推薦的前 10 個網頁中,前 n 項的網頁評分均值將它們依次繪製在圖 5-3~圖 5-5 中。. 立. 政 治 大. n. al. er. io. sit. y. ‧. ‧ 國. 學. Nat. 圖 5-1 排在第 n 名的網頁的評分均值. Ch. engchi. i n U. v. 圖 5-2 前 n 個網頁的評分均值對比 39.
(51) 政 治 大 圖 5-3 前 n 個網頁的評分均值對比(動漫本體類別) 立 ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. 圖 5-4 前 n 個網頁的評分均值對比(動漫元素類別). 40.
(52) 政 治 大. 圖 5-5 前 n 個網頁的評分均值對比(聲優/漫畫家類別). 學. ‧ 國. 立. 表 5-3 四種評估方法在不同類別的種子網頁前提下的 DCG 表現. 整體. 35.3084. 30.9400. 37.4039. 34.4132. 27.1689. 29.1072. 29.7503. 29.3304. 30.8209. 36.6954. e n g c h i 34.0753. 39.4384. al. Ch. sit. 38.5411. n. 聲優/漫畫家. 32.3191. io. 動漫元素. y. Nat. 動漫本體. 圖文比例特徵 圖文關聯. er. 類別. 圖像特徵 文字特徵. ‧. 方法. i n U. v. 40.4968 40.8913. 表 5-4 四種評估方法在不同類別的種子網頁前提下的 NDCG 表現 方法. 圖像特徵 文字特徵. 圖文比例特徵 圖文關聯. 動漫本體. 0.9252. 0.9378. 0.9517. 0.9545. 動漫元素. 0.9319. 0.9388. 0.9457. 0.9484. 聲優/漫畫家 0.9577. 0.9625. 0.9547. 0.9540. 0.9333. 0.9414. 0.9482. 0.9505. 類別. 整體. 41.
(53) 我們可以觀察到圖文關聯特徵在針對動漫本體、動漫元素時都有較優的表 現,但是在評估種子類別為“聲優/漫畫家”時,並無突出表現。 最後,我們依據動漫種子的分類,測詴了 4 種特徵(評估方法)的 DCG (Discounted Cumulative Gain)值以及 NDCG(Normalize DCG)值,如表 5-3 和表 5-4 所示,在當前實驗資料中,就 DCG 而言圖文關聯特徵整體上優於其他 三類特徵,根據 DCG 的特性,我們可以推測測詴者打分時給圖文關聯特徵這種 方法的分數相較于其他 3 種 baseline 要高,但在“聲優/漫畫家”類別的動漫種子. 政 治 大 網頁中,圖文關聯特徵並無優勢。而 NDCG 則主要衡量了網頁排名的優劣問 立. ‧ 國. 學. 題,我們可以觀察到除了“聲優/漫畫家”類別的動漫種子網頁,圖文關聯特徵在 網頁排名問題上相較于其他 3 種 baseline 特徵略佔優勢。. ‧. n. er. io. sit. y. Nat. al. Ch. engchi. 42. i n U. v.
(54) 第6章. 結論與未來工作. 本論文針對動漫網站提出結合動漫圖文特徵關連分析的相似度擷取方法,以提 供使用者根據動漫風格來查詢相似的動站網頁。通過實驗可以初步得出結論, 在動漫領域的網頁檢索中,應用圖文關聯特徵萃取網頁中的潛在語義的分析方. 政 治 大. 式,相較于單純的文字、圖像、以及將圖文進行特徵拼合的分析方式有較好的. 立. 表現。. ‧ 國. 學. 關於動漫風格方面,仍有不少值得改進的地方。首先是“風格”的定義問 題,考慮到使用者需求的動漫風格各不相同,可以在系統中讓使用者自行設定. ‧. 所需求的風格(比如偏重圖像風格或文字風格來進行檢索)。這將使得風格的定. y. Nat. io. sit. 義更符合不同人的標準。其次是“風格”的內容問題,由於本研究主要關注與動. er. 漫網頁中圖文關聯性的分析,而對於動漫的圖像,卻不僅僅只有動漫人臉一類. al. n. v i n Ch 值得關注的特徵區域。有的時候動漫人物的身體造型往往也很有代表性;有的 engchi U 時候漫畫家所描繪的背景畫風則很有其個人特色;而有的時候某些吉祥物、物 件、符號等,在某一部動漫中具備著與眾不同的含義。這些具有代表性的部份 也可以被看作是動漫圖像中的重要區域,從而嘗詴進行提取並分析。 關於研究的實驗評估方面,作為 baseline 的 3 種特徵(純圖像特徵,純文 字特徵,圖文組合特徵)都是以 LDA 分析潛在語義來獲取的。但考慮到以下兩 點原因,1)把圖像看成 facial word 時,僅由 facial word 構成的文檔中,其 word 的 distribution 並不一定符合 LDA 所要求的 multinomial distribution,2)純 43.
(55) 圖像特徵當做 facial word 來看時,word 互相之間的關聯性並不高。因此我們將 在 未 來 的 研 究 中 應 用 圖 像 分 析 領 域 較 常 見 的 Principal Component Analysis (PCA)來獲取純圖像特徵,並將純圖像的 PCA 特徵添加到評估的 baseline 中,使得在評估我們所提出的圖文關聯方法時,幾種 baseline 特徵能夠更為客 觀可靠,更有參考價值。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 44. i n U. v.
(56) 參考文獻. [1] H. Bay, T. Tuytelaars and L. Van Gool, "SURF: Speeded up Robust Features," European Conference on Computer Vision, 2006. [2] D. M. Blei, Andrew Ng and M. Jordan. "Latent Dirichlet Allocation," The Journal of Machine Learning Research, Vol.3, pp. 993-1022, 2003. [3] M. Brown and D. Lowe, "Recognizing Panoramas," The 9th International. 政 治 大. Conference on Computer Vision, pp. 1218-1227, 2003.. 立. [4] J. Canny. "A Computational Approach to Edge Detection," IEEE Transactions on. ‧ 國. 學. Pattern Analysis and Machine Intelligence, Vol.8, No.6, pp. 679-698, 1986. [5] N. Dalal and B. Triggs, "Histograms of Oriented Gradients for Human. ‧. Detection," IEEE Conference on Computer Vision and Pattern Recognition, Vol.1,. y. Nat. pp. 88–893, 2005.. sit. [6] S. Deerwester, S. Dumais, T. Landauer, G. Furnas, and R. Harshman, "Indexing. n. al. er. io. by latent semantic analysis," Journal of the American Society for Information. i n U. Science and Technology , Vol.41, pp. 391-407, 1990.. Ch. engchi. v. [7] T. Gritti , C. Shan , V. Jeanne and R. Braspenning, "Local features based facial expression recognition with face registration errors," Automatic Face & Gesture Recognition, FG '08. 8th IEEE International Conference, pp. 1-8, 2008. [8] T. Hofmann, "Probabilistic Latent Semantic Analysis," Uncertainty in Artificial Intelligence, UAI’99, pp. 289-296, 1999. [9] L. Juan and O. Gwun, "A Comparison of SIFT, PCA-SIFT and. SURF," International Journal of Image Processing, Vol. 65, pp. 143-152, 2009. [10] Y. Ke and R. Sukthankar, "PCA-SIFT: A More Distinctive Representation for Local Image Descriptors," Computer Vision and Pattern Recognition, Vol.2, 2004. [11] M. La Cascia , S. Sethi , S. Sclaroff, "Combining Textual and Visual Cues for 45.
數據
+7


相關文件
For a polytomous item measuring the first-order latent trait, the item response function can be the generalized partial credit model (Muraki, 1992), the partial credit model
This thesis mainly focuses on how Master Shandao’s ideology develops in Japan from the perspective of the Three Minds (the utterly sincere mind, the profound mind, and the
Based on historical documents and archeological evidence, this thesis provides an analysis of, raises some worth-noting questions on, the development of Western Qin Buddhism
Such analysis enables valuable applications including social entity search en- gines and substitution recommendation systems. For a social entity search engine, existing work such
一說到網路搜尋,我們就會想到 G oogle ,但其 實搜尋引擎不是 G oogle 發明的,早在 G oogle 出現 之前就已經有搜尋引擎的應用。那麼, G oogle
運用 Zuvio IRS 與台日比較文化觀點於日本文化相關課程之教學研究 Applying Zuvio IRS and Perspective on Cultural comparison between Taiwan and Japan to Teaching
To tackle these problems, this study develops a three-stage approach (i.e., firstly create a correct CAD-oriented explosion graph and then find a graph-based assembly sequence
由於資料探勘 Apriori 演算法具有探勘資訊關聯性之特性,因此文具申請資 訊分析系統將所有文具申請之歷史資訊載入系統,利用
