A Novel Optical-Header Processing and
Access Control System for a Packet-Switched
WDM Metro Ring Network
Maria C. Yuang, Senior Member, IEEE, Member, OSA, Yu-Min Lin, Member, IEEE, and Ya-Shian Wang
Abstract—Optical packet switching (OPS) has been considered to be a promising paradigm to support a wide range of applica-tions with different time-varying and high bandwidth demands for future optical metropolitan area networks (MANs). In this paper, we present the design of an experimental optical-header processing and access control system (OPACS) for an OPS wave-length-division multiplexing metro slotted-ring network. On the slotted ring, each control header is in-band time-division-mul-tiplexed with its corresponding payload within a slot. OPACS enables the optical headers across all parallel wavelengths to be efficiently received, modified, and retransmitted by means of a wavelength–time conversion technique. Moreover, OPACS em-bodies a versatile medium access control (MAC) scheme, referred to as the distributed multigranularity and multiwindow reserva-tion (DMGWR) mechanism, which is particularly advantageous for traffic of high and varying loads and burstiness. Basically, DMGWR requires each node to make reservation requests prior to transmissions while maintaining a distributed queue for ensuring fair access of bandwidth. By “multigranularity,” each node can make a reservation of multiple slots at a time. By “multiwindow,” each node is allowed to have multiple outstanding reservations within the window size. From simulation results that pit the OPACS network against two other existing networks, we show that the OPACS network outperforms these networks with respect to throughput, access delay, and fairness under various traffic pat-terns. Experimental results demonstrate that all optical headers are removed and combined with the data in a fully synchronous manner, justifying the viability of the system.
Index Terms—Medium access control (MAC), metropolitan area networks (MANs), optical packet switching (OPS), wavelength-di-vision multiplexing (WDM).
I. INTRODUCTION
O
PTICAL wavelength-division multiplexing (WDM) [1] has been shown to be successful in providing virtually unlimited bandwidth based on the optical circuit switchingManuscript received November 11, 2008; revised June 22, 2009, July 14, 2009. First publishedAugust 04, 2009; current version published September 10, 2009. This work was supported in part by the National Chiao Tung Univer-sity/Computer and Communications Laboratories Joint Research Center, and in part by the National Science Council (NSC), Taiwan, under Grant NSC95-2221-E-009-051-MY3.
M. C. Yuang is with the Department of Computer Science, National Chiao Tung University, Hsinchu 30050, Taiwan (e-mail: [email protected]). Y.-M. Lin is with the Information and Communications Research Laborato-ries, Industrial Technology Research Institute, Hsinchu 30050, Taiwan (e-mail: [email protected]).
Y.-S. Wang is with the Department of Computer Science, National Chiao Tung University, Hsinchu 30050, Taiwan, and also with the Telecommunication Laboratories, Chunghwa Telecom Co., Ltd., Taoyuan 32601, Taiwan (e-mail: [email protected]).
Digital Object Identifier 10.1109/JLT.2009.2029061
(OCS) paradigm, for supporting a large amount of steady traffic in long-haul backbone networks. Future optical metropolitan area networks (MANs) [2], [3], on the other hand, are ex-pected to cost-effectively satisfy a wide range of applications having time-varying and high bandwidth demands and strin-gent delay requirements. These demands necessitate the use of an optical-packet-switching (OPS) [2], [3] paradigm, which facilitates statistical multiplexing to efficiently share wave-length channels among multiple users. Numerous topologies and architectures for OPS-based WDM metro networks have been proposed. Of these proposals, the structure of slotted rings [4]–[10] receives the most attention. Two key challenges pertaining to OPS-based WDM networks are the header control and medium access controls (MACs).
The header control can be in-band [7]–[10], where both header and payload are modulated and transported via the same wavelength, or out-of-band [4]–[6], where control headers are carried via a dedicated control wavelength. While both control methods have their merits, from a carrier’s perspective, an out-of-band control system appears impractical due to the additional cost of a fixed transceiver on each node. Thus, we focus on the in-band header control and processing in our work. There are three basic in-band header control techniques: subcar-rier multiplexed (SCM) [8], [11]–[13], orthogonal modulation [15]–[18], and time-domain multiplexing (TDM) [19]–[21]. With the SCM technique, the header information can be carried on a subcarrier frequency that is separated from the baseband payload frequency. Most traditional SCM methods cannot potentially scale up well with the payload data rate because an expanding baseband may eventually overlap with the subcar-rier frequency. The optical carsubcar-rier suppression and separation (OCSS) technique [11], however, was shown to be able to gen-erate the header at very high subcarrier frequency and with high bit rate and extinction ratio. Nevertheless, SCM still requires stringent wavelength accuracy and stability while using a fixed optical filter to remove the header at each node. The orthogonal modulation technique, which includes amplitude-shift keying (ASK) [14], frequency-shift keying (FSK) [15], ASK/differ-ential phase-shift keying (DPSK) [16], [17], and DPSK/FSK [18], exhibits severe transmission system penalty due to the inherently low extinction ratio of a high-speed payload signal. Finally, with the TDM technique, the header and payload are serially connected in the time domain, interspaced with an optical guard time to facilitate header extraction and modifica-tion. The bit rates of the header and payload can either be the same [20], or different [19]. Generally, traditional TDM-based approaches require an extremely precise control timing and
alignment to perform header erasing and rewriting operations. The first goal of this study is to propose a simple and highly efficient TDM-based optical-header processing scheme. As will be demonstrated, in our system optical headers can also be easily modified by taking advantage of the particularly notable MAC design.
Another key performance-enhancing feature pertaining to OPS-based networks is the design of the MAC mechanism. The MAC scheme should be designed to offer fair and versatile bandwidth allocation, achieving satisfied throughput and delay performance under a wide range of traffic loads and burstiness. Moreover, the MAC protocol should take into account the scalability problem with respect to the number of wavelengths. While numerous MAC protocols for OPS-based slotted-ring networks have been proposed in the literature [2], [22], [23], our second goal is to explore a variant of a reservation-based mech-anism, IEEE 802.6 distributed queue dual bus (DQDB) [24], for the multichannel WDM metro networks. In single-channel DQDB, each node must issue a reservation request prior to the transmission. To ensure that packets are sent in the order they arrived at the network, DQDB requires each node to maintain a distributed queue via a Request (RQ) and a CountDown (CD) counters. DQDB was shown to achieve superior throughput and delay performance, nevertheless undergoes the unfairness problem due to long propagation delay under heavy traffic conditions.
In this WDM–DQDB line of work, the WDM access (WDMA) [6] protocol simply extends the basic single-channel DQDB to the multichannel case, namely, each node main-tains a single distributed queue for all of the wavelengths. Due to the use of a tunable transceiver, WDMA adopts the retransmission mechanism if the receiver contention problem occurs. With such a simple design, WDMA unfortunately results in access unfairness and inefficiencies for multichannel networks under varying traffic patterns and burstiness. The hybrid optoelectronic ring network (HORNET) [5] employs a distributed queue bidirectional ring (DQBR) protocol. Due to the use of fixed-tuned receivers, HORNET statically assigns each node a wavelength as the home channel for receiving packets. Such static wavelength assignment results in poor statistical multiplexing gain and bandwidth efficiency. As a result of the home-channel design, DQBR treats wavelengths independently and requires each node to maintain a distributed queue for each wavelength. Moreover, each node is allowed to issue multiple independent single-slot requests. With DQBR, HORNET achieves acceptable utilization and fairness at the expense of high control complexity for maintaining the same number of counter pairs as that of wavelengths. Such a design gives rise to a scalability problem. Moreover, the design of per-mitting unlimited multiple requests with single slot granularity per request unfortunately results in unfairness problems.
In this paper, we propose a novel optical-header processing and access control system, or OPACS in short, for a 10-Gb/s op-tical-packet-switched [10] WDM metro ring network. OPACS has two prominent features that set it apart from existing re-lated work. First, OPACS is designed for a dual unidirectional ring network using in-band signaling control. Each control header is time-division-multiplexed with its corresponding
data packet within a slot. By making use of signal gating and wavelength–time conversion techniques, OPACS enables the optical headers across all parallel wavelengths to be efficiently received, modified, and retransmitted. Second, taking diverse traffic patterns and burstiness into account, OPACS employs a variant of the DQDB scheme, referred to as the distributed multigranularity and multiwindow reservation (DMGWR) scheme. By “multigranularity,” DMGWR permits each node to reserve different amounts of bandwidth (slots) at a time. By “multiwindow,” DMGWR allows each node to have multiple outstanding reservations within the window size (WS). From numerical results that pit the DMGWR network against two other existing networks (WDMA-based and HORNET), we show that the OPACS network outperforms both networks with respect to throughput, access delay, and fairness under various traffic patterns. Experimental results demonstrate that all optical headers are removed and combined with the data in a fully synchronous manner, justifying the viability of the system.
The remainder of this paper is organized as follows. In Section II, we present the OPACS system architecture. In Section III, we describe the DMGWR scheme in detail. In Section IV, we draw comparisons between OPACS and two other networks via simulation results. The prototype and experimental results are demonstrated in Section V. Finally, concluding remarks are given in Section VI.
II. OPACS SYSTEMARCHITECTURE
The WDM network that is governed by OPACS at each node consists of a pair of unidirectional fiber rings, i.e., the forward and reverse rings. The signal propagates on the two rings in op-posite directions. More specifically, packets destined for down-stream and updown-stream nodes are sent along the forward and re-verse rings, respectively. Each ring carries a number of WDM data channels, which are further divided into synchronous time slots. Each slot contains a control header field followed by a fixed-size packet payload. Note that such a dual-ring network is logically a bus-based network (with two buses that are wrapped into two rings). Therefore, there is one server node located at the beginning of the two rings, which is responsible for gener-ating optical slots initially, and resetting all used optical slots each time after the slots have traveled one lap of the ring.
Specifically, each header and its payload are time-multi-plexed within a slot, operating at data rates of 1 Gb/s and 10 Gb/s, respectively. (The rationale behind the design of using different rates is described as follows. The header in OPACS is only 2 bytes long, resulting in low control overhead. Therefore, a rate of 1-Gb/s is sufficiently fast and acceptable. However, the header bit rate can be upgraded provided with a rate-com-patible burst-mode receiver, if the header size increases or the payload size decreases.) Each node is equipped with one tunable transmitter and one tunable receiver for each ring. Since the operations for accessing the two rings are identical and independent, for simplicity, we hereinafter focus on the access control for the forward ring only.
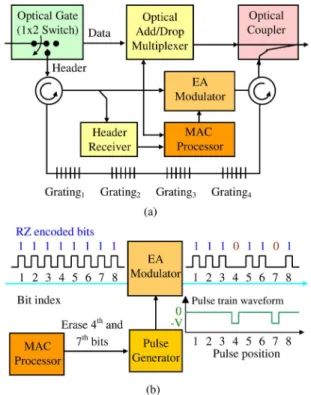
The architecture of OPACS is shown in Fig. 1. Assume there are four wavelengths used in the network. As shown in Fig. 1(a), at the input as parallels slots are passing by, an optical gate/
Fig. 1. OPACS system architecture. (a) System architecture(W = 4). (b) EA modulator—an example.
switch first separates the headers from data packets into two paths. Along the header path, the optical headers of four chan-nels are reflected by four fiber Bragg gratings, resulting in a wavelength-to-time conversion for the headers. In other words, the channels’ headers are converted from being parallel to serial in the time domain. These serial headers are later tapped to an optical-header receiver by a circulator. Once the MAC processor receives and processes the header information, it determines the reception and transmission of data packets, and then updates the headers according to the MAC algorithm described later. Sub-sequently, the optical headers are updated by the optical header rewriter, which is implemented by an electro-absorption (EA) optical modulator. After having been updated, the serial optical headers experience a reversed time-to-wavelength conversion on the outbound path through the same set of fiber Bragg grat-ings. Along the data path, the data packets are optically added or dropped via the optical add/drop multiplexer (ADM). Finally, the optical headers on different wavelengths are combined with their corresponding data packet via an optical coupler.
The operating principle of the EA modulator can be explained with one simple example illustrated in Fig. 1(b). Note first, that the control header bits are return-to-zero (RZ) encoded. One particularly notable feature of our MAC protocol is that the header bits are always updated from 1 to 0. By taking advan-tage of such a feature, the header rewriter can simply be a pulse eraser that erases the pulses that are to be updated from 1 to 0. In the example mentioned earlier, assume that the MAC processor determines to update the fourth and seventh bits of the control header. The pulse generator produces the pulse train waveform with two negative pulses on the corresponding bit positions. The EA modulator then performs a straightforward modulation (at-tenuation) on the incoming optical header pulses with the two
negative pulses, so that the fourth and seventh bits of the header are easily updated from 1 to 0.
III. MAC SCHEME
OPACS employs a MAC scheme called the distributed multi-granularity and multiwindow reservation (DMGWR) scheme. Before describing the scheme, we first introduce two constraints that will be frequently used throughout the rest of the paper. If the network node is equipped with only one tunable receiver, the receiver-contention [2] problem occurs when there is more than one packet destined to the same node in one slot time. Accord-ingly, one cannot have two packets carried by different wave-lengths in a time slot heading for the same destination node. Likewise, if there is only one tunable transmitter, any node is restricted to make at most one packet transmission in one slot time. Such a limitation is referred to as the vertical-access con-straint (by vertical, we mean the access of different wavelengths within the same slot time).
Considering all wavelengths as a whole, the DMGWR scheme allows bandwidth to be allocated dynamically both in space (granularity) and in time (window). By space, DMGWR allows different bandwidth granularity, i.e., number of slots, to be reserved at a time. By time through the multiwindow design, DMGWR permits a node to issue another reservation request prior to the satisfaction of previous requests in the event that new packets have arrived, as long as the total number of outstanding requests is less than a predetermined value, called the WS.
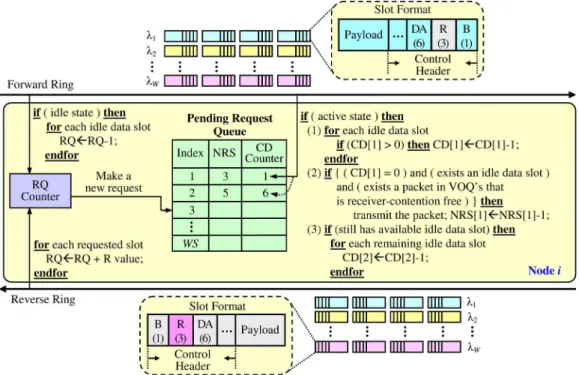
The access operation of DMGWR is described as follows. A node can be in one of the three states: idle, ready, and ac-tive. When a node has no packet to transmit, it is in the idle state. Being in the idle state, the node updates its RQ counter by adding the total number of reserved slots (NRS) for each reser-vation request passed on the reverse ring, and subtracting the RQ counter by one for each idle data slot passed on the forward ring, as depicted in Fig. 2. When a node has packets to transmit, it en-ters the ready state. Note that, we adopt the use of virtual output queues (VOQs) [2] to buffer newly arriving packets, namely, packets destined to different destinations are placed in different queues to prevent from throughput deterioration resulting from the vertical-access constraint.
Being in the ready state, the node is required to first make a reservation request by finding an available request-reservation slot on the reverse ring. The total number of slots to be reserved ranges from one to , where is the length of the request field within each slot. The node then transfers the current value of the RQ counter to the CD counter and resets the RQ counter to zero. Finally, the node saves the total NRS and the CD counter value to the pending request queue, as shown in Fig. 2. With pending requests in the queue, the node enters the active state. Being in the active state, if the node observes more new arriving packets, the node can repeat the reservation request process as long as the total number of requests is less than or equal to the WS.
An active node updates its RQ counter by adding the total number of slots reserved for each reservation request passed on the reverse ring. For all idle data slots (located vertically) on the forward ring within a single slot time, the node decreases the
Fig. 2. DMGWR scheme and illustration.
CD counter of the first reservation request by the total number of idle slots, if the CD counter is greater than the total amount of idle slots. If the total number of idle slots are greater than the CD counter, as soon as the CD counter becomes zero, the node can then transmit the next packet in the VOQ’s that is free from the receiver contention problem on one of the available idle slots. The node, in turn, decrements the corresponding NRS value of the request by one. When the NRS reaches zero, the pending re-quest entry is removed from the queue. Most importantly, if the CD counter of the first request is zero but there exist no packets in the VOQ’s that are receiver-contention free or there are more idle slots left, DMGWR applies the so-called pipelining opera-tion by decreasing the next request’s CD counter by the number of remaining idle slots. Such an operation is repeatedly and se-quentially applied to all entries in the pending request queue until no idle slots are left uncalculated. Finally, when the VOQ’s and pending request queue are empty, the node returns to an idle state.
To implement the DMGWR scheme, each slot consists of a control header and a payload field. The control header includes a 1-bit Busy (B) field, a 3-bit Request (R) field, a 6-bit Destina-tion Address (DA) field. The Busy field indicates whether the slot is Busy or Idle . The 3-bit Request field allows nodes to make a reservation request for one to seven slots . The Destination Address field is used to iden-tify the destination address of the data packet. It is worth noting that both Busy and Request control fields are designed to be always updated from 1 to 0, thereby allowing the proposed op-tical-header replacement technique to perform a rather straight-forward header rewriting operation described earlier.
IV. SIMULATIONRESULTS
We draw comparisons between the DMGWR scheme and two other existing schemes (WDMA and DQBR), and demonstrate
its performance with respect to throughput, access delay, and fairness under various system settings, via simulation. The sim-ulation is event-based and written in the C language. It is termi-nated after reaching a 95% confidence interval. In the simula-tion, there are 48 nodes in the network, numbered from 1 to 48 corresponding to the most upstream (node 1) to the most down-stream (node 48) locations. Nodes are equally spaced around the ring with an inter-nodal distance of ten-slot long without specific indication. New packets are generated at the slot bound-aries following either a Poisson distribution or a two-state (H and L) Markov-modulated Poisson process (MMPP) [25] for modeling smooth and bursty traffic, respectively. Specifically, the MMPP is characterized by four parameters ( , and ), where is the probability of changing from state H (L) to L (H) in a slot, and represents the probability of arrivals at state H (L). Accordingly, given , the mean arrival rate can be expressed as , and traffic burstiness can be given by . Furthermore, WS is seven without specific indication. The destinations of the generated packets are uniformly distributed among the network nodes. In the simulation for DQBR, home channels are assigned to nodes in a cyclic fashion.
We first draw throughput and delay comparisons among DMGWR, WDMA, and DQBR in Fig. 3. As the total number of wavelengths increases, the total load is proportionally scaled up. As a result, both WDMA and DQBR undergo deteriorating throughput and mean delay under higher loads due to the poor statistical multiplexing gain and receiver contention (for WDMA). DMGWR exceptionally outperforms both WDMA and DQBR for networks carrying extremely heavy loads (0.99). Significantly, the DMGWR scheme achieves the same degree of bandwidth efficiency regardless of the wavelength number and load of the network, which is a very attractive scal-ability feature for WDM network systems. Furthermore, as
Fig. 3. Comparisons of throughput and access delay. (a) Throughput compar-ison. (b) Mean delay comparcompar-ison.
shown in Fig. 3(b), we observe that as the burstiness and loads grow, DMGWR experiences unnoticeable delay increase, while WDMA and DQBR suffers drastic delay degradation.
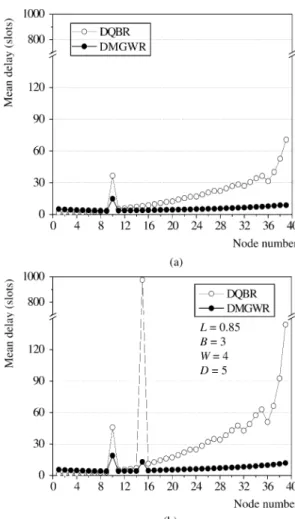
We next draw a comparison of delay fairness among the three schemes in Fig. 4 under different inter-nodal distances and burstiness . As depicted in Fig. 4, DMGWR enables fair and efficient sharing of the bandwidth among all nodes regardless of the ring length and traffic burstiness. By contrast, both WDMA and DQBR are in favor of downstream and upstream nodes, re-spectively, manifesting delay unfairness. For WDMA, a larger ring length leads to a longer wait of upstream nodes for retrans-missions in the case of the occurrences of receiver contentions. We also observe in the figure that the delay of DQBR is plotted by a serrated curve (around nodes 36 and 44) on the downstream side due to the impact of a cyclic home channel assignment of DQBR.
We furthermore draw a delay comparison between DMGWR and DQBR over a network with malicious nodes. In the sim-ulation, nodes 10 and/or 15 are set as malicious nodes, where each node generated an excessive load of 0.09 per wavelength, in a network with a total load of 0.85 per wavelength. As shown in Fig. 5, DMGWR causes the malicious nodes to suffer se-vere delays, while leaving other normal nodes completely un-affected. On the other hand, the DQBR scheme results in unex-pected delay deterioration (and thus unfairness) for the
down-Fig. 4. Comparisons of delay fairness. (a) Fairness under various inter-nodal distances. (b) Fairness under various burstiness.
stream nodes. As the number of malicious nodes increases, the delay unfairness problem worsens, as Fig. 5(b) demonstrates. In this case, DMGWR can still guarantee a high grade of fairness among all nodes. Thus, the DMGWR scheme is robust and fair even when under attack by malevolent nodes.
We finally examine the impact of the multiwindow design on throughput and delay performance under various traffic loads and burstiness. To this end, we make a comparison between the DMGWR scheme with a WS of seven and that with a WS of one. For clarity, DMGWR with a WS of one is referred to as distributed single-window reservation (DSWR). As depicted in Fig. 6(a), under a load of 0.8 (and lower) and Poisson arrivals, both DMGWR and DSWR achieve satisfactory throughput. However, as the load increases, while DMGWR guarantees throughput fairness to all nodes, DSWR renders upstream nodes suffering from throughput unfairness. This is because under heavy loads, with the multigranularity design the up-stream nodes often encounter more slot reservations requested by downstream nodes than the average idle slots passing along the ring. In such a situation, the upstream nodes have less chances to transmit packets resulting in throughput deteri-oration. We also observe in Fig. 6(b) that as the burstiness increases, DSWR undergoes worsening unfairness and incurs rapidly deteriorating delay for upstream nodes. By contrast,
Fig. 5. Delay comparisons for network with malicious nodes. (a) Malicious node (node 10). (b) Malicious nodes (nodes 10 and 15).
the DMGWR scheme invariably achieves superior delay and fairness irrespective of traffic loads and burstiness.
V. TESTBEDEXPERIMENTATION ANDRESULTS
We carried out an experiment to justify the feasibility of the header processing mechanism of OPACS. The experimental setup is shown in Fig. 7. Note that the MAC control part of OPACS is not included in the experiment. This is because the MAC performance, such as system throughput and access delay, can generally be best delineated via simulation results, as what we presented in the previous section. In the experiment, we use four tunable optical transmitters to generate optical packets, respectively at wavelengths 1548.4, 1553.8, 1554.8, and 1556.1 nm, with an average power of 0 dBm per channel. It is worth pointing out that these wavelengths are not selected following the ITU-T WDM standards, but due to the availability of grating filters on these wavelengths. However, since there is only short fiber span inside the header processor, the system is thus free from dispersion. Thus, the location of wavelengths is irrelevant to the feasibility of the architecture.
The transmitter consists of a continuous wave laser and an EA-based external modulator. A 10-GHz pulse pattern gener-ator with prestored header and payload bit sequences is used to modulate the light. The header signal is RZ-encoded at a data
Fig. 6. Impact of multiwindow design on thoughput and delay. (a) Throughput comparison. (b) Delay under various burstiness.
Fig. 7. Experimental node setup (with signal traces at stages (a)–(g) shown in Fig. 8).
rate of 1 Gb/s. Each header is 26 bits in length, including an 8-bit preamble, a 4-bit header control, and a 6-bit address, besides the guard time. The payload signal (250 bytes long) is nonre-turn-to-zero (NRZ) encoded at a data rate of 10 Gb/s. Both the header and payload are generated by the 10-GHz pattern gen-erator. Particularly, the generation of the 1-Gb/s RZ-encoded header-bit waveform is emulated through the generation of five consecutive 10-GHz NRZ pulses.
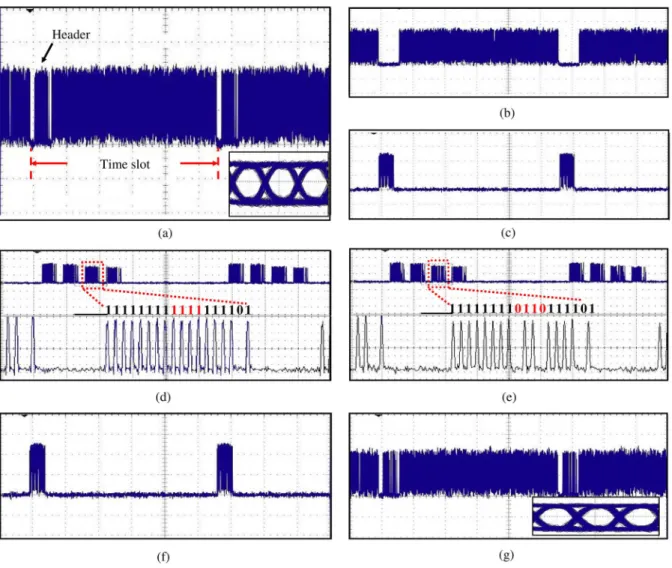
Fig. 8. Experimental results—signal traces observed at stages (a)–(g). (a) Packet signal trace with eye diagram of payload. (b) Payload part. (c) Parallel headers. (d) Serial headers. (e) Serial headers after being modified by EAM. (f) Modified parallel headers. (g) Departing packet signal trace with eye diagram of payload.
The packet signal trace is first shown in Fig. 8(a), with the eye diagram of the payload shown in the inset of the figure. At the input of the header processor, we use an optical splitter and two 2-ns-switching-time SOA-based optical gates to sepa-rate the payload [see Fig. 8(b)] from the header [see Fig. 8(c)]. In the payload path, a tunable fiber delay line is employed to ensure that payloads and headers are synchronized upon depar-ture. In the header path, the headers of different channels are reflected by fiber Bragg gratings of different distances with a total loss of 3 dB. The lengths of different channels’ round-trip paths are given as multiples of the header duration. Specifically, if channel ’s path length is , then ’s round-trip path length will be ’s round-trip length will be , and etc., where is one header duration. Accordingly in the experi-ment, the fiber length between gratings is half of the header du-ration, namely, 13 ns. With this timing arrangement, after being reflected by the grating array, the headers are converted from parallel to serial in the time domain [see Fig. 8(d)]. Therefore, instead of using a header receiver for each channel, the system requires only one header receiver and rewriter module for the update of all headers. They are then routed to the header receiver and rewriter (EA modulator) via a circulator.
The header signal is tapped by a 50/50 tap coupler and received by an optical burst-mode receiver for recovering the header information. The bottom part of Fig. 8(d) shows the RZ-encoded signal of the header on . Recall that the header information is always changed from 1 to 0 due to the MAC design, so that the header rewriter is designed as a pulse eraser. Since RZ pulses enables fast clock phase selection and can be erased with higher timing margin than NRZ pulses, we thereby adopt the RZ encoding format for the header signal. Although different headers are converted from parallel to serial by gratings, the clock phase of the combined header signal is not continuous. Thus, the header receiver determines the best clock phase for each individual header signal from the header’s preamble pulses.
As shown in Fig. 8(e), the control bits are modified (based on the DMGWR scheme) from “1111” to “0110” by the EA mod-ulator with an extinction ratio of 12 dB. The headers are then time-to-wavelength converted from serial back to parallel [see Fig. 8(f)] in the time domain through the same grating array. Through such a design, the grating array in the input section can be simultaneously used in the output section with a reversing signal propagation direction. Finally, the modified header sig-nals are recombined with the payload [see Fig. 8(g)] via an
op-tical coupler without any crosstalk between the headers and load. The eye diagram of the payload demonstrates that the pay-load signal is penalty free throughout the system.
VI. CONCLUSION
We have presented the design and experimentation of an optical-header processing and MAC system, OPACS, for a 10-Gb/s OPS WDM metro slotted-ring network. The system in-cludes an in-band TDM-based optical-header control subsystem and a DMGWR MAC scheme. To perform header-modification operations, unlike traditional TDM-based approaches that generally require highly precise control timing and alignment, OPACS allows multiple optical headers to be efficiently and simultaneously detached and attached from/to the data payload by taking advantage of the sharing of fiber Bragg grating array between the input and output sections of the system and the par-ticularly notable DMGWR design. With the ability in dynamic bandwidth reservation via the multigranularity and multi-window designs, DMGWR provides more efficient resource allocation in response to bursty data traffic and time-varying traffic conditions. Simulation results clearly demonstrate that DMGWR outperforms two existing networks with respect to throughput, access delay, and fairness under various traffic patterns. Essentially, DMGWR guarantees access fairness to all nodes regardless of the propagation distance and traffic bursti-ness. Furthermore, DMGWR is shown robust and fair even under attack by malevolent nodes. Finally, through our 10-Gb/s experimental system, we have illustrated signal traces observed at seven different stages within the system, demonstrating the viability of OPACS for optical-packet-switched WDM metro ring networks.
REFERENCES
[1] B. Mukherjee, “WDM optical communication networks; progress and challenges,” IEEE J. Sel. Areas Commun., vol. 18, no. 10, pp. 1810–1824, Oct. 2001.
[2] M. Herzog, M. Maier, and M. Reisslein, “Metropolitan area packet-switched WDM networks: A survey on ring systems,” IEEE Commun.
Surveys Tuts., vol. 6, no. 2, pp. 2–20, May 2004.
[3] M. Yuang, Y. Lin, S. Lee, I. Chao, B. Lo, P. Tien, C. Chien, J. Chen, and C. Wei, “HOPSMAN: An experimental testbed system for a 10-Gb/s optical packet-switched WDM metro ring network,” IEEE Commun.
Mag., vol. 46, no. 7, pp. 158–166, Jul. 2008.
[4] C. Linardakis, H. Leligou, A. Stavdas, and J. Angelopoulos, “Using explicit reservations to arbitrate access to a metropolitan system of slotted interconnected rings combining TDMA and WDMA,” J.
Lightw. Technol., vol. 23, no. 4, pp. 1576–1585, Apr. 2005.
[5] I. White, M. Rogge, K. Shrikhande, and L. Kazovsky, “A summary of the HORNET project: A next-generation metropolitan area network,”
IEEE J. Sel. Areas Commun., vol. 21, no. 9, pp. 1478–1494, Nov. 2003.
[6] J. Lu and L. Kleinrock, “A WDMA protocol for multichannel DQDB networks,” in Proc. IEEE Global Commun. Conf. (GLOBECOM), Nov. 1993, vol. 1, pp. 149–153.
[7] K. Bengi and H. As, “Efficient QoS support in a slotted multihop WDM metro ring network,” IEEE J. Sel. Areas Commun., vol. 20, no. 1, pp. 216–227, Jan. 2002.
[8] D. Wonglumsom, I. White, K. Shrikhande, M. Rogge, S. Gemelos, F. An, Y. Fukashiro, M. Avenarius, and L. Kazovsky, “Experimental demonstratoion of an access point for HORNET-A packet-over-WDM multiple-access MAN,” J. Lightw. Technol., vol. 18, no. 12, pp. 1709–1717, Dec. 2000.
[9] A. Carena, V. Feo, J. Finochietto, R. Gaudino, F. Neri, C. Piglione, and P. Poggiolini, “RingO: An experimental WDM optical packet network for metro applications,” IEEE J. Sel. Areas Commun., vol. 22, no. 8, pp. 1561–1571, Oct. 2004.
[10] M. Yuang, Y. Wang, and Y. Lin, “A novel medium access control and processing system for a packet-switched WDM metro ring network,” in
Proc. IEEE Opt. Fiber Commun. Conf. Expo. (OFC), San Diego, CA,
Feb. 2008, pp. 1–3, Paper OTul3.
[11] G. Chang, J. Yu, A. Chowdhury, and Y. Yeo, “Optical carrier suppres-sion and separation label-switching techniques,” J. Lightw. Technol., vol. 23, no. 10, pp. 3372–3387, Oct. 2005.
[12] G. Rossi, O. Jerphagnon, B. Olsson, and D. Blumenthal, “Optical SCM data extraction using a fiber-loop mirror for WDM network systems,”
IEEE Photon. Technol. Lett., vol. 12, no. 7, pp. 897–899, Jul. 2000.
[13] Y. Lin, W. Way, and G. Chang, “A novel optical label swapping tech-nique using erasable optical single-sideband subcarrier label,” IEEE
Photon. Technol. Lett., vol. 12, no. 8, pp. 1088–1091, Aug. 2000.
[14] Y. Lin, M. Yuang, S. Lee, and W. Way, “Using superimposed ASK label in a 10-Gb/s multihop all-optical label swapping system,” J.
Lightw. Technol., vol. 22, no. 2, pp. 351–361, Feb. 2004.
[15] T. Kawanishi, K. Higuma, T. Fujita, J. Ichikawa, T. Sakamoto, S. Shi-nada, and M. Izutsu, “High speed optical FSK modulator for optical packet labeling,” J. Lightw. Technol., vol. 23, no. 1, pp. 87–94, Jan. 2005.
[16] N. Chi, J. Zhang, P. V. Holm-Nielsen, C. Peucheret, and P. Jeppesen, “Transmission and transparent wavelength conversion of an optically label signal using ASK/DPSK orthogonal modulation,” IEEE Photon.
Technol. Lett., vol. 15, no. 5, pp. 760–762, May 2003.
[17] M. Ohm and J. Speidel, “Quaternary optical ASK-DPSK and receivers with direct detection,” IEEE Photon. Technol. Lett., vol. 15, no. 1, pp. 159–161, Jan. 2003.
[18] F. Liu and Y. Su, “DPSK/FSK hybrid modulation format and analysis of its nonlinear performance,” J. Lightw. Technol., vol. 26, no. 3, pp. 357–364, Feb. 2008.
[19] C. Guillemot, M. Renaud, P. Gambini, C. Janz., I. Andonovic, R. Bauknecht, B. Bostica, M. Burzio, F. Callegati, M. Casoni, D. Chia-roni, F. Clerot, S. Dorgeuille, A. Dupas, A. Franzen, P. Hansen, D. Hunter, A. Kloch, R. Krahenbuhl, B. Lavigne, A. Corre, C. Raffaeilli, M. Schilling, J. Simon, and L. Zucchelli, “Transparent optical packet switching: The European ACTS KEOPS project approach,” J. Lightw.
Technol., vol. 16, no. 12, pp. 2117–2134, Dec. 1998.
[20] C. Bintjas, N. Pleros, K. Yiannopoulos, G. Theophilopoulos, M. Ka-lyvas, H. Avramopoulos, and G. Guekos, “All-optical packet address and payload separation,” IEEE Photon. Technol. Lett., vol. 14, no. 12, pp. 1728–1730, Dec. 2002.
[21] H. Teimoori, J. Topomondzo, C. Ware, and D. Erasme, “Optical packet header processing using time-to-wavelength mapping in semi-conductor optical amplifiers,” J. Lightw. Technol., vol. 25, no. 8, pp. 2149–2158, Aug. 2007.
[22] A. Bianco, D. Cuda, J. Finochietto, and F. Neri, “Multi-metaring pro-tocol: Fairness in optical packet ring networks,” in Proc. IEEE Int.
Conf. Commun. (ICC), 2007, pp. 2348–2352.
[23] J. Indulska and J. Richards, “A comparative simulation study of proto-cols for a bus WDM architecture,” in Proc. IEEE Singapore Int. Conf.
Netw., 1995, pp. 251–255.
[24] Distributed Queue Dual Bus (DQDB) Subnetwork of a Metropolitan
Area Network (MAN), IEEE Standard 802.6, Dec. 1990.
[25] W. Fischer and K. Meier-Hellstern, “The Markov-modulated poisson process (MMPP) cookbook,” Perform. Eval., vol. 18, no. 2, pp. 149–171, Sep. 1993.
Maria C. Yuang (M’91–SM’03) received the Ph.D.
degree in electrical engineering and computer science from the Polytechnic University, Brooklyn, NY, in 1989.
From 1981 to 1990, she was with AT&T Bell Laboratories and Bell Communications Research (Bellcore), where she was a member of technical staff working on broadband networks and protocol engineering. In 1990, she joined the National Chiao Tung University, Hsinchu, Taiwan, where she is currently a Professor of the Department of Computer Science. Her current research interests include broadband optical networks, wireless networks, multimedia communications, and performance modeling
and analysis. She holds 17 patents in the field of broadband networking, and has more than 100 publications, including a book chapter.
Prof. Yuang was a Guest Editor for a Special Issue of IEEE JOURNAL OF
SELECTEDAREAS INCOMMUNICATIONSon Next-Generation Broadband Optical Access Network Technologies in 2009. She was a member of the technical pro-gram committee of many technical conferences, including IEEE International Communications Conference and IEEE Global Communications Conference, and has been invited to give invited talks at many technical conferences. She is a member of Optical Society of America.
Yu-Min Lin (M’08) received the B.S. degree from the Department of Electrical
Engineering, National Tsing Hua University, Hsinchu, Taiwan, in 1996, and the Ph.D. degree from the Department of Communications Engineering, National Chiao Tung University, Hsinchu, in 2003.
He joined the Department of Optical Communications and Networks, Indus-trial Technology Research Institute, Hsinchu, in 2004. His current research in-terests include broadband optical networking, optical transmissions, and optical packet switching.
Ya-Shian Wang received the M.S. degree from the
Department of Computer Science and Electrical Engineering, National Central University, Jhongli, Taiwan, in 1994. She is currently working toward the Ph.D. degree in the Department of Computer Science, National Chiao Tung University, Hsinchu, Taiwan.
In 1994, she joined the Telecommunication Lab-oratories, Chunghwa Telecom Co., Ltd., Taoyuan, Taiwan, where she is currently engaged in network control and management of broadband networks. Her current research interests include optical networking, broadband network management, and performance modeling and analysis.