A Vowel-oriented Retrieval Scheme on Minimal Perfect Hashing Searching
8
0
0
全文
(2) string of keyword as key feature in the design of MPHF. In recent study, Wang et al. [8] proposed a displacement addressing method on keywords hashing. In their method, the keywords set need to be divided into several subsets of adequate size to remain its performance of decent hashing times when the keywords set is larger. Accordingly, we develop a new MPHF to address the keywords’ locations in efficiency in this paper to avoid the set segmentations with proper size beforehand. Furthermore, the amount of processed keywords in our scheme is more than that of [8] and the hashing times in average is even lower than the execution in [8] over the experiment show. The rest sections are organized as follows. Sec. 2 describes our efficient vowel-oriented MPHF. Then an example of more keywords is illustrated and a comparative experiment for thousands of keywords is shown in Sec 3. Finally, the conclusions are given in Sec. 4.. and the last consonant as ‘A’, ‘E’ and ‘D’ are posted at locations 2, 5 and 6. For the three letters, which could be encoded into an initial number IN= 205164 of resulting from the concatenation of the three pairs of (L,R(L))s =(2,0), (5,1), (6,4), where L denote the position number of placing a letter numerated from left-to-right starting at 1 on the processed keyword and R(•) is the letter-to-number translation relation for L. Furthermore, in order to conduct the specific number SN, a modulus of prime 29 is chosen to gain SN=IN mod 29=205164 mod 29=18. A pair of (EL,SN)= (P,18) associated with “PACKED” is therefore featured. Similarly, we could obtain the other key-pairs such as (B,23) for “BEGIN” and (E,3) for “END”. Eventually, group all key-pairs (EL, SN)s associated the reserved words in PASCAL in the lexical ordering of the EL’s. The group table is then shown as Table 1 below. Observe the Table 1, we find out that the two keywords, “THEN” and “TO” in ‘T’-head group generate the same specific number SN=7, i.e. they could not to be distinguished in a hashing process. Therefore, a cyclic extraction process that generates next key-pair of (EL, SN) for the two collided words is needed to be launched until all keywords could be completely recognized. In our scheme, the next key-pairs of (EL,SN)s=(O,13), (H,19) are capable of being featured by the rest keywords “O” and “HEN”, respectively resulted from removing the head-letter of the original words. The two words collided to each other in ‘T’-head group in the first hashing would be further subdivided into a subgroup of ‘O’-head and a subgroup of ‘H’-head within the area of ‘T’-head group for next hashing use. In conclusion, the work to thoroughly distinguish all key-pairs for the reserved words in PASCAL is done. In order to further form the addressing hashing table, the CRT is employed to generate the representative constant planted inside the table for later keyword retrieval use. The application for CRT to generate the constant is now shown as follows:. 2. A Vowel-oriented Retrieval Scheme on MPHF Searching Without loss generality, each keyword considered in our scheme is assumed to be a non-trivial string of characters in English. The MPHF explored in our scheme is a way that features a key-pair of (EL, SN) in a keyword, where EL is a letter extracted from the heading letter and SN is a specific number computed from the distribution of the vowel-letters and the last consonant-letter within the keyword. These key-pairs, afterwards, are grouped into a table, named group table, in lexical ordering of the EL’s. The second components SN’s of key-pairs in each group would be then gathered into a representative constant. Meanwhile, the offset number of EL in each group is required to be recorded in order to efficiently utilize the storage space. Eventually, an addressing hashing table is thus constructed in terms of the sets of offset and representative constant. In the following, a simple example using reserved words in PASCAL is introduced to illustrate the group table generation during hashing process so as to facilitate readers to understand our proposed algorithms later. First of all, we define the letter-to-number translation relations, Rv and Rc, for the vowel-letter and consonant-letter in English, respectively. The set of vowel-letters {A,E,I,O,U} is then translated to a set of a sequence of numbers as { Rv (A)=0, Rv (E)=1, Rv (I)=2, Rv (O)=3, Rv (U)=4}. Follow this principle, the set of consonant-letter {B,C,… ,Y, Z} is also mapped to a numerical set of {Rc(B)=2, Rc(C)=3, … Rc(Y)=25, Rc(Z)=26}, where Rc(‘vowel-letter’) is undefined. Second, the key-pair of (EL, SN) is characterized from each keyword. Third, group the keywords set in lexical ordering of the heading letter EL’s of the processed keywords. Subsequently, consider a reserved word “PACKED” in PASCAL, for instance, in which the letter-vowels. Theorem 1 (Chinese remainder theorem) Let r1,r2 ,… … .rn be integers. There exists an integer C such that r1 =C (mod p 1), r2 =C (mod p2 ), … , and rn =C (mod p n ), if p i and p j are relatively prime for all i ≠ j. Theorem 2 Let pi and p j be relatively prime number, where i ≠ j and 1 ≤ i,j ≤ n. Let p1 <p2 <… <pn . Then. C =. ∑ i = 1 ( b i M i i) mod n. n. ∏ i =1. positive integer C ≡ i (mod p i ) if M i =. pi. be. ∏. such pj j≠ i. satisfies the congruence M i bi. the. smallest. and. that bi. ≡ 1(mod p i ) .. According to the Theorem 1 and 2 mentioned above, the numbers p i ’s are required to be relatively prime to 2.
(3) each other so as to construct a constant satisfying the congruence relations. Therefore, a prime translation table shown in Table 2 is built to guarantee the p i s’ conditions in CRT. To fit for our scheme, the expression of C ≡ i (mod pi ) in Theorem 2 is required to be. Step 6: Construct a representative constant for all keywords for HELi -head group by (2), where the formula in (1) would be modified into two parts containing. RC ( ELi ) ≡ 0 (mod p( SN )). for. the. p(SN)’s generated from marked keywords and RC ( ELi ) ≡ i (mod p ( SN )) , i≥1 for. adjusted as. the unmark keywords with their associated p(SN)’s. Step 7: Count the total number of all unmark keywords in HELi -head group.. RC ≡ i (mod p( SN i )) (1) As a result, the generation for RC is changed as the form. Then compute Ot (ELi ) as Ot (ELi )=. n RC = ∑ bi ∏ p ( SN j ) i mod ∏ p ( SNi ) , i =1 i =1 j ≠i (2)where ∏ p(SN j ) • bi ≡ 1(mod p (SN i )) . n. i −1. ∑G x=1. (t ) x. ,. where |G| denotes the cardinality of a group set containing unmark keywords. Step 8: Compute T(1) =. j ≠i. z. ∑G x =1. Come after the distinct key-pair (EL, SN)’s featured from the particular keywords, the RC is constructed by CRT mentioned above. Then an addressing hashing table is built instead of the particular set of keywords for retrieval use. On the way of retrieval of a keyword, the MPHF is set as the expression: Ht (EL,SN)=Ot (EL)+(RCt(EL) mod p(SN)), (3)where the numbers Ot ’s and RCt’s for t≥1 are key parameters to address each keyword. The details to generate the addressing hashing table are summarized the following algorithms.. (1) x. .. Step 9: Set t=t+1 and cut off the first letter HEL of the marked keywords in each HEL-head group to be a new processed keywords set, say HEL-NPKS(t) . Step 10: Numerate the HEL-NPKS(t) sets as NPKS 1(t), NPKS2(t), … , NPKSs (t) , where s = the total amount of the HEL-NPKS(t) sets. Step 11: Output the sets containing the non-negative integers offset O1 (ELi )’s and RC1 ((ELi )’s. Algorithm 2: The construction of an addressing hashing table. Input: The set HEL-NPKS(t) in the HEL-head group. Output: The sets of non-integers of offset Ot ’s and representative constant RCt that associate with the extracted letter EL generated in hashing t≥2. Step 1: Group the HEL-NPKS(t) with their head-letter in lexical ordering denoted by SGHEL,1(t), SGHEL,2 (t),… , SGHEL,j (t) ,… ,SGHEL,r (t) for t≥2 and extract ELj from the head-letter of processed keyword in SGHEL,j (t) . Step2: Compute the initial number IN for HEL-NPKS(t) in Step 2 of Algorithm 1. Step 3: Compute the specific number SN as SN=IN mod 29. Step 4: Compare all SN’s in the ELj -head subgroup. Mark the keywords in which the associated key-pairs have with the same SN. Step 5: Translate all SN’s to their corresponding primes p(SN)’s using Table 2. Step 6: Construct a representative constant for ELj -head group in Step 6 of Algorithm 1. Step 7: Let HEL-NPKS(t) be the ith set among the all NPKS(t) sets, 1≤i≤s. Count the total number of all unmark keywords in ELj -head subgroup. Then O(ELj )t is computed as. Algorithm 1: The basic group divisions that associate with the heading letter HEL’s in the particular keywords set. Input: A set of particular keywords with the heading letter HEL’s, say PKS. Output: The sets of non-integers of offset Ot ’s and representative constant RCt ’s that associate with HEL’s in a hashing t=1. Step 1: Set the hashing time t=1, and group all the input keywords denoted by G1(t), (t) (t) (t) G2 ,… Gi ,… , Gz with their heading letter HELi in lexical ordering. Step 2: Compute the initial number IN for each processed keyword, where IN = concatenating the pairs of (L,R(L)) for all the vowel-letters and the last consonant-letter within a processed keyword. The components L’s and R(L)’s have been defined on the previous paragraph. Step 3:Compute the specific number SN for the processed keyword as SN=IN mod 29. Step 4: Compare all the SN’s in the HELi -head group. Mark the keywords in which the generating key-pairs (ELi , SN)’s have the same component SN, where ELi = HELi . Step 5: Translate all the SN’s for each group to their corresponding primes p(SN)’s by using Table 2. 3.
(4) i −1. t −1. O(ELj ) t =. ∑T ( y ) + y =1. +. j−1. ∑. NPKS y =1. SG. (t ) HEL , y. addressing hashing table Step 1: Set the hashing time t=1. Step 2: Feature a key-pair (EL, SN) in HEL-head group for K by using the Step 2 and 3 of the Algorithm 1, where the first component EL is the head-letter of the processed keyword. Step 3: Determine the computation as D=RCt (EL) mod p(SN), IF D≠0 THEN perform the Equation (3) in HEL-head group and go to Step 4 ELSE set t=t+1 and cut off the first letter of the processed keyword to be a new keyword, then go to Step 2 to feature next key-pair (EL, SN). Setp 4: Output the mapping address of K, resulted from Ht (EL,SN).. r. ∑ ∑ SG (t ). NPKS x =1. y=1. ( t) HEL, y. ,. i. (4)where |SG| denotes the cardinality of a subgroup of keywords set. Step 8: Compute T(t) =. s. ∑. NPKS. x =1. r. (t). ∑. y= 1. ( t) SG HEL ,y. Step 9: Set t=t+1. Cut off the first letter. EL j of the. marked keywords in the each ELj -head subgroup to be a new processed keywords HEL-NPKS(t) . Step 10: Numerate the HEL-NPKS(t) sets as NPKS 1(t), NPKS2(t), … , NPKSs (t) , where s = the total amount of the HEL-NPKS(t) sets. Step 11: Go to Step 1 to reiterate until all HEL-NPKS(t) =∅ . Step 12: Output Ot ’s and RCt ’s associated with the extracted letter ELj for t≥2. After executing Algorithm 1 and 2, an addressing hashing table is constructed in terms of the sets of Ot ’s and RCt ’s for for t≥1. Next, continue to consider the reserved words in PASCAL again to illustrate the setup of the addressing hashing table according to the proposed algorithms. Inspect The ‘F’-head group of {FOR, FUNCTION, FILE}, for instance, following the Algorithm 1 the key-pair of (EL, SN)’s are first featured as {(F,2), (F,14),(F,18)}. A representative constant RC1 is then constructed based on the CRT satisfying the congruence relations as RC1 (F)= 1 (mod p(2)), RC1 (F)= 2 (mod p(14)), RC1 (F)= 3 mod (p(18)), where p(•) is a prime translation shown in Table 2. Consequently, RC1 (F)=1894 is summed up by using (2). Besides, O1 (F) is filled with 10 in the hashing table since it is counted from the total number of distinct key-pairs from the ‘A’-head group to ‘E’-head group. Then look at the marked keywords “THEN” and “TO” in the first hashing. Due to the (EL, SN)’s are the same, the second hashing process is thus launched inside the ‘T’- head group. According to the Algorithm 2, RC2 (H)=108 and RC2 (O)=42 are generated, respectively for the rest keywords “HEN” and “O” when the first letter ‘T’ is cut off from the original keywords. Meanwhile, the offset O2 (H)=31 +0=31 and O2 (O)=31+1=32 are also counted out. Lastly, the addressing hashing for reserved words in PASCAL is shown in the following Table 3. Having set the hashing table, the retrieval algorithm to address a query keyword is presented as follows:. 3. Experiments and Discussions In this Sec., we further show an example with more keywords of VAL containing 59 reserved words to demonstrate our approach. Example 3.1. Consider the 59 reserved words in VAL. Through the Algorithm 1 in our scheme, a group table, Table 4, is generated as shown in the following. In Table 4, There two groups which exist the same key-pairs have been found in ‘N’-head group and ‘T’-head group, respectively. The RC1 (T) in ‘T’-letter group, for instance, is generated as the form as RC1 (T) =1 (mod p(4)), RC1 (T) =0 (mod p(7)), RC1 (T) = 0 (mod p(20)), such that RC1 (T) =6035 and then to be stored into the addressing hashing table. Examine the marked keywords “TAG”, “THEN”, “TRUE”, “TYPE” that need to be reprocessed by the Algorithm 2. Afterwards, the four marked keywords are further subdivided into four subgroups, cited by ‘A’-head subgroup, ‘H’-head subgroup, “R”-subgroup and “Y”-subgroup, inside the area of ‘T’-head group of hashing table. Subsequently, the offsets and representative constants as O2 (A)=55, RC2 (A)=80, O2 (H)=56, RC2 (H)=38, O2 (R)=57, RC2 (R)=68 and O2 (Y)=58, RC2 (Y)=38 associated with the four reprocessed keywords are computed. Ultimately, the hashing table construction is stopped on the second process since all the 59 keywords have been come out 59 distinct key-pairs within the two hashing processes. To address the validation of hashing table, consider the keyword “TRUE” now, then the Algorithm 3 is launched. The first key-pair (T,20) is featured, then the O1 (T) and RC1 (T) are revealed to compute the D=6035 mod p(20)=0. Clearly, it is necessary to enter the second hashing process since D=0. Hence the second key-pair (R,19) of ‘R’-head subgroup inside the ‘T’-head group is obtained again. Compute D= 68. Algorithm 3: Addressing an input keyword Input: A query keyword K with heading letter HEL Output: The address of K translated from the 4.
(5) mod p(19)=1, so that H2(R,19)=O2(R)+D=57+1=58 in (3) is evaluated , which is the address of “TRUE”. The whole hashing table for reserved words in VAL is shown as Table 5 below. Compare to Wang et al.’s scheme [8] in which the cyclic letter-oriented based on the displacement addressing technique was proposed. Although a rather large amount keywords could be processed in their scheme, but the keywords need to divide an adequate size of keywords set in order to reduce the hashing times in querying a keyword. The reason is that all the collision keywords in each hashing process are gathered together to regenerate next key-pairs and then refilled into the hashing table in terms of non-negative integers. The manipulation for the rehashed keywords is too complicated so that the processed keywords are required to be divided beforehand. While in our scheme, not only the division for a larger keywords set is released, but also the less hashing times is gained, as observed from the result of the experiment show. That is to say, thousands of keywords could be directly translated into an addressing hashing table. Without loss the generality, the stored integer in hashing table is still large, but the most large integer happening in our scheme is limited a value of 28. ∏. (EL,SN) is uniquely featured from each particular keyword during the hashing processes. Eventually, the hashing table in which two set of offsets and representative constants are planted for addressing the keyword is built to utilize in later retrieval of a query keyword. The area of each heading letter group is further divided into various subgroups to accommodate the marked keywords associated with the same the key-pair in the hashing table construction. Afterwards, each marked keyword appearing in the same heading letter group is cyclically cut off the heading letter of the rest keyword itself to gain a new key-pair for rehashing use. Consequently, our scheme could process a larger amount of keywords up to thousands. It’s also apparently observed that the hashing times executed in average is notably less than that of [8] over the result of experiment. Besides, the key-pair featured on each keyword in our scheme is gained by the strategy of cyclic extraction for the letter-oriented keyword so that the intractable letter-selection on keyword in some other literatures is avoided. In conclusion, a fast searching using MPHF for a large set of keywords is efficiently achieved in our scheme. References [1] C.C. Chang, “The study of an ordered minimal perfect hashing scheme,” Comm. ACM. 27(4), 1984, 384-387. [2] R.J. Cichelli, “Minimal perfect hash functions made simple,” Comm. ACM. 23(1), 1980, 17-19. [3] Z.J. Czech, G. Havas and B.S. Majewski, “An optimal algorithm for generating minimal perfect hash functions,” Information Processing Letters 43(5), 1992, pp.257-264. [4] E.A. Fox, L.S. Heath, Q.F. Chen and A.M. Daoud, “Practical minimal perfect hash functions for large databases,” Comm. ACM 35(1), 1992, pp. 105-121. [5] G. Jaeschke, “reciprocal hashing: A method for generating minimal perfect hashing functions,” Comm. ACM 24(12), 1981, pp. 829-833. [6] B. Jenkins, “Algorithm alley: Hash functions,” Dr. Dobb’s J. 1997, pp.107-109, pp. 115-16. [7] T.G. Lewis and C.R. Cook, “Hashing for dynamic and static internal tables,” IEEE Computers, 1988, pp. 45-46. [8] S.J. Wang and J.K. Jan, “A displacement addressing method for letter-oriented keys,” The Journal of Systems and Software 46, 1999, pp. 77-88.. p ( i ) , where p(i) is derived from the Table 2. In. i= 0. practice, these digit numbers were usually stored in the form of character-string to avoid the truncation errors in data storage and then segmentalized systematically to achieve the arithmetic operation. Accordingly, the implement of the number-store hashing table is viable in real applications. In our scheme, we further perform an experiment in which there are two thousands commonly used keywords in an ordinary diction of English to illustrate the validity of our algorithms. The experiment shown in Fig 1 apparently explains that the hashing times is proportional to the set of keywords and the curve plotted in our scheme is lower than the curve shown in [8]. However, each keyword in our experiment is uniformly distributed between 2 and 20 in length. Having set up the hashing table, a simple arithmetic modular operation is required when a keyword query requests. Although the keywords set increase dramatically, the hashing times are still kept growth slowly, as observed from Fig. 1. There fore, our scheme indeed speeds up the searching time of a hashing keyword and improves the performance of algorithms proposed in [8] on more large keywords set. 4. Conclusions In this paper, we have proposed a new minimal perfect hashing function to implement the fast letter-oriented string searching. A key-pair of. 5.
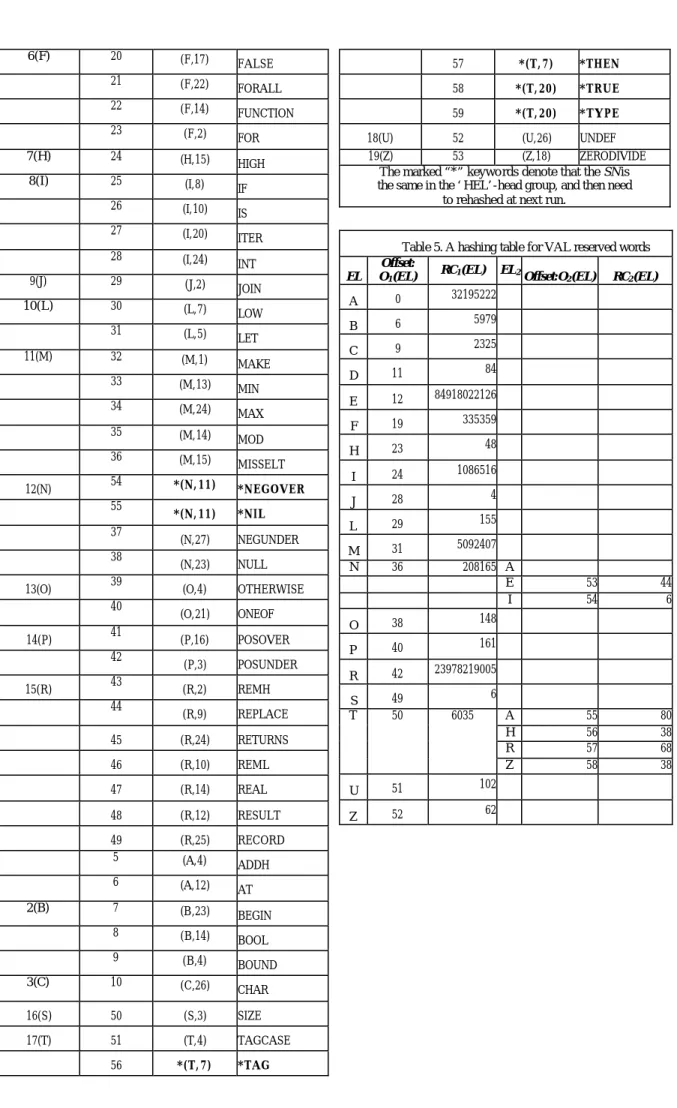
(6) Table 1. Consider the group table of keyword set of PASCAL reserved words IN. GroupKeywords 1(A). ARRAY. 1040525. AND BEGIN. 3(C). CONST. 6(F). IN. 1326 21. OR. 13218 23. 2142514 2313(P) PACKED. 205164 18. 23520. 1. PROGRAM. CASE. 2041319. 9. PROCEDURE33517491818 27. DOWNTO. 2363520 2014(R) REPEAT. DIV. 5(E). 5 12(O) OF. 1034 19. 2(B). 4(D). SN Group Keywords. Table 3. Address Hashing table for PASCAL reserved words Offset: Offset: SN EL(HEL) O1 (EL) RC1 (EL) EL O2 (EL)RC1 (EL). 22322 21. 2314 2315(S) SET. END. 1134. ELSE. 1141319 24. FOR. 23318. 214150620. RECOED. DO. 21320. *23120 *7. TYPE. 41316 20. FUNCTION 246273814 1417(U) UNTIL 2241312 1818(V) VAR. 7(G). GOTO. 2343320. 8(I). IN. 12214. 5. IF. 1226. 8. 5. *31414 *7. *TO. FILE. 4. 21435164 17. 316(T) *THEN. 2. 3360713 19. 1442512 23 20318 18. 419(W) WITH WHILE. A. 0. 672. B. 2. 84. C. 3. 25. D. 5. 28472. E. 8. 91. F. 10. 1894. G. 13. 8. I. 14. 78. K. 18. L. 16. 44. M. 17. 155. N. 18. 4235 160065. O. 20. 2248 15. P. 22. 3251412 19. Q. The asterisk ‘*’ denotes the associated word collides with other words in PASCAL. 120. R. 25. 12. S T. 27 29. 782 84. Table 2: The prime translation table. A H. 32. 108. O. 33. 42. SNi. p(SNi ). SNi. p(SNi ). SNi. p(SNi ). 1. 2. 11. 31. 21. 73. U. 30. 62. 2. 3. 12. 37. 22. 79. V. 31. 471. 3. 5. 13. 41. 23. 83. 4. 7. 14. 43. 24. 89. 5. 11. 15. 47. 25. 97. 6. 13. 16. 53. 26. 101. 7. 17. 17. 59. 27. 103. 2. (A,0). ARITHERROR. 107. 3. (A,24). ABS. 109. 4. (A,5). ARRAY. 11. (C,23). CONSTRUCT. 4(D). 12. (D,23). DO. 5(E). 13. (E,6). EXP. 14. (E,12). EMPTY. 15. (E,25). ELSEIF. 16. (E,24). ELSE. 17. (E,3). END. 18. (E,21). EVAL. 19. (E,19). ERROR. 8 9. 19 23. 18 19. 61 67. 28 0. Table 4. A heading letter group table for VAL reserved words Group Translated The key-pair Keywords (‘HEL’-head ) address (EL,SN)’s 1(A) 1 (A,1) ADDL. 10 29 20 71 SN i : the specific number computed from a keyword p(SN i ): the corresponding prime of SN under the prime translation mapping. 6.
(7) 20. (F,17). FALSE. 57. *(T, 7). *THEN. 21. (F,22). FORALL. 58. *(T, 20). *TRUE. 22. (F,14). FUNCTION. 59. *(T, 20). *TYPE. 23. (F,2). FOR. 7(H). 24. (H,15). HIGH. 8(I). 25. (I,8). IF. 26. (I,10). IS. 27. (I,20). ITER. 28. (I,24). INT. 9(J). 29. (J,2). JOIN. 10(L). 30. (L,7). LOW. 31. (L,5). LET. 32. (M,1). 33. (M,13). MIN. 34. (M,24). MAX. 35. (M,14). MOD. 36. (M,15). MISSELT. 54. *(N, 11). *NEGOVER. *(N, 11). *NIL. 6(F). 11(M). 12(N). 55 37 38 13(O). 39 40. 14(P). 41 42. 15(R). 43 44. EL A. NEGUNDER. (N,23). NULL. (O,4). OTHERWISE. (O,21). ONEOF. (P,16). POSOVER. (P,3). POSUNDER. Table 5. A hashing table for VAL reserved words Offset: RC1 (EL) EL 2 O1 (EL) Offset:O2 (EL) RC2 (EL) 32195222 0. B. 6. 5979. C. 9. 2325. D. 11. 84. E. 12. 84918022126. F. 19. 335359. H. 23. 48. I. 24. 1086516. J. 28. 4. L. 29. 155. M N. 31 36. 5092407. MAKE. (N,27). (R,2). 18(U) 52 (U,26) UNDEF 19(Z) 53 (Z,18) ZERODIVIDE The marked “*” keywo rds denote that the SN is the same in the ‘HEL’-head group, and then need to rehashed at next run.. 208165 A E I. O. 38. 148. P. 40. 161. R. 42. 23978219005. S T. 49 50. 6. REMH. (R,9). REPLACE. 45. (R,24). RETURNS. 46. (R,10). REML. 47. (R,14). REAL. U. 51. 102. 48. (R,12). RESULT. Z. 52. 62. 49 5. (R,25). RECORD. (A,4). ADDH. 6. (A,12). AT. 7. (B,23). BEGIN. 8. (B,14). BOOL. 9. (B,4). BOUND. 3(C). 10. (C,26). CHAR. 16(S). 50. (S,3). SIZE. 17(T). 51. (T,4). TAGCASE. 56. *(T, 7). 2(B). *TAG. 7. 6035. A H R Z. 53 54. 44 6. 55 56 57 58. 80 38 68 38.
(8) 2.8 8. 3.0 5. 3.2 7. Wang et al.'s hashing scheme. 2.4 35. 2.3 9. 2.3 5. 2.3 19. 2.3 1. 2 2.. 2.1 6. 2.1 43. 1.9 04. 1.8 1. 1.7 83. 1.7 29 1.4 82. 1.8 5. 2. 1.5 6 1.4 1.4 1. 1.2 1.3 89. 1.2 65. 2.3 04. 1.7 4. 2.2 4. 2.3 9. 2.5 5. Our hashing scheme. 2000. 1900. 1800. 1700. 1600. 1500. 1400. 1300. 1200. 1100. 1000. 900. 800. 700. 600. 500. 400. 300. 200. 100. 0 0. 0. hashing times. 5 4.8 4.6 4.4 4.2 4 3.8 3.6 3.4 3.2 3 2.8 2.6 2.4 2.2 2 1.8 1.6 1.4 1.2 1 0.8 0.6 0.4 0.2 0. keywords set. Fig.1. The experiment shows the hashing times in average between our scheme and Wang et al.’s scheme.. 8.
(9)
數據

相關文件
Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval pp.298-306.. Automatic Classification Using Supervised
The min-max and the max-min k-split problem are defined similarly except that the objectives are to minimize the maximum subgraph, and to maximize the minimum subgraph respectively..
• Information retrieval : Implementing and Evaluating Search Engines, by Stefan Büttcher, Charles L.A.
In accordance with the analysis of relevant experimental results carried in this research, it proves that the writing mechanism and its functions may improve the learning
In order to facilitate school personnel of DSS schools in operating their schools smoothly and effectively and to provide new DSS schools a quick reference on the
The case where all the ρ s are equal to identity shows that this is not true in general (in this case the irreducible representations are lines, and we have an infinity of ways
Associate Professor of Information Management Head of Department of Information Management Chaoyang University
Associate Professor of Information Management Head of Department of Information Management Chaoyang University
