行政院國家科學委員會專題研究計畫 成果報告
一個整合普適計算環境的運作機制之研究--無線感測網路
上省電之資料管理技術之研究
研究成果報告(精簡版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 98-2221-E-009-071- 執 行 期 間 : 98 年 08 月 01 日至 99 年 07 月 31 日 執 行 單 位 : 國立交通大學資訊工程學系(所) 計 畫 主 持 人 : 黃俊龍 報 告 附 件 : 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 99 年 10 月 31 日
Hierarchical Role-based Data Dissemination for
Large-Scale Wireless Sensor Networks with Mobile Sinks
Guo-He Ye, Lo-Yao Yeh, and Jiun-Long Huang
Department of Computer Science,National Chiao Tung University,Hsinchu 300, Taiwan, R.O.C. E-mail:[email protected]; [email protected]; [email protected]
Abstract
In this paper, we propose a Hierarchical Role-based Data Dissemination approach, named HRDD, for large-scale wireless sensor networks with multiple mobile sinks. In HRDD, we use a hierarchical cluster-based structure to discover and maintain the routing paths for distributing data to the mobile sink. We assign two roles, named Indexing Agent and Gateway Agent, to some sen-sor nodes in the wireless sensen-sor networks. Indexing Agents are used to remove unnecessary query messages, while Gateway Agents contribute to decrease energy consumption and the broadcasting messages. We evaluate and compare the impact of the number of nodes with prior approach. The simulation results justify that HRDD has the capability to reduce the energy consumption in the wireless sensor networks and to prolong network lifetime.
1
INTRODUCTION
The primary goal of a wireless sensor network (WSN) is to collect useful information such as battlefield surveillance, habitat monitoring [5] [12], disaster rescue, and traffic tracking. The sensor generating data reports is called a source node, while the control center issuing the query messages is called a sink. The sink sends query or control commands to sensor nodes and collects information from the sensors. Data dissemination protocols are the means to distribute queries and data among the sensor nodes. Although several kinds of protocols have been proposed [8] [13] [3] [14], data dissemination protocols in WSNs still have the following challenges:
1. Some research [8] [13] [14] requires all sensors equipped with positioning devices, such as Global Positioning System (GPS), to build a unique routing structure for each source. Unfortunately, posi-tioning devices usually have the following limitations: (a) the high power consumption of position-ing devices drains out the battery of a sensor node fast; and (b) the cost of positionposition-ing devices can become the most deterrent factor for large-scale deployment of WSNs.
2. In many situations, a static sink may be unfeasible because of deployment or security constraints. In addition, sink mobility may also improve the lifetime of a WSN [3]. In the applications with sink mobility, the difficulty for sensor nodes is to efficiently track the location of sink. However, broadcasting the sink information consumes much energy of all sensors [7].
3. To maintain routing information, sensor nodes must periodically broadcast control messages to neighbor nodes. In large-scale wireless sensor networks, the overall control overhead leads to large power consumption to deplete the lifetime of WSNs.
In this paper, we propose a Hierarchical Role-based Data Dissemination approach (HRDD) for provid-ing a scalable and energy-efficient data dissemination with multiple mobile sinks in WSNs. We adopt clustering techniques to build a hierarchical structure so that each mobile sink can easily maintain its data dissemination paths. HRDD assigns the special roles, index agent and gateway Agent, to some nodes to greatly improve overall system scalability and lifetime. HRDD settles the data dissemination challenges in WSNs :
S1. We exploit a clustering algorithm [1] to discover the initial location and construct a specific struc-ture to maintain the routing paths without the help of GPS devices.
S2. For efficient tracking, we set some nodes, named Index Agents, to form a virtual infrastructure formed for routing, data aggregation and data dissemination.
S3. Without periodically broadcasting messages, HRDD delegates specific nodes to perform deliver tasks. Moreover, we adopt hierarchical-based approach to construct a two-tier architecture to bal-ance the load of transferring messages.
To evaluate the performance of HRDD, several experiments are conducted. The experimental results show that the proposed Hierarchical Role-based Data Dissemination (HRDD) reduces the total energy consumption of the WSNs by 50%, achieves longer network lifetime, and outperforms our counterpart Hierarchical Cluster-based Data Dissemination (HCDD) [9] in terms of total transmission overhead.
2
Hierarchical-based dissemination schemes
In 2005, a hierarchical-based dissemination scheme is proposed, named Hierarchical Data Dissemina-tion Scheme (HDDS) [13]. A source routes data towards sinks using a hierarchy of randomly selected dissemination nodes. Because dissemination nodes have limited resources, whenever a dissemination node is overloaded, it inserts another level of dissemination nodes to reduce its load. For an energy-efficient communication scheme, data forwarding path is close to the shortest route since this path optimization is essential to prolong lifetime of sensor networks. HDDS follows a data transmission policy that forwards data to the forwarding agent directly. Thus, data may take a shorter path, and the total energy consumption and delay can be reduced.
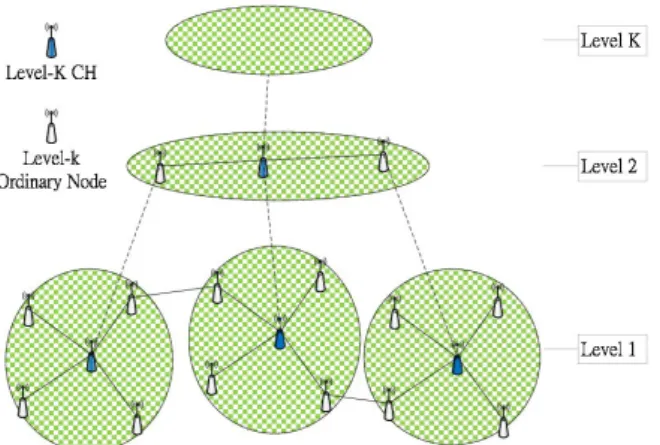
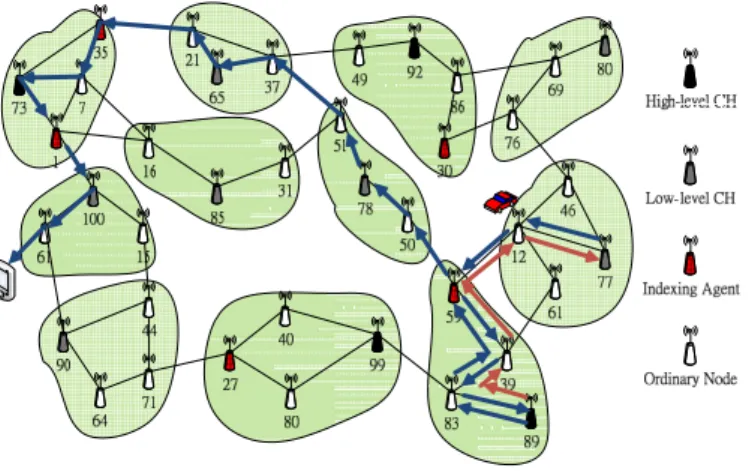
Next, a scheme named Hierarchical Cluster-based Data Dissemination (HCDD) [9] is proposed to discover and maintain the routing paths for distributing data to the mobile sink, as shown in Figure 1.
In HCDD, all nodes distributedly build a cluster structure without the location information, so each node only has to exchange the information with its neighboring nodes. There are three steps in HCDD.
Step 1. Cluster Construction: All nodes are divided into multilevel clusters by Max-Min D-Cluster Formation Algorithm [1], and each cluster will designate a node as the cluster head (CH). After the cluster construction, all of CHs in the highest hierarchical level CHs, called routing agent, should keep dynamic global information, i.e. the sink information and routing information.
Figure 1: Hierarchical Cluster-based Data Dissemination (HCDD)
Step 2. Sink Location Registration: each sink has to register at one of the routing agents, which are responsible for the management of the sink information. The sink information should only be broadcasted to routing agents, but not flooded to all sensor nodes.
Step 3. Data Delivery and Path Routing: CHs and Routing Agents cooperate to find the paths from data sources to the sink by the inter-cluster routing and the intra-cluster routing.
3
HRDD: HIERARCHICAL ROLE-BASED DATA
DISSEMINA-TION
Based on the hierarchical-based approach, we propose hierarchical role-based data dissemination scheme, named HRDD. Conceptually, HRDD consists the following five steps.
Step 1. Cluster Construction
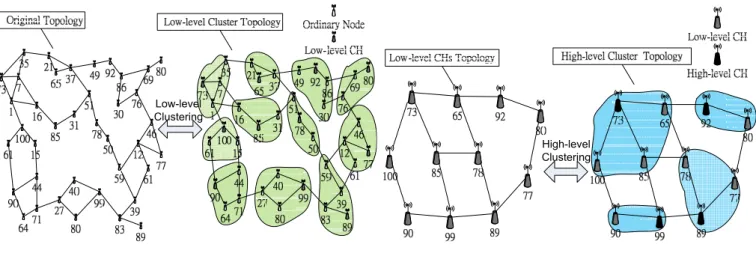
We use clustering technique to build a hierarchical structure so that each mobile sink can easily maintain its data dissemination path. Figure 2 illustrates the fundamental concept of our two-tier hierarchy infrastructure, and the numbers in the figure expresses the ID of sensor nodes.
First, all sensor nodes organize themselves into low-level clusters via a CH election process [1] [2] [6] [11], shown in Figure 2 (a). The low-level clusters, in turn, organize themselves into high-level clusters, shown in Figure 2 (b). All nodes are grouped into multilevel clusters, and each cluster will elect a node as the CH.
Step 2. Selection of Indexing Agent and Gateway Agent
Each high-level CH has to select a set of nodes as indexing agents and gateway agents to reduce the communication overhead.
Step 3. Event Detection
The sensing data are stored to its low-level CH and an event information message containing the event type and event location etc. is sent to Indexing Agent for events queries.
(a) Low-level Clustering (b) High-level Clustering
Figure 2: An Example of Hierarchical Role-based Data Dissemination (HRDD)
Step 4. Sink Location Registration
Before issuing a query, each sink will register its location information to all high-level CHs through Gateway Agents.
Step 5. Data Forwarding
When an Indexing Agent has the relevant data which a sink queries, the data will be forwarded to the sink by the reverse path.
The details of each procedure are presented in the following subsections.
3.1
Cluster Construction
Considering the implementation cost and network scale, we exploit the Max-Min D-Cluster Formation Algorithm [1] as the load-balanced clustering algorithm. The Max-Min D-Cluster algorithm guarantees that no node is more than D hops away from its CH. After the Max-Min D-cluster algorithm, CHs form a virtual backbone and may be used to route packets for nodes in their cluster. These CHs are called low-level CHs. Then, Max-Min D-cluster algorithm is performed on the low-level CHs to form high-level clusters.
3.2
Selection of Indexing Agent and Gateway Agent
After the cluster construction, the high-level CHs are aware of local information, i.e. the information of low-level clusters and the neighboring high-level clusters. The agent selecting algorithm is proposed to assign indexing agents and gateway agents by the local information. The main idea of agent selecting algorithm is selecting a set of nodes to play two roles.
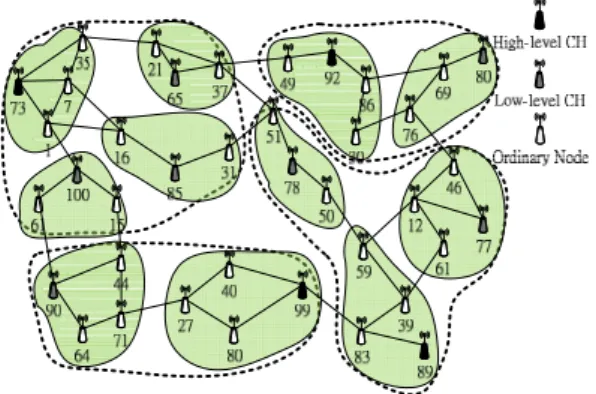
Figure 3: An Example of selecting agents
A node serves as the rendezvous area to save the event messages of neighboring low-level clusters.
(2) Gateway Agents:
A node allocates broadcasting paths for other high-level clusters.
These nodes are placed in the border nodes of high-level clusters or the border clusters of high-level clusters. In this way, when a sink issues a query, it is easy to communicate to the other high-level clusters through gateway agents and to query the interesting data by indexing agents, rather than using heavily broadcasting to the other high-level clusters and searching for all the low-level clusters.
The agent selecting algorithm consists of the following two phases:
Phase I: Agent parameters setup
• There are two input parameters for the agent selecting algorithm: agent candidates and agent candidates’ neighboring clusters.
A. Selecting indexing agents: agent candidates are the low-level border nodes in the high-level CH’s low-level cluster, and neighboring clusters are the neighboring low-level clusters of high-level CH.
For example: In Figure 3, high-level CH 73’s Indexing Agent candidates are node 1, 7, and 35, and neighboring low-level clusters are cluster 65, 85, and 100.
B. Selecting gateway agents: agent candidates are the low-level border clusters belonging to the same high-level cluster and neighboring clusters are the high-level CH’s neighbor high-level clusters.
For example: In Figure 3, high-level CH 73’s Gateway Agent candidates are cluster 65, 85 as well as 100, and neighboring high-level clusters are cluster 89, 92, and 99.
• The high-level CHs setup the relationship between agent candidates and neighboring clusters, and then build the agent table according to these relationships.
Phase II: Agent selecting
Depending on the number of neighboring clusters, high-level CHs set some agent candidate nodes connecting the most neighboring clusters to be agent nodes.
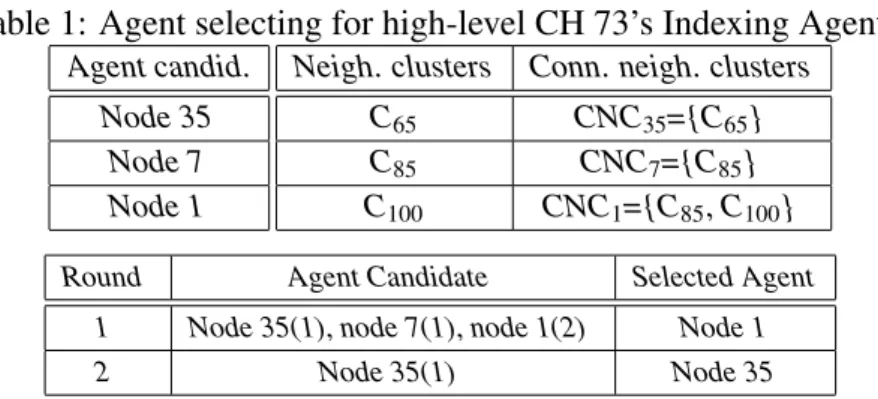
Table 1: Agent selecting for high-level CH 73’s Indexing Agents Agent candid.
Node 35 Node 7 Node 1
Neigh. clusters Conn. neigh. clusters C65 CNC35={C65}
C85 CNC7={C85}
C100 CNC1={C85, C100}
Round Agent Candidate Selected Agent 1 Node 35(1), node 7(1), node 1(2) Node 1 2 Node 35(1) Node 35
For example:Table 1 shows the example of the second phase in agent selecting algorithm for indexing agents for high-level CH 73. We briefly define some notations in this example. Cirepresents the cluster whose CH is node i. CNCi is the set of clusters connecting with node node i. First, high-level CH 73 has the information of agent candidate nodes and neighboring clusters, and lists all agent candidates node 35, 7 and 1 with their connecting neighboring clusters CNCi. Then, high-level CH 73 selects node ito be an agent, where node i=max(|CNCi|, |CNCj|), for j is the number of agent candidates. Once an node i becomes a selected agent, high-level CH 73 eliminates any cluster Ckin CNCjif (Ck∈CNCiand Ck∈CNCj) for i6=j. If |CNCj|= /0, then node j is weeded out. If no any node exists, then we finish the selection procedure.
When the agent selecting algorithm has finished, high-level CH sends messages to those nodes selected to be agents. Once being selected as index agents, these nodes will collect the information of neighboring low-level clusters which they are responsible for. Gateway agents will wait for registration messages from mobile sinks and then transmit these messages to neighboring high-level clusters.
3.3
Event Detection
HRDD proactively exploits indexing agents to support the target mobility. In the event detection, we can classify all possible situations into the following cases:
Case 1: Static event
When a source detects an event, the sensing data are sent towards the local low-level CH. After that, local low-level CH informs its indexing agent by an event information message including his own ID and the event type.
Case 2: Moving events around the same local low-level CH
When an event moves, the source is changed accordingly. Since the event only moves nearby, the new source may be still in the range of the same local low-level CH . Therefore, the sensing data are also stored in the same local CH.
Case 3: Moving events into the range of different local low-level CH
When the event moves to the new location within different local low-level CH, the sensing data are sent towards the new local low-level CH. When the old source found that an event expired, the old source will delete the sensing data of the target and informs its indexing agent. Also, the new local low-level CH should inform its event information message to the indexing agent.
Figure 4: Query Data Forwarding
3.4
Sink Location Registration
When a mobile sink issues a query, it has to register their location information to high-level CHs. The sink registration consists of two phases:
Phase 1: High-level local CH registration
When a mobile sink issues a query, it needs to send a registration message transmitted by its low-level cluster to its high-level CH.
Phase 2: High-level global CH registration.
As the sink’s high-level CH receives the registration message, it will send the registration message to the other high-level CHs through gateway agents. When the other high-level CHs receive the registration message, they should save the source path of the registration message to assure the source data can easily be forwarded back to the sink along the reverse path.
3.5
Data Forwarding
After the sink location registration, each high-level CH starts the data forwarding which consists of the following two phases:
Phase 1: Data searching
In the query data searching phase, each high-level CH forwards sinks’ queries to its indexing agent to acquire the interesting data. Once there is an indexing agent possessing the event information, it sends a request to the corresponding low-level CH holding the source data, and then goes to phase 2.
Phase 2: Data delivery
The low-level CH first sends event data to its high-level local CH, and the local high-level CH forwards event data to the sink’s high-level CH by the reverse path.
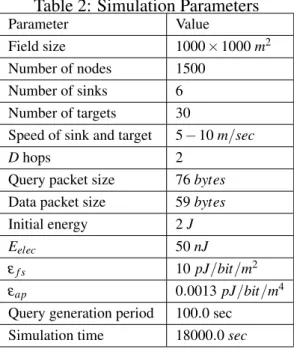
Table 2: Simulation Parameters Parameter Value Field size 1000 × 1000 m2 Number of nodes 1500 Number of sinks 6 Number of targets 30
Speed of sink and target 5 − 10 m/sec Dhops 2
Query packet size 76 bytes Data packet size 59 bytes Initial energy 2 J Eelec 50 nJ
εf s 10 pJ/bit/m2
εap 0.0013 pJ/bit/m4
Query generation period 100.0 sec Simulation time 18000.0 sec
For example: We illustrate data forwarding in Figure 4. In phase 1, the sink first issues a query to the other high-level CHs node 89, 92 and 99 through its high-level local CH node 73. Node 89, 92 and 99 will forward the sink’s query to their indexing agents node 59, 30 and 27, respectively. Indexing agent node 55 will discover that the event data are under node 77. Next, node 77 delivers the event date to its high-level CH node 89, and high-level node 89 sends the event data to sink’s high-level CH node 73. Finally, high-level node CH 73 dispatches the event data to the sink by the sink’s low-level CH node 100 and low-level node 61.
4
PERFORMANCE EVALUATION
In this section, we evaluate the performance of HRDD by simulations. We first describe our simulator implementation, simulation environment and metrics in Section 4.1. Then we compare HRDD with its counterpart HCDD on the effect of the number of nodes in Sections 4.2. The results show HRDD has the better efficiency and scalability in delivering data from sources to multiple mobile sinks.
4.1
Simulation Environmental and Metrics
We develop a simulator based on JSIM [10] to evaluate and compare HRDD with HCDD. The mobility of sinks and targets follows the standard Random WayPoint Model [4]. Table 2 lists the parameters in the simulation.
4.2
Impact of the Number of Nodes
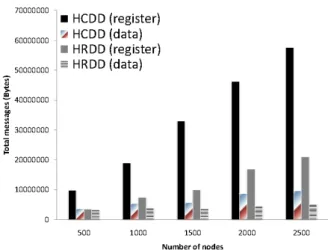
In general, the more nodes are, the more high-level CHs exist. More high-level CHs may increase the registration messages and data messages greatly. Figure 5 shows the total messages at different numbers of sensor nodes. In sink location registration procedure, since gateway agent could help to
Figure 5: Total messages vs. number of nodes
Figure 6: Total energy consumption vs. number of nodes
decrease the number of flooding messages, the registration messages in HRDD are less than that in HCDD. In data forwarding procedure, the number of data messages of HRDD is also smaller than that of HCDD. When high-level CHs forward sink queries to acquire the interesting data, they forward these queries to indexing agents in HRDD rather than forward these queries to low-level CHs in HCDD. Therefore, HCDD will increase the data messages for forwarding queries to low-level CHs while the number of high-level CHs increases. In HRDD, the usage of indexing agent makes the data messages increase slightly.
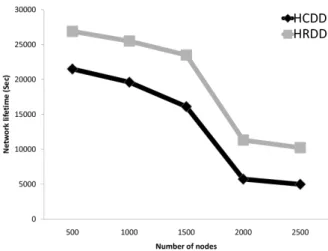
Figure 6 and Figure 7 show the energy consumption and network lifetime, respectively. The en-tire sensor network consumes much energy caused by the increase of registration messages and data messages. This result influences the network lifetime directly. Since HRDD has fewer registration mes-sages and data mesmes-sages than HCDD, HRDD has the better performance of lower energy consumption and longer network lifetime. Moreover, the more numbers of nodes are, the more performance advan-tages of HRDD have. In the case of 500 nodes, the network lifetime of HRDD and HCDD is 27002 and 21504, respectively. In the case of 2500 nodes, the network lifetime of HRDD and HCDD is 10222 and 4709.667, respectively. The advantage rate comes from 0.25 to 1.17, which means that HRDD is
Figure 7: Network lifetime vs. number of nodes
more suitable for large-scale wireless sensor networks.
5
CONCLUSIONS
In this paper, we has proposed a Hierarchical Role-based Data Dissemination (HRDD) scheme for data dissemination with multiple mobile sinks in WSNs. We assign two roles, indexing agent and gateway agent to decrease the energy consumption of broadcasting and number of flooding messages. Simulations results have shown that HRDD is more efficient than prior work in conserving the battery energy.
References
[1] A. D. Amis, R. Prakash, T. H. Vuong, and D. T. Huynh. Max-min d-cluster formation in wireless ad hoc networks. Proceedings of the 19th IEEE INFOCOM Conference, 2000.
[2] S. Basagni. Distributed clustering algorithm for ad hoc networks. Proceedings of the 4th Interna-tional Symposium on Parallel Architectures, Algorithms and Networks, 1999.
[3] S. Basagni, A. Carosi, E. Melachrinoudis, C. Petrioli, and Z. M. Wang. Controlled sink mo-bility for prolonging wireless sensor networks lifetime. ACM/Springer Wireless Networks, 14, No.6:831–858, 2007.
[4] T. Camp, J. Boleng, and V. Davies. A survey of mobility models for ad hoc network research. Wireless Communications & Mobile Computing: Special issue on Mobile Ad Hoc Networking: Research, Trends and Applications, 2:483–502, 2002.
[5] A. Cerpa, J. Elson, D. Estrin, L. Girod, M. Hamilton, and J. Zhao. Habitat monitoring: Applica-tion driver for wireless communicaApplica-tions technology. ACM SIGCOMM Computer Communica-tion Review, 2001.
[6] M. Chatterjee, S. K. Das, and D. Turgut. Wca: A weighted clustering algorithm for mobile ad hoc networks. Journal of Cluster Computing (Special Issue on Mobile Ad hocNetworks), 5, (2),:193– 204, 2002.
[7] M. do Val Machado, O. Goussevskaia, R. A. F. Mini, C. G. Rezende, A. A. F. Loureiro, G. R. Mateus, and J. M. S. Nogueira. Data dissemination in autonomic wireless sensor networks. IEEE Journal on Selected Areas in Communications, 2005.
[8] H. S. Kim, T. F. Abdelzaher, and W. H. Kwon. Minimum-energy asynchronous dissemination to mobile sinks in wireless sensor networks. Proceedings of the 1st International Conference on Embedded Networked Sensor Systems, 2003.
[9] C.-J. Lin, P.-L. Chou, and C.-F. Chou. Hcdd: Hierarchical cluster-based data dissemination in wireless sensor networks with mobile sink. Proceedings of the 2006 International Conference on Wireless Communications and Mobile Computing, 2006.
[10] J. A. Miller, R. S. Nair, Z. Zhang, and H. Zhao. Jsim: A java-based simulation and animation environment. Proceedings of the 30th Annual Simulation Symposium, 1997.
[11] M. Qin and R. Zimmermann. An energy-efficient voting-based clustering algorithm for sensor networks. Proceedings of the 6th International Conference on Software Engineering, 2005.
[12] R. Szewczyk, A. Mainwaring, J. Polastre, J. Anderson, and D. Culle. An analysis of a large scale habitat monitoring application. Proceedings of the 2nd International Conference on Embedded Networked Sensor Systems, 2004.
[13] A. Visvanathan, J.-H. Youn, and J. Deogun. Hierarchical data dissemination scheme for large-scale sensor networks. Proceedings of the IEEE International Conference on Communications, 2005.
[14] F. Ye, H. Luo, J. Cheng, S. Lu, and L. Zhang. A two-tier data dissemination model for large-scale wireless sensor networks. Proceedings of the 8th Annual International Conference on Mobile Computing and Networking, 2002.
國立交通大學博士班研究生
出席國際會議報告
報告人姓名 邱士銓
報告日期 2009.12.16
系所及年級
資訊工程所
博士班五年級
核定文號
連絡電話 0911642005
電子信箱 [email protected]
會議期間
2009.12.14~2009.12.1
6
會議地點 San Diego, USA
會議名稱
( 中 文 ) IEEE International Symposium on Multimedia (ISM2009)
workshop on Advances in Music Information Research
( 英 文 ) IEEE International Symposium on Multimedia (ISM2009)
workshop on Advances in Music Information Research
發表論文題
目
(中文)自動鋼琴縮減式編曲系統
報告內容包括下列各項:
一、 參加會議經過
此會議是由 IEEE 所舉辦,主要探討多媒體領域的研究,並針對更特
定的主題設有七個 workshop-Data Semantics for Multimedia
System and Applications, Multimedia Technologies for
e-Learning, Multimedia Information Processing and Retrieval,
Multimedia Audio and Speech Processing: advancing the
state-of-the-art, Content-based Audio/Video Analysis for
Novel TV Services, Many Faces of Multimedia Semantics,以及
Advances in Music Information Research (AdMIRe),提供來自世
界各地在多媒體與其衍伸主題方面的學者專家,交流研究發展心
得。本次的地點位於聖地牙哥米慎灣(Mission Bay)的 Hyatt 飯店舉
辦,在三天的會議期間,本人參與了最後兩天的議程
(2009/12/14~2009/12/16),並於會議第三天的最後一個 session 發
表論文,時間約為二十分鐘加提問,會後得到其他研究者的
feedback。所參與會議中,也與許多學者進行廣泛的意見交流。
二、 與會心得
雖然並非第一次準備英文的口頭報告,但從這次的報告準備中,請
教了 Native English speaker 的朋友,學習到了很多更正式地一
些用語與說法,還有問題的回答。除了自己的報告外,也聽了 Keynote
Speech 與許多其他研究者的研究發表,其中有一場是來自 HP-Lab
的華人博士 Shu-Ching Chen 介紹智慧型多媒體內容的產生,提到了
許多有關多媒體技術,包含多媒體資料標籤,多媒體內容的擷取與
搜尋,套討如何更有效率的使用多媒體的資料;另一場是我投稿的
workshop 所舉辦的 keynote speech,請到的是 Yahoo!Music 的
Malcolm Slaney 博士,探討的是音樂在快速網際網路下的研究議
題,包含如何達成線上合奏並克服網際網路傳輸上的問題等。
從 Keynote Speech 更能了解未來多媒體領域研究的趨勢。
在 Regular Paper 的研究發表,聽到了各種廣泛的主題,包含討論
音樂相似度的 similarity function 的設計並使用各種的不同層次
的特徵值來實驗;針對流行搖滾的音樂,使用接續二和弦的樣式來
做旋律與歌詞的分段…等。在 Coffee Break 中,與來自 Barry 大學
的莊靜華教授也有廣泛的交流,除了研究方面的討論,莊教授因為
從台大畢業的關係,也提到了許多他對台灣在電腦音樂學術研究環
境的了解與看法,並對研究生涯的規劃提出了許多的寶貴建議。參
加此次研討會,也透過各種形式的交流,了解很多真實、正在尋求
解決的問題,對自身研究的相當有幫助。
三、 建議
無
四、 攜回資料名稱與內容
(1) Proceeding of ISM 2009 and Its Workshop 光碟
(2) 會議手冊
(3) 紀念品(ISM 紀念紅外線投射筆)
五、 其他
感謝國科會、教育部與指導教授黃俊龍老師的幫忙,使學生可以在
有補助的情況下順利出國發表論文。
98 年度專題研究計畫研究成果彙整表
計畫主持人:黃俊龍 計畫編號:98-2221-E-009-071- 計畫名稱:一個整合普適計算環境的運作機制之研究--無線感測網路上省電之資料管理技術之研究 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 0 0 100% 篇 論文著作 專書 0 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 3 3 100% 博士生 1 1 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 2 2 75% 篇 論文著作 專書 0 0 100% 章/本 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國外 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次其他成果
(
無法以量化表達之成 果如辦理學術活動、獲 得獎項、重要國際合 作、研究成果國際影響 力及其他協助產業技 術發展之具體效益事 項等,請以文字敘述填 列。)協助辦理今年底舉辦之 Conference on Technologies and Applications of Artificial Intelligence 2010 研討會。 成果項目 量化 名稱或內容性質簡述 測驗工具(含質性與量性) 0 課程/模組 0 電腦及網路系統或工具 0 教材 0 舉辦之活動/競賽 0 研討會/工作坊 0 電子報、網站 0 科 教 處 計 畫 加 填 項 目 計畫成果推廣之參與(閱聽)人數 0