聲調在中文口語字彙觸接的時序處理:眼動研究之證據 - 政大學術集成
116
0
0
全文
(2) TEMPORAL PROCESSING OF LEXICAL TONE IN LEXICAL ACCESS OF CHINESE SPOKEN CHARACTERS: AN EYETRACKING STUDY. 立. 政 治 BY 大. ‧. ‧ 國. 學. Yuan-Jhen Syu. n. er. io. sit. y. Nat. al. A Thesis Submitted to the. Ch. i n U. v. Graduate Institute of Linguistics. engchi. in Partial Fulfillment of the Requirements for the Degree of Master of Arts. July 2012 ii.
(3) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v.
(4) 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. Copyright © 2012 Yuan-Jhen Syu All Rights Reserved. iii. v.
(5) Acknowledgements. 一直以來,我都喜歡走跟別人不一樣的路,這種路很崎嶇難走,充滿荊棘, 但是完成目標時,成就感難以言喻,就像完成這本論文的過程一樣,一路上若是 沒有貴人摯友和家人們的相挺,我絕對會走到一半就半途而廢。 每個人的生命中都會有好幾個貴人,我人生中重大的貴人之一絕對是我的論 文指導教授蔡介立老師,在學術上,他給了我最大的安全感,每每有任何學問上 疑惑,只要找老師討論就可以得到最佳的解答,除了學術以外,他還告訴我快樂 的重要,要找到快樂的因子,做任何事才會有熱情能支撐著你,人生才有意義,. 治 政 帶給我如此正面的訊息,感謝老師願意指導這麼粗枝大葉,和愚昧的我,不辭辛 大 立 勞的字字句句的幫我修改論文,包容我的毛病,幫我處理任何奇怪的事情,例如. 或許在未來,學術上的事情都會還給老師了,但我會把快樂放在心上,謝謝老師. ‧ 國. 學. 莫名其妙的推薦信之類的,能遇到如此天神般的老師,真的覺得我好幸運! 回想碩一面對完全未知的語言學世界,語言所上的優秀教授們帶給了我驚奇. ‧. 不斷的學術知識,感謝黃瓊之老師、蕭宇超老師、何萬順老師、萬依萍老師、徐 嘉慧老師教授我的一切,還有,特別感謝惠鈴助教學姊每一次對我熱切的關心,. Nat. sit. y. 叮嚀我任何一件大小瑣事。. io. er. 在 EMR baby lab 中待了兩年,確實隨時隨地都有 Excel, Matlab, R 來搞得我 日日做惡夢,好險還有 EMR baby 們,總是在我整夜沒睡的隔天,滿面愁容地看. n. al. Ch. i n U. v. 著我說媛媜你還好吧,準備回家的時候跑到我位置關心我的情況,叮嚀我要吃飯. engchi. 和休息,每當有問題時,總能放下手邊火燒屁股的進度,充滿耐心地幫我解決問 題,你們像天使般溫暖我的心情,這兩年的回憶對我來說絕對永生難忘,感謝家 興學長拒絕打球邀約願意聽我報告;聰慧機靈的婉雲 baby 幫我解決各式各樣的 怪問題,關心我的身體和生活;很有內容的熊 baby 教我實驗設計的開端還有 Matlab,他總是幫我建立自信心;佩如 baby 總能帶給大家歡樂,很不可思議的 幫我帶個小精靈給我;善良第一的怡璇 baby 讓我感到最大的溫暖,夜晚一起奮 鬥,互相勉勵;帶給了我繼續完成的動力!天使轉世的宛柔 baby 在總能在我頭 腦渾沌時,幫我解決任何問題,體貼的給我關懷;最美的瑪莉 baby 總是陪我在 夜晚走回家,讓我開心,經歷過好多事情,一起大哭一起大笑,任何事跟你分享 總能得到最大的共鳴!可愛的柏亨 baby 總是在夜晚陪伴怕鬼又怕狗的我,讓我 不再害怕,還有已經離開實驗室的 baby,翠屏、雅嵐、和致潔,每一次見面的 關懷總能帶給我力量!讓我能在挫折中爬起來,擦乾眼淚繼續往前走。 iv.
(6) 還有最親愛的語言所同學們,心綸、琬婷、淑禎、曉貞、晉瑋、書豪、美杏、 侃彧、柏溫、婉君,好懷念跟你們一起吃飯的時光,大家開讀書會的情形,我喜 歡大家的聰明,還有幽默,即使研究了不同的領域每每見面總能很有話題,笑聲 不斷,能認識你們我覺得好榮幸喔! 最後在這裡要感謝從小到大陪伴在我身旁的垃圾桶,老騷,小瓜,余胖,巫 季珍,14 姊妹,四千金,若沒有你們,我會是個一事無成,寫不出論文的人, 謝謝你們總能在夜晚接受我的騷擾電話,陪伴我度過所有低潮,散發正面能量給 我,每個都是我的情人,你們讓我覺得我好幸福!最後要感謝我媽和我最美麗的 兩個姊姊,尤其是我老媽,他最不關心我的論文,因為只擔心我的身體和生活起 居,深怕我身體有任何閃失,還有那個聽說在草地上匍匐前進時,也心繫著我論 文進度的人,一直在我旁邊給我最大的支持,包容我的神經,最後我要把這本論. 政 治 大. 文送給我在天上的老爸,我知道你一直為我感到驕傲!爸~我終於寫完啦!. 立. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. v. i n U. v.
(7) TABLE OF CONTENTS. Acknowledgements ................................................................................................................. iv List of Tables............................................................................................................................ ix List of Figures.......................................................................................................................... xi. 政 治 大. Chinese Abstract…………………………………………………………………………… xv. 立. English Abstract .................................................................................................................... xvi. ‧ 國. 學. Chapter1 Introduction............................................................................................................. 1 1.1 General background ......................................................................................................... 1. ‧. 1.2 Research questions ........................................................................................................... 4. y. Nat. io. sit. Chapter 2 Literature Review .................................................................................................. 5. er. 2.1 Processing the spoken language signal ............................................................................ 5. al. n. v i n 2.1.2 Lexical access and C models 8 h e....................................................................................... ngchi U 2.1.1 Perception of phonetic segments .............................................................................. 6. 2.2 Prosody in spoken word recognition ............................................................................. 13 2.3 Stress in lexical processing ............................................................................................ 15 2.4 Tonal processing ............................................................................................................ 17 2.4.1 Tone perception ...................................................................................................... 17 2.4.2 Tone in lexical processing ...................................................................................... 20 2.4.2.1 The role of tone compared to segment ............................................................ 20 2.4.2.2 Time course of tonal processing ..................................................................... 22 2.5 Visual world paradigm................................................................................................... 25 2.5.1 Visual world paradigm and spoken word recognition ............................................ 27 2.5.2 Visual world paradigm and tonal processing.......................................................... 29. vi.
(8) 2.6 Interim Summary ........................................................................................................... 32 Chapter 3 Experiment One ................................................................................................... 33 3.1Method............................................................................................................................ 34 3.1.1 Participants ............................................................................................................. 34 3.1.2 Material .................................................................................................................. 35 3.1.2.1Stimuli .............................................................................................................. 35 3.1.2.2 Recording ........................................................................................................ 36 3.1.2.3 Tonal recognition pretest ................................................................................. 36 3.1.3 Design .................................................................................................................... 37 3.1.4 Layout of visual stimuli.......................................................................................... 38. 政 治 大. 3.1.5 Apparatus................................................................................................................ 39 3.1.6 Procedure................................................................................................................ 39. 立. 3.2 Data analysis .................................................................................................................. 40. ‧ 國. 學. 3.3 Results ........................................................................................................................... 41 3.4 Discussion ...................................................................................................................... 50. ‧. Chapter 4 Experiment Two ................................................................................................... 53. y. Nat. sit. 4.1 Method........................................................................................................................... 54. er. io. 4.1.1Participants .............................................................................................................. 54. al. v i n Ch 4.1.2.1 Stimuli ............................................................................................................. 55 U i e h n gc 4.1.2.2 Recording ........................................................................................................ 56 n. 4.1.2 Material .................................................................................................................. 54. 4.1.2.3 Auditory Stimuli Pretest .................................................................................. 56 4.1.3 Design .................................................................................................................... 57 4.1.4 Layout of visual stimuli.......................................................................................... 58 4.1.5 Apparatus & procedure........................................................................................... 58 4.2 Data analysis .................................................................................................................. 58 4.3 Result ............................................................................................................................. 58 4.4 Discussion...................................................................................................................... 74 Chapter 5 General Discussion............................................................................................... 78 5.1 The relatively early effect of tonal information ............................................................. 78. vii.
(9) 5.2 The dependence of tonal effect ...................................................................................... 81 5.3 Tonal processing in visual world paradigm ................................................................... 83 5.4 Suggestions for future research ..................................................................................... 83 Reference ................................................................................................................................ 85 Appendixes ............................................................................................................................. 89 A. Experiment materials of Experiment 1 ........................................................................... 89 B. Experiment materials of Experiment 2 ........................................................................... 94. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. viii. i n U. v.
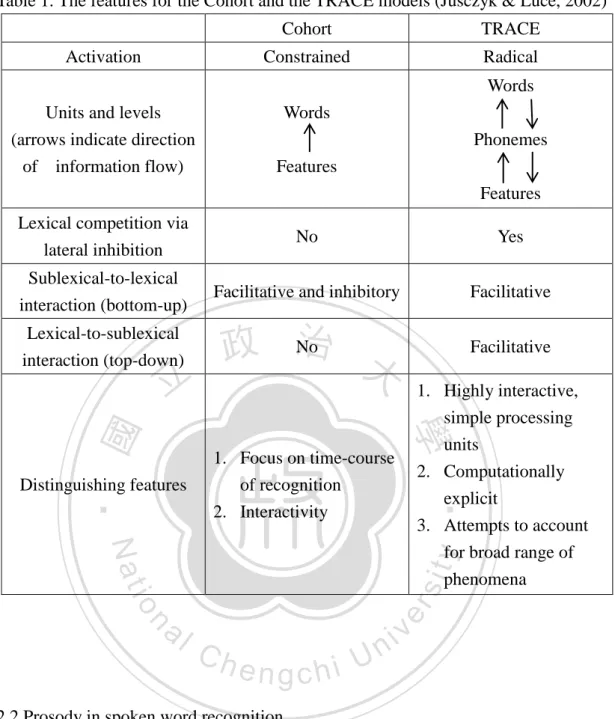
(10) List of Tables Table 1. The features for the Cohort and the TRACE models (Jusczyk & Luce, 2002) .............................................................................................................................. 13 Table 2. Means and SDs of character frequency, strokes, and homophone number for target, tonal competitor and segmental competitor .............................................. 36 Table 3. Analyses of variance by participant and item comparing mean fixation proportions to tonal and segmental competitors with those of the target and unrelated distractors from 1 msec to 1000 msec after acoustic target onset in Experiment 1 ........................................................................................................ 43. 立. 政 治 大. ‧ 國. 學. ‧. Table 4. Analyses of variance by participant and item comparing mean fixation proportions to competitors with those of the target and unrelated distractors from 1 msec to 1000 msec after acoustic target onset in Experiment 1 ....................... 46. Nat. sit. y. Table 5. The time period when mean fixation proportion had significant difference. er. io. between TAR-TC, TAR-SC, TC-UR and SC-UR by participants in Experiment 1 .............................................................................................................................. 49. al. n. v i n C h for initial tonalUprocessing in Experiment 2 ..... 54 Table 6. Predictions of two accounts engchi Table 7. Means and SDs of character frequency, strokes, and homophone number for target, cohort-tone competitor and cohort-only competitor ................................. 56 Table 8. Analyses of variance by participant and item comparing mean fixation proportions to tonal and segmental competitors with those of the target and unrelated distractors from 1 msec to 1000 msec after acoustic target onset in Experiment 2 ........................................................................................................ 64 Table 9. Analyses of variance by participant and item comparing mean fixation proportions to tonal and segmental competitors with those of the target and unrelated distractors in CVC syllable structure from 1 msec to 1000 msec after acoustic target onset in Experiment 2 .................................................................. 65 ix.
(11) Table 10. Analyses of variance by participant and item comparing mean fixation proportions to tonal and segmental competitors with those of the target and unrelated distractors in CGVC syllable structure from 1 msec to 1000 msec after acoustic target onset in Experiment 2 .................................................................. 65 Table 11. Analyses of variance by participant and item comparing mean fixation proportions to competitors with those of the target and unrelated distractors from 1 msec to 1000 msec after acoustic target onset in Experiment 2 ....................... 68 Table 12. Analyses of variance by participant and item comparing mean fixation proportions to competitors with those of the target and unrelated distractors in CVC syllable structure from 1 msec to 1000 msec after acoustic target onset in Experiment 2 ........................................................................................................ 73. 政 治 大 Table 13. Analyses of variance by participant and item comparing mean fixation 立 proportions to competitors with those of the target and unrelated distractors in. ‧ 國. 學. CGVC syllable structure from 1 msec to 1000 msec after acoustic target onset in Experiment 2 ........................................................................................................ 73. ‧. n. al. er. io. sit. y. Nat. Table 14. The time when mean fixation proportion had significant difference between TAR-CTC, TAR-CC, CTC-UR and COC-UR by participants in Experiment 2 . 74. Ch. engchi. x. i n U. v.
(12) List of Figures. Figure 1. F0 contours for the four Taiwan Mandarin tones, each combined with the syllable ma (吳聲弘, 2012).................................................................................... 3. Figure 2. A subset of the units in the TRACE. Each rectangle represents a different unit. The labels indicate the item for which the unit stands, and the horizontal edges of the rectangle indicate the portion of the TRACE spanned by each unit.. 政 治 大 by silence, are indicated for the three illustrated dimensions by the blackening of 立 The input feature specifications for the phrase “tea cup,” preceded and followed. the corresponding feature units (McClelland & Elman, 1986). ........................... 11. ‧ 國. 學 ‧. Figure 3. A four-layer modified version of the TRACE model with feature,. sit. y. Nat. phoneme/toneme, morpheme, and word node. Bidirectional arrows between. io. er. levels represent interactive feedforward and feedback excitatory connections (Zhao et al., 2011). ............................................................................................... 25. n. al. Ch. engchi. i n U. v. Figure 4. Observed data (symbols) and model fits (lines) of fixation proportions to target for the segmental and cohort conditions (Malins & Joanisse, 2010). ........ 31. Figure 5. A sample display containing pictures of a target item (/mɔ1/ ‘touch’), a tonal competitor (/wa1/ ‘dig’), and two unrelated distractors (/nu4/ ‘anger’, and /tɕy2/ ‘chrysanthemum’) ................................................................................................ 38. Figure 6. Experimental procedure and examples of a visual stimulus used in Experiment One. The display contained words: 摸 (the target), 抹 (the xi.
(13) segmental competitor), 怒 and 菊 (the unrelated distractors). ......................... 40. Figure 7. Fixation proportions to targets, competitors, and unrelated distractors for trials with tonal or segmental competitors in Experiment 1. The x-axis shows time in milliseconds from visual display onset, 200 msec before target acoustic onset, for the 1200 msec period. .......................................................................... 43. Figure 8. Mean fixation proportions to targets, competitors, and unrelated distractors. 政 治 大 target onset in Experiment 1. Each data point represents the average of fixation 立. for tonal and segmental conditions in the 1,000 msec period following acoustic. proportions across participants in the time bin of 100 msec and the error bars. ‧ 國. 學. show the standard error of the data. ..................................................................... 45. ‧. sit. y. Nat. Figure 9. Mean fixation proportions to targets, competitors, and unrelated distractors. io. er. for tonal and segmental conditions in the 1,000 msec period following acoustic target onset in Experiment 1. Each data point represents the average of fixation. al. n. v i n C h in the time binUof 100 msec and the error bars proportions across participants engchi. show the standard error of the data. Fixation proportions to target, competitors and unrelated distractors over time for 4 tones are shown respectively. ............. 49. Figure 10. Fixation proportions to targets, competitors, and unrelated distractors for trials with cohort-tone or cohort-only competitors in Experiment 2. The x-axis shows time in milliseconds from visual display onset, 200 msec before target acoustic onset, for the 1200 msec period. ............................................................ 61. Figure 11. Fixation proportions to cohort-tone/cohort-only competitors across two xii.
(14) experimental conditions in Experiment 2. The x-axis shows time in milliseconds from the display onset, for 1200 msec. ................................................................ 62. Figure 12. Fixation proportions to targets, competitors, and unrelated distractors in CVC syllable structure for trials with cohort-tone or cohort-only competitors in Experiment 2. The x-axis shows time in milliseconds from visual display onset, 200 msec before target acoustic onset, for the 1200 msec period........................ 62. 政 治 大 CGVC syllable structure for trials with cohort-tone or cohort-only competitors in 立. Figure 13. Fixation proportions to targets, competitors, and unrelated distractors in. Experiment 2. The x-axis shows time in milliseconds from visual display onset,. ‧ 國. 學. 200 msec before target acoustic onset, for the 1200 msec period........................ 63. ‧. sit. y. Nat. Figure 14. Fixation proportions to cohort-tone/cohort-only competitors in CVC and. io. er. CGVC syllable structure across two experimental conditions in Experiment 2. The x-axis shows time in milliseconds from the display onset, for 1200 msec... 63. n. al. Ch. engchi. i n U. v. Figure 15. Mean fixation proportions to targets, competitors, and unrelated distractors for cohort-tone and cohort-only conditions in the 1,000 msec period following acoustic target onset in Experiment 2. Each data point represents the average of fixation proportions across participants in the time bin of 100 msec and the error bars show the standard error of the data. ............................................................. 67. Figure 16. Mean fixation proportions to targets, competitors, and unrelated distractors for cohort-tone and cohort-only conditions in the 1,000 msec period following acoustic target onset in Experiment 2. Each data point represents the average of xiii.
(15) fixation proportions across participants in the time bin of 100 msec and the error bars show the standard error of the data. Fixation proportions to target, competitors and unrelated distractors over time for 4 tones are shown respectively. ......................................................................................................... 70. Figure 17. Mean fixation proportions to targets, competitors, and unrelated distractors in CVC syllable structure for cohort-tone and cohort-only conditions in the 1,000 msec period following acoustic target onset in Experiment 2. Each data point. 政 治 大 of 100 msec and the error bars show the standard error of the data. ................... 72 立 represents the average of fixation proportions across participants in the time bin. ‧ 國. 學. Figure 18. Mean fixation proportions to targets, competitors, and unrelated distractors. ‧. in CGVC syllable structure for cohort-tone and cohort-only conditions in the. sit. y. Nat. 1,000 msec period following acoustic target onset in Experiment 2. Each data. io. er. point represents the average of fixation proportions across participants in the time bin of 100 msec and the error bars show the standard error of the data. ..... 72. n. al. Ch. engchi. xiv. i n U. v.
(16) 國. 立. 政. 治. 大. 學. 研. 究. 所. 碩. 士. 論. 文. 提. 要. 研究所別:語言學研究所 論文名稱:聲調在中文口語字彙觸接的時序處理:眼動研究之證據 指導教授:蔡介立 研究生:許媛媜 論文提要內容:(共一冊,22,251 字,分 5 章 20 節,並扼要說明內容) 本文主要探討中文聲調在口語字彙觸接過程中所扮演的角色。實驗一藉由眼動實. 政 治 大. 驗中的 Visual World Paradigm 作業,觀察中文聲調影響口語字彙辨識的時序歷. 立. 程。受試者在聽到指導語和目標字之後,用滑鼠在螢幕上點選聽到的目標字,例. ‧ 國. 學. 如,螢幕上出現的字包含一個目標字:「摸」、一個競爭字(與目標字只有聲調相. ‧. 同:「挖」或是與目標字只有音段相同:「抹」),以及兩個聲調與音段和目標字 完全不同的無關字: 「怒」 、 「菊」 。為了觀察目標字、競爭字及無關字在口語字彙. y. Nat. io. sit. 處理時的競爭,我們會計算各個字彙的凝視比例。實驗一中由於聲調與目標字相. n. al. er. 同的競爭字與目標字的第一個音段就開始產生差異,因此未觀察到聲調早期介入. Ch. i n U. v. 的影響。實驗二透過與實驗一相同的實驗程序及方法,操弄目標字和競爭字中聲. engchi. 調和前兩個音段(Cohort)的異同以探測更早期的聲調影響。螢幕呈現包含一個目 標字「湯」 、一個競爭字(前兩個音段和聲調皆與目標字相同: 「胎」 ,或是只有前 兩個音段相同但聲調與目標字不同: 「泰」),以及兩個聲調與音段和目標字完全 不同的無關字「剖」、「痕」。結果顯示,聲調在語音訊息前兩個音段時就會產生 影響,也就是聲調的影響在語音結束前即有作用。再者,本文發現聲調無法單獨 且獨立地對於語音辨識產生影響,此看法與聲調表徵需以“toneme” node 獨立地 存在於 the modified TRACE model 的看法不盡相同 (Malins & Joanisse, 2010; Ye & Connine, 1999; Zhao, Guo, Zhou, & Shu, 2011)。. xv.
(17) Abstract. The present study aims to examine the role of tonal information during Mandarin Chinese spoken character recognition. Two eye-tracking experiments were conducted with the visual world paradigm, which participants heard a Chinese monosyllabic character and used a mouse to click on the corresponding character in a visual array of. 政 治 大. 4 characters on the screen. Experiment 1 manipulated the relationship between the. 立. spoken target characters and written characters on the screen, including a target (e.g.,. ‧ 國. 學. /mɔ1/‘touch’), a tonal competitor (the tone was the same as target except segment:. ‧. e.g., /wa1/‘dig’) or a segmental competitor (the segmental structure was the same with. y. Nat. al. er. io. sit. the target except tone: e.g., /mɔ3/ ‘wipe’), and two unrelated distractors (the segments. n. and tone were different from target: e.g., /nu4/ ‘anger’, and /tɕy2/ ‘chrysanthemum’).. Ch. engchi. i n U. v. The fixation proportions on target, competitors and the unrelated distractors were computed during the unfolding of the auditory target stimuli. The results showed tonal difference was detected before the end of auditory stream. However, no early involvement of tonal information was found, which may due to the tonal competitor and target shared no segment from the first phoneme. In order to examine the earlier tonal processing, Experiment 2 manipulated two types of cohort competitors sharing the initial two segments with the target (e.g., /tʰɑŋ1/ “soup”), a cohort-tone competitor,. xvi.
(18) e.g., /tʰaj1/ “fetus” (both tone and initial two segments are the same with target) and a cohort-only competitor e.g., /tʰaj4/ “peaceful” (initial two segments is the same with the target but with different tone). Result showed that tone affected spoken character recognition while processing the two initial segments. In addition, tone could not affect spoken character processing independently, which might be inconsistent with the assumption that tone is a separate level of representation, called “toneme” node, in. 政 治 大. the modified TRACE model (Malins & Joanisse, 2010; Ye & Connine, 1999; Zhao et. 立. al., 2011).. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. xvii. i n U. v.
(19) Chapter1. Introduction. 1.1 General background How do listeners recognize a word in a streaming of continuing auditory inputs? In. 政 治 大. order to decode a string of spoken utterance, the information needs to be extracted. 立. from the acoustic signal and mapped onto different forms of internal representation in. ‧ 國. 學. the mental lexicon. Recently, the models of spoken word recognition demonstrated. ‧. that as the spoken auditory inputs are unfolding, a set of lexical candidates compete. y. Nat. al. n. Welsh, 1978; McClelland & Elman, 1986).. Ch. engchi. er. io. sit. for recognition (Carroll, 2008; Frauenfelder & Tyler, 1987; W. D. Marslen-Wilson &. i n U. v. The present study aims to examine the tonal processing during spoken character recognition of Mandarin Chinese. Lexical tone belongs to the prosodic information, which could also be called suprasegmental information because it goes beyond and spans over segments. For Chinese spoken character recognition, the segmental and suprasegmental information are processed from acoustic signals. Segmental elements supporting a cluster of distinctive features(Roca & Johnson, 1999), including vowels and consonants. Supra-segmental elements involve pitch variations to form tones and. 1.
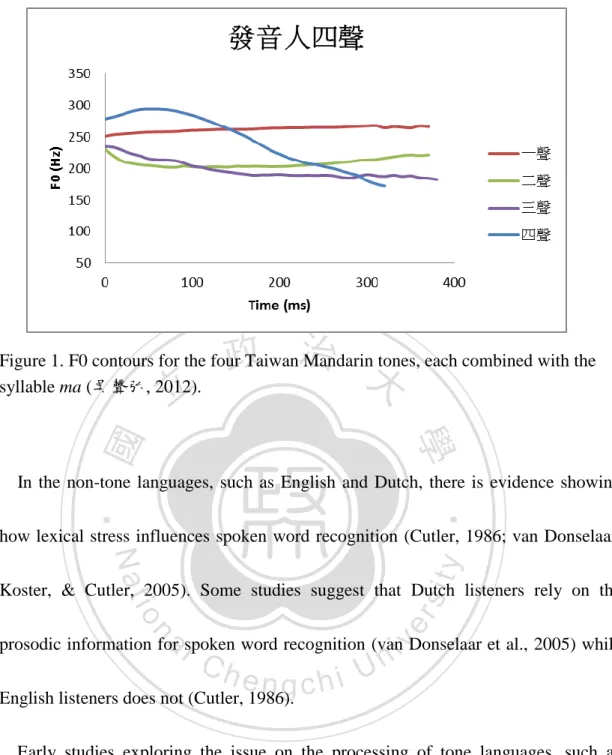
(20) 2. intonations distinctions. (Jongman, Wang, Moore, & Sereno, 2006).. According to the supra-segmental features, there are non-tone languages and tone languages. For most European languages such as English, French, and Dutch, the meaning of a word do not change irrespective of whether it is said on a rising pitch or a falling pitch. On the contrary, for tone languages like Chinese, Cantonese, lexical tones are pitch variations that serve to provide contrasts in word meaning(Ladefoged, 2005).. 立. 政 治 大. In Beijing Mandarin, there are four different tones, each displaying a distinct pitch. ‧ 國. 學. inflection: high-level (Tone 1), high-rising (Tone 2), low-dipping (Tone 3), and. ‧. high-falling (Tone 4). The same segmental context can carry different meanings as. Nat. io. sit. y. altering pitch inflection. For example, the segment ma pronounced with a high-level. al. er. tone means “mother”, while the identical segment pronounced with a high-falling tone. n. v i n Cstudy, means “scold”. In the present we used Taiwan Mandarin tone. According to hen gchi U. Chang (2010), Taiwan Mandarin tone differed from Beijing Mandarin counterparts in terms of f0 height (tonal registers) and contours. All four tones in Taiwan Mandarin are with lower tonal registers. Tones 2 and 3 tend to respectively become dipping and low-falling. Tone 3 has a low-falling pattern (i.e., half 3rd tone) in isolation. Figure 1 shows an illustration of the F0 contours of the four Taiwan Mandarin tones (吳聲弘, 2012)..
(21) 3. 政 治 大. Figure 1. F0 contours for the four Taiwan Mandarin tones, each combined with the syllable ma (吳聲弘, 2012).. 立. ‧ 國. 學. In the non-tone languages, such as English and Dutch, there is evidence showing. ‧. how lexical stress influences spoken word recognition (Cutler, 1986; van Donselaar,. sit. y. Nat. io. n. al. er. Koster, & Cutler, 2005). Some studies suggest that Dutch listeners rely on the. i n U. v. prosodic information for spoken word recognition (van Donselaar et al., 2005) while. Ch. engchi. English listeners does not (Cutler, 1986).. Early studies exploring the issue on the processing of tone languages, such as Chinese and Cantonese, utilized the tasks of lexical decision and homophone judgment. These researches demonstrated that tone was accessed later than segmental information; that is, tone plays a minor role in spoken word recognition (Cutler & Chen, 1997; Taft & Chen, 1992; Ye & Connine, 1999). However, Lee(2007) found that lexical tone played a role as important as segmental information. Differing from.
(22) 4. the behavioral task, recent studies applied the experimental techniques such as event related potentials (ERPs) or eye-tracking to examine the on-line auditory processing. These results suggest that the tonal and segmental information are accessed at a similar temporal point. Therefore, the tone and segment information might play a comparable role during spoken word recognition (Malins & Joanisse, 2010; Schirmer, Tang, Penney, Gunter, & Chen, 2005; Tsang, Jia, Huang, & Chen, 2011).. 1.2 Research questions. 立. 政 治 大. ‧ 國. 學. The present study conducts two eye movement experiments to examine the time. ‧. Nat. io. sit. research questions to be addressed are as follows:. y. course of tone information processing during spoken character recognition. Specific. al. er. (1) When is tonal information processed during spoken character recognition? Is tonal. n. v i n Cearly information processed in phase of spoken character recognition? Or, is it hen gchi U accessed in a relatively late stage of spoken character processing?. (2) In what way does tone affect lexical process with segmental information? Does lexical tone affect spoken processing independently? Or, does tonal information influence lexical process depending on segmental information..
(23) Chapter 2. Literature Review. 2.1 Processing the spoken language signal. 治 政 Processing of speech perception roughly include大 three levels: the auditory level, the 立 ‧ 國. 學. phonetic level, and the phonological level (Carroll, 2008; Frauenfelder & Tyler, 1987; Lass, 1976; Studdert-Kennedy, 1976). At the auditory level, the signal is represented. ‧. in terms of its frequency, intensity, and temporal attributes, which could be shown on. sit. y. Nat. io. n. al. er. a spectrogram. At the phonetic level, the individual phones are identified by a. i n U. v. combination of acoustic cues such as the formant transitions. At the phonological. Ch. engchi. level, the phonetic segment is converted into a phoneme, and phonological rules are applied to the sound sequence. These levels are successively processed by listeners when decoding speech signals (Carroll, 2008). Listeners firstly discriminate auditory signals from other sensory signals and decide whether the auditory stimuli are something they have heard. Then listeners identify the particular properties and qualify it as speech. Lastly, the properties would be recognized as the meaningful speech of a particular language (Carroll, 2008). 5.
(24) 6. 2.1.1 Perception of phonetic segments Concerning the speech perception, many researchers have great interest in how listeners manage to decode speech signals into phonetic units and derive meaningful words. The properties such as vowels and consonants help listeners identify phonetic segments are tightly intertwined and overlapped (Gleason & Ratner, 1998). One of the issues for speech perception is how individual words from the complex speech input. 政 治 大. are separated and then further identify them appropriately.. 立. Moreover, there is no one-to-one correspondence between the phonemes and their. ‧ 國. 學. acoustic realization. This problem could be termed as lack of invariance, which results. ‧. from the phenomenon of context conditioned variation(Carroll, 2008; Frauenfelder &. Nat. io. sit. y. Tyler, 1987; Gleason & Ratner, 1998). The context conditioned variation refers to the. al. er. production of same phonetic segment varies depending on the environment in which. n. v i n C h there are also some the segment is produced. However, e n g c h i U studies suggest that the speech. perceptions are relied on both invariant and context-conditioned cue (Cole & Scott, 1974). Another issue about the segmental perception is the phenomenon of categorical perception. Categorical perception is typically found on contrasts between many different pairs of consonants. For categorical perception, perceptual systems transform relatively linear sensory signals into absolute or categorical non-linear.
(25) 7. mental representations. In speech, listeners convert the continuous auditory signals into discretely meaningful words. According to Liberman, Harris, Hoffman, and Griffith (1957), listeners’ ultimate task is to identify [p] or [b] which belongs to one or another category of speech sounds. The minimal feature between the [p] and [b] is the voicing. To notice the difference between the voiced [b] and the voiceless [p], the time when the sound is released at the lips and when the vocal cord starts to vibrate is. 政 治 大. crucial. The vibration of voiced [b] occurs immediately but the vibration of voiceless. 立. [p] occurs after a short lag, which is termed as voice onset time (VOT). Some of the. ‧ 國. 學. categorical perception studies construct synthesized speech syllables to examine. ‧. whether categorical perception holds for nonspeech such as chirp or only for. Nat. io. sit. y. speech(Jusczyk & Luce, 2002; Liberman et al., 1957). The researchers found that. n. al. er. categorical perception was used in speech rather than the nonspeech. However, there. Ch. engchi. is still no firm argument regarding whether. iv n there U is a. special mode of speech. perception (Jusczyk & Luce, 2002; Liberman et al., 1957). Due to the continuous and noncategorical characteristic of vowels, vowel perception is different from consonant perception (Fry, Abramson, Eimas, & Liberman, 1962). Vowel has longer and larger formant but consonants are presented by the formant transitions, which transient cues forces listeners to impose a categorical identity on the stimuli more rapidly than for vowels. Therefore, after the.
(26) 8. stimuli have been identified, the cues for the consonants are lost, and only the coded stimuli remain. Additionally, because of the relatively longer duration of vowels, the perception course suggests that vowels are processed longer at the auditory level than consonant (Carroll, 2008; Frauenfelder & Tyler, 1987; Garman, 1990).. 2.1.2 Lexical access and models. 治 政 In addition to the issues on discrimination and categorization of phonetic segments, 大 立 ‧ 國. 學. many researchers are interested to expand the inquiry domain to the processes which spoken words are recognized for retrieving meanings. Psycholinguists are eager to. ‧. understand how listeners use phonological and prosodic knowledge to parse the. sit. y. Nat. io. al. n. Tyler, 1987).. er. sensory input during word recognition (Grosjean & Gee, 1987; Lyn, 1987; Uli H &. Ch. engchi. i n U. v. Models of spoken word recognition generally assume that phonological information is continuously integrated during spoken word recognition. When the speech is unfolding, lexical candidates compete for recognition as a function of phonological similarity with the speech input (Foss & Hakes, 1978; Garman, 1990; Gleason & Ratner, 1998; Myers, Laver, & Anderson, 1981). The models are different in explaining the temporal dynamics of spoken word recognition between the incoming speech stimuli and potential lexical representation..
(27) 9. One of the significant models is Cohort model (W. D. Marslen-Wilson & Welsh, 1978; William D & Marslen-Wilson, 1987). Cohort model proposes that the onset of a word activates a set of lexical candidates competing for recognition. In the first, autonomous stage, when the first phoneme of a word is heard, all of the candidates with the phonological resemblance of the words are activated. For example, if the phoneme /d/ in the word “drive” is heard, then the words beginning with /d/ may. 政 治 大. activate many candidates such as “dive,” “drink,” “date,” “dunk” and so on. This set. 立. of activated words is called the “cohort”. The words in the cohort are not assumed to. ‧ 國. 學. affect the activation levels of one another, which mean that at this stage, word. ‧. recognition is a completely data-driven or bottom-up process. In the second stage,. Nat. io. sit. y. once a cohort structure is activated, all possible sources of the auditory information. al. er. may begin to influence the selection of the target word from the cohort. The additional. n. v i n C hmay eliminate someUof the cohort words. The coming auditory phonetic information engchi phonetic information is assumed to work in a strictly left-to-right fashion. However, in this stage, the sources of higher levels information may also help to eliminate the hypothesized word cohorts. For instance, if the phoneme of the /r/ presents following the phoneme /d/, this further acoustic-phonetic information may eliminate the cohort words such as “date” and “dunk.” And then the higher level sources of the information may appear and eliminate other words of the cohort word such as “dive”.
(28) 10. and “drink,” which might be not suitable for the semantic or syntactic available information. The spoken word recognition is finally achieved when a single candidate remains in the cohort. A latter revised cohort model extends to consider other sources of information such as word frequency effect (Frauenfelder & Tyler, 1987; Gleason & Ratner, 1998; Jusczyk & Luce, 2002; W. Marslen-Wilson & Tyler, 1980; William D & Marslen-Wilson, 1987).. 政 治 大. The TRACE model is an interactive model (McClelland & Elman, 1986),. 立. assuming three levels of primitive processing units: the features, the phonemes, and. ‧ 國. 學. the words (Figure 2) . These processing units have excitatory connections between. ‧. levels and inhibitory connections within the levels. These connections can both excite. Nat. io. sit. y. and inhibit the activation levels of the nodes according to the stimulus input and the. al. er. activity in the system. For example, the stimuli with voicing such as the consonants. n. v i n /b/, /d/, or /g/ will make theC voiced level of the model become U h efeature n g caththei phoneme active. The activeness in turn passes its activation to all voiced phonemes at the next level, which in turn activates the words having those phonemes. Furthermore, via lateral inhibition among units in a level, the most activated unit may come to dominate other competing units which are also temporarily concordant with the input. For example, the word unit cat at the lexical level will inhibit the similar and competing lexical units (e.g., pat). This inhibition helps to make sure that the best.
(29) 11. candidate word will win the competition in the process (Gleason & Ratner, 1998; Jusczyk & Luce, 2002; McClelland & Elman, 1986).. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. i n U. v. Figure 2. A subset of the units in the TRACE. Each rectangle represents a different unit. The labels indicate the item for which the unit stands, and the horizontal edges of the rectangle indicate the portion of the TRACE spanned by each unit. The input feature specifications for the phrase “tea cup,” preceded and followed by silence, are indicated for the three illustrated dimensions by the blackening of the corresponding feature units (McClelland & Elman, 1986).. There are differences between the Cohort and the TRACE models (Table 1). First, the Cohort model emphasizes on the temporal dynamics of spoken word recognition..
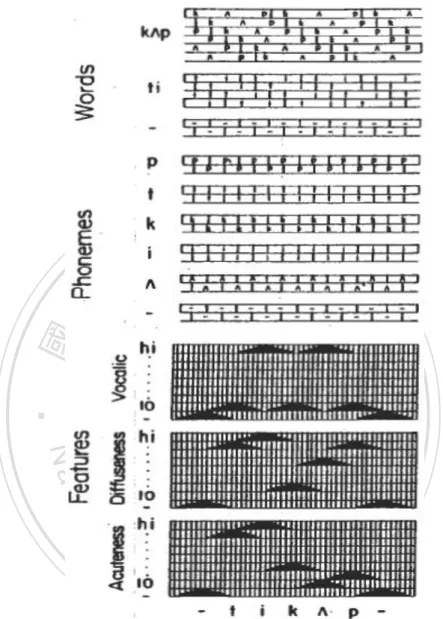
(30) 12. Cohort model suggests the significance of the initial word, which means that spoken words may be identified before their offsets if similar competitors are not active. However, the TRACE theory suggested the duplicative nodes and connections of its system through successive time slices of input. This might be questionable in treating the temporal dynamics in spoken word recognition. The time-slice solution results in an extremely complex structure. Second, although the TRACE model is relatively. 政 治 大. complex, its highly interactive feature makes it possess the computational specificity,. 立. which results in a relatively easy way to conduct a direct test of behavior simulation.. ‧ 國. 學. Therefore, this feature helps in accounting for phenomena with a broad range. On the. ‧. contrary, the lack of interactive feature causes the poverty of computational specificity. Nat. io. sit. y. in Cohort model. Last, the Cohort model emphasizes on the exact match between. al. er. auditory input and lexical representation rather than the sublexical representation.. n. v i n C hhas the phonemesUlevel which is between the words However, the TRACE model engchi level and features level (Jusczyk & Luce, 2002)..
(31) 13. Table 1. The features for the Cohort and the TRACE models (Jusczyk & Luce, 2002) Activation. Cohort. TRACE. Constrained. Radical Words. Units and levels (arrows indicate direction of information flow). Words Phonemes Features Features. Lexical competition via lateral inhibition Sublexical-to-lexical interaction (bottom-up) Lexical-to-sublexical interaction (top-down). Facilitative and inhibitory. Facilitative. No 政 治 大. Facilitative. 1. Focus on time-course of recognition 2. Interactivity. phenomena. n. al. er. io. sit. y. Nat. 1. Highly interactive, simple processing units 2. Computationally explicit 3. Attempts to account for broad range of. ‧. Distinguishing features. Yes. 學. ‧ 國. 立. No. Ch. engchi. i n U. v. 2.2 Prosody in spoken word recognition. According to Cutler, Dahan, and van Donselaar (1997), prosody is an intrinsic determinant of the spoken form in languages. This intrinsic determinant is realized as an effect on the timing, amplitude, and frequency spectrum of the utterance. Prosody includes intonation, duration, stress, and tone. One of the important features is that it spans over long segments such as syllables, words, and the utterances in speaking.
(32) 14. style, sentence type and so on. Prosodic cues can convey lexical and nonlexical information; for example, the function of distinguishing lexical meaning in tone, the prominence function in stress, or the emotion expression in the sentence intonation. Any part of the speech has duration, amplitude, and fundamental frequency. Therefore, when listeners recognize the speech, they are processing the variation determined by prosody (Cutler et al., 1997; Leena, 2012).. 政 治 大. When and how might prosodic information play a role in the processing? Early. 立. findings suggested that prosody plays an organizing role in speech. For example,. ‧ 國. 學. nonsense syllables are recalled better only if the string of the nonsense syllables. ‧. presented with sentence prosody (Epstein, 1961). In addition,.Cutler et al. (1997). Nat. io. sit. y. suggested that processing of speech input is facilitated by coherent prosodic structure. al. er. appropriate for sentences. Studies of such facilitated effects have established a. n. v i n significant role for temporalCpatterning. temporal envelops of spoken utterance, h e n gThus chi U. preserving amplitude information but virtually without spectral variation, allow listeners to recognize short utterances and even nonsense syllables almost perfectly (Cutler et al., 1997; Shannon, Zeng, Kamath, Wygonski, & Ekelid, 1995). Second, listeners use relevant acoustic information as soon as it becomes available. For instance, listeners take coarticulatory information efficiently from one segment to another(Whalen, 1991). Thus, some researchers propose that whenever the prosodic.
(33) 15. information could constrain initial lexical activation, it is important to see what and how such prosodic is processed by listeners(Cutler et al., 1997). Because of the varied characteristics of the prosodic information, the prosody information, such as stress and tone, in spoken word recognition has been investigated. Most research on lexical access have been carried out in English, hence, the prosodic structure which have been investigated is stress (Cutler, 1986; van Donselaar et al.,. 政 治 大. 2005). In English, the stress pattern can only be contrasted in multisyllabic domain. 立. rather than in monosyllable like in tone languages. Tone languages such as Cantonese. ‧ 國. 學. or Mandarin are good examples to be illustrated because tone contrasts may be. ‧. realized in a monosyllable (Cutler & Chen, 1997; Taft & Chen, 1992).. n. er. io. sit. y. Nat. al. Ch. 2.3 Stress in lexical processing. engchi. i n U. v. Studies of English vocabulary structure suggest that listeners could use the stress-pattern information in word recognition. However, some studies showed that the stress information does not facilitate English listeners in auditory lexical decision or in the grammatical category judgment. In Cutler and Clifton (1984) the participant performed a grammatical category judgment of the bisyllabic syllables with or without the standard stress pattern (for example, initial stress for noun or final stress.
(34) 16. for verbs). The result showed that the reaction time was not affected by the different stress pattern. Cutler (1986) used a cross-modal priming task to distinguish the contrast pattern of stress such as OBject-obJECT, and FORbear-forBEAR. If the stress information was used by listeners, the prime and the target would not be considered as homophones and no homophonic priming effect would be expected. Subjects were asked to listen to a sentence contained a prime which meaning was. 政 治 大. related to the target and then performed the lexical decision task. The resulted showed. 立. that the pair could prime each other. Subjects considered the stress minimal pairs as. ‧ 國. 學. homophones, suggesting that the access code did not influenced by the stress prosodic. ‧. Nat. io. sit. initial access to the lexicon.. y. information. Listeners did not discriminate from these two words for msec in the. al. er. In Dutch, the stress information involved during spoken word recognition (van. n. v i n Donselaar et al., 2005). van C Donselaar et al. (2005) also used the cross-modal priming heng chi U experiments to examine the role of suprasegmental information in processing Dutch. The result in Dutch showed that the inappropriate stressing could prevent lexical activation. The authors also suggested that the constraining of the suprasegmental during the processing was within a single syllable in Dutch, indicating that it began as soon as the relevant acoustic information was available to modulate the activation of potential candidate words. The inconsistent results between English and Dutch are.
(35) 17. probably due to that the minimal stress pairs are rare in English. Although English is a lexical-stress language, the stress cue might be redundant in lexical processing. The stress information in English can nearly always be derived from the segmental information (Cutler et al., 1997).. 2.4 Tonal processing. 立. 政 治 大. ‧ 國. 學. 2.4.1 Tone perception. ‧. Acoustic analysis about tone typically focuses on the fundamental frequency. Nat. io. sit. y. (F0), which is a quantification of the rate of vocal fold vibration and usually. al. er. expressed in Hertz (Hz). According to Jongman et al. (2006), tone is a function of the. n. v i n rate of vocal fold vibration.C Toh characterize Mandarin e n g c h i U tones, the F0 height and the F0 contour are the crucial acoustic parameters. Researchers have explored the contribution of F0 height and F0 contour to tonal perception. Some studies suggested that for Mandarin listeners, both of the F0 height and F0 height are important. However, some studies claimed a more crucial role of F0 contour (Gandour, 1984; Jongman et al., 2006).. Recently, Tsang et al. (2011) used the event-related potentials (ERPs) to examine.
(36) 18. how pitch contour and pitch height contributed to early tonal processing in an auditory passive oddball paradigm in Cantonese. Classifying six tones in Cantonese by pitch height and contour, the authors manipulated four conditions: height-large difference (Tone 6/ Tone 1), height-small difference (Tone 6/ Tone 3), contour-early difference (Tone 1/ Tone 2), and contour-late difference (Tone 6/ Tone 2). In the experiment, the stimulus (e.g., /ji1/, /ji2/, /j3/ and /ji6/) was presented while the. 政 治 大. participant was watching a self-chosen silent movie with closed captions. The result. 立. indicated that the turning point on the pitch contour could modulate the effect of pitch. ‧ 國. 學. height, suggesting that Cantonese speakers did not process pitch contour and pitch. ‧. height as totally unrelated dimensions. In Mandarin Chinese, Lai and Zhang (2008). Nat. io. sit. y. used a gating paradigm to examine the amount of tonal information needed to. al. v i n C hthe same segmental contained e n g c h i U structure. n quadruplets, which. er. correctly identify the four tones of the target. In the experiment, there were eight tone but different tones.. Subjects were asked to identify the tone for each gated stimulus (40msec increments) and provided a confidence rating on a scale of one to seven for their response by pressing the corresponding button. The stimuli were presented in a duration-blocked fashion, in which participants heard the first gate of the stimuli to the last gate, which always contained the entire syllable. The isolation point, which was the size of the segment needed to correctly identify, was examined. The result showed that the.
(37) 19. isolation point was different among four tones. The earliest isolation point was the Tone 1, followed by Tone 4, and then followed by Tone 2 and Tone 3. To sum up, the acoustic features of four tones in Mandarin affect tone perception. Whether the acoustic similarity among the four tones affects tonal perception has been examined in both Chinese and Cantonese. There are six tones in Cantonese. Tone 1 is most distinct from other tones, while other tones bear a similar point on the. 政 治 大. F0 scale. In a lexical decision task, Cutler and Chen (1997) manipulated the mismatch. 立. and match of phonological structure between prime and target In this study, Cantonese. ‧ 國. 學. tones were separated by “easy group” including Tone 1, and “hard group” including. ‧. the remaining tones. Tone 1 was in the easy group because of its acoustic distinction. Nat. io. sit. y. from other tones in Cantonese. The “hard” group comprises the tones with similar. al. er. acoustic contour. The result showed that the “easy” group had lower error rate and. n. v i n C hof the “hard” group.U As for Chinese, Ye and Connine faster response time than that engchi (1999) explored the role of tonal similarity in a vowel and tone monitoring task. In their experiment three, the Tone 2 and Tone 3 were grouped as “close” tone while the Tone 2 and Tone 4 were labeled as “far” tone. Results showed that the reaction time to. the “far” tones was longer than the “close” tones in both the vowel and tone monitoring tasks..
(38) 20. 2.4.2 Tone in lexical processing. 2.4.2.1 The role of tone compared to segment. For tonal languages, many studies had investigated on how listeners extract both tonal and segmental information from the acoustic signal to map onto the mental lexicon. Empirical evidence suggested that compared to segmental distinctions,. 治 政 lexical tone distinction could be slow and play a 大 weaker role in lexical processing. 立 ‧ 國. 學. Cutler and Chen (1997) examined the processing of lexical tone in Cantonese. In a lexical decision task, subjects were asked to judge real words and non-words by. ‧. pressing a button. The non-words differed from the real words in the mismatch of tone,. sit. y. Nat. io. n. al. er. vowel, vowel-tone, onset, onset-tone, onset-vowel, and onset-vowel-tone. The result. i n U. v. showed that there were more errors on tone mismatch compared to consonant or. Ch. engchi. vowel mismatch. In the second experiment with same-different judgment task, the two words were different in any one of the three dimensions of the syllable (consonant, vowel, and tone) or any combination of these. Result showed that the response was less accurate and slower when the only difference between them was in the tone. According to this finding, Cutler et al. (1997) argued that tonal information often arrived later than does information about the vowel that with the tone. The Experiment 1 of Ye and Connine (1999) showed the similar result. In a phoneme.
(39) 21. monitoring task, subjects judged whether there was a tone-plus-vowel (e.g., tone 2-/a/) combination for the target. The stimuli consisted of existent (known) and non-existent syllables, which contained the target. Non-target bearing syllables were different from the target in the vowel or by the tone. The result showed that the response time was slower in tone mismatch compared to vowel mismatch. Similar to Cutler and Chen (1997) ,the authors concluded that the perceptual acquisition of tonal information. 政 治 大. lagged behind that of vowel information. Both studies indicated that tones were. 立. realized on vowels. Therefore, tone could not access until the vowel information was. ‧ 國. 學. available. In addition, they suggested a perceptual advantage for vowel information. ‧. while a perceptual disadvantage for tone regarding its relatively later availability.. Nat. io. sit. y. However, some recent studies proposed a relatively strong constrain of tone. al. er. compared to earlier studies. Lee (2007) used the direct priming and mediated priming. n. v i n C hof tone in lexical Uactivation of Mandarin Chinese. If paradigms to examine the role engchi. the tone constrained the lexical activation, tonal information would allow listeners to kick out tonally incompatible candidates; therefore, there would be no priming facilitation of sharing segmental structure. In direct priming task, there were four kinds of primes sharing different phonological structure with the target: S prime (sharing segmental structure), T prime (sharing tone), ST prime (sharing both segment and tone), UR prime (no overlapping with the target). In mediated priming task, the.
(40) 22. prime and target are not directly related, but the prime is form-related to a third word that is not actually presented. For both priming tasks, subjects did lexical decision with two interstimulus intervals (ISIs) 50msec and 250msec. According to the results, Lee (2007) suggested that the “failure” of S primes to facilitate target could be interpreted as listeners’ active use of tonal information to constrain lexical activation. However, when the ISI is 50msec, there was a facilitatory priming effect in minimal. 政 治 大. tone pair condition, suggesting that the mismatch in tone did not prevent activation.. 立. This study showed that minimal tone pairs were activated in early phase of lexical. ‧ 國. 學. access because of the segment overlapping, but listeners were capable of using tonal. ‧. Nat. n. al. er. io. sit. (2007) showed a stronger tonal effect in lexical processing.. y. information quickly to eliminate the tonally incompatible candidate. The result of Lee. Ch. engchi. 2.4.2.2 Time course of tonal processing. i n U. v. In order to examine the tonal processing, most of previous studies adopted the “off-line” paradigm, such as the lexical decision task, vowel and tone judgment, same or different judgment and so on. The behavioral measures involving explicit responses by listeners might not access the on-line processing. In addition, the facilitation of form priming task might reflect a task-specific strategy by subjects. For example, in the priming paradigm, listeners could learn that there might be the same segments.
(41) 23. between initial prime and target and then were more ready to response to the target word (Lee, 2007). It was worth suspecting whether the behavioral studies were sensitive to the on-line processing. Some studies have explored how tonal processing unfolds in time. Most of these findings suggested tone and segment play a comparable role during spoken processing. Schirmer et al. (2005) used event related potentials (ERPs) to examine the role of tone and segmental information for word processing of. 政 治 大. spoken Cantonese. In this experiment, participants listened to sentences that were. 立. semantically correct (e.g., beng6; “illness”) or included a semantically incorrect word. ‧ 國. 學. and then judged whether the sentence was congruent or not. The semantically. ‧. incorrect words differed from the most expected sentence by tone (e.g., beng2;. Nat. io. sit. y. “bisquit”), segmental structure (e.g., bou6; “step”), or by both tone and segmental. al. er. structure (e.g., gwai3; “season”). The result showed that the amplitude of the. n. v i n N400-like negativity were C comparable tone and segmental violation. The h e n gbetween chi U authors suggested that tonal and segmental information were accessed at a similar point in time and played comparable roles during word recognition in Cantonese. Zhao et al. (2011) used also ERP technique to examine the time course of monosyllabic spoken word recognition. The result was similar to Schirmer et al. (2005). In the study, subjects performed a picture/spoken-word/picture task, in which they listened to spoken words and judged whether a previously presented picture and.
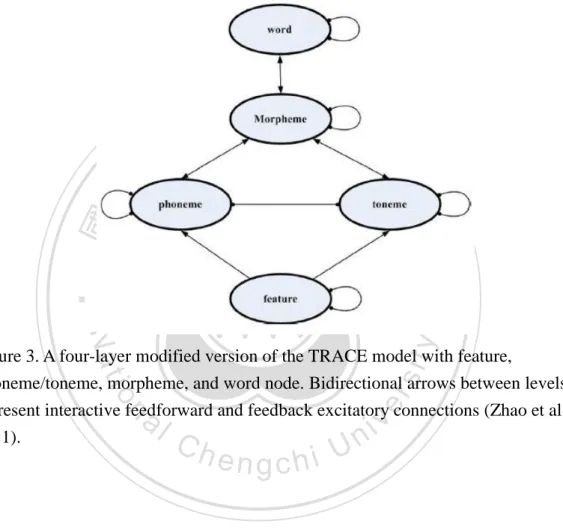
(42) 24. a subsequently presented picture belonged to the same semantic category. Each target picture was paired with five different pictures, which were either in the same or a different semantic category as the target picture. In addition, each target also corresponded to five different manipulated spoken monosyllables. Spoken words were manipulated for the relation to the name of the target picture: identical pronunciation (e.g., /bi2/-/bi2/), onset mismatched (e.g., /bi2/-/li2/), rime mismatched (e.g.,. 政 治 大. /bi2/-/bo2/), tone mismatched (e.g., /bi2/-/bi3/), and syllable mismatched (e.g.,. 立. /bi2/-/ge1/). The result indicated that during 400-500msec, both the rime and tone. ‧ 國. 學. mismatch conditions had a tendency to elicit larger negativities than the identical. ‧. condition. They suggested that the competitive effect of tone and rime during lexical. Nat. io. sit. y. activation were relatively the same and tonal information might play a comparable. n. al. incorporate detectors for. er. role as rime. In addition, this study suggested a modification of the TRACE model to. v i n C h tone. Zhao et Ual. (2011) lexical engchi. suggested that Chinese. monosyllabic spoken word computation is based on global similarity across the whole syllable rather than phonemic-based segments. Therefore, they added “toneme” nodes with phoneme node and an additional level with syllabic morpheme nodes (Ye & Connine, 1999). According to Ye and Connine (1999) and Zhao et al. (2011), the toneme nodes were at the equivalent level of phoneme nodes, but they were separated from phoneme nodes. These toneme nodes also had inhibitory connections within the.
(43) 25. other nodes. Zhao et al. (2011) also added a syllabic morpheme node to the modified TRACE model. Thus, they suggested that there were four layers in the modified TRACE model (Figure 3): feature, phoneme/toneme, morpheme, and words (from the lowest to the highest).. 立. 政 治 大. ‧. ‧ 國. 學 y. Nat. sit. Figure 3. A four-layer modified version of the TRACE model with feature,. n. al. er. io. phoneme/toneme, morpheme, and word node. Bidirectional arrows between levels represent interactive feedforward and feedback excitatory connections (Zhao et al., 2011).. Ch. engchi. i n U. v. 2.5 Visual world paradigm. In the study Cooper (1974), the author asked the participants to listen to short narratives when looking at displays showing common object which were referred to the listening text. He found that listeners’ gaze was drawn to the objects which were.
(44) 26. mentioned or related to auditory stimuli. Additionally, he also found that the eye movements of listeners were closely time-locked to the text. More than 90% of the fixations were on the triggered critical items when the corresponding word was spoken or within 200msec after the offset of the auditory word. He contended that it is a new paradigm for real-time investigation of cognitive process in particular for the detailed study of speech perception.. 政 治 大. The paradigm pioneered by Allopenna, Magnuson, and Tanenhaus (1998) is now. 立. known as “visual world paradigm.” On each experimental trial, participants were. ‧ 國. 學. presented with an array of four pictures on a computer screen and subsequently heard. ‧. an auditory stimulus corresponding to one of these items and then clicked on the. Nat. io. sit. y. target picture with a mouse. Usually, the visual display includes a target object or. al. er. picture that the name is uttered in the auditory instruction, one or two competitors. n. v i n sharing some features withC thehtarget, and distractors e n g c h i U that is unrelated to the target. The competition effects would stem from the manipulation, which the name of the. competitor picture had a phonological relationship to the spoken target. The eye movements of the participants are recorded for later analysis. The proportion of looks to target and manipulated competitors were calculated during the unfolding of the auditory stimuli to see the competition effect. The activation of the name of the picture determines the probability that the participants will shift attention to that.
(45) 27. picture and thus generate a saccadic eye movement to fixate it. When listeners detected the differences between the target and the competitors could be reflected on the divergent time point of the trajectory of target and competitors. There are some reasons why visual world paradigm becomes so widely used. Firstly, visual world paradigm can be used in an implicit and simple natural task, which makes it possible to investigate real-time language comprehension in a. 政 治 大. non-disruptive situation. Second, visual World Paradigm has provided researchers an. 立. effective tool to estimate lexical activation over time in studying the time course of. ‧ 國. 學. spoken word recognition (M. K. Tanenhaus, 2007). This paradigm is highly sensitive. ‧. on lexical activation and mapping well on the simulation results from the. Nat. io. sit. y. computational models like the TRACE model (Allopenna et al., 1998). The following. n. al. er. sections review some studies of spoken word recognition with the visual world paradigm.. Ch. engchi. i n U. v. 2.5.1 Visual world paradigm and spoken word recognition. Allopenna et al. (1998) examined whether competitors effects would be presented for objects with names that rhyme with the target. They showed participants an array of pictures containing a target picture (e.g., beaker), a cohort competitor picture (e.g., beetle) which shared an onset with the target word, a rhyme competitor (e.g., speaker).
(46) 28. which shared the rhyme structure with the target, and a picture of distractor item that was phonologically unrelated to the target or competitor. Subjects performed the task by following the spoken instruction such as “Pick up the beaker; now put it below the diamond”. Their eye movements to the pictures of four objects were recorded. The researchers found that the likelihood of fixations to the “beaker” and the “beetle” increased when the participants heard the target “beaker.” When the auditory target. 政 治 大. “beaker” began to mismatch phonologically with “beetle,” the probability of looks to. 立. “beetle” decreased when the probability of looks to the “beaker” continued to rise.. ‧ 國. 學. The proportion of looks to “speaker” started to increase when the end of the word. ‧. “beaker” unfolded. The result showed that the onset competitors of the target had a. Nat. io. sit. y. competition earlier than rhyme competitors. The result could suggest that the acoustic. al. er. information at the initial of the spoken words was more important than the later. n. v i n C h by the TRACE acoustic information. As predicted e n g c h i U model, the onset phonological overlap constrained lexical selection. Some studies have investigated the processing of phonetic detail. Bob McMurray, Tanenhaus, and Aslin (2002) used visual world paradigm to examine whether small within-category differences in voice onset time (VOT) affected lexical access.. Participants were presented by a display of four pictures which were named by spoken stimuli that varied along 0-40msec VOT continuum. The result showed that.
(47) 29. spoken word recognition had graded sensitivity to with-category voice onset time. Therefore, the fine-grained phonetic differences were preserved in patterns of lexical activation in the competition among lexical candidates and could be used to maximize the efficiency of on-line word recognition. B. McMurray, Clayards, Tanenhaus, and Aslin (2008) examined the time course of phonetic cue integration by visual world paradigm and found that the phonetic cue was use for lexical access as soon as. 政 治 大. available. During test, the pictures which names were with the voicing (e.g., /b/ vs. /p/). 立. or manner (e.g., /b/ vs. /w/) relationship were shown to participants. The result. ‧ 國. 學. showed that after the onset of the target, the probability of eye fixations on target and. ‧. competitor pictures diverged at different points in time.. n. Ch. engchi. er. io. sit. y. Nat. al. 2.5.2 Visual world paradigm and tonal processing. i n U. v. The evidence from an eye-tracking study also showed a consistent pattern with the ERP evidence(Schirmer et al., 2005; Zhao et al., 2011). Malins and Joanisse (2010) examined the tonal and segmental role in the Mandarin spoken word recognition with the visual world paradigm. In the experiment, participants were presented with an array of four pictures on a computer screen and subsequently heard an auditory stimulus corresponding to one of these items and then clicked on the target picture with a mouse. The competition effects would stem from the manipulation, which the.
(48) 30. name of the competitor picture had a phonological relationship with that of the target picture. There were three types of competitor, take the target chung2 “bed” for example: segmental competitor (e.g., chung1, “window”), which shared the segmental structure but differed in tone with target, cohort competitor (e.g., chuan2, “ship”) which shared word initial phonemes and tone with target, rhyme competitor (e.g., huang2, “yellow”) which shared word-final phonemes and tone with target, and tonal. 政 治 大. competitor (e.g., niu2, “cow”) which shared only tone but differed in segmental. 立. structure with target. In order to show the time course of accessing tonal and. ‧ 國. 學. segmental information, the authors examined the time of fixation proportion curves. ‧. for cohort or segment competitors diverging from targets and found that the. Nat. io. sit. y. divergence was at a similar time (Figure 4). The authors suggested that the similar. al. er. time course of resolution of targets from the two types of competitors indicates that. n. v i n C h were accessed concurrently segmental and tonal information and play a comparable engchi U role in constraining spoken word recognition..
(49) 31. 立. 政 治 大. ‧. ‧ 國. 學. Figure 4. Observed data (symbols) and model fits (lines) of fixation proportions to target for the segmental and cohort conditions (Malins & Joanisse, 2010).. However, it might be awkward to examine the tonal and segmental information. Nat. io. sit. y. under the segmental condition and cohort condition. The fixation proportions of the. al. er. target and competitor could also be discussed in tonal condition. If the tonal. n. v i n information had the same C effect competitor, why the target in tonal h easnsegmental gchi U condition had more fixation proportion at the early phase of spoken word recognition?. The fixation proportions of target in tonal condition should be lower in early phase of processing if tonal information had comparable effect as segment on the lexical processing. Secondly, there were only seven stimuli set in their material. The number of the experimental stimuli might be too small to show the effects..
(50) 32. 2.6 Interim Summary. The issue about the spoken word recognition of Chinese has been investigated by different experimental paradigms. However, the issue of the tonal information during lexical processing is still controversial. The tonal information spans over the syllable; therefore, the off-line experimental paradigms such as lexical decision or tone and segment judgment might not reveal the on-line tonal processing during lexical activation.. 立. 政 治 大. ‧ 國. 學. The aim of the study is to examine the time course of tonal processing during listening to Chinese spoken character. By using the visual world paradigm with. ‧. printed characters, we manipulate the phonological structure mismatch between the. sit. y. Nat. io. n. al. er. target and the competitor in two experiments. According to Huettig and McQueen. i n U. v. (2007), the printed word version might be more sensitive to phonological. Ch. engchi. manipulation than the traditional picture version. The divergence between the target and the competitor would infer the time point of accessing tone during spoken character processing..
(51) Chapter 3. Experiment One. The present experiment used the visual world paradigm and eye movement recording to examine the tone processing during Chinese spoken character recognition.. 治 政 Two phonological competitors were manipulated, 大 the tonal competitor (TC) sharing 立 ‧ 國. 學. only the tone with the target and the segmental competitor (SC) sharing the segmental structure with the target.. ‧. In order to investigate when the tonal information begins to affect the Chinese. sit. y. Nat. io. n. al. er. spoken processing, when the fixation proportion curves of targets diverge from two. i n U. v. competitors and the unrelated distractors was examined. The time point of the. Ch. engchi. divergence infers when participants could distinguish the tonal or segmental differences. According to the phonological overlap between the targets and competitors, the first set of analysis examines whether and when the competitors obtain higher fixation proportion than the unrelated distractors. If tonal competitors are activated due to sharing the same tone with target, the fixation proportion on tonal competitor will be higher than the unrelated distractors. In addition, the patterns of four tones may be 33.
數據


+7

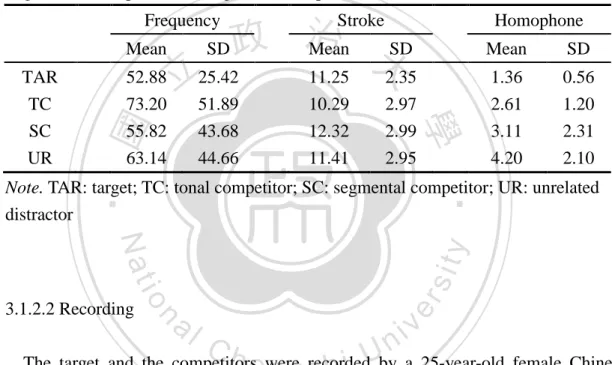

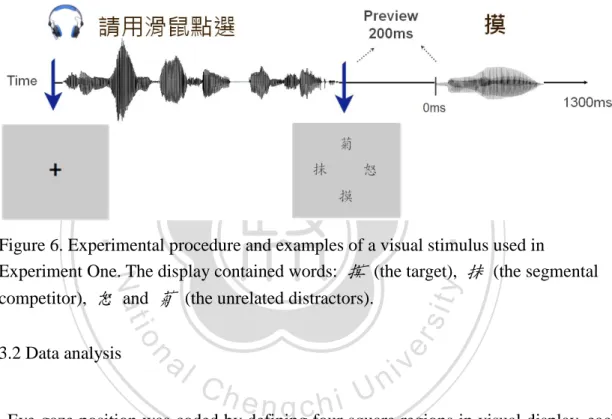
相關文件
•Last month I watched a dance class in 崇文 Elementary School and learned the new..
This project aims to cover a range of learning targets and objectives in the Knowledge, Interpersonal and Experience Strands/Dimensions, language development strategies and
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
Curriculum planning - conduct holistic curriculum review and planning across year levels to ensure progressive development of students’ speaking skills in content, organisation
Information technology learning targets: A guideline for schools to organize teaching and learning activities to develop our students' capability in using IT. Hong
Define instead the imaginary.. potential, magnetic field, lattice…) Dirac-BdG Hamiltonian:. with small, and matrix
For problems 1 to 9 find the general solution and/or the particular solution that satisfy the given initial conditions:. For problems 11 to 14 find the order of the ODE and
In order to solve the problems mentioned above, the following chapters intend to make a study of the structure and system of The Significance of Kuangyin Sūtra, then to have
