國 立 交 通 大 學
電控工程研究所
碩 士 論 文
應用多重特徵於提升材質辨識的準確性
Improving the Accuracy of Texture Recognition by
Multiple Features
研 究 生: 劉 彥 錚
指導教授: 周 志 成 博士
應用多重特徵於提升材質辨識的準確性
Improving the Accuracy of Texture Recognition
by Multiple Features
研 究 生:劉彥錚 Student:Yen-Chen Liu
指導教授:周志成 博士 Advisor:Chi-Cheng Jou
國 立 交 通 大 學
電 控 工 程 研 究 所
碩 士 論 文
A Thesis
Submitted to Institute of Electrical and Control Engineering
College of Electrical and Computer Engineering
National Chiao-Tung University
in Partial Fulfillment of the Requirements
for the Degree of Master
In
Electrical and Control Engineering
September 2013
Hsinchu, Taiwan, Republic of China
i
應用多重特徵於提升材質辨識的準確性
研究生:劉 彥 錚
指導教授:周 志 成 博士
國立交通大學電控工程研究所碩士班
摘 要
現今電腦視覺應用越來越廣泛,其中材質辨識是一個重要的課題。實證分析發現材 質的紋理會因為光線明亮、角度旋轉、尺度變化以及雜訊干擾降低辨識系統的準確度。 本研究選取常見的四種紋理特徵做為辨識依據,分別為灰階共生矩陣、局部二值化模 式、局部模式共生矩陣和紋理基元法。根據特徵特性探討,選擇單一特徵只能解決上述 部分問題。舉例來說,灰階共生矩陣僅具有辨識角度旋轉問題的能力,當相同紋理因光 亮的變化而有所不同時,將無法正確的辨識。因此本論文提出結合數個紋理特徵的方法 進行材質辨識,稱之多重特徵法。實驗結果證明多重特徵法確實有效提升材質辨識的準 確度。ii
.
Improving the Accuracy of Texture Recognition by
Multiple Features
Student:Yen-Chen Liu
Advisor:Dr. Chi-Cheng Jou
Department of Electrical and Control Engineering
National Chiao-Tung University
ABSTRACT
Recently, the use of computer vision has become more popular. One of the important uses is texture recognition. There are four major problems about the texture recognition: light, scale, angle, and noise. This thesis proposed four texture features to solve the problems: Gray Level Co-occurrence Matrix, Local Binary Pattern, Local Pattern Co-occurrence Matrix and Textons-based Approach. However, using only one of the texture features, we couldn’t solve these problems at one time. For example, using Gray Level Co-occurrence Matrix as the texture feature only solved the problem of rotational change. And the problem of light
illumination still remains. The thesis proposes a new method that combines multiple features. The new method could enhance accuracy of texture recognition. Thus the experiment proved that the method could enhance accuracy of texture recognition.
iii
致謝
首先誠摯的感謝指導教授周志成博士,老師悉心的教導使我得以一窺材質辨識領域 的深奧,不時的討論並指點我正確的方向,使我在這些年中獲益匪淺。老師對學問的嚴 謹更是我輩學習的典範。 本論文的完成另外亦得感謝家人的大力協助。因為有你的體諒及幫忙,使得本論文 能夠更完整而嚴謹。 兩年裡的日子,實驗室里共同的生活點滴,學術上的討論、言不及義的閒扯、讓人 又愛又怕的宵夜、趕作業的革命情感、因為睡太晚而遮遮掩掩閃進實驗室...,感謝眾 位學長姐、同學、學弟妹的共同砥礪,你/妳們的陪伴讓兩年的研究生活變得絢麗多彩。 感謝陳智勇、陳駿程學長們不厭其煩的指出我研究中的缺失,且總能在我迷惘時為我解 惑,也感謝李姿瑨、範育豪、簡佩珊同學的幫忙,恭喜我們順利走過這兩年。實驗室的 周敏婷學妹當然也不能忘記,妳的幫忙我銘感在心。iv
目錄
摘 要 ... i ABSTRACT ... ii 致謝 ... iii 目錄 ... iv 圖目錄 ... vi Chapter 1 序論 ...1 1.1 前言...1 1.2 文獻回顧...1 1.3 問題陳述...3 1.4 研究目的與方法...6 1.5 論文架構...7 Chapter 2 特徵抽取 ...8 2.1 灰階共生矩陣...8 2.2 局部二值化模式...10 2.3 局部模式共生矩陣...13 2.4 紋理基元法...15 Chapter 3 分類器 ...18 3.1 支持向量機...18 3.1.1 SVM 概念 ...18 3.1.2 線性 SVM 理論 ...19 3.1.3 資料不可分隔 SVM 理論 ...21v 3.2 K-最鄰近分類器 ...23 3.2.1 K-最鄰近分類器...23 3.2.2 加權式 KNN 分類器 ...24 Chapter 4 特徵特性探討 ...25 4.1 訓練資料庫...25 4.2 特徵特性實驗...25 4.3 多重特徵與材質辨識流程...27 4.4 多重特徵...28 4.4.1 TBA 與 LPCM 多重特徵實驗 ...29 4.4.2 GLCM 與 LBP 的多重特徵 ...30 Chapter 5 實驗 ...32 5.1 小樣本實驗...32 5.2 大樣本實驗...36 5.3 訓練資料變化實驗...38 Chapter 6 結論與未來展望 ...40 參考文獻 ...42
vi 圖目錄 圖 1.1(a)為自然紋理,(b)為人工紋理 ...2 圖 1.2 光亮變化,上圖為材質圖片,下圖為灰階值分布圖 ...3 圖 1.3 光亮變化特徵相似度,PCA 分布圖...3 圖 1.4 旋轉變化,其中上圖原始圖片,下方為特徵抽取結果 ...4 圖 1.5 旋轉變化特徵相似度,PCA 分布圖...4 圖 1.6 尺度上變化,其中上方為原始圖片,下方為特徵抽取結果 ...5 圖 1.7 尺度變化特徵相似度,PCA 分布圖...5 圖 1.8 雜訊參雜,其中上方為原始圖片,下方為特徵抽取結果 ...6 圖 1.9 雜訊變化特徵相似度,PCA 分布圖...6 圖 1.10 材質辨識流程圖 ...7 圖 2.1 位置變化向量 ...8 圖 2.2(a)原始圖片灰階值分布矩陣,(b)GLCM 矩陣...9 圖 2.3(a)原始灰階分布(b)8 個位置變化向量(c)全方向 GLCM 矩陣 ...9 圖 2.4(a)全方向 GLCM 矩陣,(b)GLCM 一維向量,(c)直方圖...10 圖 2.5(a)R1鄰近點 8 個,(b)R2鄰近點 8 個,... 11 圖 2.6(a)原始圖像灰階值分布,(b)二值化編碼視窗 ... 11 圖 2.7(a)均勻模式,(b)非均勻模式 ...12 圖 2.8 取得具有旋轉強健性 LBP 值過程 ...12 圖 2.9 取得直方圖流程(a)原始圖片,(b)LBP 圖片,(c)直方圖 ...13 圖 2.10(a)原始圖片,(b)高斯金字塔圖片 ...14 圖 2.11 多尺度圖片經由 LBP 轉換過程 ...14
vii 圖 2.12 GLCM 轉換過程 ...14 圖 2.13 為伽瑪校正圖示意 ...16 圖 2.14(a)前三張為原始圖片,(b)後三張圖片經過伽瑪校正 ...16 圖 2.15(a)一階高斯濾波器,(b)二階高斯濾波器, ...17 圖 2.16(a)濾波圖片集合,(b)代表向量,(c)統計直方圖 ...17 圖 3.1(a)資料切割 1,(b)資料切割 2 ...18 圖 3.2 用 2 維空間示意 SVM 的超平面位置及其與支持超平面的關係...19 圖 3.3 散佈在空間中的 KNN(a)k=3,(b)k=4 ...23 圖 4.1 資料庫 CUReT 中選出的 45 類 ...25 圖 4.2 特徵特性圖 ...27 圖 4.3 混合特徵方式 ...28 圖 4.4 新的材質辨識流程 ...28 圖 4.5LPCM+TBA 的多重特徵特性 ...29 圖 4.6GLCM+LBP 多重特徵特性 ...30 圖 5.1 結合具有互補性的特徵抽取方式 ...33 圖 5.2 結合具有相似的特徵抽取方式 ...33
圖 5.3(a) LPCM+GLCM+TBA 的多重特徵,(b) LBP+GLCM+TBA 的多重特徵, 34 圖 5.4(a)GLCM+LBP+TBA,(b)GLCM+LPCM+TBA, ...36
圖 5.5 特徵材質辨識平均準確度 ...37
圖 5.6 使用 SVM 與 KNN 的結果 ...38
1
Chapter 1 序論
1.1
前言
物件辨識(object recognition)隨著電腦進步快速發展,而材質紋理辨識(texture recognition)是其中一門重要的課題,常見的運用有:鳥瞰圖土地植披分析[1]、生醫圖像 病理分析[2]、人臉辨識[3]、指紋辨識…等等。但是現今對材質紋理沒有明確的定義, 因此幾位學者依照他們研究經驗提出對紋理的看法,Haralick 提出:材質紋理是由多個 紋理基元組成,因此紋理基元之間的空間關係可以表現出材質特性[4]。接著 Skiansky 提出:材質紋理會有相同的統計特徵或週期性的局部特徵[5]。由以上論述可歸納出,材 質特徵及其分布方式具有重複性或規律性,因此我們能依據特徵在空間的關係或其統計 量進行材質辨識。1.2
文獻回顧
文獻中常見的材質特徵抽取可分為三大類,分別為統計法、結構法和模型法,在下 面將介紹每個類別的優缺點以及常見的方法。 統計法: 統計法是利用原圖像素與像素之間的局部相關性進行統計。常見的方法有 T. Ojala 等人提出:根據局部紋理特徵統計方式[8]、Haralick 等人提出:統計兩個像素在空間中 彼此的對比度、相似度…等等[9]、Unser 和 Eden 提出:統計紋理局部線性變化[10]、 Weszka 等人提出:捕捉頻率訊號[11]、Poter 和 Canagarajah 提出:小波轉化[12]。 結構法:結構法是利用紋理之間的空間架構和合成規則描述紋理。其作法有利用高斯
2 提出:正規化邊緣檢測[13]、Davis 等人提出:使用廣義共生矩陣做紋理分析[14]。 基板模型法: 基板模型法是用已知的函數模型表示。常用的方法有 Haralick 和 Watson 提出:用 多項式與添加性的噪音模型表示[15],以及 Moser 等人提出:利用馬可夫鏈隨機模型表 示[16]。 統計法不具有空間位置關係,因此適合隨機分布紋理,像木頭、大理石…等自然紋 理,如圖 1.1(a)所示。結構法是利用紋理基元之間的空間排序規則作為依據,因此較適 合具有規則性或是週期性分布的紋理,像磁磚花紋、印刷圖案…等人工紋理,如圖 1.1(b) 所示,對於辨識自然紋理難以取得滿意效果。模型法是將紋理圖片用已知模型分布表示, 當紋理分布與模型相符,辨識效果極佳,然而參數計算過於費時,當類別過於複雜時, 難以使用單一模型表示。現實生活中大多以自然紋理為主,類別數量極為龐大,故此選 擇的特徵抽取方式皆為統計法。 有了特徵抽取方式,接下來就可以進行材質辨識,材質辨識可分為兩階段,第一個 階段為學習階段,將已知圖片進行特徵抽取,經由特徵抽取後常見的特徵型態有:直方 圖、矩陣、機率分布函數…等等,接著將特徵經由學習方式得到分類模型,常見的分類 模型有支持向量機[6]、K-最鄰近分類器、貝式網路分類器(Bayes classifier)[7]…等等。 接下來進行第二個階段為辨識階段,將未知圖片經過特徵抽取取得特徵型態,接著將其 輸入分類模型進行分類,完成材質辨識過程。 (a) (b) 圖 1.1(a)為自然紋理,(b)為人工紋理
3
1.3
問題陳述
但是在實證分析中可知,材質紋理會因為光線的明亮、角度的旋轉、尺度的變化以 及雜訊的干擾降低辨識系統的準確度,造成辨識上的困難。下面將介紹各種問題對特徵 抽取的影響。 光亮問題: 同樣的材質會因為在不同光亮下拍攝,造成灰階分布偏移或是變異度改變。如圖 1.2 四張材質圖片,(a)與(b)為同類,(c)與(d)為同類,同類材質特徵計算相似度應較為相近, 但是利用灰階分布作作為判斷依據得到如圖 1.2 下方所示,依據卡氏距離作為特徵相似 度比較,再利用主成分分析(Principal Components Analysis, PCA)得到圖 1.3,得知電腦將(a)與(c)較為相似,(b)與(d)較為相似,造成極大誤差。 (a) (b) (c) (d) 圖 1.2 光亮變化,上圖為材質圖片,下圖為灰階值分布圖 圖 1.3 光亮變化特徵相似度,PCA 分布圖 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1 (a) (b) (c) (d) 第 一 類 第 二 類
4 旋轉問題: 相同材質的紋理會因為拍攝角度不同或是物件擺設差異,造成紋理角度變化,並對 特徵造成影響。如圖 1.4 四張材質圖片,(a)與(b)為同類,(c)與(d)為同類。使用不能抵 抗旋轉變化問題的原始 LBP 特徵抽取得到結果如圖 1.4 下方所示,依據卡氏距離作為特 徵相似度比較,再利用 PCA 得到圖 1.5,得知電腦在計算特徵相似度,會以紋理走向當 作其中一個判斷依據,造成辨識結果產生誤差 (a) (b) (c) (d) 圖 1.4 旋轉變化,其中上圖原始圖片,下方為特徵抽取結果 圖 1.5 旋轉變化特徵相似度,PCA 分布圖 尺度問題: 同樣紋理常因拍攝遠近或是範圍不同,造成紋理尺度變化。如圖 1.6 的四張材質圖 片,(a)與(b)為同類,(c)與(d)為同類。使用原始 LBP 特徵抽取得到結果如圖 1.6 下方所 -0.60 -0.4 -0.2 0 0.2 0.4 0.6 0.8 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 (a) (b) (c) (d) 第 一 類 第 二 類
5 示,依據卡氏距離作為特徵相似度比較,再利用 PCA 得到圖 1.7,得知電腦以紋理尺度 當作其中一個相似度判斷依據,造成材質辨識結果誤差極大。 (a) (b) (c) (d) 圖 1.6 尺度上變化,其中上方為原始圖片,下方為特徵抽取結果 圖 1.7 尺度變化特徵相似度,PCA 分布圖 雜訊問題: 在理想情況下拍攝照片不會有雜訊點的產生,然而拍攝過程或傳輸圖片中,雜訊干 擾造成圖片產生雜訊點使判別產生誤差,圖片常見雜訊有高斯雜訊或是胡椒鹽雜訊。如 圖 1.8 的四張材質圖片,其中(a)與(b)為同類,(c)與(d)為同類。將材質圖片經由原始 LBP 特徵抽取得到結果如圖 1.8 下方所示,依據卡氏距離作為特徵相似度比較,再利用 PCA 得到圖 1.9,得知電腦判斷以雜訊點的多寡作為其中一個判斷的依據,造成材質辨識上 的誤差。 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 (a) (b) (c) (d) 第 一 類 第 二 類
6 (a) (b) (c) (d) 圖 1.8 雜訊參雜,其中上方為原始圖片,下方為特徵抽取結果 圖 1.9 雜訊變化特徵相似度,PCA 分布圖
1.4
研究目的與方法
經由上述問題探討可知,光亮、旋轉、尺度以及雜訊會造成材質辨識問題。因此在 材質辨識流程─圖 1.10─中,利用特徵抽取解決上述問題。特徵抽取是提取圖片中重要 資訊降低同類差異,進行有效辨識。然而經由實驗發現每種特徵抽取只能解決部分問題, 為了達到高準確性的辨識需倚靠大量訓練資料,因此開發出結合特徵抽取方式,提升材 質特徵解決環境變化所造成的問題,藉此提高辨識準確度並降低訓練資料量。 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 0.35 0.4 0.45 0.5 0.55 0.6 0.65 0.7 (a) (b) (c) (d) 第 一 類 第 二 類7 圖 1.10 材質辨識流程圖
1.5
論文架構
本篇論文主要分為六大章節,第一章是講述實驗動機,介紹材質辨識、現今常見的 特徵抽取方法和所遇到的問題。第二章介紹本論文中所使用的特徵抽取方式。第三章是 介紹本論文使用的分類器。第四章是探討本論文使用的特徵特性,以及講述如何結合多 個特徵,並介紹多個特徵的特性。第五章先以少量的樣本實驗探討每種特徵結合的效果。 接著以大樣本實驗驗證結果是否相符,之後測試在不同的分類器下,多重特徵是否具有 相同效果,最後使用不同訓練資料量,觀測材質辨識準確度的變化。第六章是為結論及 未來展望。8
Chapter 2 特徵抽取
本章節將介紹我們使用的特徵抽取方式。2.1 節介紹灰階共生矩陣,經由公式推論 灰階共生矩陣無法抵抗光亮變化。為了解決光亮問題將灰階共生矩陣結合 2.2 節中所介 紹之局部二值化模式,得到 2.3 節中介紹的局部模式共生矩陣。但在結合過程發現,局 部模式共生矩陣無法抵抗雜訊問題,因此在 2.4 節介紹抵抗雜訊問題的紋理基元法。2.1
灰階共生矩陣
灰階共生矩陣(GrayLevel Co-occurrence Matrix, GLCM)是統計像素在空間中相對位 置的灰階值變化,反映紋理在空間中分布狀態,GLCM 特徵可分為三個步驟如下。 步驟 1 選取位置變化向量 相對位置是由起始灰階值到觀測灰階值的向量,也稱之為位置變化向量,常見的位 置變化向量如圖 2.1 所示,箭頭是為位置變化向量 d,‖𝒅‖是位置變化向量的距離, 是 位置變化向量的角度, =0,45,…,315,i為起始灰階值, j 則是觀測灰階值。 圖 2.1 位置變化向量 步驟 2 計算 GLCM 矩陣 上一個步驟決定位置變化向量,接著統計起始灰階值i到觀測灰階值 j 在原始圖片 中所佔的個數,並將統計量放置在 GLCM 矩陣第i行第 j 列的位置上,
9
1 1 1, ( , ) ( , y ) , 0, ( , ) ( , y ) , X Y x y x y x y I x y i I x j GLCM i j I x y i I x j
若 和 若 或者 d d d d d (2.1) 其中I 為XY的圖片。舉例說明,原始圖片的灰階值分布如圖 2.2(a)所示,位置變化向 量d =
1, 0 ,統計原始灰階值分布中起始灰階值 i=1,觀測灰階值 j=2 的個數,發現符合 上述條件有 2 個因此在 GLCM 矩陣 i=1,j=2 的位置上標記為 2─如圖 2.2(b)圈選所示─ 以此類推即可得到完整的 GLCM 矩陣如圖 2.2(b)。此 GLCM 不能抵抗旋轉變化問題, 為了解決旋轉變化問題,選取 8 個位置變化向量如圖 2.1,計算其 GLCM 矩陣,並將全 部 GLCM 矩陣相加得到具有旋轉不變性的全方向 GLCM 矩陣。此時全方向 GLCM 也為 對稱矩陣如圖 2.3。 (a) (b) 圖 2.2(a)原始圖片灰階值分布矩陣,(b)GLCM 矩陣 (a) (b) (c) 圖 2.3(a)原始灰階分布(b)8 個位置變化向量(c)全方向 GLCM 矩陣 步驟 3 統計直方圖 為了計算全方向 GLCM 直方圖,我們將全方向 GLCM 矩陣由二維空間轉成一維向 量,並且將一維向量用直方圖表示,其轉化過程如圖 2.4。先把全方向 GLCM 矩陣灰色10 部分由列按照順序得到一維向量後,依照一維向量的維度放置直方圖的 x 軸,接著將對 應維度的向量直放置到 y 軸如圖 2.4(c)所示,得灰階共生矩陣的直方圖,即為其特徵。 (a) (b) (c) 圖 2.4(a)全方向 GLCM 矩陣,(b)GLCM 一維向量,(c)直方圖 經由上述步驟,可推測全方向 GLCM 無法辨識光亮變化。因此本文尋找能解決光 亮變化的特徵抽取方式,互相結合得到新方式,使得材質辨識準確度提升。因此下節將 介紹能抵抗光亮變化的局部二值化模式。
2.2
局部二值化模式
局部二值化模式(Local Binary Pattern, LBP)是一種描述材質局部紋理的特徵抽取方 式,將像素與鄰近像素的相互關係利用二值化進行編碼。其具有光亮及旋轉不變性。局 部二值化模式可以分為三個步驟如下。 步驟 1 選取編碼視窗 進行 LBP 特徵抽取前需先選取編碼視窗─如圖 2.5(a)─的大小以及鄰近點個數。編 碼視窗大小選取與材質圖片大小有關,材質圖片越大所需編碼視窗也越大。當編碼視窗 變大會產生兩個問題,第一、編碼視窗變大會使鄰近點之間間距變大─如圖 2.5(b)─對 於局部紋理描述不夠完整。為解決此問題選擇增加鄰近點個數─如圖 2.5(c)─使鄰近點 之間間距變小,對局部紋理描述較為完整。第二、當編碼視窗越大每個鄰近點到中心點 距離會不盡相同─如圖 2.5(b)─使得編碼過程產生不同標準。為了改善此問題,T. Ojala 提出將編碼視窗由方形改為圓形─如圖2 . 5 (d )─使編碼視窗中心點到每個鄰近點距離
11 相同[8],取得相同標準,但是圓形編碼視窗會發生選取的鄰近點不在原圖片像素上,為 了解決此問題,使用線性內插法近似鄰近點的灰階值。 (a) (b) (c) (d) 圖 2.5(a)R1鄰近點 8 個,(b)R2鄰近點 8 個, (c) R2鄰近點 16 個,(d) R2圓形鄰近點 8 個 步驟 2 進行編碼 首先將編碼視窗放置於原始圖片進行掃描,並利用中心點與鄰近點的相互關係計算 二值化編碼視窗如圖 2.6 所示。其中圖 2.6(a)中的灰色部分為編碼視窗,在編碼視窗中 底線 7 是進行編碼的灰階值,其餘皆為編碼視窗的鄰近點。計算二值化視窗是將編碼視 窗中鄰近點減去中心點,若是大於等於 0,在二值化編碼視窗中與編碼視窗相對應位置 上標記為 1,反之則標記為 0。
1, 0 , 0, 0 , p c p p p c g g S x y g g (2.2) 其中 pP,總共有P個鄰近點,
xp,yp
為第p個鄰近點對應位置, p g 為鄰近點灰階值, c g 為中心點灰階值,S為二值化編碼視窗如圖 2.6(b)。 (a) (b) 圖 2.6(a)原始圖像灰階值分布,(b)二值化編碼視窗12 T. Ojala 發現 90%二值化編碼視窗呈現均勻模式如圖 2.7(a)所示,剩餘二值化編碼視 窗呈現非均勻模式如圖 2.7(b)所示[8]。
,
1
0
1
1
1 g g S g g 2, 2, , P P R P c c p c p c p U LBP S g g S g g S U U
均勻模式 非均勻模式 (2.3) 觀測非均勻模式中心點對應到原始圖片相同位置上都為雜訊點,故 T. Ojala 在編碼過程 將所有非均勻模式歸為同類[8]。 (a) (b) 圖 2.7(a)均勻模式,(b)非均勻模式 二值化編碼視窗是依靠中心點與鄰近點相對應關係,對於光亮的問題能有效解決, 但旋轉變化仍是一大問題。T. Ojala 提出將均勻二值化編碼視窗第一個由 0 到 1 的元素, 放置到編碼排序中第 1 個位置,依照順時針方向進行排序,得到完整編碼排序如圖 2.8, 接著將編碼排序值相加,即可得到均勻二值化編碼視窗的 LBP 值[8]。而非均勻二值化 在均勻化的過程中已將它們編為同類,故此其 LBP 值皆為鄰近點個數加 1。如下,
1 0 , , 1, , P p c p P R s g g LBP P
均勻模式 非均勻模式 (2.4) 此時得到能解決光亮以及旋轉問題的 LBP 值。 圖 2.8 取得具有旋轉強健性 LBP 值過程13 步驟 3 局部二值化模式圖像與直方圖 將原始圖片─如圖 2.9(a)─的灰階值分布矩陣,全部經由 LBP 轉化,得到 LBP 分布 矩陣,此矩陣可稱為 LBP 圖如圖 2.9(b)所示。接著統計每個 LBP 值在 LBP 圖中所佔有 的總個數,並整理成直方圖如圖 2.9(c),此時直方圖即為 LBP 特徵。其中 x 軸為 LBP 值,y 軸是 LBP 值在 LBP 圖片佔有總個數。 (a) (b) (c) 圖 2.9 取得直方圖流程(a)原始圖片,(b)LBP 圖片,(c)直方圖 從公式中推測 LBP 特徵抽取能解決光亮與旋轉問題。因此將 GLCM 與其結合,產 生出新的特徵抽取方式,又稱為局部模式共生矩陣。在下節將會介紹其計算方式以及原 理。
2.3
局部模式共生矩陣
局部模式共生矩陣(Local Pattern Co-occurrence Matrix,LPCM)原理是將 LBP 局部紋 理特性與 GLCM 空間灰階關係做結合,藉此提高特徵抽取解決環境變化問題的能力, LPCM 主要可分為三個步驟。 步驟 1 多尺度階層圖片 實證分析中可知,紋理會因尺度不同造成辨識誤差,為了解決上述問題將原始圖片 ─如圖 2.10(a)─經由高斯金字塔(Gaussian Pyramid)產生多張不同視角圖片如圖 2.10(b) 所示,增加對整體紋理描述。本文將此圖片集合稱之為高斯金字塔階層圖片。
14 (a) (b) 圖 2.10(a)原始圖片,(b)高斯金字塔圖片 步驟 2LBP 階層圖片 上節推測 LBP 能解決光亮與旋轉變化問題,因此將高斯金字塔階層圖片全部經由 LBP 轉換,產生出 LBP 階層圖片如圖 2.11。使其不受到光亮與旋轉環境變化影響。 圖 2.11 多尺度圖片經由 LBP 轉換過程 步驟 3 GLCM 直方圖 LBP 是針對局部紋理描述,沒有空間分布特性,因此利用 GLCM 增加空間的概念, 提升 LBP 辨識準確度。作法是將 LBP 階層圖片經由 GLCM 轉換得到具有空間觀點的直 方圖如圖 2.12 所示,此直方圖即為 LPCM 特徵。 圖 2.12 GLCM 轉換過程 上述過程推測出 LPCM 能解決光亮以及旋轉問題,然而其無法解決雜訊問題。因此 下節將介紹解決雜訊問題的紋理基元法。
15
2.4
紋理基元法
紋理基元法(Textons-BasedApproach, TBA)原理是找出材質圖片中的紋理基元,統計 其個數並得到紋理特徵。然而所需計算的資料量過於龐大,因此 Varma 和 Zisserman 提 出新的紋理基元法[19],能有效壓縮需計算的資料量,並增加紋理特徵訊雜比。TBA 可 分為三個步驟如下。 步驟 1 伽瑪校正 由於同類別圖片間的光亮差異度大,因此利用伽瑪校正─如圖 2.13─使光亮差異不 會造成圖片判別誤差,其中伽瑪校正計算方式為:
,
,
min
, S x y c I x y I (2.5) I 為原始圖片,其大小為XY xX y, Y。S是經過伽瑪校正後的圖片,其大小為XY , xX yY。 假設校正後灰階值平均值為 127,最小灰階值調整為 0,最大調整為 255,代入公式 (2.5)可得
255c max I min I (2.6)
1 1 1 127 min , X Y i j c I I X Y
(2.7) 將公式(2.6)與(2.7)整理如下列公式:
1 1 255 log 127 1log max min log min X Y i j c I I c I I X Y
(2.8)
255 , max min c I I (2.9)16 將光亮差異度大的圖片如圖 2.14(a),經由上述伽瑪校正公式計算後,發現其光亮差異有 效降低如圖 2.14(b)。由此得知伽瑪校正能降低光亮差異。 圖 2.13 為伽瑪校正圖示意 (a) (b) 圖 2.14(a)前三張為原始圖片,(b)後三張圖片經過伽瑪校正 步驟 2 濾除雜訊 此步驟目的是濾除圖片中雜訊,留下重要資訊。作法是將伽瑪校正後的圖片經由濾 波器集合(filter set)得到多張濾波圖片。初始版本的濾波器集合有 48 種濾波器:分別為 1. 一階和二階高斯濾波器(first and second derivatives of Gaussians filter ),尺度有 3 種, 每種尺度下擁有 6 個角度。2. 高斯濾波器與拉普拉斯-高斯濾波器,尺度分別有 6 種。 然而此濾波器集合濾出的圖片集合含有過多無效資訊,因此 Varma 和 Zisserman(2004) 提出更新版本將 48 個濾波器減少為 38 個如圖 2.15[19],其中高斯濾波器與拉普拉斯-高斯濾波器尺度分別減少為 1 種。另外,一階和二階高斯濾波器在相同尺度的濾波圖片 中選取輸出響應最大圖片,經由這兩部份調整,濾波圖片集合由 48 張減少為 8 張,有 效壓縮輸出資料量,並提高訊雜比。
17 (a) (b) (c) 圖 2.15(a)一階高斯濾波器,(b)二階高斯濾波器, (c)上圖為高斯濾波器,下圖為拉普拉斯-高斯濾波器 步驟 3 選取代表向量,計算直方圖 由於濾波圖片集合仍有少部分雜訊,為解決圖片中殘留雜訊,將濾波圖片集合─如 圖 2.16(a)─利用 k 類平均演算法(k-means)得到 k 個代表向量如圖 2.16(b)所示,並將 k 個代表向量取代濾波圖片集合裡面的向量,並統計其佔有的總個數,整理成直方圖如圖 2.16(c)所示,此直方圖即為 TBA 特徵。 (a) (b) (c) 圖 2.16(a)濾波圖片集合,(b)代表向量,(c)統計直方圖 經由上述過程可得知 TBA 能解決光亮及雜訊的問題。下章節將介紹本論文使用的 分類器,並在第四章節中利用實驗驗證每個特徵的特性。
18
Chapter 3 分類器
本章節主要介紹本論文使用的分類器,3.1 節介紹支持向量機,3.2 節介紹 K-最鄰 近分類器。介紹的分類器分別會在第四章節與第五章節中運用。
3.1
支持向量機
支持向量機(Support Vector Machines, SVM)是根據統計學習理論而提出的機器學習 方法。它本身可以解決小樣本、非線性以及高維向量空間的分類問題。
3.1.1 SVM 概念
SVM 是在資料中找出一個超平面(hyper-plane),將兩個不同類別分開,且兩類間距 越大越好。以二維空間為例,圖 3.1(a)超平面間距比圖 3.1(b)來的大,因此圖 3.1(a)有較 好的超平面。圖片裡實線為超平面,虛線為支持超平面(support hyper-plane)。支持超平 面是與超平面平行並和最近的資料點相交的線。 (a) (b) 圖 3.1(a)資料切割 1,(b)資料切割 219
3.1.2 線性 SVM 理論
圖 3.2 用 2 維空間示意 SVM 的超平面位置及其與支持超平面的關係 已知有{𝑥𝑖, 𝑦𝑖},i = 1 … … ,n 且𝑥𝑖 ∈ 𝑅𝐷空間的點,𝑦 𝑖 ∈ {1, −1}類。圖 3.2 中實線為超 平面,虛線為支持超平面,支持超平面間的垂直距離為邊距(Margin),x𝑖為第i個點,𝑦𝑖為 第i個點所屬類別。為求得最佳超平面,需要計算最大邊距,因此將超平面定義為 : T 0 , H w X b (3.1) 兩面支持超平面寫為 1 : 0 2 : 0 , T T H w b H w b X X (3.2) 將
定義為 1 後,上式需改寫為 1 : ' ' 1 0 2 : ' ' 1 0 , T T H w b H w b X X (3.3) 假設兩面支持超平面到超平面距離分別為d 與1 d 2 1 2 ' 1 ' 1 1 ' ' ' 1 ' 1 2 , ' ' b b H d w w b b H d w w 與超平面距離 與超平面距離 (3.4) 且邊距為兩面支持超平面的距離相加,推得20 邊距 = 1 2 ' 2 min , ' 2 w d d w (3.5) 公式(3.3)得知超平面與支持超平面的間距需介於1間。因此將條件式寫為 ' ' 1, 1 ' ' 1, 1 , T i i T i i w x b y w x b y 若 若 (3.6) 將上式整理為
'T '
1 0, , i i y w x b i (3.7) 由以上公式可得知目標條件公式如下
2 1 min ' 2 'T ' 1 0 , i i w y w x b i (3.8)此條件公式符合拉格朗日乘數方法(Lagrange Multiplier Method),且為最佳化問題。因此 使用拉格朗日乘數方法求最佳解。拉格朗日乘數方法如下。
2
1 1 ', ', ' ' ' 1 , 2 N T i i i i L w b w y w x b
(3.9) 若要求最佳解,則需分別對w',b'偏微分 1 1 ' 0 ' 0 , ' N i i i i N i i i L w y x w L y b
(3.10) 上面條件總和可得下式 `21
1 1 ' 0 ' 0 ' ' ' 1 0, , 0, , ' ' 1 0 , N i i i i N i i i T i i i T i i i L w y x w L y b y w x b i i y w x b
拉格朗日乘數條件 互補鬆弛 (3.11) 此條件式又稱之卡羅需庫恩塔克條件(Karush-Kuhn-Tucker conditions, KKT 條件)。接著 將訓練資料經由公式(3.11)運算,發現部分點滿足 KKT 條件,這些點坐落在支持超平面 上且i 0,將這些點組成向量,其向量稱為支持向量(support vector)。得到支持向量便 能判斷測試點屬於哪個集合。分類公式如下
, T i i i i i T j j j i i j f x y y x x b b y x x y
(3.12) 其中分類方程式定義為 f,x為測試點,分類結果為y , j 為支持向量,i i為測試資料點。 此公式即為日後進行分類測試之公式。3.1.3 資料不可分隔 SVM 理論
理想狀況下可用一個超平面,將資料做完全分割,但是現實生活中無法將資料完全 分割,都會產生誤差點。誤差點會與正確資料點混合在一起,或是與支持超平面重疊, 需將公式(3.6)加入誤差項,將公式改寫如下,22 1 1 1 1 0 , T i i i T i i i i w x b y w x b y i (3.15) 在計算的過程當中誤差項越小越好。因此將有誤差的資料點增加懲罰項,使得產生誤 差點的成本(Cost)增加, , i i CostC
, (3.16) 其中C為懲罰的權重,將公式(3.8)改寫為:
2 1 min 2 1 0 0 , i i T i i i i w C y w x b i
和 (3.17)此條件公式符合拉格朗日乘數方法(Lagrange Multiplier Method),且為最佳化問題。因此 使用拉格朗日乘數方法求最佳解。拉格朗日乘數方法如下。
2
1 1 1 , , , , 1 , 2 N N T i i i i i i i i i i L w b w C y w x b
(3.18) 可求得新的 KKT 條件
1 1 1 0 0 0 0 1 0 0 , 0, 0 , 1 0, 0 N i i i N N i i i i i T i i i i i i T i i i i i i L y b L C y w x b and y w x b
拉格朗日乘數條件 互補鬆弛 (3.19)23
3.2
K-最鄰近分類器
3.2.1 K-最鄰近分類器
K-最鄰近分類器(K-nearest neighbor classification, KNN)是計算每個訓練資料點到測
試資料點的距離,找出距離此點最近的k個訓練資料,統計各類別在k個訓練資料中所
占有的個數後,將此測試資料點分類。計算方式如下,
arg max
arg max ,i i i i i i i k P C x k k G x y P C x k (3.20) 類別有i種,Ci為第i類群集,x為測試資料點,ki為k個訓練資料點屬於第i類的個數, i y為未知資料分類結果。此公式能將測試資料分類到佔有最多訓練資料的類別。 (a) (b) 圖 3.3 散佈在空間中的 KNN(a)k=3,(b)k=4 如圖 3.4,菱形點為測試資料點,三角點與圓點分別為不同類的訓練資料,圓圈以k 個訓練資料中距離菱形點最遠的距離為半徑。如圖 3.4(a)所示,當k=3 時,圓圈內有兩 個三角點與一個圓點,由於三角點占有多數,因此將測試資料歸類為三角點。但當k =4 時─如圖 3.4(b)─圓點與三角點都各占兩名,兩者數目相同使得 KNN 分類器無法判斷 測試資料點屬於哪個類別。為了解決此問題,而提出新的分類方式。
24
3.2.2 加權式 KNN 分類器
原始 KNN 只看k個訓練資料中哪類佔有最大比例做為判斷依據,但遇到類別數相 同時,無法判別測試資料類別。為了改善此問題,提出將訓練資料增加權重觀念。權重 計算是依據距離遠近作調整,當訓練資料與測試資料越近權重越重,當距離越遠權重越 輕,如下 , t t x x w k h (3.22) x為預定計算權重的訓練資料, t x 為測試資料,h為常數, t w 為訓練資料對應的權重。 接著將相同類別的權重相加得到每類別分數,
1 arg max , t i i i k i t j j w G x y w
(3.21) 分數最高的類別即為測試資料類別。25
Chapter 4
特徵特性探討
本章將於 4.1 節介紹實驗用的訓練資料。4.2 節利用不同測試資料對每個特徵進行特 性探討,結果發現每個特徵抽取方式只能解決部分問題,因此在 4.3 節提出多個特徵結 合方式,以解決更多環境變化的問題,提升材質辨識準確度。4.4 節利用不同的環境測 試資料進行實驗,驗證多重特徵的特性結果與本論文論述相符。4.1
訓練資料庫
CUReT 是由自然紋理組成,僅有少部分人工紋理,共有 61 類圖片,每類含有 92 張圖,且同類圖片具備光亮明暗差異、旋轉角度改變、紋理尺度變化及雜訊干擾。此特 性都與現實生活相符,故選取其中 45 類作為實驗資料庫如圖 4.1 所示。 圖 4.1 資料庫 CUReT 中選出的 45 類4.2
特徵特性實驗
這節要探討本文選出特徵抽取的特性,實驗使用 45 類中固定 10 類材質圖片,每類 隨機抽取 10 張作為訓練圖片,接著在剩餘圖片中隨機抽取 50 張做為測試圖片,將測試 圖片經由伽瑪校正、調整平均值與標準差及將圖片中所有的灰階值加上常數,做為光亮26 環境測試資料。接著將測試圖片向逆時針方向旋轉90 與180 作為旋轉環境測試資料。 再把測試圖片中的紋理放大 1.25 與 1.5 倍作為尺度環境測試資料。最後將測試圖片加入 高斯雜訊或是胡椒鹽雜訊作為雜訊環境測試資料。 將原始訓練資料經由特徵抽取,再經由 SVM 學習出分類模型。接著將不同的環境 變化測試資料分別進行特徵抽取,再經由分類模型得到分類結果,即可計算不同環境變 化下的辨識準確度。實驗重複 10 次後取平均。其中辨識準確度計算方式如下: =辨識正確張數 辨識準確度 總張數 (4.1) 有了辨識準確度,接著再計算原始測試資料與環境測試資料的相對降低準確度, =原始測試資料辨識準確度 環境變化辨識準確度 相對降低準確度 原始測試資料辨識準確度 (4.2) 相對降低準確度可以測試特徵抽取對不同環境變化的強健性表現。強健性代表環境或是 參數發生擾動使品質指標保持不變的指標,若是強健性好,代表當特徵抽取在原始辨識 過程有高準確度,則環境發生改變時仍能進行高準確度辨識。不同的環境變化測試資料 經上述實驗過程測試本論文選擇的特徵抽取方式可得到圖 4.2。光亮變化較佳表現者有 TBA、LBP 和 LPCM,旋轉變化表現較佳的有 GLCM、LBP 和 LPCM,尺度表現佳的僅 GLCM,而雜訊變化佳的只有 TBA。由此可知單一特徵抽取方式只對部分環境變化有較 佳的強健性,無法解決全部環境變化的問題,因此本論文提出結合多個特徵抽取方式增 加整體強健性,達到高準確度材質辨識。
27 圖 4.2 特徵特性圖
4.3
多重特徵與材質辨識流程
由上節可知每個特徵抽取方式能解決的環境變化不同,沒有一個特徵抽取方式能夠 解決全部環境變化問題。因此本論文提出結合多個特徵抽取方式,使整體能解決更多的 環境變化,藉此提高材質辨識的準確度。 首先將圖片經由多個特徵抽取方式取得多個紋理特徵,將所有特徵正規化並乘上其 特徵權重,全部特徵依照順序排列產生新的多重特徵,其計算方式如下。 1 1 1 2 2 1 ' ' ... 1 ' , n new i n i h h h h
(4.2) 其中hnew為結合後多重特徵,ℎ′1是將第一個特徵做正規化的結果,𝛼1則是第一個特徵權 重。把上述過程整理成圖 4.3,接著將原材質辨識流程中─圖 1.6─單一特徵抽取改為多 個特徵抽取,接著利用圖 4.3 的流程得到多重特徵,並且將原本辨識流程改為圖 4.4。權 重的計算方式是利用多次實驗結果取得最高辨識準確度後反推求得。28 圖 4.3 混合特徵方式 圖 4.4 新的材質辨識流程
4.4
多重特徵
這節會先探討具有互補性的特徵抽取結合是否能提升環境變化的強健性及原由,選 用的特徵抽取分別為 LPCM 與 TBA。從特徵抽取的特性圖 4.2 可知,LPCM 與 TBA 對 於不同的環境變化表現差異大,且能解決對方無法解決的環境變化問題,故此認定兩者 特徵抽取具有互補性。接著探討不具互補性的特徵抽取結合是否能提升環境變化的強健29 性及原由,選用的特徵抽取為 GLCM 與 LBP。從特性圖 4.2 可知,GLCM 與 LBP 對於 不同的環境變化表現差異不大,當遇到無法解決的問題,無法利用另一個特徵抽取解決, 故此認定兩者特徵抽取的特性較為相似。
4.4.1 TBA 與 LPCM 多重特徵實驗
此實驗先將圖片經由 TBA 與 LPCM 進行特徵抽取,再經由公式(4.1)將兩者的特徵 結合。訓練資料的多重特徵經由 SVM 學習得到分類模型,再將環境變化測試資料的多 重特徵,經由分類模型得到分類結果如圖 4.5。觀測光亮及尺度環境變化,LPCM+TBA 多重特徵的強健性雖然比 TBA 較為遜色,卻彌補 LPCM 無法抵抗尺度變化的缺點,並 且提升 LPCM 對於光亮變化的強健性。接著觀測旋轉環境變化,發現 LPCM+TBA 多重 特徵的旋轉強健性比 LPCM 略低,但是卻大幅降低 TBA無法抵抗旋轉環境變化的缺點, 增加強健性。會發生上述的兩種情況是因為 LPCM 與 TBA 的特性具有互補。因此當其 中一個特徵無法辨識環境變化時候,能倚靠其他特徵抽取方式進行彌補,使得環境變化 的強健性大幅提升。然而因為將無法辨識的特徵與其結合,造成原本具有抵抗環境變化 的特徵,因無效資訊參雜,使得其強健性略為下降。然而進步幅度比下降幅度大,因此 總體的強健性仍能有效提升。 圖 4.5LPCM+TBA 的多重特徵特性30
4.4.2 GLCM 與 LBP 的多重特徵
接著進行 GLCM 與 LBP 多重特徵的特性實驗,結果如圖 4.6 所示。對光亮環境變 化,GLCM+LBP 多重特徵雖然損失部分 LBP 對光亮環境變化的強健性,仍能大幅降低 GLCM 無法抵抗光亮環境變化的缺點。在尺度環境變化下 GLCM+LBP 多重特徵雖提升 LBP 強健性但提升幅度不大,而原本表現較好的 GLCM 強健性則大幅拉低,造成整體 特徵對各類別環境變化的強健性被拉低,但是觀測在光亮環境變化下 GLCM 的辨識準 確度不高,因此其在光亮變化的強健性並不具代表意義,造成上述情況發生。 由上述情況發現 GLCM+LBP 多重特徵除了在光亮環境變化下能提升其強健性,而 其他環境變化提升幅度有限。其中尺度變化發生上述問題不能具有代表性。造成上述狀 況推測 GLCM 與 LBP 特性過於相似,所以當其中一種特徵抽取方式無法抵抗環境變化 的問題,而另一特徵抽取方式也無法抵抗相同環境變化問題,造成多重特徵無法提升整 體強健性。 圖 4.6GLCM+LBP 多重特徵特性 經由上述兩種實驗可以證實,當結合的特徵抽取方式具有明顯互補性,多重特徵能 有效提升特徵抽取方式的優點並且降低其缺點,藉此提升特徵抽取方式對於環境變化的 強健性。然而當結合的特徵抽取方式較為相似,則多重特徵無法降低特徵抽取方式的缺31
點,導致環境變化的強健性無法提升。下章節將用實驗驗證當強健性上升時,能提升材 質變識準確度。
32
Chapter 5 實驗
此章節主要進行探討多重特徵的實驗,5.1 節使用小樣本實驗,先測試每個特徵抽 取方式結合的權重變化與材質辨識準確度。5.2 節將結合後辨識準確度良好的特徵抽取 擴大樣本資料庫進行測試,觀看能否提升材質辨識準確度。接著使用不同的分類器,觀 測分類器是否會造成多重特徵不同效果。5.3 節則使用不同的訓練資料量,觀測訓練資 料量對辨識準確度的影響。5.1
小樣本實驗
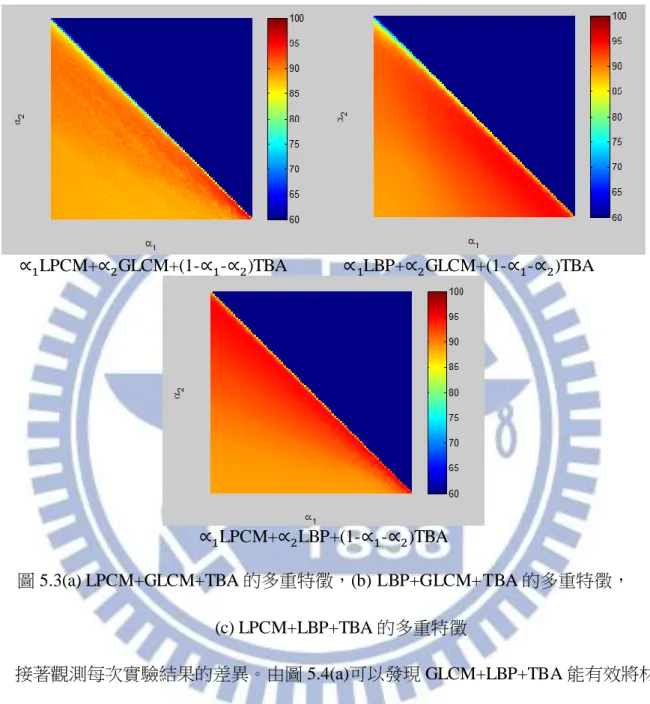
由 4.4 節得到結論,當結合具有互補性的特徵抽取方式,能增加對環境變化的強健 性。當結合相似的特徵抽取方式,則對於總體強健性無法提升。此節將實驗具有互補性 或相似性的多重特徵是否能提升材質辨識準確度。首先由 CUReT 資料庫選取 15 類,每 類隨機抽取 10 張作為訓練圖片〈共 150 張〉,剩餘的 82 張作為測試圖片〈共 1230 張〉。 經由材質辨識流程如圖 4.4 所示,即可求得材質辨識準確度。重複 10 次取得平均可得到 實驗結果。 小樣本實驗先探討將兩個特徵抽取方式做結合,得到材質辨識的結果如圖 5.1 和圖 5.2 所示。圖 5.1 是具有互補性的特徵實驗,可觀測出多重特徵能有效提升材質辨識的準 確度。圖 5.2 是具有相似性的特徵實驗,可看出多重特徵無法有效將材質辨識準確度往 上提升。由此證實當結合具有互補性的特徵抽取,其中一個特徵抽取無法對環境變化進 行辨識時,多重特徵能利用其它特徵抽取進行改善,使得材質辨識錯誤率下降。但是當 兩者特性相近,單一特徵抽取無法辨識環境變化時,另一個特徵抽取也無法進行改善, 並且因為過多無效資料參雜,造成材質辨識準確度下降。33 圖 5.1 結合具有互補性的特徵抽取方式 圖 5.2 結合具有相似的特徵抽取方式 接著要探討三個特徵抽取結合的結果與權重的影響,如圖 5.3 所示。由於 LPCM+LBP+GLCM 中隨意選出兩個特徵抽取做結合,無法提升材質辨識準確度。由此 推論,三者特徵結合只會造成更多無效資訊參雜,而不會提升材質辨識的準確度,故此 不進行 LPCM+LBP+GLCM 的結合。圖 5.3 中對角線位置對材質辨識度表現相較於其他 位置來的差,造成此狀況的原因為 LPCM,GLCM 以及 LBP 的特性都極為相似,而 LPCM,
34
LBP 及 GLCM 都與 TBA 的特性互補,除了對角線其他位置上都有少量的 TBA 參雜, 造成對角線的辨識準確度相較其他的位置都來的低。
∝1LPCM+∝2GLCM+(1-∝1-∝2)TBA ∝1LBP+∝2GLCM+(1-∝1-∝2)TBA
∝1LPCM+∝2LBP+(1-∝1-∝2)TBA
圖 5.3(a) LPCM+GLCM+TBA 的多重特徵,(b) LBP+GLCM+TBA 的多重特徵, (c) LPCM+LBP+TBA 的多重特徵 接著觀測每次實驗結果的差異。由圖 5.4(a)可以發現 GLCM+LBP+TBA 能有效將材 質辨識準確度往上提升,推測因 LBP 與 GLCM 的特性雖然大致相同,然而仍有少部分 具有互補的效果─如 4.2 節中的光亮環境變化─使得多重特徵可以進一步提升材質辨識 準確度。由圖 5.4(b)與圖 5.4(c)可發現,GLCM+LPCM+TBA 及 LBP+LPCM+TBA 的多 重特徵實驗結果與 LPCM+TBA 的多重特徵結果相差不多。推測因 LPCM 由 LBP 與 GLCM 相互結合所產生的,因此它同時具備兩者特性,使三個多重特徵無法有效提升材
35
質辨識的準確度。由上得知,材質辨識準確度不一定隨著結合的特徵抽取數量變多而提 升,需要結合具有互補性的特徵抽取,才能將材質辨識的準確度往上提升。
(a)
(b)
GLCM LBP TBA GLCM+LBP GLCM+TBA LBP+TBA GLCM+LBP+TBA
55 60 65 70 75 80 85 90 95 100
GLCM LPCM TBA GLCM+LPCM GLCM+TBA LPCM+TBA GLCM+LPCM+TBA
55 60 65 70 75 80 85 90 95 100 材 質 辨 識 準 確 度 材 質 識 準 確 度 紋理特徵 紋理特徵
36 (c) 圖 5.4(a)GLCM+LBP+TBA,(b)GLCM+LPCM+TBA, (c)LBP+LPCM+TBA
5.2
大樣本實驗
小樣本實驗得到的結果與預期相符,然而因樣本數不夠多,無法驗證結合具有互補 性的特徵能提高材質辨識。因此本章節將使用大樣本資料驗證小樣本實驗中能提升材質 辨識的多重特徵組合,然而三個特徵抽取的多重特徵,因計算量龐大且提升效果不明顯 而不進行測試。 首先從 CUReT 資料庫選取 45 類,每類隨機抽取 25 張作為訓練圖片〈共 1125 張〉, 將每類剩餘 57 張作為測試圖片〈共 2565 張〉。經由材質辨識流程如圖 4.4 所示,即可計 算出材質辨識的準確度。重複 10 次取平均得到實驗結果如圖 5.5 所示。 圖 5.5 中可知,當使用具有互補性的特徵結合,不會因樣本數的變動產生不同的結 果,仍可以提升材質辨識的準確度。另外還能得知多重特徵實驗結果的變異度比單一特 徵小。推測因為結合具有互補性的特徵抽取,使得原本無法進行環境辨識的特徵抽取, 可以經由另一個特徵抽取的特性得到有效的辨識,使得辨識結果更穩定。然而小樣本實LBP LPCM TBA LBP+LPCM LBP+TBA LPCM+TBA LBP+LPCM+TBA
78 80 82 84 86 88 90 92 94 96 98 100 材 質 辨 識 準 確 度 紋理特徵
37 驗中因為訓練資料過少,且測試資料間變異度過大,造成此特性不夠明顯。由此得知多 重特徵能有效解決更多的環境變化問題,並降低對訓練資料的依賴,使辨識的變異度變 小,但降低變異度所需要的訓練資料量仍需一定數目才能達成。經由整理得知多重特徵 能提升材質辨識準確度且降低辨識度的的變異程度。 圖 5.5 特徵材質辨識平均準確度 最後測試不同的分類器對材質辨識準確度的影響。實驗步驟如前所述,選取結合效 果最佳的 LPCM 與 TBA 作為多重特徵,使用 SVM 與 KNN 當作分類器,得到結果如圖 5.6。由圖 5.6 發現,使用 SVM 分類器時,LPCM+TBA 能有效提升 LPCM 與 TBA 的辨 識準確度並降低實驗之間的差異,當使用 KNN 分類器時,LPCM+TBA 仍能有效提升 LPCM 與 TBA 的辨識準確度並降低實驗之間的差異。因此得知當使用不同的分類器, 多重特徵都能有效提升材質辨識準確度,並可降低實驗之間的變異度。
GLCM LBP TBA LPCM GLCM+TBA LBP+TBA LPCM+TBA
65 70 75 80 85 90 95 100 材 質 辨 識 準 確 度 紋理特徵
38 圖 5.6 使用 SVM 與 KNN 的結果
5.3
訓練資料變化實驗
此節將測試不同的訓練資料量對於多重特徵的影響。先從 CUReT 資料庫中選取 30 類,每類隨機抽取 N 張訓練圖片,其中 N=10,15,…,45,並將剩餘 92-N 張數當作測試圖 片,經由辨識流程─圖 4.4─可得到分類結果,重複 10 次取平均可得實驗結果。選取結 合效果最佳的 LPCM+TBA 作為多重特徵得到結果如圖 5.7。 在圖 5.7 中,當在要求相同的準確度時,多重特徵能用較少的訓練張數達到目標。 例如當要求材質辨識準確度為 96%時,LPCM+TBA 多重特徵只需要 15 張訓練圖片, LPCM 則需 32 張訓練圖片,TBA 則無法提升到 96%。原因為多重特徵在不同的環境變 化能使用不同的特徵抽取,增加其強健性,因此對變異度大的測試圖片能進行有效辨識 並降低訓練資料量。SVM_LPCM SVM_TBA SVM_LPCM+TBA KNN_LPCM KNN_TBA KNN_LPCM+TBA 86 88 90 92 94 96 98 100 材 質 辨 識 準 確 度 紋理特徵與分類器
39 圖 5.7 訓練資料與準確度相關性 80 82 84 86 88 90 92 94 96 98 100 10 15 20 25 30 35 40 45 材質辨識準確度 每類訓練圖片數目 LPCM+TA LPCM TA
40
Chapter 6
結論與未來展望
本論文欲開發一有效辨識各環境變化的特徵抽取方法,解決目前特徵抽取皆無法同 時對各式環境變化進行有效辨識的問題。由先前實驗得知,各特徵抽取能解決之環境變 化不盡相同,所以本文提出結合多種特徵抽取─多重特徵─使特徵抽取不需倚靠大量的 訓練資料就能解決環境變化問題,提升材質辨識準確度,並對其解決環境變化之能力進 行驗證。根據實驗結果,可以得知: 1. 多重特徵須結合特性互補之特徵抽取才有意義,若結合相似之特徵抽取則無法進行 改善。 2. 特性互補之多重特徵能增加環境變化的強健性,並能夠解決更多環境變化的問題。 3. 特性互補之多重特徵能有效提升材質辨識的準確度。 4. 當具有相同材質辨識準確度的時候,特性互補之多重特徵能減少訓練資料量的使 用。 5. 特性互補之多重特徵能有效降低每次實驗結果的變異度。 由以上得知,特性互補之多重特徵能改善單一特徵抽取方式的缺點並且提升其優點, 進而提升材質辨識的準確度,減少使用的訓練資料量,並且能降低實驗結果之間的變異 度。然而目前仍有不足的地方: 1. 由於實驗中─4.3 節─選擇的三個特徵抽取太過相似,造成三個特徵結合的結果不 盡理想。未來可再進行具有互補性的三個特徵抽取結合的多重特徵,找出更有效提 升材質辨識準確度的方式。 2. 每次實驗需先測試各種權重結果,才能得知最佳權重值,造成計算時間過長。若能 找到最佳求得權重的方式,則可對實驗整體時間有效減少。41 3. 由第五章可以得知,多重特徵能降低訓練資料量,然而當訓練資料數目過低,實驗 間的變異度也會跟著變大。若能找出較好的訓練資料選取方式,則可維持少量訓練 資料並降低變異度。 4. 由於目前實驗限定於材質辨識的特徵抽取,因此利用範圍有所限制。若能增加色彩 或是形態的特徵抽取,未來利用範圍會更為廣泛。
42
參考文獻
1. Soh, L.-K. and C. Tsatsoulis, Texture analysis of SAR sea ice imagery using gray level
co-occurrence matrices. Geoscience and Remote Sensing, IEEE Transactions on, 1999.
37(2): p. 780-795.
2. Abdelrahman, A. and O. Hamid, Breast Ultrasound Images Enhancement Using Gray
Level Co-Occurrence Matrices Quantizing Technique. International Journal of
Information Science, 2012. 2(5): p. 60-64.
3. Shan, C., Learning local binary patterns for gender classification on real-world face
images. Pattern Recognition Letters, 2012. 33(4): p. 431-437.
4. Haralick, R.M., Statistical and structural approaches to texture. Proceedings of the IEEE, 1979. 67(5): p. 786-804.
5. Sklansky, J., Image segmentation and feature extraction. Systems, Man and Cybernetics, IEEE Transactions on, 1978. 8(4): p. 237-247.
6. Hsu, C.-W., C.-C. Chang, and C.-J. Lin, A practical guide to support vector
classification. 2003.
7. Devroye, L., A probabilistic theory of pattern recognition. Vol. 31. 1996: springer. 8. Ojala, T., M. Pietikainen, and T. Maenpaa, Multiresolution gray-scale and rotation
invariant texture classification with local binary patterns. Pattern Analysis and
Machine Intelligence, IEEE Transactions on, 2002. 24(7): p. 971-987.
9. Haralick, R.M., K. Shanmugam, and I.H. Dinstein, Textural features for image
classification. Systems, Man and Cybernetics, IEEE Transactions on, 1973(6): p.
610-621.
10. Unser, M. and M. Eden, Nonlinear operators for improving texture segmentation
based on features extracted by spatial filtering. Systems, Man and Cybernetics, IEEE
43
11. Weszka, J.S., C.R. Dyer, and A. Rosenfeld, A comparative study of texture measures
for terrain classification. Systems, Man and Cybernetics, IEEE Transactions on,
1976(4): p. 269-285.
12. Porter, R. and N. Canagarajah. Robust rotation-invariant texture classification:
wavelet, Gabor filter and GMRF based schemes. in Vision, Image and Signal Processing, IEE Proceedings-. 1997. IET.
13. Voorhees, H. and T. Poggio. Detecting textons and texture boundaries in natural
images. in Proceedings of the First International Conference on Computer Vision.
1987.
14. Davis, L.S., M. Clearman, and J.K. Aggarwal. A comparative texture classification
study based on generalized cooccurrence matrices. in Decision and Control including the Symposium on Adaptive Processes, 1979 18th IEEE Conference on. 1979. IEEE.
15. Haralick, R.M. and L. Watson, A facet model for image data. Computer Graphics and Image Processing, 1981. 15(2): p. 113-129.
16. Moser, G., S.B. Serpico, and J.A. Benediktsson. Markov random field models for
supervised land cover classification from very high resolution multispectral remote sensing images. in Advances in Radar and Remote Sensing (TyWRRS), 2012 Tyrrhenian Workshop on. 2012. IEEE.
17. Sun, X., et al. Multi-scale local pattern co-occurrence matrix for textural image
classification. in Neural Networks (IJCNN), The 2012 International Joint Conference on. 2012. IEEE.
18. Leung, T. and J. Malik. Recognizing surfaces using three-dimensional textons. in
Computer Vision, 1999. The Proceedings of the Seventh IEEE International Conference on. 1999. IEEE.
44
19. Varma, M. and A. Zisserman, A statistical approach to texture classification from