使用雙目標最佳化方法估算肌肉醣原分解之
代謝路徑的動力學參數
Estimation of kinetic parameters for modeling
metabolic pathways of muscle glycogenolysis
using two-objective optimization methods
研究生:張孝邦 Student:Shiao-Bang Chang指導教授:何信瑩 Advisor:Shinn-Ying Ho
國 立 交 通 大 學
生物資訊研究所
碩 士 論 文
A Thesis Submitted to Institute of Bioinformatics
College of Biological Science and Technology
National Chiao Tung University
in partial Fulfillment of the Requirements
for the Degree of Master in
Bioinformatics
January 2009
Hsinchu, Taiwan, Republic of China
使用雙目標最佳化方法估算肌肉醣原分解之
代謝路徑的動力學參數
學生:張孝邦
指導教授:何信瑩
國立交通大學生物資訊研究所碩士班
摘 要
代謝路徑的模型重建是研究系統生物學的主要課題之一,建模 的目的是為了研究蛋白質或整個代謝網路彼此之間的相互作用以及行 為模式。例如肌肉之醣原分解是人體生理機能中不可或缺的一環,並 且其代謝路徑的生化反應相當敏感。本研究的模型架構是以微分方程 式為主軸的動力學模型,此模型能在反應過程中呈現出瞬間的濃度變 化、酶所造成之通量及受酶影響之回應。 通常要重建一個動力學模型,例如肌肉醣原分解之代謝路徑模型, 可使用被收集在特定資料庫中的數據,但可能有些參數值尚屬未知。 這些動力學參數值通常是利用實驗方法去獲得,它們可能是從不同的 實驗環境或是不同物種組成分批得來。由於代謝過程之中的動力學參 數之間存在著熱力學限制以及反應代謝物的 Gibbs 生成自由能會決定 反應平衡常數,使用這類參數值所建成的模型可能未遵守熱力學原理, 導致不真實的生化反應。 本研究提出一套使用雙目標最佳化方法來估算代謝路徑模型的 動力學參數並將之應用到肌肉醣原分解之代謝路徑的模型重建,其特 色有(1)同時最小化系統總自由能來符合熱力學原理及最小化模型所 估算反應物的濃度誤差及(2)使用智慧型基因演算法精確地解此雙目 標最佳化問題的大量動力學參數。 從模擬實驗結果顯示最小化系統總自由能和最小化濃度誤差兩 目標在提高模型精確度時有所衝突,使用雙目標最佳化方法有其必要。 在模型精確度方面,我們以所提方法的估算參數值及現有方法的預設參數值所建的模型做比較,結果顯示我們的方法能獲得較低的系統總 自由能(-0.72566kJ vs. -0.06561kJ)和較小的濃度誤差(提升準確率
9.20%)。對所建模型做反應物與產物的敏感度分析,可進一步了解整 個代謝網路彼此之間的相互作用。本文所提方法亦適用於其它相似代 謝路徑的模型重建。
Estimation of kinetic parameters for modeling
metabolic pathways of muscle glycogenolysis
using two-objective optimization methods
Student:Shiao-Bang Chang Advisor:Dr. Shinn-Ying HoInstitute of Bioinformatics
National Chiao Tung University
Abstract
The model reconstruction of metabolic pathways is one of the major researches of systems biology, whose goal is to study the interaction and behaviors among proteins or whole metabolic networks. Muscle glycoge-nolysis is essential to the human physiological functions and its biochem-ical reactions of metabolic pathways are sensitive. In this study, the struc-ture of kinetic models bases on the principle of ordinary differential equa-tions, which can express the temporal changing, fluxes and responses in-fluenced by enzymes in the progress of reactions.
To construct a kinetic model, such as the metabolic pathways of mus-cle glycogenolysis, one can retrieve the values of kinetic parameters from specific databases. However, the parameter values for establishing the ki-netic models were generally obtained from experimental methods, which may be derived separately from different experiments or combination of different species. Therefore, the constructed model may violate thermo-dynamics theory or be unknown, which results in unrealistic biochemical reactions.
This study proposes a two-objective optimization approach to estima-tion of kinetic parameters for modeling metabolic pathways and its appli-cation to muscle glycogenolysis. The merits of this approach is twofold: 1) simultaneously minimizing the total Gibbs free energy of the system ac-cording to thermodynamic theory and minimizing the estimated concen-tration errors; and 2) using intelligent genetic algorithms to solve accu-rately the two-objective optimization problem with a large number of
ki-netic parameters.
The simulation results reveal that the two objectives have conflicts in pursuit of accurate models. It means that the simultaneous optimization of the two objectives is necessary. In the aspect of model accuracy, the two models using the estimated and existing kinetic parameter values were compared. The results show that the proposed model has lower total Gibbs free energy of the system (-0.72566kJ vs. -0.06561kJ) and a smaller esti-mated concentration errors (improvement 9.20%). The sensitivity analysis on the reconstructed model can further understand the interactions of the metabolic networks. The proposed method is also effective to the model reconstruction of other similar metabolic pathways.
誌謝
此篇論文的研究完成需要特別感謝指導教授-何信瑩老師的巧 思,當我在研究瓶頸中的循循善誘,讓我能逐步完成研究以及學習如 何以邏輯思考地分析研究方向。另外還能從他的身教及言教中了解作 人作事的道理所在,而這些都要感謝老師的不吝指導。 此研究的完成還須感謝清大化工系的汪上曉汪教授在化工熱力 學和反應動力學上的指教以及本所尤禎祥老師於計算化學上的指教, 感謝此兩位教授的幫忙,使得研究能逐步完成。 另外還要感謝實驗室義雄學長在我碩士生涯中於公、於私的教 訓及關心,以及實驗室交接的各項幫忙。還有冠維、鐘錡與俊維學長 在資訊能力上的教導及幫助,而佳達,凱迪及廖芹於提供實驗室生活 中的趣味,當然還要感謝慧玲學姐和瓊慧學姐的大力鼓勵。感謝實驗 室大家的關心以及和樂融融的相處能讓我不斷走下去。另外還要謝謝 怡蒨在我身邊的關心與教訓也是能讓我完成研究的一大動力。 最後要謝謝我的家人,因為有他們支持及幫忙使我在求學階段 不必擔心生活而終將完成學業上的研究!。目錄
頁次 摘 要 ... ii Abstract ... iv 誌謝 ... vi 目錄 ... vii 表目錄 ... x 圖目錄 ... xi 符 號 說 明 ... xiii 一、 緒論 ... 1 1.1 研究動機 ... 1 1.2 相關研究 ... 1 1.3 研究目的 ... 3 二、 代謝反應路徑之動力學模型的結構 ... 7 2.1 模型理論 ... 7 2.1.1 動力學模型 ... 7 2.1.2 擴展後的 Debye-Hückel 定律 ... 10 2.1.3 熱力學上的限制 ... 11 2.2 系統流程 ... 13 2.2.1 數學架構 ... 13 2.2.2 解題方法 ... 16 2.3 方法應用 ... 16 2.3.1 使用擴展 Debye Hückel 定律 ... 18 2.3.2 動力學函數以及模型 ... 19三、 最佳化演算法之使用 ... 22 3.1 智慧型基因演算法 ... 22 3.1.1 直交表與因素分析 ... 22 3.1.2 智慧型交配運算 ... 23 3.2 方法流程 ... 24 3.2.1 選擇運算 ... 24 3.2.2 智慧型交配 ... 24 3.2.3 突變運算及演化終止條件 ... 25 3.3 智慧型多目標基因演算法 ... 26 3.3.1 基於 Pareto 理論通適化且不因尺度影響之評估函數 ... 26 3.3.2 演算法流程 ... 28 四、 估算動力學參數之雙目標最佳化方法 ... 29 4.1 估算動力學參數之模組化 ... 29 4.2 評估函數的兩項目標函數 ... 31 4.2.1 以加權指數法混合雙目標 ... 32 4.2.2 以最佳解集合同時考量雙目標 ... 33 4.3 染色體編碼方式 ... 35 五、 在骨骼肌肉醣解代謝上的應用 ... 36 5.1 反應速率方程式 ... 36 5.2 計算範例說明 ... 42 六、 實驗結果 ... 45 6.1 利用智慧型基因演算法作加權指數法 ... 45 6.1.1 實驗只使用 fG模擬無雜訊之數據 ... 45 6.1.2 實驗只使用 fE模擬無雜訊之數據 ... 46 6.1.3 混合使用 fG和 fE模擬無雜訊之數據 ... 51 6.1.4 實驗混合使用 fG和 fE並使用加權指數 ... 52 6.1.5 實驗只使用 fE模擬有雜訊之數據 ... 53 6.2 用智慧型多目標基因演算法取得最佳解集合 ... 58 6.2.1 實驗模擬無雜訊之數據... 59
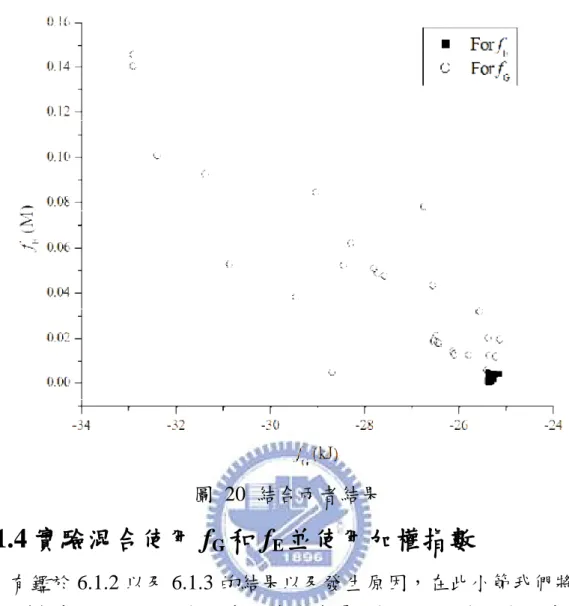
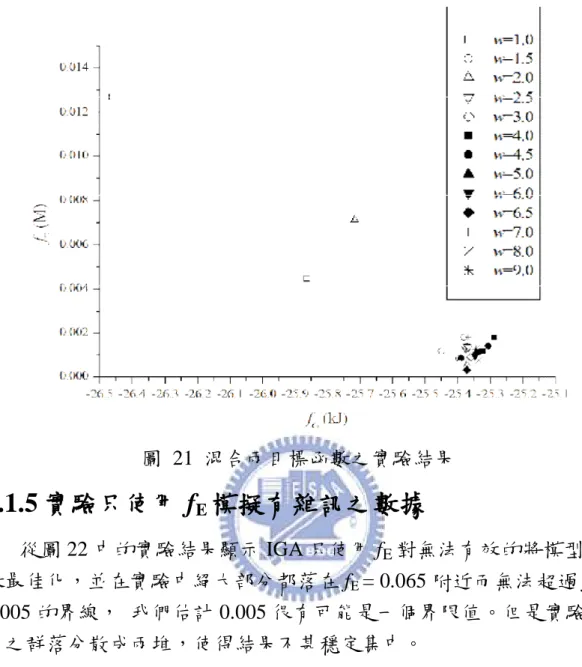
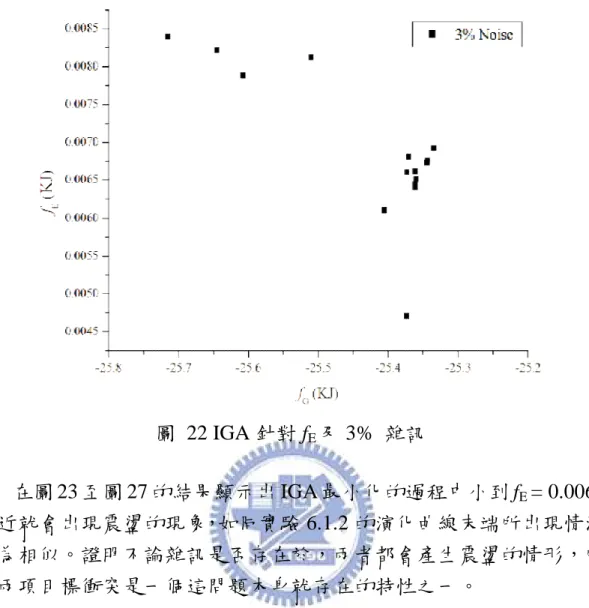
6.2.2 實驗模擬有雜訊之數據 ... 60 6.2.3 實驗中使用真實實驗數據 ... 62 6.3 與真實實驗數據之比較... 63 6.3.1 驗證 fG ... 63 6.3.2 濃度曲線圖 ... 65 6.3.3 動力學參數 ... 68 6.4 敏感度分析 ... 71 6.5 模擬結果的其餘反應物之濃度 ... 73 七、 問題討論 ... 80 7.1 討論 ... 80 7.2 未來展望 ... 81 參考文獻... 82 附錄 ... 89
表目錄
表 1 肌肉醣原分解中全部反應 ... 17 表 2 反應物簡名及標號 ... 19 表 3 反應物的起始濃度 ... 20 表 4 參與反應的酵素活性 ... 21 表 5 L8(2 7)直交表 ... 23 表 6 IGA 全實驗之統計表 ... 58 表 7 動力學參數表 ... 69 表 8 敏感度分析的實驗統計結果 ... 72圖目錄
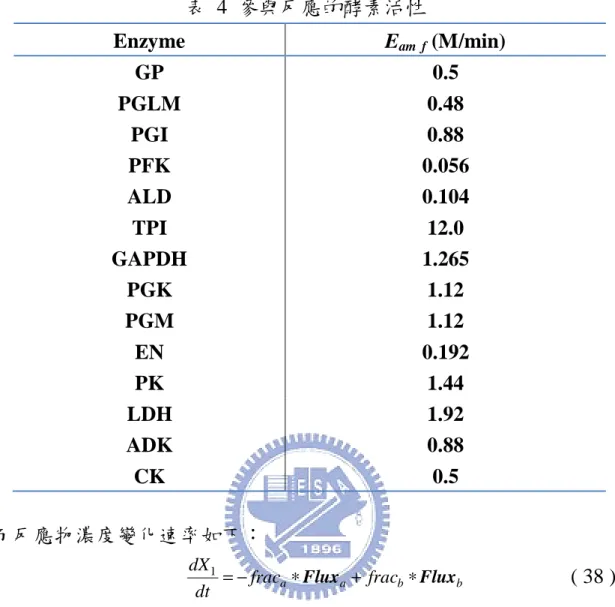
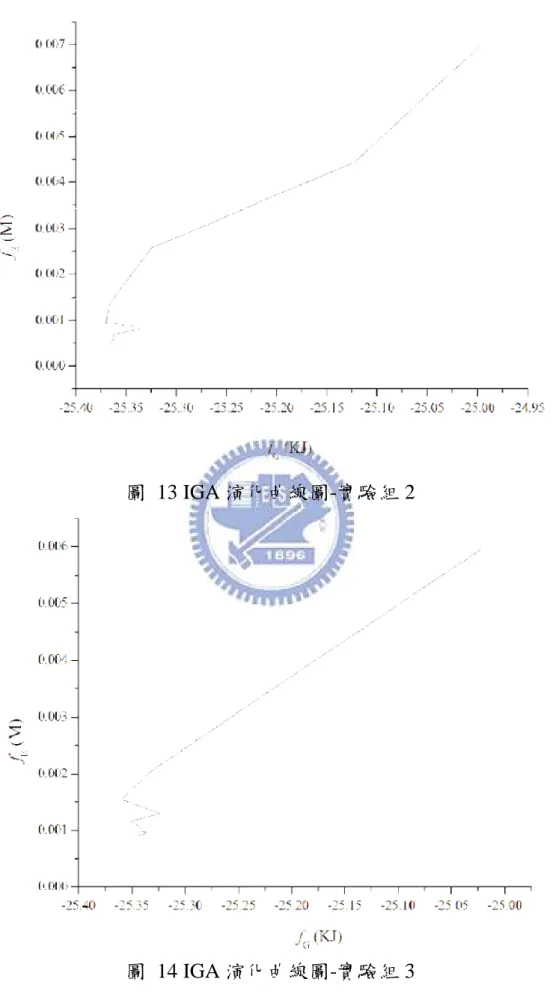
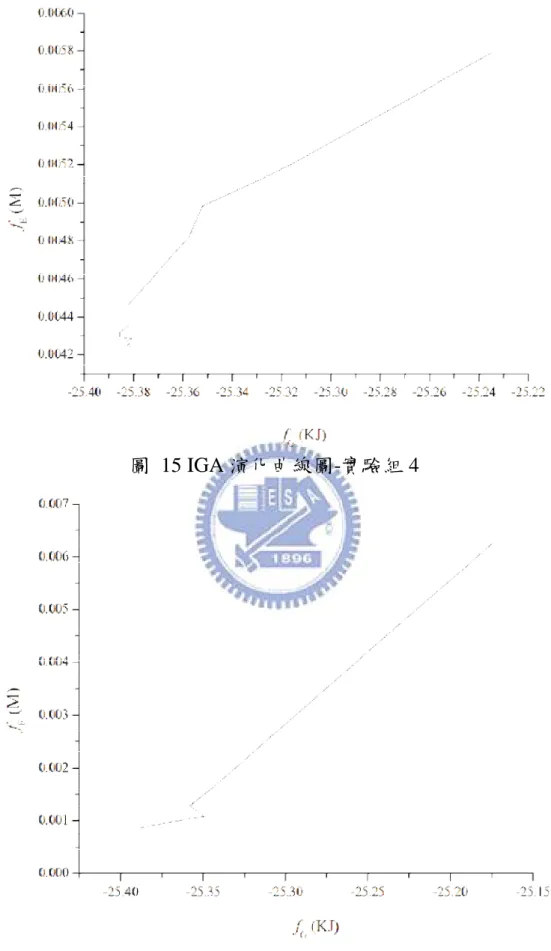
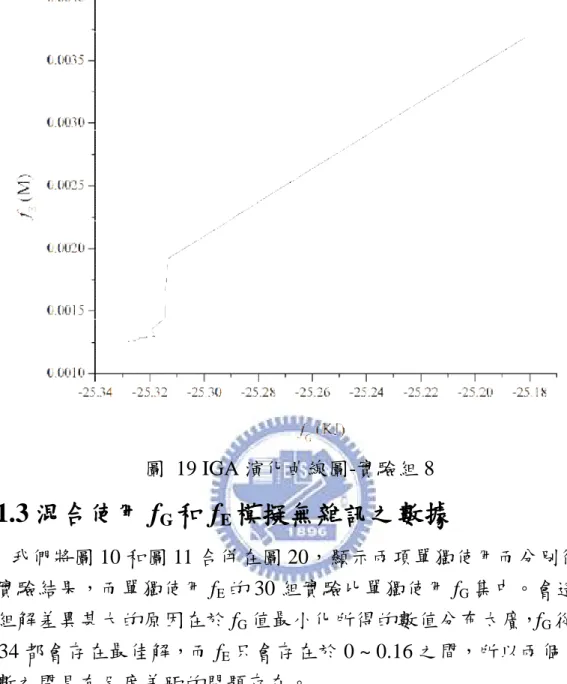
圖 1 系統概念圖 ... 5 圖 2 系統總體 Gibbs 自由能對反應程度 ... 11 圖 3 肌肉醣原分解之反應途徑 ... 18 圖 4 支配與被支配關係示意圖 ... 27 圖 5 GPSIFF 之示意說明圖 ... 27 圖 6 EKTOM 之說明及流程圖 ... 30 圖 7 應用智慧型基因演算法求最佳解之流程 ... 33 圖 8 應用智慧型多目標基因演算法求最佳解集合之流程 ... 34 圖 9 染色體的編碼方式 ... 35 圖 10 IGA 針對 fG做最佳化之結果 ... 45 圖 11 IGA 針對 fE做最佳化之結果 ... 46 圖 12 IGA 演化曲線圖-實驗組 1 ... 47 圖 13 IGA 演化曲線圖-實驗組 2 ... 48 圖 14 IGA 演化曲線圖-實驗組 3 ... 48 圖 15 IGA 演化曲線圖-實驗組 4 ... 49 圖 16 IGA 演化曲線圖-實驗組 5 ... 49 圖 17 IGA 演化曲線圖-實驗組 6 ... 50 圖 18 IGA 演化曲線圖-實驗組 7 ... 50 圖 19 IGA 演化曲線圖-實驗組 8 ... 51 圖 20 結合兩者結果 ... 52 圖 21 混合兩目標函數之實驗結果 ... 53 圖 22 IGA 針對 fE及 3% 雜訊 ... 54 圖 23 IGA 具雜訊之演化曲線圖-實驗組 1 ... 55 圖 24 IGA 具雜訊之演化曲線圖-實驗組 2 ... 55 圖 25 IGA 具雜訊之演化曲線圖-實驗組 3 ... 56 圖 26 IGA 具雜訊之演化曲線圖-實驗組 4 ... 56 圖 27 IGA 具雜訊之演化曲線圖-實驗組 5 ... 57 圖 28 雜訊存在與否之實驗示意圖 ... 57 圖 29 IMOGA 對模擬實驗數據之結果 ... 59 圖 30 IMOGA 與 IGA 比較圖 ... 60 圖 31 IMOGA 對具雜訊之模擬數據結果-實驗組 1 ... 61圖 32 IMOGA 對具雜訊之模擬實驗數據圖-實驗組 2 ... 61 圖 33 當雜訊存在,IGA 與 IMOGA 之比較圖 ... 62 圖 34 IMOGA 對真實實驗數據圖 ... 63 圖 35 三組K 在模擬反應過程中系統總能量之變化 ... 64 圖 36 ATP 及 ADP 之濃度變化 ... 66 圖 37 LAC 及 PCr 之濃度變化 ... 66 圖 38 HMP 之濃度變化 ... 67 圖 39 G3P 及 PG 之濃度變化 ... 68 圖 40 最終產物之產生速率的敏感度對反應物濃度 變化 1%的結果 . 72 圖 41 最終產物之產生速率的敏感度對反應物濃度 變化 3%的結果 . 73 圖 42 Cr 的濃度變化 ... 74 圖 43 Pi 的濃度變化 ... 75 圖 44 AMP 及 DHAP 之濃度變化 ... 76 圖 45 G6P 及 FBP 之濃度變化 ... 76 圖 46 GAP 及 1,3BPG 之濃度變化 ... 77 圖 47 NADH 及 G1P 之濃度變化 ... 77 圖 48 2PG 及 PEP 之濃度變化 ... 78 圖 49 3PG 及 PYR 之濃度變化 ... 78 圖 50 NAD 的濃度變化 ... 79
符 號 說 明
NH(i) :該反應物 i 擁有的氫離子數 pH :代表環境酸鹼度 Zi :該反應物 i 的電子價價數 I :離子強度 R :氣體常數 T :絕對溫度 nV :所有成分之總體積 P :系統壓力 nS :系統總熵 μi :反應物 i 的化學勢 ni :反應物 i 的莫耳數 i a K , :反應物 i 的解離常數 m K :金屬離子 m 的平衡常數 m eq K :反應 m 的反應平衡常數 Kj :動力學模型中的參數。j 為參數標號,j =1 … 70。 Xi :反應物 i 的濃度 Fluxm :反應 m 的反應通量 m i ω :在反應 m 中,反應物 i 的化學計量係數 ξm :反應 m 的反應程度 ∆H :反應焓 i H N :反應物 i 的平均氫離子數目 i fG ∆ :反應物 i 的莫耳生成自由能 ' o i fG ∆ :修正後的反應物 i 之莫耳生成自由能 ' o m G ∆ :經轉換後,反應 m 的莫耳反應自由能 G :系統總體 Gibbs 自由能 dG :總體 Gibbs 自由能的改變量 Eam f :第 m 個反應的正向酵素活性 Eam r :第 m 個反應的逆向酵素活性 app am E :第 m 個反應,經修正後的酵素活性 K :動力學參數組一、 緒論
1.1 研究動機
在系統生物學之中,要用電腦模擬細胞行為的研究是一項相當重 要的課題[1]。而其中關於生物化學網路的研究裡有三個主要架構,分 別是基因調節網路(genetic regulatory network )、生化網路(biochemical or metabolic network)和訊號傳遞網路 ( signal transduction network)。這 三個網路彼此交互作用而形成生物體內的運作[2-6],經由一連串的刺 激、反應跟訊息傳遞造成生物內部的行為。生化網路所進行的部分是 細胞內的化學物質之間化學變化,而這個網路的結構是來自於數個連 續的化學反應而串接起來成為一個有功能性的反應路徑,經由反應消 耗在反應中的代謝物(metabolite),生成下一個反應的受質(substrate)後 接著繼續下一個反應直到整條反應路徑達到反應平衡而中止。代謝網 路專注研究在反應之間彼此的行為,例如濃度、通量、激活或是抑制 反應。系統生物學需要利用這些行為對反應途徑建構模型,藉此探討 整條反應網路之行為變化所造成的影響。 為了能夠研究反應過程中的影響及變化,我們需要一套能作動力 學分析的模型。動力學模型通常是使用微分方程組的數學架構,此架 構存在著許多參數,參數數目與微分方程之大小成正相關。 本研究為提供一個能同時根據實驗數據以及考慮熱力學條件之下, 將動力學模型之參數作系統最佳化設計,為了能更精確地計算參數值 並正確地還原代謝反應之系統。這篇研究以肌肉醣解代謝反應為例, 其共有 16 個微分方程式,含有 70 個動力學參數。
1.2 相關研究
目前已可從過去研究區分出代謝之網路結構[7-9],為了能更深入 生化反應的網路,之前大多嘗試使用 Flux Balance Analysis (FBA) [10-12]、Biochemical Systems Theory (BST) [13, 14]、Metabolic Control Analysis (MCA)[15]以上方法建構出一個能表示出反應流程的模型,並 且藉由路徑或基本限制的方法[16-19]以應用反應通量的方式[10, 20,21] 成功地描述其模型。
Flux Balance Analysis[11, 12]是根據研究系統大小而改變其化學計 量矩陣並利用 Linear programming 找出最佳解。因為 FBA 能對應到大 型代謝網路系統上,目前大多是應用在 E. coli 上,雖然這方法有陷入 局部最佳解(local optimum)以及其解可能無效的問題存在,但依舊仍是 廣受研究者喜愛的方法之一。
Metabolic Control Analysis[22]一開始是用來研究代謝路徑的調控 關係,雖然後期被應用到信號傳遞網路及基因網路上。但此方法將變 數分成具網路性質(control coefficients)和具本身特性(elasticity coeffi-cients)兩類參數,能直接對照過去的控制理論是這方法的特性。
Biochemical Systems Theory[23]是根據微分方程組(Ordinary diffe-rential equations, ODEs)依 Power-Law 展開而成的數學模型,可根據模 型變數之指數辨別其變數對於網路之影響能力。這套方法發展至今已 有各種變形,如 S-system 模型可見一斑[24]。 還有一種方法是依據酵素動力學的反應方程式建造整個模型,我 們選擇使用動力學模型來建構本篇研究的反應模型架構,對代謝系統 建模型的方法有很多已經在論文中依各種不同的動力學架構而被發表 [25, 26]。這種方法因為具有基本的化學反應動力學理論存在,能呈現 出在反應系統之中的短暫變化及酵素所造成之通量和對其影響之回應, 使得模型具有生物意義。用系統組織的方式會有助於找出一些重要的 系統特性,但這種特徵在當簡化問題時會被隱藏起來[27],但我們並 不能判斷這些資訊是不是我們所盼望發現的資訊。並且局部、分段的 尋找解答也會限制解空間,無法更進一步的找出問題最適當的解答。 所以當使用 ODEs 作建構模型的數學架構時,必須要使用系統化的方 式計算方程組中的參數值。 在反應方程式中為了能精確的調適反應過程而需要許多動力學參 數[28],動力學參數的散佈[28-31]被用在探索反應彼此間之變化及潛 在行為,但這些參數存在著不易定量的問題。雖然目前已經有大量的 酵素動力學之參數被收集存放在一些特定資料庫之中[32, 33],但是直 接使用這些參數值卻不一定是最正確的方式[34, 35]。經由實驗取得的 數值或者是在之前文獻裡所記載的實驗數據中,大多針對著整段反應 路徑中的部分實驗所設計而經由計算而留下記錄。我們知道在實驗中 要同時取得代謝網路所需要的數據是一件辛苦兼困難的工作,根據之
前研究要將部分已知的動力學參數組織並串連成為一個完整的連續反 應中,是個廣為流傳使用的方式[25, 26]。但是在一個較複雜或是將數 個生化路徑結合起來(例如:Glycolysis 結合 TCA cycle)的生化反應系 統中,會從中發現在文獻取用的參數數值通常會是處在不同環境或不 同物種下的實驗值[28],這種問題會使得依據此數據所建造的模型可 能失去一些它們本來的正確性。 在 2005 年 Liebermeister 和 Klipp 的研究[30]中提到,參數間的微 小變化可能會影響定性上的行為模式,同時也會對系統行為有些許影 響。基於熱力學的限制之下,動力學參數並不適宜被分別挑選得出; 而統計上,這些參數同時跟其它因素相關的情況發生頻率不算小,因 為參數彼此之間會因為反應中相關反應物的濃度、反應速度的快慢及 反應熱力學的效應而互相影響其值,所以這些參數具有需要利用整體 最佳化特性存在。此外為求得動力學參數還存在著幾個問題就是實驗 測量數值之誤差、生物本身所存在的變異性以及大多數的動力學參數 都是未知或是不明、不確定[30]。 要藉由電腦計算的方式求得模型裡之大量參數數據是件不容易的 事,若要得到較為準確的化學動力學參數則還是需要依據相關的熱力 學性質[36, 37]。用數值分析及模擬處理具有詳盡動力學機制的模型會 有高維度空間(high-dimensional space)的問題[38]。要計算大量參數並 最佳化是一個難以處理的問題,因此藉由其他方法將問題降階簡化以 減少問題的複雜度和困難。這些方法目前已被接受且普遍使用[36, 38-40]。而使用演化式演算法尋找最佳解的方式是一個對使用動力學 模型處理複雜反應系統的良好方法[41],並且不會受到參數未知的限 制是這個方法的優點。使用演化式演算法做這種問題的研究通常在評 估函數上有兩種選擇:一個是對系統總 Gibbs 自由能最小化[42, 43]; 另一個則是與實驗值之誤差做最小化[44, 45]。雖然陸續已有人提出為 了使模型更接近現實情況需要再多考慮熱力學的能量[19],但都是將 其當作是一種判斷解答的限制,而不是同時將熱力學能量當成是一個 最佳化的目標函數,至今仍尚未同時考量最小化實驗數據之誤差以及 系統總能量之研究。
1.3 研究目的
從化學反應平衡的觀點,若是相當快速的化學反應或者是完全反應,大多數的反應最後幾乎都會走向平衡狀態,在生物體內的化學反 應亦是如此。而生化反應會為了需要達成某種目的而進行反應,當反 應完成隨即又會回復到一個新的穩定狀態之下,等待著下一次反應的 開始。這樣的情況稱為生理穩定(Physiological Steady State),所以當代 謝反應進行後會有一個穩定狀態的存在,但要注意的是該狀態並不會 持續存在。 在我們的研究目標是希望藉由所使用的動力學模型計算反應過程 中系統總能量的變化,找尋總能量和實驗誤差同時最小化之一組動力 學參數最佳解,直接由智慧型基因演算法求出最適合這條反應的動力 學參數。 代謝系統之中的動力學參數之間所存在的熱力學限制:反應代謝 物的 Gibbs 生成自由能經由計算會決定反應平衡常數,它會產生出反 應之間的動力學參數以及橫跨整個網路的限制。一般將來自於實驗的 動力學參數值直接放入模型使用,但這樣的使用將有可能具有熱力學 上的錯誤[34,35]。從酵素活性、質量守恆、能量守恆跟反應平衡限制 之下,使用智慧型基因演算法搜尋具有反應過程中最低總自由能的整 組反應之動力學參數。利用基因演算法的特性能有效地求解並且毫無 簡化問題本身,在眾多基因演算法中被選擇使用的方法是智慧型基因 演算法(Intelligent genetic algorithm, IGA)以及智慧型多目標基因演算 法(Intelligent Multi-Objective Genetic Algorithm, IMOGA),因為它能有 效解決大量參數的問題以及本身搜尋最佳解的優秀能力[46],而能採 用整體最佳化考量的作法去避免局部解問題的發生。 我們所使用的目標函數有兩項:最小化系統 Gibbs 自由能之最小 值以及最小化模型估算與實驗濃度數據之誤差總和。以前研究通常單 獨使用其一當成它們的目標函數,但在我們實驗中發現當同時使用兩 者會造成自相矛盾的結果:當實驗濃度之記錄無誤只用最小化誤差總 和即可,但會導致違背熱力學原則;而當實驗濃度考量本身帶有誤差 存在時,僅使用誤差總和最小化無法求得最佳解。為了處理這樣問題 的發生,我們建議增加系統 Gibbs 自由能最小化當作另一項目標函數 為參考依據。 雖然兩目標函數存在著衝突,但藉由我們所提出的演算法可適當 處理,所以我們方法適合解決此類型的問題。而本篇研究目的就在於 提出一個方法可以提供具有參數不明確問題的生化反應系統一組經過
整體系統最佳化、正確且穩定的動力學參數,並能夠同時符合熱力學 上之限制及提高動力學模型與實驗數據的相似度。 圖 1.是概略性地表示具有複雜關係之動力學參數需要經過整體最 佳化的示意圖: 圖 1 系統概念圖 第二章會將我們所作的問題做個簡單的定義。敘述整個動力學模 型的三大架構:(1) 骨架:根據生化反應式的動力學方程式組;(2) 連 接關係:利用 Debye Hückel 定律 以及 Haldane relationship 計算反應
間之通量;(3) 溶液環境:利用鍵結多項式、H+和 Mg2+的離子平衡式
以及緩衝溶液的模擬,構成整個反應系統。在 2.3 應用於肌肉的肝醣 分解之代謝機制上。
第三章介紹本篇研究使用之智慧型基因演算法機制以及所使用之 評估函數。3.3 節更進一步利用智慧型多目標基因演算法(Intelligent Multi-Objective Genetic Algorithm, IMOGA)找出 Pareto Front,並從中 提供一組最佳解供人以後參考使用。
第四章為介紹本研究所提出之方法 EKTOM(Estimation of Kinetic parameters using Two-objective Optimization Methods)之說明。並分別再 對選擇不同最佳化演算法的搭配流程做詳細敘述。
第五章將針對本篇之應用簡單說明 EKTOM 其流程。
能量中會有一個能量最低點的存在,說明使用 fG的意義並驗證。再利
用 IGA 分別對 fG、fE和 Hybrid(fG+fE)作實驗,分析當實驗濃度有無誤差
時的效果。由於 fG與 fE具有互相衝突的特性存在,故使用 IMOGA 作
Pareto front 從中提供一組最佳解以滿足雙目標之要求,將此最佳解與 Vinnakota[44]相比較其精確度及穩定性。
二、 代謝反應路徑之動力學模型的結構
2.1 模型理論
2.1.1 中介紹所使用之動力學模型的相關方程式。2.1.2 是介紹 Debye-Hückel theory 以修正在不同環境下會發生改變的標準 Gibbs 生 成自由能。2.1.3 說明考慮一化學反應系統時,熱力學的特性會使得系 統中出現的限制條件及其原則。
2.1.1 動力學模型
這套模型有一些基本假設,就是跟陽離子鍵結的成分對酵素都有 一樣的親和力,且在固定 pH 值之下我們維持 Mg2+和其他離子的濃度。 另外我們參考基本的生理狀況下,先取 pH、溫度和離子強度起始值。在方程組中有關正向酵素活性值(Ea f )的計算我們引用 Scopes et al.[47]
所收集的實驗值,而逆向酵素活性值(Ea r)值就使用 Haldane 關係式直 接計算。模型中幾個反應的速率計算式之中,我們假設酵素活性會根 據環境酸鹼度而改變,所以使用修正式改變所使用的酵素活性值。 根據熱力學公式計算出的反應平衡常數值( m eq K )當作反應指引的根 據,想讓反應過後的濃度能在該反應之平衡常數的容許範圍內。當反 應在不同環境之下, m eq K 也會根據反應環境不同而改變,在模型之中我 們會重新計算做適當修正。當 pH 及 I 存在時,須考量根據它們所產 生的影響而作應對的變化。當系統環境與實驗一致,對於同一生化反 應所測得的實驗數據還是可能會不一樣,當然所測得之數據不可避免 的還是須要考慮人為誤差。對於使用的動力學參數有不同環境的數據 存在其中,對於使用這些數據建構模型還原的準確度上就會造成影響 [34]。這份懷疑並不是指它不正確,因為之前的研究都是根據實驗數 據所作,也可從文獻中看到模擬的結果。通常的確是有如同實驗值的 傾向存在並呈現出來,但的確是有可再改善的空間。 使用建模型的反應參數想要在一致的條件跟環境之下能一次取 得的全部數據資料,相信對於建造模型會有更精準的表現[48]。但是 動力學模型架構的基本是一組微分方程組,在一組微分方程組之中最
難的問題就是該如何決定在方程式之中的大量參數[30]。我們從整個 系統能量之觀點出發,而從化學能及熱力學能量的觀點發展相關代謝 系統的研究已有先例[43, 49-52]。並且從熱力學觀點可以提供對問題的 限制[53],進而讓問題得到解決或者得到更接近真實的方法。而動力 學參數會影響到反應平衡常數,改變反應的平衡狀態而影響著整體系 統的運作。可知動力學參數與熱力學平衡關係非常密切。 目前已知道在 E coli.的細胞質液中大約會存在 0.15~0.20M 之間 的離子強度[37]。而根據擴展的 Debye-Hückel 定律[54]可將反應物之 生成自由能作計算修正,再依照各個成分的反應量計算該反應的反應 自由能,再將該反應的反應自由能根據 van’t Hoff 方程式1計算該反應 之反應平衡常數。迭代計算反應過程中的流通量、濃度、自由能、pH 值,以及反應後的反應平衡常數。 在使用動力學模型的好處是它較易於令人了解反應物所參與的 反應,例如某化學反應: A+B ↔ P +Q 。 ( 1 ) 該反應的一般速率表示式為: p q Q P q Q p P b a b A b B a A q p Q P r a b a B A f a m K K X X K X K X K K X X K X K X K K X X E K K X X E Flux + + + + + + − = 1 (2) ( 2 )式之中的 Ka、Kb、Kp和 Kq就是這篇研究所要求出的動力學參數值。 Xi是反應物 i 的濃度,Ea f和 Ea rf是正逆向的酵素活性,Fluxm是的 m 個反應的反應通量。這篇研究所使用動力學模型的定義可參閱[55]。 Eam f、Eam r兩者知其一即可藉由 Haldane 關係式,可從正向反應推算 逆向反應,反之亦可。Haldane 關係式如下:
∏
∏
= = = M m f m m eq M m r m f am r am K K K E E 1 1 (3) 以( 3 )式求出的值代入( 2 )式可得到該反應的反應通量。在( 3 )式中的 m eq K 為反應 m 的反應平衡常數,Km f是正向反應的動力學參數,Km r是 1 van’t Hoff 方程式: 1 1 ) ( ) ln( K 2 H o − ∆ − =逆向反應的動力學參數。
在開始計算反應之前需要先針對反應環境計算 o'
i fG
∆ ,其值來自
expanded Debye-Hückel theory 的計算而得第 m 個反應的莫耳反應自由 能( o' m G ∆ ),
∑
∑
∆ − ∆ = ∆ reactants o i f products o i f o m G G G ' ' ' ( 4 ) 並要考慮在環境中所存有之金屬離子的影響,我們使用 P 為陽離子鍵 結多項式(binding polynomial)[56]:∑
∑
∏
= = = + + = Q q q q N p J j j a p K Metal K H 1 1 1 , ] [ ] [ 1 P (5) 並從(5)式的 P 進一步求出當下環境的反應平衡常數:∏
∏
∗ ∆ = reactants products o m r m eq RT G K P P ) exp( ' (6) 同時,也需計算在不同環境下的平均質子鍵結數 [56],用於計算反 應中質子的變動。計算平均離子之鍵結數其詳細理論於 Alberty[54,56] 之中。但因為所使用的熱力學參數是在標準狀態下的數據,所以還要 使用 van’t Hoff 方程式根據模型所假定的溫度對參數做修正。 要能在一個環境多變的生物系統下計算精確自由能的理論值是 相當困難的,因為有太多會對反應過程造成影響,例如濃度、溫度、 電價數、離子強度或者是分子間碰撞次數都會影響到反應的能量。而 這份研究從原子不滅之平衡式開始,將氫離子和鎂離子的濃度影響以 用偏微分方程式展開[44]。[Htotal]=[Hfree]+[Hbound]+[Hreference] (7)
[ ] [ ] [ ] 2 bound 2 free 2 total + + + = + Mg Mg Mg (8) ( 7 )式是氫離子的原子守恆式,[Htotal]是氫離子總濃度,[Hfree] 是自由氫離子的濃度,[Hbound]是反應物鍵結之平均氫離子數,[Hreference] 是在反應物上的氫離子濃度。( 8 )式是鎂離子的原子守恆式,[Mgtotal2+ ] 是鎂離子總濃度,[Mgfree2+ ]是自由鎂離子的濃度,[Mgbound2+ ]是跟反應物 鍵結之平均鎂離子數。將兩式取微分並將氫、鎂的自由離子濃度移到
等式左側可得( 9 )、( 10 )式。 dt H d dt H d dt H
d[ free+ ] [ bound+ ] [ reference+ ]
− − = (9) dt Mg d dt Mg d[ free2+ ] [ bound2+ ] − = (10) 下面兩式是計算在系統中,反應物鍵結之平均氫離子數和平均 鎂離子數的變化。 dt dC N dt Mg d Mg N C dt H d H N C dt dC N C dt N d dt H d i i H I i I i i H i i H i i i H I i i i H
∑
∑
∑
= = + + + + = + + ∂ ∂ + ∂ ∂ = + = 1 1 2 2 1 bound ] [ ] [ ( ] [ ] [ ) ( ] [ (11)∑
∑
∑
= + = = + ∂ ∂ + − + ∂ ∂ = I i i i H I i I i i i Mg i i Mg C Mg N dt dC N C dt dpH pH N dt Mg d 1 2 1 1 2 bound ) 1 ( ] [ (12) 由[44]的研究中可以得知在這個生化反應系統之下,整條反應 途徑會受到[Mg2+]、[K+]和[H+]的影響。 根據[57]的研究顯示出生化反應中的酵素會隨著細胞質 pH 值 的影響而敏感地反應在酵素活性上。所以在[44]的動力學模型中已將 所使用的酵素其活性對 pH 加以修正,並放進動力學模型計算之中。 在反應不斷進行時,pH、Mg2+、酵素活性以及參與反應的反應物會不 斷變化,而反應程度會隨著[Mg2+]、[K+]和[H+]做適度調整。反應結果 我們會跟[47]中的 Exp.29 做驗證,我們將結果放在後面章節討論。2.1.2 擴展後的 Debye-Hückel 定律
各反應物的反應消耗(或生成)單位莫耳生成熱( o' i fG ∆ )算出該成分 在這個反應中所提供(或生成)的能量,計算各成份的反應能量總和可 得到反應熱。而生成熱會受到 pH、溫度(T)、離子強度(I)以及電價數 (Zi)的影響,根據擴展後的 Debye-Hückel 定律在不同溫度下的離子物 質可用下式計算[54, 58],且當離子強度為 0.05 ~ 0.25M 範圍內的計算 結果相當具有公信力。其公式如下式:2 1 2 1 2 ' 6 . 1 1 )) ( ( 91482 . 2 ) 10 ln( ) ( ) 0 ( I I pH I + − + + = ∆ = ∆ G G NH i RT Zi NH i o i f o i f (13) 根據(13)式將各個反應物的生成能 o' i fG ∆ ( pH, I ) 依固定的 pH 跟 I 逐一修正,計算出在定溫下各個代謝物的 Gibbs 生成自由能。
2.1.3 熱力學上的限制
在熱力學平衡的觀點下,一連串的化學反應依序的發生,若反 應為可逆反應,則反應終將達到反應平衡的狀態。根據勒沙特列原理 ( Le Chatelier's principle )-若一個已達平衡的系統被改變,該系統會 隨之改變來抗衡該改變。在固定環境之下只會存在一個平衡點,當環 境不變的情況下,平衡狀態就是唯一。而以圖 2 說明總體 Gibbs 自由 能(G)與反應進行程度(ξ)微分值為零,是系統總體自由能的最低點。圖 2 是對單一反應的平衡說明,圖中之∆rG代表此反應的反應自由能在紅 點上時的微小變化量,可等同於斜率理解。對單一化學反應而言,反 應自由能與總體自由能相等。 圖 2 系統總體 Gibbs 自由能對反應程度[60] 在生物體內的代謝反應是被假定在屬於在定溫定壓之環境進行 的。因為此類反應的反應量跟濃度成正比,不論是吸熱反應或是放熱 反應都不足以改變系統環境的溫度。而在生物體內的壓力同樣不會有 明顯的壓力變化存在,所以視為定壓狀態。由於生化反應路徑具有如 此的特性,所以系統總體 Gibbs 自由能(G)照理應會有最小值的存在。 反應物經過反應後會因反應物濃度的生成消耗造成 G 的改變, 因為 G 為 T、P 及系統各反應物莫耳數( ni )的函數:m m i io i I i i idn n n dT nS dP nV dG = − +
∑
µ = +ω ξ = , ) ( ) ( 1 (14) 在(14)式這個微分式當中 dG 是總體 Gibbs 自由能的改變量,nV 是總 體積,nS 是系統總熵,µi是反應物的化學勢能。 m i ω 是在第 m 個反應 中反應物 i 的化學計量數,ξ 是第 m 個反應的反應程度。因為環境m 在定溫定壓下,上式變成∑
= = I i i idn dG 1 µ (15) 根據化學勢(chemical potential, )在此環境下的定義: j n i i n nG , P , T ] ) ( [ ∂ ∂ ≡ µ (16) 在[59]中由於化學勢是很難測的一個熱力學性質,但是在定溫、定壓 的定義之下化學勢可等於 o' i fG ∆ ,所以在計算上就可以使用 o' i fG ∆ ' o i f o i ≡∆ G µ (17) 我們可將系統總自由能轉成下式:∑∑
∑
= ° = = °+ ∆ = + ∆ = M m m o m M m I i m o i f m i G G G G G 1 ' 1 1 'ξ ξ ω (18) 每個反應物 i 所提供的能量變化是 o m i f m i G ξ ω ∆ ' ,代表在反應 m 的反應自 由能 o' m G ∆ 。每次反應都會使 pH 改變造成 o' i fG ∆ 改變,故 G 也會跟著改 變。 自然界的化學反應總是會伴隨著化學能的生成及消耗,而反應 物本身會具有其物質本身的物理性質及化學性質。而反應物自己的標 準生成熱就是其物理性質。反應物本身的標準生成熱會受到所處在的 環境影響而改變,在這個研究之中會影響到標準生成熱的因素有溫度、 離子強度和 pH。在實驗之中,我們給定溫度和離子強度,pH 和[Mg2+ ] 則是隨著反應進行而改變,所以生成熱是不斷的受 pH 的影響而改變 的。 由[60]的定義中: “在封閉系統中的總體自由能,在固定 T、P的不可逆程 序中必須降低,且反應中系統總自由能 G達到最小值時,即為平衡狀態,在此平衡狀態時dG=0。因此,若混合物中各成分不在化學平衡 時,任何一個在固定 T、P下的反應都會導致G 的降低。” 所以在反應過程中,反應會朝著系統總體自由能降低的方向反 應。當達到 dG = 0 時,為反應的平衡狀態。這是化學反應系統中的熱 力學特性,可適用於研究的反應途徑的平衡狀態。由於生化反應會有 達到反應平衡的特性,在化學反應限制之下濃度變化終究會趨於平衡, 而平衡(equilibrium)是指當反應的正逆反應速率相等或者是濃度已不 再增加或減少,即可被視為濃度達到平衡。 各個代謝物的標準莫耳生成熱 o' i fG ∆ 都在表上查知,並經由( 13 ) 式計算在不同環境(例如 pH、T 及 I)所造成的影響偏差作修正,經由 化學反應方程式計算在當此反應環境下該化學反應的反應自由能 ' o m G ∆ ,所以全部反應自由能經加總起來變成整條代謝路徑的總自由能 G,而找尋反應過程中 G 的最低點就是我們設定的熱力學特性之目標 函數。
2.2 系統流程
2.2.1 數學架構
首先假設整條反應路徑有 m =1, 2, …,M ;共 M 條反應;反應 物 i 的濃度(Xi)有 i = 1, 2, …, N,共 N 個反應物;對應反應的酵素活性 Eam f同為 M 個;反應速率式中使用的動力學參數 Kj,j = 1, 2, …, L, 共 L 個參數。 若反應 1 為: A+B ↔ P +Q, (19) 分別將 XA 至 XQ代入到( 2 )式成: p q Q P q Q p P b a b A b B a A q p Q P r a b a B A f a K K X X K X K X K K X X K X K X K K X X E K K X X E Flux + + + + + + − = 1 1 1 1 (20) 1 1 1 eq B A Q P f a r a K K K K K E E = (21)) 1 ' 1 ( ) ' ln( 1 1 1 1 T T R H K K o eq eq − ∆ − =
(22) 可得到( 19 )式的 Flux1。整條反應路徑之中可能會有幾個反應會特別 對 pH 敏感,需要特別透過下面通式加以對個別反應中的酵素通量修 正以反應出 pH 對反應速度的影響[61, 62]。 2 1 , ) 10 10 1 ( 2 1 1 1 pKa pH pKa c E E pKa pH pH pKa a app a < < + + = − − (23)
上式中Ea1app是修正後的酵素活性,Ka1 及 Ka2 是第一個氫離子的
解離常數及第二個氫離子的解離常數,c 的值會因為反應酵素本身的 性質而改變。 反應物的濃度變化則是根據相關反應的通量組合計算而成,假如 一連續反應如下: XE → XF → XG (24) F E X X → ,為 Flux1;XF →XG,為 Flux2。則反應後的濃度變化如下: 1 Flux dt dXE − = (25) 1 2 Flux Flux dt dXF − = (26) 2 Flux dt dXG = (27) 而 pH 和[Mg2+]的變化速率為( 11 )、( 12 )式,若反應時間由 t 0開始, 而反應終止時間 t f由使用者決定: dt dX X XE1= Eo + E (28) dt dX X XF1= Fo + F (29) dt dX X XG1= Go + G (30) dt pH d pH pH 0 1 t t = + (31) dt Mg d Mg Mg ]t [ ]t [ ] [ 2 bound 2 2 0 1 + + + = + (32)
上列各式為在時間 t0至 t1 的濃度變化量和 pH。 從上一步得到各個成分反應通量,我們再進一步將每次反應的 反應通量用來計算在整個反應過程中,反應之間濃度的變化所造成能 量之間的變化。在計算複雜的化學反應平衡中,常以反應程度( ξ )當 做個別反應的時間軸。 m m i io i
n
n
=
+
ω
ξ
(33) 在一個封閉系統下,我們假設體積不隨反應的進行而改變,而反 應物的濃度與莫耳數成正比,所以上式變成: m m i io i X X = +ω ξ (34) 經過反應後的個別反應的反應生成能:∑
= ∆ = ∆ M m o i f m i o m G G 1 ' ' ω (35) ( 36 )式所求得的總體自由能就是當整體反應達平衡時的總自 由能,而此時 G 會是曲線的最低點。∑∑
= =∑
= ∆ + ° = ∆ + ° = M m m o m M m I i m o i f m i G G G G G 1 ' 1 1 'ξ ξ ω (36)∑
= ∆ = M m m o md G dG 1 ' ξ (37) 在我們的計算之中( 5 )式以及( 13 )式都會因為 pH 以及[Mg2+] 的影響,( 5 )式還包括[K+ ]皆會隨反應進行而改變。在( 13 )式會影響 該時間點的 o' i fG ∆ ;在( 5 )式會影響鍵結多項式,進而改變 m eq K 。接著會 使反應通量受到影響,改變了反應物的反應速度, o' i fG ∆ 以及反應速率 都會受到改變,系統的總自由能也是一樣。 而將 pH 及金屬陽離子的考量進模型之中,會使得模型的準確 度上升,其效果已呈現在[44]。而本研究更進一步試著將會受到 pH 以 及[Mg2+]的 G 當成評估函數之一,用以最小化系統總自由能。在整個 反應過程之中不斷改變的 pH 以及[Mg2+ ]一定會造成 隨反應時間 而改變。雖然變化幅度並不明顯,但這兩個因素的考量與否,會提高 濃度曲線的準確度。所以在能量上面更不能忽略這兩個因素所造成的 影響。 ' o i fG ∆將參與反應的反應物在反應過程中所產生的能量加總起來得到 整體反應的系統總自由能,每一次計算所得到的總系統自由能都在算 反應當中該階段時的總能量,但計算並不是達到總系統自由能最低點 即停止。而是在整個反應過程中能量最低點才是傳給演算法的函數分 數。
2.2.2 解題方法
我們研究在於從熱力學以及化學平衡的觀點找出一組能通用於 生化反應途徑的動力學模型之參數組,並且使之運用電腦模擬其化學 反應其過程,而增進對系統生物學的了解與發展。為了找出一組最佳 解,我們選擇使用能同時最佳化大量參數的智慧型基因演算法[46]。 關於基因的編碼,我們使用實數編碼。將全部反應速率式中會使用到 的動力學參數當成整條基因,反應速率式愈多,用到的動力學參數就 愈多,則智慧型基因演算法找尋最佳解的能力顯得就愈強。 將每個反應物對時間的變化分別當成一個微分方程式,整條反 應途徑就成了一組微分方程組。但因為有些生化反應本身的特性,讓 反應物濃度會跟複數個反應同時相關,使得反應途徑的結構產生迴圈。 具有這樣特性的微分方程組,被稱做「剛性方程式」。在[63]中使用基 因演算法解這樣的微分方程組,計算動力學模型的參數。在[44]之中 是直接使用 MATLAB(®Mathworks)中的解題器 - ode15s,可用在解 常微分剛性方程式之中。在本篇研究之中,我們使用智慧型基因演算 法搜尋最佳化的動力學參數,搭配 MATLAB 的 ode15s 解生化網路的 常微分方程式組,使用熱力學跟化學平衡當成我們的評估函數,藉此 搜尋出最好的一組參數解。2.3 方法應用
我們根據所參考論文中的反應方程式其中所列舉的反應速率常 數(Kj)嘗試用智慧型基因演算法找尋整個反應系統中最佳的反應速率 常數之組合。當染色體中的 Kj值給起始值之後就讓反應速率方程式進 行計算,模擬在單位時間下, 計算連續反應後的濃度及能量變化,取 出一組最符合我們所要求條件的解。 整條反應途徑中共 22 個反應物,在計算式裡我們以 Xio來表示 初始濃度。i =1, 2, …, 21, 22。在 Ref.44 之中提到限制 PCr + Cr 的總濃度為 30mM。在[44]所討論的反應路徑裡,所引用的反應方程式模型[55] 有包含以下特性:質量平衡和 Haldane 關係式所定義全部可逆之熱力 學計算式。在 Vinnakota[44]中有更詳細的模型計算之解說。這個骨骼 肌肉模型從 glycogen 到 lactate 共包括 16 個反應,我們將全部反應列 在表 1,反應路徑放在圖 3。 表 1 肌肉醣原分解中全部反應
Reaction Name Identifier Chemical Reaction
Glycogen Phosphorylase GP GLYn + ΣPi ↔ GLYn-1 + G1P
Phosphoglucomutase PGLM G1P ↔ G6P
Phosphoglucoisomerase PGI G6P ↔ F6P
Phosphofructokinase PFK F6P + ΣATP ↔ F1,6P + ΣADP
Aldolase ALD F1,6P ↔ GAP + DHAP
Triose Phosphate Isomerase TPI GAP ↔ DHAP
Glyceraldehyde-3-Phosphate
Dehydrogenase GAPDH
GAP + NAD + ΣPi↔ 1,3BPG + NADH
Glycerol-3-phosphate
dehydro-genase G3PDH
G3P + NAD ↔ DHAP + NADH
Phosphoglycerate Kinase PGK 1,3BPG + ΣADP ↔ 3PG + ΣATP
Phosphoglyceromutase PGM 3PG ↔ 2PG
Enolase ENOL 2PG ↔ PEP
Pyruvate Kinase PK PEP + ΣADP ↔ PYR + ΣATP
Lactate Dehydrogenase LDH PYR + NADH ↔ LAC + NAD
Creatine Kinase CK PCr + ΣADP ↔ Cr + ΣATP
圖 3 肌肉醣原分解之反應途徑
2.3.1 使用擴展 Debye Hückel 定律
依照各反應物的反應消耗(或生成)單位莫耳生成熱( o' i fG ∆ )算出該 成分在這個反應狀況下中所提供(或生成)的能量,計算各成份的反應 能量總和可得到反應熱。而生成熱會受到 pH、溫度、離子強度以及電 價數的影響,根據擴展的 Debye-Hückel 定律在不同溫度下的離子物 質可用(13)式計算[54, 58],且當離子強度為 0.05 ~ 0.25M 範圍內的計 算結果相當值得信賴。 2 1 2 1 2 ' 6 . 1 1 )) ( ( 91482 . 2 ) 10 ln( ) ( ) 0 ( I I pH I + − + + = ∆ = ∆ G G NH i RT Zi NH i o i f o i f ( 13 ) 根據上面方程式將反應中各個反應物的生成能 o' i fG ∆ (pH, I)依特定 的 pH 跟 I 逐一計算出在固定溫度下的各個代謝物的 o' i fG ∆ 。經過計算 得到 o' i fG ∆ (pH, I),然後從 2.3.2 的動力學模型計算後,我們可以得到濃 度變化值∆Xi ,但由於經反應後 pH 值會改變,所以我們需要再透過 上式計算經過反應之後 o' i fG ∆ (pH, I) 的改變,以提供下次反應計算所 使用。2.3.2 動力學函數以及模型
我們所使用的模型為具有連續性的標準微分方程之形式,而導 數為該反應式的反應速率。從 Muscle glycogenolysis 的反應途徑中所 導出的反應方程組(rate equations)中,我們要給三個種類的參數分別是 在時間 t 的反應物濃度 Xi(t)、反應 m 的反應平衡常數Keqm和在染色體 上所計算的動力學參數 Kj。將上面參數依對應反應所需要的數值代入 反應方程組裡之後,可得到該反應的反應通量(Fluxm);然後將代謝物 所參與反應的反應通量計算反應物的總反應量後,可得到該代謝物的 反應速率。 從文獻[55]中所節錄出來的反應方程式中,令每個反應中的反 應速率常數為 genes,將 genes 的值放進反應方程式裡,從 Xi(t0)開始 依序各個反應通量而改變每個反應物的濃度。所有反應物我們用表 2 表示。 表 2 反應物簡名及標號Number Abbreviation Metabolite Name Concentration. 1 GLY Glycogen X1 2 G1P glucose 1-phosphate X2 3 G6P glucose 6-phosphate X3 4 F6P fructose 6-phosphate X4 5 FBP fructose 1,6-bisphosphate X5 6 DHAP 1,3-dihydroxyacetone phosphate X6 7 G3P glycerol 3-phosphate X7 8 GAP glyceraldehyde 3-phosphate X8 9 1,3BPG glycerate 1,3-bisphosphate X9 10 3PG glycerate 3-phosphate X10 11 2PG glycerate 2-phosphate X11 12 PEP phosphoenolpyruvate X12 13 PYR Pyruvate X13 14 LAC Lactate X14 15 Pi inorganic phosphate X15 16 PCr phosphocreatine X
17 Cr Creatine X17
18 ATP adenosine-5'- triphosphate X18
19 ADP adenosine diphosphate X19
20 AMP adenosine monophosphate X20
21 NAD Nicotinamide adenine di-nucleotide
X21
22 NADH Nicotinamide adenine di-nucleotide X22 表 3 反應物的起始濃度 Metabolite Xio (mM) Metabolite Xio (mM) GLY 0.04 PEP 10-9 G1P 10-9 PYR 10-9 G6P 10-9 LAC 10-9 F6P 10-9 Pi 0.03 FBP 10-9 PCr 10-9 DHAP 10-9 Cr 0.03-PCr G3P 10-9 ATP 0.5 GAP 10-9 ADP 0.005 13BPG 10-9 AMP 10-9 3PG 10-9 NAD 0.0005 2PG 10-9 NADH 10-9 根據 Haldane relation 在全部反應之中計算逆反應速率值 Eam r, G3PDH、PGI 以及 PGK 是由逆反應速率值計算 Eam f,計算模型中所 使用的值在表 4。Eam f我們是採用[47]所記載的酵素活性,而起始條件 來自之前的研究[64-67]。 當相對應反應式中的 Eam f、Keqm、Xio以及染色體上對應的 Kj代入 方程式計算,可以得到各個反應通量 Fluxm。在反應中的反應物中除 了一開始的 glycogen 外,都同時有著生成通量和消耗通量。這些通量 經過下列函式所得的值,就是反應物濃度的增減量。
表 4 參與反應的酵素活性 Enzyme Eam f (M/min) GP 0.5 PGLM 0.48 PGI 0.88 PFK 0.056 ALD 0.104 TPI 12.0 GAPDH 1.265 PGK 1.12 PGM 1.12 EN 0.192 PK 1.44 LDH 1.92 ADK 0.88 CK 0.5 而反應物濃度變化速率如下: dt fraca a fracb b dX Flux Flux + ∗ ∗ − = 1 ( 38 ) 在[47]中第 29 號實驗中,fraca = 0.2% ;fracb = 99.8% ,其餘通 量計算皆如同( 25 )式至( 27 )式之描述。從反應通量式可得 Xi的濃度 變化,依序將 Xi的濃度變化求出,逐個將此計算值加到代入計算的濃 度,然後成為下一個時間點計算的濃度值。總反應時間的長短是依據 [47]的實驗而定,其反應總花費時間為 30 分鐘。
三、 最佳化演算法之使用
3.1 智慧型基因演算法
為解決選擇動力學模型時的大量參數最佳化問題,必須藉由一 強而有力的最佳化演算法。本文使用智慧型演化式演算法[41]做為最 佳化工具。智慧型基因演算法結合了基因演算法與直交實驗兩種方法 之特性,具有收斂速度快,精確度高的優點。3.1.1 直交表與因素分析
IGA[46]和一般基因演算法最大的不同之處在於,IGA 在交配 ( crossover)的過程使用直交表( orthogonal arrays)挑選好的參數,使得 IGA 能克服參數過多染色體過長的問題。直交表(OA)與因素分析常用 在品質控制的方法中[68],也可運用於很有效率地改善交配操作。假 設有兩水準的 N 個因素的直交表,那總共會有 2N種不同的組合。當 四組(1,1), (1,2), (2,1)及(2,2)出現在全部實驗時,那麼兩個因素在直交 表的行是彼此正交的。當任兩個因素在實驗集合是正交時,這個集合 可被稱之為直交表(OA)。為了建立兩水準 N 個因素的直交表,我們可 以得到一個整數 n = log2[log(N+1)],來建立 n 列和(n-1)行的 L n(2n-1)的直 交表,然後選擇 N 行來使用。舉例來說表 3.1 則表示 L8(2 7 )直交表。 因素分析可以評估在評估函數中的因素效果,排名最有效果的因 素以及決定每個因素的最好水準組合,進而促使評估函數有最佳的結 果。直交實驗設計可以縮減因素分析的實驗次數。直交表的實驗次數 在單一因素分析時只需 n 次。假設 yt是第 t 次實驗的函數評估值,我 們定義 Sjk是 j 因素在水準 k 的主效果: = ∑ × ( 39 ) 其中 Fk為一個旗標值,,若第 t 次實驗中第 j 個因素選用水準為 k, 則 Fk為 1;若否,則 Fk為 0。若評估函數值為望大,則較大的主效果 值表示對評估函數具有較佳的貢獻度;反之若評估函數望小,則主效 果值小者貢獻度較佳。 主效果可以顯示因素中水準的個別影響。例如主效果 Sj1 > Sj2則表示 在參數最佳化的問題中,第 j 個因素水準值 1 對於整體最佳化函數的貢獻大於水準值 2。如果相反的情形 Sj1 < Sj2,則表示水準值 2 較佳。 在各因素間無交互作用的前提下,主效果的分析可以用來推測出全實 驗的最佳解。 直交因素實驗為一種部分因素實驗方式,可以有效減少參數設 計時的實驗次數,並同時考慮實驗因素之間的交互作用。將直交因素 實驗後的數據經過主效果分析,便可以將每個因素對於設計目標的貢 獻優劣計算出來,推論出最佳解的實驗參數。 表 5 L8(2 7 )直交表 1 2 3 4 5 6 7 1 1 1 1 1 1 1 1 2 1 1 1 2 2 2 2 3 1 2 2 1 1 2 2 4 1 2 2 2 2 1 1 5 2 1 2 1 2 1 2 6 2 1 2 2 1 2 1 7 2 2 1 1 2 2 1 8 2 2 1 2 1 1 2
3.1.2 智慧型交配運算
智慧型基因演算法與傳統基因演算法最大之不同,乃是以智慧 型交配取代一般的單點交配或多點交配。傳統的交配方式無法評估染 色體中參數個別的優劣,加上交配點是由隨機方式產生,得到的後代 染色體品質不容易提昇。 事實上,我們可以將染色體交配過程視為一種因素實驗。將來 自父代的兩個染色體中已切割好欲交配的片段,做為直交實驗的因素, 並以染色體片段「互換」或「不換」做為兩種水準值。如此,以兩水 準直交實驗產生出優良品質染色體的機率便可大幅提昇,進行步驟如 下: 步驟一:令產生染色體中的油交配點所切割出的基因片段為實驗 因素;假設因素數目為 n,即有 n 個基因片段,選擇 Lβ(2β-1) 直交表的前 n 欄作為實驗之用,其中 β = 2[log(n+1)]。 步驟二:令因素 j 的水準 1 與水準 2 分別表示來自父代染色體 P1 因 素 實 驗 編 號與 P2第 j 個基因片段。 步驟三:根據直交表,計算各因素組合實驗的評估值 yt,t =1, 2,….,β。 步驟四:計算主效果 Sjk,其中 j = 1, 2,…,n,k = 1, 2。 步驟五:決定各因素的最佳水準。在評估函數望大時,則選擇主 效果值較大之水準;在評估函數望小時,則各因素的最 佳水準為主效果值較小之水準。如評估函數望大且 Sj1>Sj2, 則因素 j 的最佳水準為 1;反之則最佳水準為 2。 步驟六:根據各因素的最佳水準,選擇對應父代染色體中的基因 片段,組合成第一個子代染色體。 步驟七:將各因素的主效果差值( | Sj1 – Sj2 |)排名,差值越大者排 名越高。 步驟八:以類似第一個子代染色體的方式來組合因素,將差值排 名最差的因素,選擇與第一個子代相反的水準,則可產 生第二個子代染色體。
3.2 方法流程
本論文以智慧型基因演算法做為挑選動力學參數的核心演算法, 因此在本章節便以基因演算法的各步驟來介紹我們所提出的方法。3.2.1 選擇運算
我們選用二元競爭法作為基因演算法的選擇運算,每次進行選 擇時由族群中隨機挑選出兩條染色體,評估值較佳的染色體則可以進 入基因重組運算(即交配與突變運算)。傳統的輪盤法選擇運算,在基 因運算法演化至接近最佳解時,由於各染色體評估值變化不大時,造 成每個染色體被選擇至下一代的機率都差不多,無法有效選出優秀的 染色體。 而二元競爭選擇法的優點是,即使在染色體評估值變化不大時, 仍可透過競爭方式取出表現比較優秀的染色體,避免基因演算法演化 過早收斂。3.2.2 智慧型交配
智慧型交配運算在本論文所提方法中扮演一個相當重要的角色。智慧型交配運算結合了兩水準直交實驗與交配運算,能夠有效率的產 生具有優秀評估值的新染色體。假設我們使用 LN+1(2N) 直交表來做智 慧型交配運算,本染色體交配運算的詳細進行步驟如下: 步驟一:假設即將進行交配運算的兩條染色體為 P1、P2,比對 P1、 P2內的參數基因,並將重複出現在兩條染色體內的參數 基因移動至染色體末端,其相對應的控制基因。 步驟二:隨機將參數基因切割成[ N / 2 ]個基因片段。每個基因片 段及代表直交表的一個因素。P1中第 j 個基因片段,及代 表因素 j 的第一個水準值;P2則代表第二個水準值。 步驟三:計算直交表中每個染色體排列組合方式的適應值 ft ,t = 1,2,3,…,N+1。 步驟四:計算各因素之主效果 Sjk,j = 1,2,3,…N,k = 1,2。 步驟五:決定各因素的最佳水準。在評估函數望大時,則選擇主效 果值較大之水準;在評估函數望小時,則各因素的最佳水 準為主效果值較小之水準。如評估函數望大且 Sj1>Sj2,則 因素 j 的最佳水準為 1;反之則最佳水準為 2。 步驟六:根據各參數的最佳水準,選擇對應父代染色體中的參數, 組合出第一個子代染色體。 步驟七:將各參數的主效果差值排名,差值越大者排名越高。 步驟八:以類似第一個子代染色體的方式組合參數,除了盤明最差 的參數選擇的水準與第一個子代染色體相反,可產生第二 個子代染色體。
3.2.3 突變運算及演化終止條件
突變運算使用任意合理之亂數運算。假設一條染色體編碼之總長 為 N 個位元,突變率為 Pm,則每次的突變運算,隨機由染色體中選出 「N *Pm 」個位元,然後以亂數變化所選中的動力學參數。 基因演算法所需的演化時間必須視問題的複雜度而定,較一般 化的作法是設定演算法的評估次數與問題中的參數數目成正比。一但 終止條件達到設定值,演化即停止,並輸出所搜尋過的最佳解、用最 佳解當模型參數所計算出的各個代謝物濃度值和反應計算過程中整體自由能的值。
3.3 智慧型多目標基因演算法
IMOGA 在演化過程中基本上還是依循基因演算法的過程,但 是在評估函數方式不像 IGA 是直接將目標函數當成評估函數而作演 化判斷之根據,而是使用基於 Pareto 理論,使用通適化且不受尺度因 素影響的評估函數( Generalized Pareto-based Scale-Independent Fitness Function , GPSIFF)作為評估函數。
3.3.1 基於 Pareto 理論通適化且不因尺度影響之評估
函數
為了分辨出各染色體之間的優劣,本篇應用了基於 Pareto 理論 為基礎的記分方式以避免受到尺度因素的影響,並且對於被支配解和 未被支配解給於具有區分能力的適應函數值,用以取代傳統有失準確 性的排名法和距離方式,稱之 GPSIFF。 GPSIFF 使用類競爭式(Tournament-Like)的記分方式來評估 Pareto 解集中染色體個體 x 的適應值,GPSIFF 的數學式如下: Score(x)= p−q+ c。 ( 40 ) 其中 p 表示在目前欲評估的解集中 x 所支配的個體數目,q 表示在目 前欲評估的解集中能夠把 x 支配的個體數目,c 是一個較大的正整數, 以保證求出的適應值為一正整數。通常以目前參與評估運算的所有個 體的數目作為正整數 c 的值。 GPSIFF 的優點如下: (a)不需調整權重值:基於 Pareto 理論來評估解的好壞,沒有權 重加總法需決定權重值的困難,也不會受到人為主觀判斷的影響。(b) 不需考量尺度因素:由於各目標函數值的尺度適應值不盡相同,在權 重加總法中需考慮到尺度因素,以免使得權重設定失之準確。(c)以積 分方式有效辨識不同解的優劣程度:取代傳統排名法可能將不同的解 給予相同的排名,以及距離法有尺度因素影響的缺點,以精確的記分 評估解的優劣程度。圖 4 支配與被支配關係示意圖 我們用圖 4 表示出在兩個目標中同時做最小化問題之說明,在 Pareto 解集中所有個體在雙目標軸的關係。我們以點 B 為例,點 B 之 f1 和 f2 同時都比點 A 小,所以點 A 被點 B 所支配;同理,點 C 與點 D 位 於點 B 之左下角,點 B 就被點 C 與點 D 所支配,所以點 B 將不會被 收在 Pareto 解集中。 圖 5 GPSIFF 之示意說明圖[46] 同樣的最小化問題,在圖 5 中點上的數字為適應值 c。以 A 為例,其 c =12,™ 是未被支配解 ˜ 是被支配解,p=3,q=2,所以適應值為 13。
3.3.2 演算法流程
智慧型多目標演算法之流程,其步驟詳細敘述如下: 步驟一:(初始化) 亂數產生起初使用的族群數量 Npop個染色體以 及兩個空的優秀基因集合,一個是 E;一個是 E’。 步驟二:(評估初始值) 計算族群裡全部染色體的兩項目標函數值, 並藉由 GPSIFF 分配每條染色體一個評估值。 步驟三:(更新優秀基因集合) 將未被支配(non-dominated)的染色 體同時丟入 E 和 E’,然後清空 E’。考量 E 中的所有染 色體,將被支配(dominated)的染色體移除。若 NE的數量 大於原本所設定數量則將從中亂數去除超過的部分。 步驟四:(挑選) 從族群裡用 binary tournament selection 挑選出Npop-Nps個染色體,並從 E 中亂數挑選出 Nps個染色體形
成一組新的族群。其中 Nps=Npop×ps,若 Nps > NE,則令
Nps=NE。
步驟五:(重組) 藉由 Intelligent Gene Collector (IGC)運作從 Npop×
pc選擇親代。每次 IGC 皆是由 OA 重組因子(副產物)找
出未被支配的染色體以及兩個子代加入至 E’。
步驟六:(突變) 根據 pm對整個族群進行突變機制
步驟七:(終止條件) 假設已滿足停止條件即可停止演算,反之回 到步驟二。
四、 估算動力學參數之雙目標最佳化方法
4.1 估算動力學參數之模組化
本篇所提出的估算動力學參數的雙目標最佳化方法(Estimation of Kinetic parameters using Two-objective Optimization Methods, EKTOM) 是為了要估算動力學模型中所必要的參數,藉由同時考慮將與真實數 據之誤差以及系統熱力學之特性,利用智慧型基因演算法得出最佳化 過的所求參數。 由於不一樣的起始狀態,一樣的環境條件下最終還是會達到一樣 的平衡常數(因為溫度與壓力不變,化學反應不變則平衡狀態不變)。 所以反應速率就會因應起始濃度的不同而加速反應或減速,但確定的 是反應速率常數必定會產生改變其值使該反應能達到一樣的平衡狀 態。 我們藉由計算總體反應自由能的方法求解最小化整體反應自由能 在這反應方程組中的最佳反應速率常數之組合,基於能量的熱力學限 制加上系統最佳化在整個系統一舉得出整組速率常數值。在整個流程 計算中,我們要求的是反應速率常數、反應物濃度、反應 Gibbs 自由 能,而這些數值循序漸進求出來才有最後的總反應自由能。整體計算 過程我們將用圖來表示使過程能更清楚及容易了解。 反應總耗時設為 30 分鐘做為一次反應結束。改變基因演算法中上 的 Kj值(也就是染色體上的基因)重作計算以得到新的評估值。從不斷 改變 Kj值的組合來計算整條反應系統中最小的總體自由能,將具有 這樣條件的一組 Kj值當成是在我們已知之特定條件( T、I )下算出的 最佳解。接著其他條件不變,用[44]所使用的 Kj值放入我們的模型計 算在這樣情況下反應經過後的 G 值比較之間的差距。 要將一個代謝路徑建成動力學模型,需要的兩方面分別是定義良 好的速率方程式及精準的動力學參數。由於化學反應式都已經確定, 但根據不同模型詮釋即會產生不同的速率方程式,使用不同的速率方 程式就會需要不同動力學參數。但通常都很難將所需要的動力學參數
![圖 3 肌肉醣原分解之反應途徑 2.3.1 使用擴展 Debye Hückel 定律 依照各反應物的反應消耗(或生成)單位莫耳生成熱( ∆ f G i o ' )算出該 成分在這個反應狀況下中所提供(或生成)的能量,計算各成份的反應 能量總和可得到反應熱。而生成熱會受到 pH、溫度、離子強度以及電 價數的影響,根據擴展的 Debye-Hückel 定律在不同溫度下的離子物 質可用(13)式計算[54, 58],且當離子強度為 0.05 ~ 0.25M 範圍內的計 算結果相當值得信賴。 1 2 1](https://thumb-ap.123doks.com/thumbv2/9libinfo/8152593.167151/32.892.105.692.112.693/算出該能量計算各成份的反應能量總和可得到反應熱成熱會受當離子.webp)