Generalized perceptron learning rule and its
implications for photorefractive neural networks
Chau-Jern Cheng, Pochi Yeh,* and Ken Yuh Hsu
Institute of Electro-Optical Engineering, National Chiao Tung University, 1001 Ta Hsueh Road, Hsinchu, Taiwan 30050, China
Received September 23, 1993; revised manuscript received April 5, 1994
We consider the properties of a generalized perceptron learning network, taking into account the decay or the gain of the weight vector during the training stages. A mathematical proof is given that shows the conditional convergence of the learning algorithm. The analytical result indicates that the upper bound of the training steps is dependent on the gain (or decay) factor. A sufficient condition of exposure time for convergence of a photorefractive perceptron network is derived. We also describe a modified learning algorithm that provides a solution to the problem of weight vector decay in an optical perceptron caused by hologram erasure. Both analytical and simulation results are presented and discussed.
INTRODUCTION
Learning is one of the most intriguing properties of the neural network. In the process of learning, both mem-ory and information processing are involved. In a primi-tive network such as the perceptron' the network can be trained to classify a number of inputs by supervised learning with examples. The capability of information processing in a neural network is mainly determined by its structure, i.e., the arrangement of neurons, and its in-terconnection. Once the structure of a neural network is given, the interconnection can be obtained by learning al-gorithms. The perceptron with a single layer structure is a basic neural network that can be trained to sort a set of input patterns into category 1 (Cl) and category 2 (C2). A trained perceptron will perform the following pattern classification when the network is interrogated with an input vector X:
W X > 0 for X E C1, W X < 0 for X E C2.
In the learning process the interconnection weight W is modified according to a simple learning algorithm given by
Wk+1 = Wk + ek'lXk, (1)
where Xk is the input pattern vector, Wk is the intercon-nection weight vector, is a constant representing the learning rate, and Ek is an error signal denoted by
E ek = 1 -1 if Xk is correctly classified if Xk E C1 but is misclassified if Xk E C2 but is misclassified
where the subscript k is an integer (k = 1, 2, 3, ... ) reg-istering the number of tests (or interrogations). We note that the interconnection weight is changed when-ever there is a misclassification of an input vector. The process of weight vector update continues until all the
input patterns are correctly classified. The convergence proof of the simple perceptron can be found in Refs. 2 and 3.
A recent development in photoinduced holograms in photorefractive materials (e.g., LiNbO3, Sr.Bal-,Nb 2O6,
and BaTiO3)4 and spatial light modulators (SLM's) offers
unique possibilities for the optical implementation of neu-ral networks with a learning capability. The holograms can be recorded and erased in these media by an ap-propriate optical interferometric technique. This is ideal for implementing the interconnection weight, which must be modified in the process of learning. Several optical architectures for implementing the perceptronlike learn-ing networks have been proposed and demonstrated.A 8 Learning is achieved by use of real-time holographic tech-niques in photorefractive crystals to record the
modifi-able interconnection weight, which is proportional to the amplitude of the photoinduced hologram. By virtue of the dynamic response of the photorefractive crystal, the hologram may decay during the learning process. The hologram decay leads to a decrease of the interconnec-tion weight. We have shown that the holographic decay may affect the convergence property of the perceptron.9
Significant decay of the interconnection weight may lead to a divergence of the learning process. To overcome the hologram decay, the interconnection weight must be strengthened by optical techniques. Mathematically this is equivalent to adding a gain factor in the update equa-tion. Although some special cases of optical perceptron with weight decay1 2have been studied, a general percep-tron theory that addresses the issue of gain or decay of the interconnection weight is not available. To illustrate the need, we point out that the gain in the interconnec-tion weight may also lead to a divergence of the learn-ing process. In this paper we consider the convergence properties of a generalized perceptron algorithm with an arbitrary gain factor e for the weight vector. The decay is represented by 0 < e < 1. An important special case is the photorefractive perceptron learning network, in which the gain factor = exp(-t/re) is less than unity. 0740-3224/94/091619-06$06.00 ©1994 Optical Society of America
GENERALIZED PERCEPTRON LEARNING ALGORITHM
The weight update equation of a generalized perceptron algorithm can be written as
Wk+1 = Wk + Ek 77Xk, (3)
where Xk is the input vector, Wk is the weight vector, and
Ek is an error signal at the kth interrogation, respectively.
7 is the learning rate, and , depending on its value
relative to 1, is the gain or decay factor of the perceptron network.
Following the perceptron learning algorithm and carry-ing out a similar analysis leadcarry-ing to the proof of conver-gence, we obtain a solution for the interconnection weight vector W,+, that must satisfy the following relation (see Appendix A):
fl(p)
<
IW +112<
f2( p),(4)
where p is the total number of weight changes andNA--
1-)
1(
(5)
200 C~' '4 C.'1 150 100 50 U1 15 1C 5s 20 p 5 10 15 20 200 it 150 1.1 I2100
- A/'/
(6) f2(P)_
2(1 -
2p2with W being an arbitrary solution and
min(W - Yk) /3 for all the pattern vectors Yk in C,
(7) max(lYk12) a for all the pattern vectors Yk in C,
(8) where C C1 U C2. In Eqs. (7) and (8) Y is the input
pattern redefined in Eq. (A3) of Appendix A, and we note that Wp+l is, in general, different from W. According to inequality (4) the squared magnitude of the weight vector Wp+l is confined in the region bounded by f,( p) and f2(P). We recall that p is the total number of weight changes for training. The convergence of the learning process requires that an upper bound exist for the total number of updating steps p. The existence of an upper bound for p requires that a solution pa exist that satisfies the following equation:
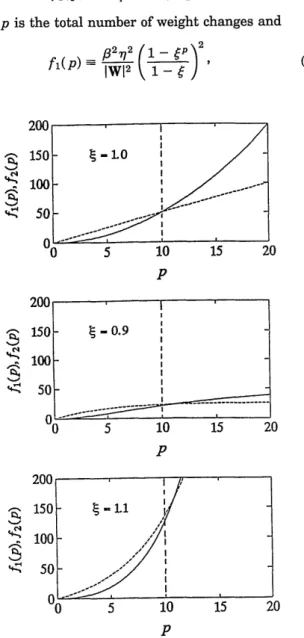
(9) In other words, these two curves must intersect. The point of intersection provides an upper bound pa for the total number of updating steps, which depends on the values of the gain factor 6 of the generalized perceptron algorithm. To understand the convergence property, we plot fi(p) and f2(P) as functions of p for various values of 6 in Fig. 1. In the example we used fi(l) = 0.5 and
f2(1) = 5 with arbitrary units for heuristic explanation. We note that the intersection occurs at pa = 10 for the case t = 1. For cases in which the gain factors t = 0.9 and t = 1.1, the point of intersection shifts toward p > 10. In other words, either gain or decay of the weight vector will lead to a higher upper bound for the number of weight changes.
Using Eqs. (5) and (6) and solving Eq. (9), we obtain the following expression for the upper bound Pa
(O - l2) - pm(l -)2
Pa= (1f - 2) + pm(1 - 2 (10) where Pm is an upper bound of the total number of weight changes of the normal perceptron algorithm2 defined by
aIWI2
Pm /32
Using Eqs. (5) and (6), we also find that [2(1)
f,1M=P
p
Fig. 1. Upper and lower bounds of the squared magnitude of the weight vector IWp+112versus updating steps p of the generalized perceptron learning network for (a) 4 = 1.0, (b) e = 0.9, and (c) e = 1.1. Solid curves, fi(p); dashed curves, f2(p). The intersection pa provides an upper bound for p. In the example
f,(l) = 0.5 and f2(1) = 5 (arbitrary units) were used.
We note that Pm is greater than 1 and covers a wide range of numbers because of the large number of so-lution weights W. Equation (10) shows that the upper bound pa is a function of the parameters t and Pm. We also note that the maximum number of updating steps
Pa of the generalized perceptron algorithm is dependent
)O, ~~~~~~~~~~~~~~~~~~~~I )o~~~~~~~~~~~~~~~~~~~~~I 01- 1-O. I ;0
_--is .
I.~~~~~~~~~~~~
(11) (12)A(P.) = MP.)
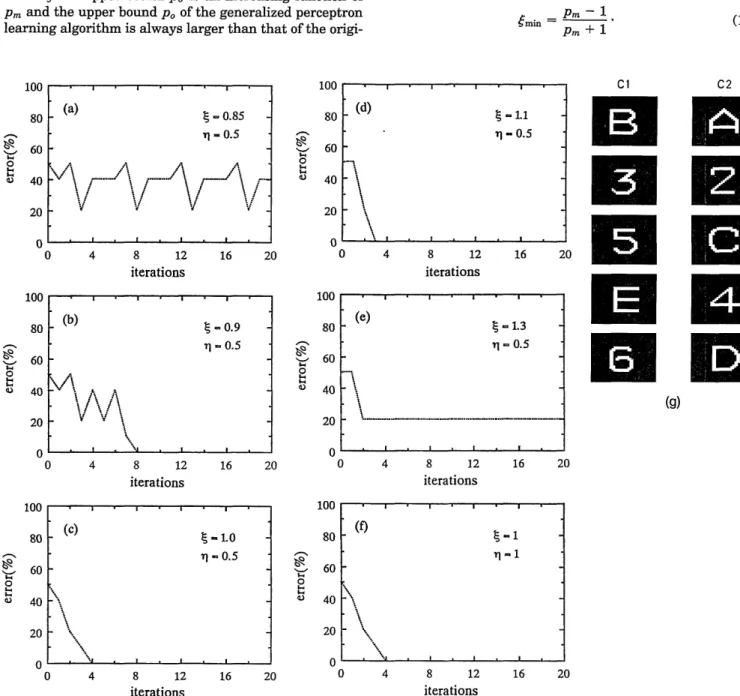
-20 0 5 10 15on the gain factor (or decay rate) and is independent of the learning rate -q. To illustrate this, Fig. 2 shows the computer simulation results of the learning behav-iors of the generalized learning algorithm described in Eq. (3) for various values of and 77. In the simula-tion we used 10 training patterns (Cl: {B, 3, 5, E, 6} and C2: {A, 2, C, 4, D}; each pattern consists of 32 X 32 pix-els) as shown in Fig. 2(g). In the learning process each iteration represents a complete cycle of interrogation of all 10 patterns. We note that, in our example, either too much gain [see Fig. 2(e), t = 1.3] or too much decay [see Fig. 2(a), = 0.85] leads to a divergence in the learning process. Comparing Figs. 2(c) and 2(f), we also see that the convergence behaviors are identical for different val-ues of the learning rate Y7.
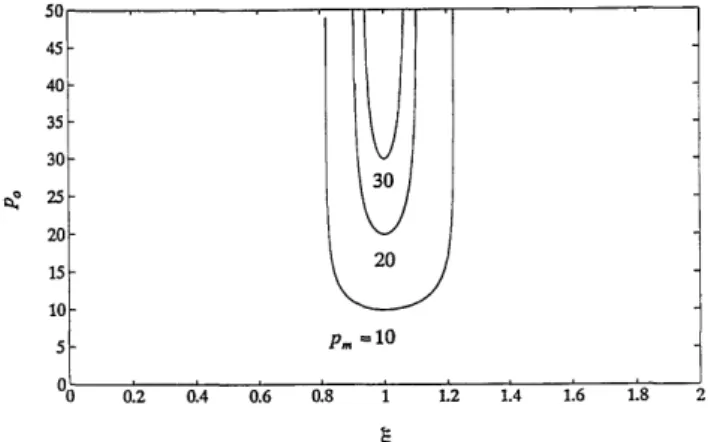
In Fig. 3 Pa is plotted as function of the gain factor f
for various values of Pm. We note that for a given gain factor the upper bound Pa is an increasing function of
Pm and the upper bound Pa of the generalized perceptron learning algorithm is always larger than that of the
origi-nal one ( = 1). That is to say, the minimum Pa occurs at = 1, where
lm
oF(1
-
2)
-
pm(1
-
)2
lim P = l(P Pm (13)
This is the case of the normal perceptron (f = 1), which has the smallest upper bound.
According to the properties of the logarithm and ana-lyzing Eq. (10), we find that a finite upper bound Pa for the total number of updating steps of the generalized per-ceptron learning algorithm exists only when t is bounded in a region given by (14) where 6 max =P Pm 1 Pm + 1 (15) (16) 0 4 8 12 iterations 0 4 8 12 iterations 16 100 80 0 60 40 20 0 20 100 80 0 4.) 60 40 20 0 16 20 100 80 0 I-4.) 60 40 20 (d) *1-0.5 0 4 8 12 16 2( iterations (e)
(e)
t
G~~~~1.3
1 0.5 ) 4 8 12 16 2( iterations ClU
IN
U_
C2U
U
U
U
p
(g) 0 . "I _1 I I . I0 .' . I . I . . 0 4 8 12 16 20 0 4 8 12 16 20 iterations iterationsFig. 2. Learning behaviors of a generalized perceptron with 10 input patterns (C1: {B, 3, 5, E, 6} and C2: {A, 2, C, 4, D}; pattern consists of 32 X 32 pixels) and for various gain factors: (a) = 0.85; (b) f = 0.9; (c) = 1.0; (d) -= 1.1; (e) f = 1.3, -= 0.5; (f) normal perceptron,
= 1, 77 = 1; (g) training patterns. Each iteration represents a complete cycle of interrogation of all 10 patterns. 100 80 60 ZRW1_1 0
t
- (a) = 0.85 1 0.5 'I f~~ -/, -- A,,.,/... ..
40 20 0 10C 8t el I-. 2. 60 40 20 100 80 ' (c) I _ 1.0 .~~~~~~~~' 0c.S\
I., 0 60 40 20 (D Y11 X . . . emin <~ St < max I I I I so25 20 -15- 2 10 -5
P.,
10 0-0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2Fig. 3. Upper bound of updating steps p of the generalized perceptron algorithm as a function of gain factor for
Pm = 10, 20, 30 as indicated.
In other words, the generalized perceptron learning algo-rithm may not converge if the gain factor
4
is out of the range specified by inequality (14). The range for the gain factor is dependent on the magnitude of Pmn. Table 1 lists the limits for various values of Pm. Figure 4 plots the limits as functions of Pm. The results in Fig. 4 indicate that, for a given set of input patterns with a given classi-fication, Pm covers a wide range of values, and the mini-mum of all these Pm's is useful in determining the range of the gain factor4.
It should be pointed out that the up-per bound Pm depends on knowledge of solution weight W. Some values of Pm can be derived from Eq. (11), in which the weight vector W is obtained by the perceptron al-gorithm described in Eq. (1). By definition these values of Pm are all greater than min(pm). In addition, the re-sults of the simulation also include the number of weight changes p for convergence. These values ofpm as well as p obtained by perceptron simulation provide informationabout min(pm). Specifically,
exp(-t/Tr). The weight update equation is thus written as
Wp+l = exp(-t/Te)Wp + [1 - exp(-t/r)]Yp, (17) where Yp is the input pattern, Wp is the interconnec-tion weight, and Tr and T
e are the rise and decay time
of the photorefractive crystal, respectively. t is the expo-sure time for each of the weight updates. Equation (17) indicates that the learning rate rq and decay rate
4
of the optical perceptron network are determined by the expo-sure time during the holographic recording and the re-sponse times of the photorefractive crystal. Using4
= exp(-t/Te) in Eq. (10), we obtain the following expression for the upper bound of the total number of weight changes of the photorefractive perceptron:Te
F
1 + Pm tanh(t/2re) 1 (18)Pa0 = e Ini I18
t L1 - Pm, tanh(t/2r,)
According to Eq. (18), a finite upper bound requires that the exposure time of the optical perceptron network be written as
0 < t < ln(Pn + 1) (19) For Pm >> 1, inequality (19) can be written as
tPm < 2Te. (20)
Inequality (20) may provide a guideline for the expo-sure time t provided that min(pm) is known. The pho-torefractive perceptron will converge in a finite number of steps provided that the exposure time is limited by inequality (20). We note that inequality (20) is a suffi-cient condition for the convergence of a photorefractive perceptron. Although there are infinite numbers of Pm,
the minimum of all these Pm's provides the guideline for the exposure time.
p < min(pm) < Pm.
In our case, Fig. 2(f), we obtained P = 7, Pm =
alWp,+i2/f32 = 368. This leads to 7 < min(pm) - 368. Further simulation results are likely to decrease the range of possible values of min( pm). As mentioned ear-lier, information about min(pm) is useful in determining the range of
4
for convergence. For Fig. 2(f) the range of4
for convergence is at least 0.995 < 4: < 1.005, which we obtain by taking Pm = 368 as the worst case. The range of4:
for perceptron convergence is useful in the implementation in which the interconnection weight is likely to suffer gain or loss because of practical issues such as noise, electrical resistance, holographic decay, and even system imperfection. The range of4
for convergence would allow a finite range of tolerance in the system design.PHOTOREFRACTIVE PERCEPTRON NETWORK
A special case of interest is the photorefractive perceptron, where the gain factor (or decay factor) is given by
4:
=exp(-t/Te), and the learning rate is given by -q = 1
-Table 1. Limits of Gain Factor 4t
Pm emin emax 5 0.667 1.500 10 0.818 1.222 15 0.875 1.143 20 0.905 1.105 1. 1.4 1.. 01 0. 0. 0. 0. 0O 10 20 30 40 50 60 70 80 90 100 Pm
Fig. 4. Limits of gain factor e as functions of Pm. Solid curve, emax; dashed curve, emin.
\
~max
.8
MODIFIED LEARNING ALGORITHM
As a result of hologram decay during the training pro-cedure, the photorefractive perceptron network may not converge or convergence may require more iterations. This can be seen from the simulation results illustrated in Figs. 2(a)-2(f). Physically the hologram decay is con-sistent with the decay of the weight vector. When there is a large number of input patterns, the weight decay may become too severe for the perceptron network to con-verge. To overcome the weight decay in a photorefractive perceptron in the learning process, a method for weight restoration3,"4 is required. The system can realize this by reading out the weight vector and then rerecording it optically in the same medium by using the technique of phase conjugation during each exposure for update by previous records in holographic associative memory.'5'1 6
Mathematically, the equation for the weight update becomes
Wp+1 = exp(-t/re)Wp + [1 - exp(-t/r)](Yp + AWp),
(21) where A is a constant. In other words, a previous weight vector is added to the input vector to compensate for the weight decay. The equation can be rewritten as
cial case of photorefractive perceptrons in which the gain factor is an exponential term accounting for holographic erasure during illumination. A feasible guideline for the exposure time of a photorefractive perceptron network is presented. A modified photorefractive perceptron with a compensation technique for overcoming the weight decay is proposed and analyzed.
APPENDIX A. CONVERGENCE PROOF OF THE GENERALIZED PERCEPTRON
We assume that the sets CI and C2 are linearly separable and that the union of these two subsets is the complete training set C. Here, without loss of generality, we also assume that the perceptron network has a zero threshold value. That is, at least one solution weight vector W exists such that
W X > 0 for X E C1,
W X < 0 for X E C2.
(Al) (A2) For the purpose of proving the convergence, we define a set of new vectors such that
for X E Cl
for X E C2 (A3)
Thus inequalities (Al) and (A2) can be written as (22)
According to the general results, inequality (14), the suf-ficient condition for the convergence of the perceptron be-comes
6.mil <
exp(-t/re)
+ A[l - exp(-t/Tr)] < max. (23) The constant A can be properly chosen to tailor the gain factor. For the case of a unity gain factor, i.e.,exp(-t/Te)
+ A[1 -
exp(-t/rr)]
=1, we obtain
A 1 - exp(-t/le) (24)
1-exp(-t/rr)
For short exposure time we obtain A T rire. Since each constant A corresponds to a unique value of 4, the results of simulation are in exact agreement with those obtained in Fig. 2.
W Y>O. (A4)
The weight update equation (3) now becomes
Wp+1= 4:Wp + Yp, (A5)
where the pattern Yp is misclassified by the weight Wp and p is now an integer registering the number of weight changes. We assume that there is no gain or decay of the weight vector during all the interrogations whose classifi-cations are correct. In other words,
4
= 1, where ek = 0. If we start with the initial weight WI = 0, we obtain the weight vector after p updating steps:Wp+1 = 4:p-1
7yl
+ eP-2, 7y2 + ... +7yp
p
= 7 I 4P kYk
k=1 (A6)
CONCLUSIONS
In conclusion, we have considered the properties of a gen-eralized perceptron learning network, taking into account a gain factor in the update of the interconnection weight. We have shown that the learning rate will not affect the convergence of the perceptron. It merely affects the scale of the input vectors. The gain factor (or decay factor) may affect the convergence of the perceptron learning process. We have derived conditions for the convergence of the learning process. The range of the gain factor () for perceptron convergence is useful in hardware imple-mentation, where the interconnection weight may suffer gain or loss during the training stage because of practi-cal issues, which would allow a finite range of tolerance in the system design. We have also considered the
spe-Taking the dot product of the above equation with solution weight vector W, we obtain
W
p+ =
IZ
-Pk (W Yk).k=1 (A7)
For a given solution weight vector W, let /3 be the mini-mum for all the inner products, i.e.,
min(W Yk) for all the pattern vectors Yk, (A8) where 13 > 0. From Eqs. (A7) and (A8) we obtain
(1 ) (A9)
Wp+1 = {exp(-t/,r) + A[l - exp(-t/r)]}Wp
+ [1
-exp(-t/rr)]Yp.
Y = X
Using the Cauchy-Schwarz inequality, lW ,112 (W Wp+l) and inequalities (A9) and (A10), we obtain
IWP+112 1 ( _
We define a function of p as
J
/W12
(I
-
)
Using Eqs. (A12) and (A18) and solving Eq. (A20), we obtain the upper bound for p:
(A10) (1- 2) - Pm(l - )2 P. = loge[ (1- 2) + Pm(l - )2 , (A21) where aPWm 2 Fm 'g2
(All)
(A22)with Pm being the maximum number of finite updating steps of the normal perceptron algorithm.2
(A12)
From Eq. (AS) we have
JWk±12= 21IWk2 + 21YkI2 + 277(Wk -Yk). (A13) Using Wk -Yk < 0 during training and 2f 7 > 0, we obtain
JWk+112 _ 4:2IWkI2
+ fl2iYkl2* (A14)
By adding these inequalities for k = 1, 2, ... , p, we ob-tain
k=1
Let the maximum magnitude of the pattern vectors be written as
max(IYkJ2) a. This leads to
IWp+l
2'• 72 _
We define another function of p as
f2(p) a cg7( 2)
Combining relations (All), (A12), (A17), obtain the following relation:
fl(p) S
IWP+
11
2' f2(P).
and (A18), we
Inequality (A19) indicates that the weight vector on com-pletion of the training Wp+1 will be localized in the region bounded by fi(p) and f2(p). We recall that p is the to-tal number of updating steps leading to a trained percep-tron. The total number of steps p must satisfy the above equation. An upper bound for p exists provided that the following equation yields a finite solution p.:
fA(P.)
= f2(Po)-ACKNOWLEDGMENTS
The research is supported by the National Science Council, Taiwan, under contract NSC 83-0416-E-009-012. Pochi Yeh acknowledges the support of the K. T. Lee/K Y. Chin Foundation.
*Permanent address, Department of Electrical and Computer Engineering, University of California, Santa Barbara, California 93106.
REFERENCES
1. F. Rosenblatt, Principle of Neurodynamics: Perceptrons
and the Theory of Brain Mechanisms (Spartan, Washington, D.C., 1962).
2. N. J. Nilsson, Learning Machines: Foundation of
Train-able Pattern-Classifying Systems (McGraw-Hill, New York, 1965).
3. R. 0. Duda and P. E. Hart, Pattern Classification and Scene Analysis (Wiley, New York, 1973).
4. See, for example, P. Yeh, Introduction to Photorefractive Nonlinear Optics (Wiley, New York, 1993).
5. D. Psaltis, D. Brady, and K. Wagner, "Adaptive optical networks using photorefractive crystals," Appl. Opt. 27, 1752-1759 (1988).
6. E. G. Paek, J. Wullert, and J. S. Patel, "Holographic imple-mentation of a learning machine based on a multicategory
perceptron algorithm," Opt. Lett. 14, 1303-1305 (1989). 7. J. Hong, S. Campbell, and P. Yeh, "Optical pattern classifier
with perceptron learning," Appl. Opt. 29, 3019-3025 (1990). 8. K. Y. Hsu, S. H. Lin, C. J. Chen, T. C. Hsieh, and P. Yeh,
"An optical neural network for pattern recognition," Int. J. Opt. Comput. 2, 409-423 (1991).
9. K. Y. Hsu, S. H. Lin, and P. Yeh, "Conditional conver-gence of photorefractive perceptron learning," Opt. Lett. 18, 2135-2137 (1993).
10. J. Hertz, A. Krogh, and R. Palmer, Introduction to the Theory
of Neural Computation (Addison-Wesley, Reading, Mass., 1991), Chap. 6, p. 157.
11. G. Parisi, "Asymmetric neural networks and the process of learning," J. Phys. A 19, L675-L680 (1986).
12. J. P. Nadal, G. Toulouse, J. P. Changeux, and S. Dehaene, 'Networks of formal neurons and memory palimpsests," Eu-rophys. Lett. 1, 535-542 (1986).
13. D. Brady, K. Hsu, and D. Psaltis, "Periodically refreshed multiply exposed photorefractive holograms," Opt. Lett. 15, 817-819 (1990).
14. Y. Qiao and D. Psaltis, "Sampled dynamic holographic mem-ory," Opt. Lett. 17, 1376-1378 (1992).
15. B. H. Soffer, G. J. Dunning, Y. Owechko, and E. Marom, "Associative holographic memory with feedback using phase-conjugation mirrors," Opt. Lett. 11, 118-120 (1986). 16. Y. Qiao, D. Psaltis, C. Gu, J. Hong, P. Yeh, and R. R.
Neurgaonkar, "Phase-locked sustainment of photorefrac-tive holograms using phase conjugation," J. Appl. Phys. 70, 4648-4648 (1991).