國 立 交 通 大 學
資訊科學與工程研究所
碩 士 論 文
公 開 金 鑰 可 搜 尋 多 關 鍵 字 之 加 密 系 統
Public Key Searchable Encryption with Conjunctive Queries
研 究 生:謝嘉雯
指導教授:陳榮傑 教授
公 開 金 鑰 可 搜 尋 多 關 鍵 字 之 加 密 系 統 Public Key Searchable Encryption with Conjunctive Queries
研 究 生:謝嘉雯 Student:Chai-Wen Hsieh 指導教授:陳榮傑 Advisor:Rong-Jaye Chen 國 立 交 通 大 學 資 訊 科 學 與 工 程 研 究 所 碩 士 論 文 A Thesis
Submitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer Science
July 2012
Hsinchu, Taiwan, Republic of China
Public Key Searchable Encryption with Conjunctive Queries
Student:Chai-Wen Hsieh Advisors:Dr. Rong-Jaye Chen
Institute of Computer Science and Engineering College of Computer Science,
National Chiao Tung University
ABSTRACT
Currently, there has been a trend for users to store their encrypted pri-vate data over the Internet on a data server. Most applications rely on the data server with powerful computing power to perform searching on those encrypted data under the circumstances that server cannot access the plaintext of the data. The searchable encryption therefore becomes a crucial technique that supports searching functionality over encrypted data. Searchable encryption provides storage and computing efficiency for searching on certain keywords without requiring the decryption key. Researchers have been focused on the public key searchable encryption since it supports for multi-user settings and is considered more suitable for actual use than symmetric key searchable encryption. On the other hand, improving the searching functionality such as supporting conjunc-tive queries and other types of queries has been deeply studied. In this thesis, we survey the prominent public key searchable encryption schemes. Then we propose our design of public key searchable encryp-tion with conjunctive queries that allows the users sharing the encrypted data among multiple users without sharing the decryption keys, as well as sending arbitrary conjunctive queries ( ) to the server without leaking information of any individual conjuncts. Our design of searchable encryption is based on bilinear pairing based cryptography, which implies it requires shorter key size than the traditional RSA pub-lic-key encryptions and implies improvement of efficiency.
公 開 金 鑰 可 搜 尋 多 關 鍵 字 之 加 密 系 統 學生:謝嘉雯 指導教授:陳榮傑 教授 國立交通大學資訊科學與工程研究所碩士班
摘要
使用者將加密後的私密資料儲存至位於網際網路上的資料儲存 伺服器已成為趨勢。有很多應用依賴具有強大運算能力的伺服器根據 關鍵字搜尋加密文件,可搜尋之加密系統因此成為重要的技術。對於 加密文件中搜尋關鍵字,此系統提供有效率的儲存與計算方式,並且 無需解密金鑰。在可搜尋之加密系統的研究之中,比起對稱金鑰可搜 尋之加密系統,公開金鑰可搜尋之加密系統較為被重視,因其支持多 使用者的環境設定。另一方面,搜尋功能如多關鍵字之查詢的改進也 已被深入探討。在這篇論文中,我們概括論述了重要的公開金鑰可搜 尋之加密系統。接著我們提出一個公開金鑰可搜尋多關鍵字之加密系 統,提供讓使用者在不透漏解密金鑰的情況下分享加密文件之功能, 以及要求伺服器在加密之文件中搜尋多個關鍵字( ), 並且不洩漏任何單一關鍵字的資訊。我們的搜尋之加密系統基於雙線 性配對之密碼系統,比起傳統 RSA 公開金鑰加密系統具有更短的密 鑰長度,提高計算上的效能。誌謝
這篇碩士論文的完成,首先要感謝我的指導老師陳榮傑教授,不僅在專業知 識部分給予我方向帶領我,也在待人處事方面以身作則,為學生樹立良好典範, 親切地對待學生有如對待子女一般,謝謝老師。謝謝范俊逸教授、張仁俊教授、 李金鳳教授擔任我的口試委員,給予我許多論文上寶貴的指正與意見,我也從口 試時的討論中獲得了一些靈感,由衷感激。 感謝密碼理論實驗室的志賢學長、順隆學長、鈞祥學長、用翔學長、輔國學 長、佩娟學姊,在我的研究所生涯中,你們分享的經驗讓我受用無窮,謝謝你們。 感謝同學禮鼎,不管在研究上或生活上都給了我很大的幫助,謝謝你。 此外,感謝系女籃的學妹們,你們用心地舉辦各種活動,讓我的研究生活充 滿活力和歡笑,讓我真正感受到我們是永遠無法拆散的 team,謝謝妳們。 最後要感謝我的家人栽培我,無條件地支持我所有的決定,盡可能為我提供 最大的幫助,也謝謝哥哥和姊姊的關心,你們的包容是我一生中最大的福氣。 謹以此論文獻給我摯愛的家人以及所有關心我的師長和朋友們,謝謝你們。Contents
ABSTRACT ... I 摘要 ... II 誌謝 ... III Contents ... IV List of Tables ...V List of Figures ... VI 1 Introduction ... 1 2 Mathematical Background ... 3 2.1 Elliptic Curves ... 32.2 Rational functions and Divisors... 4
2.3 The Tate Pairing... 6
2.4 Supersingular curves and Distortion Maps ... 8
3 Review of Searchable Encryptions ... 11
3.1 Searchable Encryption... 11
3.2 Public Key Encryption with Keyword Search ... 14
3.3 Multi-user Searchable Data Encyrption ... 16
3.3.1 ElGamal Proxy Encryption ... 19
3.3.2 Keyword Encryption... 20
3.3.3 Multi-user Searchable Data Encryption ... 22
3.4 Hidden-Vector Encryption ... 24
4 Our Construction ... 28
4.1 Public Key Searchable Encryption with Conjunctive Queries ... 28
4.2 Conjunctive Queries ... 36
4.3 Experiments ... 41
4.3.1 The Pairing-based Cryptography Library ... 41
4.3.2 Experimental Result ... 44
5 Conclusion ... 47
5.1 Summary... 47
5.2 Future Work ... 47
Bibliography ... 49
Appendix : Source Code ... 52
A.1 EPSE.h... 52
A.2 EPSEtest.c ... 54
List of Tables
Table 1.1 Comparison between Data Types on Cloud Storage…..……..2 Table 2.1: Supersingular Curves…………...………..………...9 Table 4.1: NIST Recommended Key Sizes(bits)……….…41 Table 4.2: Pairings in the PBC library……….43 Table 4.3: Comparison of Speed of Different Pairings………..………..43
List of Figures
Figure 3.1 Searchable Encryption……….…………11 Figure 3.2 Prominent Schemes of Searchable Encryption……...…….13 Figure 4.1 Performance of Individual Operations ………45 Figure 4.2 Performance of Proxy Part………,,……….46 Figure 4.3 Performance of HVE Part………46
1 Introduction
In this era of information, several issues have been given utmost attention: how data are stored, security of the data and information retrieval process; that is, how to retrieve data of use after they have been stored to the stor-age while remaining its’ secrecy. Many services have been carried out to meet these needs. Recently, the most popular information technology vi-sion, cloud computing, have risen with its numerous benefits: unlimited computing resources on demands, the ease for cloud users to build up a datacenter both publicly and privately, a hedge against data lost, and so on. Cloud computing services such as Amazon Elastic Compute Cloud can attract customers from enterprises to individual users who wish to save the effort of deploying much hardware which requires the capital outlays and human resources to maintain it.
Data Security has emerged from the issues which cloud storage ser-vices are facing. Cloud users should be assured that their data are secure against curious or malicious eavesdroppers who are not authorized by el-igible users. Generally, cloud user stores plaintext on cloud storage server. Cloud storage server is therefore capable of searching on full text in any fashion. The cloud user then requests the server to return the data of in-terest. However, in some cases, even the data server is restricted from accessing full plaintext when the cloud users wish to store confidential information on the cloud storage. A trivial solution to data security is to have cloud users store encrypted data on the server. Upon receiving re-quest for certain data, the server responded with the entire ciphertext back to the cloud user. Cloud users with correct decryption key are authorized users and have access to the plaintext. Table 1.1 compares the advantages
and disadvantages between different data types stored on cloud storage server.
Data type Advantages Disadvantages
Plaintext Message Server can easily perform operations like sorting, searching, compressing to optimize computing performance.
Breach of security at the server side. The confidential content of cloud user could be leaked out by cloud server. Encrypted Ciphertext Users are assured the security of private
data at server side. Only user-authorized party can decrypt the stored ciphertext.
Unable to access the ciphertext for server causes extra cost of storage and performance. Requires users to prepro-cess plaintext beforehand.
Table 1.1 Comparison between Data Types on Cloud Storage
For users who require absolute data privacy, or say, private database, adopting encrypted ciphertext as their cloud storage data type is inevita-ble. Nevertheless, searching ability is magnified as the amount of data grows. In this case, server should be able to search on encrypted data and return exactly the data cipher which user is searching for. Traditional public-key encryption scheme is incapable of providing this functionality. Thus we need additional encryption scheme to accomplish this goal.
The term “searchable encryption” has been applied to represent en-cryption algorithms that provide searching functionality over encrypted data without possession of decryption key. Various forms of searchable encryption have been widely discussed in the past few years [27].
The paper is structured as follows: Section 2 introduces the mathe-matical background. Section 3 reviews the previous prominent public key searchable encryptions. Section 4 covers our design of public key searchable encryption with conjunctive queries. The paper concludes and proposes some future work ideas in Section 5.
2 Mathematical Background
In this chapter, we review elliptic curves and bilinear pairings.
2.1 Elliptic Curves
Suppose that is an elliptic curve defined over a fi-nite field and is power of a prime . has points in and √ √ . These points plus , an imaginary iden-tity point at infinity, become a group with addition structure. The group is
denoted as ( ). That is,
( ) {( ) | .
The group addition operation is defined as follows. Given points ( ) and ( ) on the curve, we first draw the line through and . The line intersects the curve in ( ). We then reflect over the x-asis to obtain ( ) ( ). Suppose that is the slope of the line through and , then the coor-dinates of ( ) are and ( ) , where
{
( ) ( ⁄ ) ( ) ⁄
We also define ( ) {( ) | Suppose that ̅̅̅ is the algebraic closure of , then ( ) ( ) ( ̅ ).
Suppose that | ( ) , then we define [ ] { ( ̅ )| }. [ ] are called the r-torsion points. The r-torsion point plays an important role in pairing’s definitions.
We can also find a smallest positive integer such that | . k is called the embedding degree. There are two important facts about the
embedding degree. One is that [ ] ( ) and then we can compute the r-torsion points in ( ) rather than in ( ̅ ). The other fact is that
where { ̅ | .
2.2 Rational functions and Divisors
[ ] represents the ring of polynomials in two variables , with coefficients in . A rational function ⁄ where
[ ] and is coprime to .
Given an elliptic curve and a rational function ⁄ , we con-sider the points that ( ) and ( ) ( ). We call those points zeroes of h. We also consider the points that ( ) and ( ) ( ). Those points are called poles of . In addition, the
ze-roes are the points where and intersect.
The divisor is a useful tool for keeping track of the zeros and poles [28]. We use divisors to indicate which points are zeros or poles and their orders for a rational function over an elliptic curve. A divisor on and elliptic curve is the finite linear combination of the formal symbols with integer coefficients:
∑ [ ]
If , it indicates that is a zero, and if , it indicates that is a pole. We define ( ) as the group of divisors. For a divisor ∑ [ ], we define ( ) { | as the support of , ( ) ∑ as the degree of , and ( ) ∑ .
Now we consider only the set of divisors of degree zero. The set forms a subgroup ( ) ( ). Let be a rational function. The evaluation of a rational function on a divisor ∑ [ ] is defined by
( ) ∏ ( )
( )
The divisor of a rational function is defined as ( ) ∑ ( ) where is the zero or pole order of point on . The degree of ( ) must be zero [3]. A divisor ( ) is principal if it is the divisor of a function. The following is an important fact.
Theorem 2.1 [28]
Let be an elliptic curve and be a divisor on with ( ) . Then there is a function on with ( ) if and only if
( )
2.3 The Tate Pairing
The Tate pairing and the Weil pairing [28] are two well-studied pairings. Under the same security level, The Tate pairing is generally considered more efficient than the Weil pairing.
Let be an elliptic curve defined over a finite field and is power of a prime . Let be a cyclic subgroup of ( ) of order which is coprime to . The embedding degree is such that | . The Tate pairing is a map
( )[ ] ( ) ( ⁄ ) ⁄( )
( )[ ] is defined as [ ] ( ) and ( ) is { | ( ) and ( ) is { | . The groups and
( )
⁄ are isomorphic.
Let ( )[ ] and let ( ). Q represents a coset in ( ) ( ⁄ ). Let be a rational function with divisors ( ) [ ] [ ]. Choose a ( ) such that ( ) . Let be a divisor and [ ] [ ]. The Tate pairing is defined to be
( ) represents a coset in ⁄( ) In fact, we often want to standardize the coset representative. Therefore the reduced Tate pairing is defined to be
⁄
The Tate pairing has bilinearity property and other important proper-ties. See Theorem 2.2 [3].
Theorem 2.2
Let be an elliptic curve defined over a finite field and is power of a prime . Let be a cyclic subgroup of ( ) of order which is coprime to . The embedding degree is . The Tate pairing satisfies:
1. Bilinearity: For all , , ( )[ ] and , ,
( ),
( ) ( ) ( ) and ( ) ( ) ( ) 2. Non-degeneracy:
( ) if and only if and ( ) if and only if .
To compute the Tate pairing, we need to evaluate a rational function f that ( ) [ ] [ ]. The Miller’s algorithm [24] can help us find the function and compute the result of the Tate pairing.
2.4 Supersingular curves and Distortion Maps
Suppose that is an elliptic curve defined over a fi-nite field and is power of a prime . has points in and √ √ . If | , then is said to be supersingu-lar. Otherwise, is said to be ordinary. An important property of su-persingular curves is that their embedding degrees are low. Their embed-ding degrees are from 1 to 6. Low embedembed-ding degree is crucial for the ef-ficiency of computing a pairing. Another important property of su-persingular curves is the existence of distortion maps.
A distortion map maps a point ( ) to a point ( ) ( ) such that and ( ) are linearly independent. If is su-persingular and , the distortion map exists. If E is ordinary and , then no distortion map exists for curve E [21]. By using the dis-tortion map, we can define the modified Tate pairing.
Let be a supersingular curve defined over a finite field and is power of a prime . Let be a cyclic subgroup of ( ) of or-der which is coprime to . The embedding degree is such that | . A distortion map exists. The modified Tate pairing is a map
̂ and defined to be
̂( ) ( ( ))
We note that the first input and the second input of the modified Tate pairing are from the same group. Therefore we say the modified Tate
pairing is symmetric.
Table 2.1 [3] contains some popular supersingular curves.
k Elliptic curve data
2 over , where is a prime and ( ) has points
Distortion map ( ) ( ), where .
2 over , where is a prime and ( ) has points
Distortion map ( ) ( ), where . Table 2.1: Supersingular curves
In the rest of this thesis, we usually treat pairings as “black boxes.” It can help us focus on the design of the encryption scheme. Therefore, we now give an abstract definition of the pairing.
Definition 2.3 (Bilinear Pairing)
Let and be two additive cyclic elliptic-curve groups and be a multiplicative cyclic group. , , and are all of prime order . Let be a generator of and be a generator of . A bilinear pairing is a map: that satisfies the following properties:
1. Bilinearity, 2. Non-degeneracy, 3. Computability.
These properties are further discussed as follows: Bilinearity ( ) ( ) Non-degeneracy ( ) ( ) That is, ( ) Computability ∃ 𝐴 , a polynomial-time algorithm 𝐴 computes ( ) efficiently.
If , we have the non-degenerate symmetric bilinear pairing . Otherwise the pairing is called asymmetric. Tate pairing are generally considered more efficient than Weil pairing[3][28]. We note that symmetric pairing is usually realized as the modified Tate pairing and the asymmetric pairing is usually realized as the reduced Tate pair-ing.
3 Review of Searchable Encryptions
3.1 Searchable Encryption
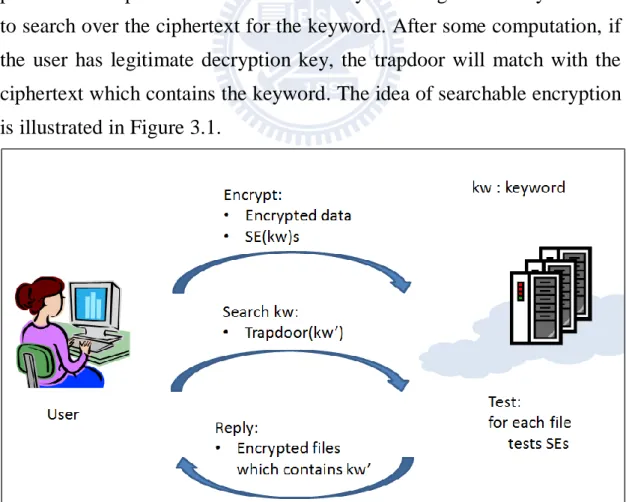
Searchable encryption is a cryptosystem that enables the users to search over ciphertext without requiring the decryption key. Let the data be the documents which user wants to encrypt with; or in practice, the data is the symmetric encryption key that encrypt the documents. Searchable en-cryption transforms the data and a set of related keywords into the ci-phertext. A trapdoor associated with a keyword is generated by the user to search over the ciphertext for the keyword. After some computation, if the user has legitimate decryption key, the trapdoor will match with the ciphertext which contains the keyword. The idea of searchable encryption is illustrated in Figure 3.1.
Searchable encryption schemes can be categorized into symmetric key or public-key searchable encryption. The searchable encryption in the symmetric key setting allows only the owner of the secret key to create searchable ciphertext, while anyone can create searchable ciphertext us-ing the public parameters in the public key settus-ing. However, the sym-metric key setting is generally faster than the public key setting.
The security of a searchable encryption can be shown by proving that a probabilistic polynomial-time algorithm differentiates the encrypted message and keywords from random data with negligible probability. The security model shows how much computing power the adversary can have. Various security models offer a trade-off between efficiency and security level. For symmetric key setting, a scheme must prove that searchable ciphertext and trapdoor do not reveal any information to ad-versary . For public key setting, the searchable ciphertext and the trapdoor that does not match must be proved to reveal nothing to the ad-versary . Two most-used models in the public key setting are the ran-dom oracle model and the standard model. The ranran-dom oracle model is used when it comes to avoiding complications, while the standard model is stronger but more costly.
The efficiency of a searchable encryption scheme can be evaluated in the following aspects:
Computational complexity
The complexity needed to create searchable ciphertext, to generate trapdoor, and to search.
Communication complexity
The complexity needed for searchable ciphertext be send/returned between the user and the server.
Storage complexity
The complexity needed to store public/private parameters, searchable ciphertext and trapdoor, as well as the storage needed by the server while performing search.
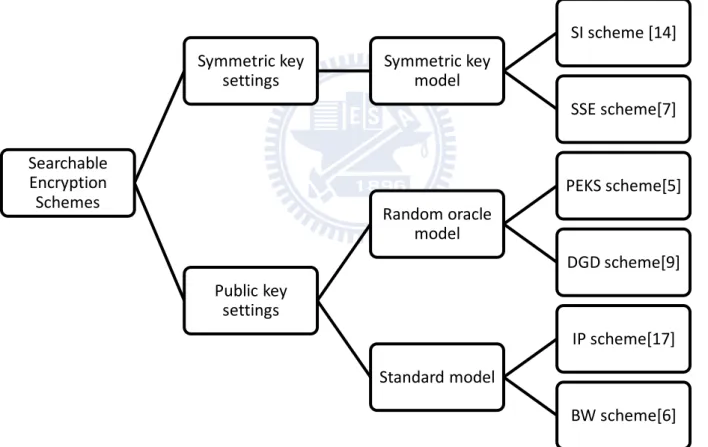
According to the key setting and the security models, Figure 3-1 depicts the searchable encryption category along with the prominent schemes in this category. In this paper, we focus on public key setting searchable en-cryption schemes. Searchable Encryption Schemes Symmetric key settings Symmetric key model SI scheme [14] SSE scheme[7] Public key settings Random oracle model PEKS scheme[5] DGD scheme[9] Standard model IP scheme[17] BW scheme[6]
3.2 Public Key Encryption with Keyword Search
Public key encryption with Keyword Search (PEKS) is introduced by Boneh et al. [5] It is the first asymmetric searchable encryption scheme that can be applied to email gateway routing. The word “public-key” points out that anyone can encrypt a message with its keywords using re-ceiver’s public key. Suppose Bob wants to send Alice an email with keywords using Alice’s public key 𝐴 . Bob sends cipher-text looked like this:
[ [ ] (𝐴 ) (𝐴 )]
where is a relatively small number. Then Alice can send a trapdoor to the email gateway server to search all the ciphertext containing keyword using her private key. The server gains no knowledge about the encrypted emails except which ciphertext contains keyword . The server then sends back the set of ciphertext that contains keyword to Alice.
Definition 3.1 (Public-key Encryption with Keyword Search)
A public-key searchable encryption scheme that consists of the following polynomial time randomized algorithms:
1. ( ): takes a security parameter and outputs public/private keys 𝐴 𝐴 .
2. (𝐴 ): takes a public key 𝐴 and a word , outputs a searchable encryption of .
3. (𝐴 ): takes user’s private key 𝐴 and a keyword , produces a trapdoor .
4. (𝐴 ): takes a public key 𝐴 , a searchable encryption (𝐴 ), and a trapdoor , outputs the test result: if , return ‘yes’; else return ‘no’.
The concrete construction of PEKS based on Decision Diffie-Hellman assumption is as follows:
( )
The input security parameter determines the size of the groups and , from the symmetric bilinear pairing . Two hash functions { and { are defined. Then randomly choose and a generator . Then, output public/private key pair 𝐴 [ ] and 𝐴 .
( )
Randomly choose , and then compute ( ( ) ) . Output (𝐴 ) [ ( )].
( )
Compute the trapdoor for keyword W as ( ) .
( )
( ( 𝐴)) . If the ‘=’ holds, return ‘yes’; else return ‘no’.
Due to the constraints of its design, PEKS scheme is applicable to search on only small number of keywords instead of the entire file.
3.3 Multi-user Searchable Data Encyrption
A Multi-user Searchable Data Encryption scheme (DGD) proposed by Dong et al.[9] is a cryptosystem that offers functionalities of sharing en-crypted data on a untrusted server among a group of authorized user, performing keyword search on encrypted data without decryption key, and adding/revoking users without restarting the service. Users rely on the data storage server to honestly perform searching calculation for them but do not trust the server with data content – the server is considered to be “honest but curious.” Three parties are involved in DGD system:
1. Users: The authorized users are able to read/write/search over en-crypted data on untrusted server. The authorized users are fully trusted. After revocation, the revoked user will no longer be able to access the data.
2. Server: The server is responsible for processing the received en-crypted data, storing the enen-crypted data, searching on receiving us-er’s query and return the encrypted data that contains the query keyword.
3. Key management server (KMS): The fully trusted KMS is respon-sible for generating/revoking user keys. Compare to untrusted data server, securing the KMS requires less effort. Also, the KMS can be kept offline most of the time.
Before introducing the multi-user searchable data encryption, we first in-troduce two definitions: negligible function and pseudorandom function.
Definition 3.2 (Negligible Function)
A function ( ) is negligible if for every positive polynomial ( ) there exists an integer such that for all ( )
( ) .
Definition 3.3 (Pseudorandom Function)
A function { { { is a pseudorandom function if for all probabilistic polynomial time algorithm , there exists a negligible function such that
| [ ( ) ] [ ( ) ]| ( )
where random key ← { and function { { .
Now let’s see the definition of the DGD scheme.
Definition 3.4 (Multi-user Searchable Data Encryption)
A searchable encryption scheme that consists of the following probabilis-tic polynomial time randomized algorithms:
1. ( ): The KMS takes the security parameter and outputs pub-lic key and a master key set .
2. ( ): The KMS takes the master key set and a user’s identity , generates the secret key set . User side key is then securely sent to the user , and server side key is sent to the server.
en-crypt a document with a set of associated keywords ( ). The output is user-side ciphertext ( ( )).
4. ( ( ( ))) : On receiving the ciphertext ( ( )) from user , the server fetches the server side key
, and outputs re-encrypted ciphertext ( ( )).
5. ( ): The user uses his user side key to gen-erate a trapdoor ( ) related to a keyword
6. ( ( ) ( ) ): The server takes as input the trapdoor ( ) and user’s identity , then test for each ( ( )) ( ) if keyword ( ). If ‘yes’, the server invokes pre-decrypt al-gorithm to obtain ( ) and send ( ) to the user .
7. ( ( )): The user takes his user key , and decrypts ( ) to obtain data .
8. ( ): Given , the data server updates the user-key mapping set ( ).
The DGD scheme is based on proxy cryptography. In the following sec-tions, we will first review ElGamal encryption scheme , then describe the proxy encryption scheme using the algorithm in ElGamal encryption scheme . Next, the keyword encryption scheme is defined. Fi-nally, with and schemes, the Multi-user Searchable Data En-cryption are presented.
3.3.1 ElGamal Proxy Encryption
Before defining ElGamal proxy encryption scheme, the ElGamal encryp-tion scheme is defined as follows:
( )
Choose prime numbers such that | , a cyclic group with generator such that is the unique order subgroup of . Choose ← and compute . Outputs the public key ( ) and private key .
( )
Choose ← and output ciphertext ( ) ( ).
( )
Decrypt ciphertext as ( ) .
The proxy encryption scheme consists of 6 algorithms: ( )
KMS runs ( ) to obtain ( ), then it outputs public parameters ( ), and master key .
( )
For each user chooses ← and computes . Then the KMS securely transmits to the user and ( )
to the proxy server.
( )
The user chooses ← and outputs ciphertext ( ) ( ). Then the user sends the ciphertext to the proxy server.
( ( ))
In this proxy re-encryption algorithm, the proxy server finds ( ) where is user‘s server side key, and computes ( )
. The stored ciphertext becomes ( ) ( ).
( ( ))
In this proxy side decryption algorithm, the proxy server finds ’s server side key and computes ( ) . The
ciphertext is partially decrypted as ( ) ( ) and is
sent to user .
( ( ))
User fully decrypts the ciphertext as ( ) .
3.3.2 Keyword Encryption
Derived from the proxy encryption scheme, the keyword encryption scheme is capable of securely encrypting keywords, allowing user to search over the encrypted data by generating trapdoors. The keyword en-cryption scheme is defined as follows:
( )
The KMS runs ( ) to obtain ( ) . Compute and choose hash function , a pseudorandom function and a random key for . Then the KMS outputs public parameters ( ), and master key ( ).
( )
For each user , the KMS runs ( ) to obtain . Then the KMS securely transmits ( ) to the user and ( ) to the proxy server.
( )
The user chooses ← . The user side trapdoor for keyword is encrypted as ( ) ( ̂ ̂ ̂ ) ( ( ̂ ) ( ))
where ( ). Then the user sends the ciphertext ( ) to the proxy server.
( ( ))
The proxy server computes trapdoor ( ) ( ) such that ( ̂ ) ̂ ̂ ( ) and ( ).
Because the keyword encryption scheme is used to generate searchable encryption which does not need to be decrypted, hence there is no de-crypting algorithm.
3.3.3 Multi-user Searchable Data Encryption
Combining the previous and algorithms, the Multi-user Searchable Data Encryption is described as the following 8 algo-rithms.
( )
The KMS runs ( ) to obtain public parameters ( ), and master key ( ).
( )
For each user , the KMS runs ( ) to obtain . Then the KMS securely transmits to the user and ( ) to the proxy server. The server side user-key mapping set is updated as ( ).
( ( ))
The user calls ( ) ( ) to encrypt data , and compute ( ) ( ( )) for each for keyword ( ). The user side ciphertext is
( ( )) ( ( ) ( ) ( )) where | ( )|
The proxy server finds ( ), the server side key of user . Then the server invokes ( ) ( ( )) , and the server calls ( ) ( ( )) for
each ( ) . The re-encrypted data
( ( )) ( ( ) ( ) ( )) is then inserted into the data storage ( ) ( ) ( ( )).
( )
The user chooses random number ← and uses his user side key ( ) to compute a trapdoor ( ) ( ) for a
keyword , where ,
, and ( ).
( ( ) ( ) )
The server perform search on receiving trapdoor ( ) ( ) from the user with . The server first compute
. Then for each keyword cipher ( ) ( ) ( ( )) in every ciphertext ( ( )) ( ), test if ( ); ‘true’ implies great probability, or say, a match is found. The server then partially decrypt all
matched encrypted data ( ) by invoking ( ) ( ( )). Note that ( ) does not need to be decrypted.
( ( ))
The server runs ( ) ( ( )) to partially decrypt the encrypted ciphertext and sends ( ) to user .
( ( ))
User fully decrypts the pre-decrypted ciphertext ( ) by calling ( ( )).
( )
To revoke user , the data server simply updates the user-key map-ping set ( ).
The correctness of the searching algorithm depends on the collision re-sistance of hash function . Hence, there exists a negligible function such that
[ ] ( )
3.4 Hidden-Vector Encryption
Boneh and Waters[6] proposed a public-key encryption system that uti-lized Hidden Vector Encryption (HVE) such that conjunctive equality, comparison, range, and subset queries are allowed. We call it ”HVE” scheme. In HVE scheme, the ciphertext is related to a vector { , and the key is related to a vector { where the
no-tation “ * ” represents “don’t care”. Both and are “hidden vector” that contain keywords implicitly. A ciphertext can be decipher once all entries of except * (don’t care) on a private key match the corre-sponding entries of the vector on the ciphertext. Symmetric pairing setting with composite group order is used to construct HVE. Here we in-troduce the latter scheme, Hidden-Vector encryption with groups of prime order (IP scheme), introduced by Iovino and Persiano[17]. The IP scheme apply the reductions of the original HVE to its construction to obtain a more efficient scheme supporting conjunctions of equality que-ries, range queries and subset queries.
Definition 3.2 (Hidden Vector Encryption Scheme)
Let and are strings of length where { and { . Define a predicate ( ) if and only if or
, for ; ( ) otherwise. An HVE is a set of probabil-istic polynomial-time algorithms (Setup,Enc,KeyGeneration,Dec) :
1. ( ): Take the i security parameter and the attribute length ( ) and output the public key set and a master key set .
2. ( ): Take as input the public key set , the plaintext , and the attribute vector { . Output the ciphertext
.
3. ( ): Take as input the master key set and string { . Output the decryption key .
4. ( ): Take as input the public key set , the ciphertext , and the secret key . Output the message .
( )
Take the input security parameter and the attribute length ( ). Choose an instance { and ← , where is the group order of and , is a symmetric biline-ar pairing and is a generator of . Set ( ) . Choose random numbers ← and set
for . Then output the public key set
[ ( ) ] and the master key set
[ ( ) ].
( )
Take as input the public key set , the plaintext , and the attribute vector { . Choose random ← and ←
for and compute the ciphertext
[ ( ) ], where ( ), and
{
{
Then, return the ciphertext .
( )
Take as input the master key set and string { . De-note and to be the set of indices such that and
. Let be the set of indices for which . If , that is, ( ), let . Else, for each , choose ← at random such that ∑ , where is from
the . Compute ( ) where
{ {
Then, output the decryption key relative to attribute vector .
( )
Take as input the public key set , the ciphertext , and the se-cret key . If , then , decrypt the ciphertext as
( ) ( )
Else, decrypt the ciphertext as
( ) ∏ ( )
( )
4 Our Construction
In Section 4.1 we described our construction in detail. We then introduce query applications of our design in Section 4.2. We give an simplified example with smaller numbers to our construction in Section 4.3. In sec-tion 4.4 we further discuss some related issues. And finally in Secsec-tion 4.5, we give out our experiment results.
4.1 Public Key Searchable Encryption with
Conjunctive Queries
We construct a searchable encryption scheme on elliptic curve groups, based on El Gamal Proxy Re-encryption and Hidden Vector Encryption. Users can share encrypted data among all authorized users while users are able to perform conjunctive keyword search. In our construction, author-ized user share encrypted data over the data server that supports the fol-lowing operations:
Get – The user requests the shared data with its id.
Search – The user asks the data server to perform conjunctive keyword
search by sending a query trapdoor associated with the keywords.
Insert – The user inserts new data into the data server by running the data
encryption algorithm to encrypt the data and the keywords.
Remove – The user requests the data server to remove encrypted data of
Since the data server – or called the proxy server since it stand as a proxy between users - is considered to be “honest and curious” which points out that the server will perform the search operation honestly but is curious about the data content. While performing the search operation for users, it is important that the data server gains no other information except:
1. which user sent the query, and
2. the set of encrypted documents which contain the queried keywords That is, the data server will learn nothing about the data content, key-words to be queried and other information.
In our design, the authorized users are able to:
Encrypt – Users encrypt data with the associating keywords and pass it
to the data server.
Query – Users query for keywords conjunctively over the encrypted
data on the data server by producing a trapdoor related to the keywords.
Decrypt – Users decrypt the encrypted data that is returned from the
data server.
Note that only authorized users in possession of a secret key can do the above operations. The user’s secret key is called user side key, which is generated and distributed securely to the users by a Key Management Server (KMS), while the corresponding server side key is securely trans-mits to the data sever by the KMS. Two keys – the user side key and the server side key – are related with a master key that is held secretly by the KMS. Hence, the KMS should keep the master key secure in order to keep the entire system free from attack.
We assume no authorized user reveals his user side key to the data server; otherwise the data server can reconstruct the master key by multi-plying the user side key with the server side key related to it. We also as-sume there is an impartial KMS which keeps master key secret and re-veals nothing but the public parameters. Under these assumptions, we build up our construction for authorized users to store and share data on
untrusted server without revealing the data content to the data server, while conjunctive queries over the encrypted data is supported by the data server.
Each algorithm in our searchable encryption scheme consists of two parts: an elliptic curve proxy encryption part to encrypt the symmetric session key that encrypts the data, and a hidden-vector encryption part to generate the conjunctive query searchable encryptions related the key-words of data. We give the definition of our construction as follows:
Definition 4.1
(Public Key Searchable Encryption with Conjunctive Queries)
Let and be strings of length where { and { . Let ( ) be the attribute vector related to data , and ( ) be encrypted data on data server. Define a predicate ( ) if and only if or , for ; ( ) otherwise.
We construct a searchable encryption scheme consisting of the following nine algorithms:
1. ( ): The KMS takes the security parameter and attribute length ( ), then outputs public key and a master key set .
2. ( ): The KMS takes the master key set and a user’s identity , generates the secret key set . User side key is then securely sent to the user , and server side key is sent to the server.
3. ( ): The user uses his user side key to encrypt a document with a set of associated attribute vector . The output is user-side ciphertext ( ).
( ) from user , the server fetches the server side key , and outputs re-encrypted ciphertext ( ).
5. ( ): On input the attribute y, the user uses his user side key to generate a trapdoor ( ).
6. ( ( ) ( ) ): The server takes as input the trapdoor ( ) and user’s server side key , then test for each ( ) ( ) if predicate ( ) . If ‘yes’, the server invokes pre-decrypt algorithm to obtain ( ) and send ( ) to the user . 7. ( ( )): The server takes the encrypted
data that contains queried keyword from the trapdoor and user’s identity as input, pre-decrypt the encrypted data with its server side key as ( ). Send ( ) to user .
8. ( ( )): The user takes his user key , and decrypts ( ) to obtain data .
9. ( ): Given , the data server updates the user-key mapping set ( ).
The following is the concrete construction of our searchable encryption. Note that both the data encryption and attribute vector (keyword related) encryption are based on pairing-based cryptography.
( )
The KMS first takes the input security parameter and the attribute
{ and ← , where is the group order of and , is a symmetric bilinear pairing and is a generator of . Set ( ) . Then the KMS chooses ran-dom numbers ← and computes
and
for . The public parameters is published by the KMS as [ ( ) ( ) ],
and the the master key is kept secret as [ ( ) ].
( )
On input the , for each user , the KMS randomly chooses ← , and compute ⁄ . Then the KMS securely transmits to the user and ( ) to the data server. The server side key mapping set is updated as ( ).
( )
The user takes as input the data where is the base filed
of , the user side key and attribute vector { . The user chooses random number ← and computes . Let and ( ) . Then he computes [ ] where , and . Next, the user
chooses ← and ← for , and computes ( ), , and { {
for . Finally, ( ) [ ( ) ( )] is sent to the data server where ( ) [ ] as ciphertext and ( ) [ ( ) ] as searchable encryption.
( ( ))
The proxy server finds the server side key of user j, ( ). It then re-encrypts the ciphertext ( ) [ ( ) ( )] by computing and . Finally, ( ) [ ( ) ( )] , where ( ) [ ] and ( ) [ ( ) ] is inserted into the data storage ( ) ( ) ( ).
( )
The user takes as input his user side key and string { . Denote and to be the set of indices such that { | and { | . Let be the
set of indices for which . If , that is, ( ), let . Else, for each , choose a number ← such that ∑ . Compute ( ) where
{ { Then, the user sends the trapdoor relative to attribute vector to the data server.
( )
Take as input the server side key of user , and the trapdoor
, the data server perform search by calculating whether for each ( ) ( ). If , then , the data server calculates as
( )
Else, the data server calculates as [∏ ( )
( )]
[∏ ( ) ( )] [ ( )∑ ( ) ∑ ] [ ( )∑ ] [ ( ) ] ( ) ( ) ( ( ))
On inputs user id and encrypted data ( ) [ ], the data server pre-decrypt ( ) to ( ) in order for user to decrypt the encrypted data. The data server computes . ( ) [ ] is then sent to the user .
( ( ))
User fully decrypts the pre-decrypted ciphertext ( ) [ ] where [ ] . He computes and where , to obtain the plaintext data . ( )
To revoke user , the data server simply updates the user-key map-ping set ( ).
encryp-tion with conjunctive queries. We will further discuss the experimental performance of each function in section 4.3.
4.2 Conjunctive Queries
In this section we show how conjunctive queries can be applied on our scheme. Let ( ) be a keyword set to be encrypted for future search. Let { and { be attribute vectors that are related to the data and the trapdoor respectively. Let ( ) and ( ) be a vector of consecutive attribute vector or , and be the length of attribute vector. Define a predi-cate ( ) if and only if or , for
and ; ( ) otherwise. Note that in the hidden vector encryptions we described in Chapters 2 and 3, for simplicity we take only one attribute vector { or { as an input. In fact, the actual input is the hidden vectors and consisting of attribute vectors. In the following we will describe the design the attribute vectors in order to perform conjunctive comparison queries, conjunctive range queries, and conjunctive subset queries.
Conjunctive Comparison Queries
Suppose there are conjunctive queries, then the width of the hidden vector encryption is . Let ( ) ( ) , that is,
is a number ranging from 1 to n. Build an attribute vector as:
For example, let , then { such that
1 n 1 n
To test whether if for any query keyword in
𝐴 ( ) ( ) , we build an attribute vector as:
{
For example, assign , then { looks like
1 n 1 n
Attribute vector is then hidden in the searchable encryption that is generated in User Encrypt step, and attribute vectors is then hidden in the trapdoor generated by user in Trapdoor step. In Search step, the pred-icate ( ) is tested to see if a ciphertext contains keywords that match/satisfy the trapdoor. The predicate ( ) if and only if for . If ( ) , then the data with keyword set ( ) is considered to be containing keywords such that
.
Conjunctive Range Queries
A system that supports conjunctive comparison queries also supports conjunctive range queries. Let be a set of keywords
0 … 0 1 1 … 1 0 … 0 1 1 … 1
( ) ( ) . A range query searches for plaintexts where keyword [ ]. For example, let . To do conjuctive range queries, build the attribute vector { as:
1 n Let the attribute vector { be:
1 n
The predicate ( ) if and only if and . To do con-junctive range queries, attach more attribute vectors to and for different ’s.
Conjunctive Subset Queries
Here we show how to design attribute vectors so the subset queries is searchable. Let ( ) , where is a size-n set of all pos-sible . Let an attribute vector be:
{
To test whether if 𝐴 for any query set 𝐴 in 𝐴 (𝐴 𝐴 ) for , build an attribute vector as:
{ 𝐴
0 … 0 1 1 … 1
The predicate ( ) if and only if 𝐴 for all . That is, ( ) , in ( ) satisfies that 𝐴 𝐴 . For example, let , build the attribute vector { as:
1 n
Build the attribute vector { according to set 𝐴 { as: 1 2 3 4 5 n
Note that ( ) if and only if 𝐴. Arbitrary number of con-junctive subset queries are also allowed by setting larger .
Subset queries using Bloom filters
We notice that in the subset queries, the space needed increases signifi-cantly as , the size of of all possible keywords, increases. The hid-den attribute vector is of size , with the same size for . We give a design using the Bloom filters to reduce the space requirement as the size of is large.
Bloom filters[4] utilizes multiple functions { . A bloom filter is a vector of size , such that { . For a key-word of arbitrary length, the bloom filter of this word is { that contains ‘1’ at positions ( ) ( ). With ( ), we have bloom filter { that contains ‘1’ at positions ( ), for , We design the attribute vectors as:
{ ( )
0 … 0 1 0 … 0
In another word, the attribute vector is set to be the bloom filter of keyword set ( ). Then for a set 𝐴 ( ), build an attribute vector as:
{ ( )
That is, the attribute vector is set to be the bloom filter of
key-word set 𝐴. The predicate ( ) if and only if set 𝐴 . The predicate ( ) indicates whether all words in set 𝐴 are contained in set . If yes, then the bloom filter is marked ‘1’ at the correspond-ing position, so does the bloom filter . If no, then “could” contains
‘1’s not in with very high probability (small collision probability). By choosing , number of functions , and , the size of a bloom filter , the false positive probability can be very small. Say,
4.3 Experiments
In this section we describe the implementation of our public key searcha-ble encryption. First we describe the pairing library used in our program in section 4.3.1. Then we have performance evaluation in section 4.3.2.
4.3.1 The Pairing-based Cryptography Library
The pairing-based cryptography (PBC) library [23] is an open source li-brary that is released under the GNU Lesser General Public License. The PBC library is written in C and provides routines such as elliptic curve generation, elliptic curve arithmetic and pairing computation.
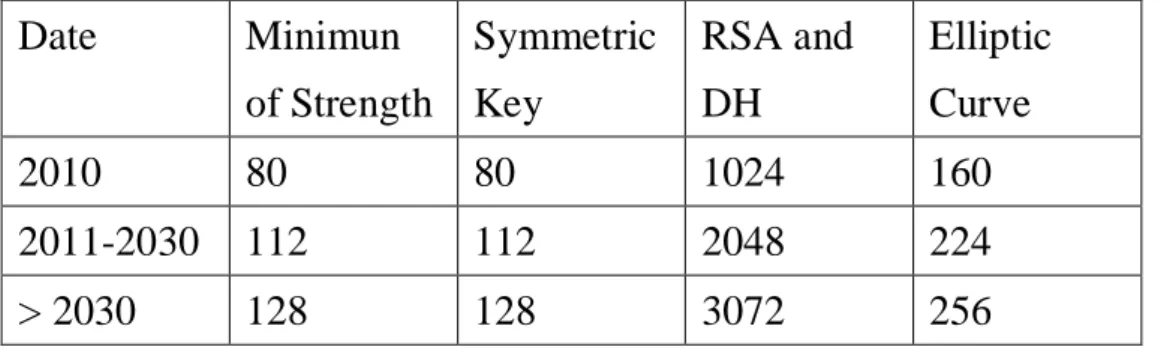
We have tested the speed of the PBC library. We performed our ex-periments on a 2.4 GHz Intel Xeon E5620 processor running Ubuntu 11.10. The security level we choose is 128-bit. Table 4.1 is the key size comparison under different security levels [29].
Date Minimun of Strength Symmetric Key RSA and DH Elliptic Curve 2010 80 80 1024 160 2011-2030 112 112 2048 224 > 2030 128 128 3072 256
Table 4.1: NIST Recommended Key Sizes(bits)
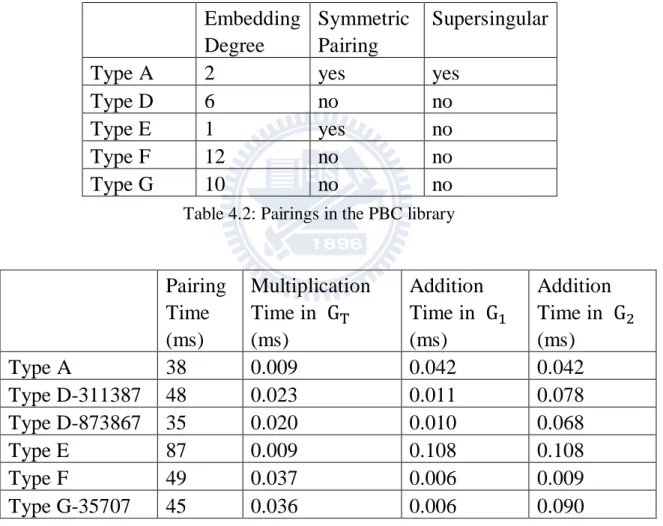
There are seven types of pairings defined in the PBC library. The seven types are type A, type B, type C, type D, type E, type F and type G. Type A, type B and Type C are supersingular curves. Type D, type E, type F and type G are based on complex multiplication (CM) method[28].
However, type B and type C are not implemented yet. The CM equation is
where the discriminant is positive. We omit the details of the CM method here.
Type A pairings are constructed on the curve over , where is a prime and ( ). E is a supersingular curve, so this pairing is a symmetric pairing . is a subgroup of because the embedding degree is 2. Therefore we choose the
group order to be 256-bit long and to be 1536-bit long, because must be 3072-bit long to achieve the same security level as 256-bit long in elliptic curve.
Type D pairings are constructed on the MNT curves of embedding degree 6 [25]. This pairing is an asymmetric pairing . is a subgroup of because the embedding degree is 6. Given
dif-ferent discriminant in the CM equation, the bits in and the bits in are determined. Therefore we choose two suitable type D pairings. One is that the discriminant is 31387, is 522-bit long and is 514-bit long. The other is that discriminant is 873867, is 486-bit long and is 442-bit long
Type E pairings are constructed on the curves of embedding 1 [21]. The pairing is a symmetric pairing . is a subgroup of because the embedding degree is 1. Therefore we choose the
group order to be 256-bit long and to be 3072-bit long, because must be 3072-bit long to achieve the same security level as 256-bit long in elliptic curve.
Type F pairings are constructed on the curves of embedding 12. This pairing is an asymmetric pairing . is a subgroup of
because the embedding degree is 12. Therefore we choose the group
order to be 256-bit long and to be 256-bit long.
Type G pairings are constructed on the curves of embedding 10 which Freeman suggests [11]. Given different discriminant in the CM equation, the bits in and the bits in are determined. Therefore we choose one suitable type G pairings. The curve is that the discriminant is 35707, is 301-bit long and is 279-bit long. Table 4.2 is a comparison of the pair-ings in the PBC library.
Embedding Degree
Symmetric Pairing
Supersingular
Type A 2 yes yes
Type D 6 no no
Type E 1 yes no
Type F 12 no no
Type G 10 no no
Table 4.2: Pairings in the PBC library
Table 4.3: Comparison of Speed of Different Pairings
For each type, we choose 10 random inputs to the pairing function and compute the average time. We also choose 100 random elements for , and for each type and compute the average time of an addition or an multiplication. The result of our test is shown in Table 4.3. We note
Pairing Time (ms) Multiplication Time in (ms) Addition Time in (ms) Addition Time in (ms) Type A 38 0.009 0.042 0.042 Type D-311387 48 0.023 0.011 0.078 Type D-873867 35 0.020 0.010 0.068 Type E 87 0.009 0.108 0.108 Type F 49 0.037 0.006 0.009 Type G-35707 45 0.036 0.006 0.090
that in our encryption scheme, we need a symmetric pairing. And the Type E pairing is the slowest pairing. Therefore, in our implementation, we choose the Type A pairing.
4.3.2 Experimental Result
We implemented our algorithms on a 2.4 GHz Intel Xeon E5620 proces-sor running Ubuntu 11.10. We used 1536-bit prime for pairing. In the first experiment, we measured the execution time of each of the following operations:
1. Initialization – KMS outputs public key and a master key set.
2. Key Generation – KMS generates user side key and server side key. 3. User Encryption – the user side proxy and searchable encryption. 4. Server Re-encryption – the server side proxy re-encryption
5. Trapdoor – the user side trapdoor generation.
6. Search – the trapdoor/searchable encryption matching test. 7. Server Pre-decryption – the server side proxy decryption. 8. User Decryption – the user side proxy decryption.
9. Revocation – the server side revocation of the user.
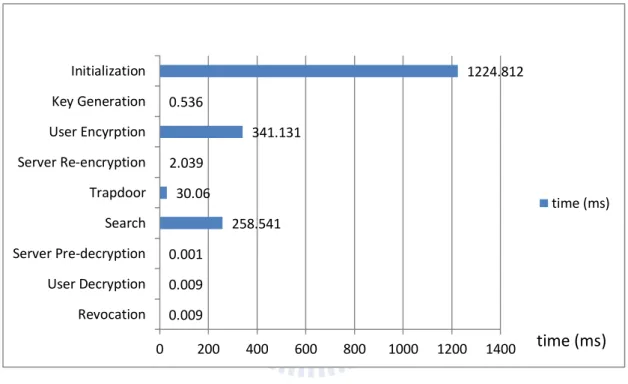
Figure 4.1 shows the results. Our test data are 2011 eprint pdf files. Note that the pdf data were encrypted with symmetric key encryption AES128. Then we took the session key of AES128 encryption as our plaintext. The user who successfully decrypts the ciphertext will retrieve the session key of the encrypted pdf file. We did not calculate the AES128 encrypting time, so the size of the pdf files was irrelevant. The time was measured in milliseconds, and it is the average of 10000 executions. We set the size hidden vectors =10. We can now see that the Initialization took up most of the time. The main cause is that it needs times pairing
ele-ment powers. So are the user encryption and search algorithms, which both need element powers. The Search and Trapdoor algorithm are significantly influenced by the number of (don’t care) appears in the attribute vector . The more , the less computation is needed, which happens in most of the application where don’t care term is much more than ‘0’s and ‘1’s.
Figure 4.1 Performance of Individual Operations
It is obvious that all algorithms that spend longer time are searchable en-cryption related. So the second and third experiments came as follows: we measured the algorithms by two parts: the proxy encryption part and hidden vector encryption part.
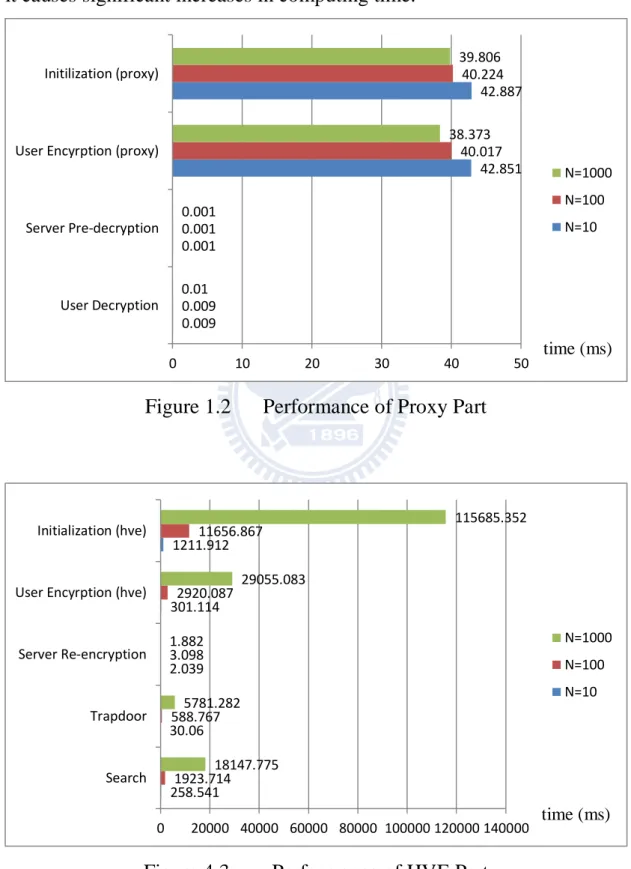
Figure 4.2 showed the result of 10000 executions of proxy encryption part algorithms. We showed that under =10, =100, =1000, we had similar execution time for the proxy encryption part. Hence, the number of keywords does not affect the encryption of the data but only affect the searchable encryption in our algorithm. As to the result of 10000 execu-tions of HVE encryption part, under =10, =100, =1000, we had
0.009 0.009 0.001 258.541 30.06 2.039 341.131 0.536 1224.812 0 200 400 600 800 1000 1200 1400 Revocation User Decryption Server Pre-decryption Search Trapdoor Server Re-encryption User Encyrption Key Generation Initialization time (ms) time (ms)
the execution time of Initialization, User Encryption, Trapdoor and Search algorithms in direct proportional with the size of hidden attribute vector . Hence, it is crucial to optimize the size of hidden vector since it causes significant increases in computing time.
Figure 1.2 Performance of Proxy Part
Figure 4.3 Performance of HVE Part 0.009 0.001 42.851 42.887 0.009 0.001 40.017 40.224 0.01 0.001 38.373 39.806 0 10 20 30 40 50 User Decryption Server Pre-decryption User Encyrption (proxy) Initilization (proxy) N=1000 N=100 N=10 258.541 30.06 2.039 301.114 1211.912 1923.714 588.767 3.098 2920.087 11656.867 18147.775 5781.282 1.882 29055.083 115685.352 0 20000 40000 60000 80000 100000 120000 140000 Search Trapdoor Server Re-encryption User Encyrption (hve) Initialization (hve) N=1000 N=100 N=10 time (ms) time (ms)
5 Conclusion
5.1 Summary
We introduced the idea of searchable encryption that is used to solve the problem of how to efficiently search on encrypted data. In Chapter 2, we introduced the mathematical background including elliptic curve and bi-linear pairings. In Chapter 3, we reviewed three prominent public key searchable encryptions: public key encryption with keyword search, mul-ti-user searchable data encryption, and hidden-vector encryption. We de-scribed the scheme, and then gave out its definition as well as its concrete construction. In Chapter 4, we described our design of searchable encryp-tion, providing a solution to sharing data on untrusted server with con-junctive keyword search. After describing our construction in detail, we introduced several applications of our scheme, including conjunctive comparison queries, range queries, and subset queries. We mentioned an interesting application that can reduce the space needed by conjunctive subset queries by apply Bloom filters on the hidden vectors. Then we de-scribed our implementation and evaluated the performance of our algo-rithms.
5.2 Future Work
For further research, we recommend for the following topics:
1. Multi-user searchable data encryption without key management
center to hold the master key. Generating user side and server side keys of all users with a single master key implies the risk of collusion attack. Also, renewing master keys requires the user to encrypt his previous encrypted data and searchable encryption again. We expect there is a multi-user searchable encryption scheme that runs without key management center.
2. Improve the performance of HVE encryption. As we can see in the performance evaluation in Chapter 4.3, most computation are cost by pairing computation. By redesigning the algorithms, we expect the precompile pairing comes in handy while, if possible, consecutive pairing computes with the same first argument. Precompile pairing improves performance significantly on a type A pairing.
3. Applications of HVE. By designing the hidden vector and
properly, the hidden vector encryption provides can do many opera-tions while the vectors are hidden. We look for more applicaopera-tions of HVE.
Bibliography
[1] M. Abdalla, M. Bellare, D. Catalano, E. Kiltz, T. Kohno, T. Lange, J. Malone-Lee, G. Neven, P. Paillier, and H. Shi, “Searchable encryption revisited: consistency properties, relation to anonymous IBE, and extensions,” Journal of
Cryptology, vol. 21, no. 3, pp. 350–391, 2008.
[2] G. Ateniese, K. Fu, M. Green, and S. Hohenberger, “Improved proxy re-encryption schemes with applications to secure distributed storage,” in
Pro-ceedings of the 12th Annual Network and Distributed System Security Symposi-um, 2005, pp. 29–44.
[3] I. F. Blake, G. Seroussi, and N. P. Smart, Advances in elliptic curve
cryptog-raphy. Cambridge Univ Pr, 2005.
[4] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,”
Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
[5] D. Boneh, G. Di Crescenzo, R. Ostrovsky, and G. Persiano, “Public key encryp-tion with keyword search,” in Advances in Cryptology-Eurocrypt 2004, 2004, pp. 506–522.
[6] D. Boneh, and B. Waters, “Conjunctive, subset, and range queries on encrypted data,” Theory of Cryptography, pp. 535–554, 2007.
[7] R. Curtmola, J. Garay, S. Kamara, and R. Ostrovsky, “Searchable symmetric en-cryption: improved definitions and efficient constructions,” in Proceedings of the
13th ACM Conference on Computer and Communications Security, 2006, pp.
79–88.
[8] A. De Caro, V. Iovino, and G. Persiano, “Fully secure anonymous hibe and se-cret-key anonymous ibe with short ciphertexts,” Pairing-Based