866 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGIJEERING, VOL 8, NO 6, DECEMBER 1996
Ming-Syan Chen,
Senior Member,
IEEE,
Jiawei Han,
Senidr Member,
IEEE,
and Philip
S.
Yu,
Fellow, lEEE
Abstract-Mining information and knowledge from large databases has been recognized by many researchers as a key research topic in database systems and machine learning, and by many industrial companies as an important area with an opportunity of major revenues Researchers in many different fields have shown great interest in data mining Several emerging applications in information providing services, such as data warehousing and on-line services over the Internet, lalso call for various data mining techniques to better understand user behavior, to improve the service provided, and to increase the business opportunities In response to such a demand, this article is to provide a survey, from a database researcher's point of view, on the data mining techniques developed recently A classification of the available data mining techniques is provided, and a comparative study of such techniques is presented
Index Terms-Data mining, knowledge discovery, association rules, classification, dala clusterir)g, pattern matching algorithms,
data generalization and characterization, data cubes, multiple-dimensional databases
I -
ECENTLY, our capabilities of both generating and col-
lecting data have been increasing rapidly. The wide- spread use of bar codes for most commercial products, the computerization of many business and government trans- actions, and the advances in data collection tools have pro- vided us with huge amounts of data. Millions of databases have been used in business management, government ad- ministration, scientific and engineering data management, and many other applications. It is noted that the number of such databases keeps growing rapidly because of the avail- ability of powerful and affordable database systems. This explosive growth in data and databases has generated an urgent need for new techniques and tools that can intelli- gently and automatically transform the processed data into useful information and knowledge. Consequently, data
mining
has become a research area with increasing impor- tance [301, [701, [761.Data mining, which is also referred to as knozuledge dis- covery in databases, means a process of nontrivial extraction of implicit, previously unknown and potentially useful in- formation (such as knowledge rules, constraints, regulari- ties) from data in databases [70]. There are also many other terms, appearing in some articles and documents, carrying a similar or slightly different meaning, such as knowledge mining from databases, knowledge extraction, data archaeology,
M.-S. Chen is with the Electrical Engineering Department, National Taiwan University, Taipei, Taiwan, Republic of China. E-mail: [email protected].
British Columbia, V5A 1 S6, Canada. E-mail: [email protected]. Yorktown, Ny 10598. E-mail: [email protected].
e J. Hun is with the School of Computing Science, Simon Fraser University, e P.S. Yu is with the IBM Thomas J. Watson Research Center, PO Box 704, Manuscript accepted Aug. 28,1996.
For information on obtaining Yeprints of this article, please send e-mail to: [email protected], and reference I E E E C S Log Number K96075.
data
dredging,
data analysis, etc. By knowledge discovery in databases, interesting khowledge, regularities, or high-level information can be extjacted from the relevant sets of data in databases and be indestigated from different angles, and large databases therebj serve as rich and reliable sources for knowledge generation and verification. Mining infor- mation andknowledge^
from large databases has been rec- ognized by many resteakhers as a key research topic in da- tabase systems and machine learning, and by many indus- trial companies as an important area with an opportunity of major revenues. The discovered knowledge can be applied to information managFment, query processing, decision making, process controp, and many other applications. Re- searchers in many different fields, including database sys- tems, knowledge-base ~systems, artificial intelligence, ma- chine learning, knowlbdge acquisition, statistics, spatial databases, and data vi$mlization, have shown great inter- est in data mining. Furthermore, several emerging applica- tions in information droviding services, such as on-line services and World 'Wide Web, also call for various data mining techniques to p t t e r understand user behavior, to meliorate the service pr'ovided, and to increase the businessIn response to suclh
4
demand, this article is to provide a survey on the data miqkng techniques developed in several research communities,) with an emphasis on database- oriented techniques imp those implemented in applicative data mining systems.4
classification of the available data mining techniques is also provided, based on the kinds of databases to be mined, the kinds of knowledge to be dis- covered, and the kinds of techniques to be adopted. This survey is organized ac$ording to one classification scheme: the kinds of knowledgei to be mined.I
opportunities. ~
CHEN ETAL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE 867
1
.I
Requirements and Challenges of Data MiningIn order to conduct effective data mining, one needs to first examine what kind of features an applied knowledge dis- covery system is expected to have and what kind of chal- lenges one may face at the development of data mining techniques.
Handling of diffzrent types of data.
Because there are many kinds of data and databases used in different applications, one may expect that a knowledge discovery system should be able to per- form effective data mining on different kinds of data. Since most available databases are relational, it is cru- cial that a data mining system performs efficient and effective knowledge discovery on relational data. Moreover, many applicable databases contain complex data types, such as structured data and complex data objects, hypertext and multimedia data, spatial and temporal data, transaction data, legacy data, etc. A powerful system should be able to perform effective data mining on such complex types of data as well. However, the diversity of data types and different goals of data mining make it unrealistic to expect one data mining system to handle all kinds of data. Spe- cific data mining systems should be constructed for knowledge mining on specific kinds of data, such as systems dedicated to knowledge mining in relational databases, transaction databases, spatial databases, multimedia databases, etc.
Efficiency and scalability of data mining algorithms.
To effectively extract information from a huge amount of data in databases, the knowledge discov- ery algorithms must be efficient and scalable to large databases. That is, the running time of a data mining algorithm must be predictable and acceptable in large databases. Algorithms with exponential or even medium-order polynomial complexity will not be of practical use.
Usefulness, certainty, and expressiveness of data mining results.
The discovered knowledge should accurately portray the contents of the database and be useful for certain applications. The imperfectness should be expressed by measures of uncertainty, in the form of approxi- mate rules or quantitative rules. Noise and excep- tional data should be handled elegantly in data min- ing systems. This also motivates a systematic study of measuring the quality of the discovered knowledge, including interestingness and reliability, by construc- tion of statistical, analytical, and simulative models and tools.
Expression of various kinds of data mining requests and results.
Different kinds of knowledge can be discovered from a large amount of data. Also, one may like to examine discovered knowledge from different views and pres- ent them in different forms. This requires us to ex- press both the data mining requests and the discov- ered knowledge in high-level languages or graphical user interfaces so that the data mining task can be specified by nonexperts and the discovered knowl- edge can be understandable and directly usable by us- ers. This also requires the discovery system to adopt expressive knowledge representation techniques.
5 ) Interactive
mining
knowledge at multiple abstraction levels.Since it is difficult to predict what exactly could be discovered from a database, a high-level data mining query should be treated as a probe which may dis- close some interesting traces for further exploration.
Inferactive discovery should be encouraged, which al- lows a user to interactively refine a data mining re- quest, dynamically change data focusing, progres- sively deepen a data mining process, and flexibly view the data and data mining results at multiple ab- straction levels and from different angles.
The widely available local and wide-area computer network, including Internet, connect many sources of data and form huge distributed, heterogeneous data- bases. Mining knowledge from different sources of formatted or unformatted data with diverse data se- mantics poses new challenges to data mining. On the other hand, data mining may help disclose the high- level data regularities in heterogeneous databases which can hardly be discovered by simple query sys- tems. Moreover, the huge size of the database, the wide distribution of data, and the computational complexity of some data mining methods motivate the development of parallel and distributed data mining algorithms.
When data can be viewed from many different angles and at different abstraction levels, it threatens the goal of protecting data security and guarding against the invasion of privacy. It is important to study when knowledge discovery may lead to an invasion of pri- vacy, and what security measures can be developed for preventing the disclosure of sensitive information. Notice that some of these requirements may carry con- flicting goals. For example, the goal of protection of data security may conflict with the requirement of interactive mining of multiple-level knowledge from different angles. Moreover, this survey addresses only some of the above requirements, with an emphasis on the efficiency and scal- ability of data mining algorithms. For example, the han- dling of different types of data are confined to relational and transactional data, and the methods for protection of privacy and data security are not addressed (some discus- sions could be found elsewhere, such as 1221, [631). Never- theless, we feel that it is still important to present an overall picture regarding to the requirements of data mining.
6 ) Mining information from different sources of data.
7 ) Protection of privacy and data security.
2
Since data mining poses many challenging research issues, direct applications of methods and techniques developed in related studies in machine learning, statistics, and database systems cannot solve these problems. It is necessary to per- form dedicated studies to invent new data mining methods or develop integrated techniques for efficient and effective data mining. In this sense, data mining itself has formed an independent new field.
868 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 8, NO. 6, DECEMBER 1996
2.1 Classifying Data Minin
There have been many advances on researches and devel- opments of data mining, and many data mining techniques and systems have recently been developed. Different classi- fication schemes can be used to categorize data mining methods and systems based on the kinds of databases to be studied, the kinds of knowledge to bq discovered, and the kinds of techniques to be utilized, as shown below.
e What kinds of databases to work on.
A data mining system can be classified according to the kinds of databases on which the data mining is performed. For example, a system is a relational data miner if it discovers knowledge from relational data, or an object-oriented one if it mines knowledge from object-oriented databases. In general, a data miner can be classified according to its mining of knowledge from the following different kinds of databases: rela- tional databases, transaction databases, object- oriented databases, deductive databases, spatial data- bases, temporal databases, multimedia databases, heterogeneous databases, active databases, legacy databases, and the Internet information-base.
0 What kind of knowledge to be mined.
Several typical kinds of knowledge can be discovered by data miners, including association rules, charac- teristic rules, classification rules, discriminant rules, clustering, evolution, and deviation analysis, which will be discussed in detail in the next subsection.
Moreover, data miners can also be categorized ac- cording to the abstraction level of its discovered knowledge which may be classified into generalized knowledge, primitive-level knowledge, and multiple- level knowledge. A flexible data mining system may discover knowledge at multiple abstraction levels.
0 What kind of techniques
to
be utilized.Data miners can also be categorized according to the underlying data mining techniques. For example, it can be categorized according to the driven method into autonomous knowledge miner, data-driven miner, query-driven miner, and interactive data miner. It can also be categorized according to its un- derlying data mining approach into generalization- based mining, pattern-based mining, mining based on statistics or mathematical theories, and integrated approaches, etc.
Among many different classification schemes, this sur- vey follows mainly one classification scheme: the kznds of
knowledge to be mined because such a classification presents a clear picture on different data mining requirements and techniques. Methods for mining different kinds of knowl- edge, including association rules, characterization, classifi- cation, clustering, etc., are examined in depth. For mining a particular kind of knowledge, different approaches, such as machine learning approach, statistical approach, and large database-oriented approach, are compared, with an empha- sis on the database issues, such as efficiency and scalability.
.2 Mining Different Kinds of Knowledge from
Databases
Data mining is an application-dependent issue and differ- ent applications may require different mining techniques to cope with. In general, the kinds of knowledge which can be discovered in a database are categorized as follows.
Mining association rules in transactional or relational databases has recently attracted a lot of attention in data- base communities [4], [7], [39], [57], [66], [73], [78]. The task is to derive a set of strong association rules in the form of
"Al A
...
AA,
*
El A ... A B,," where A, (for i E (1,...,
m } )and Bl (for j E (1,
...,
n ) ) are sets of attribute-values, from the relevant data sets in a database. For example, one may find, from a large set of transaction data, such an associa- tion rule as if a customer buys (one brand of) milk, he/she usually buys (another brand of) bread in the same transac- tion. Since mining association rules may require to repeat- edly scan through a large transaction database to find dif- ferent association patterns, the amount of processing could be huge, and performance improvement is an essential con- cern. Efficient algorithms for mining association rules and some methods for further performance enhancements will be examined in Section 3.The most popularly used data mining and data analysis tools associated with database system products are data generalization and summarization tools, which carry several alternative names, such as on-line analytical processing (OLAP), multiple-dimensional databases, data cubes, data abstraction, generalization, summarization, characteriza- tion, etc. Data generalization and summarization presents the general characteristics or a summarized high-level view over a set of user-specified data in a database. For example, the general characteristics of the technical staffs in a com- pany can be described as a set of characteristic rules or a set of generalized summary tables. Moreover, it is often desir- able to present generalized views about the data at multiple abstraction levels. An overview on multilevel data gener- alization, summarization, and characterization is presented in Section 4.
Another important application of data mining is the ability to perform classification in a huge amount of data. This is referred to as mining classification rules. Data classi- fication is to classify a set of data based on their values in certain attributes. For example, it is desirable for a car dealer to classify its customers according to their preference for cars so that the sales persons will know whom to ap- proach, and catalogs of new models can be mailed directly to those customers with identified features so as to maxi- mize the business opportunity. Some studies in classifica- tion rules will be reviewed in Section 5.
In Section 6, we discuss the techniques on data clustering.
Basically, data clustering is to group a set of data (without a predefined class attribute), based on the conceptual clus- tering principle: maximizing the intraclass simzlarity and minimizing the znterclass similarity For example, a set of commodity objects can be first clustered into a set of classes and then a set of rules can be derived based on such a clas- sification. Such clustering may facilitate taxonomy formation,
which means the organization of observations into a hierar- chy of classes that group similar events together.
CHEN ET AL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE 869
Temporal or spatial-temporal data constitutes a large portion of data stored in computers [91, [SO]. ExampIes of this type of database include: financial database for stock price index, medical databases, and multimedia databases, to name a few. Searching for similar patterns in a temporal or spatial-temporal database is essential in many data mining operations [l], [3], [56] in order to discover and predict the risk, causality, and trend associated with a spe- cific pattern. Typical queries for this type of database in- clude identifying companies with similar growth patterns, products with similar selling patterns, stocks with similar price movement, images with similar weather patterns, geological features, environmental pollutions, or astro- physical patterns. These queries invariably require similar- ity matches as opposed to exact matches. The approach of pattern-based similarity search is reviewed in Section 7.
In a distributed information providing environment, documents or objects are usually linked together to facili- tate interactive access. Understanding user access patterns in such environments will not only help improving the system design but also be able to lead to better marketing decisions. Capturing user access patterns in such environ- ments is referred to as mining path traversal patterns. Notice, however, that since users are traveling along the informa- tion providing services to search for the desired informa- tion, some objects are visited because of their locations rather than their content, showing the very difference be- tween the traversal pattern problem and others which are mainly based on customer transactions. The capability of mining path traversal patterns is discussed in Section 8.
In addition to the issues considered above, there are certainly many other aspects on data mining that are worth studying. It is often necessary to use a data mining query language or graphical user interface to specify the interest- ing subset of data, the relevant set of attributes, and the kinds of rules to be discovered. Moreover, it is often neces- sary to perform interactive data mining to examine, trans- form, and manipulate intermediate data mining results, focus at different concept levels, or test different kinds of thresholds. Visual representation of data and knowledge may facilitate interactive knowledge mining in databases.
3
MINING
ASSOCIATION
RULES
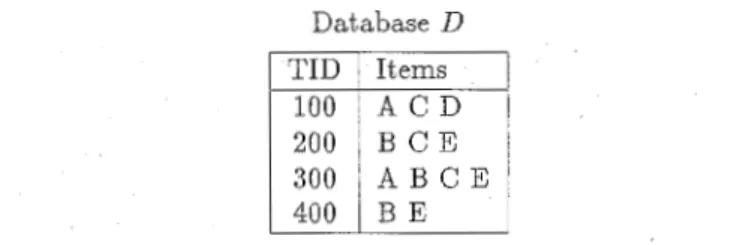
Given a database of sales transactions, it is desirable to dis- cover the important associations among items such that the presence of some items in a transaction will imply the pres- ence of other items in the same transaction. A mathematical model was proposed in [4] to address the problem of min- ing association rules. Let
I =
{i,, i2,
...,
im}
be a set of literals, called items. Let D be a set of transactions, where each transaction T is a set of items such that T E I. Note that the quantities of items bought in a transaction are not consid- ered, meaning that each item is a binary variable repre- senting if an item was bought. Each transaction is associ- ated with an identifier, called TID. Let X be a set of items. A transaction T is said to contain X if and only if Xc
T. An association rule is an implication of the form X 3 Y, whereX c I, Y c I, and X n Y =
4.
The rule X 3 Y holds in thetransaction set D with confidence c if c% of transactions in
D
that contain X also contain Y. The rule X 3 Y hassup-
port s in the transaction setD
if s% of transactions in Dcontain X v Y.
Confidence denotes the strength of implication and sup- port indicates the frequencies of the occurring patterns in the rule. It is often desirable to pay attention to only those rules which may have reasonably large support. Such rules with high confidence and strong support are referred to as
strong
rules
in 141, 1681. The task of mining association rules is essentially to discover strong association rules in large databases. In [4], [7], [66], the problem of mining associa- tion rules is decomposed into the following two steps:1) Discover the large itemsets, i.e., the sets of itemsets that have transaction support above a predetermined minimum support s.
2) Use the large itemsets to generate the association rules for the database.
It is noted that the overall performance of mining associa- tion rules is determined by the first step. After the large itemsets are identified, the corresponding association rules can be derived in a straightforward manner. Efficient counting of large itemsets is thus the focus of most prior work. Here, algorithms Apriori and DHP, developed in 171, L661, respectively, are described to illustrate the nature of this problem.
3.1 Algorithm Apriori
and DHP
Consider an example transaction database given in Fig. 1. In each iteration (or each pass), Apriori constructs a candi- date set of large itemsets, counts the number of occurrences of each candidate itemset, and then determines large item- sets based on a predetermined minimum support [7]. In the first iteration, Apriori simply scans all the transactions to count the number of occurrences for each item. The set of candidate 1-itemsets, C1, obtained is shown in Fig. 2. As- suming that the minimum transaction support required is two (i.e., s = 40%), the set of large 1-itemsets, L,, composed of candidate 1-itemsets with the minimum support re- quired, can then be determined. To discover the set of large 2-itemsets, in view of the fact that any subset of a large itemset must also have minimum support, Apriori uses
L,
*
L, to generate a candidate set of itemsets Cz where * is an operation for concatenation in this case. C2 consists of1
2
2-itemsets. Next, the four transactions in D are scanned and the support of each candidate itemset in C2 is counted. The middle table of the second row in Fig. 2 represents the re- sult from such counting in C2. The set of large 2-itemsets,
Lz,
is therefore determined based on the support of each can- didate 2-itemset in C2.1. This example database is extracted from 171.
870 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 8, NO 6, DECEMBER 1996
Database L )
i
Fig. 1. An example transaction database for data mining.
The set of candidate itemsets, C,, is generated from L, as follows. From L,, two large 2-itemsets with the same first item, such as {BC) and
(BE},
are identified first. Then, Apri- ori tests whether the 2-itemset (CEJ, which consists of their second items, constitutes a large 2-itemset or not. Since{CE]
is a large itemset by itself, we know that all the subsets
of
(BCE)
are large and then {BCEJ becomes a candidate3-itemset. There is no other candidate 3-itemset from
L,. Apriori then scans all the transactions and discov-
ers the large 3-itemsets L, in Fig. 2. Since there is no candi- date 4-itemset to be constituted from L,, Apriori ends the process of discovering large itemsets.
Similar to Apriori, DHP in 1661 also generates candidate k-itemsets from Lk-l. However, DHP employs a hash table, which is built in the previous pass, to test the eligibility of a k-itemset. Instead of including all k-itemsets from Lk,
*
Lk-l into Ck, DHP adds a k-itemset into Ck only if that k-itemset is hashed into a hash entry whose value is larger than or equal to the minimum transaction support required. As a result, the size of candidate set Ck can be reduced signifi- cantly. Such a filtering technique is particularly powerful in reducing the size of C,. DHP also reduces the database size progressively by not only trimming each individualScan .D
-
Scan D --f Scan D Itemset-
transaction size but also pruning the number of transac- tions in the database. We note that both DHP and Apriori are iterative algorithms on the large itemset size in the sense that the large k-itemsets are derived from the large
( k - 1)-itemsets. These large itemset counting techniques are in fact applicable to dealing with other data mining prob- lems [81, [191.
Generalized and Multiple-Level
In many applications, interesting associations among data items often occur at a relatively high concept level. For ex- ample, the purchase patterns in a transaction database may not show any substantial regularities at the primitive data level, such as at the bar-code level, but may show some interesting regularities at some high concept level(s), such as milk and bread. Therefore, it is important to study min- ing association rules at a generalized abstraction level
[78]
or at multiple levels [39].
Information about multiple abstraction levels may exist in database organizations. For example, a class hierarchy [50] may be implied by a combination of database attrib- utes, such as day, month, year. It may also be given explicitly by users or experts, such as Alberta c Prairies.
Consider the class hierarchy in Fig. 3 for example. It could be difficult to find substantial support of the pur- chase patterns at the primitive concept level, such as the bar codes of 1 gallon Dairyland 2% milk and 1 lb Wonder wheat bread. However, it could be easy to find 80% of customers that purchase milk may also purchase bread. Moreover, it could be informative to also show that 70% of people buy
wheat bread if they buy 2% milk. The association relation- ship in the latter statement is expressed at a lower concept level but often carries more specific and concrete informa-
Association Rules
c3
Itemset Sup.)
*
CHEN ET AL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE
~
87 1
Dairyland Foremost Old Mills Wonder
Fig. 3. An example of concept hierarchies for mining multiple-level association rules.
tion than that in the former. Therefore, it is important to mine association rules at a generalized abstraction level or at multiple concept levels.
In 1391, the notion of mining multiple-level association rules are introduced: Low-level associations will be exam- ined only when their high-level parents are large at their corresponding levels, and different levels may adopt differ- ent minimum support thresholds. Four algorithms are de- veloped for efficient mining of association rules based on different ways of sharing of multiple-level mining processes and reduction of the encoded transaction tables. In [78], methods for mining associations at generalized abstraction level are studied by extension of the Apriori algorithm.
Besides mining multiple-level and generalized associa- tion rules, the mining of quantitative association rules [79] and meta-rule guided mining of association rules in rela- tional databases [33], [75] are also studied recently, with efficient algorithms developed.
3.3 interestingness of Discovered Association Rules
Notice that not all the discovered strong association rules (i.e., passing the minimum support and minimum confi- dence thresholds) are interesting enough to present.
For example, consider the following case of mining the survey results in a school of 5,000 students. A retailer of breakfast cereal surveys the students on the activities they engage in the morning. The data show that 60% of students (i.e., 3,000 students) play basketball, 75% of students (i.e., 3,750 students) eat cereal, and 40% of them (i.e., 2,000 students) both play basketball and eat cereal. Suppose that a data mining program for discovering association rules is run on the data with the following settings: the minimal student support is 2,000 and the minimal confidence is 60%. The following association rule will be produced: "(play basketball) 3 (eat cereal)," since this rule contains the minimal student support and the corresponding confidence
2000 = 0.66
is larger than the minimal confidence required. However, the above association rule is misleading since the overall percentage of students eating cereal is 75%, even larger than 66%. That is, playing basketball and eating cereals are in fact negatively associated; i.e., being involved in one de- creases the likelihood of being involved in the other. With- out fully understanding this aspect, one could make wrong business decisions from the rules derived.
To filter out such kind of misleading associations, one may define that an association rule "A =+ B is interesting if its confidence exceeds a certain measure, or formally,
P(A n B ) P(A)
is greater than d, a suitable constant. However, the simple argument we used in the example above suggests that the right heuristic to measure association should be
P(A n B )
- P ( B ) > d ,
P ( A )
or alternatively, P(A n B ) - P(A)
*
P ( B ) > k, wherek
is asuitable constant. The expressions above essentially repre- sent tests of statistical independence. Clearly, the factor of statistical dependence among various user behaviors ana- lyzed has to be taken into consideration for the determina- tion of the usefulness of association rules.
There have been some interesting studies on the inter- estingness or usefulness of discovered rules, such as 1681, [78], [77]. The notion of interestingness on discovered gen- eralized association rules is introduced in [78]. The subjec- tive measure of interestingness in knowledge discovery is studied in [77].
3.4 Improving the Efficiency of Mining Association
Since the amount of the processed data in mining associa- tion rules tends to be huge, it is important to devise efficient algorithms to conduct mining on such data. In this section, some techniques to improve the efficiency of mining asso- ciation rules are presented.
3.4.1 Database Scan Reduction
In both Apriori and DHP, C3 is generated from L2
*
L2. In fact, a C2 can be used to generate the candidate 3-itemsets. Clearly, a C; generated from C2*
C2, instead of fromL2
*
L,, will have a size greater thanI
C3I
where C3 is gen- erated from L2*
L2. However, if IC;[ is not much larger than I C, I , and both C, and C; can be stored in main memory, we can find L, and L3 together when the next scan of the database is performed, thereby saving one round of data- base scan. It can be seen that using this concept, one can determine all Lks by as few as two scans of the database (i.e., one initial scan to determine L, and a final scan to de-872 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 8, NO. 6, DECEMBER 1996
termine all other large itemsets), assuming that Ci for k 2 3 is generated from CL-l and all CL for IC > 2 can be kept in the memory. This technique is called scan-reduction. In 1191, the technique of scan-reduction was utilized and shown to re- sult in prominent performance improvement. Clearly, such a technique is applicable to both Apriori and DHP.
3.4.2 Sampling: Mining with AGustable Accuracy
Several applications require mining the transaction data to capture the customer behavior in a very frequent basis. In those applications, the efficiency of data mining could be a more important factor than the requirement for a complete accuracy of the results. In addition, in several data mining applications the problem domain could only be vaguely defined. Missing some marginal cases with confidence and support levels at the borderline may have little effect on the quality of the solution to the original problem. Allowing imprecise results can in fact significantly improve the effi- ciency of the mining algorithms. As the database size in- creases nowadays, sampling appears to be an attractive approach to data mining. A technique of relaxing the sup- port factor based on the sampling size is devised in [65] to achieve the desired level of accuracy. As shown in [651, the relaxation factor, as well as the sample size, can be properly adjusted so as to improve the result accuracy while mini- mizing the corresponding execution time, thereby allowing us to effectively achieve a design trade-off between accu- racy and efficiency with two control parameters. As a means to improve efficiency, sampling has been used in [781 for determining the cut-off level in the class hierarchy of items to collect occurrence counts in mining generalized association rules. Sampling was discussed in
[57]
as a justi- fication for devising algorithms and conducting experi- ments with data sets of small sizes.3.4.3
Incremental
Updating
ofDiscovered
AssociationSince it is costly to find the association rules in large data- bases, incremental updating techniques should be devel- oped for maintenance of the discovered association rules to avoid redoing data mining on the whole updated database.
A database may allow frequent or occasional updates and such updates may not only invalidate some existing strong association rules but also turn some weak rules into strong ones. Thus it is nontrivial to maintain such discov- ered rules in large databases. An incremental updating technique is developed in 1211 for efficient maintenance of discovered association rules in transaction databases with data insertion. The major idea is to reuse the information of the old large itemsets and to integrate the support informa- tion of the new large itemsets in order to substantially re- duce the pool of candidate sets to be re-examined.
3.4.4 Parallel
Data
MiningIt is noted that data mining in general requires progressive knowledge collection and revision based on a huge trans- action database. How to achieve efficient parallel data mining is a very challenging issue, since, with the transac- tion database being partitioned across all nodes, the amount of internode data transmission required for reach-
Rules
ing global decisions can be prohibitively large, thus signifi- cantly compromising the benefit achievable from paralleli- zation. For example, in a shared nothing type parallel envi- ronment like SP2 [44], each node can directly collect infor- mation only from its local database partition, and the proc- ess to reach a global decision from partial knowledge col- lected at individual nodes could itself be complicated and communication intensive. An algorithm for parallel data mining, called PDM, was reported in [67]. Under PDM, with the entire transaction database being partitioned across all nodes, each node will employ a hashing method to identify candidate k-itemsets (i.e., itemsets consisting of k
items) from its local database. To reduce the communica- tion cost incurred, a clue-and-poll technique was devised in E671 to resolve the uncertainty due to the partial knowledge collected at each node by judiciously selecting a small frac- tion of the itemsets for the information exchange among nodes.
4
MULTILEVEL
DATA
GENERALIZATION,
~ ~ M M A R I Z A T I O ~ , AND HARACTERIZATION
Data and objects in databases often contain detailed infor- mation at primitive concept levels. For example, the ”item” relation in a ”sales” database may contain attributes about the primitive level item information such as item number, item name, date made, price, etc. It is often desirable to summarize a large set of data and present it at a high con- cept level. For example, one may like to summarize a large set of the items related to some sales to give a general de- scription. This requires an important functionality in data mining: data generalzzatzon.
Data generalization is a process which abstracts a large set of relevant data in a database from a low concept level to relatively high ones. The methods for efficient and flexi- ble generalization of large data sets can be categorized into two approaches:
1) data cube approach [351,[431, [831,[841, and
2) attribute-oriented induction approach [371,[401.
4.1
Data
Cube ApproachThe data cube approach has a few alternative names or a few variants, such as, ”multidimensional databases,” ”materialized views,” and ”OLAP (On-Line Analytical Processing).” The general idea of the approach is to mate- rialize certain expensive computations that are frequently inquired, especially those involving aggregate functions, such as count, sum, average, max, etc., and to store such materialized views in a multidimensional database (called a ”data cube”) for decision support, knowledge discovery, and many other applications. Aggregate functions can be precomputed according to the grouping by different sets or subsets of attributes. Values in each attribute may also be grouped into a hierarchy or a lattice structure. For ex- ample, ”date” can be grouped into “day,” ”month,” ”quarter,” ”year,” or “week,” which form a lattice struc- ture. Generalization and specialization can be performed on a multiple dimensional data cube by ”roll-up” or ”drill-down” operations, where a roll-up operation re-
CHEN ET AL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE 873
duces the number of dimensions in a data cube or gener- alizes attribute values to high-level concepts, whereas a drill-down operation does the reverse. Since many aggre- gate functions may often need to be computed repeatedly in data analysis, the storage of precomputed results in a multiple dimensional data cube may ensure fast response time and flexible views of data from different angles and at different abstraction levels.
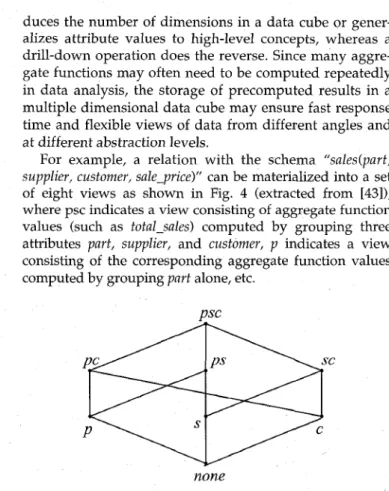
For example, a relation with the schema "sales(part, supplier, customer, sale-price)" can be materialized into a set of eight views as shown in Fig. 4 (extracted from [43]), where psc indicates a view consisting of aggregate function values (such as total-sales) computed by grouping three attributes part, supplier, and customer,
p
indicates a view consisting of the corresponding aggregate function values computed by grouping part alone, etc.none
Fig. 4. Eight views of data cubes for sales information.
There are commonly three choices in the implementation
1) physically materialize the whole data cube, 2 ) materialize nothing, and
3) materialize only part of the data cube.
of data cubes:
The problem of materialization of a selected subset of a very large number of views can be modeled as a lattice of views. A recent study [43] has shown that a greedy algo- rithm, which, given what views have already been materi- alized, selects for materializing those views that offer the most improvement in average response time, is able to lead to results within 63% of those generated by the optimal al- gorithm in all cases. As a matter of fact, in many realistic cases, the difference between the greedy and optimal solu- tions is essentially negligible.
Data cube approach is an interesting technique with many applications [83]. Techniques for indexing multiple dimensional data cubes and for incremental updating of data cubes at database updates have also been studied [83],
[86]. Notice that data cubes could be quite sparse in many cases because not every cell in each dimension may have corresponding data in the database. Techniques should be developed to handle sparse cubes efficiently. Also, if a query contains constants at even lower levels than those provided in a data cube (e.g., a query refers time in the unit of "hour" whereas the lowest concept level on time in the cube is "day"), it is not clear how to make the best use of the precomputed results stored in the data cube.
4.2 Attribute-Oriented Induction Approach
The data warehousing approach which uses materialized views are "off-line" database computation which may not correspond to the most up-to-date database contents. An alternative, on-line, generalization-based data analysis technique, is called attribute-oriented induction approach [371, [40]. The approach takes a data mining query expressed in an SQL-like data mining query language and collects the set of relevant data in a database. Data generalization is then performed on the set of relevant data by applying a set of data generalization techniques [371, 1401, 1601, including at- tribute-removal, concept-tree climbing, attribute-threshold control, propagation of counts and other aggregate function values, etc. The generalized data is expressed in the form of a generalized relation on which many other operations or transformations can be performed to transform generalized data into different kinds of knowledge or map them into different forms [40]. For example, drill-down or roll-up op- erations can be performed to view data at multiple abstrac- tion levels [361; the generalized relation can be mapped into summarization tables, charts, curves, etc., for presentation and visualization; characteristic rules which summarize the generalized data characteristics in quantitative rule forms can be extracted; discriminant rules which contrast differ- ent classes of data at multiple abstraction levels can be ex- tracted by grouping the set of comparison data into con- trasting classes before data generalization; classification rules which classify data at different abstraction levels ac- cording to one or a set of classification attributes can be derived by applying a decision tree classifier [72] on the generalized data 1421; and association rules which associate a set of generalized attribute properties in a logic implica- tion rule by integration of attribute-oriented induction and the methods for mining association rules [71, [391,[661, [781. Moreover, statistical pattern discovery can also be per- formed using attribute-oriented induction [24].
The core of the attribute-oriented induction technique is on-line data generalization which is performed by fir$ ex- amining the data distribution for each attribute in the set of relevant data, calculating the corresponding abstraction level that data in each attribute should be generalized to, and then replacing each data tuple with its corresponding generalized tuple. The generalization process scans the data set only once and collects the aggregate values in the corre- sponding generalized relation or data cube. It is a highly efficient technique since the worst-case time complexity of the process is O(n), if a cube structure is used (desirable
when the data cube is dense), or O(n log(p)), if a general- ized relation is used (desirable when the corresponding cube is rather sparse), where n is the number of tuples in the set of relevant data and
p
is the size (i.e., number of tu- ples) of the generalized relation [401.To support multiple-level data mining, especially the drill-down operations, the attribute-oriented induction technique should generalize the set of relevant data to a minimal abstraction level and maintain such a minimally generalized relation (if expressed by a relational structure) or a minimally generalized cube (if expressed by a cube struc- ture) to facilitate the traversals among multiple abstraction spaces. The roll-up of a generalized relation may simply
874 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL 8, NO 6, DECEMBER 1996 class
B.C.
Albert aB.C.
Albert aB.C.
Alberta B.C. Albert aB.C.
AlbertaB.C.
Albert aB.C.
Albert aB.C.
Albert astart with this relation; however, the drill-down of the rela- tion may start with the minimal generalized relation and perform data generalization to the corresponding abstrac- tion levels [361.
The essential background knowledge applied in attrib- ute-oriented induction is concept hierarchy (or lattice) asso- ciated with each attribute [37]. Most concept hierarchies are stored implicitly in databases. For example, a set of attrib- utes in address (number, street, city, province, c o u n t y ) in a database schema represents the concept hierarchies of the attribute address. A set of attributes in a data relation, though seemingly no strong semantic linkages exist, may also form concept hierarchies (or lattices) among their
su-
persets or subsets. For example, in the schema item(id, name, category, producer, date-made, cost, price), "{category, producer, date-made) c {category, date-made}" indicates the former forms a lower level concept than the latter. Moreover, rules and view definitions can also be used as the definitions of concept hierarchies [24]. Conceptual hierarchies for nu- merical or ordered attributes can be generated automati- cally based on the analysis of data distributions in the set of relevant data [38]. Moreover, a given hierarchy may not be best suited for a particular data mining task. Therefore, such hierarchies should be adjusted dynamically in many cases based on the analysis of data distributions of the cor- responding set of data 1381.
An an example, one may use data mining facilities to study the general characteristics of the Natural Science and Engineering Research Council of Canada (NSERC) research grant database. To compare the research grants between
'British Columbia' and 'Alberta' (two neighbor provinces in Western Canada) in the discipline of 'Computev (Science)' ac-
discipline grant -category amount -category support% comparison%
2.00
66.67
Computer Infrastructure Grant
40Ks-6OKs
1.72
33.33
2.00
66.67
1.72
33.33
2.00
50.00
3.45
50.00
38.00 63.33 37.9336.67
28.0056.00
37.93
44.00
6.00
75.00
3.45
25.00
3.00 100.00 0.00 0.00 19.0076.00
,
10.34
24.00
Computer Other20Ks-40Ks
Computer Other60Ks-
Computer Research Grant: Individual
0-2OKs
Computer Research Grant: Individual
20Ks-40Ks
Computer Research Grant: Individual
40Ks-60Ks
Computer Research Grant: Individual
60Ks-
Computer Scholarship
O-2OKs
cording to the attributes: disc-code (discipline code) and
grant-catego
y,
the following data mining query can be speci- fied in a data mining query language DMQL I421 as follows:use NSERC95
mine discriminant rule for 'BC-Grants' where 0.Province = 'British Columbia' in contrast to 'Alberta-Grants' where 0,Province = 'Alberta'
from Award A , Organization 0 , Grant-type G where A.grant-code = G.grant-code and
A.OrgID = 0.OrgID and A.disc-code =
'Computer'
related to disc-code, grant-category, count(*)%
The execution of this data mining query generates Table 1, which presents the differences between the two provinces in terms of disc-code, grant-category and the number of the research grants. The column support% rep- resents the number of research grants in this category vs. the total number of grants in its own province; where the
comparison% represents the number of research grants in this category in one province vs. that of the other. For ex- ample, the first (composite) row indicates that for Com- puter Science Infvastructure Grants in the range of 40Ks to 60Ks, British Columbia takes 2.00% of its total number of Computer Science Grants, whereas Alberta takes 1.72%; however, in comparison between these two provinces, British Columbia takes 66.67% of the share (in number) whereas Alberta takes only 33.33%. Other rows have similar interpretations.
Notice with interactive data mining facilities, such as those provided in DBMiner, a user may perform roll-up or
CHEN ET AL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE
~
875
drill-down operations conveniently. For example, one may drill down on 'grant-category' to examine even finer grant categories such as 0-lOKs, 10-15Ks, 15-20Ks, etc., or roll-up on disc-code to group together Infrastructure Grant, Research Grant: Individual, etc., into one category 'Any (Grant)'.
Overall, attribute-oriented induction is a technique for generalization of any subset of on-line data in a relational database and extraction of interesting knowledge from the generalized data. The generalized data may also be stored in a database, in the form of a generalized relation or a generalized cube, and be updated incrementally upon database updates [37]. The approach has been imple- mented in a data mining system, DBMiner, and been ex- perimented in several large relational databases [401, [421. The approach can also be extended to generalization- based data mining in object-oriented databases [41], spa- tial databases [53], 1561, and other kinds of databases. The approach is designed for generalization-based data min- ing. It is not suitable for mining specific patterns at primi- tive concept levels although it may help guiding such data mining by first finding some traces at high concept levels and then progressively deepening the data mining proc- ess to lower abstraction levels [53].
5
DATA
CLASSIFICATION
Data classification is the process which finds the common properties among a set of objects in a database and classi- fies them into different classes, according to a classification model. To construct such a classification model, a sample database E is treated as the training set, in which each tu- ple consists of the same set of multiple attributes (or fea- tures) as the tuples in a large database W, and addition- ally, each tuple has a known class identity (label) associ- ated with it. The objective of the classification is to first analyze the training data and develop an accurate de- scription or a model for each class using the features available in the data. Such class descriptions are then used to classify future test data in the database W or to develop a better description (called classification rules) for each class in the database. Applications of classification include medical diagnosis, performance prediction, selective mar- keting, to name a few.
Data classification has been studied substantially in sta- tistics, machine learning, neural networks, and expert sys- tems [82], and is an important theme in data mining 1301.
5.1 Classification Based on Decision Trees
A decision-tree-based classification method, such as [71
I,
[72], has been influential in machine learning studies. It is a supervised learning method that constructs decision trees from a set of examples. The quality (function) of a tree de- pends on both the classification accuracy and the size of the tree. The method first chooses a subset of the training ex- amples (a window) to form a decision tree. If the tree does not give the correct answer for all the objects, a selection of the exceptions is added to the window and the process continues until the correct decision set is found. The eventual outcome is a tree in which each leaf carries a class name, and each interior node specifies an attributewith a branch corresponding to each possible value of that attribute.
A typical decision tree learning system, ID-3 [71], adopts a top-down irrevocable strategy that searches only part of the search space. It guarantees that a simple, but not neces- sarily the simplest, tree is found. ID-3 uses an information- theoretic approach aimed at minimizing the expected number of tests to classify an object. The attribute selection part of ID-3 is based on the plausible assumption that the com- plexity of the decision tree is strongly related to the amount of information conveyed by this message. An information- based heuristic selects the attribute providing the highest information gain, i.e., the attribute which minimizes the information needed in the resulting subtrees to classify the elements. An extension to ID-3, C4.5 1721, extends the do- main of classification from categorical attributes to numeri- cal ones.
The ID-3 system [71] uses information gain as the evaluation functions for classification, with the following evaluation function,
where
p ,
is the probability that an object is in class i. There are many other evaluation functions, such as Gini index, chi- square test, and so forth [14], [52], [68], 821. For example, for Gini index [14], [59], if a data setT
contains examples from n classes, gini(T) is defined as,gini(T) = 1 -
&,2.
where p , is the relative frequency of class i in T. Moreover, there are also approaches for tranforming decision trees into rules [72] and transforming rules and trees into com- prehensive knowledge structures [341.
There have been many other approaches on data classifi- cation, including statistical approaches [18], [261, 681, rough sets approach [87], etc. Linear regression and linear dis- criminant analysis techniques are classical statistical models [26]. Methods have also been studied for scaling machine learning algorithms by combining base classifiers from partitioned data sets 1181. There have also been some stud- ies of classification techniques in the context of large data- bases [2], [lo]. An interval classifier has been proposed in [2] to reduce the cost of decision tree generation. The neural network approach for classification and rule extraction in databases has also been studied recently 1551.
5.2 Methods for Performance Improvement
Most of the techniques developed in machine learning and statistics may encounter the problem of scaling-up. They may perform reasonably well in relatively small databases but may suffer the problem of either poor performance or the reduction of classification accuracy when the training data set grows very large, even though a database system has been taken as a component in some of the above meth- ods. For example, the interval classifier proposed in [2] uses database indices to improve only the efficiency of data re- trieval but not the efficiency of classification since the classi- fication algorithm itself is essentially an ID-3 algorithm.
A direct integration of attribute-oriented induction with the ID-3 algorithm may help discovery of classification
876 IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 8, NO. 6, DECEMBER 1996
rules at high abstraction levels [40]. It, though efficient, may reduce the classification accuracy since the classification interval may have been generalized to a rather high level. A multiple-level classification technique and a level adjust- ment and merge technique have been developed in DBMiner to improve the classification accuracy in large databases by the integration of attribute-oriented induction and classification methods 1421.
Recently, Mehta et al. 1591 has developed a fast data clas- sifier, called supervised learning in QUEST (SLIQ), for mining classification rules in large databases. SLIQ is a de- cision tree classifier that can handle both numeric and cate- gorical attributes. It uses a novel presorting technique in the tree growing phase. This sorting procedure is integrated with a breadth-first tree growing strategy to enable classifi- cation of disk-resident datasets. SLIQ also uses a new tree- pruning algorithm that is inexpensive, and results in com- pact and accurate trees. The combination of these tech- niques enables it to scale for large data sets and classify data sets irrespective of the number of classes, attributes, and examples. An approach, called meta-learning, was proposed in 1171. In [17], methods to learn how to combine several base classifiers, which are learned from subsets of data, were developed. Efficient scaling-up to larger learning problems can hence be achieved.
Notice that in most prior work on decision tree generation, a single attribute is considered at each level for the branching decision. However, in some classification tasks, the class identity in some cases is not so dependent on the value of a single attribute, but instead, depends upon the combined values of a set of attributes. This is particularly true in the presence of those attributes that have strong inference among themselves. In view of this, a two-phase method for multiat- tribute extraction was devised in [20] to improve the effi- ciency of deriving classification rules in a large training data- set. A feature that is useful in inferring the group identity of a data tuple is said to have a good inference power to that group identity. Given a large training set of data tuples, the first phase, referred to as feature extraction phase, is applied to a subset of the training database with the purpose of identify- ing useful features which have good inference power to group identities. In the second phase, referred to as feature combznatzon phase, those features extracted from the first phase are combinedly evaluated and multiattribute predi- cates with strong inference power are identified. It is noted that the inference power can be improved significantly by utilizing multiple attributes in predicates, showing the ad- vantage of using multiattribute predicates.
LUSTER~NG
ANALYSIS
The process of grouping physical or abstract objects into classes of similar objects is called Clustering or unsupervised classification. Clustering analysis helps construct meaningful partitioning of a large set of objects based on a ”divide and conquer” methodology which decomposes a large scale system into smaller components to simplify design and implementation.
As a data mining task, data clustering identifies clusters, or densely populated regions, according to some distance
measurement, in a large, multidimensional data set. Given a large set of multidimensional data points, the data space is usually not uniformly occupied by the data points. Data clustering identifies the sparse and the crowded places, and hence discovers the overall distribution patterns of the data set.
Data clustering has been studied in statistics [18], [47], machine learning [31], 1321, spatial database [ll], and data mining [18], [27], 1621, [85] areas with different emphases.
As a branch of statistics, clustering analysis has been studied extensively for many years, mainly focused on distance-based clustering analysis. Systems based on statis- tical classification methods, such as AutoClass 1181 which uses a Bayesian classification method, have been used in clustering in real world databases with reported success.
The distance-based approaches assume that all the data points are given in advance and can be scanned frequently. They are global or semiglobal methods at the granularity of data points. That is, for each clustering decision, they in- spect all data points or all currently existing clusters equally no matter how close or far away they are, and they use global measurements, which require scanning all data points or all currently existing clusters. Hence, they do not have linear scalability with stable clustering quality.
In machine learning, clustering analysis often refers to un-
supervised learning, since which classes an object belongs to are not prespecified, or conceptual clustering, because the dis- tance measurement may not be based on geometric distance, but be based on that a group of objects represents a certain conceptual class. One needs to define a measure of similarity between the objects and then apply it to determine classes. Classes are defined as collections of objects whose intraclass similarity is high and interclass similarity is low.
The method of clustering analysis in conceptual cluster- ing is mainly based on probability analysis. Such ap- proaches, represented by [31], [32], make the assumption that probability distributions on separate attributes are sta- tistically independent of each other. This assumption is, however, not always true since correlation between attrib- utes often exists. Moreover, the probability distribution representation of clusters makes it very expensive to update and store the clusters. This is especially so when the attrib- utes have a large number of values since their time and space complexities depend not only on the number of at- tributes, but also on the number of values for each attribute. Furthermore, the probability-based tree (such as [31]) that is built to identify clusters is not height-balanced for skewed input data, which may cause the time and space complexity to degrade dramatically.
Clustering analysis in large databases has been studied recently in the database community.
plications Based on
Ng and Han presented a clustering algorithm, CLARANS (Clustering Large Applications Based upon Randomized Search) 1621, based on randomized search and originated from two clustering algorithms used in statistics, PAM (Partitioning Around Medoids) and CLARA (Clustering Large Applications) [48].
CHEN ET AL.: DATA MINING: AN OVERVIEW FROM A DATABASE PERSPECTIVE 877
The CLARANS algorithm I621 integrates PAM and CLARA by searching only the subset of the data set but not confining itself to any sample at any given time. While CLARA has a fixed sample at every stage of the search, CLARANS draws a sample with some randomness in each step of the search. The clustering process can be presented as searching a graph where every node is a potential solu- tion, i.e., a set of k medoids. The clustering obtained after replacing a single medoid is called the neighbor of the cur- rent clustering. If a better neighbor is found, CLARANS moves to the neighbor's node and the process is started again, otherwise the current clustering produces a local optimum. If the local optimum is found, CLARANS starts with new randomly selected nodes in search for a new local optimum. CLARANS has been experimentally shown to be more effective than both PAM and CLARA. The computa- tional complexity of every iteration in CLARANS is basi- cally linearly proportional to the number of objects [27], [62]. It should be mentioned that CLARANS can be used to find the most natural number of clusters knat A heuristic is adopted in 1621 to determine knat, which uses silhouette coeffi- cients, introduced by Kaufman and Rousseeuw [48]. CLARANS also enables the detection of outliers, e.g., points that do not belong to any cluster.
Based upon CLARANS, two spatial data mining algo- rithms were developed in a fashion similar to the attribute- oriented induction algorithms developed for spatial data mining [56], [37]: spatial dominant approach, SD(CLARANS) and nonspatial dominant approach, NSD(CLARANS). Both algorithms assume that the user specifies the type of the rule to be mined and relevant data through a learning request in a similar way as DBMiner 1401. Experiments show that the method can be used to cluster reasonably large data sets, such as houses in the Vancouver area, and the CLARAN algorithm outperforms PAM and CLARA.
3
6.2 Focusing Methods
Ester et al. [27] pointed out some drawbacks of the CLARANS clustering algorithm [62] and proposed new techniques to improve its performance.
First, CLARANS assumes that the objects to be clustered are all stored in main memory. This assumption may not be valid for large databases and disk-based methods could be re- quired. This drawback is alleviated by integrating CLARANS with efficient spatial access methods, like R*-tree 1111. R'-tree supports the focusing techniques that Ester et al. proposed to reduce the cost of implementing CLARANS. Ester et al. showed that the most computationally expen- sive step of CLARANS is calculating the total distances between the two clusters. Thus, they proposed two ap- proaches to reduce the cost of this step.
The first one is to reduce the number of objects consid- ered. A centroid 9uery returns the most central object of a leaf node of the R"-tree where neighboring points are stored. Only these objects are used to compute the medoids of the clusters. Thus, the number of objects taken for con- sideration is reduced. This technique is called focusing on
3. It is a property of an object that specifies how much the object truly belongs to the cluster.
representative objects. The drawback is that some objects, which may be better medoids, are not considered, but the sample is drawn in the way which still enables good quality of clustering.
The other technique to reduce computation is to restrict the access to certain objects that do not actually contribute to the computation, with two different focusing techniques: focus on relevant clusters, and focus on a cluster. Using the R*-tree structure, computation can be performed only on pairs of objects that can improve the quality of clustering instead of checking all pairs of objects as in the CLARANS algorithm.
Ester et al. applied the focusing on representative objects to a large protein database to find a segmentation of protein surfaces so as to facilitate the so-called docking queries. They reported that when the focusing technique was used the effectiveness (the average distance of the resulting cluster- ing) decreased just from 1.5% to 3.2% whereas the effi- ciency (CPU time) increased by a factor of 50.
6.3 Clustering Features and CF Trees
R-trees are not always available and their construction may be time consuming. Zhang et al. 1851 presented another al- gorithm, BIRCH (Balanced Iterative Reducing and Clus- tering), for clustering large sets of points. The method they presented is an incremental one with the possibility of ad- justment of memory requirements to the size of memory that is available.
Two concepts, Clustering Feature
and
CF tree, are introduced. A Clustering Feature CF is the triplet summarizing infor- mation about subclusters of points. Given N d-dimensional points in subcluster: { X I ] , CF is defined asCF = ( N , L i , SS)
--f
where
N
is the number of points in the subcluster, LS is the linear sum on N points, i.e.,,=l
and
SS
is the square sum of data points,$2;.
1=1
The Clustering Features are sufficient for computing clusters and they constitute an efficient storage information method as they summarize information about the subclusters of points instead of storing all points.
A CF tree is a balanced tree with two parameters: branch- ing factor B and threshold T. The branching factor specifies the maximum number of children. The threshold parameter specifies the maximum diameter of subclusters stored at the leaf nodes. By changing the threshold value we can change the size of the tree. The nonleaf nodes are storing sums of their children's CFs, and thus, they summarize the infor- mation about their children. The CF tree is build dynami- cally as data points are inserted. Thus, the method is an incremental one. A point is inserted to the closest leaf entry (subcluster). If the diameter of the subcluster stored in the leaf node after insertion is larger than the threshold value,