N a tio n a l U niversity of Kao hsi un g
國立高雄大學電機工程學系
碩士論文
深度學習影像辨識
技術於交通標誌辨識之應用
A Study on Traffic Sign Recognition
Using Deep Learning Techniques
研究生:陳彥良 撰
指導教授:吳志宏 博士
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
深度學習影像辨識
技術於交通標誌辨識之應用
指導教授: 吳志宏 博士 學生:陳彥良 國立高雄大學電機工程學系摘要
交通標誌偵測是自動駕駛車和智能交通管理的重要任務。在本研究中,設計 並實現了使用深度學習技術於交通標誌偵測的方法。要獲得準確的檢測模型必 須要有足夠的訓練影像。然而,要收集真實的交通標誌影像進行訓練是非常困難 的。為了增加交通標誌的訓練影像的數量,本研究收集官方的標準交通標誌影像, 並設計了資料擴增的方法,產生各種尺寸、亮度、角度與位置的交通標誌影像。 這些擴增影像與真實交通標誌影像一起被用來訓練。此外,為了提高偵測的精確 度,將交通標誌的模型檢測依照其形狀、標誌類型與字符做分層檢測。我們設計 了自動並持續更新偵測模型的機制。我們整合了 Haar-Adaboost 分類器和 Yolo v2 的方法,並實際測試了它們對交通標誌檢測的成效。系統以高雄市中心收集的真 實交通標誌影像進行測試。交通標誌檢測的準確率為 95.77%,模型自動標註的準 確率為 98.87%。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
A Study on Traffic Sign Recognition
Using Deep Learning Techniques
Advisor: Dr. WU, CHIH-HUNG Student: CHEN, YAN-LIANG
Department of Electrical Engineering, National University of Kaohsiung
ABSTRACT
Traffic signs detection is an essential task for autonomous car and intelligent traf-fic management. In this study, solutions for real-world traftraf-fic sign detection using deep learning techniques are designed and implemented. An accurate detection model can only be obtained if a sufficient number of training images are available. However, it is dif-ficult to collect volumes of real-world traffic signs for training. To increase the number of training images of traffic signs, this study collects standard traffic sign images from the government and designs a data augmentation method that generates volumes of traffic sign images in various sizes, luminance, angles, and locations in images. These augmented images are trained with some real-world traffic signs images. Moreover, to increase the detection accuracy, models for detecting traffic sign’s shape, type, and printed characters,
are cascaded. A retrain mechanism for automatically and continuously updating detec-tion models is designed. We integrated all these methods with Haar-Adaboost classifier and Yolo v2, respectively, and tested their effectiveness for real-world traffic sign detec-tion. The proposed system was tested with real traffic sign images collected in downtown Kaohsiung. The accuracy of traffic sign detection is 95.77%, and the accuracy of auto-matic annotation of the model is 98.87%.
Keywords: Traffic Sign Recognition, Deep Learning, YOLO, Haar-like features, Cas-caded classifier.
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
致謝
在研究所求學的這段期間裡,我要感謝吳志宏教授於對我的指導以及提供我 們這麼良好的實驗環境,也非常感老師在論文最後階段即使手邊已經一堆企劃在 趕還抽空協助我修正論文,並提供我許多寶貴的意見。 感謝實驗室的各位夥伴,不管是學長還是學弟,謝謝你們在每一周的實驗室 會議上都踴躍提出技術交流,使我的技術能力及學術知識在這段期間得到更專業 的提升。 最後我要感謝一路支持我的奶奶及父母,這段時間常常非常晚才能回到家, 周末又不見人影,家裡許多重擔都多虧了他們替我扛起。還要謝謝我的老婆,陳 秋如小姐,婚後的時間我不是忙著趕論文就是在車禍住院,這段時間完全多虧有 你照顧我的起居我才能心無旁鶩的在事業與學業上打拼。謝謝我的好朋友兼 C# 小老師,黃珮瑜小姐,時不常的替我解答程式上的問題,讓我從連字串怎麼打都 不會到現在可以完成論文裡的程式。謝謝我的好兄弟,OMG 團體,在我陷入低潮 時總是給我最大的鼓勵與支持,讓我能堅持到現在完成學業。 謹誌於國立高雄大學電機工程學系 中華民國一零八年一月N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
目錄
中文摘要 . . . i 英文摘要 . . . ii 致謝 . . . iii 目錄 . . . iv 圖目錄 . . . vii 表目錄 . . . ix 1 緒論 . . . 1 1.1 研究背景 . . . 1 1.1.1 辨識目的與應用 . . . 1 1.1.2 辨識方法與核心技術 . . . 2 1.2 動機與目的 . . . 3 1.3 研究方法 . . . 4 1.3.1 資料前處理 . . . 4 1.3.2 模型訓練自動化 . . . 4 1.3.3 交通標誌辨識系統 . . . 4 1.4 研究流程與論文架構 . . . 5 2 背景知識與文獻探討 . . . 7 2.1 深度學習 . . . 7 2.1.1 類神經網路 . . . 7 2.1.2 神經元 . . . 7 2.1.3 類神經網路架構 . . . 9 2.1.4 卷積和池化 . . . 10 2.1.5 深度學習相關應用 . . . 12 2.2 YOLO . . . 13 2.2.1 偵測方法 . . . 13 2.2.2 訓練 . . . 15 2.2.3 損失函數 . . . 15N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.3 YOLO V2 . . . 17 2.3.1 Anchor box . . . 17 2.3.2 速度 . . . 17 2.3.3 Batch Normalization . . . 18 2.3.4 Darknet-19 . . . 18 2.3.5 YOLO 物件辨識相關應用 . . . 18 2.4 影像特徵處理 . . . 20 2.4.1 色彩空間 . . . 20 2.4.2 中值濾波 . . . 22 2.4.3 Haar-like . . . 24 2.4.4 影像積分 . . . 25 2.4.5 影像特徵相關應用 . . . 27 3 問題定義與研究方法 . . . 28 3.1 交通標誌資料前處理 . . . 28 3.1.1 資料收集 . . . 28 3.1.2 資料擴增 . . . 30 3.2 訓練與辨識流程 . . . 32 3.2.1 訓練流程 . . . 32 3.2.2 辨識流程 . . . 35 3.3 模型自動訓練機制 . . . 37 4 實驗與結果分析 . . . 42 4.1 實驗環境與硬體架構 . . . 42 4.2 訓練與測試樣本 . . . 42 4.3 參數設置 . . . 43 4.4 實驗 A - YOLO 局部影像與全部影像辨識分析 . . . 46 4.5 實驗 B - 中止 YOLO 模型訓練時機分析 . . . 47 4.6 實驗 C - 模型 Retrain 實驗與分析 . . . 47 4.7 實驗 D - 合成資料與真實資料訓練實驗與分析 . . . 48N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
5 結論與未來展望 . . . 51 5.1 結論 . . . 51 5.2 未來展望 . . . 51 參考文獻 . . . 52N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖目錄
1.1 辨識系統架構圖 . . . 3 1.2 研究進行流程圖 . . . 6 2.1 神經元計算示意圖 . . . 8 2.2 倒傳遞神經網路架構圖 . . . 9 2.3 Convolution 遮罩計算 . . . 10 2.4 影像滑動式視窗示意圖 . . . 11 2.5 Convolution 示意圖 . . . 11 2.6 Pooling 示意圖 . . . 12 2.7 Yolo 偵測方法示意圖 . . . 13 2.8 IOU 示意圖 . . . 14 2.9 YOLO 流程圖 . . . 16 2.10 Darknet 與 YOLO V2 示意圖 . . . 19 2.11 YOLO V2 架構 . . . 19 2.12 YOLO V2 流程圖 . . . 19 2.13 HSV 示意圖 . . . 21 2.14 原始影像、Hue 的特徵圖 . . . 21 2.15 中值濾波器於不同大小遮罩下效果示意圖 . . . 22 2.16 中值濾波器計算示意圖 . . . 23 2.17 中值濾波器計算流程圖 . . . 23 2.18 Haar like 矩形方塊示意圖 . . . 24 2.19 AdaBoost 分類器示意圖 . . . 25 2.20 (x1,y1) 處積分影像示意圖 . . . 26 2.21 積分圖像求矩形像素值示意圖 . . . 26 2.22 積分圖計算示意圖 . . . 27 3.1 不同環境下之標誌影像 . . . 29N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
3.3 不同氣候下之標誌影像 . . . 30 3.4 資料擴增流程圖 . . . 31 3.5 資料擴增之仿真影像 . . . 31 3.6 標誌分類外觀 . . . 32 3.7 交通標誌辨識模型訓練流程圖 . . . 34 3.8 交通標誌偵測模型訓練流程圖 . . . 35 3.9 交通標誌辨識流程圖 . . . 36 3.10 YOLO V2 模型 Re-train 流程圖 . . . 38 3.11 交通標誌辨識架構圖 . . . 38 3.12 交通標誌偵測之結果 . . . 39 3.13 在 HSV 空間下符合交通標誌寬高比的二值化 Contour 影像 (圓形) . . 39 3.14 在 HSV 空間下符合交通標誌寬高比的二值化 Contour 影像 (三角形) . 39 3.15 交通標誌資料庫樣本影像 (部分) - 第一類 . . . 40 3.16 交通標誌資料庫樣本影像 (部分) - 第二類 . . . 40 3.17 交通標誌資料庫樣本影像 (部分) - 第三類 . . . 41 3.18 交通標誌資料庫樣本影像 (部分) - 第四類 . . . 41 4.1 YOLO V2 訓練樣本 (含交通標誌的整張影像) . . . 43 4.2 Haar 訓練樣本 (含交通標誌的局部影像) . . . 43 4.3 YOLO 訓練樣本 . . . 46 4.4 單一交通標誌辨識結果 . . . 50 4.5 多個交通標誌辨識結果 . . . 50N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
表目錄
4.1 實驗 A -YOLO 局部影像與全部影像辨識分析 (%) . . . 44 4.2 實驗 B -不同迭代次數辨識率比較 (%) . . . 44 4.3 實驗 C -YOLO 辨識模型 Retrain 結果 (%) . . . 44 4.4 實驗 C -Haar 偵測模型 Retrain 結果 (%) . . . 44 4.5 實驗 D -使用合成資料作為訓練資料的結果 (%) . . . 45 4.6 實驗 D -使用真實資料作為訓練資料的結果 (%) . . . 45 4.7 實驗 D -合成資料與加入真實資料作為訓練資料的結果比較 (%) . . . 46 4.8 實驗 E -HSV 色調動態取值結果 . . . 49 4.9 實驗 E -多個 Haar 模型偵測結果比較 . . . 49 4.10 實驗 E -Haar 偵測模型偵測所需時間比較 (Ms) . . . 49N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
第 1 章
緒論
1.1
研究背景
1.1.1
辨識目的與應用
近年來智慧運輸科技 (Intelligent Transportation System ,ITS) 越來越備受關注, ITS 是使用在有關運輸、交通中的規劃管理部分,透過即時資訊傳輸,以增進安 全、效率與服務,改善交通問題。根據警政署統計民國 106 年造成行人傷亡的交 通事故共約 29 萬件,多數的交通事故多是因為駕駛未注意車輛周遭環境、未保持 行車安全距離,超速等。若可藉由 ITS 輔助到各式交通載具,將能有效確保運輸 過程中行人的安全及減少交通壅塞等問題 [1]。 目前在 ITS 發展目標中最受矚目的領域為自動駕駛車技術,自動駕駛車概念 的關鍵支持在於無需人類干涉,可以透過機器自動感知,自動做出決策並且達到 自動或輔助駕駛的目的。自動駕駛車是透過許多感測器來收集周圍的資訊,其中, 交通標誌的辨識可以說是一個很重要的訊息,只要系統能夠及時根據交通標誌上 的訊息提出警告或主動反應,將能大幅降低交通事故的發生以及保障駕駛人的安 全。 在道路上交通標誌辨識中,鏡頭可透過影像辨識技術來收集交通標誌的數 據,是自動駕駛車所必備的感測器之一。影像辨識技術為目前最廣泛使用的技術, 影像裡的顏色資訊和物件結構的細節,相較於其它感測器 (如紅外線、雷達,超音 波等) 所能提供的資訊及分析結果相對來的重要及準確。 影像辨識在日常生活中已經有許多的應用,如: 車牌辨識 [2]、交通標誌辨識 [3]、行人偵測 [4]、工業影像偵測 [5] 等。應用說明如下: • 車牌辨識: 目前最常見的應用為停車場門禁系統,除了可以控管進出的車
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
輛,也節省了傳統停車場需要人力收費的問題。 • 交通標誌辨識: 目前大多使用在車輛的輔助系統上,如速限告知,方向指引 等,現在也已成為無人駕駛車上不可或缺的技術之一。 • 行人偵測: 若可藉由行人偵測的技術來達到各式交通載具的告警,將能有效 確保行人的安全。 • 工業影像偵測: 相較於傳統用人工辨識物件瑕疵的方式,透過影像檢測可大 量節省人力以及提升準確度。1.1.2
辨識方法與核心技術
大致上來說,交通標誌辨識可以分成偵測與分類兩個部分。偵測指的是在輸 入影像中找到號誌以及它的位置,而分類指的是去決定找到的號誌是什麼類型。 通常這兩個階段是獨立運作的,但在有些情況下,分類器需要依靠偵測器來提供 資訊,像是號誌的形狀或是大小。 交通標誌本身有著特定的形狀與顏色及高對比於背景的文字或符號等特色, 使得它們能被用來偵測與辨識。因此,傳統的交通標誌辨識 [6],大多是使用不 同色彩空間的顏色資訊如:RGB、HSV、HSI 等,或者抽取影像的特徵如:HOG[7]、 LBP[8]、SURF[9] 等方式來訓練一個分類器,但效果往往受光線、氣候,複雜場 景等問題所影響,導致辨識效果不佳。 目前深度學習中的即時物件辨識技術能夠較穩定的獲取影像特徵,在影像的 辨識上甚至能做到比人類還精準的程度,目前已經開發出很多用於目標檢測的演 算法,包括 YOLO[10]、SSD[11]、RCNN[12] 和 Faster RCNN[13] 等。在使用上只 需準備一些已有答案的樣本即可加以訓練得到我們的模型,而這個模型目前也被 廣泛運用在電腦視覺辨識、語音辨識,自然語言處理等領域。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
任何著名深度學習框架,輕量、依賴少、演算法高效率。基本 YOLO 架構在 GPU 上可以達到每秒 45 禎的速度,而較小的 Fast YOLO 架構甚至可以達到每秒 155 禎 的速度。這意味著 YOLO 已經可以對影像作即時運算了,在工業應用領域很有價 值。YOLO 原作者之後又提出了速度更快、精確率更好的 YOLOV2 版本,該版本 在 VOC 檢測中比起其他當前的深度學習架構在 Map 的表現是最高的,這可協助 在系統交通標誌的辨識更為精確,因此本研究將以 YOLO V2 作為辨識系統的核 心技術。 圖 1.1: 辨識系統架構圖1.2
動機與目的
深度學習除了演算法以外,還有另外兩項重點,一是資料 (Data),二是模型 (Model),而目前許多模型都已經公開,包含本論文使用的 YOLO V2 以及 Google 的 TensorFlow 等,所以模型的取得並非難事,但資料就不是如此,除了訓練及測 試樣本的收集外,對訓練物件的標示往往需要花費許多專家及人力去做特徵上的 選取,不只成本很高,所選取的特徵也很容易因不同人的主觀而產生偏差,進而 造成最終結果表現不佳。因此本研究將針對資料的生成與訓練模型的自動化兩大 部分提出方法。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
1.3
研究方法
本論文建立的系統中包含了三個子系統: 資料前處理系統、自動化訓練系統、 交通標誌辨識系統。藉由這三個系統達到同步辨識與優化模型的目的。1.3.1
資料前處理
由於目前台灣並沒有足夠的交通標誌影像資料庫,因此,基於交通部網站 (168 交通安全入口網) 取得交通標誌的標準影像,將該影像透過影像前處理進行 背景合成、添加雜質、亮度調整、大小調整等仿真效果,達到資料擴增的目的並 且自動產生 YOLO V2 訓練用標註資料。以此批仿真的訓練資料建立第一個初始 模型,接著再將每一次辨識錯誤的結果回饋進入訓練資料中進行二次三次等重複 訓練的動作,藉此來達到優化模型的目的。1.3.2
模型訓練自動化
本研究使用了機器學習常用的 Haar like 特徵與 Adaboost 分類器來偵測交通標 誌的所在位置,並將其座標轉換成 YOLO V2 訓練樣本的標註格式,再以 HSV 色 彩空間來判斷該標註區域是否符合交通標誌的色彩特徵,最後單獨擷取交通標誌 的影像部分送回 YOLO V2 再次辨識,此時因為影像特徵已經被放大,在 YOLO V2 上能能有更好的辨識表現,該系統即透過上述方法實現自動訓練的目的。
1.3.3
交通標誌辨識系統
本 研 究 的 辨 識 系 統 將 交 通 標 誌 做 分 層 辨 識, 第 一 層 依 目 標 的 幾 何 特 徵 (Geometric features) 來分類,第二層針對該特徵內的文字或符號加以辨識,第三層 針對數字做辨識,如: 限高、限速、限重等類型標誌。此系統設計方式可以預防因 外觀特徵過於相似導致誤判的情況發生,亦能加快系統比對速度。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
1.4
研究流程與論文架構
本論文的研究流程共分為五個部分,分別為問題定義、相關文獻探討、深度 學習模型自動優化問題分析、程式撰寫、實驗設置與結果。研究流程說明如下: • 研究動機:本章節探討關於深度學習用於即時交通標誌辨識,以及描述本論 文目標與架構。 • 相關文獻蒐集與探討:本章節介紹交通標誌辨識相關文獻以及運用到的色彩 空間、Haar like 等特徵及深度學習中的即時物件辨識技術等,深入了解相關 技術之發展與優缺點。 • 程式撰寫:本研究開發之程式共分為三部分,皆以 C# 開發並分別實現資料 前處理,交通標誌辨識及模型自動化再訓練的功能,程式說明如下: 1. 資料前處理: 撰寫深度學習訓練模型的標註程式,並且透過影像處理實 現資料擴增達到自我生成訓練樣本的目的。 2. 交通標誌辨識: 以 YOLO V2 演算法為主架構開發標誌的辨識程式。 3. 模型自動化再訓練: 以機器學習中的 Cascade 分類器實現自動化標註深 度學習模型所需的訓練資料。 • 實驗結果分析與結論:說明如何設置實驗與實驗結果的評估方式,探討深度 學習中模型再訓練後的成長效果,並以以投票機制方式比較機器學習中多個 模型互相判別的效果與分析。 本 論 文 架 構 分 為 五 章 節, 其 簡 述 如 下: 第 一 章 『緒 論』, 說 明 本 研 究 動 機。第二章『文獻探討』,簡述偵測物件的相關技術與背景知識,如色彩空間、 Haar-like,YOLO 等。第三章『問題定義與研究方法』,針對深度學習模型的自動N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
化訓練研究問題進行定義、分析處理該問題的方法與流程,並詳細說明整體交通 標誌辨識方法設計及流程。第四章『實驗結果與分析』,依據研究方法流程,比較 各種不同參數之實驗,並針對實驗結果分析及說明。第五章『結論與未來展望』, 總結本研究遇到的問題及方法,並且相對提出未來可以研究及更深入的方向與構 想。 圖 1.2: 研究進行流程圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
第 2 章
背景知識與文獻探討
本章介紹與本研究所提出的方法之相關技術,有些技術我們直接採用,有些 則是透過其闡述之觀念讓我們生成想法,2.1 節介紹深度學習,2.2 節介紹物件即 時辨識 YOLO,2.3 節介紹基於 YOLO 改進的 YOLO V2,2.4 節介紹影像特徵處 理相關技術。2.1
深度學習
深度學習 [14] 是實現機器學習的一種技術,機器學習是一種自動分析資料獲 得規律,並利用該規律對未知數據進行預測的演算法。本研究使用的深度學習演 算法藉由類神經網路的運算模式,以多層的運算分析出交通標誌上的影像特徵, 以交通標誌為例,第一層可能是標誌的外觀,第二層是標誌的符號,最後便可以 組成交通標誌。2.1.1
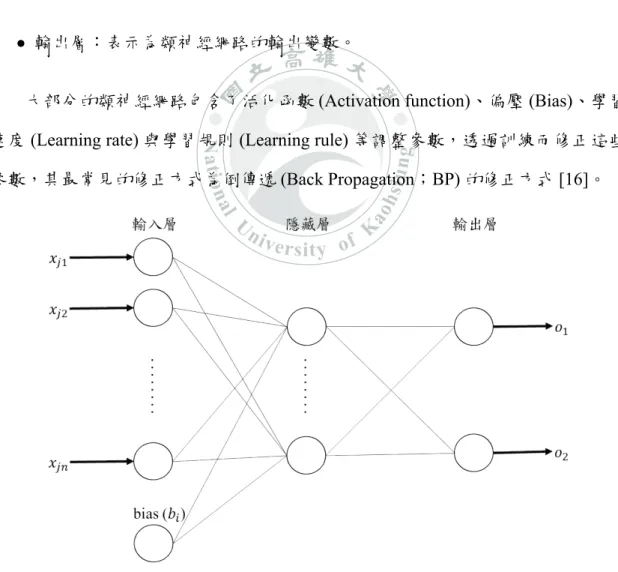
類神經網路
類神經網路 (Artificial Neural Network;ANN[15]) 是一種參考人腦內神經網路 的結構和功能的運算模型,其將大量相連的人工神經元串聯再一起,同一層中的 神經元彼此不相連,不同層間的神經元則彼此相連,藉由不斷加深整個類神經網 路的層數來提升模型的學習能力,並且經過大量資料的學習來修正參數,最後可 得到一個使電腦能夠像人類那樣具有推理能力的模型。
2.1.2
神經元
人工神經元是簡單的模擬生物神經元,它從外界環境或者其它人工神經元取 得資訊,並加以運算,之後輸出結果到外界環境或者其它人工神經元,每一個人N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
工神經元皆有多個輸入及一個輸出,如公式 (2.1),其計算代表符號如下: • W :介於輸入層與隱藏層之間的權重,可視為一種加權效果,其值越大,對 類神經網路的影響也更大。 • b:隱藏層當中的偏壓 (bias)。 • n:輸入的資料筆數。 • X : 訓練樣本,共 n 筆不同的訓練樣本。 • f (Θ):非線性轉換函數,目的是將加權成績和的值做映射得到所需要的輸出,常見的有 Sigmoid、Gaussian 和 Radius Bias Function(RBF) 等。
• O : 輸出至外界環境或是其他人工神經元的資料。 O (t) = f ( n ∑ i=1 W j× Xj + b ) (2.1) 圖 2.1: 神經元計算示意圖
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.1.3
類神經網路架構
類神經網路整體架構包含了輸入層、隱藏層和輸出層。類神經網路輸出的計 算為輸入的神經元及它的權重,經過線性組合計算出一個加總值後,再經過激活 函數的轉換得到一個輸出值。 • 輸入層:資料來源與訊息,表示為類神經網路的輸入變數。 • 隱藏層:介於輸入層與輸出層之間,通常透過實驗來決定最佳的層數及神經 元的個數,一般而已,越多的層數能處理越複雜的問題,但同時也加深學習 的難度。 • 輸出層:表示為類神經網路的輸出變數。大部分的類神經網路包含了活化函數 (Activation function)、偏壓 (Bias)、學習 速度 (Learning rate) 與學習規則 (Learning rule) 等調整參數,透過訓練而修正這些 參數,其最常見的修正方式為倒傳遞 (Back Propagation;BP) 的修正方式 [16]。
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.1.4
卷積和池化
卷積 (Convolution) 與池化 (Pooling) 是常被用來降低資料維度並保留影像資訊 方法之一,可以使卷積神經網路在計算跟效能上更為簡單與快速 [17]。卷積運算的 mask 一般稱為 kernel map,其數量是可以調整的,卷積的實作方 法為輸入圖象中的像素值與 Kernel 相乘後即為該點的輸出,而藉由給予 kernel 不 同的權重組合,也有去除噪音 (Noise) 及銳化 (Sharpen) 的效果,其計算代表符號 和計算方法如公式 (2.2) 和圖 (2.3) • m:遮罩中心點像素的列方向。 • n:遮罩中心點像素的行方向。 • I:原始影像。 • h:卷積遮罩。 Convolution(m, n) =∑ i ∑ j I(i, j)∗ h(m − i, n − j) (2.2) 圖 2.3: Convolution 遮罩計算
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
卷積在整張圖的每個位置都會運算到,運算方式一般都是從左上角開始計 算,然後橫向向右邊移動運算,到最右邊後在往下移一格,繼續向右邊移動運 算,直到整張圖都完成,如下圖 (2.4)。整張圖掃過一遍後,圖的大小會變小,以 圖2.5從原本的 7x7 變成 5x5。而 Mask 在移動的時候只能移動一格,通常在開源模 組上使用時,Convolution 部份會有一個參數叫 strides 可以設定一次想移動幾格。 圖 2.4: 影像滑動式視窗示意圖 圖 2.5: Convolution 示意圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
池化目的只是在將圖片資料量減少並保留重要資訊的方法,把原本的資料 做一個最大化或是平均化的降維計算,最終我們會得到一樣數量、但包含更少 像素的圖片。池化法會根據 feature map 的結果去做 pooling。常用的方法有 MAX Pooling、MIN Pooling、AVE Pooling、Dive Pooling 等,本研究中所使用的方法為 MAX Pooling,其運算方式為將一遮罩內的最大值做為代表該遮罩的值輸出, 圖2.6為基於取 2x2 遮罩的 Max、Min Pooling 做運算例子。 圖 2.6: Pooling 示意圖2.1.5
深度學習相關應用
目前智慧交通的領域隨處可以看到深度學習的應用。[18, 19] 利用深度學習預 測高速公路的交通情況,藉此尋找出最佳的道路指引。[20] 透過 CNN 辨識跟速度 有關的交通號誌搭配 GPS 系統來輔助行車駕駛人。[21, 22] 使用深度學習控制交 通號誌的變換,達到控制交通流量的目的。[23] 透過 eRCNN 來預測北京即發生N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.2
YOLO
YOLO 採用 GoogLeNet[24] 的結構,其模型的特性只需要對圖片作一次 CNN 便能夠判斷目標位置以及所屬類別及概率。整個網路設計是 end-to-end 的,容易 訓練,而且速度快。2.2.1
偵測方法
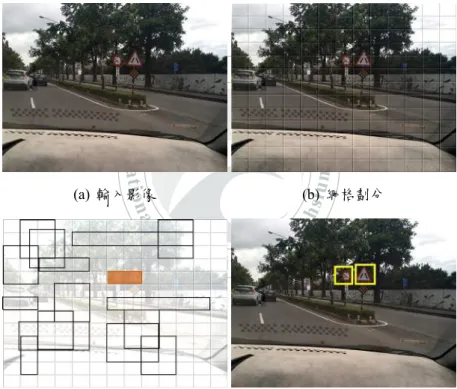
YOLO 以滑動窗格取得偵測目標,在訓練跟偵測都是透過整張圖片作為神經 網路的輸入,直接預測坐標位置與所屬的類別。以下將針對偵測部分進行說明。 (a) 輸入影像 (b) 網格劃分(c) bounding boxes and Class proba-bility map
(d) Finial detections
圖 2.7: Yolo 偵測方法示意圖
• 網格劃分: YOLO 的概念是將一張圖片切割成 S x S 個網格,如果網格中間
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
• 網路輸出: 將每一個網格對每個類別去計算該類別出現的機率,測試時是將 每個網格的分類機率與信心分數相乘,數學式可表示為 (2.3)P r (Ci| O) ∗ P r (O) ∗ IOU = P r (Ci)∗ IOU (2.3)
◦ P r : 為預測到的目標數。 ◦ IOU:是用來衡量我們的模型檢測特定的目標好壞的重要指標 [25]。 100% 代表預測框跟目標完美重合,即表示一個完美的檢測。如圖2.8。 等式左邊即為每個網格預測的類別訊息乘上每個 bounding box 預測的信心分 數。透過此公式的計算,可以得知預測的輸出框屬於某一個類別的機率以及 其準確度。最後每個網格的預測輸出可以整理如公式 (2.4) ◦ S:為影像分割的網格單元數。 ◦ B 為每個網格預測的 bounding boxes 數量。 ◦ C:為類別的總數。 S∗ S ∗ (5 ∗ B + C) (2.4) 圖 2.8: IOU 示意圖
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.2.2
訓練
YOLO 先在 ImageNet[26] 上進行了預訓練,其預訓練的分類模型採用前 20 個 卷積層,然後添加一個 Average-pool 層和全連接層,在預訓練得到的模型加上隨 機初始化的 4 個卷積層和 2 個全連接層。由於檢測任務一般需要更高清的圖片, 所以將網路的輸入從 224× 224 增加到了 448 × 448。整個網路只有最後一層是使 用線性激活函數,其他層都是使用 leaky ReLU[27]。2.2.3
損失函數
YOLO 架構中使用誤差平方合 (sum-squared error loss) 來計算分類誤差與定 位誤差,其計算方法是求預測值與真實值之間距離的平方和,其公式為 (2.5)、 (2.6)、(2.7)、(2.8) 加總,說明如下: • w, h:為 Bounding Box 的寬跟高。 • λc:為增加預測損失,賦予更大的權重。 • λn:為降低當網格內沒有目標物存在時造成的影響,賦予更小的權重。 • Iobj ij :判斷第 i 個網格中第 j 個 bounding box 是否負責這個目標。 • Iobj i :判斷在 SXS 的網格中,預測目標的中心點是否有落在此處。 STEP-1: 座標預測
預 測 不 同 大 小 的 bounding box 時, 較 小 的 bounding box 的 在 預 測 時 與 ground-truth box 產生偏移量會比大的 bounding box 造成的還明顯,導 致兩者在損失函數中佔的比重不平衡,因此為了降低偏移量,將參數 W 與 H 取平方根。且為了預防網格內沒有目標物存在導致訓練模型時
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
λc S2 ∑ i=0 B ∑ j=0 Iobj ij [ (Xi− ˆXi)2+ (Yi− ˆYi)2 ] (2.5) + λn S2 ∑ i=0 B ∑ j=0 Iobj ij [ (Wi− ˆWi)2+ (Hi− ˆHi)2 ] (2.6) STEP-2: Confidence 預測 在訓練模型的階段時,我們希望一個 bounding box 只對對應一個目標,因此 我們透過 IOU 的計算來找到 confidence score 最高的 bounding box 後,然後將其它的 bounding box 乘上 λn。 S2 ∑ i=0 B ∑ j=0 Iobj ij ( Ci− ˆCi )2 + λn S2 ∑ i=0 B ∑ j=0 Iobj ij ( Ci− ˆCi )2 (2.7) STEP-3: 類別預測 公式 (2.8) 判斷網格中是否有偵測目標的中心點存在。 S2 ∑ i=0 Iobj i ∑ c∈C ( Pi(c)− ˆPi(c) )2 (2.8) 圖 2.9: YOLO 流程圖
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.3
YOLO V2
YOLO V2[28] 是 YOLO 原作者將 V1 缺點部分提出改進而產生的架構。在辨 識速度和準確率上都有提升,對於不同圖檔大小也有很好的相容性,以下將針對 改良重點進行介紹:2.3.1
Anchor box
Anchor box 又稱為候選框,透過訓練的影像產生,用來對應物件偵測時輸出 的分數,YOLO V2 透過 K-means[29] 演算法計算出較優的候選框。不同於 YOLO 是對同一個網格下的 bounding box 统一產生一個數量為 C 的類別機率,而是對每 一個 bounding box 都產生對應的的 C 類概率。2.3.2
速度
YOLO V2 對網路做了點修正,使得預測與訓練的速度都得到提升,修正重點 如下說明: • 縮減輸入的網路,輸入的圖片大小從 448 × 448 縮減到 416 × 416 。 • 設定網路深度為 32 層,因此最終得到的特徵圖大小為 13 × 13 個 cell(416 / 32 = 13),每一個 cell 的輸出數量是 (CLASS + 5)× 5。 • 使用 sigmoid 函數作為激活函数,讓輸出值落在 [0,1] 這個區間內,提升網絡 的收斂。 因為最後得到的影像大小是一個奇數,可以得到一個單獨的 center cell。大 目標通常佔據了圖像的中間位置,所以我們可以只用一個中心的 cell 來預測 這些物體的位置。如果是偶數,就需要使用中心的四個 cell 進行預測。根據 YOLO V2 最終的實驗結果表明,網絡在精確率方面有了細微的下降 (69.5%N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.3.3
Batch Normalization
Batch Normalization 是一種處理數據的方法 [30],其原理就是對所有輸入到網 絡的數據做一個歸一化處理。因 CNN 在訓練過程中每一層輸入的分佈都不相同, 則使得訓練難度增加,因此 YOLO V2 網路中的每一個卷積層後面在加上一個 BN 層,將要進入 CNN 的參數正規化,這使得 mAP 得到了 2% 的提升。2.3.4
Darknet-19
Darknet-19 為 YOLO V2 的基礎,為了進一步提升網絡速度以及檢測效果而提 出的新的分類網絡模型,網絡中一共有 19 個卷積層以及 5 個池化層,這個框架參 考了 VGG[31] 以及 NIN[32],其架構重點說明如下: • 大量使用 3 × 3 小尺度卷積來提取特徵,並使用 1 × 1 的遮罩壓縮特徵圖。 • 使用全局平均池化技術 (global average pooling)。• 使用上面介紹的 BN 層用來穩定訓練過程以及加速收斂和對模型的正則化。
2.3.5
YOLO 物件辨識相關應用
YOLO 是 最 常 被 用 來 作 為 物 件 偵 測 的 演 算 法 之 一, 相 較 於 其 它 演 算 法, YOLO 無論在辨識速度或辨識率上都有不錯的表現。近年來隨著顯示卡能力的提 升,視覺辨識的應用早已深入我們日常生活當中。在 [33] 中使用了 YOLO 與高斯 模型的混合檢測方式來作行人偵測,並改善了 YOLO 對於檢測小目標能力較差的 缺點。在 [34] 中,改變了 YOLO 全連接層的架構,達到 45 禎的速度,使系統不 受環境影響達到即時安全監控的目的。在 [35] 中,透過使用不同大小的網格來測 試如何有效地偵測到最正確的人數,改善 YOLO 對於重疊目標無法有效正確框選 出個數的缺點。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 2.10: Darknet 與 YOLO V2 示意圖 圖 2.11: YOLO V2 架構 圖 2.12: YOLO V2 流程圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.4
影像特徵處理
特徵的提取與處理是影像處理中一個非常重要的程序,本研究透過這些特徵 進行深度學習、機器學習、影像判定等處理程序,本節將對這些特徵及其應用做 介紹。2.4.1
色彩空間
色彩空間 (Color space) 指的是對色彩的組織方式,也是一種對色彩的描述方 式,根據不同運用可以定義出不同的色彩空間,計算機顯示器顯示顏色通常會使 用 RGB 色彩空間定義,RGB 正好對應著光的三原色 (Red、Green,Blue),在計 算機領域中,其三色的範圍從 0 至 255。每一點像素上的 RGB 值,根據加法混 色原理就可以混合出我們要的顏色,其它常見的色彩空間有 GRAY、HSV、HIS, LAB 等。過去許多論文基於交通號誌本身有著固定顏色訊息的基礎上,透過不同 色彩空間的轉換去分析影像中交通號誌可能存在的位置 [36],因此在本研究中我 們運用了 RGB、RGBA、HSV 這三個色彩空間的轉換處理來達到資料仿真的目 的。RGB 轉換 HSV 如公式2.9、2.10 ,2.11所示,其計算代表符號如下: • R:為像素的 red 數值。 • G:為像素的 green 數值。 • B:為像素的 blue 數值。 • H:hue,表示色相。 • S:saturation,表示飽和度,指顏色的深淺比例,顏色越深飽和度越高,白 色所占比例越高,飽和度越低。 • V :vlue,表示明度,即為顏色的明暗程度,數值越大越亮。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
H← 60(G−B) V−Min(R,G,B) if V = R 120+60(B−R) V−Min(R,G,B) if V = G 240+60(R−G) V−Min(R,G,B) if V = B (2.9) S ← V−Min(R,G,B) V if V ̸= 0 0 Otherwise (2.10) V ← max(R, G, B) (2.11) 圖 2.13: HSV 示意圖 圖 2.14: 原始影像、Hue 的特徵圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.4.2
中值濾波
中值濾波器是最常被使用到的濾波器 [37],為一種統計排序的濾波器,該濾 波器邊長通常為奇數的方形,又稱為遮罩 (mask)、kernel。其作法是將遮罩內之像 素值進行排序,找出中間值,本研究中所使用的排序法為泡沫排序法,最後將遮 罩內中像素之灰階值以該中間值取代。該濾波器對椒鹽噪音這種較強的高頻雜訊 能夠有效的去除雜訊,而仍然能夠保持邊緣的銳度。且模糊的現象比平均平滑和 高斯平滑都來的輕微,其缺點為為非線性的低通濾波器,使用遮罩越大的中值濾 波器除了會耗費越久的時間,也會使圖形失真,本論文中以 3× 3 的遮罩做標誌 的濾波處理。 (a) 帶有雜質的灰階影像 (b) Mask = 3 (c) Mask = 5 (d) Mask = 7 圖 2.15: 中值濾波器於不同大小遮罩下效果示意圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 2.16: 中值濾波器計算示意圖 圖 2.17: 中值濾波器計算流程圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
2.4.3
Haar-like
Haar like 特徵是常用於物體辨識的技術之一,本研究使用 Haar like 特徵來偵 測交通標誌在視窗中的位置。Viola[38] 等人提出使用的 AdaBoost 演算法,用了四 個矩形方塊來作為人臉分類的依據如圖2.18,分別為 (1) 邊緣特徵,用來偵測圖像 的垂直跟水平邊緣,(2) 線性特徵,用來偵測圖像中兩邊叫中間突出的特徵,(3) 中心特徵,用來偵測圖像中中間較突出的特徵,(4) 對角線特徵,用來偵測圖像中 的斜角特徵。 圖 2.18: Haar like 矩形方塊示意圖 該矩形特徵性質如下: • 形狀簡易,容易描述座標位置。 • 黑色區塊與白色區塊像素值相減後,即為 AdaBoost 的特徵值 • 善於處理影像顏色變化大與邊緣的部分
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
該技術檢測方式如影像中指定位置的相鄰矩形方塊,該矩形由數張圖片透過 電腦訓練產生,這些矩形方塊會在圖像中移動,計算每一個矩形方塊內的像素總 和,再計算其差值,該值即為這個區域的 Haar like 特徵值。該值反映了圖像的灰 度變化情況,以人臉檢測為例,我們用矩形特徵簡單的描述人臉,眼睛要比臉頰 顏色要深,鼻樑兩側比鼻樑顏色要深,嘴巴比周圍顏色要深等。每一個矩形方塊 都是一個分類器,當輸入影像符合 Haar-like 特徵時,即可通過該分類器至下一 層,輸入影像如圖2.19通過這各層的分類器後即可找到目標區塊。 圖 2.19: AdaBoost 分類器示意圖2.4.4
影像積分
使用 Haar-like 特徵來做物件的影像偵測時,若每次在像素上面掃描一次就做 一次計算,那勢必要花上非常多的時間。使用積分圖可以快速計算矩形方塊的特 徵值,不同的檢測圖像有不同的積分值,積分值只需要計算一次,就可以求出圖 像中所有區域的像素和,之後移動的矩形方塊可以直接使用這些積分值來計算出 每個區域的特徵值,大大的提高了計算的效率。 積分值的計算定義為公式 (2.12),其計算概念如圖 (2.20) 所示,在 (x1,y1) 處 的積分值是對應左上角 (x,y) 的所有灰階值的總和,因此如果要計算輸入影像的積N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
I(x, y) = x ∑ x=0 y ∑ y=0 i (x, y) (2.12) 圖 2.20: (x1,y1) 處積分影像示意圖 圖 2.21: 積分圖像求矩形像素值示意圖 如圖 (2.21),積分圖建構出來後,就可以透過公式 (2.13) 快速得到任一矩形方 塊內的 Haar like 特徵值。 • x, y:為矩形方塊左上角點的位置。 • w:為矩形方塊的寬。 • h:為矩形方塊的高。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 2.22: 積分圖計算示意圖2.4.5
影像特徵相關應用
影像特徵處理最常應用在資料前處理的時候,在大部分的機器學習中 [39], 輸入影像的前置作業非常重要,當一張影像過大或雜質過多又必須找其特徵時經 常使用濾波器或降低資料維度的方法。透過特徵的提取我們可以修復圖像 [40]、 醫學檢測 [41, 42] 和交通號誌偵測 [42] 等其它不同的辨識應用。 在交通標誌的偵測上最常使用色彩和形狀作為特徵來偵測,因此我們可以藉 由色彩空間的轉換利用 HSV 定義出交通號誌的特徵範圍或以灰階影像搭配 Haar like 特徵來偵測目標。文獻 [43] 中,透過 Haar like 偵測市區道路的汽車流量藉此 控制交通燈號來管理交通。文獻 [44] 透過 Haar like 偵測交通號誌的燈號,並利用 SVM 分類器 [45] 來消除 Haar like 分類錯誤的圖像。文獻 [46] 中透過 RGB 色彩空 間中的 R 值做定義來偵測紅色標誌。文獻 [47] 中利用 HSV 色彩空間偵測標誌的 位置訊息,後續再透過神經網路進行標誌的分類與檢測。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
第 3 章
問題定義與研究方法
本論文提出基於 YOLO V2 架構之下,透過影像處理作為訓練資料的前置處 理方法,並且結合 Haar like 特徵來取代人工標註訓練資料的程序,使模型可以自 動化的自我訓練。本章將說明如何透過影像處理的技術將網路上搜尋到的影像資 料進行仿真,並進行模型的訓練,透過標誌本身的特徵進行不同層級的分類來降 低標誌的複雜性,最後針對自動標標註訓練樣本的問題加以介紹。3.1
交通標誌資料前處理
本研究主要應用於交通標誌的辨識上,而深度學習是非常依賴訓練資料,因 此本研究在收集資料後將影像資料做了擴增來增加訓練樣本的多樣性。以下介紹 資料收集與資料擴增的實現。3.1.1
資料收集
在交通標誌影像資料收集方面,有以下兩種來源: • 網路蒐集: 透過網路搜尋引擎關鍵字”交通標誌”的方式收集影像。 • 道路實拍: 透過汽車行車紀錄器架設車內,以及手機鏡頭,在高雄市區道路 不同時段進行拍攝收集影像,或者使用影片匯出影格 frames 作為訓練用圖 片。此方法與相片拍攝比較,最大差異是在事前篩選 (相片) 或事後篩選 (攝 影)、以及像素尺寸大小兩種,本論文收集模式是以相片為主攝影為輔,在 準備資料集階段可先用相片拍攝大量相片後,再用攝影模式拍幾段影片,之 後在訓練的過程中若發現效果不理想或有某一類型的圖片缺乏,可從影片中N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
在影像的準備上,需注意多樣及差異性,避免模型訓練發散 (Overfitting),以 準備交通標誌圖片為例,自然環境中會產生許多不利偵測與辨識標誌的因素,因 此拍攝時需注意到: • 不同環境:市區標誌多為較乾淨且無破損的完整物件,山區及郊區則多會參 雜些許雜質 (汙損、樹葉等) 及破損。 • 不同時間:光影的變化帶來的差異,直射斜射或散射光都會造成影像上像素 的差異。 • 不同氣候:雨天、晴天甚至下雪等情況時,影像上的雜質及清晰度都會受到 影響。 圖 3.1: 不同環境下之標誌影像 圖 3.2: 不同時間下之標誌影像N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.3: 不同氣候下之標誌影像3.1.2
資料擴增
透過上述兩種方式雖可獲得些許資料,但若要使模型能夠得到有效的訓練以 及避免訓練時產生訓練發散,這樣的資料量還是非常不足的。因此,為了補足資 料量不足的問題,本研究使用了影像處理的方式將網路取得的影像資料進行資料 擴增 (Data Augmentation)。Data Augmentation[48] 簡單來說,就是想辦法從舊照片 生出新照片,讓總訓練的資料數增加。我們可以把照片旋轉、切割、放大縮小、 改變顏色等做各種變形。透過資料擴增可以將一張來自交通部網站影像增加到 180 張的數量,其計算流程如圖3.4STEP-1: 將要擴增的影像轉換至 RGBA 色彩空間,使影像具有 alpha 值。
STEP-2: 取真實拍攝的市區道路影像分成任意大小作為背景,並與已經有 alpha 值的交通標誌影像作合成。 STEP-3: 取合成時的影像位置座標以 Yolo 的訓練標籤格式做計算。 STEP-4: 在 0 到 3 之間隨機產生一個數,將合成影像的 RGB 值分別乘上此數。 STEP-5: 取 30% 的影像進行中值濾波的計算,30% 的影像做椒鹽雜質的影像處 理。
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.4: 資料擴增流程圖 圖 3.5: 資料擴增之仿真影像N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
3.2
訓練與辨識流程
本研究主要目的為使用 YOLO V2 實作交通標誌辨識系統,使用該架構我們 必須先訓練自己的模型,透過此模型將辨識的結果以及座標位置取出再針對我們 要的辨識結果加以處理這些資訊。目前台灣已知的交通標誌種類超過一百種,為 了降低辨識目標的複雜度,本研究將交通標誌依外觀特徵分為四大類,並將目標 影像分成 3 層來做辨識,因此,在整個系統中我們將訓練 3 層的交通標誌的模型, 以下分別為訓練與辨識兩個流程的介紹。 圖 3.6: 標誌分類外觀3.2.1
訓練流程
以下對 YOLO V2 模型的訓練流程進行介紹,其流程如圖3.7 STEP-1: 準備資料集,資料集的組成為訓練影像與標籤 (Label),在上述中我們 說明了如何取得影像資料。N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
STEP-2: 準 備 Label, 本 研 究 使 用 自 行 開 發 的 Label 軟 體 來 製 作 標 註 資 料, YOLO V2 所需要的標註格式不同於 ImageNet 使用的 PASCAL VOC xml,而是採用 text 文字檔,第一欄為 Class 的 ID,其它皆以物件框相 對於整張圖片的比例來呈現。YOLO V2 標註檔的格式及說明如下: ⟨C, OCx, OCy, OWx, OWy⟩ • C : 類別。 • OCx : 目標中心 x 座標位在影像 x 座標的比例。 • OCy : 目標中心 y 座標位在影像 y 座標的比例。 • OWx : 目標寬度佔整張影像寬度的比例。 • OWy : 目標高度佔整張影像高度的比例。 STEP-3: 定義配置文件,YOLO V2 模型訓練時須倚靠配置文件 cfg 檔內的設定 定義網入的輸入與輸出,以下說明 cfg 的參數。 • classes : 訓練的類別數。 • batch: 每批次取幾張圖片進行訓練。 • subdivisions : 要將每批次拆成幾組,以避免 GPU 中的記憶體不 夠。 • width : 輸入影像的寬。 • height : 輸入影像的高。 • channels : 輸入影像的色彩通道數。 • Decay : 每次迭代後,學習速率隨之衰減的比率,防止訓練發散。 • angle:輸入影像角度變化,單位為度,每次生成新圖片時會隨機
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
• saturation & exposure: 輸入影像飽和度與曝光變化。
• learning rate : 學習率,控制基於損失梯度調整神經網絡權值的速 度。學習率越小,我們沿著損失梯度下降的速度越慢。 • max batches : 訓練的最大迭代次數,到此數即終止訓練。 STEP-4: 開始訓練。 圖 3.7: 交通標誌辨識模型訓練流程圖 交通標誌辨識通常分為偵測與辨識兩個部分,本研究以 YOLO V2 作為交通 標誌辨識的主要方法,但針對 YOLO V2 無法偵測或辨識錯誤的影像我們將透過 Haar like 進行進行偵測。以下為 Haar 模型的訓練流程說明,其流程如圖3.8。
STEP-1: 收集交通標誌的正面樣本 (含目標的” 局部” 圖)。
STEP-2: 收集交通標誌的負面樣本 (不含目標的任何圖)。
STEP-3: 將要訓練的影像灰階化。
STEP-4: 設定 AdaBoost 分類器的參數,並計算模型。以下說明在 OpenCV 中 使用該分類器訓練模型的常用參數。
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
• PrecalcValBufSize(Mb): 暫存記憶體大小,用來存放預先计算的特 徵值 (feature values),單位為 Mb。 • PrecalcIdxBufSize(Mb): 暫存記憶體大小,用來存放預先计算的特 徵索引 (feature indices),單位為 Mb。 • Sample width : 輸入影像的寬。 • Sample height : 輸入影像的高。 • FeatureType : 使用的特徵類型。 • MinHitRate : 每一層分類器的最小檢測率。 • MaxFalseAlarmRate : 每一層分類器的最大誤檢率。 STEP-5: 輸出交通標誌偵測模型。 圖 3.8: 交通標誌偵測模型訓練流程圖3.2.2
辨識流程
交通標誌辨識模型訓練好之後即可餵入影像進行辨識工作,在辨識流程部分 依各層的特徵,如: 形狀、文字、數字等特徵進行辨識,只要其中一層辨識失敗該 影像就算無法辨識之影像,藉此提升辨識正確率以及減少不必要的運算。以下說N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
STEP-1: 透過行車紀錄器或道路拍攝擷取交通標誌影像。 STEP-2: 將影像像素大小縮放至 544× 544。 STEP-3: YOLO V2 辨識模型計算,第一層模型依據交通標誌的外觀分類進行 分類,若辨識失敗立即終止後續流程。 STEP-4: YOLO V2 辨識模型計算,第二層模型辨識出標誌的項目,若辨識失 敗立即終止後續流程。 STEP-5: YOLO V2 辨識模型計算,第三層模型辨識有數字的標誌,例如限速、 限高等,若辨識失敗即跳過此張影像。 圖 3.9: 交通標誌辨識流程圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
3.3
模型自動訓練機制
本研究將模型做自動重複訓練的動作,辨識同時,將辨識失敗的樣本再引入 原模型的訓練資料庫中進行二次訓練,讓模型的辨識率得到成長,以下對自動重 複訓練的流程進行介紹,其流程如圖3.10STEP-1: 以機器學習的 Haar like 特徵來偵測出所有可能為交通標誌的影像,並 記錄該影像的 YOLO V2 座標,如圖3.12。
STEP-2: 將要訓練的影像灰階化。
STEP-3: 積分圖計算。
STEP-4: 設定 Cascade Classifier 的參數,並偵測交通標誌。
STEP-5: 將偵測到的影像的 RGB 訊號轉為 HSV,根據 YOLO V2 辨識成功的正 樣本中的 Hue 值作為動態閥值。
STEP-6: 計算特徵點 (Contour) 的長寬比是否符合標誌正常的比例。若否則淘汰 該影像,並使其作為 Haar Re-train 的負樣本,同步提升 Haar 模型的準 確率。
STEP-7: 放大目標特徵可以使 YOLO V2 有更好的辨識能力,因此將針對 Haar 偵測到的 ROI 範圍再送回 YOLO V2 辨識。
N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.10: YOLO V2 模型 Re-train 流程圖N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.12: 交通標誌偵測之結果 (a) 1:1 (b) 7:10 (c) 10:7 圖 3.13: 在 HSV 空間下符合交通標誌寬高比的二值化 Contour 影像 (圓形) (a) 1:1 (b) 7:10 (c) 10:7 圖 3.14: 在 HSV 空間下符合交通標誌寬高比的二值化 Contour 影像 (三角形)N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.15: 交通標誌資料庫樣本影像 (部分) - 第一類 圖 3.16: 交通標誌資料庫樣本影像 (部分) - 第二類N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 3.17: 交通標誌資料庫樣本影像 (部分) - 第三類 圖 3.18: 交通標誌資料庫樣本影像 (部分) - 第四類N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
第 4 章
實驗與結果分析
本章將介紹實驗設置與實驗結果。4.1 節介紹實驗設置的環境、4.2 節介紹實 驗的訓練與測試樣本、4.3 節說明模型訓練的參數設置 4.4 節分析 YOLO 於不同 影像大小訓練的結果、4.5 節分析 YOLO 訓練的中止時機、4.6 節證模型在 Retrain 機制下能否提升其分類能力 4.7 節分析資料擴增的影像與加入真實資料之影像所 訓練出來模型的比較,4.8 節比較使用三個 Haar Cascade 與單一個模型進行自動標 記的結果。4.1
實驗環境與硬體架構
本研究實驗環境為一台四核心電腦,CPU 型號為 Intel Core i5-6200, 2.4GHz, 記憶體大小為 8GB,作業系統為 64 位元的 Windows 10,撰寫程式使用 C# 程式語 言,並且透過 EmguCV 函式庫 [49] 做為開發環境。交通標誌資料庫是在高雄市區 以實際道路影像拍攝以及行車紀錄器上取出多種視角、不同天候及場景作為測試 影像共 3512 張。
4.2
訓練與測試樣本
在 YOLO V2 辨識模型訓練部分,輸入影像為含目標的全影像,如圖4.1,外 觀辨識模型 1 個,每一次訓練樣本 300 張 (80% 訓練;20% 測試); 標誌辨識模型共 4 個,每一次訓練樣本 250 張 (80% 訓練;20% 測試); 數字辨識模型 1 個,每一次 訓練樣本為 200 張,並取另外的 100 張作測試;Cascade 偵測模型輸入影像為含目 標的局部影像,如圖4.2,訓練正面樣本為 300 張,負面樣本為 800 張。訓練的標 誌種類依交通部網站所提供共 97 種,測試部份以高雄市區道路能採集到的交通標N
a
ti
o
n
a
l
U
niversity of
K
ao
h
si
u
n
g
圖 4.1: YOLO V2 訓練樣本 (含交通標誌的整張影像) 圖 4.2: Haar 訓練樣本 (含交通標誌的局部影像)4.3
參數設置
YOLO V2 模 型 中, 除 了 類 別 這 個 參 數 不 一 樣, 其 它 設 置 皆 相 同。 輸 入 影像部分皆是固定 416× 416,參數設置可參考 learning_rate=0.001,angle=30, decay=0.0005,channels=3,batch=64,subdivisions=8,saturation = 1.5,exposure = 1.5,max_batches = 50000。Cascade 偵測模型參數設置皆相同,參數設置可參考 Number of stage=20,Pre-calcValBufSize=1024,PrecalcIdxBufSize=1024,Sample width=50,Sample height=50, FeatureType=Haar,MinHitRate=0.995,MaxFalseAlarmRate=0.5。