行政院國家科學委員會專題研究計畫 成果報告
智慧型資訊整合於異質資料倉儲和資料探勘之模型、架
構、與績效評估-應用本體論、母型綱要、和學名結構(第 3
年)
研究成果報告(完整版)
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 96-2416-H-004-017-MY3 執 行 期 間 : 98 年 08 月 01 日至 99 年 12 月 31 日 執 行 單 位 : 國立政治大學會計研究所 計 畫 主 持 人 : 諶家蘭 計畫參與人員: 學士級-專任助理人員:張芷霖 碩士班研究生-兼任助理人員:李子佑 碩士班研究生-兼任助理人員:曾國烜 碩士班研究生-兼任助理人員:莊雅雯 博士班研究生-兼任助理人員:賴彥昌 博士班研究生-兼任助理人員:杜逸寧 博士班研究生-兼任助理人員:粘凱婷 報 告 附 件 : 國外研究心得報告 出席國際會議研究心得報告及發表論文 處 理 方 式 : 本計畫可公開查詢中 華 民 國 100 年 03 月 31 日
目錄
目錄 ... I 圖目錄 ... III 表目錄 ... IV Abstract ... V 1. Introduction ... 6 1.1 Research Motivation ... 6 1.2 Research Problem ... 6 1.3 Research Approach ... 7 2. Literature Review ... 9 2.1 XML Query Capability ... 9 2.2 XML Benchmarks ... 10 2.2.1 XMark ... 10 2.2.2 XMach ... 10 2.2.3 XOO7 ... 10 2.3 XML Benchmarks Comparison ... 11 2.4 Ontology ... 132.4.1 Ontology and Intelligent Information Integration ... 14
2.4.2 Ontology and Benchmark ... 14
3. Research Method ... 15 3.1 Research Approach ... 15 3.1.1 XML Data Model ... 17 3.1.2 XML Query Model ... 19 3.1.3 Exact Match ... 20 3.1.4 Joins ... 21
3.1.5 Regular Path Expressions ... 21
3.1.6 Document Construction ... 22 3.1.7 Ordered Access ... 23 3.1.8 Sorting ... 23 3.1.9 Missing Elements ... 24 3.1.10 Text Search ... 24 3.1.11 Data-type Cast ... 24 3.1.12 Function Application ... 25
3.2 Ontology Data Model ... 26
3.3 Ontology Query Model ... 27
3.4 Test Database Generation ... 29
3.6 Prototype Functions ... 32
3.6.1 Data Loader ... 32
3.6.2 Query Generator ... 33
3.6.3 Scheduler ... 35
3.6.4 Result Collector ... 36
4. Research Implications and Concluding Remarks ... 37
4.1 Research Implications ... 37
4.2 Concluding Remarks ... 39
5. References ... 41
6. 計畫成果自評 ... 43
圖目錄
Figure 1: Research Model ... 16
Figure 2: Graphic Representation of XML Data Model ... 18
Figure 3: XML Query Model ... 20
Figure 4: Ontology Query Model ... 28
Figure 5: Data Loader ... 33
Figure 6: Query Generator ... 34
Figure 7: Query Generator - Input ... 34
Figure 8: Query Generator – Select Standard Query Type ... 35
Figure 9: Query Generator – Set Standard Query Complexity ... 35
表目錄
Table 1: Comparison of Benchmarks over Workload Characteristics ... 12 Table 2: Comparison of Benchmarks over Query Functionalities. ... 13 Table 3: Complexity Factors Listing ... 25
Abstract
Benchmarks are vital tools in the performance measurement and evaluation of computer hardware and software systems. Standard benchmarks such as the TREC, TPC, SPEC, SAP, Oracle, Microsoft, IBM, Wisconsin, AS3AP, OO1, OO7, XOO7 benchmarks have been used to assess the system performance. These benchmarks are domain-specific in that they model typical applications and tie to a problem domain. Test results from these benchmarks are estimates of possible system performance for certain pre-determined problem types. When the user domain differs from the standard problem domain or when the application workload is divergent from the standard workload, they do not provide an accurate way to measure the system performance of the user problem domain. System performance of the actual problem domain in terms of data and transactions may vary significantly from the standard benchmarks. In this research, we address the issue of domain boundness and workload boundness which results in the ir-representative and ir-reproducible performance reading. We tackle the issue by proposing a domain-independent and workload-independent benchmark method which is developed from the perspective of the user requirements. We present a user-driven workload model to develop a benchmark in a process of workload requirements representation, transformation, and generation. We aim to create a more generalized and precise
evaluation method which derives test suites from the actual user domain and application. The benchmark method comprises three main components. They are a high-level workload specification scheme, a translator of the scheme, and a set of generators to generate the test database and the test suite. The specification scheme is used to formalize the workload requirements. The translator is used to transform the specification. The generator is used to produce the test database and the test workload. In web search, the generic constructs are main common carriers we adopt to capture and compose the workload requirements. We determine the requirements via the analysis of literature study. In this study, we have conducted ten baseline experiments to validate the feasibility and validity of the benchmark method. An experimental prototype is built to execute these experiments. Experimental results demonstrate that the method is capable of modeling the standard benchmarks as well as more general benchmark requirements.
Keywords: XML, Ontology, Intelligent Information Integration, Generic Construct, Benchmark, Workload Model, Performance Measurement and Evaluation
1. Introduction
1.1 Research Motivation
A benchmark is a standard by which something can be measured or judged. A computer system benchmark is a set of executable instructions to be enforced in controlled experiments to compare two or more computer hardware and software systems. Hence, benchmarking is the process of evaluating different hardware systems or reviewing different software systems on the same or different hardware platforms. A web search service benchmark is therefore a standard set of executable instructions which are used to measure and compare the relative and quantitative performance of two or more systems through the execution of controlled experiments. Benchmark data such as throughput, jobs per time unit, response time, time per job unit, price and performance ratio, and other measures serve to predict price and performance and help us to procure systems, plan capacity, uncover bottlenecks, and govern information resources for various user, developer, and management groups (Can et al., 2004) (David et al., 2001) (Anon et al., 1985).
Examples are the TREC, TPC, SPEC, SAP, Oracle, Microsoft, IBM, Wisconsin, AS3AP, OO1, OO7, XOO7 standard benchmarks that have been used to assess the system performance. These benchmarks are domain-specific in that
they model typical applications and tie to a problem domain. Test results from these benchmarks are estimates of possible system performance for certain pre-determined problem types. When the user domain differs from the standard problem domain or when the application workload is divergent from the standard workload, they do not provide an accurate way to measure the system performance of the user problem domain. System performance of the actual problem domain in terms of data and transactions may vary significantly from the standard benchmarks. Performance measurement and evaluation is crucial in the development and advance of web search technology. A more open and generic benchmark method is needed to provide a more representative and reproducible workload model and performance profile (Jansen et al., 2006) (Richard 2006) (Vaughan 2004) (Kraaij et al., 2002).
1.2 Research Problem
Domain boundness and workload boundness are the research problem we try to tackle in this research. As described above, standard benchmarks model certain application types in a pre-determined problem domain. They represent a fixed problem
set presented to the proposed system. When the user domain differs from the standard domain or when the user workload deviates from the standard
workload, the test results vary significantly in the real setting and under the actual application context. Users cannot reproduce the test results and predict the performance. The reason is because benchmark results are highly dependent upon the real workload and the actual application. The standard test workload cannot represent the real workload and the test suite cannot accommodate the application requirement. Standard benchmarks cannot measure the effects of the user problem on the target system nor generate the realistic and meaningful test results (Stephen 2002).
In this research, we address the issue by proposing a domain-independent and workload-independent benchmark method which is developed from the perspective of the user requirements. We propose to develop a more generalized and more precise performance evaluation method from the perspective of the common carriers of workload requirements. We create a user-driven approach which models the benchmark development in a process of workload requirements representation, transformation, and generation.
1.3 Research Approach
Benchmarks can be synthetic or empirical. Synthetic benchmarks model the typical applications in a problem domain and create the synthetic workload. Empirical benchmarks utilize the real data
and tests. Though real workloads are ideal tests, the costs of re-implementation of the actual systems usually outweigh the benefits obtained. Synthetic benchmarks are therefore the common approach chosen by developers and managers. Further, benchmark experiments are composed of the experimental factors and the performance metrics. Experimental factors represent the variables which can affect the performance of the systems. Performance metrics are the quantitative measurements to be collected and observed in the benchmark experiments. They represent the set of independent variables and dependent variables to be modeled and formulated in the benchmark.
A workload is the amount of work assigned to or performed by a worker or unit of workers in a given time period. The workload is the amount of work assigned to or performed by a system in a given period of time. The loads are best described by the amount of work, the rate at which the work is created, and the characteristics, distribution, and content of the work. Conventionally, workload modeling and characterization start with the domain survey, observation, and data collection, and continue with a study of the main components and their characteristics. In general, the workload components consist of the data, operations, and control.
involves the data analysis and the operation analysis. We analyze the size of the data, the number of records, the length of records, the types of attributes, the value distributions and correlations, the keys and indexing, the hit ratios, the selectivity factors. We investigate the complexity of operations, the correlation of operation, the data input into the operation, the attributes and objects used by the operation, the result size, and the output mode. These are further examined with the control analysis of the duration of test, the number of user, the order of test, the number of repetition, the frequency and distribution of test, and the performance metrics.
In the web search context, we develop a benchmark method that comprises a workload requirements specification scheme, a scheme translator, and a set of benchmark generators. We adopt the common carrier of generic constructs. We analyze the key web search algorithms and formulate the generic constructs. The generic constructs describe the page structure and the query structure of web search that is not tied to a per-determined search engine.
Workload Specification Scheme
The workload specification scheme is designed to model the application requirements. It is a high-level generic construct concept to describe
requirements concerning data, operation, and control. A generic construct is the basic unit of operand. An operation is the basic unit of operator. The collection of a generic construct and an operation formulate a workload unit. Each workload unit becomes a building block to compose a larger workload unit.
Scheme Translator
The scheme translator is created with a set of lexical rules and a set of syntactical rules to translate the workload specification. It performs the code generation and produces three output specifications. One is the data specification. The other is the operation specification. Another is the control specification.
Data Generator
The data generator is made up of a set of data generation procedures which are used to create the test database according to the data distribution specification.
Operation Generator
The operation generator is made up of a set of operation generation procedures to generate the search operations. These procedures select operations, determine operation precedence, schedule arrivals, prepare input data, issue tests, handle queues,
gather and report time statistics.
Control Generator
The control generator is made up of a set of control generation procedures to generate the control scripts which are used to drive and supervise the experiment execution.
2. Literature Review
2.1 XML Query Capability
Benchmarking the XML data management systems should consider many factors. Designing a set of comprehensive queries to test the XML databases’ performance is an important point. XML query languages should capture the whole characteristics of a XML document, and the functionalities they provide would influence the query performance. The W3C XML Query Language working group (Chamberlin, Fankhauser, Marchiori, & Robie, 2003) list 20 XML query language “must have” functionalities, as Table shows. Some of the expected functionalities may affect the efficiency of the system significantly.
XQuery has met all of the requirements except F12 and F16, and it becomes a standard query language to test the performance of XML data management systems. Generally speaking, queries to benchmark XML
databases would fall into several categories: Match, Join, Navigation, Casting, Reconstruction, and Update. Queries for Match are mainly used to test the database ability to handle simple string lookups with a fully specified path. Join queries can be divided into two parts: Join on References, and Join on Values. References are an important part of XML, because they allow richer relationships than just hierarchical structure. Queries Join on References would test if query optimizer can take advantage of references to be joined. Queries Join on Values, on the other hand, would test the database’s ability to handle large intermediate results. Differing from the former, their joins are on the basis of values. Navigation Queries investigate how well the query processor can optimize path expressions, and avoid traversing irrelevant parts of the tree. Strings are the basic data type in XML documents. Casting strings to another data type that carries more semantics is necessary. Queries for Casting challenge the ability of the database to cast different data types. Reconstruction Queries attempt to reconstruct the original document from its fragmentations stored in the databases. Update Queries try to add, delete, and modify elements in the XML document. These queries test the databases’ ability to manage XML document. Furthermore, other XML query functionalities such as sort, ordered access, text search, and
aggregation also should be captured in the benchmark query set.
2.2 XML Benchmarks
XMark, XMach-1 and XOO7 are three benchmarks available today that can be used to evaluate certain aspects of XML database systems.
2.2.1 XMark
XMark (Schmidt, Waas, Kersten, Carey, Manolescu, & Busse, 2002) is a single-user benchmark. The data model of XMark is an Internet auction site. Therefore, its database contains one big XML document with text and non-text data. XMark enriches the references in the data, like the item IDREF in an auction element and the item’s ID in an item element. The text data used are the 17000 most frequently occurring words of Shakespeare’s plays. The standard data size is 100MB with a scaling factor 1.0 and users can change the data size by 10 times from the standard data (the initial data) each time. However, it has no support for XML Schema. In operation model of XMark, 20 XQuery challenges are designed to cover the essentials of XML query processing, as Table shows. No update operations are specified in XMark.
2.2.2 XMach-1
XMach-1 (Böhme & Rahm, 2001)
is a scalable multi-user benchmark. The main objective of the benchmark is to stress-test XML systems under a multi-user workload. The data model of XMach-1 is designed for B2B applications and considers text documents and catalog data. It assumes that size of the data files exchanged will be small. It provides support for DTD only and does not consider XML Schema for optimization. The operation model of XMach-1 consists of eight queries and three update operations, shown in Table.
Queries specified in XMach-1 cover typical database functionality (join, aggregation, sort) as well as information retrieval and XML-specific features (document assembly, navigation, element access). Update operations cover inserting and deleting of documents as well as changing attribute values. We find that some queries contain several query functionalities. It is hard to analyze the experiment result and ascertain which feature leads to the given performance result. Specially, XMach-1 has defined three update operations that are unique across other XML benchmarks.
2.2.3 XOO7
XOO7 (Li, Bressan, Dobbie, Lacroix, Lee, Nambiar, & Wadhwa, 2001) is an XML version of the OO7 benchmark, which was designed to test
the efficiency of object-oriented DBMS. XOO7 is a single-user based benchmark for XMLMS that focuses on the query processing aspect of XML. The data model of XOO7 comes from the OO7 benchmark by mapping the OO7 schema and data set to XML. No specific application domain is modeled by the data of XOO7. It is based on a generic description of complex objects using component-of relationships. XOO7 also proposes three different databases of varying size: small, medium, and large. It supports DTD only. In operation model, XOO7 provides relational, document and navigational queries that are specific and critical for XML database applications. These queries test the primitive features and each query
covers only a few features. Table displays the queries adopted in XOO7. XOO7 contains large amount of queries, each query covers only a few features. Comparing to the other two benchmarks, XOO7 has certainly the highest ratio which stresses its data-centric focus. However, we can find that some queries are focus on the same functionality. Similar to XMark, no update operation is specified in XOO7.
2.3 XML Benchmarks Comparison A comparison of key features of these main XML benchmarks against this research is described in Table 1. The key features include application focus, evaluation scope, database and workload characteristics.
Table 1: Comparison of Benchmarks over Workload Characteristics
Feature XMark XMach-1 XOO7 This Research
Evaluation Scope Query
Processor DBMS Query Processor Heterogeneous Information Integration Application Domain E-Commerce E-Commerce Generic Generic Data Model Documents Single-docu ment Multi-docum ents Multi-docu ments Multi-docume nts Scalability of Document Number 1 10 4 ~107 Unlimited Various Scalability of
Document Size 10MB~10GB 16KB Unknown Various
Data Heterogeneity XML document only XML document only XML document only Heterogeneous data sources Nodes/KB 18 10 67 Various Operation Model Queries 20 8 23 14 Update Operation 0 3 0 0
Table 2 groups queries of each benchmark by query functionality. Compared to other XML benchmarks, XMark provides a concise and comprehensive set of queries. However, it does not provide update operations to manipulate XML documents. XMach-1 only defines a small number of XML queries that cover multiple functions and update operations for which system performance is determined. XOO7 maps the original queries of OO7 into XML, and adds some XML specific queries. In general, XMach-1, XMark, and XOO7
cover only a subset of the XML query requirements. In this research, we attempt to propose a generic workload model. In order to cover the whole functionalities of XML query processing, we combine queries of these three XML benchmarks and integrate them into ten types of queries. In particular, the intelligent information integration system is generally used for query data, not provide data manipulation functions. Therefore, the query model in this research does not support update operations.
Table 2: Comparison of Benchmarks over Query Functionalities
Query Functionality XMark XMach-1 XOO7 This
Research Exact Match ˇ ˇ ˇ ˇ Joins Join on Reference ˇ ˇ ˇ ˇ Join on Value ˇ ˇ Regular Path Expressions Full Sub-path ˇ ˇ ˇ Unknown Sub-path ˇ ˇ ˇ Document Construction Structure Preserving ˇ ˇ ˇ Structure Transforming ˇ ˇ ˇ Ordered Access ˇ ˇ ˇ ˇ Sorting By String ˇ ˇ ˇ By Non-string ˇ ˇ Missing Elements ˇ ˇ Text Search ˇ ˇ ˇ ˇ Data-type Cast ˇ ˇ Function Application ˇ ˇ ˇ ˇ Update Operation ˇ 2.4 Ontology
Ontologies play an important role for integration as a way of formally defined terms for communication. They aim at capturing domain knowledge in a generic way and provide a commonly agreed understanding of a domain, which may be reused, shared, and operationalized across applications and groups.
A good ontology should represent the domain specific knowledge explicitly. The question is how do we
know an ontology is good? The answer is the ontology benchmark. There are plenty of benchmark studies in other fields like database or compilers. However, there are no specific benchmarks studies or tools for evaluating ontology-based applications. In fact, there is still no guideline to evaluate ontologies and related technologies.
In this section, we introduce the role of ontologies in intelligent information integration first. And then we discuss a major inference task which
is the main operation of an ontology benchmark. Finally, the ontology related benchmark works are reviewed.
2.4.1 Ontology and Intelligent Information Integration
Traditional integration approaches use inexpressive models of database schemas or XML trees to integrate heterogeneous data sources. This would cause many semantic heterogeneity problems. Ontologies provide much richer modeling means with classes and properties organized into is-a hierarchy and enriched with axioms and relations processable with inference (Maier, Aguado, Bernaras, Laresgoiti, Pedinaci, Pena, & Smithers, 2003). Almost all ontology-based integration approaches ontologies are used for the explicit description of the information source semantics. With respect to the integration of data sources, they can be used for the identification and association of semantically corresponding information concepts. Some approaches use ontologies not only for content explication, but also either as a global query model or for the verification of the (user-defined or
system-generated) integration description (Wache, Vögele, Visser,
Stuckenschmidt, Schuster, Neumann, & Hübner, 2001). Ontologies are usually expressed in a logic-based language, so that fine, accurate, consistent, sound, and meaningful distinctions can be made
among the classes, properties, and relations. Therefore, ontologies not only have the expressiveness needed in order to model the data in the sources, but their reasoning ability can help in the selection of the sources that are relevant for a query of interest, as well as to specify the extraction process.
2.4.2 Ontology and Benchmark
To the best of our knowledge, the benchmark presented here is the first one for ontology-based intelligent information integration. The ontology benchmark model in this research differs from database benchmarks, such as Wisconsin benchmark, OO7 benchmark, and BUCKY benchmark. They are all DBMS-oriented and storage benchmarks, and there is no inference ability included. In this research, the ontology workload model is applied to an intelligent information integration system, and we focus on the inference ability of the ontology. Ontology and XML are often found together and are often confused. XML is a standard for marking up - adding additional information, called metadata - to documents. The purpose of XML is to tag textual information with additional structure that enables it to be “understood” and exchanged by programs. However, XML tags still require humans to interpret their meanings. Therefore, XML benchmarks only focus on structural and syntactic evaluation of systems, and they have no
semantics. On the other hand, ontology benchmark is devoted to capture the semantic expressions in the system. Thus, ontology and XML are complementary technologies: ontology provides the meaning for XML standards; XML provides a valuable medium for information exchange between programs that share the same ontology.
As mentioned above, there is still no guideline for evaluation of ontology-based application. Horrocks and Patel-Schneider (1998) benchmark description logic systems, or so-called knowledge bases. Description logics (DLs) are a family of knowledge representation languages that can be used to represent the knowledge of an application domain in a structured and formally well-understood way. Description logic systems provide their users with various inference capabilities that deduce implicit knowledge from the explicitly represented knowledge. Horrocks and Patel-Schneider try to evaluate the reasoning algorithms in description logics. Terminological part (Tbox) is a set of axioms describing the structure of domain. Assertional part (Abox) is a set of axioms describing concrete situation (Horrocks, 2002). They are related to this research. In an intelligent information integration system, the ontology can be viewed as
the Tbox, and the heterogeneous data can be viewed as Abox. However, the logic described is only a subset of the ontology languages, such as DAML+OIL and OWL. DAML+OIL and OWL can be seen to be equivalent to a very expressive description logic. They provide more constructors and allow more axioms than description logic. Therefore, the inference services of ontology are more complex than traditional description logic systems.
3. Research Method
3.1 Research Approach
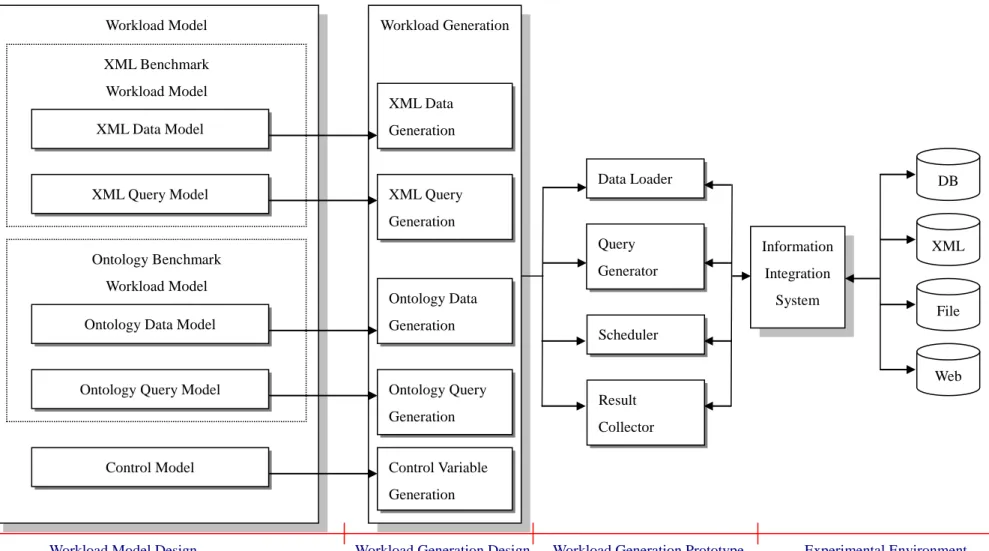
The literatures studied would help us to identify the important performance factors for XML and ontology processing. We analyze the XML-specific and ontology-specific requirements in more details to justify the design of the benchmark. The research structure is shown in Figure 1. The benchmark study consists of two benchmark workload models, the XML benchmark workload model and the ontology benchmark workload model. Both of them consist of the data model and query model according to the generic constructs and constraints requirements. Next, the control model is created before the generic workload model to be generated and executed so as to measure and evaluate the systems.
Figure 1: Research Model Workload Model XML Benchmark Workload Model Ontology Benchmark Workload Model Control Model XML Data Model XML Query Model
Ontology Data Model
Ontology Query Model
Workload Generation XML Data Generation XML Query Generation Ontology Data Generation Ontology Query Generation Control Variable Generation Information Integration System DB XML File Web Data Loader Query Generator Result Collector Scheduler
In this research, we focus on intelligent information sources integrated in XML and ontology. The benchmark model we propose would capture most features of the released XML-based and ontology-based specifications.
Developing a benchmark requires the definition of the test workload model first. In this research, we provide a benchmark workload model that combines XML and ontology in intelligent information integration. In XML workload model, the data model describes a generic XML data model and the operation model defines a comprehensive set of test queries that covers the major aspects of XML query processing. In ontology workload model, the data model describes the major ontology component, and the operation model defines some important criteria to query the ontology. The control model defines the variables that used to set up the benchmark environment.
3.1.1 XML Data Model
XML is a hierarchical data format for information exchange on the Web. An XML document consists of nested elements that contain data or other elements. The boundaries of these elements are either delimited by start-tags and end-tags, or, for empty elements, by empty-element tags. The text between start-tags and end-tags is
the content of the element. Each element has a type, identified by name, sometimes called its “generic identifier” (GI), and may have a set of attribute specifications. Each attribute specification has a name and a value (Bray, Paoli, Sperberg-McQueen, & Maler, 2000). XML documents may comply with a Document Type Definition (DTD) or a XML Schema. DTD has traditionally been the most common method for describing the structure of XML document. But DTD lacks enough expressive power to properly describe highly structured data. XML Schemas are an XML language for describing and constraining the content of XML documents. It provides a richer and more powerful means for defining the data. Therefore, XML schema becomes the most common method for defining and validating highly structured XML documents rapidly.
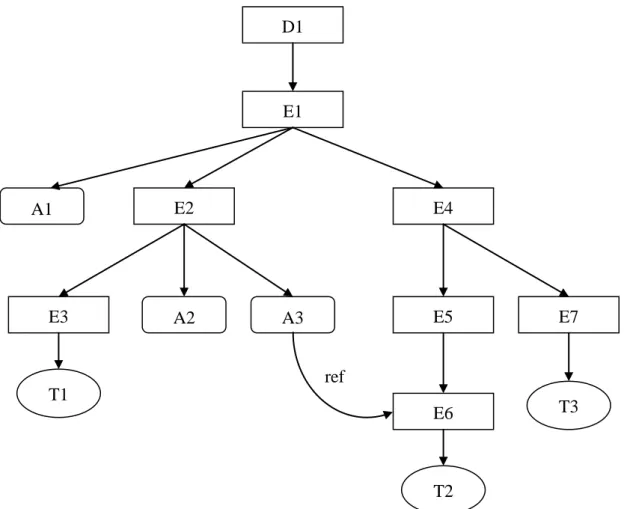
In the XQuery and XPath data model, XML documents are modeled as an ordered tree. The tree contains seven distinct kinds of nodes: document, element, attribute, text, namespace, processing instruction, and comment. In this research, for simplicity, we only consider document, element, attribute, and text nodes. The data model is a node-labeled, directed graph, in which each node has a unique identity shown in Figure 2. Document order is defined for all the nodes in the document and corresponds to the order in which the
first character of each node occurs in the XML document.
Document nodes: The document node is a virtual node pointing to the root element of an XML document. The document element in a XML document is a child of the document node.
Element nodes: Every element in the document is an element node. Element nodes have zero or more children that can be element nodes or text nodes.
Attribute nodes: Each element node has an associated set of attribute
nodes. Note that the element node that owns this attribute is called its “parent” even though an attribute node is not a “child” of its parent element. An attribute node has an attribute name and an attribute value. Attribute nodes have no child nodes. If more than one attribute of an element node exists, the document order among the attributes is not distinguished. This is because there is no order among XML attributes. Text nodes: A text node must have
only one parent and have no child nodes. A text node cannot contain an empty string as its content.
Figure 2: Graphic Representation of XML Data Model D1 E1 E3 E2 E4 A1 A2 A3 E5 E7 E6 ref T1 T2 T3
3.1.2 XML Query Model
The query model is specified in generic constructs. We further identify key factors that influence the complexity of each query. This would help users to evaluate performance of the system with increasing complex queries.
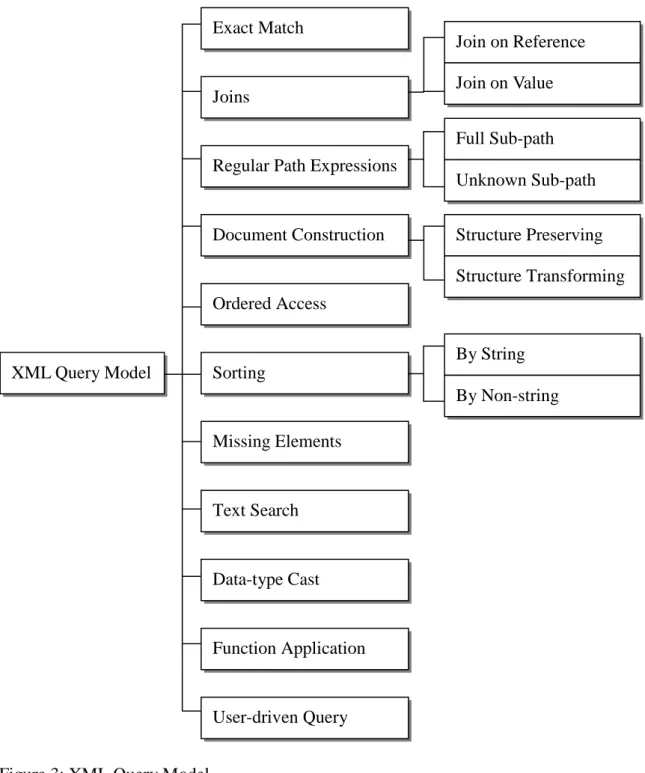
The query model we defined can be classified into ten categories. Each of them challenges different aspects of XML processing. Besides, users can specify queries according to their
requirements which is called “user-driven query”. Figure 3 shows the XML query model. The following will describe each category briefly, and express each query in generic constructs. In each query, the generic term is written in italics. Then we illustrate them in XQuery. We use E1, E2 etc. to denote a certain element, and A1, A2 etc. to denote a certain attribute. The number of them does not indicate their order in a XML document, just for representing convenience. Finally, the complexity factors will be discussed.
Figure 3: XML Query Model
3.1.3 Exact Match
This type of queries specifies a full path expression. One main concept of XQuery is the use of path expressions for selecting nodes. The length of the path expression depends on the levels of
documents. This is the simplest query type. We can use this type of queries to establish a simple “metric” comparing performance of the following queries. It tests the database ability to handle simple string lookups with a fully specified path.
XML Query Model
Exact Match
User-driven Query Joins
Regular Path Expressions
Document Construction Ordered Access Sorting Missing Elements Text Search Data-type Cast Function Application Join on Reference Join on Value Full Sub-path Unknown Sub-path Structure Preserving Structure Transforming By String By Non-string
Generic constructs are: Given a full path
expression, find elements E1 that have
an attribute A1 in a certain value X.
XQuery expression is:
FOR $a IN input()/SUBPATH/E1[@A1 = “X”] RETURN $a
3.1.4 Joins
References are an integral part of XML identifying the relationship between related data. With using of reference, richer relationships can be represented than just hierarchical element structures. The system must be able to combine separate information together using joins. Horizontal
traversals are defined in this type of queries. Joins can be on the basis of references and values. References are specified in the DTD and may be optimized with logical OIDs for example. The system should make use of the cardinalities of the sets to be joined. Joins based on values test the database’s ability to handle large (intermediate) results.
Join on Reference
Generic constructs are: Find element E1
by the reference attribute A1 of E2. The
reference attribute A1 of E2 refer to E1.
XQuery expression is:
FOR $a IN input()//E1 $b IN input()//E2 WHERE $a/@A2 = $b/@A1 RETURN $a
Join on Value
Generic constructs are: This time
reference is based on join of the data
values. Find element E1 whose attribute A1 is equal to the attribute A2 of E2.
XQuery expression is:
FOR $a IN input()//E1 $b IN input()//E2 WHERE $a/@A1 = $b/@A2 RETURN $a
3.1.5 Regular Path Expressions
Regular path expressions are a
basic building block of almost every XML language including XPath, XQuery, and XSLT. The system should
be capable of optimizing path expressions and reducing traversals of irrelevant parts of the tree. We often use wildcards in regular path expressions and the system should realize that it is not necessary to traverse the complete
document tree to execute such expressions. This type of queries tries to quantify the costs of long path traversals that do not include wildcards, and the costs of path traversals that include wildcards.
Full Sub-path
Generic constructs are: Find element E1
with a long path expression. XQuery
expression is:
FOR $a IN input()/SUBPATH/E1 RETURN $a
Unknown Sub-path
Generic constructs are: Find element E1
with a regular path expression include wildcards. XQuery expression is:
FOR $a IN input()//E1 RETURN $a
3.1.6 Document Construction
Structure is very important to XML documents. But XML documents storing in relational DBMSs often need to be broken down. Reconstructing the original document is a big challenge to
systems. We might retrieve fragments of original documents with original structures. But sometimes we may want to construct document fragments with new structures. These queries tests for the ability of the system to reconstruct portions of the original XML document.
Structure Preserving
Generic constructs are: Return a XML
document constructed by element E1
and its sub-element E2. Retrieve E2 of E1 that has an attribute A1 equal to a certain value X. XQuery expression is:
FOR $a IN input()//E1[@A1 = X] RETURN <$a> $a/E2 </$a>
Structure Transforming
Generic constructs are: Construct a new
XML document. Find element E1 with an attribute A1 equal to a certain value
X, and select several sub-element of E1 to construct a new XML document.
FOR $a IN input()//E1[@A1 = X] RETURN <output> {$a/E2/E3} {$a/E2/E4} {$a/E2/E3/E5} {$a/E6} </output> 3.1.7 Ordered Access
Order of elements is important in XML documents. Because documents will sometimes be fragmented when they are stored on disk, it is important
that the order of these fragments in the original document is preserved. The system should be able to preserve these intrinsic orders. This type of queries attempts to test how efficient the system handle queries with order constraints.
Generic constructs are: Find element E1
with attribute A1 in certain value X, and
return the first sub-element E2 of E1.
XQuery expression is:
FOR $a IN input()//E1[@A1 = X] RETURN $a/E2[1]
3.1.8 Sorting
The order by clause is the only facility provided by XQuery for specifying an order other than document order. In XML documents, the generic data type of element content is string,
but users may cast the string type to other types. Therefore, the system should be able to sort values both in string and in non-string data types. This type of queries tests whether the system can do sorting efficiently.
By String
Generic constructs are: List sub-element
E3 of element E1 sorted by sub-element E2. XQuery expression is:
FOR $a IN input()//E1 ORDER BY $a//E2
By Non-string
Generic constructs are: List sub-element
E3 of element E1 sorted by sub-element
E2. This time E2 is a non-string value.
XQuery expression is:
FOR $a IN input()//E1 ORDER BY $a//E2
RETURN $a/E3
3.1.9 Missing Elements
In XML, schemas are more flexible and may have a number of irregularities. Queries in this type are to test how well
the system knows to deal with the semi-structured aspect of XML data, especially elements that are declared optional in the schemas.
Generic constructs are: Find element E1
whose sub-element E2 has NULL value.
XQuery expression is:
FOR $a IN input()//E1 WHERE EMPTY($a/E2/text()) RETURN $a
3.1.10 Text Search
Text search plays a very important part in XML document systems. This
type of queries conducts a full-text search in the form of keyword search. They will challenge the textual nature of XML documents.
Generic constructs are: Find element E1
whose sub-element E2 contains a
specific text Y. XQuery expression is:
FOR $a IN input()//E1 WHERE CONTAINS ($a/E2, “Y”) RETURN $a
3.1.11 Data-type Cast
Strings are the generic data type in XML documents. But we often need to
cast strings to another data type that carries more semantics. These queries challenge the system’s ability to transform between data types.
Generic constructs are: Find element E1
with a constraint that contain operations need to transform data value of sub-element E2 to other data-type.
Retrieve element E1 whose sub-element E2 is bigger than a certain number X.
XQuery expression is:
FOR $a IN input()//E1 WHERE $a/E2 > X RETURN $a
3.1.12 Function Application
The following query challenges the system with aggregate functions such as count, avg, max, min and sum. Generic
constructs are: Group element E1 by
sub-element E2, and calculate the total number of elements for each group.
XQuery expression is:
FOR $a IN DISTINT-VALUES (input()//E1/E2) LET $b := input()//E1[E2 = $a]
RETURN count($b)
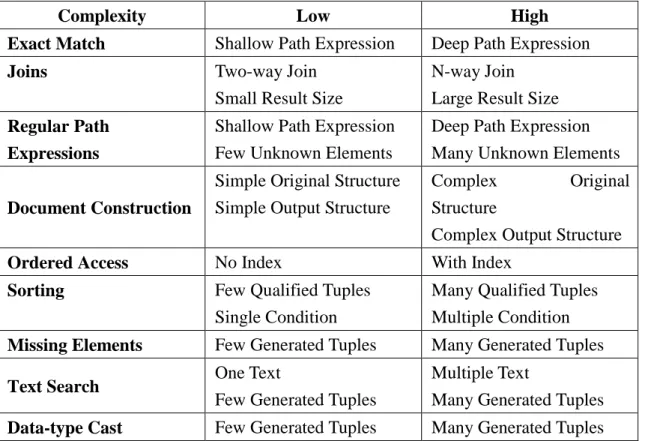
Table 3 summarizes the complexity factors of each query type. Table 3: Complexity Factors Listing
Complexity Low High
Exact Match Shallow Path Expression Deep Path Expression
Joins Two-way Join
Small Result Size
N-way Join Large Result Size Regular Path
Expressions
Shallow Path Expression Few Unknown Elements
Deep Path Expression Many Unknown Elements
Document Construction
Simple Original Structure Simple Output Structure
Complex Original Structure
Complex Output Structure
Ordered Access No Index With Index
Sorting Few Qualified Tuples
Single Condition
Many Qualified Tuples Multiple Condition Missing Elements Few Generated Tuples Many Generated Tuples
Text Search One Text
Few Generated Tuples
Multiple Text
Many Generated Tuples Data-type Cast Few Generated Tuples Many Generated Tuples
Single Casting Multiple Casting
Function Application Few Generated Tuples Many Generated Tuples
3.2 Ontology Data Model
An ontology defines the terms used to describe and represent an area of knowledge. Ontologies are used by people, databases, and applications that need to share domain information. Ontologies include computer-usable definitions of basic concepts in the domain and the relationships among them. An ontology may take a variety of forms, but necessarily it will include a vocabulary of terms, and some specification of their meaning. This includes definitions and an indication of how concepts are inter-related which collectively impose a structure on the domain and constrain the possible interpretations of terms (Uschold, King, Moralee, & Zorgios, 1998). Generally speaking, an ontology consists of the following main constructs (Stevens, Goble, & Bechhofer, 2000; Weißenberg & Gartmann, 2003).
o Facts represent explicit knowledge, consisting of:
Classes or concepts are generalizations of instances. Concepts are the focus of most ontologies. A concept is a representation for a conceptual grouping of similar terms. A concept can have subconcepts that represent concepts that are
more specific than the superconcept. Concepts fall into two kinds of (1) primitive concepts are those which only have necessary conditions (in terms of their properties) for membership of the class. (2) Defined concepts are those whose description is both necessary and sufficient for a thing to be a member of the class.
Properties can be subdivided into scalar attributes and non-scalar relations. The property can be defined to be a specialization (subproperty) of an existing property. An attribute is a property of a concept that refers to a datatype (integer, string, float, boolean etc.). An example of an attribute is “has-name” related to a string. A relation is a property of a concept that refers to another concept. Specialization / Generalization are one of the standard relations. For instance, “is a kind of” defines a relation that may be applied to the concepts “Enzyme” and “Protein”. Instances represent individual
entities and are connected by type-of relation to at least one
class; some authors only consider facts about instances as real facts. Strictly speaking, an ontology should not contain any instances, because it is supposed to be a conceptualization of the domain. The combination of an ontology with associated instances is what is known as a knowledge base. However, deciding whether something is a concept of an instance is difficult, and often depends on the application.
o Axioms are rules used to add semantics and to infer knowledge from facts. In contrast to facts, they represent implicit knowledge about concepts and relations, e.g., whether a relation is transitive or symmetric.
3.3 Ontology Query Model
Initially, ontologies are introduced as an “explicit specification of a conceptualization”. In an intelligent information integration system,
ontologies can be used to establish common vocabularies and semantic interpretations of terms from information sources. With respect to the integration of data sources, they can be used for the identification and association of semantically corresponding information concepts. People can share and exchange information in a semantically consistent way.
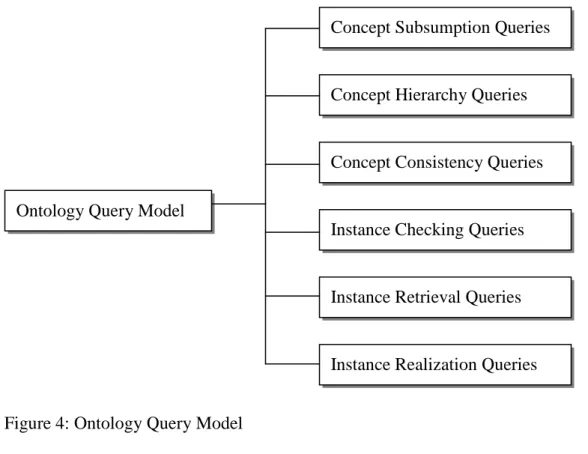
Using ontology basic components described in the previous section, users can define their own ontology in any application domain. Then we conduct a series of tests to see how the system handles such ontologies. The operation model in the ontology workload model is a set of queries, and the answers are generated by inferring from the ontology. The queries we present here are representative for different application domains. We conclude the reasoning tasks and construct six basic reasoning queries for the ontology benchmark. Figure 4 shows the ontology query model in this research.
Figure 4: Ontology Query Model
Concept Subsumption Queries: checks if one concept is a subconcept of another. Generic constructs are: Given concepts C
and D, determine if C is a subcconcept of D with respect to ontology O.
Concept Hierarchy Queries: determines the concepts that immediate subsume or are subsumed by a given concept. Generic constructs are: Given a
concept C return all/most-specific superconcepts of C and/or all/most-general subconcepts of C.
Concept Consistency Queries: checks for (in)consistency of concept definitions. Generic constructs are: Given a concept C,
determine if the definition of C is
Instance Checking Queries: given a partial description of an individual (instance) and a concept description, finds whether the concept describes the instance. Generic constructs are:
Given a concept C, determine whether a given individual A is an instance of C.
Instance Retrieval Queries: finds all instances that are described by a given concept. Generic constructs are: Given a concept C, determine
all the individuals in ontology O that are instances of C.
Instance Realization Queries: given a partial description of an instance, finds the most specific concepts that describe it. Generic constructs are: Given an individual
A, determine all the concepts in
Ontology Query Model
Concept Subsumption Queries
Concept Hierarchy Queries
Concept Consistency Queries
Instance Checking Queries
Instance Retrieval Queries
When querying the intelligent information integration system, the reasoning service may not be so straightforward. We need to evaluate the ontology with increasing complexity. When formulating the complex benchmark queries, several factors should be taken into account (Guo, Heflin, & Pan, 2003). More complex queries may be formulated according to these factors. These allow the system be evaluated under different level of workloads.
Input size: This is measured as the proportion of the class instances involved in the query to the total class instances in the benchmark data.
Selectivity: This is measured as the estimated proportion of the class instances involved in the query that satisfy the query criteria.
Complexity: We use the number of classes and properties that are involved in the query as an indication of complexity.
Hierarchy information assumed: This considers whether information of class hierarchy or property hierarchy is required to achieve the complete answer. Besides, the depth and width of class hierarchies should also been considered.
3.4 Test Database Generation
In order to evaluate the performance of the intelligent information integration system, we must define the test database. The workload consists of a test operation and a test database. The test database identifies what data must be loaded into the data sources, as well as the volume of the test data. Information integration system data sources are disparate and heterogeneous. Information comes from various sources (including structured, semi-structured and unstructured sources) and formats (such as database tables, XML files, PDF files, streaming media, internal documents, and Web pages). For this research, the data sources can be divided into three kinds: relational databases, object-oriented databases, and Web pages. For each data source, we must analyze the actual data and extract statistical data. Data analysis characterizes data in terms of the size of the database, the number of records, the length of records, the types of fields, and the value distributions.
Determine data values: A number of data types are supported in this research, including long integer number, double precision floating point number, decimal number, money, datetime, fixed-length and variable-length character strings. We must conduct extensive studies to characterize each data source with several distribution parameters. Frequency distributions are
computed and standard probability distributions are fit to the data in order to generate the value of test data. Data values are created with these common data distributions such as exponential, normal, discrete, rotating, zipfian2 or uniform distribution.
Determine scaling factors: After determining the value of the test data, we must define how much data should be generated, i.e. defining the database scaling factor. Generally speaking, the logical size for the test database used for the benchmark is at least equal to the logical size of physical memory on the host(s). For this research, we refer to the AS3AP benchmark standard.
Open data source: We must determine the test data of the open data source on the Web, but this is problematic. There is in excess of 10 billion pages on the Web, which include HTML files, text documents, PDF files, Microsoft Office documents and other similar data files. We cannot possibly download every page from the Web much less adequate sample size. Even the most comprehensive search engine currently indexes just a small fraction of the entire Web.
As such, it is important to carefully select the so-called “important” pages, so that the fraction of the Web that is
visited becomes more meaningful. In order to select these important pages, we can use several metrics for prioritizing them. For any given web page, we must define its importance using the following methods (Arasu, Cho, Garcia-Molina, Paepcke, & Raghavan, 2001):
Interest-driven. The goal is to obtain pages of interest to a particular user or set of users. Important pages are those that match user interest. One particular way to define this notion is through what we call a driving query. For any given query, the importance of a page is defined by the “textual similarity” between the page and the driving query. Assuming that query represents the user’s interest, this metric shows how relevant the page is. Another interest-driven approach is based on a hierarchy of topics. Interest is defined by a topic, and we attempt to guess the page topics that will be visited by analyzing the link structure that leads to the candidate pages.
Popularity-driven. Page importance depends on how popular a page is. For instance, one way to define popularity is to use a page’s backlink count. Intuitively, a page that is linked to by many pages is more important than one that is seldom referenced.
of a page is a function of its location, not its contents. For example, URLs ending with “.com” may be deemed more useful than URLs with other endings, or URLs containing the string “home” may be of more interest than other URLs. Another location metric that is sometimes used considers URLs with fewer slashes more useful than those with more slashes.
(3) Control Model
The control model defines the environment setup variables to execute the experiment. A common set of parameters including the steady state, the test mode, the test duration, the test sequence and the number of repetitions should be specified as follows.
Steady State: The benchmark test must be executed in a steady state, in order to return the sustained system performance.
Test Mode: There are three kinds of test mode, that is, cold mode, warm mode, and hot mode. In cold mode, there is no data in the cache. The system cannot retrieve data from the cache directly. Therefore, the performance in cold mode is usually slower than the other two modes. In warm mode, the data is left in the cache from the prior query. Because of that, the test response time decreases. In hot mode, a query is
executed in cold mode first, and then is executed with the cache data for several times. The average response time is computed.
Test Duration: Test duration means time intervals of the benchmark. Each interval must begin after the system has reached steady state and is long enough to generate the reproducible throughput. Each interval must extend uninterruptedly for a period of time.
Test Sequence: Test sequence indicates the order of the queries to be executed.
Number of Repetitions: Number of repetitions means execution repeated times.
(4)Performance Metrics
Performance metrics can be divided into two types, i.e., the speed-specific metrics and the relevance-specific metrics. The former consists of the metrics of response time and throughput. The latter has the metrics of relative recall and precision.
Response time: Response time refers to the time interval between when a request is made and when the response is received by the requester.
Throughput: Throughput refers to the number of operations completed by the system per unit time.
precision refer to two important measures of evaluation of information retrieval. However, it is very difficult, if not impossible, to directly apply these measurements to the evaluation of Web information retrieval systems due to the unique nature of the Web. There is no proper method of calculating absolute recall of search engines as it is impossible to know the total number of relevant in huge databases. The relative recall value is defined in (Clarke & Willet, 1997).
3.5 Experimental Design
We use the university campus as the test scenario of the benchmark prototype. It describes universities and departments and the activities that occur at them. The global schema for the intelligent information integration prototype system is shown on Appendix
A. For the Tamino XML server, we have defined six schemas: Department, Faculty, Student, Grad Student, Course, and Publication. These schema details are shown on Appendix C.
3.6 Prototype Functions
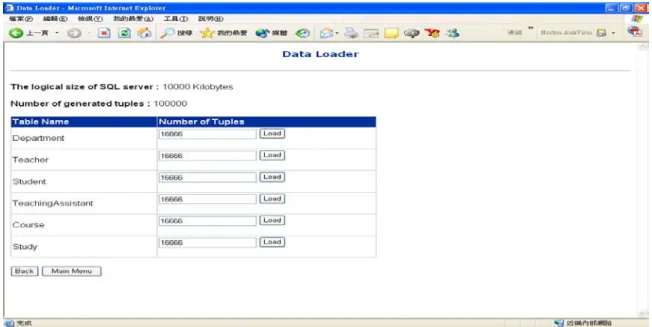
3.6.1 Data Loader
In the data loader, users can define the logical database size. The default logical database sizes for each data source are uniform and users can modify them individually. The data sources and data schema in the prototype are described in the previous section. Furthermore, in the SQL Server users can adjust the number of tuples loaded into each relation. Similarly, users can alter the number of instances generated for each schema in Tamino XML server as shown in Figure 5.
Figure 5: Data Loader
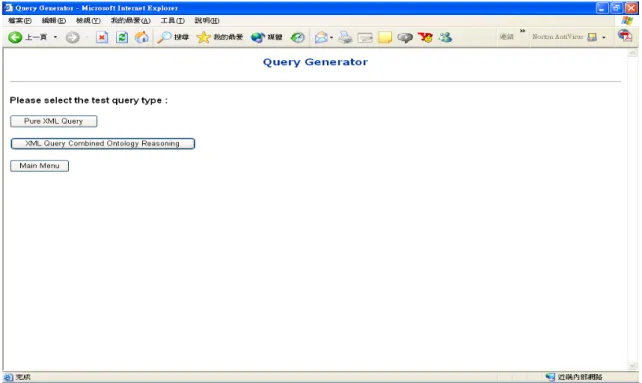
3.6.2 Query Generator
The query generator can divided into two parts: pure XML query and XML query combined ontology reasoning as shown in Figure 6. Users can evaluate pure XML processing performance of intelligent information integration systems or combined ontology reasoning services. In each of them, users can input the queries they want to test or simply select the standard query types predefined in the query selector. The queries are generated according to the XML query model. In
open query input, users can specify several queries according to global schema and their requirements. All specified queries will be executed in one test, and users can delete any one in the open query list as shown in Figure 7- Figure 9. In the standard query selector, after choosing the standard test queries, users can specify the complexity of each query further. It would help users to evaluate the system performance at different complexity levels. The complexity of query is determined by the complexity factor.
Figure 6: Query Generator
Figure 8: Query Generator – Select Standard Query Type
Figure 9: Query Generator – Set Standard Query Complexity
3.6.3 Scheduler
According to the control model, several parameters should be set to
execute the benchmark. The parameters we implement in the prototype are test sequence and number of repetitions. Both in the open query input and in the standard query selector, once the test
query set has been determined, users can set up the executed sequence and the repetitions of each query in the scheduler.
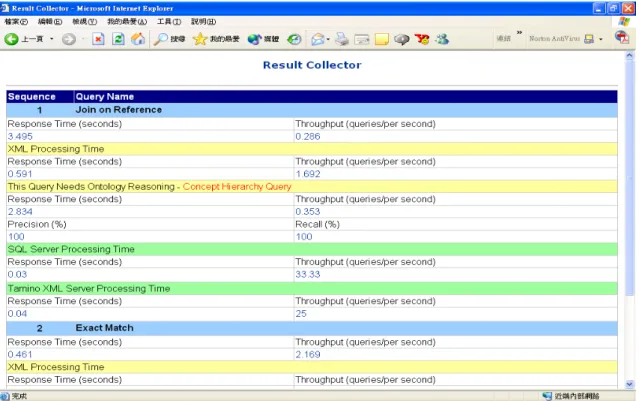
3.6.4 Result Collector
The result collector shows the test results of the queries we specified. The test results can be divided into three parts: the total execution result, the XML query test result, and test result of each data source. If the test query needs to combine ontology reasoning service, the ontology query test result will be
shown in the test result. In the total execution result, the total query response time and throughput are illustrated. In the XML query test result, it shows the query response time and throughput of the XML query processing as shown Figure 10. In the ontology query test result, it adds two extra performance metrics: recall and precision. This can help users evaluate the quality of answer entailed by the ontology. Finally, the result collector lists the query response time and throughput of each data sources.
4. Research Implications and Concluding Remarks
4.1 Research Implications
In this research, we have accomplished four main tasks. First, an analysis framework of web search and benchmark literature to lay the basis of generic construct development is developed. Our aim is to collect all related literature on the classic web search algorithms and the benchmark methods. We collected and compiled the key web search algorithms and the benchmark methods summarized to be representative. Secondly, a set of heuristics to formulate the generic constructs of web search algorithms are presented. Generic constructs are extracted from the main web search algorithms and the benchmark methods. We analyzed the algorithms and find the essential constructs. For instance, PageRank is based on inlinks and outlinks of the page so these become the key components of the algorithm where the web page” is a generic construct and the “tag” is the operation of the generic constructs. Thirdly, a more representative and reproducible workload model of web search is created. The generic constructs of a web page is extracted into the page model. The generic constructs of the search types are extracted into the query model. Designed as such, this benchmark meets the desired characteristics of scalability,
portability and simplicity. Fourthly, a
computer-assisted benchmarking process is implemented in a prototype
system. The prototype system is designed to help prove the feasibility and validity of the research method.
In this research, we have described a detailed approach to model workload requirements from the user's perspective. This results in a more realistic environment of workload representation, transformation, and generation. We have delineated the main components of the method. They include the workload specification scheme, the scheme translator, and the data and operation generators.
The method is domain-representative and workload-representative because we model from the user problem domain and characterize from the user application. The benchmark method is scalable because we can scale up or down the problem size and the problem complexity by changing the data definition and the operation definition via specification. It is reproducible because we use a high-level specification scheme to describe the general workload requirements. The method enables a custom benchmark where users can control the execution through requirements specification instead of manual manipulation.
In the new benchmark method, we have presented a common carrier
concept to capture and compose the user requirements into three carrier components of model. They are the data component model, the operation component model, and the control component model. Web search experiment requires a page model similar to the object model to abstract web as a directed labeled graph in which the nodes model objects and the outgoing edges of an object model the attributes of the object. Designed as such, the benchmark conforms to the desirable characteristics of relevance and rigorousness.
There are several limitations in this research due to the time and resource constraints. We did not verify all performance indicators through the prototype system. The validity of this research can be further improved. The data generator of the prototype system is primitive.
Due to the infinity of the Internet, we cannot precisely verify all performance variables. Thus, the validity of this research is limited which can be further improved.
In the prototype, the query generator developed is primitive. So far, it depends on the extent of functions supported by the web search service APIs.
The experiments are mainly the basic and synthetic tests. Thus, the
comprehensiveness and
completeness of experiments can be enhanced.
The future research will continue to augment the experimental prototype in order to accommodate a larger set of data, more complicated operations, more data distribution types, and a wider collection of performance metrics. We plan to develop an expert system to analyze benchmark results, pinpoint performance bottlenecks, provide possible reasons for the test results and advise on the actions to take. In addition, we will further quantify the advantages of the method in the form of metrics on cost and quality. In the future, we further enhance the method to provide users and mangers the means to diagnose and detect the strength and weakness of each benchmark.
Add more advanced generic constructs: Web search benchmark and development for new algorithms is a continuing effort. Continuously collecting the new web search-related literature can help find more advanced generic constructs. Adding more advanced generic constructs to a workload model can advance the generality. Enhance the complexity of tests:
The experiments we have performed only include the baseline test suites of algorithms. In order to completely verify the workload model, we need to test more new
algorithms. Due to the limitations of the web search APIs, we have only designed ten simple tests to be applied with the APIs. If more web search APIs can be available, we can perform more complicated tests in the future. Another direction is to provide a comparison of experimental results with those of different search engines besides Google and Yahoo.
Enhance the features of the prototype: The prototype system can be expanded to include the rest of the features of the research method in the future.
4.2 Concluding Remarks
In this research, we have developed the XML and ontology benchmark workload model in intelligent information integration, and built a workload generation prototype. We have reviewed the XML and ontology related literature to motivate the design of the workload model. The objective of this research is to develop a workload model to test whether the intelligent information integration system under EB environment can overcome the diverse formats of content and derive meaning from this content. In order to apply the workload model to different scenarios easier, it is designed in generic constructs. Finally, we validate the research model through the prototype
implementation.
Enhancing the ontology query model. The development of an ontological standard presents many opportunities and challenges. New reasoning tasks may arise in the future. Retrieval (instances of a concept) and realization (most specific class of instance) may not be sufficient. In order to make the ontology query model more comprehensive, further study to keep track of ontology progression is needed.
Improving the complexity factors of the XML query model. The complexity factors we analyze in the XML query model are still too rough. Each query type can be analyzed more carefully to refine the query model.
Implementing various data distributions. In this research, only uniform distribution is implemented. It cannot evaluate performance under different distributions. Implementation of diverse data distributions will become a user requirement.
Applying the workload model to other applications. Ontology and XML are complementary technologies, and there are other applications that can apply. In this research, we assume the
integration system is used on Intranets, such as enterprise information integration (EII), electronic business (EB), and enterprise application integration (EAI). There are other applications between enterprises that may need to integrate heterogeneous information, such as business-to-business integration (B2Bi), collaborative commerce (C-Commerce), and electronic commerce (EC). We can modify the workload model of this research to create other benchmarks that are based on XML and ontology with different characteristics.
5. References
1. Anon et al. (1985). A measure of s processing power. Datamation,
17(3), April 1, 112-118.
2. Bapna, R., Goes, P., Gupta, A., & Jin, Y. (2004). User heterogeneity and its impact on electronic auction market design: an empirical exploration. MIS Quarterly, 28(1), March, 21-43.
3. Bitton, D., DeWitt, D. J., & Turbyfill, C. (1983). Benchmarking data management Systems - a systematic approach. Proceedings
of the 9th International Conference on Very Large Data Bases, August,
8-19.
4. Bitton, D. & Turbyfill, C. (1985). Design and analysis of multiuser benchmarks for data management system. Proceedings of the HICSS-18 Conference.
5. Bohme, T. & Rahm, E. (2001). Xmach-1: benchmark for XML data management. In Proceedings
of the German Data management Conference.
6. Cardenas, A. F. (1973). Evaluation and selection of file organization - a model and system.
Communications of the ACM, 16(9),
September, 540-548.
7. Carey, M. J., DeWitt, D. J., & Naughton, J. F. (1993). The 007 benchmark. Proceedings of the
1993 ACM SIGMOD International Conference on Management of
Data, May, 12-21.
8. Carey, J. Michael, David J. DeWitt, Jeffrey F. Naughton, Mohammsd Asgarian, Paul Brown, Johannes E. Gehrke, & Dhaval N. Shah. (1997). The BUCKY object-relational benchmark. ACM SIGMOD,
135-146.
9. Cattell, R. G. G. & Skeen, J. (1992). Engineering data management benchmark. ACM Operations on
Data management Systems, 17(1),
March, 1-31.
10. Cetintemel, U., Zimmerman, J., Ulusoy, O., & Buchmann, A. (1999). Objective: a benchmark for object-oriented active data management systems. in Jthenal of
Systems and Software, 45, 31-43.
11. Clarke, S., & Willett, P. (1997). Estimating the recall performance of search engines. ASLIB
Proceedings, 49 (7), 184-189.
12. DeWitt, D. J., Futtersack, P., Maier, D., & Velez, F. (1990). A study of three alternative workstation server architectures for object-oriented data management systems.
Proceedings of the 16th International Conference on Very Large Data Bases, August, 07-121.
13. DeWitt, D. J., Ghandeharizadeh, S., & Schneider, D. (1988). A performance analysis of the gamma data management machine.
Proceedings of the 1988 ACM SIGMOD International Conference on Management of Data, May,