國立臺灣大學電機資訊學院資訊網路與多媒體研究所 碩士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
觸控裝置上基於人臉屬性及擺設之大規模照片搜尋 Large-Scale Photo Search by Facial Attributes and
Face Layout on Touch Devices
雷禹恆 Yu-Heng Lei
指導教授:徐宏民 博士 Advisor: Winston H. Hsu, Ph.D.
中華民國 101 年 7 月
July, 2012
致 致 致謝 謝 謝
兩年的碩士研究生涯,即將隨著本論文的出版而告一段落。一路上 要感謝的人很多,而我也覺得自己在這條路上十分幸運。最要感謝的 是指導教授Winston,他給了我本論文的最初想法。能得到一個既有學 術價值,又極具實用性的研究題目,是非常難得的。除此之外,他這 兩年讓我真正學到如何做一個完整的研究,相信同樣的道理未來在職
場上也能受用。而在他幽默和爽朗的個性之下,其實也教會了我們很
多人生的道理,每一次group meeting說的「題外話」,我總是銘記在 心。
這兩年在校期間,CMLab MiRA組的夥伴們永遠是我最有力的支
援。最要感謝的是博士班的陳殷盈學姊,一路走來不斷地給我意見和 鼓勵,也提供我論文核心attribute detection的程式碼。她把我們team領 導得很成功,在本身學業繁忙之餘,還要扛起許多責任,這點讓 我 非常佩服。也非常感謝去年的大學部專題生飯田來夢,他設計 的iPad UI像魔法一樣,讓整個系統更吸引人,在各個presentation的 場合上幫我加了很多分數。郭盈希學姊總是熱心助人又待人謙虛,
也是Winston口中「work hard, play hard」的好榜樣。同屆同學中,
同team的陳柏村時常和我交換意見,在研究上也是我的榜樣。吳冠龍 花了很多心力維護實驗室工作站,當大家遇到問題時總是有求必應。
曾開瑜在碩一修課時與我合作不少,也因為研究主題類似而讓我觸類
旁通。黃彥達在許多事情上總是堅持完美,和他共事時很容易感受到
一股熱血。
本論文的口試委員余能豪、陳麗芬、王浩全教授,雖然是來自很 不同的研究領域,但他們在口試時提出的觀點和想法,可能為我們整
組的研究帶來新方向,也激發我對人機互動與設計領域的興趣,希望
未來能有機會接觸。這兩年來每次presentation的對象,不論是修課報 告、寫paper、業界比賽、conference簡報、來訪教授、研替面試、或是 專利申請,這些經驗都讓我學到如何表達出每次audience感興趣的面 向。
最後,我要感謝我的家人。有他們的支持,我在台大求學的這兩年 才能無後顧之憂。
中
中 中文 文 文摘 摘 摘要 要 要
隨著數位相機及智慧型手機的風行,我們能比以往更輕易地拍攝 生活中的精采瞬間,尤其是和朋友、家人在一起的時候。一般相信家 庭照片裡多數含有人臉,卻鮮少被標記姓名。因此,人們對於如何能 夠管理及搜尋迅速增加的個人或團體照片,有著高度期待。在本篇論
文中,我們提出了一個人臉照片搜尋的新方法,可同時考量目標人臉
的屬性(例如性別、年齡層、種族)、位置、及大小。為了比對印象 中照片裡的多張人臉,我們的系統讓使用者以圖形化的方式在一「搜 尋畫布(query canvas)」上構圖,指定人臉的位置及大小,而各種人 臉屬性組合以一個圖示來簡化表示。作為次要的功能,使用者甚至可 從前一次的搜尋結果直接擺放特定人臉,以進行基於外觀相似度的搜 尋。
我們已將此使用情境實現在平板電腦上,提供使用者直覺式的操 作介面。在大於20萬張人臉的Flickr資料庫實驗中,我們提出的問題 定義和比對方法,於前100名的搜尋結果中能達到0.420的命中率(hit
rate),比起先前文獻僅考量屬性時的0.036有非常顯著的進步。我們
提出的區塊索引(block-based indexing)方法也能達到平均僅0.0558秒 的搜尋時間。
關關關鍵鍵鍵詞詞詞::: 人臉屬性、人臉搜尋、觸控式使用者介面、區塊索引
Abstract
The ubiquitous availability of digital cameras has made it easier than ever to capture moments of life, especially the ones accompanied with friends and family. It is generally believed that most family photos are with faces that are sparsely tagged. Therefore, a better solution to manage and search in the tremendously growing personal or group photos is highly anticipated. In this paper, we propose a novel way to search for face photos by simultaneously considering attributes (e.g., gender, age, and race), positions, and sizes of the target faces. To better match the content and layout of the multiple faces in mind, our system allows the user to graphically specify the face positions and sizes on a query “canvas,” where each attribute combination is defined as an icon for easier representation. As a secondary feature, the user can even place specific faces from the previous search results for appearance-based retrieval.
The scenario has been realized on a tablet device with an intuitive touch in- terface. Experimenting with a large-scale Flickr dataset of more than 200k faces, the proposed formulation and joint ranking have made us achieve a hit rate of 0.420 at rank 100, significantly improving from 0.036 of the prior search scheme using attributes alone. We have also achieved an average run- ning time of 0.0558 second by the proposed block-based indexing approach.
Keywords: Face attributes, Face retrieval, Touch-based user interface, Block- based indexing
Contents
致
致致謝謝謝 i
中 中
中文文文摘摘摘要要要 ii
Abstract iii
1 Introduction 1
2 Observations and Related Work 4
3 System Overview 7
4 Image Analysis 9
4.1 Detecting Facial Attributes . . . 9
4.2 Sparse Coding for Appearance Similarities . . . 10
5 Image Retrieval 12 5.1 Problem Formulation . . . 12
5.1.1 Maximum Weighted Bipartite Matchings . . . 12
5.1.2 Greedy Approximation . . . 14
5.2 Face Matching Scores . . . 15
5.3 Score Normalization . . . 16
5.4 Block-based Indexing . . . 17
6 Experiments 20 6.1 User Interface . . . 20
6.2 Dataset and Implementations . . . 22
6.3 Storage Estimation . . . 22
7 Performance Evaluation 24 7.1 Compared Methods . . . 24
7.2 Performance of Known-Item Search . . . 25
7.2.1 Evaluation Setup . . . 25
7.2.2 Gain from Layout Information . . . 26
7.2.3 Gain from Attribute Information . . . 27
7.2.4 Breakdown by Attribute Combinations . . . 28
7.3 Efficiency of Indexing . . . 29
8 Conclusions and Future Work 31
Bibliography 33
List of Figures
1.1 Example queries and the top 5 retrieval results . . . 2
2.1 Illustration of searching for a face image that the user remembers . . . 5
3.1 An overview of our proposed system . . . 8
4.1 Face components and low-level features used in attribute detection . . . . 10
5.1 The image ranking problem formulated as maximum weighted bipartite matchings . . . 13
5.2 Quantization of (x0, y0, w0, h0) into overlapping blocks of various positions and sizes . . . 17
5.3 The indexing structure in the proposed system . . . 18
6.1 The touch-based interface of our system . . . 21
7.1 Hit rates@K of different methods in known-item search . . . 26
7.2 The fusion weight selection to maximize hit rate . . . 27
7.3 Breakdown of the improvement of hit rate by enabling different combina- tions of attribute types . . . 28
7.4 Hit rates@100 by enabling any gender attribute and one age attribute . . . 29
8.1 More query examples from our photo search system . . . 32
List of Tables
4.1 The 3 types of 8 human attributes used in our system . . . 9 7.1 Distribution of the number of faces in the 500 query tasks . . . 25 7.2 The efficiency comparison between linear scan and block-based indexing 30
Chapter 1 Introduction
The ubiquitous availability of digital cameras has made it easier than ever to capture mo- ments of life, especially the ones accompanied with friends and family. It is generally believed that most family photos are with faces that are sparsely tagged. Therefore, a bet- ter solution to manage and search in the tremendously growing personal or group photos is highly anticipated.
Psychology research in perception shows that images with certain kinds of subjects attract more attention of the eyes [8]. Among these subjects, human faces are the most memorable, followed by images of human-scale space and close-ups of objects [11]. The phenomena becomes more obvious in consumer photos because most of them contain family members or close friends that the user cares about and usually keeps in mind.
Therefore, they are able to make use of the face content and the face layout that they remember to effectively formulate their search intentions. Furthermore, viewing the re- trieved images probably recalls more scenes in the user’s memory, so they expect to be able to refine their query interactively. For example, “viewing a photo of Alice standing next to me, it reminds me of another photo with an African kid sitting in the middle of us.”
Although consumer photos generally lack annotations, automatic face analysis techniques would make the scenario economical and scalable.
In this paper, we propose a novel system for searching consumer photos by automat- ically analyzing “wild photos” (without tag information at all) through facial attribute detection (Sec. 4.1) and appearance similarity estimation (Sec. 4.2). To better match
(a)
Query Canvas Top Ranked Results
(b)
(c)
(d)
(e)
1 2 3 4 5
Figure 1.1: Example queries and the top 5 retrieval results from our photo search system.
(a) specifies two arbitrary faces with the larger one on the left and the smaller one on the right. (b) further constrains that the left face has attributes “female” and “youth” and the right face has attribute “kid.” (c) specifies two faces of “male” and “African” on the left and right, in addition to an arbitrary face on the center. (d) specifies a particular face in the database at the desired position and in the desired size. (e) specifies the previous database face on the left, and a face of “female” and “youth” on the right.
the content and layout of the multiple faces in mind, rather than laboriously sketching detailed outline or typing text, our system allows the user to graphically specify the face positions and sizes on a query “canvas,” where each attribute combination is defined as an icon for easier representation. The query can be simply finding arbitrary faces in the de- sired layout (Fig. 1.1 (a)), or further constrained by facial attributes (Fig. 1.1 (b) and (c)).
As a secondary feature, the user can even place specific faces from the previous search results for appearance-based retrieval (Fig. 1.1 (d)), combined with other attributed faces (Fig. 1.1 (e)). Other complicated search intentions also apply.
The scenario has been realized on a tablet device with an intuitive touch interface where the user can easily refine their query by interacting with the real-time search results.
To provide effective matching in a large-scale Flickr1dataset of more than 200k faces, the
1All of the face images presented in this paper except for those by Google Image Search in Fig. 2.1 (b) and Fig. 4.1 attribute to various Flickr users under a Creative Commons License.
proposed formulation and joint ranking have made us achieve a hit rate of 0.420 at rank 100, significantly improving from 0.036 of the search scheme proposed by [15] using attributes alone. To provide efficient retrieval, we have also achieved an average running time of 0.0558 second by the proposed block-based indexing approach. The numbers are scalable to even larger photo collections.
The contributions of this paper are as follows:
• Propose the problem in how to formulate search intentions for face images as tangi- ble search queries, i.e., by graphically specifying face content and layout on a query
“canvas.” We also provide an intuitive touch-based interface for refining the search results interactively.
• Propose a formulation for matching multiple faces between the query canvas and the target image (Sec. 5.1) and effectively match a single face by simultaneously considering attributes, appearances, positions, and sizes (Sec. 5.2).
• Propose a block-based indexing approach for efficient retrieval (Sec. 5.4).
Chapter 2
Observations and Related Work
In this section, we review various query formulations and query modalities in image search systems and their applicabilities to face photo search. Fig. 2.1 is an illustration of such a scenario. The target image in the user’s mind (Fig. 2.1 (a)) is a boy’s face on the left and a larger girl’s face on the top right of it. The user vaguely remembers the face content and layout, but not the exact image file in the collection.
Existing commercial image search engines mostly rely on matching the query key- words with the surrounding text or manual tags of the target images. Fig. 2.1 (b) is obtained by Google Image Search using the keywords “boy girl” with advanced options of searching only face images. Directly matching text not only reveals little about the image content, but in this particular case, it also happens to match the movie title “It’s a Boy Girl Thing” and retrieves some irrelevant images in the scene. What’s worse, tags are often inaccurate, incorrect, or ambiguous [12]. Due to the complex motivations behind tag usage [2], tags do not necessarily describe the content of an image [13].
In content-based image retrieval, Kumar [15] proposes facial attribute classification by SVM and AdaBoost, and uses the confidence scores for image retrieval. Fig. 2.1 (c) is produced in a similar way by enabling only the attribute modality in our system.
The corresponding attributes specified are “male + kid” for boy and “female + kid” for girl. While the attributes (especially the age) are mostly correct, this approach does not consider the face layout in the user’s mind at all. On the other hand, Fig. 2.1 (d) is produced by enabling only the position and size modalities in our system. While the face
(b)
(c)
(d)
(e)
boy girl
Text-based
Attribute only
Position + Size only
Attribute + Position + Size Image in mind
male kid female kid [1]
[2]
boy girl
(a)
Figure 2.1: Illustration of searching for a face image that the user remembers. The search intention is indicated in the cloud icon in (a), where there are a boy’s face on the left and a larger girl’s face on the top right of it. Four types of approaches are shown. (b) is Google’s text-based image search with advanced options of searching only face images.
(c) is facial-attribute-based image search with text-based queries, similar to the scheme proposed by [15]. (d) is image search based on face positions and face sizes. (e) is performed by simultaneously considering facial attributes, face positions, and face sizes.
Images squared in green solid lines (blue dashed lines) are believed to be highly (partially) relevant by an average user. The results in (e) best match the search intention, showing the power of multimodal fusion in retrieval systems.
layouts are highly relevant due to accurate face detection, this approach does not consider about the face content. To utilize both the content and layout information, Fig. 2.1 (e) is produced by the full version of our system that combines all of these three modalities.
The results in Fig. 2.1 (e) best match the user’s search intention in terms of finding highly relevant (squared in green solid lines) and partially relevant (squared in blue dashed lines) images. The above illustration shows the power of multimodal fusion in retrieval systems.
Some efforts also attempt to capture the user’s search intention by visually describing both the image content and layout on a query canvas. Thanks to the growing popularity of touch devices, it has become more intuitive and convenient than ever to formulate such queries. [3] revisits the problem of sketch-based image search for scene photos. However, the gap between the user’s mind and their specified query can still be large even in such a system. For instance, users with poor drawing skills may have a hard time describing their intention accurately. In addition, some object details are naturally difficult to sketch, and many concepts are even more difficult to describe by sketching, such as the age of a face. Therefore, the practicability of sketch-based retrieval for photo management is questionable, especially for face photos.
To deal with this sketching difficulty, [19] allows the user to formulate a 2-D “se- mantic map” by placing text boxes of various search concepts at desired positions and in desired sizes. However, it is intended for generic objects, not for faces of different individuals. To apply to face photo management, [14] also allows the user to specify face positions, and face sizes on a canvas. These faces are further described by tagging names and even drawing social relationships [17]. However, non of these efforts proposes an efficient indexing method for large-scale photo retrieval. Meanwhile, typing text is not the most intuitive operation on touch devices even though these efforts aim for better user experience.
Specifically for photo management, some commercial services (e.g., Picasa [18] and iPhoto [10]) that exploit face recognition technologies to help face annotation in a semi- supervised or supervised manner have been shown promising. However, people are mostly reluctant to annotate their photos, especially when photos are taken enormously due to the ubiquitous availability of digital cameras. Also, many of consumer photos are group photos, which makes the face annotation task even more tedious. In our work, we further consider spatial layout, attributes, and appearance for face photo retrieval. We believe it can be complementary1to existing face annotation solutions.
1Face recognition or face annotation information can be exploited as another source of the “face content”
considered in this work.
Chapter 3
System Overview
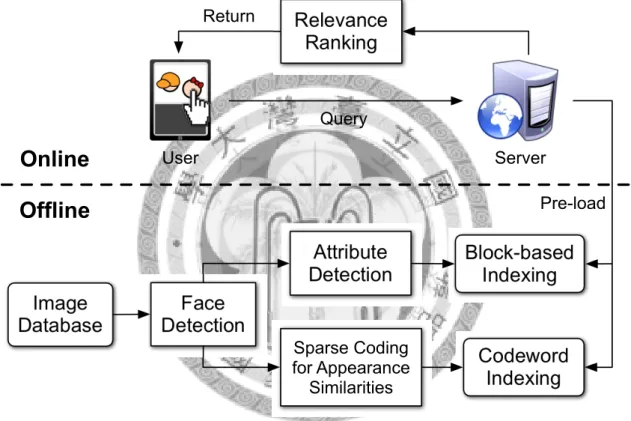
Fig. 3.1 is an overview of our proposed system named “Where is Who.” In the offline process, the image database first goes through face detection to identify and locate frontal faces in the images. These faces are then analyzed through facial attribute detection (Sec.
4.1) and sparse coding for appearance similarities (Sec. 4.2). Finally, the attribute scores along with the position and size information are incorporated into the block-based index (Sec. 5.4). The sparse codes of faces are also stored in the codeword index. These indices are pre-loaded for rapid online response. In the online process, the server retrieves can- didate images in inverted lists, ranks them by relevance (Sec. 5.2), and returns the search results back to the user. Note that appearance-based retrieval is treated as a secondary feature and is not evaluated throughout this paper.
Online Offline
User Server
Query Return
Face Detection
Codeword Indexing Block-based
Indexing Image
Database
Attribute Detection
Pre-load
Relevance
Ranking
Sparse Coding for Appearance
Similarities
Figure 3.1: An overview of our proposed system. Photos are analyzed offline through face detection, facial attribute detection, and sparse coding for appearance similarities.
The results are incorporated into the proposed block-based index and codeword index for efficient retrieval.
Chapter 4
Image Analysis
4.1 Detecting Facial Attributes
Facial attributes possess rich information about people and have been shown promising for seeking specific persons in face retrieval and surveillance systems. In this work, we utilize 8 facial attributes (Table 4.1) including 2 of gender (male, female), 3 of age (kid, youth, elder), and 3 of race (Caucasian, Asian, African) to profile faces in large-scale photos.
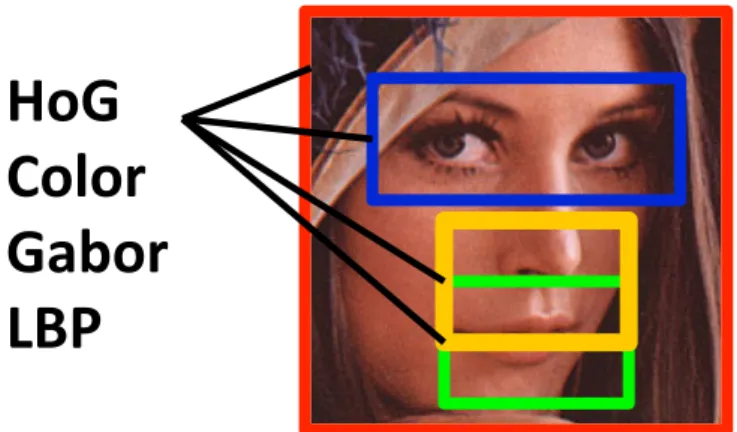
In the training phase, each attribute classifier is learned separately through a combi- nation of Support Vector Machines (SVMs) and Adaboost [9] similar to [15]. Firstly, we crawl user-contributed photos from Flickr and extract facial regions by a face detec- tor. The face images are annotated manually with positive and negative class labels. As illustrated in Fig. 4.1, the faces are then automatically decomposed into four different face components, i.e., whole face, eyes, nose, and mouth. From each of these compo- nents, four low-level features, i.e., histogram of oriented gradients (HoG) [6], grid color moments, Gabor filter, and local binary patterns (LBP) [1] are extracted.
Table 4.1: The 3 attribute types and 8 corresponding attributes detected in our system.
Type Attribute Gender male, female Age kid, youth, elder
Race Caucasian, Asian, African
!"#$
%"&"'$
#()"'$
*+, !
Figure 4.1: For each of the four face components (whole face, eyes, nose, and mouth), four low-level features (HoG, grid color moments, Gabor, and LBP) are extracted. Each of 16 combinations (e.g., <mouth, LBP>) is treated as a mid-level feature for which an SVM is learned.
A mid-level feature learned is an SVM with a specific low-level feature extracted from a specific face component, e.g., an SVM for <mouth, LBP>. Finally, the optimal weighting of the 16 (4 × 4) mid-level features for this attribute is determined through Adaboost. The combined strong classifier represents the most important parts of that attribute. For example, <whole face, Gabor> is most effective for the female attribute while <whole face, color> is most effective for the African attribute.
Experimenting with the benchmark data [15], the approach can effectively detect fa- cial attributes and achieve an accuracy of more than 80% on average. Meanwhile, the training framework is generic for various cases thus providing a potential to extend to more attributes1.
4.2 Sparse Coding for Appearance Similarities
To enable search through face appearance, we adopt the face retrieval framework of [5].
The advantage of this framework includes: (1) efficiency, which is achieved by using sparse representations of face image with inverted indexing, and (2) leveraging identity information, which is done by incorporating the partially-tagged identity information into the optimization process of codebook construction. Both of the above two points are suitable for our system. In details, detected faces are first aligned into canonical position,
1For example, the work of [16] has trained as many as 73 attribute classifiers.
and then component-based local binary patterns [1] are extracted from the images to form feature vectors. After feature extraction, sparse representations are computed from these feature vectors using an L1-regularized least square objective function. Non-zero entries of sparse representations are considered as visual words for inverted indexing.
Due to the nature of faces, images of the same individual may have high intra-class variation. To leverage the partially-tagged identity information, a regularization term is added to the objective function to force images of the same identity (tag) to have similar sparse representations. These images will propagate visual words to each other, and the query image will be able to find all images of the same individual if it is similar to at least one of them.
By incorporating such framework into our system, in addition to attributes, the user can also use a face image itself as the face content.
Chapter 5
Image Retrieval
5.1 Problem Formulation
5.1.1 Maximum Weighted Bipartite Matchings
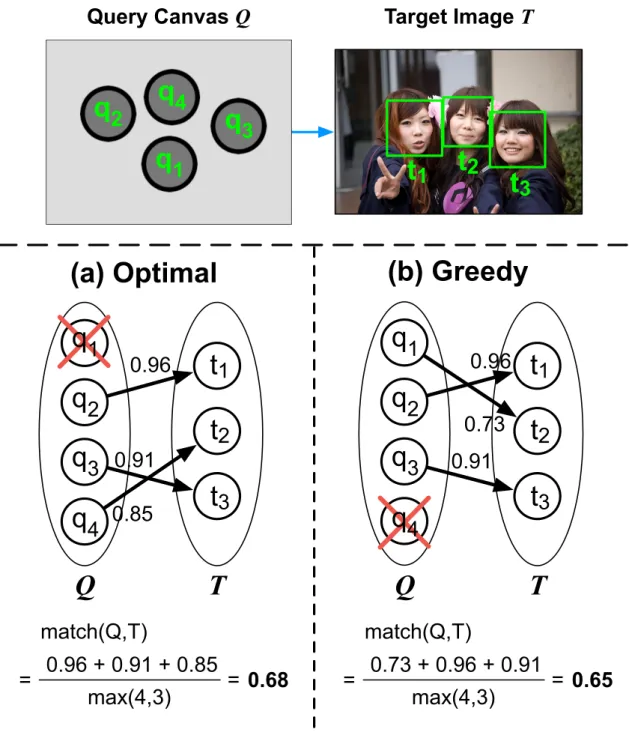
As illustrated in Fig. 5.1, for a (query canvas, target image) pair, denoted as (Q, T ), the image ranking problem is formulated as a maximum weighted bipartite matching between the two sets Q and T . The objective function match(Q, T ), or the overall matching score between Q and T , is defined as the sum of the individual face matching scores match(q, t) (defined in Sec. 5.2) divided by max(|Q|, |T |). The formulation is as the following constraint optimization problem:
match(Q, T ) =
maxh P
q∈Q
P
t∈T match(q, t)δ(q, t)i
max(|Q|, |T |) (5.1)
subject to: δ(q, t) ∈ {0, 1} ∀q ∈ Q, t ∈ T (5.2a) X
t∈T
δ(q, t) ≤ 1 ∀q ∈ Q (5.2b)
X
q∈Q
δ(q, t) ≤ 1 ∀t ∈ T (5.2c)
match(q, t) > 0 ∀q ∈ Q, t ∈ T (5.2d)
Query Canvas Q Target Image T
(a) Optimal (b) Greedy
Q T Q T
q 2
q 2 q 3 q 4
t 1
t 2
t 3
t 1
t 2
t 3 q 1
q 2 q 3 q 4 q 1
0.96 0.96
0.91 0.91
0.85
0.73
match(Q,T)
= max(4,3) 0.96 + 0.91 + 0.85
= 0.68
match(Q,T)
= max(4,3) 0.73 + 0.96 + 0.91
= 0.65
q 1 q 4
q 3
t 1 t 2
t 3
Figure 5.1: The image ranking problem as a maximum weighted bipartite matching be- tween the query canvas (set Q) and the target image (set T ). The numbering in the query canvas implies the order in which the faces are specified. The optimization in Eq. 5.1 can be carried out by (a) the optimal solution or (b) the greedy approximation. A red cross indicates a mismatched face, and match(Q, T ) means the overall matching score between Q and T .
δ(q, t) =
1, if (q, t) is matched 0, otherwise,
(5.3)
where δ(q, t) (Eqs. 5.2a and 5.3) is an indicator variable of whether (q, t) is matched.
Note that the matching ensures each query face q = q1, ..., q|Q| matches at most one target face t = t1, ..., t|T | (Eq. 5.2b), and each t is matched at most once (Eq. 5.2c). We add the subscripts here to explicitly denote the individual faces in Q and T .
The numerator of Eq. 5.1 is the objective function in maximum weighted bipartite matchings. Note the max(|Q|, |T |) in the denominator. The positive weights (Eq. 5.2d) ensure that the number of matching pairs equals min(|Q|, |T |). If the numbers of faces in Q and T are the same, dividing by |Q| or |T | is like averaging. But if |Q| and |T | are different, the overall matching score will be divided by a larger number. Thus, this formulation much favors target images that have the same number of faces as the query canvas.
Fig. 5.1 shows an illustration of matching 4 query faces with 3 target faces. The opti- mal solution, by the above formulation, always comes up with the highest match(Q, T ) among all the possible matches. As in Fig. 5.1 (a), match(Q, T ) = 0.68 for this exam- ple. However, computing the optimal solution (e.g., by the Bellman-Ford algorithm) is inefficient if we have to repeat for all target images.
5.1.2 Greedy Approximation
The inefficiency in solving Eq. 5.1 can be compromised by the proposed greedy approx- imation. By greedy, we mean the first query face q1 is the first to match by choosing the best matching face remaining (i.e., the unmatched t∗ for which match(q1, t∗) is maxi- mized), followed by q2, q3, etc.. The numbering in Q implies the order in which the faces are specified on the query canvas. The procedure is summarized in Algorithm 1.
In the example of Fig. 5.1 (b), the greedy approximation allows the first query face q1 to match first, choosing t2 to get face matching score of 0.73. The second query face q2 chooses t1 of 0.96, followed by q3 choosing the last target face t3 remaining to get 0.91.
Algorithm 1 The procedure in greedy approximation.
Input: The query canvas Q and the target image T . Output: The overall matching score match(Q, T ).
match(Q, T ) ← 0
/* Maintain a remaining set R. */
R ← T
for q ← q1, q2, ..., q|Q|do t∗ ← maxt∈R[match(q, t)]
match(Q, T ) ← match(Q, T ) + match(q, t∗) R ← R − {t∗}
end for
match(Q, T ) ← match(Q, T ) / max(|Q|, |T |)
q4 then becomes a mismatched face (indicated by a red cross in Fig. 5.1 (b)), but it could have matched t2 of 0.85 if specified in the first place. Eventually, match(Q, T ) = 0.65 in the greedy approximation. In general, although the greedy approximation has a lower match(Q, T ) than the optimal solution, it significantly reduces the computational cost and reflects the idea that the first face coming to the user’s mind is the most important.
5.2 Face Matching Scores
Our work uses multimodal fusion to determine the face matching score match(q, t) be- tween a query face q and a target face t. It is defined as a linear combination of the matching scores for facial attributes, appearance similarity, face position, and face size:
match(q, t) = wattr Y
τ
Attr(qτ, tτ)
!1/|τ |
+
wappApp(q, t) + wposP os(q, t) + wsizeSize(q, t)
(5.4)
Attr(qτ, tτ) =
tτ k, if qτ = k
1.0, if qτ = not specified,
(5.5)
where wattr, wapp, wpos, and wsizeare the weights for these four modalities.
The first term in Eq. 5.4 weights the geometric mean of the matching scores Attr(qτ, tτ) for all of the attribute types τ , i.e., gender, age, and race (|τ | = 3). As in Eq. 5.5, if qτ, or the attribute specification of the query face for type τ , is some attribute k, then
Attr(qτ, tτ) = tτ k, the attribute score of k in type t. For instance, if q specifies the age
“youth”, then Attr(qage, tage) takes the attribute score for youth of t. In notation, if for τ = age, qage = youth, then Attr(qage, tage) = tage,youth.
In contrast, if for τ , the attribute is not specified, then Attr(qτ, tτ) = 1.0, the perfect score. The choice of geometric means rather than arithmetic means is to avoid outliers for some attribute type. The second term in Eq. 5.4 weights the appearance similarity score between q and t, obtained in Sec. 4.2. Note that in our user interface (Sec. 6.1), attributes and appearance similarity (by a specific face instance) of a query face are not specified at the same time.
5.3 Score Normalization
For an attribute score tτ k, we first normalize the strong classifier’s output to zero mean and unit variance for each attribute k. Then we apply a sigmoid function to map it to (0, 1). The appearance similarity scores App(q, t) are normalized in a similar way.
For the matching scores for face position P os(q, t) and face size Size(q, t) between a query face q and a target face t, first note that in our system, coordinates are always represented as fractions of the width or height of the image (canvas). This fractional representation allows the computation to be adapted to the various aspect ratios in the the target images (query canvas). The definitions of P os(q, t) and Size(q, t) are based on the distance errors between q and t as follows:
P os(q, t) = 1 − dcenter
√2 (5.6)
Size(q, t) = 1 −dwidth+ dheight
2 , (5.7)
where dcenter is the L2 distance between the face centers, and dwidth and dheight are the L1 differences between the face widths and heights. The denominators √
2 and 2 in Eqs. 5.6 and 5.7 indicate the maximum (worst) distance between the face centers and the
...
1 2 0
347
...
...
348
85
928 86 87
56775
...
...
57174
...
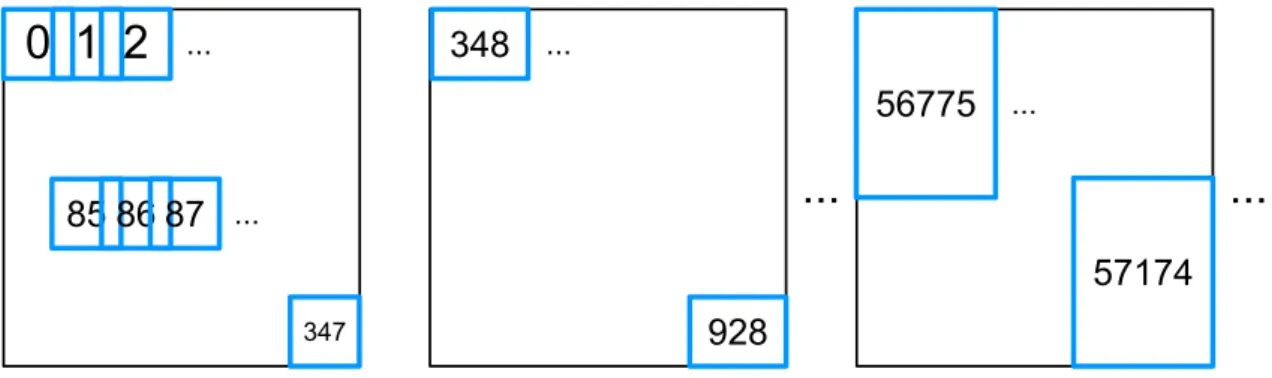
Figure 5.2: Quantization of (x0, y0, w0, h0) into overlapping blocks of various positions and sizes, where the four variables represent the already quantized horizontal and vertical positions, width, and height. The mapping between a (x0, y0, w0, h0) combination and a block ID should be unique throughout the system.
maximum width plus height differences between the faces, i.e., the diagonal line and the whole width plus whole height. Therefore, each term subtracted from 1 is now normalized into the range (0, 1).
5.4 Block-based Indexing
We apply a block-based method to spatially index all the database faces. Since the face center coordinates, width and height, denoted as x, y, w, and h, are fractions, the in- finitely many numbers in the interval (0, 1) make indexing computationally infeasible and quantization too sensitive. Therefore, we first uniformly quantize each of the four variables into L levels, denoted as x0, y0, w0, and h0, each in the range [0, L − 1]. We then quantize the valid (x0, y0, w0, h0) combinations uniquely into overlapping blocks of vari- ous positions and sizes, as illustrated in Fig. 5.2. Note that not all the L4 combinations are valid (within-boundary) blocks. The mapping between an (x0, y0, w0, h0) tuple and a block ID should be unique throughout the system. One such mapping is easily achieved by representing the block ID as an L-nary number of 4 digits. For example:
BlockID = x0+ y0L + w0L2+ h0L3. (5.8)
Block 1
Block 4 Block 2 Block 3
Img ID Attr 1
2 Attr 8 Img ID
Attr 1 2 Attr 8 Img ID
Attr 1 2 Attr 8 Img ID
Attr 1 2 Attr 8
Img ID Attr 1
2 Attr 8 Img ID
Attr 1 2 Attr 8
...
...
...
(36 Bytes)
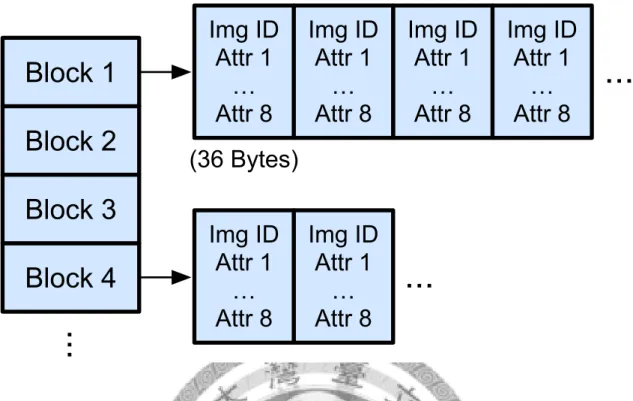
Figure 5.3: The indexing structure in the proposed system. The block IDs are treated as the visual words in typical inverted indexing. Each of them corresponds to an inverted list of structures, each being a tuple of (image ID, the 8 attribute scores) that requires 36 bytes in the implementation.
The ordering of digits does not matter as long as it is consistent. The mapping1in Eq. 5.8 is not only unique but also reversible and storage-free (no table lookup).
To build the index, the block IDs are treated as visual words in typical inverted index- ing. Each block then corresponds to an inverted list of structures, each being a tuple of (image ID, the 8 attribute scores), as in Fig. 5.3. In other words, each list contains all the faces and their attribute scores within this particular block.
Since retrieving only faces in the block of the query face is still too sensitive, in the online search, a query face runs a “sliding window” to retrieve faces in W neighboring blocks. These neighbors are found by adjusting each of the (x0, y0, w0, h0) up and down for various quantization levels to produce new combinations. An example neighbor may be (x0− 2, y0+ 1, w0+ 3, h0). Then, we apply the mapping in Eq. 5.8 to get the neighboring block IDs and retrieve the corresponding inverted lists. The range of the sliding window, denoted by parameters tolpos and tolsize, controls the level of tolerance in positions and
1As an example, suppose L = 20 levels, each being 0.05. An (x, y, w, h) combination of (0.11, 0.28, 0.42, 0.67) will be quantized into (x0, y0, w0, h0) = (2, 5, 8, 13). The block ID is then 2 + 5 · 20 + 8 · 202+ 13 · 203= 107302. The reverse mapping can restore (x0, y0, w0, h0) from the block ID.
sizes.
For multiple-face queries, each query face is processed separately to collect relevance scores from inverted lists according to Eq. 5.4. The greedy manner still applies that the first query face scans the inverted lists first. Finally, the results are merged into a ranking list according to Eq. 5.1. The retrieval results of block-based indexing and linear scan differ mostly by the quantization errors and the faces skipped by the sliding windows.
Chapter 6 Experiments
In this chapter, we describe the touch-based user interface of the proposed system named
“Where is Who” (short for WiW), followed by the dataset and implementations. We also conduct an estimation on storage cost. For a video demonstration of the system, please visit our project page:
http://www.csie.ntu.edu.tw/˜winston/projects/face/
6.1 User Interface
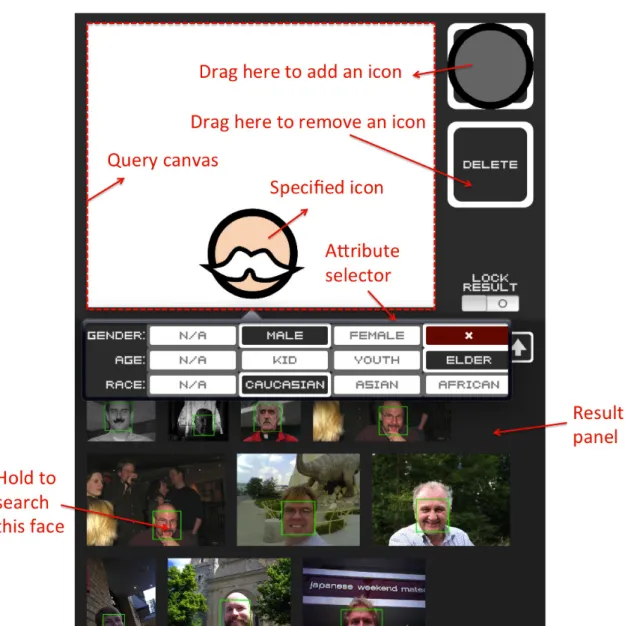
The user interface of our system is shown in Figure 6.1. The user can drag faces from the top-right area onto the canvas at desired positions. They can also pinch their fingers to adjust the sizes of the icons and the canvas. Holding an icon invokes a popup attribute selector. We have designed a total of 48 face icons (3 × 4 × 4) to represent the various attribute combinations. For appearance-based retrieval, the user can hold a face in the result panel and use the changed icon on the top-right to find similar faces in other pho- tos. For every canvas modification, the system performs a search and shows the results on the bottom so that the user can refine their search intention interactively viewing the current results. Since our system is naturally suitable for a touch-based interface, we have implemented the UI on a tablet device.
Figure 6.1: The touch-based interface of our system. The user can formulate a query by dragging face icons from the top-right area onto the canvas at desired positions. They can also pinch their fingers to adjust the sizes of the icons and the canvas. When holding an icon, a pop-up menu will show up for attribute selection. When browsing the search results on the bottom, they can also hold a face and use the changed icon on the top-right to find similar faces (appearance-based) in other photos. For every canvas modification, the system performs a search so that the user can refine their search intention interactively.
6.2 Dataset and Implementations
The dataset is composed of two portions. As mentioned in Sec. 4.1, we crawl a large number of user-contributed photos from Flickr as the first (main) portion. For appearance- based retrieval, 732 daily photos containing 1,248 faces are added to the dataset as the second portion. After face detection by a public API [7], together there are N = 115, 487 images in the dataset where the average number of faces per image is F = 2.117, so the dataset contains N × F = 244, 491 faces.
Since appearance-based retrieval is intended as a secondary feature of our system, we only estimate the appearance similarity scores in the second portion. Therefore, faces in the first portion always have zero appearance similarity scores if they are specified on the canvas.
In attribute detection, we adopt the LIBSVM software package [4] for learning the mid-level features. For the fusion weights in Eq. 5.4, we conduct a sensitivity test to select wattr, wpos, and wsize (that sum to 1) to optimize the evaluation criterion in Sec.
7.2. For block-based indexing, we empirically select the number of quantization levels as L = 20, and the tolerance (range) of the sliding window as tolpos = ±4 levels and tolsize= ±4 levels1.
The server part of WiW is implemented on a 16-core, 2.40GHz Intel Xeon machine with 48GB of RAM.
6.3 Storage Estimation
Since appearance-based retrieval is considered as a secondary feature, the storage cost of codeword index is not considered in this estimation. Following the format of the index structure in Fig. 5.3, for an inverted list structure, we require 4 bytes for an image ID and 4×8 = 32 bytes for the eight floating-point attribute scores. That is, 36 bytes for indexing a face. The cost of headers (block IDs and counts) can be neglected in the calculation.
Multiplied by N × F , it requires approximately 244.5K × 36B = 8.8MB in optimal
1Therefore, a sliding window visits W = (4 · 2 + 1)2· (4 · 2 + 1)2= 6, 561 neighboring blocks. Many of the blocks may be out-of-boundary or empty.
implementations. Reusing F = 2.117 in our dataset, an 1-million image dataset requires a storage cost of around 1M × 2.117 × 36B = 76.2MB.
Chapter 7
Performance Evaluation
In this section, we evaluate the performance of several variants of our proposed system.
We have conducted an experiment to evaluate known-item search, in which the user tries to search for a specific target image in mind. Since appearance-based retrieval is treated as a secondary feature, refer to [5] for the corresponding evaluation. We also evaluate the efficiency of indexing by measuring the running time and the number of visited faces.
7.1 Compared Methods
To the best of our knowledge, our system is the first work to address the problem of face image retrieval based on both facial attributes and face layout. So we compare four variants of the proposed system: (1) “Attr,” by enabling only wattrin Eq. 5.4 with linear scan in order to resemble the search scheme in [15], (2) “Pos + Size (index),” by enabling wpos and wsizewith block-based indexing (Sec. 5.4), (3) “Attr + Pos + Size,” by enabling wattr, wpos, and wsizewith linear scan, and (4) “Attr + Pos + Size (index),” same as (3) but with block-based indexing. (4) is the full version of WiW except for the appearance-based component.
Table 7.1: Distribution of the number of faces in the 500 query tasks.
# faces 1 2 3 4 5+ Total
# query tasks 249 147 55 22 27 500
7.2 Performance of Known-Item Search
7.2.1 Evaluation Setup
In known-item search (KIS), the user aims to search for a specific target image that they have seen. To simulate such a scenario in a large-scale dataset, 500 target images, each containing at least one face (985 faces in total), were randomly selected from our dataset (portions 1 and 2) as query tasks. The distribution of the number of faces is summarized in Table 7.1. These query tasks were equally distributed among the participants of 20 subjects invited to the experiment.
For each query task, the subject was asked to first carefully observe the target image, and then formulate a query canvas by graphically placing attributed icons at the corre- sponding positions and in the corresponding sizes for each query face. The subjects were asked to specify the positions and sizes according to the bounding boxes detected by the system in order to minimize the effect of face detection errors. The attributes were spec- ified according to their “strengths” to the subject. If either the gender, age, or race of the face was not obvious enough, the attribute would be “not specified” for this type. Finally, the 500 submitted query canvases were collected for later evaluations.
Although this simulation does not reflect the reality that the user may not accurately remember the face layout or the face content in a large image collection over a long time, our user interface makes it easy to gradually refine the canvas by providing a real-time re-query for every canvas modification. This is useful in reality because the user usually performs several trials in the same way in typical retrieval systems.
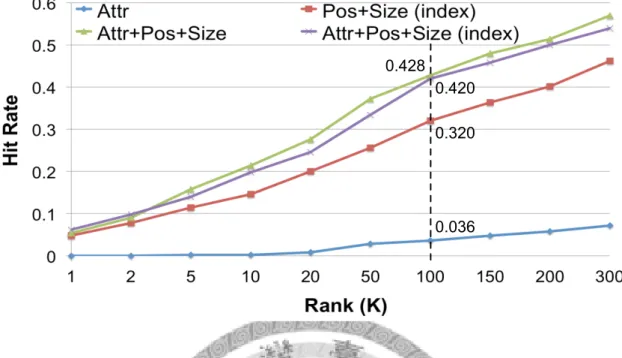
0.036 0.320 0.428
0.420
Figure 7.1: Hit rates@K of different methods over the 500 query tasks in known-item search. Adding layout information achieves a hit rate of 0.420 at rank 100 (purple line). This significantly outperforms 0.036 of using attributes alone (blue line), the search scheme proposed by [15]. In addition, adding attribute information improves the hit rate from 0.320 (red line) to 0.420 (purple line).
7.2.2 Gain from Layout Information
To evaluate how well the target image is ranked in the results, we measure the “hit rate@K” as in [3]1, the proportion of the 500 query tasks where the system can retrieve the target image within the top K search results (within rank K).
Fig. 7.1 shows the performance of the four compared methods for all query tasks.
Apparently, all three methods considering face layout significantly outperform “Attr,”
achieving hit rates of 0.320, 0.428, and 0.420 at rank 1002 that are 8.8 to 11.8 times higher than 0.036 (blue line) of using attributes alone, the search scheme proposed by [15]. This clearly explains that when the user has the face layout in mind, specifying the positions and sizes on a canvas provides much more information than specifying only the face content.
1In KIS, the performance is often measured by mean reciprocal rank. However, because there may be numerous other images with similar face content and face layout, especially images of 1 or 2 faces (Table 7.1), many of our target images are ranked up to number several thousand. Averaging by those near-zero reciprocal ranks would make it difficult to compare different methods.
2Although a hit rate of 0.420 at rank 100 may not be high enough for practical photo management, the images returned by the system are often relevant to the query canvas, as illustrated in Fig. 8.1. This high precision enables casual photo browsing when the user does not have a specific target in mind.
Hit Rate @ 100
w
posw
attr0.42 0.40
0.35
0.30
0.25
1.00
0.80
0.60
0
0.1
0.2
0.3 0.20
0.40
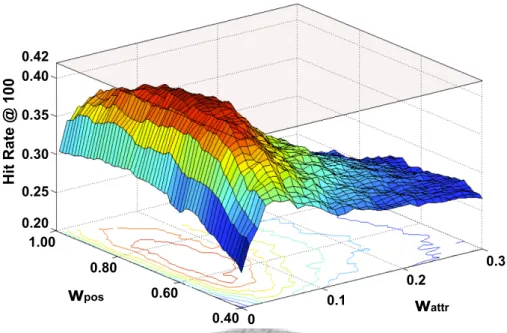
Figure 7.2: The fusion weight selection to maximize hit rate. The three axes represent wattr, wpos (in Eq. 5.4), and hit rate@100, respectively. The non-negative weights are constrained by wattr+ wpos+ wsize= 1.
Also, the hit rate of “Attr + Pos + Size (index)” (purple line) is slightly lower than its linear-scan variant “Attr + Pos + Size” (green line). This is due to the quantization errors introduced by the block-based indexing, where the exact positions and sizes are quantized into nearby blocks.
7.2.3 Gain from Attribute Information
We can also observe in Fig. 7.1 that “Attr + Pos + Size (index)” outperforms “Pos + Size (index).” In other words, adding attribute information can further improve the hit rate@100 from 0.320 (red line) to 0.420 (purple line), although in the fusion weight se- lection (Fig. 7.2), the contribution of wattr is only 5% of the total weight. The small weight can be explained by the fact that attribute detection is less robust than face detec- tion and localization.
As reported in Sec. 4.1, a single attribute detector has an average accuracy of around 80%, but when three attributes are specified in a query face, we can expect only (0.80)3 = 51% of the target faces to have all correctly detected attributes. This is challenging for a system supporting multi-attribute queries. Also, in the experiment of KIS, the sub- jects were instructed to specify the positions and sizes according to the bounding boxes
0.300 0.320 0.340 0.360 0.380 0.400 0.420
None G A R G+A G+R A+R G+A+R
Hit Rate @ 100
Figure 7.3: Breakdown of the improvement of hit rate@100 from 0.320 to 0.420 (Fig.
7.1) by enabling different combinations of attribute types. G, A, and R stand for gender, age, and race, respectively. Starting from 0.320 of no attributes, we can observe that enabling more attribute types improves the hit rate towards the highest 0.420 (G+A+R).
returned by the face detector. This accurate layout information has compromised the con- tribution of attributes in the multimodal fusion.
7.2.4 Breakdown by Attribute Combinations
Following Sec. 7.2.3, we break down the improvement of hit rate@100 from 0.320 to 0.420 (Fig. 7.1) by enabling different attribute combinations3. In Fig. 7.3, G, A, and R stand for the three attribute types gender, age, and race, respectively. “A + R,” for example, enables attributes in faces in the query tasks where the user specified any age attribute or any race attribute.
Starting from 0.320 of no attributes, we can observe that enabling more attribute types improves the hit rate towards the highest 0.420 (G + A + R). Again, this shows the power of multi-modality in retrieval systems. With more attributes available, such as the 73 de- tected attributes in [16], we can expect such a system to achieve even better performance for practical usage.
3This breakdown is merely for discussion purposes. In real-life photo albums, all people that appear may be of only one race, so there may not be much about the R component in this case.
Hit Rate @ 100 Faces with Attributes Enabled (%)
0 20 40 60 80 100
0.300 0.320 0.340 0.360
G & Kid G & Youth G & Elder
Figure 7.4: Hit rates@100 by simultaneously enabling any gender attribute and one age attribute. A red dot represents the percentage of query faces with such attributes enabled.
We can observe that “G & kid” performs the worst among all alternatives, even worse than “G & elder” that has fewer faces with attributes enabled. This reflects the intuition that it is relatively hard to tell the gender among kids.
It is also interesting to discuss the effect of using some attributes together in a query canvas. Fig. 7.4 shows the hit rates@100 by simultaneously enabling (hence the “&”
symbol) any gender attribute (G) and one age attribute. A red dot counts the percentage of faces with attributes that meet this requirement.
Generally, the higher the red dot, the more faces with attributes enabled, which is expected to raise the hit rate. However, we can observe that “G & kid” performs the worst among all alternatives, even worse than “G & elder” that has fewer faces with attributes.
It reflects the intuition that it is relatively hard to tell the gender among kids.
7.3 Efficiency of Indexing
From the 500 query tasks, we also record the average running time and the average num- ber of visited faces, including repetitive visits, in the search. Table 7.2 shows the ef- ficiency comparison between linear scan and block-based indexing. In both manners, block-based indexing speeds up around 3 times and requires only 0.0558 second in a dataset of more than 200k faces. Although there is still room for improvement (e.g., incor-
Table 7.2: The efficiency comparison between linear scan and block-based indexing, mea- sured by the average running time and the average number of visited faces (including repetitive visits) in the search.
Running time (sec) # Visited faces
Linear scan 0.2089 331,225
Block-based index 0.0558 111,303
Indexing speedup 3.74x 2.98x
porating attribute scores into the visual words, or better quantization and search methods for the (x,y,w,h) information), we believe the proposed indexing method can be extended to a million-scale dataset.
Chapter 8
Conclusions and Future Work
Our work proposes a novel way to effectively organize and search for consumer photos by placing attributed face icons on a query canvas at desired positions and in desired sizes.
With the help of automatic facial attribute detection and appearance similarity estimation in the offline process, we are able to analyze wild photos without tagging at all. In the online process, the system simultaneously considers attributes, appearances, positions, and sizes of the target faces.
The scenario has been realized on a tablet device with a touch interface. Experiment- ing with a large-scale Flickr dataset of more 200k faces, we have achieved a hit rate@100 of 0.420, significantly improving from 0.036 of prior search scheme [15] using attributes alone. We have also achieved a fast retrieval response of 0.0558 second by the proposed block-based indexing approach. Experimental results from extensive search tasks (Fig.
8.1) reveal the potential for effective and efficient photo management.
In the future work, we will exploit more facial attributes for providing better per- formance and more accurate queries. We will also investigate better quantization and indexing methods for compact storage, and learning to rank techniques will help make the ranking function more principled. Meanwhile, human factors (e.g., HCI, behavior, and cognition) will be examined more in the integration with mobile devices.
(a)
(b)
(female,youth,n/a)
(male,youth,n/a)
(n/a,youth,Asian)
(n/a,kid,n/a)
(female,n/a,n/a)
(n/a,n/a,n/a) (c)
(d)
(n/a,elderly,Caucasian)
** n/a indicates “not specified” in this attribute type.
(e)
(n/a,n/a,African)
Figure 8.1: Example query canvases and the corresponding top 10 search results. The figure demonstrates extensive search tasks ranging from very close faces ((a) and (b)) to faces spread in various ways ((c), (d), and (e)). The icons representing the attribute combinations are shown in the bottom. Images squared in green solid lines (blue dashed lines) are believed to be highly (partially) relevant by an average user.
Bibliography
[1] T. Ahonen, A. Hadid, and M. Pietikainen. Face description with local binary pat- terns: Application to face recognition. PAMI, 2006.
[2] M. Ames and M. Naaman. Why we tag: Motivations for annotation in mobile and online media. ACM CHI, 2007.
[3] Y. Cao, C. Wang, L. Zhang, and L. Zhang. Edgel index for large-scale sketch-based image search. CVPR, 2011.
[4] C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2011. Software available at http://www.csie.ntu.edu.tw/˜cjlin/libsvm.
[5] B.-C. Chen, Y.-H. Kuo, Y.-Y. Chen, K.-Y. Chu, and W. Hsu. Semi-supervised face image retrieval using sparse coding with identity constraint. ACM Multimedia, 2011.
[6] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection.
CVPR, 2005.
[7] face.com API. http://developers.face.com/.
[8] M. Freeman. The Photographer’s Eye: Composition and Design for Better Digital Photos. Focal Press, 2007.
[9] Y. Freund and R. E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. Computational Learning Theory, 1995.
[10] iPhoto from Apple Inc. http://www.apple.com/ilife/iphoto/.
[11] P. Isola, J. Xiao, A. Torralba, and A. Oliva. What makes an image memorable?
CVPR, 2011.
[12] L. Kennedy, M. Naaman, S. Ahern, R. Nair, and T. Rattenbury. How flickr helps us make sense of the world: Context and content in community-contributed media collections. ACM Multimedia, 2007.
[13] L. S. Kennedy, S.-F. Chang, and I. V. Kozintsev. To search or to label?: Predicting the performance of search-based automatic image classifiers. ACM MIR Workshop, 2006.
[14] H.-N. Kim, A. E. Saddik, K.-S. Lee, Y.-H. Lee, and G.-S. Jo. Photo search in a personal photo diary by drawing face position with people tagging. IUI, 2011.
[15] N. Kumar, P. N. Belhumeur, and S. K. Nayar. Facetracer: A search engine for large collections of images with faces. ECCV, 2008.
[16] N. Kumar, A. C. Berg, P. N. Belhumeur, and S. K. Nayar. Describable visual at- tributes for face verification and image search. PAMI, 2011.
[17] K.-S. Lee, J.-G. Jung, K.-J. Oh, and G.-S. Jo. U2mind: Visual semantic relationships query for retrieving photos in social network. ACIIDS, 2011.
[18] Picasa from Google Inc. http://picasa.google.com.
[19] H. Xu, J. Wang, X.-S. Hua, and S. Li. Image search by concept map. SIGIR, 2010.