DOI: 10.6245/JLIS.201810_44(2).0002
手寫數字辨識模型之比較研究
黃信瑜
天主教輔仁大學資訊管理學系碩士生 E-mail: [email protected]
蔡幸蓁
*
天主教輔仁大學資訊管理學系副教授 E-mail: [email protected]
關鍵詞:類神經網路;手寫數字識別;主成分分析;支援向量機;
OpenCV
【摘要】
*本研究主要目的為比較兩種不同的演算法對手寫數字識別之表現。本研究採用支援向量機
(SVM)及類神經網路(ANN)作為比較的項目,並且在資料集的處理上加以上主成分分析(PCA)
與OpenCV 為基礎的資料預處理。本實驗基於支援向量機、類神經網路、主成分分析以及 OpenCV 建構了一個手寫數字辨識模型(Hand-written Digits Recognition Model),並用此模型所訓練出 來的演算法分類器設計一系統來實測實際手寫的數字影像。實驗的結果為使用支援向量機的準確 率優於類神經網路,而在使用了主成分分析將資料集進行預處理降維後,在準確率不變的情況下,
大幅的減少了其運算的時間。
序論
科技的發展日新月異,這個世界自從工業革命之後開始進入了一個飛快改變期,特別是 電腦科技已實際地應用在生活中的各個層面,使電腦成為人類生活中不可或缺的好幫手,其 中尤以人工智慧的發展更令人矚目,各種應用接二連三被發展出來,人類史上即將面臨最偉 大技術革命,未來十年人工智慧的進步有可能改寫人類歷史、重構人類的生活樣貌。為了要 讓電腦學習人類的智慧,可以利用機器學習,讓電腦透過從過往的資料和經驗中學習並找到 其運行規則,最後展現人工智慧。
研究動機
機器學習目前已運用在許多的領域,比較為大眾所知的應用為語音辨識及影像辨識。語音辨
* 通訊作者:蔡幸蓁 [email protected]
識不僅可以將我們所說的話及時的轉換成文字呈現,在機器學習演算法的幫助下,更是可以再做 進一步的語義辨識。另一個為人們所熟知的應用領域即為影像辨識,更包含了許多耳熟能詳的應 用。舉例來說,預計會在2020 東京奧運會中被使用來進行維安工作一部分使用的人臉辨識技術 便是其中的佼佼者。人臉辨識的使用除了可以得知一張圖片中有幾個人外,透過機器學習演算法 可再更進一步的訓練使用,還可以做到身份識別的功能。影像辨識另一個常用的領域為文字 識別,如同語音一樣,在生活中我們也很常會想要更快的將書面的文字資料轉換成電子檔,但這 在以前只能選擇人工手動的將資料一一的輸入到電腦中。現在有另一個選擇,可以用文字影像辨 識的技術,只要使用照相機,就可以將想要的文字訊息轉錄成電子檔做儲存或更進一步的處理。
對於手寫數字之辨識也是非常熱門的研究領域之一,相較於工整的印刷字體,日常生活中人們有 更多的機會是要自己進行手寫的文字辨識。上述的這些應用都離不開機器學習演算法的使用,然 而所採用的演算法不同,也可能會產生不同的結果。研究學者利用多種演算法應用於手寫之文數 字之辨識,並對資料預先進行過濾或其他預處理,以求提高辨識度與時間效益。本研究欲了解在 手寫數字識別的應用中,採用不同的機器學習演算法與資料預處理的差異點在何處。除了研 究不同演算法之差異外,本研究亦設計一個可以實際識別我們真實手寫數字的系統。
研究目的
本研究的目的是要比較支援向量機(Support Vector Machine, SVM)及類神經網路
(Artificial Neural Network, ANN)這兩個演算法對於手寫數字辨識的準確率與時間。除了單 純的使用支援向量機及類神經網路以外,本研究另外使用OpenCV 對影像進行預處理,並比 較其準確率是否會優於沒有採用OpenCV 做預處理的情況。另外,在本研究中亦實作一系統 來實測上述的演算法所訓練出來的模型之表現。
文獻探討
在手寫的文數字辨識方面,Patil 和 Shimpi 於 2011 年利用類神經網路(ANN)進行手寫 英文文字之辨識,此篇論文的研究結果顯示準確率大於 70%。Holambe 與 Thool(2010)利 用支援向量機(SVM)和 K-最近鄰居法(K-Nearest Neighbor, KNN)兩種演算法路進文數字 的辨識,其實驗資料集同時採用手寫數字資料集以及印刷體數字資料集,此篇論文的研究結 果顯示,SVM 演算法擁有比 KNN 演算法更高的準確率。Arora 等學者(2010)從五個不同 的面向來探討SVM 演算法與類神經網路演算法對手寫梵文字體(Devanagari Character)辨識 能力。這五個面向分別是:訓練的複雜度、訓練的彈性、模型的選擇、分類的準確率和執行 的複雜度。此篇論文的研究結果顯示,SVM 演算法擁有比 ANN 演算法更好的表現。而 Singh 於2010 年進行光學字體辨識(OCR)印製的梵文(devnagari script),此篇論文的作者認為類 神經網路可以成功的解決梵文文字的辨識問題,其中又以48X57 矩陣大小的影像可以得到最 佳比其他比例的影像更佳的結果。Rajput 和 Mali(2010)利用數種演算法對手寫 marathi 文
進行辨識,此篇論文的實驗結果顯示NN 的準確率為 97.05%,KNN 的準確率為 97.04%,SVM 的準確率為97.85%,SVM 演算法有壓倒性的傑出表現。Barve 於 2012 年亦利用 ANN 針對 光學字體進行辨識,此篇論文的實驗結果顯示在英文字母的識別上相較於目前所有的相關方 法,此模型的表現並沒有更好。Yang(2018)利用深度學習(deep learning)在 MNIST 資料 集進行手寫數字辨識,準確率高達 99.3%。Ciresan 與 Meier(2015)利用多欄位深度類神經 模型(Multi-Column Deep Neural Networks)對中文進行辨識達到一個非常優異的辨識結果。
另外,有多個研究對欲辨識的資料預先進行處理,Sagheer 等學者(2010)建立了一套烏 爾都語的辨識系統,利用了影像過濾方法並比較了不同大小的影像辨識結果,其中以128X128 的影像大小擁有最佳的表現。此研究同時還比較了不同的影像過濾方法,其中Robert’s filter 的表現比Sobel filter 還要來的更佳。此系統有一個顯著的表現,其準確率高達 97%。
研究架構
HDI 模型
本研究根據實驗的動機與目的,設計了一套完整亦可實作的模型,本研究將此模型稱為 HDI 模型(Hand-written Digits Identification Model),圖 1 為此模型的流程與架構。
此模型分成三個部份,第一個部分為資料集的處理,會先進行預處理後再將資料集分成訓 練資料集及測試資料集。第二個部分為演算法分類器的應用,此部份又會分成三個不同演算法 應用,分別得到三個不同的演算法分類器模型,分別SVM、ANN、PCA+分類器(PCA+ANN、
PCA+SVM)。第三個部份為演算法分類器的測試,此步驟會將第一個部份的試資料集放入第二 個部份得到的演算法分類器中進行辨識的動作,最後會得到各別的準確率數值。
圖1 HDI 模型
HDI 模型-擴增
如圖2 中所示,在本研究的實驗設計中對此 HDI 模型做出擴增,此擴增為加入 OpenCV 對資料進行預處理的應用。在實驗中先使用OpenCV 對資料集先進行預處理,其後會再將資 料集分成訓練資料集及測試資料集。由於資料集的影像中除了數字的部分以外尚且還有許多 留白的部分,在此修改後的HDI 模型中會先使用 OpenCV 將圖片中影像中數字的部分進一步 的與留白的部分分割出來。接著再用此分割出來的純數字部分進行演算法模型的訓練。等到 訓練完成之後除了將一開始就分好的測試資料集拿來做準確率的測試以外,還會另外將實際 手寫的影像使用先前所訓練出來的演算法模型進行實測。
圖2 HDI 模型-擴增
資料集
本研究為比較不同演算法在手寫數字辨識上的效果,因此需要大量的訓練資料來完成訓練 模型的建置。本研究使用的資料集出自資料分析競賽網站—kaggle—手寫數字資料集,此份資 料集的原始出處為MINIST(Modified National Institute of Standards and Technology)。MINIST 是一個世界知名可提供大量用於影像識別實驗的影像資料庫,許多研究也是從MINIST 中取得 研究所需要的訓練資料集。本研究使用到的是其中的一份資料集,此份資料集中包括42000 筆 手寫數字影像的資料,每一筆影像資料長寬各28 圖元,一共擁有 784 個特徵值。
實驗設備
本研究的實驗環境為WIN 7 作業系統,使用的程式語言為 python。
實驗流程
在本研究的實驗設計中,對於演算法的相關參數設定是參考Faruqe 和 Hasan 在 2009 年 所提出的論文(Faruqe & Hasan, 2009)此篇論文是採用主成分分析以及支援向量機來進行人 臉辨識的研究。
一、資料集的處理
此份資料集中包括42000 筆手寫數字影像的資料,如圖 3 所示,每一筆影像資料長寬各 28 圖元,一共擁有 784 個特徵值。此份資料集實際要能放到演算法分類器中做使用前還有一 些資料預處理的動作需要先完成,首先將資料讀取後要先將用作表示欄位名稱的部分予以刪 除。接著將資料集中的每一筆資料分成兩個部分,這兩個部份分別為影像標籤與影像資料。
資料集中用以表示此筆資料影像為何的欄位會用一個串列予以儲存,此串列即為影像標籤。
剩餘的資料內容就被歸為影像資料。
圖3 資料集示意圖
二、演算法分類器的應用
(一)支援向量機(SVM)與類神經網路(ANN)
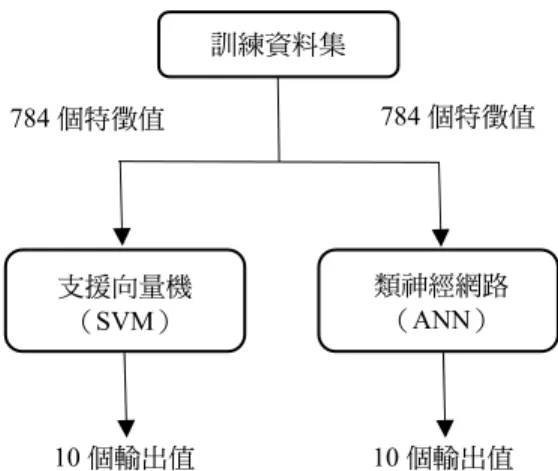
在進行訓練的時候會將所有的特徵值作為輸入的參數,也就是總共會有784 個特徵值參
數將用來計算。如圖4 中所示,對於所輸入的特徵值本研究在使用支援向量機與類神經網路
的時候並沒有做更多的處理,因此輸入資料個數即為特徵值的個數為784 個,而輸出值則為 10 個代表阿拉伯數字 0 至 9。
圖4 演算法分類器的應用-ANN & SVM
(二)主成分分析(PCA)加上支援向量機(SVM)
如圖5 中所示,一開始輸入的資料集特徵值數目亦是保持 784 個,首先使用主成分分析 來對資料集做降維的動作,經過主成分分析的處理過後會得到僅剩30 個特徵值,接著再將這 30 個特徵值當成輸入值放入支援向量機中做運算,最終會得到 10 個輸出值。
圖5 演算法分類器的應用-SVM + PCA
影像處理流程
在使用OpenCV 進行影像預處理的時候,根據本研究中的實驗需求,會經由一些步驟來 獲取圖片中比較關鍵的區域,也就是要進行辨識的部分。
1. 模糊化:首先為了要去除影像中的噪音,我們將會進行模糊化的動作。模糊化的動作會 在影像中將每一個圖元的值與其鄰近範圍的值做一個平均的處理,藉此來讓影像看起來
784 個特徵值
10 個輸出值
784 個特徵值 訓練資料集
支援向量機
(SVM)
類神經網路
(ANN)
10 個輸出值
784 個特徵值
30 個特徵值
10 個輸出值 支援向量機
(SVM)
主成分分析
(PCA)
訓練資料集
較為平滑。本實驗中採用9X9 的矩陣來進行模糊處理。
2. 閾值:取閾值的動作可以看成是一個簡單的影像分割技巧。我們會先將彩色的影像轉換 成灰階的影像,之後會設定一閾值,當圖元的值小於此閾值的時候皆設定為黑色,反之 則設定成白色。
3. Canny 邊緣檢測:在此步驟中會使用 Canny 邊緣檢測演算法來從影像中獲得更多的資訊。
Canny 邊緣檢測演算法會根據影像中的亮度尺度來偵測邊緣元素。
4. 尋找輪廓:第四個步驟為尋找輪廓,我們會根據前面的步驟中所得到的結果來更進一步 獲得項目的輪廓。在第三步驟中只有得到影像中各邊緣的分佈情況,並沒有辦法定義為 一個整體,在此會將這些邊建構成一個數字的整體形狀。
5. 限制條件:當我們在獲得物體輪廓的同時會發現一個情況,我們所得到的物體輪廓數量會 遠大於我們所感興趣的部分,這時就要加些限制來確保最終的選取目標是我們想要的。
6. 機器學習:在機器學習階段,本研究會使用兩種不同的機器學習演算法來進行訓練與建 模。此兩種演算法分別是支援向量機與類神經網路,另外還會在搭配主成分分析來做資 料處理的動作。
7. 預測/辨識:在最後一個步驟中將會使用上一步驟中所訓練好的演算法模型來對步驟五中 所得到的影像進行辨識的動作,並比較不同演算法及資料預處理方法的不同其結果表現。
演算法參數設定 一、類神經網路
表1 為類神經網路的相關參數設定,本實驗為求最佳實驗結果,進行多次參數設定實驗,
最終設定隱藏層數目為9 及隱藏層節點數為 13 來做為實驗的數據。
表1 類神經網路參數設定
參數名稱 設定值
隱藏層數目 隱藏層節點數
9 13
學習率 0.001
迭代次數 10000
Activation function Identification
solver adam
alpha 0.001
二、支援向量機
支援向量機的相關參數設定是採用Faruqe 和 Hasan 在 2009 年所提出的論文(Faruqe &
Hasan, 2009)中的數據,其數據如表 2 所示:
表2 支援向量機參數設定
參數名稱 設定值
Kernel function Degree
Polynomial 5
Gamma 1/784
Coef0 0.0
C 1.0
iteration 10000
三、主成分分析
主成分分析的相關參數設定是採用Faruqe 和 Hasan 在 2009 年所提出的論文(Faruqe &
Hasan, 2009)中的數據,本研究與此篇論文採用相同的數據選取前 30 個主成分。
實驗結果
類神經網路(
ANN)
類神經網路的使用上,本研究對於相關參數的設定如下:隱藏層層數設定為9 層,每層
節點數為 13,最大反覆運算次數為 10000 代,學習率設定為 0.001。最終的結果本研究統計 十次的結果後,進行平均處理,其結果如下:十次的平均準確率為百分之九十一,最高準確 率為百分之九十一,十次的執行時間為三分零二秒,其辨識結果如圖6 所示。
圖6 ANN 結果圖
支援向量機(
SVM)
支援向量機的使用上,本研究對於相關參數的設定如下:kernel function 使用 polynomial kernel,degree 設定為 5,最大反覆運算次數為 10000 代。最終的結果本研究統計十次的結果 後,進行平均處理,其結果如下:十次的平均準確率為百分之九十六,最高準確率為百分之 九十六,十次的執行時間為二十五分五十二秒,其辨識結果如圖 7 所示。
圖7 SVM 結果圖
主成分分析(PCA)+ 類神經網路(ANN)
主成分分析 + 類神經網路的使用上,本研究對於相關參數的設定如下:此部分又分為主 成分分析的相關參數設定及類神經網路的相關參數設定。主成分分析的部分:所選取的主成 分數量為30。類神經網路的部分:隱藏層層數設定為 9 層,每層節點數為 13,最大反覆運算 次數為10000 代,學習率設定為 0.001。最終的結果本研究統計十次的結果後,進行平均處理,
其結果如下:十次的平均準確率為百分之八十八,最高準確率為百分之八十八,十次的執行 時間為一分五十四秒。
主成分分析(
PCA)+ 支援向量機(SVM)
主成分分析 + 支援向量機的使用上,本研究對於相關參數的設定如下:此部分又分為主 成分分析的相關參數設定及支援向量機的相關參數設定。主成分分析的部分:所選取的主成 分數量為30。支援向量機的部分:kernel function 使用 polynomial kernel,degree 設定為 5,
最大反覆運算次數為10000 代。最終的結果本研究統計十次的結果後,進行平均處理,其結 果如下:十次的平均準確率為百分之九十七,最高準確率為百分之九十七,十次的執行時間 為八分十秒。
OpenCV + 類神經網路 ANN
OpenCV + 類神經網路的使用上,本研究對於相關參數的設定如下:類神經網路的部分:
隱藏層層數設定為9 層,每層節點數為 13,最大反覆運算次數為 10000 代,學習率設定為 0.001。
最終的結果本研究統計十次的結果後,進行平均處理,其結果如下:十次的平均準確率為百分 之九十,最高準確率為百分之九十,十次的執行時間為三分十四秒,其辨識結果如圖8 所示。
圖8 OpenCV + ANN 結果圖
OpenCV + 支援向量機(SVM)
OpenCV + 支援向量機的使用上,本研究對於相關參數的設定如下:支援向量機的部分:
kernel function 使用 polynomial kernel,degree 設定為 5,最大反覆運算次數為 10000 代。最 終的結果本研究統計十次的結果後,進行平均處理,其結果如下:十次的平均準確率為百分
之九十七,最高準確率為百分之九十七,十次的執行時間為十二分五秒,其辨識結果如圖 9
所示。
圖9 OpenCV + SVM 結果圖
OpenCV + PCA + ANN
在主成分分析 + 類神經網路的使用上,本研究對於相關參數的設定又分為主成分分析的 相關參數設定及類神經網路的相關參數設定。主成分分析的部分:所選取的主成分數量為30 。 類神經網路的部分:隱藏層層數設定為9 層,每層節點數為 13,最大反覆運算次數為 10000 代,學習率設定為0.001。最終的結果本研究統計十次的結果後,進行平均處理,其結果如 下:十次的平均準確率為百分之八十八,最高準確率為百分之八十八,十次的執行時間為 二分零秒。
OpenCV+ PCA + SVM
在 OpenCV + 主成分分析 + 支援向量機的使用上,本研究對於相關參數的設定又分為 主成分分析的相關參數設定及支援向量機的相關參數設定。主成分分析的部分:所選取的主 成分數量為30。支援向量機的部分:kernel function 使用 polynomial kernel,degree 設定為 5,
最大反覆運算次數為10000 代。最終的結果本研究統計十次的結果後,進行平均處理,其結 果如下:十次的平均準確率為百分之九十七,最高準確率為百分之九十七,十次的執行時間 為五分五十五秒。
結果比較
表3 的內容整理了不同演算法間的比較以及不同的資料預處理方法所產生的不同結果。
表 3 的內容可以先分為兩個部分來解讀,分別是以類神經網路演算法為主的表 4,以及以支 援向量機為主的表 5。表 3 中可以看到以準確率而言四種不同的處理方式,其準確率並沒有 太大的差異。其中沒有對資料集做任何的預處理所花費的時間最長。PCA 及 OpenCV 兩種不 同的資料預處理方式是以PCA 所花費的時間最少,其原因為經過 PCA 處理後的資料擁有較 少的特徵輸出結果,因此在後續的計算上所花費的時間就會比較少。若將二者合併使用時在 類神經網路看不出明顯的差異,但在需要大量計算時間的支援向量機演算法上就可以很明顯 的看出若是能夠先將欲輸入的資料做過處理,就可以大大的減少後續計算上要花費的時間,
進而提升效率。
表3 結果比較表
時間(十次平均) 準確率(十次平均)
ANN 3:02 91%
SVM 25:52 96%
PCA + ANN 1:54 88%
PCA + SVM 8:10 97%
OpenCV + ANN 3:14 90%
OpenCV + SVM 12:05 97%
OpenCV+PCA+ANN 2:00 88%
OpenCV+PCA+SVM 5:55 97%
表4 ANN 結果比較表
時間(十次平均) 準確率(十次平均)
ANN 3:02 91%
PCA + ANN 1:54 88%
OpenCV + ANN 3:14 90%
OpenCV+PCA+ANN 2:00 88%
表5 SVM 結果比較表
時間(十次平均) 準確率(十次平均)
SVM 25:52 96%
PCA + SVM 8:10 97%
OpenCV + SVM 12:05 97%
OpenCV+PCA+SVM 5:55 97%
實測結果
為了能使訓練出來的模型應用於實際案例,本研究中實作了一個系統來實測先前所訓練 出來的機器學習演算法模型,輸入為隨機使用者輸入的數字。圖10 至圖 12 分別為其執行結 果之系統畫面圖:
圖10 實測結果系統畫面一
圖11 實測結果系統畫面二
圖12 實測結果系統畫面三
結論與未來展望
字元辨識發展已久,本研究比較了其中兩種常用的機器學習演算法,分別是類神經網路 以及支援向量機。除了運用此兩種機器學習演算法之外,本研究的實驗中還使用了主成分分 析及OpenCV 來對資料集做一個預處理的動作,期望可以得到更多的分析。
在本研究的實驗設計中兩種機器學習演算法中所使用到的參數全部都是設定一樣的,在 搭配上PCA 及 OpenCV 的資料預處理動作,最終一共整理出八種不同的組合實驗結果。從結 果中可以很明顯的看到有先對資料集做出些預處理的動作來有效的降低輸入進機器學習演算 法中的特徵值數目的話,其結果可以在保持相同準確率水準的前提之下,大幅的減少其計算 所需要的時間。
在本研究中只對手寫數字做了比較與實測,在未來期望可以再更進一步的對文字做出辨 識,由其是對中文字的識別。在本研究的實驗中使用了OpenCV 來幫助我們取得影像中的數 字區域,其中的操作還有很大的改進空間,對於圖片的處理能夠更加細膩的話,相信在模型 的訓練建構中也會有更好的表現。
參考文獻
Arora, S., Bhattacharjee, D., Nasipuri, M., Malik, L., Kundu, M., & Basu, D. K.(2010). Performance comparison of SVM and ANN for handwritten devnagari character recognition. International Journal of Computer Science Issues, 7(3), 18-26.
Barve, S.(2012). Optical character recognition using artificial neural network. International Journal of Advanced Research in Computer Engineering & Technology, 1(4), 131-133.
Cireşan, D. & Meier, U. (2015). Multi-column deep neural networks for offline handwritten Chinese character classification. In 2015 International Joint Conference on Neural Networks (IJCNN), pp. 1-6. doi:
10.1109/IJCNN.2015.7280516
Faruqe, M. O., & Hasan, M. A. M.(2009). Face recognition using PCA and SVM. Proceedings of the 3rd International Conference on Anti-Counterfeiting, Security, and Identification in Communication (ASID'09), pp. 97-101. doi: 10.1109/ICASID.2009.5276938
Holambe, A. N., & Thool, R. C.(2010). Printed and handwritten character & number recognition of devanagari Script using SVM and KN. International Journal of Recent Trends in Engineering and Technology, 3(2), 163-166.
Patil, V., & Shimpi, S.(2010). Handwritten English character recognition using neural network. International Journal of Computer Science and Communication, 1(2), 141-144.
Rajput, G. G., & Mali, S. M.(2010). Fourier descriptor based isolated Marathi handwritten numeral recognition.
International Journal of Computer Applications, 3(4), 9-13.
Sagheer, M. W., He, C. L., Nobile, N., & Suen, C. Y.(2010). Holistic urdu handwritten word recognition using support vector machine, Proceedings of the 20th International Conference on Pattern Recognition, pp.
1900-1903. doi: 10.1109/ICPR.2010.468
Yang, R. (2018). Classifying hand written digits with deep learning intelligent information management.
Scientific Research, 10(2), 69-78.
A Comparison of Handwritten Digits Recognition Models
Hsin-Yu Huang
Graduated Student, Department of Information Management, Fu Jen Catholic University, Taiwan (R.O.C.)
E-mail: [email protected]
Hsine-Jen Tsai
Associate Professor, Department of Information Management, Fu Jen Catholic University, Taiwan (R.O.C.)
E-mail: [email protected]
Keywords: Artificial neural network; Hand-written Digits Recognition; OpenCV;
Principal components analysis; Support vector machine
【Abstract】
The purpose of our study is to compare the performance in two different kinds of machine learning algorithms on handwritten digits recognition. Our study choose support vector machine (SVM) and artificial neural network (ANN) as the comparing algorithms, and use OpenCV and principal components analysis (PCA) to preprocess the dataset. The result shows that SVM has the better performance than ANN, and the dataset preprocessing based on PCA can improve the efficiency when calculating the result. Moreover we construct a HDI model based on SVM, ANN, PCA and OpenCV, and use the classifier training from this HDI model to build a system that can recognize the handwritten digits written by ourselves.
【Long Abstract】
Introduction
The development of the technology has made our life more convenient and efficient. Things that seemed impossible in the past are now easily done. In the aspect of the communication, the ancient people trained pigeons to help people deliver letters to others in far places, but now people can use their smartphones connect to their friend in a few second.
DOI: 10.6245/JLIS.201810_44(2).0002
Recognition of handwritten digits plays an active role in daily life today. Converting handwritten documents to digital media is a very crucial and time consuming task in various applications such as office automation, e-government and other areas. We find out that it is very common for people to write the ordering amount on the menu when they visit the self-service ordering restaurants in Taiwan.
Customers need to write down the amount of what they want to eat on an ordering sheet and give it back to the clerk. The clerk will then compute the total price with the calculator and this might take some time waiting for the result. By using an ordering food system with handwritten digits recognition capability restaurant clerks can obtain the quantities that customers ordered after customers wrote down orders on smart phones or pads. The numerals can even be written on a regular sheet of paper using a pen, and then they are captured by a smart phone and processed to a binary image which is analyzed by a computer. So the system should be designed in such a way that it should be able of reading handwritten digits accurately and provide appropriate response as humans do. That is the motivation of this study.
Important Theory
Handwritten digits are varying from person to person because each one has their own style of writing, it is not an easy work for human beings sometimes. Since the computers lack recognition capability it becomes an even more challenging task for the machine to identify handwritten digits. If we expect the machine to generate accurate output, we need to provide a proper database and learning algorithms that machine can be trained and then recognize accurately. Fortunately, many machine learning algorithms have been proposed since big data era was launched. Support vector machine (SVM) is a machine learning algorithm for two-group classification problems. Support vector machine is also a kind of supervised learning. Support vector machine constructs a hyperplane to divide the data into two groups.
The distance between the data and hyperplane is called margin. The bigger margin is the better result we have. The goal of support vector machine is to identify a hyperplane with the biggest margin.
Artificial neural network (ANN) is a type of supervised learning algorithm and it imitates the biological neurons to construct a mathematical model. Artificial neural network has one or more inputs and layers of neurons. Three factors need to be put into consideration when a typical artificial neural network is employed by a learning model which are described as follows:
(1) Architecture: How the neurons construct their relationship and define the weights.
(2) Activation function: A non-linear function which the results pass through before final outputs are generated.
(3) Learning rule: Learning rules define how the weights adjust over time.
Artificial neural network have been used to solve various problems such as image and speech recognitions.
There are two factors that affect recognition systems’ performance. First one is the degree of accuracy of features that are extracted from a digit image. Learning algorithms are the second factor.
Appropriate algorithms with suitable parameters can generate more accurate results. Both factors have been put into consideration in this study.
Methodology
This paper presents a comparative analysis of the performance in two well-known machine learning algorithms on handwritten digits recognition. Our study choose support vector machine (SVM) and artificial neural network (ANN) as the learning algorithms of recognition models. Since the degree of accuracy of features that are extracted from a digit image affects the performance of the recognition models. The features extracting approach, PCA, is used in the recognition models and an image processing tool, OpenCV, is preprocess the dataset and results are compared as well. The Open Source Computer Vision Library (OpenCV) is an image identification tool which is released under a BSD license and hence it’s free for both academic and commercial use. Principal component analysis (PCA) is a mathematical procedure that converts a larger number of data into a smaller number of uncorrelated variables known as principal components that still contains most of the information in the larger group.
PCA can be used to reduce the dimension of the feature space and is a well-known feature extraction technique in data mining area.
In this paper, eight recognition models that utilizes different learning algorithms, feature extraction method and image preprocessing tool have been built. We identify and compare the accuracy and the performance of each model. Two models utilize only learning algorithms namely, SVM and ANN.
Another two models use feature extraction tool, PCA, along with learning algorithms. Another two models perform the data preprocessing procedure with image processing tool, openCV, before feed data into learning algorithms. There two models not only use feature extraction tool but also perform data preprocessing before data are put into learning algorithms.
In this study, a dataset of 42000 hand written images carried out by the MINIST (Modified National Institute of Standards and Technology) has been analyzed. The data set is divided into training set and testing set. The length and width of each image are both 28 pixels. In each image there are 784 features in total. The analysis use Python programming language and runs in the Windows 7 system. Experiments
have been conducted to decide variables such as weights, parameters and activation functions which are needed for these models to be executed correctly. 10-fold validation is used to validate the correctness of models.
Results
The results show that the model utilized SVM as learning algorithm has better accuracy than ANN regardless whether feature extraction tool or data preprocessing tool is performed. Among four models that use SVM the one with OpenCV as well as PCA has the best performance. It only takes 5 minutes and 55 seconds to complete its task, comparing with the SVM_PCA model which takes 12 minutes and 5 seconds. The model equipped with ANN as the learning algorithm along with SVM and PCA spend the shortest time but results in the lowest accuracy. The analysis also indicates the PCA can improve the efficiency while computing results. Both models that use PCA as the feature extraction tool takes less time than the models without PCA. The results showed that the contribution of the image preprocessing tool OpenCV is less obvious than PCA. It only shows obvious improvement in the model used SVM.
The SVM model with OpenCV spends half time than the one without OpenCV.
Moreover, we construct a Handwritten Digits Identification (HDI) model based on SVM, ANN, PCA and OpenCV, and use the model trained from this HDI model to build a hand written digits recognition system that can recognize the handwritten digits written by human. This system has been implemented and used in our lab.
Conclusion and Future Works
The results of this research show that SVM demonstrates the better accuracy than ANN in hand written digit recognition model regardless whether feature extraction tool or data preprocessing tool is performed. This study suggests there are more possible improvements can be put into research in the future. One of them is the image preprocessing methods. A better performance can be achieved if other tools or procedures can be used or improved.
【Romanization of references is offered in the paper.】