第4章 區塊比對電路測試範例
本論文的系統平台主要是用來進行區塊比對電路的測試,我們撰寫了一個區 塊比對電路作為測試範例,可以與系統平台的測試端整合來進行測試,本章節將 對區塊比對電路範例作簡介,並且對區塊比對電路範例中所使用的資料交錯式全 域搜尋區塊比對的硬體架構,以及帶狀直行掃瞄的硬體架構,進行詳細說明,最 後再對整個區塊比對電路範例的硬體架構,作更詳細的介紹。
4.1 區塊比對電路範例簡介
在本論文的區塊比對電路的範例,使用區塊大小為
4×4的區塊,搜尋區域
的水平與垂直位移量為
−2~1個像素,我們所採用的
4×4區塊是H.264 壓縮標準
中所支援的最小基礎區塊,區塊比對主要是採用全域搜尋的方式,會比對搜尋區
域中每一個候選的區塊,計算每一個候選區塊與目前區塊的絕對誤差和,找具有
最小的出絕對誤差和的候選區塊,也就是與目前區塊最相似的候選區塊,而在區
塊比對電路的實現,則是採用所謂的資料交錯式(Data-Interlacing)全域搜尋區塊
比對架構 [6],這種架構能透過二維的資料重複利用( 2-D data-reuse),實現全域
搜尋區塊比對演算法,在把資料輸入到硬體架構時,可以採用循序輸入(serial data
inputs),但是在硬體計算時,又可以進行平行處理(parallel processing),同時計算 每一個候選區塊的絕對誤差和;而為了配合此種架構的計算,必須以直行掃瞄 (Column Scan)的方式,將搜尋區域以及目前區塊的資料輸入此架構來進行絕對誤 差和的計算,而且在此架構中,採用Pipeline的方式來進行絕對誤差和的計算與 絕對誤差和的比較;關於資料交錯式全域搜尋區塊比對架構以及直行掃瞄的運作 方式,將在下面4.2與4.3兩節會作詳細的討論。
本章的區塊比對電路的範例,也套用了在3.5節所提出的區塊比電路套用模 型 的 架 構 , 除 了 具 有 全 域 搜 尋 區 塊 比 對 法 則 的 硬 體 功 能 , 也 能 透 過 NiosII Processor System之中的Avalon Bus來取得計算資料以及輸出計算的結果,與
NiosII Processor System整合。
4.2 資料交錯式全域搜尋區塊比對架構
如圖 4-1所示為資料交錯式(Data-Interlacing)全域搜尋區塊比對的硬體架構
圖,在架構的中間有 16 個平行的處理單元(Processing Element , PE) ,在此架構
的左右兩側也有兩條各由 16 個位移暫存器(Shift Register)串接而成的串列,而且
串列中的每個暫存器也與對應的處理單元相連接,準備將暫存器中的資料輸入處
理單元,這兩條位移暫存器串列主要負責將搜尋區域中的像素重複利用,搜尋區
域中的候選區塊之間重疊部分的像素可以不必重送,也就是搜尋區域中的像素只
要被輸入一次即可,如圖 4-3所示,當輸入搜尋區域(Search Area)的像素的時 候必須以直行掃瞄(Column Scan)的方式來輸入,而且要區別偶數行(Even Column) 與奇數行(Odd Column),偶數行(Even Column)的像素必須從左邊的位移暫存器串 列中標示為Even15 的位移暫存器開始輸入,奇數行(Odd Column)的像素也同時 會從右邊的位移暫存器串列中標示為Odd15 的位移暫存器開始輸入,因此我們將 左邊的暫存器串列稱為偶數位移暫存器串列,而右邊的暫存器串列稱為奇數位移 暫存器串列,每個clock cycle,兩條串列中的所有位移暫存器會同時位移一次,
新的資料也會進入串列;此外我們也會針對目前區塊進行直行掃瞄,每個clock cycle 掃 瞄 區 塊 中 的 一 個 像 素 , 然 後 同 時 傳 遞 給 架 構 中 的 16 個 處 理 單 元
(Processing Element , PE),而每個處理單元的構造,如圖 4-2所示,會由偶數 暫存器串列或者奇數暫存器串列,挑選出對應的候選區塊的像素來與目前區塊的 像素,進行絕對誤差和的計算,也就是先通過標示為SUB的電路作減法,然後由 標示為ABS的電路來取絕對值,然後由標示為ACC的累加器進行累計,此外,為 了絕對誤差和的計算以及每個候選區塊的絕對誤差和的比較,能夠以Pipeline的 方式進行,在PE中也使用了閂鎖電路(Latch),來控制絕對誤差和的輸出。
關於整個架構運作,預先必須花費 16 個clock cycle進行初始化,初始化的結
果如圖 4-1所示,我們將搜尋區域中第 0 行、第 2 行,輸入偶數暫存器串列,同
時也將第 1 行與第 3 行前四個像素輸入奇數暫存器串列,由於要配合區塊的計
算,因此奇數行的像素必須先延遲 4 個clock cycle,而且每輸入完一行搜尋區域 的像素,換行時必須延遲 1 個clock cycle,初始化完成之後,整個架構開始正式 運作,一開始的 4 個clock cycle,PE會允許圖 4-1中標示為藍色的位移暫存器輸 入資料,接著的 4 個clock cycle,PE則允許圖 4-1中標示為紅色的位移暫存器輸 入資料,而每 4 個clock cycle會彼此交換一次,這也就是所謂的資料交錯 (Data-Interlacing)的過程;初始化之後只需要經過 16 個clock cycle,PE就可以累 計出搜尋區域中所有的候選區塊的絕對誤差和。
值得注意的是,在計算絕對誤差和的同時,也正在進行上一個搜尋區域中所
有的候選區塊的絕對誤差和的比較,我們每個 clock cycle 挑出兩個候選區塊的絕
對誤差和送入絕對誤差和比較器(SAD Compare)進行比較,所以當累計好目前這
個搜尋區域中所有的候選區塊的絕對誤差和,也比較出上一個搜尋區域中具有最
小絕對誤差和的候選區塊。
圖 4-1 資料交錯式全域搜尋區塊比對架構
Latch ACC
SUB ABS MUX
PE
絕對誤差和 (SAD)
Odd Column Pixel Even Column
Pixel Current Block
Pixel 8
8
8 12
圖 4-2 處理單元(Processing Element)
圖 4-3 直行掃瞄的順序
4.3 帶狀直行掃瞄架構
由於4.2節所提到的資料交錯式全域搜尋區塊比對的硬體架構,需要對搜尋 區域以及目前區塊進行直行掃瞄,但是儲存在記憶體之中的動態影像的畫面,通 常在連續的記憶體位置存放的是畫面中同一列的像素,因此我們設計了一個帶狀 直行掃瞄的電路架構,可以輸入採用橫列的方式所儲存的畫面像素,但是資料交 錯式全域搜尋區塊比對電路又可以採用直行掃瞄的方式來讀取所需的畫面像素。
如圖 4-4所示,每次電路的輸入會從目前畫面與前一張畫面,取出由目前區 塊組成的Current Block Strip以及由搜尋區域交疊所形成的Search Area Strip,傳送 給我們設計的帶狀直行掃瞄(Strip Column Scan)的電路架構,如圖 4-5所示,
Current Block Strip與Search Area Strip會分別由其中Current Block Strip Column
Scan與Search Area Strip Column Scan的電路,進行直行掃瞄的動作,然後資料交
錯式全域搜尋區塊比對的電路,可以直接讀取帶狀直行掃瞄的電路架構所輸出的
資料來計算。
圖 4-4 帶狀資料
圖 4-5 帶狀直行掃瞄架構
而關於Current Block Strip Column Scan與Search Area Strip Column Scan的硬
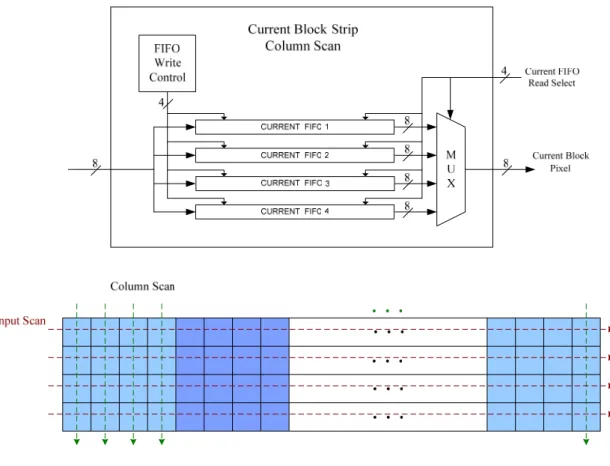
體實現,我們分別在圖 4-6與圖 4-7之中作了詳細的說明;如圖 4-6,首先將帶
狀資料Current Block Strip中的每一列像素,依列次存入電路中的FIFO Buffer,例 如第一列像素存入Current FIFO 1、第二列像素存入Current FIFO 2,依此類推,
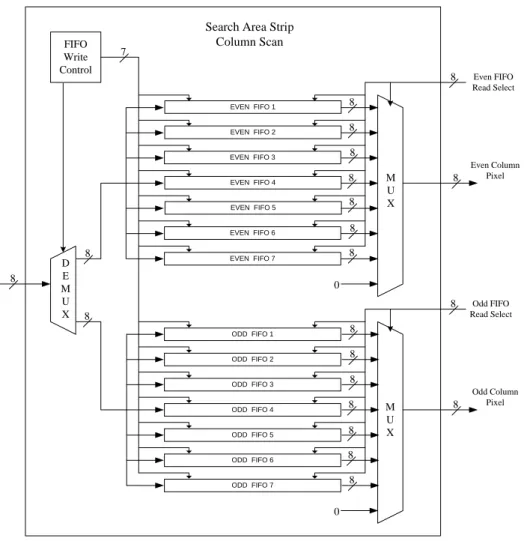
當讀取的時候,則是輪流由每一個FIFO Buffer,讀取一筆像素,如此讀取的資料 順序,便符合直行掃瞄的資料順序;而關於圖 4-7所示的Search Area Strip Column Scan,也是與Current Block Strip Column Scan的作法類似,只輸入每一列像素時,
我們還必須把同一列中偶數位置的像素與奇數位置的像素,分開儲存在不同的 FIFO Buffer,這樣讀取時,才能分別讀取偶數行與奇數行的資料。
圖 4-6 Current Block Strip Column Scan
EVEN FIFO 1
EVEN FIFO 2
EVEN FIFO 3
EVEN FIFO 4
EVEN FIFO 5
EVEN FIFO 6
EVEN FIFO 7
ODD FIFO 1
ODD FIFO 2
ODD FIFO 3
ODD FIFO 4
ODD FIFO 5
ODD FIFO 6
ODD FIFO 7
0
0
M U X
M U X 8
8
8 8 8 8 8 8 8 D
E M U X
8 8 8 8 8 8 8
8
8 8
Search Area Strip Column Scan
Even Column Pixel
Odd Column Pixel FIFO
Write Control
Even FIFO Read Select
Odd FIFO Read Select 8
8 7
Search Area Strip . . . . . . . . . . . . . . . . . . . . . . . .
Column Scan Input Scan