Genome-wide association studies in pharmacogenomics of antidepressants
Eugene Lin 1,2 and Hsien-Yuan Lane 1,3,4
1 Institute of Clinical Medical Science, China Medical University, Taichung, Taiwan
2 Vita Genomics, Inc., 7 Fl., No. 6, Sec. 1, Jung-Shing Road, Wugu Shiang, Taipei, Taiwan 3 Department of Psychiatry, China Medical University Hospital, Taichung, Taiwan
4 Department of Psychology, College of Medical and Health Sciences, Asia University, Wufeng, Taichung, Taiwan
Corresponding author: Hsien-Yuan Lane E-mail address: [email protected] Phone: +886-4-22052121-1074 Fax: +886-4-2236-1230
Abstract
Major depressive disorder (MDD) is one of the most common psychiatric disorders worldwide. Doctors must prescribe antidepressants based on educated guesses due to the fact that the effectiveness of any particular antidepressant in an individual is difficult to predict. In the recent advent of scientific research, the genome-wide association study (GWAS) is widely utilized to examine hundreds of thousands of single nucleotide polymorphisms (SNPs) by high-throughput genotyping technologies. In addition to the candidate-gene approach, the GWAS approach has recently been employed to study the determinants of antidepressant response to therapy. In this study, we reviewed GWAS studies, their limitations, and future directions with respect to the pharmacogenomics of antidepressants in MDD.
Keywords: antidepressants, genome-wide association study, major depressive disorder,
Introduction
Major depressive disorder (MDD) is a serious health concern worldwide and is predicted to be the second leading cause of disability by 2030 [1]. Antidepressants are currently the first line of medication for lifting MDD. However, doctors can only prescribe antidepressants based on a trial and error approach because the effectiveness of medical treatments for MDD in individual patients is unknown beforehand. Single nucleotide polymorphisms (SNPs) can be used in clinical association studies to determine the contribution of genes to drug efficacy, as evidence is accumulating to suggest that the combined effects of a number of genetic variants such as SNPs contribute about 50% or more to antidepressants response [2-4]. Although there are not enough data currently available to prove this hypothesis, more and more genetic variants associated with antidepressant response are being discovered [2-4]. In this paper, we reviewed the pharmacogenomics of the drug efficacy of antidepressants in MDD.
The completion of the Human Genome Project has led to a new era of scientific research such as the revolutionary genome-wide association study (GWAS), which is an alternative to the candidate-gene approach [5]. Unlike the candidate-gene approach, there is no a priori hypothesis about the involved genes in the GWAS studies, which examine
common genetic variations across the entire human genome in an attempt to identify genetic associations with observable traits by using high-throughput genotyping technologies to assay hundreds of thousands of SNPs [6, 7]. A typical GWAS study utilizes 500,000 to 2 million SNPs in cases and controls and usually has four parts including (1) selection of a large number of participants with the disease or trait of interest and a suitable control group for comparison; (2) DNA isolation, array platforms and data review to ensure high genotyping quality; (3) statistical tests for associations between SNPs and the disease and/or trait; and (4) replication of identified associations in an independent population or experiment of functional studies [8]. This GWAS approach presents several challenges, such as the issue of multiple comparisons and how to account for ethnic and geographic differences in the prevalence of SNPs [9, 10]. The situation of multiple comparisons refers to the probability that SNP frequencies in cases and controls would differ simply because chance naturally increases when there are hundreds of thousands of comparisons. The issue is usually resolved by requiring a very large sample size or by detecting a SNP with a very low P-value for strong evidence of association [11, 12].
First, we surveyed the SNPs and genes identified as genetic markers that were correlated and associated with the drug efficacy of antidepressants in the GWAS studies for
MDD patients. Furthermore, we investigated some potential candidate genes that were tested in a GWAS study and were shown to be associated with adverse drug reactions for antidepressant medications. In addition, we reviewed the genetic markers assessed in a GWAS study that may identify patients who have an increased risk of treatment-emergent suicidal ideation. Finally, we summarized the limitations and future perspectives with respect to the pharmacogenomics studies in the GWAS studies. Independent replications in large sample sizes are needed to confirm the role of the genes and SNPs found in the GWAS studies in antidepressant treatment response.
Method
In this paper, we identified recent studies on pharmacogenomics studies of antidepressants after a comprehensive search of the electronic PubMed database (2009-present). Key words used in the search were “gene,” “polymorphism,” “pharmacogenomics,” “antidepressants,” “response,” “adverse drug reactions,” “genome-wide association study,” and “GWAS” [2-4]. The use of generic key words was intentional in order to capture as many published papers as possible. In addition, we carried out a manual search of bibliographical cross-referencing. The papers obtained were manually screened, aiming at identifying original articles, reviews, and case reports focusing on pharmacogenomics studies of antidepressants.
Results
Table 1 summarizes the relevant SNPs and genes associated with antidepressant response and adverse drug reactions in the GWAS studies. This is by no means a comprehensive review of all potential markers reported in the literature. As mentioned previously, increasing numbers of markers are being identified as researchers continue to pay attention to pharmacogenomics of antidepressants.
GWAS by Ising and colleagues
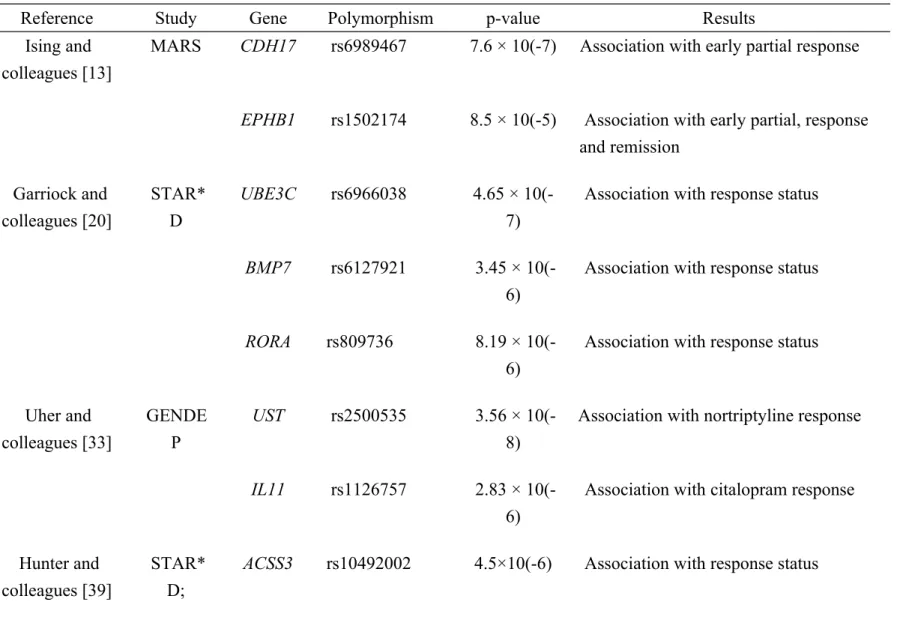
In a GWAS, Ising and colleagues studied genetic variation as a predictor of antidepressant drug treatment in depression [13]. They genotyped 339 inpatients from the Munich Antidepressant Response Signature (MARS) trial using the Human 610-quad BeadChip® (Illumina, CA, USA) [13]. In the MARS project, there were three outcome phenotypes: early partial response, derived from a 25% or greater reduction in Hamilton Depression Rating Scale (HAM-D) score after 2 weeks of treatment [13]. The responder phenotype, that required a 50% or greater reduction in HAM-D score after 5 weeks of treatment and the remission phenotype, defined by a score of 10 or less on HAM-D after 5 weeks or before discharge [13].
antidepressant drug treatment in depression [13]. The first one is the rs6989467 SNP in the cadherin-17 gene (CDH17) that was associated with early partial response (P = 7.6 × 10(-7)) [13]. The second one is the rs1502174 SNP (P = 8.5 × 10(-5)) in the Ephrin type-B receptor 1 (EPHB1) gene that was associated with all three phenotypes including early partial, response and remission [13].
The encoded protein by the CDH17 gene is a cell adhesion molecule highly expressed in human hepatocellular carcinoma and may play a role in therapeutic intervention for liver malignancy [14, 15].
The protein encoded by the EPHB1 gene is a receptor for ephrin-B family members, which mediate numerous developmental processes, particularly in the nervous system [16]. In a GWAS study of schizophrenia, Sullivan and colleagues found an association with the
EPHB1 gene in the CATIE study [17]. In addition, the association of the EPHB1 gene with
schizophrenia has received support from an independent GWAS in a Japanese population [16]. Xu and colleagues also detected a rare de novo CNV overlapping with the EPHB1 gene [18]. However, Kushima and colleagues found that there was no association between the EPHB1 gene and schizophrenia in re-sequencing analysis [19].
In a similar GWAS for antidepressant response to therapy, Garriock and colleagues studied the Sequenced Treatment Alternatives to Relieve Depression (STAR*D) study that was representative of the diverse ancestry of patients in the United States [20]. The STAR*D study, where all participants were treated with citalopram, is the largest antidepressant trial conducted to date with 1,953 participants who provided DNA samples [20]. There were two main phenotypes derived in the STAR*D study. One phenotype is response, which was defined by a 50% or greater reduction in the Quick Inventory of Depressive Symptomatology-Self Report (QIDS-SR) score from baseline to final visit [20]. The other is remission, which was defined by score of 5 or less on QIDS-SR at follow-up. In their study, they utilized the Affymetrix 500K and 5.0 Human SNP Arrays with data for 430,198 SNPs [20].
The STAR*D study is a large prospective and randomized clinical trial of outpatients with nonpsychotic MDD who were treated with the antidepressant citalopram, an SSRI antidepressant [21]. The study enrolled 4,000 ethnically diverse adults (aged 18-75 years) and implemented a standard study protocol at 14 regional centers (41 clinical sites) across the United States [21]. Study participants were enrolled without regard to race or ethnicity [22]. Participants self-reported their race as Caucasian, African-American, or other, and the
Caucasian sample was further divided into Hispanic or non-Hispanic [22]. It was found that subjects who consented to DNA collection were more likely to be older, be better-educated, be married, be retired, and be Caucasian, and were also more likely to come from a primary care clinic, have more episodes and greater comorbidity, and report a greater length of time elapsed since their first major depressive episode [23].
In their report, three SNP including rs6966038 in the Ubiquitin protein ligase E3C (UBE3C) gene (P = 4.65 × 10(-7)), rs6127921 in the Bone morphogenic protein 7 (BMP7) gene (P = 3.45 × 10(-6)), and a third intronic rs809736 SNP in the RAR-related orphan receptor alpha (RORA) gene (P = 8.19 × 10(-6)) were shown to be associated with response status [20]. These same SNPs were also found to be associated with remission [20]. However, none of these findings reached genome-wide significance [20].
Adkins and colleagues re-assessed Garriock and colleagues’ data by applying three well-established psychometric methods [24]. Their analysis identified 15 SNPs instead of 7 SNPs by the former analysis [24].
The UBE3C gene is indicated in the ubiquitin-proteasome pathway, which is associated with immune responses to inflammation [25]. Lee and colleagues indicated that the UBE3C gene is significantly involved in the risk of aspirin-intolerant asthma. [25].
Furthermore, Pasaje and colleagues suggested that the UBE3C gene may be a potent genetic marker of nasal polyps in asthma-related diseases in Korean asthmatics [26]. In addition, Jiang and colleagues showed that the UBE3C gene is a candidate gene linked with the pathogenesis of hepatocellular carcinoma [27].
The protein encoded by the BMP7 gene is a member of the transforming growth factor-β superfamily, which has unique developmental and neurotrophic effects on catecholaminergic neurons [28]. Esaki and colleagues suggested further evidence of an association between the BMP7 gene and treatment response to selective serotonin reuptake inhibitors in major depressive disorder [29].
The protein encoded by the RORA gene is a member of the NR1 subfamily of nuclear hormone receptors, which is involved in a variety of processes including neuroprotection, brain development, and the regulation of steroid hormones and circadian rhythms [30]. There was evidence for a significant association between the RORA gene and depression from a candidate gene study [31] and a GWAS [32] that found the significant SNPs to be located in the RORA gene.
GWAS by Uher and colleagues
colleagues conducted the Genome-based Therapeutic Drugs for Depression (GENDEP) study, where the subjects (n = 706) were either treated with escitalopram (n = 394) or nortriptyline (n = 312) [33]. They utilized High-quality Illumina Human610-quad chip genotyping data [33]. This study used a percentage change in Montgomery–Asberg Depression Rating Scale (MADRS) score from baseline to week 12 as their outcome [33].
Uher and colleagues revealed that the rs2500535 SNP (P = 3.56 × 10(-8)) in the uronyl 2-sulphotransferase (UST) gene was associated with nortriptyline response and the rs1126757 SNP (P = 2.83 × 10(-6)) in the interleukin-11 (IL11) gene was associated with citalopram response [33].
The protein encoded by the UST gene is an enzyme that catalyzes the transfer of a sulfate group to dermatan or chondroitin sulfate, which forms an abundant subtype of proteoglycans in the extracellular matrix of nervous system [34]. Sulkava and colleagues showed the statistical evidence for the UST gene to be associated with job-related exhaustion in a GWAS study [35].
The protein encoded by the IL11 gene is a member of the gp130 family of cytokines, which has been found to induce potent inhibitory effects on serotonin signaling [36]. Powell and colleagues investigated the IL11 gene at the transcriptional level and found it to
be expressed at a lower level in responders compared with that in nonresponders after escitalopram treatment [37]. Further, DNA methylation in the IL11 gene might be useful in predicting those patients likely to respond to antidepressants in the GENDEP project [38].
GWAS by Hunter and colleagues
Very recently, Hunter and colleagues performed the fourth GWAS among 1116 subjects with Major Depressive Disorder from the STAR*D trial to screen for genetic determinants of response to 12 weeks of citalopram therapy [39]. In their replication analyses, there were 585 subjects from the GENDEP trial [39].
Hunter and colleagues found that the strongest association with sustained as opposed to unsustained response was detected for the rs10492002 SNP (P = 4.5×10(-6)) in the acyl-CoA synthetase short-chain family member 3 gene (ACSS3) gene [39]. However, this SNP did not meet the threshold for genome-wide significance [39]. The protein encoded by the
ACSS3 gene is an enzyme that catalyzes the fundamental and initial reaction in fatty acid
metabolism [40].
GWAS by Murphy and colleagues
independent contributions of self-reported race and genetic ancestry as a predictor of antidepressant drug treatment [41]. They estimated genetic ancestry by multidimensional scaling analyses of about 500,000 SNPs [41]. Their results indicated that poorer outcomes among African American participants were explained by the perspective of genetic ancestry rather than race after correcting for socioeconomic and baseline clinical factors [41].
GWAS by Clark and colleagues
In a GWAS, Clark and colleagues investigated the STAR*D study to find SNPs affecting the susceptibility to antidepressant side-effects [42]. Their study sample consisted of 1,439 participants who were genotyped for 421,789 SNPs using the Affymetrix Human Mapping 500k Array Set and the Affymetrix Genome-Wide Human Array 5.0 [42]. There were four indicators of effects including general effect burden, sexual side-effects, dizziness, and vision/hearing-related side-effects [42].
In their report, 10 SNPs spanning ~25 kb in the SAC1 suppressor of actin mutations 1-like (SACM1L) gene (P = 4.98 × 10(-7)) were shown to be genome-wide significant and associated with bupropion’s effect on sexual adverse reactions [42]. In addition, these 10 SNPs were found to be in very high linkage disequilibrium (LD) with one another [42].
GWAS by Perroud and colleagues
Suicidal ideation or suicidal plans that emerge during the course of antidepressant treatment have received considerable public attention [43, 44]. A small subset of patients with MDD develops this uncommon adverse event [43, 44]. In another GWAS, Perroud and colleagues conducted the GENDEP study to identify SNPs involved in increasing suicidal ideation during antidepressant treatment, where the subjects (n=706) were either treated with escitalopram (n=394) or nortriptyline (n=312) [45].They utilized High-quality Illumina Human610-quad chip genotyping data [45]. There were 244 subjects who experienced an increase in suicidal ideation during follow-up[45].
Perroud and colleagues revealed that the rs11143230 SNP (P = 8.28 × 10(-7)) in the guanine deaminase (GDA) gene was significantly associated with increasing suicidality [45]. The GDA gene encodes an enzyme responsible for the hydrolytic deamination of guanine and found to be differentially expressed in thalami from patients with schizophrenia [46].
Discussion
Limitations in GWAS
With respect to the aforementioned GWAS studies, there were several limitations. First, most of the loci found in the GWAS studies are not immediately informative because they are noncoding variants, which have incomplete annotation and unknown mechanisms [47]. Therefore, extensive experimental work is needed to uncover the molecular mechanisms responsible for antidepressant response. Further, the GWAS studies did not replicate across studies or populations, causing us to question the validity of novel associations, especially when the loci found are non-coding [48].
In addition, the small size of the sample does not allow drawing definite conclusions. Small sample size can result in none of the findings reaching genome-wide significance due to insufficient statistical power [49]. In future work, independent replications in large sample sizes are needed to confirm the role of the polymorphisms found in these GWAS studies.
In the outpatient population for some cohorts, another issue was the lack of a standard measure of adherence such as serum level monitoring, which could also have affected the results [2]. The wide range of treatment period also may bias the results [2]. Furthermore,
the definitions of response, remission, intolerance, and suicidal ideation may affect the findings [2]. Moreover, these findings may not be generalizable to other antidepressant medications due to the fact that participants were treated only with specific antidepressants [2]. Another limitation involves the effects of population stratification such that true associations may be hid by the population substructure due to the wide differences in allele frequencies among self-reported ethnic groups [50]. In the STAR*D study, because the subjects providing DNA may not represent all subjects, this would affect the generalizability of the results [23]. In addition, the STAR*D cohort consisted of individuals with many comorbidities [23].
It has been suggested that gene variants with relatively large effects on drug efficacy or side effects are rare rather than common ones because of additively effects of significant loci [51]. Rare variants can only be discovered through whole-exome and whole-genome sequencing or family-based studies, instead of GWAS studies [52]. Whole genome sequencing represents a new era of scientific research and provides the most comprehensive collection of an individual's genetic variation by massively parallel sequencing [53]. Exome sequencing, which selectively sequences the nucleotides of protein-coding exons in an individual, has recently been introduced as an alternative and efficient approach for
Mendelian disorders and common diseases [54].
Finally, the possibility of gene–gene or gene–environment interaction was not considered. It is essential to address these interactions in order to describe complex traits in pharmacogenomics [2]. Epistasis analysis for gene–gene and gene–environment interactions has been advocated for deciphering complex mechanisms, particularly when each involved factor only demonstrates a minor marginal effect [55, 56]. Association studies based on individual SNPs or haplotypes, using a locus-by-locus or region-by-region approach, may overlook associations that can only be found when gene–gene and gene– environment interactions are investigated [57].
Conclusions
In this study, we reviewed several recent GWAS findings and relevant studies for the drug efficacy of antidepressants in MDD patients. The work also underscores the power of large-scale genetic studies, such as GWAS, to investigate a greater diversity of populations in the clinical expression of mental diseases and their treatments. Now we have a major new piece in the puzzle after some pieces fitting the puzzle for pharmacogenomics of antidepressants have been examined. To improve and personalize MDD treatment and prevention worldwide, the future effort will has to link these findings to other pieces until the picture of MDD treatment and prevention is sufficiently clear. Furthermore, these findings suggested that modeling tools may allow patients and doctors to make more informed decisions based on clinical factors such as SNP genotyping data.
It is highly desirable, clinically and economically, to establish tools based on genetic markers to distinguish responders from non-responders and to predict the possible outcomes of antidepressant treatment. Future research using machine learning approaches is needed in order to model associations between gene variants and antidepressant response, as well as to evaluate the epistasis among genes and clinical factors [58-61]. These machine learning techniques may provide tools for clinical association studies and assist in finding
genes and SNPs involved in responses to therapeutic drugs and adverse drug reactions [58-61]. Over the next few years, novel machine learning methods could be employed to develop molecular diagnostic and prognostic tools with big data technology, which manages massive genomics, pharmacogenomics, and clinical datasets [59-61]. However, the results of SNP-based studies can be integrated into routine clinical practice only after we overcome a number of important challenges [58-61]. Personalized therapy for MDD will become a reality after prospective large clinical trials have been conducted to validate clinical factors and genetic markers.
Future perspective
A major drawback for traditional antidepressants (such as serotonin re-uptake inhibitors) in MDD is that current therapies usually take weeks to reach efficacy [62]. Therefore, faster-acting antidepressants are needed, especially for suicide-risk patients. It has been suggested that NMDA receptor is involved in the pathophysiology of depression [63]. Both NMDA enhancer and blocker improve MDD quickly [63]. Ketamine is an antagonist of NMDA receptor and shows a rapid and sustained antidepressant effect up to two weeks [62-64]. Sarcosine is a glycine transporter-1 inhibitor that blocks the reuptake of glycine, a coagonist of N-methyl-D-aspartate (NMDA) receptor, and enhances NMDA function. Sarcosine also showed potential to improve depression promptly [65]. Future studies in the NMDA-related genes are needed to find genes and SNPs that are relevant to treatment outcome for depression.
Commercial pharmacogenomic tests have been approved by the Food and Drug Administration (FDA), and pharmacogenomics in the context of personalized medicine may provide the appropriate applications to global primary care [66, 67]. It has been suggested that performing genetic testing before prescribing antidepressant treatment may lead to greater numbers of patients experiencing remission early in treatment [68]. There
are several companies offering psychiatric genetics testing including suicidality risk from antidepressants [69]. It has been reported that barriers to pharmacogenetic implementation includes the following issues such as lack of knowledge about pharmacogenomic testing, medical mistrust, clinical usefulness of genetic data, and insufficient education [70].
In future work, it will be indispensably necessary to identify a panel of candidate genes that are reproducibly associated with antidepressant response. At this point, no genetic markers listed in the previous GWAS studies would really qualify to enter the panel due to the limitations as described above. There are several selection criteria for genetic markers to enter such a panel. One criterion is independent replications in GWAS studies to confirm associations using dense genotyping chips and a multistage approach [71, 72]. Moreover, as mentioned in the previous section, whole-exome and whole-genome sequencing is needed to identify rare variants [52]. Other potential criteria may include sampling source, diagnostic systems, observation length, compliance, response criteria, and environmental factors [73].
In future research, models will be established to predict the probability of drug efficacy to guide clinicians in choosing medications. In order to establish models for predicting drug efficacy, machine learning techniques such as the artificial neural network
approach may provide a plausible way to predict drug efficacy in antidepressant therapy [74, 75]. Finally, machine learning techniques such as the artificial neural network approach may provide a plausible way to assess gene–gene and gene–environment interactions [57, 58, 76].
Acknowledgements
The authors extend their sincere thanks to Vita Genomics, Inc. for funding this research.
Financial & competing interests disclosure
This work was funded by Vita Genomics, Inc., Taiwan Ministry of Health and Welfare Clinical Trial and Research Center of Excellence (MOHW103-TDU-B-212-113002), and China Medical University Hospital, Taiwan (CMU 101-AWARD-13, DMR-100-117 and DMR-100-119). The funding organizations played no role in the writing of this review. The authors have no other relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript apart from those disclosed.
References
Papers of special note have been highlighted as: * of interest
** of considerable interest
[1] Mathers CD, Loncar D. Projections of global mortality and burden of disease from 2002 to 2030. PLoS Med. 3(11), e442 (2006).
[2] Lin E, Chen PS. Pharmacogenomics with antidepressants in the STAR*D study.
Pharmacogenomics 9(7), 935-46 (2008).
* Review on pharmacogenomics of antidepressants based on the literature up to 2008. [3] Murphy E, McMahon FJ. Pharmacogenetics of antidepressants, mood stabilizers, and
antipsychotics in diverse human populations. Discov. Med. 16(87), 113-22 (2013). [4] Fabbri C, Porcelli S, Serretti A. From pharmacogenetics to pharmacogenomics: the way
toward the personalization of antidepressant treatment. Can. J. Psychiatry 59(2), 62-75 (2014).
[5] Johnson AD, O'Donnell CJ. An open access database of genome-wide association results. BMC Med. Genet. 10(6), (2009).
[6] Christensen K, Murray JC. What genome-wide association studies can do for medicine.
* Review on GWAS.
[7] Need AC, Goldstein DB. Whole genome association studies in complex diseases: where do we stand? Dialogues Clin. Neurosci. 12(1), 37-46 (2010).
[8] Pearson TA, Manolio TA. How to interpret a genome-wide association study. JAMA 299(11), 1335–1344 (2008).
[9] Goldstein DB. Common genetic variation and human traits. N. Engl. J. Med. 360(17), 1696-1698 (2009).
[10] Rosenberg NA, Huang L, Jewett EM, Szpiech ZA, Jankovic I, Boehnke M. Genome-wide association studies in diverse populations. Nat. Rev. Genet. 11(5), 356-66 (2010). [11] Elbers CC, van Eijk KR, Franke L et al. Using genome-wide pathway analysis to
unravel the etiology of complex diseases. Genet. Epidemiol. 33(5), 419-31 (2009). [12] Cantor RM, Lange K, Sinsheimer JS. Prioritizing GWAS results: A review of
statistical methods and recommendations for their application. Am. J. Hum. Genet. 86(1), 6-22 (2010).
[13] Ising M, Lucae S, Binder EB et al. A genomewide association study points to multiple loci that predict antidepressant drug treatment outcome in depression. Arch. Gen.
Psychiatry 66(9), 966-75 (2009).
[14] Zhu R, Wong KF, Lee NP, Lee KF, Luk JM. HNF1α and CDX2 transcriptional factors bind to cadherin-17 (CDH17) gene promoter and modulate its expression in hepatocellular carcinoma. J. Cell Biochem. 111(3), 618-26 (2010).
[15] Panarelli NC, Yantiss RK, Yeh MM, Liu Y, Chen YT. Tissue-specific cadherin CDH17 is a useful marker of gastrointestinal adenocarcinomas with higher sensitivity than CDX2. Am. J. Clin. Pathol. 138(2), 211-22 (2012).
[16] Ikeda M, Aleksic B, Kinoshita Y et al. Genome-wide association study of schizophrenia in a Japanese population. Biol. Psychiatry 69(5), 472-8 (2011).
[17] Sullivan PF, Lin D, Tzeng JY et al. Genomewide association for schizophrenia in the CATIE study: results of stage 1. Mol. Psychiatry 13(6), 570-84 (2008).
[18] Xu B, Roos JL, Levy S, van Rensburg EJ, Gogos JA, Karayiorgou M. Strong association of de novo copy number mutations with sporadic schizophrenia, Nat. Genet. 40(7), 880-5 (2008).
[19] Kushima I, Nakamura Y, Aleksic B et al. Resequencing and association analysis of the KALRN and EPHB1 genes and their contribution to schizophrenia susceptibility.
Schizophr. Bull. 38(3), 552-60 (2012).
[20] Garriock HA, Kraft JB, Shyn SI et al. A genomewide association study of citalopram response in major depressive disorder. Biol. Psychiatry 67(2), 133-8 (2010).
[21] Rush AJ, Fava M, Wisniewski SR et al. Sequenced treatment alternatives to relieve depression (STAR*D): rationale and design. Control Clin. Trials 25(1), 119–142 (2004).
[22] Trivedi MH, Rush AJ, Wisniewski SR et al. Evaluation of outcomes with citalopram for depression using measurement-based care in STAR*D: implications for clinical practice, Am. J. Psychiatry 163(1), 28–40 (2006).
[23] McMahon FJ, Buervenich S, Charney D et al. Variation in the gene encoding the serotonin 2A receptor is associated with outcome of antidepressant treatment, Am. J.
Hum. Genet. 78(5), 804-14 (2006).
[24] Adkins DE, Aberg K, McClay JL et al. A genomewide association study of citalopram response in major depressive disorder-a psychometric approach. Biol. Psychiatry 68(6), e25-7 (2010).
[25] Lee JS, Kim JH, Bae JS et al. Association analysis of UBE3C polymorphisms in Korean aspirin-intolerant asthmatic patients. Ann. Allergy Asthma Immunol. 105(4), 307-312 (2010).
[26] Pasaje CF, Kim JH, Park BL et al. UBE3C genetic variations as potent markers of nasal polyps in Korean asthma patients. J. Hum. Genet. 56(11), 797-800 (2011).
hepatocellular carcinoma revealed by exome sequencing. Hepatology 59(6), 2216-27 (2014).
[28] Ordway GA, Szebeni A, Chandley MJ et al. Low gene expression of bone morphogenetic protein 7 in brainstem astrocytes in major depression, Int. J.
Neuropsychopharmacol. 15(7), 855-68 (2012).
[29] Esaki K, Kondo K, Hatano M et al. Further evidence of an association between a genetic variant in BMP7 and treatment response to SSRIs in major depressive disorder.
J. Hum. Genet. 58(8), 568-9 (2013).
[30] Logue MW, Baldwin C, Guffanti G et al. A genome-wide association study of post-traumatic stress disorder identifies the retinoid-related orphan receptor alpha (RORA) gene as a significant risk locus. Mol. Psychiatry 18(8), 937-42 (2013).
[31] Lavebratt C, Sjöholm LK, Partonen T, Schalling M, Forsell Y. PER2 variantion is associated with depression vulnerability. Am. J. Med. Genet. B Neuropsychiatr. Genet. 153B(2), 570-81 (2010).
[32] Terracciano A, Tanaka T, Sutin AR et al. Genome-wide association scan of trait depression. Biol. Psychiatry 68(9), 811-7 (2010).
[33] Uher R, Perroud N, Ng MY et al. Genome-wide pharmacogenetics of antidepressant response in the GENDEP project. Am. J. Psychiatry 167(5), 555-64 (2010).
[34] Bovolenta P, Fernaud-Espinosa I. Nervous system proteoglycans as modulators of neurite outgrowth. Prog. Neurobiol. 61(2), 113-32 (2000).
[35] Sulkava S, Ollila HM, Ahola K et al. Genome-wide scan of job-related exhaustion with three replication studies implicate a susceptibility variant at the UST gene locus.
Hum. Mol. Genet. 22(16), 3363-72 (2013).
[36] Rudge JS, Eaton MJ, Mather P, Lindsay RM, Whittemore SR. CNTF induces raphe neuronal precursors to switch from a serotonergic to a cholinergic phenotype in vitro.
Mol. Cell Neurosci. 7(3), 204-21 (1996).
[37] Powell TR, Schalkwyk LC, Heffernan AL et al. Tumor necrosis factor and its targets in the inflammatory cytokine pathway are identified as putative transcriptomic biomarkers for escitalopram response. Eur. Neuropsychopharmacol. 23(9), 1105-14 (2013).
[38] Powell TR, Smith RG, Hackinger S et al. NA methylation in interleukin-11 predicts clinical response to antidepressants in GENDEP. Transl. Psychiatry 3, e300 (2013). [39] Hunter AM, Leuchter AF, Power RA et al. A genome-wide association study of a
sustained pattern of antidepressant response. J. Psychiatr. Res. 47(9), 1157-65 (2013). [40] Watkins PA, Maiguel D, Jia Z, Pevsner J. Evidence for 26 distinct acyl-coenzyme A
[41] Murphy E, Hou L, Maher BS et al. Race, genetic ancestry and response to antidepressant treatment for major depression. Neuropsychopharmacology 38(13), 2598-606 (2013).
[42] Clark SL, Adkins DE, Aberg K et al. Pharmacogenomic study of side-effects for antidepressant treatment options in STAR*D. Psychol. Med. 42(6), 1151-62 (2012). [43] Jick H, Kaye JA, Jick SS. Antidepressants and the risk of suicidal behaviors. JAMA
292(3), 338-343 (2004).
[44] Licinio J, Wong ML. Depression, antidepressants, and suicidality: a critical appraisal.
Nat. Rev. Drug Discov. 4(2), 165–171 (2005).
[45] Perroud N, Uher R, Ng MY et al. Genome-wide association study of increasing suicidal ideation during antidepressant treatment in the GENDEP project.
Pharmacogenomics J. 12(1), 68-77 (2012).
[46] Martins-de-Souza D, Maccarrone G, Wobrock T et al. Proteome analysis of the thalamus and cerebrospinal fluid reveals glycolysis dysfunction and potential biomarkers candidates for schizophrenia. J. Psychiatr. Res. 44(16), 1176-89 (2010). [47] Ward LD, Kellis M. Interpreting noncoding genetic variation in complex traits and
human disease. Nat. Biotechnol. 30(11), 1095-106 (2012).
pharmacogenetics and pharmacogenomics: past lessons, future directions. Drug Metab.
Rev. 40(2), 187-224 (2008).
[49] Spencer CC, Su Z, Donnelly P, Marchini J. Designing genome-wide association studies: sample size, power, imputation, and the choice of genotyping chip. PLoS
Genet. 5(5), e1000477 (2009).
[50] Perlis RH, Moorjani P, Fagerness J et al. Pharmacogenetic analysis of genes implicated in rodent models of antidepressant response: association of TREK1 and treatment resistance in the STAR(*)D study. Neuropsychopharmacology 33(12), 2810-9 (2008).
[51] Manolio TA, Collins FS, Cox NJ et al. Finding the missing heritability of complex diseases. Nature 461(7265), 747-53 (2009).
[52] Cirulli ET, Goldstein DB. Uncovering the roles of rare variants in common disease through whole-genome sequencing. Nat. Rev. Genet. 11(6), 415-25 (2010).
[53] Wheeler DA, Srinivasan M, Egholm M et al. The complete genome of an individual by massively parallel DNA sequencing. Nature 452(7189), 872-6 (2008).
[54] Bamshad MJ, Ng SB, Bigham AW et al. Exome sequencing as a tool for Mendelian disease gene discovery. Nat. Rev. Genet. 12(11), 745-55 (2011).
epistatic loci for essential hypertension. Hum. Mol. Genet. 15(8), 1365-1374 (2006). [56] Carlborg O, Haley CS. Epistasis: too often neglected in complex trait studies Nature
5(8), 618-625 (2004).
[57] Lin E, Hwang Y, Chen EY. Gene-gene and gene-environment interactions in interferon therapy for chronic hepatitis C. Pharmacogenomics 8(10), 1327-1335 (2007). [58] Lin E, Hwang Y, Liang KH, Chen EY. Pattern-recognition techniques with haplotype
analysis in pharmacogenomics. Pharmacogenomics 8(1), 75-83 (2007).
[59] Lin E, Tsai SJ. Gene-gene interactions in a context of individual variability in antipsychotic drug pharmacogenomics. Curr. Pharmacogenomics Person. Med. 9(4), 323-331 (2011).
[60] Lin E, Tsai SJ. Novel diagnostics R&D for public health and personalized medicine in Taiwan: current state, challenges and opportunities. Curr. Pharmacogenomics Person.
Med. 10(3), 239-246 (2012).
[61] Lin E. Novel drug therapies and diagnostics for personalized medicine and nanomedicine in genome science, nanoscience, and molecular engineering.
Pharmaceutical Regulatory Affairs: Open Access 1, e116 (2012).
[62] Autry AE, Adachi M, Nosyreva E et al. NMDA receptor blockade at rest triggers rapid behavioural antidepressant responses. Nature 475(7354), 91-5 (2011).
[63] Krystal JH, Sanacora G, Duman RS. Rapid-acting glutamatergic antidepressants: the path to ketamine and beyond. Biol. Psychiatry 73(12), 1133-41 (2013).
[64] Flight MH. Mood disorders: targeting protein synthesis for fast antidepressant action.
Nat. Rev. Drug Discov. 10(8), 577 (2011).
[65] Huang CC, Wei IH, Huang CL et al. Inhibition of glycine transporter-I as a novel mechanism for the treatment of depression. Biol. Psychiatry 74(10), 734-41 (2013). [66] Swen JJ, Huizinga TW, Gelderblom H et al. Translating pharmacogenomics:
challenges on the road to the clinic. PLoS Med. 4(8), e209 (2007).
[67] Bartlett G, Zgheib N, Manamperi A et al. Pharmacogenomics in primary care: a crucial entry point for global personalized medicine? Curr. Pharmacogenomics Person.
Med. 10(2), 101-105 (2012).
[68] Smits KM, Smits LJ, Schouten JS, Peeters FP, Prins MH. Does pretreatment testing for serotonin transporter polymorphisms lead to earlier effects of drug treatment in patients with major depression? A decision-analytic model. Clin. Ther. 29(4), 691-702 (2007).
[69] Couzin J. Science and commerce. Gene tests for psychiatric risk polarize researchers.
Science 319(5861), 274-7 (2008).
pharmacogenomic testing. Pharmacotherapy 34(2), 151-65 (2014).
[71] Shifman S, Bhomra A, Smiley S et al. A whole genome association study of neuroticism using DNA pooling. Mol. Psychiatry 13(3), 302-12 (2008).
[72] Heck A, Lieb R, Unschuld PG et al. Evidence for associations between PDE4D polymorphisms and a subtype of neuroticism. Mol. Psychiatry 13(9), 831-2 (2008). [73] Serretti A, Kato M, Kennedy JL. Pharmacogenetic studies in depression: a proposal for
methodologic guidelines. Pharmacogenomics J. 8(2), 90-100 (2008).
[74] Lin E, Hwang Y, Wang SC, Gu ZJ, Chen EY. An artificial neural network approach to the drug efficacy of interferon treatments. Pharmacogenomics 7(7), 1017-1024 (2006). [75] Serretti A, Smerald E. Neural network analysis in pharmacogenetics of mood
disorders. BMC Medical Genetics 5, 27 (2004).
[76] Lin E, Hsu SY. A Bayesian approach to gene-gene and gene-environment interactions in chronic fatigue syndrome. Pharmacogenomics 10(1), 35-42 (2009).
Table 1. Genes and SNPs in GWAS studies.
Reference Study Gene Polymorphism p-value Results
Ising and colleagues [13]
MARS CDH17 rs6989467 7.6 × 10(-7) Association with early partial response
EPHB1 rs1502174 8.5 × 10(-5) Association with early partial, response
and remission Garriock and colleagues [20] STAR* D UBE3C rs6966038 4.65 × 10(-7)
Association with response status
BMP7 rs6127921 3.45 ×
10(-6)
Association with response status
RORA rs809736 8.19 ×
10(-6)
Association with response status
Uher and colleagues [33] GENDE P UST rs2500535 3.56 × 10(-8)
Association with nortriptyline response
IL11 rs1126757 2.83 × 10(-6)
Association with citalopram response
GENDE P Murphy and colleagues [41] STAR* D
NA NA NA Genetic ancestry as a predictor for
treatment response Clark and colleagues [42] STAR* D SACM1L rs2742417 4.98 × 10(-7)
Association with sexual adverse reactions rs2742417 4.98 ×
10(-7)
Association with sexual adverse reactions rs2251954 4.98 ×
10(-7)
Association with sexual adverse reactions rs2742421 5.48 ×
10(-7)
Association with sexual adverse reactions rs2742423 4.98 ×
10(-7)
Association with sexual adverse reactions rs1969624 4.98 ×
10(-7)
Association with sexual adverse reactions rs2673057 4.98 ×
10(-7)
Association with sexual adverse reactions rs2742431 5.54 ×
10(-7)
Association with sexual adverse reactions rs2742435 2.12 ×
10(-6)
rs2245705 4.98 × 10(-7)
Association with sexual adverse reactions rs2742390 5.43 ×
10(-7)
Association with sexual adverse reactions
USP44 rs7136572 2.80 ×
10(-7)
Association with sexual adverse reactions
NA rs13432159 9.00 ×
10(-8)
Association with general side-effect
Perroud and colleagues [45] GENDE P GDA rs11143230 8.28 × 10(-7)
Association with increasing suicidality
ACSS3: acyl-CoA synthetase short-chain family member 3; BMP7: Bone morphogenic protein 7; CDH17: cadherin-17; EPHB1: Ephrin type-B receptor 1; GDA: guanine deaminase; GENDEP: Genome-based Therapeutic Drugs for Depression;
GWAS: genome-wide association study; IL11: interleukin-11; MARS: Munich Antidepressant Response Signature; NA: not available; RORA: RAR-related orphan receptor alpha; SACM1L: SAC1 suppressor of actin mutations 1-like; SNP: single
nucleotide polymorphism; STAR*D: Sequenced Treatment Alternatives to Relieve Depression; UBE3C: Ubiquitin protein ligase E3C; USP44: ubiquitin specific peptidase 44; UST : uronyl 2-sulphotransferase.