科技部補助專題研究計畫成果報告
期末報告
求解具有隨機限制式問題之快速篩選程序
計 畫 類 別 : 個別型計畫 計 畫 編 號 : MOST 105-2410-H-006-036-執 行 期 間 : 105年08月01日至106年07月31日 執 行 單 位 : 國立成功大學工業與資訊管理學系(所) 計 畫 主 持 人 : 蔡青志 計畫參與人員: 此計畫無其他參與人員 報 告 附 件 : 出席國際學術會議心得報告中 華 民 國 106 年 11 月 02 日
中 文 摘 要 : 模擬最佳化(Optimization via Simulation;
OvS)是從許多不同的模擬候選解中,找出期望績效最優良的候選解 ,
相較於一般的最佳化方法,可以納入更多隨機性及較大變異的考量 。
其中,排序與選擇程序(Ranking and Selection; R&S)用以處理從 少量的模擬候選解中,找出最佳候選解的問題,且其在統計上證明 其保證性。
現有的模擬演算法在處理0-1最佳化問題時,往往會因為偏向純隨機 搜尋法(Pure Random Search)而顯得效果不彰。快速篩選法(Rapid Screening Procedure; RS)為一用來處理單一隨機目標式的模擬最佳化演算法,其在處理0-1問題時, 較現有的演算法來得更有效率。本研究將原有的快速篩選法延伸至 可以處理具有單一隨機限制式的演算法,分為三種演算法。演算法 A在正確選擇機率(Probability of Correct Selection; PCS)上證明其統計保證性,但其抽樣成本 較高,且可能有浪費樣本的狀況;在演算法B中,提出限制式篩選程 序與相異樣本數下可行性驗證程序,藉以改善演算法A的缺點。此演 算法在抽樣成本上較為節省,但無法證明其統計保證性;演算法C統 合演算A與演算法B,藉由可行性驗證與目標式篩選的交互使用,不 用確認所有候選解可行性後才執行目標式篩選,且在目標式篩選階 段記錄候選解間目標式期望值的優劣。 也因為其刪除條件較為嚴格,其在有錯誤刪除發生的情境中,可以 同時兼顧樣本的節省以及正確選擇機率的保證。藉由本研究所提出 的演算法,透過對於候選解空間的搜尋能力,可以在限制的時間下 ,以系統化的方式找出最佳近似解,且在找到之最佳可行解的正確 選擇機率上,本研究亦證明其統計保證性。 中 文 關 鍵 詞 : 模擬最佳化; 目標式篩選; 限制式篩選; 相異樣本數下可行性驗證 程序; 單一隨機限制式
英 文 摘 要 : Some existing simulation optimization algorithms become pure random
search methods and thus are ineffective for the problem of zero-one
optimization via simulation. In this paper, we present a highly
efficient rapid screening procedure for solving the problem of
zero-one simulation optimization considering a single stochastic
constraint. Three algorithms adopting different mechanisms and
providing different statistical guarantees are described, and
of each
algorithm and other existing processes.
英 文 關 鍵 詞 : Optimization via Simulation; Rapid Screening,
Constraint Screening; Feasibility Check Procedure; Single Stochastic
第
第
第一
一
一章
章
章 緒
緒
緒論
論
論
1.1
研
研
研究
究
究背
背
背景
景
景與
與
與動
動
動機
機
機
在變化快速的環境下,如何在最短的時間內做出正確的決定,是所有人追求的共同 目標。現今,藉由候選解模擬的應用,我們可以在較短的時間內得到一定數量的實驗數 據,在縮短時間的同時,也藉由模擬方法中的統計保證性使我們得到的結果保有一定的 品質。候選解模擬針對已存在或預想中的候選解行為,透過套裝軟體、程式語言等工 具,進而建構出一套模型,此模型可以藉由調整參數之設定,來預測各個候選解在不同 參數下績效值的改變。然而,早期的候選解模擬僅能對單一參數進行評估,對找出多個 參數的最佳設定之能力則較為缺乏。因此,許多學者將模擬技術與最佳化手法加以整 合,進而發展出現在的模擬最佳化(Optimization via Simulation; OvS)。模擬最佳化與傳統的最佳化方法及隨機規劃方法最大的差異在於模擬最佳化是以模型 之建構為基礎,來處理現實中隨機且複雜的問題,其亦納入統計理論基礎,期望在許多 迥異的候選解中,透過模擬實驗,找出期望績效最佳的候選解,以提供決策者做為決策 依據;而傳統最佳化方法和隨機規劃方法則是針對不同的問題,建構出相對應的演算法 來處理。模擬最佳化的優點在於其可以分析較為複雜且隨機性較高的問題,且可以透過 實驗設計來分析各因子對候選解績效的影響多寡。然而其缺點則為耗時以及所需成本較 高,因此,如何在求解時間以及解的品質間做出取捨,也是一大課題。 模擬最佳化可依據可行解區域結構的不同分為三類,分別是:連續型模擬最佳 化(Continuous Optimization via Simulation; COvS)、 離 散 型 模 擬 最 佳 化(Discrete Optimization via Simulation; DOvS)和 排 序 與 選 擇 程 序(Ranking and Selection; R&S)。排序與選擇程序主要是從有限且數量較少的模擬候選解中,在一定的信心水準
下,選出期望績效最佳的候選解;離散型模擬最佳化則用以處理決策變數為離散型的隨 機問題,其可行解的數目通常為有限但數量相對較大。 大部分的模擬商業軟體主要透過啟發式演算法進行解的搜尋,在面對解空間較大、成 本及時間的限制下,透過候選解化的方式找出近似最佳解。而一些現存的模擬最佳化演 算法偏向一般的隨機搜尋法,也因為這個原因,它們在處理0-1模擬最佳化問題上效率較 為不彰。現有的模擬最佳化演算法中,大多隨機抽取固定數量的候選解或是使用類似窮 舉的方式進行求解,前者在模擬預算不足的情況下可能很難找到品質較佳的解,後者則 因為其求解所需的預算過多,而無法達到同時兼顧品質與成本的效果。有鑑於此,Tsai [20] 提出Rapid Screening Procedure 來解決0-1模擬最佳化問題,其探討的問題為找出 隨機目標式期望績效值最大的候選解,其方法納入了不同的抽樣方式、不同的統計保證 且包含有效的候選候選解搜尋法以及起始候選解的產生方式。其方法藉由每一個迭代刪 去較差的候選解並從存活下來的候選解再去找出下一組候選候選解,也就是這樣搜尋的 觀念,使之比傳統的排序與選擇程序更有效,但其程序僅針對隨機目標式進行篩選,並 未加入隨機限制式的考量。
1.2
研
研
研究
究
究目
目
目的
的
的
本研究將原有的快速篩選法延伸至處理隨機目標式以及單一隨機限制式的問題,並提 出三種不同的演算法,用以處理考慮隨機限制式下,解空間較為龐大之0-1隨機問題。演 算法A結合Andrad´ottir and Kim [1] 的可行性驗證程序及Tsai [20] 目標式快速篩選程 序,在正確選擇機率(Probability of Correct Selection; PCS)上給予統計性保證;演算 法B則針對演算法A樣本數較多的缺點做改善,提出限制式篩選程序及相異樣本數下可行 性驗證程序。演算法B結合限制式篩選、目標式篩選及相異樣本數下可行性驗證程序,其在每一個迭代均抽取固定的目標式及限制式樣本,使得抽樣數下降,但在統計保證性 上較為不足。演算法B又分為演算法B.I及演算法B.II,演算法B.II改進演算法B.I在限制 式篩選上的缺點,兩者在進入可行性驗證階段的候選解上有不同的定義。演算法C則統 合演算法A與演算法B,在每一個迭代不需在判斷出所有候選解的可行性之後才執行目標 式篩選,藉由可行性驗證與目標式篩選的交互使用,以及在目標式篩選階段紀錄兩兩候 選解間目標式期望值的優劣,來使篩選過程更有效率。
1.3
論
論
論文
文
文架
架
架構
構
構
第二章主要為文獻回顧,對本研究所使用到的方法做文獻探討,包含排序與選擇程 序(R&S)、可行性驗証程序(FCP)、選擇程序Clean-Up Procedure、與標準值比較問 題(Comparison with a Standard) 、離散型模擬最佳化、快速篩選法(Rapid Screening Procedure)。第三章為介紹本研究之研究方法,包含本研究的問題與假設以及本研究所 提出之三種演算法的架構與執行步驟。第四章則為實驗設計與分析,包含所探討的問題 介紹以及實驗的參數設定,最後是實驗結果。第五章為未來研究方向,包含本論文的總 結與貢獻,最後是未來可能的研究方向。第
第
第二
二
二章
章
章 文
文
文獻
獻
獻探
探
探討
討
討
本章節將分成兩個小節。首先,在2.1節對排序與選擇程序進行文獻探討,內容包含 無差異程序、子集合選擇程序、NSGS、與標準值比較問題和可行性判定程序。2.2節則 為快速篩選法的文獻探討,先對離散型模擬最佳化做一個簡單的介紹及分類,再對本研 究所使用到的快速篩選法(Rapid Screening Procedure)做文獻探討。2.1
排
排
排序
序
序與
與
與選
選
選擇
擇
擇程
程
程序
序
序(Ranking and Selection; R&S)
候選解模擬中,為了能使實驗的結果更具可信度,模型與真實情況的差距必須盡量 縮小,而R&S的發展正是以此要求做為基礎。此程序是由Bechhofer [2] 所提出的無差 異程序(Indifference Zone Procedure; IZ)與Gupta [7] 提出的子集合選擇程序(Subset Screening Procedure)發展而成。其概念為從有限個數(2到500)個模擬候選解中,找出 期望績效最好的候選解,而這樣的選擇會滿足某正確選取機率(Probability of Correct Selection; PCS)的保證。
而傳統的R&S大多只考慮單一隨機目標式的問題,並沒有納入隨機限制式的處 理。直到Andrad´ottir and Kim [1] 提出可行性驗證程序(Feasibility Check Procedure; FCP),其演算法用以處理較少量候選候選解下,考慮單一隨機限制式的問題,藉 由FCP找出可行候選解,進而由可行候選解中得到隨機目標函數值最佳之最佳候 選解;Batur and Kim [4] 則擴大問題的規模,發展出處理多重隨機限制式之演算 法(Multiple Feasibility Check Procedure; MFCP)。Nelson and Goldsman [15] 延伸 了原本的兩階段法,進而發展出處理與標準值比較(Comparison with a Standard; CwS)之方法,此方法將數個候選候選解與一標準候選解比較,以找出所有候選候選解與 標準候選解間的最佳候選解。以下將針對無差異程序、子集合選擇程序、與標準值比較
問題、可行性驗證程序進行更深入的介紹。
2.1.1 無無無差差差異異異程程程序序序(Indifference Zone Procedure; IZ)
無 差 異 程 序 是 由Bechhofer [2] 提 出 的 , 其 目 的 為 從k個 候 選 候 選 解 中 選 出 最 佳 候 選 解 。 通 常 假 設 期 望 值 越 大 越 好 , 且 第k個 候 選 解 為 最 佳 候 選 解 , 故 可 表 達 為µ1 ≤ µ2 ≤ . . . ≤ µk,其假設各候選解的變異數皆為相等且已知。 而各個候選解所需的抽樣數計算採用Rinnot所提出的計算方式,Ni為候選解i所需抽 樣數,其計算方式如式子(2.1),其中h為Rinnot´s常數、σ2 i為候選解i之變異數、δ為目標 式容忍水準,亦即若µk− µk−1≤ δ則判定候選解k與候選解k − 1並無差異。 Ni = » 2h2σ2 i δ2 ¼ (2.1) 在得到各候選解所需的樣本後,計算樣本平均數,選出樣本平均數最大者為最佳候選 解,且保證其正確選擇機率(Probability of Correct Selection; PCS)大於等於我們所訂 定的信心水準1 − α,其表達方式如式子(2.2)所示。
Pr{選擇 k|µk− µk−1 ≥ δ} ≥ 1 − α (2.2)
而此程序對各個候選解所需樣本數的估計較為保守,當候選解的數量上升時,其所需樣 本數將大幅提升以滿足我們所設定的信心水準,導致抽樣成本亦會隨之增加。
2.1.2 子子子集集集合合合選選選擇擇擇程程程序序序(Subset Screening Procedure)
子集合選擇程序是由Gupta [7] 所提出的,其目的為從龐大的候選解空間內選出一個 集合I ⊆ (1, 2, . . . , k)且此集合包含最佳候選解k之機率大於等於信心水準1 − α,如下所
示 Pr{k ∈ I} ≥ 1 − α 選出的子集合I若只包含單一候選解時,則判定此候選解為最佳候選解,但在抽樣數 的限制下,通常子集合I包含多個候選解,而子集合選擇程序僅能在最佳候選解k包含在 子集合I中給予統計上的保證,並無法明確給定何者為最佳候選解。 2.1.3 NSGS 有鑑於子集合選擇程序僅能找到一包含最佳候選解的子集合I,Nelson et al. [14] 結 合無差異程序與子集合選擇程序,提出NSGS程序,其為一個兩階段的程序。第一階段 先透過子集合選擇程序,藉由門檻值的使用,將較差的候選解刪除,並把較優良的候選 解放入集合I;第二階段則針對第一階段回傳的集合I進行選擇,其依據為各候選解第二 階段之樣本平均數,其好處為在應用上較為容易,且在處理候選解個數較多的問題時可 以得到較佳的結果。以下為NSGS的演算法: NSGS Procedure Step 1:設定信心水準1−α、目標式容忍水準δ、初始樣本數n0≥2和t = tn0−1,1−(1−α/2)1/(k−1), 再經由查表得到Rinnot常數h = h(k, 1 − α/2, n0)。 Step 2: 對 所 有 候 選 解 各 抽n0個 樣 本 , 並 計 算 ¯Xi(n0) = n0 P j=1 Xij/n0和Si(n0)2 = n0 P j=1 ¡ Xij − ¯Xi(n0) ¢2 /(n0− 1)。 Step 3: 計 算 兩 兩 候 選 解 間 的 門 檻 值Wil = t(Si2/n0 + Sl2/n0)1/2, 若 候 選 解i滿 足 ¯Xi(n0) ≥ ¯Xl(n0) − Wil則將候選解i放入子集合I中,其中1 ≤ i ≤ k、∀i 6= l。
合I內的候選解計算其第二階段樣本數如下列式子所示 Ni = max ( n0, &µ hSi δ ¶2') Step 5:對集合I中的候選解再多抽取Ni− n0個樣本。 Step 6:計算這些候選解的第二階段樣本平均數 ¯Xi(Ni),並選取其值最大的候選解為最 佳候選解。 然而,NSGS僅能用來處理所有候選解的起始抽樣數相等的問題,當問題隨機性較多 且變異較大時,將會面臨候選解樣本數不同的情況,使NSGS無法使用。故Boesel and Nelson [3] 提出了Clean-up 程序,且保證從子集合中選出的候選解為最佳候選解的機 率會大於等於信心水準1 − α0,解決了NSGS僅能處理相同抽樣樣本數的限制,以下即 為Clean-up Procedure的演算法: Clean-Up Procedure Step 1:設定整體信心水準1 − α0且(1/k) < 1 − α0 < 1、子集合選擇程序的信心水 準1 − αS = √ 1 − α0、選擇程序的信心水準1 − αI = √ 1 − α0以及目標式容忍水準δ。 Step 2:抽取樣本Xij, i = 1, 2, . . . , k ; j = 1, 2, . . . , n0i,計算第一階段的樣本平均 數 ¯Xi(1)和樣本變異數 Si2(1),再由此得到門檻值Wij = ¡ t2 iSi2(1)/n0i+ t2jSj2(1)/n0j ¢1/2 , 其中ti = t(1−αs)1/(k−1),n0i−1、n0i為候選解i的樣本數。 Step 3:找到一集合J = { ¯Xi(1) ≥ ¯Xj(1) − Wij, ∀i 6= j, 1 ≤ i ≤ k},並回傳子集合J為 目標式期望績效值較為優良的候選解。
得到J集合中的候選解各自所需的總抽樣樣本數Ni Ni = max ( n0i, &µ hSi(1) δ ¶2') Step 5:對集合J中的候選解再多抽取Ni − n0i個樣本。 Step 6:計算這些候選解的第二階段樣本平均數 ¯Xi(2) = Ni P j=1 Xij/Ni,並選取其值最大 的候選解為最佳候選解。 比較上述兩種方法,有兩個最大的不同點,第一點在於Clean-Up程序可以在起始樣 本數不同的情況下執行,第二點在於Rinnot常數h的定義方式, NSGS是以起始樣本 數n0做為查表依據;Clean-Up程序則因起始樣本數的不同,則使用nmin為查表依據,並 統一使用k = 2為候選解數,雖然做了此改變,其亦以實驗結果佐證其方法在統計上依舊 保持其有效性。
2.1.4 與與與標標標準準準比比比較較較問問問題題題(Comparison with a Standard; CwS)
CwS將多個候選候選解與一個標準候選解進行成對比較,Nelson and Goldsman [15] 指出標準候選解為一個標竿,若候選候選解優於標準候選解則可以此候選候選解取代標 準候選解,反之則保留標準候選解為最佳候選解。而當候選候選解帶來的利益無法抵銷 汰換標準候選解的成本時,即使候選候選解明顯較佳,亦會選擇不汰換標準候選解。我 們通常假設π0為標準候選解,亦假設µk≥ µk−1 ≥ . . . ≥ µ1,故候選解k為候選候選解中 的最佳候選解,而δ則為兩候選解間能接受之差距程度,亦即當最佳候選候選解k的績效 值比標準候選解好超過此值,才會以此候選候選解替換標準候選解。 故一般的CwS問題
必須同時滿足不等式(2.3)與(2.4)
Pr{選擇標準候選解} ≥ 1 − α 當 µ0 ≥ µk (2.3)
Pr{選擇候選候選解k} ≥ 1 − α 當 µk− µ0 ≥ δ 且 µk− µk−1 ≥ δ (2.4)
Nelson and Goldsman [15] 由此提出一個演算法,包含各候選解總抽樣樣本數Ni之
計算,並利用上述的兩條不等式作為選擇依據,當 ¯Xk ≤ ¯X0+ c時,選擇標準候選解,
否則選擇候選候選解k,其中c為一常數,且當標準候選解之期望績效已知時,以µ0取
代 ¯X0。
Comparison with a Standard Procedure
Step 1:給定k個候選候選解以及一個標準候選解,設定起始樣本數n0、容忍差異δ以及
信心水準1 − α,並決定常數g和h的數值,以計算c = δ h/g。
Step 2:對所有候選解進行抽樣,產生樣本Xi1, Xi2, . . . , Xin0,其中i = 1, 2, . . . , k。
Step 3:計算所有候選解的樣本平均數 ¯Xi(n0) = Pn0 j=1Xij/n0與樣本變異數Si2(n0) = 1/(n0− 1) Pn0 j=1(Xij − ¯Xi)2。 Step 4:決定所有候選解所需的總樣本數Ni。 Ni = max ( n0, &µ gSi(n0) δ ¶2') = max ( n0, &µ hSi(n0) c ¶2') 其中 d·e 表示無條件進位。 Step 5:對Ni > n0的候選解抽樣Ni− n0個樣本,並計算所有候選解總抽樣數下的樣本
平均數 ¯Xi = Ni P j=1 Xij/Ni。 Step 6:在信心水準大於等於1 − α的前提下,以下述兩種判斷法則執行: • Step 6a : 若 ¯X(k) ≤ ¯X0 + c則 選 擇 標 準 候 選 解 , 並 建 構 出 單 尾 聯 合 信 賴 區 間µ0 − µi ≤ ¯ X0− ¯Xi+ c,其中i = 1, 2, . . . , k。 • Step 6b : 否則,比較候選候選解的樣本平均數,並選出樣本平均數最大之 ¯X(k),且建構出與 最佳之多重比較之信賴區間 µi− max `6=i µ` ∈ " − µ ¯ Xi− max `6=i ¯ X`− δ ¶− , µ ¯ Xi− max `6=i ¯ X`+ δ ¶+#
2.1.5 可可可行行行性性性驗驗驗證證證程程程序序序(Feasibility Check Procedure; FCP)
可行性驗證程序由Andrad´ottir and Kim [1] 所提出,用於處理相同起始樣本數下候 選解之可行性驗證,其針對單一隨機限制式的問題,提出可行性判定演算法:
可可可行行行性性性驗驗驗證證證程程程序序序 首先定義和介紹在可行性判定程序所會用到之符號。 n0 ≡ 每一個候選解的初始樣本數(n0 ≥ 2); r ≡ 現在階段數 (r ≥ n0); S2 i ≡ Yi1, . . . , Yin0之樣本變異數,其中 i = 1, 2, . . . , k; g(η, n0− 1) ≡ 1 2(1 + 2η) (1−n0)/2 R(r; v, w, z) ≡ max{0, wz v − v 2r} v, w, z ∈ R, v 6= 0.
Algorithm F: Feasibility Check Procedure
設設設定定定:設定起始樣本數n0 ≥ 2以及信心水準1 − α1,給定k個候選解,並在考慮限制式為 小於等於的情況下,選定容忍水準²、限制式門檻值q,並以下列式子計算η1 > 0。 g(η1) = 1 − (1 − α1)1/k 初初初始始始化化化:令集合M = {1, 2, . . . , k}表示尚未確認其可行性之候選解集合;集合F = ∅表 示 可 行 候 選 解 之 集 合 , 且 令h2 1 = 2η1(n0 − 1)。 對 各 個 候 選 解 抽n0個 樣 本 , 並 計 算S2 i(n0)且設定r = n0,進入可行性驗證階段。 可可可 行行行 性性性 驗驗驗 證證證 階階階 段段段 : 對 尚 未 確 認 其 可 行 性 之 候 選 解 做 可 行 性 驗 證 , 若 候 選 解i符 合Pr j=1 (Yij − q) ≤ −R(r; ²; h21; Si2), 將 候 選 解i由 集 合M移 至 集 合F ; 若 候 選 解i符 合Pr j=1 (Yij − q) ≥ +R(r; ²; h21; Si2)則將候選解i由集合M刪去。
停停停止止止條條條件件件:若|M| = 0即回傳集合F 為可行候選解之集合;否則,對尚在集合M的候選 解多抽樣一個抽樣數,且令r = r + 1並回到可行性驗證階段。 然而上述之可行性判定程序僅處理包含單一隨機限制式的問題,直到Batur and Kim [4] 將其延伸,以Bonferroni不等式為基礎,擴張為FB演算法,其特色為可以處 理多重候選解及多重隨機限制式問題,但也正因為其使用了Bonferroni不等式做為其 理論基礎,其演算法得到的結果會較為保守,其方法可以確保FB在訂定的正確判定機
率(Probability of Correct Decision; PCD)下,找出可行的候選解集合,以利後續最佳 候選解之選擇,其特色為可以處理多個候選解及多個隨機限制式之最佳化問題,以下針 對多重可行性驗證做介紹。
令Yi`j為 第i個 候 選 解 , 第`條 限 制 式 , 執 行 第j次 反 覆 之 觀 測 值 , 其 中i =
1, 2, . . . , k, ` = 1, 2, . . . , s, j = 1, 2, . . . , n。 且Yij = (Yi1j, Yi2j, . . . , Yisj)T為s個 限
制式績效在第i個候選解中第j個觀測值之向量。而 yi =E[Yij] = (yi1, yi2, . . . , yis)T 表示
多元常態分配之期望績效,其中 yi` =E[Yi`j], ` = 1, 2, . . . , s, j = 1, 2, . . . , n,且Yij滿
足其提出的假設一。 假設一: Yij = Yi1j Yi2j ... Yisj IID∼ MN(y i, Σi) 其中 Σi 為 Yij之共變異數矩陣。 定義一組q0 = (q0 1, q20, . . . , qs0)T為一常數向量,用以表達隨機限制式之右手邊常數, 當第i組解滿足yi ≤ q0,則此組解即為可行解,但因為考慮隨機限制式的存在,在有限
的觀測值下很難確保所有候選解均被檢驗是否滿足s條隨機限制式,故Batur and Kim
[4]提出一概念能在符合 q−` ≤ q0` ≤ q`+的條件下,給q0
`一個範圍,表示為(q`−, q`+),其
中 q− = (q−
1, . . . , q−s)T ,q+ = (q1+, . . . , qs+)T。接著可定義出三個區域,分別是理想
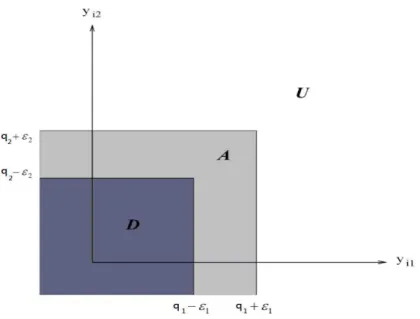
區域(Desirable Region)、可接受區域(Acceptable Region)和不理想區域(Undesirable Region),以下對這三種區域分別做介紹: • yi ≤ q−: 此區域為理想區域,任何落在此區域之候選解皆屬於可行候選解。 • (yi < q+) \ (yi ≤ q−):此為可接受區域,當候選解落入此區域時,有可能判定為 可行候選解或是不可行候選解。 • (yi1≥ q1+) ∪ (yi2≥ q2+) ∪ . . . ∪ (yis ≥ qs+):此為不理想區域,若有候選解落於此 區域時,此候選解會被判定為不可行候選解,即對此候選解進行刪除。 給定q− ` 和q`+後,即可訂定出q` = (q−` + q`+)/2和²` = (q`+− q`−)/2,其中q` 代表的意 義是第 ` 個限制式的指標值,其意義為可行候選解與不可行候選解的分界點;而 ²` 為 第 ` 個限制式的容忍水準,其意義則為使用者可容忍之差異程度。故我們可以得到兩 向量 q = (q1, q2, . . . , qs)T, ² = (²1, ²2, . . . , ²s)T 分別為指標值與容忍水準的向量。於
此,Batur and Kim進一步定義下列集合,且用圖(2.1)表示這三種區域的組成(以兩條 隨機限制式為例):
• SD : 為理想候選解之集合
• SA : 為可接受候選解之集合
圖 2.1: 候選解存在二條隨機限制式之理想區域(D),可接受區域 (A),不理想區域 (U) 示意圖。 而其中值得討論的區域為可接受區域,因為此區域包含的候選解可能為真實可行或 真實不可行,也正因為如此,在此區域的候選解可能會因為決策上的誤差,產生兩種風 險,分別如下所示: • 型一誤差 (Risk 1) :當可行候選解 i 落入可接受區域時,此可行候選解可能被判 定為不可行候選解且被刪除。 • 型二誤差 (Risk 2) :當不可行候選解 i 落入可接受區域時,此不可行候選解可能 被判定為可行候選解且被保留。 可行性判定程序在執行過後能正確回傳集合F ,此集合包含所有落在理想區域的候選 解以及部分的落在可接受區域的候選解,但不會包含任何落在不理想區域的候選解,而 此程序之正確判定機率(Probability of Correct Decision; PCD)亦滿足預先設定的信心
水準1 − α,如式子(2.5)所示: PCD ≡ Pr{CD} = Pr{SD ⊆ F ⊆ (SD∪ SA)} ≥ 1 − α (2.5) 多多多重重重可可可行行行性性性驗驗驗證證證程程程序序序 n0 ≡ 每一個候選解的初始樣本數(n0 ≥ 2); Ki ≡ 對於第i個候選解被判定為可行之限制式集合; r ≡ 現在階段數 (r ≥ n0); S2 i`(n0) ≡ Yi`1, . . . , Yi`n0之樣本變異數,其中 i = 1, 2, . . . , k; g(η, n0− 1) ≡ 1 2(1 + 2η) (1−n0)/2 R(r; v, w, z) ≡ max{0,wz v − v 2r} v, w, z ∈ R and v, w, z > 0.
Algorithm FB: Multiple Feasibility Check Procedure
設設設定定定:設定信心水準1 − α、目標值q`、容忍水準²`,其中` = 1, 2, . . . , s,並設定初始樣 本數n0 ≥ 2。 初初初 始始始 化化化 : 對 所 有 候 選 解 抽n0個 樣 本 , 並 令 階 段 數r = n0, 計 算 所 有 候 選 解 之 於 其限制式之樣本變異數S2 i`以及h(n0)以決定R(r; ε`; h(n0); Si`)2(n0) 且令Ki = ∅,其 中i = 1, 2, . . . , k。 可可可行行行性性性驗驗驗證證證階階階段段段:對所有還未確定其可行性之候選解i執行可行性驗證,若存在至少一條 限制式` /∈ Ki且符合Ci`(r) ≥ +R(r; ²`; h(n0); Si`2(n0)),則宣告此候選解為不可行候選
解; 若符合Ci`(r) ≤ −R(r; ²`; h(n0); Si`2(n0))則將`放入集合Ki,當|Ki| = s時,宣告
此候選解為可行候選解;若上述兩種情況都不符合,則設定階段數r = r + 1,並對尚未 確定其可行性之候選解多抽樣一樣本數。
2.2
快
快
快速
速
速篩
篩
篩選
選
選法
法
法(Rapid Screening; RS)
本章節在2.2.1小節先對離散型模擬最佳化做分類及文獻探討;接著在2.2.2小節針對 快速篩選法之演算法及其內容做文獻探討。
2.2.1 離離離散散散型型型模模模擬擬擬最最最佳佳佳化化化(Discrete Optimization via Simulation; OvS) 當模擬最佳化問題的決策變數為離散型時,我們就可以將之分類為離散型模擬最佳化 問題,而離散型模擬最佳化亦可依可行解個數、鄰近結構、收斂性質分為三個類別,分 別如下所示: 可可可行行行解解解個個個數數數 當可行解數量較少時,即可用一般的R&S來解決,透過對所有候選解進行抽樣來計 算其樣本統計量,並以之做為判定候選解優劣之依據,此方法的優點為其結果可以滿 足統計保證,但僅能用在可行解數量較少的問題。 而當可行解數量非常龐大時,對每 一個候選解抽樣即可能造成成本的大幅上升,通常此類問題都以隨機搜尋法(Random Search)解決,但此方法的缺點為最佳解的品質無法確立。Nelson and Swann [14] 針對 候選解數量較多的問題,提出一兩階段的方法,其在第一階段先篩選掉較差的解,並只 對保留下來的解進行第二階段的抽樣,以找出最佳解。 鄰鄰鄰近近近結結結構構構 典型的隨機搜尋法在每一次迭代即針對某一特定解進行候選解的搜尋,通常從當前解 的鄰近區域找尋下一迭代的候選解。而鄰近結構又可依照其演算法的執行方式分為固定 型和適應型,前者不將解品質的優劣納入考慮,僅以相同且固定的方式產生新的解;而 後者則隨著演算法的演進,從過程中得到可用的資訊,以較優良的候選解去產生新的候
選解。當優良的解聚集於同一區域時,適應型的演算法在表現上會較固定型演算法來得 更好。 收收收斂斂斂性性性質質質 離散型模擬最佳化依其收斂性質可分為全域收斂、局部收斂以及無收斂保證演算法。 其中全域收斂演算法在抽樣成本有限時無法達成收斂條件,而無收斂保證演算法主要透 過對各個候選解抽取一定數量的樣本,並依照樣本統計量做為後續的參考依據。
2.2.2 快快快速速速篩篩篩選選選程程程序序序(Rapid Screening Procedure)
一般的現存的模擬最佳化演算法在處理0-1最佳化問題時會變得較偏向純隨機搜尋 法(Pure Random Search),執行上亦顯得較沒效率。Tsai [20] 提出了快速篩選程序, 其應用在最大化單一隨機目標式的問題上,包含三種方法,分別採用不同的抽樣法則並 提供不同的統計保證。此外,其方法亦包含兩種候選解產生法以及起始解選擇的演算 法。其方法的優點為在每一個迭代以較優良的解刪去較差的解,並用保留下來的解去找 尋更佳的候選解,以下針對快速篩選程序的三種方法、兩種候選解產生法和起始解選擇 法做介紹。 此快速篩選法的總迭代數為R,其中迭代0, 1, . . . , R − 1為篩選程序迭代,最後一 個迭代R為選擇程序迭代,而(r)則代表第r個迭代的數值。在每一個迭代均從可行解區 域Ω產生b(r)個新的候選解,且建立集合eI(r)來儲存這b(r)個新候選解的指標(index)。 當一個解在任意迭代刪除後,其在後面迭代將不會再被拿出來當作候選解。而I0(r)為 迭代r後存活的解集合;I(r) = eI(r) ∪ I0(r)為存活的解與新產生的候選解之聯集。 而B(r)為至迭代r看過的解個數;n(r) = dn0Gre為迭代r的抽樣樣本數,其中G為樣
本成長常數。Ni(r)為候選解i至迭代r的累積抽樣樣本數、Wil(r)為迭代r時篩選候選
解i與l的門檻值,以下對通用的快速篩選法做介紹。 Generic Algorithm of Rapid Screening
初初初始始始化化化:決定信心水準1 − α、可容忍差異δ以及每一個迭代的候選解數{b(r)},而迭
代數R可以為使用者指定或依照某些停止條件來設定,同時決定各候選解的起始樣本
數n0以及樣本成長常數G ≥ 1,且令迭代數r = 0、累積解個數B(−1) = 0、存活解集
合I0(−1) = ∅。
搜搜搜尋尋尋及及及篩篩篩選選選階階階段段段:搜尋及篩選的部分可以細分為以下三個步驟:
Step 1. 選 擇b(r)組 解 , 分 別 為{SB(r−1)+1, SB(r−1)+2, . . . , SB(r−1)+b(r)}且 使eI(r) =
{B(r − 1) + 1, B(r − 1) + 2, . . . , B(r − 1) + b(r)},並使B(r) = B(r − 1) + b(r), I(r) =
I0(r) ∪ eI(r),且對於在集合eI(r)的候選解,令其Ni(r − 1) = 0。
Step 2. 對 在 集 合I(r)內 的 候 選 解 , 抽 取n(r)個 樣 本 , 且 令 累 積 樣 本 數Ni(r) =
Ni(r − 1) + n(r), 接 著 計 算 各 自 的 樣 本 平 均 數 ¯Xi(r)和 成 對 的 門 檻 值Wil(r), 其
中i 6= l。
Step 3. 經 由 篩 選 產 生 一 個 子 集 合E(r) = {i ∈ I(r) : ∃l ∈ I(r), ¯Xi(r) − ¯Xl(r) ≤
−Wil(r), l 6= i,為被篩選掉的解,並更新集合I 0 (r + 1) = I(r)\E(r)。 停停停止止止及及及選選擇選擇擇階階階段段段:令r = r + 1,若r < R,則計算下一階段的樣本數n(r) = dn0Ge,並 回到搜尋及篩選階段,直至r = R時,執行以下步驟: 若|I0(R)| = 1即停止程序,且回傳此解為最佳解,否則以Rinott’s常數h計算出所有存 活解的總抽樣樣本數Ni,並對其執行抽樣,抽樣數為抽樣樣本數 eNi與總抽樣數的差 距Ni− eNi,最後在以總抽樣樣本數計算所有解的樣本平均數,並選擇值最大的解為最佳
解。 而其中 ¯Yi(r)、Wil(r)、h、Ni、 eNi(r)的計算、訂定方式會依照方法的不同而有所改變。 而 其 提 出 的 三 種 方 法 可 以 給 予 不 同 的 統 計 保 證 , 並 可 以 考 慮 獨 立 抽 樣 或 是 納 入CRN兩種問題。法A為獨立抽樣,且對前面迭代存活的解使用累積樣本數計算其樣本 平均數及樣本變異數;而法B則用於處理考慮CRN的問題,其在每一個迭代僅使用當前 迭代的樣本來計算其參數值。法A確保最後可以將所有看過解中的最佳解挑出;而法B確 保最佳解在篩選程序後將存在一子集合中,且猜測此子集合在執行選擇程序後可以得 到最佳解。而法C僅能確保在每一個迭代所產生的子集合中包含當前集合所有解中的最 佳解,而在停止與選擇階段,法C可以從最後一個篩選迭代的子集合中挑出最佳解。而 法C無法提供在整個程序的正確選擇機率(PCS)上給予保證。也因為其統計保證性較為 薄弱,我們定義出的門檻值即更加嚴格,我們可以期望在有限的抽樣預算下,此法C可 以對更多的解進行搜尋及篩選。 Algorithm of Approach A 此方法保證正確選擇機率PCShSR−1r=0 I(r)e i ≥ 1 − α,且所有解間的模擬皆為獨立,並保 留存活解的所有樣本,其在各程序執行階段使用到的參數定義如下所示: (1) 決定篩選階段和選擇階段的信心水準1 − α1和1 − α2,並設定α 0 = α1/R。 (2) 計 算各候選解的樣本平均數 ¯Xi(r) = NPi(r) j=1 Xij/Ni(r)以及兩兩候選解間的門檻值Wil(r) = p t2 iSi2(r)/Ni(r) + t2lSl2(r)/Nl(r) ,其中ti = t(1−α0)1/(B(r)−1),N i(r)−1、S 2 i(r) = NPi(r) j=1 [Xij− ¯ Xi(r)]2/(Ni(r) − 1)。
(3) 執行選擇階段時, Ni = max ½ e Ni, »µ h2S2 i(R − 1) δ2 ¶¼¾
其中 eNi = Ni(R−1), h = h(2, (1−α2)1/(B(R−1)−1), nmin),而nmin= mini∈I0(R){Ni(R−
1)}。
2.2.2.1 起起起始始始解解解產產產生生生法法法(Setting Up Initial Solutions)
因為此快速篩選法追求的是有限時間的統計保證,故起始解的品質也格外重要,若在 較前面的迭代即產生較優良的解,在篩選及候選解產生的效率上亦會大幅提升,故其提 出一起始解選擇(SIS)演算法,藉由求解一最大邊際權重問題(Maximum edge-weighted clique problem; MEWCP)來得到起始解,其演算法敘述如下:
Selection of the Initial Solutions
Step 1:選擇S1 = (0)1×d和S2 = (1)1×d且令b = 2、m = 1 Step 2:從S1的鄰近解中挑選一個解,每個鄰近解被挑中的機率皆相等,並令此被挑中 的解為S2m+1,翻轉此解中所有的二元變數(ex.1 → 0或0 → 1),並令這組翻轉過後的解 為S2m+2 Step 3:若b < b(0)則回到Step 2;否則停止演算法,並回傳{S1, S2, . . . , Sb(0)}為起始 解集合。
2.2.2.2 候候候選選選解解解產產產生生生法法法(Generation of New Solutions)
通常經由篩選後存活下來的解其品質亦較佳,故其使用當前迭代存活下來的解去產生 下一迭代的候選解,以期望得到的候選解品值亦較隨機選擇候選解優良。第一種方法從 離該迭代存活的解最靠近的鄰近解來選擇候選解;第二種方法在較前面的迭代使用較廣 的解範圍,並隨著抽樣數的增加逐漸縮減解範圍,其提出的執行步驟分別如下所述: Nearest-Neighborhood Search Method
Step 1:將集合I0(r)內的依照其指標(index)排序,並令b = 0。
Step 2:由指標最小的解開始執行以下步驟:令 m = 1,若此解之鄰近解為空集合, 則使m = m + 1直至找到一解其鄰近解不為空集合。從此解的鄰近解中產生一個新的 解,且每個解被挑中的機率服從一均勻分配,並將此被挑中的解由解空間Ω內移除。 令b = b + 1,若b + 1 = b(r)結束此步驟。
Step 3:若b < b(r)則回到Step 2;否則,結束此候選解產生步驟。 Shrinking-Neighborhood Search Method
此方法在較前面的迭代使用較廣的解範圍,並隨著抽樣數的增加逐漸縮減解範圍。當迭 代數r較小時,最佳解可能尚未被搜尋到,因此我們可能需要較多的抽樣工作來搜尋較 為龐大的解空間,而當r逐漸上升,直至一個較優良的解被搜尋到之後,我們只要針對 其鄰近區域去做後選解的搜尋。故此方法與Nearest-Neighborhood Search Method相 似,相異數在於此方法的m是由一r的遞減函數所決定,故鄰近解的搜尋半徑會隨著迭代 數r的上升而下降。
第
第
第三
三
三章
章
章 研
研
研究
究
究方
方
方法
法
法
本章節分為兩個部份探討,3.1節為本研究的問題與假設;3.2至3.4節則為本研究所提 出的三種演算法,分別有不同的統計保證性證明且有各自的適用情境及其優缺點。3.1
研
研
研究
究
究問
問
問題
題
題與
與
與假
假
假設
設
設
本研究的研究目的為找到一以0 − 1為決策變數的向量,此向量需滿足隨機限制式,且 其期望績效為最佳,其數學模型如下所示: max S∈Ω X(S) 而其可行區域Ω必須滿足以下隨機限制式: Y(S) ≤ Q 其中X(S)為候選候選解S的目標式期望績效值,而Y(S)則為候選候選解S的限制式期 望績效值,Q則為限制式的右手邊常數。而S為d維度的決策變數向量,候選候選解空 間{0, 1}d的大小為2d,此候選候選解空間大小與d的數值成指數型成長。故我們可以就一 個候選候選解S給予他參數上的設定,Ω = {S1, S2, . . . , Sq}且q ≤ 2d。而第i個候選解即 可表達為Si = (Si1, Si2, . . . , Sid),且每一個數值皆為二元變數。而期望值X(S)、Y(S)為 未知,故我們僅能透過模擬實驗來取得。 而對候選解Si的第j個目標式樣本,我們以Xij表示;限制式樣本則以Yij表示,故X(Si)=E[Xij],Y(Si)=E[Yij]。我們亦假設目標式及限制式的樣本Xij與Yij均各自服
假設在Xij和Yij為多次獨立試驗下的平均或是在穩態模擬時,一個批量中連續的觀察值 所得的情況下,會顯得更加貼近真實。我們亦假設一組樣本(Xij, Yij)間可能有相關性存 在,當候選候選解Si時可表示如下 Xij Yij iid∼ BN X(Si) Y(Si) , Σi
其中BN表示(Xij, Yij)服從相同且獨立的二元常態分配(Bivariate Normal
Distribu-tion),X(Si)、Y(Si)為目標式及限制式之期望值,Σi為兩者的共變數矩陣。而為了表達 上的通用性,我們假設目標式期望值越大其績效越佳。 而本快速篩選法在正確選擇機率(PCS)上給予統計保證。首先定義JD為理想候選 解集合;JA為可接受候選解集合;JU為不理想候選解集合,接著可以定義正確決 定(Correct Decision; CD),正確決定表示在判定候選解可行性時,所得到的可行候選 解集合F 滿足JD ⊆ F ⊆ JD ∪ JA,亦即集合F 內包含所有理想候選解且可能包含一些可 接受候選解。我們假設有k個理想候選解,而候選解k為這些理想候選解中的最佳候選 解,如下所示 X[1] ≤ X[2] ≤ . . . ≤ X[k]
接著定義正確選擇(Correct Selection; CS),若所有候選候選解i ∈ (JD ∪ JA),且其目
標式期望績效值與理想候選解中的最佳候選解k之目標式期望績效值差距大於等於目標式
容忍水準δ,最後在選擇候選解時選出S[k]為最佳候選解,故本研究所提供的統計保證性
如下所示
其中I為所有看過的候選解。
3.2
演
演
演算
算
算法
法
法A
為處理考慮隨機限制式的問題,在可行性驗證階段,採用Andrad´ottir and Kim [1] 提出的可行性驗證程序(Feasibility Check Procedure)來驗證候選解的可行性,其方法 在起始樣本數皆相等的情況下,可以確認各候選解的可行性,且保證其正確判定機
率(Probability of Correct Decision; PCD)大於等於信心水準1 − αf;在目標式篩選階
段,採用Tsai [20] 提出的快速篩選法,從可行候選解中篩選出目標式期望值較佳的候選 解。演算法A在每一個迭代僅對當前迭代產生的新候選解執行抽樣及可行性驗證,將不 可行候選解刪除,接著對前面迭代存活的候選解與當前迭代所有的可行候選解執行抽 樣,進行目標式篩選,將篩選掉的候選解刪除,並產生下一迭代的新候選解,回到可行 性驗證階段直至篩選迭代結束。當篩選迭代結束後,對最後一篩選迭代的存活候選解執 行選擇程序,進而從中選出最佳候選解。此演算法A結合可行性驗證程序、目標式篩選 程序以及Clean-Up程序,其不同候選候選解的抽樣為獨立抽樣。其程序及符號定義如下 所示: Step 1: 決 定 整 體 信 心 水 準1 − α、 篩 選 迭 代 信 心 水 準1 − α1、 選 擇 階 段 信 心 水 準1 − α2、目標式篩選階段信心水準1 − αs、可行性驗證階段信心水準1 − αf、限制式 容忍水準²、目標式容忍水準δ、限制式門檻值Q、起始樣本數n0、總迭代數R、樣本成 長常數G,而b(r)為迭代r產生的新候選解個數,Ni(r)為候選解i至迭代r的抽樣樣本數。 建立集合I(r)來儲存迭代r篩選後存活的候選解、集合E(r)來儲存迭代r在目標式篩選階 段被篩去的候選解、集合M(r)為迭代r可行性尚未確認之候選解集合、集合F (r)為迭 代r經由可行性驗證階段判定為可行候選解之集合。
Step 2:產生b(r)個新候選解,將此迭代新產生的候選解放入集合M(r),依照起始樣本 數n0對集合M(r)內的候選解進行抽樣,計算限制式的樣本平均數及樣本變異數,執行 可行性驗證程序,將不可行的候選解由集合M(r)刪除;將可行的候選解從M(r)移入集 合F (r)中,並回傳集合F (r)。 Step 3:對集合F (r) ∪ I(r − 1)內的候選解執行抽樣,計算目標式的樣本平均數及樣本 變異數,進行目標式篩選,將篩選後存活下來的候選解移入集合I(r)。
Step 4:令r = r + 1,若r < R則並回到Step 2;否則(r ≥ R),進入Step 5。 Step 5:依照|I(R − 1)|決定是否使用Clean-Up程序選出最佳候選解。
以下為演算法A的參數計算方式以及較為詳細的演算法步驟。 演演演算算算法法法A 設設設定定定:決定整體信心水準0 < 1 − α < 1、α1+ α2 = α、(1 − αs)(1 − αf) = 1 − α1、 總迭代數R、限制式容忍水準²、目標式容忍水準δ、限制式門檻值Q、可行性驗證階段的 起始樣本數n0 ≥ 2、目標式篩選階段的起始樣本數N0、樣本成長常數G ≥ 1,並令當前 迭代數r = 0、集合I(−1) = ∅、集合M(0) = ∅、集合F (0) = ∅、集合E(0) = ∅。 初初初始始始化化化:產生b(0)個起始候選解並使M(0) = {1, 2, . . . , b(0)},依照起始樣本數n0進行 抽樣,計算限制式的樣本平均數 ¯Yi及樣本變異數Si2(n0)。
可可可行行行性性性驗驗驗證證證階階階段段段:使用Andrad´ottir and Kim [1] 提出的相同樣本數之可行性驗證來
檢驗集合M(r)內候選解之可行性,以g(η) = 1 − (1 − αf)1/k計算η,其中k值為一上界
值PR−1r=0 b(r)。執行可行性驗證程序,持續檢驗直至所有候選解的可行性皆被檢驗完
畢,得到可行候選解集合F (r)。
若i ∈ I(r−1),令Ni(r) = Ni(r−1)+dN0Gre;否則(i ∈ F (r)),令Ni(r) = dN0Gre。 以式子(3.1)與(3.2)計算目標式的樣本平均數 ¯Xi(Ni(r)) ¯ Xi(Ni(r)) = NXi(r) j=1 Xij Ni(r) (3.1) 及樣本變異數S2 i(Ni(r)) S2 i(Ni(r)) = 1 Ni(r) − 1 NXi(r) j=1 [Xij − ¯Xi]2 (3.2) 計算各候選解的ti = t(1−α0)1/(Prz=0 |F (z)|−1),N i(r)−1,其中α 0 = α s/R。以式子(3.3)計算兩 兩候選解間的門檻值 Wil(r) = s t2 iSi2(Ni(r)) Ni(r) + t 2 lSl2(Nl(r)) Nl(r) (3.3) 並對所有i 6= l的候選解做篩選,若 ¯Xi(Ni(r)) − ¯Xl(Nl(r)) ≤ −Wil(r)則將候選解i放入
集合E(r),並更新I(r) = (F (r) ∪ I(r − 1)) \ E(r)。
停停停止止止條條條件件件:令r = r+1,若r < R則產生b(r)個新候選解且使M(r) =nPr−1j=0b(j) + 1,Pr−1j=0b(j) + 2, . . . ,Prj=0b(j) o , 並依照起始樣本數n0進行抽樣,計算各候選解之限制式的樣本平均數及樣本變異數,回 到可行性驗證階段;否則(r = R),令B =PR−1r=0 |F (r)|,進入選擇階段。 選選選擇擇擇階階階段段段:若|I(R − 1)| = 1則宣告集合I(R − 1)內的候選解為最佳候選解;否則,以式 子(3.2)計算Ni(R − 1)下之樣本變異數,再以Rinnott’s常數計算集合I(R − 1)內各個候 選解的總抽樣樣本數Ni,其計算方式如式子(3.4)所示 Ni = max ( Ni(R − 1), &µ hSi(Ni(R − 1)) δ ¶2') (3.4)
其中h = h(2, (1 − α2)1/(B−1), nmin)、nmin = mini∈I(R−1){Ni(R − 1)}。 若候選解的抽樣樣本數Ni(R − 1)小於Ni則對候選解i抽樣Ni− Ni(R − 1)個目標式樣 本,並計算其總抽樣樣本數下的樣本平均數 ¯Xi = (1/Ni) PNi j=1Xij,選擇其值最大的候 選解為最佳候選解。 演算法A的執行步驟可以由圖(3.1)更清楚了解。 圖 3.1: 演算法A執行步驟 演算法A在每一個迭代皆先執行可行性驗證,接著執行目標式篩選,而可行性驗證階 段之目標式樣本(Xij)的抽樣數會被限制式樣本(Yij)所影響,此相關性會對目標式篩選階 段的篩選比較部分造成影響,故為了證明上的需要,可行性驗證階段與目標式篩選階段 的抽樣需為相互獨立,亦即可行性驗證階段的樣本在目標式篩選階段並沒有被保留,進 而造成抽樣成本上升以及樣本的浪費。另外,在可行性驗證階段,當有一候選候選解之 限制式期望值與其限制式常數非常接近(Near Boundary),會使得其可行性較難判斷, 即使能判斷出來,也需要大量的樣本數。又因其可行性驗證階段與目標式篩選階段的抽
樣互為獨立,如果其目標式期望值不佳,此候選解在目標式篩選階段亦會被其他目標式 期望值較優良的候選解篩掉,其可行性驗證階段所抽取的樣本亦被浪費。而在可行性 驗證階段,η計算所使用的k值僅能用一上界值(Upper Bound)PR−1r=0 b(r)做為其計算參 數,原因為可行性驗證程序的正確判定機率為一次檢驗k個候選解的可行性時給予的統計 保證性,而非對各個迭代均有統計保證性,由此一來,較大的k使得樣本數提升。
3.3
演
演
演算
算
算法
法
法B
為改善演算法A的缺點,本研究在3.3.1與3.3.2小節分別提出限制式篩選程序及相異 樣本數下可行性驗證程序,並提出演算法B。演算法B在每一個迭代抽取固定數量的樣 本(Xij, Yij),且在同一個迭代中,目標式樣本與限制式樣本皆有被使用。先依當前迭代 的累積抽樣樣本計算限制式樣本平均數與樣本變異數,進而算出限制式篩選門檻值,進 行限制式篩選,刪除被篩選掉的候選解,接著計算限制式篩選後存活候選解的目標式樣 本平均數與樣本變異數,得到目標式篩選的門檻值,進行目標式篩選,將篩選掉的候選 解刪除,產生下一迭代的新候選解,回到限制式篩選,重複上述步驟直至篩選迭代結 束。當篩選迭代結束後,因為各候選解產生的迭代可能均不同,其累積的抽樣樣本數亦 可能不同,故對所有存活的候選解執行“相異樣本數”的可行性驗證,直至所有候選解 的可行性皆被確認。接著對可行候選解執行選擇程序,從中選出最佳候選解。而演算 法B在篩選迭代後才進入可行性驗證階段,故參數值ηi計算中的k值不需再保守的以一上 界值當做計算參數,可以直接使用篩選迭代後存活的候選解數做為k的數值,以減少抽樣 成本。 此演算法B在每一個篩選迭代均執行限制式與目標式的篩選,若一個或多個候選解在 篩選迭代後依舊存活,表示其可行性值得我們判斷且其目標式期望值亦不差。在執行可行性驗證階段時,使用前面篩選迭代所保留的樣本,在抽樣成本的節省上亦可得到不錯 的效果。此演算法B結合限制式篩選程序、目標式篩選程序、相異樣本數下可行性驗證 程序以及Clean-Up程序,其不同候選解的抽樣為獨立抽樣,其程序及符號定義如下所 示: Step 1:決定整體信心水準1 − α、每一迭代的信心水準1 − α0、可行性驗證階段信心水 準1 − αf、限制式容忍水準²、目標式容忍水準δ、限制式門檻值Q、起始樣本數n0、總 迭代數R、樣本成長常數G,而b(r)為迭代r產生的新候選解個數、Ni(r)為候選解i至迭 代r的抽樣樣本數,建立集合I(r)來儲存迭代r篩選後存活的候選解、集合E(r)來儲存迭 代r被目標式篩選篩去的候選解、集合M為可行性驗證階段可行性尚未確認之候選解集 合、集合F 為經由可行性驗證判斷為可行候選解之集合。 Step 2:產生b(r)個新候選解,依照樣本數dn0Gre執行抽樣並更新Ni(r),計算限制式 的樣本平均數及樣本變異數,並執行限制式篩選,將存活下來的候選解放入集合I0(r)。 Step 3:計算I0(r)內候選解的目標式樣本平均數與樣本變異數,並執行目標式篩選,並 將此階段被篩選掉的候選解放入集合E(r),更新I(r + 1) = I0(r) \ E(r)。
Step 4:令r = r + 1,若r < R則回到Step 2;否則(r ≥ R),令M = I(R),並對M執 行相異樣本數下的可行性驗證程序,得到可行解集合F 並進入Step 5。
下面提出的演算法B.I和演算法B.II在可行性驗證階段的M集合上有不同的定義。演 算法B.I僅針對最後一篩選迭代後存活之候選解進行相異樣本數之可行性驗證,但演算 法B.I可能存在其缺點,在限制式篩選階段,我們僅能確保子集合內的候選解包含所有理 想候選解,但亦可能包含一些可接受候選解及不理想候選解,故在目標式篩選階段,可 能會有目標式期望績效值較差的可行候選解被目標式期望值較優良的不可行候選解篩掉 的情況。因此,我們僅能對限制式篩選程序及相異樣本數下可行性驗證程序分別給予其 統計保證性,並不能在演算法B.I上給予整體統計有效性的保證。而演算法B.II改善演算 法B.I中,可能有可行候選解被不可行候選解篩掉的缺點,在可行性驗證階段同時考慮 篩選迭代後存活之候選解I(R)以及各迭代中限制式篩選後保留但目標式篩選後被篩去之 候選解E(r)。故在演算法B.II中,最後選出來的候選解可能來自兩個集合。第一種為最 佳候選解來自集合E(r)的情況,若最佳候選解來自此集合,表示前面目標式篩選階段發 生了不可行候選解將所有可行候選解刪除的錯誤。在這樣的情況下,演算法B.I的正確 判定機率(P F S)會較差,而由於最佳候選解由E(r)集合內選出,E(r)集合內的候選解為 目標式期望值(AP )較差的候選解,故演算法B.II得到的AP 將會比演算法B.I來的差;第 二種為最佳候選解來自集合I(R)的情況,表示篩選階段並沒有發生所有可行候選解皆被 不可行候選解刪除的狀況。在這樣的情況下,演算法B.II的AP 與P F S將與演算法B.I非 常接近。而兩種演算法中,因為篩選階段的執行並無差異,故兩種演算法在產生候選 解數(AGS)上並不會有明顯的差異。樣本數的部分,演算法B.II的樣本數會相對較多, 其原因為演算法B.II在可行性驗證階段與選擇階段所考慮的候選解數(ASS)將會比演算 法B.I來得多,進而使可行性驗證和選擇階段的樣本數有所提升。兩演算法之參數計算方 式和詳細的演算法步驟如下所示:
演演演算算算法法法B.I 設設設定定定:決定整體信心水準1 − α、總迭代數R、目標式篩選階段信心水準1 − αs、α 0 = αs/R、可行性驗證階段信心水準1 − αf、限制式容忍水準²、限制式門檻值Q、目標 式容忍水準δ、起始樣本數N0 ≥ 2、樣本成長常數G ≥ 1,並令當前迭代數r = 0、集 合I(−1) = ∅、集合M = ∅、集合F = ∅、集合E(r) = ∅。 初初初始始始化化化:產生b(0)個起始候選解,使I(0) = {1, 2, . . . , b(0)},依照起始樣本數N0執行目 標式及限制式抽樣,且令Ni(0) = N0。 限限限制制制式式式篩篩篩選選選階階階段段段:對集合I(r)的候選解執行限制式篩選,以式子(3.8)與(3.9)計算各候選 解的限制式樣本平均數 ¯Yi(Ni(r))及樣本變異數Si2(Ni(r)),以式子(3.6)計算門檻值Wi0, 若{ ¯Yi(Ni(r)) − Q ≤ max(0, Wi0− ²)}則將候選解i由集合I(r)移至集合I0(r),最後回傳 集合I0(r),為限制式篩選後尚存活的候選解,其中W i0的計算方式及限制式篩選的詳細 步驟會在3.3.1節做介紹。 目目目 標標標 式式式 篩篩篩 選選選 階階階 段段段 : 對I0(r)集 合 內 的 候 選 解 進 行 目 標 式 篩 選 , 以 式 子(3.1)與 式 子(3.2)計算各候選解的目標式樣本平均數 ¯Xi(Ni(r))及樣本變異數Si2(Ni(r))以及ti = t(1−α0)1/(|I0(r)|−1),N i(r)−1, 並 以 式 子(3.3)計 算 兩 兩 候 選 解 間 的 門 檻 值Wil(r)。 對 所
有i 6= l的 候 選 解 做 篩 選 , 若 ¯Xi − ¯Xl ≤ −Wil(r)則 將 候 選 解i放 入 集 合E(r), 並 更
新I(r + 1) = I0(r) \ E(r)。
停停停止止止條條條件件件:令r = r + 1,若r < R則產生b(r)個新候選解,並依照dN0Gre對各候選解抽
樣,更新Ni(r) = Ni(r − 1) + dN0Gre並將新產生的候選解放入集合I(r),回到限制式
篩選;否則(r = R),令M = I(R),並進入可行性驗證階段。
序(3.3.2小節),令ni = Ni(R − 1),以式子(3.7)、式子(3.8)與式子(3.9)計算集合M內 各候選解的ηi、限制式樣本平均數與樣本變異數,其中k = |M|。回傳一可行候選解集 合F ,再進入選擇階段。 選選選擇擇擇階階階段段段:若|F | = 1則宣告集合F 內的候選解為最佳候選解,否則,令B = |F |,並以 式子(3.4)計算集合F 內各個候選解的總抽樣樣本數Ni,若可行性驗證階段後候選解的累 積抽樣樣本數ni小於Ni則對候選解i抽樣Ni − ni個樣本,並計算其總抽樣樣本數下的樣 本平均數 ¯Xi = (1/Ni) PNi j=1Xij,並選擇其值最大的候選解為最佳候選解。 演算法B.I的執行步驟可以由圖(3.2)更清楚了解。 圖 3.2: 演算法B.I執行步驟 演演演算算算法法法B.II 設設設 定定定 : 決 定 整 體 信 心 水 準0 < 1 − α < 1、 接 著 由Rαc + αf + αl + α2 = α決 定 出αc、αf和α2。其中R為總迭代數、αc為目標式篩選之誤差、αf為可行性驗證階段之誤 差、α2為選擇階段之誤差。 初初初始始始化化化:同演算法B.I
限限限制制制式式式篩篩篩選選選階階階段段段:同演算法B.I 目目目標標標式式式篩篩篩選選選階階階段段段:同演算法B.I 停停停止止止條條條件件件:令r = r + 1,若r < R則產生b(r)個新候選解,並依照dN0Gre對各候選解抽 樣,更新Ni(r) = Ni(r − 1) + dN0Gre,並將新產生的候選解放入集合I(r),回到限制 式篩選;否則(r = R),令M = {SR−1r=0 E(r)} ∪ I(R),並進入可行性驗證階段。 可可可行行行性性性驗驗驗證證證階階階段段段:令k = |M|,對集合M執行相異樣本數下可行性驗證程序,最後回傳 集合F 。 最最最終終終目目目標標標式式篩式篩篩選選選階階階段段段:對集合F ,以當前樣本執行目標式篩選,程序的給定誤差為αl, 將被篩選掉的候選解,從集合F 內刪除。 選選選擇擇擇階階階段段段:同演算法B.I
3.3.1 限限限制制制式式式篩篩篩選選選程程程序序序 (Constraint Screening Procedure)
本研究依照與標準比較問題(Comparison with a Standard)的觀念提出限制式篩 選 程 序 , 與 標 準 比 較 問 題 中 的 標 準 值 即 可 對 應 到 本 研 究 的 限 制 式 常 數Q, 且 其 指 標(index)為0。此限制式篩選程序保證回傳的子集合內包含所有理想候選解,如式 子(3.5)所示 Pr{JD(r) ∈ I0(r)} ≥ 1 − αc 其中 JD(r) = {i : Yi− Q ≤ −², ∀i ∈ I(r)} (3.5) 故經歷多個迭代的篩選之後依舊存活在子集合內的候選解,其候選解可行性值得我們進 一步由可行性驗證確認,限制式篩選程序的演算法如下所示:
限限限制制制式式式篩篩篩選選選程程程序序序 Step 1: 決 定 限 制 式 容 忍 水 準²> 0以 及 信 心 水 準0 < 1 − αc < 1, 給 定k個 候 選 解(k = |I(r)|)及各自的樣本數Ni(r),並建立子集合I = ∅以儲存限制式篩選後剩下的候 選解。 Step 2:對所有候選解計算其各自的樣本平均數 ¯Yi(Ni(r)) = PNi(r) j=1 Yij/Ni(r)以及樣本 變異數S2 i(Ni(r)) = (1/(Ni(r) − 1)) PNi(r) j=1 [Yij − ¯Yi(Ni(r))]2,並以式子(3.6)計算各候 選解與限制式右手邊常數間的門檻值Wi0 Wi0= v q S2 i(Ni(r))/Ni(r) (3.6) 其中h需符合Pr(V ≤ v) = 1 − αc,而V = max {T1, T2, . . . , Tk},其中T1, T2, . . . , Tk為
互相獨立且自由度皆為Ni(r) − 1的t分配隨機變數,v的計算參考Nelson and Goldsman
[15]的計算方式:
• Step 2a :
決 定 正 整 數mh與 信 心 水 準βh (Nelson and Goldsman [15] 建 議 設 定 mh =
1, 000、βh = 0.95)。 • Step 2b : 找出最小整數值uh,符合下列不等式: mh X `=uh mh ` (1 − αc)`αmc h−` ≤ βh • Step 2c :
產生V1, V2, . . . , Vmh等數個i.i.d的V ,且令bv = V(uh)。
• Step 2d :
回傳 bv。
Step 3:對各候選解進行篩選,若{ ¯Yi(Ni(r)) − Q ≤ max(0, Wi0− ²)}則將候選解i放
入集合I0(r)內並保留。
3.3.2 相相相異異異樣樣樣本本本數數數可可可行行行性性性驗驗驗證證證程程程序序序 (FCP with Unequal Sample Size)
Andrad´ottir and Kim [1] 的可行性驗證程序對所有候選解使用相同的起始樣本n0,
而演算法B中,各候選解的樣本數為每一個迭代所累積下來的抽樣樣本數。演算法B在每
一個迭代均會產生dn0Gre個新樣本,而各候選解產生的迭代均可能相異,造成在執行所
有篩選迭代過後,每一個候選解的累積樣本數Ni(R − 1)並不一定會相等,故需使用相異
樣本數的可行性驗證程序。Pichitlamken and Nelson [17] 提出一Sequential Selection with Memory(SSM)演算法,應用在找出最佳目標式期望值的問題上,其方法用於處理 在篩選過程中,某些候選解已有其各自相異的抽樣樣本數ni且所有抽樣樣本均服從相同 且獨立的常態分配之問題,而本研究將其概念使用在可行性驗證階段,用於處理可行性 驗證時,各候選解間的抽樣樣本數相異的問題。 而本研究所提出的演算法B,保留所有存活候選解在篩選迭代的所有樣本,使得每一 個存活候選解在可行性驗證階段的累積抽樣樣本數皆可能不同,故本研究提出相異樣本
數下可行性驗證程序,有別於Andrad´ottir and Kim [1] 的方法,在參數ηi、Si2(ni)的計
算上,皆使用候選解各自的累積抽樣樣本數ni,而起始階段數r的定義為所有ni的最小
值。給定k個候選解及候選解i各自的抽樣數ni,當ni小於執行可行性驗證所需的起始樣
確認其可行性且累積抽樣樣本數ni < r + 1的候選解多抽一個樣本,並更新ni = ni+ 1; 而可行性已經確認或累積抽樣樣本數ni ≥ r + 1的候選解則無需再抽樣,重複執行可行 性驗證直至所有候選解的可行性皆被確認,回傳一可行候選解集合F 。其演算法及詳細 的參數計算方式如下所示: 相相相異異異樣樣樣本本本數數數可可行可行行性性性驗驗驗證證證程程程序序序 設設設定定定:設定信心水準1 − αf、初始樣本數n0 ≥ 2,選定限制式門檻值Q、限制式容忍水 準²,給定k個候選解且令ni為候選解i的抽樣樣本數。 初初初始始始化化化:當ni < n0時,對候選解i抽n0− ni個樣本,且令ni = n0;而當ni ≥ n0時,則 無需額外抽樣,其中ni為進入可行性驗證時候選解i的抽樣樣本數。對所有候選解計算 其ηi ηi = 1 2 © {2[1 − (1 − αf)1/k]}−2/(ni−1)− 1 ª (3.7) 樣本平均數 ¯Yi(ni) ¯ Yi(ni) = ni X j=1 Yij ni (3.8) 以及樣本變異數S2 i(ni) Si2(ni) = 1 (ni− 1) ni X j=1 (Yij − ¯Yi(ni))2 (3.9) 令r = min∀ini、 尚 未 確 認 可 行 性 之 候 選 解 集 合M = {1, 2, ..., k}、 可 行 候 選 解 集 合F = ∅。 可可可行行行性性性驗驗驗證證證階階階段段段:對所有還未確定其可行性之候選解(i ∈ M)執行可行性驗證: 若r{ ¯Yi(ni) − Q} ≤ − max{0, ai− rλ},則將候選解i從集合M內移至集合F 。
若r{ ¯Yi(ni) − Q} ≥ max{0, ai− rλ},則將候選解i從集合M內刪去。 其中λ = ²/2、ai = ηi(ni− 1)Si2/2²。 停停停止止止條條條件件件:若|M| = 0,回傳集合F 為可行候選解之集合;否則(|M| > 0),對所有尚未 確定其可行性且其抽樣樣本數ni < r + 1的候選解多抽一個樣本,更新ni = ni+ 1;而可 行性已經確認或抽樣樣本數ni ≥ r + 1的候選解則無需額外抽樣。令階段數r = r + 1, 並回到可行性驗證。
3.4
演
演
演算
算
算法
法
法C
相較於演算法A在每一個篩選迭代皆使用可行性驗證程序(FCP)確認所有候選解的可 行性後才執行目標式篩選,且可行性驗證階段與目標式篩選階段的抽樣為相互獨立,而 演算法B.I僅能在限制式篩選階段保證回傳的子集合包含所有理想候選解,但可能包含 一些可接受候選解和不理想候選解,故可能造成可行候選解被目標式期望績效值較優良 的不可行候選解刪去的狀況。演算法C統合演算法A與演算法B,在篩選迭代中的可行性 驗證階段先使用當前迭代的累積抽樣樣本數判定其可行性,但不強求立即判定出所有候 選解的可行性;目標式篩選階段僅針對兩者目標式期望績效優劣尚未知的候選解做兩兩 比較篩選,期望藉由可行性判定與目標式篩選的交互使用以及目標式篩選階段兩兩候選 解間目標式期望值優劣的紀錄,使篩選過程更有效率。當有一候選候選解之限制式期望 值與限制式右手邊常數非常接近(Near Boundary),且同時其目標式期望值較差,演算 法A在可行性驗證階段花費大量的樣本判斷出其可行性後卻在目標式篩選階段被篩掉, 造成樣本的浪費;演算法C卻僅需使用當前的樣本數做一次性的判斷,使其在樣本數的 節省上較演算法A來得優異。而演算法B.I,在某些情境下,因為錯誤刪除的發生,會使 得其正確選擇機率會非常低;演算法C則在正確找尋可行解機率以及正確選擇機率上確保其統計保證性,且其篩選迭代的樣本數與演算法B.I完全相同,唯一的差別在於演算 法C在選擇階段的給定誤差α2較演算法B.I低,使其選擇階段所需樣本數較演算B.I稍微 多一點。而演算法C因為其篩選的限制較為嚴格,其在相同的模擬預算下,其產生的候 選解數,會較其他方法來得少。定義一集合SSl表示目標式期望績效值比候選解l優良的 候選解集合。若有一可行候選解i在目標式篩選階段將其他候選解l篩掉,則立即刪除此 候選解l的一切資訊;若有一候選解i之可行性尚未被判定出來,即使此候選解i擁有較候 選解l來的優良之目標式期望績效值,亦不會將候選解l篩掉,候選解i只會先被記錄在一 集合SSl內,直至候選解i之可行性被判定出來。演算法C的程序及符號定義如下所示: Step 1:決定整體信心水準1 − α、每一迭代的信心水準1 − α0、限制式容忍水準²、 目標式容忍水準δ、限制式門檻值Q、起始樣本數n0、總迭代數R、樣本成長常數G, 而b(r)為迭代r產生的新候選解個數,Ni(r)為候選解i至迭代r的抽樣樣本數、建立集 合M(r)為迭代r可行性尚未確認之候選解集合、集合F (r)為迭代r一次性可行性驗證後 判定為可行候選解之集合、集合F 為經由可行性驗證階段判定為可行候選解之集合、集 合SSi為目標式期望績效值較候選解i優良的候選解集合。其程序及符號定義如下所示: Step 2:產生b(r)個新候選解,並令L(r) =nPr−1j=0b(j) + 1,Pr−1j=0b(j) + 2, . . . ,Prj=0b(j) o , 更新M(r) = M(r − 1) ∪ L(r)及F (r) = F (r − 1)。對M(r)集合內的候選解抽樣,抽樣 數為dN0Gre,並更新Ni(r) = Ni(r − 1) + dN0Gre。 Step 3: 計 算M(r)集 合 內 各 候 選 解 限 制 式 的 樣 本 平 均 數 ¯Yi(Ni(r))及 樣 本 變 異 數S2 i(Ni(r)),並執行相異樣本數下可行性驗證,不同的是在這邊僅使用當前的抽樣樣 本數做一次性的判定,即使沒有立即判定出候選解可行性,亦不會再針對尚未判定出 可行性的候選解執行額外抽樣。若候選解i被判定為可行候選解,將候選解i由M(r)移