博士論文
Graduate Institute of Networking and Multimedia College of Electrical Engineering & Computer Science
National Taiwan University Doctoral Dissertation
以物件與事件為基礎之視訊內容調適架構
A Semantic Framework for Object-Based and Event-Based Video Content Adaptation
鄭文皇
Wen-Huang Cheng
指導教授:吳家麟 博士 Advisor: Ja-Ling Wu, Ph.D.
中華民國 97 年 6 月
I would like to thank all those who have contributed to my education as well as to my life.
First and foremost, I would like to express my sincere gratitude to my advisor, Prof. Ja-Ling Wu, for his great support and constant encouragement throughout my dissertation. One of the most valuable things I learned from him is “how to do research”, meanwhile “being open-minded to other’s work”. That, in a word, is to “stay hungry, stay foolish”. His insightful guidance and passion for knowledge really make me enjoy the fun of finding and solving scientific problems.
I would also like to thank the other members in my dissertation committee
—Profs. Lin-Shan Lee, Arbee L.P. Chen, Hsueh-Ming Hang, Jane Yung-Jen Hsu, Suh-Yin Lee, and Mark Liao. I would like to extend my thanks as well to the other professors who were in the committee of my proposal defense —Profs. Yi-Ping Hung, Wen-Chin Chen, Yung-Yu Chuang, and Winston H. Hsu.
Many thanks to Dr. Chun-Hsiang Huang and Dr. Wei-Ta Chu being my good research consultants at lab. They always have some good ideas to enlighten me when I get stuck in my research.
I would also like to thank colleagues with whom I had the pleasure to work dur- ing my doctorate program —Sung-Wen Wang, Chia-Hu Chang, Min-Chun Tien, Jyh-Ren Shieh, Ching-Ju Lin, Junn-Yen Hu, Chih-Cheng Hsu, Yi-Hon Hsiao, Ming-Fang Weng, Tz-Huan Huang, Kuan-Ting Chen, Ken-Yi Li, Edward Shen, Yun Chung Shen, and Wan-Chun Ma.
Also, thanks to members of my own research group for their support —Chi- Chang Hsieh, Ping-Chieh Chang, Hong Ming Chen, Yang-Ting Yeh, Chih-Yu Yan, Yen-Lin Huang, Heng-Yi Lin, Yi-Tang Wang, Ping-Yen Hsieh, Chen-Wei Chou, Po-Wei Chen, Kuei-Yi Hsieh, and Ming-Hsiu Chang.
Tzu Lin, Yi-Chia Lai, Jun-Cheng Chen, and I-Chun Lai, for their help to deal with all kinds of life and school stuff. Especially, I deeply appreciate Ya-Ling’s always timely reminder for me so as not to miss any important deadline of which I should be aware.
I would like to give the special thanks to my dear father and mother, Jui-Yuan Cheng and Pi-Yu Chen, for their being always by my side. What my mom has told me becomes my maxim to keep in mind, “Life is just like an endless competition and the success belongs to who keeps the enthusiasm and fighting spirit from start to finish.” Finally, Chun-Yen, thank you, my love. You’re always lighting up my heart with the things you do and say. I feel so happy just being with you.
Education
2008 Doctor of Philosophy, Graduate Institute of Networking and Mul- timedia, National Taiwan University.
2004 Master of Science, Department of Computer Science and Infor- mation Engineering, National Taiwan University.
2002 Bachelor of Science, Department of Computer Science and Infor- mation Engineering, National Taiwan University.
Experience
2007 Summer Visiting Student, University of Tokyo, Tokyo, Japan.
2007 Research Intern, IBM T.J. Watson Research Center, Hawthorne, NY, USA.
Honors
2008 Member of the Phi Tau Phi Scholastic Honor Society, Taiwan, R.O.C.
2006 Excellent Work Award, work title: “Expand your vision: glasses- based multimedia information communication platform”, the 1st Acer Long-Term Smile Contest, Taiwan, R.O.C., 2006. (only 5 among 147 works are awarded)
2006 Excellent Work Award, work title: “Life Linker - smart digital photo frame”, the 1st Acer Long-Term Smile Contest, Taiwan, R.O.C., 2006. (only 5 among 147 works are awarded)
2005 Best Paper Award, IPPR Conference on Computer Vision, Graph- ics and Image Processing (CVGIP), Taipei, Taiwan, R.O.C.
2004 Best Student Paper Award, Workshop on Consumer Electronics and Signal Processing (WCEsp), Hsinchu, Taiwan, R.O.C.
Selected Publications – Journal
J1 Wen-Huang Cheng, Chia-Wei Wang, and Ja-Ling Wu, “Video adaptation for small display based on content recomposition,”
IEEE Trans. Circuits and Systems for Video Technology, vol.
17, no. 1, pp. 43-58, January 2007.
IEEE Trans. Circuits and Systems for Video Technology, vol. 15, no. 11, pp. 1365-1372, November 2005.
J3 Wen-Huang Cheng, Wei-Ta Chu, and Ja-Ling Wu, “A visual attention based region-of-interest determination framework for video sequences” IEICE Trans. Information and Systems Jour- nal, vol. E-88D, no. 7, pp. 1578-1586, July 2005.
J4 Wei-Ta Chu, Wen-Huang Cheng, and Ja-Ling Wu, “Semantic context detection using audio event fusion,” EURASIP Journal on Applied Signal Processing, 2005.
J5 Wei-Ta Chu, Wen-Huang Cheng, Jane Yung-Jen Hsu, and Ja- Ling Wu, “Towards semantic indexing and retrieval using hier- archical audio models,” ACM Multimedia Systems, vol. 10, no.
6, pp. 570-583, 2005.
Selected Publications – Conference
C1 Wen-Huang Cheng and David Gotz, “Context-based page unit recommendation for web-based sensemaking tasks,” Proc. Intl.
World Wide Web Conf. (WWW’08), pp. 1073-1074, 2008.
C2 Chi-Chang Hsieh, Wen-Huang Cheng, Chia-Hu Chang, Yung-Yu Chuang, and Ja-Ling Wu, “Photo navigator,” Proc. ACM Intl.
Conf. Multimedia (MM’08), 2008.
C3 Wen-Huang Cheng et al., “Semantic-event based analysis and segmentation of wedding ceremony videos” Proc. ACM Intl. Work- shop on Multimedia Information Retrieval (MIR’07), pp. 95-104, 2007.
C4 Chia-Wei Wang, Wen-Huang Cheng, Jun-Cheng Chen, Shu-Sian Yang, and Ja-Ling Wu, “Film narrative exploration through ana- lyzing aesthetic elements,” Proc. Intl. MultiMedia Modeling Conf.
(MMM’07), 2007.
C5 Wen-Huang Cheng, Chun-Wei Hsieh, Sheng-Kai Lin, Chia-Wei Wang, and Ja-Ling Wu, “Robust algorithm for exemplar-based image inpainting,” Proc. Intl. Conf. Computer Graphics, Imaging and Vision (CGIV’05), pp. 64-69, 2005.
C6 Wen-Huang Cheng, Wei-Ta Chu, Jin-Hau Kuo, and Ja-Ling Wu,
“Automatic video region-of-interest determination based on user attention model,” Proc. IEEE Intl. Symposium on Circuits and Systems (ISCAS’05), pp. 3219-3222, 2005.
in audio tracks,” Proc. Intl. MultiMedia Modeling Conf. (MMM’05), pp. 38-45, 2005.
C8 Wei-Ta Chu, Wen-Huang Cheng, Ja-Ling Wu, and Jane Yung- Jen Hsu, “A study of semantic context detection by using SVM and GMM approaches,” Proc. IEEE Intl. Conf. Multimedia and Expo (ICME’04), pp. 1591-1594, 2004.
C9 Wen-Huang Cheng, Wei-Ta Chu, and Ja-Ling Wu, “Semantic context detection based on hierarchical audio models,” Proc.
ACM Intl. Workshop on Multimedia Information Retrieval (MIR’03), pp. 109-115, 2003.
Patent
P1 Wen-Huang Cheng and David Gotz, “Context-based document unit recommendation for sensemaking tasks”, US Patent, Appli- cation Number YOR920080235US1, 2008.
A Semantic Framework for Object-Based and Event-Based Video Content Adaptation
Wen-Huang Cheng
In pervasive media environments, adaptation is one key technology to support universal multimedia access by transforming multimedia contents to fit the usage environments. In terms of personalization, effective adaptation can greatly benefit from taking into account the semantics of multimedia contents. The goal of this dissertation is to be able to provide systematic approaches to improve automatic multimedia adaptation at the semantic level.
In this dissertation, a generic adaptation framework and the fundamental de- sign principles are proposed. By exploiting specific domain knowledge, we bridge the gap between low-level computational features and high-level semantic con- cepts, whereby the associated adapting operations can be effectively designed to maximize the user’s multimedia experience. Based on the proposed framework, our works focus on the semantic adaptation of video contents, where two alter- native approaches for semantics modeling are investigated: the object-based and the event-based. In the object-based approach, a visual model is constructed for locating semantic video objects so as to improve the user’s browsing experi- ence of high-quality professional videos on the devices with small displays. In the event-based approach, both the visual and aural information are exploited to char- acterize semantic video events that can be used to benefit the user’s navigation in hours-long home videos. The two systems can be viewed as the technical real- ization of the proposed adaptation framework and demonstrate the effectiveness of automatic high-level semantics analysis.
中文摘要
以物件與事件為基礎之視訊內容調適架構
鄭文皇
在普及媒體環境中,內容調適是用以實現普遍多媒體存取的一種關鍵技術。
具體而言,其藉由多媒體內容的轉換以使轉換後之多媒體內容符合相對應的使用 環境。從個人化應用的角度來看,有效的內容調適可得益於對多媒體內容語意的 深刻理解。因此,本論文的目標即在於提供一套具系統化之研究方法以提昇自動 化多媒體調適的語意層次。
在本論文中,我們提出一個通用型之調適架構以及相對應之基本設計原則。
藉由導入特定領域知識,我們適度跨越存在於低階可計算特徵值與高階語意概念 間之語意鴻溝,並藉此有效開發與其所屬之調適運算以求得使用者多媒體經驗之 最佳化。在前述所提出的架構之上,我們的研究聚焦於視訊內容之語意調適,其 中具體探討兩種用於語意模型化之方法,分別是以物件為基礎與以事件為基礎之 方法。在以物件為基礎之方法中,我們建構一個可用於定位視訊中具語意性物件 之視覺模型,以提昇使用者在小螢幕行動裝置上觀賞高畫質專業影片時之瀏覽經 驗。另一方面,在以事件為基礎之方法中,我們同時利用視訊中之視覺與聽覺資 訊,以描繪具語意性事件之多媒體特性,並應用於滿足使用者對於長時間家庭影 片之實際瀏覽需要。此兩個系統可視為前述所提出調適架構之具體技術實現,並 可藉此顯現自動化高階語意分析之可行性與有效性。
Acknowledgements v
Curriculum Vita vii
Abstract xi
List of Figures xvi
List of Tables xix
1 Introduction 1
1.1 Motivation . . . 1
1.2 Semantic Multimedia Content Adaptation . . . 4
1.2.1 A Generic Framework . . . 4
1.2.2 From Signal to Semantic Levels . . . 8
1.2.3 Adaptive Optimization . . . 12
1.3 Problem Statement . . . 14
1.4 Summary of Contributions . . . 15
1.4.1 Framework Development for Semantic Adaptation . . . 16
1.4.2 Video Adaptation Based on Semantic Objects . . . 16
1.4.3 Video Adaptation Based on Semantic Events . . . 17
1.5 Organization of the Dissertation . . . 17
2 Basics and Literature Review 19 2.1 Semantic Concept Ontology . . . 19
2.1.1 Typical Examples . . . 20
2.1.2 Relationship Building . . . 23
2.2 Semantic Concept Analysis . . . 24
2.3 Semantic Content Adaptation . . . 26
2.3.1 Adaptation Taxonomy . . . 26
2.4.1 Semantic Object Based Video Adaptation . . . 29
2.4.2 Semantic Event Based Video Adaptation . . . 30
2.5 Summary . . . 31
3 Semantic Object Based Video Adaptation 33 3.1 Introduction . . . 34
3.2 Related Work . . . 37
3.3 User-Interest Finding . . . 41
3.3.1 Visual Attention Modeling . . . 41
3.3.2 Video ROIs Determination . . . 47
3.4 Content Recomposition . . . 51
3.4.1 UIOs Extraction . . . 53
3.4.2 Background Repairing . . . 54
3.4.3 Media Aesthetics Based Video Objects Reintegration . . . 55
3.5 Experimental Results . . . 60
3.5.1 Recomposition Results . . . 61
3.5.2 User Studies . . . 65
3.5.3 Time Efficiency Analysis . . . 74
3.6 Summary . . . 75
4 Semantic Event Based Video Adaptation 83 4.1 Introduction . . . 84
4.2 Related Work . . . 87
4.3 Wedding Event Taxonomy . . . 90
4.4 Event Features Development and Extraction . . . 92
4.4.1 Key Observations . . . 92
4.4.2 Selected Features for Event Modeling . . . 96
4.5 Wedding Modeling . . . 107
4.5.1 Wedding Event Modeling . . . 109
4.5.2 Event Transition Modeling . . . 112
4.5.3 Wedding Segmentation Using HMM . . . 113
4.6 Experimental Results . . . 115
4.6.1 Event Recognition Analysis . . . 116
4.6.2 Video Segmentation Analysis . . . 119
4.6.3 Performance Comparisons with LCRF Models . . . 122
4.6.4 Extension to the Scenario with Known Event Ordering . . 124
4.7 Summary . . . 126
5.2 Future Research . . . 135
Bibliography 137
1.1 Concept of Universal Multimedia Access (UMA): Enabling inter- operable and transparent access to rich multimedia contents over various usage environments. . . 2 1.2 Two types of adaptation engines: (a) content blind and (b) content aware but without the ability of semantics extraction. . . 6 1.3 The proposed generic framework for multimedia content adapta- tion, which is characterized by the capability of active content analysis and the use of domain knowledge to enable automatic adaptation at the semantic level. . . 7 1.4 Overview of the abstraction levels of computational media descrip- tions. . . 8 1.5 The Chinese classical painting “Listening to the Qin” (partial), by Ji Zhao (Emperor Huizong of the Song Dynasty, China), 1082-1135. . . 10 1.6 Sample media descriptions of the painting in Figure 1.5, given at two abstraction levels of (a) audiovisual features and (b) perceptual arousals. . . 11 1.7 Interrelationship between the key elements (adaptation, resource, utility) of adaptive optimization in searching for the optimal adapting operation that maximizes the adaptation utility of a multimedia content.
(Figure adapted from [Cha02]) . . . 12 2.1 Illustrations of 101 TRECVID concepts. (Figure excerpted from [SWvG+06]) . . . 22 2.2 Example of a tennis match with (a) a video snapshot and (b) the types of tennis events. (Figure excerpted from [TWC+08]) . . . 22 2.3 Adaptation taxonomy with examples of the corresponding adapt- ing operations. . . 27 2.4 The work of semantic object based video adaptation is represented by the proposed generic framework given in Figure 1.3. . . 29
3.1 Flowchart of the proposed framework for conducting video adap- tation. . . 36 3.2 Examples of semantic distortion in adapted videos: (a) and (c) are two original frames from the classical film “Lawrence of Arabia”, and (b) and (d) are the corresponding adapted results using [fil], respectively.
With partial coverage, the two men of (a) no longer look at each other’s eyes when they are chatting in (b), and the man in (d) seems more like to burn himself with the burning match rather than just hold it in (c).
(Courtesy of FlikFX Ltd.) . . . 39 3.3 Example of feature maps: (a) original video frame, (b) intensity, (c) red-green color, (d) blue-yellow color, (e) x-motion, and (f) y-motion feature maps. . . 43 3.4 Examples of a video frame with (a) one and (d) two ROIs (indicated by the white squares); (b) and (e) are the corresponding saliency maps, and (c) and (f) are the 3-D profiles of the saliency maps of (a) and (d), respectively. . . 45 3.5 Comparisons of the ROI and the UIO representations for user- interests. They are respectively indicated by the solid and dotted lines.
In (a) and (b), the number of contained semantic objects (man together with a car versus one single car) is different. . . 49 3.6 Example of flooding operations with a 6×5 ROI. In (a), the number of each pixel indicates which border it belongs to. In (b), the left and the right pixels of a thick solid line are marked as the background and UIO, respectively. Their valid neighbors are connected with the arrows.
(Let Ci be a color in RGB space and dθ(C2, C3) > Td.) . . . 50 3.7 Examples of video objects separation. The columns from left to right are successively the original frames with ROIs, extracted UIOs, and repaired backgrounds. . . 52 3.8 The virtual 3-D scene model. All video objects of a frame are re- projected onto a target screen. An object is perceived larger (i.e., the star-shaped UIO) while it comes closer to the screen. . . 55 3.9 Comparison of our approach with the conventional approach (direct- resizing) for the clips of subgroup 1. . . 62 3.10 Comparison of our approach with the conventional approaches (direct- resizing and linear-resizing) for the clips of subgroup 2. . . 63
Subsection 3.5.2 for details.) . . . 66 3.12 Comparison of the user study between our approach and the con- ventional approach (direct-resizing) for the clips of subgroup 1 at differ- ent resolution formats. . . 72 3.13 Comparison of the user study between our approach and the con- ventional approaches (direct-resizing and linear-resizing) for the clips of subgroup 2 at different resolution formats. . . 73 3.14 Failure examples of our approach. The columns from left to right are successively the original frames with ROIs, extracted UIOs, and recomposed frames. . . 78 4.1 Sample key-frames of the thirteen wedding events. . . 91 4.2 Example of a music signal with (a) its spectrogram using short-time Fourier transform and (b) its corresponding line map. . . 97 4.3 Classification results of the audio types of speech (the left subplot) and music (the right subplot) on three audio datasets of (a) Internet radio, (b) Internet radio with added white noises (5 dB), and (c) audio tracks from home videos, using a multi-class SVM classifier built upon the three audio features proposed in Section 4.4.2. . . 101 4.4 Examples of (a) two power spectrums of a wedding audio from consecutive time instances, one with applause (the top solid curve) and another without applause (the bottom dotted curve), and (b) a sigmoidal filter function. . . 102 4.5 Precision-recall curves of the applause detection results using two different thresholds. (See Section 4.4.2 for details.) . . . 103 4.6 Examples of (a) a video frame with (b) the thresholded image and (c) the bridal white map with projection histograms. . . 105 4.7 Precision-recall curves of the bride indication results. (See Sec- tion 4.4.2 for details.) . . . 108 4.8 Examples of wedding event models of (a) the RE event and (b) the WK event. . . . 111 4.9 A simplified example of the HMM for wedding segmentation. (See Subsection 4.5.3 for details.) . . . 114 4.10 Edit operations for transforming (a) a reference event string to (b) the one for comparison. . . 120 4.11 (a) A sample wedding program accompanied with the transcribed event ordering, and (b) the state diagram in form of a Markov chain built according to the above event ordering. . . 125
3.1 Weights for the feature maps under different camera motion types. 46 3.2 Screen sizes used in the experiments. . . 60 3.3 Source clips used in the experiments. . . 79 3.4 Test conditions of the user studies. (See Subsection 3.5.2 for details.) 79 3.5 User study of the relative preference (RP) of our approach with regard to the conventional approaches. . . 80 3.6 Time efficiency analysis of the proposed framework for recomposing a 320 × 240 video frame. . . 81 4.1 Taxonomy of wedding events . . . 90 4.2 The tendency of wedding events in their behavior of speech/music types, applause activities, picture-taking activities, and leading roles (from the second to the fifth columns, respectively).∗ . . . 93 4.3 Examples of flash distributions of four successive wedding events in a ceremony.∗ . . . 94 4.4 The collection of six wedding videos used in our experiments. . . . 104 4.5 An even transition model of the wedding events. . . 113 4.6 The statistics of means µ and variances σ2 of event duration for each of the event categories in our video collection (unit: seconds). . . 117 4.7 The recognition results of all wedding events (unit: seconds). . . . 128 4.8 The recognition results solely based on the feature similarity of wedding events without exploiting the event transition modeling. . . . 129 4.9 The segmentation results without duration-based filtering (unit:
event segments). . . 129 4.10 The segmentation results with duration-based filtering (unit: event segments). . . 129 4.11 The percentage of total event duration for each of the event cate- gories in our video collection. . . 130 4.12 LCRF recognition results of all wedding events (unit: seconds). . . 131
4.14 LCRF segmentation results with duration-based filtering (unit:
event segments). . . 132 4.15 Segmentation results in the case when event orderings are available (unit: event segments). . . 132 4.16 The second-based recognition rate of wedding events for all clips in our video collection. . . 132
Introduction
1.1 Motivation
In recent years, multimedia has brought people a new cultural revolution and became an indispensable part of our daily lives. Rapid advances in multimedia technology speed up the creation and the distribution of multimedia contents.
One evidence is that people are now not only passive content consumers but also active content contributors. On the Internet, for example, they are able to ac- quire various kinds of multimedia information, such as music [yah], news [cnn], live sports [nba], and movie trailers [net]. Meanwhile, they can also create their own personal contents and effortlessly share with the public through social net- working websites, such as YouTube [you], Flickr [fli], Facebook [fac], and MySpace [mys]. The explosive blossom of multimedia contents constructs a ubiquitous me- dia environment and hastens the growth of innovative multimedia services and applications.
The multimedia development also drives people’s desire to stay connected with the world, regardless from everywhere, at anytime, and along with any devices, networks, and preferences. For instance, regular commuters on public transporta-
Audio Video Image Text Rich multimedia contents
Dynamic network conditions
Usage Mismatch:
Need content adaptation for universal access
Diverse client devices & user preferences
for universal access.
p
Figure 1.1: Concept of Universal Multimedia Access (UMA): Enabling inter- operable and transparent access to rich multimedia contents over various usage environments.
tion are pleased to spend time by watching broadcast TV programs through their mobile phones. In addition, homesick students may feel comfort by viewing stored photos, videos, or even voice of the loved family members from a remote home portal. However, many technical obstacles need to be overcame before we can make it all possible. As shown in Figure 1.1, the increasing variety of usage environments complicates the content delivery path and leads to a growing mis- match with the rich set of multimedia sources [BPdWK06, RJ05]. This poses great technical challenges for enabling the Universal Multimedia Access (UMA) [PB03, MSL99, BGP03], i.e., to achieve interoperable and transparent access to multimedia contents.
Adaptation generally refers to the technology that supports UMA by either adapting the multimedia content to fit a usage environment or adapting the usage environment to accommodate the content [BPdWK06, PB03, CV05]. Since the
usage environment is usually inflexible and hard to change, the research society mainly focuses on adapting the content. An intuitive solution is to have multiple versions of a content in advance (e.g. multi-version coding [CAL96]). The method is simple but its drawbacks are also obvious. It requires more storage space and is difficult (usually impossible) to offer an adapted version for every possible us- age environment. Therefore, a better and widely-accepted idea is to adapt the content during delivery, depending on the user’s actual requests and situation [BPdWK06, PB03, vBSE+03]. This is accomplished by appending adaptation hints to individual content. That is, descriptive metadata, namely media descrip- tions, are used to identify the content characteristics so as to aid in the process of making adaptation decisions under usage constraints [vBSE+03, CSP01, TLS04].
The media descriptions can be defined from different abstraction levels of low-level features to high-level semantic concepts, which relate directly to the semantic level of feasible adaptation choices associating with the content. For example, high- level descriptions (e.g. what subjects are present in a video scene) can help to semantically satisfy the user’s personal interests [TLS04]. By contrast, low-level descriptions, such as the spatial resolution hint [CSP01], can only be employed to fit the user’s physical constraints on the display size.
Therefore, in terms of personalization, effective adaptation can greatly benefit from taking into account the semantics of multimedia contents. Much research in the last few years has been conducted to reach this goal, but how to efficiently extract the semantics is still the hardest bottleneck [NH02, RH99, Chu06]. There exists a huge gap between the rich meaning and interpretation that humans could read in the content and the simplicity of low-level features that the current al- gorithms can actually compute [NH02, SWS+00, DV03, FLE04]. This makes the advance in multimedia adaptation be lagging far behind the user’s expectations
and becomes an open problem. Our work, as motivated by the above observations, focuses on developing systematic approaches to improve automatic multimedia adaptation at the semantic level. By exploiting specific domain knowledge, we bridge the gap between low-level computational features and high-level semantic concepts, whereby the associated adapting operations can be effectively designed to maximize the user’s multimedia experience. Our work attempts to enable one more step towards the development of truly semantic multimedia systems and expects to inspire more pioneering researches to march forward further.
1.2 Semantic Multimedia Content Adaptation
1.2.1 A Generic Framework
Adaptation engine is a technical realization of the adapting functionality that transforms multimedia contents in order to satisfy the usage constraints, such as device capabilities, network characteristics, and user preferences. Practical examples include the tools for format transcoding [AWSZ05], speech transcription [LL01], image mosaicing [RH99], and video summarization [BMM99]. In this section, a number of design requirements for an effective adaptation engine are first discussed. A generic framework for multimedia content adaptation is then proposed.
• Requirement 1: Application Awareness.
The basic requirement for an adaptation engine is application awareness.
The adaptation engine should be first aware of specified usage constraints associated with the target applications and then be able to properly adapt the contents. For example, when delivering high-quality videos onto the
user’s mobile phone, the information about the device capabilities has to be specified for converting the videos into affordable coding formats, such as the spatial resolution, bitrate, and frame rate [AWSZ05]. To facilitate the information exchange in between, several international bodies have recently developed a set of standardized description tools to detail the characteristics of networks, users, and terminals, e.g. the Usage Environment Description (UED) tool in MPEG-21 [BPdWK06].
• Requirement 2: Content Awareness.
The second and arguably the most important requirement is content aware- ness. Users are the final content consumers and what they are really inter- ested in is the appearances presented in the contents. An adaptation engine can well satisfy the user preferences only if it is aware of the contents to some extent. The use of media descriptions is a common technique to de- scribe information about or present in the content [vBSE+03, CSP01]. The information can be obtained either from automatic content understanding or previously computed metadata. The media descriptions are then em- ployed to guide the adaptation process. For example, instead of constant temporal subsampling, the descriptions of highlight index help to summa- rize sports videos in a more meaningful way [BKOK04]. Some standardized media descriptions can be found in the MPEG-7 standard [CSP01], such as the Description Schemes (DSs).
• Requirement 3: Semantics Extraction.
The last desirable requirement is semantics extraction. It means the ca- pability of being able to actively extracting the semantic-level information from the contents. That is, pre-computed media descriptions are not always
multimedia contents
video
usage constraints Adaptation Engine
C t t Ad ti
video
image
audio
te t
users adapted contents
Content Adapting
text
di d i ti
(a)
multimedia contents
media descriptions Adaptation Engine
video
audio
usage constraints adapted contents
Content Adapting
image text
users adapted contents
(b)
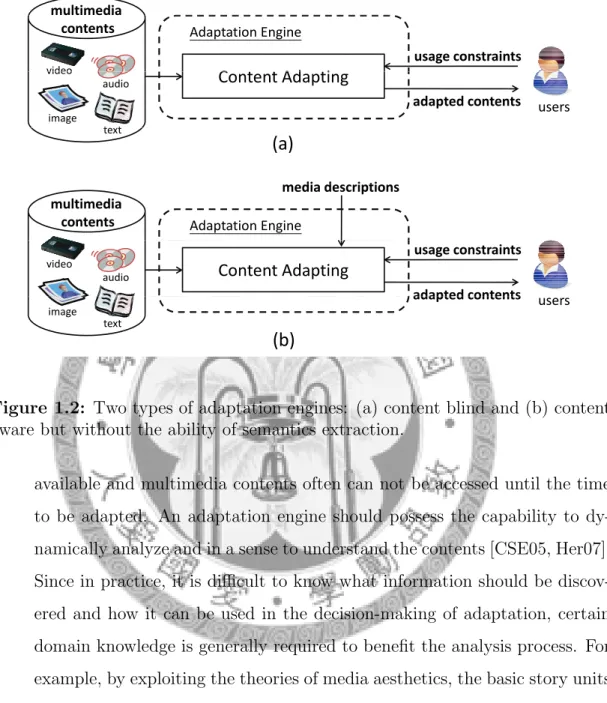
Figure 1.2: Two types of adaptation engines: (a) content blind and (b) content aware but without the ability of semantics extraction.
available and multimedia contents often can not be accessed until the time to be adapted. An adaptation engine should possess the capability to dy- namically analyze and in a sense to understand the contents [CSE05, Her07].
Since in practice, it is difficult to know what information should be discov- ered and how it can be used in the decision-making of adaptation, certain domain knowledge is generally required to benefit the analysis process. For example, by exploiting the theories of media aesthetics, the basic story units can be extracted from a movie [WCC+07].
Overall, the above criteria determine the essential capabilities of a general adaptation engine. Failing to satisfy any of the design requirements will make it suffer from a loss of generality. Two types of examples are illustrated in Fig-
domain knowledge
third party multimedia
contents
media descriptions
Semantic Concept Analysis
video audio
usage constraints
S ti C t t Ad t ti
semantic concept ontology
image text
Semantic Content Adaptation
adapted contents usersdomain knowledge domain knowledge
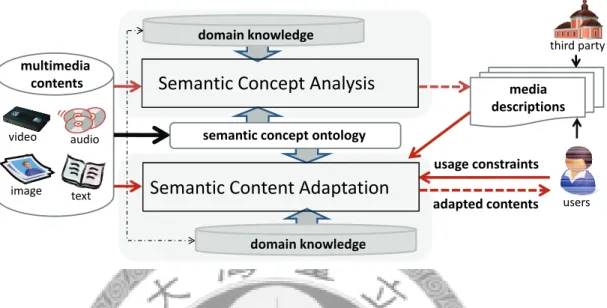
Figure 1.3: The proposed generic framework for multimedia content adaptation, which is characterized by the capability of active content analysis and the use of domain knowledge to enable automatic adaptation at the semantic level.
ure 1.2. The first type, in Figure 1.2(a), is content blind such that it is aware of only the user’s physical constraints, e.g. the format transcoder [AWSZ05] and the coding rate shaper [Ho03]. Another type, in Figure 1.2(b), is content aware but the content information depends on the provision of external algorithms. It would sacrifice some adapting functionality if the extra information is unavailable.
Therefore, based on the previous discussions, the proposed generic framework for multimedia content adaptation is illustrated in Figure 1.3, which is composed of two functional modules including: the semantic concept analysis module and the semantic content adaptation module. The semantic concept analysis module analyzes multimedia contents using specific domain knowledge and generates the corresponding media descriptions to identify the content characteristics. Based on both the media descriptions and the user’s usage constraints, the semantic content adaptation module then makes adaptation decisions and performs the adaptation
High level Taxonomy Examples Semantic!Concept Human!activity,!occasion,
location,!particular!object,!…
Perceptual!Arousal Intensity!contrast,!color!scheme, emotion,!salient!sound,!…
Audiovisual!Feature Motion,!color,!edge,!texture,!
energy RMS zero crossing Low level
energy,!RMS,!zero crossing,!…
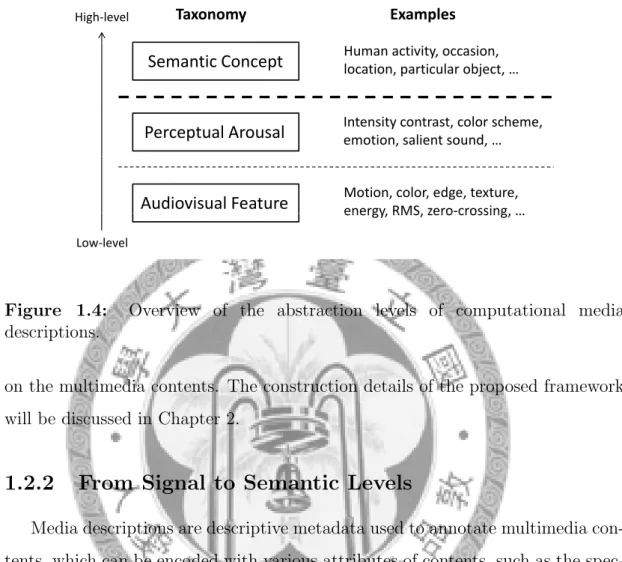
Figure 1.4: Overview of the abstraction levels of computational media descriptions.
on the multimedia contents. The construction details of the proposed framework will be discussed in Chapter 2.
1.2.2 From Signal to Semantic Levels
Media descriptions are descriptive metadata used to annotate multimedia con- tents, which can be encoded with various attributes of contents, such as the spec- trogram of an audio, the emotion of an image, and the captured events of a video [vBSE+03, CSP01, TLS04]. The supporting level of an adaptation engine in terms of the user preference is determined by the quality of obtainable media descrip- tions. To clarify the position of our work, this section first gives definitions of the computational media descriptions from different abstraction levels of low-level fea- tures to high-level concepts, and then introduces the proposed notion of semantic adaptation.
• Audiovisual Features: Audiovisual features are the measurable physical properties of the multimedia signals being observed [Chu06, Dje02]. They are directly derivable from the multimedia contents and do not need to be interpreted with any human meaning [Dje02]. Some commonly used features include motion (for video), color, edge, texture (for both image and video), energy, root-mean-square, and zero-crossing (for audio) [WLH00]. For the simplicity of extraction, most of the presented adaptation engines in the literature are built on the feature domain, involving feature matching, clus- tering, and modeling. Typical examples include the systems of content-based image retrieval [SWS+00] and scene-based video summarization [CV05].
• Perceptual Arousals: Perceptual arousals are the multimedia patterns that might lack common or objective definitions in human meaning but tend to arouse the user’s attention, feeling, or emotion [Dje02, HX05]. The arousing patterns can be viewed as the ones that are either intended to be formed by the authors or naturally perceived by the majority of users. Some examples include the speech sound in audio [MLZL02], the color arrange- ment of an artistic image [LG04], and the affective plays of a movie [WC06].
Instead of truly content understanding, the extraction of perceptual arousals is a feasible compromise in developing personalized multimedia applications, such as the attention-based detection of sports highlights [BKOK04] and the emotion-based movie indexing and summarization [HX05, WC06].
• Semantic Concepts: Semantic concepts are entities that take place or exist in time and space in the world, including activities (e.g. skiing, danc- ing), occasions (e.g. wedding, birthday), locations (e.g. beach, park), and particular objects in the scene (e.g. actor, tree) [Chu06, CEJ+07]. Several entities are able to jointly constitute a composite entity. For instance, a
Figure 1.5: The Chinese classical painting “Listening to the Qin” (partial), by Ji Zhao (Emperor Huizong of the Song Dynasty, China), 1082-1135.
“wedding” entity is formed by the “groom”, “bride”, “officiant”, “guests”, and “church” entities. Another characteristic of the semantic concepts is context dependent. The same semantic concept can convey different human meaning if the background contexts are different. For example, the concept of “people together singing a birthday song” means the wishes from one’s friends in the case of a birthday party, but it may simply indicate one of the many performances within a group singing contest. In dealing with the anal- ysis of semantic concepts, the associated context can provide the knowledge base to infer and identify the actual semantic meanings.
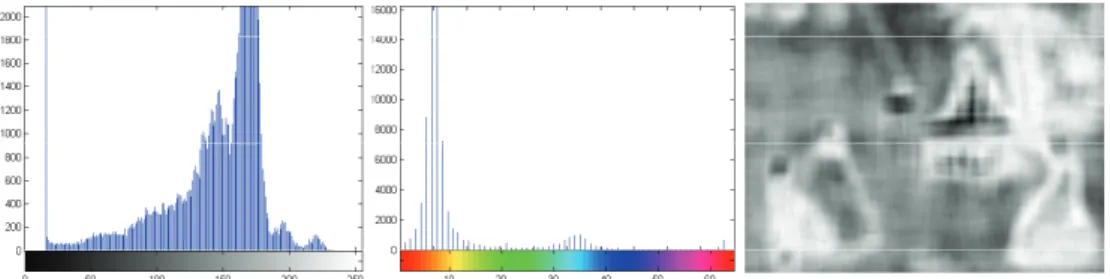
Overall, the three abstraction levels of computational media descriptions are illustrated in Figure 1.4. The abstraction levels from low to high correspond to the expressiveness of media descriptions about the “fact” contained in multime- dia contents. Consider the painting shown in Figure 1.5. At the lowest level of audiovisual features, the painting can be described as an M-by-N digitized im-
(a) Audiovisual features: intensity histogram, color histogram, and texture map [GW01].
Triadic color scheme
(b) Perceptual arousals: color scheme [LG04] and intensity map [IKN98].
Figure 1.6: Sample media descriptions of the painting in Figure 1.5, given at two abstraction levels of (a) audiovisual features and (b) perceptual arousals.
age with medium intensity, dominant brown color, and less texture, as shown in Figure 1.6(a). Alternatively, it can be presented with the perceptual arousals as containing a color harmonious layout and several intensity-attractive regions (the faces), as shown in Figure 1.6(b). Obviously, the descriptions of either way are not in normal human forms to communicate the message about the paint- ing. By contrast, the semantic concepts, such as outdoor, concert, performer, and audiences, would more faithfully reflect what users perceived from the painting.
Therefore, in our work, we attempt to go beyond the scope of conventional feature or arousal based content analysis and propose a systematic adaptation framework at the semantic level. By bridging the semantic gap between systems and users, the developed adaptation engines are able to really satisfy the human’s needs.
r3
Ad t ti R
a1 a3
r1 r3
u3 Adaptation
Space
Resource Space
Utilit r
m3 Media a Space
a2 r2
u1 u3 Utility Space Utility Function U
u r
m1 m2
Space m
u2
Utility Function U media descriptions: d(m)
m2
Figure 1.7: Interrelationship between the key elements (adaptation, resource, utility) of adaptive optimization in searching for the optimal adapting operation that maximizes the adaptation utility of a multimedia content. (Figure adapted from [Cha02])
1.2.3 Adaptive Optimization
An effective adaptation engine is able to make dynamic decisions in response to various usage environments. Meanwhile, the decisions are often required to be
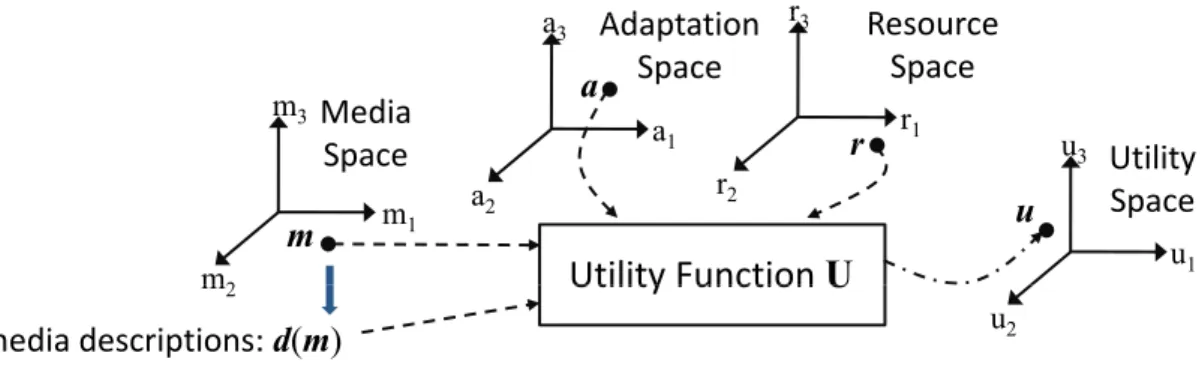
“optimal” so as to maximize the user’s multimedia experience. In the adaptation terminology, the optimality is represented with the adaptation utility [Cha02, Sun02, WKCK07]. Adaptation utility is defined as the quality of adapted contents with respect to some specific attributes that can be either at objective or subjective levels, e.g. the strength of audio signals [KMS05] versus the attractiveness of video highlights [WCC+07]. A metric used to measure the adaptation utility is then called a utility function, where a commonly used one is the peak signal-to-noise ratio (PSNR) [WOZ01]. In searching for optimal solutions to the selected utility functions, the adaptation problem can be conceptually transformed into the form of constrained optimization, namely adaptive optimization [Cha02, WKCK07, RL02].
In the state-of-the-art methodology [Cha02, WKCK07], three key elements are included in the construction of the adaptive optimization problems, i.e. adapta- tion, resource, and utility. Each individual aspect is defined using a parameter space. As illustrated in Figure 1.7, given a multimedia content m, the adaptation space is the space of feasible adapting operations a, the resource space is the af- fordable resources r under the usage constraints, and the utility space is the value range of utility values u obtained from the corresponding utility function U with m, a, and r as arguments. The formulation is as follows.
ˆ
a = argmax
a
U(m, a, r), (1.1)
where the optimal solution ˆa is adopted as the final adapting operation to be performed on m. However, it can be found that m’s media descriptions d(m) are not taken into account in the above equation. In practice, d(m) could play a more important role than m itself in the process of making adaption decisions. That is, as shown in the proposed adaptation framework (referring to the semantic content adaptation module in Figure 1.3), the knowledge about how the current adapting operation can be performed on a multimedia content is obtained from its media descriptions and their quality level has direct impacts on the estimated adaptation utility. For example, cropping images with manually-labeled regions-of-interest (ROIs) naturally receives higher subjective scores than those with automatically- detected ones [CWW07]. Similarly, the capability difference between detectors of the semantic concepts is another influential factor, such as the diverse tradeoffs between the precision and the recall performances.
Therefore, for practical applications, the preliminary formulation developed in Equation 1.1 should also include a content’s media descriptions into the com- putation of its utility values. One possibility is to extend the U’s definition to take media descriptions as additional arguments. This extension is able to pro-
vide more complete characterization of the proposed adaptation framework and allows the underlying components to be conceptually integrated in a more tightly coupled manner. In addition, some other observations can be made from the above formulation as well. First, it was originally introduced from a macro view to depict a general relationship between the key elements involved in adaptation [Cha02]. There exists much freedom to specify a workable instance for each of the elements. For example, candidates of the adapting operation for image resiz- ing can be of any related technologies, such as the nearest-neighbor, bilinear, or bicubic interpolation [GW01]. By contrast, we put more emphasis on applying the formulation to identify the operational behaviors of the proposed adaptation framework. Possible combinations of the elements are then limited to the func- tionality that a realized adaptation engine actually supports. Second, the utility function U is not universal but changed according to the target applications. In real use, if it has certain time constraints (e.g. responding to users in real time) or there is a large search space for finding the optimal solution, the computations are often forced to terminate early and simply return a sub-optimal solution from the ones examined.
1.3 Problem Statement
In this dissertation, we address the problem of semantic adaptation for multi- media contents. The problem can be described as:
Given multimedia contents and the background contexts, develop sys- tematic techniques to identify the semantic concepts, whereby the as- sociated adapting operations can be chosen to maximize the adaptation utility while satisfying the objective usage constraints.
To facilitate the achievement of our objective, the task involves the research effort from several aspects:
• The construction of semantics ontology: The subject of semantics ontology is the study of the categories of semantic concepts that exist in the context of the examined domain [DMK+05]. The product of the study provides a fundamental basis for defining the user’s semantic interests about the contents.
• The extraction of multimedia semantics: The subject of semantics extraction is the study of efficient algorithms for analyzing and extracting the semantic concepts embedded in multimedia contents. The modality integration of multimodal inputs should be investigated to offer reliable performance.
• The determination of adaptation strategy: The subject of adaptation strat- egy is the study of flexible mechanisms for making adaptation decisions in response to dynamic usage environments. The tradeoff among different constraints should be balanced to maximize the utility of adapted contents.
1.4 Summary of Contributions
This dissertation is devoted to the study of semantic adaptation for multimedia contents, where both the theoretical foundation and the practical realization are investigated in support of real-world adaptation scenarios. The main contributions of our work in solving the problems are threefold, as summarized as follows.
1.4.1 Framework Development for Semantic Adaptation
A generic framework is developed for the semantic multimedia content adapta- tion, in which the function of active content analysis is integrated for better man- agement over the contents and the use of domain knowledge effectively enhances the semantic level of computational media descriptions. In terms of adaptation utility, an optimization formulation is derived to give theoretical support of the framework, which identifies the uniqueness of our work and makes the connection to general ideas in the research fields. Meanwhile, the design principles behind the framework are explicitly specified and can be served as development guidelines for practical adaptation engines.
1.4.2 Video Adaptation Based on Semantic Objects
A methodology built upon the proposed framework is developed for enabling semantic object based video adaptation. In this work, the knowledge of media aes- thetics [Zet98, BT03] is employed to define the semantic concepts in professional videos, including the user-interest and the background objects. According to the content characteristics of the semantic objects, a unimodal approach using only the visual information is developed for the object modeling and detection. The analysis outputs are then applied to an adaptation scenario of delivering high- quality videos onto small devices. By recomposing the video content to visually emphasize the user’s semantic interests in the video, the browsing experience can be effectively improved.
1.4.3 Video Adaptation Based on Semantic Events
A methodology built upon the proposed framework is developed for enabling semantic event based video adaptation. In this work, the knowledge of wedding customs [Spa01, War06] is employed to define the semantic concepts in home videos of the western wedding ceremonies, including thirteen kinds of semantic events like the ring exchange and the wedding kiss. According to the content characteristics of the semantic events, a multimodal approach using both the visual and aural information is developed for the event modeling and detection.
The analysis outputs are then applied to an adaptation scenario of partitioning hours-long videos into semantically meaningful segments. Through the explicit recognition of semantic events, personalized applications can be built to satisfy the individual’s preferences.
1.5 Organization of the Dissertation
The rest of this dissertation is organized as follows. In the next chapter, we review the literature on studies of the semantic adaptation from aspects relating to the main building blocks of the proposed generic framework, i.e. semantic con- cept ontology, semantic concept analysis, and semantic content adaptation. The correspondence between the proposed framework and the other works we have done in this dissertation is also described. In Chapter 3 and Chapter 4, two sys- tematic approaches for modeling semantics in video contents are first investigated, respectively on object-based and event-based semantic concepts. Chapter 3 then presents an object-based mechanism for recomposing a video scene to improve the user’s browsing experience of high-quality videos on the devices with small displays. Chapter 4 exploits the computable semantic events to benefit the user’s
navigation in hours-long videos by providing a structured video index that al- lows directing access to the requested contents. Finally, Chapter 5 presents the conclusions of our work and possible directions of our future research.
Basics and Literature Review
This chapter reviews relevant literature on studies of the semantic adaptation.
It makes comparisons and gives discussions on the traditional work to further clarify the basics of our research philosophy. In particular, we conduct the review along the line of the main building blocks of the proposed adaptation framework.
Section 2.1 presents the topic of semantic concept ontology. Section 2.2 and Section 2.3 are relating to the semantic concept analysis and the semantic content adaptation, respectively. In Section 2.4, the correspondence between the proposed framework and the other works we have done in this dissertation is described.
Section 2.5 concludes this chapter.
2.1 Semantic Concept Ontology
Ontology is a form of knowledge representation about the world and usually represented as nodes and links between the nodes [Jim05, NST+06, GLF06]. The nodes represent facts within a domain (e.g. “red” and “color”) and the links represent relationships between those facts (e.g. red “is a” color). According to applications, the facts of a node can be stored either by name (e.g. the literal text of “red”) or by actual contents (e.g. a 32-bit RGB value of “red”), and allow
to be defined at different conceptual levels [CV07]. For example, by common sense, “cat” and “dog” are generally considered as facts of the same level and can be further assigned to more general notions, such as “animal”, at a higher level of the ontology. Therefore, a semantic concept ontology then refers to the ontology constructed for representing knowledge about specific semantic concepts as described in Section 1.2.2.
In the rest of this section, Section 2.1.1 first reviews several typical construc- tions of the ontology in the literature. We then discuss the relationship building between ontological nodes in Section 2.1.2.
2.1.1 Typical Examples
The use of ontologies to incorporate domain knowledge has long been studied.
A number of typical examples are described in the following.
• WordNet: WordNet is arguably the most popular and widely used lexical database of English, in which the words are manually organized into sets of synonyms (e.g. “car” and “automobile”) and related by the semantic relationships such as antonymy (an opposite to), hypernymy/hyponymy (a specialization of/a generalization of), and so forth [Fel98]. It is optimized for general-purpose use and has been extensively applied to a variety of textual analysis (e.g. keyword expansions).
• Cyc: Cyc aims to formalize facts about everyday life into a logical frame- work, in which the facts are manually translated into assertions based on the first-order logic [Len95]. For example, the fact “red is a color” can be written as an assertion in the form of a predicate-arguments tuple, i.e. “(is-a red color)”. Cyc is also equipped with inference engines to deduce new facts
from the ones already stored. As compared to Cyc, it is also for general- purpose use but could make more practical reasoning over real-world texts.
ConceptNet is a similar work inspired by Cyc [LS04].
• LSCOM (Large-Scale Concept Ontology for Multimedia): LSCOM is a collaborative research effort in creating a large set of vocabularies for describing the semantics in multimedia contents, especially for broadcast news videos, such as face, people, flag, animal, and vehicle [NST+06]. The vocabularies are handcrafted by experts from various research communi- ties (e.g. information retrieval and computational linguistics) and required to meet certain criteria, such as utility (high relevance to realistic video retrieval problems), feasibility (high likelihood of automated extraction), and observability (high frequency of occurrence in actual video data sets).
LSCOM has been shown a useful tool to benefit the video research in its target domains.
• TRECVID (TREC Video Retrieval Evaluation): TRECVID is an international competition sponsored by the National Institute of Standards and Technology (NIST) of USA for encouraging the research in content- based video retrieval [tre]. For this purpose, TRECVID standardizes a large set of high-level concepts as the benchmark for participants in com- paring their results. The TRECVID concepts are mainly extended from the LSCOM corpora [NST+06, HCY08], and they are also with an emphasis on broadcast news videos. Some examples are illustrated in Figure 2.1. Today, TRECVID has became one of the most important activities in video research communities, and the number of standardized concepts is still growing to extend the coverage on various content domains.
Figure 2.1: Illustrations of 101 TRECVID concepts. (Figure excerpted from [SWvG+06])
(a) (b)
Figure 2.2: Example of a tennis match with (a) a video snapshot and (b) the types of tennis events. (Figure excerpted from [TWC+08])
Overall, some observations can be made from the above discussions. First, in multimedia research fields, the development of ontologies has gradually shifted its focus from general-purpose to domain-specific ones [WLC06]. That does not mean the generalization is a wrong direction. However, when the background context is unknown, it is naturally more difficult to identify which facts should be taken into account and how to appropriately define their relationships, as described in Section 1.2.2. Second, for practical use, the effectiveness of a large scale ontology is not necessarily better than that of a smaller one [HCY08]. For example, a high coverage of the overall semantic space within a target domain can be achieved by adding more facts, but it may concurrently cause the problem of semantic ambiguity between the whole ones. As reported in the previous work [HCY08], the performance of interactive video retrieval could inversely go down at some point as the increase of facts. Therefore, for the ontology design, the ontological fitness to actual applications is still one of the most important considerations.
2.1.2 Relationship Building
Relationship building refers to the task of linking ontological nodes according to certain relational rules defined in the target domain [WLC06, HCY08]. For ex- ample, under the lexical domain of English, the two nodes “rock” and “stone” can be connected by the relationship of synonym. As mentioned in Section 2.1.1, most of the relationships heavily rely on handcrafting by the experts with prior domain knowledge. For the experts, it is not a difficult task but could be labor-intensive and extremely time-consuming. As described in the previous work [WLC06], for example, it took about three hours for one person to complete an animal ontology with 200 nodes. However, automating the process seems almost impossible with today’s technology [HCY08].
In the literature, a compromising approach to reduce the user’s burden is allowing the data to connect related nodes automatically and the actual rela- tional meanings are then suggested by human knowledge [HCY08, ZSX07, Fre04].
Techniques of the social network are possible solutions [Fre04]. We consider, for example, the problem of constructing relationships between English words. Given N text documents, the degree of relevance between two words, w1 and w2, can be measured by their co-occurrence using a simple similarity metric, say Jaccard coefficient JC(w1, w2) [Sal83], as defined below:
JC(w1, w2) = Θ(w1∧ w2)
Θ(w1) + Θ(w2) − Θ(w1∧ w2), (2.1) where ∧ denotes the AND operator between words, and Θ is a function that returns an estimate of the frequency of occurrence of either a single or pair of words with respect to the N documents. The relationship between any two words of high relevance are then judged by humans. In this way, it is helpful to reveal some implicit but insightful relations. For example, the word pair of “black” and
“white” is often used as representatives of “evil” and “virtue”. However, some actual relations may be also filtered out at the same time simply due to their low relevance values.
2.2 Semantic Concept Analysis
Semantic concept analysis refers to the detection of targeted semantic concepts in multimedia contents, which is often achieved by means of automatic mecha- nisms [Chu06, CEJ+07, WLC06, HCY08]. In the multimedia research communi- ties, we can observe two mainstreams on developing the detectors. One is to gen- eralize the capability of existing ones to various content types [CEJ+07, WLC06],
and another is to focus on specific application domains by exploiting the corre- sponding domain knowledge [BKOK04, Chu06], as detailed below.
Along the first direction, TRECVID [tre, HCY08] is no doubt in recent years the most influential activity that gathers major research efforts around the world for working toward effective detectors of semantic concepts, cf. Figure 2.1. As mentioned in Section 2.1.1, although the selected concepts are slightly biased to broadcast news videos, the detector design is required for general use in video contents [HCY08]. For each TRECVID participant, a standardized evaluation method is used to evaluate the performance of their detectors. Specifically, the accuracy of detection is measured by mean average precision (MAP) in a video- shot basis [tre]:
M AP = 1 R
R
X
r=1
P (r), (2.2)
where r is the participant’s rank of a detected shot for a specified semantic concept, R is the number of ranked shots in total, and P (r) is the precision in the ranking at a given cut-off rank r. Recent reports [tre, HCY08] show that there exist large variations between the attainable MAP performances of different semantic concepts, ranging from less than 0.1 (e.g. “corporate leader”) to above 0.6 (e.g. “weather”), with an average of close to 0.2. Few specialized ones (e.g.
“face”) can achieve even higher scores, but at present the overall performance seems far from practical.
On the other hand, some research effort concentrates on limited application scopes as a tradeoff to sacrifice the partial generality of detectors for acceptable accuracy [BKOK04, Chu06]. It also opens the way for taking advantage of the domain knowledge to better satisfy the application’s needs by making specific designs on the detectors. Since the study of sporting videos mostly belongs to this category, we then explain by taking the event analysis of broadcast tennis
videos as an example [TWC+08]. As illustrated in Figure 2.2, a tennis match is composed of certain events, including the fault, double fault, ace, baseline rally, and net approach. They are observed to be distinguishable by several audiovisual hints from the tennis knowledge, such as the player’s relative position in the court, the moving distance of players, the sound effects of applause or cheer, and the number of racquet hits [TWC+08]. Specifically, the recognition accuracy of the tennis events can be as high as 0.8 to 0.9 for those detectors that utilize the above information in their development.
Based on the above discussions, we believe that moderate user intervention can help to take advantage of the both methods. That is, the detectors of semantic concepts can be generalized to some extent between a single domain and the fully general ones, such as the scope of ball sports with respect to that of soccer or baseball. The user then only has to specify the target scope by some ways (e.g. a list) to benefit the selection of appropriate detectors.
2.3 Semantic Content Adaptation
In this section, we first present a brief review on the conventional catego- rization of adapting operations in Section 2.3.1. Section 2.3.2 then describes the determination of effective adaptation strategies for the adapting operations.
2.3.1 Adaptation Taxonomy
As defined in Section 1.1, the scope of adaptation technologies covers a broad class of adapting operations that either adapting the multimedia content to fit a usage environment or adapting the usage environment to accommodate the con- tent [BPdWK06, PB03, CV05]. Conventionally, by Chang’s definitions [CV05],
cropped image
MPEG 4
MPEG!2 original image
MPEG!4
(a) Format transcoding (b) Selection/reduction MPEG 2
key frames as narration
scene in 3D
video photo
(c) Replacement (d) Synthesis video
Figure 2.3: Adaptation taxonomy with examples of the corresponding adapting operations.
the adapting operations can be classified into four main categories: format transcod- ing, selection/reduction, replacement, and synthesis, as described below. Note that the taxonomy is originally proposed for video operations, but it is generic enough to be applicable for most of the multimedia operations as well.
• Format Transcoding: It refers to the conversion of multimedia contents from one form of coded representation to another. For example, MPEG-2 videos are transcoded to MPEG-4 formats for Internet streaming [XLS05].
• Selection/Reduction: It refers to the elimination/degradation of some components of the multimedia contents. For example, images are cropped to preserve only the ROI regions [HWG04].
• Replacement: It refers to the substitution of selected elements in a mul- timedia content with more efficient counterparts. For example, videos are represented with a set of key frames as the narrative summary [WCC+07].
• Synthesis: It refers to the generation of new presentations from original multimedia contents. For example, photos are to be presented in 3D for enhancing the user’s browsing enjoyment [HAA97].
Examples associated with each of the categories are illustrated in Figure 2.3.
Obviously, the taxonomy is developed based on the basic types of adapting func- tionality [CV05, TV07, AWSZ05]. In practical applications, they can also be combined to analyze more complex adapting operations.
2.3.2 Adaptation Strategy
Adaptation strategy is the study of feasible mechanisms for making adapta- tion decisions of multimedia contents, as described in Section 1.2. The strategy determination can largely benefit from the awareness of multimedia semantics and the knowledge in relation to usage environments [ABBH08, KMS05, JP08].
For example, the previous research in mobile TV shows that the user’s mini- mal perceptible size of videos is not a constant but changes according to the type of video contents [ABBH08]. Later, the influence of other factors, such as the pic- ture ratio and the audio bitrate, is also reported to be content-dependent on the user’s video experience [JP08]. Clearly, the interrelationship between multimedia contents and the usage environments plays an important role in the development of effective adapting operations. Therefore, in a sense, the proposed notion of se- mantic adaptation not only refers to the semantic level of concept analysis but also
domain knowledge Semantic Concept Analysis
Vi l Att ti M d l Semantic Concept Analysis
Vi l Att ti M d l content sources Visual Attention Model
• intensity
• color
• object motion Visual Attention Model
• intensity
• color
• object motion professional videos
• media aesthetics
• psychology original scene
media descriptions j
• camera motion j
• camera motion
semantic concepts ontology professional videos
• TV shows
• movies
• sports programs
• user!interest objects
• background object
• etc.
Semantic Content Adaptation
user!interest objects
domain knowledge
Semantic Content Adaptation
background object
users domain knowledge
• media aesthetics
• perspective projection
adapted scene adapted scene
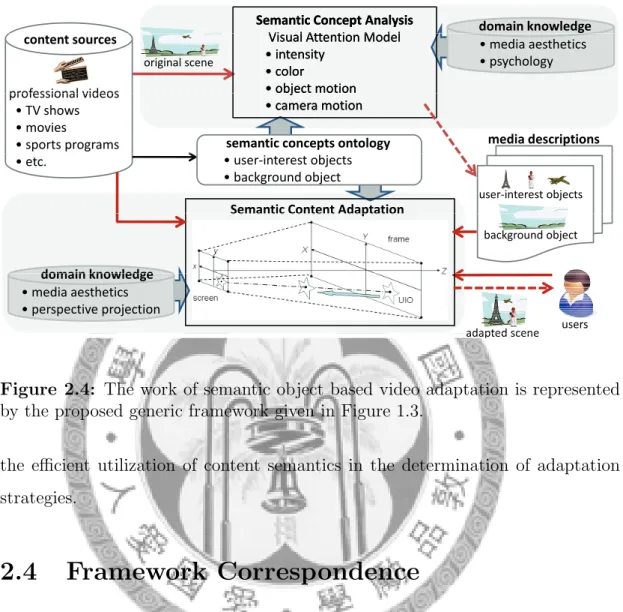
Figure 2.4: The work of semantic object based video adaptation is represented by the proposed generic framework given in Figure 1.3.
the efficient utilization of content semantics in the determination of adaptation strategies.
2.4 Framework Correspondence
In this section, we illustrate the correspondence between the proposed frame- work and the other works we have done in this dissertation, while the work details are referred to the rest of this dissertation.
2.4.1 Semantic Object Based Video Adaptation
The work of semantic object based video adaptation presented using the pro- posed framework is illustrated in Figure 2.4. This work focuses on the adaptation
domain knowledge Semantic Concept Analysis
Hidd M k M d l Semantic Concept Analysis
Hidd M k M d l
content sources Hidden Markov Model
• music/speech
• flashlight
• bride
Hidden Markov Model
• music/speech
• flashlight
• bride
• wedding traditions
• human behaviors raw footage
media descriptions
• event transition
• event transition
semantic concepts ontology home videos
• western wedding ceremonies
• thirteen kinds of wedding events
• e.g. “ring exchange”
Semantic Content Adaptation ceremonies
domain knowledge
Semantic Content Adaptation
Index of recognized events
users domain knowledge
• wedding traditions
• human behaviors
adapted video user preference
adapted video
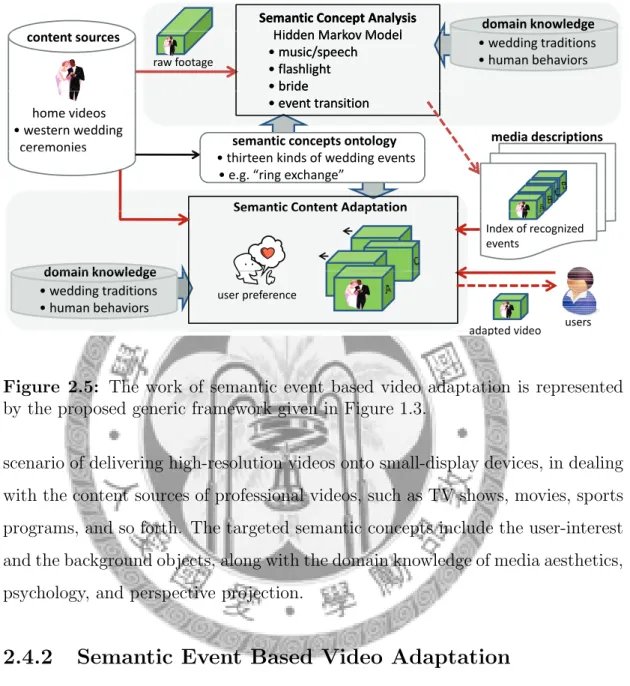
Figure 2.5: The work of semantic event based video adaptation is represented by the proposed generic framework given in Figure 1.3.
scenario of delivering high-resolution videos onto small-display devices, in dealing with the content sources of professional videos, such as TV shows, movies, sports programs, and so forth. The targeted semantic concepts include the user-interest and the background objects, along with the domain knowledge of media aesthetics, psychology, and perspective projection.
2.4.2 Semantic Event Based Video Adaptation
The work of semantic event based video adaptation presented using the pro- posed framework is illustrated in Figure 2.5. This work focuses on the adaptation scenario of partitioning hours-long home videos into semantically meaningful seg- ments, in dealing with the content sources of home videos, i.e. western wedding ceremonies. The targeted semantic concepts include thirteen kinds of wedding
events, such as the bride entering and the ring exchange, along with the domain knowledge of wedding traditions and human behaviors.
2.5 Summary
This chapter reviews relevant literature on the semantic adaptation, from sev- eral perspectives of the semantic concept ontology, the semantic concept analysis, and the semantic content adaptation. A new frontier of the research is to integrate the analysis of content semantics and the development of adapting operations for efficient adaptation, which is recognized as a promising but challenging direction.
That motivates our work of this dissertation.

![Figure 2.1: Illustrations of 101 TRECVID concepts. (Figure excerpted from [SWvG + 06])](https://thumb-ap.123doks.com/thumbv2/9libinfo/9607749.633449/44.892.167.780.194.971/figure-illustrations-trecvid-concepts-figure-excerpted-swvg.webp)