資料探勘技術於超音波旋轉肌肌群影像之診斷應用
91
0
0
全文
(2) The diagnosis of rotator cuff disease in shoulder ultrasonic images based on the data mining technology. Advisor: Dr. Ming-Huwi Horng By: Chao-Ying Chen. A Thesis Submitted to the Graduate Program of Information Management In Partial Fulfillment of the Requirements For the Degree of Master of Science in Information Management National Pingtung Institute of Commerce. Pingtung, Taiwan, R.O.C. July, 2006. 2.
(3) 摘要 由於超音波不但價格低廉,且具有非侵入式的特性,是優於其他方 法的檢測方式,臨床醫師廣泛地應用在診斷肩關節旋轉肌肌群之疾病狀 況。然而,以醫師肉眼觀察超音波影像來診斷旋轉肌肌群之疾病的正確 率卻僅接近 70%。因此更進一步開發有效的電腦輔助診斷工具,來有效 地提升臨床診斷的正確率,是具有其急迫性地。本論文使用資料探勘技 術去擷取有用紋路特徵,並且將這些特徵應用放射狀基礎函數網路和支 援向量機來把肩部超音波影像分為四類:正常、發炎、鈣化、和斷裂。 本論文研究方法主要包括三個階段,特徵擷取、紋路特徵的選取、 和疾病分類。在特徵擷取的階段,使用了五個紋路分析方法:紋路特徵 編碼法、灰階明亮度相互關係矩陣、紋路頻譜、統計特徵矩陣,以及碎 型維度等,用來計算適當的特徵。在特徵選取的階段,採用的標準為最 大交互訊息法與 F-score 法。個別被應用這兩個方法來從前述中用來分類 的紋路分析法中,找出有力的特徵。最後的分類階段,使用放射狀基礎 函數網路和支援向量機,藉著獨立地使用五摺交叉驗證,來分類全部的 肩部超音波影像。 實驗總共收集了 76 張肩部超音波影像來分析分類的效能。在特徵擷 取中,使用最大交互訊息法和 F-score 法證明了灰階明亮度關係矩陣以及. I.
(4) 紋路特徵編碼法所擷取之特徵比其他三種方法所擷取之特徵更有效。在 76 張肩部超音波影像的疾病分類中,使用支援向量機分類之最高正確率 為 77.5%,優於使用放射狀基礎函數網路分類之最高值 72.5%。. 關鍵詞:資料探勘、特徵擷取、最大交互訊息法、放射狀基礎函數網路、 支援向量機. II.
(5) Abstract Due to the inexpensive and non-invasive characteristics of the ultrasound modality superior to other examination, the clinical physician had widely applied in diagnosis of the rotator cuff diseases.. However, the diagnosis. accuracy of rotator cuff diseases is near to 70% based on the physician’s eye observations. Therefore, it is very urgent to further develop the powerful computer-aided diagnosis tool that has the effect of increasing the accuracy in the clinical diagnosis using the ultrasound examination. In this thesis, we exploit the data mining technology to extract the useful texture features and then apply them to classify the ultrasonic images into four groups that are normal, tendonitis, calcification and tears of supraspinatus using the radial basis function network and support vector machine method. The methods using in this thesis include three main stages that are the feature exaction, the selection of texture features and the diseases classification.. In the feature extraction stages, five texture analysis. methods that are the texture feature coding method, gray-level co-occurrence matrix, texture spectrum, statistical feature matrix, and fractal dimension methods are used to compute adequate features. In the feature selection stages, the adopted criterions are mutual information and F-score. The two criterions are individual applied to find powerful features among the features of above mentioned texture analysis method for classification of the four disease groups. In the final classification stage, the radial basis function network and the support vector machine technology are used to divide the all shoulder. III.
(6) ultrasonic images by using 5-fold cross-validation, independently. In experiments, the 76 shoulder ultrasonic images are collected to analyze the effects of classification. The features of gray-level co-occurrence matrix and texture feature coding method are demonstrated to be more powerful than ones extracted from other three methods using the criterions of mutual information and F-score in the feature extraction.. In the diseases. classification of the 76 ultrasonic shoulder images, the correct classification rate is 77.5% using the support vector machine is 77.5%, however, it is superior to radial basis function network that reached 72.5%.. Keywords: Data Mining, Feature Extraction, Mutual Information, Radial Basis Function Network, Support Vector Machine. IV.
(7) 目錄 摘要 ........................................................................................................................................I ABSTRACT ...................................................................................................................... III 目錄 ...................................................................................................................................... V 1.緒論 ............................................................................................................................... - 1 1.1. 1.2. 1.3. 1.4.. 前言 ...................................................................................................................- 1 研究動機與目的 ...............................................................................................- 1 研究方法概述 ...................................................................................................- 6 章節概述 ...........................................................................................................- 8 -. 2.相關理論及背景知識 ................................................................................................... - 9 2.1. 2.2.. 肩關節旋轉肌肌群 ...........................................................................................- 9 紋路分析 .........................................................................................................- 13 -. 2.3. 2.4.. 特徵選取 .........................................................................................................- 15 類神經網路分類法 .........................................................................................- 17 -. 3.研究方法 ..................................................................................................................... - 23 3.1. 3.2. 3.2.1. 3.2.2. 3.2.3. 3.2.4. 3.2.5. 3.3. 3.4. 3.5.. 研究流程 .........................................................................................................- 23 本研究所使用之紋路分析 .............................................................................- 24 紋路特徵編碼法 .............................................................................................- 25 灰階明亮度相互關係矩陣 .............................................................................- 30 紋路頻譜 .........................................................................................................- 33 統計特徵矩陣 .................................................................................................- 37 碎形維度 .........................................................................................................- 39 最大交互訊息法 .............................................................................................- 40 F-SCORE 法.......................................................................................................- 43 放射狀基礎函數網路 .....................................................................................- 44 -. 3.6.. 支援向量機 .....................................................................................................- 47 -. 4.實驗結果 ..................................................................................................................... - 51 4.1. 4.2. 4.3. 4.3.1. 4.3.2.. 實驗說明 .........................................................................................................- 51 使用最大交互訊息法與 F-SCORE 法進行特徵選取......................................- 52 放射狀基礎函數網路實驗 .............................................................................- 55 最大交互訊息法與放射狀基礎函數網路實驗結果 .....................................- 55 F-SCORE 法與放射狀基礎函數網路實驗結果...............................................- 58 -. V.
(8) 4.3.3. 4.4. 4.4.1. 4.4.2. 4.4.3. 4.4.4.. 最大交互訊息法與 F-SCORE 法使用放射狀基礎函數網路比較..................- 61 支援向量機實驗 .............................................................................................- 64 最大交互訊息法與支援向量機之實驗結果 .................................................- 64 F-SCORE 與支援向量機之實驗結果...............................................................- 66 最大交互訊息法與 F-SCORE 法使用支援向量機比較..................................- 67 比較放射狀基礎函數網路與支援向量機實驗結果 .....................................- 69 -. 5.結論 ............................................................................................................................. - 72 -. VI.
(9) 圖索引 圖 1-1、(A)旋轉肌腱群,(B)岡上肌部份斷裂 ...............................................................- 2 圖 1-2、岡上肌完全斷裂示意圖.....................................................................................- 3 圖 1-3、MRI 影像(COMPLETE SUPRASPINATUS TEARS, CORONAL OBLIQUE VIEWS).........- 4 圖 1-4、MRI 影像(COMPLETE SUPRASPINATUS TEARS, SAGITTAL VIEWS) ........................- 4 圖 1-5、. 冠狀傾斜(CORONAL OBLIQUE)及其一影像。..................................................- 5 圖 1-6、矢面(SAGITTAL)及其一影像。 ...........................................................................- 5 圖 1-7、研究流程.............................................................................................................- 8 圖 2-1、正常岡上肌影像。...........................................................................................- 10 圖 2-2、右圖為肌腱炎之長軸影像。左圖為短軸影像...............................................- 10 圖 2-3、鈣化影像。 ...................................................................................................... - 11 圖 2-4、部分岡上肌斷裂。箭頭所指為斷裂處...........................................................- 12 圖 2-5、完全斷裂。標記所指之範圍為斷裂處。.......................................................- 12 圖 2-6、(A)部分斷裂影像,(B)完全斷裂。標記所指範圍為斷裂位置。 .................- 13 圖 2-7、類神經元之數學模型.......................................................................................- 17 圖 2-8、門檻值函數 ......................................................................................................- 19 圖 2-9、區域線性函數 ..................................................................................................- 19 圖 2-10、S 字型函數 .....................................................................................................- 20 圖 2-11、高斯函數 ........................................................................................................- 20 圖 2-12、具有輸入層、隱藏層、輸出層之類神經網路架構圖.................................- 21 圖 2-13、類神經網路訓練和調整權重值流程圖.........................................................- 22 圖 3-1、研究流程...........................................................................................................- 24 圖 3-2、3X3紋路單元.................................................................................................- 25 圖 3-3、一階 4-連通 圖 3-4、二階 4-連通 ..............................................................- 26 圖 3-5、四種不同明亮度變化起伏圖 ..........................................................................- 26 圖 3-6、明亮度圖形結構變化組合圖 ..........................................................................- 27 圖 3-7、紋路單元的 8 個位置.......................................................................................- 34 圖 3-8、放射狀基礎函數網路架構圖...........................................................................- 45 圖 3-9、研究所使用放射狀基礎函數網路之架構圖 ..................................................- 46 圖 圖 圖 圖 圖 圖. 3-10、線性分割最佳超平面的基本概念 ................................................................- 49 4-1、最大交互訊息法選出之特徵以放射狀基礎函數網路分類結果 ..................- 56 4-2、最大交互訊息法選出之特徵與放射狀基礎函數網路隱藏層中心數比較 ..- 57 4-3、F-SCORE 法選出之特徵以放射狀基礎函數網路分類結果............................- 59 4-4、F-SCORE 法選出之特徵與放射狀基礎函數網路所需之中心數比較............- 60 4-5、放射狀基礎函數網路使用最大交互訊息法、F-SCORE 和全部特徵分類之正確 率比較 .....................................................................................................................- 62 -. VII.
(10) 圖 4-6、放射狀基礎函數網路使用最大交互訊息法、F-SCORE 和全部特徵分類所需中 心數之比較 .............................................................................................................- 63 圖 4-7、最大交互訊息所選出之特徵數與支援向量機分類正確率之比較圖 ..........- 65 圖 4-8、F-SCORE 法所選出之特徵數與支援向量機分類正確率之比較圖................- 67 圖 4-9、最大交互訊息法與 F-SCORE 法所選出之特徵數以支援向量機分類結果...- 68 圖 4-10、放射狀基礎函數網路與支援向量機分類之結果比較 ................................- 70 -. VIII.
(11) 表索引 表 表 表 表 表 表 表 表. 4-1、最大交互訊息法與 F-SCORE 法之特徵選取結果比較表...............................- 54 4-2、最大交互訊息法選出之特徵以放射狀基礎函數網路分類結果 ..................- 56 4-3、交互訊息法選出之特徵與放射狀基礎函數網路隱藏層中心數比較 ..........- 56 4-4、最大交互訊息法 5 個特徵,設定 7 個中心以放射狀基礎函數網路分類結果之 混淆矩陣 .................................................................................................................- 58 4-5、F-SCORE 法選出之特徵以放射狀基礎函數網路分類結果............................- 59 4-6、F-SCORE 法選出之特徵與放射狀基礎函數網路所需之中心數比較............- 60 4-7、F-SCORE 法 5 個特徵,設定 7 個中心以放射狀基礎函數網路分類結果之混淆 矩陣 .........................................................................................................................- 61 4-8、放射狀基礎函數網路使用最大交互訊息法、F-SCORE 和全部特徵分類之比較. .................................................................................................................................- 62 表 4-9、最大交互訊息法所選出之特徵數與支援向量機分類正確率結果 ..............- 65 表 4-10、支援向量機分類前 3 個特徵分類結果之混淆矩陣 ....................................- 66 表 4-11、F-SCORE 法所選出之特徵數與支援向量機分類正確率結果表..................- 66 表 4-12、最大交互訊息法與 F-SCORE 法所選出之特徵數以支援向量機分類結果.- 67 表 4-13、放射狀基礎函數網路與支援向量機分類之結果比較 ................................- 69 表 4-14、放射狀基礎函數網路與支援向量機的各類別分辨率比較 ........................- 71 -. IX.
(12) 1. 緒論. 1.1. 前言 隨著醫學的發展,逐漸研發出各種醫學影像,如 X 光、超音波、電 腦輔助斷層掃描、核磁共振掃描等,這些影像能夠提供給醫師診斷疾病, 在醫療過程中佔有相當重要的地位。然而影像中的資訊,有時候不易以 肉眼察覺,或者是因為經驗不足及人為疏失,可能會造成錯誤診斷。為 了能找出隱藏在影像中的資訊,使用影像處理技術分析醫學影像、擷取 資訊,而擷取出來的資訊可能相當繁多,所以運用資料探勘的方法,從 大量資訊中找出與目的有關,或使用者感興趣的資訊。結合數學理論及 電腦的運算能力來分析影像後,再利用機器學習的方式去訓練電腦,針 對影像的差異加以分類。這些方法都是希望能更進一步輔助醫師診斷, 提高醫學影像判讀的正確性。. 1.2. 研究動機與目的 旋轉肌腱群(rotator cuff)是薄的肌腱組織(圖 1-1) 。它環繞在上肢肱 骨頭(humeral head)上並連接於肩胛骨上(scapula)[3]。此肌腱群是由肩胛 下肌(subscapularis)、岡上肌(supraspinatus)、岡下肌(infraspinatus)與小. -1-.
(13) 圓肌(teres minor muscles)所組成。如圖一所示。它主要負責上肢手臂上 下、旋轉時的關節運動與平衡。當患者做劇烈運動或提超乎能承受的過 重重物時會造成此肌腱群斷裂(tears)或損傷。其中又以岡上肌的損傷與 斷裂最為常見。圖 1-1(b)顯示岡上肌部份斷裂的示意圖。. (a). (b). 圖 1-1、(a)旋轉肌腱群,(b)岡上肌部份斷裂. 當岡上肌發生斷裂時患者會有強烈的疼痛與上肢手臂施力與運動障 礙(無法提重物)。大部份岡上肌損傷與斷裂的患者大都不需手術修復肌 腱,只有完全斷裂(complete or full-thickness tears)的患者需要施作修復手 術。岡上肌為連接肱骨頭與肩胛骨的肌腱組織,其中接近肱骨頭的部份 較狹薄,其厚度在解剖學上大概僅 9 至 11 公釐(9-11 mm)。劇烈運動或 提超乎能承受的過重重物時會造成此肌腱群的部份斷裂(partial-thickness. -2-.
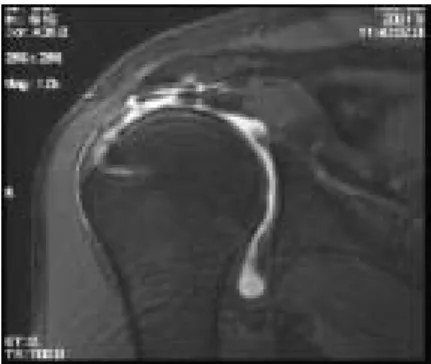
(14) tears)和完全斷裂。即使未發生斷裂,仍會造成肌腱發炎(tendinopathy)。 岡上肌的完全斷裂會發生在離肱骨頭處 1 公分附近並發生肌腱縮回 (tendon retraction)現象,不會自然回復。在臨床上需要作肌腱修補手術。 圖 1-2 為岡上肌完全斷裂的示意圖。. 圖 1-2、岡上肌完全斷裂示意圖. 診斷岡上肌斷裂的方法在臨床上借助核磁共振造影術(Magnetic resonance imaging)與高解析超音波(sonographics)來做診斷。不使用 X 光 造影與電腦斷層掃瞄之原因為 X 光造影與電腦斷層掃瞄(CT scans)都無 法將其肌腱組織明顯顯示出來。近年來有許多臨床醫師與文獻報告都普 遍使用超音波造影作為診斷工具。但是對於完全斷裂的岡上肌的診斷上 仍是以核磁共振影像為主。臨床及醫學文獻都顯示 T2-weight 的影像序 列(Fast spin-echo plus sequence T2-weight MRI scans)最易觀察岡上肌的 損傷情況。圖 1-3、圖 1-4 為其例。. -3-.
(15) 圖 1-3、MRI 影像(complete supraspinatus tears, Coronal Oblique views). 圖 1-4、MRI 影像(complete supraspinatus tears, Sagittal views). 由於肩關節非常接近人體的軀幹,因而其取像的場深(FOV; field of view)不宜太太。通常使用 12-16 公分之間。其影像的大小及其品質也因 FOV、反復時間(repetition time, TR)與回應延遲(echo delay time, TE)不同 而有差異。大抵上其切片厚度大都介於 3 至 4 公釐(3-4mm)之間。在作肩 關節的核磁共振的攝影時可以使用軸向(axial),冠狀傾斜(coronal oblique) 以及矢面(sagittal)等角度取像以獲得一序列的切面影像。其中冠狀傾斜影 像序列是以平行肩胛骨及岡上肌肌腱的角度取像。而矢面影像是垂直冠 狀傾斜來取像。冠狀傾斜影像序列可以清楚觀察到岡上肌肌腱、肩峯下/ 三 角 肌 下 關 節. (subacromial/subdeltoid. -4-. bursa) 和 肩 峯 關 節.
(16) (acromioclavicular joint)。因而臨床上都使用這個角度所取的 T2-weight 核 磁共振影像序列來作診斷。圖 1-5 為冠狀傾斜及其一影像。圖 1-6 為矢面 及其一影像。. 圖 1-5、. 冠狀傾斜(coronal oblique)及其一影像。. 圖 1-6、矢面(sagittal)及其一影像。 在修補斷裂的岡上肌肌腱可以使用開放性手術(open procedure)或者關節 鏡手術(arthroscopic surgeon)。至於要使用那一種手術方式需視患者要修 補的肌腱組織與骨骼關節的位置而定。不過近年來由於關節鏡手術技術 快速發展,因此對於完全斷裂的旋轉肌腱群的修補手術有經驗的臨床醫 師大都使用關節鏡施以手術。. -5-.
(17) 在臨床上使用超音波檢測肩關節旋轉肌肌群之疾病狀況是現今最常 使用的方式,因為不但價格低廉,而且屬於非侵入式診斷,對人體不會 產生副作用。然而診斷部分肌群斷裂之正確率僅接近 70%。因此使用超 音波作為診斷工具時,提升其效能就相當重要。因而本研究針對肩關節 旋轉肌肌群影像,使用資料探勘技術來增進診斷之正確性。 本研究在取得肩關節超音波影像後,首先使用紋路分析之技巧擷取 病灶區域中的紋路特徵。為了降低計算複雜度,以及提升正確率,先使 用特徵選取的方式選取有效的特徵,再使用放射狀基礎函數網路與支援 向量機做為分類器,用以分類肌腱發炎、鈣化、肌腱斷裂(包括部分斷 裂與全斷裂) 、以及正常的影像。. 1.3. 研究方法概述 本論文研究方法主要分為三大階段,第一階段為紋路分析,第二階 段為特徵選取,第三階段為影像分類。研究流程如圖 1-7 所示。取得肩部 超音波影像後,在第一階段紋路分析中,使用特徵擷取的方式,擷取其 紋路特徵值。本研究分別使用紋路特徵編碼法(texture feature coding method)[13],灰階明亮度相互關係矩陣(gray-level co-occurrence matrix, GLCM)[10],紋路頻譜(texture spectrum)[12][19],統計特徵矩陣. -6-.
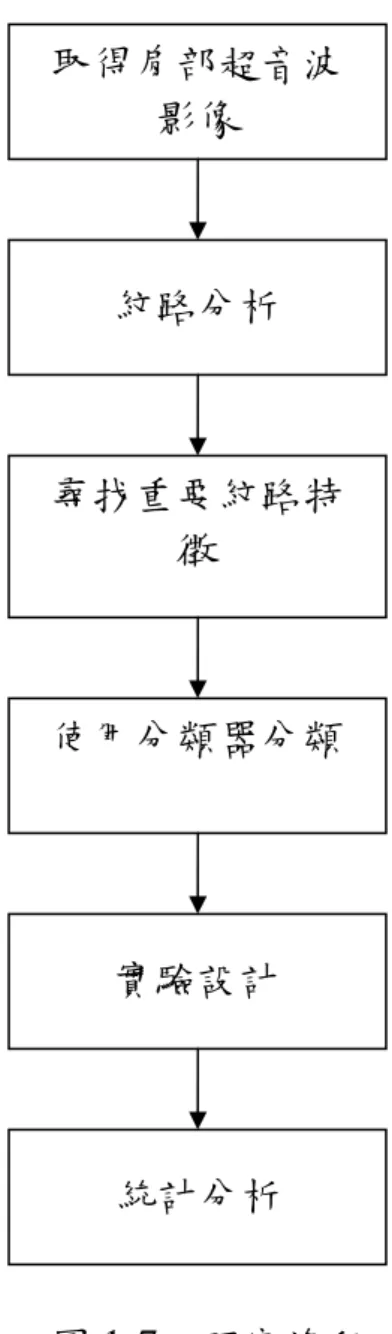
(18) (Statistical Feature Matrix)[20],以及碎型維度(fractal dimension)[5][7] 等方法進行特徵擷取。第二階段,則是分別使用最大交互訊息法(mutual information)[4]與 F-score [8]進行特徵選取,選取兩組有效特徵。接著第 三階段為影像分類,將選取出的特徵,利用放射狀基礎函數網路(radial basis function network,RBF)[11] 與支援向量機(support vector machine) [14]之分類器,進行分類訓練的工作。然後進行實驗,統計分析實驗的結 果。. -7-.
(19) 取得肩部超音波 影像. 紋路分析. 尋找重要紋路特 徵. 使用分類器分類. 實驗設計. 統計分析 圖 1-7、研究流程. 1.4. 章節概述 本篇論文章節架構如下,第一章描述背景及本篇論文的研究動機與 目的。第二章描述背景知識與相關理論。第三章描述本篇論文的研究方 法。第四章為本篇論文方法的實驗結果。最後第五章為結論。. -8-.
(20) 2. 相關理論及背景知識. 2.1. 肩關節旋轉肌肌群 在臨床上肩關節疼痛的成因很多,但是多數為與岡上肌損傷或斷裂 有關。它大致上可以分成三個分類。此三類為肌腱發炎(tendinopathy of rotator cuff)、鈣化(calcification)、以及岡上肌斷裂(supraspinatus tear) (包括部份斷裂和完全斷裂) 。診斷肩關節疼痛的普通性診斷工具為超音 波圖像(Sonogram)。在超音波的診斷上有許多特徵有助於診斷,超音波肩 關節影像可分成冠狀(coronal view)影像以及橫向(transverse)兩種影像。詳 細影像像特徵描述如下。 (1) 正常旋轉肌腱者(normal rotator cuff) 影像中岡上肌部位影像顯示正常肌腱亮度(tendons echogenics),均勻 的紋路(homogeneous texture)。整個肌腱組織有正常厚度且具有均勻 平滑的曲線並且不具有輕度回音(hypo-echoic)的現象。如圖 2-1。. -9-.
(21) 圖 2-1、正常岡上肌影像。 (2) 肌腱發炎者(tendinopathy of rotator cuff) 比對正常發現,皆肌腱組織的厚度較正常者為大,其原因為水腫 (oedema)、發炎(inflammation)出現在肌腱組織中。如圖 2-2。. 圖 2-2、右圖為肌腱炎之長軸影像。左圖為短軸影像. - 10 -.
(22) (3) 鈣化(calcification) 鈣化是由於組織變形,因而產生小白點般的鈣化沈積物覆著於肌腱 上,在超音波影像中會呈現明顯的白色班點。如圖 2-3。. 圖 2-3、鈣化影像。. (4) 岡上肌肌腱斷裂(supraspinatus tear) 部分斷裂(partial tear)時,疾病患者的超音波影像中,表現出輕度回音 並且有不均勻的紋路特性,且肌腱組織的厚度較正常者稍小,如圖 2-4。而完全斷裂(complete tear)時,肌腱組織有縮回(tendon retraction) 使得岡上肌區域曲面(surface)不完整並使肌腱組織厚度明顯減少,如 圖 2-5。. - 11 -.
(23) 圖 2-4、部分岡上肌斷裂。箭頭所指為斷裂處. 圖 2-5、完全斷裂。標記所指之範圍為斷裂處。. 在橫向影像中,可以清楚看到旋轉肌腱群損傷或斷裂的影像中,有明 顯的液體(fluid-filled)缺陷(影像中顯示出低度回音(hypoechoic)缺陷。同時. - 12 -.
(24) 岡上肌尾端的輪廓(distal end supraspinatus tendon)不易觀察到如 full-thick new tear,或有不光滑斷裂之輪廓如 partial-thickness,如圖 2-6。. (a). (b). 圖 2-6、(a)部分斷裂影像,(b)完全斷裂。標記所指範圍為斷裂位置。. 如上所述,這些影像特徵為本論文之研究主軸,希望藉由影像處理 與圖訊識別,並使用資料探勘技術來輔助醫師診斷。. 2.2. 紋路分析 紋路在影像分類和影像分析中是很重要的特性,不過紋路卻沒有唯 一並且精確的定義。儘管如此,所有研究者都同意以下兩點: 1. 紋路是影像中相鄰像素點的灰階度變化,在解析度的限制下,沒有非 同質性(non-homogeneity)。 2. 在ㄧ些空間尺度大於影像解析度情況,紋路具有同質性(homogeneous) 的特性。 每種紋理分析方法所描述的紋理特性就是從影像擷取出的特徵,因. - 13 -.
(25) 此紋理不只是根據輸入影像,也要視紋理和特徵的使用目的而定。一般 定義所謂的紋理,是由一群紋路基元(Primitive),根據某些排列規則所形 成的紋路影像[9]。而從數學上來說,紋路是影像中相鄰像素點的灰階度 變化,顏色空間的相關性,或是影像灰度和顏色隨空間位置變化的視覺 表現,如邊緣、形狀、條紋、色塊等等。一般可將紋路的種類區分為三 大類: 1. 決定性紋路(Deterministic Textures) 這類紋路影像是從一個定義好的子紋路特徵(Sub-texture)經由一定 的排列方式或規則而產生,或是由精確的數學公式表現出來,如棋盤 或數學函數產生的紋路。 2. 結構性紋路(Structural Textures) 是由一種或多種紋路基元經由某種排列規則所產生的。大多數的人工 製品為此類,如布料,竹編製品等。 3. 隨機性紋路(Stochastic Textures) 通常是指自然界中的紋路,例如雲、樹皮、波浪等等。這類紋路組成 基元的排列方式是隨機的,沒有一定的規則,但是具備同質的特性。 而紋路分析所擷取出的影像紋路的特徵,可表現出這張影像的特 性。傳統上紋路分析的方式分為兩大類: 1. 結構式分析方法(Structural Approach). - 14 -.
(26) 此類方法認為紋路影像是由紋路基元透過某種規則或排列方式不斷重 複排列所組成。所以這種方法會找出紋路基元,以及描述它的各項特 徵,如週期性(Periodicity)、方向性(Directionality)等等。如傅立. 葉的頻譜分析(Fourier Transform)常用於此類方式,依其波形可辨 識影像週期性紋路的主要方向,空間週期或光譜能量。 2. 統計式分析方法(Statistical Approach) 認為紋路影像是透過像素點明亮度值的空間分布情形而形成的。因此 此方法目的在描述灰階值的空間分佈特性。如灰階明亮度相互關係矩 陣(Gray Level Co-occurrence Matrix),即為計算影像空間中像素在 不同距離與方向角度符合預定條件下所發生之頻率的方法。. 2.3. 特徵選取 特徵選取在資料探勘中是一個重要的前處理作業。在我們取得特徵 資料後,不同的特徵變數之間可能會有重複性或是相依性,而處理不同 問題所需要的特徵變數之組合也可能會有所不同。因此透過特徵選取, 可以用來降低資料維度,同時也能減少計算複雜度;而僅挑選有效特徵 變數,移除與問題相關性較低的特徵後,還可以改善分類結果的正確率, 所以特徵選擇可以定義為依據某一個評量標準(Criteria)選擇特徵子集合 的過程。. - 15 -.
(27) 特徵選取的方法大可分為包裝器(wrapper)和過濾器(filter)兩大 類,包裝器會根據分類器(classifier)的結果,將產生高正確率的特徵選 入特徵子集合,通常需要之計算量較大;過濾器則根據獨立於分類器的 指標,來挑選特徵子集合,是著重於傳統統計和資訊理論的指標,通常 計算效率較高,但是結果可能會比較差[16]。 以下簡介常見的 3 種包裝器的特徵選取方式: 1. 循序向前選擇法(Sequential Forward Selection,SFS) 是由空的特徵變數集合開始,由一維的變數組合開始逐一測試,一次 增加一個特徵變數,直到達到所要求的特徵變數數目為止[18]。 2. 循序向後選擇法(Sequential Backward Selection,SBS) 選取步驟與上述之SFS相反,將所有的特徵變數進行逐一的篩選,一次 刪減掉一個特徵變數,直到達到所要求的特徵變數組合維度為止。 3. 浮點搜尋法(Floating Search Method,FSM) 是種常被廣泛使用的「次最佳」特徵變數選取方法,主要架構是將SBS 與SFS結合在一起,在每進行完一次SFS後,隨即進行一次SBS。假設k 為維度變數,如果SBS所找到的新k-1維組合值比之前所找到的k-1維組 合要來得高,則以此新k-1維組合為基礎繼續進行SBS;反之則不繼續 進行SBS,而以SFS後的k維組合繼續進行SFS。 本研究所使用的交互訊息法就是屬於過濾器的一種,利用交互訊息. - 16 -.
(28) 值來判斷應該選擇的特徵,不過它的演算法也是使用貪婪式的向前選擇 法來選擇特徵,每次循環都選擇具有最大交互訊息值的特徵進入子集合。. 2.4. 類神經網路分類法 類神經網路是基於生物神經系統設計的一種資訊處理技術。對生物 神經網路做出最簡單的模擬,人工神經元是最基本的類神經網路單元, 稱為處理單元(processing element)或節點(node)。. 輸入信號. x1. wj1. x2. wj2. 偏移量 θj. 活化函數 Σ. φ(.). 輸出 yj. 加法單元. xp. wjp 鍵結值. 圖 2-7、類神經元之數學模型 圖 2-7 是一個類神經網路的基本數學模型,其中有三個基本單元[1]: 1. 鍵結值(synaptic weights) 每個連結都有自己的權重值,輸入的的信號會與節點上的權重值. - 17 -.
(29) 相乘。 2. 加法單元(summing junction) 輸入訊號加上鍵結值後用加法單元加總起來。 3. 活化函數(activation function) 可以用來將一個神經元的輸出壓擠到一個限制範圍內,使得輸出 值的範圍成為一個有限的值。 可以用以下的數學式描述類神經元的輸入輸出關係: p. u j = ∑ w ji xi. (2.1). y j = ϕ (u j + θ j ). (2.2). i =1. 以及. 其中 uj 代表第 j 個神經元所獲得的整體輸入量,wji 代表第 i 維輸入至第 j 個類神經元的鍵結值,θj 代表這個類神經元的偏移值,x = (x1,…,xp)T 代 表 p 維輸入向量,xi 代表第 i 維之輸入向量,φ(.)代表活化函數,yj 代 表類神經元輸出值。 如果用 wj0 代表θj,則上式可改寫為: p. v j = ∑ w ji xi. (2.3). y j = ϕ (v j ). (2.4). i =1. 以及. 常見的活化函數有下列四種型式:. - 18 -.
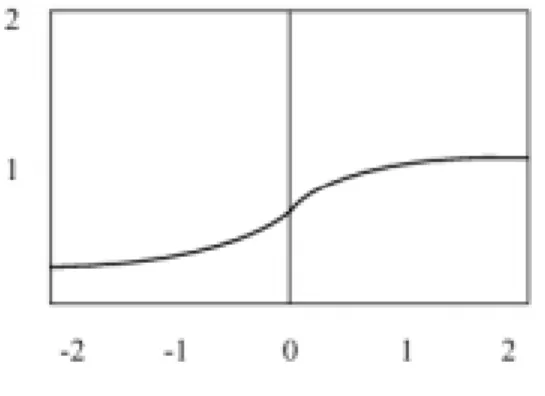
(30) 1. 門檻值函數(threshold function) 1 if v ≥ 0 0 if v < 0. ϕ (v ) = . (2.5). 根據門檻值來決定輸出值,輸出值亦可改為±1,有時用 sgn(.)來表示。. 圖 2-8、門檻值函數 2. 區域線性函數(piecewise linear function) 1 if v ≥ 0 ϕ (v) = cv if v2 ≤ v ≤ v1 0 if v < 0 . (2.6). 其中 c、v1、和 v2 是實數型常數,是個有上下限的遞增函數。. 圖 2-9、區域線性函數 3. S 字型函數(sigmoid function) ϕ (v ) =. 1 1+ exp(−cv). (2.7). 這是一個單調遞增(monotonic increasing)、平滑且可微分的函數。. - 19 -.
(31) 圖 2-10、S 字型函數 4. 高斯函數(Gaussian function) . v2 2 2σ . ϕ (v ) = −. (2.8). 其中σ為實數型的正值常數。本研究的放射狀基礎函數網路就採用此 種活化函數。. 圖 2-11、高斯函數 由以上可知,一般類神經網路具有三層之結構,輸入層、隱藏層、 輸出層。如圖 2-12 所示。. - 20 -.
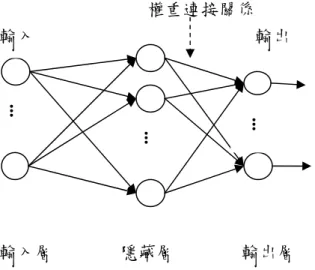
(32) 權重連接關係 輸入. 輸出. ... 隱藏層. .... ... 輸入層. 輸出層. 圖 2-12、具有輸入層、隱藏層、輸出層之類神經網路架構圖. 1.輸入層-從外面接收訊號並將此訊號傳入類神經網路中。 2.隱藏層-接受輸入層的訊號,對訊號進行處理,訊號處理過程對使用者 是隱藏起來的。 3.輸出層-接收網路處理過的訊號,將結果輸出。 類神經網路基本運作可分為訓練和模擬兩個過程。訓練過程決定網路 的權重值;模擬過程決定網路的預測輸出值,驗證網路的準確度。 如圖 2-13,網路根據輸出和目標的比較來調整,直到網路的輸出與目 標的差距達到設定的最小值。. - 21 -.
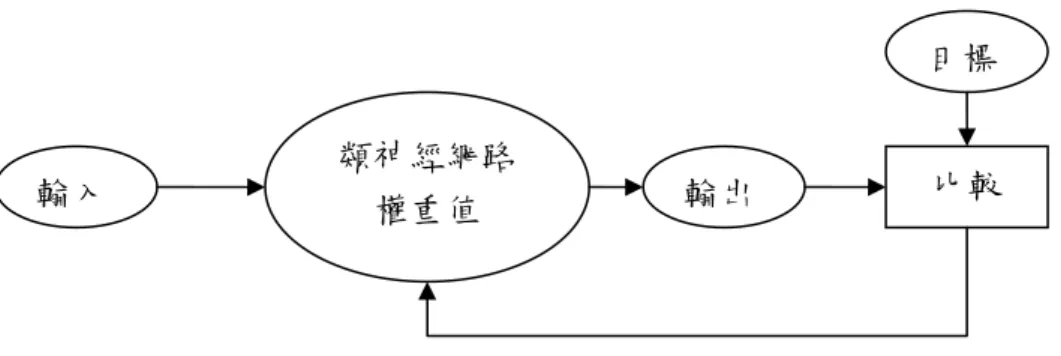
(33) 目標. 輸入. 類神經網路 權重值. 輸出. 比較. 調整權重. 圖 2-13、類神經網路訓練和調整權重值流程圖. 設計出來的類神經模型可利用輸入範例來訓練並改善輸出結果。而 這種技術可以用來分類資料。. - 22 -.
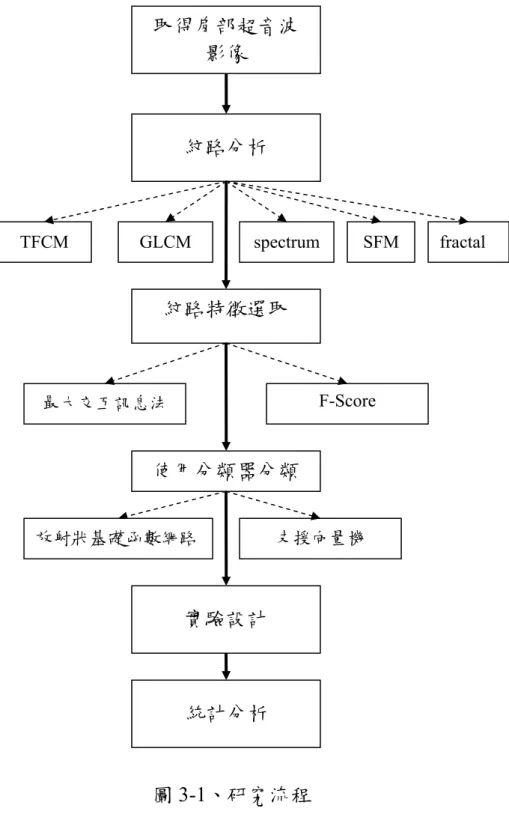
(34) 3. 研究方法. 3.1. 研究流程 本論文研究流程如下圖 3-1 所示。取得肩部超音波影像後,使用特 徵擷取的方式,擷取其紋路特徵值。已經有相當多的紋路描述法被提出 用來分辨超音波紋路影像,本研究分別使用紋路特徵編碼法(texture feature coding method,TFCM),灰階明亮度相互關係矩陣(gray-level co-occurrence matrix,GLCM),頻譜法(spectrum),統計特徵矩陣法 (Statistical Feature Matrix) ,以及碎形維度(fractal dimension)等方法進 行特徵擷取。 下個階段,使用最大交互訊息法(mutual information)與 F-score 法 進行特徵選取,選取有效特徵。接著將選取出的特徵,分別利用放射狀 基礎函數網路的類神經分類器以及支援向量機進行分類訓練的工作。然 後進行實驗,最後統計分析實驗的結果。. - 23 -.
(35) 取得肩部超音波 影像. 紋路分析. TFCM. GLCM. spectrum. SFM. fractal. 紋路特徵選取. F-Score. 最大交互訊息法. 使用分類器分類 放射狀基礎函數網路. 支援向量機. 實驗設計. 統計分析. 圖 3-1、研究流程. 3.2. 本研究所使用之紋路分析 本研究的紋路分析使用:紋路特徵編碼法,灰階明亮度相互關係矩. - 24 -.
(36) 陣,紋路頻譜法,統計特徵矩陣法,以及碎形維度等方法進行特徵擷取。 接下來簡介這些方法。. 3.2.1. 紋路特徵編碼法 紋路特徵編碼法的編碼法則(scheme)是用來產生紋路單元(Texture Unit)中的明亮度值的變化,將原始灰階明亮度紋路影像轉換成紋路特徵 影像(Texture Feature Image)。而在這個紋路特徵影像中的每個影像像素, 都是利用紋路特徵數(Texture Feature Number,TFN) 來表達。最後透過紋 路 特 徵 影 像 來 產 生 紋 路 特 徵 統 計 直 方 圖 (Texture Feature Number Histogram),並以此做為影像之間的相似性量測。紋路特徵的產生是以 3x3 紋路單元 (如圖 3-2)影像元素間明亮度的變化為基礎。較紋路頻譜法 (Texture Spectrum)進一步考慮到紋路單元中的連通性(Connectiveity)。. 2. 1. 2. 1. X. 1. 2. 1. 2. 圖 3-2、3x3紋路單元. - 25 -.
(37) 2. 1. 2. 2. 1. 2. 1. X. 1. 1. X. 1. 2. 1. 2. 2. 1. 2. +: 0° − 180° scan line 90° − 270° scan line. 圖 3-3、一階 4-連通. x: 45° − 225° scan line 135° − 315° scan line. 圖 3-4、二階 4-連通. 假設每一條掃瞄線都是由上而下、由左而右。它的三個連續影像元 素(a,b,c)為且(Ga,Gb,Gc)代表(a,b,c)相對的明亮度值。假使我們考慮兩對連 續明亮變化(Ga,Gb) 和 (Gb,Gc),它將存在四種不同型式的明亮度變化, 如方程式(3.1)及圖 3-5 所示。在方程式中,∆ 代表明亮度差異的容忍值。 (i) if ( Ga − Gb ≤ ∆ ) ∩ ( Gb − Gc ≤ ∆ ) (ii) if [( Ga − Gb ≤ ∆ ) ∩ ( Gc − Gb > ∆ )] ∪ [( Ga − Gb ≤ ∆ ) ∩ ( Gb − Gc > ∆ )] ∪ [( Ga − Gb > ∆ ) ∩ ( Gb − Gc ≤ ∆ )] ∪ [( Gb − Ga > ∆ ) ∩ ( Gb − Gc ≤ ∆ )] (iii) if [( Ga − Gb > ∆ ) ∩ ( Gb − Gc > ∆ )] ∪ [( Gb − Ga > ∆ ) ∩ ( Gc − Gb > ∆ )] (iv) if [( Ga − Gb > ∆ ) ∩ ( Gc − Gb > ∆ )] ∪ [( Gb − Ga > ∆ ) ∩ ( Gb − Gc > ∆ )]. 圖 3-5、四種不同明亮度變化起伏圖. - 26 -. (3.1).
(38) 根據圖 3-5所示,愈大的值就表示明亮度變化越劇烈。如果我們使用 的整數數對α及β分別代表了由兩條掃描線scan line 1及scan line 2 所組成 的一階及二階連通性,而每一條掃描線都可以產生出一種明亮度變的形 式。所以α及β能夠被視為是明亮度圖形結構變化圖中某兩種形式所形成 的組合。因此所有可能組合有. 4(4 + 1) = 10 種可能性,這十種可能如圖 3-6 2. 所示。. Scan line2. (i) (ii) (iii) (iv). (i) 1 2 3 5. Scan line1 (ii) (iii) 2 3 7 11 11 17 13 19. (iv) 5 13 19 23. 圖 3-6、明亮度圖形結構變化組合圖. 更精確的解釋,在圖3-3及圖3-34中,直列α中0°-180°的掃描線明 亮度改變或者代表β中45°- 225°的掃描線明亮度改變。而縱列代表α中 90°- 270°的掃描線明亮度改變或者代表β中135°- 315° 的掃描線明 亮度改變。舉例來說,如果α=11或β=11的話,對照圖 3-6我們可以知道 是其形式(ii)和(iii)的組合。. - 27 -.
(39) 最後,紋路特徵數(Texture feature number)可以由α和β的值的乘積代 表,如式(3.2)所示,令位在影像空間位置(x,y)的像素點其明亮度值為 G(x,y),它的紋路特徵數為TFN(x,y)為α(x,y)和β(x,y)的相乘。從方程式(3.2) 中,可以發現紋路特徵數的範圍是從1~529,而其中只有用到55個值。因 此將這55個紋路特徵數依其原大小重新標示為0至54。. TFN( x, y ) = α ( x, y ) β ( x, y ). (3.2). 接著可以統計每一種紋路特徵數在紋路特徵影像中出現的頻率,產生紋 路特徵統計圖。定義紋路特徵發生機率 p∆ (n) 如方程式(3.3)所示。 p∆ (n) =. N ∆ (n) , n ∈ {0,1, 2,...,54} N. (3.3). 在方程式(3.5)中,∆ 代表明亮變化容忍值。N∆(n)表示在明亮變化容忍值 為 ∆ 時,某紋路特徵數 n 在紋路特徵影像中的發生次數。且 N 為紋路影 像中所有像素點總和。紋路特徵數相互關係矩陣代表了在紋路特徵影像 中任一對紋路特徵數所共同發生的頻率。我們可以定義紋路特徵數相互 關係發生機率函數如方程式(3.4)所示。 p (i, j | d , θ ) =. N ∆ ,d ,θ (i, j ) Nt. , i, j ∈ {0,1, 2,...,54}. (3.4). 其中 N∆,d,θ(i, j) 成為在明亮度容忍值 ∆,距離 d,角度 θ 下,紋路特徵數 i 和紋路特徵 j 發生的次數,且 Nt 為相互關係矩陣中紋路特徵數共同發 生次數的總和。實驗使用了紋路特徵編碼法中的 7 個紋路特徵。前 4 個. - 28 -.
(40) 紋路特徵是由紋路特徵數統計圖導出,第 5、6、7 個特徵是基於紋路特 徵數相互關係矩陣而產生。 (1) 粗糙度(Coarseness): Coarse = ∑∑ p∆ (54) x. (3.5). y. 其中 ∆ 設定之明亮度容忍值,x 與 y 為影像的長跟寬。 (2) 平滑度(Homogeneity): Hom = ∑∑ p∆ (0) x. (3.6). y. (3) 平均數值(Mean Convergence): 54. MC = ∑. n�p∆ (n) − µ∆. n =0. δ∆. (3.7). µ∆ 和 δ ∆ 代表在明亮度容忍值 ∆ 的情況下之平均數與標準差,n 代表. 紋路特徵數。 (4) 碼變異數(Code Variance): 54. Var = ∑ (n − µ∆ ) 2 �p∆ (n). (3.8). n =0. (5) 碼熵(Code Entropy): 54. 54. CEntropy = −∑∑ p∆ (i, j | d , θ ) log p∆ (i, j | d , θ ). (3.9). i =0 j =0. p∆ (i, j | d , θ ) 為在紋路特徵相互關係矩陣中距離 d 角度θ的第 (i, j ) 個熵. 值。 (6) 發生長度密碼(Code Run Length Density):. - 29 -.
(41) 54. CS = ∑ p∆2 (i, i | d ,θ ). (3.10). i =0. (7) 正則性(Code Regularity): 54. 54. Regularity = ∑∑ i =0 j =0. p∆ (i, j | d , θ ) 1 + (i − j ) 2. (3.11). 3.2.2. 灰階明亮度相互關係矩陣 灰階明亮度相互關係矩陣(Gray-Level Co-occurrence Matrix,GLCM) 是計算影像中像素對灰階值共同發生的次數[2]。假設一個影像I,大小為 N×N,明亮度級數為Ng(Ng=(最大明亮度-最小明亮度)+1)。像素點 的距離 d,角度 θ。 p(i, j | d ,θ ) 代表了影像中的一對像素點,在距離 d 角度 θ,發生個別明亮度值 i與 j的次數。 p(i, j | d ,θ ) =. P(i, j | d ,θ ) N. (3.12). 其中 P(i, j | d ,θ ) 為正規化前的灰階明亮度相互關係矩陣中的元素值,N代 表灰階明亮度相互關係矩陣中所有元素值的總和。 px (i ) 為在正規化的灰階明亮度相互關係矩陣中的第x行的所有機率值的. 總和,即: Ng. px (i ) = ∑ p(i, j | d , θ ). (3.13). j =1. 其中x為矩陣中橫座標軸的值。 p y ( j ) 為在正規化的灰階明亮度相互關係矩陣中的第y列的所有機率值的. - 30 -.
(42) 總和,即: Ng. p y ( j ) = ∑ p(i, j | d , θ ). (3.14). i =1. 其中y為矩陣中縱座標軸的值。 Ng Ng. px + y (k ) = ∑∑ p (i, j | d , θ ) ,k = 2,3,..,2Ng i =1 j =1. i+ j =k. Ng Ng. px + y (k ) = ∑∑ p (i, j | d , θ ) ,k = 0,1,...,(Ng-1) i =1 j =1. (3.15). (3.16). i+ j =k. 基於灰階明亮度相互關係矩陣,Haralick所提出之紋路特徵:. (1) 二階度動量(Angular Second Moment) F1 = ∑∑ { p(i, j | d , θ )}2. (3.17). Ng Ng ∑∑ p (i, j | d , θ ) 2 F2 = ∑ n × i =1 j =1 n =0 i+ j = k . (3.18). i. j. (2) 對比度(Contrast) Ng −1. (3) 相關性(Correlation). ∑∑ (i × j ) × p(i, j | d ,θ ) − µ µ x. F3 =. i. j. y. . σ xσ y. (3.19). 其中 µ x 及 µ y 為 px (i) 及 p y ( j ) 的平均數, σ x 及 σ y 為 px (i) 及 p y ( j ) 的標準 差。. (4) 平方和(Sum of Squares) F4 = ∑∑ (i − µ ) 2 × p(i, j | d , θ )} i. j. - 31 -. (3.20).
(43) (5) 逆差異動量(Inverse Difference Moment) F5 = ∑∑ i. j. 1 × p(i, j | d ,θ ) 1 + (i − j ) 2. (3.21). (6) 總和平均(Sum Average) 2 Ng. F6 = ∑ i × px + y (i ). (3.22). i =2. (7) 總和變異(Sum Variance) 2 Ng. F7 = ∑ (i − F6 ) 2 × px + y (i ). (3.23). i =2. (8) 和熵(Sum Entropy) 2 Ng. F8 = − ∑ px + y (i ) × log{ px + y (i )}. (3.24). F9 = −∑∑ p(i, j | d , θ ) × log{ p(i, j | d , θ )}. (3.25). i =2. (9) 熵值(Entropy) i. j. (10) 差變異(Difference Variance) (3.26). F10 = variance of px-y. (11) 差熵值(Difference Entropy) Ng −1. F11 = − ∑ px − y (i ) × log{ px − y (i )}. (3.27). i =0. (12)、(13) 相關性的資訊量測(Information Measures of Correlation) F12 =. HXY − HXY 1 max{HX , HX }. F13 = (1 − exp[−2.0 × ( HXY 2 − HXY )]). HX,HY 分別為 px 和 py 的熵值。. - 32 -. (3.28) 1. 2. (3.29).
(44) HXY = −∑∑ p (i, j | d , θ ) × log{ p(i, j | d , θ )}. (3.30). HXY 1 = −∑∑ p(i, j | d , θ ) × log{ px (i ) × p y ( j )}. (3.31). HXY 2 = −∑∑ px (i ) × p y ( j ) × log{ px (i ) × p y ( j )}. (3.32). i. j. i. j. i. j. 3.2.3. 紋路頻譜 紋路頻譜(texture spectrum)的基本概念是一張紋路影像可以視為紋 路單元的集合,紋路單元為3x3大小的區塊,一個像素點的資訊可以從鄰 近8個像素點中擷取,藉由統計所有紋路單元所提供的資訊,我們就可以 得到整張影像的紋路資訊。 對於中央像素點V0而言,其八個鄰近的像素點為Vi{i=1,2,…,8},皆代 表像素點的明亮度值。定義紋路單元(texture unit),TU={E1,E2,…,E8}, 由於中央像素點與相鄰像素點的明亮度值有三種情形,分別為 Vi < V0 , Vi = V0 , Vi > V0 。因此,差異Ei的值是根據公式來計算: 0 if Vi < V0 Ei = 1 if Vi = V0 2 if V > V i 0 . (3.33). 每個TU有3個可能值,8個元素就總共有38=6561個可能的紋路單元。 8. N TU = ∑ Ei × 3i −1. (3.34). i =1. NTU代表紋路單元數, Ei 代表紋路單元集TU={E1,E2,…,E8}中的第 i 個元. - 33 -.
(45) 素。. a. b. d f. c e. g. h. 圖3-7、紋路單元的8個位置 基於紋路單元和紋路頻譜,定義了以下幾項紋路特徵:. (1) 黑白對稱性(Black-white symmetry) 3279 ∑ S (i ) − S (3281 + i ) ×100 BWS = 1 − i =0 6560 S (i ) ∑ i =0. (3.35). S (i ) 表示紋路單元數( i i = 0,1,2,...,6560)所發生的頻率值。公式中BWS. 經過正規化,使其值能夠落在 0~100 之間。以3280為對稱軸,計算落在 左半部(0~3279)和右半部(3281~6560)的對稱性。BWS 愈高,代表 了如果我們反轉原始影像的明亮度值,也就是將紋路單元裡 Ei 的值為0的 變成2,2的變成0,則新影像的紋路頻譜將會與原始影像的紋路頻譜非常 類似。. (2) 幾何對稱性(Geometric symmetry). - 34 -.
(46) 6560 1 4 ∑ S j (i ) − S j + 4 (i ) ×100 GS = 1 − ∑ i =0 6560 4 j =1 2 × ∑ S (i ) i =0. (3.36). S ( j ) 代表在紋路單元其排列元素為j(j = 1,2,…,8)的情況下愈高的. GS 值表示了若我們將原始的影像旋轉180之後,新影像的紋路頻譜將會 與原始影像的紋路頻譜非常類似。GS特徵顯示影像的形狀規律性。. (3) 方向性的程度(Degree of direction) 6560 1 3 4 ∑ S m (i ) − Sn (i ) × 100 DD = 1 − ∑ ∑ i =0 6560 6 m =1 n = m +1 2 × S (i ) ∑ m i =0. (3.37). 愈高的 DD 值則指出這張影像的方向性愈佳,對於影像被旋轉的情 形愈敏感。也就是說,這張影像的紋路樣式(pattern)具備了某種線性結 構的特性。. (4) 水平方向性(Micro-horizontal structure, MHS). MHS =. 6560. S (i) × HM (i) ∑ i =0. (3.38). HM (i ) = p(a, b, c) × p( f , g , h) , p (a, b, c) 表示在紋路單元數為i時,這個紋. 路單元裡Ea,Eb,Ec值相同的個數。 p( f , g , h) 則表示了Ef,Eg,Eh值相同 的個數。愈高的 MHS 值則代表原始影像具備明顯的水平線性結構。. - 35 -.
(47) (5) 垂直方向性(Micro-vertical structure, MVS) 6560. MVS = ∑ S (i ) × VM (i ). (3.39). i =0. 其中,VM (i) = p(a, d , f ) × p(c, e, h) 。 p(a, d , f ) 表示在紋路單元數為i時, 這個紋路單元Ea,Ed,Ef值相同的個數。 p(c, e, h) 則表示了Ec,Ee,Ef值 相同的個數。愈高的MVS值則代表原始影像具備明顯的垂直線性結構。. (6) 對角線1方向性(Micro-diagonal 1 structure, MDS1) 6560. MDS1 = ∑ S (i ) × DM 1(i ). (3.40). i =0. DM 1(i ) = p(d , a, b) × p( g , h, e) 。 p(d , a, b) 表示在紋路單元數為 i. 時,這個. 紋路單元裡Ed,Ea,Eb值相同的個數。 p( g , h, e) 則表示了Eg,Eh,Ee值相 同的個數。愈高的 MDS1 值則代表原始影像具備明顯的對角線方向1的 線性結構。. (7) 對角線2方向性(Micro-diagonal 2 structure, MDS2) 6560. MDS 2 = ∑ S (i ) × DM 2(i ). (3.41). i =0. 其中, DM 2(i) = p(b, c, e) × p(d , f , g ) 。 p(b, c, e) 表示在紋路單元數為 i 時,這個紋路單元裡Eb,Ec,Ee值相同的個數。 p(d , f , g ) 則表示了Ed, Ef,Eg值相同的個數。愈高的 MDS2 值則代表原始影像具備明顯的對角. 線2方向的線性結構。. - 36 -.
(48) (8) 中央對稱性(Central symmetry) 6560. CS = ∑ S (i ) × [k (i )]2. .(3.42). i =0. 其中,K(i)表示在紋路單元數為i時,其紋路單元的四個配對(Ea,Eh)、. (Eb,Eg)、(Ec,Ef)與(Ee,Ed)裡,值相同的配對個數。所以這個紋路特徵並不 受紋路單元裡元素的排列方式所影響,故其為與方向性無關 (orientation-invariant)的量測值。.. 3.2.4. 統計特徵矩陣 統計特徵矩陣(Statistical Feature Matrix)可以計算影像的像素對在一 些距離的統計特性。假設S={x,y}是一個Ly×Lx陣列點的空間座標,I(x,y) 為S中一個點的明亮度。設δ=(∆x,∆y),∆x和∆y皆為整數代表樣本內的空間 距離向量,η是影像I的平均灰階值,則δ 對比,δ 共變異數,δ 相異,分 別定義為:. {. δ contrast: CON(δ ) ≡ E I (x,y) − I ( x +∆x, y +∆y ) . 2. }. (3.43). δ covariance: COV(δ ) ≡ E {[ I (x, y ) − η ][ I ( x + ∆x, y + ∆y )] − η}. (3.44). δ dissimilarity: DSS(δ ) ≡ E { I (x, y ) − I ( x + ∆x, y + ∆y ) }. (3.45). 其中 E{•}表示期望值運算。 一個統計特徵矩陣,Msf 是一個(Lr+1)×(2Lc+1)的矩陣,而其中的(i,j) 元素是影像的統計特徵 d , d=(j - Lc, i) 是一個樣本內空間距離向量, i. - 37 -.
(49) =0,1,…,Lr,j=0,1,…,2Lc,且 Lr 和 Lc 為決定最大樣本內空間向量的常數。 對比矩陣(Mcon)、共變異數矩陣(Mcov)、和相異矩陣(Mdss),可定義為(i,j) 元素為 d 對比,d 共變異數,d 相異的矩陣。. (1) 粗糙度(Coarseness) (3.46). Fcrs = c mcrs. 其中c是正規化因子。 mcrs 這個計算方式是根據Lr=Lc=r的Mdss,計算 矩陣中所有元素的平均。. ∑. DSS (i, j ) n. (3.47). Nr = {(i, j ) :| i |, | j |≤ r}. (3.48). mcrs =. ( i , j∈N r ). Nr 為置換向量集:. N集合中元素的數目。較粗糙的影像, mcrs 值會較小,因此 Fcrs 值會較 大。. (2) 對比度(Contrast) 根據Mcon來計算,對比的計算方式為: 12. Fcon. = ∑ CON (i, j ) 4 ( i , j )∈Nl . (3.49). M dss − M dss (valley ) M dss. (3.50). (3) 週期性(Periodicity) 根據Mdss來計算 Fper =. - 38 -.
(50) M dss 為Mdss所有元素的平均, M dss (valley ) 為矩陣中最深的最低值。. 3.2.5. 碎形維度 碎形維度(fractal dimension)的方法介紹如下,對於一個影像 I(x,y),. (x,y)為其空間座標,I 為明亮度函數。(x1,y1),(x2,y2)為任兩個座標點。 依照公式(3.51): ∆r = ( x 2 − x1) 2 + ( y 2 − y1) 2. (3.51). ∆I ∆r = I ( x 2, y 2) − I ( x1 − y1). (3.52). 則簡單的碎形維度 D,可以用公式(3.53)來計算。 E (∆I ∆r ) = K (∆r ) H = K (∆r )3− D. (3.53). 其中 H 為 Hurst 係數,H=3-D。E( )為期望值函數,∆I ∆r 為明亮度變異值, ∆r 為空間距離,K 為常數。可以取 log 並使用最小平方線性回歸估計法去. 估計碎形維度值。對於 M×M 的影像 I,可以定義 di (k ) ,如公式(3.54)來估 算碎形維度向量。 M −1 M −1 M −1 M −1. di (k ) =. ∑∑∑ ∑. I ( x 2, y 2) − I ( x1, y1). x1= 0 y1= 0 x 2 = 0 y 2 = 0. pn(k ). (3.54). 其中 pn(k ) 為距離 ∆rk = ( x 2 − x1) 2 + ( y 2 − y1) 2 中所有向素對的總數目。其中 di (1), di (2), di (3),..., di(n) 稱為多尺度明亮度差異向量同時定義. f (k ) = log(di (k )) − log(di (1)). - 39 -. (3.55).
(51) 則 f (1), f (2), f (3),..., f (n) 為碎形維度向量。. 3.3. 最大交互訊息法 交互訊息法(mutual information)是可以衡量變數間相關性和資訊量 的一種有效方法,不過要計算連續變數間交互訊息非常困難,因為需要 計算變數的機率密度函數。而使用Parzen視窗密度估計法可以來估計變數 的機率密度函數,降低計算複雜性[15]。因此本研究採用基於Parzen視窗 密度估計法的交互訊息方式來做特徵選取。 假設一個離散的隨機變數X有子集X,機率密度函數p(x)= Pr{X=x}, x ∈ X,X的熵值(entropy)定義為:. H(X) = - ∑ p ( x) log p ( x). (3.56). x∈X. 當某些變數確定,某些不確定時,不確定的就用條件熵值來計算: H(Y|X) = -∑ ∑ p ( x, y ) log p ( y | x). (3.57). x∈X y∈Y. 交互訊息和熵值的關係: I(X;Y) = H(Y) - H(Y|X). (3.58). 兩個變數間的交互訊息可以定義為: I(X;Y) =. p ( x, y ). ∑ ∑ p( x, y) log p( x) p( y). (3.59). x∈X y∈Y. 要找 ( p( x), p( y ), p ( x, y ) ) 機率密度函數是非常困難的工作,因此使用Parzen. - 40 -.
(52) 視窗密度估計法來估計近似值。給定個數為n,維度為d的向量集合D =. {x1, x 2,..., xn},也就是樣本數為n,維度為d的特徵集合,xn表示的就是第n個 樣本的特徵。Parzen視窗的機率密度函數估計式為: pˆ ( x) =. 1 n ∑φ ( x − xi , h) n i =1. (3.60). 其中 φ (•)為window函數,h是window寬度參數。寬度參數需要是n的 函數: lim h( n) = 0. (3.61). d lim nh (n) = ∞. (3.62). n →∞. 而且 n →∞. 而window函數,通常使用高斯視窗函數(Gaussian window function): φ ( x − xi , h) =. 1 ( 2π ) d / 2 h d ∑. exp(− 1/ 2. z T ∑ −1 z ) 2h 2. (3.63). ∑ 為隨機變數 x − xi 的d維向量之共變異數矩陣。. 輸入特徵為連續變數,類別為離散值時,輸入特徵X和類別C的交互訊息 可表示為: I(X;C) = H(C) - H(C|X). (3.64). 其中條件熵值H(C|X)為: N. H(C|X) = -∫ p( x)∑ p(c | x)log p(c | x)dx X. c=1. 其中N是類別的數目。 根據貝式法則(Bayesian rule)條件機率 p(c | x ) 可寫成:. - 41 -. (3.65).
(53) p (c | x ) =. p (c, x ) p ( x). (3.66). 使用Parzen視窗法估計每個類別的條件聯合機率密度函數的估計值: pˆ (c, x) =. 1 ∑φ ( x − xi , h) nc i∈I c. (3.67). 其中nc是類別c的樣本數,Ic是屬於類別c的樣本索引的集合。因為條件機 率總和為1:. ∑. N k =1. (3.68). p (k | x) =1. 所以 p (c | x) 可表示為: p (c | x ) =. p (c | x ). ∑k =1 p(k | x) N. =. p (c , x ). ∑k =1 p(k , x) N. (3.69). 條件機率估計值變成: pˆ (c | x) =. ∑. 1 ∑ φ ( x − x i , hc ) n c i∈ I c N 1 ∑ i∈ I k φ ( x − x i , h k ) k =1 nk. (3.70). hc 和 hk 為類別特定的視窗寬度參數,nk是類別k的樣本數,Ik是屬於類別c. 的樣本索引的集合。如果每個類別使用相同的視窗寬度參數和共變異數 矩陣,可以改寫(3.70)式為: pˆ (c |. ( x − xi ) T ∑ −1 ( x − x i ) ) i∈I c x) = 2h 2 ( x − xi ) T ∑ −1 ( x − xi ) 1 N ) ∑ k =1 n ∑ i∈I k exp( − 2h 2 k 1 nc. ∑. exp( −. 以交互訊息進行特徵選取之演算法:. 1.初始特徵集合F,空集合S。. - 42 -. (3.71).
(54) 2.依序從F中選取一個特徵加入S,計算交互訊息值後,再從F中依序換下 一個,最後選擇加入後會有最大交互訊息值之特徵加入S。. 3.依序增加選取特徵子集合S的維度後,再回到第2步驟,一直重複直到交 互訊息值不再增加為止。. 4.最後S集合即為欲選取之特徵集合。. 3.4. F-score 法 本論文選用 F-score 法來與最大交互訊息法比較。F-score 是一個簡單 區分兩個實數集合的計算方法。給定訓練向量 xk,k = 1,...,m,如果所有 的實數分為兩類,正面示例( positive instance )和反面示例( negative. instance)的數目分別為 n+和 n-,第 i 個特徵的 F-score 值就定義為: F (i ) ≡. (x. (+) i. + xi. 1 n+ ( + ) xk ,i − xi( + ) ∑ n+ − 1 k =1. (. ) +(x − x ) ) + n 1− 1∑ ( x 2. 2. (−) i. i. n−. 2. −. k =1. (−) k ,i. ). (−) 2 i. −x. (3.72). 其中 xi , xi( + ) ,和 xi( −) 分別是資料集中全部第 i 個特徵的平均,第 1 類正面 示例中第 i 個特徵的平均,與第 2 類反面示例中第 i 個特徵的平均。xk( +,i) 是 第一類正面示例第 k 個的第 i 個特徵, xk( −,i) 則是第 2 類反面示例第 k 個的 第 i 個特徵。分子代表第 1 類正面示例與第 2 類反面示例之間的區別;分 母表示有這兩個資料集合的特徵。F-score 值越大代表這個特徵越具有辨 別性,因此這個可以用來作為特徵選取的標準。而在類別大於 2 類的情. - 43 -.
(55) 況,設類別為 l,l = 1,...,c,將公式(3.72)改寫如下: c. F (i ) ≡. ∑(x l =1 c. (l ) i. + xi. ). 2. nl 1 xk( l,i) − xi(l ) ∑∑ nl − 1 l =1 k =1. (. ). 2. (3.73). 使用 F-score 結合支援向量機進行特徵選取的流程如下:. 1. 計算每個特徵的的 F-score 值 2. 選一些可能的門檻值,去除掉低的和高的 F-score 值。 3. 對每個門檻值: a、 丟棄 F-score 值低於門檻值的特徵。 b、 隨機將訓練集分為 Xtrain 和 Xvalid c、 讓 Xtrain 成為新訓練資料,使用支援向量機分類程序去得到一個預 測器,使用預測器去預測 Xvalid. d、 重複上面的步驟五次,計算平均驗證誤差 4. 選擇有最低平均驗證誤差的門檻值 5. 丟棄 F-score 值低於選擇之門檻值的特徵,再執行分類程序。. 3.5. 放射狀基礎函數網路 放射狀基礎函數網路(Radial Basis Function Network;RBF)為具有單 一隱藏層的類神經網路,結構類似於兩層的認知機(Perceptron),其中輸 入層和隱藏層間的每個神經元完全相互連結(Full Connected)。放射狀基礎. - 44 -.
(56) 函數網路基本模式如圖 3-8 所示。假設輸入維度為 n,隱藏層類神經元的 數目為 J,網路的輸出函數 F(x)可以表示為: J. F (x) = ∑ w jϕ j (x). (3.74). j =1. x1. φ1. φ2. w1 w2 w3. Σ. F(x). φ3. xp. wj. φj. 圖 3-8、放射狀基礎函數網路架構圖. 圖 3-8 中 x = (x1,…,xp)T 代表輸入向量,φj(x)代表計算第 j 個隱藏類神 經元輸出值的基底函數,wj 代表第 j 個隱藏層類神經元到輸出層神經元的 權重值,θ= w0 代表可調整的偏移量。 本論文的放射狀基礎函數網路使用高斯函數 (3.75) 式為隱藏層神經 元的基底函數:. - 45 -.
(57) x−m j ϕ j ( x ) = exp − 2 2σ j . 2. . (3.75). 其中,x是測試樣本,mj稱為RBF 隱藏層神經元的中心點,而σ是此高斯 函數的寬度值(width), • 表示歐基里德範數(Euclidean Norm)。網路中連 接隱藏層神經元和輸出層神經元的輸出加權值都只是簡單的訊號相乘, 而輸出層神經元也僅將輸入值相加成為網路輸出。. 在放射狀基礎函數網路的訓練過程中,只要決定適當的隱藏層神經 元的中心點、寬度值及輸出加權值,就可以得到一個描述f : x→y函數 映射的放射狀基礎函數網路。 本研究放射狀基礎網路函數基本架構如圖 3-9 所示。. x1. φ1(x). w11 w21. C1(x). φ2(x). C2(x). w31 C3(x). φ3(x). xp. wm1 wmj. Cm(x). φj(x). 圖 3-9、研究所使用放射狀基礎函數網路之架構圖. - 46 -.
(58) 在本研究的放射狀基礎函數網路模型中,主要目標是在計算權重,其 決定方式是使用最小均方誤差法(Least Mean Square Error Method)。並 藉由克萊斯基分解(Cholesky decomposition) ,及使用規則化理論,去有 效地得到最佳解。 至於中心點及寬度函數則用簡單的方式決定。中心點是由使用者決定 個數,並由程式從訓練集中隨機選擇,每個核心函數的寬度函數則固定 為 5。h 是隱藏層的輸出: h = [φ1 ( x) φ2 ( x) ... φk ( x) ] .................................(3.76) T. 其中 k 是中心數目,φ1 ( x) 是輸入 x 的第一個核心函數輸出值。類別 j 個區 別函數(discriminant function)Cj(x)表示為: c j ( x) = w j T h, j = 1, 2,..., m. (3.77). 其中 m 為類別數,wj 為類別 j 之權重向量: w j = w j1 w j 2 ... w jk . T. (3.78). 分類方式為,在計算每個類別的區別函數值後,選擇分類結果中有最大 區別函數值的類別。. 3.6. 支援向量機 支援向量機(support vector machine)是一種基於統計學習理論的機器. - 47 -.
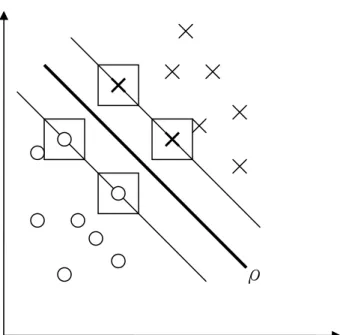
(59) 學習方法,是建立在統計理論的 VC 維度(Vapnik Chervonenks Dimension) 理論與結構風險最小法(method of structrual risk minimizatin)的原理基礎 上。其基本概念是在高維度空間中尋找一個超平面(hyperplane),能將資 料分為兩類,以保證資料最小錯誤率,而最接近超平面的向量稱為支援 向量。 如果在資料為線性可分割的情況下進行分類,首先對每筆不同的的 訓練集資料(training data)加上標註為+1 或-1,用以表示不同類別。以數 學式表示訓練集為 {(x i , di )}i =1 ,其中 xi 表示第 i 個訓練樣本,di 為相對應之 N. 目標輸出。則可線性分割之超平面公式如下: wT x + b = 0. (3.79). 其中 x 是輸入向量,w 是可調整權重向量,b 為偏移量。因此可以寫 成: w T x i + b ≥ 0 for di = + 1 w T x i + b < 0 for di = − 1. (3.80). 最接近的資料點稱為分隔邊界值(margin of separation),表示為ρ。支 援向量機的目標就是要找出具有最大的分隔邊界值的某個特定的超平 面。如圖 3-10 所示,代表的是兩類資料(o 和×),二維輸入空間的最佳 超平面。. - 48 -.
(60) ρ. 圖 3-10、線性分割最佳超平面的基本概念. 如 果 需 要 將 非 線 性 的 資 料 加 以 分 類 , 可 採 用 核 心 函 數 ( kernel. function)來改變資料型態,其主要的概念是將輸入資料由原先的低維度 空 間 (low dimensional) 藉 由 核 心 函 數 的 轉 換 對 映 到 高 維 度 空 間 (high. dimensional)中,在高維度空間中就可將原本線性不可分割的資料使用線 性分割,也就是說核心函數是將非線性的資料改為線性資料之後再行分 類,核心函數的選擇和核心參數的決定會對結果造成影響。 給 定 兩 個 類 別 的 訓 練 向 量 xk ∈ R n , k = 1,..., m , 標 籤 向 量 y ∈ R m , yk ∈ {1, −1} ,支援向量機解決二次方程最佳問題: m 1 min wT w + C ∑ ξ k .......................................(3.81) w,b ,ξ 2 k =1. 其在 yk ( wT φ ( xk ) + b) ≥ 1 − ξ k , ξ k ≥ 0, k = 1,..., m 限制下,其中訓練資料是藉由函數. - 49 -.
(61) ψ 映射到高維度空間,且 C 是一個訓練誤差的懲罰參數值。對任一測試 實例 x,決定函數(decision function) ,也就是預測器為: f ( x) = sgn( wT φ ( x) + b). (3.82). 由於支援向量機的訓練需要核心函數 k ( x, x' ) = φ ( x)T φ ( x' ) ,本研究使用 放射狀基礎函數網路(radial basis function, RBF)為核心函數: 2. k ( x, x' ) = exp(−γ x − x' ). (3.83). 使用此核心函數,在支援向量機的模型裡有兩個參數需要設定,C 和 γ。 因此研究使用網格搜尋(grid search)演算法來輔助找尋最佳參數值。演 算法說明如下:. 1. 假 設 在 (C,γ) 參 數 對 的 一 個 網 格 空 間 。 設 定 log 2 C ∈ {−5, −3,...,15} 和 log 2 γ ∈ {−15, −13,...,3} 。. 2. 將搜尋空間的每個參數對(C,γ),對訓練集進行 5 摺交叉驗證(5-fold cross validation)。 3. 選擇具有最低交叉驗證誤差率的參數對。 4. 使用最佳參數去產生模型作為預測器。. - 50 -.
(62) 4. 實驗結果. 4.1. 實驗說明 本研究實驗所使用的影像為成大醫院復健部,從 2005 年 1 月至 2006 年 3 月期間,患者的肩關節超音波影像。實際使用資料個數共 85 筆,包 括發炎 36 個,鈣化 11 個,斷裂 28 個,正常 10 個,其中由於正常的影 像較難以取得,僅取得 5 張,所以一張影像取兩個區域來取特徵值。 實驗大致上分三個階段,第一個階段會先將影像轉為灰階影像,再擷 取影像的特徵值,並將特徵資料正規化;第二個階段為特徵選取,利用 最大交互訊息法與 F-score 法進行特徵選取;第三階段為影像分類,放射 狀基礎函數網路使用之工具為 QuickRBF[17],支援向量機使用工具為. libsvm[6],使用最大交互訊息法與 F-score 法選出的特徵進行實驗。並且 使用 5 摺交叉驗證(5-fold cross validation) ,也就是將所有資料集分為互 斥的 5 等分,每份輪流當測試資料,某一份當測試資料時,剩下的就當 訓練資料。最後比較不同組合之結果。 接下來 4.2 為特徵選取結果。4.3 比較交互訊息法與 F-score 法,以及 使用全部特徵值對放射狀基礎函數網路之分類正確率;4.4 比較交互訊息 法與 F-score 法,以及使用全部特徵值對支援向量機之分類正確率;4.5. - 51 -.
(63) 綜合比較放射狀基底網路與支援向量機之分類正確率。. 4.2. 使用最大交互訊息法與 F-score 法進行特徵選取 第一階段用不同特徵擷取的方法擷取影像的特徵:. 1. 紋路特徵編碼法(texture feature coding method) 特徵值包括:(1)粗糙度(Coarseness)、(2)平滑度(Homogeneity)、(3)平 均數值 (Mean Convergence) 、 (4) 碼變異數 (Code Variance) 、 (5) 碼熵. (Code Entropy)、(6)發生長度密碼(Code Run Length Density)、以及(7) 正則性(Code Regularity),共取 7 個特徵值。. 2. 灰階明亮度相互關係矩陣(gray-level co-occurrence matrix,GLCM) 設定參數為距離等於 1,角度等於 0°。擷取出的特徵值包括: 、(2)對比度(Contrast) 、(3) (1)二階度動量(Angular Second Moment) 相關性(Correlation)、(4)平方和(Sum of Squares)、(5)逆差異動量 (Inverse Difference Moment) 、(6)總和平均(Sum Average) 、(7)總和 變異(Sum Variance) 、(8)和熵(Sum Entropy) 、(9)熵值(Entropy)、. (10)差變異(Difference Variance) 、(11)差熵值(Difference Entropy)、 (12) 相關性的資訊量測(Information Measures of Correlation) 、及(13) 最大相關係數(Maximal Correlation Coefficient)共 13 個特徵值。. - 52 -.
(64) 3. 紋路頻譜(texture spectrum) (1)黑白對稱性(Black-white symmetry)、(2)幾何對稱性(Geometric symmetry ) (3)方向性的程度( Degree of direction)、 (4)水平方向性 ( Micro-horizontal structure, MHS )、 (5) 垂直方向性( Micro-vertical. structure, MVS )、 (6) 對角線 1 方向性( Micro-diagonal 1 structure, 、(7)對角線 2 方向性(Micro-diagonal 2 structure, MDS2) 、及 MDS1). (8)Central symmetry(中央對稱性),共 8 個特徵值。 4. 統計特徵矩陣(Statistical Feature Matrix) (1) 粗 糙 度 (Coarseness) 、 (2) 對 比 度 (Contrast) 、 及 (3) 週 期 性 (Periodicity),共 3 個特徵值。 5. 碎型維度(fractal dimension) 共取出 3 個碎形維度特徵值 以上總共取出 34 個特徵值,接著第二階段中,將這些特徵值正規化, 正規化的方式,是以屬於該特徵的每個資料減去該特徵資料的平均值, 再除以該特徵資料之標準差。並使用最大交互訊息法選取 7 個特徵,為 全部 34 個特徵值中的第 13、14、3、9、17、18、和 15 個。其中選出的 分別是:灰階明亮度相互關係矩陣之中的:(6)總和平均(Sum Average) 和(7)總和變異(Sum Variance) ;以及紋路特徵編碼法中的:(3)平均數值. (Mean Convergence);再來是灰階明亮度相互關係矩陣中的:(2)對比度、. - 53 -.
(65) (10)差變異(Difference Variance),(11)差熵值(Difference Entropy),以 及(8)和熵(Sum Entropy)以上共 7 個特徵維度。 接著先將全部特徵值正規化到-1~+1 之間,再使用 F-score 法選取前 7 個特徵,為全部 34 個特徵值中的第 14、13、3、4、9、和 11 個。其中選 出的分別是灰階明亮度相互關係矩陣之中的:(7)總和變異(Sum Variance) 和(6)總和平均(Sum Average) ;紋路特徵編碼法中的:(3)平均數值(Mean. Convergence)和(4)碼變異數(Code Variance);灰階明亮度相互關係矩陣中 的(2)對比度(Contrast)、(4)平方和(Sum of Squares)、和(10)差變異 (Difference Variance)。特徵選取法之結果比較整理如表 4-1。. 最大交互訊息法. F-score 法. 1. 13. GLCM-(6)總和平均. 14.GLCM-(7)總和變異. 2. 14.GLCM-(7)總和變異. 13.GLCM-(6)總和平均. 3. 3. TFCM-(3)平均數值. 3. TFCM-(3)平均數值. 4. 9. GLCM-(2)對比度. 4. TFCM-(4)碼變異數. 5. 17. GLCM-(10)差變異. 9. GLCM-(2)對比度. 6. 18. GLCM-(11)差熵值. 11.GLCM-(4)平方和. 7. 15. GLCM-(8)和熵. 17.GLCM-(10)差變異. 排名. 表 4-1、最大交互訊息法與 F-score 法之特徵選取結果比較表. - 54 -.
(66) 可以看出不管使用交互訊息法還是 F-score 法,前 3 個都是相同的特 徵值,為灰階明亮度相互關係矩陣之中的總和變異、總和平均、和紋路 特徵編碼法中的平均數值,可見這 3 個特徵值有較強的分辨力。此外, 灰階明亮度相互關係矩陣中的對比度以及差變異,亦同時出現在兩個方 法的前 7 個中,應該也有不錯的分辨力。. 4.3. 放射狀基礎函數網路實驗 使用 QuickRBF 進行放射狀基礎函數網路實驗,將特徵選取後的特徵 值正規化後,進行 5 摺交叉驗證。在決定隱藏層中心數目的步驟,本實 驗將程式設定為從 1 測試到 69,也就是每摺訓練集之數目,做完 5 摺後 再平均 5 摺之正確率,找出最佳結果。. 4.3.1. 最大交互訊息法與放射狀基礎函數網路實驗結果 使用最大交互訊息法,找出 7 個最佳特徵子集,再依序分別用前 3、. 4、5、6、和 7 個最佳特徵以 QuickRBF 分類。結果如表 4-2 與圖 4-1 所 示,前 3 個特徵正確率為 67.5%,前 4 個為 70%,前 5 個與前 6 個為 72.5%, 具有最佳之分類結果,前 7 個則是 71.25%次之。. - 55 -.
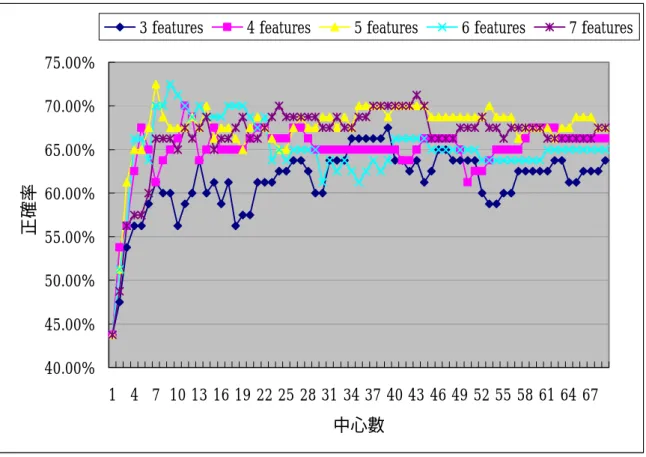
(67) 特徵數. 3. 正確率 67.50%. 4. 5. 70.00%. 6. 7. 72.50% 72.50%. 71.25%. 表 4-2、最大交互訊息法選出之特徵以放射狀基礎函數網路分類結果. MI + RBF 73.00%. 正確率. 72.00% 71.00% 70.00% 69.00% 68.00% 67.00% 66.00% 65.00% 3. 4. 5. 6. 7. 特徵數. 圖 4-1、最大交互訊息法選出之特徵以放射狀基礎函數網路分類結果. 而隱藏層的中心數整理如表 4-3,在 3 個特徵值時,中心數為 39 有 最佳正確率,前 4 個特徵值時,最佳中心數為 11,前 5 個時為 7,前 6 個為 9,前 7 個為 43。全部中心數目之比較則如圖 4-2 所示。. 特徵數. 3. 4. 5. 6. 7. 中心數. 39. 11. 7. 9. 43. 表 4-3、交互訊息法選出之特徵與放射狀基礎函數網路隱藏層中心數比較. - 56 -.
(68) 中心數越少,放射基礎函數網路所需的運算量也會越低,因此希望能 以最少的特徵值與中心數,達到最高正確率。根據表 4-2 所示,前 5 個 與前 6 個皆具有最高正確率,不過 5 個特徵數較 6 個特徵數少,而 5 個 特徵所需中心數為 7 也較 6 個特徵中心數的 9 來的少。因此使用最大交 互訊息法所取的前 5 個特徵,在放射狀基礎函數網路有最佳的效果。. 3 features. 4 features. 5 features. 6 features. 7 features. 75.00% 70.00%. 正確率. 65.00% 60.00% 55.00% 50.00% 45.00% 40.00% 1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 中心數. 圖 4-2、最大交互訊息法選出之特徵與放射狀基礎函數網路隱藏層中心數 比較. 將最大交互訊息法所選出的 5 個特徵值,以放射狀基礎函數網路,設. - 57 -.
(69) 定中心數 7 的 5 摺的分類結果整理成混淆矩陣(confusion matrix) 。如表. 4-4:. 預測. 實 際. 1 2 3 4. 1. 2. 3. 4. 平均. 31 2 6 3. 0 8 0 4. 4 0 19 3. 0 0 0 0. 88.57% 80.00% 76.00% 0.00%. 表 4-4、最大交互訊息法 5 個特徵,設定 7 個中心以放射狀基礎函數網路 分類結果之混淆矩陣. 實驗結果的平均正確率,發炎為 88.57%、鈣化 80%、斷裂 76%,然 而正常的之平均正確率是 0%,以最大交互訊息法選出來的特徵似乎無法 辨識正常的情況。. 4.3.2. F-score 法與放射狀基礎函數網路實驗結果. F-score 使用之工具為 fselect.py,為開發給 libsvm 之特徵選取工具。 程式會將特徵值依重要程度排序,本實驗取前 7 個特徵值以便與交互訊 息法比較,結果如表 4-5 及圖 4-3 所示,前 3 個為 67.5%,前 4 個為. 68.75%,前 5 個為 67.5%,前 6 個為 70%是最高值,前 7 個則是 68.75%。. - 58 -.
數據
+7
Outline
相關文件
Promote project learning, mathematical modeling, and problem-based learning to strengthen the ability to integrate and apply knowledge and skills, and make. calculated
Now, nearly all of the current flows through wire S since it has a much lower resistance than the light bulb. The light bulb does not glow because the current flowing through it
Then they work in groups of four to design a questionnaire on diets and eating habits based on the information they have collected from the internet and in Part A, and with
The case where all the ρ s are equal to identity shows that this is not true in general (in this case the irreducible representations are lines, and we have an infinity of ways
This kind of algorithm has also been a powerful tool for solving many other optimization problems, including symmetric cone complementarity problems [15, 16, 20–22], symmetric
For the data sets used in this thesis we find that F-score performs well when the number of features is large, and for small data the two methods using the gradient of the
• If we use the authentic biography to show grammar in context, which language features / patterns might we guide students to notice and help them infer rules or hypothesis.. •
• We will look at ways to exploit the text using different e-learning tools and multimodal features to ‘Level Up’ our learners’ literacy skills.. • Level 1 –
