區域性設計雨型之建立及應用
ESTABLISHMENT AND APPLICATION OF REGIONAL
DESIGN HYETOGRAPHS
Abstract
The purpose of this paper is to establish regional design hyetographs for facilitating the determination of design hyetographs at locations without gauges. First, the design hyetographs at 34 locations in northern Taiwan are analyzed using the principal components analysis and the cluster analysis. The principal components analysis shows that there are five dominant factors. The cluster analysis indicates that the time to peak rainfall has the largest influence on hyetographs. It also shows that hyetographs in northern Taiwan can be classified into three groups. Finally, the areas for these three groups of hyetographs are delineated for northern Taiwan. Then the regional design hyetographs are proposed. Actual applications of the regional design hyetographs are also performed to investigate the influence of land use on the runoff.
Keywords: design hyetograph, principal components
analysis, cluster analysis.
摘 要 本文之主要目的在於建立區域性設計雨型,以便利未 設站地區設計雨型之決定。文中首先針對台灣北部地區 34 個雨量站之單站設計雨型進行分析,先以主成份分析找出 單站設計雨型之數個最顯著因子,再以群集分析法進行分 類。主成份分析顯示有 5 個顯著的主成分。在分類上得知, 各雨量站雨型受到尖峰時間的影響最大,另知台灣北部地 區可分為三群。最後根據分類結果,劃定設計雨型之均一 區,進而綜合該均一區中各站雨型得到該均一區之區域性 設計雨型。在工程使用上,可依其工程地點,查圖即可得 其設計雨型,使用上甚為便利。本文並將區域性設計雨型 實際應用於降雨—逕流模擬中,探討開發度對於逕流量之 影響。 關鍵詞: 設計雨型、主成分分析、群集分析。
1. 前 言
在水資源相關工程中之規劃與設計中,如水庫設 計、防洪工程、排水設計及水土保持規劃等,都需以 降雨—逕流模式來模擬降雨—逕流的狀況,以得到如 設計洪水等設計所需的資料。降雨資料為模式之輸入 值,經過模擬之後,便可得到流量歷線為系統之輸出 值。其中所需之降雨資料之型態即為設計降雨。設計 降雨代表某重現期距與設計延時狀況下之降雨,是由 設計降雨深度和設計雨型兩部分所組成,其中降雨深 度可經由頻率分析求得,其結果通常以降雨強度-延時 -頻率 (Intensity-Duration-Frequency,簡稱 IDF) 曲線 或降雨深度-延時-頻率 (Depth-Duration-Frequency, 簡稱 DDF) 曲線表示之。此結果需代入一時間分佈函 數,以得到降雨量在時間上的分佈情形,此分佈函數 便稱為設計雨型。 傳統上,對於未設站地區的設計雨型通常以距離 該地最近的雨量站之設計雨型來代表,然此一做法的 合理性則值得商榷。當工程進行地點離現有測站甚遠 時,便無法直接得知該工程地點的設計雨型。為解決 此一問題,本文提出區域性的設計雨型,使得工程使 用上有一方便及合理的使用值。關於單站設計雨型相關研究始於 Keifer and Chu [1] (其法簡稱 Chicago method),而後 Huff [2] 研究 Illinois 地區許多降雨事件時雨量資料,針對其無因次 化後,依其尖峰時間發生時間之長短區分為五分點,
林 國 峰
*王 俊 明
**高 士 傑
†Gwo-Fong Lin Chun-Ming Wang Shih-Chieh Kao
*教授 **博士班研究生 †碩士 國立台灣大學土木工程學系 *
Professor **Graduate student †Master Department of Civil Engineering, National Taiwan University, Taipei, Taiwan 10617, R.O.C.
用以探討雨型之特性。而根據其結果顯示,長延時暴 雨之尖峰降雨主要集中在第四分點 (即無因次總降雨 時間之 80%) 處,短延時暴雨之尖峰降雨則集中在第 一與第二分點 (無因次總降雨時間之 20%與 40%) 處。 Pilgrim 與 Cordery [3] 則考慮無因次化雨型經由 排序後,由各時刻級序之平均來建立雨型。Bras and Rodriguez-Iturbe [4] 與 Woolhiser and Osborn [5] 也 採用無因次化雨型的概念,研究降雨量在時間上的分 佈 。 Yen and Chow [6] 提出三角形無因次雨型。 Koutsoyiannis and Foufoula-Georgiou [7] 與 Garcia- Guzman and Aranda-Oliver [8] 提出以序率方法建立 暴雨雨型。國內有關雨型之研究則有葉弘德與韓洪元 [9] 以無因次尖峰對齊法,用以建立台北地區之短延 時設計暴雨雨型。鄭克聲等 [10],以隨機碎形特性與 高斯馬可夫歷程,建立設計暴雨之無因次雨型。對於 設 計 雨 型 決 策 模 式 或 評 估 之 研 究 而 言 , 林 國 峰 等 [11~14] 利用組合法、平均法與級序平均法等方法, 探討研究區域之設計雨型,並採用降雨重心誤差、尖 峰降雨誤差與尖峰時間誤差等統計參數進行設計雨 型之評估。 在水文屬性均一區劃分的研究中,NERC [15] 之 研究中選擇面積、年平均雨量、機率雨量、主流坡度、 河川頻率、土壤含水量等變量來定義均一區。Mosely [16] 與 Bhaskar and O’Conor [17] 以年平均比洪水量 及變異係數為變量,利用群集分析將相似洪水反應之 集水區歸納為同類。Burn [18] 加入測站之相對位置 為分類變量以期分類結果能結合地理位置。Guttman [19] 利用位置經度、緯度、高程、年平均降雨量、連 續最小二個月降雨總量對連續最大二個月降雨總量 之比值及分別之起始月份等七個變量來描述降雨並 定義乾旱區。 在國內,易任 [20] 以平均降雨量數列為變量, 利用主成分分析及群集分析探討台灣年降雨量空間 分佈之群集特性。楊道昌與游保杉 [21] 取九個百分 比延時流量值,利用主成分分析及群集分析劃分流量 延時曲線均一區。游保杉與陳嘉榮 [22] 選擇測站降 雨延時曲線、年平均雨量、變異係數及測站位置等變 量,利用主成分分析、群集分析及模糊群集分析理論 探討降雨-延時曲線之群集特性,期能合理劃分測站之 空間屬性均一區。左承修 [23] 在研究區域洪水頻率 分析中,亦導入群集分析的方法,有助於精確地推估 在特定重現期距下之洪水。
2. 單站設計雨型
本文擬建立之區域性設計雨型需根據單站設計 雨型之資料而發展。如前所述,建立單站設計雨型之 方法很多,通常各國或地區或主管單位皆有建議之雨 型。我國水利主管單位水資源局 (現稱水利署) 在其 推動之水文技術規範 [24,25]中,所採用之單站設計 雨型為簡單尺度不變性高斯馬可夫 (Simple Scaling Gauss-Markov,簡稱 SSGM) 雨型。SSGM 單站雨型 為一符合隨機碎形特性與高斯馬可夫歷程的無因次 雨型 [26,27]。此雨型以非定常性一階高斯馬可夫歷 程 (nonstationary first-order Gauss-Markov process) 描述無因次年最大值事件,具備馬可夫歷程特性,且 具有最大概似度,其優點為:(1) 符合歷史尖峰降雨 (量與時間) 之統計特性,(2) 該雨型降雨量之時間分 佈與年最大暴雨事件之歷程特性一致,(3) 該雨型比 其它方法所建立之雨型更有變化性,(4) 雨型可適用 於不同延時之設計暴雨,(5) 建立雨型所使用之降雨 事件與建立降雨強度延時-頻率曲線所使用之降雨 事件大致相同。 SSGM 單站雨型之橫軸 (時間軸) 為無因次,計 有二十四時段;其縱軸亦為無因次,單位為百分比降 雨量。換言之,SSGM 雨型係由第一至第二十四時段 之百分比降雨量 x1、x2、x3、…、x24 所組成,其中 x1、 x2、x3、…、x24 因站而異,建立過程甚為複雜,詳見 文獻 (許恩菁,1999;Cheng et al., 2001)。由於 SSGM 雨型為我國水利主管單位之水文技術規範所採用,本 文便以各站之 SSGM 雨型為基礎,以建立區域性設計 雨型。3. 設計雨型主成分分析
3.1 主成分分析理論
主成分分析是以變數中的少數主要成分表示多 種變數之統計方法。於多變量分析中,通常變數間彼 此存某種程度之相關性,使得觀測數據具有某種程度 之重複訊息。假設設計雨型具有 p 個分量 (即 p 個時 段之降雨百分比),所有雨量站之第一個分量構成向量 X1,所有雨量站之第二個分量構成向量 X2,依此類推 所有雨量站之第 p 個分量構成向量 Xp。吾人可將其視 為一 p 維的向量 (X1, X2, …, Xp),以主成分進行分析, 可 在 保 留 大 部 分 原 有 變 數 特 性 下 而 降 低 變 數 之 維 度,且各成分間相互獨立,故可不重複表達大部分資 料之特性。主成分分析即將原先 p 維座標系統轉換成 一個新的座標系統。此系統具有兩個重要特性:(1) 新 系統各軸間彼此獨立且正交 (orthogonal);(2) 每一主 成分均說明了部分的原始變量,且可依佔有量 (重要 性) 之多寡依序排列。 另外,由主成分之因子負荷 (factor loading) 可知 其與原始變量間之相關程度。故主成分分析具有下列 優點:消除變量間之相關性、降低變數維度及萃取重要訊息、提供適當之現象解釋等。主成分分析之理論 如下: 觀測向量 X 具有 p 個變數,每一變數具有 n 項 (站) 觀測資料,以矩陣可表示為: 1 11 12 1 2 21 22 2 1 2 n n p p p pn X x x x X x x x X x x x ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥ ⎢= ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ X " " # # # % # " (1) 其中 xij代表第 i 變數第 j 觀測資料,i = 1, 2, …, p,j = 1, 2, …, n。變數之平均值向量為: 1 2 [ ( ) ( ) ( )] T X E X E X E Xp μ = " (2) 不同變數間之協變異數向量為Σ,其為一對稱矩陣: 1 1 2 1 2 1 2 2 1 2 E[( ) ( ) ]
Var ( ) Cov ( , ) Cov ( , ) Cov ( , ) Var ( ) Cov ( , )
Cov ( , ) Cov ( , ) Var ( )
T X X p p p p p X X X X X X X X X X X X X X X Σ = − μ − μ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ = ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ X X " " # # % # " (3) 可對Σ進行正交分解為: T Σ =C ΛC (4) (4)式中Λ 為對角矩陣,其對角線上之元素為Σ 之特徵值λ1, λ2, …, λp。C 為 p × p 維正交矩陣,且滿 足 C⋅Ct = I,其第 j 行即為相對於λj特徵值之特徵向 量。 1 2 0 0 0 0 0 0 p λ ⎡ ⎤ ⎢ λ ⎥ ⎢ ⎥ Λ = ⎢ ⎥ ⎢ ⎥ λ ⎢ ⎥ ⎣ ⎦ " " # # % # " (5) 11 12 1 21 22 2 1 2 1 2 [ ] p p p p p pp c c c c c c C C C C c c c ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥= ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ " " " # # % # " (6) 轉軸後之主成分向量 Y 表示為: 1 11 12 1 2 21 22 2 1 2 n n p p p pn Y y y y Y y y y Y y y y ⎡ ⎤ ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ =⎢ ⎥ ⎢= ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ ⎣ ⎦ Y " " # # # % # " (7) 主成分向量 Y 與原始向量 X 間存在著線性轉換關係: 1 11 1 12 2 1 2 21 1 22 2 2 1 1 2 2 j j j p pj j j j p pj pj p j p j pp pj y c x c x c x y c x c x c x y c x c x c x = + + + ⎧ ⎪ = + + + ⎪ ⎨ ⎪ ⎪ = + + + ⎩ " " # " (8) = ⋅ Y C X (9) 主成分向量 Y 之協變異數矩陣為: Cov ( ) [( ) ( ) ] [( ) ( ) ] [ ( ) ( ) ] [( ) ( ) ] T Y Y T X X T T X X T T X X T E E C C E E = − μ − μ = − μ − μ = − μ − μ = − μ − μ = Σ Y Y Y CX CX C X X C C X X C C C (10) 代入(4)式: Cov ( )Y =CCTΛCCT = Λ (11)
3.2 分析結果
本文計應用北部地區共 34 個雨量站之 SSGM 雨 型,將各站之雨型視為一具有 24 個變數的觀測值。 進行主成分分析結果如表 1 所示。由表 1 可知設計雨 型的前 5 個主成分已經解釋了 88.76%的變異特性。 表 1 設計雨型主成分特徵值及各成分百分比表Table 1 Results of principal component analysis of design hyetographs 主成分序 特徵值 解釋百分比 累積解釋百分比 1 45.913 51.56 51.56 2 17.228 19.35 70.91 3 6.746 7.58 78.49 4 5.058 5.68 84.17 5 4.085 4.59 88.76 6 2.698 3.03 91.79 7 2.047 2.30 94.09 8 1.523 1.71 95.80 9 0.986 1.10 96.90 10 0.815 0.92 97.82 11 0.435 0.49 98.31 12 0.360 0.40 98.71 13 0.246 0.28 98.99 14 0.163 0.18 99.17 15 0.156 0.17 99.34 16 0.146 0.17 99.51 17 0.110 0.12 99.63 18 0.088 0.10 99.73 19 0.079 0.09 99.82 20 0.052 0.06 99.88 21 0.048 0.05 99.93 22 0.040 0.05 99.98 23 0.021 0.02 100 24 0.000 0.00 100
4. 設計雨型群集分析
4.1 群集分析理論
群集分析是一種能根據資料變數之相似性與相 異性,客觀地進行分類分群的邏輯程序。其針對某種 指定之特性,將欲進行分類之資料依此特性劃分為多 個 群 集 , 使 同 一 群 集 中 具 有 高 度 之 均 一 性 (homogeneity) , 不 同 群 集 彼 此 具 有 明 顯 的 異 質 性 (heterogeneity)。首先將 n 個樣本各自視成一群,計算 彼此間之相似性測度,並且把具有最小測度的兩個樣 本合併成新的一群。重複分群作業,直到所有樣本都 歸為一類為止。 分群所根據之變數間多半具有不同之尺度及重 要性,為使距離合理化,可由標準化處理,以消除變 數間對分群時不同之權重關係: 'ij ij j j y y y s − = (12) 式中 i = 1, 2, …, p,j = 1, 2, …, n,其中 1 1 n ij j i y y n = =∑
(13) 1 2 2 1 1 ( ) 1 n j ij j i s y y n = ⎡ ⎤ =⎢ − ⎥ − ⎢ ⎥ ⎣∑
⎦ (14) 距離之量度為群集分析最重要的一環。距離量度 的方法有很多種,其中最常用的為歐式距離,其定義 如下: 1 2 2 1 || || ( ) N i j ik jk k Y Y y y = ⎡ ⎤ − =⎢ − ⎥ ⎢ ⎥ ⎣∑
⎦ (15) 其中 yik代表第 i 個樣本中第 k 個變數。在距離計算中, 係假設變量間彼此獨立且尺度相同。但原始變數往往 並非如此,考慮到此一影響,應用主成分建立距離, 便可使變數間為正交軸。又因轉換後之特徵值 (即變 異數),可以代表主成分之變異情形(即顯著與否)。所 以考慮此二特性後,即可提出改良後之歐氏距離公式 [28]: 1 2 1 2 1 || || ( ) n i j k ik jk k Y Y λ − y y = ⎡ ⎤ − =⎢ − ⎥ ⎢ ⎥ ⎣∑
⎦ (16) 如此便可使得距離是架構在一正交空間中且各主成 分之尺度相當。 群集分析有相當多不同的方法,本文採用華德法 又稱離差平方和法 (squares sum of dispersion method) 進行分群。本法是基於方差分析概念,以離差平方和 為相似性測度。目的是使同類樣本之間離差平方和最 小,類與類間的離差平方和最大。本文採用改良歐氏 距離作為距離量度的標準。在進行分群的過程中,以 主成分分析後的結果進行分群。因此在華德法中各離 差平方和的計算均以改良歐氏距離為準。所有距離之 計算均以 (16) 式為準。 假定已將具有 m 個變量的 n 個樣本分成 T 類,xikt 表第 t 類第 i 個樣本之第 k 個變量,nt表示第 t 類樣本 之個數,Xkt表示第 t 類第 k 個變量的重心,則第 t 類中樣本之離差平方和為: 2 1 1 (|| ||) t n m kt t ikt i k S Y Y = = =∑∑
− (17) 其中 1 1 ( ) t n kt ikt t i X X n = =∑
(18) T 個種類之離差平方和為: 2 1 1 1 1 (|| ||) t n T T m kt t ikt t t i k S S Y Y = = = = =∑ ∑∑∑
= − (19) 其中|| ||表距離的計算,需代入(16)式。華德法在合併 群集時,將 S 增加最小之二群予以合併。亦即在群與 群合併時,自全部群集兩兩配對的組合中,選出離差 平方和 S 最小的配對組合予以合併。4.2 分析結果
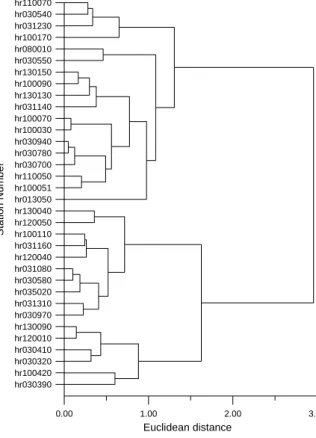
本文以各雨型主成分向量為依據,進行分類之工 作。首先由於各主成分間具有不同的尺度,所以必須 先代入 (12),進行標準化處理。進行群集分析時,選 用改良後之歐氏距離,建立各雨型間之相互關係,代 入 (16) 即可得。以群集分析之華德法,對相互關係 進行分群的工作,可得分群之樹狀圖如圖 1 所示。本 文並發現,在同一群中的設計雨型其尖峰時間 tp大都 相同。各測站之 SSGM 雨型尖峰時間在 10-16 間分 佈,分三群的結果指出,tp多以 10-12、13-14、14-16 的類別,各自分成一群,可見得對於此無因次雨型, 影響分群最多的因素是到達尖峰降雨的時間。5. 區域性雨型之建立
5.1 設計雨型均一區之劃分
某區域之雨型分為 n 群,空間中任一點必屬於其 中任一群。假設區域中有 m 個已知其類別之點,其座 標為 (x1, y1), (x2, y2), …, (xm, ym)。區域中任一點座標 為 (x,y),定義該點為第 a 群 (1≤a≤n) 的機率為 Pa (x, y)。若 Pa為 P1, P2, …, Pn其中最大者,則定義該點屬 於第 a 群。Pa在此並非指統計上真實的機率,而是一 種概念,是用以比較其屬於那一種類別的比較值。 計算 Pa時,先設定一個函數 fi,用以代表第 i 個 已知點是否屬於第 a 群,1 代表隸屬,0 代表不隸屬: 1 0 i f = ⎨⎧ ⎩ i a i a ∈ ∉ i=1, 2,",m (20) 計算 (x, y) 至 (x1, y1), (x2, y2), …, (xm, ym)的距離為 d1, d2, …, dm: 2 2 ( ) ( ) i i i d = x−x + −y y (21) 取 1/di 2 (1≤i≤m) 為權重因子,並調整權重因子之相對 大小使得Σwi =1: 2 2 1 1 1 i i m i i d w d = =∑
(22) 則任意點 (x, y) 上屬於第 a 群的機率值便為: 1 ( , ) m a i i i P x y w f = =∑
(23) 比較 (x, y) 上共 n 群之機率值,選定最大者為該點的 劃分之類別,將全區域劃分網格點,計算每一點之類 別,便可劃分出均一區。本文將分類完成之結果,依 此法劃分設計雨型均一區,分類結果如圖 2 所示。5.2 區域性設計雨型之建立
在均一區劃分後,接下來需將同類型的各站雨型 進一步結合為區域性雨型。為使運算方便及考慮其一 致性,若今有歸類為同一群之 n 個主成分 {y11, y21, …, yp1}, {y12, y22, …, yp2}, …, {y1n, y2n, …, ypn},以平均的 方式產生其代表之主成分: 1 1 n ij i j y y n = =∑
i=1, 2,",p (24) 0.00 1.00 2.00 3.00 Euclidean distance hr030390 hr100420 hr030320 hr030410 hr120010 hr130090 hr030970 hr031310 hr035020 hr030580 hr031080 hr120040 hr031160 hr100110 hr120050 hr130040 hr013050 hr100051 hr110050 hr030700 hr030780 hr030940 hr100030 hr100070 hr031140 hr130130 hr100090 hr130150 hr030550 hr080010 hr100170 hr031230 hr030540 hr110070 St at ion Nu mb e r 圖 1 台灣北部地區分群樹狀圖Fig. 1 Dendrogram of rainfall stations in northern Taiwan
圖 2 台灣北部地區設計雨型均一區
Fig. 2 Homogeneous areas of design hyetographs in northern Taiwan
再以 Y 表示此代表之主成分矩陣,X 表示所欲求得之 區域性雨型,針對 (9) 做反轉換的動作:
1
如此即可得到該分區同類型各設計雨型之代表性區 域性設計雨型,如圖 3 所示。
6. 區域性雨型之應用
得到台灣地區北部區域性設計雨型後,本文以台 北市山坡地區之數個流域為對象,應用區域性雨型於 實際的降雨—逕流模擬中,並探討開發度對於逕流量 的影響。由於篇幅所限,此處僅以內雙溪流域為代表 例。由圖 2 可知內雙溪水文測站座落於第 2 類水文均 一區中,因此其設計雨型如圖 3 所示之第 2 類雨型。 本文所採用之設計降雨,其延時為 24 小時,而重現 期距則有兩種:二百年和一百年。 由一百年重現期距 24 小時延時之降雨深度等值 線圖 [25] 可查得內雙溪水文測站之設計降雨深度為 870 mm。而由二百年重現期距 24 小時延時之降雨深 度等值線圖 [25] 則查得內雙溪水文測站之設計降雨 深度為 1,000 mm。結合設計降雨深度與圖 3 之區域性 雨型,可得流域一百年重現期距 24 小時延時和二百 年重現期距 24 小時延時之設計降雨組體圖,如圖 4 所示。 本文開發度之定義以不透水面積百分比表示。以 HEC-1 的運動波法模擬降雨—逕流的情形,使用之參 數則如表 2 所示。經由降雨—逕流模擬可得到流域在 各種不同開發度及不同設計降雨下之逕流歷線,進而 0 2 4 6 8 10 12 14 16 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 時間 (無因次) 總降 雨百分比 第一類雨型 第二類雨型 第三類雨型 圖 3 台灣北部地區區域性雨型Fig. 3 Regional design hyetographs in northern
Taiwan 0 50 100 150 200 250 300 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 時間 (hour) 降雨深度 (m m ) 200年重現期距100年重現期距 圖 4 內雙溪一百年和二百年重現期距、24 小時 延時設計降雨組體圖
Fig. 4 100-yr 24-hr and 200-yr 24-hr design hyeto- graphs for Nei-Shuang Creek Basin
分析逕流歷線可比較不同開發度及不同設計降雨下 洪峰量和總流量之變化。圖 5 為內雙溪在不同開發度 及兩種重現期距設計降雨下,洪峰增量和總流量增量 之變化情形。由圖 5 可知洪峰流量的增加量隨開發度 之增加而增加,而總流量的增加量亦隨開發度之增加 而增加。比較得知,開發度對於總流量的影響較洪峰 流量來得大。然由於研究流域面積小,開發度對於洪 峰流量及總流量之影響並不顯著;而設計降雨的重現 期距對於洪峰流量及總流量之影響則較為顯著。
7. 結 論
本文之主要結論如下: 1. 對各站設計雨型先進行主成分分析,可得到設計雨 型之主成分因子。以此主成分因子進行分群作業, 0% 1% 2% 3% 4% 5% 6% 7% 8% 9% 10% 0% 5% 10% 15% 20% 25% 30% 35% 開發度 增量 100年洪峰流量 200年洪峰流量 100年總流量 200年總流量 現狀 圖 5 內雙溪流域不同開發度及兩種重現期距之 設計降雨下洪峰流量增量和總流量增量之 變化Fig. 5 Influence of land use and design rainfall on increments of peak flow and total discharge for Nei-Shuang Creek Basin
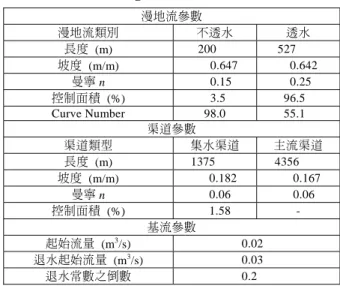
表 2 用於內雙溪流域降雨—逕流模擬之參數
Table 2 Rainfall-runoff model parameters for Nei-Shuang Creek Basin
漫地流參數 漫地流類別 不透水 透水 長度 (m) 200 527 坡度 (m/m) 0.647 0.642 曼寧 n 0.15 0.25 控制面積 (%) 3.5 96.5 Curve Number 98.0 55.1 渠道參數 渠道類型 集水渠道 主流渠道 長度 (m) 1375 4356 坡度 (m/m) 0.182 0.167 曼寧 n 0.06 0.06 控制面積 (%) 1.58 - 基流參數 起始流量 (m3/s) 0.02 退水起始流量 (m3/s) 0.03 退水常數之倒數 0.2
由於因子彼此間互為獨立,可以確保因子間無共線 性的情形發生,這樣可避免分析時有重複的資訊被 估計,增加分析結果的正確性。 2. 由台灣北部地區各雨量站之無因次 SSGM 設計雨 型之主成分分析結果,可以看出其是由五個顯著的 主成分變數控制,在參數數目上優於一些傳統上使 用之雨型,如三角形雨型以及利用 IDF 套配各樣 公式的雨型等等,使得雨型之變化性增多,可用以 適切的描述符合不同地區特性的雨型。 3. 在群集分析方面採用改良的歐氏距離,用以計算測 站間之相互關係,如此可避免人為主觀判斷主成分 的個數。 4. 由劃分完成的均一區圖中,可以發現有區域性的存 在,區域性是由各站雨型本身所顯現,可見雖然設 計雨型不同於一般降雨,但其仍有區域性的現象存 在。 5. 本文所建立之區域性設計雨型,在使用上,僅需按 圖查詢工程進行地點並找到其對應之雨型,即可使 用,在使用上相當方便。 另外在應用本文所建立之區域性雨型於實際之 降雨—逕流模擬,發現開發度對於總流量的影響較對 洪峰流量的影響來得大。又開發度和設計降雨重現期 距兩者中,以設計降雨重現期距對洪峰流量及總流量 之影響較為顯著。
參考文獻
[1] C. J. Keifer and H. H. Chu, “Synthetic storm pattern for drainage design,” Journal of the Hydraulics
Division, ASCE, Vol. 83, No. 4, 1957, pp. 1−25.
[2] F. A. Huff, “Time distribution of rainfall in heavy storms,” Water Resources Research, Vol. 3, No. 4, 1967, pp. 1007−1019.
[3] D. H. Pilgrim and I. Cordery, “Rainfall temporal patterns for design floods,” Journal of the
Hydraulics Division, ASCE, Vol. 101, No. 1, 1975,
pp. 81−95.
[4] R. L. Bras and I. Rodriguez-Iturbe, “Rainfall generation: A nonstationary time-varying multidimensional model,” Water Resources
Research, Vol. 12, No. 3, 1976, pp. 450−456.
[5] D. A. Woolhiser and H. B. Osborn, “A stochastic model of dimensionless thunderstorm rainfall,”
Water Resources Research, Vol. 21, No. 4, 1985, pp.
511−522.
[6] B. C. Yen and V. T. Chow, “Design hyetographs for small drainage structures,” Journal of the
Hydraulics Division, ASCE, Vol. 106, No. 6, 1980,
pp. 1055−1076.
[7] D. Koutsoyiannis and E. Foufoula-Georgiou, “A
scaling model of a storm hyetograph,” Water
Resources Research, Vol. 29, No. 7, 1993, pp.
2345−2361.
[8] A. Garcia-Guzman and E. Aranda-Oliver, “A stochastic model of dimensionless hyetograph,”
Water Resources Research, Vol. 29, No. 7, 1993, pp.
2363−2370. [9] 葉弘德、韓洪元,「台北市暴雨雨型之研究」, 台灣水利,第 38 卷,第 3 期,1990 年,第 36−49 頁。 [10] 鄭克聲、許恩菁、葉惠中,「具隨機碎形特性之 設計暴雨雨型」,台灣水利,第 47 卷,第 3 期, 1999 年,第 43−54 頁。 [11] 林國峰、張守陽、林民生,「台灣地區雨型之初 步研究」,國立台灣大學水工試驗所研究報告第 118 號,1991 年。 [12] 林國峰、張守陽、李汴軍,「台灣地區雨型之研 究(一)」,國立台灣大學水工試驗所研究報告第 144 號,1992 年。 [13] 林國峰、張守陽、李汴軍,「台灣地區雨型之研 究(二)」,國立台灣大學水工試驗所研究報告第 163 號,1993 年。 [14] 林國峰、張守陽、蕭長庚,「台灣地區雨型之研 究(三)」,國立台灣大學水工試驗所研究報告第 193 號,1994 年。
[15] Nature Environment Research Coucil (NERC),
Flood Studies Report, Vol. I and II, 1975.
[16] M. P. Mosley, “Delimitation of New Zealand hydrological regions,” Journal of Hydrology, Vol. 49, 1981, pp. 173−192.
[17] N. R. Bhaskar and C. A. O’Conor, “Comparison of method of residuals and cluster analysis for flood regionalization,” Journal of Water Resources
Planning and Management, Vol. 155, No. 6, 1989,
pp. 793−808.
[18] D. H. Burn, “Cluster analysis as applied to regional flood frequency,” Journal of Water Resources
Planning and Management, Vol. 115, No. 5, 1989,
pp. 567−582.
[19] N. B. Guttman, “The use of L-moments in determination a regional precipitation climates,”
Journal of Climate, 1993, pp. 2309−2325. [20] 易任,「主成分分析與群集分析應用於雨量空間 分佈之研究」,國科會專題報告研究計畫成果, 計畫編號:NSC79-0410-E002-06,1990 年。 [21] 楊道昌、游保杉,「台灣南部流域均一性之劃分」, 台灣水利,第 42 卷,第 2 期,1994 年,第 63−79 頁。 [22] 游保杉、陳嘉榮,「台灣北部區域雨量強度公式 之研究」,財團法人中興工程顧問社專案研究報
告,編號 SEC/R-HY-96-03,1996 年。 [23] 左承修,「區域洪水頻率分析之研究」,國立台 灣大學土木工程學研究所碩士論文,1997 年。 [24] 鄭克聲、王如意、林國峰、許銘熙、虞國興、游 保杉、李光敦,「水文技術規範之研訂」,水資 源局研究計畫報告,國立台灣大學生物環境系統 工程學系,2000 年。 [25] 鄭克聲、林國峰、虞國興、李光敦、王如意、許 銘熙、游保杉,「水文設計應用手冊」,水資源 局研究計畫報告,國立台灣大學生物環境系統工 程學系,2001 年。 [26] 許恩菁,「設計暴雨雨型序率模式之研究」,國 立台灣大學農業工程學研究所碩士論文,1999 年。
[27] K. S. Cheng, I. Hueter, E. C. Hsu and H. C. Yen, “A scale-invariant Gauss-Markov model for design storm hyetographs,” Journal of the American Water
Resources Association, Vol. 37, No. 3, 2001, pp.
723−735. [28] 黃俊英,多變量分析,華泰書局,台北市,1995 年。
林
國
峰
(Gwo-Fong Lin) 民國 43 年生,美國匹茲堡大學博士,現任國立台灣大學 土木工程學系教授。主要研究領域為:序率水文和水力學、計算水力學。王
俊
明
(Chun-Ming Wang) 民國 64 年生,國立成功大學水利工程學系學士、國 立台灣大學碩士,現為國立台灣大學土木工程學系博士研究生。主要研究領域為:序率 水文、類神經網路、遺傳演算法。高
士
傑
(Shih-Chien Kao) 民國 66 年生,國立台灣大學土木工程學系學士及碩士,現於美國普渡大學修讀博士學位。主要研究領域為:水文分析、水文統計。
收稿日期 91 年 4 月 17 日、修訂日期 91 年 10 月 29 日、接受日期 91 年 11 月 12 日 Manuscript received April 17, 2002, revised October 29, 2002, accepted November 12, 2002