國
立
交
通
大
學
資訊科學與工程研究所
碩
士
論
文
在異質雙核心處理器平台上研究實作 DSP 排程器
及動態精細分工的 H.264 編碼器
Design and Analysis of a DSP Scheduler and a Dynamically
Partitioned H.264 Encoder on Dual-Core Platforms
研 究 生:蘇郁淵
指導教授:蔡淳仁 教授
在異質雙核心處理器平台上研究實作 DSP 排程器及動態精細分工
的 H.264 編碼器
Design and Analysis of a DSP Scheduler and a Dynamically
Partitioned H.264 Encoder on Dual-core Platforms
研 究 生:蘇郁淵 Student:Yu-Yuan Su
指導教授:蔡淳仁 Advisor:Chun-Jen Tsai
國 立 交 通 大 學
資 訊 科 學 與 工 程 研 究 所
碩 士 論 文
A ThesisSubmitted to Institute of Computer Science and Engineering College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master in
Computer Science June 2006
Hsinchu, Taiwan, Republic of China
摘要
本論文的研究重點,是在異質雙核心平台上以視訊編碼為例,研究動態精細 工作分配法。視訊編碼演算法所需的計算量非常大。過去業界解決異質雙核心的 工作切割(partition)問題的方法,是以 profiling 的方式來測量一個應用程式的每一 個函式在 RISC 核心和 DSP 核心上運行的效率,然後再決定哪些函式要在 RISC 或 DSP 執行。因為 DSP 核心是為訊號處理運算而設計,使用 DSP 核心來運算會 比 RISC 核心的效率好,因此往往系統最終的設計會將多媒體或通訊實體層的工 作由 DSP 核心負責,而 RISC 核心負責流程控制和資料整合,這樣的做法,是屬 於靜態工作分配法。可是未來的多媒體系統會同時執行多項工作,當 DSP 核心 上實際運行的工作數量越多,由傳統靜態分工所設計出的應用程式只會一味地增 加 DSP 核心負擔。所以要在異質雙核心平台上達到最佳效能,不能只考慮應用 程式的計算特性的,還必須考慮到各核心實際運行的負載。因此本論文採用動態 精細分工的方式來設計系統,讓兩個核心互相協調溝通,根據實際運行的負載動 態地分配工作給各個核心。本論文並在 OMAP 5912 平台上,基於這個架構實作 出一個 DSP 排程器及 H.264 視訊編碼器的應用程式以驗證動態精細分工系統的效 能。Abstract
Most modern embedded multimedia devices today are built upon heterogeneous multiprocessor (HMP) platforms. For such systems, a common practice for the industry is to perform static task partition during development time. However, due to the dynamic nature of new generations of multimedia devices, this method can not reach optimal performance when the runtime system state is different from the assumed static state at development time. The research direction of this thesis is to study a new fine-granularity dynamic partitioning/scheduling framework for HMP, where the partitioning/scheduling decision of a computationally intensive task is done at runtime. A DSP scheduler that can support this framework is developed in this thesis. In addition, an H.264 intra-frame encoder is implemented following this dynamic partitioning/scheduling paradigm. Experimental results show that, with minimal programming effort, the proposed system can outperform a pure GPP or DSP implementation when there is only one task, and even a statically-partitioned dual-core solution when there are multiple tasks.
章節目錄
1.
簡介 ...10
2.
相關研究 ...12
2.1. Tightly-coupled MPEG-4 Video Encoder Framework ...12
2.2. Dynamic Concurrent Tasks Management ...13
2.3. Dataflow Kernel...14 2.4. Multi-core DSP Interface ...15
3.
系統架構與實作 ...16
3.1. DSP Manager ...16 3.1.1. DSP系統核心的啓動機制 ...17 3.1.2. DSP記憶體管理 ...20 3.1.3. 動態服務註冊管理...21 3.2. DSP System Kernel...32 3.2.1. Process ...32 3.2.2. Scheduler...38 3.2.3. Mailbox ISR...43 3.2.4. DMA設計 ...45 3.3. 適合異質多核心平台的應用程式移植步驟...47 3.3.1. 變更資料型態...47 3.3.2. 初始化記憶體位址...48 3.3.3. 資料搬移...493.4. Porting Issues for TI OMAP OSK5912 ...51
4.
動態分工H.264 編碼器設計 ...54
4.1. Loosely-coupled VS Tightly-coupled System ...54
4.2. H.264 Intra frame編碼器...56
4.2.1. 數位視訊編碼概論...56
4.2.2. H.264 Intra prediction...58
4.3. Tightly-Coupled Video Encoder ...58
5.
實驗結果 ...60
5.1. 編碼速度測試...60
5.3. DMA效率 ...64
6.
結論與展望 ...66
6.1. 研究結果討論...66
6.2. 未來工作及展望...67
List of Figures
Figure 1. A tightly-coupled dual-core system. ...13
Figure 2. Two Phase Scheduling Method...14
Figure 3. Scheduling Architecture...15
Figure 4. System Arhitecture...16
Figure 5. Bootloader Build Flowchart...17
Figure 6. Intel Hex Object Format. ...18
Figure 7. Starting Address Configuration...19
Figure 8. DSP Memory Managerment functions. ...20
Figure 9. DSP Memory Allocation Example...21
Figure 10. COFF File Structure...22
Figure 11. File Header Contents...22
Figure 12. Section Header Contents...23
Figure 13. Relocation Entry Contents ...25
Figure 14. Symbol Table Entry Contents ...25
Figure 15. Dual-core Service Image File Format...27
Figure 16. Section Size Header Contents...28
Figure 17. Section Raw Data Contents ...28
Figure 18. Sysmem Information Contents ...28
Figure 19. Relocation Informations Contents ...29
Figure 20. External AR Information Contents ...29
Figure 21. Internal AR Information Contents ...29
Figure 22. Internal AC Information Contents ...30
Figure 23. Main/Initial Entry Point Contents...30
Figure 24. Process Control Block...33
Figure 25. Process State Transitions...33
Figure 26. Initialization of Unregistered Process...34
Figure 27. Funtion init_service_slot()...35
Figure 28. Process Running Flowchart ...36
Figure 29. Wrapper Function Example ...37
Figure 30. Task Queue Operation for Context Switching ...39
Figure 31. Adding Task to Task Queue ...39
Figure 32. Task Queue Operation for Task Termination ...40
Figure 33. Auto Context Switch...41
Figure 34. Context Switch...42
Figure 35. Passive Task Framework...44
Figure 37. Shared Memory Initializatin Example ...49
Figure 38. Memcpy to Looply Copy ...50
Figure 39. 16bit Left Shift...51
Figure 40. 32bit Left Shift...52
Figure 41. Addition to Pointer...53
Figure 42. Addition to Pointer after Casting ...53
Figure 43. Addition to 32bit Value...53
Figure 44. Loosely-Coupled Video Encoder...55
Figure 45. Tightly-Coupled Video Encoder ...55
Figure 46. Simplified Video Coding Model...56
Figure 47. 4x4 Intra Prediction Mode ...58
Figure 48. Tightly-coupled Video Encoding Process...59
List of Tables
Table 1. COFF File Sections...24
Table 2. Relocation Information ...26
Table 3. DSP Registers ...40
Table 4. Dynamic Service Command ...43
Table 5. Encoding performance without Cache...60
Table 6. Encoding performance with I-Cache ...61
Table 7. Encoding Performance with Cache...61
Table 8. Overall Encoding Performance...62
Table 9. Scheduler Performance ...63
Table 10. Scheduler Overhead vs Time Quantum ...64
Table 11. DSP DMA 16to16 Performance with Burst Mode...65
1. 簡介
本論文主要的內容是研究在異質雙核心平台下要如何能有效率地同時運行 多個視訊編碼工作。在嵌入式的環境下異質雙核心平台常用來處理視訊編碼這種 大量運算的演算法,它是由一個負責介面操作和流程控制的RISC 和一個適合多 媒體運算的 DSP 所組成。但隨著嵌入式的多媒體應用演進,現在同時處理多個 多媒體工作的需求,已越來越普遍,如視訊電話,同時會需要處理無線通訊協定、 視訊解碼、視訊編碼。以傳統的靜態工作分配的方式設計的系統,在這種狀況下, 會把多媒體或通訊相關工作不斷分配給DSP,常常會使得 DSP 過於忙碌。而 RISC 發展至今,其運算能力也有大幅的提升,也有足夠的能力處理許多訊號處理的演算法。因此如果新的多媒體系統能把 RISC 和 DSP 以動態分工(dynamic task
partitioning)的方式設計,讓每一項新加入的資料處理工作,視兩個計算核心的實 際負載,分配給適當的核心,將能提昇系統的效能。 本論文實驗所採用的系統平台是 TI 的 OSK5912 發展平台[21],其核心 OMAP5912 是由 ARM 和 DSP 所組成的異質雙核心架構[20];而測試用的視訊編 碼演算法是H.264 的 Intra frame 編碼器,這是新一代的視訊壓縮標準,相對於過 去的視訊壓縮標準,有著在同資料量下能達到更好的影像水準,也就是有著更好 壓縮效率,但運算複雜度也跟著相當的高,要在這環境下要實現動態精細工作分 配法,必需考慮到兩個核心之間的溝通協調和資料傳輸所造成的計算成本的增 加,另外在 DSP 端需要有一個簡單,但高效率的排程器。而這個排程器有下面 這4 個要求: 1) 低 overhead 的多工排程 2) 快速回應溝通協調的命令 3) 有效率的資料傳輸
4) 能由 RISC 端動態控制改變 DSP 所能提供的服務。
為了符合第一項要求,本論文是以單純的時間共用(time-sharing)的方式來
設計工作排程器,並觀察在DSP 核心上的 H.264 編碼器的運作方式,設計出 low
overhead 的 context switch 機制。而在緊密結合(Tightly-coupled)的模式下執行的
視訊編碼程式,必定有許多溝通協調和資料傳輸需求。OMAP5912 提供了
mailbox、MPUI 和 shared memory 三種溝通方式。為了快速回應溝通協調的要求,
本論文針對mailbox 的 ISR 會使用到的暫存器設計出特別的架構,以改善進出 ISR
前後的context-saving 和 context-restore 所需的時間。為了設計出有效率的資料傳
輸API 的架構,本論文也深入測試分析直接存取 shared memory,或用 DMA 來
存取的效率上的差異。另外,因為 DSP 核心的內部記憶體容量並不大,所以同 時有多個工作要運行的話必定有其上限,因此就有需要能動態地抽換 DSP 核心 支援的視訊編碼服務。為了設計出一個執行檔格式來同時包裝RISC 和 DSP 的二 元程式碼,我們分析DSP 核心之 compiler 產生的連結檔和可執行檔,並寫了一 個工具來將連結檔中所參考到的程式庫都抽取出來,建立出可執行映像檔的必要 資訊,並把映像檔存放在OMAP5912 的 Flash 記憶體中,讓我們所設計的 OS 核 心內的動態服務註冊器能隨著應用程式的需求,去動態抽換 DSP 核心所支援的 視訊編碼服務。 本論文下面幾個章節的組織如下。首先,在第二章,我們會先對相關的研究 進行討論。接下來,在第三章,我們會對系統的設計概念和背景做一個介紹。第 四章則是描述實作的細節,而第五章則是討論實驗的結果。最後,在第六章會對 一些未來可能進行的系統改進方式進行討論。
2. 相關研究
隨著各種網路系統的迅速發展,每秒頻寬不斷的提升,網路應用也從早期以 文字為主的應用,進步到包含豐富圖形的應用,現在更已經達到音效視訊內容十 分普及的程度。線上收聽音樂,網路電視即時轉播,甚至是視訊電話,已經是嵌 入式設備的基本需求,所以多媒體運算的性能需求也越來越高。目前市場上的行 動式嵌入系統開發設計,都是以異質雙核心平台為主流,由一個負責介面流程控 制的RISC 核心,和一顆為多媒體運算特別設計的 DSP 核心所組成。在本章中, 我們會討論幾個異質多核心平台的分工和排程系統的研究。2.1. Tightly-coupled MPEG-4 Video Encoder Framework
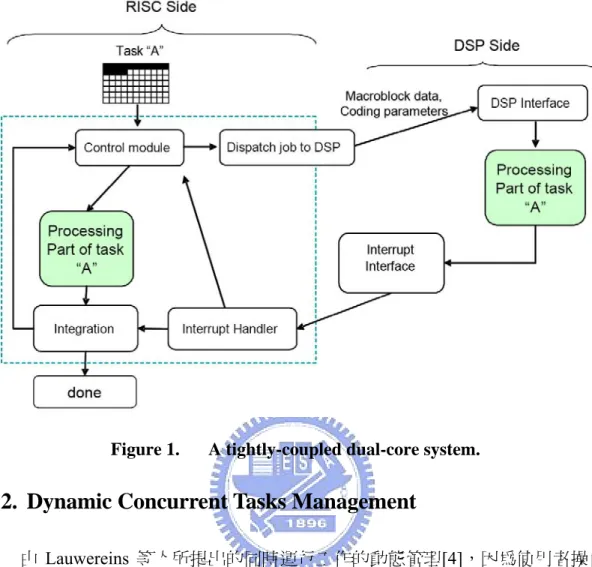
由邱正男等人所提出的一個專為異質雙核心平台設計的以 Tightly-coupled 的方式運行 MPEG-4 的視訊編碼的架構[1],相對於傳統都以靜態的 partition 方 式,來決定各核心上運行的工作分配,例如:DSP 執行多媒體編解碼或通訊實體 層的計算工作,RISC 則是負責控制管理。但隨著 RISC 設計的演進,新一代的 RISC 核心也能夠進行計算量相當大的運算,因此這裡提出了一個將視訊編碼工 作以緊密結合(Tightly-coupled)協同運算的方式,同時分配視訊編碼工作給 RISC 和 DSP 核心一起協同運算,如 Figure 1。以 OMAP1510 的硬體平台[2]運行
MPEG-4 Simple Profile[3]的視訊編碼器為測試基準,以緊密結合的方式其編碼速
Figure 1. A tightly-coupled dual-core system.
2.2. Dynamic Concurrent Tasks Management
由 Lauwereins 等人所提出的同時運行工作的動態管理[4],因為使用者操作
的多樣,造成了複雜的功耗和Timing 的 Constraint,它能達到最低功耗又能找到
符合Timing Constraint 的工作分配方式,主要是由兩個階段的 Schedule 方式,首
先從各個工作中找出可能的同步運行的部分產生MTG model[5],並再進一步將
MTG model 轉化以降低複雜和提昇平行性,並靜態地測試在各個核心運行的所
花費功耗和時間,產生運行時間對比功耗的Pareto-optimal set,在 Runtime 時再
根據靜態分析的結果,找出符合目前功耗和時間的工作分配。主要架構可以參考 Figure 2。
Figure 2. Two Phase Scheduling Method.
2.3. Dataflow Kernel
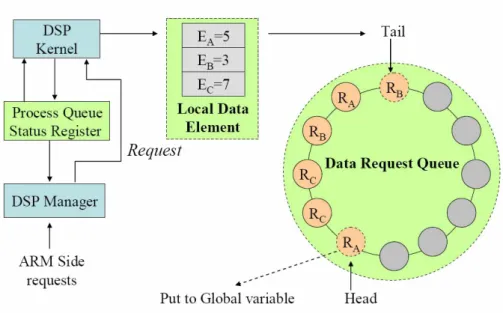
歐旭江針對異質雙核心平台設計了一個DSP Dataflow Kernel[6],以資料流的 概念,隨著進來的資料順序來對DSP上的Process排程,是一種Non-preemptive的 排程方式。而實際的排程是由運行在RISC核心上的DSP Manager所決定,如Figure 3,主要是根據各個Process和Queue的資訊,來決定是否接受RISC核心上的Process 之Request。因為RISC比DSP更適合做這些判斷決策,這樣設計的優點可以簡化 DSP Kernel複雜度,以降低提供DSP服務排程的Overhead。並且DSP Manager 提供了 DSP Process 對 RISC 發送 Request 的介面,使得 DSP 也可以使用到 RISC 的資源,另外 DSP Manager 還能動態抽換 DSP 服務, 適合動態運算多種視訊編碼使用。
Figure 3. Scheduling Architecture.
2.4. Multi-core DSP Interface
Hung 等人所提出的一個針對異質多核心平台所使用的 compiler directive extension[7]。在嵌入式設備上,為了運行多媒體應用,有許多設計都會使用 DSP 核心,甚至是異質多核心的架構,來達到高效能、低功耗、高彈性並且價格低的 需求。可是隨著這樣的平台的複雜化,其運行的軟體設計就依賴high-level 的開 發工具來加速開發速度,但其慣用的compiler 時常沒有完全利用到一些先進的硬 體設計,因此並完全發揮出這個平台所能達到最佳的效能。 所以為了在這樣異質多核心的平台下,達到軟體的移值和效能的最佳化,提 出了一個可以算是標準C/C++語言所延伸的註解語言,來指示 compiler 產生出有 利用到 DSP 硬體的運算指令,多核心的調度,資料的平行處理,以達到這個平 台應有的效能。
3. 系統架構與實作
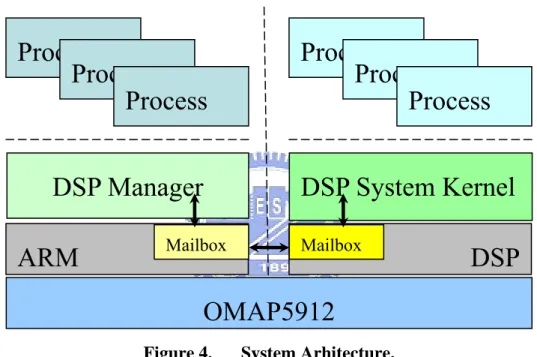
由於 DSP 的特性並不適合做複雜控制的計算,並為了使視訊編碼運算能發
揮最高效率,所以在本論文中所設計的系統架構如Figure 4 所示,會把 DSP 上
process 和記憶體空間管理,交由 ARM 這個比較適合控制管理的 RISC 來負責,
而DSP 的系統核心負責提供一個低複雜度的多工排程環境,以及和 RISC 核心間 溝通所需要的Mailbox ISR。
ARM
DSP Manager
MailboxProcess
Process
Process
DSP
DSP System Kernel
MailboxProcess
Process
Process
OMAP5912
Figure 4. System Arhitecture.
3.1. DSP Manager
DSP Manager 的工作包含下列三個項目,會以 library 的形式,提供給 ARM 端開發者使用。
1) DSP 系統核心的啓動機制 2) DSP 記憶體空間管理 3) 動態服務管理
3.1.1. DSP 系統核心的啓動機制
在DSP 上執行的系統核心之原始程式碼,經由 TI 的開發工具 CCS 編譯後, 會產生一個執行檔。一般在系統開發階段,這個執行檔是由 CCS 經由 JTAG 來 載入到 DSP 的程式記憶體空間。但對嵌入式系統而言,開發完後,要銷售的產 品,並不會有 JTAG 這種介面來載入程式,大都是將程式的執行檔燒錄到 Flash 上,開機就能獨自運行。因此 DSP 的系統核心也需要提供類似的方式來啓動(boot)。Rishi Bhattacharya 提供一個 OMAP5910 的 DSP 開機範例[10],將 DSP
的執行檔轉成一個常數資料陣列的宣告,和運行在 ARM 上的主程式一起編譯
後,再由ARM 的主程式經由 MPUI 將這個資料陣列(DSP 的系統核心)載到 DSP
的程式記憶體空間,並加以啓動,詳細步驟如Figure 5。
其中 OUT2BOOT,是隨[10]附上的程式。它會先用 CCS 裡的工具 Hex Conversion Utility(hex55.exe), 詳細使用說明可以參照 TI 的文件[11]。將執行檔 (.out 檔)轉成 Intel MCS-86 Object 的格式,再轉成 header 檔內的資料陣列宣告,
詳細格式如Figure 6。
Figure 6. Intel Hex Object Format.
可以看到這種格式可記錄的address 只有 16 bits,但由 ARM 的 MPUI 載入
DSP 的程式記憶體空間會需要 32 bits。因此被轉出來 header 檔,只固定從 0xE0010000 開始填寫到 0xE001FFFF,這也是對應到 DSP 內部的 SARAM 前 64Kbyte,以 DSP 程式記憶體空間來看是從 0x10000 的位置開始去填寫。會固定 從0x10000 開始,是根據 TI 的文件對 DSP Bootloader 的說明[12]。DSP Bootloader
做好基本的設定後,會根據 Boot 模式,跳到特定的起始位置,0x10000 是其中
的Internal memory boot 模式(5)的起始位置。為了使編譯完的執行檔,其起始位
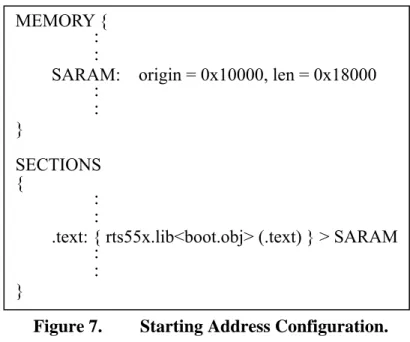
置也是0x10000,這需要對 CCS 的 linker 設定檔(.cmd 檔)做些修改,如 Figure 7,
其詳細使用說明可以參照 TI 的文件[13]。強制設定負責初始化 C 語言環境的
boot.obj 連結檔,在 static link 時,會 link 成從 0x10000 開始載入,而 boot.obj 執
MEMORY { : :
SARAM: origin = 0x10000, len = 0x18000 : : } SECTIONS { : :
.text: { rts55x.lib<boot.obj> (.text) } > SARAM :
: }
Figure 7. Starting Address Configuration.
但 這 樣 的 設 計 就 限 制 了 程 式 只 能 載 入 到 SARAM , DSP 內 部 另 外 有 DARAM,同時可以存取兩筆資料,如果我們把 DSP 系統核心的資料區域放在 DARAM,應能提升效率。如果執行檔有用到 DARAM,其轉出來的 Intel Object 會有Recode type 為 04 的 entry,代表要改變目前 24bit base address 的 high 8bit,
但原本OUT2BOOT 不支援,一處理到這種 entry 就會當掉。我們將 OUT2BOOT
提供的程式碼稍微修改後,並在轉成header 檔時,加上把 DSP 程式記憶體空間
的位置,轉成對應MPUI 或 shared memory 的位置的功能,就可以解決這個問題,
之後要ARM 設定 DSP 核心系統的記憶體就比較簡單。
但照著[10]的 DSP 開機範例去啓動 DSP 後,DSP 還是不能正常運作,後來
在OSK5912 開發板提供給 CCS 的設定檔 osk5912.gel 裡面發現類似的函式。.gel
檔的作用,是讓CCS 去對使用的核心初始化,會以類似[10]所描述的方式去啓動
DSP,但會設定更多的暫存器,而填到 SARAM 的 DSP 機械碼,只是不停執行 一個無窮迴圈而已。參考.gel 檔來改寫原本 ARM 啓動 DSP 的 dsp_init 函式,這
樣就可以很順利讓DSP 啓動,並順利執行 ARM 根據 header 檔內的資料陣列所
3.1.2. DSP 記憶體管理
DSP 可以存取的記憶體除了內部的 DARAM 和 SARAM 外,經由 DSP MMU
的設定可啟用shared memory,這樣 DSP 就可存取共用的 SRAM 和外部的 Flash
和SDRAM。本論文所設計的系統,針對這些記憶體種類和動態分配的需要,以
linked-list 來實作記憶體管理,並提供了三個函式給系統核心及應用程式使用, 如Figure 8 所示。
typedef struct _dspmem {
uint32 base; uint32 size;
int used;
int type;
struct _dspmem *next; }dspmem;
void dspmem_init();
dspmem *dspmem_alloc(uint32 size, int type); int dspmem_free(dspmem *free_dspmem)
Figure 8. DSP Memory Managerment functions.
目前系統規劃了五種不同類別的記憶體(DARAM、SARAM、SRAM、 SDRAM、Flash),所以在 dspmem_init 函式裡,會對五個 linked-list 做初始化,
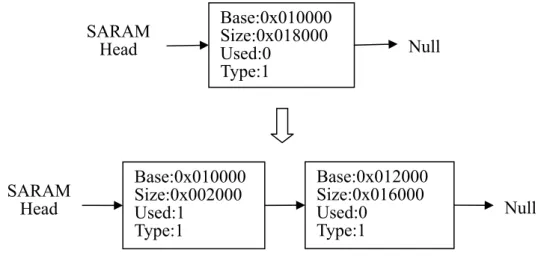
設定可以使用的位置和大小。如Figure 9,當系統或應用程式所註冊的服務要求
DSP 分配大小為 0x2000 的 SARAM 的記憶體空間以供使用,DSP 記憶體管理程
式會從 SARAM Head 開始尋找有足夠空間的節點,找到後修改它所佔用的大
小、並標示為已使用、最後新增一個節點記錄剩餘的空間。從Figure 9 可以注意
到每個節點的Base address 是用 24 bits 來記錄,這是因為透過 DSP 的記憶體管
理程式分配到的記憶體空間,是要給DSP 執行的服務所使用的,而 DSP 的資料
Base:0x010000 Size:0x018000 Used:0 Type:1 SARAM Head Null Base:0x010000 Size:0x002000 Used:1 Type:1 Base:0x012000 Size:0x016000 Used:0 Type:1 SARAM Head Null
Figure 9. DSP Memory Allocation Example.
3.1.3. 動態服務註冊管理
為了動態抽換DSP 上的服務,在 DSP 上執行的每一個服務的執行檔就必需 能(在註冊時)獨立載入。而且在載入時才能確定一些位址的值。也就是說,其 機械碼內跟記憶體位址有關的值在動態註冊時才可以決定。而原本 CCS 所產生 的執行檔是己經靜態指定執行位址的,並不支援動態載入(dynamic loading),因 此本系統的開發就需要研究CCS 的編譯器產生之連結檔的格式。CCS 使用的連結檔格式是common object file format,COFF。在系統開發的過程中,我們發展
了一個程式,分析連結檔後將所有必要的資訊(如參考到的外部程式等等)連結 進來,整合成一個映像檔,寫入到 OSK5912 的 Flash 上,其中,跟最終執行位 址相關的資料則仍保留成未定的欄位,等應用程式要註冊這個服務時,再由ARM 來處理。首先ARM 會呼叫 DSP 記憶體管理程式,分配一塊 DSP 內部記憶體做 為載入服務的空間,根據分配到的記憶體起始位置做動態載入,經由MPUI 這個 介面載入到DSP 內部記憶體,最後再向 DSP 系統核心註冊這個服務。
3.1.3.1. COFF file structure
根據 TI 文件對 COFF 檔的描述[14],每次編譯後產生的連結檔包含了 File
header、Section header、Section raw data、Section relocation information、Symbol table、String table。如 Figure 10 所示。
Figure 10. COFF File Structure.
其中File header 如 Figure 11,可得知 Version ID、Section 個數,Symbol table 的位置和有多少筆entry;而一般都不會有 Option header。File header 裡面 Version ID 的 2 個 byte 用 little-endian 方式讀取,一般都是 0x00C2,如果是 0xC200,則
代表目前的連結檔是以big-endian 編寫的。
COFF 檔裡的 Section,代表程式執行會需要的各類記憶體空間,可以分成兩類。 1) Initialized section:
其raw data 有實際內容,如機械碼、const 變數。
2) Uninitialized section:
保留的記憶體空間,只有Section 大小,在連結檔裡並沒有實質內容,例如
未被初始過的global 變數等,只是用來告知 linker 要為其保留記憶體空間。
Section header 的格式如 Figure 12,會需要用到 Section 的名稱、Size、Raw data 位置、Relocation information 位置和個數。名稱的欄位最多只能存 8 個字元,所 以字數大於8 的名稱,會記錄著 String table 裡的 offset,在 String table 裡就會有
完整的名稱。之後所有用到名稱的欄位都是以這種方式來記錄。如果是Initialized
section,Size 和 Raw data 位置的欄位都會有非零的值;Uninitialized section 則只 有Size 欄位有非零的值,Raw data 位置和 Relocation information 都會是零。如果 Section 有 Relocation information,則代表其 Raw data 裡有 Virtual address,需要 在link 時被重新定位(relocate)為 Physical address。
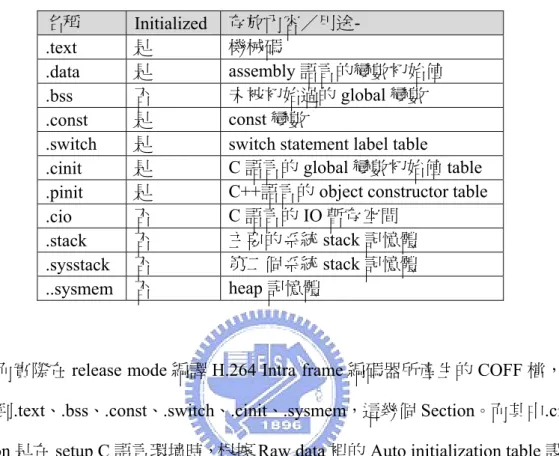
Section 的名稱是很重要的欄位,CCS 為 DSP 所產生的 COFF 檔會有 Table 1
所列的這幾種section。
Table 1. COFF File Sections.
名稱 Initialized 存放內容/用途-
.text 是 機械碼
.data 是 assembly 語言的變數初始值
.bss 否 未被初始過的global 變數
.const 是 const 變數
.switch 是 switch statement label table
.cinit 是 C 語言的 global 變數初始值 table
.pinit 是 C++語言的 object constructor table
.cio 否 C 語言的 IO 暫存空間
.stack 否 主要的系統stack 記憶體
.sysstack 否 第二個系統stack 記憶體
..sysmem 否 heap 記憶體
而實際在release mode 編譯 H.264 Intra frame 編碼器所產生的 COFF 檔,只 會用到.text、.bss、.const、.switch、.cinit、.sysmem,這幾個 Section。而其中.cinit section 是在 setup C 語言環境時,根據 Raw data 裡的 Auto initialization table 設定 global 變數的初始值,也就是要填初始值到.bss section 的所保留的空間,因此這
兩個section 是可以整合為一個 section,另外.sysmem 是只有 C 語言內建的 malloc
和 free 函式會用到,會特別再做處理。所以分析 COFF 檔後,最後只會留
下.text、.bss、.const、.switch,這四個 section 在映像檔裡。
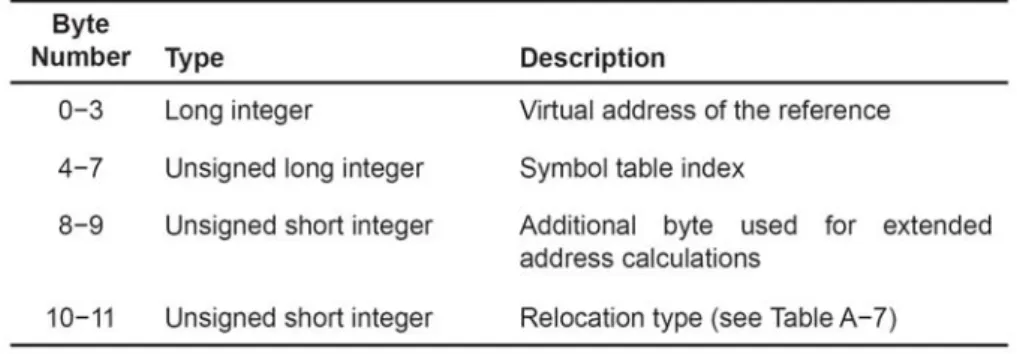
Relocation information 是為了重新定位 Symbol 的 Virtual address 到 physical address 所用的資訊,就是如何做到動態載入最主要的資訊。格式如 Figure 13。 會需要用到Virtual address、Symbol table index 和 Relocation type。這個 Virtual address 是指被重新定位的 Symbol 在 Raw data 裡的 offset,經由這個 offset 可以 讀到Relocatable field,即 Symbol 的 Virtual address。
Figure 13. Relocation Entry Contents
Symbol table 裡的 Symbol 格式如 Figure 14,會需要用到名稱、Value、Section number 和 Storage class。Section number 代表這個 Symbol 屬於哪個 Section,如 果Section number 不是 0,代表這個 Symbol 是 Internal Symbol,再根據 Storage class,分別是 Global 或是 Static,如果是 Global,可以被其他連結檔 Reference
的 Symbol,如果是 Static,則是目前連結檔裡的 Relocation information 會到的
Symbol。
如果 Section number 是 0,代表這個 Symbol 不在目前的連結檔,而是
Reference 其他連結檔的 Symbol,屬於 External Symbol。所以要由連結檔建立映
像檔之前,如果連結檔裡要重新定位的Symbol 屬於 External Symbol,則必需先
Resolve 這些 External Symbol,當發現 External Symbol 在某個連結檔裡,這個連 結檔也要一起被建立進映像檔裡。
因為TI 的文件[14]並沒有詳細說明,每一類 Relocation information,要如何 重新定位。為了能在動態重建執行檔的資訊,因此以反向工程的方式,把原本連
結檔裡的16 進位值和在 CCS 下開啟執行檔相互對照,大略可以把在 Relocation
information 所記錄的資訊,分成 Table 2 中四類。
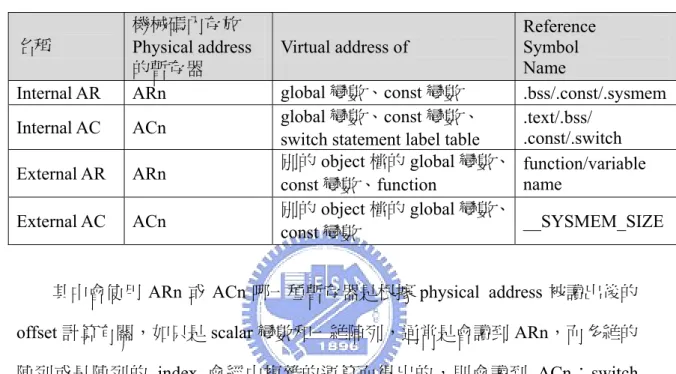
Table 2. Relocation Information
名稱 機械碼內存放 Physical address 的暫存器 Virtual address of Reference Symbol Name
Internal AR ARn global 變數、const 變數 .bss/.const/.sysmem
Internal AC ACn global 變數、const 變數、
switch statement label table
.text/.bss/ .const/.switch External AR ARn 別的const 變數、function object 檔的 global 變數、 function/variable name
External AC ACn 別的object 檔的 global 變數、
const 變數 __SYSMEM_SIZE
其中會使用 ARn 或 ACn 哪一種暫存器是根據 physical address 被讀出後的
offset 計算有關,如只是 scalar 變數和一維陣列,通常是會讀到 ARn,而多維的
陣列或是陣列的 index 會經由複雜的運算而得出的,則會讀到 ACn;switch
statement 如果比較複雜的將會使用 label table,而這 table 的 physical address 都會 載入到ACn,而 external function 的 address 則都是使用 ARn。
ARn 類的 relocation information 會用有一筆 3byte 的 Relocatable field,載入 23bit 的值到 ARn 暫存器。AC 類的 relocation information 則會用兩筆 2byte 的 Relocatable field,以組成 32bit 的值載入到 ACn 暫存器。
3.1.3.2. Virtual Address 的取得
重新定位所需要的Virtual address 取得的方式可分兩種
1) Internal:
Symbol 位於目前連結檔的某個 Section 裡,經由 Relocation information 可以 在Raw data 裡找到對應的 Relocatable field,Symbol 的 Virtual address 會在 Relocatable field 上。
2) External:
Symbol 位於其他連結檔的某個 Section 裡,這就需要 Resolve 這個 Symbol。
到其他連結檔裡的 Symbol table 去找這個 Symbol 名稱,如果找到,則其
Value 欄位代表著 Symbol 在 Section number 對應 Section 裡的 Virtual address。但這會是 byte address,如果 Symbol 不屬於 function,就是不屬於
程式記憶體空間的位址,必須再除 2 得到資料記憶體空間用的 word
address(16bit address)。
3.1.3.3. Dual-core Service Image File Format
我們從各連結檔中抽取最重要的資料,並考慮Relocation information 的種類
和Virtual address 取得的方式,設計了如 Figure 15 的映像檔格式。還多保留了
ARM 的執行檔的欄位,是因為我們的目標是能將同一個函式,編譯成包含兩個 核心執行檔的映像檔,這樣就能隨著實際各核心上的負擔,動態載入執行檔到較 低負載的核心來運行
ARM executable DSP object number Section size header Section raw data Sysmem information Relocation information Main/Initial entry point
DSP object number 欄位,標示這個映像檔中 DSP 的執行檔由有多少個連結 檔組成。每個連結檔只會留下4 種 Section,如 Figure 16,首先在 Section size header
標示每個物件各Section 的大小
.text size .bss size .const size .switch size
.text size .bss size .const size .switch size
Figure 16. Section Size Header Contents
如Figure 17,在 Section raw data 裡會有每個物件各 Section 裡的實際內容。
並且設計成連續排列的,方便載入到DSP 程式記憶體空間。
.text raw data .bss raw data .const raw data .switch raw data
.text raw data .bss raw data .const raw data .switch raw data
Figure 17. Section Raw Data Contents
Sysmem information 是專為 malloc 和 free 這類記憶體管理的函式特別設計 的。如Figure 18,它們會用到 memory.obj 和_lock.obj 這兩個連結檔,memory.obj 有一個特別的Relocation information,以 External AC 的方式來設定 Sysmem 的大 小;而_lock.obj 裡另外有一個特別的 Relocation information,會在.bss 重新定位 一個macro function 的位置。因為這兩種 Relocation information,只有這邊用到, 所以特別處理。
memory.obj ID _lock.obj ID Sysmem size
之前提到的四類Relocation information,扣掉設定 Sysmem 大小的 External AC,就只留下這三類,External AR、Internal AR、Internal AC。如 Figure 19,在
映像檔的Relocation information 欄位,每個物件都會有它自己的這三類 Relocation
information,全部都是用來修改.text 的 Raw data。每一類會先標示其數目,再接 著每筆重新定位所需的資訊。 External AR number External AR information Internal AR Number Internal AR information Internal AC number Internal AC information External AR number External AR information Internal AR Number Internal AR information Internal AC number Internal AC information
Figure 19. Relocation Informations Contents
如Figure 20,External AR 會需要其 Relocatable field 在 Raw data 裡的 offset,
和標示屬於哪一個 Section 的 Type 欄位,並且在建立映像檔時,已經把這個
External Symbol 會使用哪個外部物件找出,第三個欄位就是其 ID,最後是在外 部連結檔的Symbol table 裡讀到的 Virtual address。
Relocatable field offset Type External object ID Virtual address
Relocatable field offset Type External object ID Virtual address
Figure 20. External AR Information Contents
如Figure 21,Internal AR 類似 External AR,只是 Type 所標示的 Section 是 屬於目前物件的Section,所以不需要 External object ID。
Relocatable field offset Type Virtual address
Relocatable field offset Type Virtual address
如Figure 22,Internal AC 跟 Internal AR 最大差別,在於 Relocatable field 有 兩筆,分別代表Physical address 高低各 16bit。
High relocatable field offset Low relocatable field offset Type Virtual address
High relocatable field offset Low relocatable field offset Type Virtual address
Figure 22. Internal AC Information Contents
最後Entry point 有兩個。如 Figure 23,除了一定要提供的 Main function 的 Entry point 外,可以多提供 Initial function 的 Entry point,讓服務在第一次運行時, 可以先做初始化。
Main function entry point Initial function entry point
Figure 23. Main/Initial Entry Point Contents
3.1.3.4. 動態連結的細節
由ARM 來執行動態連結,主要有四個工作。
首先會分配一塊 DSP 內部記憶體做為服務的載入空間。接下來系統會從
Flash 讀取映像檔,先計算總共需要的記憶體大小,包含各物件的各個 Section 大
小和Sysmem 大小。用 DSP 記憶體管理函式,分配一塊 SARAM 的記憶體,並
由分配的記憶體Base address,計算各物件的各個 Section 之 Base address,並且
將Flash 裡映像檔中的各物件 Raw data 讀取到 SDRAM,做為之後做動態連結的
暫存。
根據被分配到的記憶體起始位置做動態連結。會以映像檔上面物件的順序, 以三種Relocation information 做 Virtual address 的重新定位。以 External AR 為例 子,根據External object ID 和 Type 欄位,取得 External Symbol 所在的 Section 之Base address,加上 Virtual address 後,就可以得到 Physical address,填到 SDRAM
上目前物件的.text section 的 Raw data 之 Base address 加上 Relocatable field offset 的位置。
經由MPUI 介面載入到 DSP 內部記憶體。當所有 Relocation information 都
被處理完後,暫存在SDRAM 上的 Raw data,已經跟可執行檔上的內容是一樣的
了,但要搬到DSP 的程式記憶體空間,DSP 才能夠執行。由 ARM 或是 System
DMA,經由 MPUI 來做搬到 DSP 內部的 SARAM。如果要讓 DSP 或是 DSP DMA 經由Shared memory 來搬移,則 Endianism conversion 要設定成 byte 的 order 是一 樣的,即Byte and word swap 模式。
最後再向DSP 系統核心註冊。經由 Mailbox,發送 REGISTER_SERIVCE 的
命令,因為Init function 和 Main function 的 entry point,各是 24bit,一個 Mailbox
無法傳送48bit 的訊息,所以會放在 Shared memory 上,DSP 系統核心會分配一
個Process,並從 Shared memory 上讀取 Entry point,設定為 Process 要運行的演
算法的進入點,最後用Mailbox 回傳 Process ID 給 ARM。
3.1.3.5. Invoke DSP service 要呼叫 DSP 上的服務,會用 Mailbox 傳送 INVOKE_SERVICE 命令和註冊 時分配的PID。當服務的工作運行完畢,DSP 會回傳 RETURN_INVOKE 訊息和 運行完的服務之PID。假如一個服務,同時需要被呼叫二次以上,有兩種方式可 以達成。首先一個比較簡單的方式,傳送DUPLICATE_SERVICE 和被註冊過的 服務PID,來再要求需要再被多註冊一次,DSP 系統核心會再分配一個 Process,
並且Entry point 會設定成與被傳來的 PID 所對應的服務的 Entry point。但這個方
式就必需在服務不會去修改到.bss 的空間,也是 global 變數不會被修改,這樣的 條件下,同一份執行碼才能同時被執行。另一種方式,一般的流程,用動態連結 產生另一份功能一樣的執行碼來註冊,缺點是需要多一塊記憶體空間,但除了空 間 的 限 制 外 , 就 沒 有 其 他 限 制 。 被 多 次 註 冊 得 來 Process , 一 樣 也 是 用 INVOKE_SERIVCE 命令,來要求運行服務。當服務不再需要呼叫時,可以把它
反註冊,傳送UNREGISTER_SERVICE 和要被反註冊服務 PID,將會釋放 Process 回到初始狀態。如果在這時,服務的執行碼只有被目前的Process 所使用,反註 冊後就可以把它分配到的 DSP 記憶體釋放,以達到動態抽換;如還有別的 Process,因為多次註冊而使用同一塊服務執行碼的話,必需等到最後一個 Process 反註冊時,才能釋放DSP 記憶體。
3.2. DSP System Kernel
本論文所開發的是在 DSP 方面的動態分工系統核心,在這邊的一個基本假 設是整個異質多核心系統是會由適合控制工作的ARM 來管理整個系統的工作分 配,包含DSP 上 Processes 的運行和 DSP 記憶體的分配。而 DSP 上的系統核心, 主要是為了達成多工環境,提供最基本的 Scheduler 和接受 ARM 方面傳來的動態服務命令的Mailbox ISR 所組成,並且提供兩個核心間大筆資料傳輸的 DMA
介面。
3.2.1. Process
在DSP 執行的服務會以 Process 為單位在運行。一個 Process 在執行時,會
需要Process control block 來記錄其目前的資訊。如 Figure 24。有兩種 Stack 指標, 分別代表主要的Stack 和 System stack,因為 System stack 指標和 Stack 指標共用
高的7bit,所以只需記錄低的 16bit。Process 的狀態,有 Unregistered、Ready、
Busy、IDLE,其中 IDLE 是專門給代表目前沒有服務在運行的 Process 使用。 Process 的 ID,目前設計最多有 32 個 Process。以 function 這種型態來宣告 Entry point,可以很容易去用 C 語言呼叫 Initial function 和 Main function 的。Initialized
是記錄Initial function 是否被呼叫過的 flag。剩下的 pad 是為了使 PCB 大小是 16
個16bit,讓之後要用組語去撰寫存取各個 PCB 的 base address 計算,會比較簡
typedef void(*function)(); typedef struct _PCB{ uint32 pc; uint32 sp; uint16 ssp;
enum STATE state;
int id; function init_entry_point; function entry_point; int initialized; uint16 pad[4]; }PCB;
Figure 24. Process Control Block
為了滿足動態服務的設計,Process 在運行服務時,其 State 切換會如 Figure 25,一開始建立新的 Process 後,會是在 Unregistered state。註冊一個服務後,被
分配的Process,會改成 Ready。 當 ARM 有需要 DSP 去運行服務時,會用 Invoke
命令,使得 Process 變成 Busy。運行完的 Process 會回到 Ready,可以再次被
Invoke。當不再需要 Invoke,就可以 Unregister 掉,回到初始的 Unregistered state。
init_service_ Ready
Busy Unregistered invoke terminate unregister register
如Figure 26,這是在 DSP 系統核心上運行的 Process 其建立過程的大略程式
碼,首先初始化IDLE Process,在 DSP 沒有任何服務在運行時,DSP 則會運行
這個Process,目前並沒針對功耗去做最佳化,所以 IDLE Process 其運行目的,
只是不停地從工作 Queue 中,找工作來執行。之後會用 init_service_slot 函式, 產生要運行實際服務的 Process,然後啟動 Timer,代表著 DSP 系統核心開始運 行。而process 和 IDLE_process 這兩個函式裡都是用無窮迴圈不停的執行其工作。 void main() { /* System Initialization */ : : /* System Initialization */ idle_pcb = &pcb[MAX_PROCESS]; idle_pcb->id = MAX_PROCESS; idle_pcb->state = IDLE; current_pcb = idle_pcb;
for(int i=0; i<MAX_PROCESS; i++) if(init_service_slot() != idle_pcb->id) process();
DSP_CNTL_TIMER3 |= 1; // Start the timer IDLE_process();
}
Figure 26. Initialization of Unregistered Process
實際運行服務的Process 是經由 Figure 27 的 init_service_slot 函式所建立的,
在設定完新Process 的 PCB 的初始資訊後,會繼承原本正在執行中的 idle Process
的暫存器內容,並分裂出新的 Process,return 的 Process id 是為了給呼叫
int init_service_slot() {
static int pid = 0;
uint16 *stack = (uint16 *)0x7C00 - 0x380*pid; select_pcb = &pcb[pid];
select_pcb->sp = (uint32)stack;
select_pcb->ssp = ((uint32)stack - 0x300) & 0xFFFF; select_pcb->state = UNREGISTERED;
select_pcb->id = pid++; push_and_start(); return current_pcb->id; }
Figure 27. Funtion init_service_slot()
Stack 指標的分配是從 0x7C00 到 0x0C00,屬於 DARAM 記憶體空間,會把 Stack 存放在 DARAM,是因為 C55x 的 DSP 指令集中有能夠一次進行兩筆 16bit
資料的stack operation,而 DARAM 能同時處理兩筆存取,所以把 stack 設定在
這邊可以加快context switch 的速度。因為 Stack 的使用是往低的 address 成長,
在 PCB 中 System stack 的指標是由 Stack 指標減去 0x300 得來的,就代表每個
Process 被分配的 Stack 大小為 0x300 個 16bit,而 System stack 的大小,因為每個 Process 的 Stack 指標相差 0x380,扣去 Stack 大小的 0x300,System stack 大小則 是0x80 個 16bit。
在push_and_start 函式中,會備份 IDLE Process 的暫存器內容,並切換目前
運行中的PCB 為新的 Process 的 PCB,這時從 push_and_start 函式離開後,邏輯
上就可以算可以分裂成了兩個 Process,一個是原本在執行的 IDLE Process,一
個是新建的Process,但實際上 DSP 核心正在執行的會是新建立的 Process,在系
DSP 系統核心在運行時,會有兩種 Process,一個是 IDLE Process,一個是 服務在運行的Process,各自會分別執行 IDLE_process 和 process 函式,會以 Figure 28 的方式來做切換,在 IDLE_process 函式會呼叫 yield 函式,會使目前的 Process
自願放棄DSP 使用權,並從工作 Queue 選取下一個工作,切換 PCB 並做 context
switch,IDLE Process 會以這樣的方式不停的從工作 Queue,找工作來運行,如
果有工作可以運行,就會切換到process 函式來運行服務的工作實際內容(1 號箭
頭)。服務的工作運行結束,dequeue 函式會將目前工作,從工作 Queue 裡移除。
之後呼叫yield 函式,再選取工作 Queue 裡下一個工作來執行(2 號箭頭),如果工
作Queue 裡沒有工作可執行,就會回到 IDLE process(1 號箭頭)。
其中對工作Queue 進行修改的 yield 函式和 dequeue 函式,必需要有中斷的
mask 保護,確保修改工作 Queue 時,不會有中斷發生,修改後的工作運行的順 序邏輯上才會是正確。
Figure 28. Process Running Flowchart
void IDLE_process () {
while(1) {
asm(" BSET ST1_INTM"); yield();
asm(" BCLR ST1_INTM"); }
}
void process() {
int pid = current_pcb->id;
asm(" BSET ST1_INTM"); while(1) { yield(); asm(" BCLR ST1_INTM"); if(current_pcb->init_entry_point && !current_pcb->initialized) { current_pcb->init_entry_point(pid); current_pcb->initialized = 1; } current_pcb->entry_point(pid); asm(" BSET ST1_INTM"); dequeue(pid);
} }
2
1
服務實際會執行的內容,可分成兩個部分,如果有提供初始化函式,第一次 被執行的服務,會先執行初始化函式,另一部分則是服務要進行的演算法。因為
這兩種entry point 都是以 function 的型態來宣告,所以可以直接呼叫。
服務所運行的工作函式,都會傳入一個 pid,這是用來使 ARM 傳遞參數所
會用到的,隨著演算法不同,有些可能不需要參數,有些可能需要多個參數,甚
至有需要陣列當參數,這些參數就可以放在shared memory 上參數表,經由 pid
來讀取各個服務所需的參數。為了讀取這些參數,原本演算法的函式就需要一個 wrap 函式,用來讀取參數並傳給原本的函式。
如Figure 29,原本的演算法 dequant 函式,需要四個參數,而且前兩個還是
陣列。在ARM 下 Mailbox 命令,把這項工作加到工作 Queue 之前,要先把需要
的參數根據服務的pid,填到 shared memory 上的參數表,每個參數都以 32bit 的
長度寫入,實際傳入演算法的函式前,會藉由轉型而傳入正確的長度,而陣列的
參數,其起始位置,是由 ARM 動態決定,而其內容會根據陣列長度,看是由
ARM 或是 DMA 來搬。經由 wrap 的方式,dequant 函式就能正確執行。但因為
每個演算法需要參數的個數和型態,都不是固定的,像這樣的wrap 函式,目前
還是用人工撰寫的,未來如果有特製的compiler 配合,就可以自動化這個步驟。
#define PARAMETER_TABLE 0x600000 #define PARAMETER_SIZE 4
void dequant_wrap(int16 id) {
uint32 *ptr = (uint32*)PARAMETER_TABLE + PARAMETER_SIZE * id; uint32 p0,p1,p2,p3; p0 = *ptr++; p1 = *ptr++; p2 = *ptr++; p3 = *ptr++;
dequant((int16 *)p0,(int16 *)p1, (uint32)p2, (uint32)p3); }
3.2.2. Scheduler
為 了 讓 DSP 上 運 行 的 各 個 服 務 , 能 以 較 精 細 的 多 工 方 式 (fine-grain multitasking)同時運行,就必需讓各個服務反應時間儘量快速,不會因為某個服
務佔用CPU 時間過久,而造成只需要少許 CPU 時間的服務等待過久,因此採用
了CPU 時間分配最公平的 Timer-sharing 排程方式,以 Timer 倒數完後的 Interrupt service routine 來實作 scheduler。
因為這個Scheduler 為了使 DSP 能多工運行視訊碼編工作,排程的效率也是
很重要的,目標是能達到低overhead。並且隨著運行服務增加,排程也還是要很
有效率,也要達到時間複雜度是O(1),因此採用了 Round-robin 的方式,只需要
一個工作Queue,Scheduler 就可以很容易選取下一個工作。
工作Queue 是以雙向的 linked-list 實作,因為只有單向的 linked-list,要把新
增的工作加到Queue 的最後,就必需有一個 tail 的指標,指向著 Queue,但這樣
在Timer ISR 裡面就除了改 head 外,還要再多改 tail,一般來說服務在運行是有
可能會經過多次Timer ISR,但新增只有一次,沒必要在時常被呼叫的 Timer ISR
增 加 overhead 。 如 果 不 用 tail 的 指 標 , 那 每 次 新 增 工 作 就 只 能 用 迴 圈 從 head->next,測試達到最後一個節點後,再加入,但如果 Queue 裡面的工作越多,
新增工作所花費的時間會跟著增加。因此最後決定以雙向的linked-list 來實作,
其優點是不管從Queue 裡新增或移除工作都是 O(1)的時間。
Figure 30 是當發生 context switch 前後的工作 Queue,實線指向下一個工作,
虛線指向前一個工作,原本執行的順序是T1、T0、T3,context switch 時,只要
T1 T3 T0 Head T0 T1 T3 Head
Figure 30. Task Queue Operation for Context Switching
Figure 31 是新增工作到工作 Queue,原本的執行順序是 T1、T0、T3,新增 的 T4 則插入 Head 指向的前一個位置,需修改 T1 的前一個,T4 的下一個,和 T4 的前後,共有 4 個指標 assign 運算。之後新的執行順序是 T1、T0、T3、T4。 T1 T3 T0 T1 T4 T0 T3 Head Head
Figure 31. Adding Task to Task Queue
Figure 32 是工作 T1 執行完後,要從工作 Queue 裡移除,首先把 T1 的下一
個工作T0 和 T1 的前一個工作 T4,相互連結,只要兩個指標 assign 運算,但 Head
並不在這時更改為 T1 的下一個工作 T0,因為根據之前的 Framework,從執行
dequeue 函式後,T1 就會自願放棄 DSP 使用權,就會選取下一個工作來做 context switch,這時 Head 就會更改為 T1 的下一個工作 T0。而工作 Queue 裡沒有一個
T0 T4 T3 Head T1 T1 T4 T0 T3 Head T0 T4 T3 Head
Figure 32. Task Queue Operation for Task Termination
因為在 Timer 的中斷發生時,被中斷的工作正運行到哪個指令,可以說是
隨機的,context switch 最直覺的做法就是把所有暫存器都 push 到 stack,等到選
出下個工作並切換stack 位置後,再 pop 回之前暫存的值。但越多暫存器被儲存,
就代表要花越多的時間來做context switch,這樣為了達到多工所帶來的 overhead
就會越高。DSP 的暫存器,如 Table 3 有這 13 類暫存器,總共有 55 個暫存器。
Table 3. DSP Registers
Register Description
AC0-AC3 Accumulator
XAR0-XAR7/AR0-AR7 Auxiliary Register
BK03, BK47, BKC
BSA01, BSA23, BSA45, BSA67, BSAC Circular Buffer Register
XCDP / CDP Coefficient Data Pointer
XDP / DP Data Page Register
DBIER0, DBIER1 IER0, IER1 IFR0, IFR1 IVPD, IVPH
Interrupt Register
PDP Peripheral Data Page Register
PC, RETA, CFCT Program Flow Registers
BRC0-1, BRS1, RSA0-1, REA0-1 RPTC, CSR Repeat Registers XSP / SP, XSSP / SSP Stack Pointers ST0_55-ST3_55 Status Registers T0-T3 Temporary Registers TRN0, TRN1 Transition Registers
根據DSP的文件對Stack操作的描述[15],當中斷發生時,在DSP開始執行我 們的ISR之前,會把必要的暫存器PUSH進Stack,離開ISR時,會從Stack上POP 這些暫存器備份的值。這樣的自動Context switching,輔助我們去重建被中斷的 工作之context,如Figure 33,會先把ST0_55、ST2_55、DBSTAT、ST1_55、CFCT 和RETA,push到stack裡,再把PC複製到RETA,而跟Repeat指令有關的資訊則備 份在CFCT。因此這幾個暫存器,並不需要由scheduler來備份。
Figure 33. Auto Context Switch
如果我們設計的DSP Scheduler 在每次進行 context switching 時都要把所有
暫存器存到堆疊上,顯然 overhead 會太高。因此,在本論文實作的系統中,我
們針對DSP 可能會運行的服務(i.e. H.264 的 Intra frame 編碼器)所會用到的暫存
器進行分析,得知Circular Buffer Register、Interrupt Register,Data Page Register
和Peripheral Data Page Register 等等在這些服務中並不會用到。所以剩下總共 30
個暫存器需要備份。
Figure 34 是 Timer ISR 裡主要的程式碼,可分為五個部分: 1) 把正在運行工作的資訊備份在 stack。
2) 由工作 Queue 裡取得選取下一個工作,如果 Queue 裡沒有等待的工作,就選 取Idle process。
PSHBOTH XAR7 … PSHBOTH XAR0 PSH dbl(AC3) … PSH dbl(AC0) PSH mmap(AC3G) … PSH mmap(AC0G) PSH T3,T2 PSH T1,T0 PSH mmap(ST3_55) PSHBOTH XCDP PSH mmap(BRC0) PSH mmap(RSA0L) PSH mmap(RSA0H) PSH mmap(REA0L) PSH mmap(REA0H) PSH mmap(BRS1) PSH mmap(BRC1) PSH mmap(RSA1L) PSH mmap(RSA1H) PSH mmap(RA1L) PSH mmap(REA1H) PSH mmap(CSR) PSH mmap(RPTC) PSH mmap(TRN0) PSH mmap(TRN1) MOV dbl(*(#_head)),XAR1 BCC next,AR1 != #0 MOV dbl(*(#_idle_pcb)),XAR2 MOV XAR2,dbl(*(#_select_pcb)) B noswitch next: // head = head->next MOV dbl(*AR1(#0004h)),XAR2 MOV XAR2,dbl(*(#_head)) // select = head->pid MOV *AR2,AC0 // select_pcb =&pcb[select] SFTS AC0,#4,AC0 ADD #_pcb,AC0,AC0 MOV AC0,dbl(*(#_select_pcb)) noswitch:
4
2
3
1
MOV dbl(*(#_current_pcb)),XAR1 MOV RETA,dbl(*AR1+)MOV XSP,dbl(*AR1+) MOV SSP,*AR1+ MOV dbl(*(#_select_pcb)),XAR1 MOV XAR1,dbl(*(#_current_pcb)) MOV dbl(*AR1+),RETA MOV dbl(*AR1+),XSP MOV *AR1+,SSP POP mmap(TRN1) POP mmap(TRN0) POP mmap(RPTC) POP mmap(CSR) POP mmap(REA1H) POP mmap(RA1L) POP mmap(RSA1H) POP mmap(RSA1L) POP mmap(BRC1) POP mmap(BRS1) POP mmap(REA0H) POP mmap(REA0L) POP mmap(RSA0H) POP mmap(RSA0L) POP mmap(BRC0) POPBOTH XCDP POP mmap(ST3_55) POP T1,T0 POP T3,T2 POP mmap(AC0G) … POP mmap(AC3G) POP dbl(AC0) … POP dbl(AC3) POPBOTH XAR0 … POPBOTH XAR7
5
NOP NOP NOP NOP NOP NOP RETIFigure 34. Context Switch
4) 把被選取工作的資訊從 stack 裡取出。
3.2.3. Mailbox ISR
DSP 的系統核心,為了提供動態服務的功能,所以會用到 Mailbox 來傳送跟
動態服務有關的命令和資訊,如 Table 4,各自的功能在動態服務的章節,有仔
細詳述。
Table 4. Dynamic Service Command
命令 參數 A2D_REGISTER_SERVICE None A2D_INVOKE_SERVICE Process ID A2D_DUPLICATE_SERVICE Process ID A2D_UNREGISTER_SERVICE Process ID ARM 有兩組 Mailbox 可以傳送訊息給 DSP,而運行在 DSP 的系統核心,已 經使用掉了一組,做為註冊服務和增加工作到工作 Queue 使用。剩下的一組如
果有多個工作也需要用到Mailbox 來做溝通協調的話,但 Mailbox 的 ISR 也只能
有一個,所以剩下一組的也不敷使用多個工作設置各自的ISR。因此有必要設計
一套工作用的Mailbox ISR 的機制。但如同 Timer 的中斷,Mailbox 中斷發生時,
工 作 正 執 行 到 哪 個 指 令 也 是 隨 機 的 , 所 以 需 要 對 被 中 斷 的 工 作 做 context save/restore,最簡單的做法是把所有暫存器都備份起來,但為了能儘快回應 Mailbox 的命令,針對 Mailbox ISR 的內容,只備份會改變其值的暫存器。DSP
系統核心所使用的Mailbox ISR 已經最佳化,只需要備份 XAR1-XAR4、AC0、
AC1、T0、T1 這 8 個暫存器,但是工作的 Mailbox ISR 會使用到暫存器,並不能
事先確定,這要有compiler 的支援才能幫我們自動去決定要備份哪些暫存器,所
以目前暫時使用工作命令表的方式,將ARM 要下達給工作的命令,經由 MPUI
寫到DSP 內部記憶體的工作命令表,讓各個工作去讀取。
工作可以用下面的這兩種Framework 來處理命令。
ARM 傳來的資料是命令的代號。
Figure 35. Passive Task Framework
第二個Framework,如 Figure 36,則是工作主動向 ARM 要求資料並處理完
後,再要求ARM 整合,這時 ARM 傳來的資料是為了讓工作離開 Busy wait 用的。
void task() {
int frame_no = 0;
for(; frame_no<100; frame_no++){ Command1 = 0; request_frame(frame_no); while(!Command1) ; encode_frame(frame_no); write_bitstream(); } } Task Command Table Comand0 Comand1 Comand1 Comand31 Comand0 Task Command Table void task() { while(!Command1) switch(Command1) { case 1: encode_frame(); break; case 2: row_encode(); break; default: return; } } Comand31
3.2.4. DMA 設計
OMAP5912 有提供兩個 DMA,一個是 ARM 所控制的 System DMA,另一
個則是DSP 所控制的 DSP DMA。最大的差異是其運作的記憶體空間不同,System
DMA 所運作的記憶體空間,包含 Flash、SDRAM、SRAM、MPUI,而 DSP DMA
所運作的記憶體空間,包含DARAM、SARAM、Shared memory。
這兩種 DMA 的運作方式,基本上都一樣,每傳送完一個區塊後,DMA 控
制器就會disable 這個 DMA channel,直到 ARM/DSP 再去啟動它(REENABLE),
所以再啟動之前,可以先對channel 的設定做更改。
另外還有Auto-initialization 的模式,這時每傳完一個區塊,DMA 會自動複
製channel 的 configuration 暫存器到它內部的 working 暫存器。但 Auto-initialization 的模式有兩種運行方式,一種是重覆(REPEAT)的傳送同一個區塊,這適合讓資
料隨時保持同步,另一種是每次傳送前會等 ARM/DSP 去設定完(ENDPROG)才
運作。乍看之下,ENDPROG 和 REENABLE 都是要等 ARM/DSP 再對 DMA 下
命令,但實際上是有些許差異,在 ENDPROG 方式下如果能在區塊傳送完之前
就設定好,DMA 在傳送完後可以立刻進行下一筆傳送,但 REENABLE 方式則
是要在 DMA 傳完後再去啟動,而不管啟動前有沒有更改設定。跟 ENPROG 比
較起來,REENABLE 會需要額外的等待。至於 REPEAT 的方式,雖然完全不會
有機會讓DMA 去等待,如果有要使用 DMA 的 ISR,這樣就會產生很多次不必
要的ISR 呼叫,除非是發生 ISR 後,就把這個 DMA channel 的中斷 disable,但
這需要disable DMA channel 才能去設定,直到下次需要呼叫 ISR 時,還要再去
設定,這樣使用上反而更繁雜沒效率。由此分析下來決定使用 ENDPROG 的方
式,來實作DMA 的使用。
因為 DSP 的資料記憶體空間是 16bit-addrssing,而 ARM 的記憶體空間是
DSP 的空間,直接搬移的結果,DSP 讀起來將會是兩個 8bit 資料 compact 成一
個16bit 資料,除非 DSP 上存取的演算法有特別設計,不然直接將 ARM 上運行
的程式碼port 到 DSP 是不能正確讀取的。要能正確讀取,則需要 DMA 從 ARM
空間讀一個8bit 資料就轉型成 16bit 資料寫到 DSP 空間,這樣 DMA 搬移是屬於
來源和目標的資料單位不一樣大小,可是不管是System DMA 或 DSP DMA 都只
支援來源和目標的資料單位都一樣。但DMA 有支援目標和來源 index 的大小不
同的模式,以這個模式,來源的index 設成 1、目標的 index 設成 2,這樣每次讀
取出 8bit 資料在寫入端會以間隔 8bit 來寫入。但這樣做只寫了 16bit 資料的低
8bit,而如果原本 DSP 空間上高 8bit 的位置有 0 以外的值,這樣 DMA 搬移的結
果還是不正確。因此需要在DMA 搬移之前,將 DSP 空間上的值全都設為 0,這
樣DMA 搬移的結果才會是正確。而填 0 的動作也可以交由 DMA 來執行,配合
之前提到的ENDPROG 的運行方式,我們可以先下填 0 的 DMA 命令,然後立刻
再下index 大小不一樣的 DMA 搬移,兩個 DMA 搬移就能完成,而且兩個 DMA
命令之間也不需要等待時間。反過如果是從 DSP 空間搬到 ARM 空間,因為目
3.3. 適合異質多核心平台的應用程式移植步驟
一般來說要把一個普通單核心的應用程式移植到異質多核心的平台上,首先 要把原本的程式進行分割,看哪部分工作適合這個核心執行,哪部分工作適合另 一個核心執行,但除了這種為了平行化的效能而修改演算法的工作分配之外,底 層還是需要有為了多個核心上資料的溝通,使資料共用,而對原本的程式碼做些
微修改,在這方面提出一種porting 樣式,這種 porting style 主要目的是為了簡化
這種修改,使得每次單核心版本的程式碼有更新時,要再 porting 到多核心時,
可減少不必要的額外修改。
主要分為三個步驟,(1)變更變數的資料型態,(2)初始化時變數在記憶體上 的存放位址,(3)在資料需要同步時對這類變數去做搬移。
3.3.1. 變更資料型態
一般常見的CPU 都是以 byte (8bit)為記憶體 addressing 單位,而有些 DSP 依
設計的不同可能會有以word (16bit)為記憶體 addressing 單位,為了適應不同核心
的addressing 單位,多核心要共用資料就要以 addressing 單位最大的為基準。以
下的例子就分別以CPU 用 8bit 而 DSP 用 16bit 為 addressing 單位來說明,所以
CPU 和 DSP 有共用資料的話,其 addressing 單位以 16bit 為基準。假如 CPU 和 DSP 現在要共用一個 8bit 陣列,其原本的型態假設是 uint8,這時就另外定義 share_uint8 為 uint16,並把原本的型態改成 share_uint8,這樣做的優點是,可以
很明確的知道這個陣列是要來共用的,也知道原本的型態是 uint8,而實際要存
取任一筆資料時,不管是用陣列或是指標的方式,compiler 就依照其實際的型態 uint16 來計算位址,會把 offset 的單位從 1(byte)產生成 2(halfword),所以對程式
碼來說,就只有型態有關的部分需要修改,如函數的參數傳遞、資料轉型和sizeof
uint8 可表示範圍內的值就不會有錯誤。
3.3.2. 初始化記憶體位址
一般的程式寫作大都不會強制設定變數存放的記憶體位址,而是用 malloc 這類的函式來幫我們分配其位置,但在這種異質多核心的硬體平台設計,大多會 設計讓各個核心都能存取的記憶體區塊來做為共用記憶體,如 SRAM 記憶體, 甚至有些核心會有自己專用的scratchpad 記憶體,這類記憶體的特點就是存取速 度比一般的SDRAM 記憶體還快,所以資料如果能存放在上面運算的存取速度也 就能提升。因此就有需要手動設定共用或是常存取的變數在記憶體上存放的位 址。我們可以新增一個 shared_mem.c 程式檔給多個核心共用,這樣的優點是對 各個核心的記憶體位址和大小的配置可以很容易同步,而為了適應各個核心上的 差異、如共用記憶體區塊的起始位址和 addressing 單位,可以用#if 這種方式來 判別現在是要compile 給哪個核心,然後各自定義應給的值;原本用 malloc 函式 得來的存放的位址,就改成剛設定的記憶體位址,以Figure 37 的程式碼來當例 子。假如在共用記憶體上有兩個128 byte 的陣列,在之前改變資料型態裡面所提 到的,要以addressing 單位比較大的為基準,所以陣列的每個 8bit 是儲存在 DSP的addressing 單位的 16bit(2byte)上,所以每個陣列實際會佔用 256 byte,而 DSP
因為其addressing 單位 16bit 是 ARM addressing 單位 8bit 的兩倍,所以要把記憶
share_mem.c #ifdef DSP #define SHARE_MEM 0x600000 #define MEM_UNIT 2 #else #define SHARE_MEM 0x20000000 #define MEM_UNIT 1 #endif
share_uint8 *array1_ptr = (share_uint8 *)(SHARE_MEM+0x00000)/MEM_UNIT); share_uint8 *array2_ptr = (share_uint8 *)(SHARE_MEM+0x00100)/MEM_UNIT);
init.c
#include <share_mem.h> void init()
{ array1 = (share_uint8 *) array1_ptr;//(uint8 *)malloc(128*sizeof(uint8)); array2 = (share_uint8 *) array2_ptr;//(uint8 *)malloc(128*sizeof(uint8)); }
Figure 37. Shared Memory Initializatin Example
3.3.3. 資料搬移
基本上把資料放在共用記憶體上運算,各個核心存取到的就已經當前的值,
除非是因為有核心使用了Data cache 就有可能造成 coherency 的問題,所以在需
要同步前要能 flush 掉 cache,或是事先要設定共用記憶體的這段區塊是不會被 cache 的。而之前有提到過異質多核心平台可能有會 scratchpad 記憶體的設計, 所以如果共用的資料是經常會存取的話,就在 scratchpad 記憶體多分配一份空 間,然後在同步完後搬進scratchpad 記憶體,對其運算時的存取將會加快,缺點 就是要多一次搬移的 overhead。當這類資料量太大,可以改用直接記憶體存取 (DMA)的方式,直接搬移兩個核心的記憶體,而不經由共用記憶體,可加速搬移 的時間。
正如之前在變更資料型態裡有提到的多核心共用資料要以記憶體 addressing
單位最大的為基準,如果要運算的資料單位小於最大的記憶體addressing 單位,
每 單 位 資 料 存 放 在 共 用 記 憶 體 要 用 到 的 空 間 大 小 , 也 就 是 最 大 的 記 憶 體 addressing 單位。因此資料搬移的方式,就不能使用目標和來源單位大小一致的 memcpy 函數。
for(int i=0; i<size; i++)
*((share_uint8*)dst + i) = src[i]; memcpy(dst, src, size);
Figure 38. Memcpy to Looply Copy
如Figure 38,有一個 uint8 的陣列要搬到共用記憶體上,原本的目標會和來
源一樣都是 uint8*,但最大的 addressing 單位是 16bit,因此目標就要改成
share_uint8,也就是 uint16,因此目標和來源的大小就不一致,memcpy 就要改
成用for 迴圈的方式,搬移就變比較沒有效率,但這樣搬移的結果才會是正確的;
當然最後運算完,資料整合也需要類似的方式來存取。
所以如果compiler 能針對這類的 pattern,產生出效率跟 memcpy 函式接近的
指令,或是DMA 能夠支援來源和目標的資料單位大小可以不一致,將可以減少
3.4. Porting Issues for TI OMAP OSK5912
因為DSP 是個 16bit 的處理器,在 porting 到 OSK5912 的 DSP 時,常會有
計算結果跟預期的有出入的問題。並且在記憶體的使用上有著特別的限制 運算最常出現的錯誤是跟單位資料長度有關,DSP 的 int 變數長度是 16bit,
而一般個人電腦的x86 CPU 和 OMAP5912 的 ARM 都是 32bit,所以有時候不小
心把某個變數設成 int 型態,並有可能會在上存放超 16bit 的值的,單純把程式
碼移值到DSP,就會出錯。
另一個常見的錯誤是跟compiler 有關,如 Figure 39,以 C 語言和其產生的
DSP 指令來說明,把一個 uint16 的變數左移,因為有可能會超過原本 16bit 可容
納的長度,所以他從 stack 讀出來所存放的暫存器是用 ACn 這種有 40bit 的
Accumulator,可是運算完後卻又跟 0xFFFF 做 AND 運算,最後還是只剩 16bit
的內容。會產生這樣的錯誤,最主要是compiler 對運算式的拆解後,以 button up
的方式去計算各子運算式,所以子運算式並不知道之後會被用在資料長度較長的 運算,只單純用目前的子運算式裡的變數來決定運算完後的暫存資料長度。像這
個例子中,左移這個子運算裡 a 是 16bit,所以運算完的暫存資料長度也跟著是
16bit,compiler 知道左移有可能會超 16bit,所以還再做 AND 來維持 16bit,因 此最後計算結果反而就錯了。 b = a << 10; // uint16 a; uint32 b; MOV uns(@#00h),AC0 SFTS AC0,#10,AC0 AND #65535,AC0,AC0 MOV AC0,dbl(@#02h)
所以如果原先預期的運算結果有可能有超過 16bit 的運算式,為了避免被 compile 產生出錯誤的指令,就必需明確的做轉型,如 Figure 40。藉著運算前先
轉型成長度較長的資料型態,所以左移的子運算裡變數長度最大的就是 32bit,
因此左移後的暫存資料型態也就是 32bit,這樣就不需要再做 AND 來維持 16bit
的長度了,最後計算結果也就跟著正確了。
b = (uint32)a << 10; // uint16 a; uint32 b; MOV uns(@#00h),AC0
SFTS AC0,#10,AC0 MOV AC0,dbl(@#02h)
Figure 40. 32bit Left Shift
在TI 的文件對於各種 Data Addressing Mode,都有著類似下面這段文字,”All
additions to and subtractions from the pointers are done modulo 64K. You cannot address data across main data pages without changing the value in the extended auxiliary register (XARn).”[17],指出其指標的運算都會 modulo 64K 這個特性,
這是來於DSP 有著 64K 的 page boundary,這造成了三個限制,(1)DSP 的 stack
和system stack 必需在同一個 page 上,(2)malloc 函式所分配的計憶體區塊不能跨
過page boundary,也因此最大只能要求到 64K 個 16bit,(3)指標的 address 計算
是用16bit 的運算指令。
除了第一個是因為 DSP 的暫存器設計讓 SP(stack)和(SSP(system stack)共用
高位元的 8bit,另外兩個應該可以說是 compiler 的問題。如 Figure 41,DSP 的
compiler 對於 address 計算所產生的指令,因為 DSP 記憶體空間總共需要 23bit
的 address,所以指標變數存在 stack 上會用到兩個 16bit,才足夠容納 23bit 的
address,而指標存取的 indirect 搬移指令要用 23bit 的 Auxiliary register XARn,
首先從stack 上讀兩個 16bit 暫存到 XARn,但然後只用 16bit 的指令來對 XARn
的低位元的16bit 做運算,因此如果剛好在計算發生 overflow,高位元的 7bit 卻