I-Shou University Institutional Repository:Item 987654321/21422
37
0
0
全文
(2) 基於卷積神經網路之影像超解析 Image Super Resolution Based on Convolutional Neural Nework. 研究生:. 周柏宇. Student:. Bo-Yu Zhou. 指導教授:. 林義隆 博士. Advisor:. Dr. Yih-Lon Lin. 共同指導老師:. 鄭志宏 博士. Co-advisor:. Dr. Jyh-Horng Jeng. 義守大學 資訊工程研究所 碩士論文. A Thesis Submitted to Department of Information Engineering I-Shou University In Partial Fulfillment of the Requirements For the Master Degree In Information Engineering June,2017 Kaohsiung,Taiwan,Republic of China. 中華民國一零六年六月 .
(3)
(4) 致謝 當碩士生兩年的日子結束了,回想起大四下學期剛進這間研究所到現在要畢 業了,在這期間學了很多東西,感謝我的指導老師林義隆老師,教導我許多我不 知道的知識,更深入去了解其內容,提醒我所沒想到的問題以及指導我要以不同 方式去思考,並且讓我累積不同的經驗,像是去聽其他學校演講以及當任高中社 團的指導助理,在接近畢業口試時將寶貴的時間花費在我身上,還有在這期間中 許多待人處事的態度,不厭其煩的教導著我,真的非常謝謝您,我也要感謝共同 指導老師鄭志宏老師,不僅僅教導新知,還讓我了解不管生活還是做事都要有「品 味」,並且分享自己在國外的經驗,讓我增廣見聞,另外我要感謝當任我口試委 員的謝哲光老師以及胡武誌老師,能抽空來參與我的畢業口試,指導我的論文並 給許多建議,使我受益良多。 感謝陪我在實驗室度過兩年的崴勝學長,在我遇到問題時總是教我該如何做, 回答我遇到的問題,也常常共同討論事情,學習到生活上許多事情,也要謝謝陪 我度過的銘展、盟鈺、姿釩、家麒以及佳煜,一起熱心地幫忙各種問題,讓我在 實驗室的生活更加精采。謝謝各位陪我度過我兩年的碩士生活,在各方面都獲得 了非常多的知識。 最後我要感謝我的家人,時常關心我的狀況,在我遇到困難時一直支持我鼓 勵著我,幫助我度過難關,讓我有信心,使我能夠順利完成我的學業。. .
(5) 目錄 圖目錄...........................................................................................................................II 表目錄..........................................................................................................................III 摘要..............................................................................................................................IV Abstract.........................................................................................................................V 第 1 章 研究動機與文獻探討......................................................................................1 第 2 章 超解析..............................................................................................................3 2.1 影像退化模組............................................................................................3 2.2 影像超解析...............................................................................................5 第 3 章 深度學習……..................................................................................................6 3.1 類神經網路...............................................................................................6 3.2 卷積神經網路...........................................................................................8 3.3 全卷積網路.............................................................................................12 第 4 章 研究方法與步驟............................................................................................15 第 5 章 實驗結果........................................................................................................20 第 6 章 結論................................................................................................................25 參考文獻......................................................................................................................26. I .
(6) 圖目錄 圖 2.1、低高解析度影像表示......................................................................................3 圖 2.2、影像退化模型..................................................................................................4 圖 2.3、高解析度影像及低解析度影像......................................................................4 圖 3.1、類神經網路架構圖..........................................................................................7 圖 3.2、卷積神經網路架構圖......................................................................................9 圖 3.3、卷積運算圖....................................................................................................10 圖 3.4、以 2×2 區塊為一組所進行的最大池化圖....................................................11 圖 3.5、Dropout 圖....................................................................................…………..11 圖 3.6、全卷積網路架構圖........................................................................................12 圖 3.7、反池化圖........................................................................................................13 圖 4.1、訓練影像與目標影像…................................................................................17 圖 4.2、影像超解析之卷積神經網路架構圖............................................................18 圖 4.3、影像超解析之全卷積網路架構圖................................................................19 圖 5.1、測試影像與比較影像....................................................................................20 圖 5.2、影像 Lena 實驗結果圖..................................................................................22 圖 5.3、影像 Butterfly 實驗結果圖............................................................................24. II .
(7) 表目錄 表 5.1、影像 Lena 測試結果.......................................................................................23 表 5.2、影像 Butterfly 測試結果.................................................................................24. III .
(8) 摘要 影像超解析在影像處理領域是一個流行的研究主題,影像超解析是從單張或 多張低解析度的影像增加像素數量得到高解析度影像的一個過程。而近年來深度 學習受到許多領域的高度關注,所有相關領域中都有出色的效果,其中卷積神經 網路被廣泛的應用在電腦視覺和影像辨識上。 本研究中,將以深度學習中的卷積神經網路以及全卷積網路的方式來做影像 超解析,探討出架構上對於整體解析度的影響,透過反卷積方法理解卷積神經網 路及全卷積網路過程,進而做出有效的調整改善其影像解析度,與傳統內插法做 比較。. 關鍵字:超解析、卷積神經網路、深度學習. IV .
(9) Abstract Image super-resolution has been a popular research topic in the field of image processing. It is a process of getting a high-resolution image from one or multiple low-resolution images to increase the number of pixels. Deep learning has been highly concerned by many fields in recent years, and all related fields have excellent results. Convolutional neural networks are widely used in computer vision and image recognition. In this thesis, adopt deep learning of convolutional neural network and full convolution network to do super-resolution, to explore the structure for the impact of resolution. Through the deconvolution method to understand the process of convolutional neural network and full convolution network, and then make effective adjustments to improve its image resolution, compared with the traditional interpolation method.. Keywords: Super resolution, Convolutional neural network, Deep learning.. V .
(10) 第 1 章 研究動機與文獻探討 影像的解析度高低代表著影像品質,品質越佳則表示細節能表現更加細膩, 也代表著影像上可以顯示的資訊越多,而為了得到更好的解析度,自從 1969 年 CCD 與 COMS 感光元件被發明後,影像解析度提升的討論與研究一直都是注目 的焦點,並且廣泛應用在許多領域上,例如在娛樂方面可以帶來視覺新體驗,在 醫療方面能提昇診斷的準確率,在識別方面有利於提高辨識正確率。影像解析度 的提升分為兩種方式,一種是加強硬體設備如:擷取時使用更多感光元件或更好 的感光元件,另一種是透過軟體如:影像處理產生高解析度影像。但考慮到加強 硬體設備成本的費用,改由通過影像處理方式獲得,將影像利用超解析(Super-R esolution; SR)方式去提升解析度。 影像超解析由 C. Dong,C. C. Loy,K. He 以及 X. Tang[1-2]提出使用深度 學習架構中的卷積神經網路(Convolutional Neural Nework; CNN)進行解析度上 的提升,主要概念是提出一種用於單張影像超解析的深度學習,將低解析度影像 作為輸入,輸出高解析度影像,透過卷積神經網路進行學習低解析度影像和高解 析度影像之間的端與端映射,而該卷積神經網路並無池化層,不同於傳統的稀疏 編碼分別處理每一層,而是整合所有階層學習訓練。Z. Wang[3]等四位作者提出 以稀疏編碼優先的深度學習影像超解析,可以有效的提高訓練速度以及減少許多 的運算時間。M. H. Cheng[4]等四位作者提出以類神經網路的影像超解析,使用 類神經網路能確實的提高影像品質。另外還有不同方式使用超解析的研究,有濾 波器[5],不同方式分解影像方式[6]、注重在紋理特徵[7],以影像金字塔(Image Pyramid)作為影像分解方式以及取得不同階段特徵提升影像解析度[8]。在深度學 習中眾多的影像處理方式逐漸被重視,透過低解析度影像映射高解析度影像來達 到重建出影像,並且訓練資料隨著增加使重建出的影像品質更好。 本論文將於第 2 章介紹影像超解析以及如何取得退化模型,第 3 章介紹卷積 神經網路和全卷積神經網路的結構以及運算方式,並且透過反向過程瞭解網路中 1.
(11) 的每一層,第 4 章介紹以卷積神經網路和全卷積神經網路為結構做出的影像超解 析其方法跟步驟,第 5 章為實驗結果。. 2.
(12) 第 2 章 影像超解析 影像解析度可分為顯示器的解析度、擷取影像設備的解析度,和影像本 身的解析度,而影像的解析度為單位面積上像素(Pixel)的數量,影像亮度一般常 見最亮亮度為 255,最暗亮度為 0,即每個像素用 8 個位元表示。在為了能夠獲 得更多影像的資訊與細節,而增加單位面積的像素數量,也就是將低解析度影像 轉換為高解析度影像的過程就稱為超解析。例如:128×128 大小的低解析度影像 轉換為 256×256 大小的高解析度影像,如圖 2.1 所示。. (a) Low-Resolution image (128×128). (b) High-Resolution image (256×256). 圖 2.1、低高解析度影像表示 圖 2.1 分別顯示了低解析度影像和高解析度影像,雖然顯示在同一畫面上, 但因為單位面積上像素的數量差異,低解析度影像顯示較小而高解析度影像顯示 較大。. 2.1 影像退化模型 為了能獲得因擷取設備的不佳或環境影響所導致模糊的影像,透過數學模型 來表示低解析度影像。退化模型是透過模糊高解析的影像得到低解析影像,將高 3.
(13) 解析影像使用高斯模糊(Gaussian Blur)以及次取樣(Downsampling)後,因尺寸和 高解析度影像不同,再上取樣(Upsampling)及高斯模糊產生相對應的低解析度影 像,流程如圖 2.2 所示。. 圖 2.2、影像退化模型. 高解析度影像為 X ,如圖 2.3(a),低解析度影像為 Y ,如圖 2.3(b)。高解析度 影像經過高斯模糊和次取樣後得到低解析度影像,相關公式如下. Y DGX. (2.1). 其中 D 為次取樣,而 G 則為高斯模糊濾波器。. (a) High-Resolution image. (b) Low-Resolution image. 圖 2.3、高解析度影像及低解析度影像. 4.
(14) 2.2 影像超解析 影像超解析主要分為單張影像及多張影像使用超解析提升影像解析度,兩者 的差異在於單張影像在提升影像解析度時所得到的資訊較少,因此提升的難度比 多張影像還困難,但由於資訊少表示計算量也少,所以訓練過程中所相對需要的 時 間 就 縮 減 不 少 。 在 傳 統 影 像 處 理 中 使 用 內 插 技 術 線 性 內 插 法 (Linear interpolation)和非線性內插法(Nonlinear interpolation)兩種,其中線性內插運算上 快 速 方 便 且 對 於 階 次 (Order) 運 算 量 較 低 , 一 般 常 用 的 有 鄰 近 內 插 法 (Nearest-Nieighbor Interpolation) 、零性內插法(Zero-order Interpolation)、雙線性 內插法(Bilinear Interpolation)等。 影像解析度的提升使用內插法雖然方法簡單,但放大後效果模糊且邊緣會產 生鋸齒效果,而原因在於未考慮到影像特徵,為此提出一種方式,利用深度學習 技術透過單張影像找出影像特徵,通過特徵學習以及分層提取特徵,重建出高解 析度影像。. 5.
(15) 第 3 章 深度學習 深度學習(Deep Learning)是機器學習(Machine Learning)中一種基於對資料 進行特徵學習的方式,結構上含有多層層次,透過訓練資料逐層特徵提取進行分 類與預測,提升分類與預測的精度。架構上是將每層較低層的輸出做為更高層輸 入,從大量輸入資料中學習有效的特徵表示,而高層會有輸入資料的許多結構資 訊,能夠用於資訊檢索、分類和回歸等特定問題中。現在深度學習中在許多領域 上都有突破性的發展,例如語音及音頻識別、影像分類與識別、影像檢索、影像 超解析度重建等。. 3.1 類神經網路 深度學習概念源自於類神經網路(Artificial Neural Network, ANN),一些深度 學習架構搭配了各式各樣特別的類神經網路階層,所以常被稱為深度神經網路 (Deep Neural Network, DNN)。 類神經網路是一種模擬人類大腦的結構與功能的數學模型,利用電腦的快速 計算能力推論結果,複雜程度高的資訊處理網路,以神經元(neuron)為基本結構, 以多組神經元所組成,分成輸入層、隱藏層、輸出層,層與層之間連結進行平行 運算與處理資訊的功能,其中輸入層不是神經元,其優點在於不用知道數學模型 為何,而是以神經網路取代數學模型,一樣得到輸入與輸出之間的關係。 類神經網路架構為輸入一組資料經由與鏈結值相乘後輸出至隱藏層神經元, 透過激活函數(Activation Function)運算後得到值在從隱藏層輸出至輸出層的神 經元,最後由輸出層輸出獲得一組輸出資料,如圖 3.1 所示。. 6.
(16) uj. zi. fo1(s1). fh1(u1). z1. v ji. fhj (uj ). zn. sk. rj. wkj. fhm(um). z n 1. y1. yk. fok(sk ). yk. fop(sp ). yp. rm 1 圖 3.1、類神經網路架構圖. 而透過倒傳遞演算法(Back-propagation algorithm)的類神經網路方式來更新 參數,使輸出接近目標值。倒傳遞演算法為一種監督式學習演算法,是基於最陡 波降法的(Steepest Descent Method)進行參數更新,因此透過對參數值 w 進行微分 比對誤差平方和 E 而對 w 進行更新,其中 為學習速率(Learning rate),如公式 (3.1). wkj wkj . E wkj. (3.1). 然後依據連鎖律推導出公式(3.2). E E s k E rj wkj s k wkj s k. (3.2). 定義 ok 為輸出層開始之誤差,如公式(3.3). ok . E E yk d k yk f ''ok sk sk yk sk. 合併上面公式(3.1) -(3.3),可得出更新 w 公式,如公式(3.4). 7. (3.3).
(17) wkj wkj . E wkj ok r j wkj. (3.4) 同理,輸入層到隱藏層的參數更新也能一樣,如公式(3.5). v ji v ji . E v ji. (3.5). 然後依據連鎖律推導出公式(3.6). E E u j E zi v ji u j v ji u j. (3.6). 定義 ok 為隱藏層開始之誤差,如公式(3.7). hj . E E E rj f 'hj u j rj u j rj u j. p E sk f 'hj u j k 1 sk rj . (3.7). p f 'hj u j ok wkj k 1 合併上面公式(3.5) -(3.7),可得出更新 w 公式,如公式(3.8). wkj wkj . E wkj ok r j wkj. (3.8). 類神經網路已開發出許多類神經網路階層、架構和初始化的方式,如卷積神 經網路(Convolutional neural network, CNN)、遞歸神經網路(Recurrent neural network, RNN)、受限玻爾茲曼機(Restricted Boltzmann machine, RBM)等。. 3.2 卷積神經網路. 8.
(18) 卷積神經網路基於類神經網路架構,它的多層結構可以自動學習特徵,是由 一或多個卷積層和全連通層所組合而成,裡面包括關聯參數和池化層,其中每層 卷積層由不一定數量的卷積單元組成,而每個卷積單元的參數都是通過反向傳播 算法優化得到的,其目的為取出輸入來源的不同特徵, 越多卷積層越能從低級 特徵中疊代取出更複雜的特徵,從而做分類與回歸。 卷積神經網路是根據影像中三種重要特性,第一個是影像的特徵大部分都在 整張影像的一個小區塊,如許多臉部特徵是整個表面積中的某個區域範圍,第二 個是許多相似特徵存在於影像不同的局部區塊,如許多臉部特徵可能存在於影像 不同的位置,第三個是影像經過次取樣後上面的物件並不會消失,而是仍然存在 於影像中,如影像經簡單次取樣後並不會改變原本顯著的臉部特徵。上述前兩個 特性強調說明影像具有區域局部相似的特性,而第三者則說明取樣並不改變特性, 是卷積神經網路分別是卷積(convolution)和池化(pooling)的作法,另外卷積神經 網路為了能不斷增強訊號傳遞至下一層而使用線性整流函數(Rectified Linear Unit, ReLU)[11-13],每一層均可得到更不錯的參數值,達到更深度的學習,廣泛 運用在影像處理上,著名應用如數字識別[9]、人臉識別[10]。 卷積神經網路整體架構包含輸入層、卷積層、池化層、平化層(flatten)、全 連結層(fully connected)到輸出層等,如下圖 3.2 所示。. 圖 3.2、卷積神經網路架構圖 卷積層是由許多濾波器所組成,假設一個 6×6 輸入影像通過 3×3 過濾器, 過濾器每次移動一個單元的方式對輸入局部資料進行卷積運算,運算中還有一個 bias,每個卷積都是一種特徵提取方式,將影像中挑選出不同特徵,圖 3.3 所示。 9.
(19) 圖 3.3、卷積運算圖 卷積層運算後會使用 ReLU 函數其公式如下. Re LU x max0, x. (3.1). 將值固定在一定範圍內,可以增強判定函數以及整體的非線性特性,並且不會改 變卷積層,並且保證每層輸出值都是正數,也就是保證每層的特徵值為正值,它 可以提升神經網絡的訓練速度,而並不會對預測造成產生顯著影響。 池化層是將輸入的影像劃分為數個矩形區塊,以一種次取樣的形式,取出每 個子區域最大值。之所以能有效地原因在於提取一個特徵之後,它的精確位置沒 有比其他特徵相對位置的關係重要。池化層會不斷地減少資料的空間,使參數的 數量和計算量也跟著下降,在一定程度上也會控制了過度訓練(overfitting),在卷 積神經網路的卷積層之間都會插入池化層。目前最常用形式的池化層是每隔 2 個元素從圖像劃分出 2x2 的區塊,然後對每個區塊中的 4 個數取最大值,這將會 減少 75%的數據量,圖 3.4 所示。. . 10.
(20) 圖 3.4、以 2×2 區塊為一組所進行的最大池化圖 最後為了防止過度訓練而重複學到不好的特徵,所以需要 Dropout[14-16], 它會暫時隨機刪除一定比例的神經元,但輸入輸出神經元個數保持不變,讓輸入 資料通過已修改後網路結構,訓練調整完對應參數後還原刪掉的神經元,之後等 下一次疊代重複,這樣可以達到更好的訓練成果,並且提升訓練速度,如圖 3.5 所示。. 圖 3.5、Dropout 圖 卷積神經網路與類神經網路不同之處在於有兩種方式可以降低參數數目,第 一種方式叫做局部連結,第二種方式叫做參數共享。局部連結是只對影像的一小 區域進行採樣,不需要全部進行採樣,因為距離相近的像素相關性會比較大,而 11.
(21) 距離越遠的像素相關性則越小,然後在更高層會將小區域的資訊綜合起來進而得 到影像全部的資訊。 但即使使用局部連結參數數量依然過多,就需要參數共享,在局部連結當中, 每個神經元都對應著參數,如果這些參數都為相等的,則參數數目就會大幅度減 少,這可以當成像是提取特徵的方式,而影像中部分的統計特徵方式跟其他部分 都一樣,也就代表著這部分學習特徵的方式也可以用在另一個部份上,在影像中 的任一位置使用同樣學習特徵的方式。. 3.3 全卷積網路 全卷積網路(Fully Convolutional Networks, FCN)不同於卷積神經網路,它對 影像進行像素分類,對每個像素做預測並保留原始輸入影像空間訊息,利用反卷 積層對最後卷積層的特徵圖進行上採樣,恢復到輸入影像相同尺寸,最後在對特 徵圖進行像素分類,著名應用如影像分割[17]。 全卷積網路架構是將卷積神經網路中的全連接層轉化成卷積層,如圖 3.6 所 示。. 圖 3.6、全卷積網路架構圖. 全連接層與卷積層不同之處在於卷積層中的神經元是只有局部連結的,並且 共享參數。. 12.
(22) 為了瞭解網路中的每一層,可透過反卷積和反池化來可視化,顯示各層提取 出的特徵圖。池化是不可逆的過程,但是通過池化過程中記錄最大值位置,在反 池化時只把值放入池化過程中最大值位置,其它位置值則填入為 0,所以反池化 只是池化做出一種近似,做出池化前的卷積層特徵如圖 3.7 所示。. 圖 3.7、反池化圖. 左邊表示池化過程,右邊表示反池化過程。假設的輸入影像大小是 4×4,使 用 2×2 最大池化後,會變成 2×2 大小的影像,得到最大值並記錄其位置,而當 反池化時會把值填入到之前所記錄位置,其他則會填入 0,如果沒有記錄位置時 則會直接全部填入最大值。 ReLU 函數則是用於保證每層輸出的值都是正數,因此在反向過程,同樣 需要保證每層的特徵值也是正數,也就是說這個反向過程和正向過程並無差別, 所以直接採用 ReLU 函數。 而反卷積又稱為轉置卷積(Transposed Convolution),原理為卷積的前向傳播 過程就是反卷積的反向傳播過程,卷積的反向傳播過程就是反卷積的前向傳播過 程,以計算過程來說,卷積層的前向反向計算分別為乘矩陣和反矩陣,而反卷積. 13.
(23) 層的前向反向計算則反過來分別為乘反矩陣和矩陣,兩者的前向傳播和反向傳播 剛好交換。. 14.
(24) 第 4 章 研究方法與步驟 本研究以卷積神經網路和全卷積網路分別做為架構進行影像超解析,利用六 張影像的低解析與高解析去訓練參數,以 128×128 低解析影像當作訓練影像,而 256×256 高解析影像做為目標影像,如圖 4.1 所示。. (a) bird (128×128). (b) bird (256×256). (c) baboon (128×128). (d) baboon (256×256). 15.
(25) (e) baby (128×128). (f) baby (256×256). (g) barbara (128×128). (h) barbara (256×256). (i) pepper (128×128). (j) pepper (256×256) 16.
(26) (k) bridge (128×128). (l) bridge (256×256). 圖 4.1、訓練影像與目標影像. 在進行訓練參數時先以一張影像去訓練,等效果提升到好成效之後則在加入 下一張影像與之前影像一起訓練,這是為了防止訓練過多不同影像時容易產生出 過度訓練,而卷積神經網路架構的影像超解析如圖 4.2 所示。. 17.
(27) 圖 4.2、影像超解析之卷積神經網路架構圖. 將一張 128×128 低解析影像做為輸入,通過卷積層提取特徵,並使用 ReLU 將值固定在一定範圍內,之後池化層進行次取樣,然後卷積與池化再做一次後平 化進入全連結,通過 Dropout 得到好的訓練成果,重新建構為影像後進行反池化 跟反卷積各兩次,在中間使用 Merge 將之前卷積結果合併均化後再做處理,最後 得到輸出結果。而全卷積網路架構的影像超解析如圖 4.3 所示。. 18.
(28) 32×128×128 32×64×64. 1×128×128. Convolutions. MaxPooling. 32×128×128. 32×64×64. Convolutions. 32×32×32. MaxPooling. 32×32×32. Convolutions. 32×16×16. MaxPooling. 32×16×16. Convolutions. 32×64×64 Deconvolution Merge. Merge. Upsampling 32×128×128. 32×128×128. 32×64×64. 32×64×64. Deconvolutions. Deconvolutions. 32×32×32. Upsampling. 32×32×32. Deconvolutions. 32×16×16. Upsampling. 32×256×256 1×256×256. Upsampling. Deconvolutions. 圖 4.3、影像超解析之全卷積網路架構圖. 除了將中間過程中的平化與全連結層轉化成卷積層外,其它架構與卷積神經 網路架構的影像超解析一樣,而中間卷積部分則是繼續卷積與池化然後再逆向反 卷積跟反池化。 在卷積神經網路和全卷積網路架構中增加 Merge 層,是因為隨著卷積與池化 越多時,進行反池化跟反卷積時誤差有可能越來越大,而 Merge 層可以將輸出為 同樣大小的輸出層合併,把前面卷積層的輸出與反卷積層的同樣大小輸出合併均 化,使誤差能夠更小,得到品質更好的影像。. 19.
(29) 第 5 章 實驗結果 下列實驗使用 Lena 、Butterfly 兩張大小為 128×128 的灰階化影像,影像在 經過二值化後,使用卷積神經網路以及全卷積網路進行影像超解析,以 256×256 高解析影像做為預測影像,依據第四章所提的方法以及改變不同方式所得出的結 果與資料,圖 5.1 為測試影像與比較影像。. (a) Lena (128×128). (b) Lena (256×256). (d) Butterfly (128×128). (d) Butterfly (256×256). 圖 5.1、測試影像與比較影像. 20.
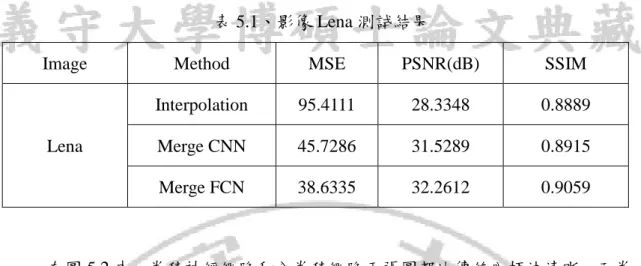
(30) 而為了能比較品質,將利用均方誤差(Mean Squared Error, MSE)、影像訊號 雜訊比(Peak Signal to Noise Patio, PSNR)以及結構相似性(Structural Similarity Index, SSIM)三種方式來比較。其公式如下: 1. 均方誤差:. MSE =. 1 m−1 n−1 ( f (i, j ) − g (i, j ))2 ∑∑ m × n j =0 i =0. (5.1). 2. 影像訊號雜訊比:. 2552 PSNR = 10 × log10 MSE . (5.2). 3. 結構相似性:. SSIM ( x, y ) =. (µ. (2µ µ x. 2 x. y. + c1 )(2σ xy + c2 ). )(. + µ y + c1 σ x + σ y + c2 2. 2. 2. ). (5.3) 假設原始影像為 f 而比較影像為 g ,當 MSE 值越小且 PSNR 值越大時,表 示兩者影像失真程度越低,也就是比較影像越接近原始影像。另外假設兩者影像 分別為 x 和 y 比較, µ 和 σ 分別為 x 和 y 的影像像素值的平均值和差異,兩張 影像的共變異數為 σ xy , c1 = (k1 × L ) 、 c2 = (k 2 × L ) 為穩定參數,其中 k1 =0.01、 2. 2. k 2 =0.03, L 為每一個亮度像素值的動態範圍,當 SSIM 越接近於 1 時則表示兩. 張影像越相近,若越接近於 0 時則反之。 依照第四章的結構,卷積神經網路以及全卷積網路以 3×3 過濾器進行卷積計 算與反卷積計算,並以相同的激活函數 ReLU 和 2×2 區塊做最大池化,並先訓練 後所做的實驗,圖 5.2 為影像 Lena 實驗結果。. 21.
(31) (a) Ground true image. (b) Interpolation. (c) CNN Super-Resolution. (d) FCN Super-Resolution. 圖 5.2、影像 Lena 實驗結果圖. 表 5.1 是以影像 Lena 做為測試影像,將影像大小為 128×128 低解析度影像 提升解析度為影像大小為 256×256 高解析度影像,卷積神經網路和全卷積網路的 效果比較。. 22.
(32) 表 5.1、影像 Lena 測試結果 Image. Lena. Method. MSE. PSNR(dB). SSIM. Interpolation. 95.4111. 28.3348. 0.8889. Merge CNN. 45.7286. 31.5289. 0.8915. Merge FCN. 38.6335. 32.2612. 0.9059. 在圖 5.2 中,卷積神經網路和全卷積網路兩張圖都比傳統內插法清晰,而卷 積神經網路和全卷積網路比較明顯差別在於全卷積網路的 Lena 肩膀邊緣較白, 從表 5.1 中比較兩者,卷積神經網路比一般內插法高 3.1941 dB,結構相似度提 高了 0.0026,全卷積網路則是高於 3.9264 dB,結構相似度提高了 0.0026,而圖 5.3 為影像 butterfly 實驗結果。. (b) Interpolation. (a) Ground true image. 23.
(33) (c) CNN Super-Resolution. (d) FCN Super-Resolution. 圖 5.3、影像 Butterfly 實驗結果圖. 表 5.2 是以影像 Butterfly 做為測試影像,將影像大小為 128×128 低解析度影 像提升解析度為影像大小為 256×256 高解析度影像,卷積神經網路和全卷積網路 的效果比較。. 表 5.2、影像 Butterfly 測試結果 Image. Butterfly. Method. MSE. PSNR(dB). SSIM. Interpolation. 423.4552. 21.8627. 0.8327. Merge CNN. 204.5037. 25.0238. 0.8439. Merge FCN. 259.1385. 23.9955. 0.8061. 在圖 5.3 中,卷積神經網路和全卷積網路兩張圖差別比較不明顯,但表 5.1 中比較兩者,卷積神經網路比一般內插法高 3.1611 dB,結構相似度提高了 0.0112, 全卷積網路只高於 2.1328 dB,結構相似度卻降低了 0.0266。. 24.
(34) 第 6 章 結論 在本論文中使用卷積神經網路以及全卷積網路進行影像超解析,主要是探討 兩者架構對重建影像品質上的影響,並改良其架構提升影像品質。而主要作法是 先出建立卷積神經網路以及全卷積網路架構,透過特徵學習方式,一層一層的提 取特徵,將低解析度影像經由分析出的特徵圖重建出品質好的高解析度影像。 在實驗的過程中發現在卷積以及池化越多時容易在反向過程中將誤差變得 更大,透過在架構上增加 Merge 層可以使誤差減少。 除了本實驗中的架構外還有許多不同組合的架構,而不同的架構是否可以產 生出更好的影像品質或增加更多的影像去訓練出更好的效果都值得往後去研 究。. 25.
(35) 參考文獻 [1]. C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 2, pp. 295-307, 2015.. [2]. C. Dong, C. C. Loy, K. He, and X. Tang, “Learning a deep convolutional network for Image super-resolution,” In Proceedings of European Conference on Computer Vision, vol. 8692, pp. 184-199, 2014.. [3]. Z. Wang, D. Liu, S. Chang, Q. Ling, Y. Yang, and T. Huang, “Deep networks for image super-resolution with sparse prior,” In Proceeding of International Conference on Computer Vision (ICCV), 2015.. [4]. M. H. Cheng, N. W. Lin, K. S. Hwang, and J. H. Jeng, “Fast video super-resolution using artificial neural networks,” 8th IEEE International Symposium on Communication Systems, Networks and Digital Signal Processing(CSNDSP), Poznan, Poland, pp. 1-4, 2012.. [5]. 邱垂汶,「使用視覺高頻增強濾波器之高品質超解析度影像與視訊研究」, 國立雲林科技大學電機工程系碩士論文,2004。. [6]. L. Shen, Z. Y. Xiao, and H. Han, “Image super-resolution bases in MCA and wavelet-domain HMT,” Information. Technology. and. Applications, pp.. 264-269, 2010. [7]. G. Jing, Y. Shi, and B. Lu, “Single-image super-resolution bases on decomposition and sparse representation,” Information Conference on Multimedia Communication, pp. 127-130, 2010.. [8]. C. Y. Tsai, D. A. Huang, M. C. Yang, L. W. Kang, and Y. C. F. Wang, “Context-aware single image super-resolution using locality-constrained group. 26.
(36) sparse representation,” Visual Communications and Image Processing, pp. 1-6, 2012. [9]. Y. LeCun, L. Buttou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceeding of IEEE, november, 1998.. [10] S. Lawrence, C. L. Giles, A. C. Tsoi, and A. D. Back, “Face recognition: a convolutional neural-network approach,” IEEE Transactions on Neural Network, vol. 8, pp. 98-113, 1997. [11] X. Glorot, A. Bordes and Y. Bengio, “Deep sparse rectier neural networks,” Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS-11), pp. 315-323, 2011. [12] A. L. Maas, A. Y. Hannun, and A. Y. Ng. “Rectifier nonlinearities improve neural network acoustic models,” ICML Workshop on Deep Learning for Audio, Speech, and Language Processing (WDLASL 2013), 2013. [13] K. He, X. Zhang, S. Ren and J. Sun, “Delving deep into rectifiers: surpassing human-level performance on imagenet classification,” IEEE International Conference on Computer Vision (ICCV), pp. 1026-1034, 2015. [14] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” The Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929-1958, 2014. [15] P. Baldi and P. J. Sadowski, “Understanding dropout,” Advances in Neural Information Processing Systems 26(NIPS 2013), pp. 2814-2822, 2013. [16] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever and R. R. Salakhutdinov, “Improving neural networks by preventing co-adaptation of feature detectors,” arXiv preprint arXiv:1207.0580, 2012.. 27.
(37) [17] E. Shelhamer, J. Long and T. Darrell, “Fully convolutional networks for semantic segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. pp, iss. 99, 2016.. 28.
(38)
數據


相關文件
{ Title: Using neural networks to forecast the systematic risk..
Ongoing Projects in Image/Video Analytics with Deep Convolutional Neural Networks. § Goal – Devise effective and efficient learning methods for scalable visual analytic
CAST: Using neural networks to improve trading systems based on technical analysis by means of the RSI financial indicator. Performance of technical analysis in growth and small
CAST: Using neural networks to improve trading systems based on technical analysis by means of the RSI financial indicator. Performance of technical analysis in growth and small
Kyunghwi Kim and Wonjun Lee, “MBAL: A Mobile Beacon-Assisted Localization Scheme for Wireless Sensor Networks,” The 16th IEEE International Conference on Computer Communications
Selcuk Candan, ”GMP: Distributed Geographic Multicast Routing in Wireless Sensor Networks,” IEEE International Conference on Distributed Computing Systems,
Yeh, I-Cheng, “Modeling slump flow of concrete using second-order regressions and artificial neural networks,” Cement and Concrete Composites, Vol.29, 474-480 (2007). Yeh,
Kyunghwi Kim and Wonjun Lee, “MBAL: A Mobile Beacon-Assisted Localization Scheme for Wireless Sensor Networks”, the 16th IEEE International Conference on Computer Communications
