線上個人化參考文獻管理系統
71
0
0
全文
(2) 線上個人化參考文獻管理系統 研究生: 陳莉君. 指導教授: 柯皓仁博士,楊維邦博士. 國立交通大學資訊科學研究所. 摘 要 參考文獻管理系統提供使用者儲存與管理文件的功能,文件儲存主要以記錄 特徵(Feature)的方式,例如文件作者、出版年份、內容摘要等來代表某篇文件。 而蒐集的文件可以依照使用者自定的類別來歸類,達到個人化管理的功能。 本論文提出的個人化文獻管理系統除了上述機制外,並且能夠做到個人化文 獻推薦的功能,其概念為分析文件內容語意,亦即語意歧異 解析(Word Sense Disambiguation, WSD),將相同語意的文件分在同一群,若使用者有文件屬於某 一群,則系統能將此群中的其他文件推薦給該使用者。在語意歧異解析方面,本 論文提出一個新的語意歧異解析方法來決定文件內容中字詞的語意,這個方法是 以建立字詞語彙鍵結(Lexical Chain)為基礎,並搭配 WordNet 得到詞彙概念 (Concept),建立的語彙鍵結依概念關係的強度而有不同的權重,利用這些權重來 判斷該字詞可能的語意。實驗中,我們採用 Semantic Concordance Corpus (SemCor) 文件集來評估語意歧異解析方法的好壞。結果顯示,我們所提的方法有不錯的表 現,平均來說,正確率可以達到 65.26%,優於[Suarez99]所提出的 59.11%。. 關鍵字:參考文獻管理系統、個人化推薦、語意分析、語意歧異解析、語彙鍵 結. II.
(3) 致 謝 感謝指導教授柯皓仁老師及楊維邦老師的悉心指導,讓我學習到完成一篇論 文或一項研究所需經歷的整個過程與自我挑戰的階段,也讓我了解到作為一個研 究生所須具備的實事求是與追根究底的精神。 感謝實驗室的同學們,你們適時溫馨的幫助與實驗室和樂的氣氛是使我完成 論文的一大動力,在那種環境下,具有讓人放鬆心情及專心思考的魔力。還有感 謝圖書館參考諮詢組和計畫室的成員們,你們偶爾天南地北的閒聊和加油打氣是 使我繼續衝刺的良方。 感謝親愛的家人永遠不變的支持與鼓勵,也感謝朋友的關懷。在研究所的這 兩年當中,有摸索、有茫然、有討論、有歡笑、有瓶頸、也有解決方法,這段過 程是獨一無二且滿懷回憶的。謝謝你們。. June, 2003. III.
(4) 目 錄 英文摘要 ........................................................................................................................I 中文摘要 ...................................................................................................................... II 致 謝 ...........................................................................................................................III 目 錄 ...........................................................................................................................IV 圖目錄 .......................................................................................................................... V 表目錄 .........................................................................................................................VI 第一章 簡介 ................................................................................................................. 1 第一節 第二節 第三節 第四節. 參考文獻管理系統 ..................................................................................... 1 研究動機 ..................................................................................................... 3 研究目的 ..................................................................................................... 4 本論文內容與架構 ..................................................................................... 6. 第二章 文獻管理系統之相關研究工作 ..................................................................... 7 第一節 語意歧異解析 ............................................................................................. 7 第二節 文件分群方法 ........................................................................................... 16 第三節 個人化參考文獻服務系統 ....................................................................... 18 第三章 改良型語意歧異解析演算法 ....................................................................... 22 第一節 第二節 第三節 第四節. 名詞語意歧異解析與複合語意權重表示法 ........................................... 22 鍵結擴充-語意歧異解析的策略 ........................................................... 25 改良型語意歧異解析演算法 ................................................................... 28 實驗結果分析與評估 ............................................................................... 29. 第四章 個人化參考文獻管理系統之實作 ............................................................... 44 第一節 系統流程與說明 ....................................................................................... 44 第二節 應用於個人化環境 ................................................................................... 51 第五章 結論與未來研究方向 ................................................................................... 57 第一節 結論 ........................................................................................................... 57 第二節 未來研究方向 ........................................................................................... 58 附錄 A:Stemming-Porter’s Algorithm................................................................ 59 參考文獻 ..................................................................................................................... 62. IV.
(5) 圖目錄 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖 圖. 1:語意歧異解析(WSD)的相關研究工作 ............................................................ 8 2:car 在 WordNet 中定義的五種語意 ............................................................... 10 3:名詞 “car” 的語意關係 ................................................................................. 10 4:考慮 Mr.及 person 所產生的不同語彙鏈結組合.......................................... 12 5:Mr., person 及 machine 所產生的不同語彙鏈結組合 .................................. 13 6:語彙鏈結的第一種可能建構結果 ................................................................. 14 7:語彙鏈結的第二種可能建構結果 ................................................................. 14 8:方便使用者瀏覽與管理的分群結果 ............................................................. 16 9:使用者可自行調整的分群系統 ..................................................................... 17 10:RefWorks 登入後提供的操作介面 .............................................................. 19 11:RefWorks 的新增參考文獻介面 .................................................................. 20 12:BoW 的階層索引瀏覽功能 .......................................................................... 21 13:語意歧異解析的範例 1 ................................................................................ 23 14:語彙鍵結的建構結果 1 ................................................................................ 23 15:語彙鍵結的建構結果 2 ................................................................................ 23 16:語意歧異解析的範例 2 ................................................................................ 24 17:sister 在 WordNet 中定義的四種語意 ......................................................... 26 18:與定義相關的策略的範例圖 ....................................................................... 26 19:year 在 WordNet 中定義的四種語意 ........................................................... 27 20:month 在 WordNet 中定義的二種語意........................................................ 27 21:SemCor 的 15 類文件主題 ........................................................................... 30 22:SemCor 文件的範例 ..................................................................................... 31 23:文件字詞語意分析的流程 ........................................................................... 44 24:文件分群及推薦的流程 ............................................................................... 48 25:Bottom-Up Hierarchy 分群方法示意圖 ....................................................... 49 26:系統流程圖 ................................................................................................... 50 27:選擇新增各種文獻類型 ............................................................................... 51 28:新增期刊論文 ............................................................................................... 52 29:自定(新增)資料夾......................................................................................... 52 30:選擇瀏覽、編輯、刪除文獻 ....................................................................... 53 31:瀏覽及顯示文獻詳細資訊 ........................................................................... 53 32:編輯(更新)文獻資料..................................................................................... 54 33:刪除、剪下、複製文獻,並可將文獻歸類入資料夾(手推車功能)......... 54 34:簡易搜尋及進階搜尋功能 ........................................................................... 55 35:系統推薦使用者文獻 ................................................................................... 56. V.
(6) 表目錄 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格 表格. 1:已知參考文獻管理系統之功能比較 ........................................................... 2 2:本論文提出的 MyLibrary 文獻管理系統與其他系統之比較 .................... 6 3:字詞語意判斷前後的向量表示 ................................................................. 25 4:參考[Suarez93]得到的數據 ........................................................................ 35 5:採用語彙鍵結(Lexical Chain)得到的數據 ................................................ 35 6:未加入策略的改良型語意歧異解析方法得到的數據 ............................. 36 7:三種語意歧異解析方法的比較 ................................................................. 37 8:加入策略 1 的改良型語意歧異解析方法得到的數據 ............................. 37 9:加入策略 1 和策略 2 的改良型語意歧異解析方法得到的數據 ............. 38 10:語意歧異解析方法的完整比較資訊 ....................................................... 38 11:利用改良型語意歧異解析方法判斷多語意名詞的正確比率 ............... 40 12:各種文件分群方法之比較 ....................................................................... 43 13:計算字詞的 IDF 與 Signal 值之比較....................................................... 47. VI.
(7) 第一章 簡介 第一節 參考文獻管理系統 近年來隨著資訊數位化的技術逐漸成熟以及電腦科技的進步,幾乎各式各樣 的資訊都能經由網路取得,網際網路的蓬勃發展使得數位圖書館的資源日益豐 盈,而人們也可以方便地獲取知識。這些電腦與網路科技的發展已逐漸影響人類 生活的許多方式,並改變了資訊與知識的產生、處理及傳播。舉例而言,早期使 用者要利用圖書館資源只能實地到圖書館內尋找,而在「數位圖書館(Digital Library)」[26]這個概念被提出並且建置後,現在的使用者已經不一定要到圖書館 內找資料了,他們可以透過網際網路來取得數位圖書館的資料。 一般來說,使用校園數位圖書館的目的不外乎館藏查詢、電子資料庫查詢及 電子期刊查詢等,而會用到後兩項的使用者主要都是為了研究目的,我們稱之為 學術研究者(Academic User)[22],他們時常需要接觸並閱讀相關的研究論文與報 告。然而,由於個人習慣的差異,有些人閱讀或下載後的文獻常放在零散的地方, 導致將來想要整合時還得花費一番功夫。 有鑑於此,一個可依個人需求來調整且便於管理資料的文獻管理系統就顯得 有需要了,目前文獻管理系統中較著名者包括線上參考目錄 BoW(Bibliography on the Web)系統[24]以及個人線上參考文獻資料庫 RefWorks 系統[27],總結這些系 統的功能,一個好的文獻管理系統必須提供下列幾項服務: Ø. 不受時間與空間的限制,使用者可以在任何時間、任何地點使用文獻管 理系統。. Ø. 使用者可以方便地新增資料並且組織及管理個人目錄。. Ø. 使用者可以藉由搜尋功能方便找到所需的文獻。. Ø. 使用者可以利用唯讀方式將個人之文獻資料分享給其他的研究人員。 1.
(8) 表格 1 是這兩個系統的主要功能比較。 文獻管理系統 功. 線上參考目錄. 個人線上參考文獻. BoW. 資料庫 RefWorks. 支援遠端存取. √. √. 新增文獻資料. √. √. 能. √. 組織及管理資料(夾) 建立文獻索引(index). √. 文獻搜尋服務. √. √. 資源共享. √. √. 自動文獻分群. √. 表格 1:已知參考文獻管理系統之功能比較. 在表格 1 的這些功能中,支援遠端存取及新增文獻資料是一個文獻管理 系統所需提供的基本功能,而一個貼心的文獻管理系統尚需讓使用者依自己的 習慣組織及管理資料或資料夾,因此前三項服務是文獻管理系統的基本功能。 而建立一個好的文獻管理系統的關鍵技術在於(1)如何建立文獻索引、(2)提升 文獻搜尋結果之服務、(3)與他人共享資源及(4)自動文獻分群。 (1) 建立文獻索引:線上參考目錄 BoW 系統[24]提出的索引建立方法為階 層式的概念索引,它從文件中的作者名、出版商、註解等挑選出關鍵字作為索 引,在字詞的權重計算上採用資訊擷取(Information Retrieval)方法的 TF*IDF [1]。這種藉由計算 TF*IDF 的權重公式雖然簡單,但相對地,因為它並沒有判 斷出文件字詞的語意,因此可能會導致非相關的文件搜尋結果或錯誤的文件分 群。解決方法可以加入字詞的語意來建立文件索引,而在判斷字詞語意方面, 包 括 字 典 導 向 方 法 (Dictionary-Based Method) 、 監 督 式 方 法 (Supervised Method)、非監督式方法(Unsupervised Method)以及混合型方法(Hybrid Method) 2.
(9) 都可以用來判斷字詞語意,其中字典導向方法是目前最多人採用且準確度較高 的方法,一些相關研究如[3][4][5][6][7][8][19]等都是對照 WordNet 這個詞典 (Thesaurus),利用詞典中所定義的字詞關係來決定字詞間的語意。 (2) 文獻搜尋服務:良好的搜尋必須兼顧快速回傳資料及提升搜尋準確 度,因此系統通常會先建立文件的索引,索引建立的方式依系統或使用者的需 求而有所不同,若系統只提供字串比對的搜尋服務,則資訊擷取(Information Retrieval)方法[1]建立的索引就已足夠,但利用此方法建立的索引並不能保證 搜尋的準確度;若系統希望滿足使用者搜尋的準確度,意即搜尋到語意相關的 資料,則可以利用判斷出的字詞語意建立索引。 (3) 資源共享:線上參考目錄 BoW 系統[24]以及個人線上參考文獻資料庫 RefWorks 系統[27]可以藉由搜尋功能找出相關的文獻,並且提供使用者以唯讀方 式共享他人的資源。但同樣地,系統提供的共享資源中可能有一些和使用者非相 關的文獻,解決方法同樣可以加入字詞的語意來代表文獻。. (4) 自動文獻分群:文獻分群與文獻索引息息相關,計算所有已經建立好索 引文獻的相似度,則可以達到自動文獻分群的功能,不過問題在於分在同群中的 文獻是否真正相關,解決方法同樣可以加入字詞的語意來代表文獻。. 以上所述的線上參考目錄 BoW 系統[24]以及個人線上參考文獻資料庫 RefWorks 系統[27]都沒有判斷出字詞的語意,因此我們開發的文獻管理系統將著 眼於語意的分析且建立具語意的字詞索引。. 第二節 研究動機 過去的文獻管理系統大多著重於提供一個便於操作的介面,這個介面可以讓 使用者依個人需求來調整且管理所蒐集的文件,最多加上檢索的功能讓使用者能. 3.
(10) 快速搜尋文件及達到資源共享。有鑑於此,本論文研究的動機便是希望能夠提升 文獻管理系統的價值,藉由分析使用者蒐集的文件,將文件分群並推薦相關的資 料給使用者。因此我們認為一套好的文獻管理系統還必須滿足以下兩個條件: Ø. 分在一群的文件必須確實相關;. Ø. 推薦的文件必須符合使用者的需求;. 為了滿足上述的兩個要求,一套較佳的文獻管理系統必須要能夠理解文件的 內容,即文件的真正語意,因此本論文提出一個可以判斷字詞語意的演算法,利 用此演算法得到的字詞語意當作文件索引,進而將文件分群,分群後的結果並推 薦給相關的使用者。. 第三節 研究目的 綜合以上說明,本論文主要的研究在於判斷文件字詞語意,並利用分群方法 將這些判斷出字詞語意的文件分群。實作的系統呈現(推薦)給使用者的是一個有 組織、有架構的文件分群結果,使用者可以從這些推薦給他的文件中選取自己想 要的資訊,並可以依照自己的喜好新增、修改、儲存整群文件等,而使用者所做 的這些動作都將被系統記錄下來作為其個人設定檔(User Profile)的一部分,以應 用到下次他的文件分群中。 整套個人化文獻管理系統提供的功能有: Ø. 輸入功能(Import):讓使用者將欲儲存的文件輸入空白表單中-利用複 製和貼上(Copy and Paste)。. Ø. 管理資料夾功能(Organize Folders):讓使用者自定資料夾,並將文件分 門別類歸納入各個資料夾,並可對資料夾更名、新增、刪除、修改。. Ø. 瀏覽功能:由使用者選擇排序欄位瀏覽儲存的文件。. 4.
(11) Ø. 搜尋功能:分為簡易搜尋及進階搜尋兩種;搜尋使用者儲存的文件。. Ø. 文件分群及推薦功能:系統將全部蒐集的文件經斷詞切字處理及字詞語 意判斷後,進行文件分群,分群後的文件推薦給擁有該群某些資料的使 用者。. Ø. 回饋(Feedback)及共享功能:使用者可以評估推薦結果,並將滿意度回 傳給系統,系統可藉此調整分群演算法,進一步達到個人化服務的目的。. 我們並希望透過經由語意分析後分群好的文件,來達到以下目標: Ø. 自動文件分類: 已知分群後的每群群中心,則新增的文件分別和每群群中心計算相似. 度,若最大相似度超過設定的門檻值(Threshold),則這個新增文件歸類在最 大相似度的群中;若最大相似度沒有超過門檻值,則此新增文件單獨成一 群。如此一來即可以做到自動文件分類。 Ø. 推薦使用者新進文件: 這個目標可以利用與內容相關的方法(Content-Based Method)來完成,若. 利用前述自動文件分類方法將某新增文件歸類到最大相似度的一群中時,這 個新增文件同時會被推薦給擁有該群某些資料的使用者。. 綜合以上所述的功能,我們提出的 MyLibrary 文獻管理系統與線上參考目錄 BoW 系統[24]以及個人線上參考文獻資料庫 RefWorks 系統[27]比較的功能如表 格 2:. 5.
(12) 文獻管理系統. 線上參考目錄. 個人線上參考文獻. MyLibrary文. BoW. 資料庫 RefWorks. 獻管理系統. 支援遠端存取. √. √. √. 新增文獻資料. √. √. √. √. √. 功 能. 組織及管理資料(夾) 建立文獻索引(index). √. √. 文獻搜尋服務. √. √. √. 資源共享. √. √. √. 自動文獻分群. √. √ √. 推薦文獻功能 表格 2:本論文提出的 MyLibrary 文獻管理系統與其他系統之比較. 我們提出的 MyLibrary 文獻管理系統不僅提供基本功能,亦提供滿足並符合 使用者需求的進階功能。. 第四節 本論文內容與架構 本論文共分為五章,第二章介紹文獻管理系統之相關研究工作,包括判斷字 詞語意以建立文件索引、文件分群和個人化參考文獻服務系統;第三章提出一個 新的判斷字詞語意的演算法,利用語彙鍵結為基礎,改良字詞語意權重表示法並 加入兩種策略來決定字詞語意,且對這個演算法及以這個演算法為核心技術的文 件分群結果進行實驗分析與評估;第四章說明實作的「個人化參考文獻管理系 統」,結合 MyLibrary@NCTU 呈現給使用者;第五章則歸納結論與未來研究方 向。. 6.
(13) 第二章 文獻管理系統之相關研究工作 本論文提出的參考文獻管理系統著重於建立文獻語意索引及文獻分群與推 薦功能,因此本論文主要的目的在於將使用者儲存的文獻資料加以語意分析並分 群,然後將分群結果與使用者個人設定檔(User Profile)對照後推薦給使用者作為 學術研究時的參考。 整個文獻管理系統的相關研究工作包括判斷字詞語意以建立語意索引;文件 分群;以及個人化參考文獻服務系統,將在本章中逐一說明。 首先第一節介紹判斷字詞語意的問題-語意歧異解析及如何利用語意歧異 解析的方法來選取關鍵字詞當作文件索引,第二節說明文件分群的方法及進一步 達到個人化分群的技術,第三節描述個人化參考文獻服務系統的相關研究。. 第一節 語意歧異解析 選取關鍵字詞來作為文件索引是分析文件的第一個步驟,本篇論文也不例 外。關鍵字詞的選取是非常重要的,它關係著這些字詞是否能正確代表某篇文 件。傳統純粹經由資訊擷取過程計算字詞頻率(Term Frequency)和該字詞出現文 件數的反轉頻率(Inverse Document Frequency)所得到的關鍵字詞並不具有任何語 意[1]。為了解加入語意的分群結果是否比傳統不具語意的分群結果為佳,本篇 論文將比較兩者的分群結果且著重於具語意的關鍵字詞選取。. 判斷字詞語意的問題稱為語意歧異解析(Word Sense Disambiguation, 簡寫為 WSD),如何達成語意歧異解析是在處理自然語言時的一個常見問題,也是尚待 解決的難題[3]。目前為止解決這個問題的方法主要分為四種類型: 1. 字典導向方法(Dictionary-Based Method) :這種方法又稱為知識導向 (Knowledge-Driven)的語意歧異解析方法[8],採用方式為對照一個具大量 7.
(14) 詞彙及語意的字典(Dictionary),常見的字典如 WordNet[28],再藉由該字 典所組織的相關詞彙語意集合找出某字詞的可能語意,如 [3][4][5][6][7][8][19]。 2. 監督式方法(Supervised Method):限定某類主題的文件集,且關於這類主 題中的字詞已經訓練好語意。之後蒐集到的該類主題文件則依據已訓練 好的字詞決定其語意,如[9][10][11]。 3. 非監督式方法(Unsupervised Method):沒有採用任何資訊或知識,純粹由 蒐集的文件去判斷字詞語意,如[12][13][14][15]。 4. 混合型方法(Hybrid Method):任意結合上述三種類型的方法,例如結合 某類文件集與字典的方法,如[9][10][16][17][18]。 我們依照年份及類型整理了關於語意歧異解析的相關研究工作,如圖 1:. 混合型 方法. 字典導 向方法. 監督式 方法. 非監督 式方法. 圖 1:語意歧異解析(WSD)的相關研究工作. 8.
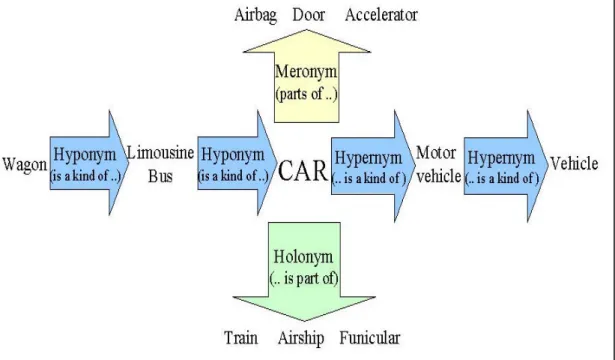
(15) 由圖 1 可知字典導向方法是解決語意歧異解析最常用的方法,且最常被用 來對照使用的字典是 WordNet,因此本篇論文也採用對照 WordNet 的方式。在對 照 WordNet 的相關研究工作中,其技術包含:(1)語彙鍵結(Lexical Chains) [6]; (2)語意密度(Semantic Density) [3]。下面將依序介紹 WordNet 及利用 WordNet 解 決語意歧異解析的技術。. 2.1.1 WordNet. WordNet [2]是一個線上詞彙參考資料庫,它的設計靈感是從人類詞彙記憶中 的心理語言學(Psycholinguistics)而來。在 WordNet 中,英文名詞、動詞以及形容 詞組織成同義字集合(Synonym Sets, Synsets),每個集合代表一個基本的詞彙概 念,同義字集合間會以不同的關係串聯。 以英文名詞來說,在 WordNet 中定義了四種關係: 1. Synonym / Antonym 同義詞 / 反義詞關係 2. Hypernym / Hyponym (relation is a kind of) 上位詞 / 下位詞關係 3. Holonym (relation is part of) 完全關係 4. Meronym (relation parts of) 附屬關係 舉例而言,“car”這個英文名詞在 WordNet 中有五種語意,每種語意代表一 種 synset,這五種語意及其相關解釋分別代表(1) auto 汽車;(2) railcar 火車車廂; (3) cable car 纜車;(4) gondola 氣球、氣船;(5) elevator car 升降廂,如下圖所示:. 9.
(16) The noun "car" has 5 senses in WordNet. 1. car, auto, automobile, machine, motorcar -- (4-wheeled motor vehicle; usually propelled by an internal combustion engine; "he needs a car to get to work") 2. car, railcar, railway car, railroad car -- (a wheeled vehicle adapted to the rails of railroad; "three cars had jumped the rails") 3. cable car, car -- (a conveyance for passengers or freight on a cable railway; "they took a cable car to the top of the mountain") 4. car, gondola -- (car suspended from an airship and carrying personnel and cargo and power plant) 5. car, elevator car -- (where passengers ride up and down; "the car was on the top floor") 圖 2:car 在 WordNet 中定義的五種語意. “car”在 WordNet 中定義的四種相關語意關係如圖 3 所示:. 圖 3:名詞 “car” 的語意關係[10]. 由圖 3 中可以看出名詞 “car” 與其他字詞間的關係,例如 Ø. Limousine is a kind of car, limousine 是 car 的下位詞(Hyponym)。. Ø. Car is a kind of Motor vehicle, motor vehicle 是 car 的上位詞(Hypernym)。. 10.
(17) Ø. Car is part of train, train 和 car 屬於完全關係(Holonym),且是部份完全關 係(Member Holonym)。. Ø. Airbag, door, accelerator 都是 car 的附屬物件,所以它們和 car 屬於附屬 關係(Meronym)。. 由於 WordNet 具備豐富的詞彙語意集合及關係,因此它是最常用來判斷字 詞語意,解決語意歧異解析的工具。接下來的兩個小節介紹利用 WordNet 解決 語意歧異解析的技術。 2.1.2 語彙鍵結(Lexical Chain) 語彙鏈結(Lexical Chain) [6]是文章中具有相同意義的字詞所構成的集合,每 個語彙鏈結代表文章中所描述的一個概念(Concept)。一般來說,建構語彙鏈結的 程序可分為下列三個步驟:. 1. 挑選候選的字詞。 2. 對於每個候選的字詞,針對每個語彙鏈結,衡量該字詞所代表的語意與 語彙鏈結中每個字詞的語意關聯度,藉此找出相關聯的語彙鏈結。 3. 如果找到適當的語彙鏈結,便將該字詞加入語彙鏈結中;如果沒有找到 的話,便建構新的語彙鏈結。 上述步驟中,用來衡量語意相關的方法,乃是利用 WordNet 來判斷字詞間 的關係。主要的關係定義有三種:(1) Extra-strong (定義字詞與其同義字詞間的關 係 ) , (2) Strong ( 定 義 兩 個 字 詞 在 WordNet 中 存 在 直 接 關 聯 的 關 係 ) , (3) Medium-strong (定義兩個字詞在 WordNet 中存在間接關聯的關係)。 在建構過程中,給予鍵結一強度值,用來表示字詞語意關聯的程度:若某鍵 結為同義詞關係(Synonym),則給予 10 分;鍵結為完全關係(Holonym),則給予. 11.
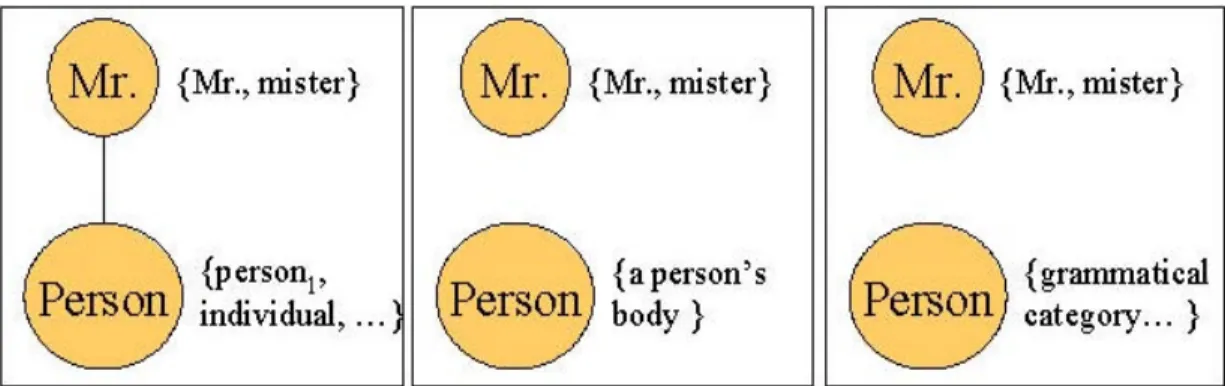
(18) 7 分;鍵結為上位詞關係(Hypernym),則給予 4 分。語彙鍵結的強度值是衡量一 個字詞語意的主要指標。 以下例說明如何建構語彙鏈結。其中,粗體字型為挑選出的候選字詞,注意 挑選出的候選字詞以名詞為主。 Mr. Kenny is the person that invented an anesthetic machine which uses micro-computers to control the rate at which an anesthetic is pumped into blood. Such machines are nothing new. But his device uses two micro-computers to achieve much closer monitoring of the pump feed the anesthetic into patient. 對於第一個字詞 “Mr.”,首先建構語彙鏈結 [lex “Mr.”, sense {mister, Mr.}]。 接著,考慮第二個字詞 “person”,由 WordNet 中可知 person 具有三種不同的涵 義,分別為(1)“human being”;(2)“a person's body”及(3)“grammatical category of pronouns and verb forms”。為了正確地選擇區別字詞的真正涵義,建構過程便需 考慮所有可能的鏈結組合,如圖 4 所示,Mr.及 person 會產生三種不同的語彙鏈 結組合。. 圖 4:考慮 Mr.及 person 所產生的不同語彙鏈結組合. 其中,涵義為 “human being”的 person 是 Mr.的上位詞,因此它們之間的鍵 結強度為 4 分。再接著考慮第三個字詞 “machine”,由 WordNet 中可知 machine 具有五種不同的涵義,第 1 種涵義為 “an efficient person”,以 machine1 表示,此. 12.
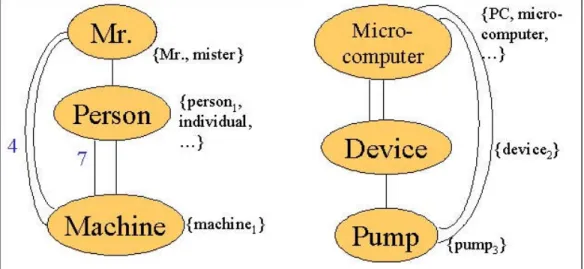
(19) 種涵意是 holonym of person。因此 machine 1 和 person 之間的鍵結強度為 7 分。而 machine 的其他四種語意 machine 2 ∼machine5 和 Mr.以及 person都沒有其他關係。 Mr., person 及 machine 產生的所有可能的語彙鏈結組合如圖 5 所示。. 圖 5:Mr., person 及 machine 所產生的不同語彙鏈結組合. 上述這樣的作法保留所有可能的鏈結組合,相對地,在建構過程中便產生許 多無意義的語彙鏈結;因此必須衡量每個語彙鏈結的重要性,以刪去無用的語彙 鏈結。計算語彙鏈結中所有字詞間的相關連結及程度來衡量該語彙鏈結的重要 性,便可以將不具代表意義的語彙鏈結刪除,以便有效且快速地建構語彙鏈結。. 13.
(20) 上例中最後建構出的語彙鏈結有兩種可能,如圖 6 及圖 7 所示,衡量 machine 在兩圖中的鍵結強度:11 分及 30 分,因此選擇圖 7 為語彙鍵結結果。 圖 7 中清楚地看到 Mr.與 person 被歸類在相同的語彙鏈結,其所要表達的概念為 『人』 ;Machine,Micro-computer,Device 以及 Pump 則被歸類在另一個語彙鏈 結中,其所要表達的概念為『機器』。由此可知,語彙鏈結確實可以反映出某字 詞在文件中的語意。. 圖 6:語彙鏈結的第一種可能建構結果. 圖 7:語彙鏈結的第二種可能建構結果. 美中不足的是,藉助 WordNet 以衡量兩兩語詞間語意的關聯程度,可能因 為某個語詞的語意辨認錯誤,而產生錯誤的語彙鏈結;如此,該語彙鏈結所要表 達的知識概念便可能偏離原文所要表達的涵義。. 14.
(21) 2.1.3 語意密度(Semantic Density) 語意密度(Semantic Density) [3]的定義為:兩個或多個字詞間的語意距離 內,相同字詞出現的個數。若兩個字詞的語意關係愈接近,其語意密度愈高。在 上述定義中,有關度量語意密度時所採用的字詞詞性必須先解釋清楚: 語意密度度量的是一對動詞-名詞(Verb-noun Pair)間的語意距離,語意距離通 常以一個句子(Sentence)為單位,因為一個句子一般而言都可以簡短地用動作與 物體(Action-object Pair)來表示。舉例而言:He has to investigate all the reports 可 以簡短地用 investigate-report 這個動作-物體對來描述。 在度量語意密度時,首先利用判斷詞性的演算法,如 Part-of-speech Tagging, 標示出字的動詞、名詞等詞性,然後考慮一個句子中的動詞-名詞配對,再利用 WordNet 找出該動詞與名詞的所有語意。若動詞有 k 個語意,名詞有 m 個語意, 以 <v1 , v2 , … v k> 及 <n1 , n2 , … nm > 表示,對每一個可能的 v i - nj pair,計算語意 密度的演算法如以下步驟:. 1.. 在 WordNet 中,動詞 synset 的註解會提供該動詞的上下文相關名詞。 找出該動詞的相關名詞及這些名詞的 synset 與 hypernym set, 組成包含 該動詞 v i 的階層(Hierarchy)。. 2.. 利用 WordNet 找出名詞 nj 的 synset 與 hypernym set, 組成包含該名詞 nj 的階層。. 3.. 比較動詞與名詞的階層,計算這兩個階層相同字詞出現的個數 Cij。在 此 Cij 的算法為: cd. C ij =. ij. ∑w. k. k. log( desc j ). 15.
(22) −. 對動詞 v i 的階層而言,wk 代表與該動詞有關的名詞 sv k 在階層中的 權重(Weight),在這裡權重用階層的高度(Level)來計算。. −. cdij 是在動詞階層與名詞階層中,相同概念出現的個數。. −. descj 是名詞 nj 的階層中的總個數。. 計算所有 v i 和 nj 所形成的 Cij 之後,最大的 Cij 即代表動詞最可能的語意 i 與 名詞最可能的語意 j,因此決定了字詞的語意。. 第二節 文件分群方法 本篇論文希望呈現並推薦給使用者的是一個有組織、有架構的文件分群後的 結果,分好的每群以概念來描述它,以方便使用者瀏覽與管理。呈現結果類似圖 8 所示。. 圖 8:方便使用者瀏覽與管理的分群結果. 16.
(23) 其中,左框架的每個資料夾(目錄)代表一群,每群以一個概念(Concept)表示 之,概念後的小括弧中代表的數字為該群包含的文件數,例如第一群的概念為 Software,包含 15 篇文件;第二群的概念為 Linux,包含 12 篇文件,以此類推。 右框架則顯示左框架每群中包含的文件詳細資料。. 分群方法主要分為兩種類型:(1)非監督式分群法(Unsupervised Clustering)和 (2)不完全監督式分群法(Semi- supervised Clustering)。非監督式分群法會在演算過 程中自動達到一個最佳的分群數目,並且將資料指定到某群中,然而要達到一個 最佳的分群數目並不容易,因此研究如何達到一個最佳的分群數目仍然是一個重 要的議題[20][21]。不完全監督式分群法則結合非監督式分群法及一些已知的資 訊,這些資訊包含分群的數目及每群中已有的一些資料,因此不完全監督式分群 法主要是用來判斷出某個不知道類別的資料該歸屬於哪一類。 在[Tan02]中提到,使用者可以對呈現給他的分類資料加以新增或刪除,而 使用者的這些動作會被儲存起來,作為下次分類資料的依據,換句話說,使用者 能夠自行調整分群結果來滿足自己的需求,亦即達到個人化分群的目的。圖 9 為使用者可自行調整的分群系統示意圖:. 圖 9:使用者可自行調整的分群系統[22] 17.
(24) 由圖 9 中可知,當蒐集的資訊,如文件等經過分群系統組織分群後,這些 分群好的資訊會先透過個人化模組加以調整,個 人化模組儲存使用者的個人設定 檔等,而系統加以調整好的資訊才會藉由使用者介面呈現給使用者以期滿足個人 需求。. 第三節 個人化參考文獻服務系統 有關個人化參考文獻服務的研究方面,線上參考目錄 BoW 系統[24]以及個 人線上參考文獻資料庫 RefWorks 系統[27]提出個人化參考文獻服務的架構,概 括來說,所謂的個人化參考文獻服務,應該要具備以下條件:(1) 儲存使用者所 蒐集的文獻,以便於組織及管理資料;(2) 支援使用者以唯讀模式讀取他人的資 料庫,以達到資源共享的目的;(3) 提供個人化的搜尋服務,快速找到自己蒐集 的參考資料,並可以依主題搜尋他人的參考資料。. 由 Cambridge Scientific Abstracts (CSA) 所發展的個人線上參考文獻資料庫 RefWorks 系統[27],架構於全球資訊網(WWW),主要提供個人參考文獻管理與 編製的解決方案,它具備以下特色: Ø. 無需安裝任何軟體工具:它是一 WWW-based 的服務,適用於任何平台 上的主要瀏覽器。. Ø. 不受時間與空間的限制:使用者只需要透過網際網路,就可以在任何時 間、任何地點連接到 RefWorks.. Ø. 與多數電子資源系統相容:使用者可以快速且方便地匯入主要電子資源 系統及參考文獻編輯工具所產生之參考文獻資料。. Ø. 個人化服務:RefWork 為個人化的參考文獻資料庫管理工具,使用者只 需以個人使用者帳號及密碼登入,即可享受個人化的服務。. 18.
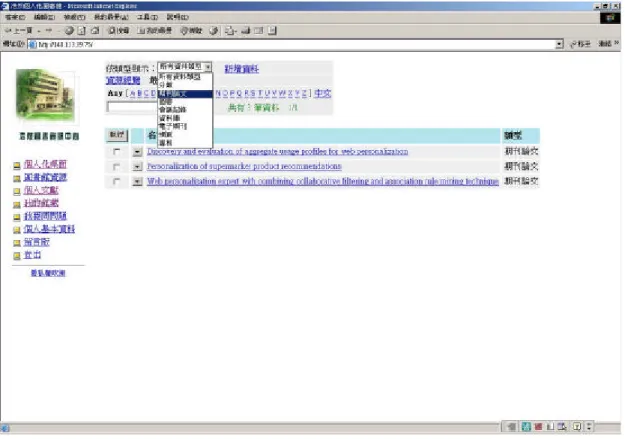
(25) Ø. 資源分享:可以透過匯出參考文獻記錄或使用唯讀密碼將個人之參考文 獻資料分享給其他的研究人員。. Ø. 多國語言介面:目前提供九種國際間常用的語言介面,使用者可以在最 習慣的語言環境中使用 RefWorks 提供的服務。. RefWorks 的主要提供功能有: Ø. 匯入資料;. Ø. 組織及管理個人資料;. Ø. 將文獻中的參考文獻以不同的樣式格式化;. Ø. 匯出資料;. Ø. 產生文稿的參考文獻;. Ø. 將引文(篇號)寫入文稿中。. RefWorks 的操作介面如圖 10:. 圖 10:RefWorks 登入後提供的操作介面. 19.
(26) 在圖 10 的左框架為登入者姓名及各種查詢方式的介面,右框架的上方為 RefWorks 提供的幾項功能,依照各種功能的結果呈現在右框架的下方中,舉例 而言,若使用者點選“新增參考文獻”,則如圖 11 所示:. 圖 11:RefWorks 的新增參考文獻介面. RefWorks 的新增參考文獻可以選擇要新增到哪一個文件夾,並且輸入參考 文獻的一些相關資料。. 線上參考目錄 BoW(Bibliography on the Web)系統[24]是依據階層式概念索 引連結物件的一個線上書目儲存系統,BoW 建立的主要目的為創造一個方便使 用與管理線上書目資料的環境。在階層中每一個節點稱為概念頁面 (Concept Pages),亦即 BoW 所蒐集的文獻資料,愈上層頁面所代表的概念愈廣泛,而包 含某些概念頁面節點及其子樹的頁面稱為主題(Topic)。BoW 取概念頁面的作者 名、出版商、註解等當作索引,建構出階層式的概念索引,以提高搜尋的正確性。. 20.
(27) BoW 提供的主要功能有: Ø. 新增資料. Ø. 依照使用者新增的資料建立概念式的階層索引. Ø. 階層索引中的文件瀏覽. Ø. 匯出資料. Ø. 搜尋功能. BoW 的操作介面如圖 12。下方網頁的左框架為階層索引,範圍愈大的索引 包含的頁面愈多,右框架則是階層索引中的文件瀏覽。上方的網頁為新增資料的 操作介面。. 圖 12:BoW 的階層索引瀏覽功能. 21.
(28) 第三章 改良型語意歧異解析演算法 在本章中,我們針對參考文獻的特性,選擇適合的語意歧異解析演算法。由 於在文獻管理系統中,文件儲存主要是以記錄特徵(Feature)的方式,例如文件作 者、出版年份、內容摘要等來代表某篇文件。其中我們選取 “摘要” 中的字詞進 行語意歧異解析,因為摘要通常不會太長,且在簡短的摘要中,相同的字詞通常 具有相同的語意。 針對上述特性,我們假設在簡短而有限的一段摘要中,其內的字詞只會擁有 一種語意。因此我們以會判斷出字詞最有可能語意的 “語彙鍵結(Lexical Chains)” 方法[6]為基礎,分析文件中「名詞」的語意,並提出幾點改進:(1) 複合語意與 權重:針對每個名詞的涵義,考量最後建構出的幾個語彙鍵結,將每個名詞的語 意依照鍵結強度賦予不同的權重。(2) 鍵結擴充:為了防止語彙鍵結過少,加入 一些策略讓每個名詞盡量能判斷出語意,以降低無法判斷語意的比率。我們將這 種方法稱之為改良型語意歧異解析方法。 在本章中,第一節及第二節分別介紹改良型語意歧異解析方法的複合語意權 重表示法及鍵結擴充,第三節說明整個改良型語意歧異解析演算法的流程,第四 節計算實驗數據並評估本論文提出的改良型語意歧異解析方法的效能。. 第一節 名詞語意歧異解析與複合語意權重表示法 為了方便說明所提出的改良型語意歧異解析方法,在此以相關研究工作中語 彙鍵結方法(Lexical Chain)的範例來驗證。 在此範例中,分析的文件內容為:. 22.
(29) Mr. Kenny is the person that invented an anesthetic machine which uses micro-computers to control the rate at which an anesthetic is pumped into blood. Such machines are nothing new. But his device uses two micro-computers to achieve much closer monitoring of the pump feed the anesthetic into patient.. 圖 13:語意歧異解析的範例 1. 分析此文件中挑選出來的候選字詞,在此候選的字詞皆為名詞,如黑體字所 示,其最後建構出來的語彙鏈結有兩種可能,如圖 14 及圖 15 所示:. 圖 14:語彙鍵結的建構結果 1. 圖 15:語彙鍵結的建構結果 2. 23.
(30) machine 這個名詞在圖 14 中所表示的語意為 machine 1 ,其鍵結強度為 11 分;而在圖 15 的語意則為 machine 4 ,其鍵結強度為 30 分,因此最後 machine 會被判斷成 machine4 這個語意,也就是指定它的概念為「機器」。 但這種只單取一個語意的決定似乎有點專斷,因為還是有可能 machine 的真 正語意是 machine1 而不是 machine4 。以下面圖 16 這段文字而言: Mr. Kenny is not only the boxer, a magnificent fighting machine, but also the person that invented an anesthetic mechanism which uses micro-computers to control the rate at which an anesthetic is pumped into blood. His device uses two micro-computers to achieve much closer monitoring of the pump feed the anesthetic into patient. 圖 16:語意歧異解析的範例 2. 最後建構出來的語彙鍵結結果仍然是圖 14 與圖 15,但是 machine 的真正語意 卻應該是鍵結強度較弱的 machine 1 而非 machine4。為了考量類似的情形並使得語 彙鍵結方法更精確,我們將此方法加以改良,使得具有不同語彙鍵結的字詞以「複 合語意」來表示,而只有一個語彙鍵結的字詞則直接指定其語意。. 以圖 13 的範例而言,我們讓 machine 這個名詞以複合語意來表示,並賦予 每個語意強度值,成為 machine{machine1 :11;machine4 :30},而其他的字詞 Mr., person, micro-computer, device, pump 則可以直接指定語意為{mister, person1 , micro-computer, device2 , pump3 }。因此整篇文件中,我們以 Mr. {mister};person {person1 } ; machine {machine 1 : 11/41 ; machine4 : 30/41} ; micro-computer {micro-computer};device {device2 };pump {pump3 }這些名詞語意來代表此文件。 假設在挑選這些候選字詞時,已經利用 TF*IDF 計算出權重,即(Mr. person, machine, micro-computer, device, pump)的權重為(0.4, 0.3, 0.9, 0.7, 0.8, 0.7),則加 入 語 意 後 形 成 的 向 量 變 成 (Mr., person1 , machine 1 , machine4 , micro-computer,. 24.
(31) device2 , pump 3 )的權重為(0.4, 0.3, 0.9*11/41, 0.9*30/41, 0.7, 0.8, 0.7),下面表格 3 顯示此文件經語意判斷前後的字詞權重向量。. microMr.. person. machine. device. pump. 0.8. 0.7. device 2. pump3. 0.8. 0.7. computer 未決定語意前計算 0.4. 0.3. Mr.. person1. 0.9. 0.7. 好的權重(weight) 判斷出的語意. microM1. M4 computer. 分析語意後的權重. 0.4. 0 .9 * 11 41. 0.3. 0 .9 * 30 41. 0.7. 表格 3:字詞語意判斷前後的向量表示. 我們將每篇文件挑選出的候選名詞判斷出的語意依照此方式來代表文件向 量的表示式,有了這些具語意的文件向量表示法,即可將這些文件分群,並進行 後續的其他工作。. 第二節 鍵結擴充-語意歧異解析的策略 在語彙鍵結方法中,若某一候選字詞與其他候選字詞皆沒有語意上的關聯, 則這個候選字詞無法形成任何鍵結,也就是說,無法判斷出這個候選字詞的語意。 為了讓每個名詞能盡量判斷出語意,我們參考[8]提出的改善方法,觀察文 件中名詞的特性,提出兩點策略如下: 1. 與定義相關的策略(Strategy of Definition) 這裡的定義(Definition) 指的是 WordNet 中關於字詞的註解(Gloss),也可 以說是註解的策略(Strategy of Gloss)。. 25.
(32) 若某字詞的語意在 WordNet 註解中含有其他字詞,我們可以說這兩個字 詞間含有某種程度的關聯。舉例而言,若某篇文件中含有(sister, person) 這兩個字詞,它們在 WordNet 中並沒有任何關係,也就是說不會出現這 兩個字詞互相連接的語彙鍵結。但 sister 在 WordNet 中有四種語意:. The noun "sister" has 4 senses in WordNet. 1. sister, sis -- (a female person who has the same parents as another person; "my sister married a musician") 2. Sister -- ((Roman Catholic) a title given to a nun (and used as a form of address); "the Sisters taught her to love God") 3. sister -- (a female person who is a fellow member of a sorority or labor union or other group; "none of her sisters would betray her") 4. baby, sister -- ((slang) sometimes used as a term of address for attractive young women) 圖 17:sister 在 WordNet 中定義的四種語意. 其中,sister 的第一種語意和第三種語意的註解都包含 “person”,第一種 語意(sister1 )有 2 個 “person”;第三種語意(sister3 )有 1 個 “person”,因此 在“person” 所建構出來的語彙鍵結下,我們可以加入 person 與 sister 的 連結,其強度單位指定為 3 分,出現次數愈多則強度值愈大。. Person. Person. 3*2=6 Sister1. Person. 3 Sister3. Sister2, 4. 圖 18:與定義相關的策略的範例圖. 圖 18 顯示 sister 的四種語意和 person 之間的鍵結關係與強度示意圖。. 26.
(33) 2. 一般性(Common)字詞的策略 這個策略主要是用來解決語意差異性過小的問題。舉例而言,(year, month) 這種字詞,它們在 WordNet 中定義的語意彼此間的差異性很小,因此實 在不需要再判斷出哪一個才是正確語意。在實作上,雖然這些字詞有多 個語意,不過可以直接將它們指定為某一種語意。 year 在 WordNet 中定義的 4 種語意如下:. The noun "year" has 4 senses in WordNet. 1. year, twelvemonth, yr -- (a period of time containing 365 (or 366) days; "she is 4 years old"; "in the year 1920") 2. year -- (a period of time occupying a regular part of a calendar year that is used for some particular activity; "a school year") 3. year -- (the period of time that it takes for a planet (as, e.g., Earth or Mars) to make a complete revolution around the sun; "a Martian year takes 687 of our days") 4. class, year -- (a body of students who graduate together; "the class of '97"; "she was in my year at Hoehandle High") 圖 19:year 在 WordNet 中定義的四種語意. month 在 WordNet 中定義的 2 種語意如下:. The noun "month" has 2 senses in WordNet. 1. calendar month, month -- (one of the twelve divisions of the calendar year; "he paid the bill last month") 2. month -- (a time unit of 30 days; "he was given a month to pay the bill") 圖 20:month 在 WordNet 中定義的二種語意. 由圖 19 和圖 20 可以看出 year 的四種語意都是代表“年”,month 的兩 種語意都是代表“月”。. 27.
(34) 這個策略由於是藉由人為判斷某字詞的語意是否差異性不大,因此它的 執行過程主觀性較強,也比較需要花費人力,我們規定此策略必須等前 述第一節複合語意權重表示法及第二節的與定義相關的策略執行完後 才可以依照需求繼續執行此策略。 將第一節中提出的複合權重表示法加入上述兩點鍵結擴充策略,我們希望能 夠提高語意歧異解析的正確性,並減少無法判斷出字詞語意的比率。. 第三節 改良型語意歧異解析演算法 總結上述兩節和範例說明,整個改良型語意歧異解析演算法分為五個步驟及 兩個策略,其描述如下: −. Step1:利用 TF*IDF 計算文件中的名詞權重,挑出權重>threshold 的名 詞當作候選字詞。Document={W1 , W2 , … Wn }. −. Step2:對每一個候選字詞 Wi,查詢 WordNet 找出其所有語意。Si={Si1 , Si2 , … Sim }. −. Step3: For each word { For each sense { 和現存的語彙鍵結比較其涵義: 若屬於 WordNet 定義的字詞間的關係,則連接現存的語彙 鍵結並存在一鍵結強度值; 否則無法連接,建立一個新的語彙鍵結。 } }. 28.
(35) −. Step4: 對每一個語彙鏈結,計算其中所有字詞間的相關連結及程度來衡量該 語彙鏈結的重要性,將不具代表意義的語彙鏈結刪除。. −. Step5: 計算保留下來的語彙鍵結中每個字詞所屬的強度值。 若某個字詞具有兩個以上語彙鍵結,則按照強度值分配權重; 否則直接指定其語意。. −. 與定義相關的策略 (Strategy of Definition): For all non-disambiguation senses { For all words that belong to the context { 搜尋此 sense 的註解中是否包含這些字詞, 若有,則兩者存在一鍵結且按照出現次數給予鍵結強度。 } }. −. 一般性 (Common) 字詞的策略:搜尋執行完上述五個步驟及與定義相 關的策略後仍未決定語意的字詞,查詢 WordNet 這些字詞的語意,以 專家的角度判斷某字詞的多個語意是否差異性不大,若語意間差異性不 大,則指定該字詞為第一個語意,並將此字詞儲存起來,以後遇到相同 情況時則直接指定該字詞的語意。. 透過這個改良型語意歧異解析演算法分析文件後,下一節我們將計算實驗數 據並評估我們提出的改良型語意歧異解析方法的效能。. 第四節 實驗結果分析與評估. 29.
(36) 本節闡述上述所提出的改良型語意歧異解析方法的實驗結果及相關討論。 3.4.1 小節簡介實驗文件集;3.4.2 小節說明評估的方法,包括針對語意歧異解析 的評估方法與針對文件分群的評估方法;3.4.3 小節討論改良型語意歧異解析方 法的效益評估;3.4.4 小節討論以改良型語意歧異解析方法來執行文件分群的可 行性評估。 3.4.1 實驗資料說明 本實驗利用的文件集為 Semantic Concordance Corpus (簡寫為 SemCor)。 SemCor 包含 500 篇文件,每篇文件的字數均超過 2000 字,這 500 篇文件分為 15 大類 (A~R 類),可以作為評估文件分群時的一個標準文件集。15 大類的主題 如圖 21 所示:. A. PRESS: REPORTAGE (44 texts) B. PRESS: EDITORIAL (27 texts) C. PRESS: REVIEWS (17 texts) D. RELIGION (17 texts) E. SKILL AND HOBBIES (36 texts) F. POPULAR LORE (48 texts) G. BELLES-LETTRES (75 texts) H. MISCELLANEOUS: GOVERNMENT & HOUSE ORGANS (30 texts) J. LEARNED (80 texts) K. FICTION: GENERAL (29 texts) L. FICTION: MYSTERY (24 texts) M. FICTION: SCIENCE (6 texts) N. FICTION: ADVENTURE (29 texts) P. FICTION: ROMANCE (29 texts) R. HUMOR (9 texts) 圖 21:SemCor 的 15 類文件主題. 為了評估語意歧異解析的結果,本實驗從 SemCor 中挑選 186 篇文件來測試 (SemCor 中對文件的名詞指定好語意的只有 186 篇)。SemCor 中儲存文件的字詞 詞性與語意,它的字詞語意標示是以 WordNet 1.7 版為依據,和本論文建立語彙 30.
(37) 鍵結所對照的 WordNet 版本一致,因此我們拿它來作為字詞語意判斷的文件集。 圖 22 是 SemCor 中 J 大類第 59 篇文件的第一個句子的表示方式。. 1 <contextfile concordance=brown> 2 <context filename=br-j59 paras=yes> 3 <p pnum=1> 4 <s snum=1> 5 <wf cmd=done pos=RB lemma=rather wnsn=1 lexsn=4:02:02::>Rather</wf> 6 <wf cmd=done pos=RB ot=notag>than</wf> 7 <wf cmd=done pos=VBG ot=notag>being</wf> 8 <wf cmd=done pos=VB lemma=deceive wnsn=1 lexsn=2:41:00::>deceived</wf> 9 <punc>,</punc> 10<wf cmd=ignore pos=DT>the</wf> 11<wf cmd=done pos=NN lemma=eye wnsn=2 lexsn=1:09:00::>eye</wf> 12<wf cmd=done pos=VBZ ot=notag>is</wf> 13<wf cmd=done pos=VB lemma=puzzle wnsn=1 lexsn=2:31:00::>puzzled</wf> 14<punc>;</punc> 15<wf cmd=done pos=RB lemma=instead wnsn=1 lexsn=4:02:00::>instead</wf> 16<wf cmd=ignore pos=IN>of</wf> 17<wf cmd=done pos=VB lemma=see wnsn=1 lexsn=2:39:00::>seeing</wf> 18<wf cmd=done pos=NN lemma=object wnsn=1 lexsn=1:03:00::>objects</wf> 19<wf cmd=ignore pos=IN>in</wf> 20<wf cmd=done pos=NN lemma=space wnsn=1 lexsn=1:03:00::>space</wf> 21<punc>,</punc> 22<wf cmd=ignore pos=PRP>it</wf> 23<wf cmd=done pos=VB lemma=see wnsn=1 lexsn=2:39:00::>sees</wf> 24<wf cmd=done pos=NN lemma=nothing wnsn=1 lexsn=1:23:00::>nothing</wf> 25<wf cmd=done pos=RB lemma=more wnsn=2 lexsn=4:02:01::>more</wf> 26<wf cmd=done pos=JJ ot=notag>than</wf> 27<punc>-</punc> 28<wf cmd=ignore pos=DT>a</wf> 29<wf cmd=done pos=NN lemma=picture wnsn=1 lexsn=1:06:00::>picture</wf> 30<punc>.</punc> 31</s> 32</p>. 圖 22:SemCor 文件的範例 31.
(38) 圖 22 的具體說明如下: Ø. 每行前面的數字是為了解說方便而標示的,與原來的文件無關。. Ø. 第 2 行的 filename=br-j59 代表 SemCor 中 J 大類第 59 篇文件。. Ø. <p pnum=1> 的 p 代表段落,pnum=1 是第 1 段。. Ø. <s snum=1> 的 s 代表句子,snum=1 是第 1 句。. Ø. 因圖 22 為 SemCor 中 J 大類第 59 篇文件的第一個句子。接下來的第 5 行到第 30 行就是這個句子所包含字詞的相關分析。也就是說整個句子 為: Rather than being deceived, the eye is puzzled; instead of seeing objects in space, it sees nothing more than-a picture.. Ø. 以第 5 行為例,Rather 這個字詞的 cmd=done 代表它不是停用字(Stop Word),而若 cmd=ignore,如第 10 行的 the,則為停用字;pos=RB 的 pos 是 part-of-speech 的縮寫,亦即該字的詞性,詞性對照表為: NN(noun):名詞 VB(verb):動詞 RB:副詞 JJ:形容詞 IN:介系詞,前置詞 CD:連接詞. VBG:現在分詞 VBZ:助動詞 WRB:疑問副詞 PRP:代名詞 TO:介系詞,後置詞 DT:冠詞. lemma=rather 的 lemma 為 Rather 這個字的標題字,亦即該字經 stemming 後的詞幹;wnsn=1 代表該字的語意是對照 WordNet 1.7 版得到的第 1 個 sense。 3.4.2 實驗評估方法. 32.
(39) 本小節將分別介紹針對語意歧異解析的評估方法和針對文件分群的評估方 法。 & 針對語意歧異解析的評估方法 在比較改良型語意歧異解析方法與 SemCor 所指定語意的差異時,我們分別 計算幾種比率如下: Ø. 正確率:針對多語意的名詞(Polysemous Nouns)來計算,計算方式為: 與 SemCor 指定的語意相同的多語意名詞數目/所有多語意名詞的數目。. Ø. 全正確率:以全部的名詞來計算,計算方式為:與 SemCor 指定的語意 相同的名詞數目(包含只有一個語意的名詞)/全部名詞的數目。. Ø. 錯誤率(Incorrect):與 SemCor 指定的語意不同的數目/全部名詞的數目。. Ø. 無法判斷率(Ambiguous):無法判斷出語意的數目/全部名詞的數目。. 由於本論文只針對名詞的語意,因此在比較時僅比較名詞語意歧異解析的效 能。 & 針對文件分群的評估方法. 分群好的文件,我們分別計算 inter-cluster 值與 intra-cluster 值,這兩個評估 值是傳統上評估分群方法好壞的依據,其描述如下: Ø. inter-cluster:計算整個分群體中群與群之間的平均分開程度。若計算的 是群與群間的距離,距離愈大,表示群與群愈不相似,因此這個值要愈 大愈好;但若計算的是群與群間的相似度,則這個值要愈小才能表示群 與群愈不相似。在此我們是用群與群間的相似度來計算,計算公式如下:. 33.
(40) inter =. (. 1 ∑ X ij − X n −1. ). 2. 1 n −1. =. X ij = Sim ( Ci , C j ) i ≠ j. n=. [∑ (X. Sim(C i ,C j ) =. di × d j. =. ∑w. 2. ]. i , j are two cluster. k ,i. X=. ∑X n. × wk , j. k =1. ∑ (w ) t. k =1. Ø. − nX. (# of cluster )(# of cluster - 1) 2. t. di • d j. ). 2. ij. 2. k,i. ×. ∑ (w ) t. k =1. 2. k,j. intra-cluster:計算整個分群體中每群內的相似度,即群內個體的緊密程 度。因為是用相似度來計算,因此這個值要愈大愈好。. intra =. ∑ average. similarity of each cluster # of cluster. 3.4.3 改良型語意歧異解析方法之評估 下面表格 4-表格 6 的數據是對 SemCor 中部分文件(br-j03∼br-j09)所實驗 的結果,其中表格 4 是參考[10]中抄錄下來的數據,[10]的語意歧異解析是一種 監督式方法(Supervised Method),此方法先利用 br-j01 與 br-j02 選取出來的名詞 當作訓練資料(Training Data),而 br-j03∼br-j09 則依據已訓練好的名詞決定其語 意,它是用來對照語彙鍵結結果及本論文所提出的改良型語意歧異解析的結果。 表格 5 是利用語彙鍵結(Lexical Chain)得到的數據;而表格 6 則是利用未加 入鍵結擴充策略的改良型語意歧異解析方法所得到的數據。由於本論文提出的改 良型語意歧異解析方法將一篇文件中的名詞以複合語意來表示,但為了計算正確 率和全正確率,我們將同一個名詞的不同語意取最大權重的那個語意來計算。. 34. ij.
(41) 多語意 名詞. 判斷正確 的語意. (poly.). (對 poly.). 356 340 492. 280 266 407. br-j06. 455. br-j07 br-j08 br-j09. 文件 名稱. 名詞 個數. 正確率 % (針對 poly.). 全部正確 的語意. 全正確率 %. br-j03 br-j04 br-j05. 195 130 131. 69.64% 48.87% 32.19%. 271 204 216. 76.12% 60.00% 43.90%. 339. 140. 41.30%. 256. 56.26%. 529 427. 413 362. 216 156. 52.30% 43.09%. 332 221. 62.76% 51.76%. 435. 306. 145. 47.39%. 274. 62.99%. 47.83%. 59.11%. 表格 4:參考[10] (Suarez93)得到的數據. 多語意 名詞. 判斷正確 的語意. (poly.). (對 poly.). 356 340. 280 266. br-j05. 492. br-j06 br-j07. 文件 名稱. 名詞 個數. 正確率 % (針對 poly.). 全部正確 的語意. 全正確率 %. br-j03 br-j04. 158 139. 56.43% 52.26%. 234 213. 65.73% 62.65%. 407. 240. 58.97%. 325. 66.06%. 455 529. 339 413. 214 224. 63.13% 54.24%. 330 340. 72.53% 64.27%. br-j08. 427. 362. 228. 62.98%. 293. 68.62%. br-j09. 435. 306. 162. 52.94% 57.28%. 291. 66.90% 66.68%. 表格 5:採用語彙鍵結(Lexical Chain)得到的數據. 35.
(42) 多語意 名詞. 判斷正確 的語意. (poly.). (對 poly.). 356 340 492. 280 266 407. br-j06. 455. br-j07 br-j08 br-j09. 文件 名稱. 名詞 個數. 正確率 % (針對 poly.). 全部正確 的語意. 全正確率 %. br-j03 br-j04 br-j05. 174 152 254. 62.14% 57.14% 62.41%. 250 226 339. 70.22% 66.47% 68.90%. 339. 228. 67.26%. 344. 75.60%. 529 427. 413 362. 242 242. 58.60% 66.85%. 358 307. 67.67% 71.90%. 435. 306. 170. 55.56%. 299. 68.74%. 61.42%. 69.93%. 表格 6:未加入策略的改良型語意歧異解析方法得到的數據. 表格的第一行為實驗的文件名稱,因為在[10]中挑選 SemCor 的 J 大類 03 篇 到 09 篇來測試,為了與[10]比較結果,我們也挑選這七篇文件來實驗。第二行 代表每篇文件包含的名詞個數;第三行代表每篇文件中多語意名詞(Polysemous Nouns)的個數;第四行是針對多語意的名詞中,各種演算法判斷出正確語意的個 數;第五行的正確率是計算多語意名詞的正確率,計算方式為第四行除以第三 行;全部正確的語意個數包含只有單一語意的名詞及判斷正確的多語意的名詞; 全正確率計算全部正確的語意除以名詞個數。. 由表格 4 中可知, [10]提出的語意歧異解析方法的結果並不穩定,有時好 有時差,這是因為它採用的是監督式方法,用 br-j01 和 br-j02 當訓練資料,而 br-j03 ∼br-j09 則依據已訓練好的名詞決定其語意,因此若有一篇文件與訓練資料不太 相關,則其結果將較差。 而由上面三個表格中的數據,我們可以看出和語彙鍵結相關的方法得到的數 據較平均。這是因為它考慮的是整篇文件,用整篇文件中字與字在 WordNet 中 的關聯來決定語意,不需要訓練資料的介入。這種特性適宜用在文獻管理系統。. 36.
(43) 由表格 6 也可看出本論文提出的未加入鍵結擴充策略的改良型語意歧異解 析方法比語彙鍵結方法的正確度多了 4.14%。 以上三個表格只呈現關於正確語意的部分,我們加入錯誤率和無法判斷率的 結果,其數據如表格 7 所示: 正確率. 全正確率. 錯誤率. 無法判斷率. 監督式方法[10] 語彙鍵結. 47.83% 57.28%. 59.11% 66.68%. 20.84%. 12.48%. 改良型(未加策略). 61.42%. 69.93%. 17.59%. 12.48%. 表格 7:三種語意歧異解析方法的比較. 未加入鍵結擴充策略的改良型語意歧異解析方法比語彙鍵結方法的錯誤率 少,但二者的無法判斷率是相同的,為了降低無法判斷率,本論文加入鍵結擴充 策略並實驗評估加入策略的結果。 接下來呈現加入與定義相關的策略(策略 1)以及加入兩個策略後的數據。 多語意 名詞. 判斷正確 的語意. (poly.). (對 poly.). 356 340 492. 280 266 407. br-j06. 455. br-j07 br-j08 br-j09. 文件 名稱. 名詞 個數. 正確率 % (針對 poly.). 全部正確 的語意. 全正確率 %. br-j03 br-j04 br-j05. 177 156 259. 63.21% 58.66% 63.64%. 253 230 344. 71.07% 67.65% 69.92%. 339. 231. 68.14%. 347. 76.26%. 529 427. 413 362. 248 244. 60.05% 67.40%. 364 309. 68.81% 72.37%. 435. 306. 175. 57.19%. 304. 69.89%. 62.61%. 70.85%. 表格 8:加入策略 1 的改良型語意歧異解析方法得到的數據. 由表格 8 可知加入與定義相關的策略後的改良型方法比語彙鍵結的方法正 確度多了 5.32%;比未加入任何策略的改良型方法正確度多了 1.19%。. 37.
(44) 多語意 名詞. 判斷正確 的語意. (poly.). (對 poly.). 356 340 492. 280 266 407. br-j06. 455. br-j07 br-j08 br-j09. 文件 名稱. 名詞 個數. 正確率 % (針對 poly.). 全部正確 的語意. 全正確率 %. br-j03 br-j04 br-j05. 191 171 278. 68.21% 64.29% 68.30%. 267 245 363. 75.00% 72.06% 73.78%. 339. 247. 72.86%. 363. 79.78%. 529 427. 413 362. 271 262. 65.62% 72.38%. 387 327. 73.16% 76.58%. 435. 306. 197. 64.38%. 326. 74.94%. 68.01%. 75.04%. 表格 9:加入策略 1 和策略 2 的改良型語意歧異解析方法得到的數據. 由表格 9 可知加入策略 1 和策略 2 的改良型語意歧異解析方法比語彙鍵結 的方法正確度多了 10.73%;比未加入任何策略的改良型方法正確度多了 6.59%; 比加入策略 1 的改良型方法正確度多了 5.4%。. 表格 10 呈現上述方法的正確率、全正確率、錯誤率和無法判斷率的完整資 訊。 正確率. 全正確率. 錯誤率. 無法判斷率. 監督式方法[10] 語彙鍵結. 47.83% 57.28%. 59.11% 66.68%. 20.84%. 12.48%. 改良型(未加策略). 61.42%. 69.93%. 17.59%. 12.48%. 改良型+策略 1(S1) 改良型+S1+S2. 62.61% 68.01%. 70.85% 75.04%. 18.82% 20.86%. 10.33% 4.1%. 表格 10:語意歧異解析方法的完整比較資訊. 加入鍵結擴充策略的訴求是要降低無法判斷字詞語意的比率,但因為加入策 略 1 後,每篇文件可以新增判斷出 10±3 個名詞,不過因為判斷正確的比率小於 一半,所以非正確率提高。同樣地,加入策略 2 後,每篇文件可以新增判斷出 30±5 個名詞,但也會導致非正確率提高。 38.
(45) 在評估本論文提出的改良型語意歧異解析方法中,我們亦針對每個名詞的語 意數計算正確率,表格 10 是從 SemCor 中的 15 大類挑選出的 186 篇文件中,每 篇文件的名詞數和語意歧異解析的正確比率。. 表格 10 中的第二行表示 15 大類(A∼R)中選取的文件數,第三行到第八行 分別針對多語意的名詞進行語意歧異解析計算,例如在 A 大類中,第三行顯示 有兩個語意的名詞的個數為 492 個,利用改良型語意歧異解析方法判斷正確的有 415 個,所以大約有 0.8335 的正確率。 語意愈多的名詞,理論上可以正確判斷出語意的比率愈少。表格 10 的結果 亦符合此一現象。. 39.
(46) docum_# 7. 2 sense 492 415 0.843495935. 3 sense 343 255 0.743440233. 4 sense 241 165 0.684647303. 5 sense 196 147 0.75. 6~10 630 265 0.420634921. >=11 242 22 0.090909091. B 正確個數 比率. 2. 124 91 0.733870968. 109 64 0.587155963. 99 75 0.757575758. 70 21 0.3. 177 74 0.418079096. 44 14 0.318181818. 623 339 54.42%. 843 559 66.31%. C 正確個數 比率. 3. 208 182 0.875. 147 118 0.802721088. 124 63 0.508064516. 114 54 0.473684211. 264 87 0.329545455. 80 9 0.1125. 937 513 54.75%. 1218 794 65.19%. D 正確個數 比率. 4. 253 209 0.826086957. 191 123 0.643979058. 229 120 0.524017467. 154 63 0.409090909. 380 137 0.360526316. 154 44 0.285714286. 1361 696 51.14%. 1655 990 59.82%. E 正確個數 比率. 14. 1092 797 0.72985348. 981 641 0.653414883. 786 518 0.659033079. 561 346 0.616755793. 1671 666 0.398563734. 405 141 0.348148148. 5496 3109 56.57%. 7010 4623 65.95%. F 正確個數 比率. 19. 1339 1203 0.898431665. 1060 827 0.780188679. 1014 682 0.672583826. 744 397 0.533602151. 1772 723 0.408013544. 579 244 0.421416235. 6508 4076 62.63%. 8700 6268 72.05%. G 正確個數 比率. 18. 1205 905 0.751037344. 944 616 0.652542373. 1049 701 0.668255481. 750 264 0.352. 1609 588 0.365444375. 576 123 0.213541667. 6133 3197 52.13%. 7650 4714 61.62%. H 正確個數 比率. 12. 922 764 0.828633406. 666 409 0.614114114. 689 355 0.515239478. 544 244 0.448529412. 1406 418 0.297297297. 384 145 0.377604167. 4611 2335 50.64%. 5996 3720 62.04%. J 正確個數 比率. 43. 3249 2996 0.922129886. 2370 2009 0.847679325. 1977 1427 0.721800708. 1867 1269 0.679700054. 5113 1843 0.360453745. 1453 610 0.41982106. 16029 10154 63.35%. 20801 14926 71.76%. K 正確個數 比率. 29. 1544 1162 0.752590674. 1102 670 0.607985481. 1279 857 0.67005473. 916 487 0.531659389. 2207 657 0.297689171. 1071 418 0.390289449. 8119 4251 52.36%. 10480 6612 63.09%. L 正確個數 比率. 11. 415 357 0.860240964. 367 242 0.659400545. 449 277 0.616926503. 261 136 0.521072797. 774 267 0.34496124. 357 116 0.324929972. 2623 1395 53.18%. 3392 2164 63.80%. M 正確個數 比率. 2. 113 87 0.769911504. 71 44 0.61971831. 86 51 0.593023256. 43 14 0.325581395. 123 48 0.390243902. 47 15 0.319148936. 483 259 53.62%. 627 403 64.27%. N 正確個數 比率. 10. 428 342 0.799065421. 399 236 0.591478697. 299 238 0.795986622. 369 267 0.723577236. 839 315 0.375446961. 430 126 0.293023256. 2764 1524 55.14%. 3456 2216 64.12%. P 正確個數 比率. 6. 281 203 0.722419929. 203 123 0.60591133. 222 125 0.563063063. 182 61 0.335164835. 394 181 0.459390863. 218 93 0.426605505. 1500 786 52.40%. 1962 1248 63.61%. R 正確個數 比率. 6. 339 249 0.734513274. 246 182 0.739837398. 243 165 0.679012346. 153 72 0.470588235. 477 165 0.34591195. 120 11 0.091666667. 1578 844 53.49%. 2123 1389 65.43%. Total. 186. A 正確個數 比率. 表格 11:利用改良型語意歧異解析方法判斷多語意名詞的正確比率. 40. poly_num total_num 2144 2901 1269 2026 59.19% 69.84%.
(47) 每大類主題因為文件內容不同而有相異的判斷正確率,不過大致上來說正確 率(針對多語意的名詞)可以達到 55%,其中 J 大類的正確率最高。全正確率(針對 全部的名詞)則可以達到 65%,平均為 65.26%。 3.4.4 採用改良型語意歧異解析方法來分群文件之評估 從 SemCor 中挑選 186 篇文件,每類(群)挑選的文件數如下所示,第一行表 示類別,第二行為每類別挑選出的文件數。. A. B. C. D. E. F. G. H. J. K. L. M. N. P. R. 7. 2. 3. 4. 14. 19. 18. 12. 43. 29. 11. 2. 10. 6. 6. 分群後的文件,主要比較下列四種分群方法,說明如下:. 1.. 基準分群(Base-cluster):針對這 186 篇文件,我們分別計算 inter-cluster 和 intra-cluster 的值,當作基準值。. 2.. 無 語 意 分 群: 利用資訊擷取方法得到 的關鍵字 做 文 件 分 群 , 計 算 inter-cluster 和 intra-cluster 的值與 1.比較。. 3.. 語彙鍵結分群:利用語彙鍵結方法判斷出語意的關鍵字做文件分群,計 算 inter-cluster 和 intra-cluster 的值與 1.比較。. 4.. 改良型語意歧異解析分群:利用改良型語意歧異解析方法得到的關鍵字 做文件分群,計算 inter-cluster 和 intra-cluster 的值與 1.比較。. 不論要計算 inter-cluster 值或 intra-cluster 值,在每一種分群方法中代表一篇 文件的向量維度(Dimension)必須要一致,這樣計算出來的評估值才具有意義。因 此我們將每篇文件的關鍵字向量(Keyword Vector)加以修改,修改過程如下: Ø. 無語意分群(關鍵字沒有詞性分別,不過為了方便計算,還是只挑名詞 當作關鍵字) 41.
(48) −. 若有一篇文件的關鍵字向量表示法為:D (n1, n2, n3, n4). −. 為了改變向量維度,將其中沒有語意的名詞指定為最常使用的語 意,而權重也分配到這個最常使用的語意上。. −. 若 n1 有兩種語意(Sense),且最常使用的語意為 n11;n2 有四種語 意,且最常使用的語意為 n23;n3 有一種語意;n4 有三種語意, 且最常使用的語意為 n42。則 D 修改為(n11, n12, n21, n22, n23, n24, n31, n41, n42, n43),其中這個向量權重≠0 的是 n11, n23, n31, n42。. Ø. 語彙鍵結分群(關鍵字具有語意,且只有名詞) −. 某篇文件經由語彙鍵結方法得到的關鍵字向量為: D (n1, n21, n31, n42),其中 ni 表示第 i 個名詞,nij 表示第 i 個名詞 的第 j 個語意。. −. 只有判斷出的關鍵字語意才有權重,如果這個關鍵字無法判斷語 意,例如 n1,則 n11, n12 的權重相同(指定為原來的一半)。. −. D 修改為(n11, n12, n21, n22, n23, n24, n31, n41, n42, n43),其中 n11, n12 的權重為 n1 的一半,n22, n23, n24, n41, n43 的權重=0。. Ø. 改良型語意歧異解析分群(關鍵字以複合語意表示,且只有名詞) −. 某篇文件經由改良型語意歧異解析方法得到的關鍵字向量為: D (n1, n21, n22, n23, n31, n41, n42). −. 每個關鍵字語意的權重值按照建構出來的語彙鍵結所佔的鍵結關 係程度的比率來分配,如果這個關鍵字無法判斷語意,例如 n1, 則 n11, n12 的權重相同(指定為原來的一半)。. −. D 修改為(n11, n12, n21, n22, n23, n24, n31, n41, n42, n43) ,其中 n11, n12 的權重為 n1 的一半,n24, n43 的權重=0。. 42.
(49) 四種分群方法計算出來的評估數據如表格 12 所示: Method (Keyword_threshold=0.05). Intra-cluster. Inter-cluster. 基準分群(SemCor). 0.091. 0.0157. 無語意分群. 0.126. 0.0128. 語彙鍵結分群. 0.183. 0.0104. 改良型語意歧異解析分群. 0.196. 0.0101. 表格 12:各種文件分群方法之比較. Intra-cluster 計算整個分群體中每群內的相似度,即群內個體的緊密程度, 因此這個值要愈大愈好。結果顯示利用改良型語意歧異解析方法計算出來的 intra-cluster 值是最大的。 而 inter-cluster 代表整個分群體中群與群之間的平均分開程度。我們採用的 計算方式為群與群間的相似度,則這個值要愈小才能表示群與群愈不相似,亦即 群與群之間愈分開。結果顯示利用改良型語意歧異解析方法計算出來的 iner-cluster 值是最小的。 因此在分群應用上,利用改良型語意歧異解析方法將文件中的字詞分析其語 意,並以之代表一篇文件的關鍵字向量,這種方法可得到較佳的分群結果。. 43.
(50) 第四章 個人化參考文獻管理系統之實作 本章描述我們實作的個人化參考文獻管理系統,第一節詳細介紹系統流程與 採用的機制;第二節呈現應用於交大浩然圖書館個人化環境 MyLibrary@NCTU 的參考文獻管理系統。 個人化參考文獻管理系統的流程分為兩個部分:第一個部分為文件分析,第 二個部分為文件分群及推薦。文件分析包含系統對使用者蒐集的文獻資料的語彙 處理-詞幹轉換、計算文件字詞權重以得到索引關鍵字、以及利用第三章提出的 改良型語意歧異解析方法為基礎的關鍵字語意判斷。文件分群及推薦則包含計算 文件的語意相似度來分群以及推薦使用者相關的文獻資料。. 第一節 系統流程與機制 4.1.1 文件分析的流程 文件分析即文件字詞的語意分析,其流程如圖 23 所示:. 文件集 words. 語彙處理. 詞幹轉換. Lexical Processing. Word-Stemming. 產生關鍵字(候選字). 權重計算. Keyword Generation. Word-Weighting 判斷出正確. 改良型語意歧義解析 方法 Modified WSD. 圖 23:文件字詞語意分析的流程. 44. 語意的 words.
數據

+7


Outline
相關文件
Proceedings of the 19th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval pp.298-306.. Automatic Classification Using Supervised
“Ad-Hoc On Demand Distance Vector Routing”, Proceedings of the IEEE Workshop on Mobile Computing Systems and Applications (WMCSA), pages 90-100, 1999.. “Ad-Hoc On Demand
Hofmann, “Collaborative filtering via Gaussian probabilistic latent semantic analysis”, Proceedings of the 26th Annual International ACM SIGIR Conference on Research and
Mehrotra, “Content-based image retrieval with relevance feedback in MARS,” In Proceedings of IEEE International Conference on Image Processing ’97. Chakrabarti, “Query
in Proceedings of the 20th International Conference on Very Large Data
(1999), "Mining Association Rules with Multiple Minimum Supports," Proceedings of ACMSIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego,
The New Knowledge-Infrastructure: The Role of Technology-Based Knowledge-Intensive Business Services in National Innovation Systems. Services and the Knowledge-Based
Lange, “An Object-Oriented Design Method for Hypermedia Information Systems”, Proceedings of the Twenty-seventh annual Hawaii International Conference on System Sciences, 1994,
