SCALABLE MODULE-BASED ARCHITECTURE FOR MPEG-4 BMA MOTION
ESTIMATION
Mei-Yuiz
Hsu, Hao-Chieh Charzg, E-Chu
Waizg
and
Liang-Gee Cheiz
DSP/IC Design Lab
Department
of
Electrical Engineering, National Taiwan University
1, Sec.
4,
Roosevelt Road, Taipei 106; Taiwan
Email :
{
yun,howard,lgchen} @video.ee.ntu.edu.tw
sequence giga operation operation
rectangular 18.398 100
per second ratio(%)
(GOPS) (/rectangular)
weather 12.787 69.50
news 11.211 60.93
children 6.435 34.9s
ABSTRACT
In this paper, we present a scalable module-based architecture for block matching motion estimation algorithm of MPEG-4. The ba- sic module comprises one set of processing elements based on one-dimensional systolic array architecture. To support various applications, modules of processing elements can be configured to form the processing element array to meet the requirements,
such as variable block size, search range and computation power.
And this proposed architecture has the advantage of few I/O port counts. Based on eliminating unnecessary signal transitions in the processing element, power dissipation of datapath can be reduced to about half without decreasing the picture quality.
% of 70 of
.
opaque boundary MB MB 100 0 46.03 28.16 39.02 26.29 7.37 33.12 1. INTRODUCTIONIn video systems, motion estimation is a widely adopted technique to explore the temporal redundancy of sequences. Full search block matching algorithm is commonly used in motion estimation. Because of the requirement of high computation power, dedicated
hardware is usually employed.
For various video applications in the present and future. the ar- chitecture of motion estimation should be more flexible to support different requirements. Many previous works have reported the similar approaches. Some designs aim to support different block size and search range by modifying architecture parameters and cascading [I]-[8]. Some of these architectures are based on two- dimensional systolic array [6][8]. In the condition of larger block size, these designs have to spend much more resources. In addi- tion, two-dimensional systolic array often needs to access many data elements once at some cycles, hence the wordwidths or ports of memory would be large. The increment of memory ports would influence delay and area of memory significantly [9]. Some are based one-dimensional systolic array [ I O ] [5] [7], but they may require various processing elements designed with irregular data flow or use more registers. This will lead to more power consump- tion and larger chip area. As a result, a scalable architecture based on one-dimensional systolic array module with fewer registers and regular data flow is proposed, and the port number can be reduced by well-arranged data flow. Besides, unnecess'ary switching of circuits in processing elements are eliminated to reduce the power consumption of datapath.
The organization of this paper is as follows. In section 11, we briefly review the MPEG-4 motion estimation and its computation analysis. In section 111. the scalable module-based architecture is presented. In section IV. the comparison results of the proposed
I
architecture with other designs found in the literature are repre- sented. Finally, section V concludes this paper.
2. MEPG-4 MOTION ESTIMATION
In MPEG-4 [ I I]. content-based representation is employed. For motion estimation of arbitrarily shape video object (VO), the SAD calculation of block matching has to be modified. Only the errors that locate inside video object are accumulated. The formula is as follows.
!Y .v
r = l , , = I
where A' is block size,
ct = 1 (inside object) or 0 (outside object) .
Motion Estimation is performed for marcoblock that is en- tirely inside object or lies on the boundary of object. In the fol- lowing, the computation requirements of three video objects are calculated for MPEG-4 Core Profile Level 2 (CPL?). In MPEG-4 CPL2, the maximum number of macroblock per second is 13760, and the typical visual session size is CIF (352x188). Assume that the search range is [-16,151, and the type of macroblock is already known. The calculation of SAD is counted three operations. In boundary macroblock there is an additional operation to check whether the pixel lies in the object or not. If the pixel is not in the object, operations of SAD are not counted. The result of oper- ation analysis for four sequences is shown in Table 1. In general, the computation load of object based motion estimation would be lower than the one of rectangular frame. The percentage of reduc- tion depends on the characteristic of video object. However, there may be multiple visual objects in a scene, so total computation load would depends on the object number, too.
11-245
input
data
motlon vector
minimum SAD
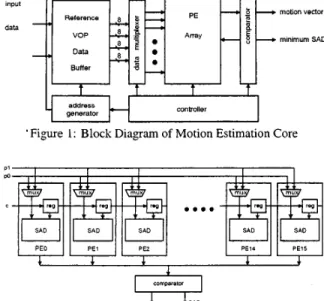
'Figure 1: Block Diagram of Motion Estimation Core
P l
Po
Figure 2 : Block Diagram of One-Dimensional Systolic Array
3. MODULE-BASED ARCHITECTURE. FOR MEPG-4 MOTION ESTIMATION
3.1. MOTION ESTIMATION CORE
Fig. I depicts the proposed architecture of motion estimation core. This architecture mainly includes two data buffers, processing ele- ment (PE) array, flexible address generator. controller. data mul- tiplexer and comparator. Two data buffers are utilized to store current block and reference dau, respectively. The current block buffer stores both texture 'and shape of current block. The refer- ence VOP data buffer exports at most four different pixels at each clock cycle. and data multiplexer outputs proper data to every PE module according to the configuration of PE array. The compara- tor finds minimum of accumulated errors from PE array and cal- culates the corresponding motion vector.
3.1. PROCESSING ELEMENT MODULE
The processing element module is based on one-dimensional sys-
tolic array
[E].
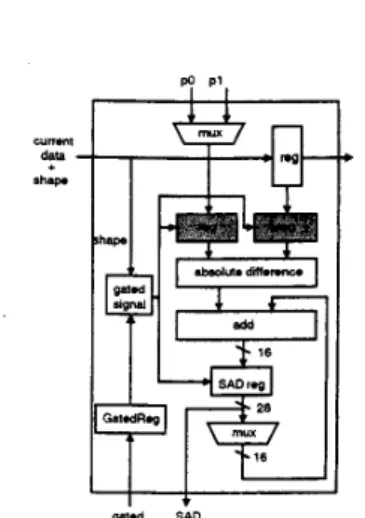
The block diagram of one-dimensional systolic m a y with 16 PES is shown in Fig. 2 . Reference data, PO and p l , are broadcasted to every PE. and current data propagate through PE 'may every clock cycle. Every PE calculates SAD of one spe- cific candidate of motion vector in the search range.6
PE module is responsible for one row of candidates. Fig. 3 illustrates which rows of the reference VOP data are accessed every clock cycle.3.3. SCALABLE ARCHITECTURE
For various applications, motion estimation core needs to be scal- able to support different block size, search area, and operation fre- quency. In the following, we show that how the module can be cascaded to support various requirements. Assume that a PE mod- ule can handle
N
xAV
block and the search range is [-P, P - 11.pixels locate at ith row in sear<:h range
P l
"nnmnr;J
* * *"I-TiL~
* *PO [
--
0 ~ 1 ~ 2 ~ 3 ~* * * I 1 1 2 1 3 ( 4 1 * * 4 ~ 5 ~ 6 ~ ' ~0 16 32 48 256 288 clock cycltts
Figure 3: Illustration of Reference Data (PO and p l ) Source for One PE Module
3.3.1. Case I : larger block size
If the block size increases from N x N to 2N x 2 N , two PE mod- ules can be connected to keep data flow the same. Fig. 4 shows the
connected module architecture. The reference data of two PE mod-
ules are the same, and the current block data propagate through modules. If the search range, frame size, and frame rate remain the same, the change of block size would not influence the total operation amount per second. Because the number of PE is dou- ble, the frequency of operation would become half of the original one for the same throughput.
3.3.2 Case II: increasing search range
For search range (2P) that is a multiple of N. one motion vector
is generated every
(2P)'
xfi
cycles. Now the search range isincreased from [-P. P
-
11 to [-2P. 2P - 11. If only one PE module is used, the cycles of generating a motion vector wouldbecome (4P)' x A-. If we want to maintain the same operation fre-
quency and throughput, the nurnber of PE modules has to increase to four. Every module is responsible for different rows of motion vector candidates. The cascaded module architecture is depicted in Fig. 5. And Fig. 6 shows the distribution of motion vector cancli-
dates in every PE module under the assumption of N = 4. P = 2 .
The timing of each PE module would delay I 6 cycles after the for-
' 5 4 51 52 53 54 55 56:57 58 inmodule3 5-?-66% 1p? 6 5 - 6 6 1 6 7 68 -62
nl.rmse data uud
70 71 n 73 74 75 76 n 78
Figure 6: Distribution of motion vector candidates.
1 - 7 . : P I
e
,-,.I d . .
-.
mer PE module for X=16. Fig. 7 depicts the rows that reference VOP data locate every cycle for four modules. At each cycle, PE 'array accesses at most four different pixels. The maximum num- ber of pixels accessed at a clock cycle can be limited to four if the
number of PE modules is not larger than
N.
-
--
-
0 I O 2 I) D M -0 .D
3.3.3. Case 111: lower operatioil freqiieizcy
Through increasing the number of PE module, the operation fre- quency can be lowered. As mentioned above. we can get one
motion vector every (2P)' x X cycles for one PE module. For
the same amount of operation, doubling the number of PE module would decrease the operation frequency :o half, and every (2P)' x
.\-/2 cycles a motion vector is generated.
3.4. PE WITH POWER-SAVING OPERATION
According to the block matching criterion. the candidate with the smallest SAD would be selected. If the accumulating SAD of the candidate were larger than the present minimum SAD, we can stop calculating this candidate further. By eliminating the unneces-
snry operations. the operation amount of motion estimation can
decrease while preserving the optimal picture quality. The ex- periment result is shown in Table 2 and Fig. 9. The amount of
operation reduces to about 40% to 60% of original one. For the larger search range, the percentage of remaining operations would be lower. For sequence with lower amount of movement and lower spatial detail, like "hall" and "mother and daughter", the amount of eliminated operations would be larger.
This power-saving concept is implemented in the PE design.
As shown in Fig. 8, two registers (shaded blocks) are employed in
the PE to store current block and reference data. In normal mode.
these registers are transparent. Input data are directly bypassed to the circuit for S A D . As the accumulated SAD is larger than the present minimum SAD, PE would receive the "gated" signal
Figure
gad SAD
8: Block Diagram of Processing Element
Table 3: Percentage of Remaining Operations
children
I
50.43I
37.75weather
I
40.65I
34.16from the comparator in PE module. This signal would be stored in the register, GatedReg. The SAD register and block data registers would be gated. For the remaining clock cycles of this candidate, the circuit for calculating SAD would not switch any more. There- fore. the power dissipation in PE can be reduced. When the PE begins to process new candidate, GatedReg will be clear, and let the circuit come back to work.
To support MPEG-4 polygon matching, the shape informa- tion of current block is required during processing boundary mac- roblock. When the pixel doesn't locate in video object, the two extra registers will hold the previous input data and the register of SAD will hold the value of previous accumulated sum.
4. PERFORMANCE COMPARISON AND DISCUSSION
In this section, we present some comparisons among the proposed architecture and other designs. Because no bubble cycles are re-
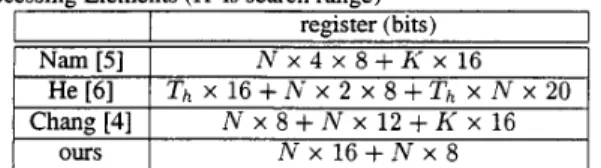
register (bits) N x 4 x 8
+
h’x 16 Ai x 8+
N x 12+
h’
x 16Ai
x 16+
N
x 8 ~m [51 He [6] Chang [4] ours T h X 16+
X 2 X 8+
T h X N X 20quired when changing candidates or blocks in these architectures. the cycles needed to produce one motion vector would be the same under the same number of PES. However, for different strategies of data flow, the number of registers used in a PE module would be very different. For general operations, the two extra registers are not included in our PE, and the wordlength of SAD register would be 16. The total wordlength of registers used in a PE module with A- processing elements are compared. Table 3 lists the analysis re- sult. T,, and TH are the vertical and horizontal dimensions of the tile respectively defined in [6]. Table 4 shows the analysis result of memory access from on-chip buffer to PE array based on 16 PES. Because of flexible designs, two specifications are used to compare the performance of these designs. One is 16 PES with search range [-8.71. The other is 64 PES with search range [-16,151. Table5 shows the result. We can find that the proposed architecture can use fewer registers in both cases. And the amount of memory ac- cess is acceptable. For larger search range. the amount of memory access wouldn’t increase substantially.
6. REFERENCES
[ 13 L. D. Vos and M. Steghen: “Parameterizable VLSI architec- tures for the full-search block-matching algorithm,” IEEE
5. CONCULSION design
am
~ 5 1 He161
C h a g [41 OUTSIn this paper, we have presented a scalable motion estimation ar- chitecture for MPEG-4. The architecture is based on modules of one-dimensional systolic array. Through cascading of multiple modules, different processing element arrays can be constructed to meet various applications, such as larger block size, search range and various operation frequencies. Through well-arranged data
flow. the number of YO ports is reduced. Using simple termination
judgment to eliminate unnecessary switching of circuits, process-
ing element with power saving is achieved. The power dissipation
Table 5 : Comparison of Designs for Two Specifications
memory access for one block (bytes) IEEE Transactions on Circuits arid Systeins f o r Kdeo Tecli-
rzology, vol. 5, pp. 407-4115, Oct. 1995.
[3] L. D. Vos and M. Schobinger. “VLSI architecture for a flex- (-hi i- - l ) ( N
+
- l)/(Th T i , ) ible block matching processor,” IEEE Trarisacrjoiis 011 Cir..cirits and Systeins for Kdeo Techiiol3gy. vol. 5, pp. 417-428,
Oct. 1995.
h*
= 2 P h- = 4 P( K + N
-
1) x N x K ( K+
N
- 1) xN
xh-
( 2 N - 1) x
N
x h-I
( 2 N - 1) xN
x h- x 2design 16 PES with SR [-8,7]
I
64 PES with SR [-16,151register#
I
BWI
register#I
BW[4] S. Chang, J.-H. Hwang, anti C.-W. Jen, “Scalable array archi- tecture design for full search block matching.” IEEE Traris- actions 012 Circuits arid Systerns for Kdeo Tecliriolog~. vol. 5 ,
[5] S. H. Nam and M. K. Lee, “Flexible VLSI architecture of motion estimator for video image compression,” IEEE TKU~S-
actioris on Circuits arid Systems - 11: Analog arid Digital Sig-
rial Processirig, vol. 43, pp. 467470. June 1996.
[6] Z. L. He and M. L. Liou. “Cost effective VLSI architec- ture for full-search block-matching motion estimation algo-. rithm,” Joirnzal of VLSI S i p d Processbig, vol. 17. pp. 225- 240, Nov. 1997.
[7] S. H. Nam and M. K. Lee. “High-throughput block-matching
VLSI archjtecture with low memory bandwidth.” IE€E
Traiisacrioiis 017 Circuits a d Systeitzs - 11: Aizalog arid Digi-
tal Sigiinl Processing, vol. 45, pp. 508-5 12. Apr. 1998. [8] Y.-H. Yeh and C.-Y. Lee, “Cost-effective VLSI architectures
and buffer size optimization for full-search block matching algorithms,” IEEE Trarisactiorzs 011 Circuits arid Sysreiiis for Kdeo Tecliriology, vol. 7. pp. 345-358. Sept. 1999. [9] S. Dutta, K. J. O’Connor, IN. Wolf, and A. Wolfe. ” A design
study of a 0.25pm video signal processor,” IEEE Trrrrisac-
tioizs 0 1 1 Circuits arid Systiwis for Video Techriology. vol. 8.
IO] S. H. Nam. J. S. Baek. and M. K. Lee. “Flexible VLSI ar- chitecture of full search mcition estimation for video applica- tions.” IEEE Trnrisactioris on Coiisiiriier Electroiiics. vol. 40.
pp. 176-184, May 1994.
1 I] JTCl/SC29/wGl1. N250:!a. Geiieric Codirig of Audio- Visual Objects: Ksital 13496-2, Filial Draft IS. Atlantic City: ISOfiEC. 1998.
121 K.-M. Yang, M.-T. Sun. :md L. Wu, “ A family of VLSI designs for the motion compensation block-matching algo- rithm,” IEEE Tiniisactiorzs on Circuits arid Svsteiiis. vol. 36, pp. 332-343, Aug. 1995. pp. 501-519. Aug. 1998. pp. 1317-1325, Oct. 1989. Nam [5] He [61 Chana T41 1-- , OUTS
I
384I
7936I
1536I
7936(bits) (bytes) (bits) (bytes)
768 7936 4096 6016
1600 19456 6400 23104
576 7936 3328 6016