Neural-network-based FO text-to-speech synthesiser
for Mandarin
S.-H. Hwang S.-H. Chen
Indexing t m : Mandarin speech synthesiser, Neural networks
Ahtract: A neural-network-based approach to synthesising FO information for Mandarin text-to- speech is discussed. The basic idea is to use neural networks to model the relationship between lin- guistic features, extracted from input text and parameters representing the pitch contour of syll- ables. Two MLPs are used to separately synthe- sise the mean and shape of pitch contour, using different linguistic features. A large set of utter- ances is employed to train these MLPs using the well known back-propagation algorithm. Pronun- ciation rules for generating F O information are automatically learned and implicitly memorised by the MLPs. In the synthesis, parameters rep- resenting the mean and shape of the pitch contour of each syllable are generated using linguistic fea- tures extracted from the given input text. Simula- tion results confirmed that this is a promising approach for FO synthesis. The resulting synthe- sised pitch contours of syllables match well with their original counterparts. Average root mean square errors of 0.94ms/frame and 1.00ms/frame were achieved.
1 Introduction
Speech is an effective and natural way for human beings to communicate with a computer. For two-way commun- ication, the computer must speak like a person. Part of the requirement to reach this goal is to give the computer the ability to generate natural and fluent speech in response to any input text. A text-to-speech system is designed for this purpose. The synthesis of fundamental frequency (FO) is one of the most important things to influence the quality of the synthesised speech. This work studies the synthesis of FO information for Mandarin text-to-speech.
phonological rules for synthesis [l-81. In this approach, input text is first analysed to extract linguistic features relevant to FO synthesis, usually of different levels. These include lexical information, such as phonetic structure and accentuation of a word or syllable, syntactical struc- ture, intonation pattern or declination effect for sentential In the past, the general approach was to invoke,
0 IEE, 1994
Paper 1421K (E5,
a),
6rst received 9th August 1993 and in revised form 14th June 1994The authors are with the Department of Communication Engineering and Cmter For Telecommunications Research, National Chiao Tung
University, Hsinchu, Taiwan 300, Republic of China
384
utterance, semantic features etc. Phonological rules for synthesis are then used to generate FO information. Fig. 1 is a schematic diagram of this approach. Phonological rules are inferred by observing a large set of utterances with the help of Linguists. The relationship between the linguistic features of input texts and the FO contour pat- terns of utterances is explored. Although this can be done by induction, it is generally difficult to explore the effect of mutual interaction of linguistic features at different levels. Hence, the inferred phonological rules for synthesis are always incomplete. Some synthesised speech therefore sounds monotonous and unnatural.
Fig. 1 Schematic diagram o j a general FO synthesiser
in an alternative approach, a statistical model [9] was used to synthesise F O contours of syllables for Mandarin text-to-speech. The idea is to substitute a statistical model for explicit synthesis rules. The model is used to describe the relationship between FO contour patterns of syllables and contextual linguistic features. In the training process, parameters of the model are empirically estim- ated from a large training set of sentential utterances. Phonological rules for synthesis are then automatically deduced and implicitly memorised in the model. In the synthesis process the best combination of F O contour patterns of syllables is estimated based on the model, provided that linguistic features are given by analysing the input text. The primary advantage of the statistical approach is that pronunciation rules can be automatic- ally extracted from the training data set through the training process and implicitly stored in the model. A major disadvantage of this approach is the need for a tremendously large set of utterances to properly train the statistical model as the number of parameters increases.
Motivated by the success of both the statistical approach [9] and NETalk [lo], we propose a novel neural-network-based F O synthesiser for Mandarin text- to-speech, taking neural networks as a mechanism for generating FO information in response to the input lin- guistic features. This is similar to the statistical approach above. However, the requirement for large set of training utterances can be alleviated by taking advantage of the excellent interpolation property of neural networks. A similar idea was used in References 11 and 12. In Refer- ence 11, two NETalk-like neural networks were used to
This study was supported by the National Science Council, Republic of China. The database is pro- vided by TL, MOTC, Republic of China.
generate the FO value of a phoneme and the FO fluctua- tions within that phoneme by using the linguistic features of several neighbouring phonemes. Promising results were obtained in the simulation using a small data set. In Reference 12, neural networks were used in Japanese text-to-speech to generate parameters of FO contour, including the maximum, average and differential FO of a ‘mora’. Better performance than the conventional rule- based method was reported based on simulation results. This is the first study of a neural-network-based approach to synthesising FO information for Mandarin speech. The study uses two multilayer perceptrons (MLPs) to generate the mean and shape of the pitch contour of syllables from linguistic features extracted from the input text. A large set of sentential utterances accompanying the texts is used to train the MLPs by adjusting their weights. The relationship between the FO information of natural speech and linguistic features extracted from the text associated with the speech is then automatically explored and memorised in the weights of the MLPs. Several advantages can be found. First, as with the statistical approach, pronunciation rules are automatically inferred without the help of linguists and are implicitly contained in the MLPs. Secondly, the syn- thesised speech is usually more natural because the MLPs are trained using real speech. This mainly results from the strong learning capability of MLPs to make their outputs mimic the corresponding target patterns given in the training process.
2
FO information is the most important prosodic informa- tion to synthesise in a text-to-speech system for produc- ing natural and fluent speech. In a normal sentential utterance the FO contour is, in general, following a spe- cific pattern known as the intonation. For a declarative sentential utterance,the FO contour is usually declining. But, as mentioned above, many other factors may also affect the pronunciation of FO contour. The following dis- cusses the properties of FO contour in Mandarin speech in detail.
Mandarin Chinese is a tonal language, the basic pro- nunciation unit of which is the syllable. Each written character is pronounced as a syllable with a tone. It is therefore very natural to choose the syllable as the basic unit of synthesis in a Mandarin text-to-speech V S )
system. Fig. 2 displays the phonetic structure of a syll- able. It is composed of a vowel-final and an optional
Properties of the FO information in Mandarin speech
initial final
(consonant) (medial) main (ending)
k b d
vowelPhonetic structure of a syllable in Mandorin speech Fig. 2
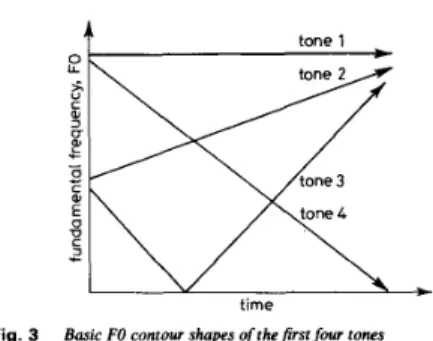
consonant-initial. There are 39 finals and 22 initials in total. Syllables with the same phonemic constituents (i.e. initial-final) and different tones have different lexical meanings. The tones of syllables are mainly characterised by their FO contours. There are only five lexical tones, namely, high-level, mid-rising, mid-falling-rising, high- falling and neutral tones. They are commonly referred to as Tone 1-Tone 5. A previous study [6] concluded that the FO contour of each of the first four tones can be simply represented by a standard pattern (Fig. 3). As for Tone 5, the pronunciation is usually highly context- I E E Proc.-Vis. Image Signal Process., Vol. 141, No. 6, December I994
dependent, so that its FO contour shape is relatively arbitrary. Moreover, it is always pronounced short and light. It would therefore seem that the FO contours of
tone 4
U L L
timeFig. 3 Basic FO contour shapes of thefirst four tones
sentential Mandarin speech are more regularly pro- nounced, so as to make synthesis for a TTS system much simpler. However, in practice, the contours of syllables are subject to various modifications in continuous speech. They are determined primarily by the tones and phrasal conditions of syllables and the coarticdation effect makes them affected by the FO contours of neigh- bouring syllables. Influence also comes from neighbour- ing tones. This effect is known as snadhi rules. They are also greatly affected by the intonation pattern or decli- nation effect of a sentence. Sometimes the semantics will change their shapes or mean levels. Moreover, emotion or the habit of speaking may also affect the pronun- ciation of FO contour in running speech. Therefore, syn- thesis is not a trivial task.
3 The proposed approach
We now discuss the proposed neural-network-based approach of FO synthesis for Mandarin text-to-speech. In this approach, the pitch contours of syllables are taken as basic synthesis units. These are first generated syllable by syllable and then concatenated to form the synthesised pitch contour for the given input sentential text. In our realisation, the pitch contour of a syllable is regarded as a pattern represented by certain parameters, which are gen- erated instead of synthesising the pitch contour of each syllable frame-by-frame. The idea to adopt this approach is twofold. First, based on observing pitch contours of syllables in real Mandarin speech, we found that they are all smooth curves and suitable for parametric representa- tion using curve-fitting techniques, such as polynomial expansion with few parameters. Secondly, it @ves us an opportunity to isolate the influences of different linguistic features on the generation of pitch contour. As we decompose the pitch contour of a syllable into several components, we expect that ideally the coefficients of these components will be exclusively affected by different groups of linguistic features. Due to the fact that the pitch level of a syllable in Mandarin speech is more sig- nificantly affected by global linguistic features than by local features, and that the shape is more significantly affected by local features, the mean and shape of pitch contour are considered separately. Some global linguistic features, such as positional information in a sentence or clause, as well as some local features, such as tones of neighbouring syllables, are used to synthesise pitch means of syllables for mimicking the intonation pattern 385
of the input sentence. On the other hand, only local lin- guistic features extracted from neighbouring syllables a re chosen to determine the pitch shape for each syllable to simulate the effects of coarticulation and sandhi rules. To be more specific, the pitch contour of a syllable is rep- resented by a smooth curve formed by orthonormal poly- nomial expansion using coefficients up to the third order
[13]. The zero-th-order coefficient represents the mean of
the pitch contour and the other three coefficients rep- resent its shape. The basic functions of the orthonormal polynomial expansion are normalised in length to CO, I] and expressed as 180N3
"(i)
= [ ( N - 1XN+
2XN+
3) x[($
-(;)
+
3
( 3 ) 2800N5@'(+)
= [ ( N - IXN - 2"+
"2+
3XN+
4)for O < i
<
N , where N+
1 is the length of the FO contour and N>
3. These basis functions are, in fact, dis-crete Legendre polynomials. Using this representation, the pitch contour of a syllable can then be expressed as
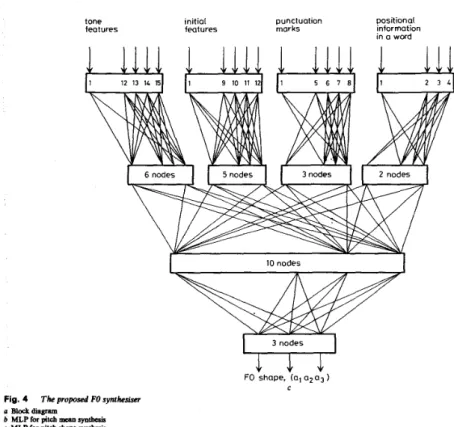
tone initio1 punctuation
features features marks
for 0
<
i<
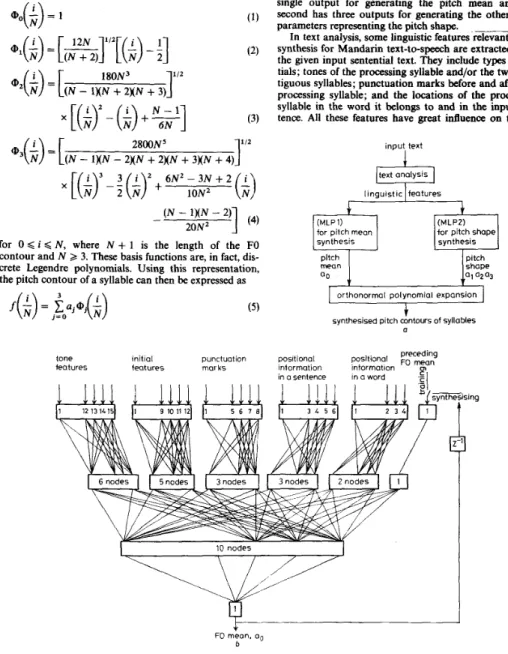
N. These four coefficients are partitioned into two groups, a, and a,, a,, a3, to be synthesised using separate neural networks with different input linguistic features.Fig. 4 is a schematic diagram of the proposed FO syn- thesis scheme. It is composed of two main parts, one being the text analysis for linguistic feature extraction and the other the neural networks for synthesising pitch contour. The input sentential text is first analysed to extract linguistic features relevant to the FO synthesis. Two MLPs are then employed to generate parameters of the pitch contour of each syllable. The first MLP has a single output for generating the pitch mean and the second has three outputs for generating the other three parameters representing the pitch shape.
In text analysis, some linguistic features relevant to F O synthesis for Mandarin text-to-speech are extracted from the given input sentential text. They include types of ini- tials; tones of the processing syllable and/or the two con- tiguous syllables; punctuation marks before and after the processing syllable; and the locations of the processing syllable in the word it belongs to and in the input sen- tence. All these features have great influence on the FO
input text
(MLP1)
for pitch meon synthesis
pitch
for pitch shape shape orthonormal polynomiol expansion synthesised pitch contours
i
of syllablesa
positional preceding information intormotion Fo
m6an
in o sentence in o word .f] 10 nodes'
5
)-+
synthesisingk-
I FO meon, o,? btone
features initial features punctuation marks positionol information in a word
I
3 nodes5 . 1
FO shape. (a, a z o j ) C Fig. 4 a Blockdiagram b MLP for itch mean synthcnire MLP for pitch shape syntbssis The proposed FO synthesiw
pronunciation of Mandarin speech, and can be roughly categorised into global and local linguistic features. Lin- guistic features related to the intonation of a clause or a sentence are generally classified as global. Other features related to the phonetic structure of the processing syll- able, as well as the contextual features extracted from neighbouring syllables, are local.
The coarticulation between the pitch contours of two contiguous syllables is affected by the type of initial of the latter syllable.
As
mentioned before, them is a total of 22 initials in Mandarin speech. These are broadly classified into six types, according to the manner of articulation, and were taken as input features (Table 1). Twelve binary linguistic features representing the initial types of two neighbouring syllables of the pr-ocessing syyable are used.The pitch contour pattern of the processing syllable is determined primarily by its tone. It is also greatly affected by the two neighbouring tones resulting from sandhi rules. Fifteen binary features representing the tones of the processing and the two neighbouring syll- ables are used.
Table 1 : Six broad types of initials Type Initial 1 2 h, sh. shi 3 b. d, g 4 U, j, ji 5 P. t. k 6
IEE Proc.-Vis. Image Signal Process., Vol. 141, No. 6, December I994 m, n, 1, r, 'null'
ts, ch, chi, f, s
Punctuation marks are generally used as prosody control in pronunciation. From obsevations of real Man- darin speech, the level of pitch contour usually has large jumps at syntactical boundaries set by punctuation marks. Punctuation marks used in this study are classi- fied into four categories, as shown in Table 2. Thus eight binary features indicating the punctuation marks before and after the processing syllable are used.
Table 2: Four broad types of punctuation mark Type Punctuation mark
1 Boundary of sentence
2 Comma
3 Pause, colon, semicolon 4 Query
Words are basic meaningful pronunciation units in Mandarin Chinese. There exist monosyllabic, disyllabic and polysyllabic words. In FO pronunciation, intraword coarticulation is, in general, more significant than inter- word coarticulation. Besides, the rhythm of a sentential utterance seems to roughly match with words. Three types of positional information are specified to indicate whether the processing syllable is located at the begin- ning, intermediate or end position of a word. Mono- syllabic words are specially indicated. Hence four binary features are used.
In running Mandarin speech the
FO
contour of a sen- tential utterance will follow an intonation pattern. For a declarative utterance, the F O contour usually declines,Tosimulate the declination effect, the position of the pro- cessing syllable in the input sentential text is labelled as one of six levels and taken as a global linguistic feature. The labelling is a linear quantisation operation starting from the beginning syllable with step size equalling two syllables. So, six binary features are used. For a short sentence, only the first one or two of these six binary features are used, so as to make the synthesised pitch means stay in high-pitch frequency. For a long sentence, the synthesised pitch means for syllables following the 12th syllable will stay in low-pitch frequency and are smooth without abrupt change.
In this study, Features 1-4 and Features 1-5 are used, respectively, in the two MLPs for synthesising the shape and mean of pitch contour. One additional nonbinary input representing the pitch mean of the preceding syll- able is used in the MLP for synthesising pitch mean to more accurately model the intonation. Both the MLPs are three-layer in structure, with two hidden layers. The first hidden layer of each is a concentration layer. Nodes on this layer are partitioned into several groups to be separately connected by different input features. The node number in each group is empirically determined to roughly consider the relative importance and variability of the input features. With this arrangement, input fea- tures can be more compactly encoded so that the com- plexities of the MLPs are reduced. The outputs of the MLPs are, respectively, the zero-th order and the follow- ing three coefficients of orthonormal polynomial expan- sion of the reproduction pitch contour of the processing syllable. Linear activation functions are used in all nodes of the output layer to linearly generate these coefficients.
Two phases are included in this FO synthesis approach, the training phase and the synthesis phase. In the training phase, a large set of sentential utterances accompanying their texts is used to train the MLPs by using the well known back-propagation (BP) algorithm. The training process is done syllable by syllable. For each syllable of a training utterance, the linguistic features dis- cussed previously are extracted from the corresponding text and taken as input features. Coefficients of orthonor- mal polynomial expansion extracted from the pitch contourf(i/N) of the syllable in the training utterance are taken as targets. Formulations for coefficient extraction are expressed as
The process of the BP training algorithm is to recursively adjust the weights of the MLPs with the goal of mini- mising the mean square error between the actual outputs and the desired targets. By sequentially feeding with training samples, the training process is continued until a convergence is reached. The criterion of convergence is simply defined as
SE,- 1 - S E ,
< 0.001
S E i - , (7)
where SE, is the mean square error of the ith iterative epoch. By this training process, the pronunciation rules of FO information are expected to be automatically inferred and implicitly memorised in the MLPs. In the synthesis phase, the pitch contour for the input test sen- tential text is synthesised syllable by syllable. For each syllable, linguistic features are first extracted from the input text and then fed into the MLPs. The outputs are then used to generate the pitch contour of the processing
388
syllable by orthonormal polynomial expansion. It is noted that the real value and the synthesised value of the pitch mean of the preceding syllable are used in the train- ing and in the synthesis test, respectively, as the non- binary input of the MLP which synthesises pitch mean.
4 Simulation results
The validity of the approach was examined by simula- tion. Two sets of reading utterances recorded by Tele- communication Laboratories (TL) were used. The first data set used for training consists of 30 522 syllables and the second one for testing contains 9014 syllables. The texts of these utterances include some phonetically bal- anced sentences and some paragraphic newspaper texts arbitrarily chosen from a large text file. All utterances are spoken naturally and fluently by a single male speaker. The speech signals were first 0-4.5 kHz lowpass filtered, sampled at 10 kHz and A/D converted into a 16 bit data format. They were then pre-emphasised and segmented into 10 ms frames. Preprocessing, including syllable seg- mentation, pitch detection and orthogonal transform, as then performed to extract one parameter vector for each syllable. The syllable segmentation was done manually by Telecommunication Laboratories, who provide the data- base with the help of observations of waveform and hearing. The pitch contour was detected by using the SIFT algorithm and then manually corrected. The first component of the parameter vector represents the mean of the pitch contour of the syllable, and the other three components represent the shape. Texts associated with all utterances were also analysed to extract various linguistic features. In the training, linguistic features and parameter vectors were respectively taken as the inputs and the desired output targets to properly train the MLPs using the BP algorithm. Over 400 epochs were needed to reach convergence for both MLPs. In the synthesis test, linguis- tic features were fed into the MLPs to generate output parameter vectors for synthesising pitch contours.
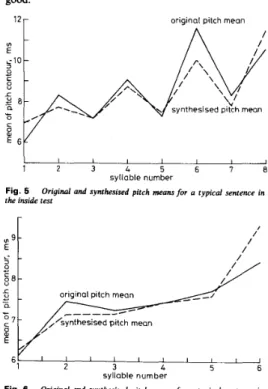
As discussed previously, the mean and shape of pitch contour were synthesised separately for each syllable. For the MLP synthesising pitch mean a total of 46 inputs, including 45 binary global and local linguistic features and one nonbinary feature feedback from the pitch mean of the preceding syllable, were used. The local linguistic features, such as tonality, initial type and positional infor- mation in a word, were used to simulate the local varia- tion on the pitch level change, whereas the global linguistic features, such as positional information in a sentence, were used to simulate the intonation of a sen- tential utterance. Two typical examples of the inside and the outside tests are displayed in Figs. 5 and 6, respect- ively. An inside test means that the input text belongs to the training set, whereas the input text in an outside test is an untrained text. As seen in these two Figures, most synthesised pitch means of syllables match well to their original counterparts. It is worth noting that the intona- tion patterns of these two original pitch contours seem to be correctly synthesised. Table 3 lists the average root mean square error (RMSE) of the synthesised pitch
Table 3: Average RMSEs of t h e synthesised FO means RMSE
0.85 mslframe Inside test
Outside test 0.90 mslframe Statistics of FO mean Bo = 8.09 mslframe
a- = 1.55 mslframe Note: a, is the pitch mean
means. Average RMSEs of 0.85 ms/frame and 0.90 ms/ frame were achieved for the inside and the outside tests, respectively. These experimental results are reasonably good.
original pitch mean
I
I I I I I I I1 2 3 4 5 6 7 8
Original and synthesised pitch m o n s for a typical sentence in
syllable number
Fig. 5 the inside test
E9F
/' /
original pitch mean syllable number
6F
I
1
IJ
I ; I;
IFig. 6 the outside test
Original and synthesised pitch means for a typical sentence in
For the MLP synthesising pitch shape, a total of 39 binary inputs composed of only local linguistic features were used to simulate the local variation on the shapes of pitch contours of syllables. Table 4 lists the average RMSE of the synthesised pitch shapes. Average RMSEs of 0.39 ms/frame and 0.43 ms/frame were achieved for the inside and the outside tests, respectively. These experi- ment results are also reasonably good. By combining the results shown in Tables 3 and 4, the overall average RMSEs of the synthesised pitch contours of syllables are 0.94 ms/frame and 1.00 ms/frame for the inside and the outside tests, respectively.
Table 4: Average RMSEs of the synthesised H) shapes RMSE
Inside test 0.39 rnslfrarne Outside test 0.43 rnslfrarne
Statistics of FO shapes U, = 0.66 ms/frarne
Note: ub =
[,;,
1
(a,
-a,)-
z r ( a , , a 2 , a 3 ) isthe pitchshapeFigs. 7 and 8 display two typical synthesised pitch contours of sentential utterances in the inside and outside tests, respectively. As seen in these two Figures, both syn- thesised pitch contours resemble their original counter- parts. Some pitch-level jumps appear at the boundaries of IEE ploc.-Vis. Image Signal Process., Vol. 141, No. 6, December 1994
two connected pitch contours of contiguous syllables, but they are not significant because there is always an energy dip at the boundary of two contiguous syllables. Besides,
SDeech waveform
0 25 000
sentence: thing-3 pa-3 che-4 Ian-2 tu4tzu-3sung4tsou-3'
Fig. 7 the inside test
speech waveform
Original and synthesised pitch contuurs for a typical sentence in
* - a t
oriqinal Ditch contour
e
svnthesised Ditch contour
k
. . .0 27000 sentence:'to-l shih-2 fen-I hsin-1 100-2 ti-5 00-4 chung-lching-l tsoi-L'
Fig. 8
the outside test Original and synthesised pitch contours for a typical sentence in these pitch jumps are small, so they are usually imperceptible. By comparing all synthesised pitch con- tours with their original counterparts we found that, at some syntactic or semantic boundaries, the pitch-level change on the synthesised pitch contour cannot follow the abrupt jump of pitch level in the original utterance. This mainly results from the fact that both syntactic information and semantic information are not used in this approach.
Finally, a syllable-based Mandarin lTS system was implemented for the purpose of informally evaluating the quality of intonation of the synthesised speech. The basic speech synthesiser used in the TTS system is a linear prediction-based one with quality comparable to the CELP coder. All parameters were automatically gener- ated by the system to synthesise the speech in response to an input text. Using an informal listening test, we found that most synthetic sentential utterances generated by this system sounded clear and natural. Only a few suf- fered from distortions of unnaturalness. These mainly resulted from the above-mentioned defect of synthesis occurring at some syntactic and semantic boundaries. Nevertheless, they were all still highly intelligible.
From the above simulation results, most synthesised pitch contours of syllables were confirmed to match well with their original counterparts.This shows that most pronunciation rules had been learned and memorised in the MLPs. This system was proved to be reasonably good. Of course, if more linguistic information could be incorporated into the system, further improvement to emulate a specific emotional status on the synthetic speech would be possible. Finally, an advantage of this neural-network-based approach over the statistical
approach [9] is discussed. In the statistical approach, the pitch contour of a syllable is vector quantised so that only a finite set of pitch contour patterns can be synthe- sised. In the neural-network-based approach, all param- eters representing a pitch contour are unquantised, such that an infinite number of FO contours can be generated by these MLP models.
5 Conclusion
In this paper, a novel-neural-network-based approach to synthesising FO information for Mandarin text-to-speech has been discussed. It differs from a conventional rule- based approach by using MLPs to learn and memorise the pronunciation rules for generating F O information. Simulation results confirmed that it performs well. Average RMSEs of 0.94 ms/frame and 1.0 ms/frame have
been achieved for the synthesised pitch contour in the inside and the outside tests, respectively.
Some advantages of this approach are h t , that the difficulty of analysing natural Mandarin language syn- tactically or semantically is avoided. Only simple linguis- tic features were used in our simulations. Secondly, the pronunciation rules of prosody are automatically inferred. Thirdly, the synthesised speech sounds more natural than that of a conventional rule-based approach.
6 References
1 HART, J.’t, and COHEN, k : ‘Intonation by rule: a perceptual guest’, J . Phonet, 1973,1, pp. 309-327
2 OLIVE, J.P., and NAKATANI, H.L.: ‘Rule-synthesis of speech by word concatenation: a 6rst step’, 1. Acmst. Soc. Am., 1974, 35, pp. 660-666
3 OLIVE, J.P.: ‘Fundamental frequency rules for the synthesk of simple declarative English sentenas’, 1. A c m t . Soc. A m , 1975.57, pp. 47-2
4 FUJISAKI, H, HIROSE, K, TAKAHASHI, N, and MORI- KAWA, H.: ‘Acoustic characteristics and the underlying ruks of intonation of the common Japanese used by radio and TV announcers’, IEEE Int. CO& A c m . Speech Signal Process, 1986, pp. 2039-2042
5 MANG, J.: ‘Acoustic paramem and phonological d e s of a text- t o - s d system for Chinese’. ICASSP. Tokvo. JaDaIL AD^ 1986. . . . ~ . _
pp. k23-2626
6 LEE, L.S, TSENG, C.Y., and OUH-YOUNG, M.: The synthesis rules in a Chinese t e x t - t o - s d svstem’. IEEE Trans.. 1989. ASSP-
.
.
.
. ,37, pp. 1309-1319
7 SAGISAKA, Y.: ‘On the prediction of global FU shape for Japanese text-to-speech’, 1990, ICASSP, pp. 325-328
8 CHAN, N.C. and CHAN, C.: ‘Prosodic rules for connected man-
darin synthesis’, 1. lnfonr Sci. Enginetr, 19928, pp. 261-281 9 CHEN, S.H., LEE, S.M., and CHANG, S.: ‘A Chinese fundamental
frequency synthesizer lm.4 on a statistical model: ICSLP, 1990, ~ o b e , Japan, pp. 829-832
10 SENOWSKI, TJ., and ROSENBERG, C.R: “ET&: a parallel network that learns to read aloud’, Johns Hopkins Uniacrsity EECS ~ e c h n i c d Report, 1986
11 SCORDILIS, M., and GOWDY, J.: ‘Neural network based gener-
ation of fundamental frequency contours’, ICASSP, 1989, 1, pp. 219-222
12 ABE, M, and SATO, H.: Two-stage M mntrol model using syU- abk based FO units’. ICASSP. 1992,2, pp. 53-56
13 CHEN, S.H., and WANG, Y.R.: ‘Vector quantization of pitch infor- mation in Mandarin speech’, IEEE Tram., 1990, COM-38, pp. 13 17-1 320
14 LIPPMANN, R.P.: ‘An introduction to computing with neural nets’, IEEE ASSP Mag, 1987,4 pp. 4-22