I.COVER
Program for Promoting Academic Excellence of Universities(Phase II)
Midterm
知識管理之尖端研究 – 子計畫十:以知識為基礎的推薦
Advanced Research in Knowledge Management:
Sub Project 10: Knowledge-based Recommendation
(Serial No. NSC 96-2752-H-110 -005 –PAE)
Overall Duration: Month 4 Year 2006 - Month 3 Year 2010 Report Duration: Month 4 Year 2006 - Month 3 Year 2008
National Sun Yat-sen University
2008/2/5
TABLE OF CONTENTS
II.(FORM1) BASIC INFORMATION OF THE PROGRAM ………..4
III.(FORM 2)LIST OF WORKS,EXPENDITURES,MANPOWER, AND MATCHING SUPPORTS FROM THE PARTICIPATING INSTITUTES……….6
IV.(FORM 3)STATISTICS ON RESEARCH OUTCOME OF THIS PROGRAM………..7
V.(FORM4)ABSTRACT AND KEYWORDS………..8
V.(FORM4)RESEARCH OUTCOMES OF THIS PROGRAM………..…………..…………..……….9
VII.APPENDIX II:PUBLICATION LIST …………..…………..…………..……….…………..………35
VIII.APPENDIX III:LIST OF PUBLICATIONS IN “TOP”JOURNALS AND CONFERENCES……..………36
II.(FORM1) BASIC INFORMATION OF THE PROGRAM
Program Title:
Program Title: 知識管理之尖端研究 – 子計畫十:以知識為基礎的推薦
Advanced Research in Knowledge Management :
S10: Knowledge-based Recommendation
Serial No.:
NSC 96-2752-H-110 -005 –PAE
Affiliation國立中山大學
NSYSU
Name
黃三益 (San-Yih Hwang)
Name吳文惠(Wen-Hui Wu)
Tel:
07-5252000 ext. 4723
Tel:07-5252000 ext. 4781
Fax:
07-5254799
Fax:07-5254799
Prin ci pa l In vestig ato r[email protected]
Progr am C oor di nat or E-mail
[email protected]
Expenditures1 (in NT$1,000) Manpower2:Full time/Part time(Person-Months)Projected Actual Projected Actual
FY 96
910
650
(as of Dec. 2007)
7 7
FY XX FY XX - - FY XX - - OverallSerial No. Project Title Principal
Investigator Title Affiliation
Sub-Project 10 以知識為基礎的推薦 (Knowledge-based Recommendation) 黃三益 San-Yih Hwang 教授 (Professor) 國立中山大學 (NSYSU)
Notes: 1,2 Please explain large differences between projected and actual figures.
III.(FORM 2)LIST OF WORKS,EXPENDITURES,MANPOWER, AND MATCHING SUPPORTS FROM THE PARTICIPATING INSTITUTES(REALITY).
Serial No.: NSC 96-2752-H-110 -005 –PAE Program Title: 以知識為基礎的推薦 (Knowledge-based Recommendation)
Expenditures (in NT$1,000) Manpower (person-month) Research Item (Include sub projects) Major tasks and objectives Salary Seminar/ Conference-re lated expenses Project- related expenses Cost for Hardware & Software Total Principal Investigators Consultants Research/ Teaching Personnel Supporting Staff Total
Matching Supports from the Participating Institutes (in English & Chinese)
S10 Knowled ge-based Recomme ndation 404 95 151 0 650 1 0 0 6 7
Servers, Library databases (伺 服器—資管系、資料庫—圖 書館)
IV.(FORM 3)STATISTICS ON RESEARCH OUTCOME OF THIS PROGRAM
LISTING TOTAL DOMESTIC INTERNATIONAL SIGNIFICANT1 CITATIONS2 TECHNOLOGY TRANSFER
JOURNALS 1 CONFERENCES 1 PUBLISHED ARTICLES TECHNOLOGY REPORTS 2 PENDING - PATENTS GRANTED -
COPYRIGHTED INVENTIONS ITEM
ITEM WORKSHOPS/CONFERENCES3
PARTICIPANTS
HOURS TRAINING COURSES
(WORKSHOPS/CONFERENCES) PARTICIPANTS
HONORS/AWARDS4
KEYNOTES GIVEN BY PIS PERSONAL ACHIEVEMENTS
EDITOR FOR JOURNALS
ITEM
LICENSING FEE TECHNOLOGY TRANSFERS
ROYALTY INDUSTRY STANDARDS5 ITEM
ITEM - - -
TECHNOLOGICAL SERVICES6
SERVICE FEE - - -
1 Indicate the number of items that are significant. The criterion for “significant” is defined by the PIs of the program. For example, it may refer to Top journals (i.e., those with impact factors in the upper 15%) in the area of research, or
conferences that are very selective in accepting submitted papers (i.e., at an acceptance rate no greater than 30%). Please specify the criteria in Appendix IV.
2 Indicate the number of citations. The criterion for “citations” refers to citations by other research teams, i.e., exclude self-citations. 3 Refers to the workshop and conferences hosted by the program.
4 Includes Laureate of Nobel Prize, Member of Academia Sinica or equivalent, fellow of major international academic societies, etc. 5 Refers to industry standards approved by national or international standardization parties that are proposed by PIs of the program.
V.(FORM4) EXECUTIVE SUMMARY ON RESEARCH OUTCOMES OF THIS PROGRAM
Abstract in English
Personalization and customization have been shown to be an indispensable function in today’s e-commerce businesses and highly applauded by their customers. Due to the emergence of the concept and practice of Web 2.0, the construction of complex social networks becomes possible, and many researches have been devoted to turning social network into actionable knowledge. In this first two years of the sub-project, we studied the various approaches that incorporate social network of scholars and/or article content in a literature digital library for making recommendation that meet users’ short term interests. We applied the proposed approaches to a set of articles collected from prestigious data mining conference proceedings and journals. We show that the social network-based approach performs better than content-based approach in scenarios where selected articles exhibit a high degree of content similarity and has higher chance to avoid recommending articles of low quality. We subsequently developed three hybrid approaches, namely
switching, proportional, and fusion, that combine content-based and social network-based approaches. Our
experimental results show that the hybrid approaches generally achieve performance higher than or comparable to the best of the primitive methods (that use only a single source of knowledge) under various scenarios. In addition, the hybrid approach is effective in giving lower rank to the articles of low quality. A paper that describes the pure social network-based recommendation research work has been submitted to Information Processing and Management, and another paper that reports the hybrid recommendation research results will be submitted to Online Information Review shortly. Abstract in Chinese 個人化和客製化的服務已是今日電子商務裡不可或缺的一環,事實上,電子商店所提供個人化服務的深度和廣 度常是實體商店所望塵莫及,也因此個人化服務成為區分實體商務和電子商務的一個重要指標。近幾年來Web 2.0 的概念和實作大為風行,造就了不少新興的網站如 Youtube、Facebook,和 Google 群組,即使一般電子商 務網站也紛紛加入顧客彼此互動的功能,凡此種種皆使得早年極難獲得的社會網絡資料變得相對容易許多,也 吸引了許多研究者研究利用社會網絡來提供各種有用服務的方法,最終的目的常是為了進一步提高商業利益。 在本子計畫的第一年,我們提出一些利用社會網絡資料來進行推薦的方法,這些方法被應用在文獻資料庫的推 薦,我們利用文章作者來建置學者的社會網絡,然後當讀者選擇數篇他感興趣的文章後,我們便利用這些文章 作者的社會網絡來推薦另一些文章,以滿足讀者即時的資訊需求。我們實作了這些方法,並收集資料探勘領域 的知名會議論文和期刊論文資料共約6000 篇來評估這些方法。實驗結果發現當讀者所選擇的論文呈現高度內容 相似度時,相較於傳統以文章內容為基礎的推薦,以社會網絡為基礎的推薦可以得到比較好的推薦結果。反之, 當讀者所選擇的論文呈現高度內容分歧時,以文章內容為基礎的推薦可以獲得較佳的推薦結果,也就是說以文 章內容為基礎的推薦和以社會網絡為基礎的推薦各擅所長。因此,在本計劃的第二年,我們接著發展出三個結 合社會網絡和文章內容資訊的推薦方法,實驗結果顯示這些混合的方法在大部分的環境裡都比僅利用單一資訊 來源的推薦方法獲得更好或類似的推薦結果。研究的結果已經寫成兩篇論文,已經或即將投稿到相關的國際期 刊。 Keywords
社會網路(social network),推薦系統(recommender system),社會網絡為基礎的推薦(social
network-based recommendation),混合推薦(hybrid recommendation),文獻資料庫(literature
digital library)
1. Introduction
Recent advances in networking and Web technologies have made possible the availability and accessibility of many genres of information, including the various types of audio, video, and textual data. It was estimated that by 2010, the rate of digital data generated worldwide will be close to one zettabytes per year (Gantz et al. 2007). Facing the enormous amount of data, many people find it difficult to identify a handful of information relevant to their information need. The traditional information searching mechanisms that require the specification of keywords are ineffective and inefficient. In the past few years, many Web sites have provided recommendation functions that intended to offer personal recommendations for various types of products and services. As the effectiveness of customization and personalization has been highly applauded, recommender systems have become the indispensable service of many online stores and Web sites. Notable examples include recommending books, CDs, and other products at Amazon.com (Linden et al. 2003) and Epinions.com (Massa & Bhattacharjee 2004), and movies by MovieLens (Miller et al. 2003) and FilmTrust (Golbeck & Hendler 2006).
Recommendation techniques have been extensively researched in the past decade, e.g., see (Adomavicius & Tuzhilin 2005) for a comprehensive coverage. Based on the types of data and techniques used to arrive at recommendation decisions, recommendation systems can broadly be classified into the following approaches—popularity-based,
content-based, collaborative filtering, association-based, demographics-based and reputation-based (Wei et al. 2002).
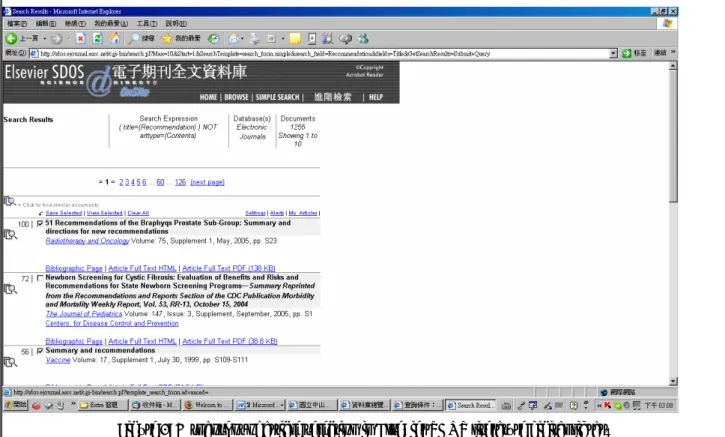
However, most of these recommendation techniques are not suitable for recommending literatures in digital libraries because they rely on either the explicit specification of users’ interests or the implicit derivation from users’ past browsing behavior or transactions. Such techniques require the identification of each user, which is usually not feasible in literature digital library because most literature digital libraries do not require users to identify themselves. Under such a circumstance, the task-focused approach is deemed more appropriate for the recommendation in literature digital libraries (Hwang, Hsiung & Yang 2003). The task-focused approach recommends articles that resemble the articles the user has selected. Figure 1 shows a snapshot of article selection in Elsevier SDOS. The set of selected articles is called a session in our subsequent discussion.
The task-focused approach computes the similarities between articles and the session of a user and subsequently recommend articles of high similarities to the user. Previous work mainly use content or usage log in defining article similarities (Hwang & Chung 2004). With the emergence of P2P and Web 2.0, a precious source—human relationships—is becoming increasingly available. We reports our endeavors of incorporating human relationships into the recommendation techniques in literature digital libraries.
Human relationships are embodied by social networks, which are often visualized as a graph. The social networks have been adopted in marketing for a long time since people heavily relied on “word of mouth” from friends and colleagues in decision making. In recent years, many researches that utilize social networks to discover actionable knowledge have been reported. These applications include building referral chains to find suitable people with desired expertise (Kautz 1997), locating customers with the highest network values for marketing (Domingos & Richardson 2001), and predicting whether people will collaborate in the near future (Liben-Nowell & Kleinberg 2003).
There are many ways to form a social network. For example, using email records (Kautz, Selman & Milewaki , 1995), analyzing responses and citations in newsgroups (Chang, Chen & Chung 2002, Sack 2000), being acquainted by friends (Friend of a Friend Project, Matsuo et al. 2004), coauthoring the same articles (Newman 2001), linking to friends’ homepages (Adamic & Adar 2003), participating the same projects (Matsuo et al. 2004), and attending the same events (Counts & Geraci 2005). In academic environments, coauthoring relationships between scholars are perhaps one of the most important types of connections. Thus, many researches have been devoted to the analysis of the coauthor-based social networks and the identification of some useful knowledge (Newman 2001, Oh et al. 2005, Yoshikane & Kageura 2004). Moreover, Lam (2004) proposed a hybrid approach that integrates social networks into traditionally collaborative filtering systems, and his experiment showed that collaborative filtering systems with social network elements outperform the traditional ones.
In this report, we propose to incorporate social networks into the task-focused approach for literature recommendations in a literature digital library. We then compare these new methods with the traditional content-based approach and find that there is not clear winner. While social network-based approach prevails when a session contains article of similar content, the content-based approach achieve better performance otherwise. We hence propose to integrate these two kinds of approaches and utilize both content and social network features in an appropriate way. Experiments using articles collected from prestigious conference proceedings and journals demonstrate that the hybrid approach achieves the best performance under most operating regions.
This report is structured as follows. Related work is described in Section 2. Section 3 discusses how to construct the scholar social network using the coauthoring relations. Various recommendation methods for utilizing the social network are described in Section 4. Section 5 present several hybrid methods that utilize both content and social networks. Evaluation results are presented and discussed in Section 6. Finally, Section 7 summarizes this paper and points out future research directions.
2. Related work
We first review the current techniques in recommender systems. Then we give an introduction on the social network analysis, which lays the foundation for social networks, and discuss the properties of a social network and the applications of social networks. Finally, we introduce some recommender systems that utilize social networks to make recommendations.
2.1 Recommender Systems
Recommender systems typically suggest items (information, products or services) to the users based on their interest profiles derived from customer demographics, features of interested items, and/or user preferences (e.g., ratings or purchasing history) (Wei et al. 2002). Users’ interest profiles could be generated using explicit or implicit relevance feedback. Explicit relevance feedback asks the users to explicitly indicate their preferences on some items. On the contrary, implicit relevance feedback is to infer users’ interests by observing their actions. Interest profile of a user then facilitates the estimation of the ratings of items unseen by the user, and items of high estimated ratings are subsequently recommended.. There have been many techniques proposed for rating estimation. The most widely used techniques are
Content-based recommendation, Collaborative filtering and Hybrid approaches (Balabanovic & Shoham 1997): Content-based Recommendation
The content-based recommendation establishes a user’s interest profile by analyzing the content features of his preferred items and represents user’s interest profile as a vector with each element indicating the user’s preference on a selected term. Though there have been several ways proposed to determine the importance of a selected term in the content of an item, the most widely used measure today is TF-IDF (Salton & McGill 1983). The content of an item diis
define as Content(di) = (wi,1, wi,2, …, wi,n), where wi,j is the TF-IDF weight of the jth keyword in the item di.
The content-based system recommends the items which are similar to those items the user liked in the past. Let
ContentBasedProfile(c) denote the taste of user c in the past, represented as a vector of weights (wc,1, wc,2, …, wc,n),
which can be computed from individually rated content vectors using a variety of techniques. One widely used technique is to compute ContentBasedProfile(c) as the weighted sum of the content vectors the user has rated (Balabanovic & Shoham 1997). A content-based function may then use some similarity measure to calculate the closeness between an item and the interest profile. The following shows the closeness between an item, represented as
s
w
, and the interest profile, represented asw
c, using cosine similarity function:( )
∑
∑
∑
=
×
⋅
=
= = = n i is n i ic n i ic is s c s c s cw
w
w
w
w
w
w
w
w
w
1 2 , 1 2 , 1 , , 2 2,
cos
,where n is the total number of keywords. The items with top scores will be recommended.
Collaborative Filtering
Collaborative filtering systems try to predict the utility of an item for a particular user based on the rating of the item previously given by other users. More formally, the utility
u ,
( )
c
s
of an item s for user c is estimated based on the utilitiesu
( )
c
j,
s
assigned to item s by those usersc
j∈
C
who are “similar” to user c. For example, in a movie recommendation application, in order to recommend movies to user c, the collaborative recommender system tries to find the “peers” of user c, i.e., other users that have similar tastes in movies. Then, only the movies that are liked by the “peers” of user c would be recommended.According to Breese et al. (1998), algorithms for collaborative recommendations can be classified into two general classes: memory-based and model-based. Memory-based algorithms essentially are heuristics that make rating
predictions based on the entire collection of previously rated items by all users. That is, the value of the unknown rating
rc,s for user c and item s is usually computed as an aggregate of the ratings of some other users for the same item s:
s c C c s c
aggr
r
r
, ˆ , ′ ∈=
,where
Cˆ
denotes the set of N users that are the most similar to user c and who have rated item s. In the simplest case, the aggregation can be a simple average. However, the most common aggregation approach is to use the weighted sum:( )
∑
∈ ′ ′×
′
=
C c s c s ck
sim
c
c
r
r
ˆ , ,,
,where k is the normalizing factor and
sim
( )
c
,
c
′
measures the similarity between users c and c’. That is, the more similar users c andc′
are, the more weight ratingr
c,′swill carry in the prediction ofr
c,s.The two most popular similarity measures are Pearson correlation and cosine function.In contrast to memory-based methods, model-based algorithms use the collection of ratings to learn a model, which is then used to make rating predictions. For example, Breese et al. (1998) proposed a probabilistic approach to collaborative filtering, and the predicted rating of an item s to a user c is
( )
∑
(
)
= ′∈
′
=
×
=
=
n i c s c s c s c s cE
r
i
r
i
r
s
S
r
0 , , , ,Pr
,
,where the range of rating values are integers between 0 and n. Two probabilistic models, namely cluster models and Bayesian networks, were proposed.
Hybrid Approaches
Several efforts have been attempted to combine content-based and collaborative approaches for avoiding their respective limitations (Balabanovic & Shoham 1997, Pazzani 1999, Soboroff & Nicholas 1999, Torres et al. 2004). Burke (2002) classified hybrid approaches into the following categories:
Weighted – The score of a recommended item is the weighted sum of the scores computed using
content-based and collaborative approaches.
Switching –Based on some criterion, the score of a recommended item is computed by either content-based or
collaborative approach.
Mixed – The recommendation list is formed by combining top items of content-based and collaborative
approaches.
Feature Combination – Collaborative information are treated as additional features associated with each
example, and content-based approach is employed over this augmented data set.
Cascade – One recommendation technique is employed first to produce a coarse ranking of candidates and a
second technique refines the recommendation from among the candidate set.
Task-Focused Approach
Many research efforts described above were devoted to the acquisition of users’ long-term interests. In contrast, users also have short-term interests, which refer to the immediate information need for the task at hand. Short-term interests may or may not relate to long-term interests, and thus it is inappropriate to derive a user’s task profile from her previous ratings or historical data. Instead, a task profile is dynamically specified by a list of example documents that are related
to the task. When a user chooses to browse a document A, those documents that are either similar to A in their content or often accessed together with A by other users are recommended. Such a function has already been provided by many digital libraries (e.g., Googlescholar and the ACM Digital Library). The task profile of a user can be extended to include a set S of documents that the user recently accessed, and the goal becomes to recommend a set of documents whose contents are similar to and/or that are often accessed together with the documents in S. This approach has been widely applied to the recommendation of Web pages (Srivastava et al. 2000). Typical approaches for recommending Web pages involve making use of Web content or Web usage logs (Yan et al. 1996, Mobasher et al. 2000, Yang et al. 2001). These approaches were extended by Hwang et al. (2003, 2004) to literature recommendation of digital libraries.
2.2 Social Network Applications
Social network was originated from sociology, and has been the major subject to be researched in recent years (Staab et al. 2005). Social networks display people and relations in nodes and edges respectively. Wasserman & Faust (1994) classified the relations into eight sorts as below:
• Kinship: brother of, father of
• Social Roles: boss of, teacher of, friend of • Affective: likes, respects, hates
• Cognitive: knows, views as similar • Actions: talks to, has lunch with, attacks • Flows: number of cars moving between • Distance: number of miles between
• Co-occurrence: is in the same club as, has the same color hair as
Relations could be directional or undirectional. For example, roommate relationship is undirectional, whereas thesis advising relation (between student and professor) is directional. In addition, there could be strengths on relations, represented as edge weights. For example, number of years being roomates could be used as the edge weight for roommate relations.
In the past decade, social networks have found its way into many applications. Chang, Chen & Chung (2002) reported their experiences in designing a newsgroup browser which identifies reciprocal sub-groups in newsgroup discussions, and utilizes visual methods to help users look for leading authors and provocative articles. Social networks of scholars constructed using coauthorship of articles have been widely studied to shed the light on the inter-personal characteristics of various research communities (Newman 2001; Oh, Choi & Kim 2005; Yoshikane & Kageura 2004). Further applications include building referral chains to find suitable people with desired expertise (Kautz 1997), locating customers with the highest network values for marketing (Domingos & Richardson 2001), and predicting whether people will collaborate in the near future (Liben-Nowell & Kleinberg 2003; Adamic & Adar 2003).
Social networks have also been used for recommendations. Lam (2004) proposed to enhance automated collaborative filtering with social network information. Recall that in collaborative filtering, the predicted rating of an item s by a user c is the weighted sum of its peers:
( )
∑
∈ ′ ′×
′
=
C c s c s ck
sim
c
c
r
r
ˆ , ,,
Lam (2004) proposed to redefine the similarity measure sim(c, c’) by considering both rating similarity and social distance between users c and c’. Specifically,
)
'
,
(
1
)
'
,
(
c
c
, ' , 'rsim
c
c
sim
dcc dcc⎟
⎠
⎞
⎜
⎝
⎛ −
+
=
η
η
,where rsim(c, c’) is the rating similarity between c and c’, the tunable parameter η ≤ 1 controls the level of emphasis given to close friends, and the function dc,c’ is a measure of distance between users c and c’ in the social network. The
idea is to start from the rating similarity rsim(c, c’)and boost it for users with close relationship to the active user c. It has been shown that incorporating social network information (i.e., η > 0) can significantly improve recommendation effectiveness.
Golbeck and Hendler (2006) proposed to integrate Semantic Web-based social networks, augmented with trust, to recommend movies. In addition to rating movies, the social networking component of the Web site requires users to provide a trust rating for each person they added as a friend. The experiment showed that the accuracy of the trust-based predicted ratings in this system is significantly better than the accuracy of a simple average of the ratings assigned to a movie (i.e., the popularity-based method) and also the recommended ratings from a Pearson correlation based recommender system.
3. Constructing scholar social network
The scholar social network can be derived from the target literature digital library D. Specifically, the scholar social network is a directed graph (V, E) with V being the set of scholars who have coauthored at least one article in D and (si, sj)∈E, where si, sj∈V, if si and sj have coauthored at least one article in D. In other words, an edge (si, sj) indicates that
there is a professional connection between si and sj. However, some edges can be stronger than the others. To indicate
the strength of each edge, we propose to associate weight on each edge.
Consider two scholars si and sj. Let Ai and Aj denote the sets of articles which scholar si and sj authored or coauthored
with other scholars. Thus, | Ai
∩
Aj | is the number of articles on which scholar si coauthored with scholar sj. Weregard the strength of collaboration between scholars to be asymmetric. For example, a (well-established) scholar Ai
may collaborate with many other scholars, whereas another (junior) scholar Aj (e.g., a Ph.D. student of Ai) may only
collaborate with Ai. In this case, the strength from Aj to Ai is regarded high, while that from Ai to Aj could be much
lower. To model this scenario, we view the scholar social network as a directed graph with the strength Ci, j on an edge
(si, sj) being defined as follows:
|
|
|
|
C
, i j i j iA
A
A
∩
=
.It is clear that 0<Ci, j ≤1. When Ci, j is large, we can infer that user j covers much of user i’s professional expertise. Thus,
if one likes user i’s work, it is likely that she will be interested in user j’s work.
4. Using scholar social network for recommendation
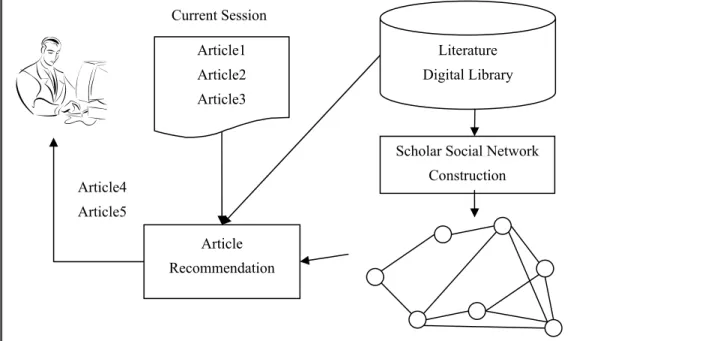
Figure 1: Architecture of article recommendation using social networks
In the architecture, the Scholar Social Network Construction module constructs a social network using coauthoring information existed in the articles of the literature digital library. Each user, when logging onto the digital library, may specify a number of articles that are of interest to her/him. Given the set of articles selected by the current user, referred to as session, the Article Recommendation module will select a number of unseen articles based on the scholar social network. To do so, we need a way to measure the similarity between article authors. We propose four schemes to define the closeness between two scholars based on the scholar social network, namely direct closeness, maximum indirect
closeness, maximum path weight, and direct author. Direct Closeness
The direct closeness scheme determines the closeness between two scholars simply based on the existence of edges in the scholar social network. Let Ci,j denote the strength of an edge (si, sj) in the scholar social network. The closeness
from si to sj, denoted C*i,j, is defined below.
C*ij = Cij if there is an edge (i, j) in the scholar social network;
0 otherwise.
Maximum Indirect Closeness
The maximum indirect closeness scheme determines the closeness of a pair of scholars by considering their common neighbors in addition to their direct link. The intuition is that a pair of scholars who have strong links to many common colleagues is more likely to have strong professional link. Specifically, let n be the number of scholars in the social network, C*i,j is defined by
))
(
,
(
*
, , , 1 , ,j i j k nk i j ik k j iMax
C
Max
C
C
C
≠ ≠ ≤ ≤=
Maximum Path Weight
The maximum path weight generalizes the maximum indirect closeness scheme by considering all paths between a given pair of scholars. We define the closeness of a path (si1, si2, …sir) in the scholar social network as
∏
< ≤j r + i ij j
C
1 , 1 . The Article1 Article2 Article3 Literature Digital LibraryScholar Social Network Construction Article Recommendation Current Session Article4 Article5
closeness of si to sj, denoted
C
i*, j, is the maximum of closeness for all paths that connect si to sj. We call such a scheme maximum path weight because it regards the closeness from one scholar to another as the largest closeness computedfrom all paths that connect the two scholars.
Author Direct
Unlike all the previous schemes, author direct does not consider pair-wise coauthoring relations. Thus, we define
C
i*, jas 1 if i = j and 0 otherwise. We can use Identity matrix to represent the closeness matrix for author direct scheme. Specifically, if there are n scholars, C* = In =
1 0 0 0 1 0 0 0 1 ⎡ ⎤ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎢ ⎥ ⎣ ⎦ L L M M O M L .
Let A be the matrix that records the authors of every article ri, called article-author matrix. The ri is represented as a
vector, < ri,1, ri,2, …, ri,n>, where n is the number of scholars and ri,j = 1, if scholar j is an author of article ri, and 0
otherwise. Then we construct closeness matrix C* for different schemes described above. After that, we can extend the authors of each article by combining A and C*, resulting in an extended article-author matrix T. Specifically,
) * ( , , 1 , ik k j n k j i Max A C T = ⋅ ≤
≤ . For example, consider three scholars a, b, and c, and an article i is co-authored by a and b.
Thus, Ai = (1, 1, 0). Assume that Ca, c = 0.5 and Cb, c = 0.7. We can get Ti,c= Max(0.5, 0.7) = 0.7. That is, the extended
author vector of article i becomes (1, 1, 0.7).
We also calculate the social similarity between articles by using the cosine function. The social similarity between a session R and an article r is defined as follows:
)) , ( (cos ) , ( i R r ine r r Max r R Sim i∈ =
Here we do not use the average method to compute social similarity so as to avoiding the dilution of social effects. In our data collection, the social similarities between articles are very low. For example, when we use the direct closeness method to construct social closeness, in average an article has only 59 peer articles with similarities 0.1 or higher. On the contrary, in average an article has 331 peer articles whose content similarities are above 0.1. In fact, if an article has similar authors to one of our favorite articles, it is sufficient to say that this article could be of interest to us because this article could be from the same research group of one of our favorite articles.
5. Combining social network and content for recommendation
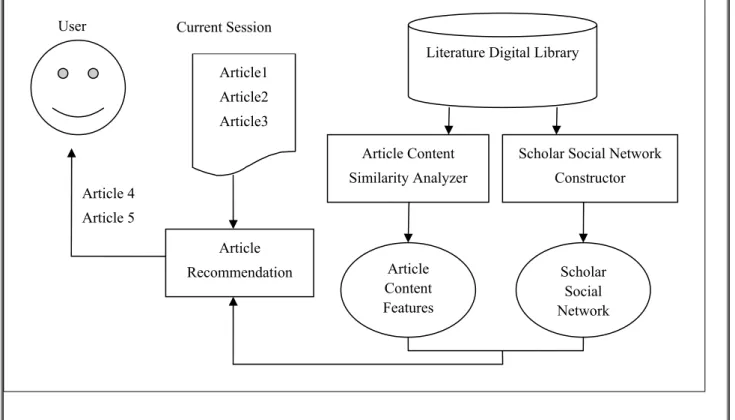
This section presents hybrid approaches that intend to combine co-authoring relations and content information that are both available in the literature digital library. The system architecture of the hybrid recommendation framework is shown in Figure 2.
Figure 2: Architecture of hybrid recommendation
In this architecture, the Scholar Social Network Constructor module constructs a social network using coauthoring information existed in the articles of the literature digital library as described in the previous section. The Article
Content Similarity Analyzer module represents the content features of each article using TF-IDF. The Article Recommendation module will select a number of unseen articles for a given user based on the scholar closeness and/or
content similarity.
Switching
As will be shown by our experimental results in Section 6, the content-based approach performs worse than the social network counterpart when articles in a session exhibit high degree of content similarity but tends to give better recommendation otherwise. Thus, the switch approach selects the content-based or social-network based approach based on the closeness of the articles in the session. The closeness of articles in the session, also called session similarity, is defined as the average pair-wise content similarity of the articles in the session. In the switching approach, we specify a threshold TH for the session similarity. When the session similarity is higher than TH, social network-based approach is chosen for making recommendations. Conversely, when the session similarity is lower than TH, the content-based approach will be selected.
Proportional
In this method, both content-based and social network-based methods are executed to obtain two recommendation lists. The number of items selected from each recommendation list is proportional to the weight of its respective method. Here the weight of each method is determined according to the difference between the session similarity and the threshold. When the session similarity is equal to the threshold TH, each method has equal weight and thus provides the same number of recommended articles. When the value of session similarity is larger, the social network-based approach gets a higher weight and content-based approach is assigned a lower weight, and vice versa. The method with higher weight contributes more articles to the final recommended list. Specifically, let sim and Ntotal be the session
similarity and the number of all articles that recommended to users respectively. , The number of articles selected from Article
Recommendation
Literature Digital Library Article1 Article2 Article3 Current Session Article 4 Article 5
Scholar Social Network Constructor Scholar Social Network Article Content Features Article Content Similarity Analyzer User
the recommendation list of content-based approach, Nc, and the number of articles chosen from that of the social
network-based approach, Ns, are shown below.
Ns = sim / TH * (Ntotal / 2) if sim ≤ TH
(Ntotal / 2) + (sim – TH) / (1 –TH) * (Ntotal / 2) otherwise Nc = Ntotal – Ns,
For example, when Ntotal = 20, sim is 0.4 and TH = 0.1, the top 13 articles of the social-network based approach and the
top 7 articles of the content-based approach will be recommended.
Fusion
The last hybrid method is fusion, which runs the two approaches in parallel and generates a final recommendation list by merging the results together. The generation of the final recommendation list is as follows: every article receives a score that is the summation of the ranks in their original recommendation lists. The final recommendation list is sorted based on these scores in ascending order. Therefore, an article that is ranked 3rd from content-based approach and 2nd
from social network approach will receive a score of 5. The lower the score of article, the closer it is to the top. However, such an approach requires each of the content-based and social network-based approaches sort all the articles based on their respective (content- or social-similarity) scores, which could be time-consuming. To remedy this problem, we slightly modify the fusion method by requiring each of the content-based and social network-based approaches report a top-K’ recommendation list, where K’ is empirically determined as will be shown in Section 6. For an article that appears in both recommendation lists, its score is the summation of the ranks in the two lists. If an article appears in only one recommendation list, its score is simply the rank in the list. For the fusion method, we give priorities to the articles that appear in the both lists, listed in ascending order of their scores. When there are rooms for more articles, we append to the recommendation list the articles with low scores that appear in only one list.
6. Empirical evaluations
6.1 Data Collection
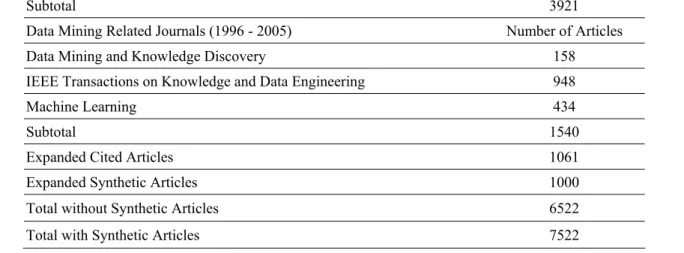
We collected articles from seven major data mining conferences and three top data mining journals during the year 1996 to 2005, as listed in Table 1. We also retrieve totally 64 articles that are published in the aforementioned journals during 2005 to June 2006 and cite at least eight of our collected articles. The citations of these 64 articles served as the source for making up sessions, and thus they are called test articles. To ensure that all the citations of the test articles appear in our collection, we further expanded the article set by including articles cited by the 64 test articles. The number of such expanded articles is 1061. After such expansion, for each test article, the average number of cited articles that appear in our collection is about 32, the minimum is 17, and the maximum is 72.
Table 1: The summary of collected articles
Data Mining Related Conferences (1996 - 2005) Number of Articles
ACM CIKM 738
IEEE ICDM 565
ACM SIGKDD 624
SIAM International Conference on Data Mining 155
ACM SIGIR 716
ACM SIGMOD 494
Subtotal 3921
Data Mining Related Journals (1996 - 2005) Number of Articles
Data Mining and Knowledge Discovery 158
IEEE Transactions on Knowledge and Data Engineering 948
Machine Learning 434
Subtotal 1540
Expanded Cited Articles 1061
Expanded Synthetic Articles 1000
Total without Synthetic Articles 6522
Total with Synthetic Articles 7522
In addition, we added 1000 synthetic articles into the data collection for evaluating the fidelity of recommendation. The content and authors of each synthetic article follow the same trend as our collected articles but are determined in a random manner, as will be described below. As can be imagined, synthetic articles are of low quality and had better not to be recommended.
To determine the set of authors for each synthetic article, we first randomly determine the number of authors for a synthetic article by following the distribution on the number of authors of the articles in our article set, which is shown in Figure 2. As can be seen, 90% of the articles are authored or coauthored by no more than four persons. Then we randomly choose an author in inverse proportion to the number of articles published by each author in our collected articles. The rationale is that people who published more papers in prestigious conferences or journals tend to have lower chance of writing low-quality papers.
To determine the content (in the abstract) of the articles, we first randomly determine the number of sentences N by following the distribution on the number of sentences in the abstract of each collected article, which is shown in Figure 3. Then we randomly choose an article (by following uniform distribution) and select the first N1 sentences, where N1
follows uniform distribution [1, N]. We then randomly choose another article and select the next N2 sentences, where N2
follows uniform distribution [1, N−N1]. This procedure is repeated until we get all N sentences for the tested article.
Distribution of number of authors
0% 5% 10% 15% 20% 25% 30% 35% 40% 1 2 3 4 5 6 7 8 9 10 Number of authors
Distribution of nunber of sentences 0% 2% 4% 6% 8% 10% 12% 14% 16% 18% 20% 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Number of sentences
Figure 3: Distribution of the number of sentences in the abstract of our collected articles
Processing data
We first parsed the abstract of each article and represented each article as a vector of TF-IDF measures. The 4000 terms with the highest average TF-IDF values are chosen as features, and each article is represented as a 4000-dimensional vector. We calculate the content similarity between articles using the cosine function. Following the previous work (Hwang, Yang & Chung 2004), the content similarity between a session R and an article r is defined as follows:
( )
( )
R
r
r
sim
content
r
R
Sim
r R i i∑
∈=
,
_
,
.The social network of authors in our collection is thereby formed using the approach described in Section 3. As described in Section 4, the social similarity between a session R and an article r is defined as follows:
( )
(
( )
i)
R rr
r
sim
Social
r
R
Sim
Max
i,
_
,
∈=
,where Social_sim(r, ri) is the cosine of the extended author vectors of r and ri, derived using some scheme described in
Section 4.
6.2 Experiments and Results Experimental design
We regard each test article as a subject, and the articles cited by the test article are assumed to be of interest to the subject. Let the set of cited articles of a test article ti be Ii. We split Ii into two sets: the session set Si and the prediction
set Pi. In our experiments, we adopt each approach to recommend 40 articles given Si, and evaluate how the set of
recommended articles is close to Pi, called hit rate, which is defined as the proportion of recommended articles that are
in the prediction set. Specifically, Let Ri be the set of articles recommended to the subject i and Pi be the prediction set
of subject i. Hit rate = | | | | i i i P R P ∩
We have also tried other settings that recommend 20 and 60 articles and reached similar results.
close scenario, each session Si, Si⊂ Ii, comprises articles that have similar content to each other, leaving Ii−Si as Pi. On
the other hand, in diversified scenario, articles in each session have low content similarity to each other. And the
fifty-fifty scenario is the compromise of close and diversified scenarios. Half of the sessions in fifty-fifty scenario are
derived using close scenario and the other half using diversified scenario. We intend to examine how the different recommendation approaches perform under these three different scenarios.
We first run experiments for each primitive approach that uses only a single source for recommendation in order to shed the light on the usefulness of content and social network in the context of recommendation. Then, we proceed to evaluate the hybrid methods in terms of hit rate and fidelity. Finally, we will compare the results of hybrid methods and primitive approaches.
Comparing hit rates of primitive approaches
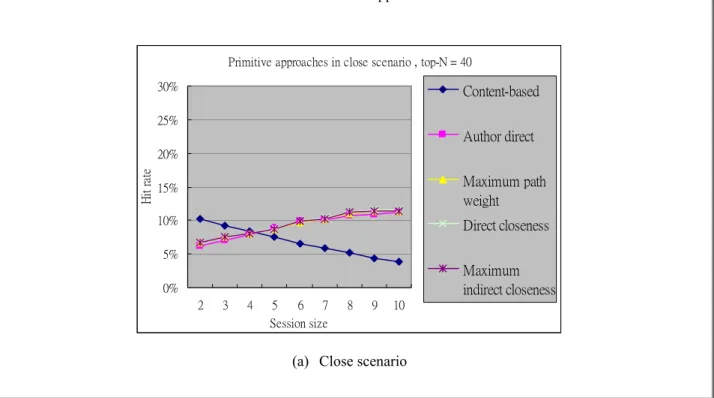
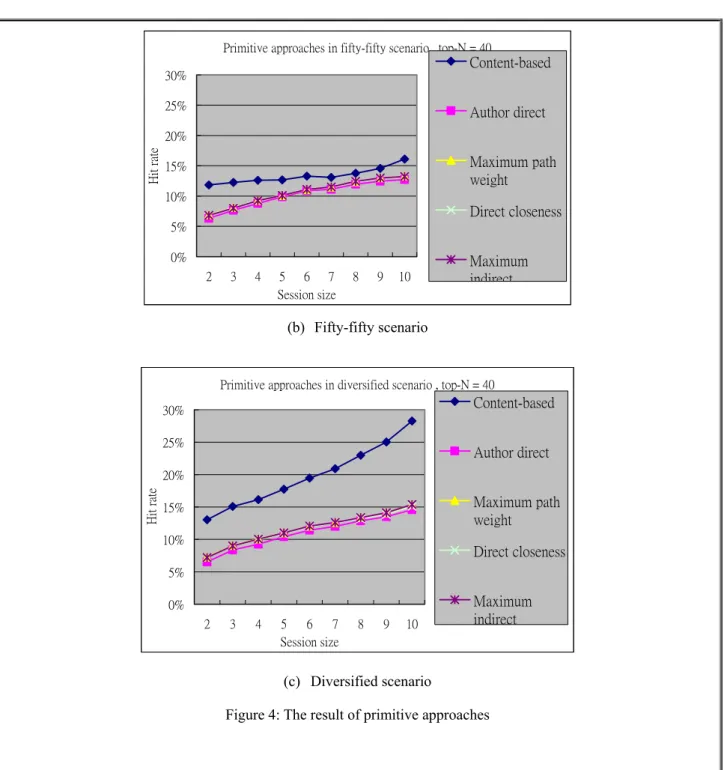
Figure 4 shows the hit rates of several primitive approaches under the three scenarios: close, fifty-fifty, and diversified. It can be seen that the hit rate of author direct method is the lowest among all social network-based methods under all three scenarios. Note that author direct method does not expand the authors of each article. The experimental result demonstrates the usefulness of extending social relationship in recommendation. The other three social-network based methods, namely direct closeness, maximum indirect closeness, and maximum path weight, has similar performance, which conforms to the finding of previous research that distant social relationships do not benefit. Between the content-based and social-network based approaches, we can observe that content-based approach is very sensitive to session size and content coherence in the session. When session size is small, content-based approach performs the best under all the three scenarios. When session size is large (larger than 5), it performs worse than the social network counterpart in close scenario but has much higher hit rate in diversified scenario. In fifty-fifty scenario, the performance difference between the content-based and social network-based approaches becomes smaller.
Primitive approaches in close scenario , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Content-based Author direct Maximum path weight Direct closeness Maximum indirect closeness
Primitive approaches in fifty-fifty scenario , top-N = 40 0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size Hi t ra te Content-based Author direct Maximum path weight Direct closeness Maximum indirect (b) Fifty-fifty scenario
Primitive approaches in diversified scenario , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Content-based Author direct Maximum path weight Direct closeness Maximum indirect (c) Diversified scenario
Figure 4: The result of primitive approaches
Setting threshold for switching and proportional methods
The switching method requires a threshold value based on which either content-based and social network-based approach is selected. The proportional method also needs a threshold setting for deciding the proportion for each of the content-based and social network-based approaches. The threshold TH should be such set that most sessions in close scenario have session closeness lower than TH and most sessions in diversified scenarios have session similarity higher than TH.
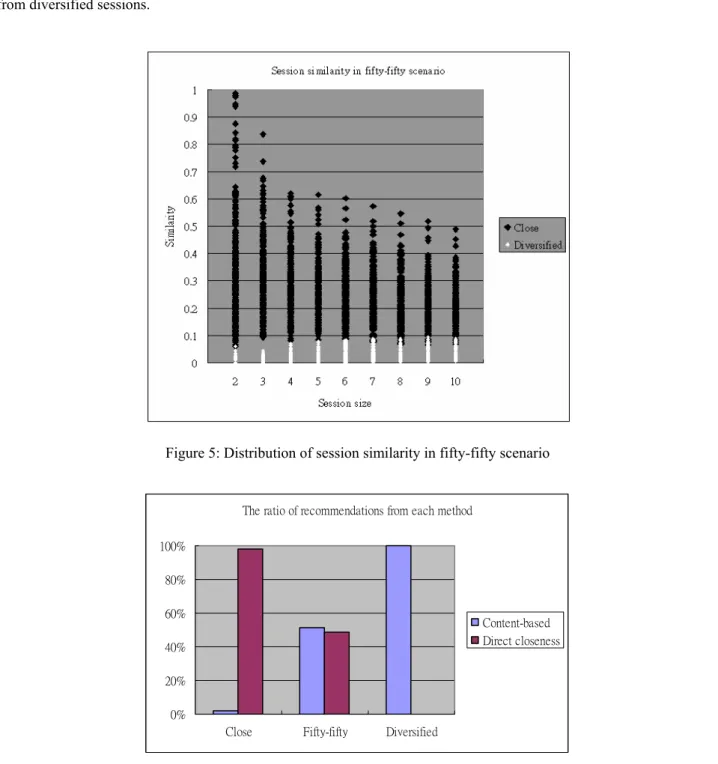
We look into the session similarities in both close scenario and diverse scenario. The similarities of close sessions and diversified sessions in fifty-fifty scenario as shown in Figure 5, where the black points represent the similarities of sessions generated from close scenario and white points are those from diversified scenario. It can be seen that almost all sessions generated from close scenario have session similarities ranging between 0.1 and 0.6, and the session similarities of those from diversified scenario are mostly below 0.1. Thus, we set TH at 0.1. We then applied the switching method (using direct closeness as the social network-based alternative) in close, fifty-fifty, and diversified scenarios and intended to see the proportions of content-based and social network-based methods being applied in each scenario. Figure 6 shows that in close (diversified) scenario the switching method is almost reduced to the social
network-based (content-based) method, and in fifty-fifty scenario, content-based and social network-based methods are approximately equally applied. We thus conclude that by setting TH at 0.1, it is effective to distinguish close sessions from diversified sessions.
Figure 5: Distribution of session similarity in fifty-fifty scenario
The ratio of recommendations from each method
0% 20% 40% 60% 80% 100%
Close Fifty-fifty Diversified
Content-based Direct closeness
Figure 6: The proportions of content-based and social network-based methods being adopted in various scenarios for switching approach when setting threshold at 0.1
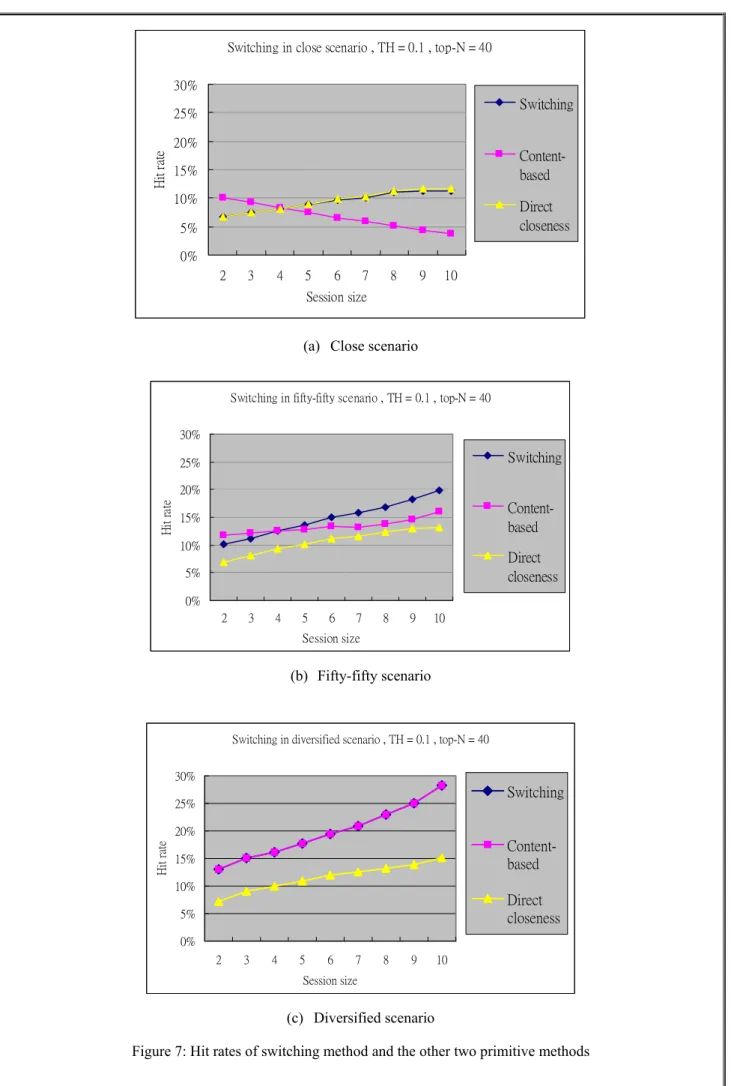
Comparing hit rates of switching method and primitive methods
Figure 7 shows the hit rates of different methods by varying session sizes. In extreme scenarios (close and diversified), the results of switching approach are similar to the best primitive methods. In fifty-fifty scenario, the performance of switching is higher than either of the two primitive methods when the session size is larger than 4. When the session size is 2 or 3, the performance of switching is not as good as content-based method because content-based method performs better with small session size even in close scenario. Thus, an obvious amendment to the switching method is to always adopt content-based approach when the session size is less than 4.
Switching in close scenario , TH = 0.1 , top-N = 40 0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size Hit r ate Switching Content-based Direct closeness
(a) Close scenario
Switching in fifty-fifty scenario , TH = 0.1 , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Switching Content-based Direct closeness (b) Fifty-fifty scenario
Switching in diversified scenario , TH = 0.1 , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Switching Content-based Direct closeness (c) Diversified scenario
Comparing hit rates of proportional method and primitive methods
We performed similar experiments for the proportional approach, and the results are shown in Figure 8. The trends are different from what we observed in the previous experimental results because even in the extreme scenarios, the proportion approach will adopt parts of the recommendations lists from both methods, as shown in Figure 9. We note that in close scenario, the proportion of recommended articles contributed by the content-based method is still high (40%). It is because the average of session similarity in close scenario is 0.27, which allows for only a ratio of 0.6 (i.e., 0.5 + 0.5 * (0.27−0.1)/0.9) recommended articles from social network-based approach.
In close scenario, the hit rates of proportional approach are between the rates of content-based and direct closeness method in most operating regions. As mentioned, it is due to the fact that a significant part of recommended articles are from the content-based method which are not good in close scenario when the session size is large. In diversified scenario, it is close to content-based method because, as shown in Figure 9, only 10% recommended articles are from social network-based method. As for fifty-fifty scenario, it performs better than either primitive method because it adjusts well in response to the change of session similarities.
Proportional in close scenario , TH = 0.1 , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Proportional Content-based Direct closeness
(a) Close scenario
Proportional in fifty-fifty scenario , TH = 0.1 , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Proportional Content-based Direct closeness (b) Fifty-fifty scenario
Proportional in diversified scenario , TH = 0.1 , top-N = 40 0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Proportional Content-based Direct closeness (c) Diversified scenario
Figure 8: Hit rates of the proportional method and the other two primitive methods
The ratio of recommendations from each method
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Close Fifty-fifty Diversified
Content-based Direct closeness
Figure 9: The ratios of content-based and social network-based methods being adopted in various scenarios for proportional approach when setting threshold at 0.1
Comparing hit rates of fusion method and primitive methods
The fusion approach requires the setting of K’, the number of articles recommended from each primitive method. We compare the hit rates of fusion with K’ varying from 20 to 300 in each scenario, as shown in Figure 10. It can be seen that the hit rate generally becomes stable for K’ larger than 100. Thus, we set K’ at 100 in our subsequent experiments.
Fusion with different K' in each scenario (session size = 5) , top-N = 40 0% 5% 10% 15% 20% 25% 20 50 100 200 300 K' H it ra te Close Fifty-fifty Diversified
Figure 10: Hit rate of the fusion approach with different values of K’ in each scenario
Figure 11 shows the comparisons of the fusion approach and the other two primitive methods. In close and fifty-fifty scenario, the overall trends are similar to those of proportional method. However, there some subtle differences. In close scenario the fusion approach performs better than both primitive methods when session size is below 6. In other words, fusion method performs the best when the session size is below 6 and only slightly worse than the social network-based method when the session size is above 6. In diversified scenario, the results of fusion and content-based are almost the same, making fusion method the best in both close and diversified scenarios. We conjectured that the unexpected good performance of the fusion method is due to the fact that fusion method gives higher priority to an article appears in the recommendation lists of both primitive methods. We therefore changed the top-N of recommendations of fusion from 40 to 10, and then discovered that the performance of fusion becomes significantly better as shown in Figure 12. The fusion approach tends to give higher priority to the articles that appear in the recommendation lists of both primitive methods. For example, if an interesting article ranked 20th by content-based method in the recommendation list and
ranked 25th by social network-based method, it may appear in the top-10 recommendation list of fusion because both
primitive methods’ lists have this article. In contrast, the top-40 list contains higher ratio of articles from a single source, thereby jeopardizing its performance.
Fusion in close scenario , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Fusion Content-based Direct closeness
Fusion in fifty-fifty scenario , top-N = 40 0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Fusion Content-based Direct closeness (b) Fifty-fifty scenario Fusion in diversified scenario , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size Hit r ate Fusion Content-based Direct closeness (c) Diversified scenario
Figure 11: Hit rates of fusion method and the other two primitive methods
Fusion in diversified scenario , top-N = 10
0% 2% 4% 6% 8% 10% 12% 14% 2 3 4 5 6 7 8 9 10 Session size Hit ra te Fusion Content-based Direct closeness
Figure 12: Hit rate of fusion and the primitive methods under diversified scenario when Top-N is set at 10
The hit rates of the three hybrid approaches are shown in Figure 13. In close scenario, the switching method is reduced to the social network method. Thus, the proportional and fusion approaches perform better than switching method when the session size is below 6. However, when the session size is above 6, they become worse due to the poor performance of content-based method. In fifty-fifty scenario, it is hard to distinguish which one is better because the results of three hybrid approaches are almost the same. As for diversified scenario, the results of three approaches again are almost the same. But when top-N is smaller, as demonstrated by Figure 14 (top-N = 10), we can clearly see that the performance of fusion is better than the other two hybrid methods under diversified scenario.
Hybrid apporaches in close scenario , top-N = 40
0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size H it ra te Switching Proportional Fusion
(a) Close scenario
Hybrid approaches in fifty-fifty scenario , top-N = 40
0% 5% 10% 15% 20% 25% 2 3 4 5 6 7 8 9 10 Session size Hit r ate Switching Proportional Fusion (b) Fifty-fifty scenario
Hybrid approaches in diversified scenario , top-N = 40 0% 5% 10% 15% 20% 25% 30% 2 3 4 5 6 7 8 9 10 Session size Hit rate Switching Proportional Fusion (c) Diversified scenario
Figure 13: Hit rates of the three hybrid approaches
Hybrid approaches in diversified scenario, top-N =10
0% 2% 4% 6% 8% 10% 12% 14% 16% 2 3 4 5 6 7 8 9 10 Session size Hit ra te Switching Proportional Fusion
Figure 14: Hit rates of the hybrid approaches in diversified scenario, top-N = 10
Comparing fidelity of the various approaches
As we can imagine, one of the major weaknesses with content-based approach is the potentially poor quality of the recommended articles. Even though the content-based approach can recommend articles similar to the current session in their content, the quality of the recommended articles could be questionable. On the other hand, social network-based approaches can alleviate the fidelity problem because it makes recommendation based on article authors. Thus, we conjectured that the hybrid approach can also avoid the recommendation of low-quality articles to some extent because it adopts parts of social network recommendation. To demonstrate this, we added 1000 synthetic articles into our article set, as mentioned in Section 6.1, resulting in totally 7522 articles for the following experiments. We compared the experimental results with and without synthetic articles. Only the experimental results under fifty-fifty scenario are reported here because experiments under other scenarios demonstrate similar results.
Hite rate drop in fifty-fifty scenario , top-N = 40 0.0% 0.5% 1.0% 1.5% 2.0% 2.5% 3.0% Content-based Direct closeness
Switching Proportional Fusion
D rop o f hi t ra te
Figure 15: Drop of hit rate in fifty-fifty scenario
Figure 15 presents the hit rate drop after incorporating synthetic articles. We notice that the drop of hit rate of the social network approach (namely direct closeness) is significantly lower than that of the content-based method. However, compared to the content-based method, the hybrid approaches have similar hit rate drop. We then examined the rank of the first synthetic article recommended by the various approaches, as presented in Figure 16. The result shows that content-based approach tends to recommend synthetic articles within the top 10 of recommendation list. On the other hand, the first synthetic article recommended by the social network-based approach (direct closeness) is of much lower rank (after 40), and ranks of the first synthetic articles recommended by the various fusion methods are in the middle. Comparing the fusion methods incorporating various social network methods, we can see that the ranks of direct closeness, maximum indirect closeness and maximum path weight are in decreasing order. This is because, as each article is extended to contain more distance authors in the social network, there will be more chance to cover some unpopular authors.
Rank of first synthetic article in fifty-fifty scenario
0 10 20 30 40 50 60 2 3 4 5 6 7 8 9 10 Session size Rank Fusion (Author direct) Fusion (Maximum path weight) Fusion (Direct closeness) Fusion (Maximum indirect closeness) Content-based Direct closeness
Figure 16: Rank of the first synthetic article for various methods in fifty-fifty scenario
From the above three experiments, we conclude that the content-based approach is very sensitive to low quality articles, and the social network-based approach help remedy this problem. The hybrid approach, though has only slightly better fidelity rate, tends to give low-quality articles much lower ranks when compared to the content-based approach.
7. Conclusions and Future work
In this report, we described several approaches that incorporate content and/or social networks for task-focused recommendations. We empirically compared these approaches using articles collected from major data mining conference proceedings and journals. In summary, we reach the following conclusions:
1. In close scenario, fusion approach is the best when the session size is small. When session size increases, social network-based approach becomes the best.
2. In fifty-fifty scenario, the performances of the three hybrid approaches are close and all better than content-based and social network approaches.
3. In diversified scenario, the hit rates of the three hybrid approaches are almost the same and equally good as the content-based method. But fusion method performs better when the recommendation list is short.
4. The social network-based approach is effective in alleviating articles of low quality from its recommendation list. The hybrid approach, though has only slightly better fidelity rate than the content-based approach, tends to give low quality articles much lower ranks when compared to the content-based approach.
Although switching and proportional hybrid approaches can provide slightly better performances in some scenarios, determining the best threshold value may be time-consuming. We thus conclude that fusion method is a promising approach for task-based recommendation in most scenarios.
In this work, we simply used co-authorships for constructing social networks of scholars. However, there could be some other types of information that could be incorporated into the relations between scholars. For example, a well established scholar, judging by the number of articles published in top conferences and journals, should have higher weights on its incoming edges in social networks so that their articles have higher chance to be recommended. Such information could be incorporated into recommendation techniques for making more effective recommendation.
References
Adamic, L. A., & Adar, E. (2003). Friends and Neighbors on the Web. Social Networks, 25, 211-230.
Adomavicius, G., & Tuzhilin, A. (2005). Toward the Next Generation of Recommender Systems: A Survey of the State-of-the-Art and Possible Extensions. IEEE Transactions on Knowledge and Data Engineering, 17(6), 734-749.
Balabanovic, M., & Shoham, Y. (1997). Fab: Content-Based, Collaborative Recommendation. Communications of the
ACM, 40(3), 66-72.
Breese, J. S., Heckerman, D., & Kadie, C. (1998). Empirical Analysis of Predictive Algorithms for Collaborative Filtering. Proceedings of the Fourteenth Annual Conference on Uncertainty in Artificial Intelligence, 43-52 Burke, R. (2002). Hybrid Recommender Systems: Survey and Experiments. User Modeling and User-Adapted
Interaction, 12(4), 331-370.
Chang, C. L., Chen, D. Y., & Chung, T. R. (2002). Browsing Newsgroups with A Social Network Analyzer.
Proceedings of the Sixth International Conference on Information Visualization, 750-755.
Counts, S., & Geraci, J. (2005). Incorporating Physical Co-Presence at Events into Digital Social Networking.
Proceedings of 2005 International Conference on Human Factors in Computing Systems, 1308-1311.
Domingos, P., & Richardson, M. (2001). Mining the Network Value of Customers. Proceedings of the Seventh ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining, 57-66.
Gantz, J. F., Reinsel, D., Chute, C., Schlichting, W., McArthur, J., Minton, S., Xheneti, I., Toncheva, A., & Manfrediz, A., (2007). The Expanding Digital Universe: A Forecast of Worldwide Information Growth Through 2010. IDC
white paper, International Data Corporation.
Golbeck, J., & Hendler, J. (2006). FilmTrust: Movie Recommendations using Trust in Web-Based Social Networks.
Consumer Communications and Networking Conference 2006, 1, 282-286.
Hwang, S.-Y., Hsiung, W.-C., & Yang, W.-S. (2003). “A Prototype WWW Literature Recommendation System for Digital Libraries,” Online Information Review, 27(3), pp. 169-182.
Hwang, S.-Y., Chuang, S.-M. (2004). “Combining Article Content and Web Usage for Literature Recommendation in Digital Libraries,” Online Information Review, 28(4), pp. 260-272.
Kautz, H., Selman, B., & Milewaki, A. (1995). Agent Amplified Communication. Proceedings of the Thirteenth
National Conference on Artificial Intelligence.
Kautz, H., Selman, B., & Shah, M. (1997). Referral Web: Combining Social Networks and Collaborative Filtering.
Communications of the ACM, 40(3), 63-65.
Lam, C. (2004). SNACK: Incorporating Social Network Information in Automated Collaborative Filtering. Proceedings
of the 5th ACM Conference on Electronic Commerce, 254-255.
Liben-Nowell, D., & Kleinberg, J. (2003). The Link Prediction Problem for Social Networks. Proceedings of the
Twelfth International Conference on Information and Knowledge Management, 556-559.
Linden, G., Smith, B., & York, J. (2003). Amazon.com Recommendations: Item-to-Item Collaborative Filtering. IEEE
Internet Computing, 7(1), 76-80.
Massa, P., & Bhattacharjee, B. (2004). Using Trust in Recommending Systems: an Experimental Analysis. Proceedings
of iTrust2004 International Conference.
Matsuo, Y., Tomobe, H., Hasida, K., & Ishizuka, M. (2004). Finding Social Network for Trust Calculation.
Proceedings of the 16th European Conference on Artificial Intelligence, 510-514.
Miller, B. N., Albert, I., Lam, S. K., Konstan, J. A., & Riedl, J. (2003). MovieLens Unplugged: Experiences with an Occasionally Connected Recommender System. Proceedings of International Conference on Intelligent User
Interfaces.
Mobasher, B., Dai, H., Luo, T., Sung, Y., & Zhu, J. (2000). Integrating Web Usage and Content Mining for More Effective Personalization. Proceedings of the International Conference on E-Commerce and Web Technologies, 165-176.
Newman, M. E. J. (2001). Scientific Collaboration Networks. I. Network Construction and Fundamental results.
American Physical Society Journals, 64(1), 016131.
Oh, W., Choi, J. N., & Kim, K. (2005). Coauthorship Dynamics and Knowledge Capital: The patterns of Cross-Disciplinary Collaboration in Information System Research. Journal of Management Information Systems,
22(3), 265-292.
Pazzani, M. (1999). A Framework for Collaborative, Content-Based, and Demographic Filtering. Artificial Intelligence
Review, 393-408.
Sack, W. (2000). Conversation Map: A Content-Based Usenet Newsgroup browser. Proceedings of the 5th
International Conference on Intelligent user interfaces, 233-240.
Salton, G. and McGill, M. J. (1983). Introduction to modern information retrieval. McGraw-Hill.
Soboroff, I., & Nicholas, C. (1999). Combining Content and Collaborative in Text Filtering. Proceedings of
International Joint Conference on Artificial Intelligence Workshop: Machine Learning for Information Filtering.
Srivastava, J., Cooley, R., Deshpande, M., & Tan, P. N. (2000). Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data. Proceedings of the ACM SIGKDD Explorations, 1(2), 12-33.
Staab, S., Domingos, P., Mika, P., Golbeck, J., Ding, L., Finin, T., et al. (2005). Social Networks Applied. IEEE