行政院國家科學委員會專題研究計畫
成果報告
模糊統計分析在資料採礦以及軟計算方法之理論探討及其應
用
計畫類別:個別型計畫 計畫編號: NSC91-2213-E-004-007-執行期間:91 年 08 月 01 日至 92 年 07 月 31 日 執行單位:國立政治大學應用數學學系 計畫主持人:吳柏林 報告類型:精簡報告 處理方式:本計畫涉及專利或其他智慧財產權,1 年後可公開查詢中 華 民 國 92 年 10 月 13 日
模糊統計分析在資料採礦以及軟計算方法之理
論探討及其應用
計畫編號
: NSC91-2213-E-004-007
吳柏林 國立政治大學應用數學系
2003/8/2
Introduction
Data mining for knowledge discovery is a new and rapidly developing area of research towards applications in this information age. Although this area falls into the field of multivariate data analysis, there is a tendency to consider alternative techniques to traditional multivariate statistical techniques, which are borrowed from computer science and artificial intelligence, such as neural networks, and rough sets theory(see, e.g., [5], [7]). This emerging technique are somewhat ad-hoc and lack theoretical foundations. As Elder [2] pointed out, there is a compelling reason to look at statistical perspectives of knowledge discovery in databases(KDD). This is mainly due to the fact that recent statistical contributions to multivariate data analysis did not fully spread out to the KDD community. Needless to say, the advantage of using statistical methodology is that it will provide a firm theoretical foundation for deriving inference procedure in decision-making.
In this research project, we will show that a relatively new area of probability theory and statistics, namely random sets theory(see, e.g., [4], [7], and [15]), is suitable as a framework for data mining problems.
Theorem 2.1. Let X be a universal set and A be a fuzzy set on X . Then the
complement of fuzzy set, A , is denoted byc (1 )
( c)(1 ) ( ) c c A A A ( 1- )∨ . (2.3) where ( )c A
is the level set of A , c
) 1 ( ) (Ac is a (1 ) cut of A , and c ∨
denotes the finite fuzzy union.
Theorem 2.2. Let X be a universal set, A and B be two fuzzy sets on X . For
any significant levels 1,2[0,1], the standard fuzzy union and intersection of A and B are denoted by
(i) F [ ( ) ( ) ] F[ ( ) ( ) ] A B A B A B ∨ ∨ 1 2 ( ) ( ) [ ( ) F ( )] F[( ( ) ) F( ( ) )] A B Ker A Ker B A B ∨ ∨ . (2.11) (ii) F [ ( ) ( ) ] F[ ( ) ( ) ] A B A B A B ∨ ∨ 2 ( ) [ ( ) F ( )] F [ ( ) F ( ( ) )] B
Ker A Ker B Ker A B
∨ 1 ( ) [( ( ) ) ( )] F F A A Ker B ∨ 1 2 ( ) ( ) [( ( ) ) ( ( ) )] F F A A B B ∨ ∨ . (2.12)
where ( )A is the level set of A, ( )B is the level set of B, ( A) is a
cut ofA , (B) is a cut of B , F and F denote the standard fuzzy union and
intersection respectively
The data analyzed here comes from the ICU of Taipei Veterans General Hospital, 2001. The data records RRI of the dead patients and survival patients for the first four days of ICU. The RRI data for each patient is measured with 30 minutes. By discarding the first 100 observation, we analysis the 101 to 600 observations from each patient which contains about 1800 ~ 3000 observations of RRI. The purpose of this study is to extract features and identify nonlinear time series for the ICU patients. Figure 4.1 (a) and (b) plot respectively the dead and survival patients’ RRI.
The 2nd Day for 1st Dead Patient The 2nd Day for 1st Survival Patient
The 2nd Day for 2nd Dead Patient The 2nd Day for 2nd Survival Patient
The 2nd Day for 3rd Dead Patient The 2nd Day for 3rd Survival Patient
The 2nd Day for 5th Dead Patient The 2nd Day for 5th Survival Patient
(a) (b)
Figure 4.1 Plots of RRI for dead and survival patients
For the 500 observations, we can find the cluster centers for each data set. Now, under the significant level
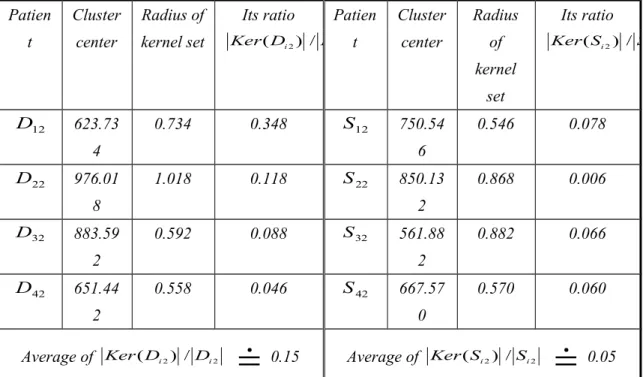
= 0.9, we can construct our kernel sets by the proposed procedures in the Section 3. In following, the dead patients’ and the survival patients’ cluster centers, radiuses of kernel set and ratios are showed in Table 4.1.Table 4.1 The dead and the survival patients’ cluster centers, radiuses and ratios
Patien t Cluster center Radius of kernel set Its ratio 2 2) / (Di Di Ker Patien t Cluster center Radius of kernel set Its ratio 2 2) / (Si Si Ker 12 D 623.73 4 0.734 0.348 S12 750.54 6 0.546 0.078 22 D 976.01 8 1.018 0.118 S22 850.13 2 0.868 0.006 32 D 883.59 2 0.592 0.088 S32 561.88 2 0.882 0.066 42 D 651.44 2 0.558 0.046 S42 667.57 0 0.570 0.060
Average of Ker(Di2) /Di2
0.15 Average of Ker(Si2) /Si2
0.05The kernel set learned from the dead patients is ( ) 4 ( 2) 1F i i Ker D D Ker . Then,
we can give the following testing-hypothesis procedure:
0
H : the data belongs to the dead patterns.
1
H : the data doesn’t belong to the dead patterns.
if there exist i, such that Ker(Dnew) Ker(Di2) 1aD then we accept H0.
Otherwise, we rejectH0.
Similarly, the kernel set learned from the survival patients is ( ) 4 ( 2) 1F i i Ker S S Ker ,
and the testing-hypothesis procedures:
0
H : the data belongs to the survival patterns.
1
H : the data doesn’t belong to the survival patterns.
Decision rule: for the new sample Ker(Snew), under the significant level D, if
there exist i, such that Ker(Snew) Ker(Si2) 1D then we accept H0.
Otherwise, we reject H0.
Now, we examine two new RRI samples of patients from ICU. First, we can find the cluster centers for each data set and construct their kernel sets under the significant level
= 0.9. Then we can find radiuses of kernel sets for these samples. Finally, we can get their patterns according to their features by above the testing-hypothesis procedures.For these two samples, we get the cluster centers 592.624 and 761.658 respectively. We can calculate the membership for each observation via the distance between observation and its cluster center. Under the significant level
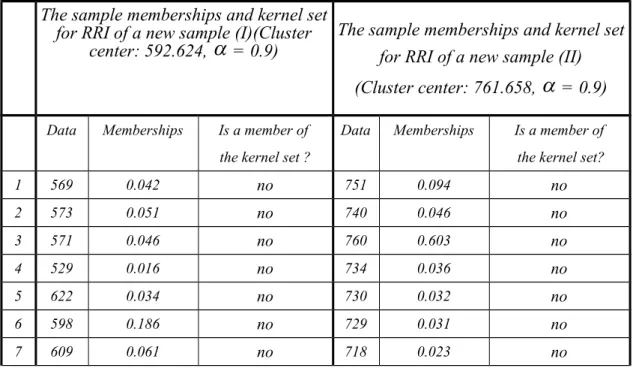
= 0.9, if the membership of observation is lager than 0.9, then this observation is a member of the kernel set. Therefore, the results of two new samples are showed in Table 4.2.Table 4.2 The sample memberships and kernel set for RRI of new samples The sample memberships and kernel set
for RRI of a new sample (I)(Cluster
center: 592.624,
= 0.9)The sample memberships and kernel set for RRI of a new sample (II)
(Cluster center: 761.658,
= 0.9)Data Memberships Is a member of
the kernel set ?
Data Memberships Is a member of
the kernel set?
1 569 0.042 no 751 0.094 no 2 573 0.051 no 740 0.046 no 3 571 0.046 no 760 0.603 no 4 529 0.016 no 734 0.036 no 5 622 0.034 no 730 0.032 no 6 598 0.186 no 729 0.031 no 7 609 0.061 no 718 0.023 no
8 614 0.047 no 713 0.021 no 9 608 0.065 no 708 0.019 no 10 605 0.081 no 741 0.048 no 491 591 0.616 no 737 0.041 no 492 591 0.616 no 725 0.027 no 493 591 0.616 no 722 0.025 no 494 595 0.421 no 717 0.022 no 495 598 0.186 no 721 0.025 no 496 598 0.186 no 721 0.025 no 497 595 0.421 no 717 0.022 no 498 592 1.000 yes 725 0.027 no 499 598 0.186 no 736 0.039 no 500 596 0.296 no 728 0.030 no Tota l 47 (0.094 > 0.05) 17 (0.0340.05)
From Table 4.2 we can find that:
(1) For these two new samples, the radiuses of sample kernel sets are 0.624 and 0.658 respectively. This information seems insufficient if we want to classify them by using the traditional identification method.
(2) For the new sample (I), the observations which belongs to the sample kernel set with respect to total observations is 0.094 (=47/500), which is larger than 0.05. By the radius of sample kernel set and the ratio 0.094, we can say that the patient has the same features of dead patients.
From Table 4.1, we obtain the significant level D= 0.05. Under this
condition, we find that the number of observations which belongs to the sample kernel set with respect to the number of Ker(Di2)is lager than 0.95, i 3,4. By
the decision rule, the RRI of this patient will be identified into the learned dead pattern of RRI.
(3) Similarly, for new sample (II), the observations which belongs to the sample kernel set with respect to total observations is 0.034(=17/500), which is smaller than 0.05. By the radius of sample kernel set and the ratio 0.034, we can say that the patient has the same features of survival patients.
Under the significant level D= 0.05, we find that the number of
observations which belongs to the sample kernel set with respect to the number of
) (S22
identified into the learned survival pattern of RRI.
Conclusion
In the medical science analysis discussed above the time series data have the uncertain property. If we use the conventional clustering methods to analyze these data, it will not solve the orientation problem. The contribution of this paper is that it provides a new method to cluster and identify time series. In this paper, we presented a procedure that can effectively cluster nonlinear time series into several patterns based on kernel set. The proposed algorithm also combines with the concept of a fuzzy set. We have demonstrated how to find a kernel set to help to cluster nonlinear time series into several patterns.
Our algorithm is highly recommended practically for clustering nonlinear time series and is supported by the empirical results. A major advantage of this framework is that our procedure does not require any initial knowledge about the structure in the data and can take full advantage of much more detailed information for some
ambiguity.
However, certain challenging problems still remain open, such as:
(1) Since hardly ever any disturbance or noise in the data set can be completely eliminated, therefore, for the case of interacting noise, the complexity of multivariate filtering problems still remains to be solved.
(2) The convergence of the algorithm for clustering and the proposed statistics have not been well proved, although the algorithms and the proposed statistics are known as fuzzy criteria. This needs further investigation.
Although there remain many problems to be overcome, we think fuzzy statistical methods will be a worthwhile approach and will stimulate more future empirical work in time series analysis.