A fast algorithm for reliability-oriented task assignment in a distributed
system
Chin-Ching Chiu
a,*, Yi-Shiung Yeh
b, Jue-Sam Chou
baDepartment of Management Information System, Private Takming College, Ney Hwu, Taipei, Taiwan, ROC bInstitute of Computer Science andInformation Engineering, National Chiao Tung University, Hsinchu, Taiwan, ROC
Received 6 March 2001; revised 7 January 2002; accepted 28 January 2002
Abstract
Distributed systems (DS) have become a major trend in computer systems design today because of their high speed and high reliability. Reliability is an important performance parameter in DS design. The distribution of programs and data ®les can affect the system reliability. Usually, designers add redundant copies of software and/or hardware to increase the system's reliability. The reliability-oriented task assignment problem, which is NP-hard, is to ®nd a task distribution such that the program reliability or system reliability is maximized. In this paper, we developed a reliability-oriented task allocation scheme, based on a heuristic algorithm, for DS to ®nd an approximate solution. The simulation shows that, in most test cases with one copy, the algorithm ®nds suboptimal solutions ef®ciently. When the algorithm cannot obtain an optimal solution, the deviation is very small; therefore, this is a desirable approach for solving these problems. q 2002 Elsevier Science B.V. All rights reserved.
Keywords: Distributed system reliability; Task assignment; Heuristic algorithm
1. Introduction
Distributed systems (DS) have become increasingly popular in recent years. The advent of VLSI technology and low-cost microprocessors have made distributed computing economically practical in today's computing environment. DS can provide appreciable advantages, including high performance, high reliability, resource shar-ing, and extensibility [1]. Reliability improvements in DS are possible because of program and data-®le redundancy. Reliability evaluations of DS have been widely published [1±8]. To evaluate the reliability of a DS, including a given distribution of programs and data ®les, it is important to obtain a global reliability measure that describes the degree of system reliability [10±15].
For a given distribution of programs and data ®les in a DS, distributed program reliability (DPR) [9] is the prob-ability that a given program can be run successfully and will access all of the required ®les from remote sites despite faults occurring among the processing elements and communication links. The second measure, distributed system reliability (DSR), is de®ned as the probability that all of the programs in the system can be run successfully.
Kumar et al. [9] demonstrated that redundancy in resources, such as computers, programs, and data ®les can improve the reliability of DS [9]. The study of program and data-®le assignment with redundancy considerations is therefore important in improving DSR.
Assume that there are n processing nodes, P programs, F data ®les and k copies. The total number of possible assign-ment cases is nk P1F: Thus, the optimal program and ®le
allocation on the processing nodes are a problem of expo-nential complexity [15]. This implies that optimum solu-tions can be found only for small problems. For larger problems, it is necessary to introduce heuristic algorithms that generate near-optimum solutions.
We have presented some algorithms for computing a DS. The ®rst algorithm generates disjoint FSTs by cutting differ-ent links and computing the DPR and DSR based on a simple and consistent union operation on the probability space of the FSTs [8]. The second algorithm eliminates the need to search a spanning tree during each subgraph generation. The algorithm reduces both the number of subgraphs generated and the actual execution time is more required for analysis of DPR and DSR [11]. Both algorithms assume that the copies of each program and ®le set are dynamically dependent upon the system capacity. The third algorithm reduces the total amount of execution time for optimizing the k-node reliability under the given
www.elsevier.com/locate/comcom
0140-3664/02/$ - see front matter q 2002 Elsevier Science B.V. All rights reserved. PII: S0140-3664(02)00057-9
* Corresponding author. Tel.: 188-62-26585801x393. E-mail address: chiu@imd.takming.edu.tw (C.C. Chiu).
capacity constraint [16]. The size of each program and ®le set is not discussed separately. Hwang and Tseng proposed k copies of the distributed task assignment (k-DTA) problem. The k-DTA models the assignment of k copies for both distributed programs and their data ®les to maximize the DSR under some resource constraints. Because the k-DTA problem is NP-hard [13], this study proposed a heuristic algorithm to ®nd an approximate solution. The simulation results show that the exact solution can be obtained in most cases with one copy using the proposed algorithm. When the algorithm fails to obtain an exact solution, the deviation from the exact solution is very small. When the number of copies is greater than one, an approximate solution is obtained, because the number of assigned redundant copies will be constrained on the nodes, whose size is suf®cient to allocate the ®le.
Section 2de®nes the task assignment reliability in a DS. Section 3 gives our algorithm and an illustrated example. Section 4 provides the results and a discussion of the problem from Section 2. Our conclusions are presented in Section 5.
2. Computing optimal reliability
To clarify our research objectives, the problem addressed herein is described.
2.1. De®nitions
The following de®nitions are used in this work.
De®nition 1. A DS is de®ned as a system involving coop-eration among several loosely coupled computers (proces-sing elements). This system communicates (by links) over a network.
De®nition 2. A distributed program is de®ned as a program for some DS that requires one or more ®les. For successful distributed program execution, the local host, the processing elements possessing the required ®les and the interconnecting links must be operational [9].
Nomenclature
G V; E an undirected DS graph, where V denotes a set of processing elements, and E represents a set of commu-nication links
n the number of nodes in G, n uVu
vi an ith node represents the ith processing element
c(vi) the capacity of the ith node
e the number of links in G, e uEu
ei,j an edge represents a communication link between viand vj
ai,j the probability of success of link ei,j
bi,j the probability of failure of link ei,j
d(vi) the number of links connected to the node vi
w(vi) the weight of the ith node
w(ei,j) the weight of the link ei,j
F total number of ®les in the DS P total number of programs in the DS pi distributed program i
fi ®le i
s(pi) the size of program pi
s(fi) the size of data ®le fi
pfi distributed program or ®le i
k the number of copies of pfi
AFL(pi) list of ®les required for pito complete its execution
APL(fi) list of programs, which are required fito complete their execution
DPR(pi) distributed program reliability of pi
FST ®le spanning tree consisting of the root node (processing element that runs the program) and some other nodes, which hold all the ®les needed for the program held in the root node under consideration
MFST minimal FST containing no subset ®le spanning tree
MFST(pi) set of minimal ®le spanning trees associated with program pi
sneed(vi) the total capacity requires from vi
PAi when a program pjis assigned to a node vi, set bit pai;j21of PAi 1; otherwise, set bit pai;j21 of PAi 0
FAi when a data ®le fjis assigned to a node vi, set bit fai;j21of FAi 1; otherwise, set bit fai;j21of FAi 0:
w(pi) the weight of program i, the value is the total size of ®les in AFL(pi)
De®nition 3. A dependent set is de®ned as a set S of distributed programs and ®les such that no partition exists that divides S into two disjoint S1and S2, where S1< S2 S;
and S1> S2 B; such that each program and the ®les
required are within the same subset [13].
De®nition 4. The DTA problem is de®ned ®nding an assignment for a dependent set under some resource constraints in a DS such that the DS has maximum reliabil-ity [13].
De®nition 5. A k-DTA problem is de®ned as determining the assignments for k copies of a dependent set to maximize the DSR under some resource constraints in a DS [13]. 2.2. Problem statements
Bi-directional communication channels operate between processing elements. A DS can be modeled using a simple undirected graph. For a DS topology with four nodes and ®ve links, if two programs and three data ®les should be allocated, the number of different combinations of programs and data ®les for allocation is 45, that is, 1024. For example,
the program p1requires data ®les f1, f2, and p2requires data
®les f1, f2, f3, for completing execution. Assume that these
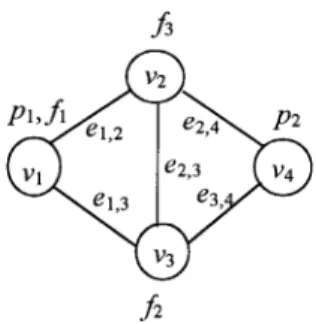
®les are allocated as shown in Fig. 1.
For program p1, there are three MFSTs, v1v3e1;3;
v1v3e1;2e2;3; v1v3e1;2e2;4e3;4: Therefore, DPR p1
Pr S3i1MFSTi: Once all of the minimal ®le spanning
trees have been generated, the next step is to ®nd the prob-ability that at least one MFST is working, which means that all of the edges and vertices included in it are operational. Any terminal reliability evaluation algorithm based on path or cut-set enumeration can be used to obtain the DPR of the program under consideration. The reliability of program p1
can be computed using a sum of mutually disjoint terms [4]. DPR p1 b1;2a1;31 a1;2a1;3b2;3b2;41 a1;2a1;3b2;3a2;4b3;4
1 a1;2a2;3a2;4b3;41 a1;2a2;3b2;41 a1;2a2;4a3;4
Assume that the probability of each link is 0.9. Then, DPR p1 0:98829:
In the same way, all of the eight MFSTs for program p2
are as follows. v1v2v3v4e1;2e1;3e2;4; v1v2v3v4e1;2e2;3e2;4; v1v2v3v4e1;2e2;4e3;4; v1v2v3v4e1;3e2;3e3;4; v1v2v3v4e1;3e2;4e3;4; v1v2v3v4e1;2e1;3 e3;4; v1v2v3v4e1;3e2;3e3;4; v1v2v3v4e1;2e2;3e3;4 DPR p2 Pr [8 i1 MFSTi ! a1;2a1;3b2;3a2;4b3;4 1 a1;2b1;3a2;3a2;4b3;41 a1;2b1;3b2;3a2;4a3;4 1 b1;2a1;3a2;3a2;4b3;41 a1;2a1;3a2;3a2;4b3;4 1 b1;2a1;3b2;3a2;4a3;41 a1;2a1;3b2;3a3;4 1 b1;2a1;3a2;3a3;41 a1;2a2;3a3;4 0:97686 DSR Pr \p i1 pi ! Pr \p i1 MFST pi !
Therefore, the results for all MFSTs of the intersection of the two programs are as follows.
v1v2v3v4e1;2e1;3e2;4; v1v2v3v4e1;2e2;3e2;4; v1v2v3v4e1;2e2;4 e3;4; v1v2v3v4e1;3e2;3e3;4; v1v2v3v4e1;3e2;4e3;4; v1v2v3v4 e1;2e1;3e3;4; v1v2v3v4e1;2e2;3e3;4; v1v2v3v4e1;3e2;3e3;4 DSR Pr \p i1 pi ! a1;2a1;3b2;3a2;4b3;4 1 a1;2b1;3a2;3a2;4b3;41 a1;2b1;3b2;3a2;4a3;4 1 a1;3a2;3a2;4b3;41 b1;2a1;3b2;3a2;4a3;4 1 a1;2a1;3b2;3a3;41 a1;2a1;3b2;3a3;4 1 a1;2a2;3a3;4 0:97686
A reliability-oriented task assignment problem can be char-acterized as follows.
Given
Topology of a DS.
The reliability of each communication link.
The available memory space for each processing element. A set of distributed programs.
A set of data ®les.
The sizes of each distributed program. The size of each data ®le.
Files required by each distributed program for execution. Assumption
Each node is perfectly reliable.
Each link is either in the working (ON) state or failed (OFF) state.
A graph G does not have any self-loops.
The failure of a link is independent of the failure of other links.
Each node on a DS can have only one copy of the data ®les.
Constraint
The memory space limitation of each processing element. Goal
Maximize the DSR of the system (or maximize DPR of a given program).
Reliability optimization can be de®ned as the maximum reliability for computing a given task under some constraints. For a given task, the reliability can be computed as R1; R2; ¼; Rx for x situations, where x may be an astro-nomical ®gure. In doing so, the reliability optimization for the task is the maximal reliability in R1; R2; ¼; Rx: The
heuristic algorithm involves obtaining an approximate solu-tion, which is close to the maximal reliability in R1; R2; ¼; Rx: Restated, a task assignment must be found
under the given DS such that the DPR of a given program or DSR of the system is adequate.
The main problem can be mathematically stated as follows:
Given
distributed system parameters, memory capacity of each node,
memory requirement of each program and data ®le, number of copies of each program and data ®le; Object : maximize DSR Pr \P i1 pi " # ; subject to XP j1 s pjPAi;j1 XF j1 s fjFAi;j 0 @ 1 A # c vi; i 1; ¼; n; Xn
i1PAi;j k; k is the number of copies of pfi;
Xn i1
FAi;j k; k is the number of copies of pfi
Obviously, this problem requires a large execution time. Herein, we develop an ef®cient method that allows task assignment optimization in the DS that achieves the desired performance. Owing to its computational advantages, a proposed method may improve the execution time.
3. Heuristic algorithm for reliability-oriented task assignment methodology
Our problem involves program and data ®le assignments. The network topology is ®xed. The size of every node is also ®xed. The proposed algorithm generates two node queues according to the weight of the node and link, respectively, constructs the access relation list and assigns each program and data ®le dependent upon the above two results. 3.1. Development of HROTA
The development of HROTA is described in the follow-ing subsections.
3.1.1. Compute the weight of each node
The number of ports at each node (degree of a node) and number of links directly impact the system reliability. Relia-bility decreases with a decrease in the number of links [5]. For any node, the degree that node affects the number of information paths that can be transferred from other nodes. The node with the higher degree is more likely to have more paths to the destination nodes than those with lower degrees. Therefore, we employed a simple means for computing the node weight, which takes less time and can quickly compute the weight of every node. The following formula is used to compute the weight of node vi[16].
w vi 1 2 Y d vj z1 bj;tz 1 Subproc NodeWeight(vi)
Let Ei {ei, juei, jis incident with vi}.
Select a link ei, jfrom Ei.
Let w vi ai;j:
Let Ei Ei2 ei;j:
Dowhile (uEiu . 0)
Select a link ei, jfrom Ei.
Let w vi w vi 1 1 2 w viai;j: Let Ei Ei2 ei;j:
End_Dowhile Return w(vi).
end NodeWeight
3.1.2. Sort nodes in descending according to their weight After obtaining each node weight, all of the nodes are sorted according to their weight in descending order and placed into a queue.
Subproc NodeDesByNodeWeight( ) Let queue Q1 B:
Dowhile (there is a node vi[ V and viÓ Q1)
Let vi max{w viuvi[ V and viÓ Q1} Add vito queue Q1.
Return Q1.
End NodeDesByNodeWeight 3.1.3. Compute the weight of each link
The reliability of a set of two nodes depends on their links and the link reliability. In the network, two nodes may contain many paths between them. The length of a path is between 1 and n 2 1. To reduce the computational time, we considered a path in which the length is not greater than two. The following formula is used to evaluate the weight of link ei, j.
w ei;j 1 2 bi;j
Yyi;j
z1
bi;kzakz;j 2
where yi, jdenotes the number in which the length of a path
between viand vjis two. In addition, yi, jis not greater than
n 2 2. The weight of ei, jcan be computed in one subtraction
and 2(yi, j1 1) multiplication. Thus, in the worst case, when
the graph is a complete graph, we can obtain all of the weights for each link in n(n 2 1)/2subtractions and n(n 2 1)(n 2 2)/2 multiplication.
Subproc LinkWeight(ei, j)
Let Si {ei;kek;jupath ei;kek;jexists between viand vj}
Let w ei;j ai;j: /pthe reliability of a link ei;j:p/
Dowhile (uSiu . 0)
Select a path ei;kek;j from Si
Let w ei;j w ei;j 1 1 2 w ei;jai;kak;j:
Let Si Si2 ei;kek;j:
End_Dowhile Return w(ei, j)
End LinkWeight
3.1.4. Sort nodes in descending according to all of the link weight
After obtaining the link weights, the nodes are sorted in descending order according to the link weights. This method chooses two nodes incident to the link with the greatest weight ®rst. The order nodes are then appended one by one according to their link weight and the link incident to the selected nodes.
Subproc NodeDesByLinkWeight( ) Let queue Q2 B:
Let ei;j max{w ei;juei;j[ E}:
If w vi $ w vj
Add vi, vjto queue Q2in order.
Else
Add vj, vito queue Q2in order.
End_If
Dowhile(there is a node, say vi[ V; viÓ Q2)
S1 {ei, juei, j is incident with a node in queue Q2,
either vior vjis in Q2}
S2 {viuviis adjacent to a node in queue Q2and viis
not in Q2}
Let vi max{w ei;juei;j[ S1and vi[ S2}
Add vito queue Q2
End_Dowhile Return Q2.
End NodeDesByLinkWeight 3.1.5. Construct APL( fi) andAFL(pi)
In most cases, the total required memory size dominates the number of nodes needed. We therefore simply used the total memory size of piand its associated ®les to
approx-imate the number of required nodes. We used the following formula to evaluate the weight of each program and data ®le. w pi X s fi; where fi[ APL fi: w fi Xs pi; where pi[ AFL pi: Assume that s p1 2; s p2 3; s f1 2; s f2 3; s f3 3; AFL p1 {f1; f2}; AFL p2 {f2; f3}; there-fore, APL f1 {p1}; APL f2 {p1; p2}; APL f3 {p2}; w p1 s f1 1 s f2 5; w p2 s f2 1 s f3 6; w f1 s p1 2; w f2 s p1 1 s p2 5; and w f3 s p2 3: The order of program according to
weight is p2, p1, and the order of ®le is f2, f3 and f1. We
rearrange the APL( fi) and AFL(pi) as follows: AFL p1
{f2; f1}; AFL p2 {f2; f3}; APL f1 {p1}; APL f2
{p2; p1}; and APL f3 {p2}:
3.1.6. Construct AR-list
An AR-list represents that the sequence of programs and data ®le assignment will be considered. We constructed an AR-list according to each APL( fi) and AFL(pi).
For example, according to Section 3.1.5, the AR-list was constructed as p2! f2! f3! p1! p2! f1! f2! f3!
p1 ! f1 if the number of copies is two.
Subproc AccessRelateList(copy) Let queue Q3 B:
Let pfi max{w piui 1; ¼; P}: /pstart at a program
for assignment p/
Let type 0: /pset task type to denote programp/
Let parent NULL:
Add (pfi, type) to queue Q3. /psave the information for
processingp/
Add (pfi, type, parent) to the tail of AR-list. /pappend
the record to AR-listp/
Let k_copy[pfi][type] k_copy[pfi][type] 2 1. /p a
copy of the task has assignedp/
Dowhile Q3± B
Let (pfi, type) delete (Q3, front).
Let parent the address of the node of AR-list that include (pfi, type).
If (type 0) /pa programp/
current programp/
next_type 1. /pset task type to denote data ®lep/
Else /pa data ®lep/
Copy APL(pfi) to S1. /p programs, which are
required the data ®lep/
next_type 0. /pset task type to denote programp/
End_If
Let Q4± B: /preset the queue Q4p/
Dowhile S1± B
pfi delete(S1, ®rst). /pobtain a task p/
If (k_copy[pfi][type] . 0) /pthe copies of the task
is insuf®cientp/
If ((pfi, next_type) is same as its grand_parent)
Add (pfi, next_type) to queue Q4. /pdelay to
assign the taskp/
Else /passign the task to the current nodep/
Add (pfi, next_type, parent) to AR-list.
Add (pfi, next_type) to queue Q3.
Let k_copy[pfi][type]
k_copy[pfi][type] 2 1
End_If End_If End_Dowhile If Q4± B
Let (pfi, next_type) delete (Q4, front)
Add (pfi, next_type, parent) to AR-list.
Let k_copy[pfi][type] k_copy[pfi][type] 2 1.
End_If End_Dowhile Return AR-list. End AccessRelateList
3.1.7. Allocate each program and data ®le according to the AR-list andeither Q1or Q2
The most reliable assignment for k copies of some program or data ®le is to assign these copies to k distinct nodes [13]. The total number of programs and ®le size assigned to a node is at most as large as the capacity of the node.
Subproc TaskAssign(AR-list, Q)
Let vi delete (Q, front). /pobtain the weightiest node
from queue Qp/
Let ptr AR-list. /p initialize the pointer ptr as the
starting address of AR-listp/
Let PAi PAiu 0 £ 0001 ! ptr ! j 2 1: /passign pj
to vip/
Let c(vi) c(vi) 2 s(pj). /p compute the remainder
capacity of node vip/
Delete the node pointed to by the ptr pointer from the AR-list.
Let ptr AR-list. /pmove the pointer ptr to next recordp/
Dowhile(TRUE) /ptraversal each record of AR-listp/
Let difference Maxvalue. /pset all of the bits of
difference to 1p/
Dowhile (ptr! NULL) /puse best ®t to assign taskp/
Let size (ptr ! type program)?s(pptr!j):
s( fptr!j). /pobtain the current task sizep/
If (difference $ c vi-size)
/p k-copies of some program of data ®le is to
assign to distinct nodesp/
If ((ptr ! type program) and (PAi, and (0 £
0001 ! (ptr ! j 2 1))) 0)uu
((ptr ! type ®le) and (FAi, and
0 £ 0001 ! (ptruj 2 1))) 0)
Let candidate_ptr ptr. /pthe best record in
AR-list until currentp/
Let difference c(vi)-size.
End_If End_If
ptr ptr ! next. /pexamine next record of
AR-list. p/
End_Dowhile
If (difference Maxvalue) /p c(v
i) is insuf®cient to
assign a program or ®lep/
Let vi delete (Q, front). /p the next node for
assigning task p/
Else
If (candidate_ptr ! type program) /passign p j
to vip/
Let PAi PAiu0 £ 0001 ! (candidate_ptr !
j 2 1)) /pto assignp/
Let c(vi) c(vi) 2 s(pcandidate_ptr!j). /p compute
the available capacity of vip/
End_If
If (candidate_ptr ! type ®le) /passign f jto vip/
Let FAi FAiu0 £ 0001 ! (candidate_ ptr !
j 2 1)) /pto assignp/
Let c(vi) c(vi) 2 s( fcandidate_ptr!j). /p compute
the available capacity of vip/
End_If
If c vi 0 /pthere is no available capacity in vip/
Let vi delete (Q, front). /p next node be
consider to assignp/
End_If
/p the task in the record point by candidate_ ptr
pointer has been assignedp/
Delete the node point to by the candidate_ ptr from the AR-list.
End_If
ptr AR-list. /p reset the ptr pointer point to the
starting address of AR-listp/
End_Dowhile
Return PAi, FAi,for i 1; ¼; n:
End Task Assign
3.2. Complete algorithm of HROTA
The detail steps for HROTA are described as follows: Algorithm HROTA
Read DS parameters: n, e, ai, j, c(vi),
task parameters: k, P, F, s(pi), s( fi), AFL(pi).
step 1 /pCompute each node weight using Eq. (1), each
link weight using Eq. (2). p/
For each vi[ V do
w(vi) NodeWeight(vi). /pcall function to evaluate
the weight of vip/
End_do
For each ei, j[ E do
w(ei, j) LinkWeight(ei, j). /pcall function to
evalu-ate the weight of ei, j p/
End_do
step 2/pGenerate two queue according to the weight of
the node and link, respectively.p/
Q1 NodeDesByNodeWeight( ). /psort nodes
depen-dent on the node weight p/
Q2 NodeDesByLinkWeight( ). /p sort nodes
depen-dent on the link weight p/
step 3 /pConstruct APL( f
i) and AFL(pi).p/
Compute the weight of each program and data ®le, then construct APL( fi) and AFL(pi).
step 4 /pConstruct AR-listp/
Access Relate List(k)
step 5 /pAllocate each program and data ®le according to
the AR-list and either Q1or Q2.p/
Task Assign (AR-list, Q1). /pcall functionp/
Task Assign (AR-list, Q2). /pcall functionp/
step 6 /p Compute the DSR and output the best task
assignment. p/
Compute the reliability for the ®nal result task assign-ment indicated at PAiand FAi using SYREL [4] and
Output the task assignment. End HROTA
3.3. An illustrate example
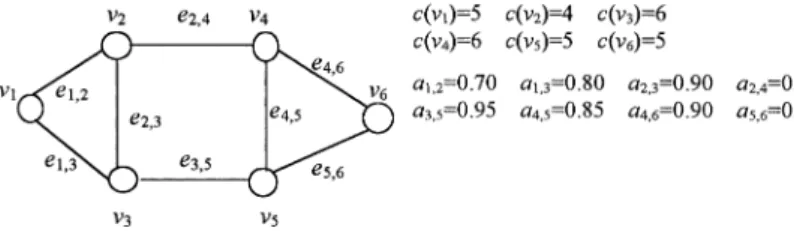
The topology of a DS with six nodes and eight links is described as follows. The c(vi) represents the capacity of
node vi, and ai, jrepresents the reliability of link ei, j(Fig. 2).
If there are two programs, p1, p2, and three data ®les, f1, f2,
f3, with sizes p1, p2, f1, f2, f3, is 2, 3, 2, 3, and 3, respectively.
The program p1needs f1, f2, and program p2needs f1, f2, f3,
for complete execution, e.g. AFL(p1) is {f1, f2}, AFL(p2) is
{f1, f2, f3}. Our problem is to ®nd the maximal DS reliability
under the allocated programs and ®les.
In step 1, the weight of each node and link are evaluated using Eqs. (1) and (2), respectively. The weight of v1,
v2,¼,v6 is 0.94, 0.9925, 0.999, 0.9962, 0.9996, 0.995,
respectively. The weight of e1,2, e1,3,¼,e5,6is 0.916, 0.926,
0.956, 0.75, 0.95, 0.9783, 0.9808, and 0.9883, respectively. In step 2, after sorting by the weight of nodes, we obtained Q1 v5; v3; v4; v6; v2; v1: After sorting by the
weight of links, we obtained Q2 v5; v6; v4; v3; v2; v1:
In step 3, AFL p1 {f2; f1}; AFL p2 {f2; f1; f3};
APL f1 {p2; p1}; APL f2 {p2; p1}; APL f3 {p2}:
In step 4, AR-list p2! f2! f1! f3! p1! p2!
p1 ! f1! f2! f3:
In step 5, (a) task assignment according to AR-list and Q1,
we obtained PA1 0; > PA2 1; PA3 0; PA4 2;
PA5 2; PA6 1; and FA1 0; FA2 1; FA3 6; FA4
2; FA5 1; FA6 4: That is, the task assignment is as
shown in Fig. 3.
(b) task assignment according to AR-list and Q2, we
obtained PA1 0; PA2 1; PA3 0; PA4 2; PA5 2; PA6 1; and FA1 0; FA2 1; FA3 6; FA4 4; FA5 1; FA6 2: That is, the task assignment is as Fig. 3, except f3is allocated into v4and f2is allocated into v6.
In step 6, generate all of the MFSTs according to the results in step 5. In case (a), we obtained v2v3v5e2;3e3;5;
v2v3v4v5e2;4e3;5e4;5; v1v2v3v5e1;2e1;3e2;3e3;5; v3v5v6e3;5e5;6; v2v3v4e2;3e2;4; v1v2v3v4e1;2e1;3e2;4; v2v4v6e2;4e4;6; v4v5v6 e4;5e4;6; v4v5v6e4;6e5;6; v4v5v6e4;5e5;6: In case (b), we obtained v2v3v5e2;3e3;5; v3v5v6e3;5e5;6; v1v2v3v5e1;2e1;3e2;3 e3;5; v2v3v4v5e2;4e3;5e4;5; v3v5v6e3;5e5;6; v2v3v4e2;3e2;4; v1v2 v3v4e1;2e1;3e2;4; v2v4v6e2;4e4;6; v4v5v6e4;5e4;6; v4v5v6e4;5e5;6;
v4v5v6e4;6e5;6: The algorithm computes the DSR using
SYREL and Outputs the task assignment. The reliability is 0.9994969. In each case, we use the formula DSR pr Tpi1pi pr Tpi1MFST pi to compute its reliability. Therefore, the reliability count is equal to 2.
Fig. 2. The DS with six nodes and eight links.
4. Results and discussion
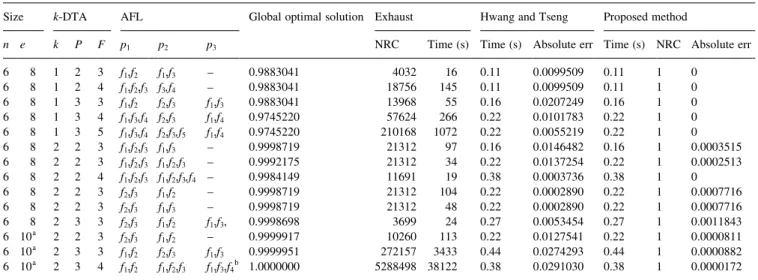
Table 1 presents the data on the results obtained using three different methods for various DS topologies with different allocated programs and data ®les. In contrast to the exhaustive method, the number of reliability computa-tions grows rapidly, when the size of the DS topology or the number of programs and data ®les are increased. The proposed method is constant, which is independent of the size of the DS topology and the number of programs and data ®les. The deviation is very small, when the proposed method cannot obtain an optimal solution. These data show that the proposed method is more effective than the conven-tional methods.
In this paper, we proposed a new technique for solving the k-DTA reliability problem. The complexity of the proposed algorithm in steps 0; ¼; 6 is O(1), O(n3), O(en),
O(P 1 F), O(k(P 1 F)), O((P 1 F)2), and O(m2), where k
denotes the number of copies of the programs and ®les and m represents the number of paths for the set of assigned nodes [4]. Other notations, such as n, ps, P, F, cc and mc, are de®ned in Nomenclature. Therefore, the complexity of the proposed algorithm is O n31 P 1 F21 m2: Results obtained from our algorithm were compared with those from the exhaustive method and the Hwang and Tseng method [13]. Although the exhaustive method, which has a time complexity of O m2nk P1F; can yield the optimal
solution, it cannot effectively reduce the number of reliabil-ity computations and the time complexreliabil-ity. An application occasionally requires an ef®cient algorithm for computing reliability owing to resource considerations. Under this circumstance, deriving the optimal reliability may not be a promising option. Instead, an ef®cient algorithm yielding
approximate reliability is preferred. The time complexity for the Hwang and Tseng method [13] is O n31 kn P 1 F 1 m2; which is slightly quicker than our method, but the deviation from the exact solution is not ideal [13].
In contrast to the computer reliability problem, which is static-oriented, the task assignment problems in the DS are dynamically oriented, because many factors, such as the DS topology, node capacity, link reliability, the size of the programs or ®les, ®les requested by each program, copies of programs and ®les and the number of paths between each node can signi®cantly affect the ef®ciency of the algorithm [4]. Thus, quantifying the time complexity exactly is extre-mely dif®cult. The accuracy and ef®ciency of the proposed algorithm were veri®ed by implementing simulation programs in C language executed in Pentium III with 128M-DRAM on MS-Windows 98. In our simulation case, the number of reliability computations for the proposed algorithm was constant. The exact solution can be obtained in most cases, when there is only one program and ®le copy. In almost every case, if the number of copies exceeds one, the DSR is close to one and the redundant ®le may constrain the remaining node capacity. The proposed method can obtain an approximate solution, in which the average deviation from the exact solution is under 0.001. 5. Conclusion
This paper presented a heuristic algorithm for computing k-DTA reliability problem. The proposed algorithm uses an effective algorithm to select a program and ®le assignment set that has maximal or nearly maximal system reliability. Our numerical results show that the proposed algorithm may
Table 1
The results obtained using exhaustive method, Hwang and Tseng method and our proposed method for various DS topologies and k-DTAs (n, the number of nodes in G; e, the number of links in G; NRC, the number of reliability computation; Exhaust, the exhaustive method; k, the number of copies of programs and data ®les)
Size k-DTA AFL Global optimal solution Exhaust Hwang and Tseng Proposed method
n e k P F p1 p2 p3 NRC Time (s) Time (s) Absolute err Time (s) NRC Absolute err
6 8 1 2 3 f1,f2 f1,f3 ± 0.9883041 403216 0.11 0.0099509 0.11 1 0 6 8 1 2 4 f1,f2,f3 f3,f4 ± 0.9883041 18756 145 0.11 0.0099509 0.11 1 0 6 8 1 3 3 f1,f2 f2,f3 f1,f3 0.9883041 13968 55 0.16 0.0207249 0.16 1 0 6 8 1 3 4 f1,f3,f4 f2,f3 f1,f4 0.9745220 57624 266 0.22 0.0101783 0.22 1 0 6 8 1 3 5 f1,f3,f4 f2,f3,f5 f1,f4 0.9745220 210168 1072 0.22 0.0055219 0.22 1 0 6 8 2 2 3 f1,f2,f3 f1,f3 ± 0.9998719 21312 97 0.16 0.0146482 0.16 1 0.0003515 6 8 2 2 3 f1,f2,f3 f1,f2,f3 ± 0.9992175 21312 34 0.22 0.0137254 0.22 1 0.0002513 6 8 2 2 4 f1,f2,f3 f1,f2,f3,f4 ± 0.9984149 11691 19 0.38 0.0003736 0.38 1 0 6 8 2 2 3 f2,f3 f1,f2 ± 0.9998719 21312 104 0.22 0.0002890 0.22 1 0.0007716 6 8 2 2 3 f2,f3 f1,f3 ± 0.9998719 21312 48 0.22 0.0002890 0.22 1 0.0007716 6 8 2 3 3 f2,f3 f1,f2 f1,f3, 0.9998698 3699 24 0.27 0.0053454 0.27 1 0.0011843 6 10a 2 2 3 f 2,f3 f1,f2 ± 0.9999917 10260 113 0.22 0.0127541 0.22 1 0.0000811 6 10a 2 3 3 f 1,f2 f2,f3 f1,f3 0.9999951 272157 3433 0.44 0.0274293 0.44 1 0.0000882 6 10a 2 3 4 f 1,f2 f1,f2,f3 f1,f3,f4b 1.0000000 5288498 38122 0.38 0.0291030 0.38 1 0.0000172
a Addition two links e
2,5, e3,4and a2;3 0:9; a3;4 0:95: b s f
4 1; s p1 2; s p2 3; s p3 3; s f1 2; s f2 3; s f3 3; s f4 2; s f5 2 ; if k 1, then c v1 5; c v2 4; c v3 6; c v4 6;
obtain the exact solution in most one copy cases and the computation time is signi®cantly shorter than that needed for the exhaustive method. When the proposed method fails to give an exact solution, the deviation from the exact solu-tion appears very small. The technique presented in this paper might be helpful for readers to understand the rela-tionship between task assignment reliability and DS topol-ogy.
References
[1] K.K. Aggarwal, S. Rai, Reliability evaluation in computer commu-nication networks, IEEE Trans. Reliab. R-30 (1981) 32±35. [2] K.K. Aggarwal, Y.C. Chopra, J.S. Bajwa, Topological layout of links
for optimizing the S±T reliability in a computer communication system, Microelectron. Reliab. 22 (3) (1982) 341±345.
[3] A. Satyanarayna, J.N. Hagstrom, New algorithm for reliability analy-sis of multiterminal networks, IEEE Trans. Reliab. R-30 (1981) 325± 333.
[4] S. Hariri, C.S. Raghavendra, SYREL: a symbolic reliability algorithm based on path and cuset methods, IEEE Trans. Comput. C-36 (1987) 1224±1232.
[5] F. Altiparmak, B. Dengiz, A.E. Smith, Reliability optimization of computer communication networks using genetic algorithms, Proc. IEEE Int. Conf. Syst. Man Cybern. 5 (1998) 4676±4680.
[6] D.W. Coit, A.E. Smith, Reliability optimization of series±parallel systems using a genetic algorithm, IEEE Trans. Reliab. R-45 (1996) 254±260.
[7] D. Torrieri, Calculation of node-pair reliability in large networks with unreliable nodes, IEEE Trans. Reliab. R-43 (1994) 375±377. [8] D.J. Chen, T.H. Huang, Reliability analysis of distributed systems
based on a fast reliability algorithm, IEEE Trans. Parallel Distribut. Syst. 3 (1992) 139±154.
[9] V.K.P. Kumar, C.S. Raghavendra, S. Hariri, Distributed program relia-bility analysis, IEEE Trans. Software Engng SE-12(1986) 42±50. [10] A. Kumar, D.P. Agawal, A generalized algorithm for evaluation
distributed program reliability, IEEE Trans. Reliab. R-42(1993) 416±426.
[11] D.J. Chen, R.S. Chen, T.H. Huang, Heuristic approach to generating ®le spanning trees for reliability analysis of distributed computing systems, J. Comput. Math. Appl. 34 (1997) 115±131.
[12] P. Tom, C.R. Murthy, Algorithms for reliability-oriented module allocation in distributed computing systems, J. Syst. Software 40 (1998) 125±138.
[13] G.J. Hwang, S.S. Tseng, A heuristic task assignment algorithm to maximize reliability of a distributed system, IEEE Trans. Reliab. R-42(1993) 408±415.
[14] M. Ka®l, I. Ahmad, Optimal task assignment in heterogeneous distributed computing systems, IEEE Concurrency 6 (1998) 42±51.
[15] A. Kumar, R.M. Pathak, Y.P. Gupta, Genetic algorithm based approach for ®le allocation on distributed systems, Comput. Ops. Res. 22 (1) (1995) 41±54.
[16] C.C. Chiu, Y.S. Yeh, R.S. Chen, Reduction of the total execution time to achieve the optimal k-node reliability of distributed computing systems using a novel heuristic algorithm, Comput. Commun. 23 (2000) 84±91.
Chin-Ching Chiu
Education: September 1993±October 2000 PhD in Computer Science andInformation Engineering, Department of EE andCS, National Chiao-Tung University. September 1988±June 1991 MS in Computer Science, Department of EE andIE, Tamkang University. He receiveda BS degree in Computer Science from Soochow University.
Professional Background: December 2000ÐNow Associate Professor, Department of Information Management, Tak-Ming College. September 1991±November 2000 Instructor, Department of Information Manage-ment, Tak-Ming College. April 1984±August 1991 Computer Engineer in Data Communication Institute of Directorate General of Telecom-munications. October 1982±April 1984 System Analyst of SYSCOM computer company.
Research Interest: Reliability Analysis of Network andDistributed Systems, Genetic Algorithms, DNA computing.
Yi-Shiung Yeh
Education: September 1981±December 1985 PhD in Computer Science, Department of EE andCS, University of Wisconsin-Milwau-kee. September 1978±June 1980 MS in Computer Science, Department of EE andCS, University of Wisconsin-Milwaukee.
Professional Background: August 1988ÐNow Associate Professor, Institute of CS andIE, National Chiao-Tung University. July 1986± August 1988 Assistant Professor, Department of Computer andInfor-mation Science, Fordham University. July 1984±December 1984 Doctorate Intern, Johnson Controls, Inc. August 1980±Octpber 1981 System Programmer, System Support Division, Milwaukee County Gov. Research Interest: Data security andPrivacy, Information andCoding Theory, Game Theory, Reliability andPerformance.
Jue-Sam Chou
Education: He is currently working towards the PhD degree in Depart-ment of CS andIE, National Chiao-Tung University.
Professional Background: September 1991ÐNow Instructor, Depart-ment of Information ManageDepart-ment, Ta-Hua College.
Research Interest: Reliability andPerformance Evaluation: Networks andDistributedSystems, DNA computing.