國立臺灣大學理學院數學系 博士論文
Department of Mathematics College of Science
National Taiwan University Doctoral Dissertation
電阻抗斷層掃描的一種最佳化-最小限度化演算法 A Majorization–Minimization Algorithm for
Electrical Impedance Tomography
劉于國 Yu-Guo Liu
指導教授:陳宜良博士 Advisor: I-Liang Chern, Ph.D.
中華民國 107 年 7 月 July, 2018
誌謝
我感謝姜明老師,陳宜良老師,和口試委員們對此篇論文提供背景 知識及建議。我的摯愛璟琳和摯友家賢,感謝你們無條件的支持。感 謝我的爸媽,我將此篇文章獻給你們。
Acknowledgements
I am glad to thank Dr. Ming Jiang, Dr. I-Liang Chern, and oral defense committee members for providing background knowledges and suggestions for this paper. I thank to my dear love Jing-Lin Li and my dear friend Mazer Lin, you are very supportive. Thank to my parents, I dedicate this paper to you.
摘要
本論文對電阻抗斷層掃描協同一普遍類型的非光滑正則提出了一 統整的最佳化-最小限度化 (MM) 演算法,其中包含了稀疏與總變差正 則。我們證明此提出之 MM 演算法的全域收斂性,且呈現源自模擬數 據的數值重建結果。此 MM 演算法的數值結果顯示了對目標能量的快 速遞減及對內含物的強度和位置有好的估計。此外,我們比較此 MM 演算法和廣為所用的高斯-牛頓法,此 MM 演算法對模擬導電率有較好 的逼近。
關鍵字: 電阻抗斷層掃描, 最佳化-最小限度化演算法
Abstract
In this paper, a unified majorization–minimization (MM) algorithm is pro- posed for electrical impedance tomography with a general type of nonsmooth convex regularization, including sparse and total variation regularizations.
We prove the global convergence of the proposed MM algorithm and show numerical reconstructions from simulated data. The numerical results of the MM algorithm show a fast decrease in objective energy and good estimates of the intensity and location of inclusions. Besides, we compare the MM al- gorithm to the widely used Gauss-Newton method, and the MM algorithm shows better approximation to the simulated conductivity.
Keywords: Electrical impedance tomography (EIT), majorization–-minimization (MM) algorithm.
Contents
誌謝 iii
Acknowledgements v
摘要 vii
Abstract ix
1 Introduction 1
2 preliminary 3
3 Mathematical Modeling 5
3.1 Complete Electrode Model . . . 5
3.2 Finite Element Method based Model . . . 8
3.3 Reconstruction using Regularization Problems . . . 10
4 A Majorizaton-Minimization Algorithm 15 5 The Computation 19 6 Numerical Results 25 6.1 FEM Simulation and Reconstruction Setup . . . 26
6.2 Precalculation . . . 30
6.3 Reconstructions using the MM-CP algorithm . . . 32
6.4 Comparison with the Gauss-Newton Method . . . 41
7 Discussion 45
8 Conclusion 47
Appendices 49
A Proof of Proposition 1 49
B Proof of Proposition 2 51
C Proximity Operator Formulas 59
Bibliography 63
List of Figures
3.1 An illustration of signal process for CEM-based EIT with electrodes on contact boundaries eℓdefined in (3.1), current injecting on e1, e2, and volt- age difference measured on e5, e6. . . 6 3.2 An illustration of Adjacent Method for the CEM-based EIT data acquisi-
tion with the measured data set{⟨
nqi, U (nq′
i)⟩
: i = 1, . . . , 13} defined in (3.4),(3.5). . . 7
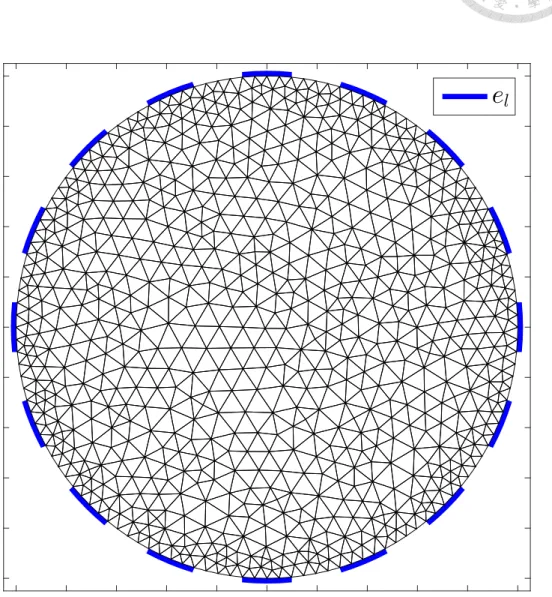
6.1 Conductivity distributions ς[T18230, sp] : ΩT18230 → R defined in (6.1) for FEM data simulation are shown in (b)–(e) with FEM domain ΩT18230 shown in (a) and conductivity basis coefficient sp ∈ {0.5, 1, 1.5}18230. . . 28 6.2 FEM domain ΩT1480 constructed by 1480 disjoint triangles for reconstruc-
tion is attached by 16 electrodes on contact boundaries el, l = 1, . . . , 16. . 29 6.3 The graphs of eFp(10y) defined in (6.12) are depicted by 101 uniformly
sampled points y1,...,101 ∈ [−10, 10], and corresponding minimums are computed by GSS. . . 31 6.4 Least Square reconstructions using MM-CP algorithm with 2, 10, 50 itera-
tions from the 1% gaussian noise data gpdefined in (6.5). Column one are simulated conductivity distributions defined in Figure 6.1; Column 2,3,4 are reconstructed ones with coefficient skp,0 defined in (6.13) computing k-th iteration of MM-CP algorithm. . . . 33 6.5 Sparse reconstructions using MM-CP algorithm with 2, 10, 50 iterations
from the 1% gaussian noise data gp defined in (6.5). Illustrations are the same as in Figure 6.4. . . 34
6.6 TV reconstructions using MM-CP algorithm with 2, 10, 50 iterations from the 1% gaussian noise data gp defined in (6.5). Illustrations are the same as in Figure 6.4. . . 35 6.7 Least Square reconstructions using MM-CP algorithm with 50 iterations
from the 1% gaussian noise data gpdefined in (6.5). Column one are sim- ulated conductivity distributionsDp defined in Figure 6.1; Column two are reconstructed onesRp with coefficient s50p,0 defined in (6.13) comput- ing 50-th iteration of MM-CP algorithm. We compareDp,Rp in last two columns by uniformly sampling 100 points on Γ1,2 defined on top. . . 36 6.8 Sparse reconstructions using MM-CP algorithm with 50 iterations from
the 1% gaussian noise data gp defined in (6.5). Illustrations are the same as in Figure 6.7. . . 37 6.9 TV reconstructions using MM-CP algorithm with 50 iterations from the
1% gaussian noise data gpdefined in (6.5). Illustrations are the same as in Figure 6.7. . . 38 6.10 Comparison of least square, sparse , TV reconstructions using MM-CP
algorithm with 50 iterations from the 1% gaussian noise data gp defined in (6.5). We show simulated conductivity in column one, and show least square, sparse , TV reconstructions in column 2,3,4, respectively. . . 39 6.11 Energy Ep,a(skp,a) for least square, sparse, TV reconstructions are shown
in (a),(b),(c) respectively. . . 40 6.12 Comparison of the simulated and reconstructed conductivity distributions.
First column: simulated distributions. Second and third columns: Sparse and TV reconstructed distributions using the MM-CP algorithm, respec- tively. Fourth and fifth columns: Sparse and TV reconstructed distribu- tions using the GN method, respectively. . . 42 6.13 Comparison with the energy decrease of the MM algorithm and GN method. 42
List of Tables
6.1 Estimate of background conductivity, contact impedance . . . 31 6.2 Error estimates of the reconstructed conductivities using the MM-CP al-
gorithm and the Gauss-Newton method with β = 10−6. . . 43 6.3 Error estimates of the reconstructed conductivities using the GN method
with smooth parameters β = 10−3, 10−9. . . 43
Chapter 1 Introduction
Electrical impedance tomography (EIT) is a signal to image process in which we estimate the conductivity distribution of an object by injecting currents and measuring voltages from its boundary. This process is a nonlinear, ill-posed inverse problem; thus, a direct formula is unavailable. However, the least-squares reconstruction with some regulariza- tions are viable, such as Tikhonov regularization [26], sparse regularization [9], and total variation (TV) regularization [4].
In this paper, we focus on solving the regularization problem of complete electrode model (CEM)-based EIT [25]. In the case of smooth regularizations, Gauss–Newton type methods [17, (2.25)] are widely used, e.g., see [19] for Tikhonov regularization with level set representation of conductivity distributions and see [4],[10],[11] for smoothed TV reg- ularizations. In the case of non-smooth regularizations, Monte Carlo sampling methods were discussed in [17] for sparse and TV regularizations, and an iterative soft shrinkage- type algorithm was proposed in [9] for sparse regularization. However, in the regulariza- tion problem of CEM-based EIT, an iterative method for both sparse and TV regulariza- tions with global convergence to a critical point is rarely discussed.
We propose a unified majorization–minimization (MM) algorithm [15] for CEM-based EIT with a general type of nonsmooth convex regularization, including sparse and TV reg- ularizations. The MM algorithm is an iterative method that monotonically decreases the objective energy by minimizing an appropriate chosen majorizer [15, (1)]. The majorizer we propose is based on the monotonicity relation [13, Lemma 2.1], which is a kind of
squeeze theory for elliptic partial differential equations and was used in CEM-based EIT for shape reconstruction [8, (5)] and resolution guarantees [14, Thm 2]. In addition to those applications of the monotonicity relation, we show that it can be used in CEM-based EIT for developing a globally convergent MM algorithm.
With regard to the computational efficiency of MM algorithms, the main cost is the majorizer–minimizing step. Due to the convexity of the proposed majorizer, in the mini- mization step, we can apply the Chambolle-Pock (CP) algorithm [6, (38)], which is a gen- eral uniformly convex optimization solver with a convergence rate of O(1/k2) [6, Thm 2].
The organization of the paper is as follows. In Chapter 2 we introduce the general sub- gradient for defining the critical point, function spaces for proving global convergence, , MM definition and related operators for computations. Finally, we introduce matrix nota- tions for describing the regularization problem. In Chapter 3, we give the problem formu- lation for CEM-based EIT. In Chapter 4, we describe the main regularization problem in this paper and develop the MM algorithm based on the monotonicity relation. In Chapter 5, we cast the MM algorithm into a framework of uniformly convex optimization that can be solved by O(1/k2) CP algorithm and then results in the MM-CP algorithm. In Ap- pendices,we prove the propositions and formulas used in MM-CP algorithm. We show the numerical results in Chapter 6, discuss relevant results in Chapter 7, and conclude the paper in Chapter 8.
Chapter 2 preliminary
For classes of differentiable functions, by referring to [20, §1.2.2], we denote by CL1,1(U ) the class of functions f :Rn→ (−∞, ∞] that are continuously differentiable on U ⊂ Rn and satisfy|f(x)|, ∥∇f(x)∥, ∥∇f(x) − ∇f(y)∥/∥x − y∥ ≤ L for all x, y ∈ U, x ̸= y.
In variation analysis [23], for f : Rn → (−∞, ∞], we define dom f = {x ∈ Rn : f (x) < ∞}. For x ∈ dom f, we define b∂f(x) = {v : f(y) ≥ f(x) + ⟨v, y − x⟩ + o(|y − x|)} to be the regular subgradient of f at x, and we define ∂f(x) = {v : ∃ xn → x, vn→ v with f(xn)→ f(x), vn∈ b∂f(xn)} to be the general subgradient of f at x. For f ∈ CL1,1(U ), we have ∂f (x) = ∇f(x) for x ∈ U [23, Exer 8.8(b)]. In general, we say x is a critical point of f if 0∈ ∂f(x) [2, (1)].
In convex analysis [3], we denote Γ0(Rn) to be the set of lower semicontinuous convex function f : Rn → (−∞, ∞] with dom f ̸= ∅. For J ∈ Γ0(Rn), we have ∂J (x) = {p : J(y) ≥ J(x) + ⟨p, y − x⟩} [23, Prop 8.12]. The indicator function IE, defined by IE(x) = 0 if x∈ E and IE(x) =∞ if x ∈ Rn− E, belongs to Γ0(Rn) if E is closed and convex.
For the MM algorithm, by referring to [15], we say a family of functions {fy}y∈Y
(uniformly) majorizes f if fy(x)≥ f(x), fy(y) = f (y), fy ∈ Γ0(Rn)∀ y ∈ Y ⊂ Rn, x∈ Rn(and∃γ > 0, fy(y′)≥ f(y′) + γ∥y′− y∥2∀ y, y′ ∈ Y ). We call such family {fy}y∈Y
a majorizer of f . By contrast, we say{fy}y∈Y minorizes f if{−fy}y∈Y majorizes−f.
Then, we say yk+1 = argminy∈Y fyk(y) is an MM algorithm for miny∈Y f (y) if{fy}y∈Y
majorizes f . We define the proximity operator prox[f ](x) = argmin f (y) + 1∥y − x∥2
and projection operator PE(x) = prox[IE](x) for computations.
In matrix notation, A ≻ 0 and A ≽ 0 denote that A is a real symmetric positive and a semi-positive definite matrix, respectively. For A ≻ 0, we define the inner product
⟨x, y⟩A = ⟨x, Ay⟩ and its norm ∥x∥A = √
⟨x, x⟩A. For K ∈ Rm,n, the matrix norm is defined by∥K∥ = max∥x∥≤1∥Kx∥.
Chapter 3
Mathematical Modeling
Thus the highest form of generalship is to balk the enemy’s plans.
The Art of War by Sun Tzu - Chapter 3 : Attack by Stratagem
3.1 Complete Electrode Model
Given a domain Ω⊂ R2,3and electrodes on eℓ⊂ ∂Ω with contact impedances zℓ > 0, ℓ = 1, . . . , L, the injecting current I and measured voltages U = U (I) on e1,...,Lare supposed to satisfy the Complete Electrode Model (CEM) [27] :
−∇ · (ς∇u) = 0 in Ω u + zℓς∂u
∂ν = Uℓ on eℓ, ℓ = 1, . . . , L
∫
eℓ
ς∂u
∂ν ds = Iℓ for ℓ = 1, . . . , L ς∂u
∂ν = 0 on ∂Ω− ∪Lℓ=1eℓ,
(3.1)
where ς ∈ L∞+(Ω) = {f : s+ < f|Ω < M for some s+, M > 0} is a conductivity distribution, and
U, I ∈ RL⋄ = {
y∈ RL:
∑L
yℓ = 0 }
.
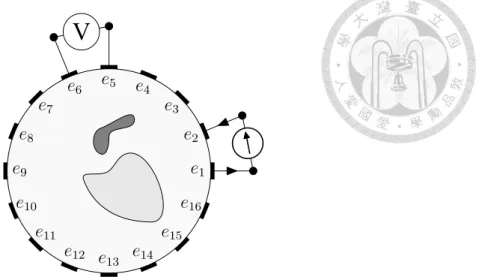
The signal process of CEM-based EIT is illustrated in Figure 3.1.
V
e1 e2 e3 e4 e5 e6 e7 e8 e9
e10
e11
e12 e13 e14 e15
e16
Figure 3.1: An illustration of signal process for CEM-based EIT with electrodes on contact boundaries eℓdefined in (3.1), current injecting on e1, e2, and voltage difference measured on e5, e6.
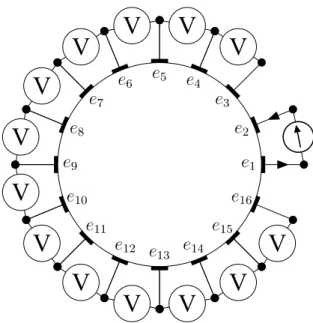
For data acquisition we adopt the Adjacent Method that measuring the voltage differ- ence on an adjacent electrode pair by injecting current on another adjacent electrode pair, see [18] for detail. Mathematically the measured data set for Adjacent Method can be formulated as
M = {⟨np, U (np′)⟩ | ⟨np, np′⟩ = 0; 1 ≤ p′ < p≤ L}, (3.2)
where we set
n1 = [1,−1, 0, . . . , 0]t n2 = [0, 1,−1, 0, . . . , 0]t n3 = [0, 0, 1,−1, 0, . . . , 0]t
...
nL−1 = [0, . . . , 0,−1, 1]t nL= [−1, 0, . . . , 0, 1]t
(3.3)
and set p′ < p to exclude symmetric data ⟨np′, U (np)⟩ = ⟨np, U (np′)⟩ to be verified in (3.8). For example, ⟨n3, U (n1)⟩ is the voltage difference on electrode pair 3-4 with injecting current on electrode pair 1-2. For example,⟨n3, U (n1)⟩ is the voltage difference on electrode pairs 3-4 with injecting current on electrode pair 1-2.
From (3.2),(3.3) the total amount of measured data is m = L(L− 3)/2, then there exists sequences qi, q′i, i = 1, . . . , m such that
M = {⟨
nqi, U (nq′ i)⟩
: i = 1, . . . , m}. (3.4)
For example, if L = 16 we can choose
(q1, q′1) = (3, 1), ...
(q13, q13′ ) = (15, 1), (q14, q14′ ) = (4, 2),
...
(q104, q104′ ) = (16, 14)
(3.5)
and we show the data set{⟨
nqi, U (nq′ i)⟩
: i = 1, . . . , 13} in Figure 3.2. Next, we simulate M in (3.4) by the finite element method (FEM) [27].
V V V V
V V V
V
V V V V V
e1 e2 e3 e4
e5 e6
e7 e8 e9
e10 e11
e12 e13 e14
e15 e16
Figure 3.2: An illustration of Adjacent Method for the CEM-based EIT data acquisition with the measured data set{⟨
nqi, U (nq′ i)⟩
: i = 1, . . . , 13} defined in (3.4),(3.5).
3.2 Finite Element Method based Model
In [25], the solution of (3.1) (u, U ) = (u, U )(I)∈ H = H1(Ω)⊕ RL⋄ is shown to satisfy
Vς((u, U ), (u′, U′)) =FI((u′, U′)) (3.6)
for all (u′, U′)∈ H, where H1(Ω) is the Sobolev space and
Vς(·, ·) = Cς(·, ·) +
∑L ℓ=1
1
zℓBℓ(·, ·), FI((u′, U′)) =⟨I, U′⟩
withCς(·, ·), Bℓ(·, ·) defined by
Cς((u, U ), (u′, U′)) =
∫
Ω
ς∇u · ∇u′dx Bℓ((u, U ), (u′, U′)) =
∫
eℓ
(u− Ul)(u′ − Ul′) dS.
Then,∀ zℓ > 0, ς ∈ L∞+(Ω), we have positivity
Bℓ(w, w)≥ 0, Cς(w, w)≥ 0, Vς(w, w) > 0 (3.7)
for all 0̸= w ∈ H and the symmetry
⟨nqi, U (nq′ i)⟩
=Fnqi((u, U )(nq′ i))
=Vς((u, U )(nqi), (u, U )(nq′ i))
=Vς((u, U )(nq′
i), (u, U )(nqi))
=Fnq′
i
((u, U )(nqi)) =⟨ nq′
i, U (nqi)⟩ .
(3.8)
In the FEM, we assume
Ω =
∪n j=1
△j (3.9)
is composed by the union of disjoint triangles (tetrahedrons)△1,...,ninR2(R3) over given
N nodes v... 1,...,...
N. Additionally, we assume
ς =
∑n j=1
sjχ△j, (u, U ) =
N =...
N +L−1
∑
k=1
akΦk, (3.10)
where χ△j are characteristic functions on△j and
Φk =
(ξk, 0) if k = 1, . . . ,...
N (0, nk−...
N) if k = ...
N + 1, . . . , N
with ξkbeing piecewise linear basis functions satisfying ξk(vk′) = δkk′, which is the Kro- necker delta over index k, k′ = 1, . . . ,...
N . By substituting (3.9) and (3.10) into (3.6) and by choosing (u′, U′) = Φkfor k = 1, . . . , N we have
Vsa = b(I), (3.11)
where
[Vs]kk′ =V∑nj=1sjχ△j(Φk, Φk′)
=
∑L ℓ=1
1
zℓBℓ(Φk, Φk′) +
∑n j=1
sjCχ△j(Φk, Φk′), [b(I)]k =FI(Φk), for k, k′ = 1, . . . , N.
Setting [Bℓ]kk′ =Bℓ(Φk, Φk′) and [Cj]kk′ =Cχ△j(Φk, Φk′), we have
Vs=
∑L ℓ=1
1 zℓ
Bℓ+
∑n j=1
sjCj.
With those equations and (3.7), we obtain
Bℓ, Cj ≽ 0, Vs ≻ 0
for all sj > 0, j = 1, . . . , n, ℓ = 1, . . . , L. Explicitly, we have
Bℓ =
Bℓ1 Bℓ2 Bℓ3 Bℓ4
, Cj =
Aj 0
0 0
, b(I) =
0 F (I)
with [Bℓ3] = [Bℓ2]tand
[Aj]kk′ =
∫
△j
∇ξk· ∇ξk′dx, k, k′ = 1, . . . ,...
N , [Bℓ1]kk′ =
∫
eℓ
ξkξk′dS, k, k′ = 1, . . . ,...
N , [Bℓ2]kp =−[np]ℓ
∫
eℓ
ξkdS, k = 1, . . . ,...
N , p = 1, . . . , L− 1, [Bℓ4]pp′ =|eℓ| [np]ℓ[np′]ℓ, p, p′ = 1, . . . , L− 1,
Fp(I) = ⟨I, np⟩ , p = 1, . . . , L − 1.
According to (3.10) and (3.11), we assume (u, U )(nq′
i) = ∑N
k=1αkΦk with Vsα = b(nq′
i). Then, by (3.8), we have
⟨nqi, U (nq′ i)⟩
=Fnqi((u, U )(nq′
i)) =Fnqi(
∑N k=1
αkΦk)
=
∑N k=1
αkFnqi(Φk) =⟨α, b(nqi)⟩ =⟨
b(nqi), b(nq′
i)⟩
Vs−1,
by which (3.4) becomes
M = {⟨ϕi, ϕ′i⟩Vs−1 : i = 1, . . . , m} (3.12)
with ϕi = b(nqi), ϕ′i = b(nq′ i).
3.3 Reconstruction using Regularization Problems
From (3.12), we define the coefficients-to-data mapping
fi(s) =⟨ϕi, ϕ′i⟩Vs−1, i = 1, . . . , m
with dom fi = [s+,∞)nfor some s+ > 0. Then, we formulate the regularization problem of CEM-based EIT as
mins∈E E(s), (3.13)
where
E(s) = ϵJ (s) + F(s), F(s) = 1
2∥f(s) − g∥2
being with given measured data g, a box constraint E⊂ [s+,∞)n, regularization param- eter ϵ, and the regularization function J , which is discussed next.
For the regularization J used in CEM-based EIT, by referring to [17, (4.5),(4.7)], we define the zero function J0, the sparse regularization J1, and total variation J2by
J0(ς) = 0, J1(ς) =∥ς − s∗∥L1(Ω), J2(ς) =
∫
Ω
|∇ς| dx
with s∗ ∈ R being a precalculated background conductivity discussed in Chapter 6.2.
Then by (3.10) we have
J1(ς) =
∑n j=1
|sj − s∗| |△j|
and
J2(ς) = 1 2
∑n i,j=1
|si− sj| |∂△i∩ ∂△j|
=
∑κ k=1
|stk − st′k| |∂△tk ∩ ∂△t′k|
for some subsequence tk, t′ksuch that|∂△tk∩∂△t′k| > 0 and tk ̸= t′k∀ k = 1, . . . , κ. That implies
J1(ς) =∥C1(s− s∗I)∥1, J2(ς) =∥C2s∥1
withI represents all 1 vector, C1 ∈ Rn×ndefined by
C1 = diag(|△1|, . . . , |△n|)
and C2 ∈ Rκ×ndefined by
[C2]kl=
|∂△tk∩ ∂△t′k| if l = tk
−|∂△tk∩ ∂△t′k| if l = t′k 0 if l̸= tk, t′k.
Then, J0,1,2are in the form of
Ja = Ja(s, s∗) =∥Ca(s− da(s∗))∥1, a = 0, 1, 2 (3.14)
with d0(s∗) = d2(s∗)∈ {0}n, d1(s∗)∈ {s∗}n, and C0being the zero matrix.
As pointed in Chapter 1, the Gauss-Newton type method [17, (2.25)] with a line search is widely used for solving smooth regularization problem of CEM-based EIT. Numerically for solving (3.13) the Gauss-Newton type method with line search iterates as
sk+1 =Aσ(sk) := sk− σ(ϵ∇2J (sk) + f′(sk)tf′(sk))−1∇E(sk),
with f′(s) :Rn → Rmdefined by f′(s)ij = (∇fi(s))j and
σ = argmin
σ′>0
E(Aσ′(sk))
computed by line search method [5, (9.16)].
For solving non-smooth regularization problem of CEM-based EIT an iterative soft shrinkage-type algorithm proposed in [9] for sparse regularization J1is based on the prox- imity (see Preliminary) type algorithm proposed in [28] that solves (3.13) by
sk+1=Bσ(sk) := proxσϵJ1(sk− σ∇F(sk)),
for some σ > 0 satisfying
E(Bσ(sk))≤ max
max{k−5,0}<k′≤kE(sk′)− 10−5σ∥Bσ(sk)− sk∥2 that ensures accumulation points of{sk}k∈Nare critical points of E.
To sum up, a numerical method for solving the non-smooth regularization problem of CEM-based EIT with global convergence to a critical point is rarely discussed. In this paper, we propose a Majorization-Minimization (MM) algorithm (see Preliminary) to solve the non-smooth regularization problem of CEM-based EIT with regularizations of
the form (3.14) including sparse, TV regularizations. We prove the global convergence of proposed MM algorithm and show numerical results from simulated data next.
Chapter 4
A Majorizaton-Minimization Algorithm
Based on the finite element method (FEM) [27], it is shown in Chapter 3 that the regular- ization problem of CEM-based EIT can be formulated as Problem 1.
Problem 1. Given g ∈ Rm, ϵ > 0, f : Rn → (−∞, ∞]m, J ∈ Γ0(Rn) and E ⊂ Rn, we solve
mins∈EϵJ (s) + 1
2∥f(s) − g∥2 that satisfies∀ i = 1, . . . , m,
• dom fi = [s+,∞)n, E = [s, s]n, 0 < s+< s < s.
• fi(s) =⟨ϕi, ϕ′i⟩Vs−1for some ϕi, ϕ′i ∈ RN, where Vs =∑L ℓ=1
1
zℓBℓ+∑n j=1sjCj
for some Bℓ, Cj ≽ 0, zℓ > 0 such that Vs≻ 0 ∀ sj > 0.
• J (s) =∥C(s − d)∥1for some matrix C and vector d.
In Problem 1, g, ϵ, and J are the measured data, regularization parameter, and reg- ularization function, respectively. f is the conductivity-to-data mapping, in which the ϕi and ϕ′i represent the i-th voltage measuring and current injecting vector, respectively.
Vs, Bℓ, Cj are the associated FEM matrices, and zℓ is the contact impedance between the object and the ℓ-th electrode. Finally, ∥C(s − d)∥1 is a general form representing the sparse or TV regularization.
We use Proposition 1 to construct a majorizer to develop an MM algorithm for Problem 1.
Proposition 1. Under the assumptions in Problem 1, for s, t ∈ (0, ∞)n, we denote
t s
2∈ (0, ∞)nwith element t2j/sj, and for φ∈ RN, we defineGφ : (0,∞)n→ R by
Gφ(s) =∥φ∥2V−1 s . Then, for all s, t∈ (0, ∞)n, φ∈ RN, we have
(a) (∇Gφ(s))j =− ⟨Vs−1φ, CjVs−1φ⟩ ≤ 0.
(b) Gφ ∈ CL1,1(E) for some L > 0.
(c) Gφ(s)≥ Gφ(t) +⟨∇Gφ(t), s− t⟩.
(d) Gφ(s)≤ Gφ(t)− ⟨∇Gφ(t),t s
2− t⟩.
We prove Proposition 1 in Appendix A and refer Proposition 1(c)(d) to a vector version of the monotonicity relation [13, Lemma 2.1]. Observe in Problem 1 and Proposition 1 that
fi(s) =⟨ϕi, ϕ′i⟩Vs−1 = 1 4
(Gϕi+ϕ′i(s)− Gϕi−ϕ′i(s))
, (4.1)
by which and Proposition 1(c)(d) we have
fi(t) +1 4
⟨∇Gϕi+ϕ′i(t), s− t⟩ +1
4⟨∇Gϕi−ϕ′i(t),t s
2− t⟩
≤fi(s) (4.2)
≤fi(t)− 1 4
⟨∇Gϕi−ϕ′i(t), s− t⟩
− 1
4⟨∇Gϕi+ϕ′i(t), t s
2− t⟩.
Then, for each t∈ E, by (∇Gφ(t))j ≤ 0 (Proposition 1(a)), we construct a convex (con- cave) function that is greater (less) than fi(s) in (4.2), which results in the following MM algorithm (4.3) for Problem 1.
Proposition 2. Under the assumptions in Problem 1 and Proposition 1, for t∈ E, i = 1, . . . , m, we define
ψi = ϕi+ ϕ′i, θi = ϕi− ϕ′i, hti(s) = fi(t)− gi− 1
4⟨∇Gθi(t), s− t⟩ − 1
4⟨∇Gψi(t), t s
2− t⟩,
lti(s) = fi(t)− gi+1
4⟨∇Gψi(t), s− t⟩ +1
4⟨∇Gθi(t),t s
2− t⟩,
Hit(s) = max{hti(s),−lti(s)}, Dt(s) = 1 2∥s − t
s
2∥2
with dom hti = dom − lit= dom Dt= [s+,∞)n. Then, (a) {Dt}t∈Euniformly majorizes 0∀ i = 1, . . . , m.
(b) {Hit}t∈Emajorizes|fi− gi| ∀ i = 1, . . . , m.
(c) ∀ δ, ϵ > 0, s0 ∈ E,
sk+1 = argmin
s∈E δDsk(s) + ϵJ (s) +1
2∥Hsk(s)∥2 (4.3)
converges to a critical point ofIE + ϵJ + 12∥f − g∥2.
We prove Proposition 2 in Appendix B and relate MM algorithm (4.3) to the proximity (see Preliminary) iteration
sk+1 = argmin
s∈E
δ
2∥s − sk∥2+ ϵJ (s) +1
2∥f(s) − g∥2
= prox [
IE+ ϵ δJ + 1
2δ∥f − g∥2 ]
(sk),
where 12∥s − sk∥2,∥f(s) − g∥2 are replaced by majorizers Dsk(s),∥Hsk(s)∥2in (4.3).
By definition of (uniformly) majorization in Preliminary and Proposition 2(b) we have
{(Hit)2}t∈E majorizes (fi − gi)2, by which and Proposition 2(a) we have {
δDt+ ϵJ +1 2∥Ht∥2
}
t∈E
uniformly majorizes ϵJ + 1
2∥ bf− g∥2
for all δ, ϵ > 0. That confirms that (4.3) is an MM algorithm for Problem 1; moreover, it is a sequence of convex optimization problems. Thus, an efficient numerical solver is critical and is discussed next.
Chapter 5
The Computation
For the computation of (4.3), we use the O(1/k2) CP algorithm that is proposed to solve the saddle point problem
min
x∈RM max
y∈RM ′⟨Kx, y⟩ + G(x) − F (y) (5.1) by the following iteration
yk+1 = prox[σkF ](yk+ σkK ¯xk) xk+1 = prox[τkG](xk− τkKtyk+1) θk= 1/√
1 + 2γτk, τk+1 = θkτk, σk+1 = σk/θk
¯
xk+1 = xk+1+ θk(xk+1− xk)
. (5.2)
In (5.1), it assumes that K ∈ RM′×M, F ∈ Γ0(RM′), and G is uniformly convex with parameter γ > 0 (used in (5.2)), i.e.,
G(x′)≥ G(x) + ⟨∂G(x), x′ − x⟩ +γ
2∥x′− x∥2 ∀ x′, x∈ RM.
In (5.2), the initializations are given by (x0, y0) ∈ RM × RM′, ¯x0 = x0, and σ0, τ0 > 0 with σ0τ0∥K∥2 ≤ 1.
To apply the CP algorithm, we transform (4.3) to the form of (5.1). Proposition 2(b)
implies Hit≥ |fi− g| ≥ 0, which implies
(Hit(s))2 = (max{hti(s),−lti(s)})2
= min
ri ∈ R hti(s)≤ ri
−lti(s)≤ ri
ri2
(5.3)
for i = 1, . . . , m. Then, by (5.3), iteration (4.3) becomes
sk+1 = argmin
s∈ E Dsk(s) + ϵ
δJ (s) + 1
2δ∥Hsk(s)∥2
= argmin s∈ E hsk(s)≤ r
−lsk(s)≤ r
∥s∥
2
2
+1 2∥(sk)
s
2
∥2+ ϵ
δJ (s) +∥r∥
2δ
2
. (5.4)
We define Ak, Bk∈ Rm×n, ck1, ck2 ∈ Rm, Rk ⊂ Rn× Rnby
[Ak]ij =(
−∇Gψi(sk))
j/4 [Bk]ij =(
−∇Gθi(sk))
j/4 ck1 = f (sk)− g − (Ak+ Bk)sk ck2 = g− f(sk)− (Ak+ Bk)sk Rk ={(s, t) ∈ Rn× Rn: sjtj ≥(
skj)2
, s∈ E}.
(5.5)
Then, we have
hsk(s) = Bks + Ak(sk) s
2
+ ck1,
−lsk(s) = Aks + Bk
(sk) s
2
+ ck2
for all s∈ E, and
sk+1 = argmin s∈ E
Bks + Akt + ck1 ≤ r Aks + Bkt + ck2 ≤ r
t = (sk) s
2
∥s∥
2
2
+ ∥t∥
2
2
+ ϵ
δJ (s) + ∥r∥
2δ
2
(5.6)
= argmin s∈ E
Bks + Akt + ck1 ≤ r Aks + Bkt + ck2 ≤ r
t≥ (sk) s
2
∥s∥
2
2
+ ∥t∥
2
2
+ ϵ
δJ (s) + ∥r∥
2δ
2
(5.7)
= argmin s
Bks + Akt + ck1 ≤ r Aks + Bkt + ck2 ≤ r
(s, t)∈ Rk
∥s∥
2
2
+ ∥t∥
2
2
+ ϵ
δJ (s) + ∥r∥
2δ
2
, (5.8)
where (5.4)⇐⇒ (5.6) and (5.7) ⇐⇒ (5.8) because of (5.5) and (5.6) ⇐⇒ (5.7) because
∥t∥2,∥r∥2, [Ak]ij, [Bk]ij ≥ 0 force (5.6) and (5.7) to share the same optimal (s, t).
Note that (5.8) is a uniformly convex optimization problem with constraints that clearly satisfies Slater’s condition [5, (5.26)]. Then, it is equivalent to solve (5.8) by the following saddle point interpretation [5, §5.4]:
s, t, rmin (s, t)∈ Rk
maxy, w y≥ 0 w∈ Qδ,ϵ
⟨Bks + Akt + ck1 − r, y1
⟩+
⟨Aks + Bkt + ck2 − r, y2
⟩+
⟨w, C(s − d)⟩ + ∥(s, t)∥
2
2
+∥r∥
2δ
2
,
(5.9)
where y = (y1, y2)∈ Rm× Rm and
Qδ,ϵ ={w : ∥w∥∞ ≤ ϵ } =[
−ϵ ,ϵ]
× · · · ×[
−ϵ , ϵ]
(5.10)
such that
ϵ
δJ (s) = ϵ
δ∥C(s − d)∥1 = max
w∈Qδ,ϵ
⟨w, C(s − d)⟩ .
Substitute r in (5.9) with the optimal value δ(y1+ y2) and define
Tδ(y) =I{y≥0}(y) +δ
2∥y1+ y2∥2
then, we reduce (5.9) to mins, t max
y, w
⟨Bks + Akt + ck1, y1⟩ +
⟨Aks + Bkt + ck2, y2⟩
+⟨w, C(s − d)⟩ +
∥(s, t)∥
2
2
+IRk(s, t)− Tδ(y)− IQδ,ϵ(w).
(5.11)
By comparing (5.11) to (5.1), we have
Kk=
Bk Ak Ak Bk
C 0
(5.12)
Gk(s, t) = 1
2∥(s, t)∥2+IRk(s, t), Fk(y, w) = Tδ(y)−⟨
ck, y⟩
+IQδ,ϵ(w) +⟨w, Cd⟩
corresponding to (K, G, F∗) in (5.1) with Gk(s, t) is uniformly convex with parameter 1.
Then the substitution of Kk, Gk, Fk∗ into (5.2) results in Algorithm 1 that computes skin (4.3) by MM-CP(s0, k, lmax, C, d, g, δ, ϵ), where s0 ∈ E is the initial conductivity and lmax
is the maximum iteration number of CP algorithm.
![Figure 6.1: Conductivity distributions ς[ T 18230 , s p ] : Ω T 18230 → R defined in (6.1) for FEM data simulation are shown in (b)–(e) with FEM domain Ω T 18230 shown in (a) and conductivity basis coefficient s p ∈ {0.5, 1, 1.5} 18230 .](https://thumb-ap.123doks.com/thumbv2/9libinfo/9599027.628568/44.892.258.779.81.492/figure-conductivity-distributions-defined-simulation-domain-conductivity-coefficient.webp)
![Figure 6.3: The graphs of e F p (10 y ) defined in (6.12) are depicted by 101 uniformly sampled points y 1,...,101 ∈ [−10, 10], and corresponding minimums are computed by GSS.](https://thumb-ap.123doks.com/thumbv2/9libinfo/9599027.628568/47.892.270.781.84.410/figure-defined-depicted-uniformly-sampled-corresponding-minimums-computed.webp)





