國立臺灣大學工學院土木工程學系 碩士論文
Department of Civil Engineering College of Engineering
National Taiwan University Master Thesis
應用全卷積神經網絡:U-Net 於鏽蝕語義分割影像辨識 Corrosion Semantic Segmentation for Steel Bridge Using
Fully Convolutional Networks: U-Net
陳思愷 Su-Kai Chen
指導教授:陳柏翰 博士 Advisor: Po-Han Chen, Ph.D.
中華民國 108 年 7 月
July 2019
誌謝
感謝這一路上給予我幫助的人們,特別感謝 白博升 學長,在起初決定題目 的時候與我討論了許多這個題目的限制以及展望,讓我能夠往更加明確的方向去 努力,也很感謝 白博升 學長留下了許多珍貴的研究素材以及文獻資料,讓我能 夠從過去學長們的努力成果再去做精進。另外也要特別感謝實習期間給予我許多 影像辨識技術上教學的 葉肇元 學長 以及 楊証琨 學長,從最基礎的影像處理 到辨識模型的搭建,都給予了我相當多的幫助和建議,真的很感謝實習期間能夠 跟著你們學習,萬分感謝。還有每次開會都給予相當實用的回饋以及充分支持的 陳柏翰 教授,儘管這學習花了很多時間在職涯的自我摸索,老師仍然願意支持 我,無論在生活或是研究,都受到您相當多的照顧,感謝您。
最後也謝謝 713 研究室的各位,感情莫名的很好,雖然碩二之後很多瑣事,
就比較少去實驗室,但各位還是有團都會相揪,真的感謝。研究室對於我來說,
就像一個避風港,累了就會想到研究室轉一轉,找人講講話,打打電腦,遇到了 人生的大事也能找人一起討論討論。碩士這兩年最珍貴的莫過於認識了各位,以 後有空在出來吃個飯阿。
中文摘要
由於台灣氣候相當潮溼以及炎熱,使得鋼橋等等的鋼結構設施相當容易生鏽,
為此,希望能夠建立一個有效率且客觀的鏽蝕偵測工具,來降低鏽蝕例行檢測的人 力、時間成本,以及提高檢測成果的可信度。
過往的鏽蝕偵測相關研究主要著重於利用邊緣演算法對鏽蝕的邊緣進行刻劃,
進而計算鏽蝕面積,主要會面臨到的問題在於能夠辨識的鏽蝕種類受到限制,以及 難以辨識異物與鏽蝕之間的差距。
本研究引入目前流行的深度學習技術,利用全卷積神經網絡建立辨識模型對 鏽蝕圖像進行語義分割,來改善以往辨識方式中面臨到的限制。
關鍵字: 機器學習(Machine Learning) 深度學習(Deep Learning)
全卷積(Fully Convolutional Networks, FCN) 語義分割(Semantic Segmentation)
Abstract
The weather in Taiwan is hot and wet, which makes steel structures, such as steel bridges, easy to rust. Therefore, establishing an effective method for corrosion detection is important in maintaining infrastructure’s “health” and reducing the corresponding lifecycle cost.
Browsing past research efforts, there were a number of image processing techniques (IPTs) proposed for quick and effective recognition. A crucial issue has been on
distinguishing real corrosion from noises or patterns which look like rust. Also, there is a limit to the type of the rust which can be detected.
In this research, the fully convolutional neural network named U-Net will be explored to establish an image semantic segmentation model, which will be able to deal with a wide range of rust type.
Keywords: Machine Learning, Deep learning,
Fully Convolutional Networks(FCN), Semantic Segmentation
目錄
誌謝 ... i
中文摘要 ... ii
Abstract ... iii
目錄 ... iv
圖目錄 ... vi
表目錄 ... viii
第 1 章 緒論 ... 1
1.1 研究背景 ... 1
1.2 研究動機 ... 2
1.3 研究目的 ... 2
1.4 研究範圍與限制 ... 2
1.5 研究方法與流程 ... 3
1.6 論文內容與架構 ... 4
第 2 章 文獻回顧 ... 5
2.1 鋼橋梁鏽蝕檢測 ... 5
2.2 影像辨識演算法 ... 5
2.3 相關軟體資源 ... 9
第 3 章 資料收集及前處理 ... 10
3.1 訓練影像資料收集 ... 10
3.2 資料標註與前處理 ... 10
第 4 章 影像辨識任務分析 ... 12
4.1 影像辨識種類 ... 12
4.2 影像分類 ... 13
4.3 語義分割 ... 13
4.4 物體偵測 ... 14
4.5 實例分割 ... 15
第 5 章 類神經網路介紹 ... 16
5.1 機器學習 ... 16
5.1.1 欠擬合 ... 16
5.1.2 過擬合 ... 17
5.2 類神經網路 ... 18
5.3 深度學習 ... 19
第 6 章 全卷積神經網路–U-net ... 20
6.1 卷積神經網路基本架構 ... 21
6.1.1 卷積層(Convolution Layer) ... 21
6.1.2 激勵函數(Activation Function) ... 22
6.1.3 池化層(Pooling Layer) ... 23
6.1.4 全連接層(Fully connection) ... 23
6.2 全卷積神經網路 ... 24
6.2.1 卷積化 ... 24
6.2.2 上採樣 ... 24
6.3 FCN 模型 ... 25
6.3.1 跳級結構 ... 25
6.3.2 FCN-32s ... 26
6.3.3 FCN-16s ... 26
6.3.4 FCN-8s ... 27
6.4 U-net ... 28
第 7 章 成果分析 ... 29
7.1 鏽蝕樣圖介紹 ... 29
7.2 辨識效果討論 ... 30
7.2.1 辨識成果 ... 30
7.2.2 辨識效果比較 ... 37
7.3 研究限制 ... 42
7.4 資料集精度比較 ... 43
第 8 章 結論與建議 ... 46
8.1 結論及研究貢獻 ... 46
8.2 建議及後續方向 ... 46
參考文獻 ... 47
圖目錄
圖 1.1 研究方法與流程 ... 3
圖 2.1 邊緣檢測運算子成果比較 ... 9
圖 3.1 真實鏽蝕圖 ... 10
圖 3.2 Labelbox 介面示意圖 ... 10
圖 3.3 Labelbox 標註示意圖 ... 11
圖 3.4 原始鏽蝕圖與遮罩圖 ... 11
圖 4.1 電腦視覺辨識任務 ... 12
圖 4.2 手寫辨識任務 ... 13
圖 4.3 語義分割示意圖 ... 13
圖 4.4 語義分割研究成果 ... 14
圖 4.5 物體偵測示意圖 ... 14
圖 5.1 欠擬合 ... 16
圖 5.2 過擬合 ... 17
圖 5.3 適度擬合 ... 17
圖 5.4 神經網路示意圖 ... 18
圖 6.1 資料分析技術流變 ... 20
圖 6.2 卷積層運算(完成)... 21
圖 6.3 特徵萃取示意圖 ... 21
圖 6.4 感知器運算 ... 22
圖 6.5 ReLU 激勵函數 ... 22
圖 6.6 最大池化層 ... 23
圖 6.7 卷積神經網路範例 ... 23
圖 6.8 全卷積神經網路範例 ... 24
圖 6.9 跳級結構 ... 25
圖 6.10 FCN-32s ... 26
圖 6.11 FCN-16s ... 26
圖 6.12 FCN-8s ... 27
圖 6.13 辨識結果比較 ... 27
圖 6.14 U-net 範例結構 ... 28
圖 7.1 人工鏽蝕圖 ... 29
圖 7.2 實地拍攝鏽蝕圖 ... 29
圖 7.3 依塗裝顏色進行資料蒐集 ... 30
圖 7.4 準確率曲線(上)及誤差曲線(下) ... 33
圖 7.5 研究辨識成果展示 ... 37
圖 7.6 模型對於非鏽蝕物體的辨識 ... 37
圖 7.7 與過去論文成果辨識比較 ... 42
圖 7.8 塗裝底色與鏽蝕太過相近 ... 43
圖 7.9 影像含有景深 ... 43
圖 7.10 第一組訓練集指標變化圖 ... 44
圖 7.11 第二組訓練集指標變化圖 ... 44
圖 7.12 第三組訓練集指標變化圖 ... 45
表目錄
表 1.1 重新塗裝之判定 ... 1
表 1.2 論文架構 ... 4
表 2.1 鏽蝕面積檢測判斷 ... 5
表 2.2 邊緣檢測運算子優缺點 ... 8
表 7.1 混淆矩陣 ... 30
表 7.2 二元交叉熵算例表(一) ... 32
表 7.3 二元交叉熵算例表(二) ... 32
表 7.4 資料集指標數字變化 ... 44
第 1 章 緒論
1.1 研究背景
台灣地理位置位於板塊交接處,地形起伏劇烈,致使地形多樣且複雜,在交通 方面時常仰賴橋梁作為交通連接,由此可見橋梁工程對於台灣的重要性。在劉韋村 於 2016 的研究指出,台灣橋樑總數超過 28000 座,橋齡超過 30 年的佔 50%以上,
且位置於亞熱帶且地理環境四面環海,高溫、高濕度的氣候使得鋼結構易於生鏽,
此外,目前國內鋼結構的施工處裡以及組裝後的防蝕措施尚無嚴謹的規範以及技 術手冊,容易忽略嚴重腐蝕環境以及未進行適當的防護處理所產生的危險性,致使 結構物發生嚴重鏽蝕影響整體安全及使用性。
表 1.1 重新塗裝之判定
國內目前對於鏽蝕程度的判斷,主要是依據國內公路鋼結構橋梁之檢測及補 強規範中所定義(表 1.1),為人眼進行面積百分比之判斷,以觀測面積一平方米中 鏽蝕所占面積的比例,做為檢測的標準,因此進近年來不斷有國內外研究,利用影 像辨識的手法,期望能提供更加便立及客觀的檢測工具。
近年來,硬體運算能力的提升以及資料分析技術的成熟,促使機器學習、深度學習 等等的技術蓬勃發展,在影像辨識的領域當中更是受惠於此,近年來辨識的精準 度、實用度因為深度學習的技法而大大的提升,故本研究希望能夠引進目前被廣泛 應用的深度學習技術於土木領域,提升鏽蝕影像辨識的可行性。
1.2 研究動機
。
現行的「客觀檢測」,仍位受到檢測人員的主觀判斷所影響,為了使檢測結果 更加客觀、可供應用,應該應用影像辨識的技術來進行鏽蝕區域面積的量化,同時 降低例行檢測所需要的人力、時間成本,提升檢測可行性以及可靠性。
1.3 研究目的
過去研究所提出的演算法大多為「顏色」或是「梯度」作為運算基礎的邊緣偵 測演算法,運算速度快速,但其能夠處理的鏽蝕影像種類較為受到限制,且無法判 斷所觀測的影像是否為鏽蝕,距離真正應用上尚有需要克服的部分。為此,本研究 希望藉由深度學習技術中的全連接卷積神經網路建立一個能夠應用於大部分鏽蝕 種類的影像辨識模型,提供一個快速、客觀且實用的檢測輔助工具。
1.4 研究範圍與限制
由於本研究中,作為訓練資料用的鏽蝕影像均為自行拍攝收集,數量約莫為 200 張,尺寸為 4032*3024,拍攝素材為鋼鐵工廠的鋼材以及鋼製結構物的鏽蝕,
涵蓋的鏽蝕種類有限,且底色大多與鏽蝕的顏色不同,加上人力成本的考量,無法 準備好大量完成前處裡的資料,故本研究在上述情境中有如下的限制:
1. 影像中若有涵蓋景深的部分,會被模型誤判.
2. 若塗層或結構物底色與鏽蝕顏色相近,亦會被模型誤判
發生原因可能是,訓練用的影像集當中,缺少了上述情境的照片給與模型學習,
深度學習是一種從訓練集、標註中學習預測脈絡的技術,其表現的優劣相當仰賴訓 練集的數量以及其涵蓋情境的範圍。由於人力以及時間上的限制,無法在此次研究 中訓練中族以處理所有情境的模型,但這個技術最可貴的地方在於,隨著訓練資料 的累積,訓練出來的模型將越來越符合實際情況的需求,準確度也將越來越高。
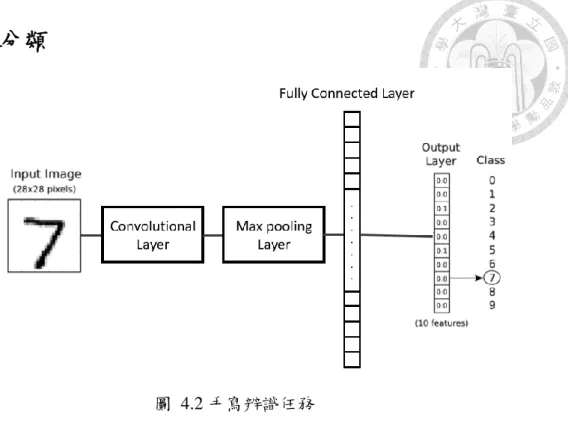
1.5 研究方法與流程
圖 1.1 研究方法與流程
1.6 論文內容與架構
表 1.2 論文架構
章節 簡述
第一章
緒論
本章節描述此研究的背景、動機、目的以及限制等等的相 關基本資訊
第二章
文獻回顧
本章節陳述文獻回顧後的重點節錄
第三張
資料處理及
模型訓練
本章節介紹使用到的軟硬體、資料標註工具、選擇的模型 架構,以及資料前處理以及整體訓練的流程。
第四張
成果分析
本章節將與過去文獻的演算法做比較,證明本研究在某些 情境下為較佳的演算法。
第五章
結論與建議
本章節將客觀的評論本研究演算法的優缺點以及未來能夠 改善的方向。
第 2 章 文獻回顧
2.1 鋼橋梁鏽蝕檢測
中華民國交通部[2]的研究指出,鋼橋鏽蝕的主因為水分,在所有的鏽蝕樣本 之中,由降雨導致的比例約為 30%~40% ; 由水氣導致的比例約為 35%~40% ; 其 餘則為腐蝕性微粒所造成的鏽蝕,嚴重情況隨地區特性有所差異。防蝕塗裝主要是 利用隔絕鋼材與水份來達到保護內部鋼材的效果,若塗裝產生破裂則失去了防護 的功能,鋼材便會從破裂處開始產生鏽蝕,進而讓塗裝產生更大範圍的破裂。目前 橋檢人員決定是否進行鋼橋樑維修(追蹤、重塗)的指標之一即為鋼橋鏽蝕百分比:
表 2.1 鏽蝕面積檢測判斷
2.2 影像辨識演算法
黃世昌[3]利用神經網絡預測影像辨識處理中所需的最佳閾值,並表示訓練樣 本數量越多,預測出來的結果越精確。從結果的角度上來看,此系統仍然無法有效 處理光影不均的問題,而且使用預測出來的閾值進行辨識的結果時常也不甚令人 滿意,原因可能在於,模型所產出的,僅為滿足訓練集所涵蓋情境的最佳閾值,若 要處理沒有在訓練集內的影像,使用預測出來的閾值顯然不一定會適用,不過在引 入類神經網路的這部分給予了本研究相當程度的信心,相信此技術確實會是解決 問題的重要手法之一。
戴佳信[4]所建置的系統會先判斷出 RGB 三個獨立影像平面的差異性,
選取差異性大的平面進行小波轉換產生四塊矩陣,一塊涵蓋低解析度的不分,剩餘 三塊代表細節的部份。低解析度部分含有座高量的資訊以及輪廓,並且對於鏽蝕的 面積在做一次相同的處理,分出不同深淺區域後分別乘上折減係數。此演算法對於 紅色的底漆辨識效果就為不佳,且同樣無法處理光照不均的問題。
楊雅晴[5]以 L*a*b 色彩空間為基礎,發展出了 AEA、BENFA 等演算法,對 於光照不均有相當程度的抵抗能力。
Shen[6] 以「背景像素差異 必定小於 鏽蝕像素差異」的核心概念發展出了 FT- DEDA (Fourier-Transform-Based Steel Bridge Coating Defect Detection Approach) + RUDERM (Rust Defect Recognition Method) 模型。此演算法會將影像分割成許多的 小單元,後把判定沒有為沒有鏽蝕的單元從流程中移除,接著開始對剩下的部分進 行鏽蝕區域的搜索。
尹昱翰[7]將現有的 K-means 演算法結合雲端架構,實現分散式運算,提升整 體處裡的效率。
李奕霆[8]的系統經 HIS 色彩空間將影像劃分為三種不同類別,再各自套用不 同的演算法進行鏽蝕辨識,使用的包含了雙圓心半徑法、LS-SVM 來提升整體精確 度。另外,不同於部分研究,此研究使用的鏽蝕影像是自然圖而非人工圖(人工剪 貼鏽蝕圖案拼貼至其他背景),相當具有實用性方面的參考價值,故本研究也參照 此手法,選擇自然圖作為研究的素材,期望能建置出真實符合實際應用需求的辨識 模型。
劉韋村[9]建置的演算法與過往色彩為基礎的演算法不同,改採用「梯度」做為 技術基底來抓取鏽蝕的邊界,此演算法計算效率極高,且硬體需求低,配合搭載於 行動裝置上的技術,能夠實現即時鏽蝕影像辨識。
Chen & Chang[12][13][14]提及影像得品質會影響辨識的成果,而通常光照不均為 最難以處理以及最關鍵的問題。在[12]這篇文獻中,系統會將照片分割成三個區域,
在以類似黃世昌[3]的手法,利用神經網絡預測各自最佳的閾值。
Lee[15][16]提到現行鋼橋檢測流程已經越來越客觀,但是鏽蝕辨識的精確度仍 受到光影、髒污、模糊等等的影響。這些在拍攝時都是相當容易產生的,若是在影 像攝取的條件上加上太多的限制,那麼辨不符合真實實用性的需求,為此,本研究 選擇使用深度學習,期望藉由含有上述情境的影像進行訓練,來達到成功辨視的效 果。
He & Han[17]提到,圖像檢測的方式中,較為常見的是閾值分割,決定閾值的 方式有很多,除了上述提到的神經網絡,還有長條圖雙峰法,Otsu 法、矩量保持 法、梯度統計法以及這些方法在二維上的推廣。其中,Otsu 法因為分割效果好,被 眾多研究所使用
賴玉霞[18]提及,利用 K-means 進行數據的群聚分類其理論可靠、算法簡單,
但由於聚落的起始中心點為隨機,其缺點在於從不同中心點出發會產出不同的結 果。
Medina-Carnicer[19]以及 Maini[20]比較了幾種的演算法的效能,整體的優劣順 序大致為: Otsu, CannyEdge, LoG, Sobel, Prewitt, Robert’s. 其中,Otsu 擁有相對較 佳的效能,且所需的硬體規格低,計算成本低。
Shrivakshan[21]提及,使用 CannyEdge 可以透過高斯模糊來降低雜訊,加上使用「非 最大抑制技術(Non-Maximum Suppression)」來使輸出的邊緣最薄。這裡提到,透過 參數的調整,能使演算法適用於不同狀況,本研究認為若要隨著不同情境去調整不 同的參數、進行參數最佳化,那麼也不契合實用性的理念,為此希望能夠建置出計 算成本不低,但毋須對於不同影像情境進行參數調整,能夠適用於大部分環境的辨 識模型。
Bin[22]測試了許多種邊緣檢測運算子,並提出 CannyEdge 應為最佳的演算法,
因為 CannyEdge 中使用了兩個閾值進行強邊緣與弱邊緣的雙重判定,所以較不容 易受到雜訊影響。
Young‐Jin Cha[23] 提出利用卷積神經網路對於裂縫影像進行裂縫的辨識,這 篇於 2017 年提出的論文在全球土木工程領域影響相當深厚,因其為第一篇引進深 度學習到土木領域影像辨識的論文,其收集了裂縫相關的影像並加以註記後(label) 後輸入到卷積神經網路(Convolutional Neural Networks(CNN))進行訓練,訓練完成 後對於想預測的影像進行裂縫辨識,進而在影像上呈現出裂縫的範圍以即其大致 的裂縫面積。本研究深受此論文影響,故嘗試以發展更加完全的深度學習影像辨識 手法進行鏽蝕的辨識,期望能達到更加精確以及實用的辨識模型。
直觀上的會認為,鏽蝕影像的標註越仔細,模型的訓練就會越精確,這的確是 不爭的事實,但在時間以及人力有限的情況下,我們不得不面對這個議題: 應該進 行大量而中度精準的標註,還是小量而高精度的標註。在 Will Nash[24] 於 2018 年 1 月 提 出 的研 究 (Quantity beats quality for semantic segmentation of corrosion in images)中指出,比較 10 張由專家進行專業標註的影像以及 250 張由大學生進行一 般標註的影像訓練過後的結果,經過混淆矩陣以及 f-score 的計算證明,大量而一 般程度標註的影像集表現的成果是優於少量而精確標註的影像集。依照這篇研究 的結果所述,本研究因此決定進行 213 張鏽蝕影像一般程度的標註。
表 2.2 邊緣檢測運算子優缺點(節錄自 Raman Maini[20])
圖 2.1 邊緣檢測運算子成果比較(節錄自 Li Bin[21])
2.3 相關軟體資源
本研究使用 python、Tensorflow、Keras 進行深度學習的模型建置,其中 python 版本需為 2.7-3.5,Keras 的版本需大於 1.0。
第 3 章 資料收集及前處理
3.1 訓練影像資料收集
由於過去研究留存的鏽蝕影像大小不均,有些甚至只有 256*256 像素,對於現 在人手一支行動裝置所拍攝的影像大小有很大的落差,若以太小像素的影像建立 模型恐無法達成真實應用上的目標,除此之外,留存的影像數量對於模型的訓練也 稍嫌不足。因此,本研究前往桃園市世紀鋼鐵進行鋼構的鏽蝕拍攝,使用拍攝設備 為 iPhone 6 plus (機型型號 : NGAF2TA/A,軟體版本: 12.2),拍攝內容涵蓋不同塗 裝顏色、不同塗裝風化狀態、不同鏽蝕種類,前後兩次的拍攝總共 213 張鏽蝕影 像,大小皆為 4032*3024,期望多樣且大尺寸的鏽蝕影像能使辨識模型更加貼近真 實應用。
圖 3.1 真實鏽蝕圖
3.2 資料標註與前處理
拍攝之鏽蝕影像素材約為 213 張,因本研究選用手法為全卷積神經網路,需要 將訓練資料進行人工標註,以輸入全卷積神經網路模型進行訓練。為此,選用
“labelbox” 影像標註工具進行資料的標註。
圖 3.2 Labelbox 介面示意圖
使用”labelbox”能夠以手繪的方式對圖片進行標註(圖 3.3),花費於每張影像 素材的標註時間不等,端看影像中鏽蝕的分布以及所占面積,十五分鐘到一個小 時不等。由於時間以及人力上的限制,本研究僅以拍攝取得的 213 張影像進行標 註,產生的結果雖然尚可,但若能將訓練資料擴充,涵蓋更多的鏽蝕種類以及各 式情境(ex: 光影不均、模糊、異物),訓練出來的影像辨識模型將會更加健全。
在標註過程中,由於時常遇到影像不知道是否該被歸類為鏽蝕、塗裝脫落亦或是 破裂等等,為了資料標註的一致性以及便利性,在此研究範疇,標註過程中若非 正常塗裝部分,一率皆視為鏽蝕。
圖 3.3 Labelbox 標註示意圖
將資料標註完畢後,經由”labelbox”能夠產出影像標註後的遮罩(圖 3.4),原 鏽蝕影像與 labelbox 產出的遮罩影像將成為模型的一組訓練資料,進行模型的訓 練,意即在告訴模型,輸入原影像後預期的結果應該要為遮罩影像。有關於標 註,百分百無誤差的標註是無法達成的,人眼有其極限且礙於時間以及人力上的 考量,我們在進行資料的標註時都會面臨到一個問題,究竟要產生大量但標註精 度中等的資料還是少量但精度較高的資料? 這個問題我們經由 Will Nash[24]的研 究結果,我們決定進行 200 張鏽蝕影像一般程度的標註,來做為訓練資料,以及 對 13 張鏽蝕影像做較為精確的標註作為測試集(一張平均約花費 1~2 個小時),來 做為這次研究的資料素材,同時資料也盡量涵蓋不同的塗裝顏色、紋理、光影狀 態,來讓模型更加的完善。
圖 3.4 原始鏽蝕圖與遮罩圖
第 4 章 影像辨識任務分析
4.1 影像辨識種類
目前應用深度學習於影像辨識的任務,主要分成四的部份: 影像分類 (Classification)、語義分割(Semantic Segmentation)、物體偵測(Object detection)、
實例分割(Instance Segmentation),不同的影像辨識任務會對應到不同的深度模型 架構以及資料前處理、手法,本次研究為了能夠刻劃出鏽蝕所佔圖像的部份,選 用了語意分割(Semantic segmentation)進行鏽蝕辨識的任務。
圖 4.1 電腦視覺辨識任務(資料來源:[26])
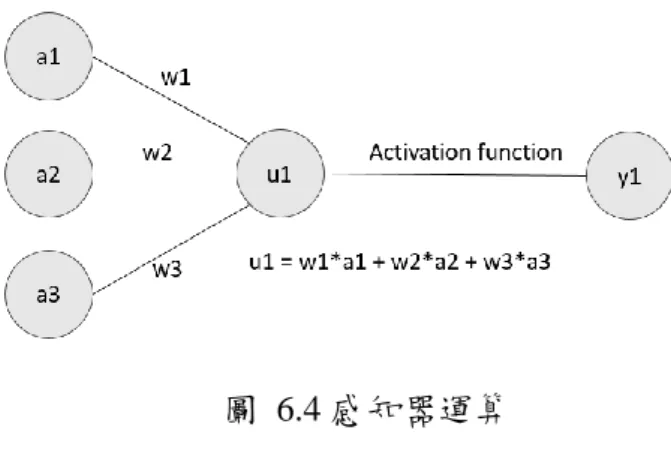
4.2 影像分類
圖 4.2 手寫辨識任務
影像分類,意指機器能夠就接收到的圖片就種類上的分類,例如辨識動物的 圖片為貓、狗或其他的動物,以及最著名的手寫辨識任務,如圖 4.2 所示,藉由 發展已趨成熟的卷積神經網路(Convolutional Neural Network),辨識的準確率已經 可以達到相當高的精度,且在模型的最後會產出各個對應結果的機率,使用者可 以由此觀測到機器對於這張圖片的認知詳情,最後選擇機率最高的做為最後結 果。除了上述的分類任務外,亦可用於分類「是或不是」類型的任務,例如這張 照片張是否有鏽蝕,是則模型最後 output 為 1,否則為 0,但這樣的產出對於本 研究的幫助不大,不適合用於本研究。
4.3 語義分割
語義分割(Semantic Segmentation),即為機器自動從圖像中分割出對象區域,
並識別其中的內容,機器在做分類時,會具體分類到像素的層級,也就是說每一 個像素都會被分類成某一個類別,如圖 4.3 所示。
圖 4.3 語義分割示意圖(資料來源:[27])
可以清楚看出,此種影像辨識手段能夠刻劃出欲辨識物體的邊緣,符合本研 究需求,故本次研究選用語義分割的手法進行鏽蝕的辨識,將鏽蝕部分邊緣進行 刻劃,下圖為一範例(圖 4.4)
圖 4.4 語義分割研究成果
此辨識手法的模型不僅需要清楚辨識出鏽蝕以及塗裝的部份,還要能夠標出 彼此的邊界,因此與分類的任務不同,相關模型要具有像素級的密集預測能力。
在 2014 年加州大學柏克里分校的 Long 等人提出全卷積神經網路(Fully Convolutional Networks)後,CNN 的架構被進一步的更新,在不帶有全連階層的 情況下,使模型能夠進行像素等級的密集預測能力,詳細的模型架構將於後續章 節作介紹。
4.4 物體偵測
圖 4.5 物體偵測示意圖
在物體偵測的影像辨識任務中,機器需要能夠辨識物體種類(Classification)以 及物體定位(object localization),在影像中框出物體並進行種類辨識。定位問題,
相較於影像分類,除了需要影像中目標的種類標籤,更需要給定物體在影像中的 正確位置,才能以監督式學習的方式進行模型訓練,另外,和影像分類問題相 同,物體定位問題輸入影像可以含有一個或多個物體。同時對多個物件 作分類且定位,則屬於物體偵測問題。
4.5 實例分割
實例分割簡而言之,即為機器進行物體偵測後,在不同的窗選框中進行語意 分割將物體的邊緣進行刻劃,我們以圖 4.1 做解釋,若是以語義分割,機器會把 氣球的邊緣刻劃出來,但不會曉得圖片中會有幾個氣球;若是使用物體偵測,機 器則能夠窗選出氣球,同時知道氣球的個數,實例分割即為兩者的結合。現在著 名的模型為 Google 所釋出的 Mask R-CNN。
第 5 章 類神經網路介紹
5.1 機器學習
機器學習為人工智慧的一個分支,其中涵蓋領域眾多,涉及概率論、統計學、
逼近論、凸分析、計算複雜性理論等多門學。其宗旨在於建立一套能夠讓機器自動
「學習」的演算法,讓機器能夠從資料中自動分析獲得規律、脈絡,並利用這些規 律對未知的資料進行預測。換句話說,機器學習是一種弱人工智慧(narrow AI),它 從資料中得到複雜的函數(或樣本)來學習以創造演算法(或一組規則),並利用它來 做預測。
在機器學習中有相當多的模型可供使用,從較為單純的 naive bayes 分類器、
decision tree(決策樹),但較為複雜、結合了眾多簡單分類器的集成分類器,例如 random forest、Bagging、Boosting 等等,都能從資料中萃取出規律,進而用此對未 知的資料進行預測。
在模型的訓練過程中,成果的好壞其實受到許多因素的影響,時常會面臨到 的就是欠擬合(Underfitting)以及過擬合(Overfitting)兩種情況。
5.1.1 欠擬合
再評比機器學習模型的訓練成果時,常會以模型的泛化能力來最為評斷標 準,泛化能力意思為,以現有資料訓練出來的模型,是否能夠適用於未知的資料 結果預測上,從數學上來看,則是模型所學習出來的函數,是否符合資料的分布 函式,其中,欠擬合(Underfitting)既代表模型的複雜程度不足、參數過少,訓練 次數過少、資料不足,模型的解釋力不足以對現況進行合理的模擬與解釋,因此 在訓練集以及測試集的表現都不佳。
圖 5.1 欠擬合
x Y
5.1.2 過擬合
當擁有相對充足的資料與時間時,模型能夠充分的訓練進而以更加複雜的函 式去對未知的資料做預測,但有時我們所擁有的資料,可能只是整個資料母群體 的一部分,如果讓機器不斷的對同一組資料進行訓練,那可能會得到一組過度符 合我們所擁有資料分布的函式,如圖 5.2 所示,很明顯我們並不希望機器學出這 種函式,這種過度擬和資料分布的情況便稱做過擬合(overfitting),模型在訓練集 的表現優異,但在測試集的表現不佳。
我們所希望機器經過學習所得到的函式應該如圖 5.3 所示,符合資料走向的 函式,有許多作法能夠幫助我們避免產生過擬合的情況,例如在訓練資料中切出 適當比例的資料做為驗證資料進行交叉驗證(Cross-validation),或是若使用的是神 經網路,可以使用 dropout 的手法等等,避免模型產生過擬合的現象。
圖 5.2 過擬合
圖 5.3 適度擬合
x Y
Y
x
5.2 類神經網路
生物學上的神經元研究,啟發了 AI 領域關於「類神經網路」(或稱人工神經 網路) 的概念。神經系統由神經元構成,彼此間透過突觸以電流傳遞訊號。是否 傳遞訊號、取決於神經細胞接收到的訊號量,當訊號量超過了某個閾值
(Threshold)時,細胞體就會產生電流、通過突觸傳到其他神經元。承接生物學中 神經元研究的概念,機器學習的領域中逐漸發展出了「類神經網路」(或稱人工神 經網路) 的概念。每個神經元我們稱為一個感知器(Perceptron),感知器中的訊息 會彼此交互作用後傳遞到下一個感知器,以同樣的概念搭建起密集的類神經網 路,如圖 5.4 所示。
圖 5.4 神經網路示意圖(資料來源:[28])
神經元與神經元間有權重,這個權重的值一開始為隨機,接著隨著神經網路 的訓練過程而不斷的被修正,神經元與神經元間藉由值與權重的乘積、總合等等 的數學運算建立起數字間的線性組合關係,之後再透過激勵函數(Activation Function)產生非線性的變化,讓整個神經網路能夠適用更加廣泛的情境,增加其 泛用性。
5.3 深度學習
上述提到了類神經網路的概念,也從圖 5.4 中介紹了神經元彼此作用的方 式,當今天神經元的層數越來越深,權重以及神經元等等的相關參數數量越來越 多,就會逐漸涉及到深度學習的領域。
大致來說,深度學習(deep learning)是機器學習的分支,是一種以類神經網 路為基礎進行架構疊加,對資料進行表徵學習的演算法,深度學習中根據模型的 建制方式不同或者神經元間數學運算方式的不同,其實能夠分成相當多的種類,
例如: 擅長處理語音以及影像辨識的卷積神經網路(Convolutional Neural
Network)、本研究所使用的全卷積神經網路(Fully Convolutional Network)、與時間 序列有關的長短期記憶網路(LSTM)等等,都是屬於深度學習的範疇。
在本研究中,由於探討的是影像方面的處理,故選用了卷積神經網路做為研 究的基礎,考慮進我們所想達到的辨識效果,選用了卷積神經網路的進一步應 用,全卷積神經網路(Fully Convolutional Network),做為本次研究的主要手法,
詳細的架構會在後續章節做介紹。
第 6 章 全卷積神經網路–U-net
上述介紹了機器學習、類神經網路、深度學習到此章節準備介紹的卷積神經 網路,這些概念其實是一連串的流變,如圖 6.1 所示。此研究主要使用的手法為 全卷積神經網路,是卷積神經網路的延伸,深度學習的一個部分。此章節將會從 卷積神經網路的基本架構開始介紹,再接著介紹從卷積神經網路到全卷積神經網 路的改變以及原因。
圖 6.1 資料分析技術流變(資料來源:[36])
這次研究主要使用全卷積神經網路來作為技術的基底,因其為目前深度學習 應用於影像分割的重要概念,以此為概念發展出了相當多目前應用於語義分割任 務的模型,例如 FCN-8s、U-net、DeconvNet、SegNet、Deeplab v3+等等。在此研 究中,我們選用 U-net 作為這次研究的主要手法,原因在於 U-net 所使用的跳級 結構,能夠有效的進行深、淺層的訊息融合,增進語義分割效果,另外因為本次 研究資料皆為實地拍攝,因時間與人力成本有限,能夠使用的資料量並不算多,
若選用如 Deeplab v3+ 此種模型參數數量多,架構複雜的模型,在資料量有限的 情況下重複訓練容易造成過擬合的情況。從資料來源[38]中可以得知,U-net 適用 於小資料集的原因與其模型的對稱架構有關,且於資料來源[38]以及資料來源[39]
中的語義分割任務中,前者為空拍影像,後者為衛星影像,都屬於數量不多的資 料集,在最後的辨識結果上都有著良好的結果,再資料來源[40]亦有提到其他更 多應用 U-net 於語義分割的任務。綜上所述,本次的研究將選用 U-net 作為主要 辨識的模型。因此,參數量較少,模型架構較輕量的 U-net 相較之下是較適合本 研究的手法。
6.1 卷積神經網路基本架構
卷積神經網路的基礎架構主要涵蓋卷積層(Convolution Layer)、激勵函數 (Activation Function)、池化層(Pooling Layer)、全連接層(Fully connection),此結 構組成使得卷積神經網路能夠輸入二維資料進行訓練,使其在圖片分類、辨識上 有著相當不錯的表現。此外,相較於其他由全連接層堆疊的深度神經網路,卷積 神經網路的參數量相對較少,運算成本較低。
6.1.1 卷積層(Convolution Layer)
卷積層中涵蓋了許多的滑窗(filter),這些滑窗會在輸入的影像中進行卷積運 算,如圖 6.2 所示,當整張圖片都運算完後,會得到一張維度下降(尺寸變小)的特 徵圖(feature map),每個滑窗都會對應到一個特徵圖,故可得知,通過卷積層後的 影像資料厚度將等於卷積層滑窗的個數。
圖 6.2 卷積層運算(完成) (資料來源:[29])
此階段目的在於藉由滑窗來幫助我們做照片特徵的自動提取,特徵提取的概 念類似人腦在判斷事物時,亦是由物體的紋理、顏色等等的特徵去進行事物的判 斷,此處進行的特徵提取即是電腦視覺中取得事物判斷依據的過程。
圖 6.3 特徵萃取示意圖(資料來源:[29])
6.1.2 激勵函數(Activation Function)
在談論激勵函數之前,我們必須先了解感知器、或稱神經元的運算模式,如 下圖:
圖 6.4 感知器運算
神經元在層與層之間進行數字運算時,是如圖中所示進行線性組合,其中 w 即為神經網路中的各個權重,可隨訓練過程中逐漸優化。但線性組合所能呈現出 來的訊息範疇有限,若期望計算結果能夠更加多元更加符合真實世界的情況,需 要再此引入非線性的變換,為此,我們在總和 u 的後方在接上激勵函數
(Activation Function)進行非線性的轉換,在此以研究所用的 ReLU 作介紹:
圖 6.5 ReLU 激勵函數
由圖 6.5 可知,當總和 u 小於 0 時,y1 即為 0,當 u 大於 0 時則 y1 維持原 數字,通過 ReLU 的轉換,使得最後結果 y1 有了非線性的轉變過程,能傳遞更 多元的訊息種類。
結合上述提到卷積層的概念,進行完了整張影像的卷積運算後,將結果通過 ReLU 後,在輸入下一層,池化層(Pooling Layer)。
6.1.3 池化層(Pooling Layer)
池化層通常有兩種操作,平均池化(Average pooling)以及最大池化(Max pooling),在此以研究使用的最大池化為例:
最大池化的概念在於,將影像分割成各個小區域,將區域中的最大值選擇出來,
如圖 6.6 所示。
圖 6.6 最大池化層(資料來源:[30])
使用 max pooling 的好處在於,藉由擷取最大值來保留圖片上的訊息,同時 解少參數,加入訓練過程、降低訓練成本以及減少過擬和情形的發生。
6.1.4 全連接層(Fully connection)
圖 6.7 卷積神經網路範例(資料來源:[31])
從圖 6.7 來做介紹,我們可以看到,前面經過卷積層、激勵函數、池化層等 等一系列的操作中,目的在於學習影像的特徵(Feature),在學習到數量眾多的特 徵後,這些特徵的組合可以幫助我們分辨現在這個影像是屬於哪一個種類,此時 即可以藉由加入全連結層(Fully connection)來進行特徵的排列組合,進而進行分 類。因此,一般的卷積神經網路由於最後面接的是全連接層,任務大多是影像的 分類,與我們所期望達到的影像語義分割不同,為此,我們選用了 FCN。
6.2 全卷積神經網路
圖 6.8 全卷積神經網路範例(資料來源:[32])
如圖 6.8 所示為 FCN 的範例結構,與 CNN 不同,在模型的最後不接全連接 層,而改成繼續接卷積層結構進行上採樣,最後輸出成二維的影像資料作為結 果。
6.2.1 卷積化
在 CNN 的架構之中,我們會在最後面連結全連接層,這步驟會將原先的二 維矩陣壓縮成一維的向量,此過程會丟失資料的空間資訊,但 CNN 通常是用於 解決分類的問題,空間資訊在這個範疇之下顯得相對不重要,經過全連接層後會 輸出一個一維向量,對應到最後欲分類的種類。
而語意分割,需要做到影像上逐像素點分類,從而刻劃出影像的輪廓,換句話 說,模型最後的產出需要是二維的,為此 FCN 捨棄了全連接層,換上卷積層,
這個步驟就稱為卷積化。從圖 6.8 中可以看出,模型在不斷經過卷積層、池化層 作用之後,影像的尺寸會越來越小,CNN 便會在最後連結全連結層進行分類任 務,但 FCN 選擇繼續連接卷積結構進行上採樣(Upsampling)藉由反卷積
(Deconvolution),將資料維持在二維的狀態並進行放大。
6.2.2 上採樣
使影像尺寸變大的過程,我們稱之為上採樣(Upsampling),而能達到上採樣 的手法有很多種,最簡單的便是影像處理方式中的重新採樣或內插值,而 FCN 中採取的手法稱之為反卷積(Deconvolution)。反卷積為上述提到的卷積層的反向 操作,利用尺寸縮小的 feature map 反推出尺寸較大的影像進行上採樣,不同的反 卷積層參數能夠對應到不同的放大效果,例如兩倍反卷積、四倍反卷積、八倍反 卷積等等,能將影像的大小以倍數放大。
6.3 FCN 模型
在經過卷積層和池化層運作的過程中,隨著影像尺寸變小,機器會不斷的進 行特徵提取,在較為前面的層中,機器會學習到的是屬於位置訊息較為豐富的特 徵,意即這些特徵應該出現在圖片的什麼位置,特徵應該要有什麼紋理的訊息相 對較低;而在較深一些的層中,由於影像尺寸越來越小,機器所學習到的特徵大 多為紋理方面的語義訊息,與空間相關的位置訊息則較少。由此可見,淺、深層 分別學習到了相對應的特徵型態,捨棄任何一種都不合理,為了能夠同時保留位 置、文理的特徵訊息,FCN 的相關研究中提到了相當重要的手法,稱做跳級結 構。
6.3.1 跳級結構
若我們直接對最底層的預測結果進行上採樣,損失了太多位置空間資訊的情 況下,得出來的結果勢必不精確,為此,我們利用前幾層預測的結果保留下來,
加入到後續上採樣的過程中,來達到同時保留文理、位置空間訊息的目的。
圖 6.9 跳級結構(資料來源:[27])
如上圖 6.9 所示,簡單來說,便是把最後一層預測結果與前幾層池化層的預 測結果結合後再進行上採樣,舉例而言,若是先將最後一層預測結果做兩倍反卷 積,尺寸放大兩倍後便與上一池化層的預測結果進行逐點相加(fusion),出來的結 果再進行三十二倍反卷積的上採樣,將影像放大到與一開始輸入時相同,那這個 模型我們就稱它為 FCN-32s,後續還有 FCN-16s 以及 FCN-8s,概念相同,只是 融合了更多前層的資訊後再進行上採樣到原影像尺寸。
6.3.2 FCN-32s
圖 6.10 FCN-32s(資料來源:[33])
有了上述的跳級結構概念後,我們便能夠進一步了解 FCN 網路結構的設計 思想,如圖 6.10 所示,這是 FCN-32s 的範例模型,模型的最後直接將最後預測結 果進行了三十二倍的上採樣,因此得名,但此種作法出來的結果由於損失了太多 位置空間訊息,結果並不十分理想。
6.3.3 FCN-16s
圖 6.11 FCN-16s(資料來源:[33])
如圖 6.11 所示為 FCN-16s 的範例模型,模型會對最後一層的預測結果進行兩 倍上採樣,加上一些補零(Padding)的動作後使其尺寸與上一個池化層出來預測結 果相同,並進行逐點相加(fusion),出來的結果在進行十六倍的上採樣回復到原影 像尺寸。
6.3.4 FCN-8s
圖 6.12 FCN-8s(資料來源:[33])
如圖 6.11 所示為 FCN-8s 的範例模型,模型將最後的預測結果先進行兩倍上 採樣以及補零的動作,先與上一池化層的預測結果逐點相加,出來的結果在進行 上採樣的動作使其與更上一層的池化層預測結果尺寸相同,進行第二次的逐點相 加,再將最後結果進行八倍的上採樣到原影像尺寸,過程中融合了前兩層結果,
保留了更多的淺層資訊,表現優於上述兩種模型。至於為何不繼續融合更多更上 層的資訊,當初發明這套模型的作者進行的實驗當中證實,再融合更多的上層資 訊表現並沒有比較好,便停止於此。
圖 6.13 辨識結果比較(資料來源:[26])
上圖 6.12 為各個模型最後的輸出結果,可以看到,FCN-8 由於保留了淺、深 層的訊息,模型最後的逐點預測結果優於前面兩者。
6.4 U-net
圖 6.14 U-net 範例結構(資料來源:[34])
上述介紹完了經典的 FCN 模型以及重要的跳級結構概念,接著介紹的是本 次研究所使用的模型: U-net。U-net 一詞最早於 2015 的 MICCAI(Medical Image Analysis)被提出,其於醫療影像辨識的表現相當令人驚豔,也成為了日後各式醫 療影像語義分割任務中,被拿來作為表現基準(baseline)的模型。
上圖 6.13 所示即為 U-net 的範例模型架構,第一階段為特徵提取,與前面介 紹的 FCN 類似,藉由卷積層與池化層對影像的特徵做提取,同時影像資料的尺 寸通過池化層後也以倍數縮小,厚度的變化隨卷積層滑窗個數改變。接著便是上 採樣的部分,一樣應用了上述提及的跳級結構概念,但在此結合的手法並非之前 提及的逐點相加,而是直接疊加,厚度增厚後再接續卷積層的操作,最後再利用 反卷積進行倍數放大的上採樣,不斷重複此過程直至最後的二維語義分割影像產 出。
第 7 章 成果分析
此章節將會介紹此研究的研究成果、限制,以及與過去邊緣演算法的成果比 較,證明此研究能夠辨識更多的鏽蝕種類,辨識模型的泛用性更高,同時也擁有 高的準確率。
7.1 鏽蝕樣圖介紹
過去的研究當中,曾利用剪貼鏽蝕影像於人工背景以製作人工鏽蝕圖來方便 計算模型辨識的準確度,此研究打算利用真實鏽蝕圖作為本次研究的素材,並以 labelbox 所標示出來的測試集遮罩成果作為標準答案計算準確度以及誤差。此 外,此研究本研究所使用的鏽蝕影像皆為實地拍攝,拍攝過程中同時也盡量涵蓋 各種不同底色的塗裝、各式狀態的鏽蝕、噪聲、紋理等等,期望訓練出來的模型 能夠更加貼近真實的應用。
圖 7.1 人工鏽蝕圖(資料來源:[9])
圖 7.2 實地拍攝鏽蝕圖
收集資料的過程中,為了讓模型有更好的泛化能力,因此特別針對不同底色 的鏽蝕影像進行拍攝,如圖 7.3 所示:
圖 7.3 依塗裝顏色進行資料蒐集
7.2 辨識效果討論
7.2.1 辨識成果
此研究利用 FCN 概念中的 U-net 架構,並將 200 張鏽蝕影像以及遮罩作為訓 練資料輸入模型中進行訓練,並將 13 張標註較為精細的資料做為測試。在探討 模型表現之前,我們需先了解分類任務中,常需要被拿出來討論的混淆矩陣:
表 7.1 混淆矩陣
TN: True Negative 答案為否,預測也為否。
FN: False Negative 答案為是,預測為否。
FP: False Positive 答案為否,預測為是。
TP: True Positive 答案為是,預測也為是。
在分類任務中,我們能夠利用這四個數字組合出許多不同的指標,例如 Accuracy、Recall、Precision、F-Score 等等,每種指標都有適用的情境,例如異 常偵測,大部分都為正常只有少數為異常的任務,就可以利用 precision 來進行評 估。其中,準確度(Accuracy)的計算方式為 (TN+TP)/總像素量,適用於比例相差 不懸殊的分類任務,此研究中,由於鏽蝕以及正常塗裝的像素比例並沒有相差的 十分懸殊,故我們選用 Accuracy 作為我們評估模型表現的其中一項指標。
另外,這裡的像素預測值由於都會經過模型中的激勵函數運作,出來的值都 會介於 0~1 之間,越靠近 1 代表模型認為是鏽蝕。Tensorflow 套件中的 Accuracy 中的操作閾值設為 0.5,所以當像素被預測出來的值大於 0.5 時,在計算 accuracy 時便會被認定「是」,值小於 0.5 的像素部分便會被認定為「否」。
Accuracy =
(TP+TN)(TP+FP+FN+TN)
除了準確度(Accuracy),也利用了另外一個名為二元交叉熵(Binary Cross Entropy)的指標作為誤差(Loss)評估。二元交叉熵用以衡量預測結果與正確答案的 相似性,數字越低,相似程度越高,下方為二元交叉熵的計算公式:
H = ∑ ∑ −𝑦
𝑐,𝑖𝑙𝑜𝑔
2(𝑝
𝑐,𝑖)
𝑛
𝑖=1 𝐶
𝐶=1
C 為類別數,n 為資料數,y_(c,i)為 binary indicator (以 0 或 1 做表示),
p_(c,i)為第 i 筆資料被預測為 C 類別的機率,我們在此舉一個簡單的例子:
表 7.2 二元交叉熵算例表(一)
表 7.3 二元交叉熵算例表(二)
上述為兩個模型對於資料進行男、女、其他類別進行預測之結果,可從表中 看出,從預測的錯誤率來看皆為 0.25,顯然無法用此指標判斷模型的表現,模型 二的預測能力顯然比模型一來的優秀,為此,我們利用計算兩個模型的 Cross- Entropy,來判斷兩個模型的表現:
Model 1 Cross-Entropy
= 類別(男) Cross-Entropy + 類別(女) Cross-Entropy + 類別(其他) Cross-Entropy
= -(1 × log(0.4)+ 0 × log(0.3)+ 1 × log(0.5)+ 0 × log(0.8)) + -(0 × log(0.3)+ 1 × log(0.4)+ 0 × log(0.2)+ 0 × log(0.1)) + -(0 × log(0.4)+ 0 × log(0.3)+ 0 × log(0.3)+ 1 × log(0.1)) = 6.966
Model 2 Cross-Entropy 如上計算後得出結果為 2.310
很明顯能夠看出,若模型預測的越準確,對於對的預測機率數字越高,那計算出 來的 Cross-Entropy 數字則越低,由此可得知,預測結果越接近真實答案者,
Cross-Entropy 的值則越低,故可利用此特性進行模型的表現評估。
了解了模型評估的指標,即可藉由觀察指標數字的變化來檢視模型的訓練成 效,下圖為訓練集影像在模型訓練過程中,準確度(Accuracy)以及誤差(Loss)經過 了數個 epoch 後,所呈現的變化曲線。
(epoch : 一個 epoch 代表過了一遍訓練集中的所有樣本)
圖 7.4 準確率曲線(上)及誤差曲線(下)
在訓練集中,最後的準確度可以達到 0.95 ,而誤差可以降至 0.167,但這些數 字僅供參考用以監視模型的訓練過程,真正用以檢驗模型準確度的為額外獨立出 來沒有加入訓練的測試用 13 張鏽蝕影像及遮罩。
利用 evaluate_generator 的手法批次將測試資料丟入模型後進行評分,得出的 準確率為 0.956,誤差為 0.264。
以下為 13 張測試資料原圖以及辨識成果的展示,白色部份為機器辨識之鏽 蝕區域 (左側為原始圖,右側為模型辨識結果):
Accuracy: 0.975 Loss: 0.13
Accuracy: 0.952 Loss: 0.083
Accuracy: 0.91 Loss: 0.58
Accuracy: 0.92 Loss: 0.47
Accuracy: 0.991 Loss: 0.125
Accuracy: 0.984 Loss: 0.106
Accuracy: 0.93 Loss: 0.67
Accuracy: 0.94 Loss:0.75
Accuracy: 0.93 Loss: 0.12
Accuracy: 0.95 Loss: 0.13
Accuracy: 0.981 Loss: 0.08
Accuracy: 0.979 Loss: 0.103
圖 7.5 研究辨識成果展示
值得一提的是,在收集訓練資料的過程中,此研究有特意拍攝了一些非鏽蝕 或完整塗裝等等不含鏽蝕的影像,在標註過程中即空白沒有進行標註(無鏽蝕區 域),目的在於讓模型接觸到「反例」,加強模型的辨識能力,使其能夠真正辨識
「鏽蝕」,而非只是從影像中進行邊緣的抓取。
圖 7.6 模型對於非鏽蝕物體的辨識
7.2.2 辨識效果比較
此研究與 白博升[25] 進行聯繫,取得了當時相關的辨識成果以及使用的鏽 蝕影像。取得的資料中包括成功辨識以及未能成功辨識的影像及辨識成果,此研 究從過去未能成功辨識的影像著手,將影像輸入到此研究的模型中進行辨識,證 明此研究模型的泛用性以及精確度都有著相較於過往研究不錯的表現。
過去研究所無法辨識的影像大致可分為三類:
a. 鏽蝕面積大於正常塗裝
b. 大範圍鏽蝕或塗裝上有紋理、噪聲 c. 淺綠色塗裝
將這三類過去演算法所無法辨識的鏽蝕影像,輸入到本次研究的辨識模型,
產出辨識結果,並與過去的辨識成果進行比較,如下所示:
(左方為本次辨識成果,右方為博升學長辨識成果)
Accuracy: 0.989 Loss: 0.09
a. 鏽蝕面積大於正常塗裝
b. 大範圍鏽蝕或塗裝上有紋理、噪聲
c. 淺綠色塗裝
圖 7.7 與過去論文成果辨識比較
從過去辨識失敗的影像中可以得知,對於鏽蝕涵蓋面積大於正常區域時,過 去的演算法有很大的機率會辨識失敗,除此之外,對於非屬鏽蝕的紋路、噪聲、
大面積鏽蝕、塗裝顏色等等都會造成誤判。對比而言,此研究的辨識成效明顯有 優於過去演算法的部份,當鏽蝕面積相較正常區於大時、塗裝表面有紋路、影像 含有噪聲、大面積鏽蝕、塗裝顏色不同等等情況都能夠成功進行影像辨識。
7.3 研究限制
此研究辨識模型的泛用性能夠隨著資料的累積而逐漸增強,但目前在一些影 像上仍無法進行有效辨識,如下所示的幾種類別,推測可能原因主要在於影像資 料不足(與鏽蝕顏色相近的塗裝影像以及含有景深的影像不足)。
以下為此研究辨識模型目前尚待克服的部分:
1. 當影像中塗裝底色與鏽蝕相近時,會造成辨識不精確。
圖 7.8 塗裝底色與鏽蝕太過相近
2. 當影像中含有景深的部份時,模型會出現誤判。
圖 7.9 影像含有景深
3. 辨識速度與過去邊緣演算法相比較慢,約一秒一張
7.4 資料集精度比較
此次研究中,為了探討訓練集資料標註精度對於模型表現成果的影響,
特地將相同數量的資料集輔以不同比例的高精度標註來進行觀察:
主要分為三組:
1. 共 213 張,輔以 10 張高精度標註資料,其餘為中精度標註。
2. 共 213 張,輔以 20 張高精度標註資料,其餘為中精度標註。
3. 共 213 張,輔以 30 張高精度標註資料,其餘為中精度標註。
Accuracy 和 Loss 數字隨 epoch 變動情況如下所示:
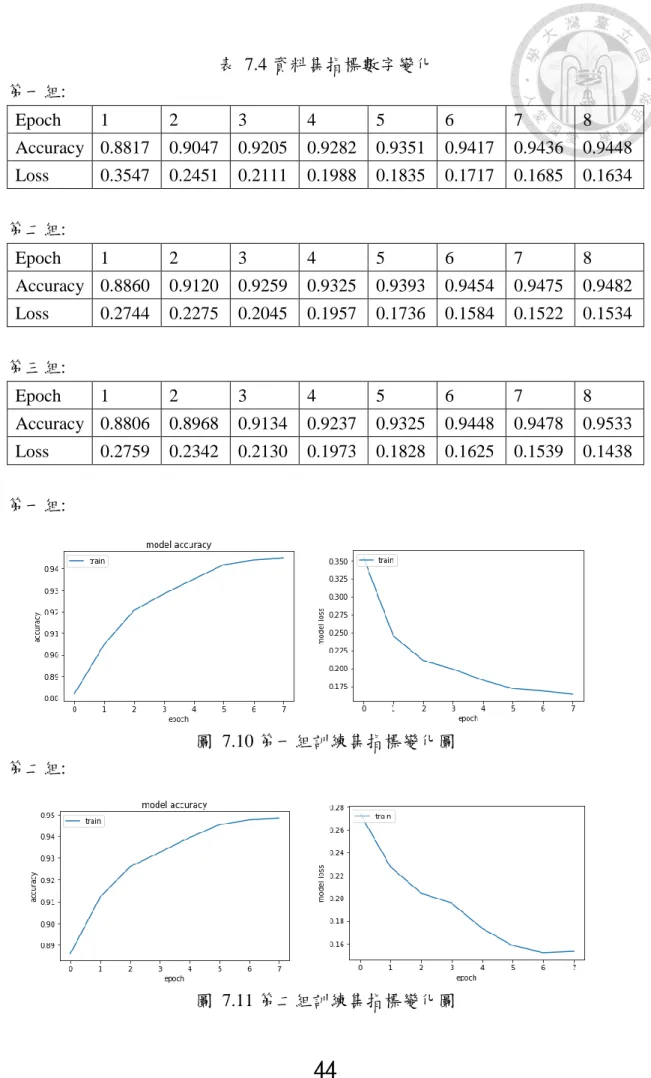
表 7.4 資料集指標數字變化 第一組:
Epoch 1 2 3 4 5 6 7 8
Accuracy 0.8817 0.9047 0.9205 0.9282 0.9351 0.9417 0.9436 0.9448 Loss 0.3547 0.2451 0.2111 0.1988 0.1835 0.1717 0.1685 0.1634
第二組:
Epoch 1 2 3 4 5 6 7 8
Accuracy 0.8860 0.9120 0.9259 0.9325 0.9393 0.9454 0.9475 0.9482 Loss 0.2744 0.2275 0.2045 0.1957 0.1736 0.1584 0.1522 0.1534
第三組:
Epoch 1 2 3 4 5 6 7 8
Accuracy 0.8806 0.8968 0.9134 0.9237 0.9325 0.9448 0.9478 0.9533 Loss 0.2759 0.2342 0.2130 0.1973 0.1828 0.1625 0.1539 0.1438
第一組:
圖 7.10 第一組訓練集指標變化圖 第二組:
圖 7.11 第二組訓練集指標變化圖
第三組:
圖 7.12 第三組訓練集指標變化圖
從上述的表格和圖中可以得知,模型的表現確實有隨高精度資料集的比例增 大而變好,這部分在預料之中,高精度的標註能為模型帶來更為準確的訊息,只 是增進的幅度不如預期,故未來若想增進模型的表現,作者認為持續增加資料集 的數量會是較有效益的做法。
第 8 章 結論與建議
8.1 結論及研究貢獻
隨著資料儲存以及收集的技術提升,資料分析的相關技術蓬勃發展,各個產 業也都積極的引進資料處理的技術。影像辨識的領域也受到相當大的影響,隨著 神經網路的技術再度被提起,卷積神經網路技術的成熟,應用深度學習的技法也 為影像辨識帶來了許多的突破。
此研究引入了深度學習中,全卷積神經網路的目的:
1. 希望能夠提升鏽蝕影像辨識演算法的實用性,以往的演算法中,對於鏽蝕影像 的限制多,過多的噪聲、光影變化、塗裝色彩、塗裝紋路都會影響到辨識的品 質,另外,能夠辨識的鏽蝕種類也受到限制。使用此研究的辨識方法,只要訓練 資料數量足夠,含蓋的影像情況豐富,上述的問題都能夠得到克服。
2. 此研究使用的是深度學習的手法,訓練資料的數量與品質將會直接影響到模型 的表現,因此,隨著訓練資料不斷的累積,我們能夠合理的預期模型的辨識精確 度以及泛用性將會越來越精進。
8.2 建議及後續方向
此研究使用的深度學習概念、模型架構以及語言框架等等,都還是在蓬勃發 展中的技術,因此筆者認為,若後續有研究者對於此題目有興趣,或許能夠朝以 下方向去做嘗試:
1. 選用更輕量的神經網路架構進行辨識。本研究選用的架構進行運算的效率約為 一秒一張,仍還無法達到即時影像辨識的標準,或許可以選用運算成本較低的架 構,降低所需的參數數量,提升辨識效率。
2. 結合行動裝置進行實地辨識。近期利用手機載具搭載深度學習模型的技術已越 來越成熟,或許能夠考慮結合載具 app,讓辨識模型更具實用價值。
3. 收集更加完備的資料以及精度更高的標註。若要使用深度學習的手法,資料將 會直接影響到模型的表現,甚至應該選擇的架構。
參考文獻
[1] unet for image segmentation: https://github.com/zhixuhao/unet
[2] 中華民國交通部,「公路鋼結構橋梁之檢測及補強規範」,初版,交通部,2008。
[3] 黃世昌,「智慧型影像處理於橋樑維護與檢驗技術之研究」,行政院國家科學 委員會專題研究計畫成果報告,2000。
[4] 戴佳信,「小波理論於智慧型影像處理在鋼構橋梁表面銹蝕面積檢測之應用」, 國立交通大學土木工程系所碩士論文,2004。
[5] 楊雅晴,「運用智慧型彩色影像辨識於鋼橋生鏽檢測」,國立臺灣大學工學院 土木工程學研究所碩士論文,2008。
[6] Heng-Kuang Shen, "Automatic Color Image Recognition for Steel Bridge Rust Defects Assessment", Department of Civil Engineering College of Engineering National Taiwan University Doctoral Dissertation, 2013.
[7] 尹昱翰,「鋼構件鏽蝕影片運用雲端辨識系統之初步開發」,國立臺灣大學工 學院土木工程學研究所碩士論文,2014。
[8] 李奕霆,「鋼橋鏽蝕區域之數位影像辨識」,國立臺灣科技大學營建工程系研 究所碩士論文,2014。
[9] 劉韋村,「以手持裝置進行鋼材鏽蝕即時影像辨識之系統開發」,國立臺灣大 學工學院土木工程學研究所碩士論文,2016。
[10] Heng-Kuang Shen, Po-Han Chen, and Luh-Maan Chang, "Automated Steel Bridge Coating Rust Defect Recognition Method Based on Color and Texture Feature", Automation in Construction, Vol.4, pp.338-356, 2013.
[11] Heng-Kuang Shen, Po-Han Chen, and Luh-Maan Chang, "Support-Vector- Machine-Based Method for Automated Steel Bridge Rust Assessment", Automation in Construction, Vol.23, pp.9-19, 2012.
[12] Po-Han Chen, and Luh-Maan Chang, "Intelligent Steel Bridge Coating Assessment Using Neuro-Fuzzy Recognition Approach", Computer-Aided Civil and Infrastructure Engineering, Vol.17, pp.307-319, 2002.
[13] Po-Han Chen, Yuh-Chin Chang, and Luh-Maan Chang, "Application of Multiresolution Pattern Classification to Steel Bridge Coating Assessment", Journal of Computing in Civil Engineering, Vol.16(4), pp.244-251, 2002.
[14] Po-Han Chen, Ya-Ching Yang, Chi-Yang Lei, and Luh-Maan Chang, "Automated Bridge Coating Defect Recognition Using Adaptive Ellipse Approach", Automation in Construction, Vol.18, pp.632-643, 2009.
[15] Sangwook Lee, Luh-Maan Chang, and Miroslaw Skibniewski, "Automated Recognition of Surface Defects Using Digital Color Image Processing", Automation in Construction, Vol.15, pp.540-549, 2006.
[16] Sangwook Lee, "Digital Image Processing Methods for Bridge Coating Management and Their Limitations", Journal of Civil Engineering and Architecture, Vol.1 (38), pp.39-47, 2011.
[17] Qing-Yuan He, and Chuan-Jiu Han, "Image Thresholding Segmentation with Otsu Based on Particle Swarm Optimization Algorithm", Journal of Guilin University of Electronic Technology, May 2006.
[18] 賴玉霞 , 劉建平,「 K-means 算法的初始聚類中心的優化」, Computer Engineering and Application,Vol.44 (10),pp.147-149,2008。
[19] R. Medina-Carnicer, A. Carmona-Poyato, Rafael Muñoz-Salinas, and Francisco José Madrid-Cuevas, "Determining Hysteresis Thresholds for Edge Detection by Combining the Advantages and Disadvantages of Thresholding Methods", IEEE Transactions on Image Processing, Vol.19 (1), pp.165-173, 2010.
[20] Raman Maini, and Himanshu Aggarwal, "Study and Comparison of Various Image Edge Detection Techniques", International Journal of Image Processing, Vol.3, pp.1-11, 2009.
[21] G.T. Shrivakshan, and C. Chandrasekar, "A Comparison of Various Edge Detection Techniques Used in Image Processing", International Journal of Computer Science Issues, Vol.9 (5), pp.272-276, 2012.
[22] Li Bin, and Mehdi Samiei Yeganeh, "Comparison for Image Edge Detection Algorithms", IOSR Journal of Computer Engineering, Vol.2, pp.1-4, 2012.
[23] Young‐Jin Cha, "Deep Learning‐Based Crack Damage Detection Using Convolutional Neural Networks", 2017
[24] Will Nash, "Quantity beats quality for semantic segmentation of corrosion in images", 2018
[25] 白博升,「結合擴增虛擬實境與即時影像辨識之工程應用---以鋼橋鏽蝕辨識 為例」,國立臺灣大學工學院土木工程學研究所碩士論文,2017。
[26] 劉曉坤,「先理解 Mask R-CNN 的工作原理,然后构建颜色填充器应用」
https://www.jiqizhixin.com/articles/Mask_RCNN-tree-master-samples-balloon
[27] 十分鐘看懂圖像語義分割技術 http://bangqu.com/6MT5L6.html
[28] 神經網路模型
https://www.ibm.com/support/knowledgecenter/zh-
tw/SS3RA7_sub/modeler_mainhelp_client_ddita/components/neuralnet/neuralnet_mod el.html
[29] Yeh James , [ 資 料 分 析 & 機 器 學 習 ] 第 5.1 講 : 卷 積 神 經 網 絡 介 紹 (Convolutional Neural Network) https://medium.com/jameslearningnote/%E8%B3%87%E6%96%99%E5%88%86%E6
%9E%90-%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92-
%E7%AC%AC5-1%E8%AC%9B-
%E5%8D%B7%E7%A9%8D%E7%A5%9E%E7%B6%93%E7%B6%B2%E7%B5%A 1%E4%BB%8B%E7%B4%B9-convolutional-neural-network-4f8249d65d4f
[30] File:Max pooling.png
https://en.wikipedia.org/wiki/File:Max_pooling.png
[31] RunningSucks,卷積神經網路結構
https://blog.fangweb.com/2019/03/15/%E5%8D%B7%E7%A9%8D%E7%A5%9E%E7
%B6%93%E7%B6%B2%E8%B7%AF%E7%B5%90%E6%A7%8B/zh-tw/
[32] 全卷积网络 FCN 详解
https://blog.csdn.net/sinat_24143931/article/details/78696442
[33] 【個人整理】一文看盡全卷積網絡 FCN 設計架構以及設計思想 https://www.twblogs.net/a/5cb813cabd9eee0f00a2110e
[34] U-Net: Convolutional Networks for Biomedical Image Segmentation https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
[35] 什麼是人工智慧、機器學習和深度學習?
https://medium.com/@chih.sheng.huang821/%E4%BB%80%E9%BA%BC%E6%98%
AF%E4%BA%BA%E5%B7%A5%E6%99%BA%E6%85%A7-
%E6%A9%9F%E5%99%A8%E5%AD%B8%E7%BF%92%E5%92%8C%E6%B7%B 1%E5%BA%A6%E5%AD%B8%E7%BF%92-587e6a0dc72a
[36] 機器/深度學習: 基礎介紹-損失函數(loss function)
https://medium.com/@chih.sheng.huang821/%E6%A9%9F%E5%99%A8-
%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-
%E5%9F%BA%E7%A4%8E%E4%BB%8B%E7%B4%B9-
%E6%90%8D%E5%A4%B1%E5%87%BD%E6%95%B8-loss-function-2dcac5ebb6cb
[37] Semantic Segmentation of Small Data using Keras on an Azure Deep Learning Virtual
https://www.microsoft.com/developerblog/2018/07/18/semantic-segmentation-small- data-using-keras-azure-deep-learning-virtual-machine/
[38] Dstl Satellite Imagery Feature Detection
https://www.kaggle.com/c/dstl-satellite-imagery-feature-detection/overview
[39] U-Net: Image Segmentation Network https://neurohive.io/en/popular-networks/u-net/
![表 2.2 邊緣檢測運算子優缺點(節錄自 Raman Maini[20])](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603705.630024/17.892.130.780.99.967/表22邊緣檢測運算子優缺點節錄自RamanMaini2.webp)
![圖 2.1 邊緣檢測運算子成果比較(節錄自 Li Bin [21] )](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603705.630024/18.892.281.753.184.282/圖21邊緣檢測運算子成果比較節錄自LiBin21.webp)
![圖 4.1 電腦視覺辨識任務(資料來源:[26])](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603705.630024/21.892.248.646.379.707/圖41電腦視覺辨識任務資料來源26.webp)
![圖 6.14 U-net 範例結構(資料來源:[34])](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603705.630024/37.892.141.785.110.907/圖614Unet範例結構資料來源34.webp)

![圖 7.5 研究辨識成果展示 值得一提的是,在收集訓練資料的過程中,此研究有特意拍攝了一些非鏽蝕 或完整塗裝等等不含鏽蝕的影像,在標註過程中即空白沒有進行標註(無鏽蝕區 域),目的在於讓模型接觸到「反例」,加強模型的辨識能力,使其能夠真正辨識 「鏽蝕」,而非只是從影像中進行邊緣的抓取。 圖 7.6 模型對於非鏽蝕物體的辨識 7.2.2 辨識效果比較 此研究與 白博升[25] 進行聯繫,取得了當時相關的辨識成果以及使用的鏽 蝕影像。取得的資料中包括成功辨識以及未能成功辨識的影像及辨識成果,此研](https://thumb-ap.123doks.com/thumbv2/9libinfo/9603705.630024/46.892.129.793.110.380/研究辨識成果展示值得一提是在收集訓練資料過程中此研究白博升.webp)