开发指南
文档版本
06
发布日期
2019-04-04
版权所有 © 华为技术有限公司 2020。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或默示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
华为技术有限公司
地址: 深圳市龙岗区坂田华为总部办公楼 邮编:518129
网址:
https://www.huawei.com
客户服务邮箱:
[email protected]
客户服务电话:4008302118目 录
1 开发流程...1
2 准备开发环境... 3
2.1 开发环境简介... 3
2.2 准备运行环境... 3
2.2.1 准备 Windows 运行环境... 3
2.3 下载样例工程... 4
2.4 配置并导入工程...6
3 开发 HBase 应用... 12
3.1 典型场景说明...12
3.2 开发思路... 13
3.3 样例代码说明...14
3.3.1 配置参数... 14
3.3.2 创建 Configuration... 15
3.3.3 IAM 集群认证...15
3.3.4 创建 Connection... 16
3.3.5 创建表... 16
3.3.6 删除表... 18
3.3.7 修改表... 18
3.3.8 插入数据... 19
3.3.9 删除数据... 21
3.3.10 使用 Get 读取数据...22
3.3.11 使用 Scan 读取数据... 22
3.3.12 使用过滤器 Filter... 23
4 开发 OpenTSDB 应用...25
4.1 典型场景说明...25
4.2 开发思路... 28
4.3 样例代码说明...29
4.3.1 配置参数... 29
4.3.2 IAM 集群认证...30
4.3.3 写入数据... 31
4.3.4 查询数据... 33
4.3.5 删除数据... 34
4.4 性能调优... 35
5 开发 GeoMesa 应用...36
5.1 典型场景说明...36
5.2 开发思路... 36
5.3 样例代码说明...37
5.3.1 配置参数... 37
5.3.2 创建 DataStore...37
5.3.3 创建数据表... 37
5.3.4 插入数据... 38
5.3.5 查询数据... 38
6 开发 HBase Elasticsearch 全文检索应用... 40
6.1 应用背景... 40
6.2 使用前提... 40
6.3 典型场景说明...40
6.4 HBase Elasticsearch schema 说明...41
6.5 开发思路... 42
6.6 样例代码说明...42
6.6.1 配置参数... 42
6.6.2 创建 Configuration... 43
6.6.3 创建数据表开启 Elasticsearch 索引... 44
6.6.4 写入数据... 45
6.6.5 查询数据... 47
7 调测程序...50
7.1 在 Windows 中调测程序... 50
7.1.1 编译并运行程序...50
7.1.2 查看调测结果... 50
7.2 在 Linux 中调测程序... 51
7.2.1 安装客户端时编译并运行程序...51
7.2.2 未安装客户端时编译并运行程序... 55
7.2.3 查看调测结果... 58
8 对外接口...59
8.1 HBase Java API...59
8.2 OpenTSDB API... 59
8.2.1 OpenTSDB API 简介... 59
8.2.2 写入数据... 60
8.2.3 查询数据... 63
8.2.4 查询 first 数据... 71
8.2.5 查询 last 数据...73
8.2.6 管理数据生命周期... 76
8.2.7 响应码... 78
8.2.8 使用限制... 79
8.3 GeoMesa Java API... 80
A 修订记录... 81
1 开发流程
本文档主要介绍在CloudTable集群模式下如何调用HBase、OpenTSDB或GeoMesa的 开源接口进行Java应用程序的开发。
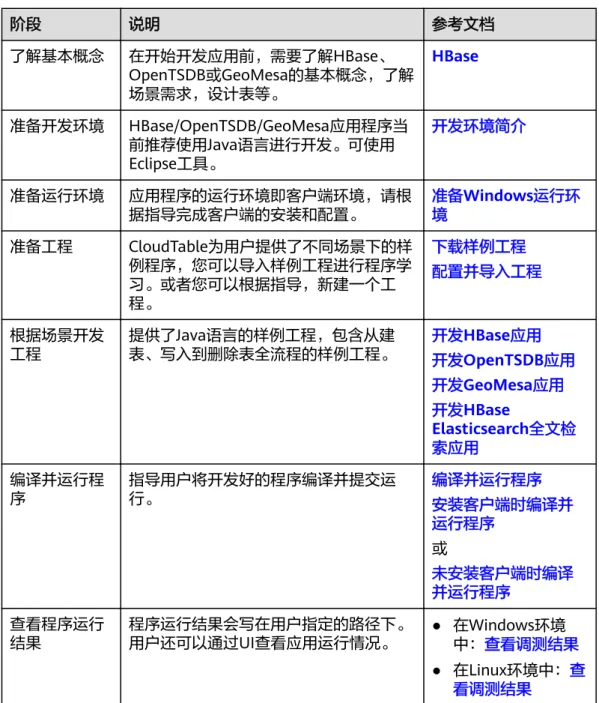
开发流程中各阶段的说明如图1-1和表1-1所示。
图
1-1 应用程序开发流程
表
1-1 应用开发的流程说明
阶段 说明 参考文档
了解基本概念 在开始开发应用前,需要了解HBase、
OpenTSDB或GeoMesa的基本概念,了解 场景需求,设计表等。
HBase
准备开发环境 HBase/OpenTSDB/GeoMesa应用程序当 前推荐使用Java语言进行开发。可使用 Eclipse工具。
开发环境简介
准备运行环境 应用程序的运行环境即客户端环境,请根
据指导完成客户端的安装和配置。
准备Windows运行环 境
准备工程 CloudTable为用户提供了不同场景下的样 例程序,您可以导入样例工程进行程序学 习。或者您可以根据指导,新建一个工 程。
下载样例工程 配置并导入工程
根据场景开发 工程
提供了Java语言的样例工程,包含从建 表、写入到删除表全流程的样例工程。
开发HBase应用 开发OpenTSDB应用 开发GeoMesa应用 开发HBase
Elasticsearch全文检 索应用
编译并运行程 序
指导用户将开发好的程序编译并提交运 行。
编译并运行程序 安装客户端时编译并 运行程序
或
未安装客户端时编译 并运行程序
查看程序运行 结果
程序运行结果会写在用户指定的路径下。
用户还可以通过UI查看应用运行情况。 ● 在Windows环境 中:查看调测结果
● 在Linux环境中:查
看调测结果
2 准备开发环境
2.1 开发环境简介
在进行二次开发时,要准备的开发环境如表2-1所示。
表
2-1 开发环境
准备项 说明
操作系统 Windows系统,推荐Windows 7及以上版本。
安装JDK 开发环境的基本配置。版本要求:1.7或者1.8。考虑到后续版 本的兼容性,强烈推荐使用1.8。
说明基于安全考虑,CloudTable服务只支持TLS 1.1和TLS 1.2加密协议,
IBM JDK默认TLS只支持1.0,若使用IBM JDK,请配置启动参数
“com.ibm.jsse2.overrideDefaultTLS”为“true”,设置后可以同时支 持TLS1.0/1.1/1.2。详情请参见IBM官方网站的相关说明。
安装和配置Eclipse 用于开发CloudTable应用程序的工具。
网络 确保开发环境或客户端与表格存储服务主机在网络上互通。
2.2 准备运行环境
2.2.1 准备 Windows 运行环境
操作场景
CloudTable应用开发的运行环境可以部署在Windows环境下。按照如下操作完成运行 环境准备。
操作步骤
步骤1 确认CloudTable集群已经安装,并正常运行。
步骤2 准备Windows弹性云服务器。
具体操作请参见准备弹性云服务器章节。
步骤3 请在Windows的弹性云服务器上安装JDK1.7及以上版本,强烈推荐使用JDK1.8及以上 版本,并且安装Eclipse,Eclipse使用JDK1.7及以上的版本。
说明
● 若使用IBM JDK,请确保Eclipse中的JDK配置为IBM JDK。
● 若使用Oracle JDK,请确保Eclipse中的JDK配置为Oracle JDK。
● 不同的Eclipse不要使用相同的workspace和相同路径下的示例工程。
----结束
2.3 下载样例工程
前提条件
确认表格存储服务已经安装,并正常运行。
下载样例工程(集群模式)
步骤1 下载样例代码工程。
登录表格存储服务管理控制台,单击“帮助”,在帮助页面右侧的“常用链接”区域 下方单击“样例代码下载”,下载样例代码工程安装包。如图2-1所示。
图
2-1 样例代码下载链接
步骤2 下载完成后,将样例代码工程安装包解压到本地,得到一个Eclipse的JAVA工程。如图
2-2所示。
图
2-2 样例代码工程目录结构
----结束
Maven 配置
样例工程中已经包含了hbase的客户端jar包,也可以替换成开源的HBase jar包访问表 格存储服务,支持1.X.X版本以上的开源HBase API。如果需要在应用中引入表格存储 服务的HBase jar包,可以在Maven中配置如下依赖。
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1.0305-cloudtable</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>1.3.1.0305-cloudtable</version>
</dependency>
</dependencies>
使用如下任意一种配置方法配置镜像仓地址(本文提供了如下两种配置方法)。
● 配置方法一:
在setting.xml配置文件的mirrors节点中添加开源镜像仓地址:
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<url>https://repo1.maven.org/maven2/</url>
</mirror>
在setting.xml配置文件的profiles节点中添加如下镜像仓地址:
<profile>
<id>huaweicloudsdk</id>
<repositories>
<repository>
<id>huaweicloudsdk</id>
<url>https://repo.huaweicloud.com/repository/maven/huaweicloudsdk/</url>
<releases><enabled>true</enabled></releases>
<snapshots><enabled>true</enabled></snapshots>
</repository>
</repositories>
</profile>
在setting.xml配置文件的activeProfiles节点中添加如下镜像仓地址:
<activeProfile>huaweicloudsdk</activeProfile>
说明
华为云开源镜像站不提供第三方开源jar包下载,请配置华为云开源镜像后,额外配置第三 方Maven镜像仓库地址。
● 配置方法二:
在二次开发工程样例工程中的pom.xml文件添加如下镜像仓地址:
<repositories>
<repository>
<id>huaweicloudsdk</id>
<url>https://mirrors.huaweicloud.com/repository/maven/huaweicloudsdk/</url>
<releases><enabled>true</enabled></releases>
<snapshots><enabled>true</enabled></snapshots>
</repository>
<repository>
<id>central</id>
<name>Mavn Centreal</name>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
2.4 配置并导入工程
背景信息
将CloudTable样例代码工程导入到Eclipse,就可以开始CloudTable应用开发样例的学 习。
前提条件
运行环境已经正确配置,请参见准备Windows运行环境。
操作步骤
步骤1 把样例工程上传到Windows开发环境中。样例工程的获取方法请参见下载样例工程。
步骤2 在应用开发环境中,导入样例工程到Eclipse开发环境。
1. 选择“File > Import > General > Existing Projects into Workspace > Next >
Browse”。
显示“浏览文件夹”对话框。如图2-3所示。
2. 选择样例工程文件夹,单击“Finish”。
图
2-3 导入样例工程
步骤3 右键单击cloudtable-example工程,在弹出的右键菜单中单击“Properties”,弹出
“Properties for cloudtable-example”窗口。
1. 在左边导航上选择“Java Build Path”,单击右侧“Libraries”标签页,按图2-4 所示将报错的JDK选中后,单击“Remove”删除。
图
2-4 删除报错的 JDK
2. 单击“Add Library...”按钮,如图2-5所示,在弹出的窗口中选择“JRE System Library”。
图
2-5 选择增加的 library 类型
3. 在“Add Library”页面中,通过“Alternate JRE”或“Workspace default JRE”
选项选择JDK版本。如图2-6所示,选中“Alternate JRE”后,选择JDK版本。
图
2-6 选择 JRE
4. 单击“Finish”关闭窗口完成设置。
步骤4 设置Eclipse的文本文件编码格式,解决乱码显示问题。
1. 在Eclipse的菜单栏中,选择“Window > Preferences”。
弹出“Preferences”窗口。
2. 在左边导航上选择“General > Workspace”,在“Text file encoding”区域,选 中“Other”,并设置参数值为“UTF-8”,单击“Apply”后,单击“OK”,如
图2-7所示。
图
2-7 设置 Eclipse 的编码格式
步骤5 打开样例工程中的“conf/hbase-site.xml”文件,修改“hbase.zookeeper.quorum”
的值为正确的Zookeeper地址。
<property>
<name>hbase.zookeeper.quorum</name>
<value>xxx-zk1.cloudtable.com,xxx-zk2.cloudtable.com,xxx-zk3.cloudtable.com</value>
</property>
其中:value中的值为ZooKeeper集群的域名。登录表格存储服务管理控制台,在左侧 导航树单击“集群模式”,然后在集群列表中找到所需要的集群,并获取相应的“ZK 链接地址”。
----结束
3 开发 HBase 应用
3.1 典型场景说明
通过典型场景,我们可以快速学习和掌握HBase的开发过程,并且对关键的接口函数 有所了解。
场景说明
假定用户开发一个应用程序,用于管理企业中的使用A业务的用户信息,如表3-1所 示,A业务操作流程如下:
● 创建用户信息表。
● 在用户信息中新增用户的学历、职称等信息。
● 根据用户编号查询用户姓名和地址。
● 根据用户姓名进行查询。
● 查询年龄段在[20–29]之间的用户信息。
● 数据统计,统计用户信息表的人员数、年龄最大值、年龄最小值、平均年龄。
● 用户销户,删除用户信息表中该用户的数据。
● A业务结束后,删除用户信息表。
表
3-1 用户信息
编号 姓名 性别 年龄 地址
1200500020
1 A Male 19 Shenzhen,
Guangdong 1200500020
2 B Female 23 Shijiazhuang, Hebei 1200500020
3 C Male 26 Ningbo, Zhejiang
1200500020
4 D Male 18 Xiangyang, Hubei
编号 姓名 性别 年龄 地址 1200500020
5 E Female 21 Shangrao, Jiangxi 1200500020
6 F Male 32 Zhuzhou, Hunan
1200500020
7 G Female 29 Nanyang, Henan
1200500020
8 H Female 30 Kaixian, Chongqing 1200500020
9 I Male 26 Weinan, Shaanxi
1200500021
0 J Male 25 Dalian, Liaoning
数据规划
合理地设计表结构、行键、列名能充分利用HBase的优势。本样例工程以唯一编号作 为RowKey,列都存储在info列族中。
3.2 开发思路
功能分解
根据上述的业务场景进行功能分解,需要开发的功能点如表3-2所示。
表
3-2 在 HBase 中开发的功能
序号 步骤 代码实现
1 根据典型场景说明中的信息创建表。 请参见创建表。
2 导入用户数据。 请参见插入数据。
3 增加“教育信息”列族,在用户信息中新增用 户的学历、职称等信息。
请参见修改表。
4 根据用户编号查询用户姓名和地址。 请参见使用Get读取数
据。
5 根据用户姓名进行查询。 请参见使用过滤器Filter。
6 用户销户,删除用户信息表中该用户的数据。 请参见删除数据。
7 A业务结束后,删除用户信息表。 请参见删除表。
关键设计原则
HBase是以RowKey为字典排序的分布式数据库系统,RowKey的设计对性能影响很 大,具体的RowKey设计请考虑与业务结合。
3.3 样例代码说明
3.3.1 配置参数
步骤1 执行样例代码前,必须在hbase-site.xml配置文件中,配置正确的ZooKeeper集群的地 址。
配置项如下:
<property>
<name>hbase.zookeeper.quorum</name>
<value>xxx-zk1.cloudtable.com,xxx-zk2.cloudtable.com,xxx-zk3.cloudtable.com</value>
</property>
其中:value中的值为ZooKeeper集群的域名。登录表格存储服务管理控制台,在左侧 导航树单击“集群模式”,然后在集群列表中找到所需要的集群,并获取相应的“ZK 链接地址”。
步骤2 在样例代码工程中修改IAM认证相关的参数。
● 如果CloudTable集群开启了IAM认证的功能
在样例代码工程中修改com.huawei.cloudtable.hbase.examples.TestMain类中
“IAM_AUTH_MODE”必须为“true”,同时配置user、ak和sk参数。
代码如下:
private static boolean IAM_AUTH_MODE = true;
private static String user = "XXXXXX";
private static String ak = "XXXXXX";
private static String sk = "XXXXXX";
–
user:为用户名。如果集群是由用户的子用户创建的,子用户访问集群时
user必须配置为“子用户.最终用户”。最终用户访问集群时user配置为用户 名即可。–
ak和sk:AK(Access Key ID)为访问密钥ID,SK(Secret Access Key)为
私有访问密钥,分别设置为AK明文和SK明文。将鼠标移到管理控制台右上角 的用户名,单击“我的凭证”,再单击“管理访问密钥”,可以查看已有的 访问密钥,也可以单击“新增访问密钥”进行创建。说明
IAM认证方式的安全性高于普通模式,建议CloudTable集群开启IAM认证功能,并在客户 端或应用程序代码中采用IAM认证方式连接集群。
● 如果CloudTable集群没有开启IAM认证的功能
com.huawei.cloudtable.hbase.examples.TestMain类中“IAM_AUTH_MODE”必 须为“false”。
----结束
3.3.2 创建 Configuration
功能介绍
HBase通过加载配置文件来获取配置项。
说明
1. 加载配置文件是一个比较耗时的操作,如非必要,请尽量使用同一个Configuration对象。
2. 样例代码未考虑多线程同步的问题,如有需要,请自行增加。其它样例代码也一样,不再一 一进行说明。
代码样例
下面代码片段在com.huawei.cloudtable.hbase.examples包中。
private static void init() throws IOException { // Default load from conf directory
conf = HBaseConfiguration.create(); // 注[1]
String userdir = System.getProperty("user.dir") + File.separator + "conf" + File.separator;
Path hbaseSite = new Path(userdir + "hbase-site.xml");
if (new File(hbaseSite.toString()).exists()) { conf.addResource(hbaseSite);
}}
注意事项
● 注[1] 如果配置文件目录conf已经加入classpath路径中,那么后面的加载指定配 置文件的代码可以不执行。
3.3.3 IAM 集群认证
功能介绍
如果CloudTable集群开启了IAM认证功能,那么就需要先使用最终租户的AK和SK进行 认证,才有权限可以进行后续的操作。
代码样例
private static boolean IAM_AUTH_MODE = true;
private static String user = "";
private static String ak = "";
private static String sk = "";
public static void login(Configuration conf) throws IOException { if (IAM_AUTH_MODE) {
UserProviderExtend.loginWithAKSK(conf, user, ak, sk);
} }
说明
在进程的生命周期内,UserProviderExtend.loginWithAKSK函数只需要调用一次即可。
3.3.4 创建 Connection
功能介绍
HBase通过ConnectionFactory.createConnection(configuration)方法创建Connection 对象。传递的参数为上一步创建的Configuration。
Connection封装了底层与各实际服务器的连接以及与ZooKeeper的连接。Connection 通过ConnectionFactory类实例化。创建Connection是重量级操作,而且Connection是 线程安全的,因此,多个客户端线程可以共享一个Connection。
典型的用法,一个客户端程序共享一个单独的Connection,每一个线程获取自己的 Admin或Table实例,然后调用Admin对象或Table对象提供的操作接口。不建议缓存或 者池化Table、Admin。Connection的生命周期由调用者维护,调用者通过调用
close(),释放资源。
说明
建议业务代码连接同一个CloudTable集群时,多线程创建并复用同一个Connection,不必每个 线程都创建各自Connection。Connection是连接CloudTable集群的连接器,创建过多连接会加 重Zookeeper负载,并损耗业务读写性能。
代码样例
以下代码片段是创建Connection对象的示例:
private TableName tableName = null;
private Connection conn = null;
public HBaseSample(Configuration conf) throws IOException { this.tableName = TableName.valueOf("hbase_sample_table");
this.conn = ConnectionFactory.createConnection(conf);
}
3.3.5 创建表
功能简介
HBase通过org.apache.hadoop.hbase.client.Admin对象的createTable方法来创建表,
并指定表名、列族名。创建表有两种方式(强烈建议采用预分Region建表方式):
● 快速建表,即创建表后整张表只有一个Region,随着数据量的增加会自动分裂成 多个Region。
● 预分Region建表,即创建表时预先分配多个Region,此种方法建表可以提高写入 大量数据初期的数据写入速度。
说明
表名以及列族名不能包含特殊字符,可以由字母、数字以及下划线组成。
代码样例
public void testCreateTable() { LOG.info("Entering testCreateTable.");
// Specify the table descriptor.
HTableDescriptor htd = new HTableDescriptor(tableName); // (1)
// Set the column family name to info.
HColumnDescriptor hcd = new HColumnDescriptor("info"); // (2) // Set data encoding methods. HBase provides DIFF,FAST_DIFF,PREFIX // and PREFIX_TREE
hcd.setDataBlockEncoding(DataBlockEncoding.FAST_DIFF); // 注[1]
// Set compression methods, HBase provides two default compression // methods:GZ and SNAPPY
// GZ has the highest compression rate,but low compression and // decompression efficiency,fit for cold data
// SNAPPY has low compression rate, but high compression and // decompression efficiency,fit for hot data.
// it is advised to use SANPPY
hcd.setCompressionType(Compression.Algorithm.SNAPPY);
htd.addFamily(hcd); // (3) Admin admin = null;
try {
// Instantiate an Admin object.
admin = conn.getAdmin(); // (4) if (!admin.tableExists(tableName)) { LOG.info("Creating table...");
admin.createTable(htd); // 注[2] (5) LOG.info(admin.getClusterStatus());
LOG.info(admin.listNamespaceDescriptors());
LOG.info("Table created successfully.");
} else {
LOG.warn("table already exists");
}
} catch (IOException e) {
LOG.error("Create table failed.", e);
} finally {
if (admin != null) { try {
// Close the Admin object.
admin.close();
} catch (IOException e) {
LOG.error("Failed to close admin ", e);
} }
} LOG.info("Exiting testCreateTable.");
}
解释
(1)创建表描述符
(2)创建列族描述符
(3)添加列族描述符到表描述符中
(4)获取Admin对象,Admin提供了建表、创建列族、检查表是否存在、修改表结构 和列族结构以及删除表等功能。
(5)调用Admin的建表方法。
注意事项
● 注[1] 可以设置列族的压缩方式,代码片段如下:
//设置编码算法,HBase提供了DIFF,FAST_DIFF,PREFIX和PREFIX_TREE四种编码算法 hcd.setDataBlockEncoding(DataBlockEncoding.FAST_DIFF);
//设置文件压缩方式,HBase默认提供了GZ和SNAPPY两种压缩算法 //其中GZ的压缩率高,但压缩和解压性能低,适用于冷数据
//SNAPPY压缩率低,但压缩解压性能高,适用于热数据 //建议默认开启SNAPPY压缩
hcd.setCompressionType(Compression.Algorithm.SNAPPY);
● 注[2] 可以通过指定起始和结束RowKey,或者通过RowKey数组预分Region两种 方式建表,代码片段如下:
// 创建一个预划分region的表 byte[][] splits = new byte[4][];
splits[0] = Bytes.toBytes("A");
splits[1] = Bytes.toBytes("H");
splits[2] = Bytes.toBytes("O");
splits[3] = Bytes.toBytes("U");
admin.createTable(htd, splits);
3.3.6 删除表
功能简介
HBase通过org.apache.hadoop.hbase.client.Admin的deleteTable方法来删除表。
代码样例
public void dropTable() { LOG.info("Entering dropTable.");
Admin admin = null;
try {
admin = conn.getAdmin();
if (admin.tableExists(tableName)) { // Disable the table before deleting it.
admin.disableTable(tableName);
// Delete table.
admin.deleteTable(tableName);//注[1]
}
LOG.info("Drop table successfully.");
} catch (IOException e) {
LOG.error("Drop table failed " ,e);
} finally {
if (admin != null) { try {
// Close the Admin object.
admin.close();
} catch (IOException e) {
LOG.error("Close admin failed " ,e);
} }
} LOG.info("Exiting dropTable.");
}
注意事项
注[1] 只有在调用disableTable接口后, 再调用deleteTable接口才能将表删除成功。
因此,deleteTable常与disableTable,enableTable,tableExists,isTableEnabled,
isTableDisabled结合在一起使用。
3.3.7 修改表
功能简介
HBase通过org.apache.hadoop.hbase.client.Admin的modifyTable方法修改表信息。
代码样例
public void testModifyTable() { LOG.info("Entering testModifyTable.");
// Specify the column family name.
byte[] familyName = Bytes.toBytes("education");
Admin admin = null;
try {
// Instantiate an Admin object.
admin = conn.getAdmin();
// Obtain the table descriptor.
HTableDescriptor htd = admin.getTableDescriptor(tableName);
// Check whether the column family is specified before modification.
if (!htd.hasFamily(familyName)) { // Create the column descriptor.
HColumnDescriptor hcd = new HColumnDescriptor(familyName);
htd.addFamily(hcd);
// Disable the table to get the table offline before modifying // the table.
admin.disableTable(tableName);
// Submit a modifyTable request.
admin.modifyTable(tableName, htd); //注[1]
// Enable the table to get the table online after modifying the // table.
admin.enableTable(tableName);
}
LOG.info("Modify table successfully.");
} catch (IOException e) {
LOG.error("Modify table failed " ,e);
} finally {
if (admin != null) { try {
// Close the Admin object.
admin.close();
} catch (IOException e) {
LOG.error("Close admin failed " ,e);
} }
} LOG.info("Exiting testModifyTable.");
}
注意事项
注[1] 只有在调用disableTable接口后, 再调用modifyTable接口才能将表修改成功。
之后,请调用enableTable接口重新启用表。
3.3.8 插入数据
功能简介
HBase是一个面向列的数据库,一行数据,可能对应多个列族,而一个列族又可以对 应多个列。通常,写入数据的时候,我们需要指定要写入的列(含列族名称和列名 称)。HBase通过HTable的put方法来Put数据,可以是一行数据也可以是数据集。
代码样例
public void testPut() { LOG.info("Entering testPut.");
// Specify the column family name.
byte[] familyName = Bytes.toBytes("info");
// Specify the column name.
byte[][] qualifiers = { Bytes.toBytes("name"), Bytes.toBytes("gender"), Bytes.toBytes("age"), Bytes.toBytes("address") };
Table table = null;
try {
// Instantiate an HTable object.
table = conn.getTable(tableName);
List<Put> puts = new ArrayList<Put>();
// Instantiate a Put object.
Put put = new Put(Bytes.toBytes("012005000201"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("A"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("19"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Shenzhen, Guangdong"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000202"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("B"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Female"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("23"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Shijiazhuang, Hebei"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000203"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("C"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("26"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Ningbo, Zhejiang"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000204"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("D"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("18"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Xiangyang, Hubei"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000205"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("E"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Female"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("21"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Shangrao, Jiangxi"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000206"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("F"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("32"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Zhuzhou, Hunan"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000207"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("G"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Female"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("29"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Nanyang, Henan"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000208"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("H"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Female"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("30"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Kaixian, Chongqing"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000209"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("I"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("26"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Weinan, Shaanxi"));
puts.add(put);
put = new Put(Bytes.toBytes("012005000210"));
put.addColumn(familyName, qualifiers[0], Bytes.toBytes("J"));
put.addColumn(familyName, qualifiers[1], Bytes.toBytes("Male"));
put.addColumn(familyName, qualifiers[2], Bytes.toBytes("25"));
put.addColumn(familyName, qualifiers[3], Bytes.toBytes("Dalian, Liaoning"));
puts.add(put);
// Submit a put request.
table.put(puts);
LOG.info("Put successfully.");
} catch (IOException e) { LOG.error("Put failed " ,e);
} finally {
if (table != null) { try {
// Close the HTable object.
table.close();
} catch (IOException e) {
LOG.error("Close table failed " ,e);
} }
} LOG.info("Exiting testPut.");
}
注意事项
不允许多个线程在同一时间共用同一个HTable实例。HTable是一个非线程安全类,因 此,同一个HTable实例,不应该被多个线程同时使用,否则可能会带来并发问题。
3.3.9 删除数据
功能简介
HBase通过Table实例的delete方法来Delete数据,可以是一行数据也可以是数据集。
代码样例
public void testDelete() { LOG.info("Entering testDelete.");
byte[] rowKey = Bytes.toBytes("012005000201");
Table table = null;
try {
// Instantiate an HTable object.
table = conn.getTable(tableName);
// Instantiate a Delete object.
Delete delete = new Delete(rowKey);
// Submit a delete request.
table.delete(delete);
LOG.info("Delete table successfully.");
} catch (IOException e) {
LOG.error("Delete table failed " ,e);
} finally {
if (table != null) { try {
// Close the HTable object.
table.close();
} catch (IOException e) {
LOG.error("Close table failed " ,e);
} }
} LOG.info("Exiting testDelete.");
}
3.3.10 使用 Get 读取数据
功能简介
要从表中读取一条数据,首先需要实例化该表对应的Table实例,然后创建一个Get对 象。也可以为Get对象设定参数值,如列族的名称和列的名称。查询到的行数据存储在 Result对象中,Result中可以存储多个Cell。
代码样例
public void testGet() { LOG.info("Entering testGet.");
// Specify the column family name.
byte[] familyName = Bytes.toBytes("info");
// Specify the column name.
byte[][] qualifier = { Bytes.toBytes("name"), Bytes.toBytes("address") };
// Specify RowKey.
byte[] rowKey = Bytes.toBytes("012005000201");
Table table = null;
try {
// Create the Table instance.
table = conn.getTable(tableName);
// Instantiate a Get object.
Get get = new Get(rowKey);
// Set the column family name and column name.
get.addColumn(familyName, qualifier[0]);
get.addColumn(familyName, qualifier[1]);
// Submit a get request.
Result result = table.get(get);
// Print query results.
for (Cell cell : result.rawCells()) {
LOG.info(Bytes.toString(CellUtil.cloneRow(cell)) + ":"
+ Bytes.toString(CellUtil.cloneFamily(cell)) + ","
+ Bytes.toString(CellUtil.cloneQualifier(cell)) + ","
+ Bytes.toString(CellUtil.cloneValue(cell)));
}
LOG.info("Get data successfully.");
} catch (IOException e) { LOG.error("Get data failed " ,e);
} finally {
if (table != null) { try {
// Close the HTable object.
table.close();
} catch (IOException e) {
LOG.error("Close table failed " ,e);
} }
} LOG.info("Exiting testGet.");
}
3.3.11 使用 Scan 读取数据
功能简介
要从表中读取数据,首先需要实例化该表对应的Table实例,然后创建一个Scan对象,
并针对查询条件设置Scan对象的参数值,为了提高查询效率,最好指定StartRow和 StopRow。查询结果的多行数据保存在ResultScanner对象中,每行数据以Result对象 形式存储,Result中存储了多个Cell。
代码样例
public void testScanData() { LOG.info("Entering testScanData.");
Table table = null;
// Instantiate a ResultScanner object.
ResultScanner rScanner = null;
try {
// Create the Configuration instance.
table = conn.getTable(tableName);
// Instantiate a Get object.
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// Set the cache size.
scan.setCaching(1000);
// Submit a scan request.
rScanner = table.getScanner(scan);
// Print query results.
for (Result r = rScanner.next(); r != null; r = rScanner.next()) { for (Cell cell : r.rawCells()) {
LOG.info(Bytes.toString(CellUtil.cloneRow(cell)) + ":"
+ Bytes.toString(CellUtil.cloneFamily(cell)) + ","
+ Bytes.toString(CellUtil.cloneQualifier(cell)) + ","
+ Bytes.toString(CellUtil.cloneValue(cell)));
} }
LOG.info("Scan data successfully.");
} catch (IOException e) {
LOG.error("Scan data failed " ,e);
} finally {
if (rScanner != null) { // Close the scanner object.
rScanner.close();
}
if (table != null) { try {
// Close the HTable object.
table.close();
} catch (IOException e) {
LOG.error("Close table failed " ,e);
} }
} LOG.info("Exiting testScanData.");
}
注意事项
1. 建议Scan时指定StartRow和StopRow,一个有确切范围的Scan,性能会更好些。
2. 可以设置Batch和Caching关键参数。
– Batch
使用Scan调用next接口每次最大返回的记录数,与一次读取的列数有关。
– Caching
RPC请求返回next记录的最大数量,该参数与一次RPC获取的行数有关。
3.3.12 使用过滤器 Filter
功能简介
HBase Filter主要在Scan和Get过程中进行数据过滤,通过设置一些过滤条件来实现,
如设置RowKey、列名或者列值的过滤条件。
代码样例
public void testSingleColumnValueFilter() { LOG.info("Entering testSingleColumnValueFilter.");
Table table = null;
ResultScanner rScanner = null;
try {
table = conn.getTable(tableName);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
// Set the filter criteria.
SingleColumnValueFilter filter = new SingleColumnValueFilter(
Bytes.toBytes("info"), Bytes.toBytes("name"), CompareOp.EQUAL, Bytes.toBytes("I"));
scan.setFilter(filter);
// Submit a scan request.
rScanner = table.getScanner(scan);
// Print query results.
for (Result r = rScanner.next(); r != null; r = rScanner.next()) { for (Cell cell : r.rawCells()) {
LOG.info(Bytes.toString(CellUtil.cloneRow(cell)) + ":"
+ Bytes.toString(CellUtil.cloneFamily(cell)) + ","
+ Bytes.toString(CellUtil.cloneQualifier(cell)) + ","
+ Bytes.toString(CellUtil.cloneValue(cell)));
} }
LOG.info("Single column value filter successfully.");
} catch (IOException e) {
LOG.error("Single column value filter failed " ,e);
} finally {
if (rScanner != null) { // Close the scanner object.
rScanner.close();
}
if (table != null) { try {
// Close the HTable object.
table.close();
} catch (IOException e) {
LOG.error("Close table failed " ,e);
} }
} LOG.info("Exiting testSingleColumnValueFilter.");
}
4 开发 OpenTSDB 应用
4.1 典型场景说明
通过典型场景,我们可以快速学习和掌握OpenTSDB的开发过程,并且对关键的接口 函数有所了解。
场景说明
假定用户开发一个应用程序,用于记录和查询城市的气象信息,记录数据如下表
表
4-1 原始数据
城市 区域 时间 温度 湿度
Shenzhen Longgang 2017/7/1 00:00:00 28 54 Shenzhen Longgang 2017/7/1 01:00:00 27 53 Shenzhen Longgang 2017/7/1 02:00:00 27 52 Shenzhen Longgang 2017/7/1 03:00:00 27 51 Shenzhen Longgang 2017/7/1 04:00:00 27 50 Shenzhen Longgang 2017/7/1 05:00:00 27 49 Shenzhen Longgang 2017/7/1 06:00:00 27 48 Shenzhen Longgang 2017/7/1 07:00:00 27 46 Shenzhen Longgang 2017/7/1 08:00:00 29 46 Shenzhen Longgang 2017/7/1 09:00:00 30 48 Shenzhen Longgang 2017/7/1 10:00:00 32 48 Shenzhen Longgang 2017/7/1 11:00:00 32 49 Shenzhen Longgang 2017/7/1 12:00:00 33 49
城市 区域 时间 温度 湿度 Shenzhen Longgang 2017/7/1 13:00:00 33 50 Shenzhen Longgang 2017/7/1 14:00:00 32 50 Shenzhen Longgang 2017/7/1 15:00:00 32 50 Shenzhen Longgang 2017/7/1 16:00:00 31 51 Shenzhen Longgang 2017/7/1 17:00:00 30 51 Shenzhen Longgang 2017/7/1 18:00:00 30 51 Shenzhen Longgang 2017/7/1 19:00:00 29 51 Shenzhen Longgang 2017/7/1 20:00:00 29 52 Shenzhen Longgang 2017/7/1 21:00:00 29 53 Shenzhen Longgang 2017/7/1 22:00:00 28 54 Shenzhen Longgang 2017/7/1 23:00:00 28 54
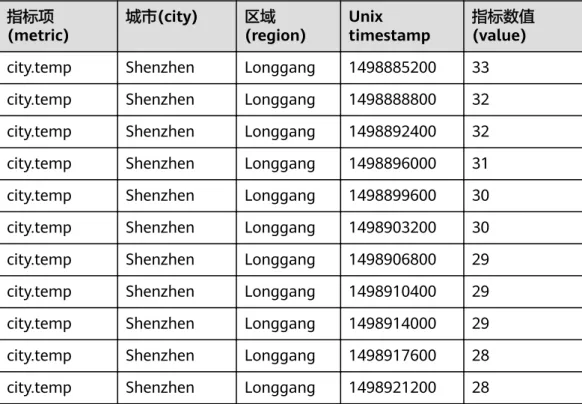
该场景里我们记录了深圳市龙岗区在2017年7月1日零时的温度和湿度数据,这里通过 OpenTSDB的方式建模实质上是两组数据点。
表
4-2 指标数据点 1
指标项
(metric)
城市(city) 区域(region) Unix
timestamp
指标数值(value)
city.temp Shenzhen Longgang 1498838400 28 city.temp Shenzhen Longgang 1498842000 27 city.temp Shenzhen Longgang 1498845600 27 city.temp Shenzhen Longgang 1498849200 27 city.temp Shenzhen Longgang 1498852800 27 city.temp Shenzhen Longgang 1498856400 27 city.temp Shenzhen Longgang 1498860000 27 city.temp Shenzhen Longgang 1498863600 27 city.temp Shenzhen Longgang 1498867200 29 city.temp Shenzhen Longgang 1498870800 30 city.temp Shenzhen Longgang 1498874400 32 city.temp Shenzhen Longgang 1498878000 32 city.temp Shenzhen Longgang 1498881600 33指标项
(metric)
城市(city) 区域(region) Unix
timestamp
指标数值(value)
city.temp Shenzhen Longgang 1498885200 33 city.temp Shenzhen Longgang 1498888800 32 city.temp Shenzhen Longgang 1498892400 32 city.temp Shenzhen Longgang 1498896000 31 city.temp Shenzhen Longgang 1498899600 30 city.temp Shenzhen Longgang 1498903200 30 city.temp Shenzhen Longgang 1498906800 29 city.temp Shenzhen Longgang 1498910400 29 city.temp Shenzhen Longgang 1498914000 29 city.temp Shenzhen Longgang 1498917600 28 city.temp Shenzhen Longgang 1498921200 28表
4-3 指标数据点 2
指标项
(metric)
城市(city) 区域(region) Unix
timestamp
指标数值(value)
city.hum Shenzhen Longgang 1498838400 54 city.hum Shenzhen Longgang 1498842000 53 city.hum Shenzhen Longgang 1498845600 52 city.hum Shenzhen Longgang 1498849200 51 city.hum Shenzhen Longgang 1498852800 50 city.hum Shenzhen Longgang 1498856400 49 city.hum Shenzhen Longgang 1498860000 48 city.hum Shenzhen Longgang 1498863600 46 city.hum Shenzhen Longgang 1498867200 46 city.hum Shenzhen Longgang 1498870800 48 city.hum Shenzhen Longgang 1498874400 48 city.hum Shenzhen Longgang 1498878000 49 city.hum Shenzhen Longgang 1498881600 49 city.hum Shenzhen Longgang 1498885200 50指标项
(metric)
城市(city) 区域(region) Unix
timestamp
指标数值(value)
city.hum Shenzhen Longgang 1498888800 50 city.hum Shenzhen Longgang 1498892400 50 city.hum Shenzhen Longgang 1498896000 51 city.hum Shenzhen Longgang 1498899600 51 city.hum Shenzhen Longgang 1498903200 51 city.hum Shenzhen Longgang 1498906800 51 city.hum Shenzhen Longgang 1498910400 52 city.hum Shenzhen Longgang 1498914000 53 city.hum Shenzhen Longgang 1498917600 54 city.hum Shenzhen Longgang 1498921200 54其中这两组指标数据点都有2个标签:
● 标签(tag):城市city、区域region
● 标签值(tag value):ShenZhen、Longgang 用户可以执行以下数据操作:
● 获取每天的监控数据,通过OpenTSDB的put接口将两个组数据点写入数据库中。
● 对已有的数据,使用OpenTSDB的query接口进行数据查询和分析。
4.2 开发思路
功能分解
根据上述的业务场景进行功能分解,需要开发的功能点如表4-4。
表
4-4 在 OpenTSDB 中开发的功能
序号 步骤 代码实现
1 根据典型场景说明建立了数据模型 请参见写入数据
2 写入指标数据 请参见写入数据
3 根据指标项进行数据查询 请参见查询数据
4 删除指定范围的数据 请参见删除数据
4.3 样例代码说明
4.3.1 配置参数
步骤1 执行样例代码前,必须在样例代码工程中修改
“com.huawei.cloudtable.opentsdb.examples.OpenTsdbSample”类中的如下参数:
private final static String OPENTSDB_IP = "opentsdb-vdswm7gj45awlom.cloudtable.com";
private final static int OPENTSDB_PORT = 4242;
● OPENTSDB_IP:修改为CloudTable集群信息页面上的OpenTSDB的URL地址。
● OPENTSDB_PORT:端口修改为4242。
步骤2 如果CloudTable集群开启了IAM认证的功能,在样例代码工程中,修改
“com.huawei.cloudtable.opentsdb.examples.OpenTsdbSample”类中的如下参数:
private final static boolean securityMode = true;
private final static String PROJECT_ID = "XXXXXX";
private final static String USER = "XXXXXX";
private final static String AK = "XXXXXX";
private final static String TOKEN = "XXXXXX";
● securityMode:设置为true。如果CloudTable集群未开启IAM认证功能,必须将 该参数设置为false。
说明
IAM认证方式的安全性高于普通模式,建议CloudTable集群开启IAM认证功能,并在客户 端或应用程序代码中采用IAM认证方式连接集群。
● PROJECT_ID:设置项目ID。将鼠标移到管理控制台右上角的用户名,单击“我的 凭证”。在“项目列表”页面可以查看项目ID。
● USER:设置为IAM用户名。如果集群是由用户的子用户创建的,子用户访问集群 时user必须配置为“子用户.最终用户”。最终用户访问集群时user配置为用户名 即可。
● AK:Access Key ID,即访问密钥ID。将鼠标移到管理控制台右上角的用户名,单 击“我的凭证”,再单击“管理访问密钥”,可以查看已有的访问密钥,也可以 单击“新增访问密钥”进行创建。
● TOKEN:可以通过
org.apache.hadoop.hbase.security.token.web.AKSKWebTokenCommonUtil#cre atePassword方法生成。
步骤3 (可选)如果不使用样例工程,样例代码只需要依赖如下第三方jar:
1. gson
<!-- https://mvnrepository.com/artifact/com.google.code.gson/gson -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.2.4</version>
</dependency>
2. httpcore
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpcore -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.4</version>
</dependency>
3. httpclient
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
步骤4 每个HTTP请求都应该设置超时间,设置超时时间的方法如下:
public static void addTimeout(HttpRequestBase req) {
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(5000) .setConnectionRequestTimeout(10000).setSocketTimeout(60000).build();
req.setConfig(requestConfig);
}
----结束
4.3.2 IAM 集群认证
功能简介
如果CloudTable启用了IAM认证功能,那么OpenTSDB必须使用HTTPS进行连接,并 且在HTTP请求的HEADER中携带必需的参数,如下表所示:
表
4-5 HTTP Header 携带的参数
HTTP Header Value
X-TSD-IamAuth true
X-Auth-ProjectId 集群所在的ProjectID
X-Auth-User 租户名
X-Auth-AK 租户的AccessKey
X-Auth-Token 使用租户AccessKey和SecretKey生成的 Token信息
说明
Token的生成方法如下:
在客户端主机的操作系统的shell界面中执行。在客户端机器上进入HBase目录后执行Token工 具,Token工具的命令格式如下:
./bin/hbase com.huawei.cloudtable.tool.RestTokenUtil <AccessKey> <SecretKey>
<UserName>
“AccessKey”:用户的AccessKey。
“SecretKey”:用户的SecretKey。
“UserName”:用户名。
例如:
./bin/hbase com.huawei.cloudtable.tool.RestTokenUtil YourAccessKey YourSecretKey YourUserName
样例代码
使用HTTPS连接的时候,应用侧需要跳过校验证书。使用如下方法创建的HTTP Client 可以跳过校验证书:
private static CloseableHttpClient createSSLClientDefault() { try {
X509TrustManager x509mgr = new X509TrustManager() {
public void checkClientTrusted(X509Certificate[] xcs, String string) { }
public void checkServerTrusted(X509Certificate[] xcs, String string) { }
public X509Certificate[] getAcceptedIssuers() { return null;
} };
SSLContext sslContext = SSLContext.getInstance("TLS");
sslContext.init(null, new TrustManager[] { x509mgr }, null);
@SuppressWarnings("deprecation")
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext, SSLConnectionSocketFactory.ALLOW_ALL_HOSTNAME_VERIFIER);
return HttpClients.custom().setSSLSocketFactory(sslsf).build();
} catch (KeyManagementException e) { throw new RuntimeException(e);
} catch (NoSuchAlgorithmException e) { throw new RuntimeException(e);
} catch (Exception e) {
throw new RuntimeException(e);
} }
在构造HTTP请求的时候,需要在HTTP请求中增加必需的HEADER,方法如下:
HttpPost httpPost = new HttpPost(PUT_URL);
httpPost .addHeader("X-TSD-IamAuth", "true");
httpPost .addHeader("X-Auth-ProjectId", PROJECT_ID);
httpPost .addHeader("X-Auth-User", USER);
httpPost .addHeader("X-Auth-AK", AK);
httpPost .addHeader("X-Auth-Token", TOKEN);
4.3.3 写入数据
功能简介
使用OpenTSDB的接口写入数据。
函数genWeatherData()模拟生成的气象数据,函数put()发送气象数据到OpenTSDB 服务端。
样例代码
private static String PUT_URL = (securityMode ? "https://" : "http://") + OPENTSDB_IP + ":"
+ OPENTSDB_PORT + "/api/put/?sync&sync_timeout=60000";
static class DataPoint { public String metric;
public Long timestamp;
public Double value;
public Map<String, String> tags;
public DataPoint(String metric, Long timestamp, Double value, Map<String, String> tags) {
this.metric = metric;
this.timestamp = timestamp;
this.value = value;
this.tags = tags;
}}
private String genWeatherData() {
List<DataPoint> dataPoints = new ArrayList<DataPoint>();
Map<String, String> tags = ImmutableMap.of("city", "Shenzhen", "region", "Longgang");
// Data of air temperature
dataPoints.add(new DataPoint("city.temp", 1498838400L, 28.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498842000L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498845600L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498849200L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498852800L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498856400L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498860000L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498863600L, 27.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498867200L, 29.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498870800L, 30.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498874400L, 32.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498878000L, 32.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498881600L, 33.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498885200L, 33.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498888800L, 32.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498892400L, 32.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498896000L, 31.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498899600L, 30.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498903200L, 30.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498906800L, 29.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498910400L, 29.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498914000L, 29.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498917600L, 28.0, tags));
dataPoints.add(new DataPoint("city.temp", 1498921200L, 28.0, tags));
// Data of humidity
dataPoints.add(new DataPoint("city.hum", 1498838400L, 54.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498842000L, 53.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498845600L, 52.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498849200L, 51.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498852800L, 50.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498856400L, 49.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498860000L, 48.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498863600L, 46.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498867200L, 46.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498870800L, 48.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498874400L, 48.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498878000L, 49.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498881600L, 49.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498885200L, 50.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498888800L, 50.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498892400L, 50.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498896000L, 51.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498899600L, 51.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498903200L, 51.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498906800L, 51.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498910400L, 52.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498914000L, 53.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498917600L, 54.0, tags));
dataPoints.add(new DataPoint("city.hum", 1498921200L, 54.0, tags));
Gson gson = new Gson();
return gson.toJson(dataPoints);
}
public void put() throws ClientProtocolException, IOException { try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpPost httpPost = new HttpPost(PUT_URL);
// 请求需要设置超时时间 addTimeout(httpPost);
String weatherData = genWeatherData();
StringEntity entity = new StringEntity(weatherData, "ISO-8859-1");
entity.setContentType("application/json");
httpPost.setEntity(entity);
HttpResponse response = httpClient.execute(httpPost);
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("Status Code : " + statusCode);
if (statusCode != HttpStatus.SC_NO_CONTENT) {
System.out.println("Request failed! " + response.getStatusLine());
} }}
说明
PUT_URL中加入了sync参数,表示必须等到数据写入HBase后才可以返回,强烈建议使用此参 数;如果不使用sync,表示采用异步写入HBase的方式,可能存在丢失数据的风险。具体信息请 参考OpenTSDB API简介。
4.3.4 查询数据
功能简介
使用OpenTSDB的查询接口读取数据。
函数genQueryReq()生成查询请求,函数query()把查询请求发送到OpenTSDB服务 端。
样例代码
private static String QUERY_URL = (securityMode ? "https://" : "http://") + OPENTSDB_IP + ":"
+ OPENTSDB_PORT + "/api/query";
static class Query { public Long start;
public Long end;
public boolean delete = false;
public List<SubQuery> queries;
}
static class SubQuery { public String metric;
public String aggregator;
public SubQuery(String metric, String aggregator) { this.metric = metric;
this.aggregator = aggregator;
}}
String genQueryReq() { Query query = new Query();
query.start = 1498838400L;
query.end = 1498921200L;
query.queries = ImmutableList.of(new SubQuery("city.temp", "sum"), new SubQuery("city.hum", "sum"));
Gson gson = new Gson();
return gson.toJson(query);
}
public void query() throws ClientProtocolException, IOException { try (CloseableHttpClient httpClient = HttpClients.createDefault()) { HttpPost httpPost = new HttpPost(QUERY_URL);
// 请求需要设置超时时间 addTimeout(httpPost);
String queryRequest = genQueryReq();
//System.out.println("Request=" + queryRequest);
StringEntity entity = new StringEntity(queryRequest, "ISO-8859-1");
entity.setContentType("application/json");
httpPost.setEntity(entity);
HttpResponse response = httpClient.execute(httpPost);
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("Status Code : " + statusCode);
if (statusCode != HttpStatus.SC_OK) {
System.out.println("Request failed! " + response.getStatusLine());
}
String body = EntityUtils.toString(response.getEntity(), "ISO-8859-1");
System.out.println("Response content : " + body);
}}
4.3.5 删除数据
功能简介
在OpenTSDB的查询接口中增加delete参数,并且设置delete参数为true。函数 genQueryReq()生成删除请求,函数delete()把删除请求发送到OpenTSDB服务端。
样例代码
private static String QUERY_URL = (securityMode ? "https://" : "http://") + OPENTSDB_IP + ":"
+ OPENTSDB_PORT + "/api/query";
static class Query { public Long start;
public Long end;
public boolean delete = false;
public List<SubQuery> queries;
}
static class SubQuery { public String metric;
public String aggregator;
public SubQuery(String metric, String aggregator) { this.metric = metric;
this.aggregator = aggregator;
}}
String genQueryReq() { Query query = new Query();
query.start = 1498838400L;
query.end = 1498921200L;
query.queries = ImmutableList.of(new SubQuery("city.temp", "sum"), new SubQuery("city.hum", "sum"));
Gson gson = new Gson();
return gson.toJson(query);
}
String genDeleteReq() { Query query = new Query();
query.start = 1498838400L;
query.end = 1498921200L;
query.queries = ImmutableList.of(new SubQuery("city.temp", "sum"), new SubQuery("city.hum", "sum"));
query.delete = true;
Gson gson = new Gson();
return gson.toJson(query);
}
public void delete() throws ClientProtocolException, IOException { try (CloseableHttpClient httpClient = HttpClients.createDefault()) { HttpPost httpPost = new HttpPost(QUERY_URL);
// 请求需要设置超时时间 addTimeout(httpPost);
String deleteRequest = genDeleteReq();
StringEntity entity = new StringEntity(deleteRequest, "ISO-8859-1");
entity.setContentType("application/json");
httpPost.setEntity(entity);
HttpResponse response = httpClient.execute(httpPost);
int statusCode = response.getStatusLine().getStatusCode();
System.out.println("Status Code : " + statusCode);
if (statusCode != HttpStatus.SC_OK) {
System.out.println("Request failed! " + response.getStatusLine());
} }}
说明
query.delete的参数设置为true后,表示会把查询到的数据都执行删除。具体请参考OpenTSDB API简介。
4.4 性能调优
OpenTSDB服务的吞吐量可以通过扩容tsd节点数量来横向扩展,当前采用Round Robin DNS的机制来把应用端的请求均衡负载到不同的tsd节点。为了使应用端的http 请求更加细粒度地均衡分发,可以优化应用端DNS域名解析缓存。
JVM 优化
● 代码中关闭JVM的DNS域名缓存,同时使用http连接池发送请求。
java.security.Security.setProperty("networkaddress.cache.ttl" , "0") private static CloseableHttpClient httpClient;
static {
PoolingHttpClientConnectionManager cm = new PoolingHttpClientConnectionManager();
cm.setMaxTotal(200);
cm.setDefaultMaxPerRoute(20);
cm.setDefaultMaxPerRoute(50);
httpClient = HttpClients.custom().setConnectionManager(cm).build();
}
● 代码中设置JVM的DNS域名缓存时间为1秒。
java.security.Security.setProperty("networkaddress.cache.ttl" , "1");
● 如果需要考虑扩容后不重启应用能够识别出新的IP地址,可以考虑设置连接的 TTL,但是对性能会有一点影响。
HttpClients.custom().setConnectionTimeToLive(600, TimeUnit.SECONDS);
OS 优化
● Linux操作系统关闭本地DNS域名解析缓存。检查/etc/init.d/目录下是否有nscd 或 者 named 或者 dnsmasq,如果存在,分别执行如下命令关闭缓存。
/etc/init.d/nscd stop /etc/init.d/named stop /etc/init.d/dnsmasq stop
● Windows操作系统关闭本地DNS域名解析缓存。在cmd中执行如下命令。
net stop dnscache
5 开发 GeoMesa 应用
5.1 典型场景说明
通过典型场景,我们可以快速学习和掌握GeoMesa的开发过程,并且对关键的接口函 数有所了解。
场景说明
假定用户开发一个应用程序,用于记录和查询其与朋友见面约会信息:与谁在什么时 间什么地点做了什么,记录数据格式如表:
字段名称 字段类型
Who String
What Long
When Date
Where Point
Why String
5.2 开发思路
根据上述的业务场景进行功能分解,需要开发的功能点如表:
序号 步骤 代码实现
1 连接GeoMesa集群 请参见创建DataStore。
2 创建数据表 请参见创建数据表。
3 插入数据 请参见插入数据。
4 查询数据 请参见查询数据。
5.3 样例代码说明
5.3.1 配置参数
步骤1 执行样例代码前,必须在hbase-site.xml配置文件中,配置正确的ZooKeeper集群的地 址。
配置项如下:
<property>
<name>hbase.zookeeper.quorum</name>
<value>xxx-zk1.cloudtable.com,xxx-zk2.cloudtable.com,xxx-zk3.cloudtable.com</value>
</property>
其中:value中的值为ZooKeeper集群的域名。登录表格存储服务管理控制台,在左侧 导航树单击“集群模式”,然后在集群列表中找到所需要的集群,并获取相应的“ZK 链接地址”。
----结束
5.3.2 创建 DataStore
功能简介
使用GeoMesa的接口连接GeoMesa集群创建DataStore,DataStore实例提供可对 GeoMesa指定目录操作的接口。
样例代码
// find out where -- in HBase -- the user wants to store data CommandLineParser parser = new BasicParser();
Options options = getCommonRequiredOptions();
CommandLine cmd = parser.parse(options, new String[]{"--bigtable_table_name", "geomesa"});
// verify that we can see this HBase destination in a GeoTools manner Map<String, Serializable> dsConf = getHBaseDataStoreConf(cmd);
DataStore dataStore = DataStoreFinder.getDataStore(dsConf);
5.3.3 创建数据表
功能简介
在指定目录的DataStore中创建数据表。
样例代码
// establish specifics concerning the SimpleFeatureType to store String simpleFeatureTypeName = "QuickStart";
// list the attributes that constitute the feature type
String attributes = "Who:String,What:java.lang.Long,When:Date,*Where:Point:srid=4326,Why:String";
// create the bare simple-feature type
SimpleFeatureType simpleFeatureType = SimpleFeatureTypes.createType(simpleFeatureTypeName, attributes);
dataStore.createSchema(simpleFeatureType);