國立臺灣大學電機資訊學院電機工程學系 博士論文
Department of Electrical Engineering
College of Electrical Engineering and Computer Science
National Taiwan University Doctoral Dissertation
隱私保存的高效率資料分類方法
Efficient Data Classification with Privacy-Preservation
林耕霈 Keng-Pei Lin
指導教授:陳銘憲 博士 Advisor: Ming-Syan Chen, Ph.D.
中華民國一百年七月
July, 2011
摘要
資料分類是被廣泛使用的資料探勘技術。資料分類從已標記的資料去學習出分類 器,用以去預測無標記資料的可能標記。在資料分類演算法中,支持向量機器具 有目前最佳的效能。資料隱私是使用資料探勘技巧的關鍵議題。在本論文中,我 們研究如何在使用支持向量機器時達成對資料隱私的保護,並且探討如何有效率 的產生支持向量機器分類器。
在當前的雲端運算趨勢中,運算外包漸為流行。因為支持向量機器的訓練演算法 牽涉到大量的運算,將運算外包到外部的服務提供者可幫助僅具備有限運算資源 的資料所有人。因為資料可能內含敏感的資訊,資料隱私是運算外包中被嚴重關 切的問題。除了資料本身,從資料所產生的分類器亦是資料所有人的私有資產。
現有的支持向量機器的隱私保存技巧在安全性上較弱。在第二章中,我們提出了 高安全性的具備隱私保存的支持向量機器外包方法。在所提出的方法中,資料經 由隨機線性轉換所打亂,因此相較於現有的作品,有較強的安全性。服務提供者 從打亂的資料去產生支持向量機器分類器,而且所產生的分類器亦是打亂的形式,
服務提供者無法存取。
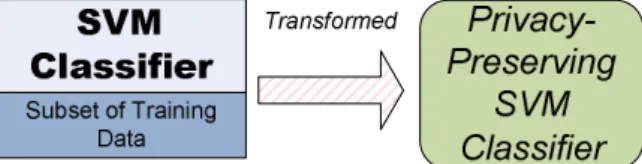
在第三章,我們探討使用支持向量機器分類器所固有的違反隱私問題。支持向量 機器訓練分類器的方法是藉由解決最佳化問題來決定訓練資料集中的那些資料個 體做為支持向量。支持向量是提供必要資訊用以組成支持向量機器分類器的資料 個體。因為支持向量是從訓練資料集中所取出的完整個體,釋出支持向量機器分 類器供公眾或他人使用將會揭露支持向量的私密內容。我們提出一個對支持向量 機器分類器作後處理的方法,用以轉換其至具有隱私保存的支持向量機器分類器,
來避免揭露支持向量的私密內容。此方法精確的去近似高斯核心函數支持向量機 器分類器的決策函數,而不去洩漏個別支持向量的內容。具備隱私保存的支持向
量機器分類器可以在不違反個別資料隱私的情況下去釋出支持向量機器分類器的 預測能力。
支持向量機器的效率亦是個重要的議題。因為對於大規模的資料,支持向量機器 的解法收斂得很慢。在第四章,我們利用在第三章所發展的核心近似技術,用以 設計一個高效率的支持向量機器訓練演算法。雖然核心函數給支持向量機器帶來 了強大的分類能力,但是在訓練過程亦導致了額外的運算成本。相對的,訓練線 性支持向量機器有較快的解法。我們使用核心近似技術由明確的低維度特徵值的 內積去計算核心值,以利用高效率的線性支持向量機器解法去訓練非線性支持向 量機器。此法不僅是一個高效率的訓練方法,還能直接獲得具備隱私保存的支持 向量機器分類器,亦即其分類器沒有揭露任何的資料個體。
我們做了廣泛的實驗用以驗證所提出的方法。實驗結果顯示,具備隱私保存的支 持向量機器外包方法、具備隱私保存的支持向量機器分類器,以及基於核心近似 的高效率支持向量機器訓練方法,皆可達到相似於一般支持向量機器分類器的分 類精確度,並且具備了隱私保存及高效率的特性。
關鍵詞:資料探勘,分類,支持向量機器,核心函數,隱私保存,外包
Abstract
Data classification is a widely used data mining technique which learns classifiers from labeled data to predict the labels of unlabeled instances. Among data classification algo- rithms, the support vector machine (SVM) shows the state-of-the-art performance. Data privacy is a critical concern in applying the data mining techniques. In this dissertation, we study how to achieve privacy-preservation in utilizing the SVM as well as how to efficiently generate the SVM classifier.
Outsourcing has become popular in current cloud computing trends. Since the training algorithm of the SVM involves intensive computations, outsourcing to external service providers can benefit the data owner who possesses only limited computing resources. In outsourcing, the data privacy is a critical concern since there may be sensitive information contained in the data. In addition to the data, the classifier generated from the data is also private to the data owner. Existing privacy-preserving SVM outsourcing technique is weak in security. In Chapter 2, we propose a secure privacy-preserving SVM outsourcing scheme. In the proposed scheme, the data are perturbed by random linear transformation which is stronger in security than existing works. The service provider generates the SVM classifier from the perturbed data where the classifier is also in perturbed form and cannot be accessed by the service provider.
In Chapter 3, we study the inherent privacy violation problem in the SVM classifier.
The SVM trains a classifier by solving an optimization problem to decide which instances of the training dataset are support vectors, which are the necessarily informative instances to form the SVM classifier. Since support vectors are intact tuples taken from the training dataset, releasing the SVM classifier for public use or other parties will disclose the private content of support vectors. We propose an approach to post-process the SVM classifier to transform it to a privacy-preserving SVM classifier which does not disclose the private content of support vectors. It precisely approximates the decision function of the Gaussian kernel SVM classifier without exposing the individual content of support vectors. The
privacy-preserving SVM classifier is able to release the prediction ability of the SVM classifier without violating the individual data privacy.
The efficiency of the SVM is also an important issue since for large-scale data, the SVM solver converges slowly. In Chapter 4, we design an efficient SVM training algo- rithm based on the kernel approximation technique developed in Chapter 3. The kernel function brings powerful classification ability to the SVM, but it incurs additional com- putational cost in the training process. In contrast, there exist faster solvers to train the linear SVM. We capitalize the kernel approximation technique to compute the kernel evaluation by the dot product of explicit low-dimensional features to leverage the effi- cient linear SVM solver for training a nonlinear kernel SVM. In addition to an efficient training scheme, it obtains a privacy-preserving SVM classifier directly, i.e., its classifier does not disclose any individual instance.
We conduct extensive experiments over our studies. Experimental results show that the privacy-preserving SVM outsourcing scheme, the privacy-preserving SVM classifier, and the efficient SVM training scheme based on kernel approximation achieve similar classification accuracy to a normal SVM classifier while obtains the properties of privacy- preservation and efficiency respectively.
Keywords: Data mining, classification, support vector machines, kernel function, privacy- preserving, outsourcing
Table of Contents
1 Introduction 1
1.1 Motivation . . . 1
1.2 Overview of the Dissertation . . . 3
1.2.1 Privacy-Preserving Outsourcing of the SVM . . . 3
1.2.2 Privacy-Preserving Release of the SVM Classifier . . . 4
1.2.3 Efficient Training of the SVM with Kernel Approximation . . . . 5
1.3 Organization of the Dissertation . . . 5
2 Secure Support Vector Machines Outsourcing with Random Linear Trans- formation 6 2.1 Introduction . . . 6
2.2 Related Work . . . 11
2.3 Preliminary . . . 15
2.3.1 Review of the SVM . . . 15
2.3.2 Privacy-Preserving Outsourcing of SVM with Geometric Pertur- bations and Its Security Concerns . . . 17
2.4 Secure SVM Outsourcing with Random Linear Transformation . . . 20
2.4.1 Secure Kernel Matrix with the Reduced SVM . . . 21
2.4.2 Building the Secure Kernel Matrix from Data Perturbed by Ran- dom Linear Transformation . . . 25
2.4.3 Performing Parameter Search Process on Randomly Transformed Data . . . 28
2.4.4 Privacy-Preserving Outsourcing of Testing . . . 31
2.4.5 Computational Complexity and Communication Cost . . . 32
2.5 Security Analysis of the Outsourcing Scheme . . . 32
2.6 Enhancing Security with Redundancy . . . 34
2.7 Experimental Analysis . . . 37
2.7.1 Utility of Classification . . . 38
2.7.2 Efficiency of Outsourcing . . . 39
2.7.3 Utility Comparison with k-Anonymity . . . . 41
2.8 Summary . . . 43
3 On the Design and Analysis of the Privacy-Preserving SVM Classifier 44 3.1 Introduction . . . 44
3.2 Related Work . . . 49
3.3 SVM and Privacy-Preservation . . . 52
3.3.1 Review of the SVM . . . 52
3.3.2 Privacy Violation of the SVM Classifiers . . . 55
3.4 Privacy-Preserving SVM Classifier . . . 57
3.4.1 Construction of the Privacy-Preserving Decision Function . . . . 57
3.4.2 PPSVC: Approximation of the Privacy-Preserving Decision Func- tion . . . 63
3.4.3 Complexity of the PPSVC . . . 65
3.5 Security and Approximating Precision of the PPSVC . . . 66
3.5.1 Security of the PPSVC Against Adversarial Attacks . . . 67
3.5.2 Approximating Precision Issues of the PPSVC . . . 70
3.6 Experimental Analysis . . . 72
3.6.1 Approximating the SVM Classifier . . . 72
3.6.2 Effect of the Constraint on Kernel Parameter . . . 75
3.6.3 Scalability to Large-Scale Datasets . . . 76
3.6.4 Performance Comparison with k-Anonymity . . . . 77
3.7 Summary . . . 78
4 Efficient Kernel Approximation for Large-Scale Support Vector Machine Clas-
sification 79
4.1 Introduction . . . 79
4.2 Preliminary . . . 83
4.2.1 Related Work . . . 83
4.2.2 Review of the SVM . . . 85
4.3 Approximating the Gaussian Kernel Function by Taylor Polynomial-based Monomial Features . . . 86
4.4 Efficient Training of the Gaussian Kernel SVM with a Linear SVM Solver and TPM Feature Mapping . . . 91
4.4.1 Complexity of the Classifier . . . 93
4.4.2 Data Dependent Sparseness Property . . . 94
4.4.3 Precision Issues of Approximation . . . 95
4.5 Experiments . . . 97
4.5.1 Time of Applying TPM Feature Mapping . . . 99
4.5.2 Comparison of Accuracy and Efficiency . . . 100
4.6 Summary . . . 102
5 Conclusion 103
Bibliography 105
List of Figures
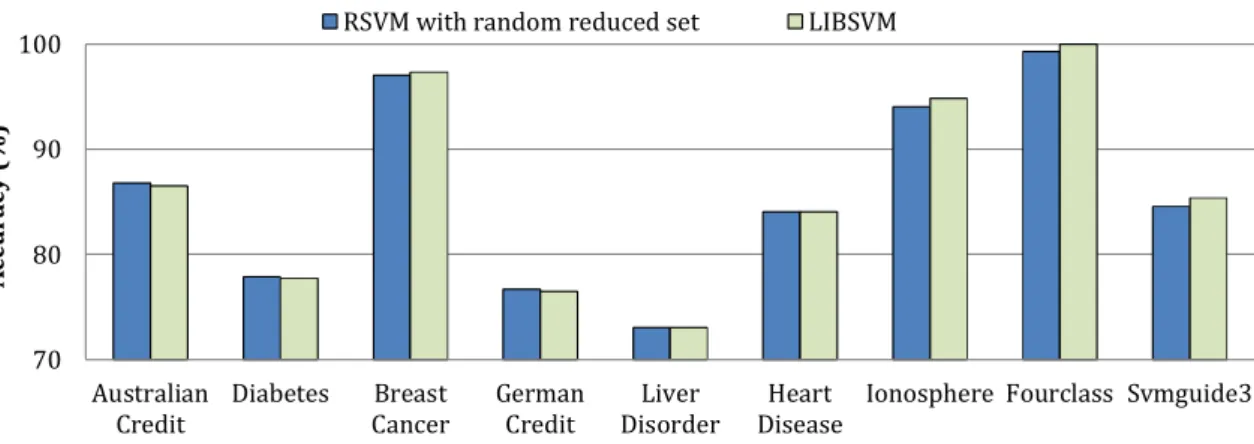
2.1 Privacy-preserving outsourcing of the SVM. . . 9 2.2 Comparison of the classification accuracy between the RSVM with ran-
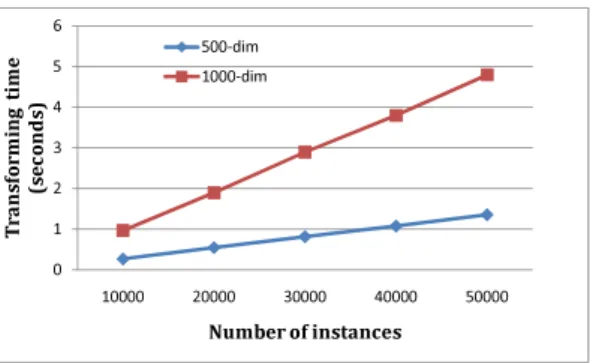
dom reduced set and a conventional SVM. . . 39 2.3 Computing time of perturbing data by random linear transformation. . . 41 2.4 Classification performance comparison between the RSVM with random
reduced set and the SVMs trained from k-anonymized data. . . . 42 3.1 Application scenario: Releasing the learned SVM classifier to clients or
outsourcing to cloud-computing service providers without exposing the sensitive content of the training data. . . 47 3.2 The PPSVC post-processes the SVM classifier to transform it to a privacy-
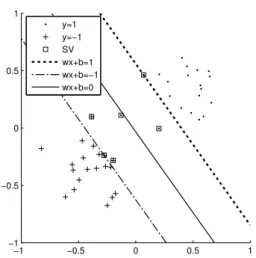
preserving SVM classifier which does not disclose the private content of the training data. . . 48 3.3 The SVM maximizes the margin between two classes of data. Squared
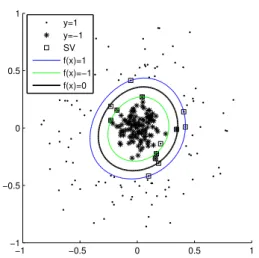
points are support vectors. . . 53 3.4 A Gaussian kernel SVM classifier: All support vectors must be kept in
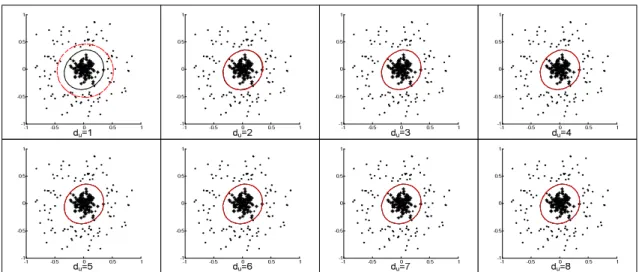
the classifier, which violates privacy. . . 56 3.5 The PPSVC’s approximation of the decision boundary from du = 1 to
du = 8. The solid curve in each sub-figure is the original decision boundary, and the dotted curve is the approximation of the PPSVC. From du = 5, the two curves are almost overlapped together. . . 64 3.6 The flow diagram of deriving the privacy-preserving SVM classifier (PPSVC). 65 3.7 The approximation of exp(x) by its 5-order Taylor polynomial at 0. . . . 71
3.8 Classification Accuracy of the original SVM classifier and PPSVCs with du = 1 to 5. . . 74 3.9 Classification accuracy comparison of g with and without upper bound
1
#attributes in parameter search. . . 76 3.10 Comparison of classifier complexity between the original SVM classifier
and the PPSVC. . . 77 3.11 Performance comparison with k-anonymity. . . . 78 4.1 Approximate training of the Gaussian kernel SVM by TPM feature map-
ping with a linear SVM solver. . . 92 4.2 The approximation of the Gaussian kernel SVM by the linear SVM with
TPM feature mapping. In each sub-figure, the solid curve is the decision boundary obtained by the Gaussian kernel SVM, and the dotted curve is obtained by the linear SVM with TPM feature mapping from du = 1 to du = 4. . . 93
List of Tables
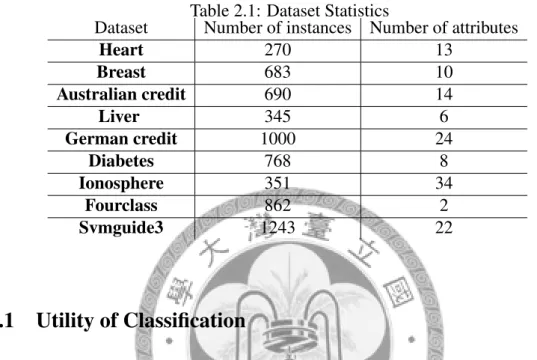
2.1 Dataset Statistics . . . 38 2.2 Time comparison of training SVMs with/without outsourcing . . . 40 2.3 Time comparison of testing 10,000 instances with/without outsourcing . . 41 4.1 Dataset statistics. . . 96 4.2 Comparison bases - Running time and accuracy of Gaussian kernel and
linear SVMs. . . 98 4.3 Time of applying degree-2 TPM feature mapping and the number of nonzero
features in mapped data. . . 98 4.4 Classification results - Training time and testing accuracy of three explicit
mapping with linear SVM. . . 99 4.5 Testing time of the classifiers. . . 99
Chapter 1 Introduction
1.1 Motivation
The popularity of electronic data held by commercial corporations has increased the con- cern on the privacy protection of personal information. The advent of cloud computing paradigm, which stores data and performs computations in remote servers, further raises the concerns on data privacy. Data mining [11], an important and widely used information technology, has been viewed as a threat to the sensitive content of data. This has led to research for privacy-preserving data mining techniques [2, 4, 32].
Data classification, an important and frequently used data mining technique, has re- ceived a significant amount of research efforts over decades [20]. The classification al- gorithm trains a classifier from the labeled data for predicting the labels of future data.
There have been various privacy-preserving classification schemes [1,4]. Among the data classification techniques, the support vector machine (SVM) [6, 55] is a statistically ro- bust classification algorithm which shows the state-of-the-art performance. The SVM finds an optimal separating hyperplane which maximizes the margin between two classes of data in the kernel-induced high-dimensional feature space. The SVM, as a powerful classification algorithm, has also attracted lots of attention from researchers who studied privacy-preserving data mining techniques [9, 26]. However, some critical privacy issues in utilizing the SVM are still not addressed in the literature.
In this dissertation, we consider on two kinds of privacy concerns of utilizing the SVM
and provide the solutions for privacy-preserving outsourcing of the SVM and the release of the classifier utility without violating individual privacy. In addition to the privacy aspects, we also consider the efficiency issue of using the SVM since training the SVM is a computationally intensive task.
In the first part of this dissertation, we design a privacy-preserving outsourcing scheme of the SVM. Current trends of information technology industry have been towards cloud computing. Since training the SVM is very computationally intensive, outsourcing the computations of SVM training to cloud computing service providers can benefit the data owner who possesses only limited computing resources. In outsourcing, data privacy is a critical concern since the service provider may be malicious or compromised. Both the data and the classifier generated from the data are valuable assets of the data owner, whose access should be protected.
The second part is for privacy-preserving release of the utility of the SVM classifier without violating the individual data privacy. Since the classifier learned by the SVM contains some intact instances of training data, releasing the SVM classifier to public or other parties will disclose the content of some training instances. Our objective is to release the SVM classifier without revealing the training data while preserving the classifier utility for predicting labels. We design a scheme to release a privacy-preserving form of the SVM classifier, which is a kind of aggregate information of data, without disclosing the individual content.
In the third part of this dissertation, we consider on the efficiency issue of using the SVM, which is also a critical concern since training the SVM on large-scale data is usually very time-consuming. Although the kernel trick brings powerful classification ability to the SVM, it incurs additional computational cost in the training process. We design a kernel approximation method which approximates the kernel function by the dot product of explicit low-dimensional features to leverage the efficient linear SVM solver to train a nonlinear kernel SVM.
These three parts act different roles in utilizing the SVM for efficient data classifica- tion with privacy-preservation.
In the complete privacy-preserving scenario, the first part is a front-end privacy- preserving scheme for outsourcing the SVM training, and the second part is a back-end privacy-preserving scheme for releasing the prediction ability of the built classifier. The front-end scheme protects the data from the external service provider in training, and the back-end scheme protects the data from the classifier users in testing. In both parts, the training data of the data owner are not revealed. The external service provider builds the SVM classifier for the data owner without accessing the actual training data, and then the data owner releases the prediction utility of the SVM classifier for others without disclosing the training data included in the classifier.
The third part of the dissertation is not merely en efficient training scheme of the SVM.
It extends the work of the second part to generate a privacy-preserving SVM classifier directly and efficiently. With the efficient training scheme of the third part, there is no need to train an SVM classifier first and then post-processes it to a privacy-preserving form. It generates a privacy-preserving classifier directly, which provides an efficient way to locally train a privacy-preserving SVM classifier.
1.2 Overview of the Dissertation
1.2.1 Privacy-Preserving Outsourcing of the SVM
The support vector machine (SVM) is a popular classification algorithm. Since training the SVM is very time-consuming, outsourcing the computations of solving the SVM to external service providers benefits the data owner who is not familiar with the techniques of the SVM or has only limited computing resources. In outsourcing, the data privacy is a critical concern for some legal or commercial reasons since there may be sensitive information contained in the data. Existing privacy-preserving data mining works are either not appropriate to outsourcing the SVM or weak in security.
In Chapter 2, we propose a scheme for privacy-preserving outsourcing of the SVM, which perturbs the data by random linear transformation. The service provider solves the SVM from the perturbed data without knowing the actual content of the data, and
the generated SVM classifier is also perturbed, which can only be recovered by the data owner. Both the privacy of data and generated classifiers are protected. The proposed scheme is stronger in security than existing techniques, and incurs very little additional communication and computation cost. The experimental results show that the proposed scheme imposes very little overhead on the data owner, and the classification accuracy is similar to a normal SVM classifier.
1.2.2 Privacy-Preserving Release of the SVM Classifier
The SVM trains a classifier by solving an optimization problem to decide which instances of the training dataset are support vectors, which are the necessarily informative instances to form the SVM classifier. Since support vectors are intact tuples taken from the train- ing dataset, releasing the SVM classifier for public use or shipping the SVM classifier to clients will disclose the private content of support vectors. This violates the privacy- preserving requirements for some legal or commercial reasons. The problem is that the classifier learned by the SVM inherently violates the privacy. This privacy violation prob- lem will restrict the applicability of the SVM. To the best of our knowledge, there has not been work extending the notion of privacy-preservation to tackle this inherent privacy violation problem of the SVM classifier.
In Chapter 3, we exploit this privacy violation problem, and propose an approach to post-process the SVM classifier to transform it to a privacy-preserving classifier which does not disclose the private content of support vectors. The post-processed SVM clas- sifier without exposing the private content of training data is called Privacy-Preserving SVM Classifier (abbreviated as PPSVC). The PPSVC is designed for the commonly used Gaussian kernel function. It precisely approximates the decision function of the Gaussian kernel SVM classifier without exposing the sensitive attribute values possessed by sup- port vectors. By applying the PPSVC, the SVM classifier is able to be publicly released while preserving privacy. We prove that the PPSVC is robust against adversarial attacks.
The experiments on real datasets show that the classification accuracy of the PPSVC is comparable to the original SVM classifier.
1.2.3 Efficient Training of the SVM with Kernel Approximation
Training support vector machines with nonlinear kernel functions on large-scale data are usually very time-consuming. In contrast, there exist faster solvers to train the linear SVM. Although the kernel trick brings powerful classification ability to the SVM, it incurs additional computational cost in the training process.
In Chapter 4, we capitalize the kernel approximation technique developed in PPSVC of Chapter 3 to leverage the linear SVM solver to efficiently train a nonlinear kernel SVM. We approximate the infinite-dimensional implicit feature mapping of the Gaussian kernel function by a low-dimensional explicit feature mapping. By explicitly mapping data to the low-dimensional features, efficient linear SVM solvers can be applied to train the Gaussian kernel SVM, which leverages the efficiency of linear SVM solvers to train a nonlinear kernel SVM. Experimental results show that the proposed technique is very efficient and achieves similar classification accuracy to a normal nonlinear SVM solver.
1.3 Organization of the Dissertation
The rest of this dissertation is organized as follows. Chapter 2 shows our work for se- cure privacy-preserving outsourcing of the SVM. In Chapter 3, we present the privacy- preserving SVM classifier which releases the classifier utility without exposing the con- tent of support vectors. In Chapter 4, we devise an algorithm to efficiently train the SVM based on the technique developed for the privacy-preserving SVM classifier. Chapter 5 concludes this dissertation.
Chapter 2
Secure Support Vector Machines Outsourcing with Random Linear Transformation
2.1 Introduction
Current trends of information technology industry have been towards cloud computing.
Major companies like Google and Microsoft are constructing infrastructures to provide cloud computing services. The cloud computing service providers have powerful, scal- able, and elastic computing abilities, and are expert in the management of large-scale software and hardware resources. The maturity of cloud computing technologies has built a promising environment for outsourcing computations to cloud computing ser- vice providers. This benefits small companies to run larger applications in the cloud- computing environment. Compared with performing computations in-house, outsourcing can help save much hardware, software and personnel investments and help them focus on their core business.
The data mining technique [11], which discovers useful knowledge from collected data, is an important information technology and has been widely employed in vari- ous fields. Data mining algorithms are usually very computationally intensive, and the
datasets for performing data mining can be very large, for example, the transactional data of chain stores, the browsing histories of websites, and the anamneses of patients.
To execute data mining algorithms on large-scale data will require many computational resources and may consume a lot of time. The data owner who collects the data may not possess sufficient computing resources to execute data mining algorithms efficiently.
With only limited computing resources, performing data mining for large-scale data may consume a lot of time or it may even not be able to tackle the tasks. Investing on new powerful computing devices is a heavy burden for smaller organizations and is not effi- cient in cost benefit. Therefore, outsourcing data mining tasks to cloud computing service providers which have abundant hardware and software resources could be a reasonable choice for the data owner instead of executing all by itself.
Data privacy is a critical concern in outsourcing the data mining tasks. Outsourcing unavoidably gives away the access of the data, including the content of data and the out- put of operations performed on the data like aggregate statistics and data mining models.
Both the data and data mining results are valuable asset of the data owner, but the external service providers may not be trustworthy or be malicious. The interest of the data owner will be hurt if the data or the data mining results are leaked to its commercial competi- tors. Leaking the data may even violate the laws. For instance, HIPAA laws require the medical data not to be released without appropriate anonymization [21], and the leakage of personal information is also prohibited by laws in many countries. Therefore, the data privacy needs to be appropriately protected when outsourcing the data mining, and the privacy of the generated data mining results is also considered important. This causes the issue of outsourcing the computations of data mining without giving access of the actual data to the service providers.
The support vector machine (SVM) [55] is a classification algorithm which yields state-of-the-art performance. However, training the SVM is very time-consuming due to the intensive computations involved in solving the quadratic programming optimization problems, and there are usually hundreds of SVM subproblems to be solved in the pa- rameter search process of training the SVM [22, 46]. Outsourcing the parameter search
process to cloud computing environment can capitalize on the clustering of computers to solve those subproblems concurrently, which will significantly reduce the overall running time.
There have been studies for privacy-preserving outsourcing of the SVM by geometri- cally transforming the data with rotation and/or translation [9, 10], which transforms data to another vector space to perturb the content of instances but preserves the dot prod- uct or Euclidean distance relationships among all instances. Since the SVMs with com- mon kernel functions depend only on the dot products or Euclidean distance among all pairs of instances, the same SVM solutions can be derived from the rotated or translated data. However, the preservation of the dot product or Euclidean distance relationships is a weakness in security. If the attacker obtains some original instances from other informa- tion sources, the mappings of the leaked instances and their transformed ones can be iden- tified by comparing the mutual distance or dot products among pairs. For n-dimensional data, if the attacker knows n or more linearly independent instances, after identifying the mappings, all the transformed instances can be recovered by setting up n linear equations.
The work of [10] defended this security weakness by adding Gaussian noise to degrade the preserved distance, but this contradicts the objective of the rotational/translational transformation which aims to preserve the necessary utility of data for training the SVM.
Most existing privacy-preserving SVM works do not address the privacy issues for outsourcing the SVM. The works of [26, 34, 35, 54, 58, 59] focused on how to train SVMs from the data partitioned among different parties without revealing each one’s own data to others. The work of [31] considered the privacy issues of releasing the built SVM classifiers. These privacy-preserving SVM works cannot be applied to protect the data privacy in outsourcing the SVM training to external service providers. General privacy- preserving data mining techniques mainly focused on releasing data for others to perform data mining, which either anonymizing data to prevent from being identified [50] or pol- luting the data by controlled noises in which some aggregate statistics are derivable [4]. In these techniques, data are not hidden but only protected in degraded forms, and distorted data mining models are able to be built.
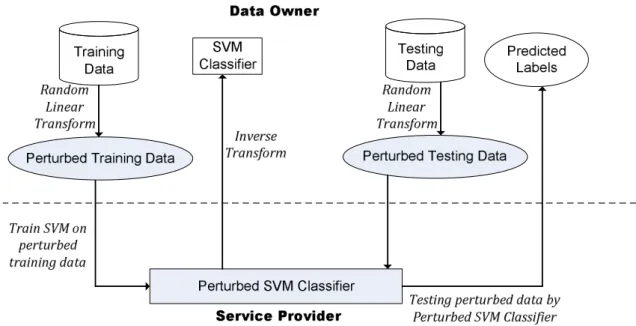
Figure 2.1: Privacy-preserving outsourcing of the SVM.
In this chapter, we discuss the data privacy issues in outsourcing the SVM, and design a scheme for training the SVM from the data perturbed by random linear transformation.
Unlike the geometric transformation, the random linear transformation transforms the data to a random vector space which does not preserve the dot product and Euclidean distance relationships among instances, and hence is stronger in security. The proposed scheme enables the data owner to send the perturbed data to the service provider for out- sourcing the SVM without disclosing the actual content of the data, where the service provider solves SVMs from the perturbed data. Since the service provider may be un- trustworthy, the perturbation protects the data privacy by avoiding unauthorized access to the sensitive content. In addition to the content of data itself, the resulted classifier is also the asset of the data owner. In our scheme, not only the data privacy is protected, the classifier generated from the perturbed data is also in perturbed form, which can only be recovered by the data owner. The service provider cannot use the perturbed classifier to do testing except the perturbed data sent from the data owner for privacy-preserving outsourcing of the testing.
Figure 2.1 shows the application scenario of the proposed scheme for outsourcing the SVM with privacy-preservation. The left side of the figure demonstrates the training phase. The data owner randomly transforms the training data and sends the perturbed
data to the service provider. The service provider derives the perturbed SVM classifier from the perturbed training data and sends it back to the data owner. Then the data owner can recover the perturbed SVM classifier to a normal SVM classifier for performing test- ing. The proposed scheme not only allows to solve an SVM problem from the perturbed training data, but also includes the whole parameter search process by cross-validation for choosing an appropriate parameter combination to train the SVM. The testing can also be outsourced to the service provider, which is shown on the right side of Figure 2.1.
The data owner sends the perturbed testing data to the service provider, and the service provider can use the generated perturbed SVM classifier to test the perturbed testing data, which predicts labels of the testing data.
In privacy-preserving outsourcing of the data mining, the additional computational cost imposed on the data owner should be minimized and the redundant communication cost should also not be too much, or the data owner rather performs data mining by itself than outsourcing. In the proposed scheme for privacy-preserving outsourcing of the SVM, the data sent to the service provider is perturbed by a random linear transformation. Since the linear transformation can be executed very fast, it incurs very little computational overhead to the data owner. The redundant communication cost for training is about 10%
of the original data size, and none for testing.
The following summarizes our contributions:
• We propose a scheme for outsourcing the SVM with the data perturbed by random linear transformation, in which both the data and the generated SVM classifiers are perturbed. The scheme does not preserve the dot product and Euclidean distance relationships among the data and hence is stronger in security than existing works.
• We address the inherent security weakness of revealing the kernel matrix to the service provider, and tackle this issue by using a perturbed secure kernel matrix.
We also analyze the robustness of the secure kernel matrix in the situation of under attack.
• Extensive experiments are conducted to evaluate the efficiency of the proposed
outsourcing scheme and its classification accuracy. The results show that we can achieve similar accuracy to a normal SVM classifier. We also compare the classifi- cation accuracy with the popular anonymous data publishing technique k-anonymity.
The rest of this chapter is organized as follows: In Section 2.2, we survey related works of privacy-preserving outsourcing and privacy-preserving data mining techniques.
Then in Section 2.3, we review the SVM for preliminaries, and we discuss the secu- rity weakness of outsourcing the SVM with data perturbed by geometric transformations.
Section 2.4 describes our proposed scheme, which solves the SVM from randomly trans- formed data for privacy-preserving outsourcing of the SVM. Section 2.5 analyzes the security of the proposed scheme. Then in Section 2.6, we enhance the security by apply- ing redundancies in the perturbation. Section 2.7 shows the experimental results. Finally, we conclude the chapter in Section 2.8.
2.2 Related Work
Data privacy is a critical concern in outsourcing the computations if the content of the data is sensitive. It seems to be a paradox to generate useful results without touching the actual content of the data, and seeing the generated results is also prohibited. Some operations can be performed on encrypted data to generate encrypted results without knowing their actual content by utilizing the homomorphic encryptions [17,38]. The fully homomorphic encryption scheme [16] developed a theoretical framework which enables arbitrary func- tions to be homomorphically operated on encrypted data with appropriate encryptions.
The scheme is theoretically applicable for privacy-preserving delegation of computations to external service providers. However, its computational overhead is very high, which is still far from practical use.
The research of privacy-preserving data mining techniques have developed various schemes for releasing modified data to provide the utilization of the data for other parties to perform data mining tasks without revealing the sensitive or actual content of the data [4, 50]. A popular approach for releasing modified data for data mining is perturbing
the data by adding random noises [4, 14]. The data are individually perturbed by noises randomly drawn from a known distribution, and data mining algorithms are performed on the reconstructed aggregate distributions of the noisy data. The work of [4] addressed on learning decision trees from noise-perturbed data, and the work of [14] addressed on mining association rules.
Generating pseudo-data which mimic the aggregate properties of the original data is also a way for performing privacy-preserving data mining. The work of [1] proposed a condensation-based approach, where data are first clustered into groups, and then pseudo- data are generated from those clustered groups. Data mining algorithms are performed on the generated synthetic data instead of the original data.
The anonymous data publishing techniques such as k-anonymity [45,50] and l-diversity [33] have been successfully utilized in privacy-preserving data mining. Anonymous data publishing techniques modifies quasi-identifier values to reduce the risk of being iden- tified with the help of external information sources. The k-anonymity [50] makes each quasi-identifier value be able to indistinguishably map into at least k-records by generaliz- ing or suppressing the values in quasi-identifier attributes. The l-diversity [33] enhances the k-anonymity by making each sensitive value appear no more than m/l times in a quasi-identifier group with m tuples. The work of [23] studied the performance of the SVM built upon the data anonymizing by the k-anonymity technique and enhanced the performance with the help of additional statistics of the generalized attributes.
The techniques of releasing modified data for data mining can partly fulfill the ob- jective of privacy-preserving outsourcing of data mining tasks which aims to let external service providers build data mining models for the data owner without revealing the actual content of the data. However, there are some privacy issues in outsourcing data mining with such techniques.
The first issue is that the data privacy is still breached since the modified data disclose the content in degraded precision or anonymized forms. The data perturbed by noises drawn from certain distributions to preserve aggregate statistics can be accurately recon- structed to their original content [2]. The k-anonymity techniques also breach the privacy
due to the disclosure of generalized quasi-identifier values, and other non-quasi-identifier attributes are kept intact. In addition to these disclosures, it also incurs the risk of being identified from the help of external information sources. Furthermore, the distortion of data in k-anonymity may degrade the performance of data mining tasks.
The other issue is that the built data mining models are also disclosed if such tech- niques are adopted for outsourcing. Privacy-preserving outsourcing of data mining usu- ally requires protecting the access of both the data and the generated data mining models.
An important family of privacy-preserving data mining algorithms is distributed meth- ods [32, 39]. The purpose of such techniques is for performing data mining on the data partitioned among different parties without compromising the data privacy of each party.
The dataset may either be horizontally partitioned, vertically partitioned, or arbitrarily partitioned, where protocols are designed to exchange the necessary information among parties to compute aggregate results to build data mining models on the whole data with- out revealing the actual content of each party’s own data to others. This method capi- talizes the secure multi-party computations from cryptography. For example, the works of [25, 53] designed protocols for privacy-preserving association rule mining on the data partitioned among different parties, and the work of [32] considered for building decision trees.
Several privacy-preserving SVM works [26, 54, 58, 59] also belong to this family. In the works of [54, 58, 59], training data owners cooperatively compute the Gram matrix to build the SVM problem without revealing their each own data to others by utilizing the secure multi-party integer sum. The work of [26] utilizes homomorphic encryptions to design a private two-party protocol for training the SVM. In these distributed methods, at the end of running the protocols, each party will hold a share of the learned SVM classifier, where testing must be cooperatively performed by all involved parties.
Non-cryptographic techniques are also proposed for privacy-preserving SVMs on par- titioned data. The works of [34,35] adopt the reduced SVM [28] with random reduced set for cooperatively building the kernel matrix to share among parties without revealing each party’s actual data. Our random linear transformation-based outsourcing scheme also uti-
lizes the RSVM with random vectors as the reduced set, which has been used in [34, 35]
for privately computing the kernel matrix on the data partitioned among different parties.
However, the way the RSVM is employed with random vectors in our work is different from [34, 35]. In our privacy-preserving SVM outsourcing scheme, we capitalize on ran- dom vectors to prevent the inherent weakness in the full kernel matrix and enable the computation of the kernel matrix from randomly transformed training data.
Existing privacy-preserving SVM works mostly focused on the distributed data sce- nario or other privacy issues. For example, the work of [31] considered the problem of releasing a built SVM classifier without revealing the support vectors, which are a subset of the training data. To the best of our knowledge, currently only the works of [9, 10] ad- dress the privacy-preserving outsourcing of the SVM, in which geometric transformations are utilized to hide the actual content of data but preserve their dot product or Euclidean distance relationships for solving the SVM. The SVM classifiers built from the geomet- rically transformed data are also in geometrically transformed forms, which can only be recovered by the data owner. However, protecting the data by geometric transformations is weak in security as we have mentioned in the introduction.
Although privacy-preserving outsourcing of data mining can also be viewed as a form of distributed privacy-preserving data mining, the above-mentioned distributed privacy- preserving SVM works are designed for cooperatively constructing data mining models on separately held data. They are not applicable to the scenario of privacy-preserving outsourcing of data mining where the whole data are owned by a single party, and that party wants to delegate the computations of data mining to an external party to construct data mining models but the external party is prohibited from the access of both the actual data and the generated models. These issues of outsourcing the data mining tasks are seldom addressed in the literature of privacy-preserving data mining.
A privacy-preserving data mining technique dedicated to outsourcing is the work of [56]. It designed a scheme for privacy-preserving outsourcing of the association rule mining, in which the items in the database are substituted by ciphers to send to external service providers. The cipher-substituted items protect the actual content of data but
preserve the counts of itemsets for performing association rule mining. The association rules obtained by the service provider are also in ciphered forms, which can only be recovered by the data owner itself.
There have been many works considering for outsourcing the database queries with privacy-preservation. For example, the works of [3, 19] proposed schemes for performing comparison operations and SQL queries on encrypted databases, and the work of [57]
proposed a scheme for performing k-nearest neighbor queries on randomly transformed database. Outsourcing data mining with privacy-preservation is less discussed since there are usually complex operations involved in data mining algorithms.
2.3 Preliminary
In this section, we first briefly review the SVM. Then we discuss the related work which perturbs the data by geometric transformations to outsource the SVM, and show the se- curity weakness of utilizing this scheme.
2.3.1 Review of the SVM
The SVM [55] is a statistically robust learning method with state-of-the-art performance on classification. The SVM trains a classifier by finding an optimal separating hyperplane which maximizes the margin between two classes of data. Without loss of generality, suppose there are m instances of training data. Each instance consists of a (xi, yi) pair where xi ∈ Rndenotes the n features of the i-th instance and yi ∈ {+1, −1} is its class label. The SVM finds the optimal separating hyperplane w· x + b = 0 by solving the quadratic programming optimization problem:
arg min
w,b,ξ
1
2||w||2+ C
∑m i=1
ξi
subject to yi(w· xi+ b)≥ 1 − ξi, ξi ≥ 0, i = 1, ..., m.
Minimizing 12||w||2in the objective function means maximizing the margin between two classes of data. Each slack variable ξi denotes the extent of xi falling into the erroneous region, and C > 0 is the cost parameter which controls the trade-off between maximizing the margin and minimizing the slacks. The decision function is f (x) = w· x + b, and the testing instance x is classified by sign(f (x)) to determine which side of the optimal separating hyperplane it falls into.
The SVM’s optimization problem is usually solved in dual form to apply the kernel trick:
arg min
α
1
2αTQα−
∑m i=1
αi
subject to
∑m i=1
αiyi = 0, 0≤ αi ≤ C, i = 1, ..., m
(2.1)
where Q is called kernel matrix with Qi,j = yiyjk(xi, xj), i = 1, . . . , m, j = 1, . . . , m.
The function k(xi, xj) is called kernel function, which implicitly maps xi and xj into a high-dimensional feature space and computes their dot product there. By applying the kernel trick, the SVM implicitly maps data into the kernel induced high-dimensional space to find an optimal separating hyperplane. Commonly used kernel functions include Gaussian kernel k(x, y) = exp(−g||x − y||2) with g > 0, polynomial kernel k(x, y) = (gx· y + r)d with g > 0, and the neural network kernel k(x, y) = tanh(gx· y + r), where g, r, and d are kernel parameters. The original dot product is called linear kernel k(x, y) = x· y. The corresponding decision function of the dual form SVM is
f (x) =
∑m i=1
αiyik(xi, x) + b, (2.2)
where αi, i = 1, . . . , m are called supports, which denote the weights of each instance to compose the optimal separating hyperplane in the feature space.
Without appropriate choices on the cost and kernel parameters, the SVM will not achieve good classification performance. A process of parameter search (also called model selection) is required to determine a suitable parameter combination of the cost and
kernel parameters for training the SVM. Practitioners usually evaluate the performance of a parameter combination by measuring its average accuracy of cross-validation [22, 46], and the search of parameter combinations is often done in a brute-force way. For ex- ample, with the Gaussian kernel, the guide of LIBSVM [7, 22] suggests performing a grid-search with exponential growth on the combinations of (C, g). The parameter com- bination which results in the highest average cross-validation accuracy will be selected to train an SVM classifier on the full training data.
The parameter search process can be very time-consuming since there are usually hundreds of parameter combinations to try, and for each parameter combination, with c-fold cross-validation, there are c SVMs to be trained on c−1c of the training data. For example, the default search range of LIBSVM’s parameter search tool for Gaussian kernel is C = 2−5 to 215and g = 2−15to 23, both stepped in 22, where 5-fold cross-validation is used. There are 11× 10 = 110 parameter combinations to be tested in its default setting, and hence there are totally 5× 110 = 550 SVMs to be trained in the parameter search process.
If the training dataset is large, training an SVM is already costly, and the parameter search process even involves training hundreds of SVMs along with hundreds of testings.
Due to the heavy computational load, for a data owner who has only limited computing resources, it is reasonable to outsource the SVM training to an external service provider.
It is noted that the SVM problems in the parameter search process are independent, and hence the parameter search process can be easily parallelized in cloud computing envi- ronment. Since the service provider may be untrusted or malicious, the actual content of the data needs appropriate protections to preserve the data privacy.
2.3.2 Privacy-Preserving Outsourcing of SVM with Geometric Per- turbations and Its Security Concerns
Perturbing the data by geometric transformations like rotating or translating the attribute vectors of instances can be utilized for privacy-preserving outsourcing of the SVM [9,10].
Since SVMs with common kernel functions rely only on the the dot product or Euclidean
distance relationships among instances, and such relationships of data are completely preserved in the their geometrically perturbed forms, the SVM problems constructed from the original instances can be equivalently derived from the geometrically perturbed ones.
The geometric perturbation works as follows: Consider the dataset {(xi, yi)|i = 1, . . . , m} with m instances. The content of each attribute vector xi ∈ Rnis deemed to be sensitive, while the class labels yi’s are usually not. Let M denote an n×n rotation matrix, where the content of M , i.e., the angle of rotation, is kept secret. The data are perturbed by multiplying all instances with the matrix M . Although the content of instances is modi- fied in their perturbed versions M xi, i = 1, . . . , m, the dot products of all pairs of original instances are retained: M xi · Mxj = (M xi)TM xj = xTi MTM xj = xTi Ixj = xTi xj, 1 ≤ i, j ≤ m, where MT = M−1 since the rotation matrix is an orthogonal matrix, whose transpose is equal to its inverse. The Euclidean distances are also preserved since the square of the Euclidean distance can be computed from the dot products by
||xi − xj||2 = xi · xi− 2xi· xj + xj · xj. In addition to rotation, the translation pertur- bation also preserves the Euclidean distance relationship of data. The translation pertur- bation is done by adding a random vector to all instances, which moves all instances in a certain distance and the same direction, where the relative distance among instances are the same in the translated data. The translation perturbation can be applied together with the rotation perturbation.
Since the dot product or Euclidean distance relationships are preserved in the geomet- rically perturbed data, the SVM problem (2.1) derived from the geometrically perturbed dataset is equivalent to that derived from the original dataset. Therefore, the data owner can outsource the computations of solving the SVM without revealing the actual content of data by sending the geometrically perturbed dataset to the service provider, and the ser- vice provider can construct the SVM problem which is equivalent to the one constructed from the original dataset. The service provider sends back the solution of the SVM to the data owner after solving the SVM problem, and the data owner gets the classifier by pairing the returned solution, which composed of the supports of each instance and the bias term, with the original data to make up the decision function (2.2).
Although perturbing with geometric transformations preserves the required utilities of data like the dot product or Euclidean distance relationships for forming the SVM problems with common kernel functions, the perturbation preserving such utilities suffers from the dot product or distance inference attacks.
Suppose the attacker, i.e., the service provider, obtains some of the original instances from external information sources. Since the Euclidean distance or dot product relations are preserved in the perturbed dataset, the mappings of the leaked instances and their perturbed ones can be inferred by comparing the Euclidean distance or dot products of all pairs of leaked instances to that of all pairs of the perturbed instances. In general, the same dot product or Euclidean distance happening to different pairs of instances is in low probability. Hence the corresponding pairs of the leaked instances in the perturbed dataset are usually able to be identified by comparing Euclidean distance/dot product. Once the pairs in the perturbed dataset are all recognized, the exact mappings of leaked instances and their corresponding perturbed instances can be deduced by tracking the Euclidean distance/dot product between pairs.
In the perturbation preserving dot products, for n-dimensional data, if n or more lin- early independent instances are known and the mappings to their perturbed ones are suc- cessfully determined, all other perturbed instances, whose original content is unknown to the attacker, can be recovered by setting up n equations as the following lemma shows:
Lemma 1 For n-dimensional data, the perturbation preserving the dot product can be broken if the content of n linearly independent instances and the mappings of their per- turbed ones are known.
Proof 1 Let x1, . . . , xm ∈ Rn denote a set of instances, and c1, . . . , cm are their corre- sponding perturbed instances, where xi· xj = ci · cj for any 1≤ i, j ≤ m. Without loss of generality, assume that the attacker have obtained n linearly independent instances x1, . . . , xn, and identified that c1, . . . , cn are the corresponding perturbed instances by inferring the dot product relations. Then any other perturbed instances cu, n < u ≤ m
can be recovered to the original xu’s by solving the n simultaneous linear equations:
xi· xu = ci· cu for i = 1, . . . , n.
The perturbation which preserves the Euclidean distance can be broken in a similar way given that n + 1 linearly independent instances are leaked and the mappings of their perturbed ones are identified.
In addition to the perturbation preserving Euclidean distance or dot product relation- ships, allowing the service provider to construct the kernel matrix Q of the SVM problem (2.1) also possesses the risk as well as preserving the Euclidean distance or dot product in the perturbed instances since such utilities of data can be derived from the elements of the kernel matrix.
Lemma 2 For SVMs with common kernel functions, revealing the kernel matrix is inse- cure as preserving the Euclidean distance or dot product relationships of data
Proof 2 The elements of the kernel matrix are the kernel values between all pairs of instances. With the linear kernel, the kernel matrix contains the dot products between all pairs of instances, including the dot products of an instance with itself. With the Gaussian kernel, the Euclidean distance of two instances can be derived from computing the natural logarithm of their kernel value and then dividing it by the kernel parameter.
The polynomial kernel and the neural network kernel are based on dot products. The dot product between instances can be derived by computing the d-th root and the tanh−1, respectively.
2.4 Secure SVM Outsourcing with Random Linear Trans- formation
In this section, we design a secure scheme which outsources SVMs to a potentially ma- licious external service provider with the data perturbed by random linear transforma- tion. This random linear transformation-based scheme overcomes the security weakness
of the geometric transformation since the Euclidean distance and dot product relation- ships among instances are not preserved, which endows the scheme with the resistance to distance/dot product inference attacks and hence provides stronger security in data pri- vacy. Our random linear transformation-based privacy-preserving outsourcing scheme includes both the training and testing phases, as well as the parameter search process for the training.
2.4.1 Secure Kernel Matrix with the Reduced SVM
Since the full kernel matrix Q of the conventional SVM formulation (2.1) with common kernel functions is built upon the dot products or Euclidean distance among all training instances, if the service provider needs to build the full kernel matrix to solve SVM prob- lems, there will be similar security weakness like the rotationally/translationally trans- formed data. We avoid the use of the full kernel matrix by applying the reduced SVM (RSVM) with random reduced set [27, 28, 34, 35] for solving SVMs, which helps to pre- vent the disclosure of dot product/Euclidean distance relationships among instances and also plays an important role in our scheme for the utilization of random linear transfor- mation to perturb the data in outsourcing the SVM.
The Reduced SVM with Random Reduced Set
In the following, we first briefly describe the RSVM, and then explain the RSVM with completely random vectors as the reduced set. The RSVM is a SVM scaling up method, which utilizes a reduced kernel matrix. Each element of the reduced kernel matrix is computed from an instance in the training dataset and an instance in the reduced set, which can be a subset of the training dataset. The number of instances in the reduced set is typically 1% to 10% of the size of the training dataset [27, 28]. Hence the reduced kernel matrix is much smaller than a full kernel matrix and can easily fit into the main memory.
Without loss of generality, let xi ∈ Rn, i = 1, . . . , m denote the instances of the training dataset, and yi ∈ {1, −1}, i = 1, . . . , m are their corresponding labels. Let
R = {rj|rj ∈ Rn, j = 1, . . . , ¯m} denotes the reduced set, where ¯m << m. The original RSVM paper adopted a subset of the training dataset as the reduced set [28]. The reduced kernel matrix K is an m× ¯m matrix where
Ki,j = k(xi, rj), i = 1, . . . , m, j = 1, . . . , ¯m. (2.3)
The RSVM problem is formulated as
arg min
v,b,ξ
1
2(||v||2+ b2) + C
∑m i=1
ξi2
subject to yi(Kv + b)≥ 1 − ξi, i = 1, . . . , m
(2.4)
where ξi, i = 1, . . . , m are slack variables, and C is the cost parameter. The solutions of the optimization problem, v = (v1, . . . , vm¯)T, b, and the vectors of the reduced set constitute the decision function
f (x) =
¯
∑m j=1
vjk(x, rj) + b. (2.5)
The optimization problem of the RSVM can be solved by a normal linear SVM solver [30] or the smooth SVM [29] used in the original RSVM paper [28]. Empirical studies showed that the RSVM can achieve similar classification performance to a conventional SVM [27, 28, 30].
An interesting property of the RSVM is that the reduced set R is not necessary to be a subset of the training dataset [27]. Completely random vectors can act as the in- stances of the reduced set [34, 35]. In the RSVM, the instances of the reduced set work as pre-defined support vectors. Unlike the conventional SVM which selects the instances near the optimal separating hyperplane as support vectors, the RSVM fits the optimal separating hyperplane to pre-defined support vectors by determining appropriate support values [27]. A larger value of the cost parameter C is usually required to let the RSVM fit well to the pre-defined support vectors [28, 30].
If random vectors are adopted as the reduced set, then an element in the reduced kernel
matrix is the kernel evaluation between an instance in the training dataset and a random vector in the reduced set but not the kernel evaluation between the training instances like the kernel matrix of a conventional SVM. Therefore, revealing the reduced kernel matrix with random vectors as the reduced set does not reveal the information of the dot product or Euclidean distance relationships among instances. This constitutes the secure kernel matrix, which avoids the security weakness from disclosing the kernel matrix of a conventional SVM given that the random vectors of the reduced set are kept secret, i.e., revealing the secure kernel matrix to the service provider for solving the RSVM problem will not incur the risk of disclosing dot product or Euclidean distance relationships of the training data.
Note that just building and sending the secure kernel matrix to the service provider is not appropriate for outsourcing the SVM training since a reduced kernel matrix is com- puted from a fixed kernel parameter, while there are various SVMs with different kernel parameters to be trained in the parameter search process. The data owner will be imposed much computation load as well as much communication cost to build and send many se- cure kernel matrices with different kernel parameters to the service provider. Our goal is to outsource the SVM training which must minimize as much load of the data owner as possible.
In the following, we first discuss the robustness of the secure kernel matrix, and then in next subsection, we design a scheme which enables the service provider to build the secure kernel matrix from the data perturbed by random linear transformation.
Robustness of the Secure Kernel Matrix
In the following, we prove that the service provider who has the secure kernel matrix K along with some leaked training instances obtained from some external information sources is not able to derive the content of both the random vectors in the reduced set and the remaining secret training instances.
Lemma 3 The service provider cannot obtain the content of random vectors of the re- duced set from the secure kernel matrix with leaked training instances.
Proof 3 Suppose the service provider has obtained m− 1 training instances and at least n of them are linearly independent, where m is the number of training instances and n is the dimensions of the data and m > n. If the service provider is able to know which ele- ments of the matrix K the n linearly independent leaked training instances involve with, it can derive the content of rj’s by first inferring the underlying dot product/Euclidean distance of the kernel values and then utilizing the leaked instances and the inferred dot product/Euclidean distance to set up equations to derive the content of rj’s. However, the service provider cannot identify which elements the leaked instances are involved because this requires the knowledge of the random vectors. In the case of m < n, it is straight- forward that the random vectors of the reduced set cannot be derived due to insufficient number of linearly independent instances to set up simultaneous equations.
Without knowing the content of the random vectors in the reduced set, the service provider cannot derive the content of secret training instances from the secure kernel matrix even if there is only one training instance not leaked.
Corollary 1 The service provider cannot derive the content of unknown training in- stances even if m− 1 of all m training instances are leaked.
Proof 4 Since each element of the secure kernel matrix K consists of Ki,j = k(xi, rj), i.e., it is evaluated from a training instance and a secret random vector, to derive any xi from elements of K, the content of rj’s is required. However, the service provider cannot obtain the content of random vectors in the reduced set as shown in Lemma 3. Hence the service provider is not able to derive the content of remaining secret training instances.
As shown in Lemma 3 and Corollary 1, as long as the random vectors of the reduced set are kept secret, the secure kernel matrix is robust in security even if part of training instances are leaked.
2.4.2 Building the Secure Kernel Matrix from Data Perturbed by Random Linear Transformation
After we are able to permit the service provider to have the secure kernel matrix for solv- ing the RSVM, in the following, we show how to enable the service provider to build the secure kernel matrix from the data perturbed by random linear transformation. The random linear transformation does not preserve the dot product or distance relationships between training instances and hence is stronger in privacy preservation. Then the data owner can outsource the SVM by sending the random linearly transformed training in- stances to the service provider, and then the service provider builds a secure kernel matrix without knowing the actual content of the training data where the secure kernel matrix built by the service provider is exactly the same with the one built from the original train- ing data.
The data owner will send the perturbed training instances as well as the perturbed random vectors of the reduced set to the service provider for computing secure kernel matrices. A secure kernel matrix K is computed from training instances and random vectors of the reduced set by Ki,j = k(xi, rj), i = 1, . . . , m, j = 1, . . . , ¯m. Our objective is to let the service provider compute the same K from perturbed training instances and random vectors, while the perturbation scheme should not allow the security weakness of the geometric perturbation schemes, i.e., the dot product and Euclidean distance among training instances should not be preserved. The perturbation scheme needs to preserve the kernel evaluations between a training instance and a random vector for computing secure kernel matrices. We utilize the random linearly transformation perturbation for computing the dot product of two differently transformed instances [57]. Note that the attribute vectors xi’s of training instances are usually considered sensitive, but the class labels yi’s are usually not.
Let M be a nonsingular n× n matrix composed of random values. We perturb the instances of the training dataset by a random linear transformation L :Rn → Rn, where the matrix M works as the random linear operator. All training instances are perturbed by