國立臺灣大學電機資訊學院資訊工程學系 碩士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Master Thesis
具達成內部平衡之決策模型的使用者感知自主服務型 機器人
A Homeostasis Based Decision Making System on Human-Aware Autonomous Service Robot
林敬 Ching Lin
指導教授:傅立成博士 Advisor: Li-Chen Fu, Ph.D.
中華民國 105 年 7 月 July, 2016
誌謝
兩年的碩士生活要結束了,在台大待了七年終於也要離開了。我之 所以能夠畢業,首先要感謝傅立成老師給我們足夠的空間尋找自己的 論文題目。老師並沒有根據自己的喜好直接指派題目,而是讓研究生 們在學習中自行探索,找尋自己研究的方向。在學生迷失的時候,老 師偶爾也會出來擔任指路燈,讓學生們在無際的黑暗中屏著微薄的光 芒前進。如此一來論文才有一種是「自己的」實感。
感謝士桓學長,在我們遇到問題時請教他都能憑著經驗為我們解 惑。實驗室的大小雜事也常常是他處理,給我們更多時間進行研究。
士桓學長畢業後想必實驗室的學弟妹會很辛苦吧。感謝趙姸、時安和 江元,有一群一起努力的伙伴才能夠分擔痛苦,互相砥礪,若不是他 們我可能中途就放棄了。感謝瑞紘在我指派工作給他時便毫無怨言的 接下,且隨時接受傳喚,拍攝影片時不但擔任演員還熬夜負責剪輯,
我想我還欠他一頓飯。感謝宜倫在我最忙的時候協助我整合計劃的內 容,若不是妳幫我分擔整合工作我想我論文到現在還是寫不完。感謝 所有學弟妹們任我們呼來喚去,跑腿打雜等等,我能畢業都是靠大家 的功勞。
經過這次的磨練,我想我們在各方面,尤其是抗壓性上有了不少的 成長,想必可以成為我們未來人生的助力吧。希望畢業後能夠一帆風 順,也預祝學弟妹們畢業順利。
摘要
服務型機器人需要能夠選擇行為,在缺乏使用者命令下自行進行決 策,甚至主動提供服務,才能被稱為「自主」。對於掃地機器人、取物 機器人等單用途機器人而言,由於它們有個明確的目標,因此可以人 工建構一個完整的決策模型作為它們的行為準則。但是對於多用途機 器人而言,他們的目標較為曖昧、模糊,甚至沒有明確目標,此時便 較難以為他們建立完整的行為模型,使得它們的自主性較低。
「內部平衡理論 (homeostatic drive theory)」是一個在社交機器人中常 見的決策理論,它使機器人試著維持其內部狀態的恆定,並根據自身 的需求選擇行為。雖然此方法可以提高機器人的自主性,由於此方法 忽略了使用者的需求,讓「使用者感知」的能力降低,因此需要調整 才能應用於服務型機器人身上。本篇論文將「使用者意圖」以及「使 用者回饋」結合至內部平衡理論中,讓決策模型更以使用者為中心,
同時保有機器人的高自主性。機器人的內部需求 (drives) 將轉化為動機 (motivations),且機器人將同時考慮自身的動機以及使用者的意圖來決 定自身的行為。機器人每個行為的效果並非事先定義好的,而是在互 動中利用增強式學習 (reinforcement learning) 所得,使得機器人對於環 境以及使用者的先前知識的需求都能降到最低。此決策模型於模擬環 境中進行測試及訓練,並將機器人在模擬環境中所學知識轉移至真實 的機器人進行實地測試。結果顯示機器人在滿足使用者需求的同時也 能夠維持自己體內的恆定,提升自主運作時間,同時達成高自主性以 及使用者感知能力。
Abstract
For a service robot to reach high autonomy, it should choose what to do, make it’s own decisions without user command, and even provide service to the user proactively. For single purpose robots, such as object fetching robots or cleaning robots, since a specific goal is given to each of them, the well- structured decision processes could easily proceed, and decision about that task could be made. However, for robots with vague goals or no specific goal at all, such as caring robots or personal service robots, it is harder to construct a general purpose decision process for them, lowering their auton- omy. Homeostasis drive theory is a dominating psychological approach in decision making for social robots. A robot adopting this theory would try to maintain its internal status, and act according to its own need. While achieve better autonomy, this approach ignores the needs of its human user, resulting in low degree of human awareness. This work integrated human intention and human feedback into a homeostasis based system, making the decision process more user-centric, while maintaining high autonomy. The robot’s internal needs (drives) generate motivations, and the robot will choose its ac- tions considering both the need of the user and its own motivation. The effects of its actions are not predefined and are learned during interactions by rein- forcement learning, making the system require little prior knowledge about the user. The proposed system has been tested in simulations and on a real robot. The results show that the robot can not only satisfy its own needs but also serve the user proactively.
Contents
口試委員會審定書 iii
誌謝 v
摘要 vii
Abstract ix
1 Introduction 1
1.1 Background and Motivation . . . 1
1.1.1 Service Robots . . . 1
1.1.2 Autonomy . . . 2
1.1.3 Human Awareness . . . 3
1.2 Objectives . . . 3
1.3 Related Work . . . 5
1.4 System Overview . . . 7
1.5 Thesis Organization . . . 8
2 Preliminaries 9 2.1 Markov Models . . . 9
2.1.1 Markov Decision Processes . . . 10
2.2 Reinforcement Learning . . . 12
2.2.1 Standard Modeling . . . 12
2.2.2 Value Functions and Action-Value Functions . . . 13
2.2.3 Q-Learning . . . 15
2.3 Intention Recognition . . . 16
3 Methodology 17 3.1 Terminologies . . . 17
3.1.1 Drive . . . 17
3.1.2 Stimulus . . . 18
3.1.3 Motivation . . . 19
3.1.4 Environment . . . 20
3.1.5 Action . . . 21
3.2 System Model . . . 22
3.2.1 Internal and External States . . . 24
3.2.2 State Reduction . . . 25
3.2.3 Object-Q Learning . . . 27
3.2.4 Selecting Action . . . 27
3.2.5 Reward and Feedback . . . 28
3.2.6 Proposal and Pseudo Update . . . 30
3.3 System Design . . . 31
3.3.1 Drives and Motivations . . . 31
3.3.2 Objects, Stimuli and Actions . . . 35
3.3.3 Degree of Dedication . . . 36
4 Evaluation 39 4.1 Evaluation Metrics . . . 39
4.2 Simulation . . . 42
4.2.1 Setup . . . 42
4.2.2 Result . . . 46
4.2.3 Effects of Motivation Factor . . . 49
4.2.4 Effects of pseudo update . . . 51
4.2.5 Effects of Degree of Dedication . . . 52
4.3 Field Test . . . 55 4.3.1 Robot Platform . . . 55 4.3.2 Result . . . 56
5 Conclusion 59
Reference 61
List of Figures
1.1 Overview of the decision making system . . . 7
2.1 The graphical presentation of the Markov Decision Process. . . 11
2.2 General frameworks of reinforcement learning techniques . . . 13
2.3 Bayesian network used to recognize user’s intention. . . 16
3.1 Relation between system parameters. . . 17
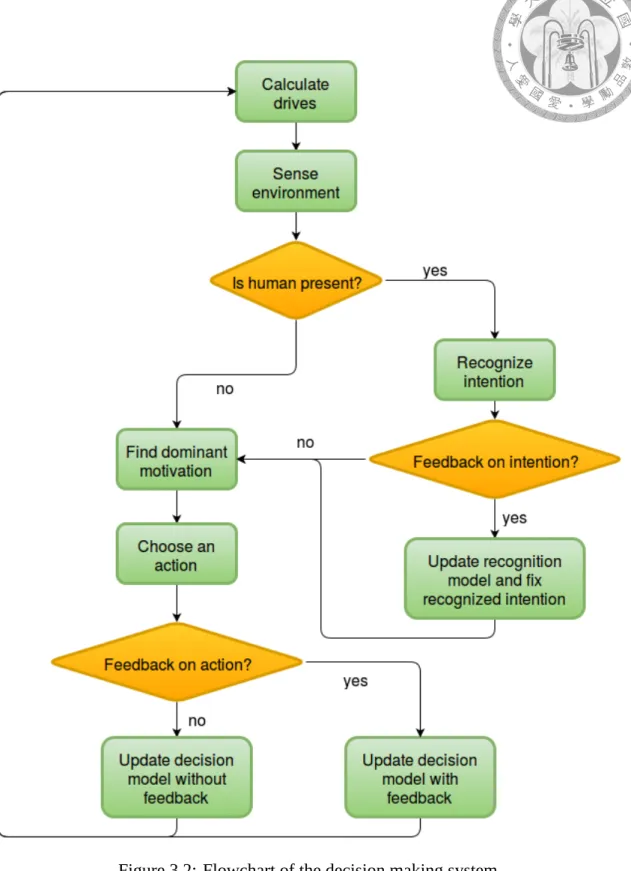
3.2 Flowchart of the decision making system . . . 23
3.3 Weights of drive under different Degree of Dedication. . . . 38
4.1 Value of drives in the simulation process . . . 48
4.2 The change in HSR and RSR in the simulation process . . . 48
4.3 Effect of motivation factor on different metrics. . . 50
4.4 Effect of pseudo update on different metrics. . . 53
4.5 Effect of Degree of Dedication on different metrics. . . . 54
4.6 The Pepper robot. . . 55
List of Tables
2.1 Different Types of Markov Models . . . 10
3.1 Selected Internal Variables . . . 34
3.2 Selected Stimuli . . . 36
3.3 Selected Actions . . . 37
4.1 The Effects of Action in Simulation . . . 43
4.2 Increase Rate of Drives in Simulation . . . 43
4.3 Predefined Intentions in the Simulation . . . 44
4.4 Additional parameters used in simulation . . . 46
4.5 Various metrics in the end of simulation . . . 49
4.6 Mapping from temperature status to NRes . . . . 56
4.7 Outcome of DoD = 0.25 . . . . 58
4.8 Outcome of DoD = 0 . . . . 58
Chapter 1
Introduction
1.1 Background and Motivation
1.1.1 Service Robots
Throughout the past decades, the research and applications of robots have shifted from industrial robots to service robots [1]. Domestic service robots have always been a vision of ours, and the presence of them could often be seen in our imagination of the future, such as science fiction books and movies. The attempts on domestic service robots in early years are usually rather simple and single purpose, with possibly the most famous example being Roomba [2]. These single purpose robots have their own special goal, and they plan their actions around that goal (or not, since some are purely reactive agents such as early Roombas.)
In recent years, many try to develop service robots of more general purposes, such as healthcare robots [3, 4], office robots [5, 6], home service robots [7], personal robots [8, 9], etc. These service robots have designated working environments, however, unlike a task- specific service robot, lack specific goals. Their purpose is to “sense, think, and act to benefit or extend human capabilities and to increase human productivity” [10], yet lacking a specific goal within makes them hard to act on their own and often have to wait for human orders, lowering their autonomy.
1.1.2 Autonomy
Autonomy, different from automaticity, is the ability to make decisions and act on its own. According to the definition by Clough [11], “automatic means that a system will do exactly as programmed, it has no choice. Autonomous means that a system has a choice to make free of outside influence, i.e., an autonomous system has free will”, which indicates that an autonomous robot should be able to sense the environment and choose its actions according to it. Bekey [12] and Cañamero [13] also gave similar definitions. Thus, in order to achieve a higher level of autonomy, the robot should be able to choose what to do at each moment according to the status of environment at the time, instead of waiting for user’s orders or input. In other words, the robot should have it’s own decision making ability. This interpretation also matches the statements in [14].
To achieve autonomy, one popular approach is to find inspiration from animals or hu- man [15]. The behavior of living creatures are studied neurobiologically and psycholog- ically. The goal is to have human/animal behaviors studied, modeled, and implemented on agents, giving them full autonomy. This kind of biological approach is widely used in the control of robots, social robotics, and cognitive robotics.
In social robots, a dominant psychological approach is the homeostatic drive the- ory [16]. In this theory, an agent is modeled to have internal needs, and the goal of the agent is to satisfy those needs in order to maintain a stable internal state. While this ap- proach does give social robots a goal based on which to choose their actions, and keep the robot content; the needs of its human user wasn’t taken into consideration. Since the main feature of social robots is the ability to communicate and interact with humans/agents so- cially, the ability to serve isn’t necessarily a high priority. However, if we wish to retain the characteristic of “sense, think, and act to benefit or extend human capabilities and to increase human productivity” from service robots, the system should make decisions based on not only its own internal needs, but also the need of its human user. This leads to a higher degree of human awareness.
1.1.3 Human Awareness
Human awareness is the ability to be aware of the presence and the needs of humans.
The robot should be able to understand the user to a certain degree and make decisions taking human into consideration. The skills required to achieve human awareness in- clude [17]:
1. human-oriented perception: human detection and tracking, gesture and speech recog- nition, etc.
2. user modeling: understanding human behaviors and making appropriate decisions.
3. user sensitivity: adapting behavior to user, measuring user feedback, and recogniz- ing human state.
Accordingly, the abilities to understand the need of the user, make decisions upon it, measure user feedback and adapt to the user’s preference are all important to achieve human awareness. We also believe these are also important traits to build a successful autonomous service robot.
1.2 Objectives
Combining the statements in Section 1.1, the conceived ideal form of service robot is the one that have both high level of autonomy and human awareness. This work aims to propose a decision making system for service robots that chooses actions autonomously, and serves the user proactively. To achieve this, there are three important aspects of this system:
• To understand the user’s need
In order to serve the user proactively, first the user’s need must be understood. Other than directly commanding the robot, the user might express his/her intention through body language, context of dialog, movements and/or other subtle features in an in- teraction. These features, expressed intentionally or unintentionally, could be gath- ered, and the underlying intention could be extracted through a recognition process.
A Bayesian network based intention recognition model have been proposed by our lab previously [18], and it has been adopted to understand the user’s intention, which is taken into consideration when making decisions.
• To make decisions autonomously considering both the user and itself
To achieve high level of autonomy, biologically inspired approaches are often used.
Although the psychology based homeostasis drive theory is a dominating approach in social robot genre and indeed endows high autonomy, the underlying self-centricity makes it hard to be adopted on service robots at first glance. The research in this thesis, inspired by this theory and works such as [19, 20, 16], aim to propose a sys- tem that’s both homeostatic and human-aware. That is, the decision making system should consider the human intention while trying to maintain its internal needs. In this way, the robot could benefit from the autonomy introduced by homeostasis, while retaining the role as a service robot.
• To learn and adapt to user’s preference through interactions
Without preference of the user predefined in the robot’s prior knowledge, it is very likely that the decisions made by the robot are not the best choice, or even acceptable to the user at first. This could be solved by injecting a large amount of user profile before the robot’s execution. However, this solution is not used in this work, as it re- quires extensive manual parameter tuning, and is generally not adaptable to changes.
Moreover, the user profiles are not usually available beforehand. The robot should learn the correct actions corresponding to user’s intention through interactions, and receive user feedback as indications.
With these abilities, the system should be able to make decisions autonomously with- out predefined goals. It requires little prior knowledge about its user, yet is able to serve the user proactively according to his/her current need through interactive learning.
1.3 Related Work
The methods in decision making are various, with popular ones being Bayesian mod- els, Markov models and their variations. Elinas et al. [5] used a factored Partially Ob- servable Markov Decision Process (POMDP) to model the behaviors and the decision theoretic planner of a visually guided interactive mobile robot. The difference in time scales between execution layer and deliberative layer was considered using the factored POMDP, and a heuristic was also proposed to speed up the solving process. Feyzabadi et al. [21] proposed a hierarchical solution to the constrained Markov decision process (CMDP) problem. They partitioned the state space of the original CMDP into multiple clusters, solved the smaller abstract CMDP, and projected the abstract policy back to the original space. This method tackles sequential decision problems with multiple objec- tives, and is implemented in a path planning scenario. Omidshafiei et al. [22] used De- centralized POMDP (Dec-POMDP) to solve multi-robot planning problems in continuous spaces. Actions were abstracted into macro-actions, simplifying the original Dec-POMDP problem, making it solvable using discrete methods. Liu et al. [23] introduced Episodic Memory-driving MDP (EM-MDP) to solve planning problems. They used state neurons and episodic memories to store learned experience, reducing the high-dimensionality of observation, and is easier to solve than the traditional POMDP model. Zhang et al. [24]
proposed a combination of logical reasoning and POMDP planning in a dialog system.
The prior knowledge of commonsense was used to filter the possible words. Then, a method called P-log was used to extend the logical reasoning results to probabilities, and the probabilities was transferred to POMDP as the current belief of states. The proposed method was shown to be more efficient and accurate than POMDP without commonsense reasoning.
Although these models are popular in robotics, they are more of a planning method of a given task. Without a given task or a well crafted model, these method become somewhat unsuitable. Other than theses models, there are still different approaches. Ko et al. [25]
adopted confabulation theory, using symbols to represent the environment contexts, and wills and behaviors of an virtual agent. Behaviors were first filtered by the dominant wills
and the perceived contexts, then evaluated using Choquet fuzzy integral. Smith et al. [26]
introduced a fuzzy multi-objective decision making system for the motion control of a mobile robot.
As mentioned before, the biologically inspired approaches, where researchers tried to mimic the mind of human neurobiologically or psychologically, are also popular recently.
Maes et al. [27] proposed ANA architecture, where the behavior selection and motivation competitions were done using a neural-network based system. Bellas et al. [28] intro- duced Multilevel Darwinist Brain (MDB) architecture, where artificial neural networks (ANNs) were used to represent the world model, internal model, and satisfactory model of the robot. The three models worked together to evaluate the behaviors, and the selected behavior was determined by the output of the satisfactory model. The system of Ando et al. [29] sensed the environment and generated urges. Urges competed through predefined priorities, and the dominant urge drove the compensating action. Hoefinghoff et al. [30]
used somatic markers on each stimuli-action pair. The meaning of a somatic marker is the possible emotion of choosing that action given the stimuli. The somatic markers are used to filter out inappropriate actions, and the remaining actions are chosen randomly.
Wilson [31, 32] tried to consider the morality of the actions of the robot, and proposed to choose actions based on utilities that is modified to reflect the moral effect.
In psychological approaches, homeostasis drive theory based systems are one of the dominating methods. The term homeostasis was first introduced by Cannon [33], and was described as a regulatory system to maintain the body in a stable physiological state. Af- ter being adopted by robot decision making systems, it usually means that the agent has several internal needs that need to be checked and maintained. When a need become un- satisfied, a drive will be created, triggering appropriate correcting actions. Many famous robots adopted this method, such as AIBO [34] or Kismet [35]. Cao et al. [16] introduced ROBEE architecture, where internal needs generate drives. A predefined satiator, a list of preconditions-action pairs, was used to satisfy the highest drive. Cañamero et al. [36, 13]
introduced motivational states, the intensity of which was affected by both the internal drives and external stimuli. After the intensity of motivations were obtained, the inten-
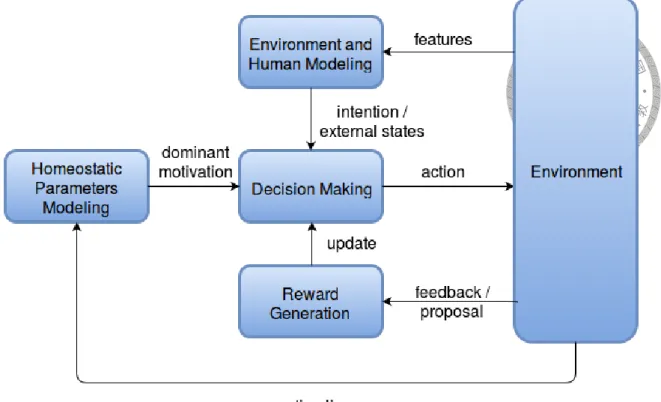
Figure 1.1: Overview of the decision making system
sity of behaviors were calculated accordingly. The behavior with the highest intensity will be the selected one. Gandaho et al. [37, 38] associated robot’s goal with homeostatic variables, and used reinforcement learning on the robot’s adaptive controller. Inspired by both Cañamero and Gandoho, Castro-González [19] used drives to model the robot’s in- ternal needs, which, along with stimuli, trigger the robot’s motivations when unsatisfied.
The motivation were competed through intensities, and an action was selected trying to match the dominant motivation. The correlations between actions and motivations were not predefined, and must be learned in the interactions. This work, largely influenced by [19], used similar formulation of the robot’s internal variables, while introducing the human user’s intention and feedbacks into the decision system, making the robot more human-aware and able to serve human proactively.
1.4 System Overview
This work, inspired by [20] and such, models the robot’s internal needs as drives, which generate motivations when needs are unsatisfied, since homeostasis requires the drives to
be kept in range. The intensity of each motivations are calculated, which would then be used to determine the dominant motivation. The dominant motivation would become the internal state of the robot. On the other hand, the robot will extract the status of the en- vironment and recognize the user’s intention, passing them to the action selection module as external state. The action selection module, combining both internal and external state, will choose an action accordingly. After the execution of the chosen action, the robot will calculate the effects of the action, receive feedback from the user, and update the model to adapt to the user’s preference. Figure 1.1 shows the overview of the proposed system.
The main difference of this work and related works such as [20, 16] is that the user is explicitly modeled into the decision making process, rather than treated as a general object. In other works, the robot behaves solely to achieve homeostasis, and the user has little means to affect the robot’s decisions. In this work, the user can directly affect the robot’s decisions through expressing intention and giving feedback. The robot will choose its action considering both homeostasis and the user’s need.
1.5 Thesis Organization
The rest of this thesis is organized as follows. In Chapter 2, the mathematical tools used in this work, such as Bayesian network, reinforcement learning and its based formulation Markov decision process, are described. The adopted intention recognition method is also described here. In Chapter 3 the terminologies, model formulation of the system, and system design details are described. In Chapter 4, the author proposed several evaluation metrics to measure the performance of the system. Both the simulation results and field test outcomes are shown here. Finally, Chapter 5 concludes the whole thesis.
Chapter 2
Preliminaries
2.1 Markov Models
The Markov model is a statistical tool used to represent the system or the stochastic process’s behavior with temporal information. It is a model that assumes the Markov property, which especially assumes future states of the system only depended upon the present state; that is, the present states characterize all the necessary information of the past events and thus enable the reasoning with the model to be tractable. Markov Models can be divided into four different types depending on whether those system are observable, controllable or not, as shown in Table 2.1. Firstly, if the system’s states are fully observable and changing spontaneously, then the system is modeled as Markov chains. Secondly, the system can be modeled as Dynamic Bayesian Networks (DBN), a generalized hidden Markov model, if the states of this system cannot be fully observed but still be changing spontaneously. On the other hand, if the transition of system’s states is held in the system’s hand and is fully observable, we call this model as Markov Decision Processes (MDPs).
Finally, if states of system are not fully observable and is controlled by the system itself, we define this model as Partially Observable Markov Decision Processes (POMDP). The POMDP model is the most complex architecture due to consideration of the uncertainty and system’s decision simultaneously.
Table 2.1: Different Types of Markov Models
Fully observable Partially observable System is autonomous Markov Chains Dynamic Bayesian Networks
(DBNs) System is controllable Markov Decision
Processes (MDPs)
Partially Observable Markov Decision Processes
2.1.1 Markov Decision Processes
In Markov Decision Processes (MDPs), the agent fully observes the current state and decides an action to perform. The next state to which the process transfers depends on the current state and the system’s action. Hence, a Markov decision process is a quadruple:
M DP = ⟨S, A, T, R⟩ (2.1)
where
• S is a finite set of system’s states, describing information of the environment that agent concerns,
• A is a finite set of system’s actions,
• T is the transition probability of system’s states. As a result of executing action a ∈ A in state s ∈ S, the environment transitions to state s′ ∈ S with probability T (s, a, s′). It is worthy noting that each transition in MDPs is defined as a non- deterministic one.
• R is the reward function. After the system state changes to the next state, the envi- ronment responds with an expected reward r, where r ∈ R, R : S × A × S → R is a bounded function.
A comprehensive illustration of those relationship is shown in Fig. 2.1. To deal with noisy and incomplete state information, the basic MDP framework can be extended to Partially Observable Markov Decision Processes (POMDPs), where states of the system
Figure 2.1: The graphical presentation of the Markov Decision Process. The transition of the system is depended on the action A, and the selection of the action is determined by the reward function R.
are represented as hidden states and must be inferred from system’s observations and ac- tions, causing the state space become too large to solve the optimal policy efficiently. For a complete introduction of POMDPs, please refer to [39].
Given an MDP, the objective is to construct a policy π : S → A that maximizes the expected future accumulated reward from each state s. The agent then chooses its appro- priate actions according to the policy. This policy, comparing to the immediate received reward, is determined based on the desirability to the goal, which is shaped by the reward function R, in the long run. When decisions are made or evaluated following the policy, the values of action choices are concerned. The expected return of following a policy π from a state s is defined by the value function as shown below:
Vπ(s) = Eπ[r(t) + γr(t + 1) + γ2r(t + 2) + . . .|st = s]
= Eπ[
∑∞ k=0
γk· r(t + k)|st= s]
= Eπ[r(t) + γVπ(st+1)|st= s]
(2.2)
where t is the current time step and rtis the reward received at the time step t. This quan- tity Vπ(s) is called the value of the state s under the policy π. The future rewards are discounted by a factor γ so that the recent returns are emphasized more. Those can be computed using dynamic programming methods, such as value iteration or policy itera- tion [40, 41]. However, though the optimal policy of MDPs can be solved by dynamic programming methods, this requires the specification of all the parameters of MDPs. In real world applications, those parameters, especially the transition probability T , are too vague to be defined clearly due to complexity and uncertainty of our world. Therefore, the reinforcement learning is proposed to deal with this problem; specifically, instead of solving the optimal policy directly, we learn it through the interaction between agents and the environment.
2.2 Reinforcement Learning
Reinforcement Learning (RL) [42] is usually known as goal-directed learning methods to deal with the problem that can be modeled as a Markov Decision Process. The agent is not instructed what to do but should discover the actions which lead to the most profits.
To be more specific, reinforcement leaning is the learning that maps situations to actions so that by following the learned policy, the agent collects the maximum rewards. Chain effect is a tricky part of reinforcement learning problem where actions not only affect the current reward but also influence the subsequent situations and future rewards. The agent generally learns under exploration and exploitation and figures out how to take actions in the environment to maximize the long-term returns.
2.2.1 Standard Modeling
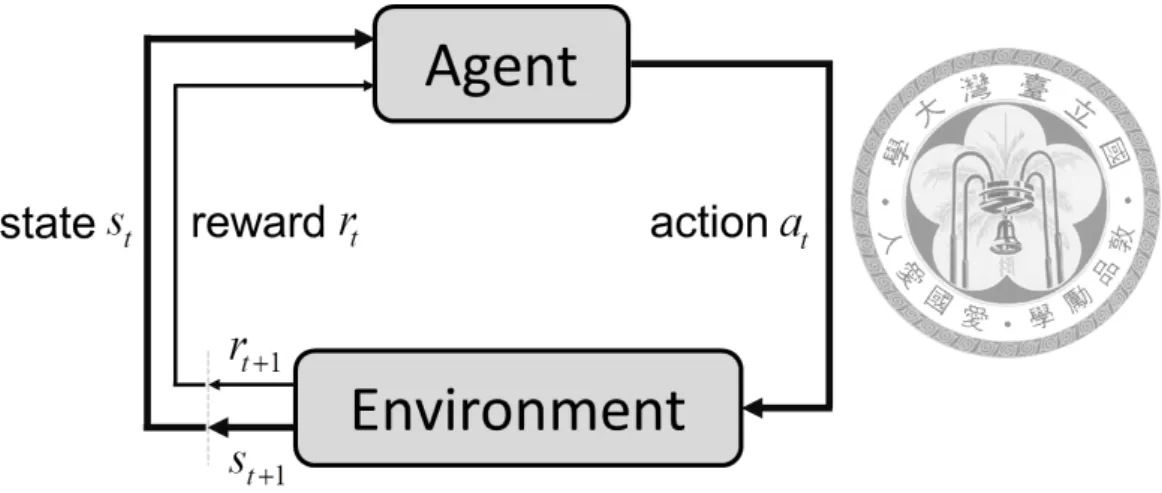
The standard modeling of a reinforcement learning problem is shown in Figure 2.2.
There are an agent and an environment. The learning process proceeds as follows: at each time t, the environment is in a state st, and then the agent observes the state of environment stand deliberately selects an action at for execution. The action results in
Figure 2.2: General frameworks of reinforcement learning techniques
the state transition of the environment from stto st+1at time t+1. The agent then receives the reward rt+1.
Under the global view of the learning agent and the environment, basic reinforcement learning models consist of the two elements of MDPs: a set of system’s states S and a set of actions A. The major difference between dynamic programming methods and reinforcement learning techniques is that RL requires the agent to observe the transition of the system and to study its action’s influence on the system’s state transition, while the dynamic programming method must specify the detail of the transition probability in prior and solve the problem offline. RL is referred to a kind of interactive learning method.
2.2.2 Value Functions and Action-Value Functions
Since the objective of reinforcement learning techniques (or generally, the MDP prob- lem) is to learn the optimal policy that maximizes the expected future accumulated re- ward by mapping each state to the agent’s action, and the value function introduced in Section 2.1.1 serves this purpose. It memorizes the experience that the learning agent had and indicates how likely the states can reach the agent’s goal. In this section, we introduce two basic ways to represent the experience of the learning agent in reinforcement learning techniques.
The first one is the value function, described in Eq. (2.2). With the knowledge of the transition T and reward functions R, this function can be re-written in the form of Bellman
equation:
Vπ(s) = R(s, π(s)) + γ∑
s′
T (s, π(s), s′)Vπ(s′) (2.3)
The maximum value that can be obtained by a policy is usually denoted as V∗, which is defined as:
V∗(s) = max
a (R(s, π(s)) + γ∑
s′
T (s, π(s), s′)V∗(s′)) (2.4)
Similarly, another representation called action-value functions, often simplified as Q function, describes the expected long-term return of taking an action a in a state s under the policy π, and the optimal action-value function denoted as Q∗is described below:
Qπ(s, a) = R(s, a) + γ∑
s′
T (s, π(s), s′)Vπ(s′) (2.5)
Q∗(s, a) = R(s, a) + γ∑
s′
[T (s, a, s′) max
a′ Q∗(s′, a′)] (2.6) Furthermore, due to the fact that the optimal policy always chooses the action with the maximum action value, the relationship between value and action-value are expressed as:
V∗(s) = max
a Q∗(s, a) (2.7)
Once the learning agent obtains the optimal action-value function, it is obvious that the agent can easily take the greedy strategy to choose the best action based on the highest action-value they will receive in the next step, as shown by Eq. (2.7); that is, the optimal policy that follows Q∗ is derived as the following form:
π∗(s) = arg max
a
Q∗(s, a) (2.8)
It is worth to note that either the value function V or action-value function Q require the transition probability T to compute their values. In the next section, the Q-learning al-
gorithm which does not require the specification of transition T will be introduced briefly.
2.2.3 Q-Learning
Q-learning [43] is often used to find an optimal action-selection policy for a given Markov decision process (MDP). It is a model-free reinforcement learning technique since the model of the environment is not required by the algorithm. This algorithm works by learning the action-value function Q (see Eq. (2.5)) through the interaction between the learning agent and the environment. The procedure of Q-learning in iteration n is presented as below:
• observes the environment’s current state sn,
• selects and performs an action an,
• observes the subsequent state s′n,
• receives an immediate reward rn, and
• adjusts its Qn−1values using a learning factor αn, according to the update function:
Qn(s, a) =
(1− αn)Qn−1(s, a) + αn[rn+ γVn−1(yn)] if s = sn,
Qn−1(s, a) otherwise
(2.9)
where the initial action-value Q0(s, a) is assumed given for all states and actions, and the function did not require the specification of the transition probability T .
This algorithm has been shown that it will converge correctly if the action-value func- tion is represented via a look-up table representation [43]. More generally, Q-learning can be combined with function approximation. This may speed up the learning process and let the algorithm be able to deal with problems in continuous space.
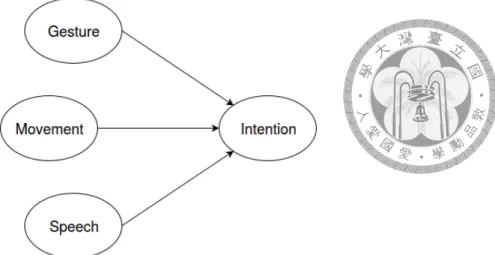
Figure 2.3: Bayesian network used to recognize user’s intention. The parameters are updated using EM algorithm if user feedback is received.
2.3 Intention Recognition
In order for the robot to achieve human-awareness, first it have to understand human behaviors and make appropriate actions accordingly [44]. One way to accomplish this is to recognize user intention and take this intention into consideration when making decisions.
This work adopts the intention recognition method from [18], using human user’s ges- ture, movement, and spoken sentence as features and construct a Bayesian network ac- cordingly. Figure 2.3 shows the Bayesian network used in this work, and the recognized intention is calculated as:
hirecog = arg max
hi∈HI
P (hi| z) (2.10)
where hi is an human intention, and z is the observations about human.
To adopt to the user’s preference, user feedback about his/her intention could be made, and the model will be updated on-line. If the robot fails to recognize the user’s intention, or the recognition result is incorrect, the user could make a feedback, clarifying his/her true intention. When the robot receives this feedback, it will update the parameters of the Bayesian network using expectation-maximization (EM) algorithm [45]. In this way, little or no prior knowledge about the user’s behavior is needed, and the relation between user’s actions and his/her intentions could be learned through interactions.
Chapter 3 Methodology
3.1 Terminologies
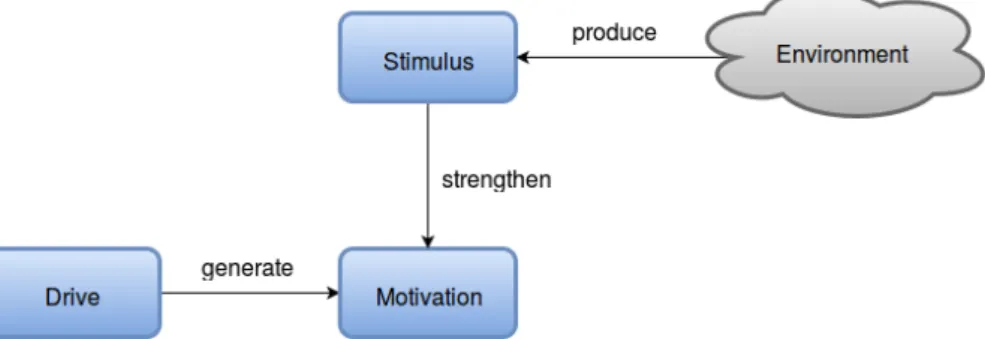
According to homeostatic drive theory [46], “homeostasis means maintaining a stable internal state.” This work, inspired by both [20] and [16], uses drive, motivation and stimulus to determine a robot’s internal status. The relation between these parameters are illustrated in Figure 3.1. The meaning and definition of these and other terms used in this system will be described below.
3.1.1 Drive
In this work, the internal needs of the robot are modeled as drives. Drives are internal parameters of the robot in the form of real numbers. A drive represents a certain need of the robot, such as its battery level or a sense of loneliness, and the value of the drive indicates
Figure 3.1: Relation between system parameters.
the degree of dissatisfaction of that certain need. The set of drives used in the system is denoted by D. Each drive d∈ D is normalized to the range of [0, 100], with 0 meaning the need is fully satisfied (thus no compensating drive) and 100 meaning the need is totally unsatisfied (thus high compensating drive). The value of a drive could be affected by time, the robot’s internal status, and the outcome of the selected action. Each drive d is also accompanied with an activation threshold. When a drive exceeds its activation threshold, the degree of dissatisfaction is considered high enough, and the corresponding motivation will emerge. In this thesis, the term need and drive are sometimes used interchangeably.
Definition 1. Drives D is a set of internal needs of the robot, the values of which indicate
the current degrees of dissatisfaction in different aspects. ∀d ∈ D : d ∈ [0, 100].
Definition 2. Activation thresholds AT is a set of thresholds representing robot’s toler-
ances to its needs. There is a bijection mapping from D to AT. That is, for each d ∈ D, there is one and only one corresponding threshold at ∈ AT. In this work, the subscript index i is used to indicate this mapping (i.e., ati ∈ AT is the corresponding threshold of di ∈ D). ∀at ∈ AT : at ∈ [0, 100].
Definition 3. When di > ati, diis considered unsatisfied.
3.1.2 Stimulus
The factors that affect the robot’s motivation are twofold, the internal needs — the drives — and the external conditions — the stimuli. Stimuli are defined as external condi- tion that could affect the intensity of one or more motivations. The set of possible stimuli is denoted by ST. It could be the presence of a certain object, the recognized intention of a human, etc. For example, our motivation to eat could be affected by our hunger, an inter- nal drive, and the presence of food, an external stimulus. Similarly, we expect the robot’s motivation to serve would be enhanced if the robot sensed the human user’s intention. A stimulus could have different effects on different motivations.
Definition 4. Stimuli ST is a set of external conditions that could affect the intensity of
motivations of the robot. Given an observed environment, a stimulus st ∈ ST could be
either present or absent. The set of presenting stimuli is denoted by STexist, STexist ⊆ ST.
3.1.3 Motivation
Motivations (M ) can be considered as the goal of the robot. Motivations are triggered by unsatisfied needs (i.e., drives that exceed activation thresholds) and external stimuli.
The relation between drives and motivations are one-to-one, which means that for each drive in the system, a correlated motivation exists. Given the current drive values and the existing external stimuli, the intensity of each motivation can be calculated. The intensity of a motivation represents its strength. The higher the intensity is, the more likely that motivation will prevail. For the motivation with the highest intensity, it is considered dominant, and the robot should try to act according to it.
Definition 5. Motivations M is a set of goals for the robot to compensate for a unsatisfied
drive. There is a bijection mapping from D to M , that is, for each d∈ D, there is one and only one corresponding m∈ M. In this work, the subscript index i is used to indicate this mapping (i.e., mi ∈ M is the corresponding motivation of di ∈ D).
Definition 6. In every iteration, the intensity of the motivations could be calculated by
the drive values and the stimuli of that time. A motivation is considered activated if its intensity is greater than 0.
Definition 7. In every iteration, the dominant motivation mdomis chosen according to the intensities of all motivations. mdomdetermines the internal state of the robot.
According to Lorenz’s hydraulic model [47], internal drive strength interacts with ex- ternal stimulus strength. If the drive is low, then a strong stimulus is needed to trigger motivation; if the drive is high, then a mild stimulus is sufficient [46]. To illustrate this model, Malfaz [20] used the following equation to calculate the intensity of motivation:
intensity(mi) =
0 if di < ati
di+ effect(sti, mi) otherwise
(3.1)
Where intensity(mi) is the intensity of motivation mi ∈ M, diis the corresponding drive, and effect(sti, mi) is the effect of related external stimulus sti on motivation mi. The physical meaning of equation Equation (3.1) is that the motivation will be activated only if the corresponding need is unsatisfied. Since in the definition of this work, a stimulus could affect several motivations, and a motivation could be affected by several stimuli, the above equation is adjusted to Equation (3.2).
intensity(mi) =
0 if di < ati
di+ ∑
stk∈STexist
effect(stk, mi) otherwise
(3.2)
If there are multiple activated motivation, all activated motivations will compete with one another through comparing intensities, and the motivation with the highest intensity will become the dominant motivation mdomof that iteration.
mdom= arg max
m∈M (intensity(m)) (3.3)
3.1.4 Environment
There is no common solution to the representation of environment in the research of robotics. The design is often up to the purpose of the robot system. While a navigation system focuses on the location of itself and the obstacles [48], a service robot might uses a higher level of representation of objects [49].
In this work, we regard the key aspect for a personal service robot is conceived to interact with different kinds of objects and/or the human user to satisfy to needs of the robot itself or to serve the user. For example, if the robot is low on energy level, it should operate the charger to meet its need; when the user’s intention is to watch television, the robot should turn on television to provide service. Following this requirement, the environment in this work is composed of one or more objects and a human user. Each object is assumed to be recognizable to the robot for simplicity in this work, and is described by a set of object variables. The object variables describe the status of the object, and the relation between
it and the robot. Similarly, the human user is described by his/her recognized intention, and also the relation with robot.
Definition 8. Obj denotes a set of objects recognized and considered by the robot. Each
o∈ Obj is represented by a set of object variables.
Definition 9. There is one human user of the robot. The robot will try to recognize the
intention, infer the spatial relation, and determine the interaction status of its user.
Definition 10. For each iteration, when the human user is present, the robot will try to
recognize the intention of the human user, and choose the most possible one out of all the possible human intentions HI. The chosen intention is denoted by hirecog.
3.1.5 Action
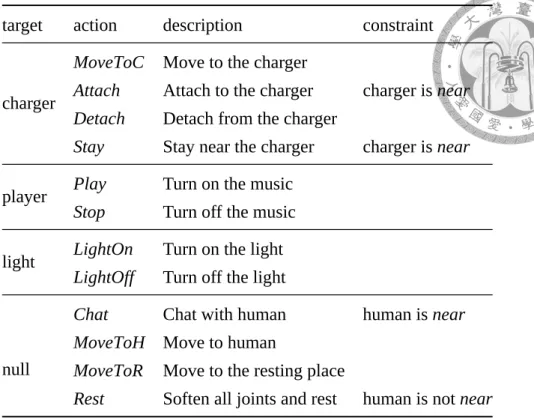
The goal of the proposed system is to choose an action out of a predefined action set to cope with the current situation. The purpose of an action is to satisfy the robot’s needs and/or to serve the human user through its execution. The target of each action could be an object, the human user, or the robot itself. For example, plug and unplug could only be operated on the charger, while chat can only be used on the human user. To group the actions, we can get several subsets according to the target of an action. However, two of the subsets are distinct from the others, namely, the subset whose target is the human, and that whose target is the robot itself. Besides these two subsets, the targets of all the other subsets are objects. To make the notation uniform, we introduce a null object, which serves as the target object for all non-object-related actions.
Definition 11. A denotes a set of actions that the robot can perform. Each action has an
execution target, and Ao denotes the subset of actions of which the target is object o. For actions without target objects — the target of action is the human user or robot itself — a null object is defined to serve as their target. As indicated by Equation (3.4), A could be seen as the union of Aos for all o∈ Obj plus the null object.
A = Anull∪ ∪
o∈Obj
Ao (3.4)
3.2 System Model
After defining the internal parameters of the robot in the previous section, the robot should decide its own actions to keep its drives in check, and achieve homeostasis. In the mean time, the robot should also consider the user’s intention, serve the user when applicable, and learn the user’s preference through feedback. These are necessary features for a robot to achieve higher-level human-awareness ability [18]. In the work, a Q-learning based decision making system is proposed. The design of this system is highly influenced by [20], and the feedback method described in [18] is integrated into the system.
Following Figure 1.1, a flowchart is shown in Figure 3.2 to illustrate the decision making process. First the drives are calculated, generating motivations. The motivations compete with each other by comparing intensities, and a dominant motivation will be chosen. The dominant motivation will be passed to the action selection module as internal state. On the other hand, the robot will extract the status of the environment and recognize the user’s intention, passing them to the action selection module as external state. The action selection module, combining both internal and external state, will choose an action accordingly. After the execution of the chosen action, the robot will calculate the effects of the action, receive feedback from the user, and update the decision making model.
The main difference of this work and the related works such as [20] or [16] is that the user is explicitly modeled into the decision making process, rather than is treated as a general object. In other works, the robot behaves solely to achieve homeostasis, and the user has little ways to affect the robot’s decisions. This characteristic is applicable to pure social robots, but is unsuitable if we wish the robot to also have serviceability. In this work, the user can directly affect the robot’s behavior through expressing intention and giving feedback. The robot will choose its action considering both homeostasis and the user’s need.
In the following section, first the state used by the system will be defined in Sec- tion 3.2.1, and the state reduction method will be described in Section 3.2.2. To cope with the collateral effect in state reduction, a modified version of Q-learning proposed in [19] will be described in Section 3.2.3. We will describe the stochastic action-selection
Figure 3.2: Flowchart of the decision making system
method in Section 3.2.4, and the reward function in Section 3.2.5. Finally, a special kind of user feedback called proposal and user-induced pseudo update will be described in Section 3.2.6.
3.2.1 Internal and External States
In general, the state to be used in the decision making system is composed of the internal state of the robot and the external state of the environmental context, as in Equa- tion (3.5).
S = Sinternal× Sexternal (3.5)
In this work, the internal state is the selected dominant motivation of the robot. The dominant motivation is selected as stated by Equation (3.3). Thus:
Sinternal = mdom= arg max
m∈M (intensity(m)) (3.6)
In [19], the external state is the combination of the states of all the objects in the environment in relation to the robot:
Sexternal = ∏
o∈Obj
So (3.7)
An object state could contain the spatial relation between the object and the robot, the on/off status of the object, etc. Different kinds of objects could have their own definitions of state variables. In Equation (3.7), the state of the human was also treated as an object state. To achieve higher-level of human awareness, we try to integrate the state of the human user into the external state, and thus:
Sexternal = Shum× ∏
o∈Obj
So (3.8)
To explicitly model the state of the human (assuming the robot has only one human user), his/her intention and the spatial relation between the user and the robot are consid-
ered. The human state is modeled as follows:
Shum = hirecog× {near, far, absent} (3.9)
where hirecog ∈ HI is the recognized intention in Equation (2.10), and {near, far, absent}
indicate the spatial relation between the robot and the user.
3.2.2 State Reduction
However, as the number of features and objects increase, the state space will grow exponentially. With larger state space, more training data will be required to acquire a usable model. In the case of reinforcement learning such as this work, it means the ex- ploration phase (learning phase) will be exponentially longer to reach a stable decision model, because the Q-value of each state-action pair Q(s, a) would needs to be evaluated several times to converge.
Many works had addressed and worked on this problem, such as the ones which use factored Markov Decision Processes (FMDPs) [50, 51]. They represent the complex state space by a finite set of random variables, using a set of dynamic Bayesian networks (DBNs) [52] to express the transition model. Another approach is to perform state ag- gregation or state abstraction. Li et al. [53] showed several methods for state abstraction.
Some require given model structures [54, 55], while some performs aggregation through interaction and construct the abstract states hierarchically [56] or through statistical eval- uations [57].
Castro-González et al. [19] proposed a simple yet effective state reduction method for this scenario, and adopted it in their later works [20, 58, 59]. They assumed that the states related to each objects have little effect on each other, and thus could be considered inde- pendent of one another. This assumption is based on the observation of human behavior, since “when we interact with different objects in our daily life, one, for example, takes a glass without considering the rest of objects surround.” [19]. As a result, each object states could be considered separately rather than as Cartesian products. Then, Equation (3.7) could be simplified into Equation (3.10).
Sexternal ={So | o ∈ Obj} (3.10)
Following this reduction method, Equation (3.8) could be reduced into the Cartesian product of Shumand one of the object states So. This product is denoted by Shum,o.
∀o ∈ Obj : Shum,o = Shum× So (3.11)
For each Shum,o, only the actions that perform on object o (i.e., Ao) are considered in the decision process. In other words, for the Q-value of a state-action pair to exist, the state and the action must related to the same target object. As mentioned in Section 3.1.5, the target of an action could be an object, human, or the robot itself, and a null object was introduced to represent the non-object targets. Thus, other than using product of all Shum,o as the external state space, the null object space should also be considered to make the notation uniform. The null object space is defined to be an empty space, simply serving as a placeholder. Equation (3.12) shows the definition of the whole external state space, and Equation (3.13) shows the condition for a state-action pair to be considered in the decision making process.
Sexternal = Shum,null∪ ∪
o∈Obj
Shum,o (3.12)
∀o ∈ (Obj ∪ {null}) : ∃Q(s, a) ⇐⇒ (s ∈ Sinternal× Shum,o)∧ (a ∈ Ao) (3.13)
The advantage of this reduction method is that the human-object relation could still be preserved, as the intention of the human might be wishing the robot to operate on an object. Viewing objects separately also means that the additional and removal of an object won’t compromise the structure of the state space. One could simply add the new object state to the set of external state. If state abstraction method such as [57] is used, since the abstract states are built upon the ground states that contain every object features, changing
state space means that the old abstraction is no longer usable.
3.2.3 Object-Q Learning
Although the object states are assumed independent of each other, the action of the robot break this independence. When a robot performs an action, the effect of the action might affect multiple object states. These collateral effects are identified and dealt with in [19]. In order to take these effects into consideration, they proposed a modified Q- learning algorithm call Object Q-learning. In Object Q-learning, the way of updating Q-value is modified into the following equation:
Qoi(s, a) = (1− α) · Qoi(s, a) + α· (r + γ · Voi(s, s′)) (3.14)
Voi(s, s′) = max
a∈Aoi
(Qoi(s′, a)) +∑
m̸=i
∆Qomaxm(s, s′) (3.15)
where Qoi indicate that the Q-value is in relation to the object oi, and s∈ Sinternal× Shum,oi
is the reduced state considering object oi. Action a ∈ Aoi is the chosen action to be performed on object oi, s′ is the new state in relation to object oi, r is the reward received, γ is the discount factor and α is the learning rate. Voi(s′) is the value of s′considering the collateral effects on other object states, including the missed and acquired opportunities on other objects after an action.
∆Qomaxm = max
a∈Aom
(Qom(s′, a))− max
a∈Aom
(Qom(s, a)) (3.16)
3.2.4 Selecting Action
To choose the best action in object Q-learning, the action with the highest Q-value in the given state, should be chosen. However, always choosing action with the highest value often leads to local optimum, weakening the learning process. To escape local optimum, a certain degree of randomness is often introduced. In reinforcement learning, a common stochastic approach is the softmax probability function [60]:
P (s, a) = eQo(s,a)/τ
∑
o∈Obj
∑
a∈Ao
eQo(s,a)/τ
(3.17)
where P (s, a) represents the probability of choosing action a under state s, and τ is a positive value called temperature. The higher τ is, the higher the probability that non- optimal actions are chosen. With τ → ∞, the probabilities of choosing each action will become uniform, regardless of their Q-values; with τ → 0+, the probability to choose the optimal action will become 1, making the decision process deterministic. To achieve better result, usually a higher rate of exploration — higher τ — should be used in the beginning of the training, and the rate should be lowered as the learned values are somewhat stabilized.
3.2.5 Reward and Feedback
The reward function indicates the quantified evaluation of the robot action. In this work, chosen actions would be evaluated in two aspects:
1. the reduction in drives (internal reward), and 2. the feedback of human user (external reward).
r = rdrives+ rfeedback (3.18)
After the execution of each action, each drive will be affected in various degrees. We could examine the difference in these drives before and after the execution of an action, and calculate the reward according to the difference.
rdrives =−∑
i
ωi· ∆di =∑
i
ωi· (di,before− di,after) (3.19) The drives represent the needs of the robot, so the difference in drives indicates the difference in degree of satisfaction of the robot. A good action is expected to minimize the internal needs, making the robot more content. Since drives are the lower the better, so the negative of difference in drives is taken as the internal reward. The variable ωi is the
weight related to each drive, indicating the implicit importance of each drive. The weights could be designed so that the robot would value each drive differently, creating different personalities for robots.
However, in Equation (3.19), the importance of dominant motivation wasn’t empha- sized. When the robot has a dominant motivation, we expect it to select an action accom- modating to its motivation. In (3.19), the dominant motivation wasn’t taken into consid- eration, so an action may be given the highest reward even it has nothing to do with the dominant motivation. To make the dominant motivation more influential, we have added a motivation factor to the internal reward function, resulting in (3.20). Assuming that mdom= mk, and dk is the corresponding drive:
rdrives =∑
i
(1 + δik· ξ) · ωi· (di,before− di,after) (3.20)
where ξ > 0 is the motivation factor, and δimis Kronecker delta:
δik =
1 if i = k 0 if i ̸= k
(3.21)
Another aspect of the reward function is the human feedback. At the beginning, the robot doesn’t know how to serve the human user, since no prior knowledge about the user was injected. To endow the robot with the ability to serve, the user feedback is modeled into the reinforcement learning process. The resulting reinforcement learning with human guidance let the user enter the decision making loop of the robot. The human could then teach robot how to serve, or even how to satisfy the needs of the robot itself.
After execution of an action, the human user could give the robot a positive or a neg- ative feedback. A positive feedback means that the action of the robot met the user’s intention, while a negative feedback means otherwise. So the feedback part of the reward function could be represented as:
rfeedback =
f if feedback is positive
−f if feedback is negative 0 if no feedback is given
(3.22)
where f is a predefined feedback value, f > 0. Combining Equation (3.18), (3.20), and (3.22), we could get the final reward function.
3.2.6 Proposal and Pseudo Update
To endow the user with more influence on the robot’s decisions, we define another form of feedback called proposal. When the user gives a negative feedback, he/she could also propose a correct action for the robot to learn. Providing the robot with this additional information could accelerate the learning process, making the robot to correlate the user intention with the correct action in fewer iterations. Thus, when a proposal happens, other than giving negative reward to the current action, the robot should also update the Q-value of the proposed action as if it received positive feedback. This proposal-induced update is called a pseudo update in this work. However, the main problem in updating in such fashion is that Q-learning is a model-free learning method. The transition result of performing a certain action is unknown unless the action is actually performed. Without the newer state s′, Voi(s, s′) in (3.14) couldn’t be calculated precisely. In this work, several approximations are made to reach a pseudo new state:
1. Since the proposed action is treated as the solution to the user’s intention, the drive related to serving the user will be updated in the pseudo new state, while other drives are assumed to remain static.
2. The stimuli are assumed to be unchanged.
3. The state of the human and the object states remain the same.
With the above assumptions, a pseudo new state s† is generated. One could observe that the pseudo new state s†and the original state s differ only in the internal state, which