A Fuzzy Rule-based System for Structure Decomposition on Handwritten Chinese Characters
Hahn-Ming Lee, Member, EEE and Chiung-Wei Huang
Department of Electronic Engineering National Taiwan Institute of Technology
Taipei, Taiwan E-mail: hmlee @et.ntit.edu. tw
Abstract
In this paper, a fuzzy rule-based system for decomposing the structure of divisible handwritten Chinese characters is proposed. The decomposition is aimed at obtaining a radical that can be used as the preclassification information for handwritten Chinese character recognition (HCCR). Since the writings of handwritten Chinese characters vary a lot, we adopt fuzzy set theory to deal with the recognition of these fuzzy in nature pattems. Fuzzy rules which r e p s e n t the character structures are used to combine the extracted strokes into compound strokes or radicals. The capability of the system can be enhanced by increasing fuzzy rules appropriately. Besides, since the number of rules of a fuzzy system is much less than that of a general rule- based system, the computation effort is not heavy.
Moreover, except the poor thinning results and mis- extracted characters, an average of 95% recognition rate on the radical recognition of 542 test characters which are selected from the 100th samples of HCCRBASE (character image database provided by CCL, I T N , Taiwan) is obtained. It not only confirms the feasibility of the proposed system, but also suggests that applying fuzzy set theory on HCCR is an efficient and promising approach.
I. Introduction
The recognition of handwritten Chinese character (HCCR) is of great importance as an automatic input method for the Chinese Electronic Data Processing (EDP). It also build a friendly man-mxhine interface for people who are not familiar with computers. However, due to the characteristics of handwritten Chinese characters, i.e., large character sets of characters (at least 5401s for daily use), very complex in structure, and different writing styles, it is very difficult to recognize them well 111. Related researches in this field have been
conducted for at least 20 years [l].
For tackling such a huge amount of characters, hierarchical recognition approach, i.e., the so-called preclassification technique, is usually needed. In addition, a Chinese character can be decomposed into radicals and strokes, e.g.,
'f
is a radical and @ is a primitive stroke, so choosing radicals as the preclassification information is an intuitive and efficient method [2]. Based on the structure of the Chinese characters, characters can be classified into special characters, indivisible characters and divisible characters, i.e., left-right characters and top-bottom characters [I].For example, " " is a left-right character, and "
R " is a top-bottom one.
In general, a handwritten primitive stroke of Chinese character may have various degrees on different stroke types. For example, a stroke 0 may have degree 0.4 as horizontal line and degree 0.7 as right-slanting line.
Thus, we may treat this stroke as a horizontal line or a right-slanting line. In this way to keep the candidates of strokes, the results of radical extraction will be more reasonable and reliable. Besides, due to few fuzzy rules can be used to deal with the fuzziness of human concepts or controls [3], the number of rules and the computation effort are less than that of a general rule-based system.
Therefore, we propose a fuzzy rule-based system for the structure decomposition, i.e., radical extraction, on the preclassification of HCCR.
{=
II. System Architecture
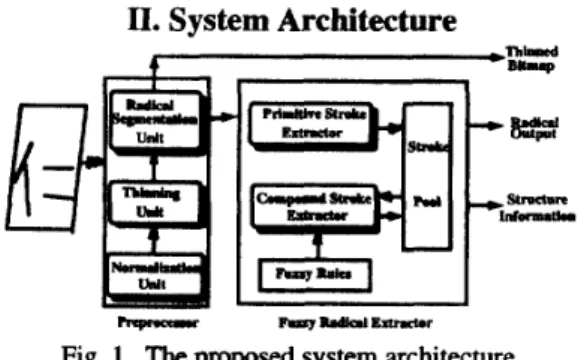
Fig. 1. The proposed system architecture.
The architecture of the proposed system is shown in Fig. 1. It is composed of a Preprocessor and a Fuzzy Radical Extractor. Preprocessor deals with the normalization, thinning, and radical segmentation. It sends the structure information, i.e., the character is a left- right divisible, top-bottom divisible, or indivisible, and the radical block area which indicates the radical location to the Fuzzy Radical Extractor. The Fuzzy Radical Extractor is organized by the Primitive Stroke Extractor, Compound Stroke Extractor, and a Stroke
Pool. Also there are some fuzzy rules given to combine strokes. The Primitive Stroke Extractor is aimed at extracting basic strokes of handwritten Chinese characters from inputs. Also it assigns degrees to the extracted strokes according to the membership definition for each stroke type, and stores these information into the Stroke Pool. Afterwards, the Compound Stroke Extractor combines the extracted strokes appropriately into compound strokes or a radical by applying fuzzy rules.
Finally, the obtained radical and structure information are sent to the classifier as the preclassification information.
A. Preprocessor
Once an input is obtained, normalization helps to get an uniform character bitmap size, e.g., 100x100. It tolerates the size variants caused by writers’ writing habits. Then thinning is applied to get a thinned character image. It ignores the variants on stroke width which often varies on using different writing tools.
Afterwards, radical segmentation proceeds to segment the normalized character image in order to obtain the radical block area. The widely-used method, named histogram projection, is used to accomplish this function. It is an efficient method. For some characters, however, it is difficult to segment the radical block precisely by only applying histogram projection. Though they are not what we want, it would not cause problems in our system since we treat smkes as fuzzy objects.
B. Stroke Extracting Strategy
After the radical block is identified, stroke extracting strategy will be applied to extract strokes from the thinned radical block. The stroke extracting strategy is developed in our laboratory by Mr. Chung-Chieh Sheu.
It uses a two-pass fast extraction strategy instead of a window-oriented tracing approach which causes the time- consuming problem. The pass I checks the character image row by row, i.e., row-oriented tracing, so it extracts out vertical strokes and slanting strokes. In pass 11, the character image is examined by column-oriented tracing approach, so it extracts the horizontal strokes.
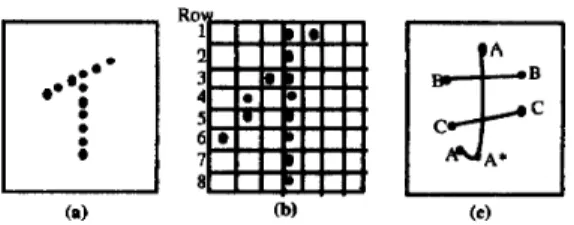
Then a combining phase proceeds to combine the appropriate strokes into comer strokes. At last, output the extraction results. Fig. 2. shows the thinned character image and the result of stroke extraction.
C. Primitive Stroke Extractor primitive strokes from the radical block.
The Primitive Stroke Extractor is aimed at extracting Since the
Fl
A*(a) (e)
Fig. 2. Examples for discussing stroke extracting strategy. (a) is an ideal thinning result. (b) is the actual thinning results. (c) is the stroke extraction result.
Symbols in (c) represent the end points of extracted stroke. Also they denote the extraction order, and A*
expresses the comer point. That is, the stroke marked A is the first extracted stroke and marked B is the second one, etc.
Chinese character is constructed by radicals and strokes, many researchers have spent a lot of effort on how to decompose the character structure. Thus, there are many key-in methods based on the structure decomposition for Chinese characters, e.g., Changjei [4], Dayi, Wuhsiami, Four-comer, etc. In Taiwan, Changjei method is widely used. It almost provides an unique way for every Chinese character. Based on its decomposition on Chinese character structure, we choose Horizontal, Vertical, Left-Slanting, Right-Slanting, and Corner- Strokes as our primitive features.
Table 1 Primitive Strokes.
Seven primitive strokes of the Chinese characters used in our system.
Slr okt Shr p
I
S- T mI
AbemhtiouIn Table 1, all the primitive strokes defined in the Primitive Feature Extractor are listed. Our membership definition for each stroke type is given as follows:
(1) Horizontal:
l - ( m ( x ) ( , k < x j < l ;
PMX>
= {
0, others, where m(x) denotes the slope of line x.
488
(2) Vertical:
, where m(x) denotes the slope of line x.
(3) Left-Slanting:
where 9(x) denotes the angle between line x and the horizontal line.
(4) Right-Slanting:
, where 9(x) denotes the angle between line x and the horizontal line.
( 5 ) Comer Strokes:
(Right-Comer, Left-Comer, and Bottom-Comer)
, where len() denotes the length of the specified stroke.
The comer stroke defined here is a consecutive stroke which has a corner inside. That is, there is a direction change in the whole stroke, for example b, 7 . For convenience, the substroke before the direction change is called the former substroke, and the other one is called the latter substroke. The important features of comer stroke are its corner point and the length of latter substroke. One stroke without corner point is undoubtedly not a corner stroke. That is the reason we define the membership function of Comer Stroke in this way.
Furthermore, in order to commit the fuzzy characteristics, a special ct level set degree, named REGULARITY, is used to determine the accepted regularity of input characters. If the degree of the extracted primitive stroke for one specific stroke type does not meet the requirement of a level, it would not be considered as a candidate of this stroke type. For example, if the a is set as 0.7 and one extracted stroke gets degree 0.8 for Horizontal line and 0.2 for Right- Slanting line, the Primitive Stroke Extractor treats the stroke as a Horizontal line only. However, if we set a to be 0.1, the stroke can be either treated as a Horizontal line or a Right-Slanting line. That is, if we set the a degree high, it only accepts characters which are written in a very regular manner. In contrast, if the degree of a level set is low, more cursive writings will be accepted.
However, if the degree is set too low, it would take some computation effort on determining the stroke type CandidateS.
D. Compound Stroke Extractor
The Compound Stroke Extractor combines primitive strokes into compound strokes or radicals. Fuzzy rules are used to carry out the strokes combination. During extraction, the Primitive Stroke Extractor extracts out primitive strokes and stores them into the Stroke Pool.
After that, the Compound Stroke Extractor fetches the extracted information from Stroke Pool and takes a look at the connection type of the two consecutively fetched strokes. Then checks if they can be combined or not.
Fuzzy rules are applied in this phase. Repeating the fetching and combination, the radical will be obtained as the preclassification information for the classifier. Thus, the determination of the connection type of two strokes is very important in the Compound Stroke Extractor.
Before we discuss the definition of connection type, measurements on stroke distance and the calculation of midpoints of strokes will be given first.
Midpoint of a specified stroke:
where ( X i , yl) and (X2, y2) denote the coordinates of starting point and terminating point of stroke S, respectively.
Minimum distance between two specified strokes:
minDistance(S 1, S2)=
min(minDistance-of-end_points(S 1 , S 2 ) , minDistance-of-midpoint-to-end-points( S 1, S2)) *
, where minDistance-of-end-points() denotes the minimun distance between end points of two specified strokes, and minDistance-of-midpoint-to.-end-points() denotes the minimun distance between midpoint of one specified stroke and end points of the other specified stroke.
In Fig. 3, we gives an example for calculating the minimum distance of two specified strokes. For convenience, we let A, B, C denoting the starting point, midpoint, and terminating point of stroke S1, respectively. And let D, E, F denoting the starting point, midpoint, and terminating point of stroke 52, respectively. Though we only define the minimum distance between two straight strokes, it can be generalized into calculating the minimum distance between a straight stroke and a comer stroke. This is because a comer stroke is composed of two straight
strokes. Thus, the minimum distance between the straight stroke S1 and a corner stroke S2 can be translated into min(minDistance(S 1, S2A), minDistance(S1, S2B)), where S2A and S2B are the two straight strokes of S2. Furthermore, the generalization of calculating minimum distance between two corner strokes is also in the same way.
min(kn(A, D), W A , p3, WC, D), h ( C , F), m M k n 0 , D), lea@, P), lea(& A), b@, CJ )
1:
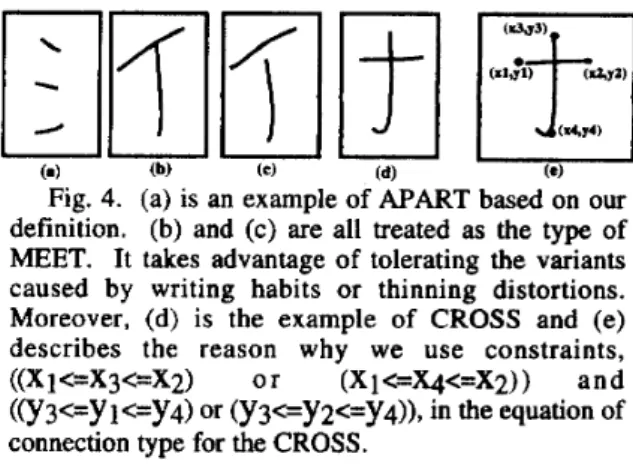
Fig. 3. An example for calculating the minimum distance between two strokes. The first part is to calculate the minimum distance between end points of the specified strokes, and the second part is to measure the minimum distance between midpoint of one stroke and the end points of the other stroke.In what follows, we discuss the definition of connection type. Fig. 4 shows the examples of connection types. During the determination of connection type, the first step is to check if the two strokes are crossed together by using ((Xi<=X3<=X2) or (Xl<=Xq<=X2)) and ((y3<=yl<=y4) or (y3<=y2<=y4)) constraints. The definition is based on the relation of coordinates of two crossed strokes.
Fig. 4(e) shows the case of cross connection. However, if they are not crossed, the minDistance(S I , S2)<=(1/2)*min(len(Sl), len(S2)) is used to determine if the connection type is meet together or apart.
Connection-Type( S 1, S2) :
CROSS: ((Xi<=X3<=X2) or (Xl<=Xq<=Xz)) MEET:
minDistance(S1, S2) <= I*min(len(Sl), len(S2)) 2
APART:
minDistance(S 1 , S2) > l*min(len(Sl), len(S2));
2
of one of the specified stroke, and (X3, y3), (Xq, y4) denote the end points of the other stroke.
and ((y3<=yl<=y4) or (Y3<=Y2<=Y4));
, where (Xi., y l ) and (X2, y2) denote the end points
Once the connection type of two consecutive stroke are determined, fuzzy rules which represent the character structure of Chinese will be applied to combine them. After the strokes are combined as a compound stroke, its stroke type degree should be
Fig. 4. (a) is an example of APART based on our definition. (b) and (c) are all treated as the type of MEET. It takes advantage of tolerating the variants caused by writing habits or thinning distortions.
Moreover, (d) is the example of CROSS and (e) describes the reason why we use constraints, ((Xi<=X3<=X2) o r (Xl<=X4<=X2)) and ((y3<=Yl<=y4) or (y3ey2c=y4)), in the equation of connection type for the CROSS.
reevaluated according to the following equation:
CombinationDepree(s 1 ,s2) = min(deg(s l),deg(s 2)) specified stroke.
, where deg() denotes the stroke type degree of the
After the extraction and combination, the radical obtained will be sent to the classifier as a preclassification information to make the recognition result more reasonable and reliable.
III.
Fuzzy RulesIn the proposed system, we do not have to store the detail information for each stroke, i.e., length, angle, and location, in the feature base. Because it not only takes much time on recognition, but also raises the difficulty of matching since the handwritten Chinese characters vary a lot in size, shape, and position. In contrast, fuzzy rules are used to represent the structure knowledge of Chinese characters. Due to the handwritten Chinese characters are fuzzy in mature, the fuzzy rules can be used to deal with the fuzziness of human handwritings. In addition, fuzzy rules provides a systematic framework for dealing with linguistic terms such as horizontal, vertical, etc., which often eases the implementation effort and also reduces the rules to a great deal. In this way, the computation effort is reduced a lot. After the primitive strokes are extracted from the thinned radical block, the Compound Stroke Extractor fetches them from the Stroke Pool according to the order of extraction. Then the Compound Stroke Extractor determines the connection type of consecutive strokes and combines them under the control of fuzzy rules. For example, if there is a right-slanting stroke and a vertical stroke connected in MEET type, they can be combined as the radical according to the following rule:
490
If S1 is RS, S2 is VL, and Connection-type is &ET then
combine-S L-and-S2 as " "
Fig. 5 . Combination rule for radical
f.
Fig. 5 illustrates the combination rule for radical
f
in graph. From the above descriptions and the example, it is without saying that we only apply appropriate rules for strokes combination during inference. That is, our inference strategy is not like that of a general fuzzy system, and we do not try to match each rule in the rule base for generating a defuzzification result. Thus, it would not cause problems on the time issue.
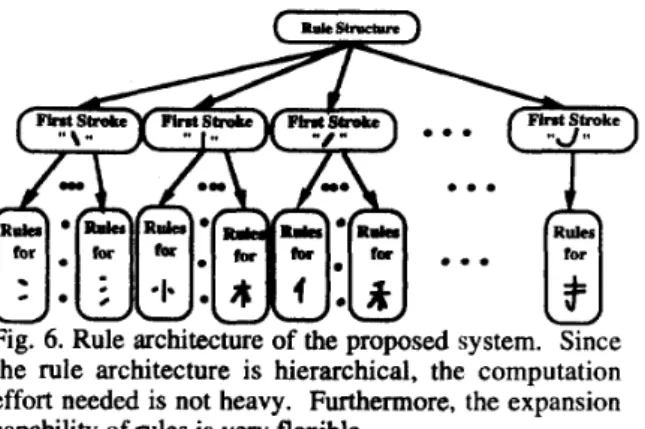
Furthermore, due to the hierarchical rule structure is provided, the computation effort does not increase proportional to the number of rules increase. Fig. 6 depicts the rule architecture of the proposed system Our partition method on rules is based on the order of extracted stroke. That IS, the radical with the same first stroke is grouped together. Then the grouped rules is further divided into rule sets for radicals according to the second stroke, third stroke, connection types, and so on.
Besides, since the fuzzy rules indicate the character structure of Chinese, the capability of the system dealing with 20 radicals can be extended to SO radicals or even more by only adding the structure knowledge into the system. The capability of flexible expansion is very promising. In the proposed system, 60 rules are used to deal with 20 radicals.
IV. Experimental Results
In order to show the feasibility of proposed method, the widely -used handwritten Chinese character database, named HCCRBASE provided by Computer and Communication Laboratories, lRTI, Taiwan, is used to conduct our experiments. The database contains 5401 categories commonly-used handwritten Chinese characters. They are written by a b u t 2600 persons and each character category collects 2 14 to 284 writing samples. All the samples are reordered in script regularity for each category. That is, the first one third
Fig. 6. Rule architecture of the proposed system. since the rule architecture is hierarchical, the computation effort needed is not heavy. Furthermore, the expansion capability of rules is very flexible.
samples of each category are written in a regular manner, and the last one third samples of each category are written in more cursive approach.
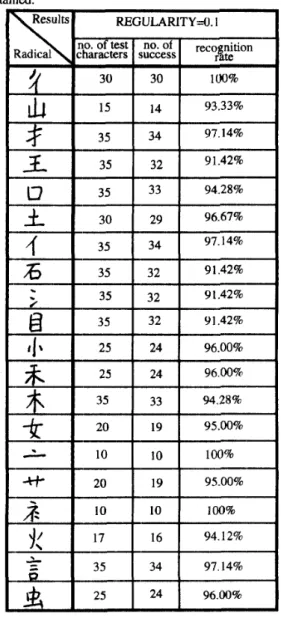
In Table 2, the detail recognition results for each radical group are listed. There are two reasons why the number of test characters are different for different radicals. One is the Occurrence frequency of characters are quite different in the 5401 commonly-used Chinese characters. Thus, it is difficult to collecl an identical number of test characters for each radical. The other reason is that some characters get very poor thinning results or its strokes are mis-extracted. Thus, the tested number are different for different radicals. Except the poor thinning results and mis-extracted characters, an average of 95% recognition rate is obtained, the feasibility of the proposed system is confirmed.
V. Discussion
Based on the above experimental results, we can find that the proposed method is feasible. In what follows, we discuss the characteristics of the proposed system.
A. Stroke candidates
Due to fuzzy set theory is adopted, its outstanding characteristic, i.e., candidates provision, are demonstrated to deal with the variants of writing styles in proposed system.
B. Computation effort
Since we define the stroke type and stroke relation as simple as possible, so that it would not take much time on detecting the stroke shapes and stroke relations for handwritten Chinese characters like other systems.
Moreover, due to hierarchical rule sets are used to proceed the strokes combination. Thus, the overall computation effort is decreased to a great deal.
Table 2 Experimental results.
Except the poor thinning results and mis-extracted characters, an average of 95% recognition rate is obtained.
C. Extensibility
Since rules are used to indicate the character structures, the capability can be extended by enhancing combination rules appropriately. That is, the expansion capability of proposed system is very flexible.
D. Thinning
Like other systems, poor thinning results will also cause the stroke extraction fail in our system. Once the strokes are mis-extracted, the proposed system would
possibly return a wrong radical for the input character.
E. Stroke extraction
Like other system which treats strokes as features, it is possibly to mis-extract a radical on cursive handwritings or complex characters. Thus, further study on the stroke extracting strategy is still needed for accomplishing a robust Chinese character recognition system.
F. Rules
Rules need to be constructed for the proposed method.
However, it takes advantage of needless to compare the information of inputs with built-in prototypes. Besides, based on the structure of Chinese character, the number of rules needed is few.
VI. Conclusion
A new method for decomposing the Chinese character structure on extracting radicals as the preclassification information for handwritten Chinese character recognition has been proposed. It takes advantage of fuzzy set theory, and meets the needs of dealing with handwritten Chinese characters whose writings are fuzzy in nature.
Since few fuzzy rules and hierarchical rule sets are provided, the computation effort is not heavy. Besides, the capability of the whole system can be enhanced by increasing f u u y rules appropriately. The proposed method is of great flexibility. Furthermore, experiments on 542 characters which are selected from the 100th samples of HCCRBASE not only show the feasibility of proposed method, but also suggest that applying fuzzy set theory on the recognition of Chinese characters is an efficient and promising method.
References
[ I ] Fang-Hsuan Cheng and Wen-Hsing Hsu, “ Research on Chinese OCR in Taiwan,” International Journal of Pattern Recognition and Artificial Intelligence, vol. 5 , no. 1&2, pp. 139-164, 1991.
[2] Mark W. Mao and James B. Kuo, ‘‘ A coded Block Adaptive Neural Network System with a Radical- Partitioned Structure for Large-Volume Chinese Characters Recognition,” Neural Networks, vol. 5 , pp.
[ 3 ] Zhiqiang Cao and Abraham Kandel, “ Applicability of Some Fuzzy Implication Operators,” Fuzzy Sets and Systems. vol. 31, pp. 151-186, 1989.
[4] Hong-Lien Shen, “ Handbook of The Fifth Generation Changjei Key-In Method,” Sung-Kung Computer Book C b . , Ltd., Taipei, Taiwan, 1993. (in Chinese edition) 835-841, 1982.
492