Workload and Capacity Optimization for
Cloud-Edge Computing Systems with Vertical and Horizontal Offloading
Minh-Tuan Thai, Ying-Dar Lin, Fellow, IEEE, Yuan-Cheng Lai, and Hsu-Tung Chien
Abstract—A collaborative integration between cloud and edge computing is proposed to be able to exploit the advantages of both technologies. However, most of the existing studies have only considered two-tier cloud-edge computing systems which merely support vertical offloading between local edge nodes and remote cloud servers. This paper thus proposes a generic architecture of cloud-edge computing with the aim of providing both vertical and horizontal offloading between service nodes. To investigate the effectiveness of the design for different operational scenarios, we formulate it as a workload and capacity optimization problem with the objective of minimizing the system computation and communication costs. Because such a mixed-integer nonlinear programming (MINLP) problem is NP-hard, we further develop an approximation algorithm which applies a branch-and-bound method to obtain optimal solutions iteratively. Experimental results show that such a cloud-edge computing architecture can significantly reduce total system costs by about 34%, compared to traditional designs which only support vertical offloading. Our results also indicate that, to accommodate the same number of input workloads, a heterogeneous service allocation scenario requires about a 23% higher system costs than a homogeneous scenario.
Index Terms—capacity optimization, edge computing, fog com- puting, optimization, workload offloading.
I. INTRODUCTION
Cloud service providers traditionally rely on massive data centers to provide virtualized computational resources to users with the advantages of high availability and rapid elasticity [1].
Unfortunately, such an approach is not capable of accommo- dating real-time and delay-sensitive services, such as high- quality video streaming or instant emergency alarms, which require immediate responses. In fact, the transmission of such service workloads to and from remote data centers results in long network latency which might significantly downgrade their performance. Furthermore, the data centers, which pro- vide computational resources in a centralized manner, cannot handle the requirements of mobility and geo-distribution of mobile and Internet of things (IoT) services efficiently.
To overcome such issues of cloud computing, an edge computing paradigm [2]–[6] aims to process service workloads
Minh-Tuan Thai is with the Department of Information Technology, Can Tho University, Can Tho, Vietnam.
Ying-Dar Lin and Hsu-Tung Chien are with the Department of Computer Science, National Chiao Tung University, Hsinchu, Taiwan.
Yuan-Cheng Lai is with the Department of Information Management, National Taiwan University of Science and Technology, Taipei, Taiwan.
Minh-Tuan Thai is the corresponding author (e- mail:tmtuan@cit.ctu.edu.vn).
Manuscript received
locally, near their sources. In other words, the concept allows deploying virtualized resources of computing and communica- tion on mobile/IoT devices, network edges, and core servers by leveraging virtualization technologies. By doing so, the end- to-end delay for accessing the resources is reduced since the network distance between them and end-users is significantly shortened. Hence, edge computing is likely more suitable for real-time or delay-sensitive services than cloud computing.
Furthermore, edge computing enables virtualized resources to be geographically distributed at network edges which can potentially address the requirements of mobility and geo- distribution of mobile and IoT services.
While cloud computing provides high availability, reliabil- ity, and good resource utilization, and has almost capacity limit, edge computing offers mobility and enhances perfor- mance. As a result, integration of cloud with edge computing has been proposed to exploit the advantages of both these tech- nologies [7]. Conceptually, the approach allocates computation and communication virtualized resources into th hierarchy, such as to end device, network edge, central office, and data center tiers, to handle incoming service workloads. By doing so, cloud-edge computing can efficiently accommodate differ- ent types of services whose characteristics are diverse while maintaining availability and reliability. In fact, although end devices and network edges are suitable for real-time and delay- sensitive services, they may not be able to handle services which demand a significant amount of computing capacity.
The workloads of such services must thus be redirected to central offices or data centers for executions.
In practice, a cloud-edge computing system must serve a vast, diverse, and ever-increasing volume of service workloads.
It is thus crucial and challenging to manage its capital expen- diture (CAPEX) and operating expenses (OPEX) efficiently, while guaranteeing service quality (e.g., delay constraints).
Research papers such as [7]–[14] have attempted to address these requirements of cloud-edge computing. However, these studies only considered simple two-tier systems, i.e., local network edge nodes and remote cloud servers, or neglected the horizontal offloading between service nodes in the same tier, such as device-to-device and edge-to-edge offloading.
To this end, we first derive generic architecture of cloud- edge computing, taking into consideration both vertical and horizontal offloading between service nodes. We then model a workload and capacity optimization problem with the objective of minimizing system computation and communication costs.
This would then allow us to study the architecture perfor-
mance with different input workloads, service allocations, and capacity price scenarios. Since the problem is a mixed- integer nonlinear programming (MINLP) problem, which is very difficult to address, we develop a branch-and-bound algorithm to obtain optimal solutions iteratively. Experimental results show that our cloud-edge computing design, which sup- ports both vertical and horizontal offloading, can significantly reduce system costs for various operational scenarios by about 34%, compared to a traditional approach which only provides vertical offloading.
Compared to related work, the contributions of this paper are across three aspects: (i) this paper is the first study, to the best of our knowledge, which considers both vertical and horizontal offloading in a cloud-edge computing system and formally models its architecture into an optimization problem;
(ii) we derive a branch-and-bound algorithm to reduce the complexity and obtain optimal solutions for the problem; and (iii) various experimental simulations were conducted to in- vestigate important operating scenarios along with significant observations.
Although the proposed algorithm can solve our optimization problem efficiently, its long-running time, especially in large- scale cloud-edge systems which consist of a large number of service nodes and network connections, would be a limitation of this work. Also, our architecture assumes that service nodes fairly treat all submitted service requests. Thus, it is not suitable for a situation in which some service nodes with special capabilities can process particular services more quickly than the others. Besides, the implementation of hori- zontal offloading capability on end devices and network edges is an extremely complex task due to their greatly varied characteristics [15], [16].
The remainder of this paper is organized as follows. In Section 2, we review existing papers on workload and capacity optimizations for cloud-edge computing, which are closely related to our work. We then develop our architecture of cloud-edge computing and present the problem formulation in Section 3. In Section 4, we elaborate a branch-and-bound algorithm to address the problem. Evaluation study and exper- imental results are presented in Section 5. Finally, Section 6 concludes this paper.
II. RELATED WORK
A variety of research papers [7]–[14] has dealt with the collaborative integration between cloud and edge computing to exploit the advantages of both these technologies. Some of these papers have investigated simple two-tier systems which considered only vertical offloading between local edge nodes and remote cloud servers [7]–[11]. The authors of [12], [13] attempted to provide four-tier architectures of cloud-edge computing, wherein each tier has different capacity, vicinity, and reachability for end-users. Unfortunately, the horizontal offloading between the service nodes in the same tier was not addressed in these architectures.
The reason for these limitations of existing studies, from our understanding, is to reduce the complexity of their optimiza- tion models. Besides, the papers seemed to encounter some
difficulties, such as the horizontal offload capacity modeling and the loop situations between service nodes, while formu- lating both vertical and horizontal offloading between service nodes into their optimization models. To address the issues, this paper defines the definitions of parent and sibling nodes of a service node, to which it can do vertical and horizontal offloading, respectively. Also, the node cannot receive the workloads of a service from its siblings if it already horizon- tally offloads this type of workload in order to prevent loop situations. The consideration of both vertical and horizontal offloading obviously increases the computational complexity of our model, compared to those of existing studies. Thus, we develop an approximation algorithm applying a branch- and-bound approach to obtain solutions for our optimization problem.
Table I summarizes those papers which address workload and cost optimization for cloud-edge computing. It must be noted that in this paper, we use the terms edge computing and fog computing interchangeably. Generally, the objectives of these cited papers are to minimize system costs or the end- to-end delay of services offered. For example, the paper [8]
presented an integration approach to minimize service delay, which utilizes both VM migration and transmission power control. Deng et al. [9] formulated a trade-off between power consumption and delay in a cloud-edge computing system as an MINLP problem. The authors of [10] considered four components, the energy cost of cloud servers, cost of network bandwidth, propagation delay, and the compensation paid for end devices, while formulating a total cost minimization problem for a cloud-edge computing system. Lin et al. [11]
introduced a two-phase iterative optimization algorithm which aims to minimize the capacity cost of a three-tier cloud- edge system. Resource allocation problems with the objective of service delay minimization were studied by Souza et al.
in [12], [13]. The authors of [14] considered both vertical offloading between edge and cloud nodes and horizontal offloading between neighboring edge nodes in a study on online workload optimization. Unfortunately, the authors only investigated a simple case of single service in this work.
To sum up, our optimization model shares the same ob- jective with related work [9]–[11] which is to minimize computation and communication costs, e.g., CS and CN, of the system, while satisfying the end-to-end delay constraints of service requests. Note that some related work [7], [8], [12]–
[14] has reversed objective and constraints with our model. In other words, the studies aim to minimize the end-to-end delay Dof service requests while ensuring all service allocations.
III. GENERIC ARCHITECTURE OF COLLABORATIVE CLOUD-EDGE COMPUTING AND OPTIMIZATION MODEL
A. Generic architecture of collaborative cloud-edge comput- ing
Our proposed design of collaborative cloud-edge computing is described in Figure 1. The novel aspect of the design is that it deploys virtualized communication and computation services to four different hierarchical tiers. The first tier of the hierarchy is composed of end devices, such as smartphones,
TABLE I: Comparison of studies on workload and capacity optimization for cloud-edge computing
# Tiers
# Services
Horizontal
offloading Variables Objective (Minimize)
Optimization
problem Solution
[8] 2
(Device/Edge) 1 No R A D NLP Integrated VM migration and TPC
[9] 2
(Device/Cloud) 1 No W O and C A CS MINLP Decomposition algorithm
[7] 2
(Edge/Cloud) Multiple No W O D MIP Simulated annealing algorithm
[10] 2
(Device/Cloud) Multiple No W O CS+ CN MINLP Distributed Jacobian algorithm
[11] 3
(Device/Edge/Cloud) 2 No W O and C A CS NLP Two-phase iterative optimization
[12] 4
(Device/Edge 1/Edge 2/Cloud) Multiple No R A D ILP Solved by optimization tools
[13] 4
(Device/Edge 1/Edge 2/Cloud) Multiple No Multiple R A D Knapsack Solved by optimization tools
[14] 2
(Device/Cloud) 1 Yes W O D MINLP Online k-secretary algorithm
Ours 4
(Device/Edge/Office/Cloud) Multiple Yes W O and C A CS+ CN MINLP Branch-and-bound algorithm (Abbreviation - W O: workload offloading, C A: capacity allocation, R A: resource allocation, D: system delay, CS: computation cost, CN: communication cost, MINLP: mixed-integer nonlinear programming, MIP: mixed-integer programming, ILP: integer linear programming, NLP: nonlinear programming, TPC:
transmission power control)
IP cameras and IoT sensors, which directly receive service workloads from their sources. In our design, a device can by itself locally process (i.e., carry out local offloading) a fraction of the input workloads or horizontally offload some of the other workloads to neighboring devices, using various short-range wireless transmission techniques such as LTE D2D, Wi-Fi Direct, ZigBee, and Bluetooth. For the remaining workloads, the device needs to vertically offload to network edge nodes (e.g., edge servers, switches, routers, base stations) in the second tier using access network technologies such as Ethernet, Wi-Fi, and 4G/5G. The edge nodes, in turn, can also process a part of received workloads. Further, horizontal and vertical offloading can be carried out by the nodes to dispatch their workloads to nearby edge nodes, and to central offices in the third tier, by leveraging core network technologies.
Similar to devices and edge nodes, a central office, which is re- structured as a small-size data center, can also carry out local processing, and horizontal offloading to neighboring central offices and vertical offloading to a remote federated data center in the fourth tier. In our design, the central offices are connected to each other and to the data center using backbone network technologies. The data center, which is located in the top-most tier of the cloud-edge computing hierarchy, acts as the backstop to the whole system. In other words, it is responsible for processing the remaining workloads which cannot be handled by lower tiers.
Our aim is to develop a generic architecture which can be used to deploy different types of services. Taking a real-time vehicle congestion avoidance service in smart cities as an example, IP cameras, which are used for traffic monitoring, can provide instant alarms of emergency events such as car accidents by detecting abnormal traffic behavior. Note that only a fraction of the volume of the captured data is dispatched to an edge server for detailed analysis. The server then processes the data to obtain more refined information which can be sent to automobile drivers or conveyed to news
outlets across the whole city. If there is a lack of computation capacity, the server can send the data to nearby edge servers for execution. In cases of serious situations, some data can also be redirected to central offices or even to a remote data center for running traffic re-routing algorithms which need very high computation capacity. Note that the proposed architecture is generic which includes four different hierarchical tiers, such as end device, network edge, central office, and data center which provide both vertical and horizontal offloading between service nodes. In real deployments, the design can be customized and adjusted by, for example, merging the central office and the data center into a cloud tier or removing the horizontal offloading capability between end devices. By doing so, the design becomes specific architectures, such as Edge server, Coordinate device and Device cloud [16] which can accommodate different types of cloud-edge services and applications.
In the following subsection, we provide an optimization model for the proposed cloud-edge computing architecture.
We then formulate a cost minimization problem for the model whose important notations are summarized in Table II.
B. Optimization model
1) Workload model: Let f ∈ F denote an offered service of a cloud-edge computing system. Each service f has a computation size ZSf which is the number of mega CPU cycles required to process a request for service f . Also, communication size ZN
f indicates the data size of the request in megabytes. Let Iα, Iβ, Iγ, and Iδ be the sets of devices, network edges, central offices and data centers of the system, respectively. A service node i ∈ I could process a set of services Fi ⊆ F, where I is the set of all service nodes of the system, i.e., I= Iα∪ Iβ∪ Iγ∪ Iδ.
a) Local processing: Let pif denote the workload (in requests per second) of a service f which is locally processed
TABLE II: Summary of important notations
Notation Meaning Attribute
Service
f , F index and set of system services Input
ZSf, ZfN computation and communication size of service f Input
Service node - Capacity
i, I index and set of all service nodes Input
Fi set of services supported by a node i Input
Iα, Iβ, Iγ, Iδ sets of devices, network edge nodes, central offices and data centers Input
Hi, Vi, Ki sets of sibling, parent, child nodes of a node i Input
µiS computation capacity of a node i ∈ Iα∪ Iβ Variable
ni, νiS number of active servers and computation capacity of a server of a node i ∈ Iγ∪ Iδ Variable
µi, jN communication capacity of network connection from i to j Variable
Workload
λif input workload of service f to a device i ∈ Iα Input
pif workload of service f locally processed by a node i Variable
xi, jf horizontal offloading workload of service f from i to j, where j ∈ Hi Variable uj, if horizontal offloading workload of service f from j to i, where j ∈ Hi Variable yi, jf vertical offloading workload of service f from i to j, where j ∈ Vi Variable vi, jf vertical offloading workload of service f from j to i, where j ∈ Ki Variable Delay
DiS computation delay of a node i Output
Di, jN communication delay of a network connection from i to j Output
Dα, Dβ, Dγ, Dδ delay of device tier, edge tier, central office tier, and data center tier Output Dα, Dβ, Dγ, Dδ delay thresholds of device tier, edge tier, central office tier, and data center tier Input Cost
WαS, WβS, WγS, WδS computation cost of a device, edge node, central office, and data center Input Wα, αN , Wα, βN , Wβ, βN ,
Wβ,γN, Wγ,γN, Wγ, δN communication cost of a device-to-device, a device-to-edge, edge-to-edge, edge-to-office,
office-to-office, and office-to-center connection Input
CS, CN, C computation cost, communication cost, and total cost of the system Output
Fig. 1: The generic architecture of collaborative cloud-edge computing
by a node i. We have pif =
(≥ 0, if f ∈ Fi, ∀i ∈ I,
= 0, if f < Fi, ∀i ∈ I. (1) b) Sibling node and horizontal offloading: The set of siblings Hi of a node i ∈ I consists of service nodes which are located in the same tier as i, and to which i can horizontally
offload its workloads. Also, let xi, jf be the workload of a service f which is horizontally offloaded from i to a service node j ∈ Hi. Similarly, let ufj,i be the workload of a service f which is horizontally offloaded from j ∈ Hi to i. Here, we assume that a service node i can offload the workload of a service f to a sibling node j on condition that j is able to process f , i.e., f ∈ Fj. In addition, to prevent loop situations, a node cannot receive the workloads of a service f from its siblings if it already horizontally offloads this type of workload. Thus, we have
xi, jf =
(≥ 0, if f ∈ Fj, ∀j ∈ Hi, ∀i ∈ I,
= 0, if f < Fj, ∀j ∈ Hi, ∀i ∈ I, (2a) ufj,i =
(≥ 0, if f ∈ Fi, ∀j ∈ Hi, ∀i ∈ I,
= 0, if f < Fi, ∀j ∈ Hi, ∀i ∈ I, (2b) xi, jf ∗ Õ
j ∈Hi
ufj,i = 0, ∀ f ∈ F, ∀i ∈ I. (2c)
c) Parent/child node and vertical offloading: The set of parents Vi of a service node i ∈ I consists of the nodes located in the next tier up with i, and to which i can vertically offload its workloads. Let yi, jf be the workload of a service f which is vertically offloaded from i to a node j ∈ Vi. The set of children Ki of i consists of the nodes which are located in the right lower-tier with i, and from which i receives incoming workloads. Let vj,if denote the workload of a service f which is vertically offloaded from j ∈ Ki to i. Since a device i ∈ Iα directly receives service workloads from external sources, it
has no child nodes, i.e., Ki = ∅, ∀i ∈ Iα. Similarly, a data center i ∈ Iδ is in the most-top tier of the system, and hence has no parent nodes, i.e., Vi = ∅, ∀i ∈ Iδ. Opposed to horizontal offloading, a service node can carry out vertical offloading for all services f ∈ F. In other words, it can dispatch all types of workloads to its parents. Thus, we have
yi, jf ≥ 0, ∀ f ∈ F, ∀ j ∈ Vi, ∀i ∈ Iα∪ Iβ∪ Iγ, (3a) vj,if ≥ 0, ∀ f ∈ F, ∀ j ∈ Ki, ∀i ∈ Iβ∪ Iγ∪ Iδ. (3b) Let λif denote the submitted workload of a service f from external sources to a device i ∈ Iα. We have
λif ≥ 0, ∀ f ∈ F, ∀i ∈ Iα. (4) Hence, the workload balanced constraints of the system are defined as
Í j ∈ Hi
uj, if + λif= Í j ∈ Hi
xi, jf + Í j ∈Vi
yi, jf + pif if i ∈ Iα, Í
j ∈ Hi uj, if + Í
j ∈Ki vj, if = Í
j ∈ Hi xi, jf + Í
j ∈Vi
yi, jf + pif if i ∈ Iβ∪ Iγ∪ Iδ. (5)
2) Computation and Communication delay:
a) Computation delay of device and edge nodes: In the case of a service node i is a device or a network edge, i.e., i ∈ Iα∪ Iβ, where there is only a single server in the node which is responsible for processing incoming workloads. Hence, the M/M/1 queuing model [17, Ch. 2] is employed to compute the node’s computation delay DSi as
DSi = 1
µSi − Í
f ∈Fi
pif ∗ ZSf, (6) Õ
f ∈Fi
pif ∗ ZSf < µiS ≤µS, M AXi , ∀i ∈ Iα∪ Iβ, (7)
where µSi is the computation capacity (in mega CPU cycles per second), i.e., service rate, of the node i; and Í
f ∈Fi
pif ∗ ZfS is the total CPU cycles per second demanded for executing all workloads pif, ∀ f ∈ Fi, which have to be locally processed by i. Note that µSi cannot exceed the maximum value µS, M AXi .
b) Computation delay of central office and data center nodes: In the case where a service node i is a central office or a data center, i.e., i ∈ Iγ∪ Iδ, there are multiple parallel servers in the node which can process incoming workloads. Therefore, we apply the M/M/n queuing model in [10] to compute the node’s computation delay DSi as
DSi = 1
ni∗νiS− Í
f ∈Fi
pif ∗ ZSf + 1
νiS, (8)
ni∗νiS > Õ
f ∈Fi
pif ∗ ZSf, ∀i ∈ Iγ∪ Iδ, (9a) νiS ≤νiS, M AX, ∀i ∈ Iγ∪ Iδ, (9b)
ni ∈ N, (9c)
ni ≤ niM AX, ∀i ∈ Iγ, (9d) where ni is the number of active servers of the node i, and which cannot exceed the maximum value nM AXi , ∀i ∈ Iγ; and
νiS is the computation capacity of the servers which cannot exceed the maximum value νiS, M AX. Note that we assume that the servers are identical and there is not constraint of an upper limit for the number of active servers νiSof a data center i ∈ Iδ. c) Communication delay of network connections: Let (i, j) be a network connection from a service node i to another node j, where j ∈ Hi ∪ Vi. Each connection (i, j) has a communication capacity µi, jN, i.e., network bandwidth, which is measured in megabytes per second. The total amount of data transmitted through (i, j) per second is Í
f ∈Fi
xi, jf ∗ ZNf or Í
f ∈F
yi, jf ∗ ZfN .Thus, its communication delay Di, jN is calculated by the M/M/1 queuing model as
Di, jN =
1 µi, jN− Í
f ∈Fi
xi, jf ∗ZfN +N i, jLS if j ∈ Hi,
1 µi, jN−Í
f ∈F
yi, jf ∗ZfN +N i, jLS if j ∈ Vi, (10)
Õ
f ∈Fi
xi, jf ∗ ZNf < µi, jN, ∀j ∈ Hi, ∀i ∈ Iα∪ Iβ∪ Iγ, (11a) Õ
f ∈F
yi, jf ∗ ZNf < µi, jN, ∀j ∈ Vi, ∀i ∈ Iα∪ Iβ∪ Iγ, (11b)
where NLSi, j is the propagation delay of a network connection (i, j); and where Ni, j is the distance between i and j, and LS is the speed of light, i.e., approximately3 ∗ 108m/s.
d) Computation and communication delay of the cloud- edge computing system: The delay of a tier in our cloud-edge computing architecture which consists of its computation and communication delay is defined as
Dα= 1
|Iα| Õ i ∈ I α
DSi + 1
|Hi| Õ i ∈ I α
Õ j ∈ Hi
Di, jN, (12a)
Dβ= 1
|Iβ| Õ
i ∈ I β DiS+ 1
|Hi| Õ
i ∈ I β Õ j ∈ Hi
Di, jN + 1
|Vi| Õ i ∈ I α
Õ j ∈Vi
Di, jN
+ 1
|Hi| Õ i ∈ I α
Õ j ∈ Hi
Di, jN, (12b)
Dγ= 1
|Iγ| Õ i ∈ I γ
DiS+ 1
|Hi| Õ i ∈ I γ
Õ j ∈ Hi
Di, jN + 1
|Vi| Õ
i ∈ I β Õ j ∈Vi
Di, jN
+ 1
|Hi| Õ
i ∈ I β Õ j ∈ Hi
Di, jN + 1
|Vi| Õ i ∈ I α
Õ j ∈Vi
Di, jN + 1
|Hi| Õ i ∈ I α
Õ j ∈ Hi
Di, jN, (12c)
Dδ= 1
|Iδ| Õ
i ∈ I δ
DiS+ Di, jN + 1
|Vi| Õ i ∈ I γ
Õ j ∈Vi
+ 1
|Hi| Õ i ∈ I γ
Õ j ∈ Hi
Di, jN
+ 1
|Vi| Õ
i ∈ I β Õ j ∈Vi
Di, jN + 1
|Hi| Õ
i ∈ I β Õ j ∈ Hi
Di, jN + 1
|Vi| Õ i ∈ I α
Õ j ∈Vi
Di, jN
+ 1
|Hi| Õ i ∈ I α
Õ j ∈ Hi
Di, jN, (12d)
where Dα, Dβ, Dγ, and Dδ are the delay of device, edge, central office, and data center tier, respectively. Since a cloud-
edge computing system has to satisfy its delay constraints, we then have
Dα ≤ Dα, (13a)
Dβ ≤ Dβ, (13b)
Dγ ≤ Dγ, (13c)
Dδ≤ Dδ, (13d)
where Dα, Dβ, Dγ, and Dδ are the delay thresholds of device, edge, central office, and data center tier, respectively.
3) Total Cost Minimization Problem: Here, we focus on minimizing the total cost of a cloud-edge computing system which consists of the computation cost of service nodes and the communication cost of network connections.
a) Computation cost of service nodes: Let WαS, WβS, WγS, and WδS be the computation capacity cost (in money units/mega CPU cycles per second) of a device, an edge node, a central office, and a data center, respectively.
Thus, the computation cost of the system is
CS= WαS∗Õ i ∈ Iα
µiS+WβS∗Õ i ∈ Iβ
µiS+WγS∗Õ i ∈ Iγ
ni∗νiS+WδS∗Õ i ∈ Iδ
ni∗νiS. (14)
b) Communication cost of network connections: Let Wα,αN , Wα,βN , Wβ,βN , Wβ,γN , Wγ,γN, and Wγ,δN denote the communi- cation capacity cost (in money units/MBps) of a device-to- device, a device-to-edge, an edge-to-edge, an edge-to-office, an office-to-office, and an office-to-center connection, respec- tively. Thus, the communication cost of the system is
CN = CαN+ CβN + CγN, (15) where
CαN = Õ
i ∈Iα
Õ
j ∈Vi
Wα,αN ∗µi, jN +Õ
i ∈Iα
Õ
j ∈Hi
Wα,βN ∗µi, jN, (16a)
CβN =Õ
i ∈Iβ
Õ
j ∈Vi
Wβ,βN ∗µi, jN +Õ
i ∈Iβ
Õ
j ∈Hi
Wβ,γN ∗µi, jN, (16b)
CγN =Õ
i ∈Iγ
Õ
j ∈Vi
Wγ,γN ∗µi, jN +Õ
i ∈Iγ
Õ
j ∈Hi
Wγ,δN ∗µi, jN. (16c) c) System total cost: The total system cost C of a cloud- edge computing is defined as
C = CS+ CN. (17)
Since we aim to minimize the total cost of the cloud-edge computing system while guaranteeing its delay constraints, we hence have an optimization problem which is defined as
(P) min
pif,xi, jf ,yi, jf ,µiS,ni,νiS,µi, jN C, (18a) s.t. (1) − (5), (7), (9), (11), (13). (18b) IV. ALGORITHM DESIGN- BRANCH-AND-BOUND WITH
PARALLEL MULTI-START SEARCH POINTS
As can be seen, the problem P has integer variables ni and nonlinear delay constraint functions. Thus, P is an MINLP problem, which is generally very difficult to solve. We thus
apply the Branch-and-bound algorithm [18] to address the problem. The general idea is to relax P to a tree whose nodes are nonlinear programming (NLP) subproblems, which are easier to tackle, by removing the integrality conditions of P, i.e., variables ni can be continuous. Each subproblem node in the tree is iteratively selected for solving using a depth-first search strategy. When a feasible solution with variables ni as integers is found, it provides an upper bound solution for the original problem P. Other nodes that exceed this bound are pruned, and the enumeration is conducted until all leaf nodes of the tree are resolved or the search conditions are reached.
Algorithm 1 shows the pseudo-code of our proposed algo- rithm, in which C(N, O) denotes the current optimal solution for P, where N and O are the sets of determined integers and continuous variables of the solution, respectively. In the algorithm, we first attempt to find an initial solution by applying a Feasibility Pump [19] relaxation heuristic (lines 2-5), before starting the branch-and-bound procedure. If a feasible solution C∗(N∗, O∗) is reached, it becomes the current optimal solution C(N, O) (line 4). After that, an NLP sub- problem SP, which is generated by removing the integrality conditions of variables ni of the problem P, is added to the tree data structure T (lines 6-7). Next, the branch-and- bound procedure starts to iteratively solve the sub-problem SP ∈ T by the well-known Interior/Direct algorithm [20]
with parallel multiple initial searching points. Then we have four possibilities. If a feasible solution C∗(N∗, O∗) which is smaller than the current optimal solution C(N, O) is obtained and N∗ are integers, it becomes the current optimal solution and the node SP is pruned, i.e., we remove SP and its sub-nodes from T (line 13-14). If N∗ is not an integer, a branching operation is performed on a variable ni ∈ N∗. In other words, two new sub-problems SSP1 and SPP2 of SP are created and added intoT using the Pseudo-cost branching method [19] (line 16). In cases where C∗(N∗, O∗) is equal to or greater than C(N, O), or there is no a feasible solution, the node SP is also pruned. The branch-and-bound procedure is repeated until all nodes ofT have been resolved (line 8).
Note that we solve an NLP problem SP ∈ T using the Interior/Direct algorithm which can just yield a local optimal solution C∗(N∗, O∗). To address this issue, we apply the parallel multiple-start point method which attempts to obtain a global optimal solution by running the Interior/Direct algorithm with different initial values of the variables of the problem SP. In this paper, the values are randomly generated, which satisfies the lower and upper bound constraints of the variables.
V. NUMERICAL RESULTS
In this section, we present the numerical results which were obtained from simulation experiments carried out to investi- gate the performance of our proposed cloud-edge computing architecture.
A. Experiment parameter settings
For simplicity, but without the loss of generality, we carried out simulation experiments using a tree topology of a cloud- edge computing system whose number of service nodes and
Algorithm 1: Branch-and-bound with parallel multi-start search points
1 C(N, O) ← ∞, T ← ∅;
/* Attemp to find an initial solution
*/
2 Solve P by Feasibility Pump heuristic;
3 if find a feasible solution C∗(N∗, O∗) then
4 C(N, O) ← C∗(N∗, O∗);
5 end
/* Begin branch-and-bound procedure */
6 SP ← Relax integrality constraints of P;
7 Add(T , SP);
8 while ∃SP ∈ T has not been reached or pruned do
9 Select a subproblem SP ∈T by depth-first strategy;
10 Solve SP by Parallel Multi-start Interior/Direct algorithm;
11 if find a feasible solution C∗(N∗, O∗)< C(N, O) then
12 if N∗∈ N then
13 C(N, O) ← C∗(N∗, O∗);
14 Prune(T , SP);
15 else
16 Create 2 subproblem nodes SSP1, SPP2 of SP by Pseudo-cost branching on a ni ∈ N∗;
17 end
18 else
19 Prune(T , SP);
20 end
21 end
their network distances are summarized in Table III. In the topology, a service node has only one parent node, and the nodes with the same parent can carry out horizontal offloading to each other. Note that the topology can be extended to more service nodes with similar results. Table IV shows the important parameters applied in our experiments, refer- ing [9] and [10]. All optimization problems were modeled by AMPL [21], [22], and the algorithm 1 was implemented using Knitro [23] optimization solvers.
In these experiments, we compared our cloud-edge com- puting architecture design (WH) which supports horizontal offloading to a traditional design (NH) which does not support horizontal offloading between service nodes. The optimization model of NH is similar to the problem P, but its service nodes have no sibling nodes, i.e., Hi = ∅, ∀i ∈ I. Consequently, the nodes can only carry out local and vertical workload offload- ing. It is appropriate because NH shares common character- istics with related work [7]–[14]. Two designs WH and NH were evaluated under light, medium, and heavy workload cases in which the arrival rate λif was adjusted to generate submitted service workloads whose total demanded computation capacity was about10%, 50%, and 100%, respectively, of the maximum capacity of all service nodes in device, edge, and central office tiers.
Note that the objective of our optimization model is to minimize the total system cost C which consists of the computation cost of service nodes and the communication cost
TABLE III: Service nodes and their distances in experiments
Service node Value Distance Value
# devices per edge 4 device-to-device 0.1 Km
# edges per central office 3 device-to-edge 1 Km
# central offices 3 edge-to-edge 1 Km
# data center 1 edge-to-central office 10 Km office-to-office 100 Km office-to-data center 1000 Km
of network connections. It obviously is the main performance metric of our experiments. We also present the results of other metrics such as computation capacity allocation, workload allocation, and horizontal offloading workloads to explain the phenomenon observed from the experiments.
B. Analysis of results
The simulation results presented in this section evaluate the effectiveness of WH and NH designs under three different operational scenarios. We first investigate their performance in the unbalanced and balanced input workload scenarios.
Then, two service allocation strategies, i.e., homogeneous and heterogeneous, are tested. Finally, the impact of different situations of computation capacity costs on WH and NH designs is observed.
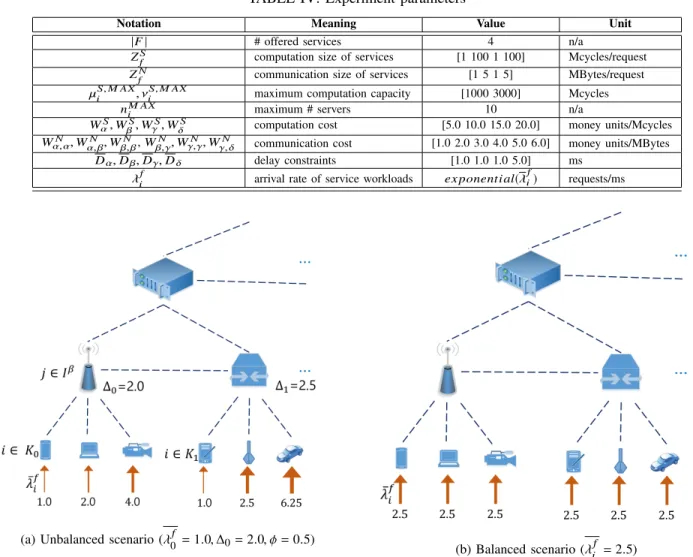
1) Unbalanced vs. Balanced workload scenario: We ob- served the performance of WH and NH designs under un- balanced and balanced workload scenarios. As can be seen in Figure 2, in an unbalanced scenario, the input workloads λif of a device i ∈ Iα were randomly generated according to an exponential distribution with different mean values λif calculated using Equations 19 and 20 whereas the workloads were exponentially distributed with the same value of λif in a balanced scenario. In the unbalanced scenario, λ0f and ∆0
were set to0.1 and 2.0 for all workload cases, and φ was set to 0.5, 1.0, and 1.5 for light, medium, and heavy workload cases.
In the balanced workload scenario, λif was set to2.5, 10.0 and 25.0 for these cases.
λif =(λ0f, if i= 0,
λi−1f ∗ ∆j, otherwise, ∀i ∈ Kj, ∀j ∈ Iβ, (19) where
∆j =
(∆0, if j= 0,
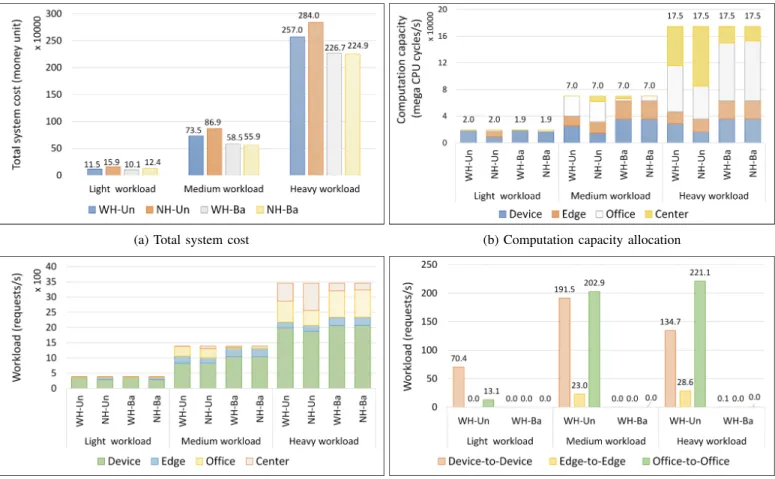
∆j−1+ φ, otherwise, ∀j ∈ Iβ. (20) As can be seen in Figure 3a, the design with horizontal offloading WH can significantly reduce the total system cost in an unbalanced workload scenario, compared to the NH design which has no horizontal offloading ability. In the case of a light workload, for example, the cost was decreased approximately 4.4 (i.e., from 15.9 to 11.5) ten thousands of a money unit by the WH design, which means about a 28% decrease. The cost difference was12.6 and 27.0 ten thousands of money unit, which means about15% and 10% lower in medium and heavy workload cases. The improvement is explained in Figure 3b, 3c, and 3d. Compared to the NH design, the WH approach can process more workloads in the service nodes of lower tiers instead of vertical offloading to those in higher tiers,
TABLE IV: Experiment parameters
Notation Meaning Value Unit
|F | # offered services 4 n/a
ZSf computation size of services [1 100 1 100] Mcycles/request
ZfN communication size of services [1 5 1 5] MBytes/request
µiS, M AX, νiS, M AX maximum computation capacity [1000 3000] Mcycles
nM AXi maximum # servers 10 n/a
WαS, WβS, WγS, WδS computation cost [5.0 10.0 15.0 20.0] money units/Mcycles Wα, αN , Wα, βN , Wβ, βN , Wβ,γN, Wγ,γN, Wγ, δN communication cost [1.0 2.0 3.0 4.0 5.0 6.0] money units/MBytes
Dα, Dβ, Dγ, Dδ delay constraints [1.0 1.0 1.0 5.0] ms λif arrival rate of service workloads ex ponential(λif) requests/ms
(a) Unbalanced scenario (λf
0 = 1.0, ∆0= 2.0, φ = 0.5)
(b) Balanced scenario (λif = 2.5) Fig. 2: Unbalanced and balanced input workload scenarios
by carrying out horizontal offloading to utilize lower tiers’
nodes. In other words, the WH approach can allocate more computation capacity in the service nodes of lower tiers to process the workloads, and since the costs of the computation capacity of lower tiers are lower than those of higher tiers, the total system cost was significantly reduced using this approach.
Figure 3a also clearly shows that in a balanced workload scenario, the total system cost of the WH and NH designs was roughly the same in every workload case. The numerical results in Figures 3b and 3c also illustrate that the computation capacity and workload allocation were approximately equal in these two approaches. The reason why the WH design did not produce much improvement is that its service nodes received the same input workloads. As a result, horizontal offloading did not contribute to a decrease in the total system cost by utilizing the service nodes in lower tiers; it might increase the cost by adding extra communication cost. The nodes either had to process by themselves or vertically offload their received workloads to parents, and had almost no horizontal offloading operations (see Figure 3d). In other words, the WH and NH designs behaved similarly in a balanced workload scenario which led to their performance being roughly the same.
2) Service allocation - Homogeneous vs. Heterogeneous:
We conducted a further experiment to investigate the per- formance of the WH and NH designs in homogeneous and heterogeneous service allocation scenarios. In a homogeneous scenario, all service nodes i ∈ I have the same capability which can process all services f ∈ F, i.e., Fi = F, ∀i ∈ I. On the other hand, in a heterogeneous scenario, their capability Fi can differ from each other. Note that this experiment was conducted with unbalanced input workloads.
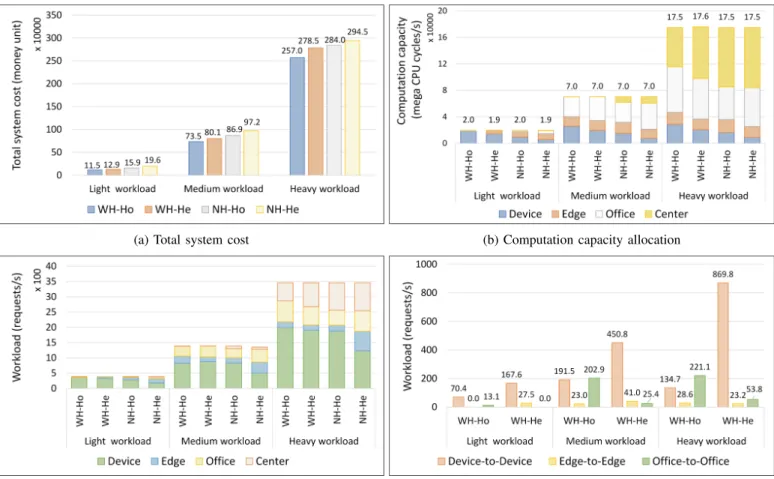
As anticipated, Figure 4a shows that a heterogeneous service allocation scenario required higher system cost in both WH and NH designs, compared to a homogeneous scenario. For example, in the case of a light workload, the cost increased by about 12% and 23% (i.e., from 11.5 to 12.9, and from 15.9 to 19.6 of ten thousands of money unit) in WH and NH designs. This phenomenon can be explained by the fact that in a heterogeneous scenario, a service node might receive the workload of a service which it cannot accommodate.
The workloads were then horizontally or vertically offloaded which resulted in an increase in total system cost. As can be seen in Figure 4c, in the homogeneous scenario, more workloads were vertically offloaded from lower to higher tiers for processing. Consequently, the two designs had to allocate
(a) Total system cost (b) Computation capacity allocation
(c) Workload allocation (d) Horizontal offloading
Fig. 3: Performance of WH and NH designs in unbalanced and balanced workload scenarios.(WH-Un: With horizontal offloading in unbalanced scenario, NH-Un: Without horizontal offloading in unbalanced scenario, WH-Ba: With horizontal offloading in balanced scenario, NH-Ba: Without horizontal offloading in balanced scenario)
more computation capacity to higher ties this scenario (see Figure 4b).
Figure 4a also shows that in a heterogeneous scenario, compared to the NH design, the WH design decreased the system cost more in light and medium workload cases. The cost was decreased by about 34% (i.e., from 19.6 to 12.9) and 18% (i.e., from 97.2 to 80.1), in these two cases. The corresponding numbers for a homogeneous scenario were28%
(i.e., from 15.9 to 11.5) and 15% (i.e., from 86.9 to 73.5).
However, in the case of heavy workload, the cost improvement for the heterogeneous scenario was only about5%, instead of 10% as for the homogeneous scenario.
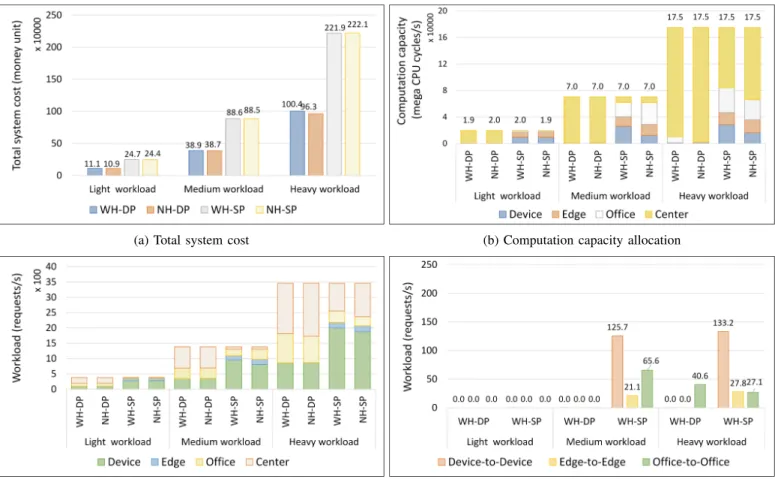
3) Impact of computation capacity costs: In this exper- iment, the performance of the WH and NH designs was investigated in decreased and equal computation capacity cost situations. In other words, the costs of computation capacity of lower tiers were more expensive than those of higher tier in a decreased cost situation. On the other hand, the costs were the same in every tier in an equal-cost situation. The costs WαS, WβS, WγS, WδS were set to [20.0 15.0 10.0 5.0] and [12.5 12.5 12.5 12.5] in money units, in the decreased and equal computation capacity cost situations, respectively. Note that the homogeneous service allocation and unbalanced input workload scenarios were used for this experiment.
As can be seen in Figure 5a, experimental results showed
that the WH design did not produce any noticeable improve- ment, compared to the NH design. In other words, the system cost of two designs was approximately the same in every workload case in both computation capacity cost situations.
Figure 5d illustrates that there was almost no horizontal offloading by the WH design in the decreased cost scenario.
Although the design still carried out some horizontal offload- ing operations in the equal-cost scenario, it did not lead to a significant decrease in the system cost.
Figure 5b clearly shows that most of the computation capacity was allocated to the data center tier in the decreased cost scenario since it had the cheapest computation cost. A significant number of workloads was processed by lower tiers, such as device, edge, and central office (see Figure 5c). It meant that the workloads of small computation size were processed by lower tiers. On the other hand, those of large size were offloaded to the data center tier for processing in this computation cost situation.
VI. CONCLUSION
In this paper, we have developed a cloud-edge computing architecture which includes vertical and offloading to effi- ciently and promptly process different virtualized computing services. The workload and capacity optimization model of
(a) Total system cost (b) Computation capacity allocation
(c) Workload allocation (d) Horizontal offloading
Fig. 4: Performance of WH and NH designs in homogeneous and heterogeneous service allocation scenarios. (WH-Ho: With horizontal offloading in homogeneous scenario, WH-He: With horizontal offloading in heterogeneous scenario, NH-Ho: Without horizontal offloading in homogeneous scenario, NH-He: Without horizontal offloading in heterogeneous scenario)
the design was then formulated as an MINLP problem to investigate its effectiveness in different operational scenarios.
We further derived an approximation algorithm which applied branch-and-bound method to find an optimal solution for the problem iteratively.
Experimental results showed that our proposed cloud-edge computing design could significantly reduce the total system cost by 34% in an unbalanced input workload scenario, compared to conventional designs which only provided ver- tical offloading. However, the total system cost of these two designs was roughly the same in a balanced input scenario.
Furthermore, the results also show that a heterogeneous service allocation required 12% and 23% more system cost than a homogeneous scenario in WH and NH designs, respectively.
Another interesting observation was that in contrast, as in an increased computation capacity cost situation, horizontal offloading did not produce a noticeable improvement in system cost in decreased and equal-cost situations.
There are still some important research problems come out of this paper which should be carefully studied in our future work when we will focus on extending our problem formulation to study the impact of service diversity on the performance of cloud-edge computing. Furthermore, a two- tier global and local optimization approach, which carries out a global level optimization on groups of service nodes,
and concurrent local level optimizations on service nodes of every group of the system, will also be considered to provide the scalability for large-scale cloud-edge computing systems. Another possible future work is to develop a real testbed which allows us to implement and study different resource management and optimization models for cloud-edge computing systems.
ACKNOWLEDGMENT
The authors would like to thank the support from the H2020 collaborative Europe/Taiwan research project 5G- CORAL (grant number 761586). This work was done when the first author was with the EECS International Graduate Program, National Chiao Tung University, Hsinchu, Taiwan.
REFERENCES
[1] M. Gharbaoui, B. Martini, and P. Castoldi, “Anycast-based optimizations for inter-data-center interconnections [Invited],” IEEE/OSA Journal of Optical Communications and Networking, vol. 4, no. 11, pp. B168–
B178, Nov. 2012.
[2] Y. Mao, C. You, J. Zhang, K. Huang, and K. B. Letaief, “A Survey on Mobile Edge Computing: The Communication Perspective,” IEEE Communications Surveys Tutorials, vol. 19, no. 4, pp. 2322–2358, 2017.
[3] P. Mach and Z. Becvar, “Mobile Edge Computing: A Survey on Architecture and Computation Offloading,” IEEE Communications Surveys & Tutorials, vol. 19, no. 3, pp. 1628–1656, 2017, arXiv:
1702.05309. [Online]. Available: http://arxiv.org/abs/1702.05309