國立臺灣大學電機資訊學院資訊工程學系 博士論文
Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Taiwan University Doctoral Dissertation
延伸機器感知在有遮蔽時進行多目標追蹤:
從單一感測器到異質性多感測器案例
Extended Machine Perception in Multi-Target Tracking with Occlusion: from Single Sensor to Heterogeneous Sensors
陳俊甫 Jiun-Fu Chen
指導教授﹕周承復 博士 Advisor: Cheng-Fu Chou, Ph.D.
中華民國 一百零八 年 六 月 June, 2019
誌謝
首先要感謝家人,尤其是母親的全力支持與鼓勵,讓我可以全心地專注於 博士學位的研究工作上,不需要擔憂與煩惱。接著要感謝兩位指導教授,周承 復教授與王傑智教授,感謝他們提供專業且豐富的見解與經驗,在我進行博士 研究的期間,提出許多種思考面向,讓研究內容可以不斷精進。也感謝他們不 時的討論可能的問題解法,與提醒需要注意的問題點,讓研究工作可以順利進 展,並讓論文可以更完整。
此外,也要感謝在機器人知覺與學習實驗室及通訊與多媒體實驗室所遇到 的室友們,在研究期間互相提攜與幫助,一起迎接研究上遇到的挑戰。特別要 感謝嚴孝杰,感謝他在百忙之中,來幫忙口試的預演與準備口試的相關事務,
更感謝他提出專業意見來幫忙修改報告要點。感謝這些一起研究討論的伙伴 們,讓實驗室充滿溫馨與歡樂。
最後要感謝各位口試委員李明穗老師、連
豊力老師、李綱老師、郭振華老 師、與吳曉光老師提供他們的獨特見解來補足這篇論文的不足之處,讓這篇論 文可以更完整。最後的最後要感謝其他幫助過我的人,讓我在博士研究期間,
可以在研究上有各種新的想法與不同的嘗試。
2019/06/05 於通訊與多媒體實驗室
多移動物體追蹤是許多智慧型應用系統所必需的關鍵基礎能力。為了要完 成多移動物體追蹤的任務,非常需要來自感測器的重要觀測資訊。特別是在沒 有感測資料時,像是有遮蔽發生時,幾乎不可能使用傳統的演算法來完成多移 動物體追蹤;而且在有遮蔽的狀態下,移動物體會更難被成功追蹤到。在都會 區交通情境中,遮蔽狀態會降低駕駛安全性;而在人體關節追蹤的應用情境,
遮蔽狀態可能會造成估測錯誤,並且誤導對於復健運動成效的評估結果。因此
本篇論文分別對兩個情境提出使用單顆二維光達 (LIDAR) 與使用異質性多感
測器 (Heterogeneous Sensors) 的系統架構。第一個架構利用虛擬觀測模型
(Virtual Measurement Model) 與互動物體追蹤 (Interacting Object Tracking) 演
算法來處理在擁擠都會區下遮蔽狀態所造成的影響;而第二個架構則是運用異
質性感測器同時定位、追蹤、與建立模型 (Heterogeneous Sensor Simultaneous
Localization, Tracking, and Modeling) 演算法來整合異質性感測器資訊,並且提
供估測給中風復健動作評估使用。實驗結果顯示,在第一個應用中所提出的演
算法可追蹤都會區路口中超過 57%的被遮蔽移動物體;而第二個使用模擬生成
與收集來自十位受測者資料的應用結果顯示出,提出的演算法可以得到無遮蔽
時誤差 4.6 公分,有遮蔽時誤差 18.1 公分的成果。由此本篇論文成功展示了在
都會區與室內環境下,解決遮蔽造成的問題與影響的能力。
EXTENDED MACHINE PERCEPTION IN MULTI-TARGET TRACKING WITH
OCCLUSION:
FROM SINGLE SENSOR TO
HETEROGENEOUS SENSORS
Jiun-Fu Chen
Department of Computer Science and Information Engineering National Taiwan University
Taipei, Taiwan
June 2019
Submitted in partial fulfilment of the requirements for the degree of
Doctor of Philosophy
Advisor: Dr. Cheng-Fu Chou and Dr. Chieh-Chih Wang Thesis Committee:
Cheng-Fu Chou
Chieh-Chih Wang (National Chiao Tung University) Ming-Sui Lee
Feng-Li Lian Kang Li Jen-Hwa Guo
Hsiao-Kuang Wu (National Central University)
Jc IUN-FUCHEN, 2019
ABSTRACT
M
ULTI-TARGETtracking is a key ability for many intelligent systems in lots of applications. In order to accomplish the multi-target tracking, the measure- ments from the perceptive sensor plays a very important role. It is impossible to perform the multi-target tracking without sensory data especially such as occlusion situation, which increases the difficulty of the tracking task. Moreover, in the urban traffic situation, occlusion decreases the driving safety; and in the case of human joint tracking, occlusion may fails the estimates and leads to wrong judgement for eval- uating the performance of rehabilitation activities. Here, two frameworks are presented and described for a stationary 2D LIDAR and for heterogeneous sensors. The first frame- work introduces the virtual measurement model with interacting object tracking scheme to tackle the effects of the occlusion in crowded urban environments. The second frame- work applies the heterogeneous sensor simultaneous localization, tracking, and modeling algorithm to fuse heterogeneous sensors and to provide estimates within occlusion for mo- tion evaluation in stroke rehabilitation process. The ample experimental results of the first application show that the interact object tracking scheme tracks over 57% of occluded mov- ing object for the daunting task in an urban intersection. While the results of the second application with synthetic data and collected from ten subjects reveal that the proposed approach yields 4.6 cm error in observed cases and 18.1 cm error during burst occlusion.We successfully demonstrate the capability to resolve issues and effects in occlusion for both urban and indoor environments.
TABLE OF CONTENTS
ABSTRACT . . . iii
LIST OF FIGURES . . . vii
LIST OF TABLES . . . xi
CHAPTER 1. Introduction . . . 1
1.1. Motivation . . . 1
1.2. Background . . . 3
1.3. Contribution and Statement . . . 5
CHAPTER 2. Related Work . . . 9
2.1. Multiple Target Tracking Approaches . . . 9
2.2. Motion Modeling regarding Interactions with Scene and Moving Targets . . . 11
2.3. Tackle the Occlusion in Urban . . . 12
2.4. Short Discussion for Urban Cases . . . 13
2.5. Motion Tracking by Conventional Optical Sensors . . . 15
2.6. Motion Tracking by Newly Optical Sensors . . . 15
2.7. Motion Tracking by Inertial Measurement Units . . . 17
2.8. Multiple Sensor Fusion Approaches . . . 18
CHAPTER 3. Single Sensor Approach: Interacting Object Tracking with A Stationary LIDAR in Urban Areas . . . 21
3.1. Variable Structure Multiple Model Estimation . . . 22
3.1.1. Theory . . . 22
3.1.2. Interacting Object Tracking Framework . . . 23
3.2. Occluded Area Detection . . . 25
3.3. Scene Interaction Model . . . 26
3.3.1. Learning : Modeling and Representing . . . 28
3.3.2. Inference: Prediction and Update . . . 30
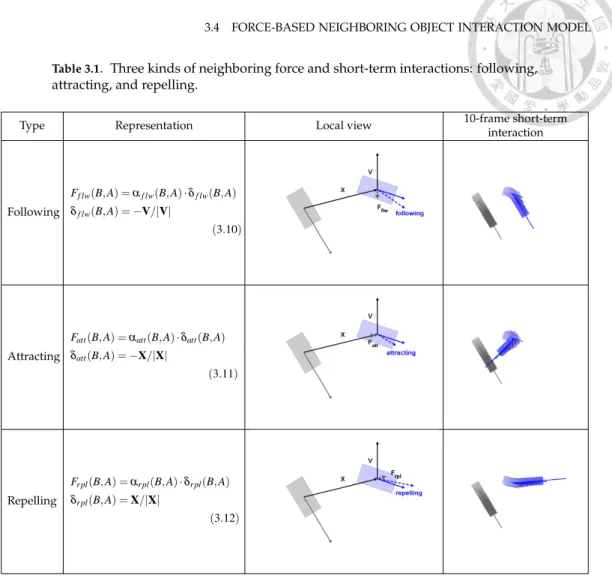
3.4. Force-based Neighboring Object Interaction Model . . . 34
3.4.1. Modeling: Following, Attracting, and Repelling Interactions . . . 35
3.4.2. Short-term Interaction Prediction . . . 37
3.5. Virtual Measurement Model . . . 38
CHAPTER 4. Heterogeneous Sensor Approach: Simultaneous Localization, Tracking, and Modeling for Stroke Rehabilitation with Heterogeneous Sensors in Indoor Environment . . . 41
4.1. Heterogeneous Sensor Simultaneous Localization, Tracking, and Modeling
Framework . . . 42
4.2. Augmented State Representation for 3D Space . . . 45
4.3. Spatial Relationships in Robotics . . . 46
4.4. Location-based Measurement Model . . . 48
4.5. Acceleration-based Measurement Model . . . 50
4.6. Orientation-based Measurement Model with Virtual Relative Orientation Technique . . . 50
4.7. Motion Models for Prediction . . . 52
4.8. Kinematics Model for Upper Extremities . . . 53
4.8.1. Parameter Representation and Estimation . . . 53
4.8.2. Virtual Parameters and Virtual Joint Location Generation . . . 56
CHAPTER 5. Experimental Result . . . 59
5.1. Application One: 2D LIDAR in Urban Environment . . . 59
5.1.1. Benchmark with 3D LIDAR for Evaluation . . . 59
5.1.2. IOT Analysis in the Observed Area . . . 63
5.1.3. Virtual Measurement Model Evaluation in the Occluded Area . . . 65
5.2. Application Two: Heterogeneous Sensor Fusion in Indoor Environment . . . 67
5.2.1. Synthetic Data Generation . . . 69
5.2.2. Orientation Drift Analysis with Synthetic Data . . . 73
5.2.3. Performance Analysis with Synthetic Data . . . 75
5.2.4. Occlusion Analysis with Ten Subjects . . . 78
CHAPTER 6. Conclusion . . . 87
6.1. Accomplishments of Single Sensor Approach . . . 87
6.2. Accomplishments of Heterogeneous Sensor Approach . . . 88
APPENDIX A. Numerical Jacobian Matrix Method . . . 89
BIBLIOGRAPHY . . . 93
LIST OF FIGURES
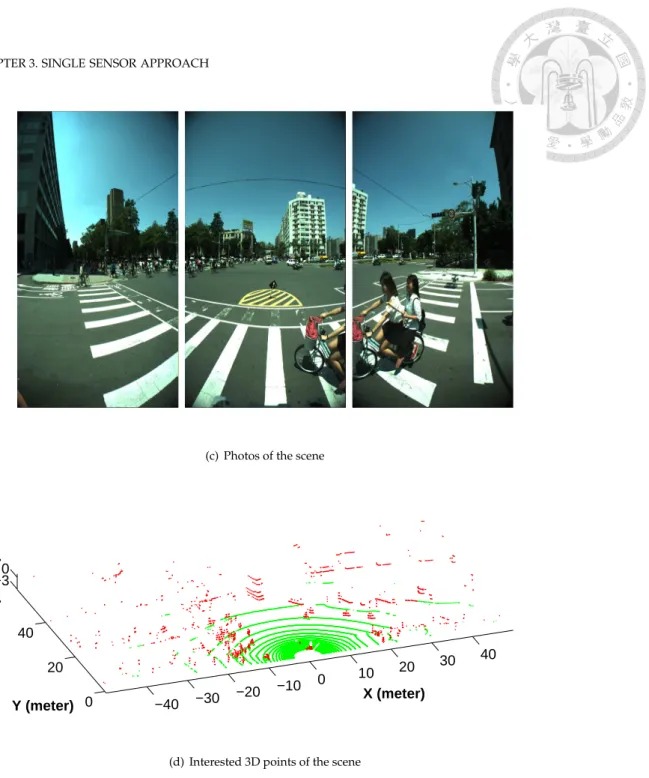
3.1 2D/3D LIDAR occlusion grid map and the corresponding photos and 3D points.
Gray areas are occluded and white areas are observed. Red points are the 2D/3D laser points accordingly, and green points are ground points, per 3D LIDAR.
Results show that the occluded areas/shadows caused by the nearby bike were extracted successfully in both 2D/3D cases. And the 3D LIDAR provides information in 2D occluded areas. . . 27 3.1 2D/3D LIDAR occlusion grid map and the corresponding photos and 3D points.
Gray areas are occluded and white areas are observed. Red points are the 2D/3D laser points accordingly, and green points are ground points, per 3D LIDAR.
Results show that the occluded areas/shadows caused by the nearby bike were extracted successfully in both 2D/3D cases. And the 3D LIDAR provides information in 2D occluded areas. . . 28 3.2 The scene interaction map is composed of occupancy-motion grids, each of which
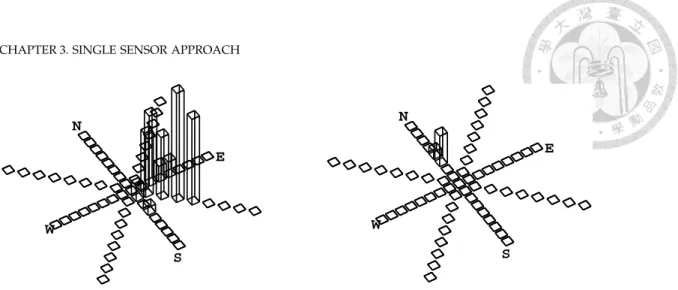
contains information of occupancy, speed, and direction. The speed is discretized to 10 km/hr interval from zero to over 80 km/hr and the moving direction is divided to 8 directions shown as boxes. Starting as stationary from the middle, the farer box represents the higher speed. Each bin on a box represents the occurrence count of the speed interval and direction accordingly. Two examples are shown in which different motion patterns are embedded into the map. The left map is from a road lane and that on the right is from a crosswalk. . . 30 3.3 The scene interaction map contains the occurrence count of each sector. The upper
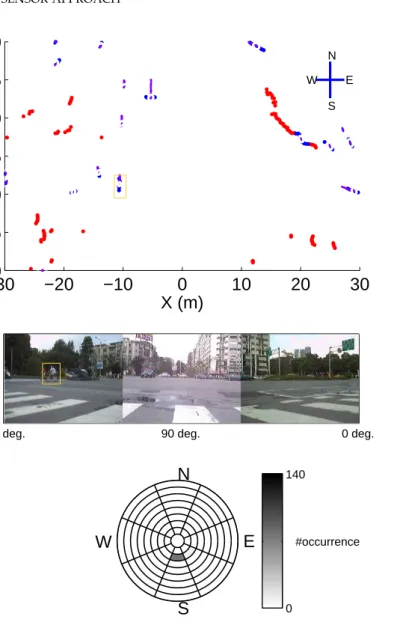
figure shows the range data and result of tracking. Red points and blue points indicate stationary objects and moving objects, respectively. Purple lines indicate the trajectories of moving objects. The middle figure shows the images at the same time from cameras. The orange rectangles in the upper and middle figures denote the same object. And the bottom figure shows the information of the scene interaction map at grid (-11, 9.5) occupied by the object. The colorbar shows the correspondence between the number of occurrence and shade of gray in each sector while the pie chart reveals the discretized sectors for different speeds and directions to show the number of occurrence. Speeds are stepped with 10 km/hr from zero to over 80 km/hr while directions are divided to 8. The learned information is consistent with the tracking result and the camera image. . . 31 3.4 Another scene interaction map learned according to a different traffic behavior
pattern. As shown in Fig. 3.3, the learned information is changed, although it is
contained in the same grid cell. The camera image and tracking results reveal the different traffic behavior pattern. . . 32 3.5 Scene interaction maps for three different behavior patterns of an urban scene. For
each grid cell, arrows show only the most observed motion direction. Black grids correspond to stationary objects, and white grids to unobserved or unoccupied areas. The robot is at the origin (0, 0) of the map. These patterns are switched cyclically at the intersection. . . 33 3.5 Scene interaction maps for three different behavior patterns of an urban scene. For
each grid cell, arrows show only the most observed motion direction. Black grids correspond to stationary objects, and white grids to unobserved or unoccupied areas. The robot is at the origin (0, 0) of the map. These patterns are switched cyclically at the intersection. . . 34 3.6 Local frame for neighboring force interaction. The blue A is the tracked target and
the gray B is its neighboring moving object, each with their moving velocity. X and V are the relative position and velocity between A and B. Fneiis the neighboring force with a dashed moving velocity affected by the neighbor B. . . 36 4.1 Framework for heterogeneous sensor simultaneous localization, tracking, and
modeling (HS-SLTAM) . . . 43 4.2 A graphical model of one-phase heterogeneous sensor simultaneous localization,
tracking, and modeling approach . . . 44 4.3 Overview of all coordinates from nodes. Blue dashed lines are odometry of nodes
while green dash-dot lines are observations from different sensors. . . 47 4.4 Overview of upper extremity model of each joint. J0is the spine shoulder and J1is
the shoulder at the base of the upper extremity. J2is the elbow, J3is the wrist, and J4is the hand respectively. . . 55 5.1 Snapshots of 3D occluded moving segment results. Different colors for the points
represent different segments. The gray area is the occlusion grid map from 2D LIDAR and the darker gray points are the data from 3D LIDAR. In frame 19416, occluded moving segments at upper right were extracted while occluded moving segments in the front were revealed in frame 20394. In both frames, the occluded pedestrians moving on the left were also extracted successfully. . . 61 5.1 Snapshots of 3D occluded moving segment results. Different colors for the points
represent different segments. The gray area is the occlusion grid map from 2D LIDAR and the darker gray points are the data from 3D LIDAR. In frame 19416, occluded moving segments at upper right were extracted while occluded moving segments in the front were revealed in frame 20394. In both frames, the occluded pedestrians moving on the left were also extracted successfully. . . 62 5.2 The blue line is the occluded area ratio from 2D LIDAR and the red line is
the number of occluded moving segments from the evaluation data with the benchmark system. . . 63 5.3 Average weights of motion models in different motion model sets in observed area 64 5.4 Number of tracking estimates in different motion model sets in observed area . . 64
LIST OF FIGURES
5.5 1-Norm index and number of estimates with respect to observed frames. The blue line is the mean of the 1-Norm index. The red line is the number of estimates with respect to the observed frames. . . 65 5.6 Accuracy along with different evaluation thresholds. The blue line reveals the
accuracy for Galceran et al. (Galceran et al., 2015), the green line illustrates the accuracy with IOT, and the red line shows the accuracy of the virtual measurement model. Note that the increments of the accuracy are decreasing while the threshold is growing. . . 66 5.7 Case 1: A bike goes from the bottom to the top with occlusion in the middle and
reappears again. The number next to the moving object indicates track ID. Red and blue points are the stationary and moving points of 2D LIDAR, and orange rectangles are the segmentation results. Purple eclipses and lines are the previous estimates and trajectory in the observed area, and teal eclipses and lines are those in the occluded area. Finally, the magenta eclipse and line are the current estimate and the current orientation of the velocity, respectively. At the bottom, the tracked object is highlighted with a magenta rectangle. . . 68 5.7 Case 1: A bike goes from the bottom to the top with occlusion in the middle and
reappears again. The number next to the moving object indicates track ID. Red and blue points are the stationary and moving points of 2D LIDAR, and orange rectangles are the segmentation results. Purple eclipses and lines are the previous estimates and trajectory in the observed area, and teal eclipses and lines are those in the occluded area. Finally, the magenta eclipse and line are the current estimate and the current orientation of the velocity, respectively. At the bottom, the tracked object is highlighted with a magenta rectangle. . . 69 5.8 Case 2: A bike moves downward; midway, it interacts with a nearby moving object. 70 5.8 Case 2: A bike moves downward; midway, it interacts with a nearby moving object. 71 5.9 Case 3: A pedestrian walks within a highly crowded group and interacts with each
other while occluded by other moving objects. . . 72 5.9 Case 3: A pedestrian walks within a highly crowded group and interacts with each
other while occluded by other moving objects. . . 73 5.10Motion sequence to be evaluated. Left: hand placed on top of head; Right: hand
raised forward to shoulder level. . . 74 5.11Results with and without geomagnetic field sensor. The red line is with the
geomagnetic field sensor; the blue line is that without the sensor. The geomagnetic field sensor provides the measurements to compute the proposed virtual relative orientation. . . 74 5.12Snapshot of the proposed approach from 3 different views. The gray dot with
arrows is the ground truth of the location and orientation. The blue dot with arrows is the RGB-D node and the red dot with arrows is the wearable node. . . . 76 5.13Estimation error of phone location in each dimension. The red line is the offset
from the estimation mean to the ground truth, and the green line is the results from Tian et al. (Tian et al., 2015) for reference. The black rectangles indicate occlusion. 77
5.14Errors of arm length parameters. The blue line is for |−→
L1| (shoulder to elbow), the red line is for |−→
L2| (elbow to wrist), and the green line is for |−→
L3| (wrist to hand) respectively. . . 78 5.15Location results with/without virtual measurements in each dimension from three
joints. The red line is the result with virtual measurements while the blue line is without virtual measurements. The green line is arm observation and cyan line shows the virtual measurements given the proposed upper extremity model for reference. The figures from top to down show the results of the x, y, and z axes respectively. The black rectangles indicate occlusion. . . 79 5.15Location results with/without virtual measurements in each dimension from three
joints. The red line is the result with virtual measurements while the blue line is without virtual measurements. The green line is arm observation and cyan line shows the virtual measurements given the proposed upper extremity model for reference. The figures from top to down show the results of the x, y, and z axes respectively. The black rectangles indicate occlusion. . . 80 5.15Location results with/without virtual measurements in each dimension from three
joints. The red line is the result with virtual measurements while the blue line is without virtual measurements. The green line is arm observation and cyan line shows the virtual measurements given the proposed upper extremity model for reference. The figures from top to down show the results of the x, y, and z axes respectively. The black rectangles indicate occlusion. . . 81 5.16Mean Euclidean distance error of all cases in seated pose. Blue line is for elbow, red
line for wrist, and green line for hand, given increasing numbers of single occluded frames. . . 83 5.17Mean Euclidean distance error of all cases in standing pose. Blue line is for elbow,
red line for wrist, and green line for hand given increasing numbers of single occluded frames. . . 84 5.18Mean Euclidean distance error of all cases in seated pose. Blue line is for elbow, red
line for wrist, and green line for hand, given increasing numbers of consecutive occluded frames. . . 85 5.19Mean Euclidean distance error of all cases in standing pose. Blue line is for elbow,
red line for wrist, and green line for hand given increasing numbers of consecutive occluded frames. . . 86
LIST OF TABLES
2.1 Various approaches and their models for different tracking levels . . . 13 3.1 Three kinds of neighboring force and short-term interactions: following, attracting,
and repelling. . . 37 4.1 Working coordinates of different sensing nodes . . . 46 4.2 Denavit-Hartenberg parameters of upper extremity kinematics model . . . 54 5.1 Average weights of different motion models, and number of estimates in different
model sets in observed area. . . 63 5.2 Average accuracy and the number of tracked occluded segments of the three
approaches. Numbers inside parentheses are the improvement comparing to Galceran et al. (Galceran et al., 2015). . . 66 5.3 Mean Euclidean distance error of all cases in both seated and standing poses with
15 single or consecutive occluded frames. . . 83
CHAPTER 1
Introduction
M
ACHINEperception is the capability that a computer system could inter- pret data in the way similar to humans or animals use their senses to relate to the world around them. In other words, machine perception is the ability of the man-made machine to realize their surrounding envi- ronments as humans and animals are able to do through different kinds of sensors. Unlike the conventional definition that the inputs for computer were only mouse and keyboard, here, advanced sensors such as LIDAR to low-end sensors such as accelerometer and gy- roscope are utilized in this dissertation. To fully exploit and to smoothly fuse these sensor measurements, advanced and novel algorithms are necessary. In this dissertation, a wide developed area, multi-target tracking, is focused with the state of the art sensors and the proposed approaches to extend the machine perception barrier regarding occlusion.1.1. Motivation
There are four major cases of sensor information failures and are concluded to two different types. Two of them are raised because of the sensor itself and the other two are caused by the environmental reasons. The first type failures are the malfunction of the sen- sor and the sensor limitation like field of view or sampling rate. The former can be solved with advanced measurement models or simply by special signals while the latter have to redesign the sensor attachment or the sensor itself. In this type of failure, we compen- sate the effects with the hardware solution or advanced measurement models. The other two failures of the second type which cause by the environment is solved with software or algorithm techniques. The first one is the missing or wrong data which is tackled with the measurement model and historical measurements from the environment to figure out
those outliers. The second one is the occlusion with the avoidance of the sensibility. In this dissertation, we proposed several algorithms to deal with the challenging occlusion problems.
Occlusion is a critical issue for multi-target tracking. In urban area, most of the traffic accidents happened due to the unawareness of the front. And the occlusion makes it even worse to focus on the front of the vehicles. Highly crowded urban environments compli- cate motion modeling with their many occlusion areas. Different motion patterns from a wide variety of moving objects make motion modeling difficult. Usually, occlusions occur because of a limited sensor field of view and because of surrounding objects.
In urban environments, temporally- and spatially-varying surrounding objects intro- duce dynamic occluded areas which further complicate the tracking moving targets task.
Failure to track under occlusion could lead to traffic accidents for any moving entity in the scene. Although, multiple sensors, inter-vehicle communication, and vehicle to infras- tructure communication can reduce occlusion, the problem remains for non-communicated nodes on the road such as pedestrians and single vehicles. The occlusion still cause dangers for urban traffic.
Additionally, as medical technology improves, society continues to age, increasing long-term care and rehabilitation requirements due to strokes and other chronic diseases.
Meanwhile, low birth rates lead to fewer caregivers, increasing the burden on the health care system. Thus, the demand of home-based rehabilitation and remote health care ser- vices is increasing. To improve the coverage of the health care system and to decrease the workload of care staff, we seek to facilitate the use of rehabilitation exercises anytime and anywhere. In addition, for a more feasible remote care system, we also seek to ensure the easy set-up of rehabilitation devices with effective but low-cost sensors.
In the state of the art of existing rehabilitation approaches, there are two main focuses (Mousavi Hondori & Khademi, 2014): accuracy and reliability. We note that occlusion is also important, as it can lead to misjudgments during rehabilitation. During the stroke re- habilitation process, occlusion can be caused by the patient himself/herself, by health care staff, or by the environments, for instance walking bars. Therefore, a reliable remote re- habilitation system must not only provide information for rehabilitation exercises, such as joint angle values, but must also decrease the rate of occlusion or provide robust estimates when occlusion does occur.
1.2 BACKGROUND
Obviously, occlusion do affect the multi-target tracking task in indoor environment such as human motion tracking during rehabilitation. With the occlusion, the location of joints are impossible to track and can not provide the pose information of a patient in post- operative rehabilitation. The missing joints made the medical staffs difficult to evaluate the performance of rehabilitation. Algorithms are proposed with a sensor fusion framework to provide the estimates of joints with and without occlusion. With heterogeneous sensors, not only the occlusion is reduced but also different kinds of estimates like the rotations of joints are provided. These temporally and spatially estimates are stored and send back to doctors for rehabilitation evaluation. Thus, the rehabilitation is able to be performed in almost anywhere and anytime.
1.2. Background
Tracking is a natural skill for human survival far before the stone age and its extension, multiple target tracking, is an important issue in many aspects. Concerning the environ- ment and the numbers of tracked objects, there are three different levels of tracking in general.
1. Level 1: Tracking in a free space.
The moving object moves freely within the environment. For example, track a plane in the sky, a ship on the surface, or a vehicle on the plain.
2. Level 2: Tracking in a constrained space.
Objects must follow certain rules when moving. For example, road vehicles fol- low traffic rules, ships follow instructions in a port, and planes obey the orders from the control tower.
3. Level 3: Tracking with multiple moving objects.
For instance, vehicles and pedestrians moving in a metropolis. Not only are rules considered, but we also focus on the interaction with the surrounding moving objects and environment.
In Table 2.1, it shows the usage models for different tracking levels in Galceran et al. (Gal- ceran et al., 2015), interacting object tracking (IOT) (Wang et al., 2007) (Wan et al., 2008) (Lin et al., 2011), and the virtual measurement model (Chen et al., 2018).
Level-three tracking – that is, multiple target tracking – is a critical capability for surveillance, scene understanding, intelligent transportation systems, robotics, and human
motion capture applications. The ability to track multiple moving objects in urban envi- ronment is the basic requirement to provide driving safety information from intelligent traffic infrastructures. There are challenging issues to solve in the level-three tracking such as data association, motion modeling, measurement modeling, and the occlusion. Several approaches for multiple targets are proposed to solve these issues accordingly. However, rare approaches tackle on the occlusion problem which makes a critical role in the mul- tiple target tracking. As the estimation difficulty rises with the level number. Classical tracking methods do not estimate tracking successfully because of the lack about occlusion handling. Therefore, two novel frameworks are demonstrated to tackle the occlusion cases with different sensor settings.
The RGB-D sensor is widely used as a build-in sensor on the smart phones and has become an integral part of daily life and rehabilitation application (Ye et al., 2016) ( ˇTupa et al., 2016) (Knippenberg et al., 2017) (Yang et al., 2018). In the following experiments, we exploit the classical RGB-D camera, Kinect V2, as a sensor source for joint location detec- tion. Although, the RGB-D type sensor provides depth data in addition to conventional optical sensors, the occlusion problem remains. Note also that conventional optical inputs such as cameras require sources from multiple viewpoints to reconstruct 3D model and reduce occlusions.
However, inertial measurement unit (IMU) sensors are used by some motion capture approaches (Zhang et al., 2015) (Leardini et al., 2014). Most current wearable devices and smart apparel use IMU sensors to provide measurements such as acceleration, angular rate, and magnetic field strength. Although, IMU sensors provide continuously measurements without any occlusion, they must be re-calibrated due to errors that accumulate over time;
the resulting data can be noisy and sensitive.
We combine RGB-D and IMU sensors under a sensor fusion scheme based on the pro- posed HS-SLTAM that utilizes their advantages and provides estimate under occlusion.
For fusion within the global frame, we have carefully examined the properties of the two sensors. There are two issues regarding the relative orientation to solve. First, the initial relative orientation between RGB-D and IMU sensors is unknown. And second, the vary- ing orientation to the initial orientation from IMU sensors can not be compensated by the RGB-D sensor directly. To figure the relative orientation between RGB-D and IMU sensor, markers can be placed on the IMU to determine orientation (Santos et al., 2006), the camera
1.3 CONTRIBUTION AND STATEMENT
can be attached to the IMU to observe the environment or moving objects for orientation (Bloesch et al., 2015), or the IMU trajectory can be accumulated in the very beginning for matching with the RGB-D sensor observations (Croitoru et al., 2005). To resolve issues about relative orientation, Tian et al. (Tian et al., 2015) setup their system to parallel the Earth frame, in which is the frame for IMUs’ global orientation. With this parallel setting, the initial relative orientation between RGB-D and IMUs is known. However, this setting limits system feasibility regarding orientation. To relax this limitation, we use virtual rela- tive orientation technique by exploiting the initial global orientation of the IMU in the Earth frame. Thus, the proposed system do not have to be parallel to Earth frame. The second issue about relative orientation is resolved by using virtual relative orientation technique with global orientation measurements. As for the first issue, we assume that the initial relative orientations between RGB-D and IMUs are given to work around since providing robust estimates during occlusion is what we focus in this dissertation.
In order to track human joints under occlusions, not only are multiple heterogenous sensors used, but an arm model is built to represent the structure of human upper extrem- ities. A representation called, Denavit-Hartenberg parameteric representation (Denavit &
Hartenberg, 1955), is used to describe the relationship of each joint from body to hand. The parameters, such as lengths of different arm parts, joint rotations, and rotations around arm parts, are estimated following inverse kinematics techniques when observations from the RGB-D sensor are available. Once the structure is learned by the parameters, the first type of virtual measurement, known as arm model estimates, are generated with forward kinematics to provide virtual locations for each joint from shoulder to hand. Since the up- per extremity structure is estimated along the time, the arm model in the proposed system is naturally suitable for different patients in different rehabilitation stages along time. With these generated virtual measurements, we can track joint locations under occlusion.
1.3. Contribution and Statement
In this dissertation, we propose methods and algorithms to reduce the effects from occlusion. First, the limitation and the effects of a single sensor are discussed. In this ap- proach, we propose a framework to perform multiple interacting object tracking in urban areas using a stationary laser scanner based on the given segmentation results without any classification. Under the finding that moving objects prefer to maintain their behavior,
this approach estimated moving objects with occlusion. The framework is composed of a virtual measurement model for tracking in occlusion and interacting object models that describe the interactions between the nearby moving objects and the environment.
In our initial study (Wang et al., 2007), (Wan et al., 2008), (Lin et al., 2011), the eval- uation was conducted using a manually-labeled benchmark; we propose a benchmark- generating system that uses 3D LIDAR to provide the occluded information in 2D. To quantify the occlusion between 2D and 3D sensors and to build the benchmark system, an occluded area detection module is also proposed to extract occluded grids.
The interacting object models are composed of the scene interaction model and the neighboring object interaction model for long-term and short-term interactions, respec- tively. The scene interaction model is represented using a stationary occupancy map and moving object maps for the monitored scene. The occupancy-motion grids are utilized to store the collected moving object information such as speed and moving direction, and the k-means clustering algorithm (MacQueen, 1967) is applied to cluster the samples in order to provide predictions with means and covariances. The neighboring object interaction model is extended from (Wang et al., 2007) from a simple following interaction to three kinds of interactions: following, attracting, and repelling. These interacting object models not only solve the challenging modeling problem but also yield higher-level scene under- standing. These interacting object models are consistent in occlusion and the weights of the motion models are utilized as the representation of a moving object’s motion feature. We also find that the motion features of moving objects tend to vary little, with small changes in the weights of motion models. Thus, these interacting object models are applied to compute the virtual measurement model with the stored motion features for tracking in occluded space.
In the second approach, we show a system framework that fuses different sensor mea- surements to simultaneously track human joints and model adjustable upper extremities to provide estimates during occlusion. Based on the proposed heterogeneous sensor simulta- neous localization, tracking, and modeling (HS-SLTAM) algorithm, sensors are located in a global frame within which human joints are tracked directly. Occlusions are first reduced by the use of heterogeneous sensors. In this part, two types of virtual measurements are used. The first is arm model estimates, which are generated based on the upper extremity
1.3 CONTRIBUTION AND STATEMENT
model to provide further estimates during occlusion. The second, virtual relative orienta- tion, is a technique based on sensor data to relax limitations of system settings. In order to provide robust estimates during occlusion, the upper extremity model is built in to the HS-SLTAM algorithm. The first virtual measurements are directly generated according to estimates from the adjustable upper extremity model. Furthermore, using the adjustable upper extremity model, the proposed framework is suitable for different patients and at different progress of the rehabilitation process.
The proposed system is composed of a stationary RGB-D camera and wearable de- vices on a person to track human joints. Measurements from these sensors are fused to assist stroke patients or other patients in the postoperative rehabilitation stage. The pro- posed algorithm is developed from multi-robot simultaneous localization and tracking (MR-SLAT) (Chang et al., 2016). First, the state vector is extended to 3D space and the orientation representation is replaced with quaternions to reduce the linearization error.
Second, different measurement models are used in HS-SLTAM to take into account dif- ferent observations from multiple heterogeneous devices; these including location-based, acceleration-based, and orientation-based models. Third, a kinematics model of the up- per extremities is part of the proposed system. Based on Denavit-Hartenberg parameter representation (Denavit & Hartenberg, 1955), the kinematics model can be customized ac- cording to different subjects in different stages of the rehabilitation process. With these three extensions to the initial study (Chang et al., 2016), we have HS-SLTAM, which fuses measurements in 3D space and describes the upper extremities of different subjects with the proposed kinematics model for occlusion.
In this part, we not only provide a heterogeneous sensor fusion framework to track joints during occlusion but also provide an adjustable arm model for the rehabilitation pro- cess. With the proposed HS-SLTAM, we reduce occlusion by integrating sensor measure- ments and provide robust joint tracking under occlusion by utilizing virtual measurements.
We develop two types of virtual measurements: arm model estimates for use under occlu- sion to track joints based on the proposed arm model, and virtual relative orientation as a technique for relaxing the system limitation regarding orientation respectively. Since each patient is unique, the rehabilitation process has many stages, and patients improve dur- ing the course of rehabilitation; as such the rehabilitation system should be customizable along each stage of the process. The proposed approach involves a two-phase estimation
framework for online training and testing. In the first phase we track joint locations, and in the second phase we construct the arm model. These two phases cooperate together to provide model training and testing as well as to provide the rotation rate and variance of joints so that medical staff can judge the rehabilitation performance. The proposed system demonstrates a way to produce online estimates for each patient and for each rehabilitation exercise.
Even thought it is difficult to resolve the occlusion, we contribute approaches to tackle issues and effects caused by occlusion in different environments including urban traffic and indoor rehabilitation activity; and in different sensor settings from a single sensor to het- erogeneous sensors. The boundary of the existed sensors and sensor fusion frameworks are explored. These approaches not only extend the estimating capabilities under occlu- sion, but also expand the working spaces from a surface in the traffic scene to a 3D space for postoperative rehabilitation. Especially in the second part, different models of hetero- geneous sensors are introduced accompanying with an augmented state space to represent the sensor fusion results for the approach. Moreover, the online adjustable relationship model, upper extremity model, is demonstrated to provide extra measurements for reha- bilitation and to evaluate the performance during the rehabilitation.
The following chapters of this dissertation are organized as such. Chapter 2 describes the related work about the multiple target tracking, human motion tracking approaches with different sensors, how to tackle the occlusion in urban, multiple sensor fusion ap- proaches, and a discussion regarding the comparison between the existing approaches.
Chapter 3 introduces the single sensor approach to tackle the occlusion issue. The nec- essary modules and mathematical foundations of interacting object tracking with virtual measurement model are described in details. As for the heterogeneous sensor fusion ap- proach, the framework based on heterogeneous sensor simultaneous localization, tracking, and modeling, the necessary heterogeneous sensor measurement models, and the upper extremity model for occlusion are represented in Chapter 4. The evaluation results from the single sensor approach and the heterogeneous sensor fusion approach were revealed in Chapter 5. In the end, Chapter 6 concludes the findings and the achievements of the proposed frameworks on tackling the occlusion issue.
CHAPTER 2
Related Work
I
Norder to assist machines and robots understand the world better, it is necessary to explore the limitation of the current sensor ability. Some approaches which ex- ploited different sensors were developed in specific areas for multiple target track- ing. Here, several aspects regarding the multiple target tracking, applying with dif- ferent types of sensors, and reducing or dealing with occlusion for either single or multiple sensor fusion were described and discussed in this chapter. The baseline and the funda- mental knowledge were established with the existed works in these aspects and provided a glance to extend machine perception for multiple target tracking.2.1. Multiple Target Tracking Approaches
The moving object tracking problem can be formulated with probabilistic robotics rep- resentation as
P(xt, st|Zt) (2.1)
where xt is the state estimates of the moving target, st is the motion mode of the target, and Zt is the all measurements until the time stamp t. This area had been developed for decades with numerous approaches in many applications. The formulated moving object problem had been extended for multiple target tracking at least from (Reid, 1979). Reid has summarized the state of the art at that time and proposed a framework for multiple target tracking, also tackling many important modules and issues for the later approaches such as initiating tracks, accounting for false or missing reports, and processing sets of dependent reports. This work also indicates the challenging data association issue in multiple target tracking.
Data association and motion modeling are two of the most challenging problems in multi-target tracking. The classical approaches such as the multiple hypothesis track- ing (MHT) algorithm (Cox & Hingorani, 1996) and the joint probabilistic data association (JPDA) approach (Fortmann et al., 1983) have been extensively applied to solve data as- sociation in many applications. Different motion patterns from a wide variety of moving objects make motion modeling difficult. Thus, (Magill, 1965) provides a straight forward multiple model approach and with different types of the model interaction, (Blom & Bar- Shalom, 1988) proposed the interacting multiple model approach to estimate various mo- tion models for moving object tracking.
Due to complicated maneuvers from the multiple moving targets, several multiple motion model approaches has been demonstrated. There are three generation of the multi- ple model approaches for moving object tracking. The first generation is called autonomous multiple model (AMM). As an example of AMM, Magill (Magill, 1965) estimates the mov- ing object with different motion model filters and generates the result with weighting sum of these multiple models. The second generation lets the motion models cooperate each other and that is why also called cooperating multiple model (CMM). And many differ- ent cooperation strategies have also proposed such as generalized pseudo-Bayesian algo- rithms of order n (GPB1, GPB2, GPBn) (Jaffer & Gupta, 1971), (Bar-Shalom & Li, 1993), (Sugimoto & Ishizuka, 1983), and interacting multiple model (IMM) (Blom & Bar-Shalom, 1988). These approaches use a fixed and same memory depth to reduce the hypothesis of modeling switching tree. With the mixing step, IMM provides a more cost-effective reini- tialization method than those of GPBn.
After the proposed of the first and second generation of the multiple model approaches, (Li & Jilkov, 2005) has summarized these approaches and described the third generation of the multiple model approach, the variable structure multiple model method. The third generation removes the fixed structure assumption and organizes the motion models to different motion model sets dependently along the time. It is more computation effective than the multiple model methods in the previous two generations for wide variety motion patterns.
2.2 MOTION MODELING REGARDING INTERACTIONS WITH SCENE AND MOVING TARGETS
2.2. Motion Modeling regarding Interactions with Scene and Moving Targets Only a few works address the observation and motion modeling issues of interactions among the tracked objects and the scene implicitly. Khan et al. (Khan et al., 2005) pro- pose a Markov chain Monte Carlo (MCMC)-based particle filter to track interacting ants, in which interactions are modeled through a Markov random field motion prior. Their interaction potential is based only on static poses which yield no higher-level scene under- standing. Smith et al. (Smith et al., 2005) use a simple interaction model to penalize object overlapping. Sullivan and Carlsson (Sullivan & Carlsson, 2006) propose constructing an interaction graph and then apply a two-stage clustering scheme to label the identity of the target. Instead of modeling interactions explicitly, these studies use the term “interaction”
to describe situations in which the target and adjacent objects share the common measure- ments and cannot be correctly labeled. In these existing approaches, interactions represent opposite information to avoid wrong estimates.
Besides the interactions among moving objects, there are approaches addressing the scene understanding and semantic mapping issues. In (Kostavelis & Gasteratos, 2015), Kostavelis and Gasteratos classify the existed works in semantic mapping field accord- ing to four major aspects, scalability, topological map, temporal coherence, and inference model. For scalability, they categorize semantic mapping-related works as either indoor or outdoor and single-scene or large-scale. For example, Trevor et al. (Trevor et al., 2013) introduce an efficient connected component solution in RGB-D data for single scene point cloud. They interpret the single scene point cloud to different objects ready to provide semantic meanings.
Liu et al. (Liu & von Wichert, 2014) extract the semantic of domestic environment based on the occupancy grid map. Utilizing the Markov chain Monte Carlo(MCMC) based sampling and the maximum posterior solution, (Liu & von Wichert, 2014) extract occu- pancy grids to semantic rooms for their later human robot interaction application. Sen- gupta et al. (Sengupta et al., 2012) exploit two conditional random fields to provide a street-level semantic map from visual imagery. The sematic map classifies the route to 13 different classes as, road, building, tree, ...etc in 14.8 km route. This work, however, focuses on static scenes or objects. Because it does not provide information on moving objects, ex- isting work is unable to model moving objects in such environments. In general, most of
the semantic mapping approaches focus on the static scenes or objects, while the input data is from visual images, 2D occupancy map, or even 3D point cloud.
Wolf et al. (Wolf & Sukhatme, 2008) not only focus on the semantic terrain mapping problem, but also introduce a solution to the semantic activity mapping problem using su- pervised learning techniques, namely hidden Markov models (HMMs) and support vector machines (SVMs). In their activity-based semantic mapping, HMMs and SVMs are ap- proaches for determining the spatial usage of dynamic entities in urban environments.
Later on, the space has been classify to two categories, street and sidewalk. Nevertheless, the final semantic map from (Wolf & Sukhatme, 2008) is not for directly tracking moving objects: it only summarizes how the moving objects utilize space.
2.3. Tackle the Occlusion in Urban
The occlusion occurred due to the limitation of the sensor perception capability, sur- rounding objects, and the environments. The surrounding objects lead to occlusion when the density of the objects is high. And the different environments make different percep- tion results contain with different occlusion areas from crowded urban to free space. There are lots of approaches handling the occlusion problem from partial occlusion to fully oc- clusion in the Computer Vision literature. In (Yilmaz et al., 2004), the occlusion is detected and the shape of the tracked object is recovered the contour according to the shape model for tracking. Ross et al.(Ross et al., 2008) introduce a forgetting factor with incrementally updating eigenbasis and mean of the target appearance for tracking. With the ability with track variations, it can track under partial occlusion. And Tang et al.(Tang et al., 2014) pro- posed a double-person detector model for human detector in order to handle the partial occlusion in crowded urban environment.
Not only in the computer vision literature, the occlusion problem is also raised with other sensors. Nashashibi and Bargeton (Nashashibi & Bargeton, 2008) compensate for occlusion issue by determining about the occluded sides and use object classification to identify the occluded part, and then the confidence level estimation is used in Kalman filter-based tracking. On the other hand, Almeida (Almeida, 2010) assumes that points do not change while be occluded and creates a new data with occluded points to compensate the sensor data for tracking. Wyffels et al. (Wyffels & Campbell, 2015) utilize occlusion as negative information in which they assume the tracked targets will exist in the next step
2.4 SHORT DISCUSSION FOR URBAN CASES
Table 2.1. Various approaches and their models for different tracking levels
Galceran et al.
(Galceran et al., 2015)
Interacting object tracking (Wang et al., 2007)(Wan et al., 2008) (Lin et al., 2011)
Virtual measurement model (Chen et al., 2018)
Tracking scheme hGMM VSMM VSMM
L1 tracking Driving behavior
model CV/CA model CV/CA model
L2 tracking Road network model Scene interaction model Scene interaction model L3 tracking N/A Neighboring interaction model Neighboring interaction model
In occlusion
Hypotheses with driv- ing behavior model and road network model
VSMM prediction Virtual measurement model
and treat missing targets as negative information to estimate the occlusion or to remove nonexistent tracks. Most such works attempt to balance the effects of occlusion and utilize information to remove fake tracks.
In (Yu & LaValle, 2012), Yu et al. proposed to estimate objects in occluded areas. By splitting and merging shadow regions through time, they create a graph of the shadow information spaces through time to find occluded targets. Then, given the probability dis- turbance of the observation, the max flow or probability mass propagation algorithm is applied to find the number of hidden agents. (Yu & LaValle, 2012) topologically estimates occluded objects, while (Galceran et al., 2015) attempts to precisely track occluded objects inside shadow regions. Galceran et al. (Galceran et al., 2015) introduce a road network model and a driving behavior model to perform estimation under occlusion. The road net- work model is composed of a discrete set of policies with a prior map of the environment, while the driving behavior model is composed of prescribe commands of steering-wheel- angle and forward-speed pairs. A hybrid Gaussian mixture model is applied to capture the estimates under occlusion within multiple hypotheses. However, this approach is suitable only for multi-lane roads or for single-lane intersections. The limited road network model is not easily applied to multi-lane intersections, and the fact that it does not take interac- tions between moving targets into account makes (Galceran et al., 2015) it unsuitable for heavy traffic intersections.
2.4. Short Discussion for Urban Cases
The developing path of the first approach was described here and the difference for improvements were pointed out accordingly. Wang et al. (Wang et al., 2007) propose a variable structure multiple model (VSMM) estimation framework (Li & Bar-Shalom, 1996)
with a scene interaction model and a neighboring object interaction model to perform mul- tiple interacting object tracking in urban areas using a laser scanner. The scene interaction model and the neighboring object interaction model respectively take the long-term and short-term interactions between the tracked object and its surroundings into account. This approach not only solves the data association problem but also provides higher level scene understanding. The neighboring object interaction model is extended from (Wang et al., 2007) from a simple following interaction to three kinds of interaction: following, attract- ing, and repelling.
Table 2.1 shows the usage models for different tracking levels in Galceran et al. (Gal- ceran et al., 2015), interacting object tracking (IOT) (Wang et al., 2007) (Wan et al., 2008) (Lin et al., 2011), and the proposed virtual measurement. As shown in Table 2.1, interact- ing object tracking and (Chen et al., 2018) better handle level-3 tracking; the approaches are even better for level-2 tracking than (Galceran et al., 2015), because its road network model models only the lane area for vehicles, which in contrast is part of the scene inter- action model in (Wan et al., 2008) and in (Chen et al., 2018), which models the long-term intensions of all moving objects of the environment to provide information for multitar- get tracking. Considering that moving objects do not change behavior suddenly and in fact interact with their surroundings, (Chen et al., 2018) exploits both short-term and long- term interactions in managing the data association problem, thereby providing a precise estimate in occluded areas.
In our initial study (Wang et al., 2007), (Wan et al., 2008), (Lin et al., 2011), the eval- uation was conducted using a manually-labeled benchmark; we propose a benchmark- generating system that uses 3D LIDAR to provide the occluded information in 2D. This is done because 3D LIDAR provides more and critical information comparing to occlusion in 2D. To quantify the occlusion between 2D and 3D sensors and to build the benchmark sys- tem, an occluded area detection module is also proposed to extract occluded grids. The key contributions of the first approach (Chen et al., 2018) are providing feasible approaches for modeling short-term and long-term interactions in urban environments, providing a laser based interacting object tracking framework with occlusion detection, an automatic bench- mark generated system with 3D LIDAR data for verification, and successfully tracking in challenging scenarios.
2.6 MOTION TRACKING BY NEWLY OPTICAL SENSORS
2.5. Motion Tracking by Conventional Optical Sensors
In an aging society, there is an increasing demand for long-term care. Two of the most relevant areas are elderly care and stroke rehabilitation. During the past decades, much research has been done on elderly care and stroke rehabilitation, and new technologies and sensors have been introduced in these fields to reduce the effort of health care staff.
Human motion tracking for rehabilitation has been an active research topic since the 1980s. At that time, many optical-based approaches appeared, and technology such as vision-based motion capture was developed. Zhou and Hu (Zhou & Hu, 2008) categorized visual tracking systems as either marker-based or marker-free. They introduce classical approaches for vision-based motion capture with a single camera or multiple cameras. At that time, the technology for video capture motion tracking had its creation for 25 years, but was not applied to rehabilitation in 5 years. Akhavizadegan and Idris (Akhavizadegan &
Idris, 2015) propose a real-time human arm tracking system for home-based rehabilitation.
This approach uses an expensive camera and a laptop to extract the velocity and angular measurements for critical arm joints.
2.6. Motion Tracking by Newly Optical Sensors
From 2010, new optical-based sensors were introduced for stroke rehabilitation; these were categorized as RGBD cameras or so-called depth cameras, including Microsoft Kinect, Asus Xtion Pro, and Intel Real Sense. Now, the core technology of these sensors are using on the iPhone X and other next generation smartphones. Da et al. (Da Gama et al., 2015) indicate a rising trend in the use of Kinect as a motor rehabilitation tool. To reveal this direction, a PRISMA protocol was used to examine the literature in the IEEE Xplore and PubMed databases. The technical and clinical impact of Kinect is addressed by Mousavi and Khademi (Mousavi Hondori & Khademi, 2014). They classify papers into three cate- gories: evaluating Kinect accuracy and reliability, addressing rehabilitation systems with clinical evaluation involving patients, and addressing rehabilitation systems lacking clin- ical validation. Webster and Celik (Webster & Celik, 2014b) summarize Kinect applica- tions in elderly care, stroke rehabilitation, and series games for rehabilitation. In stroke rehabilitation, not only is the spatial accuracy of Kinect evaluated but also the proposed rehabilitation methods with Kinect are described.
Mobini et al. (Mobini et al., 2014) apply the first-generation Kinect to evaluate the location accuracy of upper-body joints and the skeleton. They utilized a stationary wooden model as the ground truth to compute the maximum value of error and root mean square of the joints and other related parameters. They also address that errors were larger for other approaches due to errors from a marker-based motion capture system and the definition of the joint’s centers in the coordinates. Webster and Celik (Webster & Celik, 2014a) also evaluate the performance of Kinect with simple movements for rehabilitation. With the support of the OptiTrack system as the benchmark, two perpendicular boxes movements along the OptiTrack X and Z axes with the wrist joint tracker are applied. These movements are a subset of the basic movements for rehabilitation evaluations such as the Wolf Motion Function Test (Taub et al., 2011), the Action Research Arm Test (Carroll, 1965), and the Fugl-Meyre Assessment (Duncan et al., 1983).
In (Monir et al., 2012), Monir et al. propose a learning-based posture recognition approach to classify poses for motion control. To recognize human body poses, a novel angular representation and joint positions are exploited to provide scale- and rotational- invariant features. An incremental learning system is used to add new postures into the database when no match is found with the current model. Three different cost functions are evaluated with the scheme: the accuracy of the weighted match method is higher in most cases. Since the Kinect is a low-cost, easily installed sensor, game therapies have been utilized including (Saini et al., 2012) and (Sadihov et al., 2013). Saini et al. (Saini et al., 2012) propose an innovative game framework for home-based rehabilitation to improve motivation in the continuous recover process. With a novel gesture-based user interface and standard joint angle representation of body motion, they construct an online knowl- edge database for rehabilitation performance and feed back. Sadihov et al. (Sadihov et al., 2013) propose a VR approach with three game applications for stroke rehabilitation. Hap- tic gloves are used with Kinect as the sensors for performing rehabilitation and assessing the process. To remove the mal-functionality of the motors, three games with specific daily activities are chosen: cleaning the table as soon as possible, training grasp reaction and strength, and training the range of motion of the arms.
Ye et al. (Ye et al., 2016) exploit the depth camera of Microsoft’s Kinect V2 as the mo- tion capture system. They use a single depth camera to implement the telerehabilitation approach. To evaluate the performance of their system, a marker-based motion capture
2.7 MOTION TRACKING BY INERTIAL MEASUREMENT UNITS
system called VICON is used for gait analysis. Further, Yang et al. (Yang et al., 2018) uti- lize three RGB-D cameras to build up another marker-less motion capture system. They apply geometrical trilateration to track human gait precisely. Tupa et al. ( ˇTupa et al., 2016) evaluate the performance of Kinect V2 based on the Motor Assessment Scale (MAS) for stroke motor function assessment. Note that, they use healthy subjects in experiments to simulate stroke patients for rehabilitation. Another systematic review by Knippenberg et al. (Knippenberg et al., 2017) focuses on approaches that use Kinect for upper limb stroke rehabilitation. In this review, they indicate that none of the studies report an individual- ized training program based on a client-centred approach, which is nevertheless important in neurological rehabilitation. Most current approaches are time-consuming and costly in clinical practice. In these vision-based motion capture system approaches, a common prob- lem is occlusion due to a single camera setting. Though multiple view points could relax this issue, it increase the complexity in both systematically and computationally (Zhou &
Hu, 2008).
2.7. Motion Tracking by Inertial Measurement Units
In contrast, electromagnetic technology has improved and smaller and accurate iner- tial measurement units have been developed; thus IMU-based mo-cap is widespread and mechanical-based tracking systems are also evolved. Zariaffa et al. (Zariffa et al., 2012) use a robotic arm as the rehabilitation support device to collect quantitative data to track the progress of improvements. This robotic quantitative data is also compared with man- ual clinical assessment scores to identify the status of the rehabilitation after cervical spinal cord injury. In (Badesa et al., 2016), Badesa et al. develop a dynamic adaptive robot assisted rehabilitation system. By utilizing two-stage fuzzy controller, they regulate the complexity of the therapy on line for ten subjects. Huo et al. (Huo et al., 2016) review existed wearable robots including exoskeletons and active orthoses approaches and point out that human motion intention plays an important role in rehabilitation.
Zhang et al. (Zhang et al., 2015) apply a novel fuzzy kernel motion classifier to classify motion. They collect measurements from an XSens IMU module placed on the wrist joint.
Six motions are supported, including handshake, straight arm palm press, shoulder hori- zontal flexion and extension, forehead reaching with elbow, shoulder touching, and wrist turn. They successfully evaluate the classifier with 14 patients at different Brunnstrom
stages of stroke recovery (1-5) to determine the influence of motion quality on classifica- tion. In (Leardini et al., 2014), Leardini et al. perform gait analysis with Riablo, an IMU- based human tracking system. They evaluate the system with a VICON motion capture system and demonstrate that IMU is suitable as a sensor for human tracking systems. One problem with such IMU-based approaches, however, is sensor measurement drift, or di- vergence. Most approaches use sensor re-calibration to mitigate accumulated error. This limitation affects the usability of the approach for home or remote rehabilitation.
Nguyen et al. (Nguyen et al., 2011) describe the optical linear encoder (OLE), a novel sensor to track a link’s orientation, acceleration, and joint angles instead of using mea- surements from conventional motion capture systems, such as optical systems, IMU-based systems, and mechanical tracking systems, which unfortunately all have their limitations (Nguyen et al., 2011). Though, optical systems are accurate, they are expensive, requiring setup, calibration, and data processing. They also have problems with occlusion and a lack of portability. Thus conventional optical approaches are not ideally suited for home rehabilitation systems. For IMU-based tracking systems, accumulated errors (gyroscope) and high sensitivity to disturbances by metallic objects (magnetic sensor) necessitate care- ful sensor alignment and re-calibration after long periods. Thus IMU-based systems are not a good choice for home rehabilitation either. Finally, mechanical tracking systems are cumbersome and not very portable. Moreover, as they require special safe work spaces, they are not suitable for home environments.
2.8. Multiple Sensor Fusion Approaches
A substitution to relax the occlusion is multiple sensor fusion. Moreover, to comple- ment the advantages from different sensors, some researchers have fused the sensor data of optical-based and IMU-based mo-cap. Such a combination of heterogeneous sensors compensates for their weakness, improves accuracy, and reduces variance and the number of unobservable states.
Tao et al. (Tao et al., 2007) use a monocular camera and inertial sensors. To fuse these measurements, an Extended Kalman Filter (EKF) scheme is applied using a prediction step by the inertial sensors and updates with the visual sensor. Marker-based motion capture systems such as CODA and Qualisys are utilized to evaluate the performance with circular and rectangular motion as test cases. After the Kinect is developed, Bo et al. (Bo et al., 2011)
2.8 MULTIPLE SENSOR FUSION APPROACHES
exploit inertial sensors - the gyroscope and accelerometer - as the sources of major measure- ments in estimating joint angles. They also use a Kalman Filter with the Kinect for online calibration of the inertial sensors when the Kinect is available. Otherwise, they use the in- ertial sensor estimates directly. They propose a scheme to fuse the inertial sensors and the RGB-D camera sensor measurements. Hondori et al. (Hondori et al., 2012) use inertial sen- sors and a Kinect to estimate states of daily activity. In contrast to other approaches, they attach the accelerometers on utensils on a table. They collect measurements for important activities such as eating and drinking in front of a table for Tele-Rehab applications. In an evaluation with healthy subjects, they simulate daily activities and successfully estimate activities using sensor fusion.
Tian et al. (Tian et al., 2015) propose a sensor fusion scheme that integrates IMU and Kinect. Their IMU includes an accelerometer, a geomagnetic sensor, and a gyroscope, which provide accurate measurements to estimate joint poses. However, for initial cali- bration of their IMUs the system is positioned parallel to the Earth frame, due to the ge- omagnetic sensor which returns measurements relative to the global Earth frame. They apply an unscented Kalman filter to smoothly integrate sensor sources. In the following experimental results, we take their approach as a reference benchmark for comparison.
CHAPTER 3
Single Sensor Approach: Interacting Object Tracking with A Stationary LIDAR in Urban Areas
T
HEjourney of the extended machine perception starts from pushing a sensor until to its maximum limitation. Here, an approach to extend a 2D LIDAR was represented with details that describes the corresponding modules to achieve the task. High crowdedness complicates motion modeling, and oc- clusion makes tracking difficult as well. Based on the variable-structure multiple-model (VSMM) estimation framework, this thesis extends an interacting object tracking (IOT) scheme with occlusion detection and a virtual measurement model for occluded areas.With a single stationary 2D LIDAR, interacting object tracking with occlusion was accom- plished with exploiting this sensor to track moving objects in an intersection. IOT is com- posed of a scene interaction model and a neighboring object interaction model. The scene interaction model considers the long-term interactions of a moving object and surround- ings, and the neighboring object interaction model considers three short-term interactions.
These interaction models were also called interacting object models. With these interacting object models, the motion feature of a moving object can be represented with the weight of each model. Follow up, given the finding that moving objects prefer to maintain their behavior, a virtual measurement model is proposed to exploit the motion feature with the IOT scheme under occlusion. The proposed approach was validated using a stationary 2D LIDAR. To verify in occlusion, a 3D LIDAR based benchmark system was developed to extract occluded moving segments.
In this chapter, we will first describe the framework of IOT and how we integrate the basic maneuver and interaction models at Section 3.1. Before introducing the interacting