國立臺灣大學電機資訊學院資訊網路與多媒體研究所 碩士論文
Graduate Institute of Networking and Multimedia College of Electrical Enginnering and Computer Science
National Taiwan University Master Thesis
以生成對抗網路達成非監督式文章摘要及主題模型
Unsupervised Text Summarization and Topic Modeling using Generative Adversarial Networks
王耀賢 Yau-Shian Wang
指導教授:李琳山 教授 Advisor: Lin-shan Lee, Ph.D.
中華民國一百零八年七月
July, 2019
摘要
隨著網際網路的興起,人類在網路上留下各式各樣的資料,由於這些資料大 多是未標註的,使用未標註資料來做訓練的非監督式學習成了近年來重要的研究 課題。在本論文中,我們使用生成對抗網路來探索非監督式學習在自然語言處理 上的可能性,並專注在在兩個不同的主題上。
第一個主題是非平行抽象式文章摘要,亦即不需要平行成對的訓練文章搭配 其人類撰寫的摘要便可訓練機器撰寫文章的非抽象式摘要。在這個主題中,我們 使用摘要來作為文章自編碼器的潛在表徵,並且使用生成對抗網路來限制此潛在 表徵必須具備人類可讀的形式,只要提供較少量的人類撰寫的不相關的內容的文 章摘要作為辨識器的範本就可讓機器學習人類是如何寫摘要的。我們衡量我們所 提出的模型在英文以及中文的新聞摘要資料庫上,模型的表現也驗證了這樣的方 法的可行性。
第二個主題則是非監督式文章主題模型,希望機器可以自動發現文章的接近 人類認知的主題。我們使用資訊生成對抗網路來模擬文章的產生是由一個離散的 主題分佈,以及一個連續的向量來控制主題下的文章的變異,而不若前人所提出 的主題模型模擬文章的產生是由若干瑣碎的次要主題所產生。實驗顯示我們的模 型在文章分類的任務上,以及所抽取出的每一個主題的關鍵詞的品質上,相較於 先前的研究結果均有著顯著的進步。
英文摘要
With the development of the Internet, humans put various data on the Internet. As most of the data is unannotated, how to efficiently utilize unlabeled data for unsupervised learning, becomes an important research direction. In this thesis, we use Generative Adversarial Network (GAN) to explore the possibility of unsupervised learning on NLP, which mainly covers the two different topics.
The first topic is unsupervised abstractive text summarization. That is text summarization without any paired data. We use summaries as latent representations of an auto-encoder and use GAN to constrain the latent representation to be human-readable. WIth fewer summaries as examples for discriminator, machine can understand how humans write summaries for documents. The results on English and Chinese news datasets demonstrate the effectiveness of our model.
The second topic is unsupervised topic model. The goal of this section is to train a machine that is able to automatically discover the latent topics similar to humans' cognition. Unlike prior topic models which models text generated from a mixture of sub-topics, we utilize InfoGAN to model texts generated from a discrete code controlling high-level topics and a
continuous vector controlling variance within the topics. Compared to prior works, our proposed method greatly improves the performance on
unsupervised classification and topical word extraction.
Contents
口試委員會審定書 . . . i
中文摘要 . . . ii
一、導論 . . . 1
1.1 研究動機 . . . 1
1.2 研究方向 . . . 5
1.3 章節安排 . . . 5
二、背景知識 . . . 7
2.1 深層類神經網路(Deep Neural Network) . . . 7
2.1.1 模型架構 . . . 7
2.1.2 類神經網路的訓練 . . . 8
2.2 遞迴式類神經網路 . . . 10
2.2.1 基本模型 . . . 10
2.2.2 長短期記憶模型 (Long Short-Term Memory, LSTM) . . . 10
2.2.3 序列至序列網路 . . . 11
2.2.4 專注式序列至序列網路 . . . 11
2.2.5 混合式指標網路 . . . 12
2.3 自編碼器(Autoencoder) . . . 13
2.3.1 基本原理 . . . 13
2.3.2 變分自編碼器(Variational Autoencosder, VAE) . . . 14
2.4 生成對抗網路(Generative Adversarial Neural Networks, GAN) . . . 15
2.4.1 基本原理 . . . 15
2.4.2 使用生成對抗網路產生語言 . . . 16
2.4.3 資訊生成對抗網路(Info-GAN) . . . 20
2.5 本章總結 . . . 20
三、使用生成對抗網路達成非監督式抽象文章摘要 . . . 21
3.1 任務簡介 . . . 21
3.2 訓練方法 . . . 22
3.2.1 方法概述 . . . 22
3.2.2 最小化重構損失 . . . 24
3.2.3 生成對抗網路的訓練 . . . 25
3.3 實驗 . . . 29
3.3.1 資料介紹 . . . 29
3.3.2 實做細節 . . . 30
3.3.3 評量方法 . . . 31
3.3.4 非平行式摘要用於英文十億詞 . . . 32
3.3.5 半監督式摘要於英文十億詞 . . . 34
3.3.6 遷移式學習於英文十億詞 . . . 35
3.3.7 非平行式摘要用於有線電視日常信件 . . . 36
3.3.8 非平行式摘要用於中文十億詞 . . . 37
3.4 本章總結 . . . 38
四、使用資訊生成對抗網路達成文章主題模型 . . . 42
4.1 任務簡介 . . . 42
4.2 訓練方法 . . . 43
4.2.1 方法簡介 . . . 43
4.2.2 模型介紹 . . . 44
4.2.3 模型的訓練 . . . 46
4.2.4 由產生的詞袋向量產生文章 . . . 48
4.3 實驗 . . . 48
4.3.1 資料介紹 . . . 48
4.3.2 模型架構與參數 . . . 50
4.3.3 非監督式文章分類 . . . 50
4.3.4 主題一致性 . . . 52
4.3.5 切除分析 (Ablation Study) . . . 56
4.3.6 分離式表徵 . . . 58
4.4 本章總結 . . . 59
五、結論與展望 . . . 65
5.1 結論與主要貢獻 . . . 65
5.2 未來展望 . . . 67
5.2.1 使用兩階段式的方法達成非平行式文章摘要 . . . 67
5.2.2 使用遞迴式類神經網路的文章主題模型 . . . 67
參考文獻 . . . 68
圖
圖 圖目 目 目錄 錄 錄
2.1 類神經網路示意圖. . . 8
2.2 自編碼器的模型示意圖. . . 13
3.1 模型示意圖。 給定長文,生成器設法產生摘要,它所產生的摘要 必須最小化重構損失並且讓鑑別器認為產生的摘要為真,也就是要 設法騙鑑別器讓它認為此摘要來自於人類。 . . . 22
3.2 提出模型的詳細的架構。 . . . 24
3.3 自我批判學習強化法的實際例子。 . . . 26
3.4 英文十億詞的例子。 . . . 33
3.5 英文十億詞的例子。 . . . 34
3.6 有線電視新聞網的例子。 . . . 37
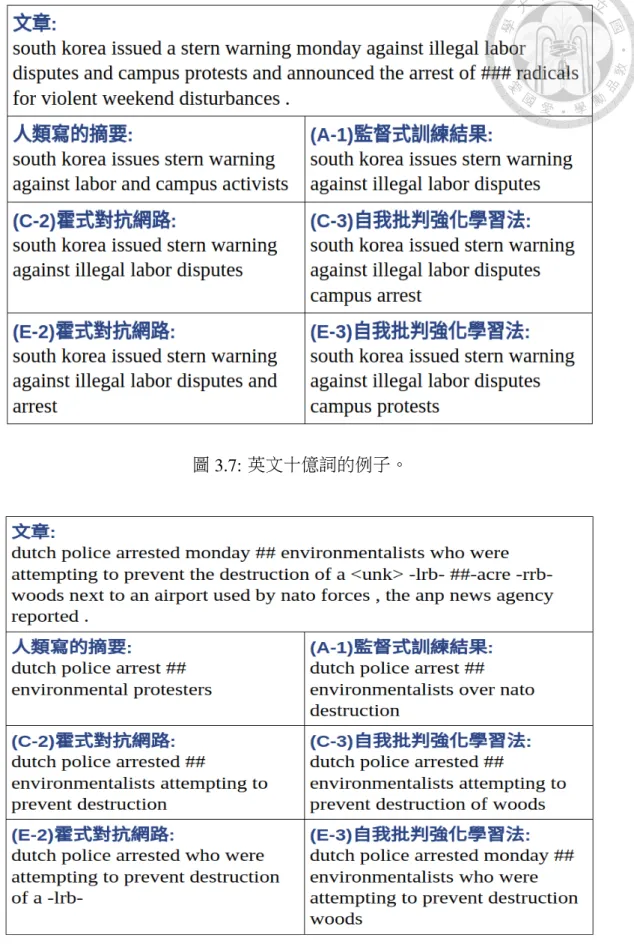
3.7 英文十億詞的例子。 . . . 39
3.8 英文十億詞的例子。 . . . 39
3.9 英文十億詞的例子。 . . . 40
3.10 英文十億詞的例子。 . . . 40
3.11 英文十億詞的例子。 . . . 41
3.12 英文十億詞的例子。 . . . 41
4.1 我們的模型的示意圖。 (A)在左邊的部份中,生成器 G 以離散的文 章主題分佈 c 以及連續的雜訊向量 z 為輸入來產生詞袋向量;鑑別 器 D以詞袋向量為輸入並且鑑別其是來自於人類或者生成器;主 題分類器 Q 以生成的詞袋向量為輸入並且預測文章的隱藏主題。 在(A) 右邊的部份則是自編碼器的訓練,自編碼器的訓練以人類寫 的文章的詞袋向量為輸入,其中雜訊預測器 E 以及主題分類器 Q 形成一個編碼器,而 G 則是解碼器,他們要設法重構輸入的詞袋 向量。 (B)則是文章的生成,首先 G 會先產生詞袋向量,再來 G0 設法根據輸入的詞袋向量並且設法產生文章。 . . . 44
表
表 表目 目 目錄 錄 錄
3.1 The caption . . . 28
3.2 ROUGE分數在有線電視日常信件的資要庫上。 . . . 36
3.3 ROUGE分數在中文十億詞資料庫上。 . . . 38
4.1 非監督式文章分類準確度。 . . . 52
4.2 主題一致性的分數,越高越好。 . . . 53
4.3 由我們模型所發現的主題所產生的主題詞。 在資料庫百科中主題 1 是有關於音樂,主題 2 是有關於建築而主題 3 是有關於運動。在英 文十億詞主題 1 是有關於經濟,主題 2 是有關於疾病,而主題 3 是 有關於政治。 . . . 55
4.4 表 4.3中的主題所產生的對應的文章。在相同資料庫的文章是由相 同 z 但是不同的 c 所產生的。 . . . 56
4.5 切除分析在非監督式文章分類上,表中的數字代表準確度。 . . . 57
4.6 由表 4.3 主題編號 2 所產生的文章,他們來自於相同的 c 但是不同 的 z。 . . . 58
4.7 由表 4.3 英文十億詞中主題 2 不同的雜訊向量 z 所產生的文章,很 明顯的每個文章都與疾病有關。 . . . 60
4.8 在雅虎問答中我們的模型所產生的文章主題詞。 . . . 61
4.9 在雅虎問答中 ProdLDA 所產生的文章主題詞。 . . . 62
4.10 在雅虎問答中 NVDM 所產生的文章主題詞。 . . . 63
4.11 在雅虎問答中 LDA 所產生的文章主題詞。 . . . 64
第 第
第 一 一 一 章 章 章 導 導 導論 論 論
1.1 研 研 研究 究 究 動 動 動機 機 機
在現今人工智慧興起的時代,使用機器學習(Machine learning)相關的技巧處問題 已成未來的趨勢,許多科技公司期望能利用機器學習來處理更為複雜的問題,並 且推出更好的產品以及服務。舉例來說,蘋果(Apple)利用機器學習推出智慧語音 助理Siri,透過語音的互動幫助人們解決生活中各式的煩惱;亞馬遜(Amazon)也 利用機器學習推出居家語音智慧助理Alexa,幫助人類居住生活更為便利;谷 歌(google)也亦利用深層學習(Deep Learning)推出谷歌翻譯的功能,讓人與人的互 動交流能夠跨越語言的障礙。
早期的機器學習主要依賴人類專家的先驗知識(Prior Knowledge)來抽取出問 題的特徵(Feature),接著再利用傳統機器學習的相關模型像是支援向量機(Support Vector Machine, SVM) [1],決策樹(Decision Tree) [2]及感知器(Perceptron)等方法來 解決問題。早期的方法會需要人類的先驗知識主要是因為早期的計算資源的不 足,讓機器無法處理極為複雜的模型,又或者處理模型的時間會極為緩慢;以及 訓練資料的稀少,迫使機器無法抽取出廣泛有效的特徵。
然而現今隨著計算資源的大幅度進步,尤其是圖形處理器(GPU)的發展,機 器得以處理極為複雜的模型,並且能夠以數十倍甚至數百倍的速度來處理模型的 運算;以及隨著網路世界的興起,人類在網路世界中留下各式各樣的足跡,也就 讓機器有了各式各樣訓練的資料,現今主流的模型像是深層學習就傾向於讓機器 透過大量的訓練資料,自己去發現人類專家所學習到的先驗知識,並且除了傳統 的分類問題外,也能解決更多更複雜的問題,像是複雜的生成(Generation)問題,
複雜的生成問題有像是圖片的生成,文句翻語音的生成(Text to Speech),又或者
是自然語言處理(Natural Language Processing, NLP)的生成像是機器翻譯(Machine Translation),又或者是文章摘要(Text Summarization)。
因為模型更為複雜能夠更好的模擬問題,在有充足資料的問題上,利用大量 標註訓練資料的監督式學習(Supervied Learning)都能有不錯的表現,然而在網路 世界中大部份的資料都是未經標註的,像是網路上大量的文章,上傳到社群軟體 上的照片,又或者在網路播放器上的沒有字幕的影片,要人工標註這些幾近無限 的未經標註的資料是一件十分昂貴並且不可行的事情,因此如何利用這些未經標 註資料的訓練方法就成為現今最為熱門的研究問題。這類問題包含用少量標註資 料以及大量未標註資料的半監督式學習(Semi Supervised Learning),只利用大量未 標註資料的非監督式學習(Unsupervised Learning),又或者將其他領域學習到的知 識廣泛化到目標領域的遷移學習(Transfer Learning)。
我選擇研究非監督式學習類的問題,並且將此問題應用在自然語言處理的 領域上,這類的問題的核心精神是要讓機器能夠有如人類一般,藉由閱讀大量 的文字資料,就能從這些資料中學習新知,像是了解句子與句子之間的關係、
文法架構,並且進一步理解這些文字背後深層的含意。然而在實際上要讓機器 理解這些是十分困難的,因為機器所學習到的資料的特徵往往與人類的認知有 著極大的差異,但這類的研究仍然吸引研究者很大的注意,因為如果能讓機 器如同人類一般,從未標註的文本學習出更廣泛的知識,幾乎所有的其他自 然語言處理的任務都能因此而進步。在近期相關領域也有許多著名的研究,
舉例來說BERT(Bidirectional Encoder Representations from Transformers) [3]就預訓 練(Pre-training)轉換器模型(Transformer) [4]在大量的未標註文本上,他們訓練模型 在兩個自我訓練 (Self-Training) 任務上,藉由達成這兩個自我訓練的任務,模型得 以成功的學習到更廣泛的知識,並且將預訓練後的模型微調在許多其他自然語言
的任務上也取得最佳的表現。
本論文的研究則專注在其他的相關問題上,可以分為兩個不同的主題,第 一個主題是有關於非配對式文章摘要(Unpaired Text Summarization),這個主題的 目標是希望機器能夠設法由大量的文章中去做抽象式文章摘要 (Abstractive Text Summarization),第二個主題則是文章主題模型的建立,目標是希望藉由閱讀大 量的文本,能讓機器如同人類一般,去發現文章各式的主題,像是文章是屬於政 治類的主題亦或是運動類的主題。
首先先來介紹非配對式文章摘要,在現今抽象式文章摘要的問題上,模型的 訓練往往需要依賴極為大量人工標註的資料,因為人工標註資料的取得不易,因 此這類模型往往只能訓練在有大量標註資料的任務上像是新聞的摘要,然而在其 他資料取得不易的任務上像是演講的摘要、課程的摘要,這些往往都是沒有人工 標註的資料的,然而這些資料也是非常需要摘要來幫助人們一眼了解所述,因此 我希望能讓機器能用少量的摘要就能夠達成學習,甚至在不看到任何摘要的情況 下就完成學習。
非配對式文章摘要的方法啟發於人類做摘要的方式,一個好的摘要首先必 須要精簡,再來摘要必須要能包含大部分的文意,我發現在深層學習的領域中 有種模型的概念與之極為接近,那就是自編碼器(Auto-Encoder),自編碼器希望 能用更精簡的表徵(Representation)來表徵資料,並且這種精簡的表徵還要能夠重 構(Reconstruct)回原本的資料,因此這精簡的表徵必須要抓住資料的重點,直觀來 看這精簡的表徵就好似資料的摘要。然而,摘要還有另外一個重要的特徵,那就 是摘要必須要是人類能夠理解的,由於自編碼器的表徵只有機器才能理解,因此 我選用近來最為成功的生成模型(Generative Model)中的生成對抗網路(GAN) [5]來 限制自編碼器產生人類可讀的表徵。
再來要談的是非監督式文章主題模型的建立,主題模型是機器學習以及自然 語言處理一個非常經典的問題,這個問題的價值在於他給予人類一種方式去分析 以及了解歸納文章的主題。然而不論傳統的文章主題模型亦或是使用類神經網路 的主題模型,他們都有些共同的通病,那就是他們必須要設定很多的文章主題數 目,舉例來說在一個新聞的資料庫,他可能只有”運動”,”政治”以及”體育”這三 類不同的文章,就人類直觀而言這個資料庫應該只有三種不同的主題,然而由於 先前的主題模型的方法上的限制,他們必須要設定遠遠高於三個以上的主題,可 能是50甚至100個,這樣子他們就必須要將一個運動類主題拆成許多不同的子主 題,像是依據不同運動來劃分主題,由於這樣子拆解主題違反人類直觀上的主題 的定義,於是我就提出個全新的方法設法讓機器能夠有如人類般直接學習這些較 高層次的主題。
我發現在圖像上已經有人處理過類似主題模型的問題,前人提出資訊生成對 抗網路(Info-GAN) [6]來將圖片歸類成為不同的類別,因此我設法將此模型應用到 文章主題模型中,然而我發現直接套用這個模型在文字上很難讓模型成功學會有 意義的主題,因此我額外再提出些額外的延伸來幫助此模型能夠在文字資料上也 能取得成功,這些延伸包含使用詞嵌入(Word Embedding)來幫助機器學習有意義 的話題,將資訊生成對抗網路與自編碼器結合等等,最後這些延伸也在實驗中被 證實能大幅提升效能。
由於文字的離散特性,使用生成對抗網路訓練文字資料仍然是一件非常困難 的事情,這個領域仍然遠遠稱不上是成熟,但有鑑於生成對抗網路在電腦視覺上 所取得的巨大成功,我相信這仍舊是個值得探索的方向,因此我選擇這主題作為 我的碩論主軸,並且藉由上述的這兩個成功的應用,更進一步探索可能的訓練方 法,以及如何應用在實際的問題上。
1.2 研 研 研究 究 究方 方 方向 向 向
本論文之研究方向為使用生成對抗網路 (Generative Adversarial Networks)達成非監 督式自然語言文意理解,主要包含以下幾點:
• 本論文會探討兩種不同的使用生成對抗網路在非監督式自然語言處理的題 目,包含非配對式文章摘要,以及非監督式文章主題模型。
• 由於使用生成對抗網路產生文句是一件極為困難的事情,因此本論文會探討 如何成功的使用生成對抗網路產生文句,首先會介紹文字生成的困難之處,
再來介紹最近的研究如何提出新的生成對抗網路的目標函式以及如何使用強 化學習(Reinforcement Learning)來解決此問題,再來會說明本篇文章如何將 前人的方法做結合,並且提出一種新的使用生成對抗網路產生文字的方法,
此方法也在實驗中被證實能成功產生出合理的文字。
• 使用資訊生成對抗網路(Info-GAN)在電腦視覺的領域上取得巨大的成功,因 為能夠達成非監督式地分類圖片,然而由於文字十分難生成,以及十分難學 出合理的類別,因此先前的研究在這方面的嘗試都沒有取得很好的結果。
本論文嘗試將資訊生成對抗網路與霍氏生成對抗網路(Wasserstein Generative Adversarial Networks)結合以及與自編碼器結合來讓訓練更為穩定,並且提出 使用預訓練的詞向量來鼓勵模型學到有意義的文章主題。
1.3 章 章 章 節 節 節安 安 安排 排 排
本論文之章節安排如下:
• 第二章:介紹本論文相關背景知識。
• 第三章:介紹使用生成對抗網路達成非監督式抽象文章摘要。
• 第四章:介紹使用生成對抗網路達成文章主題模型。
• 第五章:本論文之結論與未來研究方向。
第
第 第 二 二 二 章 章 章 背 背 背景 景 景知 知 知識 識 識
2.1 深 深 深層 層 層 類 類 類神 神 神經 經 經網 網 網路 路 路(Deep Neural Network)
2.1.1 模 模 模型 型 型架 架 架構 構 構
深層類神經網路為現今機器學習最著名的模型之一,它可以被視為一個函式,
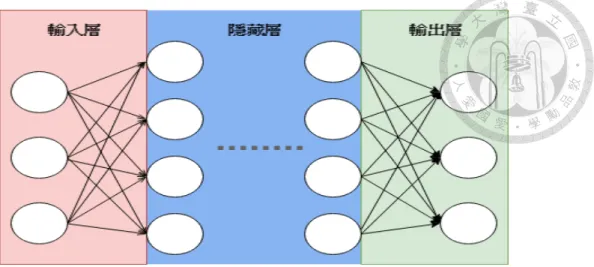
會將輸入向量映射到輸出向量。它的靈感是來自於人類神經元的運作模式,人 類的神經元的節點是彼此相互連結在一起的,並且只有通過某個閾值 (Threshold) 才會激發訊號繼續往下傳遞。受此啟發,最基本的順向類神經網路 (Feedforward Neural Network) 由許多層 (Layer) 所構成,並且如圖 2.1 所示,層跟層之間的節點 都是彼此緊密的連結在一起的,下個層的輸入是由上層而來,如此一來輸入經由 不斷的轉換後就能階層式地抽取出低層次到高層次的特徵。
簡單來說,首先輸入層會先接收來自於輸入 (Input) 的訊號,再來輸入的訊號 會進入隱藏層做複雜的處理以及運算,最後經由輸出層產生輸出(Output)。 每層 的運算方式都是相似的,每層都把該層的每一個節點的輸入訊號都乘上一個可以 被訓練的權重(Weight),圖 2.1 中的每個箭頭即代表一個權重,下一層的節點為上 層所有節點的權重加總,再加上一個可訓練的偏移值(Bias),最後為了避免模型只 是個簡單的線性模型並且讓模型能表示更複雜的函數,線性轉換的輸出會再通過 一個激發函數(Activation Function),每一層的輸出f(x)如下:
f (x) = σ(W x + b) (2.1)
其中 W 是所有可訓練的權重所排成的矩陣 (Matrix) ,而 b 則是所有節點偏移值所 排成的向量, x 是該層的輸入,σ 則是激發函數。通常來說,激發函數有整流線
圖 2.1: 類神經網路示意圖.
性單元 (ReLU) 或S型函數 (Sigmoid) :
Relu(z) = max(z, 0) Sigmoid(z) = 1
1 + e−z
(2.2)
其中 z 是線性轉換 W x + b 的值。類神經網路的輸出層則不會使用上列的激發函 數,而是會隨著訓練任務的不同使用其他的輸出函數,將在下一節作詳細的介 紹。
2.1.2 類 類 類神 神 神經 經 經網 網 網路 路 路的 的 的訓 訓 訓練 練 練
要訓練類神經網路,首先必須要定義一個損失函數 (Loss Function) ,類神經網 路的目標就是要找出一組類神經網路的參數來盡可能的最小化損失函數,此損 失函數會隨著訓練任務的不同而有所變動,而輸出層的輸出函數也會隨著損失 函數而改變。在此要由機器學習其中兩個著名的訓練任務說起,第一個是迴歸 (Regression)任務第二個則是分類 (Classification) 任務。
迴歸任務的輸出是個連續的值,像是預測溫度、預測年齡甚至是圖形的生成 都可以被形成一個迴歸任務。為了讓模型能夠輸出任何的值,有時輸出層不會額
外再放輸出函數,而是直接拿輸出層線性的輸出來做為模型的輸出,在這任務最 常使用的損失函數是均方差 (Mean Square Error, MSE) ,均方差要最小化模型的輸 出與目標的值,其式如下:
LM SE =X
i
kyi− f (xi; θ)ik2 (2.3)
其中 f(xi; θ) 是個輸入為第 i 筆資料 xi 並且參數為 θ 的類神經網路的輸出, yi是 第 i 筆資料的正確的標籤。
再來要介紹的是分類問題,我要介紹的是多元分類問題 (Multiclass Classifica- tion),多元分類指類別的數目大於二的分類問題,圖片的鑑別或文章的分類都可 以被視為多元分類問題,值得一提的是文句的產生也可以被視為一個多元分類的 問題: 依序產生文字,產生文字時每一個字都是一個獨立的類別,正確的字則是被 視為正確的類別。 多元分類問題的輸出層的輸出是一個機率分佈,機率分佈的輸 出通常會使用軟性最大化函數 (Softmax) ,輸出層第 i 個節點經過軟性最大化函數 後的機率如下:
Sof tmax(x)i = exi Pk
j=1exj (2.4) 與之搭配的損失函數則是交叉熵 (Cross Entropy, CE) 函數,其數學式子如下:
LCE = −X
i
yi· log(f (x; θ)i) (2.5) 有了上述這些輸出函數以及損失函數後,我們就可以調整類神經網路的參數 來最小化損失函數,最常使用的是梯度下降法(Gradient Descent Algorithm) 輔以反 向傳播演算法(Back Propagation) 來訓練。梯度下降法首先會計算損失函數對於參 數的梯度(Gradient),接著為了最小化損失函數,會將模型參數往梯度的相反方向 做更新。藉由不斷迭代更新參數,損失函數會逐漸下降,每次更新式子如下:
θ0 = θ − η∂L(x, y; θ))
∂θ (2.6)
其中 θ0 是更新過後的參數。
2.2 遞 遞 遞 迴 迴 迴式 式 式類 類 類神 神 神經 經 經網 網 網路 路 路
2.2.1 基 基 基本 本 本模 模 模型 型 型
上一個章節介紹的順向類神經網路雖然能解決許多問題,但是在序列性的資料 (Sequential Data),像是語音、文字或影片,這類網路就不能表現十分良好,關鍵 在於它不能夠由左至右地 “記憶” 並且處理這些資料,人類在處理序列性的資料 時,會由左至右,依序儲存資料中重要的部分在記憶中,最後在形成對於資料的 表示。為了模仿人類的這個特性,遞迴式類神經網路會依序讀入資料到記憶體單 元 (Memory Cell) 中,在第 t 個時間點會讀入 xt,再將 xt與上個時間點的記憶體 單元 ct−1結合成新的記憶體 ct, ct經過輸出層後會產生輸出 ht, ct也會同時傳入 下個時間點,其處理資料函數如下所示:
ct= σc(Wxxt+ Ucct−1+ bc) ht = σh(Whct+ bh)
(2.7)
其中 σ 代表激活函數,而 W, U, b 都是可訓練的參數。
2.2.2 長 長 長短 短 短期 期 期記 記 記憶 憶 憶模 模 模型 型 型 (Long Short-Term Memory, LSTM)
然 而 原 始 的 遞 迴 式 類 神 經 網 路 在 更 新 較 長 的 序 列 時 會 有 很 嚴 重 的 梯 度 消 失(Gradient Vanishing) 的問題,因為遞迴式類神經網路每經過一次激活函數他的 梯度都會下降些,在較長的序列中往往最後會減至為零,也造成參數無法更新。
為了解決此問題,先前研究者提出一種新的遞迴式類神經網路,其名為長短期記 憶模型 [7],長短期記憶模型的處理資料方法如下所示:
ft = σg(Wfx + Ufht− 1 + bf) it= σg(Wix + Uiht− 1 + bi) ot = σg(Wox + Uoht− 1 + bo)
ct = ft◦ ct−1+ it◦ σc(Wcxt+ Ucht−1+ bc) ht= ot◦ σh(ct)
(2.8)
其中 f, i, o 分別是遺忘閘門 (Forget Gate) 、輸入閘門 (Input Gate) 、 以及輸出閘門 (Output Gate), f 控制上個時間點的記憶單元要遺忘多少, i 控制那些資料要被 輸入, o 控制那些潛在特徵要被輸出。如果對 ct微分可以發現當 ft為 1 時,梯度 可以完全地傳遞到上一個時間點的 ct−1也因此長短期記憶模型能夠有效的減緩梯 度消失的問題。
2.2.3 序 序 序 列 列 列至 至 至序 序 序 列 列 列網 網 網路 路 路
一個序列至序列網路 [8]由一個編碼器以及一個解碼器所構成,不論編碼器 或解碼器都是一個遞迴式迴歸網路。編碼器會輸入一段長度為 l 的序列資料 x = x1, x2, . . . ., xl ,再將最後一個時間點的隱藏狀態 (Hidden State) hl 餵給解碼 器,在此最後一個時間點的隱藏狀態向量代表著編碼器對於輸入序列資料的理 解;接著解碼器會用編碼器最後一個時間點的隱藏狀態來初始化他自身的隱藏狀 態,再根據此去產生長度為 m 的序列化的輸出 y = y1, y2, . . . ., ym。
2.2.4 專 專 專注 注 注式 式 式序 序 序 列 列 列至 至 至序 序 序 列 列 列網 網 網路 路 路
原始的序列至序列網路解碼器只會拿編碼器的最後一個隱藏狀態,然而這麼做可
能會較為忽略先前時間點的重要資訊,為了讓機器能夠專注在先前某個時間點的 重要資訊,研究者提出了專注力 (Attention) [9]機制,讓機器在產生輸出時也能夠 專注在先前的若干時間點重要的輸入上。
專注式序列至序列網路的編碼器與原始的序列至序列網路相同然而編碼器做 了如下的改變,首先在時間點 t 要產生一個輸出時,他會先計算要專注在編碼器 的哪個時間點,如下:
eti = vTtanh(Whhi+ Wsst+ battn) at= sof tmax(et)
(2.9)
eti代表著編碼器第 i 時間點的資訊對於解碼器第t個時間點的重要性,而 st是 目前解碼器的隱藏狀態,hi 是編碼器的第 i 個隱藏狀態,Wh 和 Ws都是可訓練的 參數,最後的 at則是要專注編碼器哪個時間點的機率分佈。
再來根據這個機率分佈,可以得出一個前後文向量 (Context Vector) h∗t:
h∗t =X
i
atihi (2.10)
這個式子的意思就是把編碼器的隱藏狀態根據專注機率分佈來做加權平均得出前 後文向量。最後這個前後文向量會再跟解碼器的隱藏狀態一起產生最後的詞分佈 機率:
pvocab = sof tmax(V‘(V [h∗t, st] + b) + b‘) (2.11)
2.2.5 混 混 混合 合 合式 式 式指 指 指標 標 標網 網 網路 路 路
在文章摘要的任務中,因為摘要中的許多詞都會與編碼器的輸入文章中的詞相 同,因此研究者提出指標網路 (Pointer Network) [10]設法直接由文章複製詞成為摘 要。指標網路是一種專注式序列至序列網路的變形,他以專注式序列至序列網路
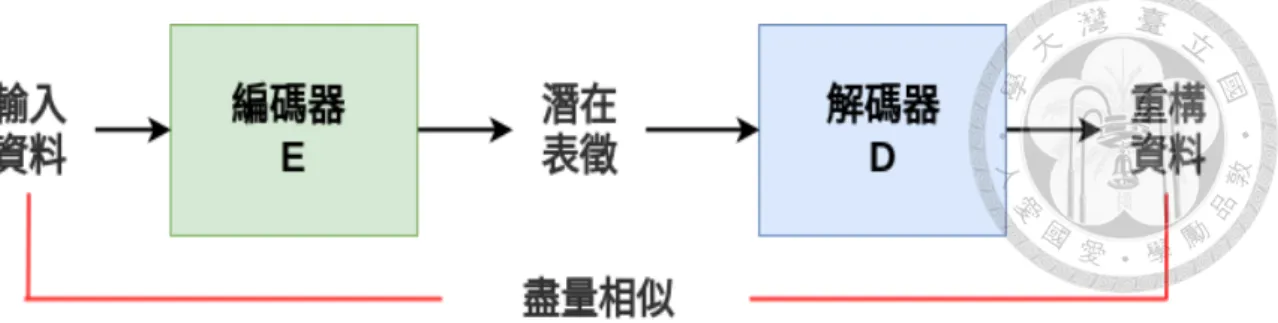
圖 2.2: 自編碼器的模型示意圖.
所產生的專注機率 at來由文章複製詞。然而,摘要並非完全由文章的詞而來,於 是研究者針對此特點進一步的提出混合式指標網路 (Hybrid Pointer Network) [11],
讓指標網路不只能由文章中去複製詞,更能如同一般的專注式序列至序列網路直 接去產生詞的分佈。具體來說混合式指標網路改寫式 2.11 如下:
u = sigmoid(whT∗h∗t + wsTst+ wxTxt+ bu) Pvocab‘ = uPvocab + (1 − u) X
i:wi=w
ati
(2.12)
上式以可訓練的參數 u 來控制新的字的機率分佈要由原來的專注式序列至 序列網路的字分佈而來或者由文章中複製而來,其中如果字沒有出現在文章 中Pi:wi=wati 就為 0 ,否則為那個字被專注的機率。
2.3 自 自 自編 編 編碼 碼 碼器 器 器(Autoencoder)
2.3.1 基 基 基本 本 本原 原 原理 理 理
自編碼器是一種非監督式學習的方法,希望能學習到代表資料的潛在表徵(Latent Representations),此潛在表徵可以被視為機器對於資料的理解,一個好的潛在 表 徵 能 幫助機器達成各類任務,此外自編碼器也可以被用做模型的預訓練 (Pre-training)。如圖 2.2 所示,自編碼器通常會具備兩個元件:編碼器 (Encoder)
以及解碼器 (Decoder) ,編碼器會先將資料壓縮成一個維度相較於原本資料較小的 瓶頸向量,解碼器再設法由瓶頸向量去重構 (Reconstruct) 原本的資料,它訓練的 目標是最小化重構損失函式,根據資料的不同或選用不同的損失涵式,如果資料 是連續的像是語音或者圖片,就會使用均方差的減損函數;而如果資料是離散的 像是文字,通常就會使用交叉熵函數。
2.3.2 變 變 變 分 分 分自 自 自編 編 編碼 碼 碼器 器 器(Variational Autoencosder, VAE)
原來的自編碼器傾向於將資料編碼成一個個點狀的離散分佈,只有在潛在空 間(Latent Space)中自編碼器看過的資料才能夠被解碼器解碼為有意義的資料,因 此自編碼器並非一個好的生成模型(Generative Model),因為在潛在空間中大部份 的點都不能被解碼器解碼為合理的資料。
為了解決此問題,研究者提出變分自編碼器 [12],希望將每筆的資料不再編 碼成一個點,而是一個分佈 (Distribution) 。首先由機率模型的假設開始推導起,
一個機率模型我們期望他最大化資料的似然度 (Likelihood) log(p(x)),於是可以利 用變分推論 (Variational Inference) 將 log(p(x)) 展開如下:
log(p(x)) = Ez∼q(z|x)[log(x|z)] − DKL[q(z|x) k p(z)] + DKL[p(z|x) k p(z|x)]
| {z }
>=0
>= Ez∼q(z|x)[log(x|z)] − DKL[q(z|x) k p(z)]
(2.13)
如此一來我們可以定義證據下界 (Evidence Lower Bound, ELBO) 為:
ELBO = Ez∼q(z|x)[log(x|z)] − DKL[q(z|x) k p(z)] (2.14) 最大化證據下界即為間接地最大化 p(x) ,並且證據下界可拆為兩個不同的目 標,第一項 Ez∼q(z|x)[log(x|z)] 就是原先的自編碼器的目標函式,他要設法將由 q(z|x) 所抽樣的 z 重構回原來的 x ,第二項則是要最小化編碼器編碼的 q(z|x) 與
先驗分佈 p(z) 間的庫雷散度 (Kullback-Leibler Divergence) ,意即要讓兩個分佈之 間的距離越近越好。一般來說,大多數人選擇使用標準常態分佈 (Standard normal Distribution): N (0, 1) 來作為先驗分佈。
2.4 生 生 生成 成 成對 對 對 抗 抗 抗網 網 網路 路 路(Generative Adversarial Neural Net- works, GAN)
2.4.1 基 基 基本 本 本原 原 原理 理 理
生成對抗網路 [5]成功的被應用在無數的任務上,包含非監督式學習,半監督式學 習,語音的生成以及圖片的生成。 生成對抗網路主要由兩個模組所組成,第一個 模組是生成器 (Generator) G,第二個模組是鑑別網路 (Discriminator) D,這兩個網 路會彼此相互對抗,這對抗的過程稱之為最小值最大化遊戲(Minimax Game),當 這個最小值最大化遊戲平衡時,我們期望生成器由先驗機率 Pz 所產生的資料分 佈G(z)能與真實資料分佈 Px 相近,這個真實的資料分佈可以是人類所拍攝的照 片、人類所講的語音又或是人類所書寫的文字。
• 鑑別網路 (Discriminator)
鑑別網路 D 的目標只有一個,就是要設法鑑別他的輸入是由真實的資料 分佈(Distribution) Px 中抽樣的,又或是由生成器G所產生的分佈G(z)所抽樣 的,其損失函數可以寫成如下所示:
LD = −(Ex∼Pdata[log(D(x))] + Ez∼Pnoise[log(1 − D(G(z)))]) (2.15)
值 得 一 提 的 是 因 為 這 是 一 個 二 元 分 類 的 問 題 , 因 此 在D的 輸 出 層 是 一 個sigmoid函式。
• 生成器 (Generator)
生成器 G 的目標是要某個分佈(Distribution) Pz 映射到另外一個我們所期望 的由人類所產生的分佈 Px,也就是說我們希望生成器所產生出的輸出分 佈G(z)能夠越像 Px 越好。為了達成 通常來說這個我們所期望的分佈是像是 人類所產生的資料的分佈,像是人類所拍攝的照片、人類所講的語音又或是 人類所書寫的文字,換句話說我們期望生成器能夠由 Pz產生出像是人類所 產生的真實分佈 Px。為了達成此目地,生成器所產生的輸出必須要設法騙 過鑑別網路,也就是說要設法讓鑑別網路認為它所產生出的輸出是出自於人 類,其數學式子如下:
LG = −Ez∼Pnoise[log(D(G(z)))] (2.16)
可以發現 G 的損失函數和 D 的損失函數是完全相反的,也就是說他們會一 直互相對抗。2.16與2.15會一直不斷地交替的訓練下去,並且在訓練一方時 另外一方的參數是固定的,這個訓練會一直持續到生成器能夠完全地騙過對 抗網路,也就是說生成器所產生的分佈已經與真實資料的分佈一模一樣了。
2.4.2 使 使 使用 用 用生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路產 產 產生 生 生語 語 語言 言 言
使 使
使用用用生生生成成成對對對抗抗抗網網網路路路產產產生生生文文文字字字的的的困困困境境境
根 據 霍 氏 生 成 對 抗 網 路(Wasserstein Generative Adversarial Networks, WGANs) [13]的推 導 , 當 鑑 別 網 路 被 最 佳 化 時 ,GAN 的 公 式 2.15 可 以 被 視 為 要 最 小 化 由 生 成 器 產 生 的 分 佈 以 及 人 類 產 生 的 真 實 資 料 分 佈 間 的JS散 度(JS diver-
gence),JS散度在當兩個分佈間完全沒有交集時會是定值,這個意味著公式 2.15將無法提供任何的梯度給生成器,當想要產生的分佈是離散的分佈時,這個 問題會更加嚴重,因為兩個離散的分佈間是幾乎沒有任何交集的,由於語言離散
的特性,因此這個問題在產生文字上會更加嚴重,也造成原來的生成對抗網路無 法成功的運用在語言的生成上。
為了解決此問題,近年的研究朝向兩個方向發展,第一個方向是提出一種新 的目標函式,這個目標函式必須要能更精準的評估兩個分佈間的距離,即使在兩 個分佈間沒有交集也必須要能夠衡量他們間的距離,並且提供梯度給生成器。第 二種方向則是使用強化學習(Reinforcement Learning, RL),強化學習的優勢在於它 能夠使用獎勵(Reward)來最佳化無法微分的目標函式。
使 使
使用用用新新新的的的目目目標標標函函函式式式
這類的方法不只適用於讓機器能夠產生離散的文字,也期望能讓生成對抗網路的 訓練更加穩定,在此我要介紹的是霍氏生成對抗網路這個新的生成對抗模型。
由於原始的生成對抗模型使用的JS散度是造成訓練不穩定以及兩個分佈沒有重疊 時沒有梯度的主要原因,因此他們期望找到一種新的衡量兩個分佈間距離的方 法,此方法必須要能夠衡量兩個沒有重疊分佈間的距離,於是在霍氏生成對抗網 路中,作者將目光投射到一種名為推土距離(Earth-Mover Distance 又稱 Wasserstein Distance)的距離衡量方法,而兩個分佈間的推土距離約可以寫成如下的式子:
W (Pr, Pg) ≈ maxw:|fw(x1)−fw(x2)|≤K|x1−x2|Ex∼Prfw(x) − Ex∼Pgfw(x) (2.17)
這個式子的意思是兩個分佈間的推土距離可以被一個能夠最大化右式的函式f所衡 量,並且要求這個函式必須要滿足立氏 (Lipschitz) 連續條件,一個函示要滿足立 氏連續條件,它的一階導函數必須不能超過某個範圍。在深度學習的領域中,每 個類神經網路都可以被視為一組函式,這個函式由他的參數來掌握他的輸出,在 對抗式生成器中這個要衡量兩個距離的函式即為鑑別器D,而兩個分佈一個是來 自於人類所產生的真實資料分佈,另外一個則是是來自於生成器G,於是 D 的損
失函數可以被寫成如下,
LD = −Ex∼PrD(x) + Ez∼PzD(G(z))) (2.18)
直觀上,式子2.18可以理解為要讓真實的資料分佈有著越高的分數越好,而由生 成器所產生的資料分佈有著越低的分數越好。為了要使D滿足立氏連續條件霍氏 生成對抗網路使用梯度懲罰(Gradient Penalty) [14]來限制 D 的微分越接近1越好。
因此加上梯度懲罰後,D 的式子變成如下,
LgpD = LD+ λExb[(kObxD(bx)k2− 1)2] (2.19)
其中x 是由真b 實資料與生成器所產生的輸出內差而來。 由於G的目標與鑑別 網路剛好相反,因此他的目標就是要讓D給他越高的分數越好,如下:
LG= −Ez∼PzD(G(z))) (2.20)
與原本的生成對抗網路相似,式子2.19 跟式子2.20也是交替著訓練。由於 D 的任 務由二元分類任務改為直接輸出分數的迴歸任務,因此D輸出層的sigmoid也因此 被拿掉了。
使 使
使用用用強強強化化化學學學習習習
這裡我要介紹的是這個方法中最有名的一篇文章序列生成對抗網路 (Sequence GAN, Seq-GAN) [15],這個方法跟上述方法的最大不同之處在於上述的方法是 直接把G的輸出詞分佈(Word Distribution)直接輸入 D,然而在使用強化學習類的 方法中,會先根據每個時間點G所產生的詞分佈機率去抽樣一串詞,這一串詞 也就是一個句子,然後再被餵進鑑別網路中,由於抽樣這個操作是無法微分 的,因此會造成梯度無法由 D 流回 G,因此為了能讓 G 能夠最佳化它與 D 相
關的目標函式,強化學習成為最佳的選擇。一個強化學習的問題必須要定義 幾個重要的要件,第一個是何為狀態(State),第二個是狀態間要如何轉移(State Transition),第三個是獎勵的函式(Reward Function)為何,最後是行為者(Agent)的 行動空間(Action Space)為何。 如果要將語言生成套用在強化學習的框架,它的行 為者是產生文字的深度學習模型,通常此模型是遞迴式類神經網路,狀態則是目 前產生了哪些詞的抽象表示,也就是遞迴式類神經網路得隱藏狀態,狀態的轉移 則是由行為者所決定的產生下一個詞的機率,它每個時間點的行動則是產生一個 詞,因此他所有可能的行為數目就是詞典中詞的數目。由於G的目標函式是要騙 過D,亦即讓D的分數越高越好,因此自然是 D 的分數越高,他的獎勵越大。 對 於 D 來說,他的目標函式依然不變,因此與式子2.15相似,只是多了個由 G 抽樣 一個句子這個操作,如下所示:
LD = −Ex∼Pxlog(D(x)) − Es∼G(z),z∼Pz(log(1 − D(s))) (2.21)
其中s是由G(z)所產生的分佈中抽樣出來的句子。接著 G 則使用強化學習中的策 略梯度 (Policy Gradient) 來進行學習,其損失函數 LG定義如下:
ri = −Es∼G(z),z∼PzD(s) LG = −1
L
L
X
i=1
ri · log(G(z)i)
(2.22)
其中 L 是句子的長度,而 G(z)i 代表生成器在第 i 個時間點所產生的詞分佈,
ri是在第 i 個時間點的獎勵。然而由於這樣子做會使得生成器在每個時間點拿到的 獎勵都會相同,於是在序列生成對抗網路中他在每個時間點都會做蒙地卡羅樹狀 搜尋 (Monte Carlo Tree Search, MCTS),由目前的時間點 i 不斷的抽樣完整的句子 給鑑別器評分,再用所有評分的平均當作第 i 時間點的獎勵 ri。
2.4.3 資 資 資訊 訊 訊生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路(Info-GAN)
如前所述,生成對抗網路是由一個先驗分佈 Pz 所抽樣的向量 z 去產生資料,然 而 z 的每一個維度並沒有學到分離的,各自具有代表意義的特徵,以圖片生成為 例,通常我們會期望 z 的某一個維度能夠代表圖片的種類,角度等等之類的特 徵,為了讓生成對抗網路能夠學習更具有代表性的特徵,資訊生成對抗網路設法 由一個干擾分佈 z 以及一個希望能學習到有代表特徵的 c 去產生資料 G(z, c) ,並 且最大化 G(z, c) 以及 c 之間的相互資訊(Mutual Information)。
然而,要衡量 G(z, c) 與 c 之間的相互資訊需要知道後驗機率 P (c|G(z, c)) , 由於在實際中我們無法知道後驗機率,因此資訊生成對抗網路 [6]使用變異推論來 估計此項的證據下界,他們推出可以使用一個輔助函式 Q 來估計此最低限制, Q 可以是可訓練的類神經網路。訓練 Q 的方法很簡單,就是要盡量讓 Q 能由生成器 的輸出 G(z, c) 去預測它的特徵向量 c ,因此我們可以把 Q, G , D 的目標函式寫成 如下:
minQ,G max
D Ex∼Pxlog(D(x)) + Ec∼Pc,z∼Pz log(1 − D(G(c, z))) + Ec∼Pc,z∼Pzc log(Q(G(c, z))) (2.23) 由式中可以發現 Q 與 G 的目標是相同的,他們都期望可以盡量讓 Q 去預測 G 的輸入向量 z 。另外值得一提的是在原始的論文中 Q 與 D 的部分參數是共享 的。
2.5 本 本 本章 章 章總 總 總結 結 結
這個章節介紹了本論文所會用到的有關於深層學習的背景知識,首先介紹深層網 路以及其相關模型,再來介紹深層對抗網路以及其如何用於文字的生成。
第
第 第 三 三 三 章 章 章 使 使 使用 用 用生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路達 達 達成 成 成非 非 非監 監 監督 督 督式 式 式抽 抽 抽 象
象 象文 文 文章 章 章摘 摘 摘要 要 要
3.1 任 任 任務 務 務簡 簡 簡介 介 介
首先要介紹的是何為文章摘要 (Text Summarization) ,文章摘要顧名思義就是要把 一段較長的文章擷取其精華,濃縮成一段較短的文字,這個較短的文字可能是標 題,又或者是一小段的摘要。
而文章摘要的方法大致上可以分為兩大類,第一大類是抽取式文章摘要 (Extractive Text Summarization),抽取式文章摘要這類的方法是要為文章中的每一 小段文字評估其重要程度,並且取重要程度分數高於個閾值或是重要前幾高的文 字段落來當作摘要,通常這種每一小段文字會以句子為單位。
然而,事實上人類在做摘要時並非是抽取式的文章摘要,因為抽取式的文章 摘要所選出的句子不見得會組成一段合理的短文,此外這樣選出的句子極有可能 含有許多不必要的贅詞或者不重要的資訊,因此近年來研究者提出另一種更為接 近人類的摘要方式,稱為抽象式摘要 (Abstractive Text Summarization) ,抽象式摘 要是讓機器先讀過文章並且消化文章後,再根據機器對於文章主旨的吸收,一個 詞一個詞的去產生摘要,並且摘要的詞不限於是否在文章出現過,因此機器能夠 選擇更精簡抽象的詞來描述文章。
相較於抽取式文章摘要,抽象式文章摘要需要極為大量的資料來做訓練,因 為文字的生成遠比句子的評分來的困難得多,然而在許多情況下取得大量的文章 以及相對應的摘要並非易事,像是課程、會議的紀錄往往就沒有相對應的摘要。
因此本論文設法讓機器由大量的沒有摘要的文章中去學習生成其抽取式摘要,並
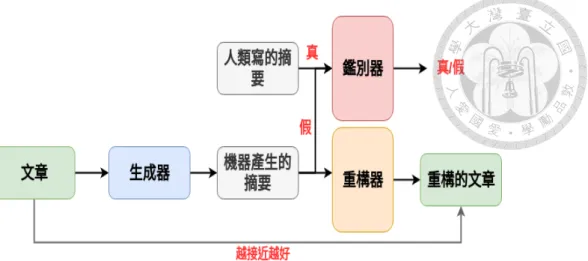
圖 3.1: 模型示意圖。 給定長文,生成器設法產生摘要,它所產生的摘要必須最小 化重構損失並且讓鑑別器認為產生的摘要為真,也就是要設法騙鑑別器讓它認為 此摘要來自於人類。
且提供少量的人類寫的摘要當作範本讓機器瞭解人類是如何寫摘要的,這些人類 寫的範本摘要並非需要和機器訓練的文章是配對的,並且本論文將這種訓練情境 稱為非配對式文章摘要。
3.2 訓 訓 訓練 練 練方 方 方法 法 法
3.2.1 方 方 方法 法 法概 概 概 述 述 述
方法主要的靈感來自於自編碼器,如先前章節所介紹的,自編碼器會將資料編碼 成代表資料的潛在表徵,此潛在表徵相較於原來的資料有著較低的維度,並且潛 在表徵為了要能夠良好的重構回原來的資料,他必須要抓住資料中重要的部分,
因此這個潛在表徵就可以被視為資料的摘要。然而此潛在表徵跟文章摘要不同的 地方是文章摘要是人類可讀的語言,於是本論文設法讓編碼器使用人類可讀的語 言作為潛在表徵,為了達成此目標,本論文使用生成對抗網路來限制中間的潛在
表徵是人類可讀的語言。
如圖 3.1 所示,模型由三個模組所構成,分別是生成器 G ,鑑別器 D 以及 重構器 R,其中 G 和 D 組成一個生成對抗網路,而G 和 R 組成一個自編碼器。
G 的網路架構是一個混合式指標網路,並且有兩個角色,一個角色是生成對抗 網路的生成器,另外一個角色則是自編碼器中的編碼器,它以長度為 M 的文章 x = {x1, x2, . . . , xM}為輸入,其中每個 x 代表一個詞,並且設法把文章編碼成長 度為 N 的人類可以理解的語言潛在表徵 G(x) = {y1, y2, . . . , yN},其中每個 yi 都 是一個詞的機率分佈。為了讓 G(x) 是文章的摘要,G(x) 必須要能夠重構回原本 的文章 x,並且要能夠騙過鑑別器 D,讓它誤以為這是人類寫的摘要。
而 D 的 模 型 架 構 則 是 一 個 長 短 期 記 憶 模 型 , 它 的 角 色 則 是 生 成 對 抗 網 路中 的 鑑 別 器 , 它 以 機 器 產 生 的 摘 要 G(x) 或 者 人 類 寫 的 摘 要 yreal = {y1real, yreal2 , . . . , yrealN }為輸入,並且要設法鑑別此摘要是人類寫的或者機器產生 的,其中 D 輸入的人類寫的範本摘要跟 G 所輸入的文章是完全無關的,只是要讓 G了解人類寫的摘要的寫法。第三個網路 R 的角色就好比自編碼器中的解碼器,
它以 G 所產生摘要為輸入,並且設法將此摘要重構回原來 G 所輸入的文章。 可 以把 D, R, G 的目標函數寫成數學式如下:
LD = Eyreal∼P
yreallog(D(yreal)) + Ex∼Px,ys∼G(x)log(1 − D(ys)) LR= Ex∼Px,ys∼G(x)−
M
X
i
xi· log(R(ys)i)
minG,R max
D LD+ αLR
(3.1)
其中 LR 是重 構 回 原 來 文 章 的 重 構 損 失,α 則是控制重構損失比例的超參數 (Hyper-parameter),而 LD 則是生成對抗網路訓練的目標,值得專注的是 R 及 D 並非直接輸入 G(x) ,而是由 G(x) 分佈抽樣一個句子 G(x)s = {ys1, y2s, . . . , ysN}出 來,上標 s 代表是根據機率隨機抽樣的,其中每個 ys都是一個離散的詞。
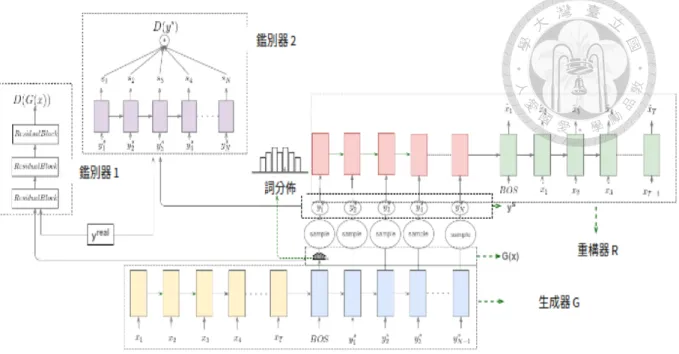
圖 3.2: 提出模型的詳細的架構。
3.2.2 最 最 最小 小 小化 化 化重 重 重構 構 構損 損 損失 失 失
然而,實際上上述的 LR對於 G 來說是沒有辦法直接得到來自於 R 的梯度的,因 為中間有經過抽樣這個離散的操作。於是,為了使 G 能夠最小化 LR ,我使用強 化學習中的策略梯度來解決此問題,對於生成器來說其損失函數如下:
Ex∼Px −
N
X
i
rRlog(G(x)i) (3.2)
其中 rR是 −LR,上標 R 的意思是這個獎勵是來自於重構網路 R ,然而由於重構 損失隨著資料的不同會有很大的差異,也造成 rR的變異 (Variance) 非常大,於是 這裡引入強化學習中最常被拿來使用降低變異的方法:將獎勵減去基準 (Baseline)
。本論文選擇一種被拿來用在序列產生的基準,自我批判 (Self-Critic) [16]來做訓 練,首先他還會再用貪婪 (Greedy) 算法抽樣一個句子,貪婪算法就是在每個時間 點都選擇機率最大的詞,最後使用貪婪算法所抽樣的句子 ya輸入 R 的分數當作
基準,於是 rR可以被寫成如下:
rR=
M
X
i
[xi· log(R(ys)i)] −
M
X
i
[xi· log(R(ya)i)] (3.3)
3.2.3 生 生 生成 成 成對 對 對抗 抗 抗網 網 網路 路 路的 的 的訓 訓 訓練 練 練
生成對抗網路訓練的目的是希望生成器能夠學習如何產生很像人類寫的摘要的輸 出,在本節我們試著用兩種方法來達成生成對抗網路的訓練,一種是不做抽樣,
直接將生成器的輸出詞分布輸入鑑別器來評分,並且使用霍氏對抗網路來做訓 練;另外一種則是我們所提出的強化學習的方法,此方法會對生成器的輸出詞分 佈做抽樣,再將抽樣的輸出輸入鑑別器來鑑別真偽。
霍 霍
霍氏氏氏對對對抗抗抗網網網路路路學學學習習習法法法
如圖 3.2 所示,最左邊的鑑別器-1 是此方法所使用的鑑別器,由數個殘差網路 (Residual Blocks) 所構成,以生成器所輸出的一系列的詞分佈作為輸入,由於在此 使用霍氏生成對抗網路,因此改寫式 3.1 的 LD函數如下:
LD =Ex∼PxD1(G(x)) − Eyreal∼PrealD1(yreal) + β1Eyi∼Pi(∆yiD1(yi) − 1)2
(3.4)
其中 yi是產生的 G(x) 以及任意挑選的 yreal內差而來,此方法實施梯度懲罰在 yi 上,而 β1則是控制梯度懲罰大小的超參數。
而生成器的損失函數如下:
LG= −Ex∼PxD1(G(x)) (3.5)
, 生成器損失函數的目的就是要盡量混搖 D,也就是盡量讓生成器產生的資料 G(x) 由 D 得到較高的分數。
圖 3.3: 自我批判學習強化法的實際例子。
自 自
自我我我批批批判判判強強強化化化學學學習習習法法法
有鑑於霍氏對抗網路學習法所產生的文字品質仍然不夠好,我們試著提出一種新 的強化學習訓練方式來改善原先序列生成對抗網路,並且將其與霍氏生成對抗網 路結合。
序列生成對抗網路最大的問題在於它在每個時間點都必須要使用蒙第卡羅搜 尋樹來衡量目前時間點生成器的獎勵,否則生成器所產生的整個序列的獎勵都會 相同,也會因此而無法有效的訓練生成對抗網路。然而,蒙地卡羅搜尋樹是很花 時間的,會使訓練的時間與序列長度的平方成正比,在訓練速度本身就極慢的遞 迴式類神經網路更是加深了此問題。
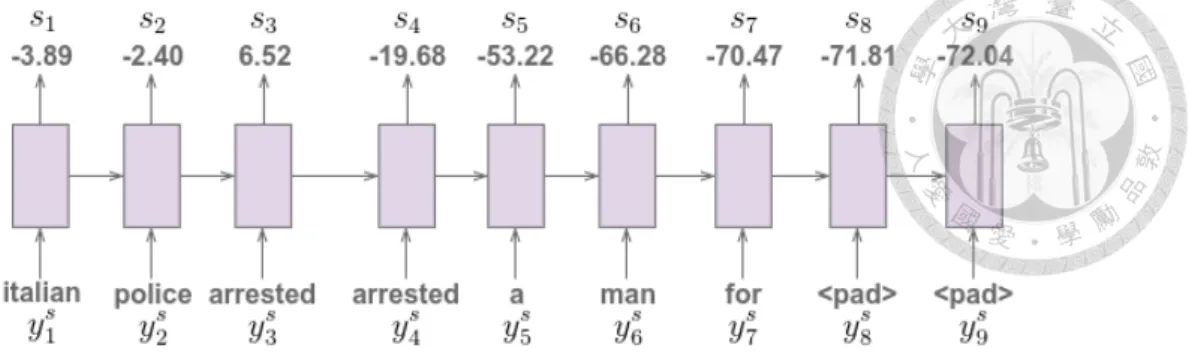
為了解決此問題,本論文試著不做蒙地卡羅搜尋樹,而是直接使用一個長短 期記憶體網路來估計在每個時間點生成器應該要拿到的獎勵。此方法使用的鑑別 器是圖 3.2 的 鑑別器-2 簡寫為 D2,D2 以由 G(x) 所抽樣的 ys 或者人類所產生的 yreal為輸入,並且如圖 3.2 所示 ,D2在每個時間點i 都會輸出一個分數 si ,si代 表著截至目前時間點 i,y1:i = {y1, y2, . . . , yi} 是否像人類寫的摘要,越高分代表 越像人類寫的摘要,並且 D2 要盡可能地在越早的時間點鑑別它的輸入是來自於 人類亦或是生成器。
舉例來說,如圖 3.3 所示,因為 “arrested” 這個詞重複出現了,在第二個
“arrested”出現後,鑑別器判斷這是一個由生成器所產生的句子,因此序列後面的 詞也同樣被打了很低的分數,並且由於 D2 使用霍氏生成對抗網路來做訓練,它 所輸出的分數不限於 0 到 1之間。 具體而言,為了定義 D2 的損失函數,給予一 個句子 y = {y1, y2, . . . , yN}為 D2 的輸入, D2 會輸出 s = {s1, s2, . . . , sN},再來 定義 D2 的損失函數 LD2 如下:
D2(y) = 1 N
N
X
i=1
si
LD2 = Eys∼G(x)D2(ys) − Eys∼PrealD2(yreal) + β2Eys∼Pi(∆yiD2(yi) − 1)2
(3.6)
其中 D2(y) 代表鑑別器預測的分數的平均,而 yi 則是由 ys 與任意 yreal內插而 來。 LD2 鼓勵 D2 盡早鑑別出它的輸入是人類寫的摘要或者生成器產生的,因為 一旦在某個時間點鑑別出 y 來自於生成器,D2 就能將此時間點後的分數都降低,
也就是說 D2(y) 能夠變得更低。
而生成器則是用強化學習中的策略梯度來做學習,首先定義第 i 個時間點來 自於 D2 的獎勵如下:
riD =
si if i = 1 si− si−1 otherwise.
其中 si − si−1代表以上個時間點的分數當做基準 (Baseline) ,這個時間點的句子 變好或變壞了多少,選擇以上一個時間的分數當作基準是因為整個句子可能只有 一個詞是不合理的,但這個不合理的詞卻會讓之後時間點的詞分數跟著變低,因 此如果以上個時間點當作基準就能夠更準確的評估句子是在哪個時間點產生不合 理的詞。
生成器使用策略梯度來最大化來自於鑑別器的損失函數如下:
Ex∼Px −
N
X
i=1
riDlog(G(x)i) (3.7)
任務 標註數量 方法 R-1 R-2 R-L
(A)監督式學習 3.8M
(A-1)監督式學習的生成器 33.19 14.21 30.50 (A-2) 專注式序列至序列 [17] 29.76 11.88 26.96 (A-3) 卷積式專注式序列至序列 [18] 33.78 15.97 31.15 (A-4) 選擇式編碼網路 [19] 36.15 17.54 33.63 (B) 簡單的標準方法 0 (B-1)前 8 個詞為摘要 21.86 7.66 20.45
(C)非平行式學習 0
(C-1)預訓練的生成器 21.26 5.60 18.89 (C-2)霍氏對抗網路 28.09 9.88 25.06 (C-3) 自自自我我我批批批判判判強強強化化化學學學習習習法法法 28.11 9.97 25.41
(D) 半監督式學習
10K
(D-1)霍氏對抗網路 29.17 10.54 26.72 (D-2) 自自自我我我批批批判判判強強強化化化學學學習習習法法法 30.01 11.57 27.61
500K
(D-3)離散語言壓縮 [20] 30.14 12.05 27.99 (D-4)霍氏對抗網路 32.50 13.65 29.67 (D-5) 自自自我我我批批批判判判強強強化化化學學學習習習法法法 33.33 14.18 30.48
1M
(D-6)離散語言壓縮 [20] 31.09 12.79 28.97 (D-7)霍氏對抗網路 33.18 14.19 30.69 (D-8) 自自自我我我批批批判判判強強強化化化學學學習習習法法法 34.21 15.16 31.64
0
(E-1)預訓練的生成器 21.49 6.28 19.34 (E) 遷移式學習 (E-2)霍霍霍氏氏氏對對對抗抗抗網網網路路路 25.11 7.94 23.05 (E-3) 自自自我我我批批批判判判強強強化化化學學學習習習法法法 27.15 9.09 24.11
表 3.1: ROUGE分數在英文十億詞資料庫上。
3.3 實 實 實驗 驗 驗
3.3.1 資 資 資料 料 料 介 介 介紹 紹 紹
我 們 評 估 我 們 的 模 型 在 三 個 不 同 的 資 料 集 上 , 分 別 是 英 文 十 億 詞(English
Gigaword),中文十億字 (Chinese Gigaword) 以及有線電視日常信件 (CNN/Daily Mail)。
英 英
英文文文十十十億億億詞詞詞
英文十億詞來自於語言資料聯盟 (Linguistic Data Consortium, LDC) ,此資料庫收 集了紐約時報 (New York Times, NYT),英文新華社 (Xinhuan News English, XIE),
聯合世界潮流英文報導 (Associated Press Worldstream English, APW),以及法國英 文報導機構 (Agence France Press English, APW) 的新聞。由於原始的資料庫極為 雜亂,如氏 (Alexander M. Rush) [17]對其做了預處理並且將其分割出380萬筆的 訓練資料 (Training Set),40萬筆的驗證資料 (Validation Set) 以及40萬筆的測試資 料 (Testing Set),為了能夠與前人的研究成果比較,我們使用先前文章所提供 的2000筆測試資料來測試而非原來的測試資料。其中每筆資料都由成對的新聞第 一句話以及其對應的標題所組成 ,因為它將長句壓縮成短句,因此是一個句子摘 要(Sentence Summarization) 的資料庫。
在做非平行式的訓練時,我們使用其中 190 萬篇文章以及 40 萬則人類寫的摘 要做訓練,我們只取文章的前 50 個詞作為生成器的輸入,摘要的前 13 個詞作為 範本摘要,並且設詞彙量為 1.5 萬詞。
有 有
有線線線電電電視視視日日日常常常信信信件件件
有線電視日常信件的性質與中文十億詞相似都是長文摘要的資料庫,它由成對的
摘要以及文章所組成,每則摘要平均有3.75句話,每篇文章平均有781個詞。它由 那氏 (Ramesh Nallapati) [21] 進行預處理,並且切成 29 萬筆訓練資料,一萬三千 筆驗證資料以及一萬一千筆測試資料。在使用此資料庫做非平行式的訓練時,我 們使用其中 15 萬筆文章做訓練,5 萬筆摘要作為範本摘要,並且只取文章的前 250個詞作為生成器的輸入,摘要的前 50 個詞作為範本摘要,而詞彙則設量為 1.5 萬詞。
中 中
中文文文十十十億億億字字字
中文十億詞來自於語言資料聯盟,它是一個長文摘要的資料庫,由成對的文章以 及其標題所組成,此資料庫收集了1991年到2002年間台灣中央社與中國新華社的 新聞報導,其中中央社的新聞佔67%,其餘為新華社新聞。我們將長度小於20字 的文章以及長度大於150字的文章去掉,再隨機取出 110 萬篇文章用做編碼器的訓 練,20萬則標題當做鑑別網路的範本標題, 1 萬筆資料用做驗證資料,1 萬筆資 料用做測試資料。在使用此資料庫做非平行式的訓練時,我們取文章的前 60 個字 作為生成器的輸入,摘要的前 15 個字作為範本摘要,並且設字彙量為 6 千字。
3.3.2 實 實 實做 做 做細 細 細 節 節 節
模 模
模型型型架架架構構構
生成器和重構器的模型架構是完全一模一樣的,除了輸入和輸出的長度,他們都 是混合式指標網路,並且編碼器和解碼器都是一層有著 600 隱藏維度的長短期記 憶體。 而在章節 3.2.3 中霍氏對抗網路學習法中,鑑別器的參數為 4 層有著 512 隱藏維度的殘差網路;而在章節 3.2.3 中的自我批判學習法中,模型架構是一層 512隱藏維度的長短期記憶體。
訓 訓
訓練練練細細細節節節
在非平行式訓練中我們設式 3.1 中的超參數 α 為 25 ,在章節 3.2.3 中霍氏對抗網 路學習法中,我們設式 3.5 中控制梯度懲罰的 β1為 10 ,並且使用訓練速率為 1e-5 的 RMSProp 優化器 (optimizer) 在生成器上, 使用訓練速率為 1e-3 的 RMSProp 優 化器在鑑別器上。
在章節 3.2.3 中的自我批判學習法中,我們設式 3.6 中控制梯度懲罰的 β1 為 1,並且使用學習速率為 1e-5 的 RMSProp 優化器在生成器上, 使用訓練速率為 1e-3 的 RMSProp優化器在鑑別器上。
3.3.3 評 評 評量 量 量方 方 方法 法 法
我們使用 ROUGE (Recall-Oriented Understudy for Gisting Evaluation) [22]來作為主 要 的 評 分方法, ROUGE 是林欽佑博士 (Dr. Chin-Yew Lin) 在2004年時提出的 一種自動摘要評分方法,現今大多自動摘要的論文都以此作為主要的評分方 法,ROUGE 分數越高代表生成摘要的品質越佳。1
ROUGE 主要是在評量人類寫的參考摘要以及生成的摘要兩者間的重疊,
它會先計算重疊的數目,再依此計算精確率 (Precision) 以及召回率 (Recall) , 最後得出 F1 分數 (F1-score),普遍來說,大多論文都以 F1 分數來當作 ROUGE 分 數 。ROUGE 依 照 需 求 的 不 同 有 數 種 不 同 的 衡 量 的 情 境 , 像 是 ROUGE-N (N=1,2,3,4) 或者 ROUGE-L,底下會再做詳細的介紹。
ROUGE-N
首先要介紹的是 ROUGE-N 的 F1 分數的計算方式,其中 N 代表計算參考摘要以
1我們使用 pyrouge 來衡量模型,並且用參數 -m -n 2 -w 1.2 來衡量所有的實驗。